A curated list for Efficient Large Language Models
- Knowledge Distillation
- Network Pruning / Sparsity
- Quantization
- Inference Acceleration
- Efficient MOE
- Efficient Architecture of LLM
- KV Cache Compression
- Text Compression
- Low-Rank Decomposition
- Hardware / System
- Tuning
- Survey
- Leaderboard
Please check out all the papers by selecting the sub-area you're interested in. On this page, we're showing papers released in the past 60 days.
- May 29, 2024: We've had this awesome list for a year now 🥰! It's grown pretty long, so we're reorganizing it and would divide the list by their specific areas into different readme.
- Sep 27, 2023: Add tag
for papers accepted at NeurIPS'23.
- Sep 6, 2023: Add a new subdirectory project/ to organize those projects that are designed for developing a lightweight LLM.
- July 11, 2023: In light of the numerous publications that conduct experiments using PLMs (such as BERT, BART) currently, a new subdirectory efficient_plm/ is created to house papers that are applicable to PLMs but have yet to be verified for their effectiveness on LLMs (not implying that they are not suitable on LLM).
Paper from May 26, 2024 - Now (see Full List from May 22, 2023 here)























| Title & Authors | Introduction | Links |
|---|---|---|
| BOND: Aligning LLMs with Best-of-N Distillation Pier Giuseppe Sessa, Robert Dadashi, Léonard Hussenot, Johan Ferret, Nino Vieillard et al |
 |
Paper |
| Enhancing Data-Limited Graph Neural Networks by Actively Distilling Knowledge from Large Language Models Quan Li, Tianxiang Zhao, Lingwei Chen, Junjie Xu, Suhang Wang |
 |
Paper |
| DDK: Distilling Domain Knowledge for Efficient Large Language Models Jiaheng Liu, Chenchen Zhang, Jinyang Guo, Yuanxing Zhang, Haoran Que, Ken Deng, Zhiqi Bai, Jie Liu, Ge Zhang, Jiakai Wang, Yanan Wu, Congnan Liu, Wenbo Su, Jiamang Wang, Lin Qu, Bo Zheng |
 |
Paper |
| Key-Point-Driven Mathematical Reasoning Distillation of Large Language Model Xunyu Zhu, Jian Li, Yong Liu, Can Ma, Weiping Wang |
 |
Paper |
| Don't Throw Away Data: Better Sequence Knowledge Distillation Jun Wang, Eleftheria Briakou, Hamid Dadkhahi, Rishabh Agarwal, Colin Cherry, Trevor Cohn |
Paper | |
| Multi-Granularity Semantic Revision for Large Language Model Distillation Xiaoyu Liu, Yun Zhang, Wei Li, Simiao Li, Xudong Huang, Hanting Chen, Yehui Tang, Jie Hu, Zhiwei Xiong, Yunhe Wang |
 |
Paper |
| BiLD: Bi-directional Logits Difference Loss for Large Language Model Distillation Minchong Li, Feng Zhou, Xiaohui Song |
 |
Paper |
| LLM and GNN are Complementary: Distilling LLM for Multimodal Graph Learning Junjie Xu, Zongyu Wu, Minhua Lin, Xiang Zhang, Suhang Wang |
 |
Paper |
 Adversarial Moment-Matching Distillation of Large Language Models Chen Jia |
 |
Github Paper |











































| Title & Authors | Introduction | Links |
|---|---|---|
| LazyLLM: Dynamic Token Pruning for Efficient Long Context LLM Inference Qichen Fu, Minsik Cho, Thomas Merth, Sachin Mehta, Mohammad Rastegari, Mahyar Najibi |
 |
Paper |
| Adaptive Draft-Verification for Efficient Large Language Model Decoding Xukun Liu, Bowen Lei, Ruqi Zhang, Dongkuan Xu |
 |
Paper |
| Multi-Token Joint Speculative Decoding for Accelerating Large Language Model Inference Zongyue Qin, Ziniu Hu, Zifan He, Neha Prakriya, Jason Cong, Yizhou Sun |
 |
Paper |
 LiveMind: Low-latency Large Language Models with Simultaneous Inference Chuangtao Chen, Grace Li Zhang, Xunzhao Yin, Cheng Zhuo, Ulf Schlichtmann, Bing Li |
 |
Github Paper |
| S2D: Sorted Speculative Decoding For More Efficient Deployment of Nested Large Language Models Parsa Kavehzadeh, Mohammadreza Pourreza, Mojtaba Valipour, Tinashu Zhu, Haoli Bai, Ali Ghodsi, Boxing Chen, Mehdi Rezagholizadeh |
 |
Paper |
| Sparser is Faster and Less is More: Efficient Sparse Attention for Long-Range Transformers Chao Lou, Zixia Jia, Zilong Zheng, Kewei Tu |
 |
Paper |
 EAGLE-2: Faster Inference of Language Models with Dynamic Draft Trees Yuhui Li, Fangyun Wei, Chao Zhang, Hongyang Zhang |
 |
Github Paper |
| Interpreting Attention Layer Outputs with Sparse Autoencoders Connor Kissane, Robert Krzyzanowski, Joseph Isaac Bloom, Arthur Conmy, Neel Nanda |
 |
Paper |
| Near-Lossless Acceleration of Long Context LLM Inference with Adaptive Structured Sparse Attention Qianchao Zhu, Jiangfei Duan, Chang Chen, Siran Liu, Xiuhong Li, Guanyu Feng, Xin Lv, Huanqi Cao, Xiao Chuanfu, Xingcheng Zhang, Dahua Lin, Chao Yang |
 |
Paper |
 MoA: Mixture of Sparse Attention for Automatic Large Language Model Compression Tianyu Fu, Haofeng Huang, Xuefei Ning, Genghan Zhang, Boju Chen et al |
 |
Github Paper |
| Optimized Speculative Sampling for GPU Hardware Accelerators Dominik Wagner, Seanie Lee, Ilja Baumann, Philipp Seeberger, Korbinian Riedhammer, Tobias Bocklet |
 |
Paper |
| HiP Attention: Sparse Sub-Quadratic Attention with Hierarchical Attention Pruning Heejun Lee, Geon Park, Youngwan Lee, Jina Kim, Wonyoung Jeong, Myeongjae Jeon, Sung Ju Hwang |
 |
Paper |
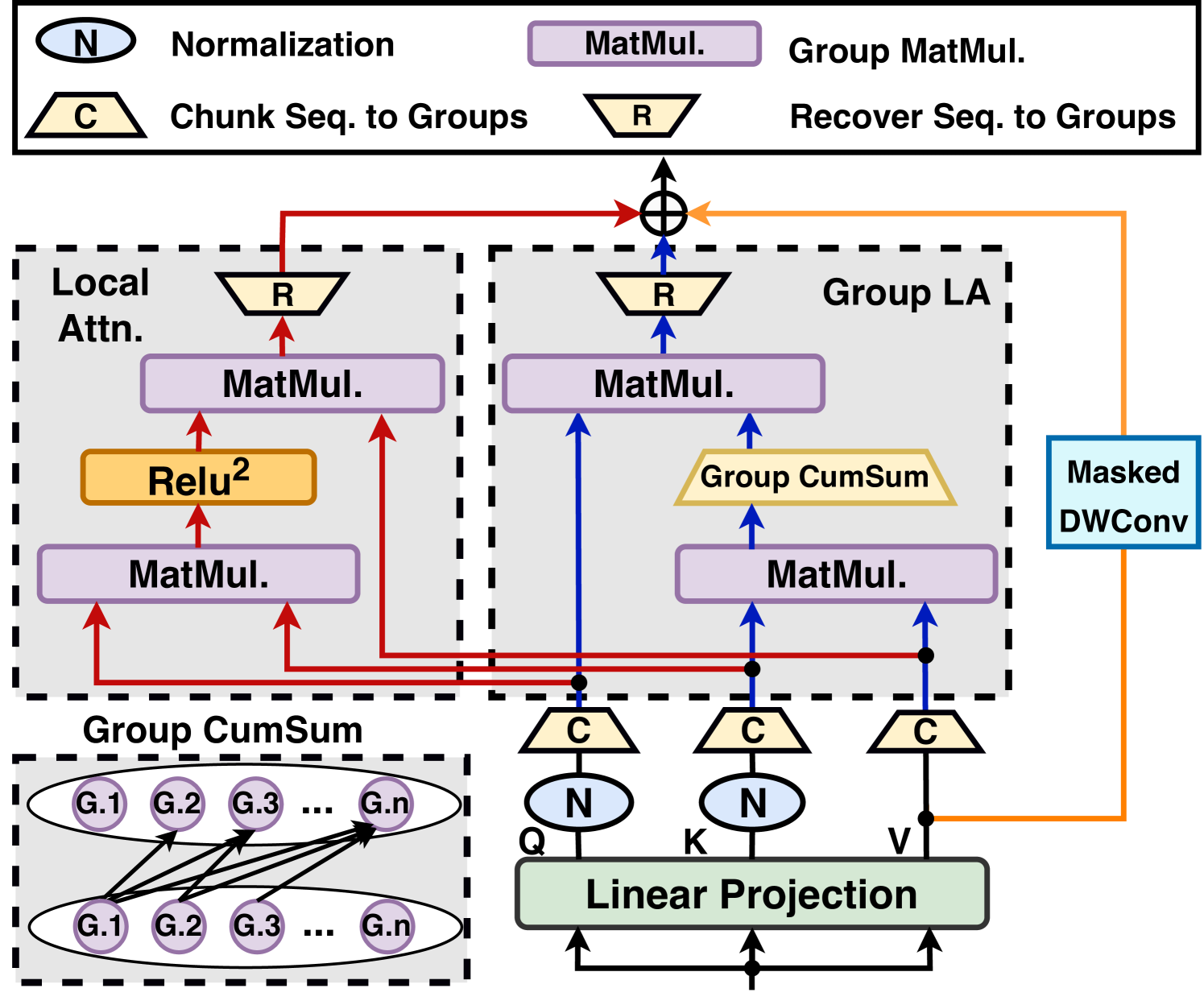
 When Linear Attention Meets Autoregressive Decoding: Towards More Effective and Efficient Linearized Large Language Models Haoran You, Yichao Fu, Zheng Wang, Amir Yazdanbakhsh, Yingyan (Celine)Lin |
 |
Github Paper |
 QuickLLaMA: Query-aware Inference Acceleration for Large Language Models Jingyao Li, Han Shi, Xin Jiang, Zhenguo Li, Hong Xu, Jiaya Jia |
 |
Github Paper |
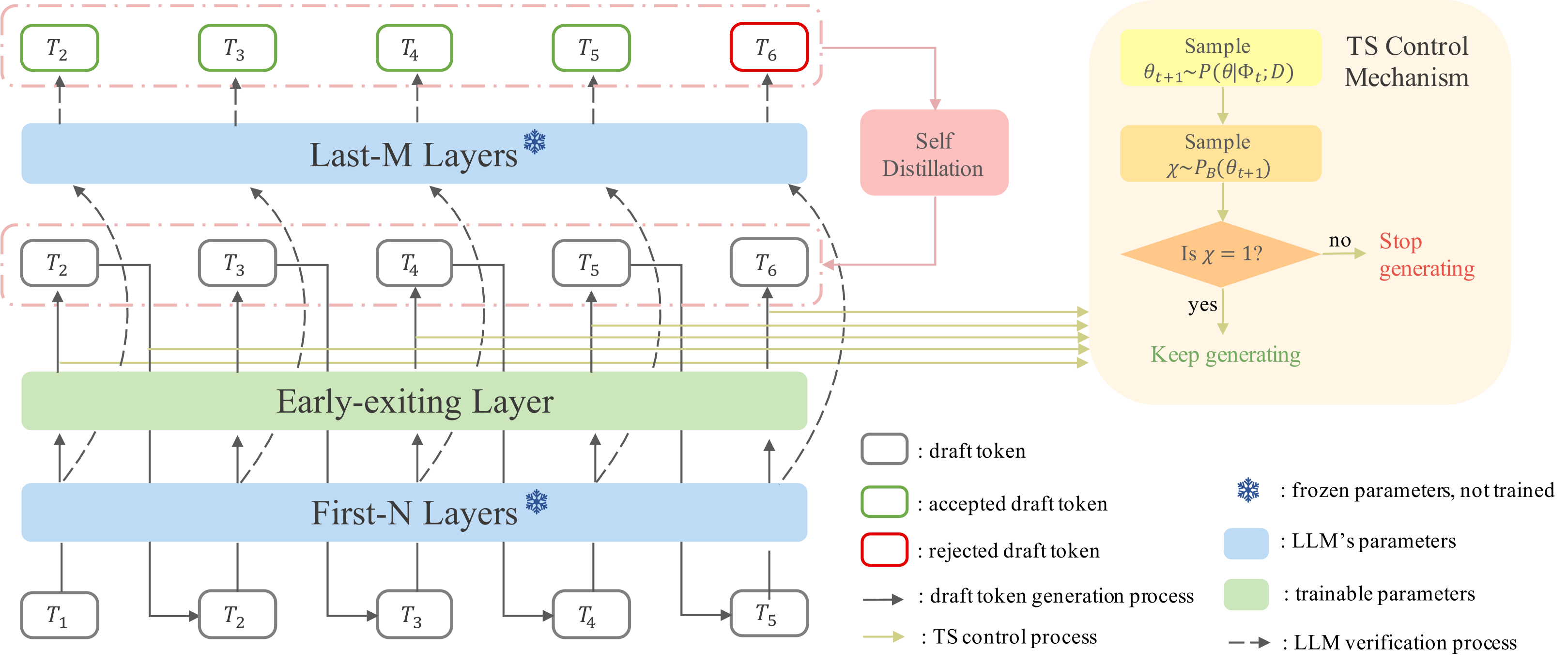
Speculative Decoding via Early-exiting for Faster LLM Inference with Thompson Sampling Control Mechanism Jiahao Liu, Qifan Wang, Jingang Wang, Xunliang Cai |
 |
Paper |
| Faster Cascades via Speculative Decoding Harikrishna Narasimhan, Wittawat Jitkrittum, Ankit Singh Rawat, Seungyeon Kim, Neha Gupta, Aditya Krishna Menon, Sanjiv Kumar |
 |
Paper |
 Hardware-Aware Parallel Prompt Decoding for Memory-Efficient Acceleration of LLM Inference Hao (Mark)Chen, Wayne Luk, Ka Fai Cedric Yiu, Rui Li, Konstantin Mishchenko, Stylianos I. Venieris, Hongxiang Fan |
 |
Github Paper |




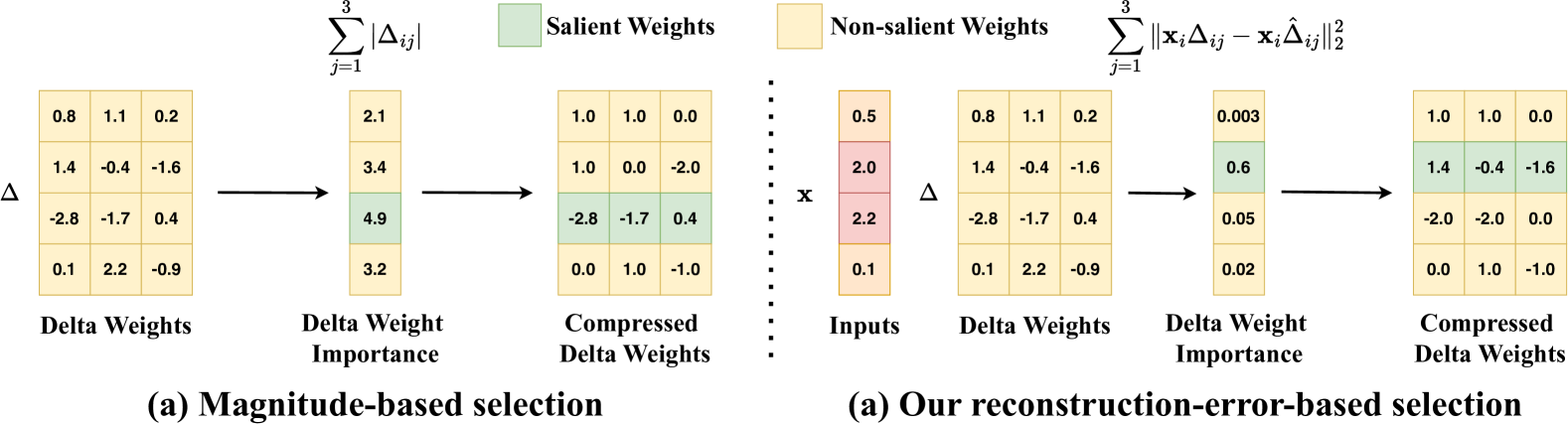





| Title & Authors | Introduction | Links |
|---|---|---|
 Efficient LLM Training and Serving with Heterogeneous Context Sharding among Attention Heads Xihui Lin, Yunan Zhang, Suyu Ge, Barun Patra, Vishrav Chaudhary, Xia Song |
 |
Github Paper |
 Beyond KV Caching: Shared Attention for Efficient LLMs Bingli Liao, Danilo Vasconcellos Vargas |
 |
Github Paper |
Block Transformer: Global-to-Local Language Modeling for Fast Inference Namgyu Ho, Sangmin Bae, Taehyeon Kim, Hyunjik Jo, Yireun Kim, Tal Schuster, Adam Fisch, James Thorne, Se-Young Yun |
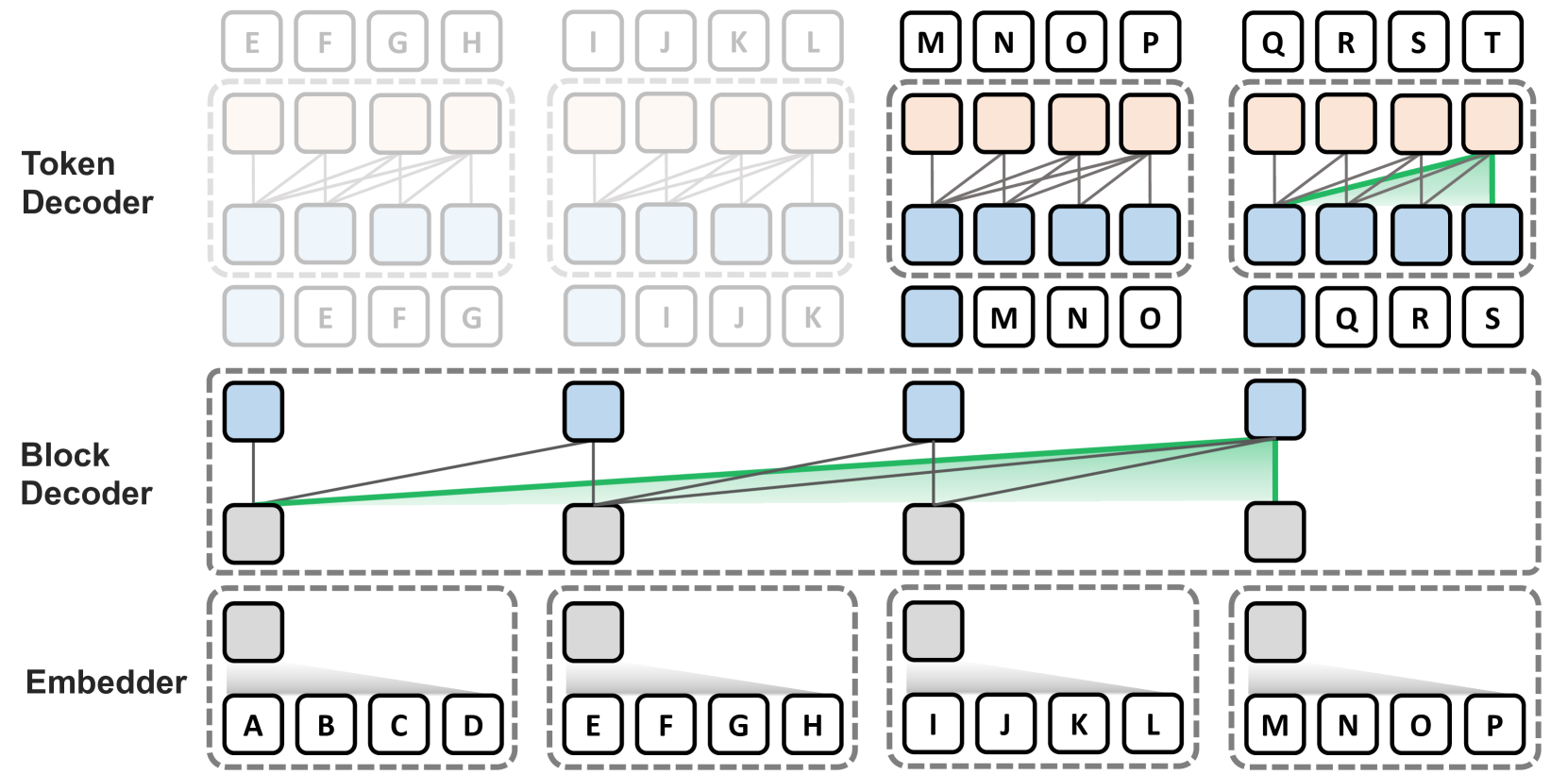 |
Github Paper |

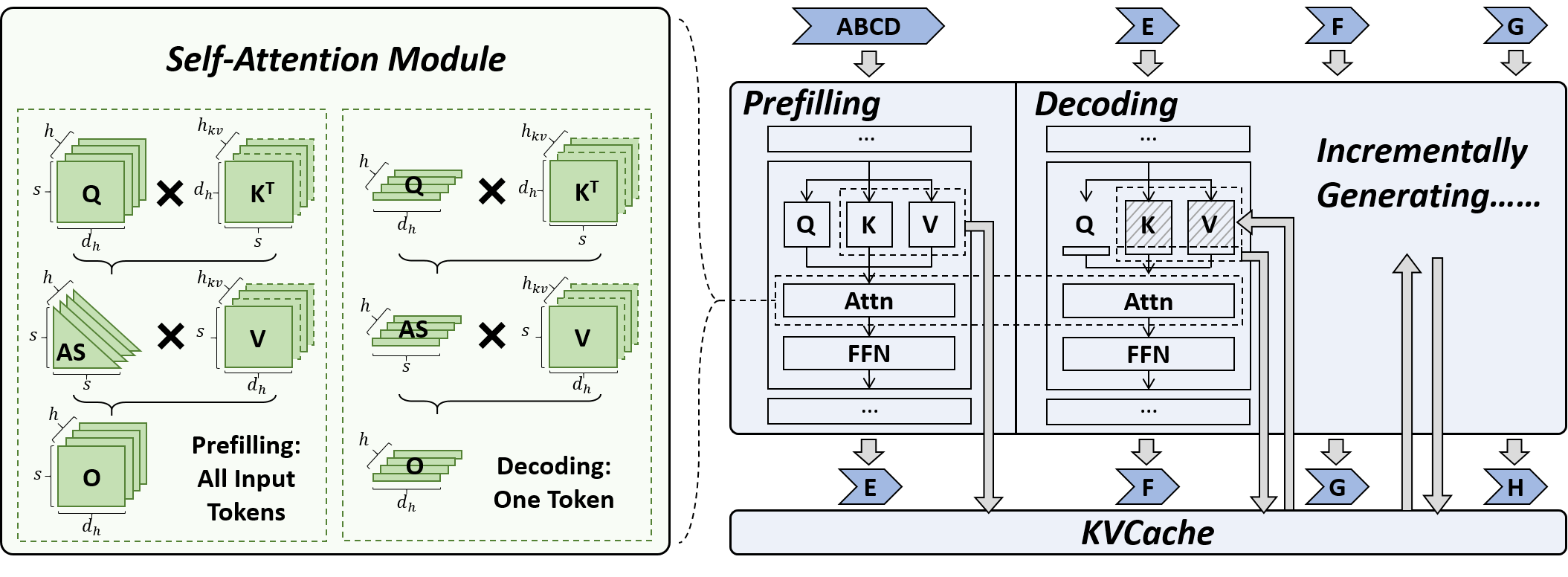



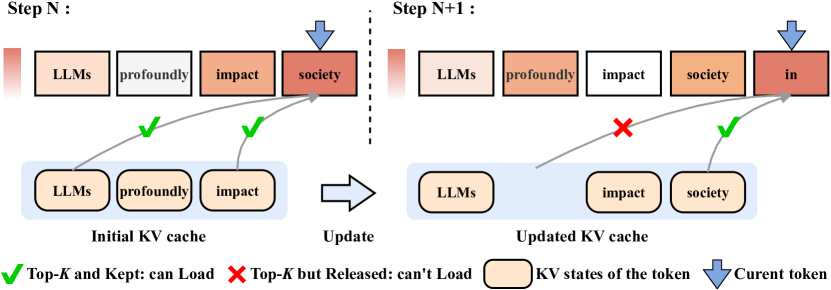








| Title & Authors | Introduction | Links |
|---|---|---|
Characterizing Prompt Compression Methods for Long Context Inference Siddharth Jha, Lutfi Eren Erdogan, Sehoon Kim, Kurt Keutzer, Amir Gholami |
 |
Paper |
| Entropy Law: The Story Behind Data Compression and LLM Performance Mingjia Yin, Chuhan Wu, Yufei Wang, Hao Wang, Wei Guo, Yasheng Wang, Yong Liu, Ruiming Tang, Defu Lian, Enhong Chen |
 |
Paper |
| PromptIntern: Saving Inference Costs by Internalizing Recurrent Prompt during Large Language Model Fine-tuning Jiaru Zou, Mengyu Zhou, Tao Li, Shi Han, Dongmei Zhang |
 |
Paper |
| Brevity is the soul of wit: Pruning long files for code generation Aaditya K. Singh, Yu Yang, Kushal Tirumala, Mostafa Elhoushi, Ari S. Morcos |
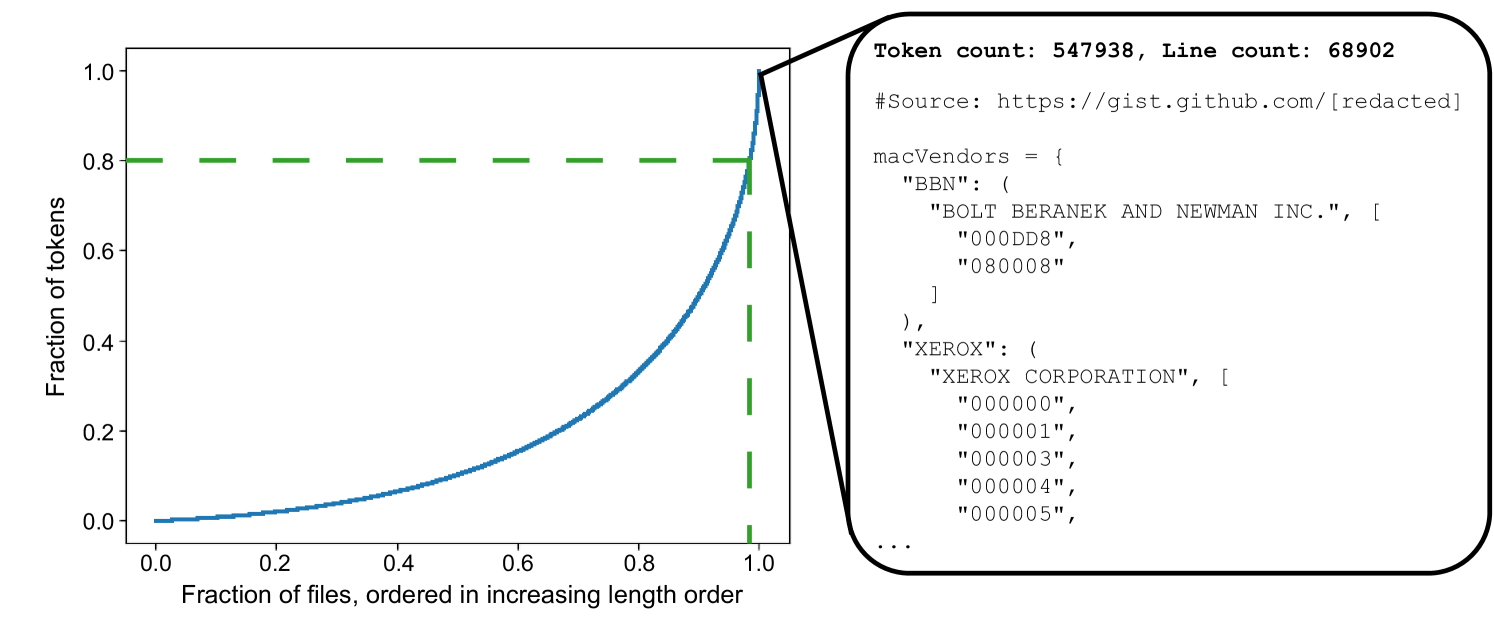 |
Paper |
| Title & Authors | Introduction | Links |
|---|---|---|
| MCNC: Manifold Constrained Network Compression Chayne Thrash, Ali Abbasi, Parsa Nooralinejad, Soroush Abbasi Koohpayegani, Reed Andreas, Hamed Pirsiavash, Soheil Kolouri |
 |
Paper |






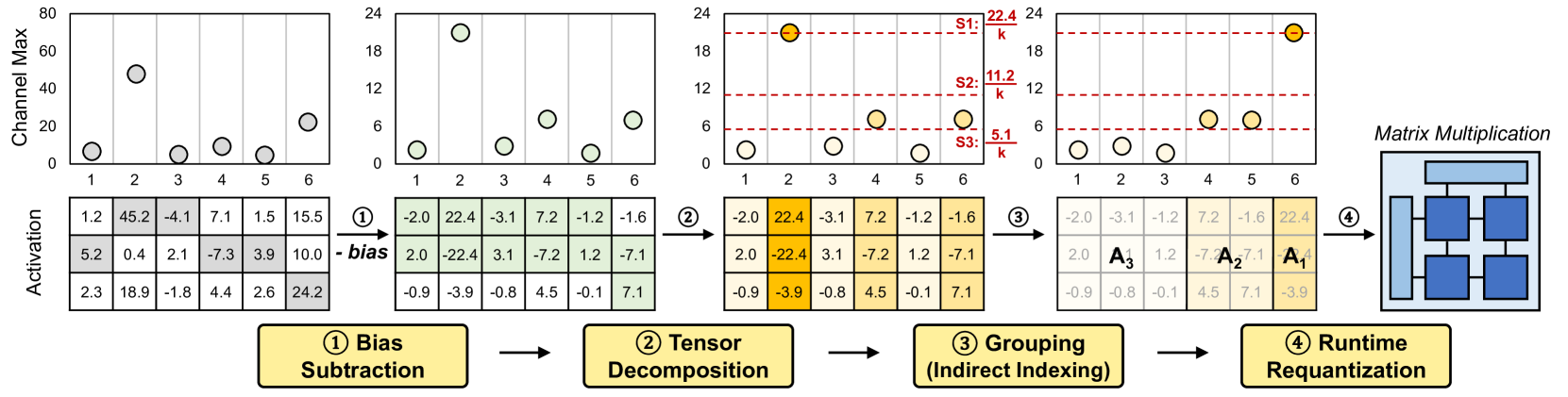









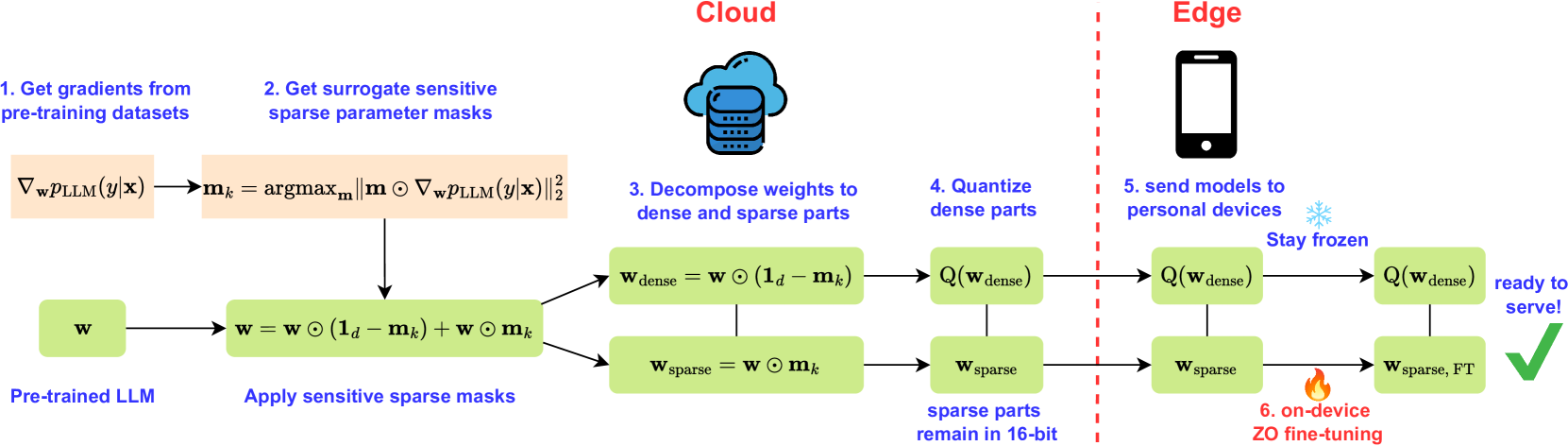
| Title & Authors | Introduction | Links |
|---|---|---|
Inference Optimization of Foundation Models on AI Accelerators Youngsuk Park, Kailash Budhathoki, Liangfu Chen, Jonas Kübler, Jiaji Huang, Matthäus Kleindessner, Jun Huan, Volkan Cevher, Yida Wang, George Karypis |
Paper | |
| Survey on Knowledge Distillation for Large Language Models: Methods, Evaluation, and Application Chuanpeng Yang, Wang Lu, Yao Zhu, Yidong Wang, Qian Chen, Chenlong Gao, Bingjie Yan, Yiqiang Chen |
 |
Paper |
| Memory Is All You Need: An Overview of Compute-in-Memory Architectures for Accelerating Large Language Model Inference Christopher Wolters, Xiaoxuan Yang, Ulf Schlichtmann, Toyotaro Suzumura |
 |
Paper |
If you'd like to include your paper, or need to update any details such as conference information or code URLs, please feel free to submit a pull request. You can generate the required markdown format for each paper by filling in the information in generate_item.py and execute python generate_item.py. We warmly appreciate your contributions to this list. Alternatively, you can email me with the links to your paper and code, and I would add your paper to the list at my earliest convenience.