Landmark Recurrent Network: An efficient and robust framwork for Deepfakes detection
The implementation for paper: Improving the Efficiency and Robustness for Deepfakes Detection through Precise Geometric Features (CVPR2021).
LRNet is a light-weight and effective Deepfakes detection framework. It analyzes the sequence of geometric features in facial videos to capture the temporal artifacts (such as unnatural expressions) and make predictions.
It takes three steps to discriminate a forged face video:
- Extract the 2-D facial landmark sequence from the video. It can be conveniently realized by some open-source toolkit like Dlib, OpenFace, MediaPipe, etc.
- De-noise the sequence by our carefully-devised calibration module. It utilizes optical flow and Kalman filter techniques to alleviate the noise caused by different landmark detectors.
- Embed the landmark sequence into two feature sequences and input them into two RNN. The output of two RNN are merged to obtain the final prediction.
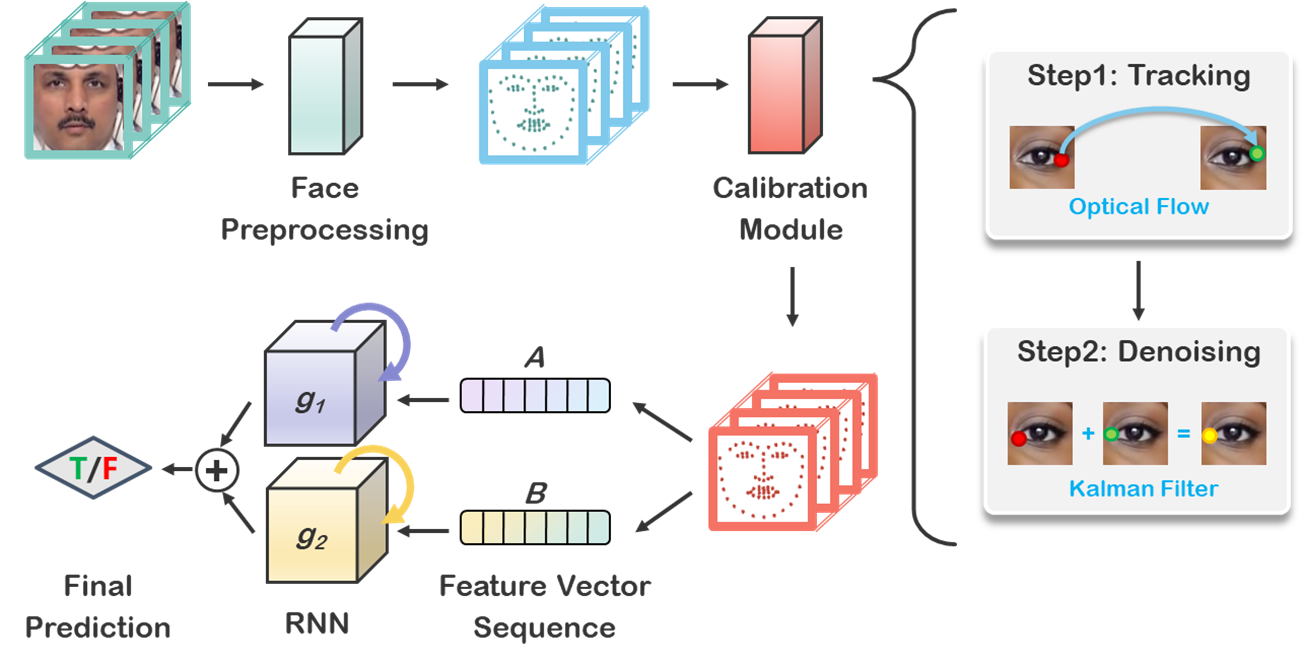
To go through the whole procedure of LRNet's forgery detection (from an input video sample to its corresponding predicted label), you can enter the
./demo/for more details.For easily training and evaluating the LRNet, you can enter the
./training/for more details.If you would like to use your own landmark detector to generate the dataset, you can enter the
./calibrator/for more details.
Firstly clone the repo via:
git clone https://github.com/frederickszk/LRNet.git
cd LRNetAfterward, you could prepare the environment at a time, which supports all functions of this repo, by the following instructions.
Or you could alternatively configure for a specific function as described above (such as demo or training) following the README.md file in those subfolder.
Optional: It's recommended to create a conda environment:
conda create -n lrnet python=3.10
conda activate lrnetThen install the dependencies:
pip install -r requirements.txtThe common setup is convenient for LINUX system with the latest CUDA-Driver support. But there would be exceptions such as:
- For WINDOWS or MACOS system, the CPU-version of
PyTorchis installed by default. - For LINUX system, the latest
PyTorch-GPUis installed, but it may not be compatible with your CUDA driver or device. - Because
LRNetcould be run on CPU, you may want to install the CPU-version ofPyTorch.
Under these circumstances, you could firstly customize the installation process of PyTorch.
For instance, if you want to install the PyTorch-GPU with the latest CUDA on WINDOWS, you could install it by:
pip install torch --index-url https://download.pytorch.org/whl/cu121For other configurations, you could consult the Official website.
Then install the remaining dependencies:
pip install -r requirements-no-torch.txtIf our work helps your research, welcome for the citation:
@inproceedings{sun2021improving,
title={Improving the Efficiency and Robustness of Deepfakes Detection through Precise Geometric Features},
author={Sun, Zekun and Han, Yujie and Hua, Zeyu and Ruan, Na and Jia, Weijia},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
pages={3609--3618},
year={2021}
}- Upload the demo.
- Organize the codes into the sub-folder. (2022/3/16)
- Greatly refactor and upgrade the landmark extractor (2022/10/22)
- Update the demo's model to PyTorch version. (2024/01/08, LATEST)
- Optimize the stability of landmark extraction. (2024/01/08, LATEST)
- Update the calibration module.
- Update the pyramidal LK with numpy and openCV.
- Implement the pyramidal LK with openCV API.
- Provide API for easier use.
- Provide utils for calibrating the dataset (under OpenFace workflow).
- Optimize the stability of landmark extraction. (2024/01/08, LATEST)
- Optimize the model.
- Update the training codes.
- For PyTorch version, optimize the dropout layer.
- Greatly refactor the training and evaluation codes for PyTorch version. (2022/3/10)
- Update the Jupyter Notebook version training/evaluation codes. (2022/3/20)
- Update the weights for the whole FF++ dataset. (2022/4/28)
- Update AUC evaluation codes. (Both .py and .ipynb) (2022/5/2)
- Update the model with optimized structure and trained with new version datasets (2022/11/5).
- Update the model trained with new version datasets (2024/01/08, LATEST)
- Gradually release the datasets
- FF++ (2024/01/08, LATEST)
- c23
- raw
- c40
- FF++ (2024/01/08, LATEST)
2021/5/18
-
Update the demo's model weights. Now we provide demo's weights trained on FF++ (./demo/modelweights/ff) and Deeperforensics-1.0 (./demo/modelweights/deeper). We use
deeperby default, because the given examples are from this dataset. You can change toffinclassify.pyL107--L113. - Provide faster LK tracker. We now use openCV optical api to achieve LK track. It would be faster and more stable.
- Update GPU support. We restrict Tensorflow not to use up the memory of GPU when it is supported. Although CPU is enough for inference. The GPU memory occupation may be < 1G.
2021/11/13
- Update the training and testing codes.
- Release FF++(c23) landmark datasets.
- Update the plug-and-use landmark calibrator API.
2022/3/10
- Provide utils for calibrating the dataset. Currently it is devised for OpenFace work flow. We consider add more workflow supports in the future.
- Greatly refactor the training and evaluation codes for PyTorch version. They can help perform more flexible training and evaluating strategies, which is convenient for further research.
2022/3/16
-
Organize the demo codes. Now the demo codes are gathered in the
./demo/folder , making the project's home page clean and tidy. -
Discussion: the selection of landmark detector in demo.
We also try several landmark detectors and find that
Dlibis relatively good solution. Although it's accuracy and stability are not the SOTA, it helps alleviate preparing burdensome dependencies (especially for deep-learning-based models). Besides, it's inference speed is fast and suitable for reproducing the LRNet's framework. You could also replace it with other advanced landmark detectors.
2024/1/8
-
Optimize the landmark extraction.
As shown above, when extracting the landmarks in a video (image sequence), we now use a FIXED face size for all the frame. It's calculated by averaging the face size in each frame. This can extract a more consistent landmark sequence. -
Update the model in demo to PyTorch version. The model structure and usage in
demois now kept in sync with the one in thetraining. The weights indemoare trained on thedfodataset for better generalization ability, while the weights intrainingare trained onFF++for evaluations.
