YOLOv5 release v6.0 #5141
YOLOv5 release v6.0 #5141
Conversation
|
ohhhhh,finally!Great job! |
|
Amazing work as always @glenn-jocher |
About Reported SpeedsmAP values are reproducible across any hardware, but speeds will vary significantly among V100 instances, and seem to depend heavily on the CUDA, CUDNN and PyTorch installations used. The numbers reported above were produced on GCP N1-standard-8 Skylake V100 instances running the v6.0 Docker image with:
# Pull and Run v6.0 image
t=ultralytics/yolov5:v6.0 && sudo docker pull $t && sudo docker run -it --ipc=host --gpus all $t
Our speed command is: # Reproduce YOLOv5s batch-1 speeds in table
python val.py --data coco.yaml --img 640 --task speed --batch 1
We tried several options, including AWS P3 instances, pulling more recent base versions ( |


So Focus() has been removed for its almost equivalent performace to a simple Conv() layer in most cases? |
|
@PussyCat0700 There is no any Focus() layer in |
|
@glenn-jocher Can I know now what is the difference between yolov5s and yolov5s6 both have V6 backbone and Head just the input is different? |
|
@myasser63 yolov5s is a P5 model trained at --img 640 while yolov5s6 is a P6 model trained at --img 1280. See release v5.0 notes for details on these two model types: |
|
Does P5 models has focus layer? |
|
@myasser63 no. See #4825 |
|
@glenn-jocher thanks for sharing your great effort as Yolov5 series. |
* Update P5 models * Update P6 models * Update with GFLOPs and Params * Update with GFLOPs and Params * Update README * Update * Update README * Update * Update * Add times * Update README * Update results * Update results * Update results * Update hyps * Update plots * Update plots * Update README.md * Add nano models to hubconf.py
YOLOv5 release v6.0 PR - YOLOv5n 'Nano' models, Roboflow integration, TensorFlow export, OpenCV DNN support
This release incorporates many new features and bug fixes (465 PRs from 73 contributors) since our last release v5.0 in April, brings architecture tweaks, and also introduces new P5 and P6 'Nano' models: YOLOv5n and YOLOv5n6. Nano models maintain the YOLOv5s depth multiple of 0.33 but reduce the YOLOv5s width multiple from 0.50 to 0.25, resulting in ~75% fewer parameters, from 7.5M to 1.9M, ideal for mobile and CPU solutions.
Example usage:
Important Updates
python export.py --include saved_model pb tflite tfjs(Add TensorFlow and TFLite export #1127 by @zldrobit)Detect()anchors for ONNX <> OpenCV DNN compatibility #4833 by @SamFC10).Focus()with an equivalentConv(k=6, s=2, p=2)layer (Is the Focus layer equivalent to a simple Conv layer? #4825 by @thomasbi1) for improved exportabilitySPPF()replacement forSPP()layer for reduced ops (AddSPPF()layer #4420 by @glenn-jocher)C3()repeats from 9 to 6 for improved speedsSPPF()at end of backboneC3()backbone layerNew Results
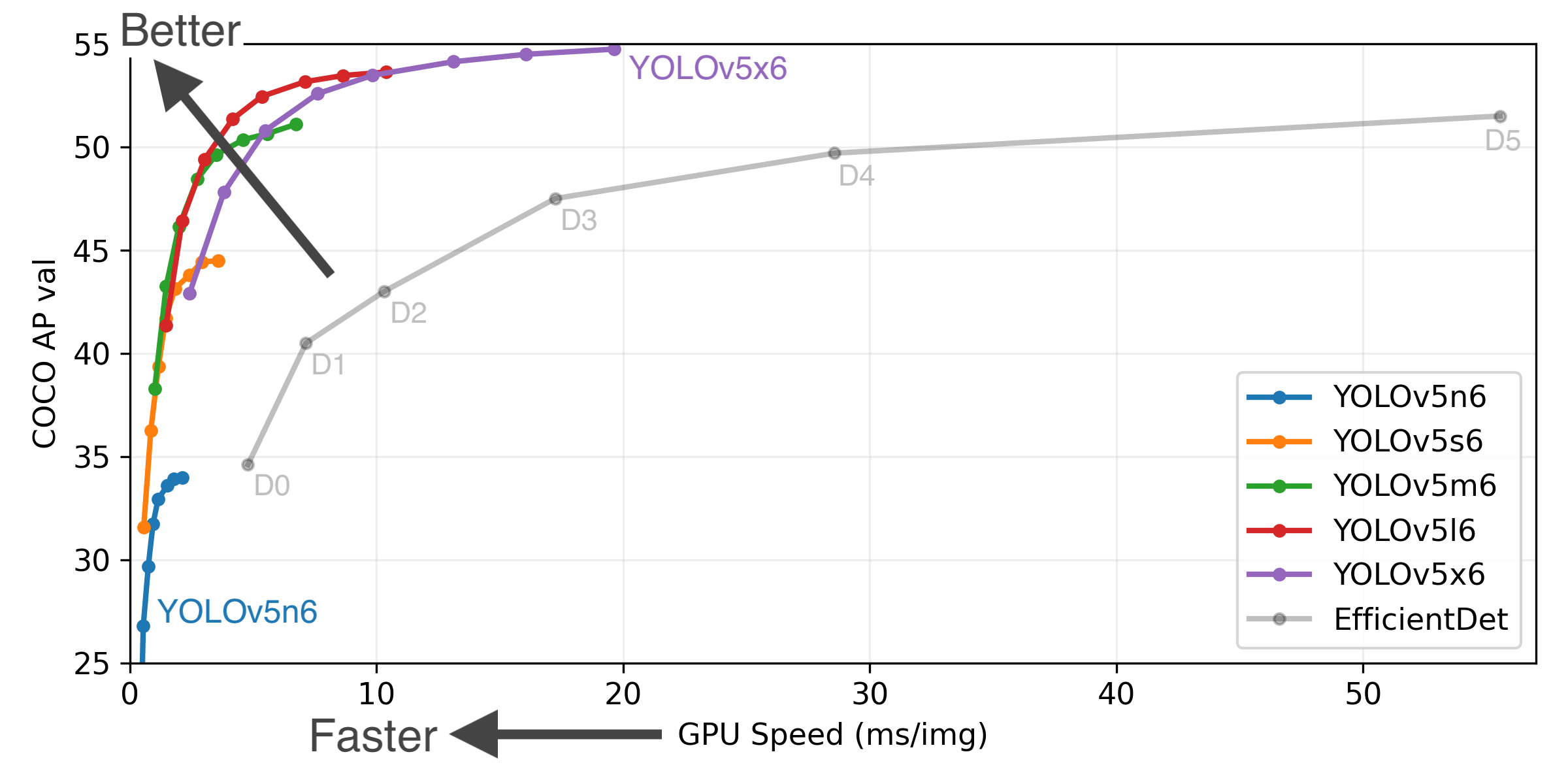
YOLOv5-P5 640 Figure (click to expand)
Figure Notes (click to expand)
python val.py --task study --data coco.yaml --iou 0.7 --weights yolov5n6.pt yolov5s6.pt yolov5m6.pt yolov5l6.pt yolov5x6.ptmAP improves from +0.3% to +1.1% across all models, and ~5% FLOPs reduction produces slight speed improvements and a reduced CUDA memory footprint. Example YOLOv5l before and after metrics:
Large
(pixels)
0.5:0.95
0.5
CPU b1
(ms)
V100 b1
(ms)
V100 b32
(ms)
(M)
@640 (B)
Pretrained Checkpoints
(pixels)
0.5:0.95
0.5
CPU b1
(ms)
V100 b1
(ms)
V100 b32
(ms)
(M)
@640 (B)
+ TTA
1536
55.4
72.3
-
-
-
-
-
Table Notes (click to expand)
Reproduce by
python val.py --data coco.yaml --img 640 --conf 0.001 --iou 0.65Reproduce by
python val.py --data coco.yaml --img 640 --conf 0.25 --iou 0.45Reproduce by
python val.py --data coco.yaml --img 1536 --iou 0.7 --augmentChangelog
Changes between previous release and this release: v5.0...v6.0
Changes since this release: v6.0...HEAD
New Features and Bug Fixes (465)
--save-cropbug fix by @glenn-jocher in detect.py streaming source--save-cropbug fix #3102--include torchscript onnx coremlargument by @CristiFati in Add--include torchscript onnx coremlargument #3137onnx>=1.9.0by @glenn-jocher in Update requirements.txtonnx>=1.9.0#3143--opset-versionby @CristiFati in Parameterize ONNX--opset-version#3154deviceargument to PyTorch Hub models by @cgerum in Adddeviceargument to PyTorch Hub models #3104plot_one_box()defaultcolor=(128, 128, 128)by @yeric1789 inplot_one_box()defaultcolor=(128, 128, 128)#3240--image-weightsnot combined with DDP by @glenn-jocher in Assert--image-weightsnot combined with DDP #3275batch_size % utilized_device_countby @glenn-jocher in checkbatch_size % utilized_device_count#3276crops = results.crop()return values by @yeric1789 in PyTorch Hubcrops = results.crop()return values #3282git clonemaster by @glenn-jocher in Explicitgit clonemaster #3311@torch.no_grad()decorator by @glenn-jocher in Implement@torch.no_grad()decorator #3312hashlibby @glenn-jocher in Updated cache v0.2 withhashlib#3350.train()mode fix by @ChaofWang in ONNX export in.train()mode fix #3362*.txtlabels by @glenn-jocher in Ignore blank lines in*.txtlabels #3366--weights URLdefinition by @glenn-jocher in Enable direct--weights URLdefinition #3373cv2.imread(img, -1)for IMREAD_UNCHANGED by @tudoulei incv2.imread(img, -1)for IMREAD_UNCHANGED #3379is_pip()function by @glenn-jocher in Createis_pip()function #3391cv2.imread(img, -1)for IMREAD_UNCHANGED" by @glenn-jocher in Revert "cv2.imread(img, -1)for IMREAD_UNCHANGED" #3395alpha=beta=32.0by @glenn-jocher in Update MixUp augmentationalpha=beta=32.0#3455timeout()class by @glenn-jocher in Addtimeout()class #3460check_git_status()5 second timeout by @glenn-jocher in Addcheck_git_status()5 second timeout #3464check_requirements()offline-handling by @glenn-jocher in Improvedcheck_requirements()offline-handling #3466output_namesargument for ONNX export with dynamic axes by @SamSamhuns in Addoutput_namesargument for ONNX export with dynamic axes #3456test.pyanddetect.pyinference to FP32 default by @edificewang in Revert FP16test.pyanddetect.pyinference to FP32 default #3423github.actorbug fix by @glenn-jocher in Stalegithub.actorbug fix #3483model.eval()callif opt.train=Falseby @developer0hye in Explicitmodel.eval()callif opt.train=False#3475opencv-pythonby @glenn-jocher in check_requirements() excludeopencv-python#3495opencv-pythonby @glenn-jocher in check_requirements() excludeopencv-python#3507developbranch intomasterby @glenn-jocher in Mergedevelopbranch intomaster#3518--halfargument for test.py and detect.py by @glenn-jocher in Update FP16--halfargument for test.py and detect.py #3532dataset_stats()for HUB by @glenn-jocher in Updatedataset_stats()for HUB #3536pycocotoolspip install by @glenn-jocher in On-demandpycocotoolspip install #3547check_python(minimum=3.6.2)by @glenn-jocher in Updatecheck_python(minimum=3.6.2)#3548optfrom `create_dataloader()`` by @glenn-jocher in Removeoptfromcreate_dataloader()` #3552is_cocoargument fromtest()by @glenn-jocher in Removeis_cocoargument fromtest()#3553halfargument by @glenn-jocher in Remove redundant speed/studyhalfargument #3557sys.path.append()by @glenn-jocher in Update export.py, yolo.pysys.path.append()#3579normalize=Trueflag by @glenn-jocher in Add ConfusionMatrixnormalize=Trueflag #3586normalize=Truefix by @glenn-jocher in ConfusionMatrixnormalize=Truefix #3587dataset_stats()by @glenn-jocher in Updatedataset_stats()#3593check_file()by @glenn-jocher in Updatecheck_file()#3622**/*.torchscript.ptby @glenn-jocher in Add**/*.torchscript.pt#3634verify_image_label()by @glenn-jocher in Updateverify_image_label()#3635is_cocolist fix by @thanhminhmr inis_cocolist fix #3646dataset_stats()to list of dicts by @glenn-jocher in Updatedataset_stats()to list of dicts #3657/weightsdirectory by @glenn-jocher in Remove/weightsdirectory #3659train(hyp, *args)to accepthypfile or dict by @glenn-jocher in Updatetrain(hyp, *args)to accepthypfile or dict #3668WORLD_SIZEandRANKretrieval by @glenn-jocher in UpdateWORLD_SIZEandRANKretrieval #3670torch.distributed.runwithgloobackend by @glenn-jocher in Update DDP fortorch.distributed.runwithgloobackend #3680total_batch_sizevariable by @glenn-jocher in Eliminatetotal_batch_sizevariable #3697train.run()method by @glenn-jocher in Addtrain.run()method #3700if dist.is_nccl_available()by @glenn-jocher in Update DDP backendif dist.is_nccl_available()#3705img2label_paths()order by @glenn-jocher in Fiximg2label_paths()order #3720check_datasets()for dynamic unzip path by @glenn-jocher in Updatecheck_datasets()for dynamic unzip path #3732data/hypsdirectory by @glenn-jocher in Createdata/hypsdirectory #3747wby @glenn-jocher in Force non-zero hyp evolution weightsw#3748pathattribute by @glenn-jocher in Add optional dataset.yamlpathattribute #3753xyxy2xywhn()by @developer0hye in Addxyxy2xywhn()#3765nn.MultiheadAttentionfix by @glenn-jocher in Remove DDPnn.MultiheadAttentionfix #3768accumulateby @yellowdolphin in Fix warmupaccumulate#3722feature_visualization()by @glenn-jocher in Updatefeature_visualization()#3807dataset_stats()with updated data.yaml by @glenn-jocher in Fix fordataset_stats()with updated data.yaml #3819TransformerBlock()by @glenn-jocher in ConciseTransformerBlock()#3821LoadStreams()dataloader frame skip issue by @feras-oughali in FixLoadStreams()dataloader frame skip issue #3833AutoShape()detections in ascending order by @glenn-jocher in PlotAutoShape()detections in ascending order #3843--evolve 300generations CLI argument by @san-soucie in--evolve 300generations CLI argument #3863*.yamlreformat by @glenn-jocher in Models*.yamlreformat #3875utils/augmentations.pyby @glenn-jocher in Createutils/augmentations.py#3877hyp['anchors']fix by @glenn-jocher in Evolution commentedhyp['anchors']fix #3887map_location=deviceby @glenn-jocher in Hub modelsmap_location=device#3894/root/hub/cache/dirby @johnohagan in Save PyTorch Hub models to/root/hub/cache/dir#3904torch.hub.list('ultralytics/yolov5')pathlib bug by @glenn-jocher in Fixtorch.hub.list('ultralytics/yolov5')pathlib bug #3921setattr()default for Hub PIL images by @jmiranda-laplateforme in Updatesetattr()default for Hub PIL images #3923feature_visualization()CUDA fix by @glenn-jocher infeature_visualization()CUDA fix #3925dataset_stats()for zipped datasets by @glenn-jocher in Updatedataset_stats()for zipped datasets #3926albumentations>=1.0.2by @glenn-jocher in Updatealbumentations>=1.0.2#3966np.random.random()torandom.random()by @glenn-jocher in Updatenp.random.random()torandom.random()#3967albumentations>=1.0.2by @glenn-jocher in Update requirements.txtalbumentations>=1.0.2#3972Ensemble()visualize fix by @seven320 inEnsemble()visualize fix #3973probabilitytopby @glenn-jocher in Updateprobabilitytop#3980test.pytoval.pyby @glenn-jocher in Renametest.pytoval.py#4000--sync-bnknown issue by @glenn-jocher in Add--sync-bnknown issue #4032val.pyrefactor by @glenn-jocher inval.pyrefactor #4053super().__init__()by @glenn-jocher in Modulesuper().__init__()#4065ncandnameshandling in check_dataset() by @glenn-jocher in Missingncandnameshandling in check_dataset() #4066export.pyby @glenn-jocher in Refactorexport.py#4080export.pyby @glenn-jocher in Addition refactorexport.py#4089--img-sizefloor by @glenn-jocher in Add train.py--img-sizefloor #4099log_training_progress()by @imyhxy in Fix indentation inlog_training_progress()#4126opset_versiontoopsetby @glenn-jocher in Renameopset_versiontoopset#4135loggersby @glenn-jocher in Refactor train.py and val.pyloggers#4137export.pyONNX inference suggestion by @glenn-jocher in Addexport.pyONNX inference suggestion #4146--data path/to/dataset.zipfeature by @glenn-jocher in Train from--data path/to/dataset.zipfeature #4185@try_exceptdecorator by @glenn-jocher in Add@try_exceptdecorator #4224requirements.txtlocation by @glenn-jocher in Explicitrequirements.txtlocation #4225max_pool2d()warning by @glenn-jocher in Suppress torch 1.9.0max_pool2d()warning #4227python train.py --freeze Nargument by @IneovaAI in Addpython train.py --freeze Nargument #4238profile()for CUDA Memory allocation by @glenn-jocher in Updateprofile()for CUDA Memory allocation #4239train.pyandval.pycallbacks by @kalenmike in Addtrain.pyandval.pycallbacks #4220DWConvClass()by @glenn-jocher in AddDWConvClass()#4274python train.py --cache diskby @junjihashimoto in Featurepython train.py --cache disk#4049int(mlc)by @glenn-jocher inint(mlc)#4385utils.google_utilstoutils.downloadsby @glenn-jocher in Fix renameutils.google_utilstoutils.downloads#4393yolov5s-ghost.yamlby @glenn-jocher in Addyolov5s-ghost.yaml#4412encoding='ascii'by @glenn-jocher in Removeencoding='ascii'#4413plot_one_box(use_pil=False)by @glenn-jocher in Merge PIL and OpenCV inplot_one_box(use_pil=False)#4416SPPF()layer by @glenn-jocher in AddSPPF()layer #4420attempt_loadimport by @OmidSa75 in Update hubconf.pyattempt_loadimport #4428--weights yolov5s.ptby @glenn-jocher in Fix default--weights yolov5s.pt#4458check_requirements(('coremltools',))by @glenn-jocher incheck_requirements(('coremltools',))#4478install=Trueargument tocheck_requirementsby @glenn-jocher in Addinstall=Trueargument tocheck_requirements#4512python models/yolo.py --profileby @glenn-jocher in Fix forpython models/yolo.py --profile#4541image_weightsDDP code by @glenn-jocher in Removeimage_weightsDDP code #4579Profile()profiler by @glenn-jocher in AddProfile()profiler #4587plot_one_boxwhen label isNoneby @karasawatakumi in Fix bug inplot_one_boxwhen label isNone#4588Annotator()class by @glenn-jocher in CreateAnnotator()class #4591plots.pyto class-first by @glenn-jocher in Re-orderplots.pyto class-first #4595on_train_end()speed improvements by @glenn-jocher in TensorBoardon_train_end()speed improvements #4605Detect()inputs by @YukunXia in Fix: add P2 layer 21 to yolov5-p2.yamlDetect()inputs #4608check_git_status()warning by @glenn-jocher in Updatecheck_git_status()warning #4610matplotlibplots after opening by @glenn-jocher in Closematplotlibplots after opening #4612torch.jit.trace()--sync-bnfix by @glenn-jocher in DDPtorch.jit.trace()--sync-bnfix #4615plot_evolve()string argument by @glenn-jocher in Fix forplot_evolve()string argument #4639is_cocoon missingdata['val']key by @glenn-jocher in Fixis_cocoon missingdata['val']key #4642ComputeLosscode by @zhiqwang in Remove redundantComputeLosscode #4701check_suffix()by @glenn-jocher in Fixcheck_suffix()#4712check_yaml()comment by @glenn-jocher in Updatecheck_yaml()comment #4713user_config_dir('Ultralytics')by @glenn-jocher in Adduser_config_dir('Ultralytics')#4715crops = results.crop()dictionary by @ELHoussineT in Addcrops = results.crop()dictionary #4676multi_labeloption for NMS with PyTorch Hub by @jeanbmar in Allowmulti_labeloption for NMS with PyTorch Hub #4728onnx-simplifierrequirements check by @Zegorax in Scopeonnx-simplifierrequirements check #4730user_config_dir()for GCP/AWS functions by @glenn-jocher in Fixuser_config_dir()for GCP/AWS functions #4726--data from_HUB.zipby @glenn-jocher in Fix--data from_HUB.zip#4732detect.pytiming by @glenn-jocher in Improveddetect.pytiming #4741callbacksto train function in W&B sweep by @jveitchmichaelis in Addcallbacksto train function in W&B sweep #4742is_writeable()for 3 OS support by @glenn-jocher in Fixis_writeable()for 3 OS support #4743.gitignoreby @glenn-jocher in Add TF and TFLite models to.gitignore#4747.dockerignoreby @glenn-jocher in Add TF and TFLite models to.dockerignore#4748is_writeable()for 2 methods by @glenn-jocher in Updateis_writeable()for 2 methods #4744user_config_dir()decision making by @glenn-jocher in Centralizeuser_config_dir()decision making #4755path.absolute()withpath.resolve()by @glenn-jocher in Replacepath.absolute()withpath.resolve()#4763export.pyby @glenn-jocher in Add TensorFlow formats toexport.py#4479--int8argument by @glenn-jocher in Add--int8argument #4799--resumefix by @glenn-jocher in Evolution--resumefix #4802forward()method profiling by @glenn-jocher in Refactorforward()method profiling #4816PIL.ImageDraw.text(anchor=...)removal, reduce to>=7.1.2by @glenn-jocher inPIL.ImageDraw.text(anchor=...)removal, reduce to>=7.1.2#4842cache_labels()by @glenn-jocher in Sorted datasets update tocache_labels()#4845cache_versiondefinition by @glenn-jocher in Singlecache_versiondefinition #4846init_seeds()by @glenn-jocher in Consolidateinit_seeds()#4849print_args()by @glenn-jocher in Refactor argparser printing toprint_args()#4850sys.path.append(str(ROOT))by @glenn-jocher in Updatesys.path.append(str(ROOT))#4852check_requirements()usage by @glenn-jocher in Simplifycheck_requirements()usage #4855LOGGER.info()by @glenn-jocher in Fix DDP destructionLOGGER.info()#4863check_font()RANK -1 remove progress by @glenn-jocher in Annotatorcheck_font()RANK -1 remove progress #4864os.system('unzip file.zip')->ZipFile.extractall()by @glenn-jocher in Replaceos.system('unzip file.zip')->ZipFile.extractall()#4919rootreferenced before assignment by @glenn-jocher in Fixrootreferenced before assignment #4920best.pton train end by @glenn-jocher in Validatebest.pton train end #4889check_file()search space by @glenn-jocher in Scopecheck_file()search space #4933cwdby @glenn-jocher in Allow YOLOv5 execution from arbitrarycwd#4954ROOTlogic by @glenn-jocher in Update relativeROOTlogic #4955roboflowby @glenn-jocher in Addroboflow#4956isascii()method calls for python 3.6 by @d57montes in Fixisascii()method calls for python 3.6 #4958ROOTPytorch Hub custom model bug by @glenn-jocher in Fix relativeROOTPytorch Hub custom model bug #4974--img 64CI tests by @glenn-jocher in Faster--img 64CI tests #4979torch.hub.load()test by @glenn-jocher in Reverttorch.hub.load()test #4986opt.deviceon--task studyby @glenn-jocher in Fix missingopt.deviceon--task study#5031--save-periodlocally by @glenn-jocher in Implement--save-periodlocally #5047yaml.safe_load()ignore emoji errors by @glenn-jocher in Fixyaml.safe_load()ignore emoji errors #5060ADDArial.ttf by @glenn-jocher in Update Dockerfile toADDArial.ttf #5084OSErrorby @glenn-jocher in Fix SKU-110K HUB:OSError#5106requeststo requirements.txt by @sandstorm12 in Addrequeststo requirements.txt #5112LOCAL_RANKtotorch_distributed_zero_first()by @qiningonline in PassLOCAL_RANKtotorch_distributed_zero_first()#5114--devicefor--task studyby @glenn-jocher in Pass--devicefor--task study#5118--speedand--studyusages by @glenn-jocher in Update val.py--speedand--studyusages #5120pad = 0.0 if task == 'speed' else 0.5by @glenn-jocher in Update val.pypad = 0.0 if task == 'speed' else 0.5#5121ROOTas relative path by @maltelorbach in FixROOTas relative path #5129Detect()anchors for ONNX <> OpenCV DNN compatibility by @SamFC10 in RefactorDetect()anchors for ONNX <> OpenCV DNN compatibility #4833detect.pyin order to support torch script by @andreiionutdamian in updatedetect.pyin order to support torch script #5109New Contributors (73)
* @robmarkcole made their first contribution in https://github.com//pull/2732 * @timstokman made their first contribution in https://github.com//pull/2856 * @Ab-Abdurrahman made their first contribution in https://github.com//pull/2827 * @JoshSong made their first contribution in https://github.com//pull/2871 * @MichHeilig made their first contribution in https://github.com//pull/2883 * @r-blmnr made their first contribution in https://github.com//pull/2890 * @fcakyon made their first contribution in https://github.com//pull/2817 * @Ashafix made their first contribution in https://github.com//pull/2658 * @albinxavi made their first contribution in https://github.com//pull/2923 * @BZFYS made their first contribution in https://github.com//pull/2934 * @ferdinandl007 made their first contribution in https://github.com//pull/2932 * @jluntamazon made their first contribution in https://github.com//pull/2953 * @hodovo made their first contribution in https://github.com//pull/3010 * @jylink made their first contribution in https://github.com//pull/2982 * @kepler62f made their first contribution in https://github.com//pull/3058 * @KC-Zhang made their first contribution in https://github.com//pull/3127 * @CristiFati made their first contribution in https://github.com//pull/3137 * @cgerum made their first contribution in https://github.com//pull/3104 * @adrianholovaty made their first contribution in https://github.com//pull/3215 * @yeric1789 made their first contribution in https://github.com//pull/3240 * @charlesfrye made their first contribution in https://github.com//pull/3264 * @ChaofWang made their first contribution in https://github.com//pull/3362 * @pizzaz93 made their first contribution in https://github.com//pull/3368 * @tudoulei made their first contribution in https://github.com//pull/3379 * @chocosaj made their first contribution in https://github.com//pull/3422 * @SamSamhuns made their first contribution in https://github.com//pull/3456 * @edificewang made their first contribution in https://github.com//pull/3423 * @deanmark made their first contribution in https://github.com//pull/3505 * @dependabot made their first contribution in https://github.com//pull/3561 * @kalenmike made their first contribution in https://github.com//pull/3530 * @masoodazhar made their first contribution in https://github.com//pull/3591 * @wq9 made their first contribution in https://github.com//pull/3612 * @xiaowk5516 made their first contribution in https://github.com//pull/3638 * @thanhminhmr made their first contribution in https://github.com//pull/3646 * @SpongeBab made their first contribution in https://github.com//pull/3650 * @ZouJiu1 made their first contribution in https://github.com//pull/3681 * @lb-desupervised made their first contribution in https://github.com//pull/3687 * @batrlatom made their first contribution in https://github.com//pull/3799 * @yellowdolphin made their first contribution in https://github.com//pull/3722 * @Zigars made their first contribution in https://github.com//pull/3804 * @feras-oughali made their first contribution in https://github.com//pull/3833 * @vaaliferov made their first contribution in https://github.com//pull/3852 * @san-soucie made their first contribution in https://github.com//pull/3863 * @ketan-b made their first contribution in https://github.com//pull/3864 * @johnohagan made their first contribution in https://github.com//pull/3904 * @jmiranda-laplateforme made their first contribution in https://github.com//pull/3923 * @eldarkurtic made their first contribution in https://github.com//pull/3934 * @seven320 made their first contribution in https://github.com//pull/3973 * @imyhxy made their first contribution in https://github.com//pull/4126 * @IneovaAI made their first contribution in https://github.com//pull/4238 * @junjihashimoto made their first contribution in https://github.com//pull/4049 * @Justsubh01 made their first contribution in https://github.com//pull/4309 * @orangeccc made their first contribution in https://github.com//pull/4379 * @ahmadmustafaanis made their first contribution in https://github.com//pull/4376 * @OmidSa75 made their first contribution in https://github.com//pull/4428 * @huuquan1994 made their first contribution in https://github.com//pull/4455 * @karasawatakumi made their first contribution in https://github.com//pull/4588 * @YukunXia made their first contribution in https://github.com//pull/4608 * @zhiqwang made their first contribution in https://github.com//pull/4701 * @ELHoussineT made their first contribution in https://github.com//pull/4676 * @joaodiogocosta made their first contribution in https://github.com//pull/4727 * @jeanbmar made their first contribution in https://github.com//pull/4728 * @Zegorax made their first contribution in https://github.com//pull/4730 * @jveitchmichaelis made their first contribution in https://github.com//pull/4742 * @kimnamu made their first contribution in https://github.com//pull/4787 * @NauchtanRobotics made their first contribution in https://github.com//pull/4893 * @SamFC10 made their first contribution in https://github.com//pull/4914 * @d57montes made their first contribution in https://github.com//pull/4958 * @EgOrlukha made their first contribution in https://github.com//pull/5074 * @sandstorm12 made their first contribution in https://github.com//pull/5112 * @qiningonline made their first contribution in https://github.com//pull/5114 * @maltelorbach made their first contribution in https://github.com//pull/5129 * @andreiionutdamian made their first contribution in https://github.com//pull/5109🛠️ PR Summary
Made with ❤️ by Ultralytics Actions
🌟 Summary
Update improves YOLOv5 model benchmarks, introduces new model variants, and refines training hyperparameters.
📊 Key Changes
YOLOv5nandYOLOv5n6, optimized for speed.P6models, which are larger-scale variants.hubconf.pyscript to allow easy loading of the new models.🎯 Purpose & Impact
YOLOv5n,YOLOv5n6) offer additional options for users who need faster inference times, which can be especially beneficial for edge computing or devices with limited computational power.hubconf.pystreamline the process for users to use the pretrained models in their applications.These changes can potentially lead to wider adoption and more effective implementation of YOLOv5 models in various real-world applications. ⚙️🚀