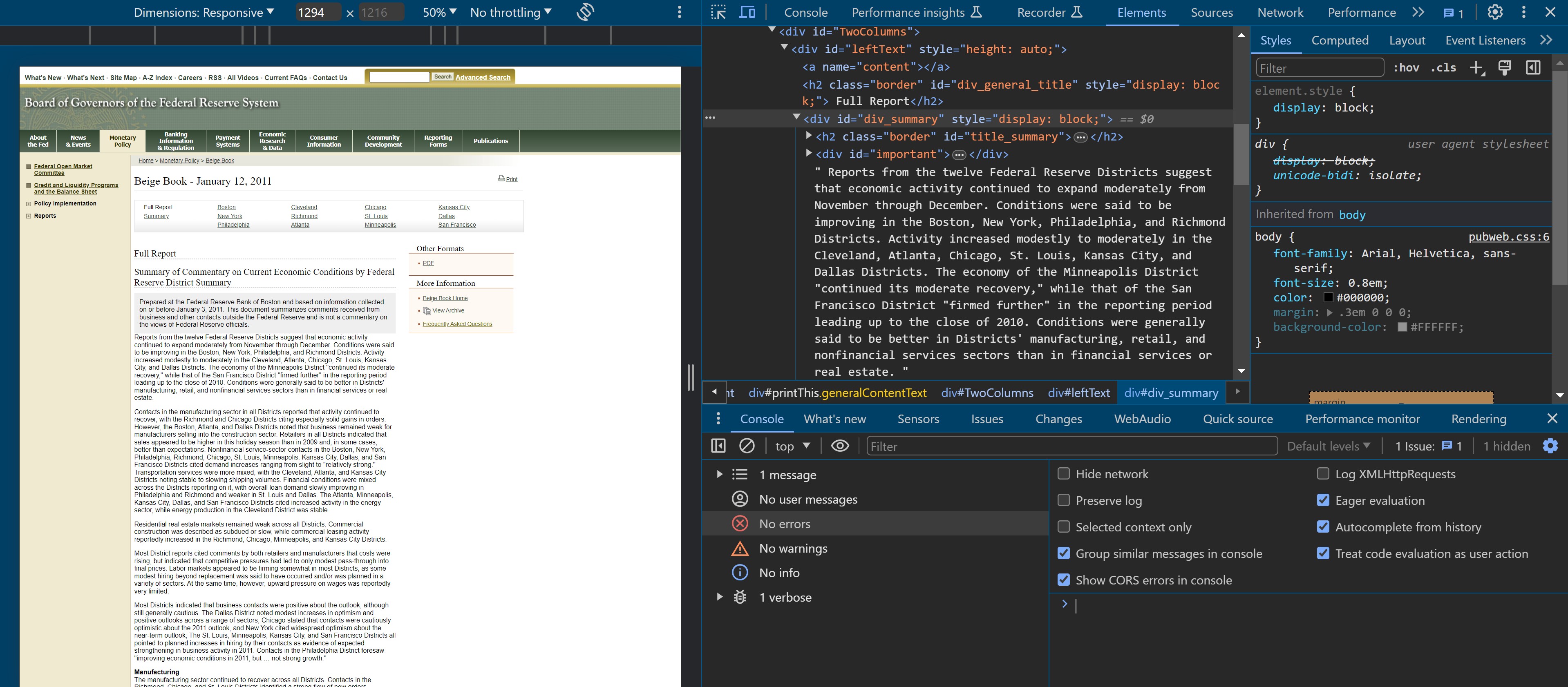
We want to obtain the summary of economic conditions for each Federal Reserve bank district. We know that this information is contained in the archived Federal Reserve Beige Book publications.
Web scraping is our most direct option. We will perform it using Python's Beautiful Soup library.
We have already obtained the summary of economic conditions for the years 2017 up through the most recent Beige Book publication and we know that archived reports can be viewed by year:
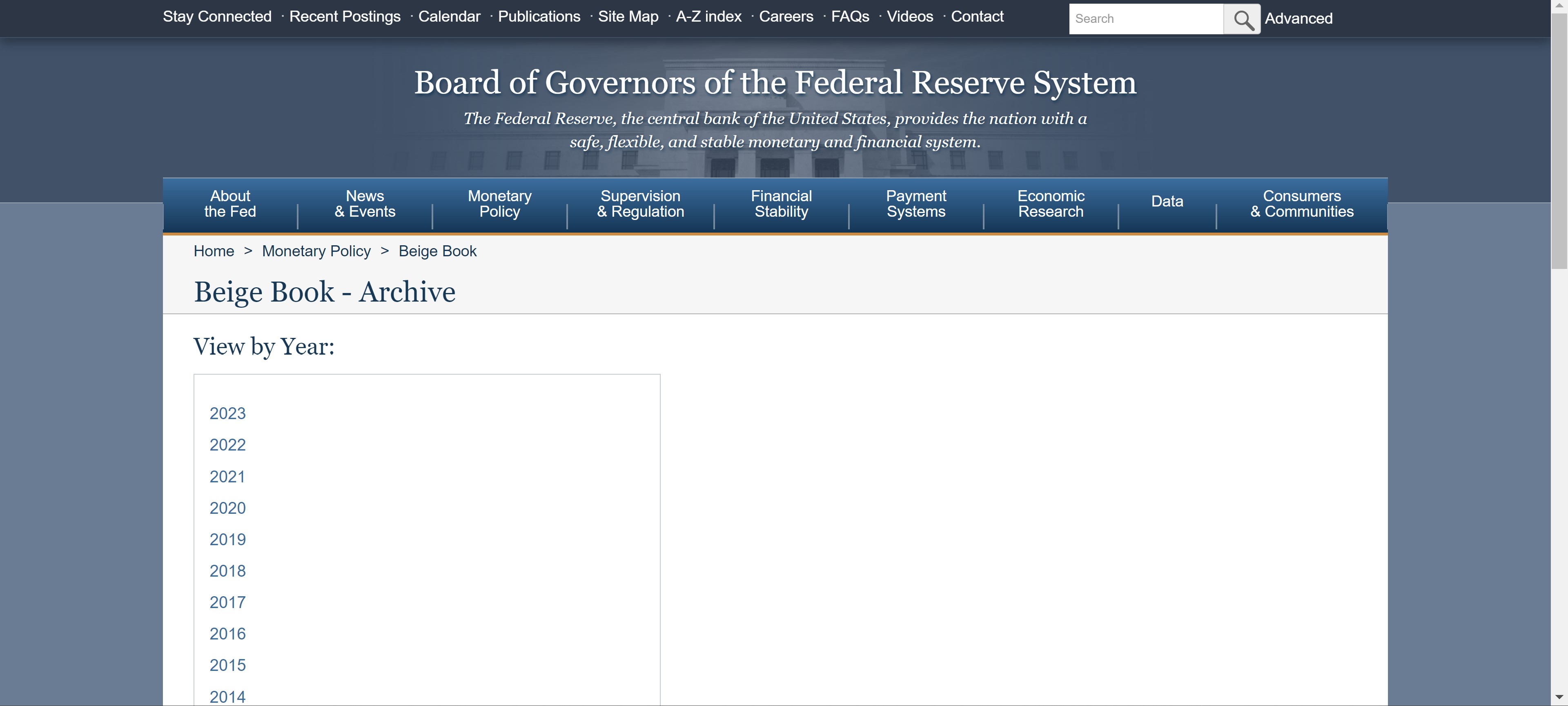
We will specify a range of years and iterate through each one in order to parse all of the Beige Book publication dates to faciliate next steps.
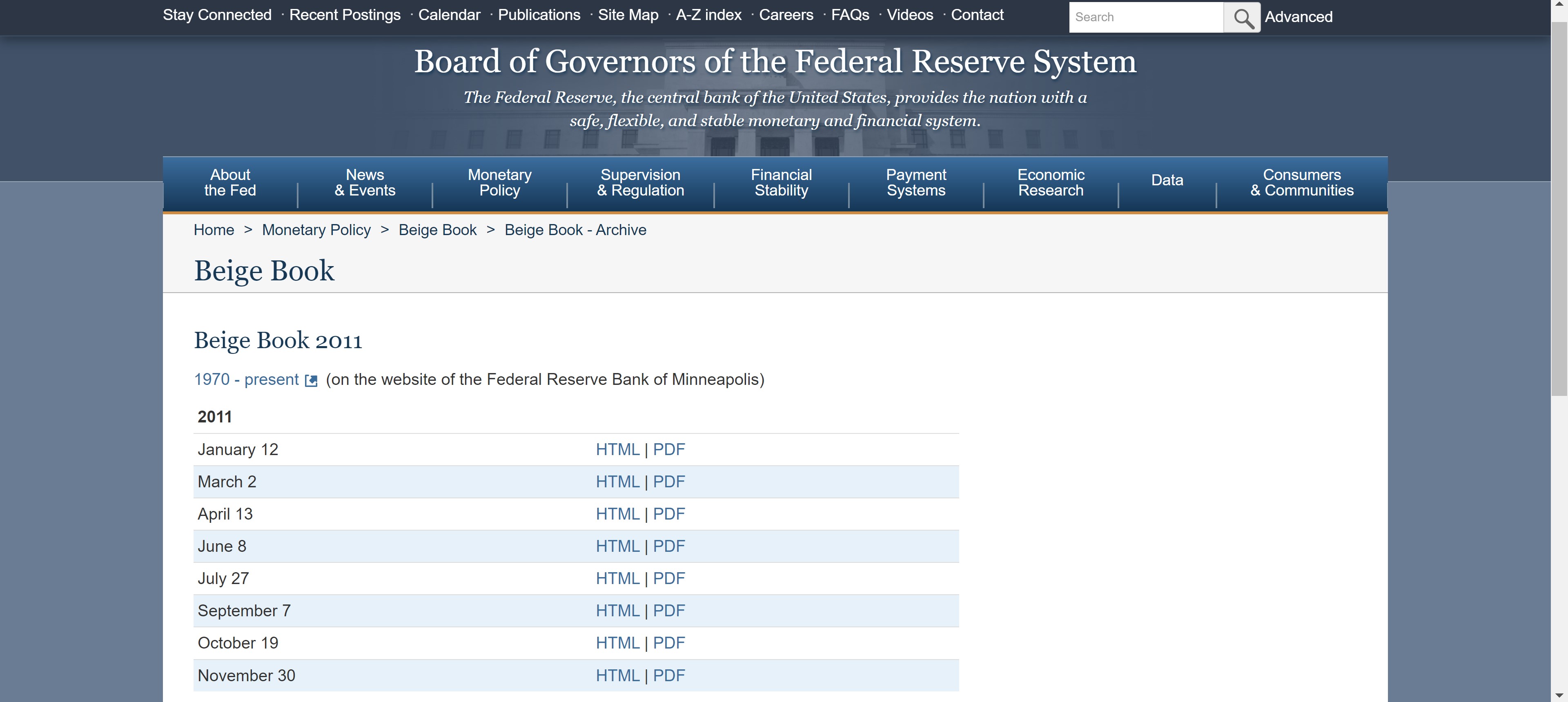
Having collected the publication dates, we use the year and month substrings to ingest the HTML for each given Beige Book publication and parse the national summary in addition to the summary of economic conditions for each district.
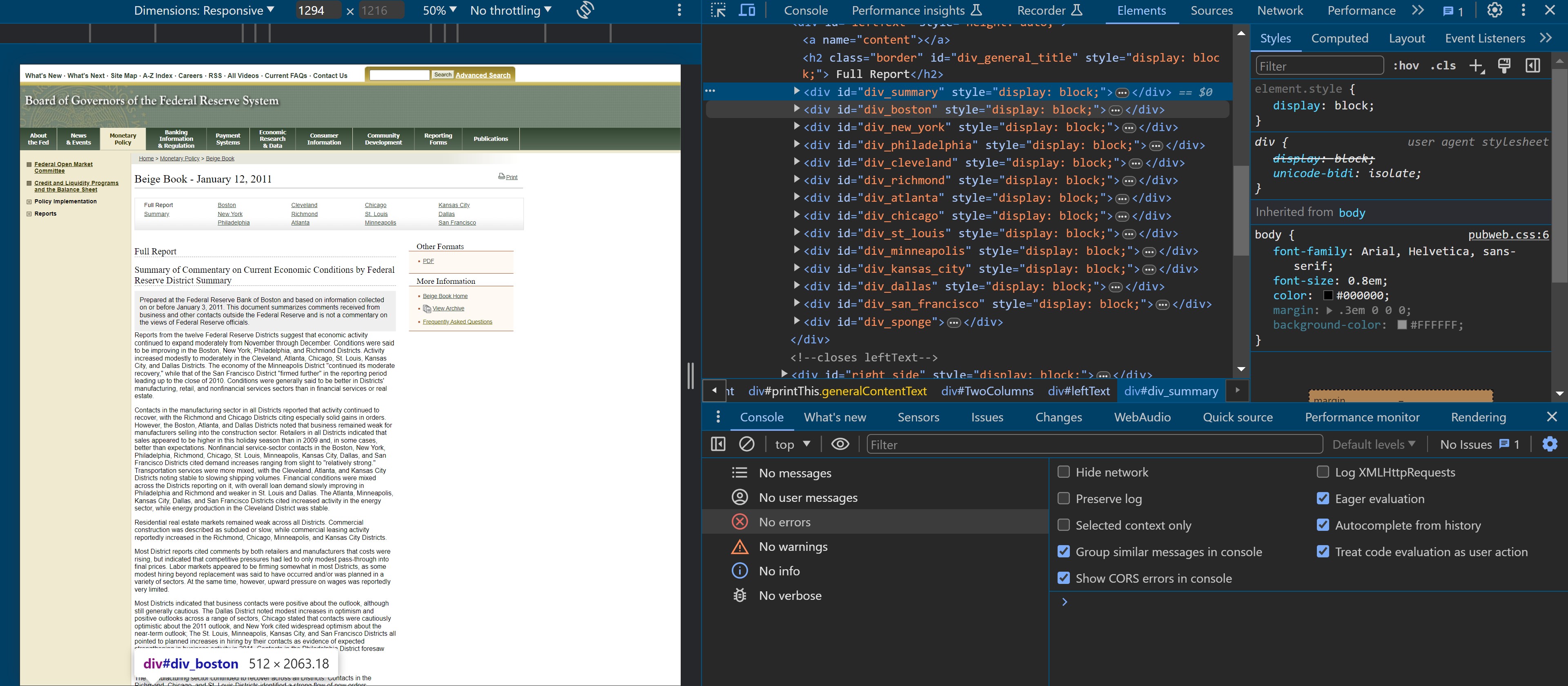
As you can see from the results, we now have some data cleaning to do -- but we'll save that for another lesson 😆
See you next time!