This is the project code for my seminar paper on Deep Reinforcement Learning applied to Blackjack. My focus laid specifically on the mathematical foundations of Reinforcement Learning. This repository corresponds to the implementation, testing, and optimization of Deep-Q-Networks and testing out how different configurations affect the Network's performance and the embedding of game states.
The project was developed with Python 3.6 using Tensorflow 2.1.0 on a machine with a slightly overclocked eight-core CPU and a GTX 980TI.
| module name | function |
|---|---|
| BlackjackEnv.py | Environment, simulation of the game |
| Dqn.py | Dynamic generation of network structures |
| ReplayBuffer.py | Replay Buffer, save states of the environment |
| Exploration.py | Abstract class for a exploration strategy, implementation of the greedy strategy |
| DqnAgent.py | Agent, framework for development and testing out different combination of parameters |
The rewards were modeled as follows: in the beginning the agent starts with a bet of one. In every move, the agent can decide between one of five moves:
- stick, game ends, bet stays same
- hit, draw new card, bet stays same
- split, split two cards and draw one new for each of them, bet doubles
- double, double bet, bet doubles
- surrender, game ends, returns half of bet
If the agent wins the game, it gets back the whole bet as the reward. Otherwise, the reward is the negative value of the bet.
| network structure* | reward** |
|---|---|
| (10,3) | -0.288 |
| (10,5) | -0.40 |
| (10,7) | -0.33 |
| (15,3) | -0.166 |
| (15,5) | -0.156 |
| (15,7) | -0.175 |
* generated with 'generate_layers_linear()' in module 'Dqn.py'
** average of 1000 played games after 500.000 epoch training
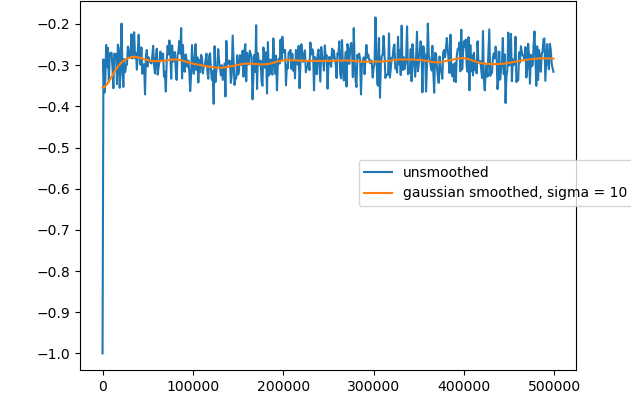
training graph of the best (15,5) network structure with a learning rate of 0.1
 |
 |
|---|---|
| before training | after ~800.000 episodes of training |
t-SNE visualization with perplexity=30
shows representation of different classes of inputs in the last layer of the network
Each color corresponds to one action the agent can take