Kubernetes Event-Driven Autoscaling (KEDA) is a single-purpose event-driven autoscaler for Kubernetes that can be easily added to your Kubernetes cluster to scale your applications. It aims to make application auto-scaling dead-simple and optimize for cost by supporting scale-to-zero.
KEDA takes away all the scaling infrastructure and manages everything for you, allowing you to scale based on 50+ built-in scalers, use external scalers from the community or extend it with your own tailor-made scalers (pull-based, push-based, or REST API-driven). Learn more about the available scalers in our documentation.
Users only need to create a ScaledObject (docs) or ScaledJob (docs) that defines the workload you want to scale, what your autoscaling criteria is and KEDA will handle all the rest!

It allows you to scale anything; even if it’s a CRD from another product you are using, as long as it implements /scale sub-resource. This allows us to build an ecosystem of products to integrate with and make them more powerful and successful.
To provide production-grade security, we've introduced TriggerAuthentication and ClusterTriggerAuthentication (docs) allowing users to move authentication information out of their application into a separate CRD. This not only allows for re-use, but operators can manage the authentication separately in a centralized place and avoid applications running with higher privileges than they need. End-users can use a wide range of authentication providers, including Azure, AWS, GCP, HashiCorp and more.
KEDA's sole focus is to scale applications running on Kubernetes, it is most powerful when combined with Kubernetes' Cluster Autoscaler as well as Virtual Kubelet.
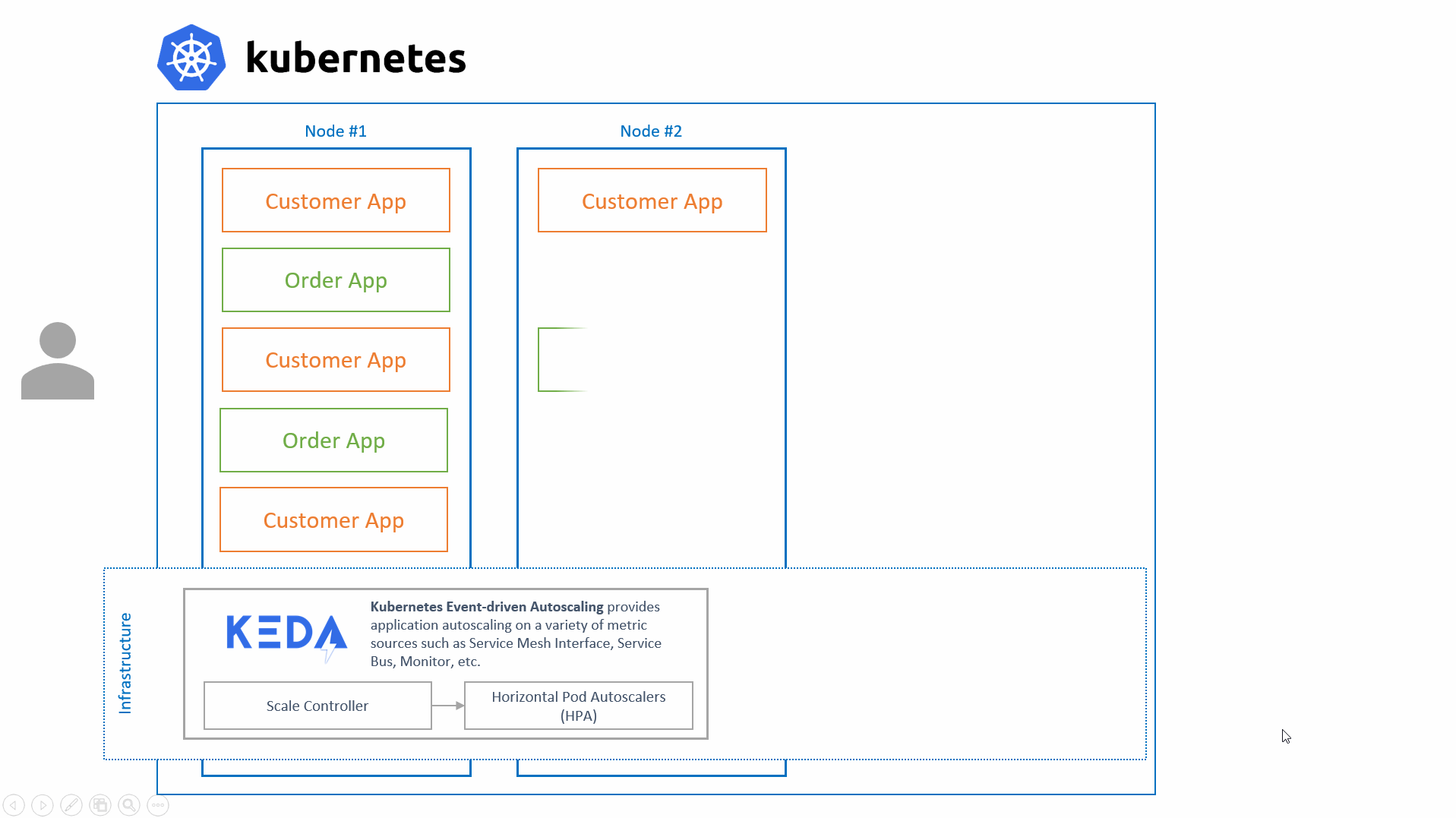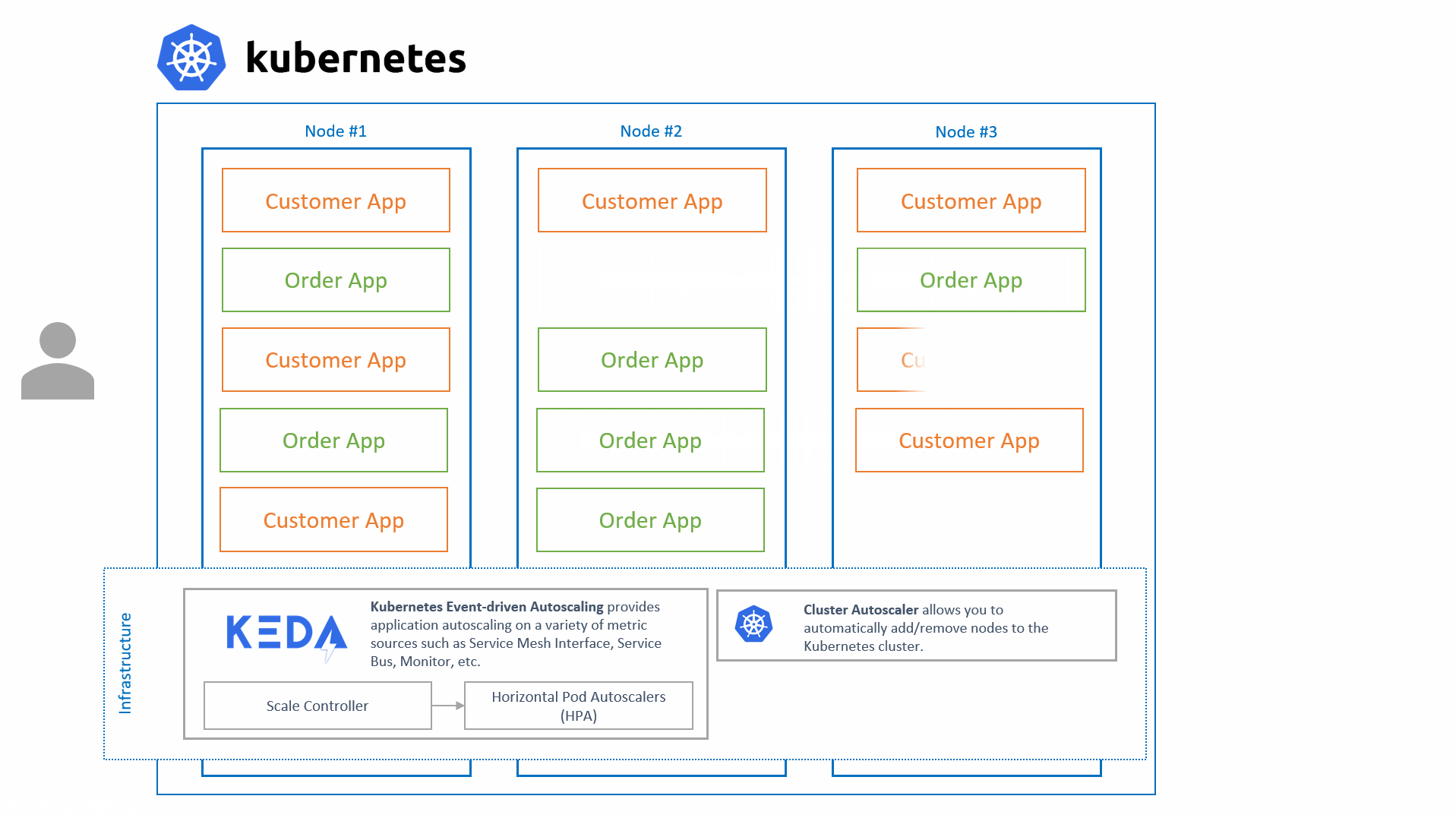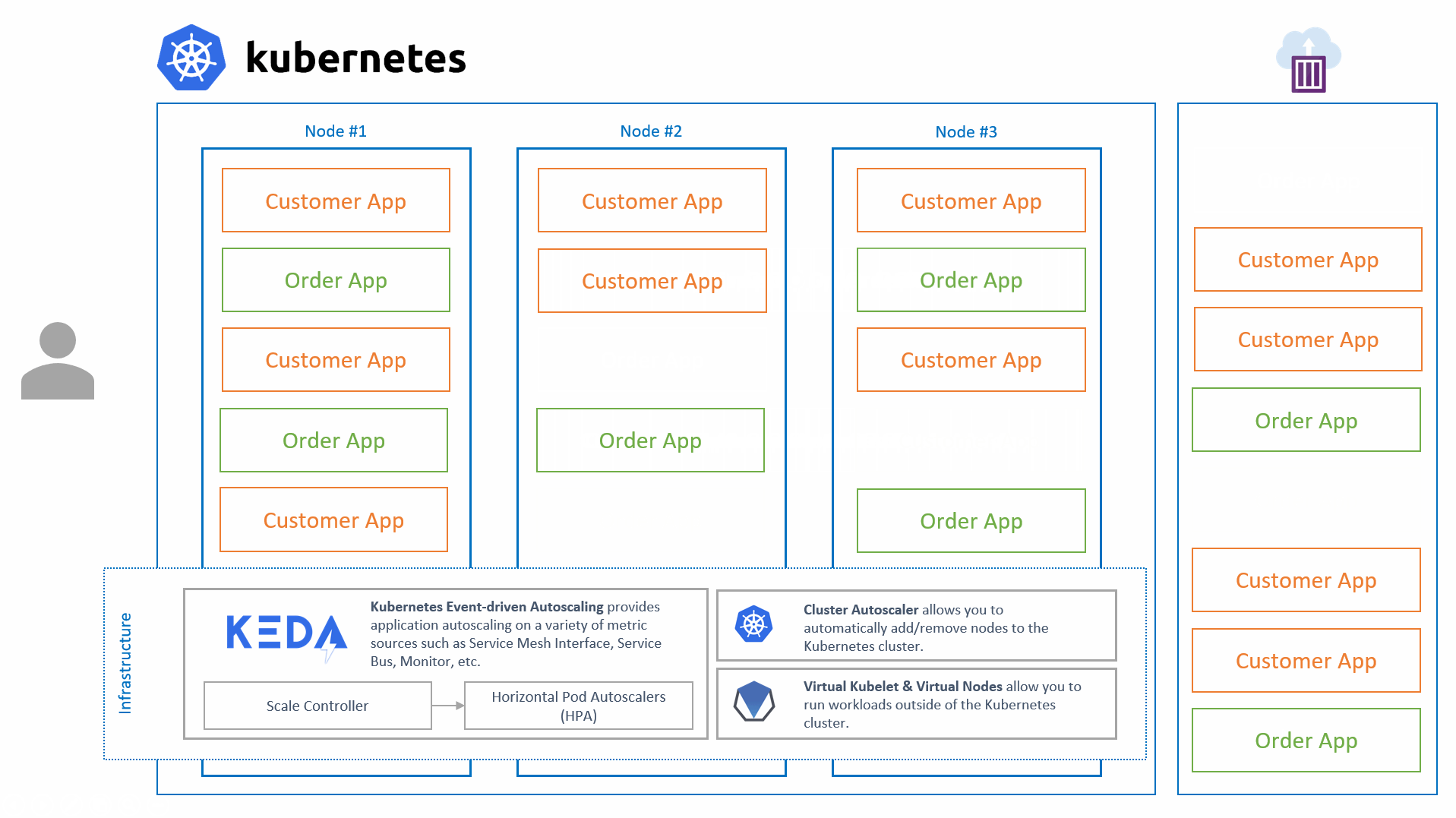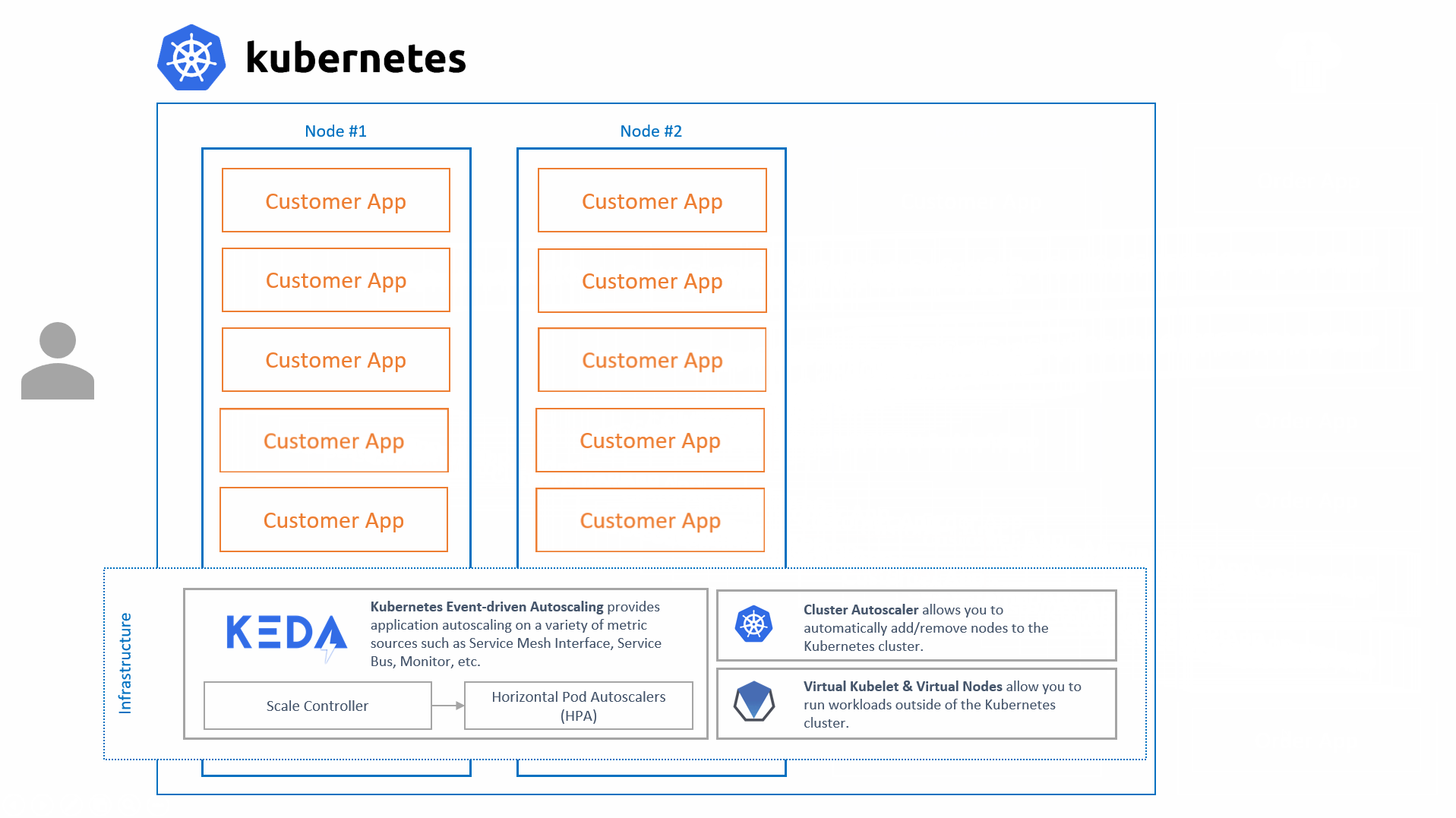
We are strong believers of re-using technologies that already exist, rather than re-inventing them. That is why KEDA is built on top of Kubernetes and builds on top of the Horizontal Pod Autoscaler (HPA) by offering additional features on top of it such as:
- Simplified autoscaling infrastructure by using KEDA as the metric adapter with its wide range over scalers
- Support for different autoscaling mechanics (job & deamon-like workloads)
- Pausing autoscaling
- Provide operational awareness through Kubernetes events, Prometheus metrics and soon OpenTelemetry metrics and CloudEvents
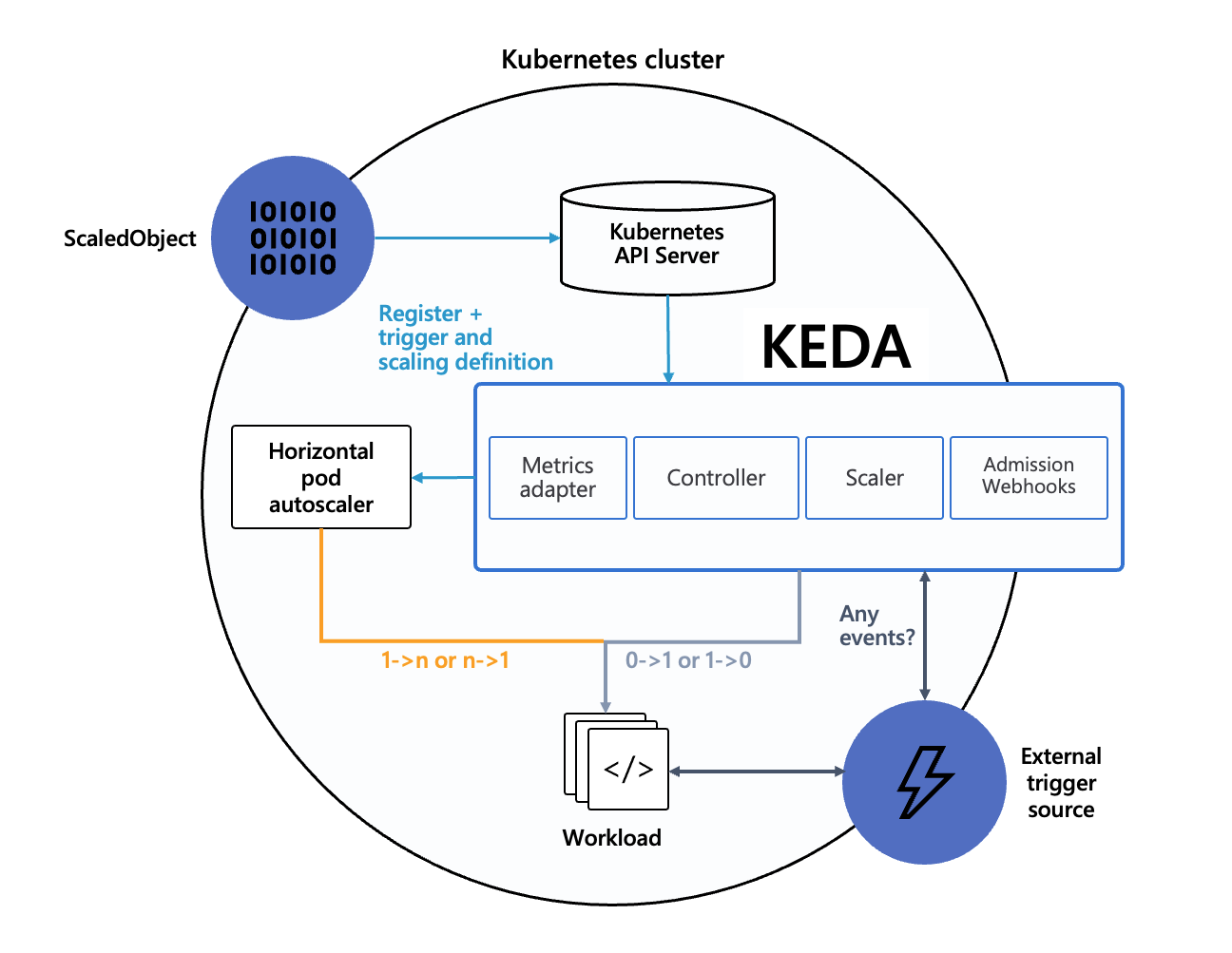
While KEDA handles the 0 -> 1 & 1 -> 0 scaling, it fully relies on the HPA for all of the rest. This allows us to focus on the event-driven scaling and not have to worry about the rest.
As a CNCF project, KEDA integrates with the CNCF landscape and is built on top of the following CNCF projects.
This is important to us as we want to build an extensible and open ecosystem that is easy to integrate with, and re-use existing technologies instead of re-inventing them.
Here is a list of the CNCF projects that KEDA integrates with and some that we are planning to add in the next couple of months:
- The scaler catalog supports a variety of cloud-native technologies including Prometheus & NATS from the CNCF or Cassandra & Apache Kafka from the Apache Software Foundation
- KEDA provides Prometheus metrics to operate the autoscaling infrastructure
- Artifact Hub provides support for adding external KEDA scalers which are discoverable in our documentation
- Knative is prototyping an integration with KEDA to enable autoscaling of Knative Eventing infrastructure.
- We are actively collaborating with the Environmental Sustainability TAG as we are on a mission to help reduce the environmental footprint of Kubernetes workloads.
- We have been working in this area already with scale-to-zero, but are planning to expand our features in this area in the future based on this collaboration
- In the future, we are planning to expand these integrations
- We are adding a variety of events that will be emitted as CloudEvents by KEDA to provide operational awareness, extensibility and additional control to extend KEDA.
- KEDA will be able to autoscale workloads based on OpenTelemetry metrics and is planning to provide OpenTelemetry metrics
Since KEDA was accepted as a CNCF Incubation project, we have been working hard to improve the project and have done 6 releases since then (v2.3 and newer).
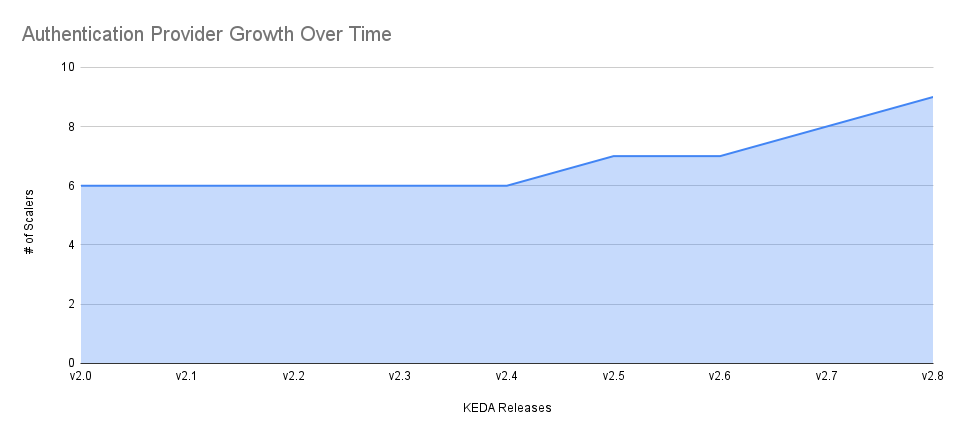
Every release introduced new scalers and different options to authenticate to external systems and have seen a lot of growth in this area.
For example, KEDA v2.8 now supports 9 authentication providers (50% growth), including major cloud providers and HashiCorp Vault.
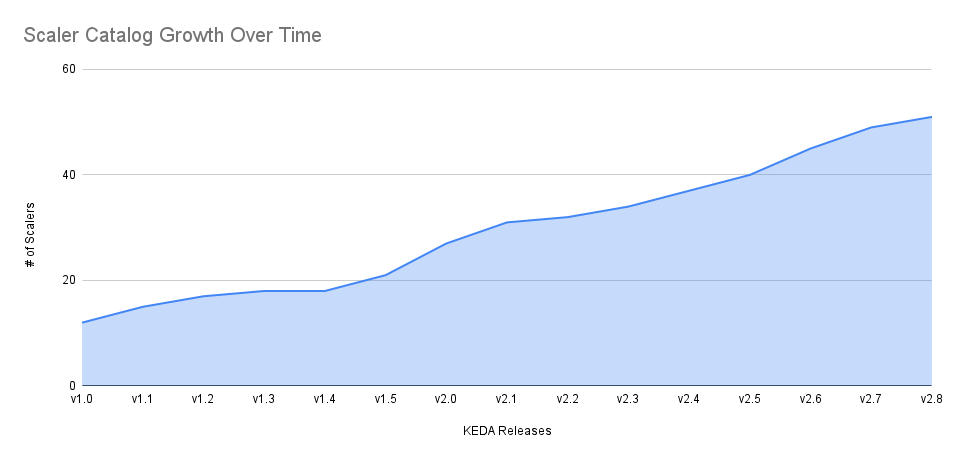
Our scaler catalog has grown from 32 to 51 scalers (60% growth) in 6 releases:
As part of this effort, we have integrated Artifact Hub as our centralized place for external scalers to build an ecosystem for external scalers.
As part of our goal to make autoscaling dead-simple, we've introduced a new range of features to provide more control over the scaling process:
- Pausing of autoscaling allows end-users to pause autoscaling for a specific workload to perform maintenance or other operations, without having to delete the
ScaledObjectorScaledJob(~their autoscaling rules). - Fallback support enables users to define a fallback value for when the scaler is unable to get metrics from the external system. This allows them to avoid scaling down because of a dependency issue and keep their platform up-and-running.
- Support for idle lets applications scale to 0 when there is no work to do, but use a minimum amount of replicas that is 1 or more. This allows users to save cost, but still have a decent chunk of replicas running once work starts.
We have also made a significant investment in enabling new deployment scenarios by providing support for ARM machines and are signing all new container images with Cosign to verify their integrity.
Our end-users can now benefit from security improvements that we have done now that KEDA is secure-by-default and runs as non-root, regardless if it's deployed through the official Helm chart or raw YAML manifests. Additionally, Azure customers can now use permission segregation across the cluster so that team can use dedicated Azure AD identities. This is supported for both Azure AD Pod Identity as well as Azure AD Workload Identity.
Our documentation has also seen a lot of improvements, with listing of external scalers from Artifact Hub, capability to search across our scaler catalog, dedicated page around support in KEDA and managed offerings and last but not least, every authentication provider has a dedicated page, similar to the scalers.
Over the past year, we've introduced a variety of improvements to our governance model to make it more transparent and better reflect the community's needs in terms of expectations and building product-grade software:
- We have introduced a more in-depth roadmap so that our community better understands our current priorities and what to expect in the next release. This initiative comes with dedicated guidance on how to use our roadmap, how we triage issues and when to expect new KEDA versions.
- Our scaler governance provides clarity on when a scaler should be built-in or external, how the community can contribute to our scaler ecosystem and what to expect in terms of maintenance
- Our support policy is now on keda.sh and provides clarity on what to expect in terms of support and how to get help. This includes helping end-users use one of the existing offerings with commercial support.
- Based on the CNCF Incubation feedback, we've changed our voting process so that multiple maintainers from a single company share the same vote.
- A release policy was introduced, based on end-user feedback in CNCF Incubation reviews
- Our security policy and preventive measures are now documented and have made improvements in this area:
- Automatically scan published images & Dockerfile in PRs with Snyk
- Use Whitesource Bolt for GitHub & Trivy to find vulnerabilities in dependencies
- Use GitHub Advanced Security to scan for vulnerabilities in code and identify vulnerabilities based on GitHub Advisory Database
- A new breaking changes & deprecations policy is being finalized to provide clarity on what end-users can expect and put guard rails on the changes contributors are allowed to make.
Over the past couple of years, we've had the pleasure of seeing KEDA grow from an open-source project that end-users started to play around with to an industry-leading app autoscaler.
As an example, we have published a blog post on how and why Alibaba Cloud decided to use KEDA to scale their Enterprise Distributed Application Service (EDAS) offering. Later on, CastAI followed to help their customers optimize cloud cost and reduce their environmental footprint.
Dysnix has built PredictKube, an AI-based predictive autoscaler, which is built on top of KEDA to scale workloads in advance to coop with the upcoming load. We have also seen KEDA being adopted by large corporations such as Zapier to scale their platform and significantly improve their performance.
Cloud providers are starting to build new offerings that are using open-source technologies (such as KEDA) and leverage them to their customers, for example Azure Container Apps that went generally available in 2022.
Lastly, vendors have started seeing the adoption of KEDA as well and have started providing commercial support for KEDA, such as Red Hat and Azure Kubernetes Service.
As an example of our growth in terms of end-users, when we opened our proposal for KEDA to become a CNCF Incubation project on March 25th 2021 we had 11 listed end-users:

In a little over a year, we have grown to 36 listed end-users past October 2022 which is a 227% growth:

And there are major KEDA adopters from the gaming and retail industry that we are eager to talk about, but cannot share publicly because of legal reasons. However, we should be able to get in contact for anonymous interviews if there is interest.
KEDA has a growing community of adopters and contributors that help to make KEDA better every day.
To help our community keep on doing that, we've been working hard to make KEDA more accessible to contributors in a few areas:
- We've made it simpler to get started by expanding our contribution guide, improve our docs for adding new scalers as well as make it simpler to do documentation improvements by providing more documentation in our README
- When contributors are ready to start writing code, they can now easily create a GitHub Codespace that is fully configured and ready to be used according to our coding standards & needs
- It is now easier for contributors to debug our metric server based on our new debugging documentation
- Our end-to-end tests have been migrated from Typescript to Go, making it easier for contributors as they can re-use their existing knowledge and skills instead of having to learn another language
- As part of the pull request, maintainers & contributors can now easily trigger a full end-to-end test run by using comments to trigger the process, or only start them for a subset of scalers
- When contributors have questions during development, they can now easily ask them in our Slack workspace and get help from our community and maintainers with our dedicated #keda-dev channel
These investments have proven to be valuable as our recent Q2 2022 media and velocity report showed that 28 companies and 136 developers are contributing to KEDA during Q2.
Here are some details of the various companies that have contributed to KEDA during Q2:
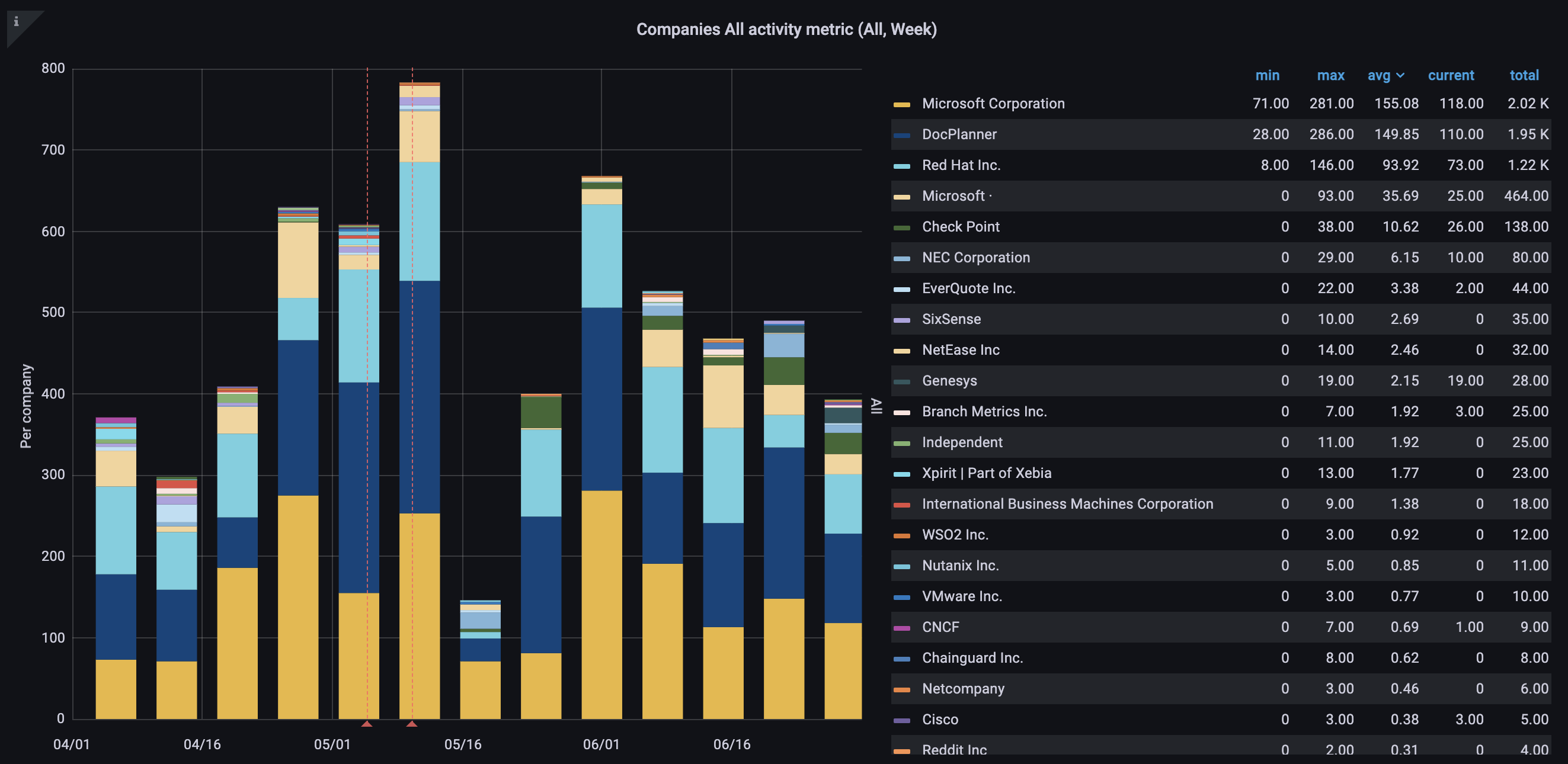
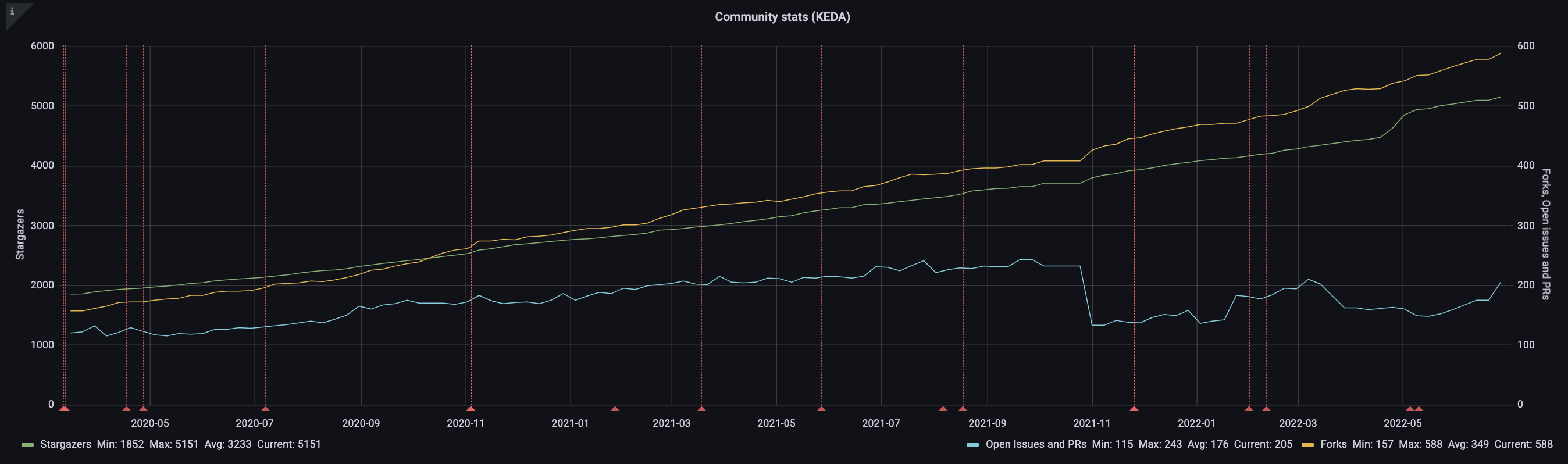
Since the joining the CNCF as a sandbox project, we've seen a steady growth in people forking and/or starring while keeping open issues and PRs under control:
Project should address each graduation criteria listed below
KEDA has maintainers from 4 different companies (Microsoft, Red Hat, Snowflake & another company soon (between jobs) - See maintainers.md) and contributions from a variety of companies, as per the CNCF DevStats.
* Have achieved and maintained a Core Infrastructure Initiative Best Practices Badge.
* Have completed an independent and third party security audit with results published of similar scope and quality as this example which includes all critical vulnerabilities and all critical vulnerabilities need to be addressed before graduation.
The security audit has been started with OSTIF and is ongoing.
* Explicitly define a project governance and committer process. The committer process should cover the full committer lifecycle including onboarding and offboarding or emeritus criteria. This preferably is laid out in a GOVERNANCE.md file and references an OWNERS.md file showing the current and emeritus committers.
This is documented in our governance documentation available here as well as our contribution guide for making contributions.
We have also introduced scaler governance which defines when they become part of our core, or when we recommend our community to build external scalers and to list them on Artifact Hub.
* Explicitly define the criteria, process and offboarding or emeritus conditions for project maintainers; or those who may interact with the CNCF on behalf of the project. The list of maintainers should be preferably be stored in a MAINTAINERS.md file and audited at a minimum of an annual cadence.
This is documented in our governance documentation available here.
* Have a public list of Project adopters for at least the primary repo (e.g., ADOPTERS.md or logos on the Project website). For a specification, have a list of adopters for the implementation(s) of the spec. Refer to FAQs for guidelines on identifying adopters.
KEDA provides a full overview of publicly listed end-users on its website, but there are others that we are not allowed to list but can be interviewed.
Here's a quick overview of the end-users at the time of writing:

The Incubation Due Diligence(DD) document can be found here.
KEDA is currently on track for Incubation status. During the due diligence process we identified a number of recommendations that we would like to see addressed in the future on the path to gradation.
- Documenting the release versioning scheme, which is currently in progress as described in the Incubation Criteria Summary, should be completed before the TOC votes on KEDA Incubation. Meanwhile, this DD document can be opened for public comment to check for any other blocking criteria.
- Update: this is now documented here
- We do not believe that any of the other recommendations described in this document are requirements for Incubation stage. Additionally, we recommend that the Kubernetes and TOC community consider the alignment between KEDA and Kubernetes autoscaling, as described in KEDA and Kubernetes HPA. There are no known issues or conflicts, simply a question of whether there should be a single community interested in Kubernetes autoscaling. Although this question was highlighted by the DD process, it is beyond the scope of the KEDA project alone, and should not block Incubation.