Remember how we have to click and classify our work mails based on themes ? 🤔 Dont we all get lost at what theme should the mail be classified into ? And worst when we have to retrive the important mails and we forgot to put them in a folder incase we missed to assign a theme ! 🤕
What if I tell you that we can automate this ?
All you need is some data and some NLP ! 🎊
This is exactly what we are trying to achieve via this project . Making your life simple one project at a time 😄
Let us understand in detail about the data
Here is a quick view of my journey to achieve the goal :
-
Using BERT Model: https://github.com/princyiakov/email_classifier/blob/main/Bert_Email_Classifier.ipynb
-
Using SVC and other models: https://github.com/princyiakov/email_classifier/blob/main/Email%20Classifier_Attempt2.ipynb
Classification labels based on the Label encode value assigned:
[0] `company image -- current`
[1] `alliances / partnerships`
[2] `california energy crisis / california politics`
[3] `company image -- changing / influencing`
[4] `internal company operations`
[5] `internal company policy`
[6] `internal projects -- progress and strategy`
[7] `legal advice`
[8] `meeting minutes`
[9] `political influence / contributions / contacts`
[10] `regulations and regulators (includes price caps)`
[11] `talking points`
[12] `trip reports`
Mail Sample :
Date: Wed, 13 Jun 2001 06:05:07 -0700 (PDT)
From: [email protected]
To: [email protected], [email protected]
Subject: Enron Expatriates in India
Mime-Version: 1.0
Content-Type: text/plain; charset=us-ascii
Content-Transfer-Encoding: 7bit
X-From: Kean, Steven </O=ENRON/OU=NA/CN=RECIPIENTS/CN=NOTESADDR/CN=B86DC838-ECAFDC13-8625693C-57FA6D>
X-To: Lay, Kenneth </O=ENRON/OU=NA/CN=RECIPIENTS/CN=KLAY>, Skilling, Jeff </O=ENRON/OU=NA/CN=RECIPIENTS/CN=JSKILLIN>
X-cc:
X-bcc:
X-Folder: \JSKILLIN (Non-Privileged)\Deleted Items
X-Origin: Skilling-J
X-FileName: JSKILLIN (Non-Privileged).pst
John Brindle, David Cromley and others in the Corporate Business Controls group (formerly part of EBS) have been working over the last several weeks to make sure that we can get our people out of Dabhol if there are threats to their safety. While no plan is perfectly reliable (particularly during monsoon season) we believe that we are as ready as we can be.
---------------------- Forwarded by Steven J Kean/NA/Enron on 06/13/2001 08:00 AM ---------------------------
From: David Cromley@ENRON COMMUNICATIONS on 06/12/2001 09:18 AM
To: Steven J Kean/NA/Enron@Enron
cc:
Subject: Enron Expatriates in India
Steve,
I wanted to give you the latest figures on Enron expatriates in India. There are currently 19 Enron expatriate employees based in India, accompanied by six dependants. In addition, Enron has responsibility for 15 expatriate contractors working for DPC and Lingtec, primarily at Dabhol. The total of 40 expatriates for whom Enron is directly responsible is broken down by location as follows: 21 in Mumbai, 16 at Dabhol, and three in Baroda. By company, they are broken down as follows: Enron India - eight plus three dependants; EOGIL - nine plus one dependant; EBS - one plus two dependants; DPC - seven; and Lingtec - nine. These figures are likely to continue to trend downward; Jane Wilson's departure on Friday, for example, will reduce the Enron India expatriate presence to seven plus three dependants.
We are confident that the evacuation plan now in place provides the best possible prospect of successfully evacuating all of these expatriates in the event of danger. As a contingency, the plan also includes the evacuation of all 137 expatriates working at the Dabhol site, although a large-scale evacuation from Dabhol is more problematic, especially now that the monsoon season has started. A coordinated plan was needed since the limited number of available helicopters meant that the evacuation plans drawn up by individual contractors such as Bechtel were all drawing upon the same resources.
As you know, Enron's security situation in India remains stable. We are in the final stages of implementing security upgrades for our employees and offices there.
Dave
Performed different data cleaning techniques for NLP.
- Basic cleaning of data from unique characters
- Added new stop words which improved the model performace
- Removed URLs
- Lowercase the data
- Explored stemming and lemmatization where model performed better on using lematization
Every Data has a story to tell . Let's understand the story behind this one !
-
TARGET THEME DISTRIBUTION : As we see, the data is not equally distributed . We have ample amount of data to train for "reguations and regulators" but only four data for "trip reports" !
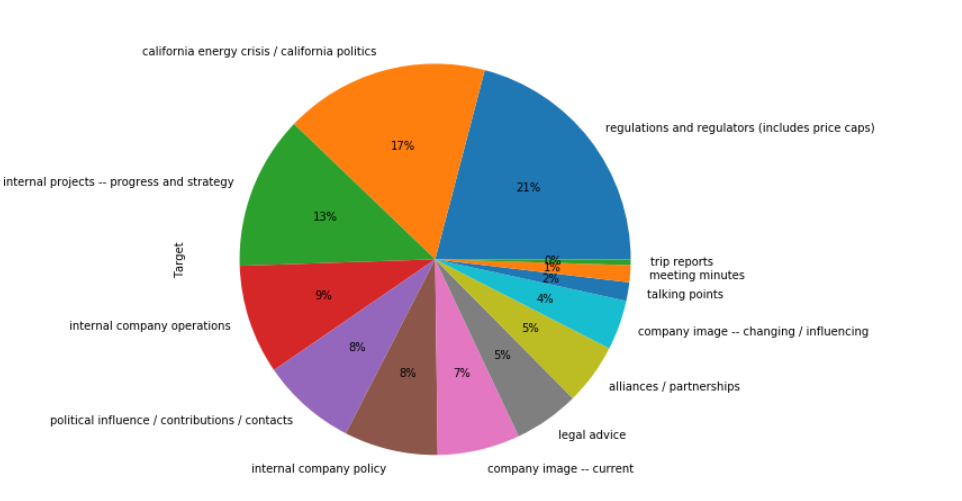
-
MAILS DISTRIBUTION BASED ON MONTHS : Maximum mails have been sent in the month of July and least in January.
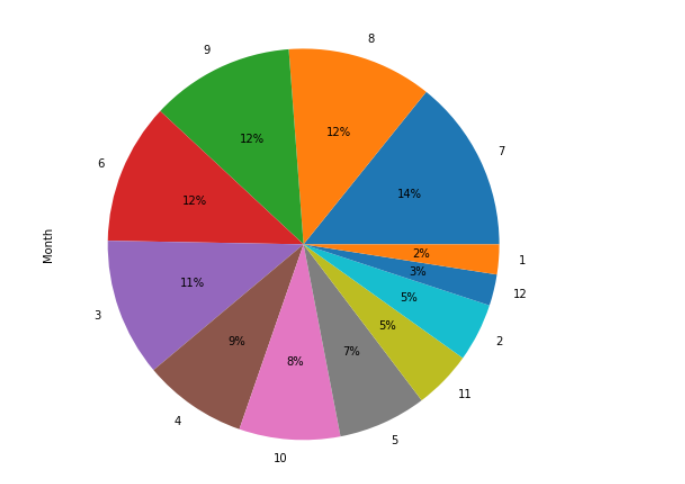
-
What were they discussing during these two months ?! Lets see ! July was more about "regulations and regulators (includes price caps)" and "california energy crisis / california politics"
January was relaxed and more about understanding the future plans as the mails were "internal projects -- progress and strategy" and "legal advice"
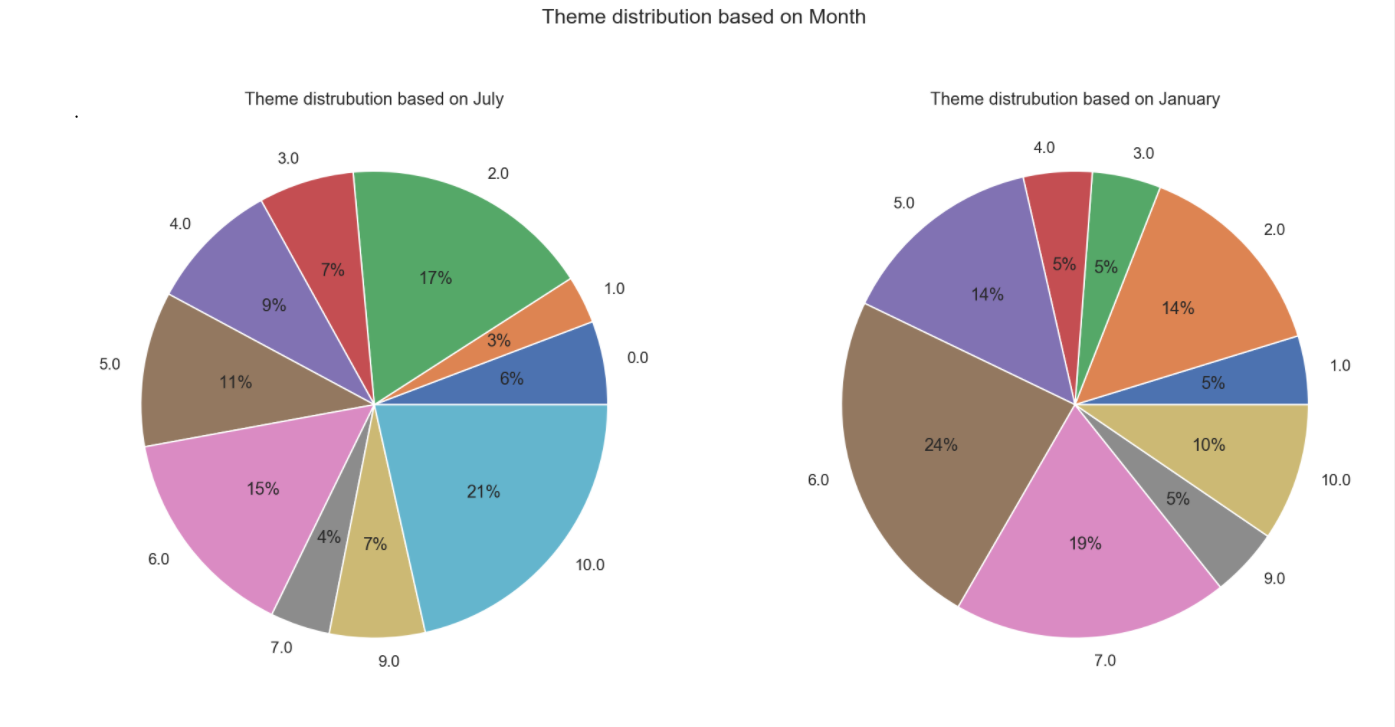
-
Lets dig deeper! In a month, what is the distribution, start, middle and end .
Beginning of the month and end of the month looks a bit similar with more focus on "california energy crisis / california politics" and "regulations and regulators ". By the end of the month a little more focus on "internal company policy" and "internal projects -- progress and strategy" We see a rise in company mails regarding "internal company operations" in the middle of the month .
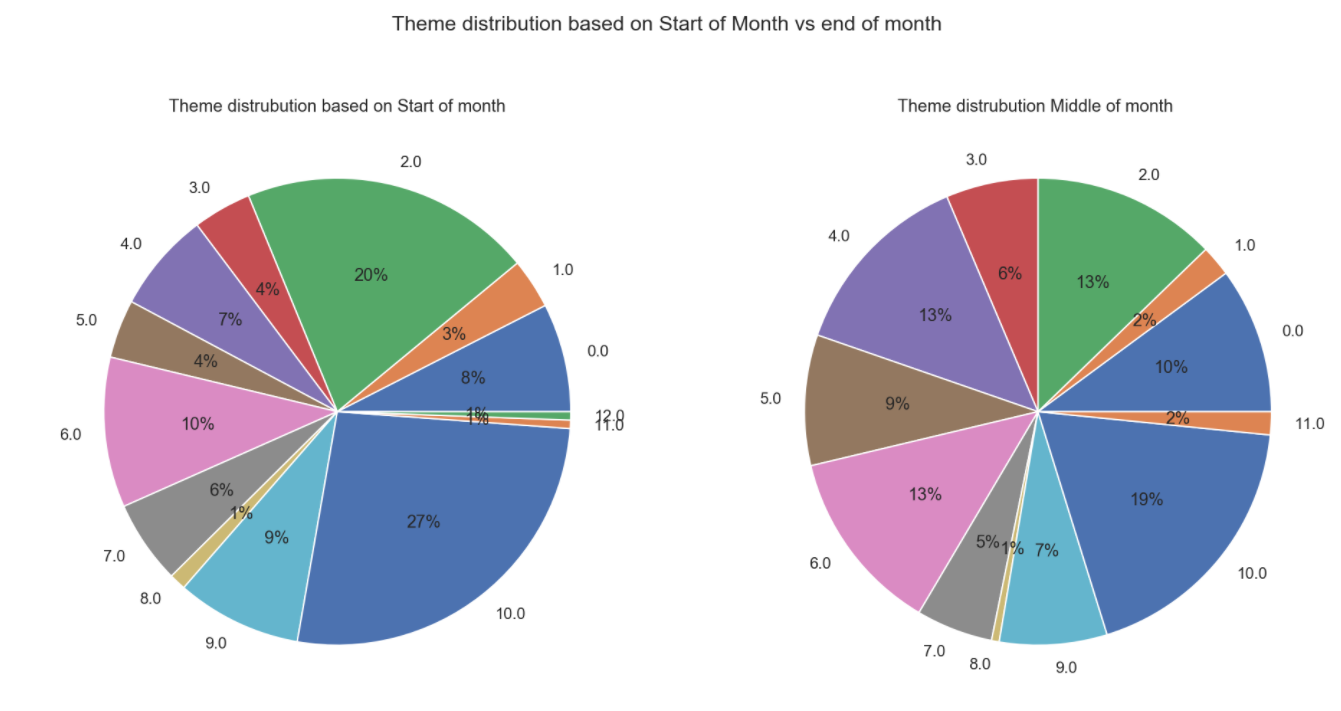
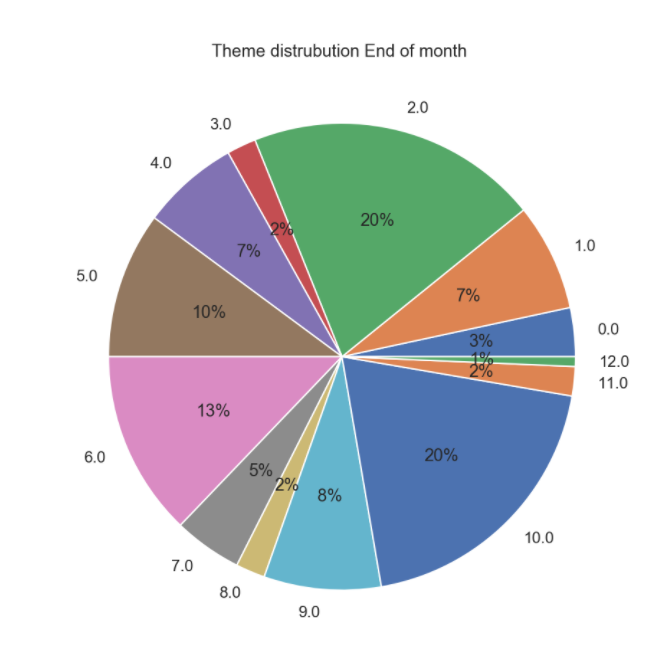
-
Lets see what hours maximum mails are sent. I bined the Hours in 4 timeslots . We see that maximum mails were sent during afternoon working hours, followed by morning working hours
Time slot Value 00:00 hrs - 08:00 hrs 0 08:01 hrs - 12:00 hrs 1 12:01 hrs - 18:00 hrs 2 18:01 hrs - 23:59 hrs 3 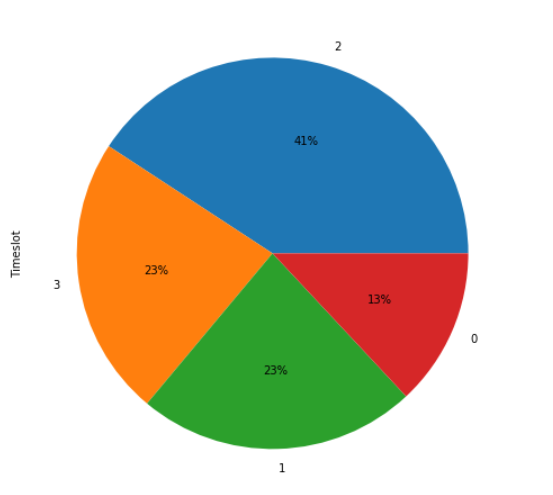
-
Since we are doing NLP implementation, lets see which words compose the moset in each theme.






| WordCloud for theme company image -- current | Word Cloud for theme alliances / partnerships |
|---|---|
 |
 |
| WordCloud for theme california energy crisis / california politics | Word Cloud for theme company image -- changing / influencing |
|---|---|
 |
 |
| WordCloud for theme internal company operations | Word Cloud for theme internal company policy |
|---|---|
 |
|
| WordCloud for theme internal projects -- progress and strategy | Word Cloud for theme legal advice |
|---|---|
 |
 |
| WordCloud for theme meeting minutes | Word Cloud for theme political influence / contributions / contacts |
|---|---|
 |
 |
| WordCloud for theme regulations and regulators | Word Cloud for theme talking points |
|---|---|
 |
 |
WordCloud for theme trip reports |

A quick sneak peek into the top 40 common words in the mail corpus :

Classify the emails I explored the following models :
- SVC
- KNeighborsClassifier
- MultinomialNB
- DecisionTreeClassifier
- LogisticRegression
- RandomForestClassifier
- AdaBoostClassifier
- ExtraTreesClassifier
- GradientBoostingClassifier
- XGBClassifier
Out of which SVC provided better results on fitting on Text values solely . GradientBoostingClassifier performed better on introducing Datetime element .
However, the model performance needs to be improved drastically for being capable of production.
Follow up for improving the model :
-
Gather More data
-
Implement Over Sampling
-
Implementation of BERT transformers.I have already initiated the implementation: https://github.com/princyiakov/email_classifier/blob/main/Bert_Model.ipynb .
I need to implement the slicing of long sentences as bert accommodates only 512 token size .
Follow up for the project :
- create a front end