In the spring of 2018, Google launched the Landmark Recognition Challenge, a competition that involves engaging a classifier to recognize the world's famous buildings and monuments. In this project we implemented a series of models including: VGG-16 pre-engineered on ImageNet to which we trained only the final classifier and modified VGG-16 pre-modulated to which we added a module of attention.
The dataset consists of approximately 12 million images with 14,952 buildings (classes), which we downloaded from the Internet, then we got the most definite 27 classes, ie about 11.5% of the dataset size (46GB) and 0.18% of the number classes. A histogram showing the weight of the most definite 50 classes in the dataset is described. It can easily be observed that data is unbalanced, varying from 49091 examples for class 9633 to 1 for several dozen classes (9936, 99, etc.). The dataset was divided into 3 train (70%), validation (15%) and test (15%).

Data was augmented, namely: on train: rotation at ± 45 °, random crop at 224 × 224, change of illumination up to 25% and random flip, on validation and test: center crop at 224 × 224 and rotation at ± 45 °. The architecture used is VGG-16 to which the final classification sequence has been modified using Dropout after each fully-connected layer for regularization. The training of the model is done only on the classification sequence, while the feature extraction sequence remains frozen during training, as the VGG-16 is already pre-trained on 1000 classes, expected to return a number of well-defined features, either classified.

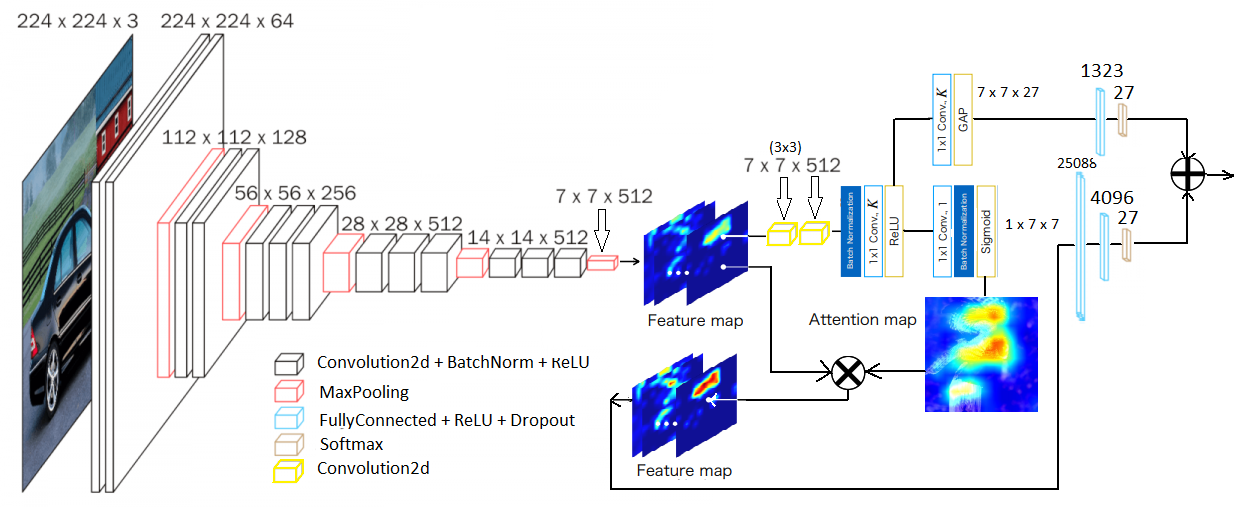
- We continue to expand our previous network to an Attention Branch Network (ABN) which is nothing but VGG-16 with the branch structure and attention module. The branch architecture is suggested only after applying the ReLU function after the two convolutional 7x7x512 filter (3x3). The purpose of the attention module is to force the network to look only on certain areas of the image. I mention that the architecture used is similar to that described in the paper Attention Branch Network: Learning of Attention Mechanism for Visual Explanation.
- Attention map is based on four convolutions in the feature map, reducing the number of channels from 512 to the number of classes (to us 27) then by applying the sigmoid. This is a 7x7 map in our case of values between 0 and 1, in which areas with a score close to 1 are of interest and those close to 0 not.
- By multiplying each channel in the feature map with the attention map, a new feature map is obtained.
Loss is calculated as a linear combination of the bottom (attention map + classification) and top (GAP (works on the idea of blurring information)).
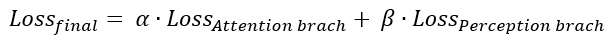
- alfa and beta are the hyperparameter that measures how much attention (top) and perception (bottom)


| Model | VALIDATION | TEST |
|---|---|---|
| VGG-16 | 87.92% | 87.97% |
| VGG-16 with Attention Branch (alfa = 0.25 and beta = 1) | 30.54% | 27.66% |
| VGG-16 with Attention Branch (alfa = 0 and beta = 1) | 32.71% | 32.58% |
| Model | Epoch 1 | Epoch 2 | Epoch 3 |
|---|---|---|---|
| VGG-16 |  |
 |
 |
| VGG-16 with Attention Branch (alfa = 0.25 and beta = 1) |  |
 |
 |
| VGG-16 with Attention Branch (alfa = 0 and beta = 1) |  |
 |
 |
- In the above table we see the difference in accuracy after 3 epochs between the three models, one reason being the larger number of parameters of the last two models.
- An interesting aspect is given by the last two lines in the table that suggest that the network that has the only loss on the classification branch (the perception) has a slightly higher convergence rate compared to the network that has accumulated the loss on both sides, thus suggesting that the blurred (general) information does not add to our classification case.
| VGG-16 with Attention Branch (alfa = 0.25 and beta = 1) | VGG-16 with Attention Branch (alfa = 0 and beta = 1) |
|---|---|
 |
 |
 |
 |
 |
 |
- Attention gets focused on the elements of interest in the image, but learning is hampered by the more complex model and requires more careful tuning of hyperparametres and greater attention to the optimization process
- The attention module is a general concept that can be applied to any task involving convolutional patterns and can be applied to various levels of the network, which has not been treated in this paper. (ending with feature extraction)