v1.1.1
图片批量离线OCR文字识别程序。输入图片路径,输出识别结果json字符串,方便别的程序调用。
本程序的GUI形式:Umi-OCR 批量图片转文字工具
下载 PaddleOCR-json v1.1.1 并解压,即可。
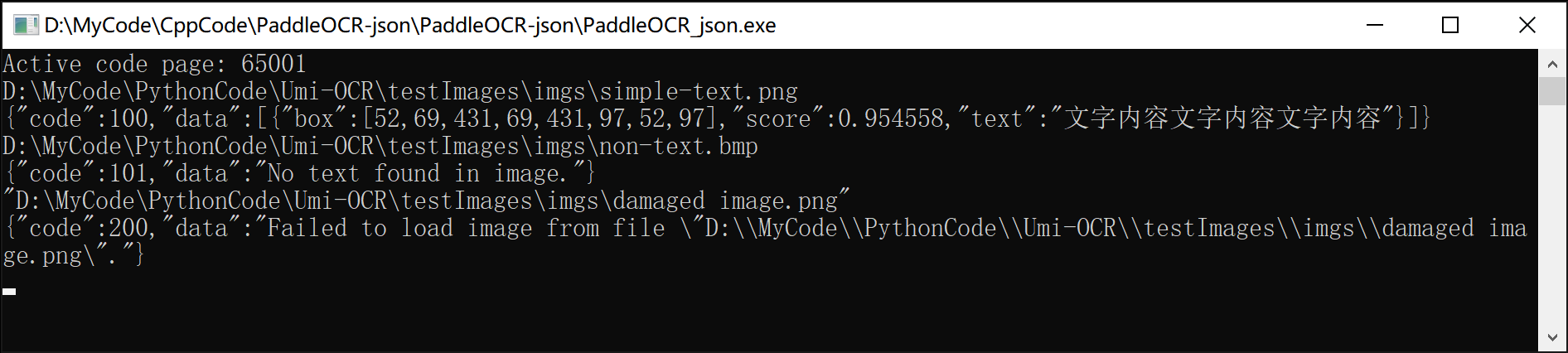
直接打开PaddleOcr_json.exe。输入图片路径,回车。
- 任务成功时,输出图片识别信息json字符串。格式见下。
- 任务失败时,输出错误信息json字符串。
- 输出一条信息后,可继续接收路径输入;程序是死循环。
- 支持输入带空格的路径。
- 命令行模式下仅支持英文路径。
程序接受gbk编码输入,而输出是utf-8。因此,命令行模式下,无法识别输入的非英文字符。
示例:
- 通过管道与识别器程序交互。
- 支持中文路径:将含中文字符串编码为
gbk输入管道,即可被正确识别。 - 输入内容必须以换行符结尾。
import subprocess
import json
imgPath = "测试文件夹\\测试图片.png\n" # 待检测图片路径,支持中文和空格,结尾必须有换行符。
# 打开管道,启动识别器程序
ret = subprocess.Popen(
exePath,
stdout=subprocess.PIPE,
stdin=subprocess.PIPE,
)
ret.stdout.readline() # 读掉第一行
# 发送图片路径,获取识别结果
ret.stdin.write(imgPath.encode("gbk")) # 编码gbk
ret.stdin.flush() # 发送
getStr = self.ret.stdout.readline().decode('utf-8', errors='ignore') # 获取结果,解码utf-8
getObj = json.loads(getStr) # 反序列化json
print("识别结果为:",getObj)
ret.kill()这个调用demo不完善,存在一些问题。建议查看1.2.0及以后版本。
- 处理OCR结果的业务函数 OcrFlow 不运行在主窗口中,所以用Windows PowerShell运行代码似乎不会显示它输出的内容,只有在vscode中运行才可以看到。
- 编码转换问题,得到的 $ocrStr 的内容是utf-8但编码是gbk,因此表现为中文乱码,要重新将字符串编码为utf-8才行。
- 任务结束退出程序时似乎存在问题,OCR识别器进程能被正常关闭,而powershell进程未结束,exit不起作用。(或许需要强制杀死本进程$pid?)
PaddleOcr_json.exe 将把识别信息以json格式字符串的形式打印到控制台。根含且只含两个元素:状态码code和内容data。状态码code为整数,每种状态码对应一种data形式:
- data内容为数组。数组每一项为字典,含三个元素:
text:文本内容,字符串。box:文本包围盒,长度为8的数组,分别为左上角xy、右上角xy、右下角xy、左下角xy。整数。score:识别置信度,浮点数。
- data为字符串:
No text found in image.
- data为字符串:
Failed to load image form file "{图片路径}".
需要下载和简单修改配置文件。以法文为例:
- 前往 PP-OCR系列 多语言识别模型列表 下载对应的 推理模型
french_mobile_v2.0_rec_infer.tar和 字典文件french_dict.txt。 - 在
PaddleOCR-json目录下创建文件夹rec_fr,将解压后的三个模型文件放进去。字典文件可直接放在目录下。 - 复制一份识别器
PaddleOCR_json.exe,命名为PaddleOCR_json_fr.exe - 复制一份配置单
PaddleOCR_json_config.txt,命名为PaddleOCR_json_fr_config.txt - 打开配置单
PaddleOCR_json_fr_config.txt,将# rec config相关的两个配置项改为:# rec config rec_model_dir rec_fr char_list_file french_dict.txt
本程序兼容v2和v3版本模型库,但个人实测v3的效果不稳定,v2在速度和精确性上均占优。(见issue #4)(推测,可能是本项目对v3模型的优化不够好;未来将尝试解决这个问题。)
- 下载模型
- 前往PaddleOCR下载一组推理模型(非训练模型)。中英文超轻量PP-OCRv2模型 体积小、速度快,中英文通用PP-OCR server模型 体积大、精度高。一般来说,轻量模型的精度已经非常不错,无需使用标准模型。
- 放置模型
- 将下载下来的方向分类器(如
ch_ppocr_mobile_v2.0_cls_infer.tar)、检测模型(如ch_PP-OCRv2_det_infer.tar)、识别模型(如ch_PP-OCRv2_rec_infer.tar)解压,将文件分别放到对应文件夹cls、det、rec。
- 调整配置
- 仿照修改语言的方法,复制一份
PaddleOcr_json.exe及其配置单[exe名称]_config.txt,修改其中的路径参数。打开exe,若无报错,则模型文件已正确加载。“Active code page: 65001”是正常现象。 - 配置单中,可设置更多OCR识别参数等。调整它也许能获得更高的识别精度和效率。具体参考官方文档配置文件内容与生成、更多支持的可调节参数解释。
- 注意,如果修改了exe名称,也需要同步修改配置文件名的前缀。
- 为了提高速度,PaddleOCR预先将长度超标的图片进行压缩,再执行文字识别。这可能导致超大分辨率(4k以上)图片的识别准确度下降,比如漏掉小字。调整
启用压缩阈值可改善该问题,方法见issue #5。注意,减少压缩可能导致识别耗时大幅增加。
- 下载并编译飞桨PaddleOCR C++预测库,可参考 官方 VS2019 & CMake 编译指南 或 这篇教程 或 。注意PaddleOCR c++源码必须使用 v2.1.1版本 。
- 将本项目
src、include目录中的文件替换进去。
- 为何通过控制台传入图片路径而不是通过启动参数传递?因为本程序初始化时要载入不少模型库文件,若每次启动程序只识别一张图片,则批量处理会多出额外的初始化开销。所以采用了一次初始化,后续多次传入路径的设计。
- 理论上,程序对于传入的异常文件会有处理,返回错误码200;不影响后续工作。(异常文件指:不存在的路径,opencv不支持的图片格式,已损坏的图片。)
但使用中,若通过管道传入的gbk编码含中文路径若存在异常(如
测试文件夹\\已损坏的图片.png),大多数情况下能处理,有小概率进程直接挂掉。如果是纯英文路径(如test\\damaged image.png),则貌似没有这个问题。目前尚未清楚原因,目测跟opencv的imread()有关。 当然,含中文路径不存在异常时,不会出现以上bug。 建议,如果已知要处理的图片 有出现异常的风险,则调用OCR前先判断一下。 - 我使用VS2019编写这个项目。代码中所有以中文结尾的注释,必须多加一个空格;否则它会吞掉行尾换行符导致编译器把下一行也当成注释。编辑器并不会提示这个错误,编译的时候才会不通过。
本项目中使用了 configor :
“一个为 C++11 量身打造的轻量级 config 库,轻松完成 JSON 解析和序列化功能,并和 C++ 输入输出流交互。”
- 修正了漏洞:当
文本检测识别到区域但文本识别未在区域中检测到文字时,可能输出不相符的包围盒。
- 修改了json输出格式,改为状态码+内容,便于调用方判断。