
This repository contains the code for our National Innovation Project, which focuses on the problem of how to accurately triage the patients in the hospital to a specific department; the Project was rated as Good.
When first entering a hospital, patients are not sure which department they should visit, so hospital guidance station is prone to congestion during peak periods, especially in the context of the current epidemic, which may cause a series of problems such as the transmission of diseases, bringing many inconveniences to patients and hospitals.
The frequently model used for now as the solution has several problems:
- Not efficient, the algorithm used to be trained with the large model, and this may slow down the feedback
- Not accurate, and this may lead to an increased risk of patients wrongly visiting and burdens the medical stress
- Not mapping precisely to the existing departments in a hospital, it usually maps the result to a very general department and some hospital may not contains or have a different name
-
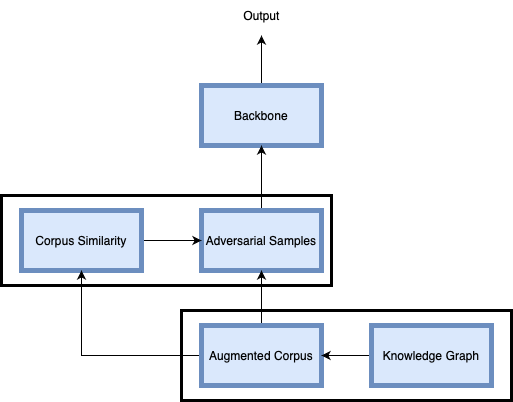
Adding Knowledge Graph
-
After obtaining the user consultation text, the text is firstly divided into words using the Chinese word separation library: jieba, and then each word in the text is searched for all its triples in the knowledge graph, and one triple is randomly selected and put into brackets, and added into the original word. Although simple, the table in the results section shows that such an embedding method can bring some improvement to the model.
-
Process of adding Knowledge

-
Knowledge Embedding Algorithm

-
-
Adding Adversarial Samples
It is difficult to distinguish the symptom descriptions in medical texts, and the similarity between texts is easy to generate, therefore, identifying similar texts is the key to improving the accuracy of the model
-
Process of noise embedding

- The unsupervised learning of TF-IDF features is performed on the symptom description texts of each department in the training corpus, words with less than 500 occurrences are filtered out, and the cosine similarity of TF-IDF features of symptom description texts of two departments is calculated and normalized with respect to the conversion probability.
- In the training reading samples, each sample can be replaced with the label of another department with a 20% probability based on the conversion probability and keep the original label unchanged with an 80% probability
- This method takes into account the special characteristics of the medical text to introduce noise, which effectively enhances the noise resistance and robustness of the model, prevents the model from overfitting, and makes the accuracy rise further.
-
-
Semantic Enrichment

- As the text described by the patients may be too vague, and concise as well as carry little information, the knowledge graph is needed to guide the patients in an appropriate way to enrich the semantics and inject the knowledge used in training to further improve the accuracy of the model.
-
Design of the Error Correction
-
Process of Error Correction

-
After the user input at the first time, the model does not return the result immediately but focuses on the departments corresponding to the top three dimensions of the output vector, and for these three departments, the corresponding symptoms are queried in the knowledge graph, and the user is asked with the same symptoms for three rounds with four relevant options and one "none of these" options in each round.
-
After that, we re-put the information selected by the user into the sentence and re-enter the model, and repeat the above process until the dimension with the largest value of the vector is the same dimension twice in a row, then the output department is queried in the hospital database to get the actual department name of the hospital and returned to the user.
-
-
Precisely Mapping
[TODO]
- After the model returns the result, the department corresponding to the hospital selected by the user and the department result returned by the model is queried in the database, and its name is returned to the user to ensure that the department exists in the hospital where the user is located.
The final results of Medi-BERT on the test set when using the unaugmented dataset are shown in the following table:
+------------------------------------+-----------+--------+---------+---------+
| Department Type | Precision | Recall | F Score | Support |
+------------------------------------+-----------+--------+---------+---------+
| Gastroenterology | 0.9903 | 0.9935 | 0.9919 | 615 |
| Plastic and Reconstructive Surgery | 0.9732 | 0.9732 | 0.9732 | 598 |
| Otolaryngology | 0.9706 | 0.976 | 0.9733 | 541 |
| Cardiothoracic Surgery | 0.9819 | 0.9819 | 0.9819 | 608 |
| Urology | 0.9854 | 0.987 | 0.9819 | 616 |
| Nephrology | 0.9615 | 0.9664 | 0.964 | 595 |
| Male Medicine | 0.9631 | 0.9729 | 0.968 | 590 |
| Obstetrics | 0.9887 | 0.9887 | 0.9887 | 618 |
| Ophthalmology | 0.9851 | 0.9722 | 0.9786 | 612 |
| Orthopedic Surgery | 0.9894 | 0.979 | 0.9842 | 572 |
| Pediatrics | 0.9543 | 0.9665 | 0.9603 | 626 |
| Anorectology | 0.9827 | 0.981 | 0.9818 | 578 |
| Hepatobiliary Surgery | 0.9772 | 0.9756 | 0.9764 | 614 |
| Psychology | 0.9747 | 0.9659 | 0.9703 | 558 |
| Rheumatology and Immunology | 0.9919. | 0.9935 | 0.9927 | 613 |
| Venereal Diseases | 0.9886 | 0.9902 | 0.9894 | 613 |
| Neurology | 0.9511 | 0.9445 | 0.9478 | 577 |
| Oncology | 0.9721 | 0.9721 | 0.9721 | 610 |
| Genetic Diseases | 0.9532 | 0.9641 | 0.9586 | 612 |
| Respiratory Medicine | 0.9736 | 0.972 | 0.9728 | 607 |
| Gynecology | 0.9966 | 0.995 | 0.9958 | 595 |
| Psychiatry | 0.9754 | 0.9737 | 0.9746 | 571 |
| Burns | 0.9577 | 0.9393 | 0.9484 | 626 |
| Endocrinology | 0.9799 | 0.9915 | 0.9857 | 589 |
| Dermatology | 0.9455 | 0.9332 | 0.9393 | 614 |
| General Surgery | 0.9618 | 0.9682 | 0.965 | 598 |
| Stomatology | 0.981 | 0.9913 | 0.9861 | 574 |
| Infertility | 0.9766 | 0.9653 | 0.9709 | 605 |
| Cardiology | 0.9983 | 0.9866 | 0.9924 | 595 |
| Orthopedics and Traumatology | 0.9788 | 0.9875 | 0.9832 | 562 |
| Hematology | 0.9561 | 0.9544 | 0.9552 | 570 |
| Traditional Chinese Medicine | 0.9812 | 0.9948 | 0.9879 | 576 |
| Infectious Diseases | 0.9795 | 0.9812 | 0.9803 | 584 |
| Pediatric Surgery | 0.9649 | 0.9821 | 0.9735 | 224 |
| Neurosurgery | 0.9775 | 0.9713 | 0.9744 | 627 |
| Pediatric Internal Medicine | 0,9677 | 0.9677 | 0.9677 | 589 |
+------------------------------------+-----------+--------+---------+---------+- From the specific prediction results in the above table, we can find that the accuracy of the model reaches 97.48%.
- The detection rate, accuracy rate and precision rate of 36 categories all exceed 90%.
