503 errors when scaling down, or rolling out a new application version #7665
Comments
|
@mandarjog @PiotrSikora it sounds like we need Envoy to properly enter a lameduck mode upon receiving SIGTERM. Is this something that Envoy currently supports? A quick look at the admin interface didn't reveal anything obvious. |
|
@nmittler what about https://www.envoyproxy.io/docs/envoy/latest/intro/arch_overview/draining? Do we care about Also, does Pilot know about the pods being terminated to update routes to the particular service? Since draining will only help with not accepting new connections/requests, but they still have to be routed elsewhere. |
|
I agree with @PiotrSikora - from my observations - envoy and the app drain fine when they get a Is there anyone actively looking at this work by the way? This is a real stickler for us as we fundamentally can't move any of our more critical applications as this problem results in client impacting events whenever a pod is terminated (rollout, reschedule, node upgrades, scaling). I can actively demonstrate this on our pre-prod cluster and can dedicate as much time as needed to helping whoever can work on this problem, or even give them access to our test cluster. |
|
@mandarjog IIRC you were looking into this ... can you confirm or re-assign as appropriate? |
|
I checked the kube client code as well as the docs. https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/#pod-and-container-status There is no way for pilot to know whether a pod is being terminated, as that status doesn't exist in the API. If someone finds it, please let me know. Otherwise, retry seems like the best solution so far |
|
@rshriram I don't think you need to know if the other container is being terminated. That's not really what I was trying to get across in the original issue. Think about the kubernetes lifecycle, when a pod is terminated, both containers, eg the app and istio-pilot receive a Both the app, and istio-proxy handle the SIGTERM asynchronously, and drain accordingly, however we observe upstream istio-proxys on other applications still attempting to send traffic to the now draining container that has been SIGTERMd. At the point of termination; the pod should be removed from istios registry, and any other istio-pilots trying to talk to it should send their traffic elsewhere. |
|
OK, apologies - I think I miss read your comment. In relation to pilot not knowing a pod is being terminated, wouldn't it get that event from the endpoint change? As I mentioned before, when a pod is being terminated it is removed from the endpoints. If that's not the case, couldn't you get |
|
I'm having the same issue. |
|
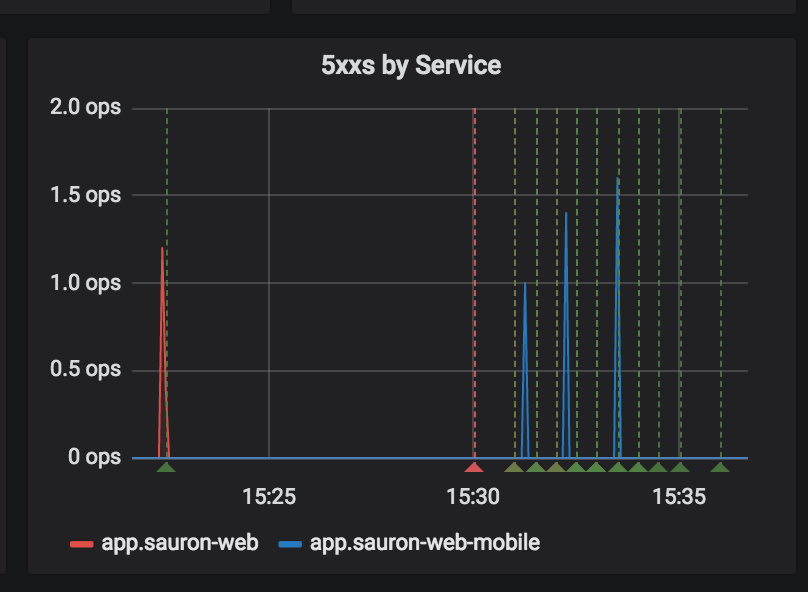
@diegomarangoni it sucks :-( but it is improved in istio 1.0.1 You can see these green lines as our deployments here and the blips are a small amount of ops/s:
We then use a RetryRule on the services: Which further smoothes it. But yes, I'd much rather we had a proper solution to this :-( |
|
A chosen endpoint not being available can happen on the data path at any time. The sending proxy knows there is a problem when it receives conn reset, or 503 from upstream. The datapath must be able to handle the case where it has slightly stale endpoints. Pilot cannot guarantee removal of endpoints in a timely manner. This is because 1. The event may be delivered late to pilot |
|
@Stono your workaround is working, increased the latency as expected, but working. |
|
Glad it helped @diegomarangoni. @mandarjog I largely agree with you, but we have to be very careful not to rely/fallback to "just do retries". As retries can very quickly cascade (in a large microservice architecture like ours), and cause other problems. They can also mask other issues. I'm not sure how best to approach it, and I agree that 0 503's is probably unattainable, but there should be some sort of measured target/SLO that is tested as part of the istio release lifecycle, or we risk more and more sneaking in. |
|
@rshriram just a question related to this - does istio proxy use draining during rolling updates? If it uses, is it via |
|
@rshriram when you get time, can you please help with this? |
|
@Stono Can't the circuit-breaking feature be used in this issue? |
|
I've set up a simple POC to reproduce this bug using minikube. |
|
@thspinto maybe combined with retries. Circuit breaker would only kick in after a few fails |
|
@ramaraochavali sorry I missed your comment. As @nmittler mentioned, we need a way for Envoy to immediately enter into a lameduck mode where it stops accepting inbound connections. We also need a more principled approach to container termination (terminate envoy and then the app - per nathan's K8S feature request for dependency driven container start in a pod). |
|
@rshriram how about using POD's Delete hook where you could run a command/binary or a better option a finalizer. With finalizer POD does not get removed until finalizer removes itself form the list. So the controller which implements a finalizer could track the actual app state and once everything is settled to let k8s cluster to remove pod. |
|
That is a nice idea. A bit more machinery but allows for a cleaner way to remove pods. |
|
@rshriram if you already tracking POD's with envoy in some controller, then it will be really easy to add, otherwise it will require a new controller tracking all envoy enabled pods. |
|
@rshriram No problem. Thanks. We are in the same situation where we do not use active health checks and hence can not use the draining feature. During k8s rolling upgrades we see spikes in 503s. We are experimenting to see if combination of retry/outlier detection can help reduce the 503s. Probably Envoy should have the same behaviour on SIGTERM or some other equivalent of |
|
@ramaraochavali I was using retry to mitigate the 503s issues, but I can’t rely on that because some requests can’t just be repeated. |
|
As of 1.0.5 version I no longer see 503 errors when scaling down my applications or when deleting a random pod. However, when rolling out a new application version the deployment file must have readiness and liveness probes configured in order to avoid downtime. |
|
I cannot reproduce the issue in 1.1-snaptshot as well. The application has liveness and readiness configured. |
|
@Stocco @iandyh thanks for the update. Quick update on my end, I have a PR out for review that should even further reduce the likelihood of encountering 503s during pod churn: #10566 The main thing that this PR does is to apply a reasonable default retry policy to outbound clusters. As a part of this PR, I added an e2e test to cause 503s by churning pods. I expected the new default to resolve the 503s, but I saw little improvement. Digging further, I found a couple things that were limiting the performance of the retry policy:
The PR is basically ready to go ... I just need to do some final testing and cleanup. It will definitely be in 1.1. |
|
@Stono Thanks for the effort. Speaking of retry, since Envoy really confuses me with connection error/timeout, I don't know whether retry will have impact on non-idempotent requests. In Nginx world, you can define what errors the retry will be performed. In Envoy/istio, it only says timeout. But connection timeout is different than application timeout. From my understanding, if the pod is created carefully with liveness/readiness and |
|
Connection timeout ( Retry policy ( Separately, the Hope this helps! |
|
@PiotrSikora Thanks for the clarification. Things are getting much clearer than before. Right now, unfortunately istio does not expose |
Partially addresses istio#7665.
* fix the test (#10837) Signed-off-by: Kuat Yessenov <[email protected]> * Allow prometheus scraper to fetch port outside of sidecar umbrella (#10492) See issue #10487 - kubernetes-pods job is now keeping all targets without sidecar or with expicit prometheus.io/scheme=http annotation - kubernetes-pods-istio-secure is now discarding targets with expicit prometheus.io/scheme=http annotation * Relax test for kubeenv metric to only error on 'unknowns' (#10787) * Relax test for kubeenv metric to only error on 'unknowns' * Add check to ensure that at least one metric is found * Address lint issues * Fix Citadel Kube JWT authentication result (#10836) * Fix Citadel Kube JWT authentication. * Small fix. * Fix unittest. * Add unit test for coverage. * Adding Sidecar CRD and renaming Sidecar role (#10852) * Sidecar config implementation Signed-off-by: Shriram Rajagopalan <[email protected]> * build fixes Signed-off-by: Shriram Rajagopalan <[email protected]> * adding CRD template Signed-off-by: Shriram Rajagopalan <[email protected]> * format Signed-off-by: Shriram Rajagopalan <[email protected]> * model.Sidecar to model.SidecarProxy Signed-off-by: Shriram Rajagopalan <[email protected]> * nits * gen files in galley Signed-off-by: Shriram Rajagopalan <[email protected]> * nit Signed-off-by: Shriram Rajagopalan <[email protected]> * test fix Signed-off-by: Shriram Rajagopalan <[email protected]> * e2e tests Signed-off-by: Shriram Rajagopalan <[email protected]> * comments Signed-off-by: Shriram Rajagopalan <[email protected]> * compile fix Signed-off-by: Shriram Rajagopalan <[email protected]> * final snafu Signed-off-by: Shriram Rajagopalan <[email protected]> * fix yaml path * typo * bad file name * future work Signed-off-by: Shriram Rajagopalan <[email protected]> * fix bad namespace * assorted fixes Signed-off-by: Shriram Rajagopalan <[email protected]> * fixing CDS Signed-off-by: Shriram Rajagopalan <[email protected]> * formatting Signed-off-by: Shriram Rajagopalan <[email protected]> * vendor update Signed-off-by: Shriram Rajagopalan <[email protected]> * lint Signed-off-by: Shriram Rajagopalan <[email protected]> * build fixes Signed-off-by: Shriram Rajagopalan <[email protected]> * undos Signed-off-by: Shriram Rajagopalan <[email protected]> * lint Signed-off-by: Shriram Rajagopalan <[email protected]> * nits Signed-off-by: Shriram Rajagopalan <[email protected]> * test fix Signed-off-by: Shriram Rajagopalan <[email protected]> * validation Signed-off-by: Shriram Rajagopalan <[email protected]> * format Signed-off-by: Shriram Rajagopalan <[email protected]> * comments Signed-off-by: Shriram Rajagopalan <[email protected]> * format Signed-off-by: Shriram Rajagopalan <[email protected]> * new crd yaml Signed-off-by: Shriram Rajagopalan <[email protected]> * nix listener port Signed-off-by: Shriram Rajagopalan <[email protected]> * kubernetes hack for parsing namespace Signed-off-by: Shriram Rajagopalan <[email protected]> * some code cleanups and more TODOs Signed-off-by: Shriram Rajagopalan <[email protected]> * more undos Signed-off-by: Shriram Rajagopalan <[email protected]> * spell check Signed-off-by: Shriram Rajagopalan <[email protected]> * more nits Signed-off-by: Shriram Rajagopalan <[email protected]> * lint Signed-off-by: Shriram Rajagopalan <[email protected]> * leftovers Signed-off-by: Shriram Rajagopalan <[email protected]> * undo tests * more undos Signed-off-by: Shriram Rajagopalan <[email protected]> * more undos Signed-off-by: Shriram Rajagopalan <[email protected]> * del Signed-off-by: Shriram Rajagopalan <[email protected]> * sidecarproxy Signed-off-by: Shriram Rajagopalan <[email protected]> * format Signed-off-by: Shriram Rajagopalan <[email protected]> * compile fixes Signed-off-by: Shriram Rajagopalan <[email protected]> * run log Configure before running server and validation (#10643) * run log Configure before running server and validation * remove p.logConfigure func from patchTable * fix lint * fix rebase error * fix rebase error * fix lint * add domain parameter to proxy of istio-policy. (#10857) * Use strings.EqualFold to compare strings (#10859) * Call check licenses only once (#10866) * add sample httpbin service in nodeport type (#10833) * Skip prow e2e test cleanup (#10878) * Use 128bit traceids in envoy (#10811) * Use 128bit traceids in envoy * Update unit test golden files for bootstrap config * Update to latest istio/api changes with MCP enhancements (#10628) * sync with latest istio.io/api This PR syncs to the latest changes from istio.io/api. Notably, this PR includes the enhanced MCP service definitions and protos (ResourceSink and ResourceSource) along with several API cleanups. Minimal changes have been made to fix the build and tests so that subsequent istio.io/api changes can be merged into istio/istio. An additional PR will be introduced to implement the enhanced MCP service layer. * address review comments * remove bad find/replace * Add a newline at the end of each certificate returned by Vault (#10879) * Add a newline at the end of a certificate * Fix the mock test * Fix a lint error * Filter flaky query from galley dashboard test (#10176) * IPv4 forwarding off for some CircleCI builds (#10777) * Log additional information about build machine * Attempt to enable IPv4 forwarding * tabs to spaces * stop mcpclient when mixer stops (#10772) * stop mcpclient when mixer stops * fix test * pushLds should not verify versions (#10861) * add integration test that mTLS through identity provisioned by SDS flow (#10887) * add integration test that mTLS through identity provisioned by SDS flow * format * remove unused files (#10890) * fix pilot goroutine leak (#10892) * fix pilot goroutine leak * remove done channel * Add missing copyright header (#10841) * Do not fail envoy health probe if a config was rejected (#9786) (#10154) * Do not fail envoy health probe if a config was rejected (#9786) * Adjust so that rejection is also an allowed state of health probe for envoy. Co-authored-by: Ralf Pannemans <[email protected]> * Add unit tests for envoy health probe Co-authored-by: Ralf Pannemans <[email protected]> * Fixed linting Co-authored-by: Ralf Pannemans <[email protected]> * Fix another linting problem Co-authored-by: Ralf Pannemans <[email protected]> * Add new stats to String() method * Use better wording in log message * Fix linting Co-authored-by: Ulrich Kramer <[email protected]> * Move everything related to spiffe URIs to package spiffe (#9090) * Move everything related to spiffe URIs to package spiffe Co-authored-by: Ulrich Kramer <[email protected]> * Fix end-to-end tests after merge Co-authored-by: Julia Plachetka <[email protected]> * Adapt and fix unit tests. Co-authored-by: Ralf Pannemans <[email protected]> * Adapt and fix unit tests. * Fix lint errors and unit tests * Fix lint errors * Fix lint errors * Fix lint errors. Exit integration test in case of nonexisting secret * Remove duplicate trustDomain * Fixed compile errors * Fixed lint errors * Fixed lint errors * Do not panic and small fixes * Do not panic when spiffe uri is missing some configuration values * Remove environment variable ISTIO_SA_DOMAIN_CANONICAL * Fix SNA typo * Comment why testing for a kube registry Co-authored-by: Holger Oehm <[email protected]> * goimports-ed Co-authored-by: Holger Oehm <[email protected]> * Adapt test to getSpiffeId no longer panicing Co-authored-by: Holger Oehm <[email protected]> * Fix formatting Co-authored-by: Holger Oehm <[email protected]> * Fix lint errors and unit tests Co-authored-by: Holger Oehm <[email protected]> * Fix double declared imports Co-authored-by: Ralf Pannemans <[email protected]> * Fix more import related linting Co-authored-by: Ralf Pannemans <[email protected]> * Add retry to metrics check in TestTcpMetrics (#10816) * Add retry to metrics check in TestTcpMetrics * Small cleanup * Fix typo * set trust domain (#10905) * Fix New Test Framework tests running in kubernetes environment (#10889) * Fix New Test Framework tests running in kubernetes environment After the change #10562 Istio Deployment in new test framework started failing. This PR tries to fix that * Minor fix * Add Pod and Node sources to Galley. (#10846) * Add Pod and Node sources to Galley. Also plumbing annotations and labels through from the source. * adding access for pods/nodes to deployment. * plumbing labels/annotations through Pilot * implement empty header value expression (#10885) Signed-off-by: Kuat Yessenov <[email protected]> * provide some context on bootstrap errors (#10696) - rebased on release-1.1 * fix(#10911): add namespace for crd installation jobs (#10912) * restore MCP registry (#10921) * fix a typo to get familiar with the PR process (#10853) Signed-off-by: YaoZengzeng <[email protected]> * Mixer route cache (#10539) * rebase * add test * fix lint * Revert "Mixer route cache (#10539)" (#10936) This reverts commit 024adb0. * Clean up the Helm readiness checking in test cases (#10929) * Clean up the Helm readiness checking in test cases The e2e test cases are often flakey because of the logic of Helm readiness checking in the test cases. Instead of checking of the Pod is in the "RUNNING" state, check that Tiller is able to provide service via the `helm version` operation. If the server is not ready, this will return 1, otherwise 0 will be returned. * Fix CLI call error We have an older version of helm which lacks the proper flag. Instead we rely on the retry with a 10 second context timer. * Test for PERMISSIVE mode, checks Pilot LDS output. (#10614) * injector changes for health check, pilot agent take over app readiness check. (#9266) * WIP injector change to modify istio-proxy. * move out to app_probe.go * Iterating sidecartmpl to find the statusPort. * use the same name for ready path. * Get rewrite work, almost. * Some clean up on test and check one container criteria. * fix the injected test file. * Add inject test for readiness probe itself. * Add missing added test file. * fix helm test. * fix lint. * update header based finding the port. * return to previous injected file status. * fixing TestIntoResource test. * sed fixing all remaining injecting files. * handling named port. * fixing merginge failure. * remove the debug print. * lint fixing. * Apply the suggestions for finding statusPort arg. * Address comments, regex support more port value format. * add app_probe_test.go * add more test. * merge fix the test. * WIP adding test not working. * change k8s env applycontents. * pilot_test.go working adding the policy. * adding authn in the setup. * progress, app is in istio-system. * simplify the pilot_test.go * get config dump for app a. * config is dumped and testhttp pass. * WIP need to figure out why config dump is different than lds output. * finally hacked to get lds output. * almost ready to verify the listener config * get test working, remove some debugging print. * move to permissive_test.go * clean up on test file. * add back auth_permissive_test.go * add some doc and remove infolog. * refine comments. * goimports fix. * bin/fmt.sh * apply comments. * add one more test case. * rename the ConstructDiscoveryRequest. * comment out unimplemented test. * change back logging level. * Sidecar config implementation (#10717) * Sidecar config implementation Signed-off-by: Shriram Rajagopalan <[email protected]> * build fixes Signed-off-by: Shriram Rajagopalan <[email protected]> * adding CRD template Signed-off-by: Shriram Rajagopalan <[email protected]> * format Signed-off-by: Shriram Rajagopalan <[email protected]> * model.Sidecar to model.SidecarProxy Signed-off-by: Shriram Rajagopalan <[email protected]> * nits * gen files in galley Signed-off-by: Shriram Rajagopalan <[email protected]> * nit Signed-off-by: Shriram Rajagopalan <[email protected]> * test fix Signed-off-by: Shriram Rajagopalan <[email protected]> * e2e tests Signed-off-by: Shriram Rajagopalan <[email protected]> * comments Signed-off-by: Shriram Rajagopalan <[email protected]> * compile fix Signed-off-by: Shriram Rajagopalan <[email protected]> * final snafu Signed-off-by: Shriram Rajagopalan <[email protected]> * fix yaml path * typo * bad file name * future work Signed-off-by: Shriram Rajagopalan <[email protected]> * fix bad namespace * assorted fixes Signed-off-by: Shriram Rajagopalan <[email protected]> * fixing CDS Signed-off-by: Shriram Rajagopalan <[email protected]> * formatting Signed-off-by: Shriram Rajagopalan <[email protected]> * vendor update Signed-off-by: Shriram Rajagopalan <[email protected]> * lint Signed-off-by: Shriram Rajagopalan <[email protected]> * build fixes Signed-off-by: Shriram Rajagopalan <[email protected]> * undos Signed-off-by: Shriram Rajagopalan <[email protected]> * lint Signed-off-by: Shriram Rajagopalan <[email protected]> * nits Signed-off-by: Shriram Rajagopalan <[email protected]> * test fix Signed-off-by: Shriram Rajagopalan <[email protected]> * validation Signed-off-by: Shriram Rajagopalan <[email protected]> * format Signed-off-by: Shriram Rajagopalan <[email protected]> * comments Signed-off-by: Shriram Rajagopalan <[email protected]> * format Signed-off-by: Shriram Rajagopalan <[email protected]> * new crd yaml Signed-off-by: Shriram Rajagopalan <[email protected]> * nix listener port Signed-off-by: Shriram Rajagopalan <[email protected]> * kubernetes hack for parsing namespace Signed-off-by: Shriram Rajagopalan <[email protected]> * some code cleanups and more TODOs Signed-off-by: Shriram Rajagopalan <[email protected]> * more undos Signed-off-by: Shriram Rajagopalan <[email protected]> * spell check Signed-off-by: Shriram Rajagopalan <[email protected]> * more nits Signed-off-by: Shriram Rajagopalan <[email protected]> * lint Signed-off-by: Shriram Rajagopalan <[email protected]> * leftovers Signed-off-by: Shriram Rajagopalan <[email protected]> * compile fixes Signed-off-by: Shriram Rajagopalan <[email protected]> * undo lint fix * temp undo * ingress and egress listeners on ports Signed-off-by: Shriram Rajagopalan <[email protected]> * nits Signed-off-by: Shriram Rajagopalan <[email protected]> * if-else Signed-off-by: Shriram Rajagopalan <[email protected]> * missing inbound port fixes Signed-off-by: Shriram Rajagopalan <[email protected]> * remove constants Signed-off-by: Shriram Rajagopalan <[email protected]> * lint Signed-off-by: Shriram Rajagopalan <[email protected]> * final fix Signed-off-by: Shriram Rajagopalan <[email protected]> * lints Signed-off-by: Shriram Rajagopalan <[email protected]> * fix http host header Signed-off-by: Shriram Rajagopalan <[email protected]> * lint Signed-off-by: Shriram Rajagopalan <[email protected]> * more if-elses Signed-off-by: Shriram Rajagopalan <[email protected]> * more lint Signed-off-by: Shriram Rajagopalan <[email protected]> * more lint and code cov Signed-off-by: Shriram Rajagopalan <[email protected]> * format Signed-off-by: Shriram Rajagopalan <[email protected]> * simplifications * remove GetSidecarScope Signed-off-by: Shriram Rajagopalan <[email protected]> * coverage Signed-off-by: Shriram Rajagopalan <[email protected]> * missing configs Signed-off-by: Shriram Rajagopalan <[email protected]> * 80 Signed-off-by: Shriram Rajagopalan <[email protected]> * remove invalid test case * fixing rds bug Signed-off-by: Shriram Rajagopalan <[email protected]> * remove comment Signed-off-by: Shriram Rajagopalan <[email protected]> * RDS unit tests Signed-off-by: Shriram Rajagopalan <[email protected]> * format Signed-off-by: Shriram Rajagopalan <[email protected]> * lint again Signed-off-by: Shriram Rajagopalan <[email protected]> * Filter Nodes/Pods in Galley temporarily until custom sources land. (#10938) This is due to the fact that Pod yaml cannot currently be parsed into unstructured types. See: #10891. * fix concurrent map read/write (#10895) * fix concurrent map read/write * simplify EndpointShardsByService * Update integration test job (#10888) * Fix integration test scripts * Making TestMain exit with the proper return code * Update local env references to native * Fix linter errors * Skipping integration tests in codecov since they fail * grant execute permission to e2e_pilotv2_auth_sds.sh (#10908) * grant execute permission to e2e_pilotv2_auth_sds.sh * fix typo * fix typo * typo * coredump * remove deprecated plugin from nodeagent (#10952) * Fix flaky test by reducing poll interval. (#10962) * Add interceptor to create noop spans when sampling is false (#10826) * Add interceptor to create noop spans when sampling is false * Add tests using mocktracer to determine whether span is created * Update dependencies to include OpenTracing mocktracer * Minor change * Updated dependencies again * Add support for ErrSpanContextNotFound error * Fix test and add one for x-b3-sampled=true * Fix lint error * set cluster.LoadAssignment only when service discovery type equals Cluster_STATIC Cluster_STRICT_DNS or Cluster_LOGICAL_DNS (#10926) * Remove Envoy's deprecated --v2-config-only (release-1.1). (#10960) Signed-off-by: Piotr Sikora <[email protected]> * update check proxy version (#10769) * Add AWS CloudwatchLogs Adapter (code from #10400) (#10882) * Add AWS CloudwatchLogs Adapter (code from #10400) * Improve codecov * Even moar coverage * remove duplicate LoadAssignment set (#10977) * Enable server side control over maximum connection age (#10870) * add server side maximum connection age control to keepalive options * add server maximum connection age to the gRPC server keepalive options * missing space between concatenated strings * added tests for default values and setting via command line * fix golangci unconvert comment * add helm value file to google ca param (#10563) * add helm value file to preconfig param for googleca * cleanup * Allow pulling images from private repository (#10763) * Only compute diff for ServiceEntry (#10446) * Only compute diff for ServiceEntry This change prevents coredatamodel controller to compute the diff for all the types and it narrows it down to only ServiceEntry. * Add a dummy event for other config types - this dummy event allows DiscoveryServer to purge it's cache * Trigger a single clear cache event * add exponential backoff for retryable CSR error in nodeagent (#10969) * backoff * add unit test * clean up * lint * lint * address comment * typo * Fix flakiness in redisquota tests (#10906) * Fix flakiness in redisquota tests by adding retry for getting requests reported by prometheus One of the things I observed in flaky tests is that total number of requests reported by prometheus was not equal to traffic sent by Fortio. Thus adding a retry to make sure prometheus is queries till we get all requests reported. * Add a buffer for 5 requests to be allowed to be not reported. This buffer is within the error we allow for 200s and 429s reporting. * Fix based on reviews * Fix lint errors * Adding make sync to integ test script (#10984) * Removing Galley pod and node datasets from tests (#10953) * Use common image for node agent (#10949) * Use comment image for node agent * Revert node-agent-k8s * Sort the package * fix MCP server goroutine leak (#10893) * fix MCP server goroutine leak * fix race condition * fix race condition between reqChannel blocking and stream context done (#10998) * add default namespce for istio-init namespace. (#11012) * Handle outbound traffic policy (#10869) * add passthru listener only for mesh config outbound traffic policy ALLOW_ANY * add outbound traffic policy to configmap template and values * add the listener and blackhole cluster in case of outbound policy REGISTRY_ONLY * update DefaultMeshConfig with OutboundTrafficPolicy * use ALLOW_ANY outbound policy by default in tests * add OutboundTrafficPolicy to the default meshconfig of galley * Revert "use ALLOW_ANY outbound policy by default in tests" This reverts commit 9045789. * use REGISTRY_ONLY OutboundTrafficPolicy for galley tests * adopt notion of collections throughout galley/mcp (#10963) * adopt notion of collections throughout galley/mcp * add missing 's/TypeURLs()/Collections()' * fix linter errors and missing dep * linter fixes * another linter fix * address review comments * use correct collection name in copilot test * fix TestConversion/config.istio.io_v1alpha2_circonus * update copilot e2e tests * fix pilot/pkg/config/coredatamodel/controller_test.go unit test * re-add TypeURL and remove typeurl from collections * add Bearer prefix in oauth token that passed to GoogleCA (#11018) * Add bionic and deb_slim base images, optimize size for xenial (#10992) * Remove redundant pieces of code (#11014) * Increase timeout (#11019) * mixer: gateway regression (#10966) * gateway test Signed-off-by: Kuat Yessenov <[email protected]> * prepare a test Signed-off-by: Kuat Yessenov <[email protected]> * Merge the new tests for isolation=none, some fixes (#10958) * Merge the new tests for isolation=none, some fixes * Add a local directory with certs, can be used with the basedir for local tests * If a BaseDir meta is specified, use it as prefix for the certs - so tests don't need / access * Add the pilot constant and doc * Fix mangled sidecarByNamespace, scope issue * Fix binding inbound listeners to 0.0.0.0, test * Format * Lint * Add back the validation * Reduce flakiness, golden diff reported as warning * Manual format, make fmt doesn't seem to help * Fix authn test * Fix authn test * Reduce parallel to avoid flakiness, fix copilot test * format * remove 'crds' option in relevant manifests (#11013) * remove crds option in istio chart. * delete crds option in values*.yaml * add istio-init as prerequisite of istio chart. * Delete this superfluous script. (#11028) * Refactor in preparation for reverse and incremental MCP (#11005) This PR refactors the MCP client, server, and monitoring packages in preparation for introducing reverse MCP. This includes the following changes: * Structs/Interfaces common to MCP sinks are moved into the sink package. * Structs/Interfaces common to MCP sources are moved into source packages. * The client and server metrics reporting logic is merged into a single reporter interface and implementation, since the majority of code is duplicated. This makes it easier to use a single reporter interface across all source/sink and client/server combinations. * Plumb through source/sink options * Port Mixer's TestTcpMetricTest in new Test framework (#10844) * Port Mixer's TestTcpMetricTest in new Test framework * Look at values file too to determine if mtls is enabled for the test or not. * Add unix domain socket client and server to pilot test apps (#10874) * Add unix domain socket client and server to pilot test apps Signed-off-by: Shriram Rajagopalan <[email protected]> * snafu Signed-off-by: Shriram Rajagopalan <[email protected]> * appends Signed-off-by: Shriram Rajagopalan <[email protected]> * compile fix Signed-off-by: Shriram Rajagopalan <[email protected]> * template fixes Signed-off-by: Shriram Rajagopalan <[email protected]> * more gotpl Signed-off-by: Shriram Rajagopalan <[email protected]> * undos * undo Signed-off-by: Shriram Rajagopalan <[email protected]> * Fixing new framework integration test (#11038) Fixes are as follows: 1) PolicyBackend close is failing when closing the listener in natice environment. Thus ignoring it's error and making policy backend a system component, so that it is just reset between the tests and not really closed. 2) Skipping conversion test in local environment as it requires kubernetes environment. 3) Increasing timeout of tests in kubernetes environment 4) Adding test namespace in mixer check test. * Use proxyLabels that were collected earlier (#11016) * Fix comment on defaultNodeSelector comment (#10980) * tracing: Provide default configuration when no host specified for k8s ingress (#10914) * tracing: Provide default configuration when no host specified for k8s ingress * Remove jaeger ingress in favour of one ingress with context based on provider * Updated to remove $ from .Values * Add ymesika to pilot owners (#11053) * Restart Galley in native test fw. component to avoid race. (#11048) There is a race between Galley reading the updated mesh config file and processing of input config files. This change restarts Galley every time mesh config is updated, to avoid race. * Update Istio API to include selector changes in AuthN/AuthZ. (#11046) The following changes are included from istio.io/api: aec9db9 Add option to select worload using lables for authn policy. (#755) 2dadb9e add optional incremental flag to ResponseSink and ResourceSource services (#762) d341fc8 assorted doc updates (#757) 48ad354 Update RBAC for Authorization v2 API. (#748) f818794 add optional header operations (#753) Signed-off-by: Yangmin Zhu <[email protected]> * update proxy SHA (#11036) * update proxy SHA * Update Proxy SHA to d2d0c62a045d12924180082e8e4b6fbe0a20de1d * Add an example helm values yaml for Vault integration user guide (#11024) * Add an example helm values yaml for Vault integration user guide * Add a comment * Add retry logic to the SDS grpc server of Node Agent (#11063) * Quick fix for #10779 (#11061) * Basic fix to Ingress conversion. * Makes changes based on Ingress changes. * Linter fix. * Remove labels as well. * session affinity (#10730) * handle special char in trustdomain (to construct sa for secure naming) (#11066) * replace special char * update comment * enabled customized cluster domain for chart. (#11050) * enabled customized cluster domain for chart. * update webhook unit test data. * Restructure Galley sources (#11062) * Restructure Galley sources This is a series of simple moves in preparation for #10995 * addressing comments * assign back to s.mesh when reload the mesh config file (#11000) Signed-off-by: YaoZengzeng <[email protected]> * Moving Galley source to dynamic package. (#11081) This is in preparation for #10995. Trying to do this move in order to preserve history. * Add reasonable default retry policy. (#10566) Partially addresses #7665. * Reduce flakiness in metrics test in new test framework (#11070) * Reduce flakiness in metrics test in new test framework * Fix based on review * Fix merge
|
FYI #10566 has landed and will be included in 1.1. |
|
@nmittler can this be closed? |
|
I think so |
|
Any reason Istio doesn't plan to incorporate Envoy active health checks? I don't think there's any reason to keep an unhealthy endpoint in the load balancing pool. |
|
For anyone arriving here with similar issues in 1.1.x, I've opened a new issue: #13616 |
|
Hi...We are using Istio 1.18.5 and facing 503 error during scale down. Because of this we have currently fixed number of pods deployed based on peak load to avoid 503's. Can anyone help me fix this issue. |
Describe the bug
Hey,
We are noticing blips in services under load during kubernetes rollouts. We observe a handful of 503 errors from istio-proxy on the pod being removed (either because of a rollout, or a scale down). This screenshot is from three separate "scale downs":
When scaling down, this is the sequence of events we observe:
As you can see here:
At the moment, our only saving grace is that we have configured a retry policy which means our end users experience a bit of a slow request, but not a failure - however relying on a retry mechanism in this scenario doesn't feel right.
Expected behavior
The isito-proxy on the application being scaled down should not receive any requests after it has entered a TERMINATING state.
Steps to reproduce the bug
As above, but I can get on hangouts and show you this in detail.
The application itself gracefully handles sigterms and drains and have confirmed this with load tests without istio-proxy in play. I have also added a preStop hook to the application with istio, to ensure the app doesn't receive a SIGTERM until well after istio-proxy shuts down.
Version
gke 1.10.5, istio 1.0
Is Istio Auth enabled or not?
Yes
Environment
GKE
The text was updated successfully, but these errors were encountered: