![]()
![]()
torchtitan is currently in a pre-release state and under extensive development. Currently we showcase pre-training Llama 3.1, Llama 3, and Llama 2 LLMs of various sizes from scratch. To use the latest features of torchtitan, we recommend using the most recent PyTorch nightly.
torchtitan is a proof-of-concept for Large-scale LLM training using native PyTorch. It is (and will continue to be) a repo to showcase PyTorch's latest distributed training features in a clean, minimal codebase. torchtitan is complementary to and not a replacement for any of the great large-scale LLM training codebases such as Megatron, Megablocks, LLM Foundry, Deepspeed, etc. Instead, we hope that the features showcased in torchtitan will be adopted by these codebases quickly. torchtitan is unlikely to ever grow a large community around it.
Our guiding principles when building torchtitan:
- Designed to be easy to understand, use and extend for different training purposes.
- Minimal changes to the model code when applying 1D, 2D, or (soon) 3D Parallel.
- Modular components instead of a monolithic codebase.
- Get started in minutes, not hours!
We provide a detailed look into the parallelisms and optimizations available in torchtitan, along with summary advice on when to use various techniques: TorchTitan: One-stop PyTorch native solution for production ready LLM pre-training.
@misc{torchtitan,
title={TorchTitan: One-stop PyTorch native solution for production ready LLM pre-training},
author={Wanchao Liang and Tianyu Liu and Less Wright and Will Constable and Andrew Gu and Chien-Chin Huang and Iris Zhang and Wei Feng and Howard Huang and Junjie Wang and Sanket Purandare and Gokul Nadathur and Stratos Idreos},
year={2024},
eprint={2410.06511},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2410.06511},
}
You may want to see how the model is defined or how parallelism techniques are applied. For a guided tour, see these files first:
- train.py - the main training loop and high-level setup code
- torchtitan/parallelisms/parallelize_llama.py - helpers for applying Data Parallel, Tensor Parallel, activation checkpointing, and
torch.compileto the model - torchtitan/parallelisms/pipeline_llama.py - helpers for applying Pipeline Parallel to the model
- torchtitan/checkpoint.py - utils for saving/loading distributed checkpoints
- torchtitan/float8.py - utils for applying Float8 techniques
- torchtitan/models/llama/model.py - the Llama model definition (shared for Llama 2 and Llama 3 variants)
- FSDP2 with per param sharding
- Tensor Parallel (including async TP)
- Selective layer and operator activation checkpointing
- Distributed checkpointing (including async checkpointing)
- Checkpointable data-loading, with the C4 dataset pre-configured (144M entries)
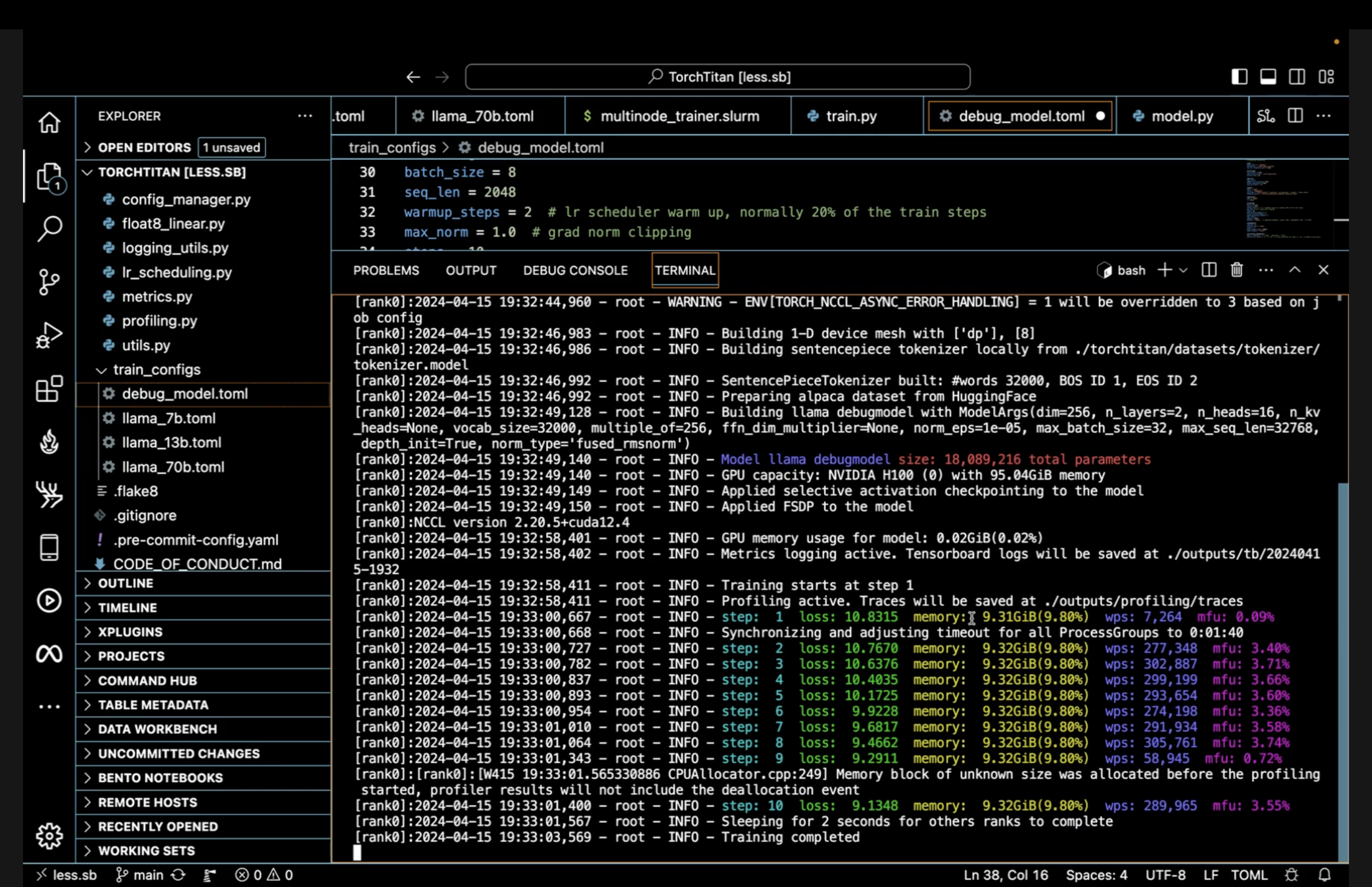
- Loss, GPU memory, tokens-per-second, and MFU displayed and logged via TensorBoard
- Learning rate scheduler, meta-init, optional Fused RMSNorm
- Float8 support (how-to)
torch.compilesupport- DDP and HSDP
- All options easily configured via toml files
- Interoperable checkpoints which can be loaded directly into
torchtunefor fine-tuning - Debugging tools including CPU/GPU profiling, memory profiling, Flight Recorder, etc.
We report our Performance verified on 64/128 GPUs.
- Pipeline Parallel (and 3D parallellism)
- Context Parallel
git clone https://github.com/pytorch/torchtitan
cd torchtitan
pip install -r requirements.txt
pip3 install --pre torch --index-url https://download.pytorch.org/whl/nightly/cu121 # or cu118torchtitan currently supports training Llama 3 (8B, 70B), and Llama 2 (7B, 13B, 70B) out of the box. To get started training these models, we need to download a tokenizer.model. Follow the instructions on the official meta-llama repository to ensure you have access to the Llama model weights.
Once you have confirmed access, you can run the following command to download the Llama 3 / Llama 2 tokenizer to your local machine.
# Get your HF token from https://huggingface.co/settings/tokens
# Llama 3 or 3.1 tokenizer.model
python torchtitan/datasets/download_tokenizer.py --repo_id meta-llama/Meta-Llama-3-8B --tokenizer_path "original" --hf_token=...
# Llama 2 tokenizer.model
python torchtitan/datasets/download_tokenizer.py --repo_id meta-llama/Llama-2-13b-hf --hf_token=...Llama 3 8B model locally on 8 GPUs
CONFIG_FILE="./train_configs/llama3_8b.toml" ./run_llama_train.shTo visualize TensorBoard metrics of models trained on a remote server via a local web browser:
-
Make sure
metrics.enable_tensorboardoption is set to true in model training (either from a .toml file or from CLI). -
Set up SSH tunneling, by running the following from local CLI
ssh -L 6006:127.0.0.1:6006 [username]@[hostname]
- Inside the SSH tunnel that logged into the remote server, go to the torchtitan repo, and start the TensorBoard backend
tensorboard --logdir=./outputs/tb
- In the local web browser, go to the URL it provides OR to https://localhost:6006/.
For training on ParallelCluster/Slurm type configurations, you can use the multinode_trainer.slurm file to submit your sbatch job.
To get started adjust the number of nodes and GPUs
#SBATCH --ntasks=2
#SBATCH --nodes=2
Then start a run where nnodes is your total node count, matching the sbatch node count above.
srun torchrun --nnodes 2
If your gpu count per node is not 8, adjust:
--nproc_per_node
in the torchrun command and
#SBATCH --gpus-per-task
in the SBATCH command section.
If you encounter jobs that timeout, you'll need to debug them to identify the root cause. To help with this process, we've enabled Flight Recorder, a tool that continuously collects diagnostic information about your jobs.
When a job times out, Flight Recorder automatically generates dump files on every rank containing valuable debugging data. You can find these dump files in the job.dump_folder directory.
To learn how to analyze and diagnose issues using these logs, follow our step-by-step tutorial link.
This code is made available under BSD 3 license. However you may have other legal obligations that govern your use of other content, such as the terms of service for third-party models, data, etc.