 source: https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/lora_diagram.png
source: https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/lora_diagram.png
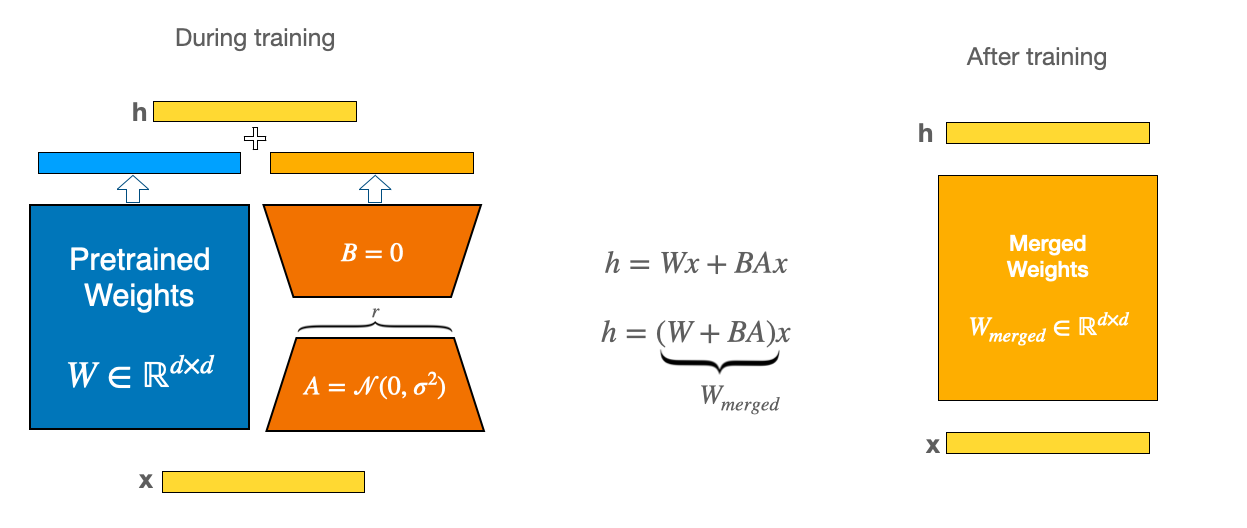{kind=link}
Fine-tuning large scale pre-trained transformers leads to huge performance gains, and offers a paradigm to achieve state of the art performance in NLP tasks at a fraction of the cost compared to building an LLM from scratch. However, as modern pre-trained transformers scale in size to trillions of parameters, the ability to store and fine-tune without a high-performance computer becomes impossible. This issue has been addressed with PEFT, Parameter-Efficient Fine-Tuning. Which only fine-tunes a small number of (extra) model parameters while freezing most parameters of the pretrained LLMs, thereby greatly decreasing the computational and storage costs. This project demonstrates the use of Low-Rank Adaptation of LLMs using HuggingFace and PyTorch to fine tune Flan-T5-Large (~880M Parameters) to summarize content using consumer hardware, easily running on google-collab. The project also uses a scratch built GPT, along with a fine-tuned GPT-2 for content generation that can be used independently or for summarization tests.
The purpose of this project was for me to get hands on exposure using LLMS for NLP tasks in a practical setting
Install (MacOS)
git clone https://github.com/iansnyder333/FakeNews-GPT_Project.git
cd FakeNews-GPT_Project
python3.11 -m venv venv
source venv/bin/activate
pip3.11 install -r requirements.txtRun (MacOS)
#Generate News
python3.11 streamlit run FakeNewsApp.py
#Summary
python3.11 streamlit run SummaryApp.pyGenerate News
GPTDev.mov
Summarize Text
SummaryDemo.mov
Full preprocessing and training scripts are located in the data folder.
All training for both the character level gpt, and full fine tuned gpt-2 models were done using the CNN Dailymail dataset.
Training for the LORA Configured Flan-T5 model was done using the Samsum dataset. The model was trained with 2 epochs.
Performance for the Flan-T5 Summary Model

This project is still in development for production Training scripts are all located in their respective config files. I will have visuals uploaded to readme in a future commit. The model training was done using Google Collab and exported using HuggingFace to be stored locally on my 2016 macbook for sample inference.