Matlab implementation of a feature selection algorithm based on set-wise mutual information
Many variants of the idea of using mutual information (MI) to determine salience of a feature in a pattern recognition task have been suggested in literature. They have their limitations, however: computing MI between pairs of variables does not capture more complex interactions among groups of variables, whereas computing MI for subsets of the feature space larger than 2 quickly becomes computationally intractable. Indeed, some authors (see Kwak & Choi, 2002) have briefly outlined a full set-based mutual information algorithm only to brush it aside as computationally so hard as to be impossible in practice.
The algorithm implemented here, a quick method to compute MI for groups, effectively resolves the computational intractability altogether.
The algorithm is based on two simple mathematical facts:
-
mutual information is unchanged under injective (one-to-one) functions, i.e. for random variables U and V, I(U; V) = I(U; g(V)) for any injective function g, and
-
the combination of injective functions is itself an injective function.
Essentially, this algorithm applies a number of injective functions to the feature space to arrive at a representation that can be handled at an otherwise unattainable efficiency. The total complexity of the algorithm is sub-quadratic with respect to the number of data points, linear in relation to the number of features, in sharp contrast to the exponential complexity of the brute-force approach. The illustration below gives an actual example of the steps:
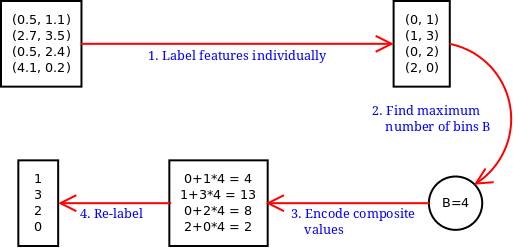
The algorithm is discussed in detail by Lampen (2004).
There are two main files, both executable without needing to set any parameters:
-
main.mcreates some synthetic input data, splits it in a 50/50 ratio into training and testing sets, and uses the proposed algorithm to compute a ranking of the features. It then tests the performance of an ensemble of classifiers on feature subsets of increasing size in the ranked order. -
main_wdbc.mis the same asmain.mexcept that it reads input from a file and uses ten-fold crossvalidation for the testing. The Wisconsin Diagnostic Breast Cancer data set is the best starting point (not included in this repository, so you need to get it from UCI first).
Each of these is intended as an illustration of the use of the algorithm, not a useful utility in its own right. Some alternatives (e.g. using Battiti's MIFS instead of the proposed algorithm) are presented in comments in the sources.
Matlab. The Netlab toolbox is required for the classification test, although the ranking algorithm itself does not have any dependencies on Netlab.
While this algorithm makes full setwise evaluation computationally feasible even for large numbers of features, the curse of dimensionality can make the feature space unwieldily large, requiring an inordinate amount of data to make conclusions with statistical reliability. Thus, in some cases, selection may be computationally feasible but not sensible.
When dealing with data from a continuous numberical domain, the performance of this approach is in many cases highly dependent on sensible choice of binning method and its parameters, as is common with discrete methods.
A further caveat is that this algorithm was formulated and implemented in 2004 and has not been revised since. A practitioner working on feature selection today would possibly benefit more from later work, such as the paper by Liu et al. (2009) and other work by the same authors, as well as the code in this repository.
-
N. Kwak and C.-H. Choi: Input feature selection for classification problems. IEEE Transactions on Neural Networks, 5:143-159, 2002.
-
L. Lampen: An efficient mutual information based feature selection method. University of Exeter, MSc thesis, 2004. Full text.
-
Huawen Liu, Jigui Sun, Lei Liu and Huijie Zhang: Feature selection with dynamic mutual information. Pattern Recognition, 42(7):1330-1339, 2009.