{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Construction of an ideal high-density lipoprotein analyzing its structural and functional properties
High-density lipoproteins are small (diameter of 8 to 10 nanometers) complex particles consisting of a variety of lipid components and apolipoproteins with the transportation of excess cholesterol from peripheral cells to the liver for degradation being their main function. Apolipoproteins and lipids are important for the structural formation of the lipoprotein particles and they possess a key role in lipoprotein metabolism and interaction. With the use of statistical methods, lipids such as phospholipids, fatty acids, triglycerides and cholesterol and apolipoproteins such as APOA1, APOE3, and APOC3 were analyzed in an effort to understand the underlying association between them and three major biological functions of HDL: 1) Reverse Cholesterol Transfer, 2) Antioxidant Function, 3) Anti-inflammatory Function. These three HDL functional properties are directly associated with the risk of atherosclerosis development and progression and include the HDL particle capacity to efflux cellular cholesterol and the antioxidative and anti-inflammatory properties. Specifically, multivariate data analysis and machine learning techniques such as regression, random forests, and general inferential statistics were used in order to test hypotheses based on previous research and discover variables that affect in a great extend the above three major functional HDL properties. Part of data and other information have originated from the combination of two research publications, [(Zvintzou, et al. 2017), (Filou, et al. 2016)] both regarding the analysis of HDL and some of its subpopulations in specific genetic background mice (C57BL/6 and Apoe-/- x Apoa1-/-, respectively) infected with adenoviruses expressing three different human apolipoproteins, APOC3 and APOA1, APOE3, respectively.
The main issue faced was the sample size in the given datasets which lead to results that could not be generalized in other datasets with same attributes. As it will be mentioned in further chapters, future work is already in place to get a bigger sample size and test this specific analysis for better and more generalizable results.
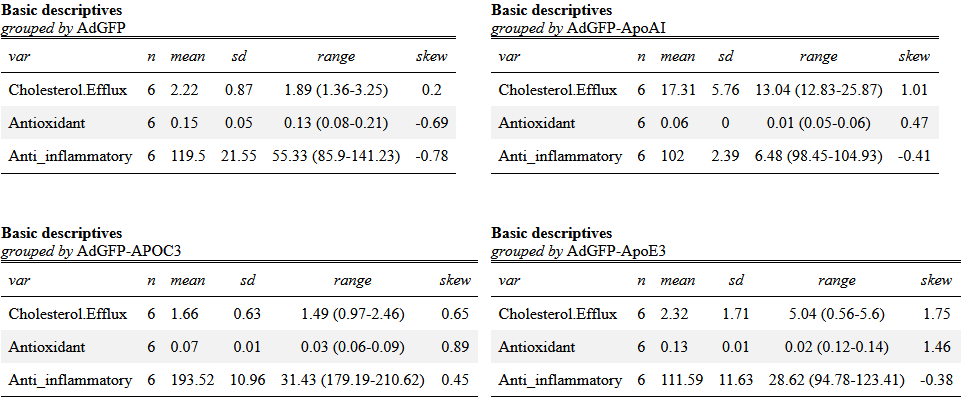
A log-transformation was applied in each function in an attempt to reconstruct their respective distributions, but no change was observed in later analysis; the original values where ultimately used.
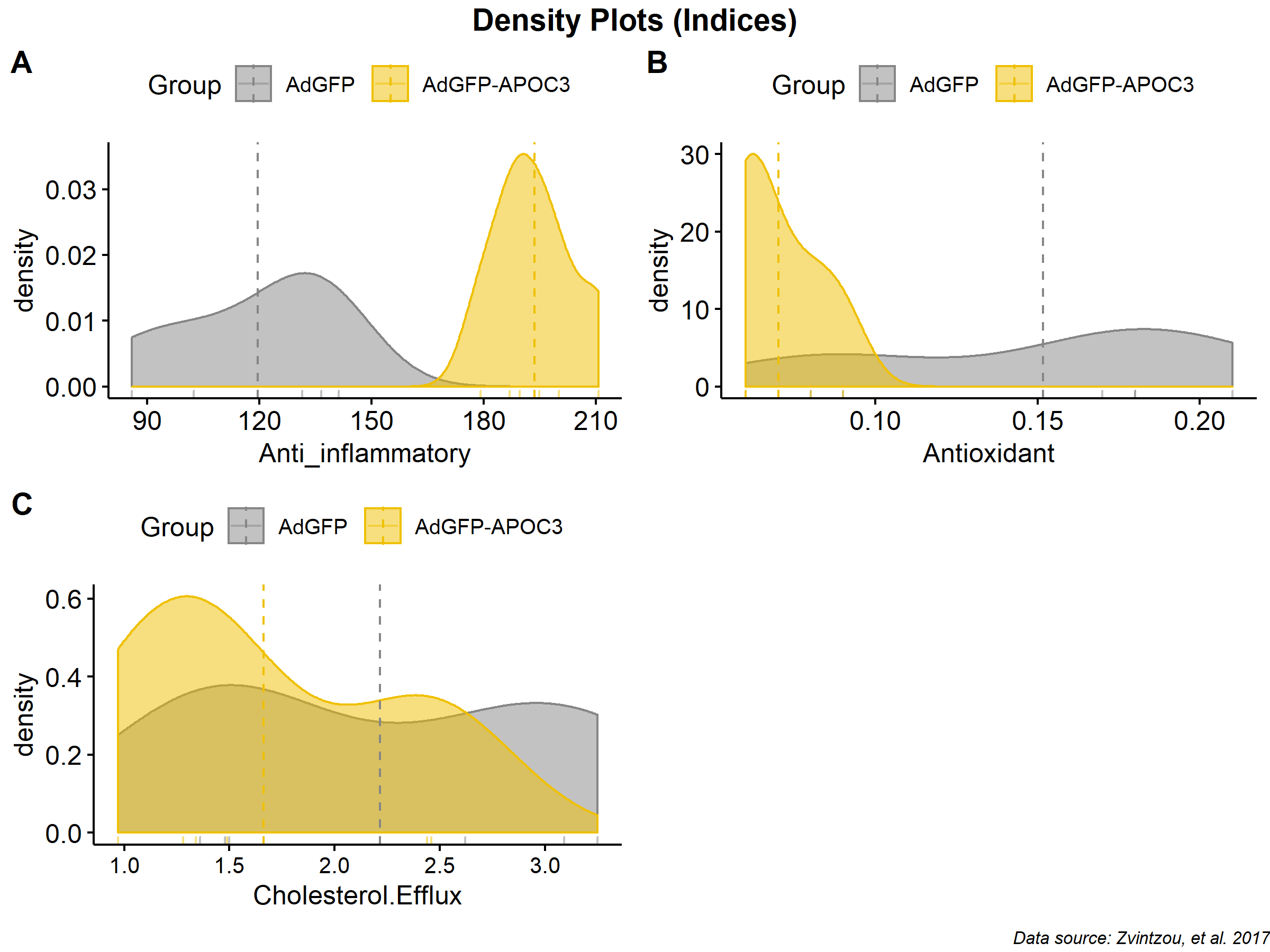
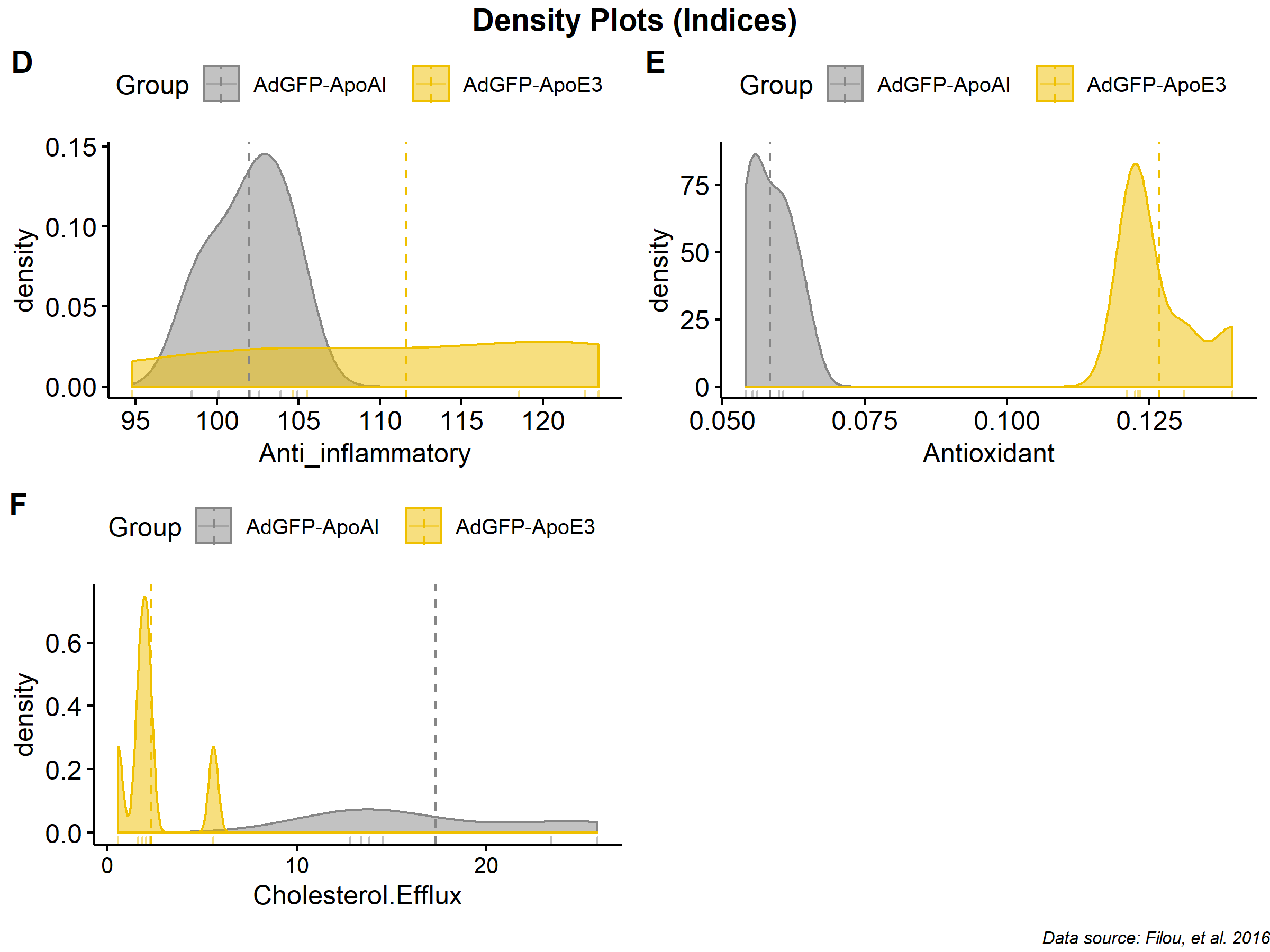
To avoid problems where some algorithms, may face difficulties with variables with low or zero variance, the following tests were performed removing each variable met the following conditions:
- Find variables with a unique value for each sample (zero variance)
- Find variables that belong to one of the following two cases
o have very few unique values relative to the number of samples (at least 10)
o the ratio of the frequency of the most frequently occurring value to the frequency of the second most frequently occurring value is large (the ratio was set to 95/5 in this work)
An attempt to optimize also the number of trees was made but with no effect in the final model except the realization that small number of trees are resulting to lower RMSE in the final model; no further investigation was made on this part. Below, illustrations are presented for some test cases from the Lipid Species category (AdGFP-APOE3, Filou, et al.).
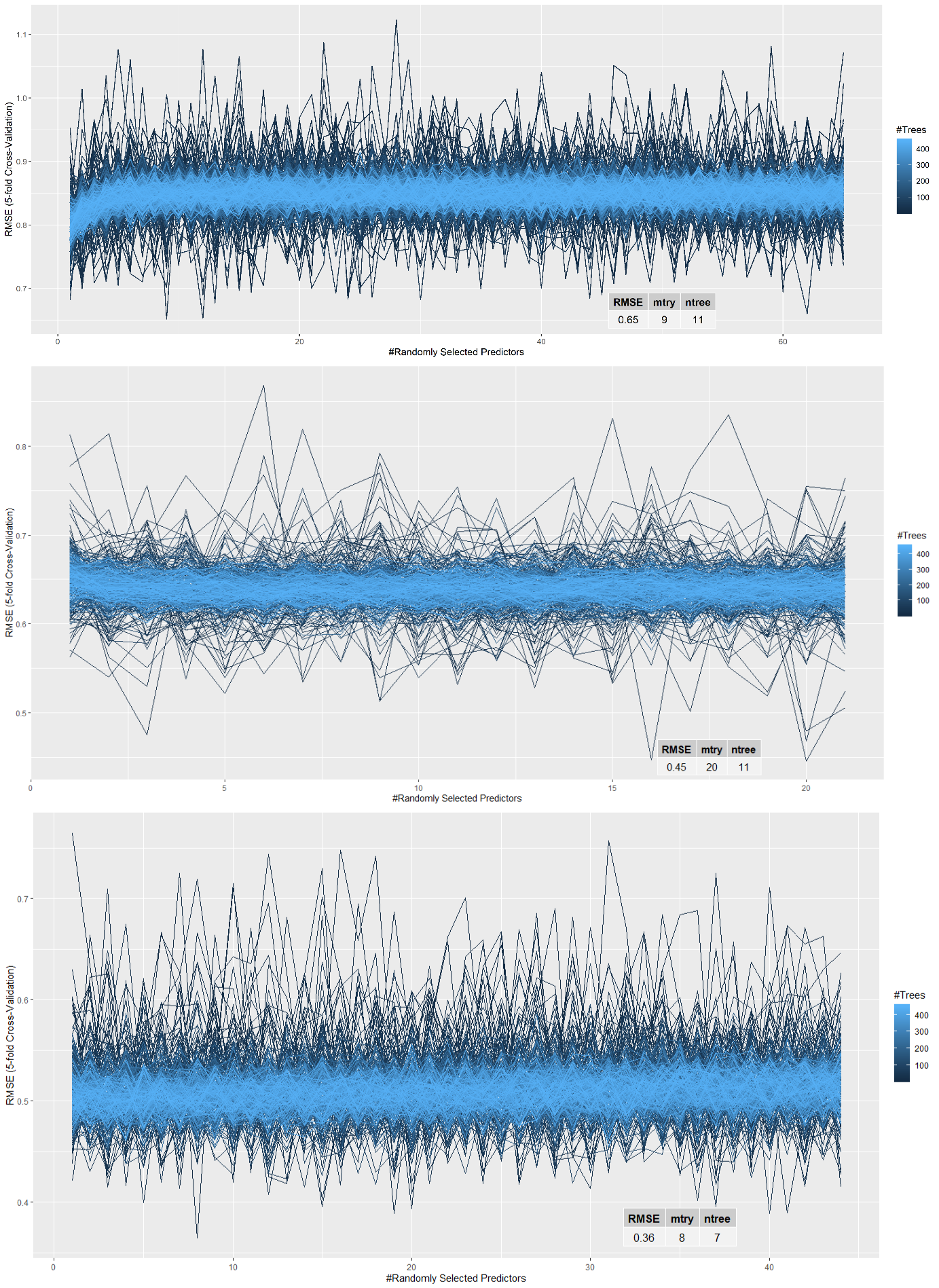
This framework is designed to extract variables (fatty acids in this case) that have predictive power over three indices of interest that consist of specific HDL functions: Cholesterol Efflux, Antioxidant function, Anti-inflammatory function. Random forests introduced by Friedman present a very useful tool for ranking variables used for constructing the model based on some metric of choice. One of the most robust and illuminating metrics for numerical variables is the Percent Increase in Mean Square Error (%IncMSE) which is computed by permuting each variable present in the model.
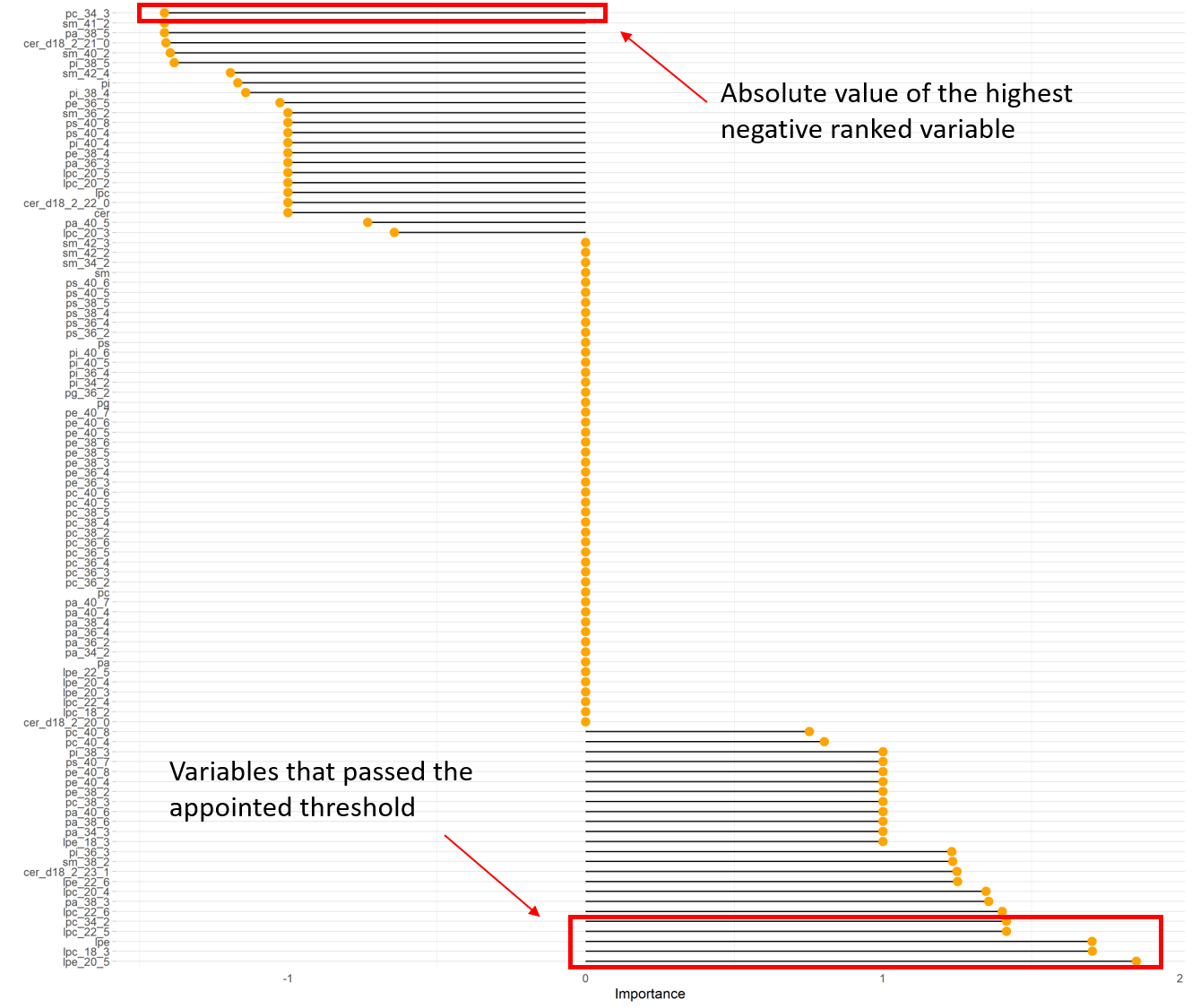
The step of filtering variables based on absolute values, is used only for setting a respective threshold. During the presentation of results of this thesis, variable importance, will be interpreted as ranking and not as absolute values of each variable.