@Brief: Experimental study notes on Linux file system
@Author: [machy](exaids66 (machy) (github.com))
This is a public repository created to collate data from past projects, and we have uploaded some of the non-private content here for safekeeping.
- 文件系统概念
- 什么是文件系统
- 目前较为流行的文件系统类型
- Linux虚拟文件系统层
- 调用流程
- 文件系统读流程图
- 文件预读
- 文件系统读实例
- 实验
- 用工具测试速率
- 修改内核测试速率
- 关闭中断
狭义:文件系统是实现对磁盘、软盘或者光盘等块设备的数据进行存取的方法。
广义:文件系统未必需要建立在磁盘之上,还可以构建在网络或者内存之上。
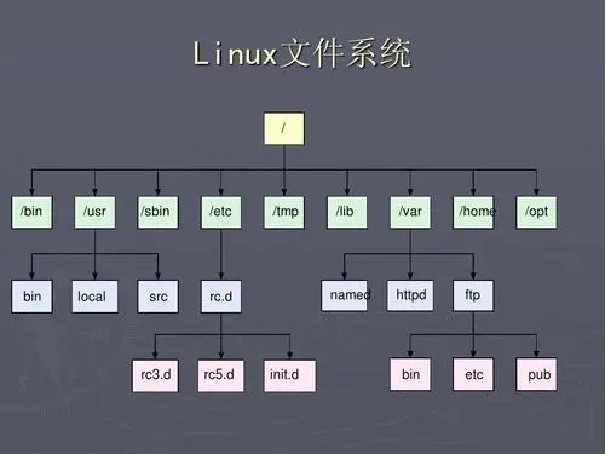
总的来说,文件系统就是向下针对物理存储设备进行数据的格式化管理,同时向上对用户或者应用提供读写方法。
据不同的存储设备、应用场景,采用特定的文件系统(即存储格式和读写方法),可提高生产过程的效率以及存储设备的使用寿命、节约成本。
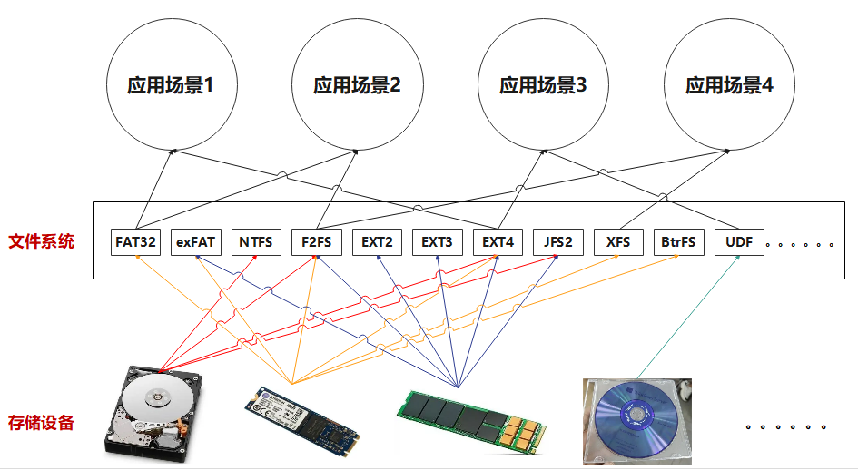
总的来说,文件系统就是向下针对物理存储设备进行数据的格式化管理,同时向上对用户或者应用提供读写方法。
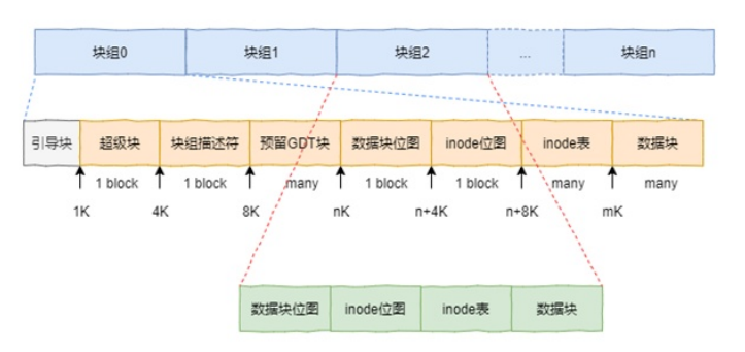
实现我们一些基础的组织结构,包括inode、superblock......
在ext2的基础上添加了日志功能
重构了相关组织磁盘的数据结构,并向下兼容ext3格式化后的设备,并自带日志功能
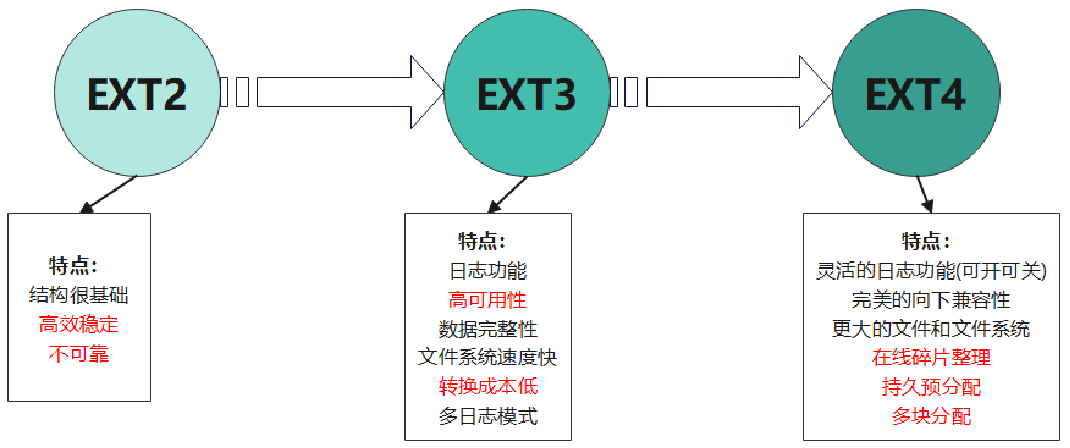
从EXT文件系统的发展过程,可以看出,安全性逐渐得到了重视。
- FAT表:
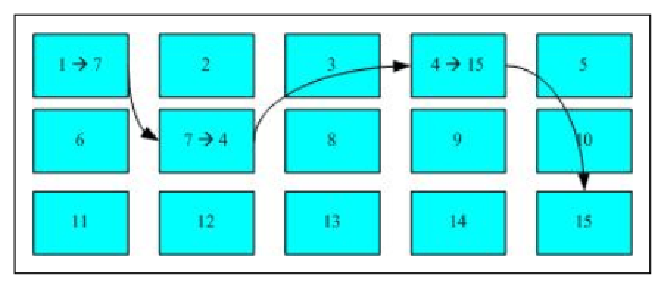

FAT文件系统通过FAT表来组织各个物理块的关系。
FAT最早是由微软开发并应用到Windows的文件系统。之后考虑到用户数据的安全性,微软在FAT文件系统的基础上强化了其隐私安全、权限控制等功能,推出了NTFS文件系统。
总的来说,FAT在400MB以内具有开销小、效率高的特点,但安全性不够,容易受到攻击;NTFS在400MB以上具有高效、安全的特点,广泛应用于当今Windows、MAC的计算机上。
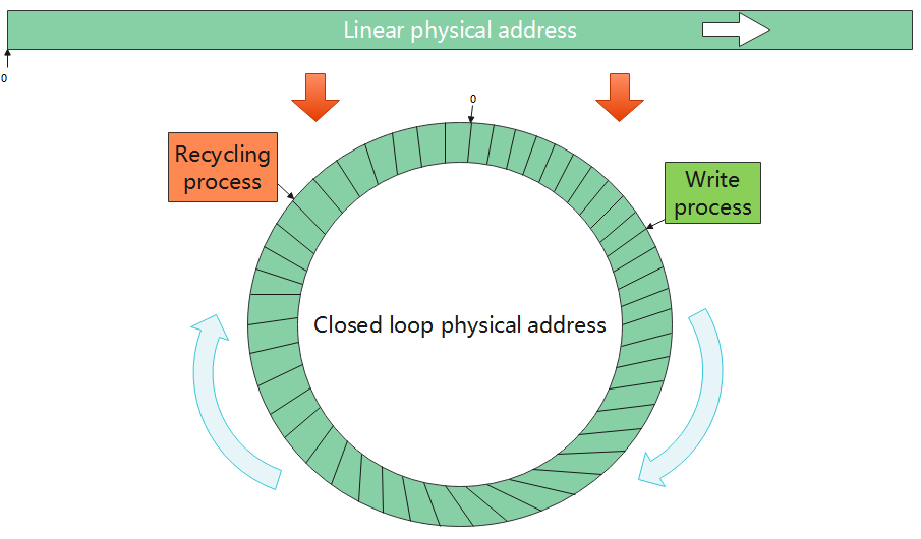
F2FS充分考虑了闪存单元的写次数上限的特点,让闪存每一个单元的平均写次数几乎接近,不会出现其中一个单元频繁刷新写入导致寿命降低。
总的来收,F2FS文件系统的出现体现了当今有针对性、有目的性的研究推出特定应用的文件系统的趋势。
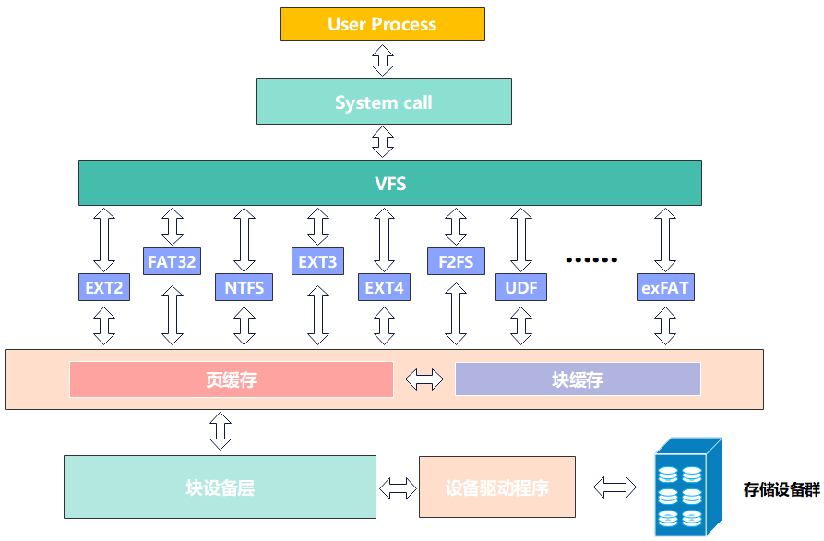
VFS向下,封装各个文件系统的接口函数以及一些文件系统的信息,如inode、operation等等。同时,向上,为系统开发、应用程序提供统一的接口函数。
从以上文件系统结构图可以看出,虚拟文件系统为上层开发者或系统调用提供统一操作存储的接口,简化开发过程。
文件系统起初创造出来是为了采用一种方法来管理存储设备中的数据,让存储数据具有一种格式。之后随着存储设备的增多,以及出于系统安全性、增长的规模、出现新型存储设备考虑,文件系统开始复杂化、多样化。为了便于系统开发者统一管理,向上推出了一层虚拟文件系统来抽象化各个文件系统的信息,抽象为superblock、inode、data block、directory block等结构体,统一管理各个文件系统。
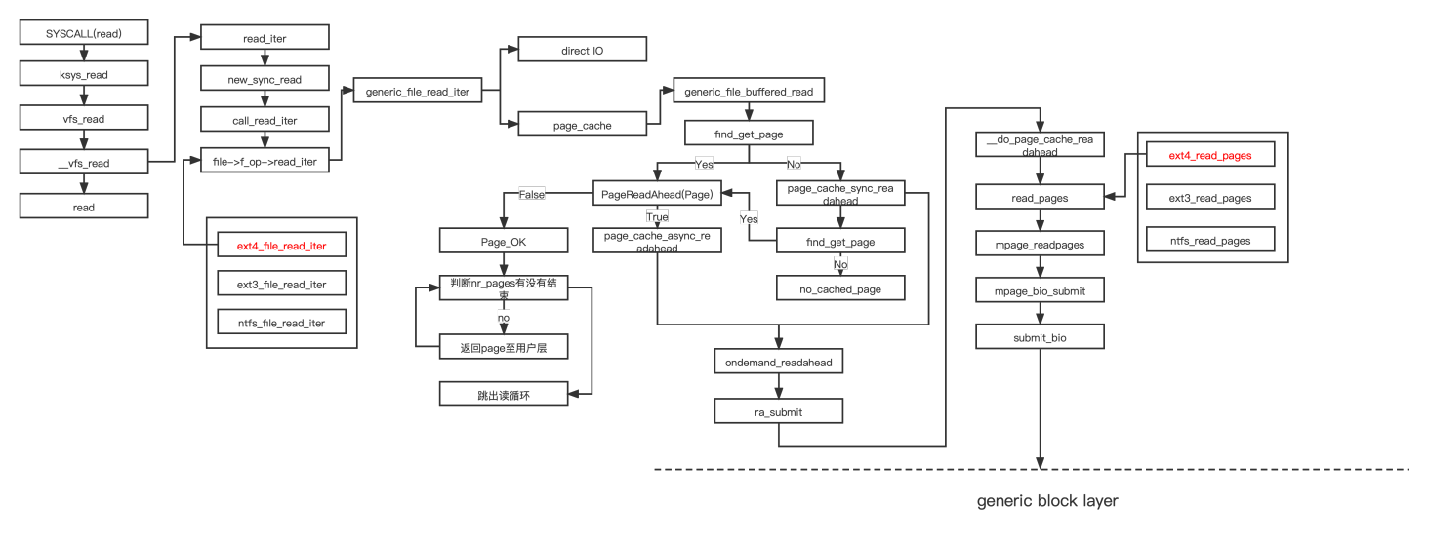
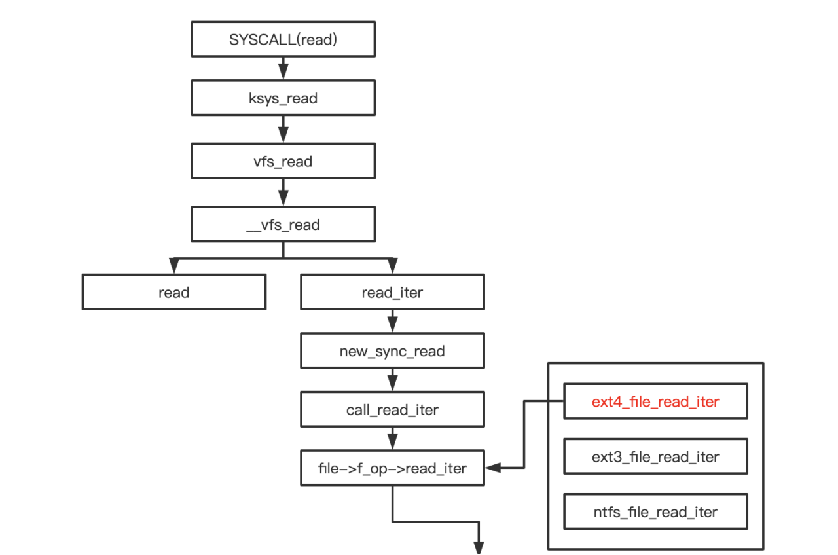
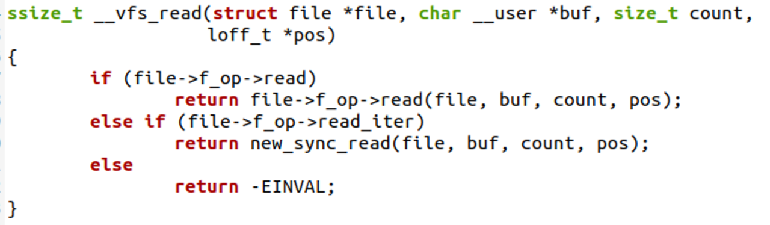
注册的 file_operations 有 read 方法,调用 read 方法,一般的设备文件会注册此类接口若 file_operations 有 read_iter 方法,调用 new_sync_read()。一般普通文件注册此类方法。
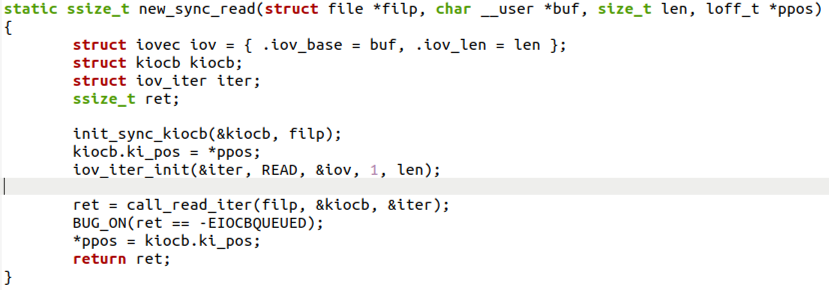
这个函数用到了两个结构体iovec和kiocb,分别用来记录文件侧和内存侧的文件读取进度。
省流:散布读集中写
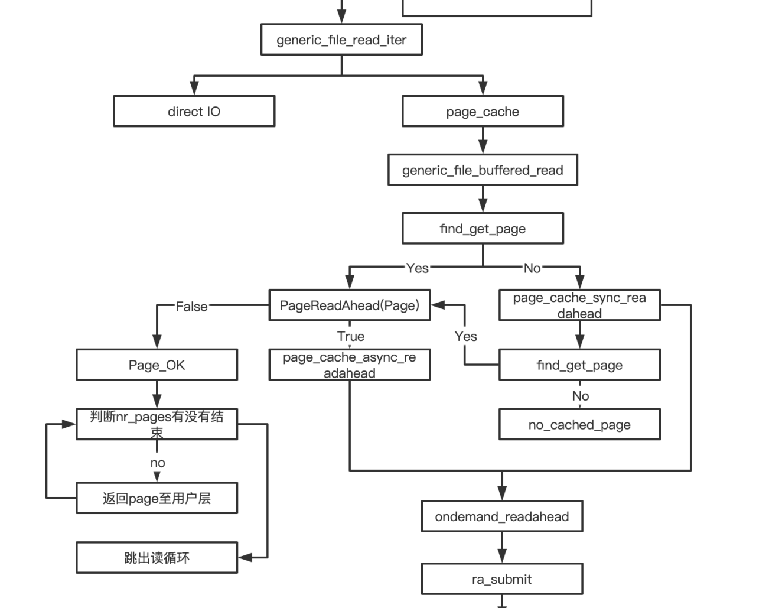

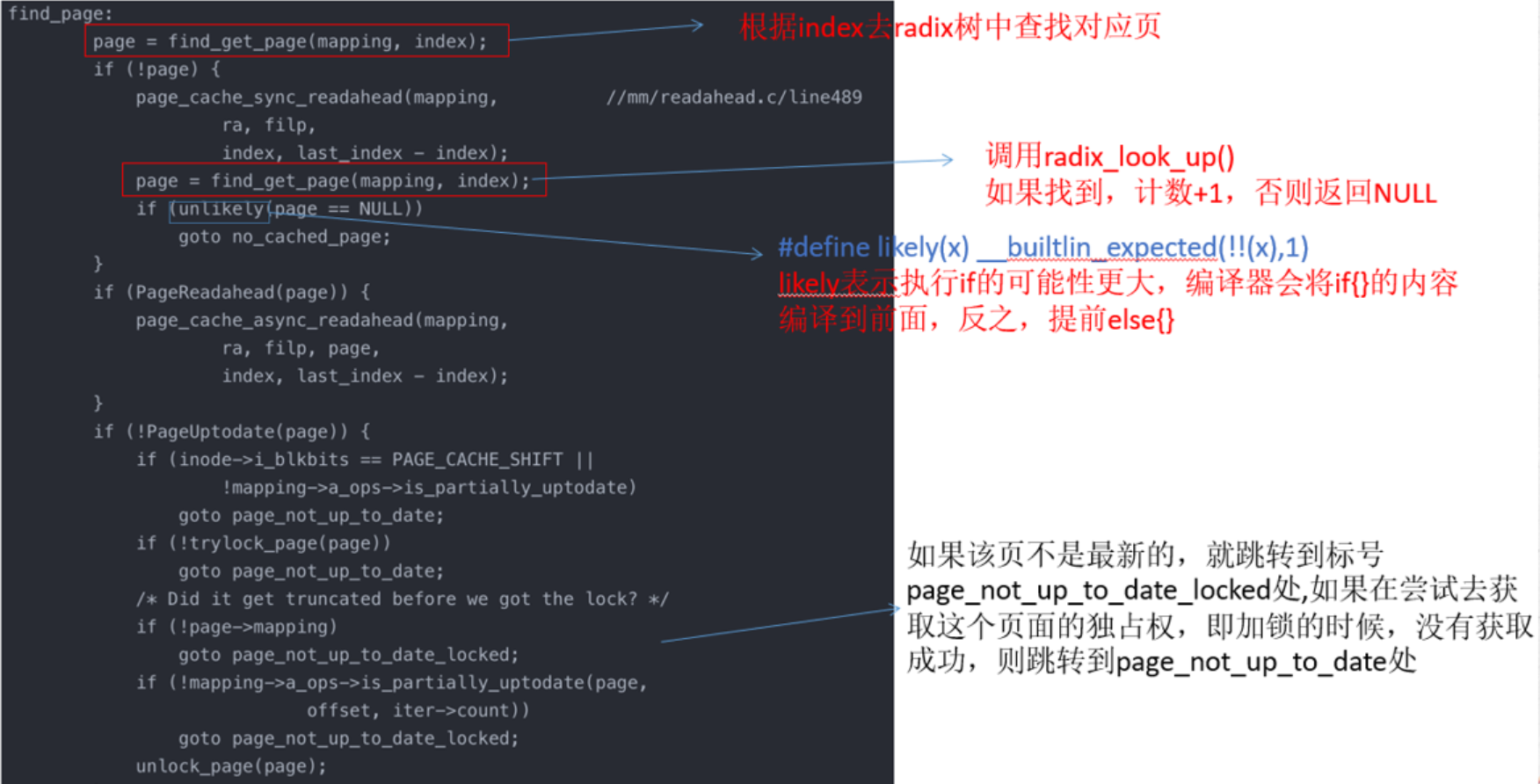
index为对应页缓存中的页号,而offset是对应的页内偏移,在address_space中根据index的页号,找对应的页。
CPU预取,有利于提高预取指令的正确性,以此提高效率。
如果页面已经在页高速缓存(page_cache)中。
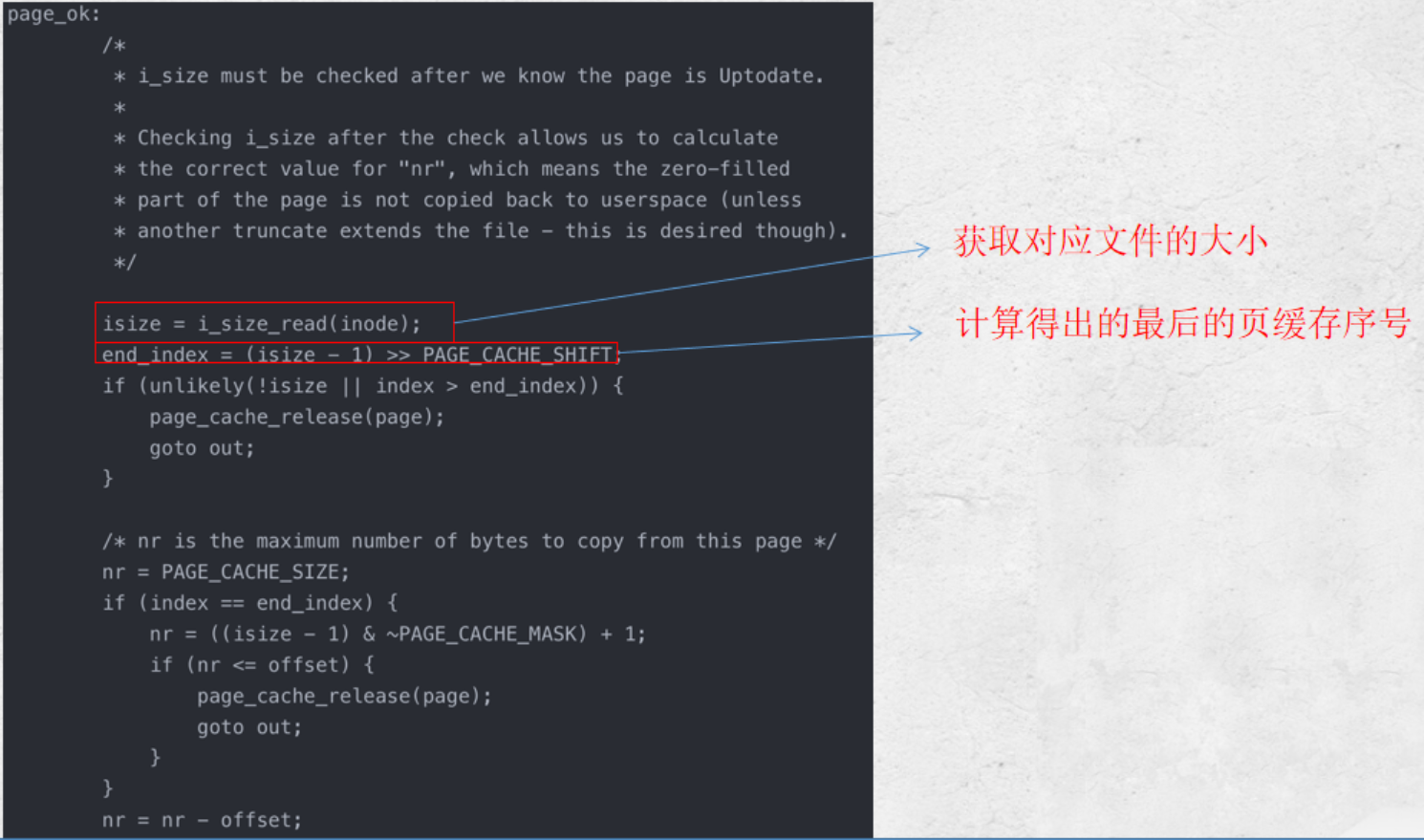
则选择下一个要获取的页。
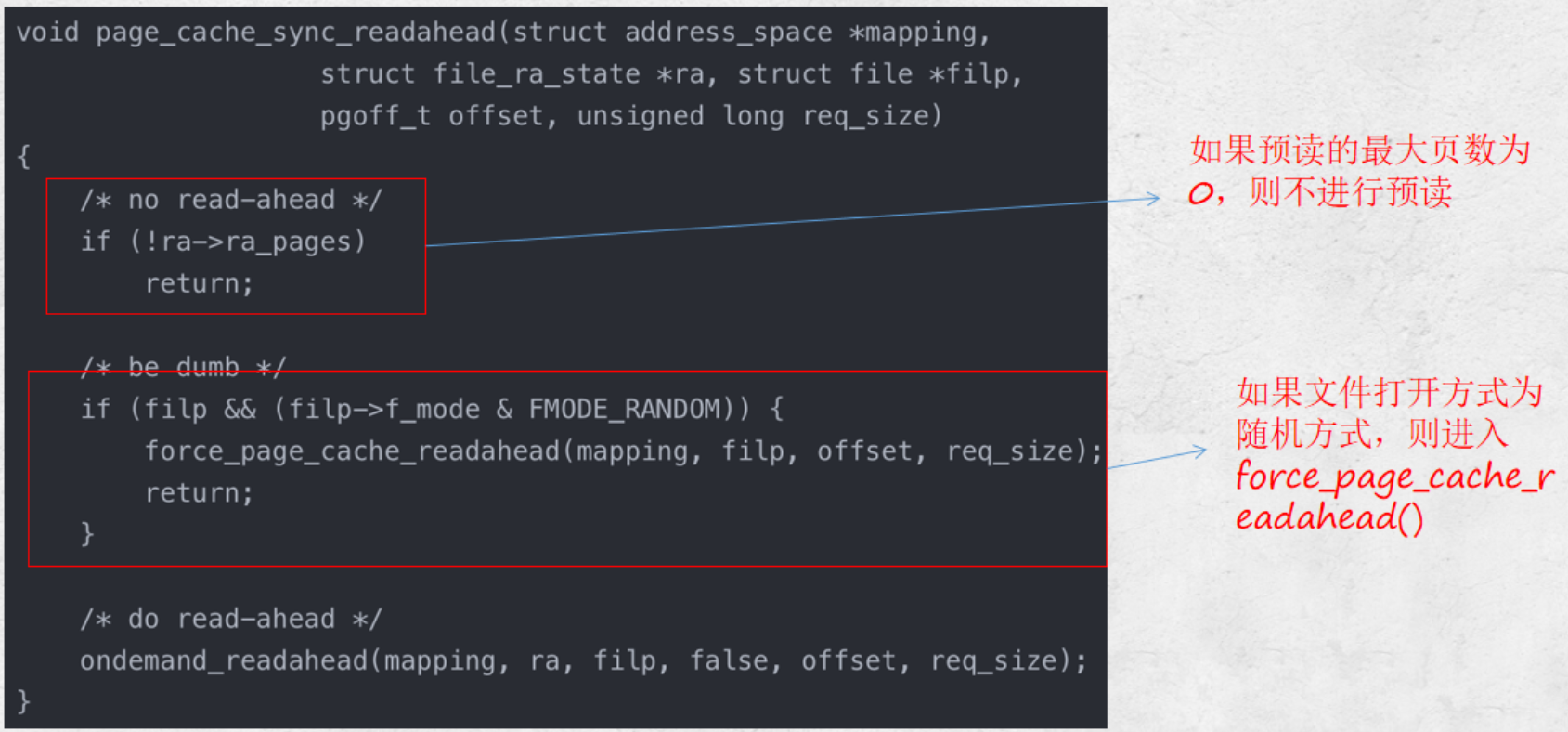
同步预读入口判断。
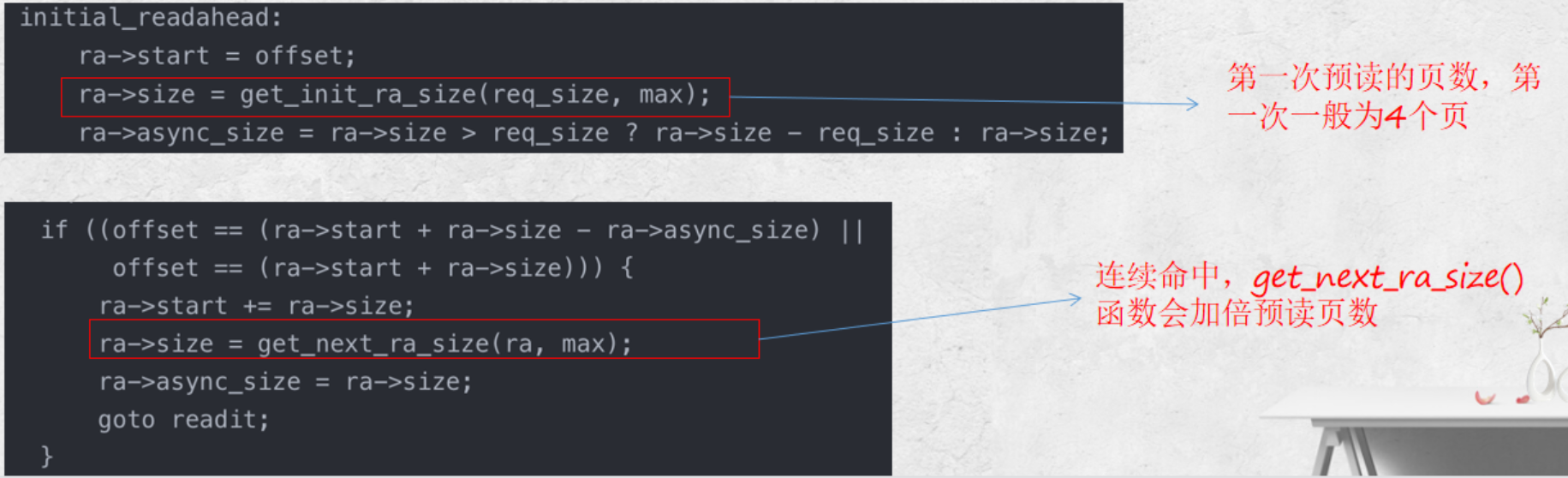
- 首先判断如果是从头文件开始读取的,则认为是顺序读,初始化预读信息。默认设置预读为四个page。
- 如果不是从文件头开始读,则判断是否是连续的读取请求,如果是,则扩大预读数量,一般等于上次预读数量 ×2。
- 否则就是随机的读取,不适用预读,只读取 sys_read 请求的数量。
- 调用 ra_submit() 提交读请求。
用户需要连续访问某个文件连续32个页(page index=0~31)的数据,那么它在预读机制下的访问行为是:
用户访问第一个页,page index=0,触发同步预读机制,一次性从磁盘读取4个页,即第14个页(page index=03)
用户访问第二个页,page index=1,含有特殊标志,触发异步预读机制,一次性从磁盘读取8个页,即第512个页(page index=411)
用户访问第三个页,page index=2,命中,直接返回给用户
用户访问第四个页,page index=3,命中,直接返回给用户
用户访问第五个页,page index=4,含有特殊标志,触发异步预读机制,一次性从磁盘读取16个页,即第1328个页(page index=1227)
用户访问第六个页,page index=5,命中,直接返回给用户
用户访问第七个页,page index=6,命中,直接返回给用户
用户访问第八个页,page index=7,命中,直接返回给用户
用户访问第九个页,page index=8,命中,直接返回给用户
用户访问第十个页,page index=9,命中,直接返回给用户
用户访问第十一个页,page index=10,命中,直接返回给用户
用户访问第十二个页,page index=11,命中,直接返回给用户
用户访问第十三个页,page index=12,含有特殊标志,触发异步预读机制,一次性从磁盘读取32个页,即第1242个页(page index=1343),但是由于page index=1227的页上一次预读就将页读入了page cache,因此会跳过,实际上只会从磁盘读取page index=2843页。
…以此类推
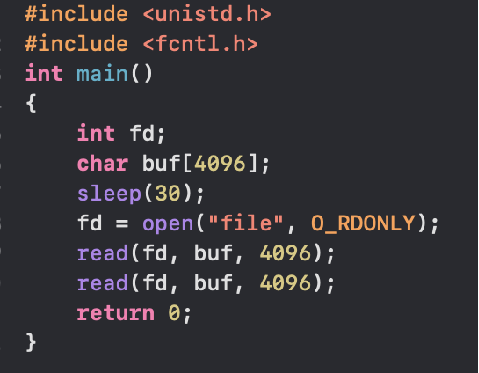
在Linux中,内存充当硬盘的page cache,所以,每次读的时候,会先check你读的那一部分硬盘文件数据是否在内存命中,如果没有命中,才会去硬盘;如果已经命中了,就直接从内存里面读出来。
如果是写的话,应用如果是以非SYNC方式写的话,写的数据也只是进内存,然后由内核帮忙在适当的时机writeback进硬盘代码中有2行read(fd, buf, 4096),第1行read(fd, buf, 4096)发生的时候,显然”file”文件中的数据都不在内存,这个时候,要执行真正的硬盘读,app只想读4096个字节(一页),但是内核不会只是读一页,而是要多读,提前读,把用户现在不读的也先读,因为内核怀疑你读了一页,接着要连续读,怀疑你想读后面的。与其等你发指令,不如提前先斩后奏(存储介质执行大块读比多个小块读要快),这个时候,它会执行预读,直接比如读4页,这样当你后面接着读第2-4页的硬盘数据的时候,其实是直接命中了。
- 当你执行完第一个read(fd, buf, 4096)后,”file”文件的0~16KB都进入了pagecache,同时内核会给第2页标识一个PageReadahead标记,意思就是如果app接着读第2页,就可以预判app在做顺序读,这样我们在app读第2页的时候,内核可以进一步异步预读。

- 我们紧接着又碰到第二个read(fd, buf, 4096),它要读硬盘文件的第2页内容,这个时候,第2页是page cache命中的,这一次的读,由于第2页有PageReadahead标记,让内核觉得app就是在顺序读文件,内核会执行更加激进的异步预读,比如读文件的第16KB~48KB。
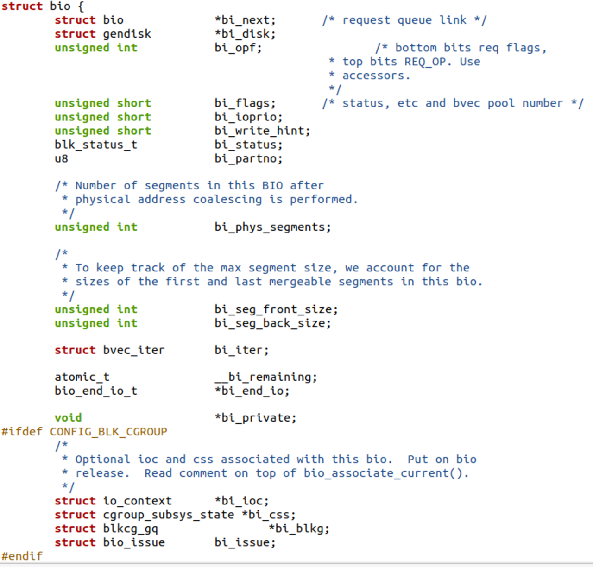
第一次的read(fd, buf, 4096),变成了读硬盘里面的16KB数据,到内存的4个页面(对应硬盘里面文件数据的第016KB)。但是我们还是不知道,硬盘里面文件数据的第016KB在硬盘的哪些位置?我们必须把内存的页,转化为硬盘里面真实要读的位置。
在Linux里面,用于描述硬盘里面要真实操作的位置与page cache的页映射关系的数据结构是bio。它是一个描述硬盘里面的位置与page cache的页对应关系的数据结构,每个bio对应的硬盘里面一块连续的位置,每一块硬盘里面连续的位置,可能对应着page cache的多页,或者一页,所以它里面会有一个bio_vec *bi_io_vec的表。
-
第1种情况是page_cache_sync_readahead()要读的0~16KB数据,在硬盘里面正好是顺序排列的(是否顺序排列,要查文件系统,如ext3、ext4),Linux会为这一次4页的读,分配1个bio就足够了,并且让这个bio里面分配4个bi_io_vec,指向4个不同的内存页:

-
第2种情况是page_cache_sync_readahead()要读的0~16KB数据,在硬盘里面正好是完全不连续的4块 (是否顺序排列,要查文件系统,如ext3、ext4),Linux会为这一次4页的读,分配4个bio,并且让这4个bio里面,每个分配1个bi_io_vec,指向4个不同的内存页面:

-
比如0
8KB在硬盘里面连续,816KB不连续: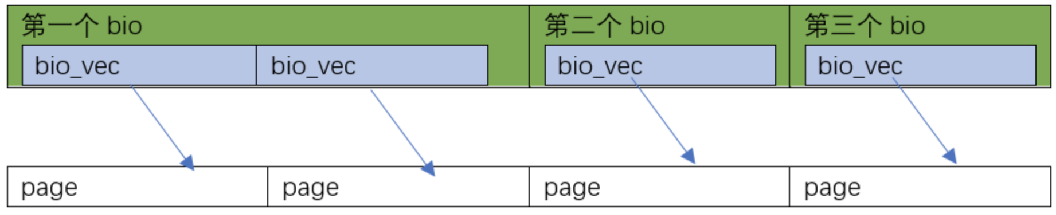

mpage_readpages()会间接调用ext4_get_block(),真的搞清楚0~16KB的数据,在硬盘里面的摆列位置,并依据这个信息,转化出来一个个的bio。
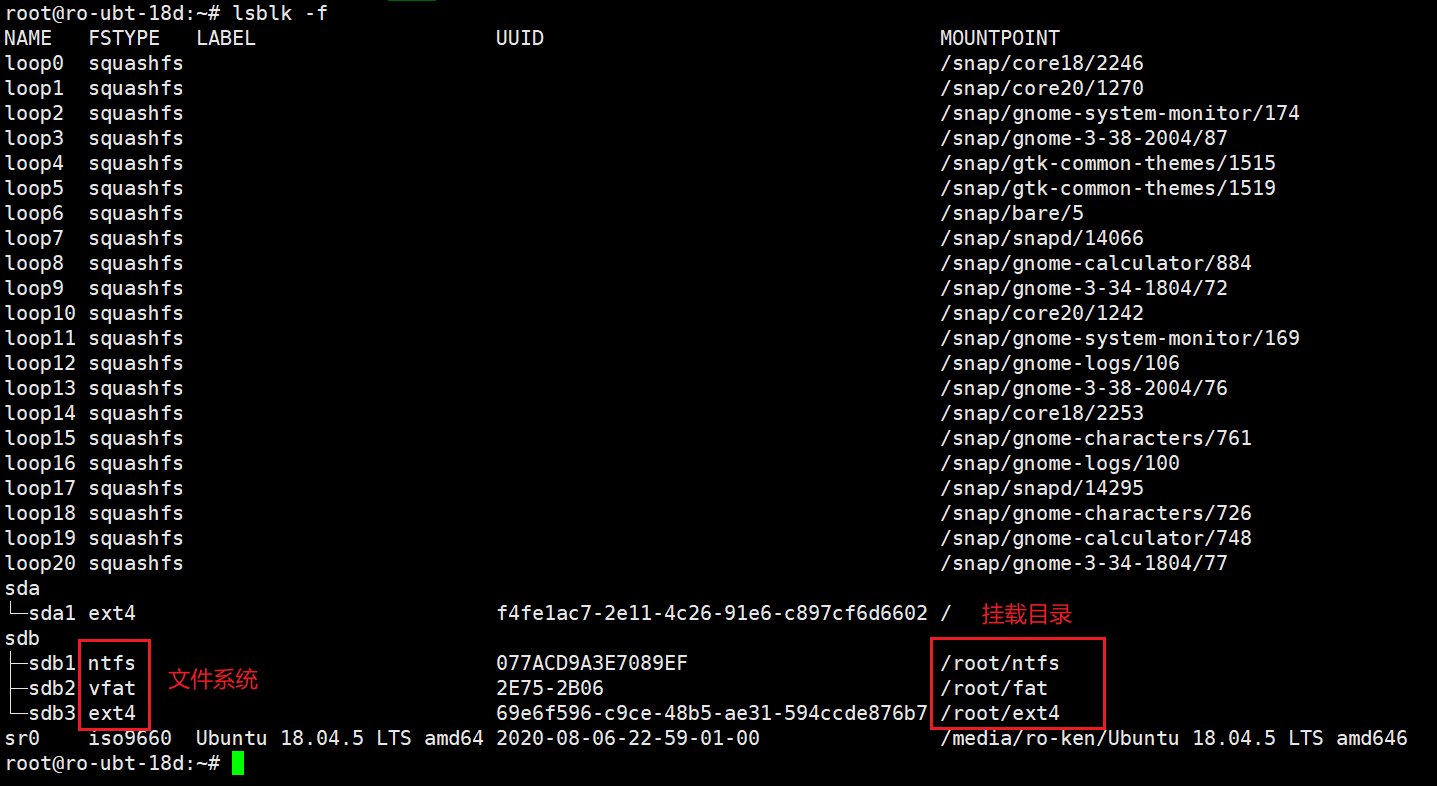
挂载结果如下:
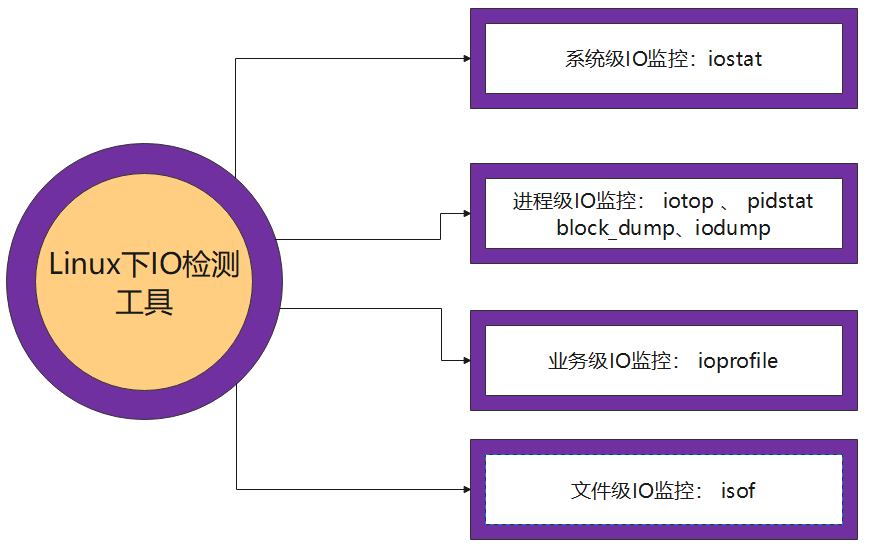
分类依据:测试主体不同
本组采用:pidstat
测试条件:拷贝一部1.7G的电影到各个文件系统
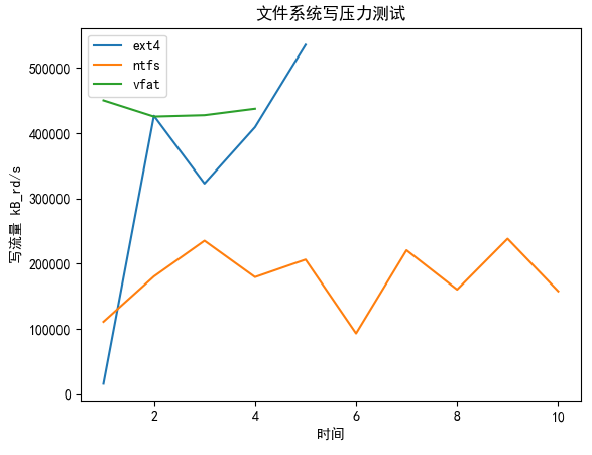
结果:
- vfat平均在400MB/s-500MB/s
- Ext4较陡峭,峰值超过500MB/s
- Ntfs较慢,在300MB/s以下
实验问题:
- 时间太短,结果不明显
解决方案:写大文件
测试条件:拷贝一部9G的镜像到各个文件系统
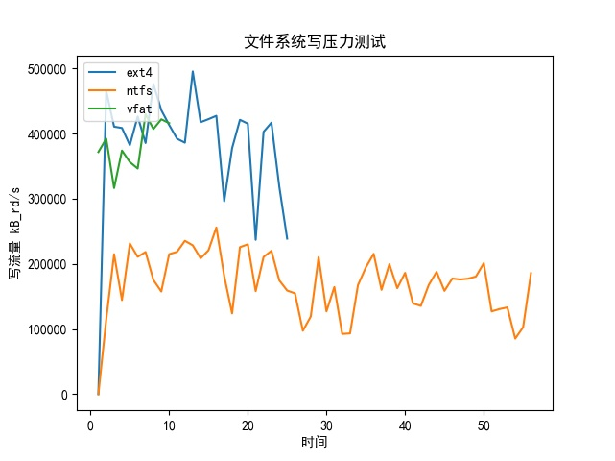
实验结果分析:
- 总体性能EXT4较好
实验问题:
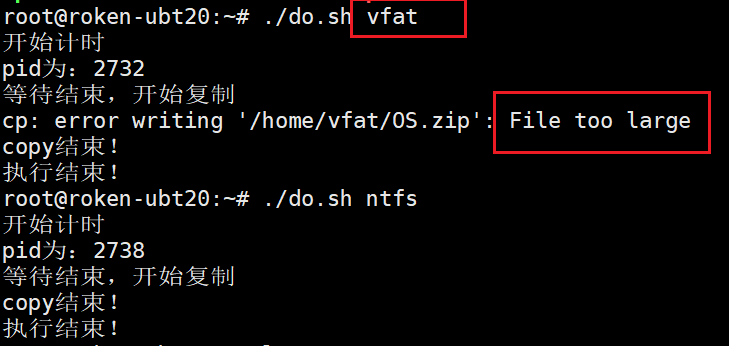
- FAT提前结束
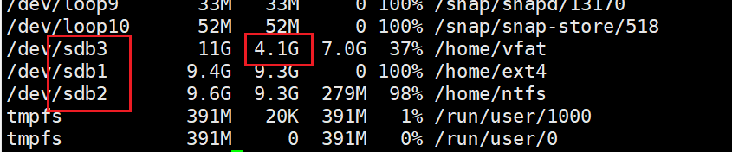
问题分析
- 查看各个分区:
- 错误提示:
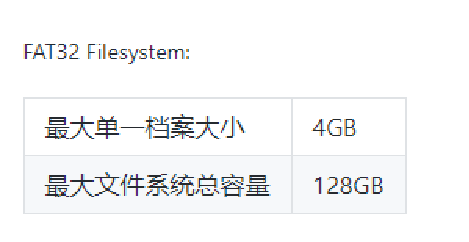
- 原因:
测试条件:用vim打开刚刚拷贝的文件系统
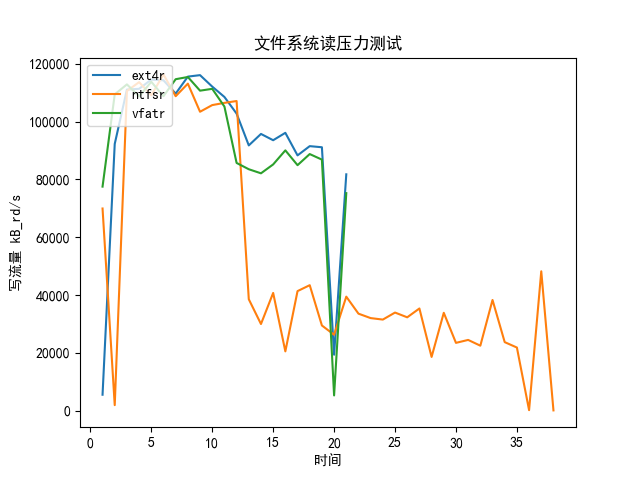
结果:
- 读取最大流量都在120MB/s左右
- EXT4和VFAT的曲线比较像
- NTFS在后面读取变慢了很多
测试条件:播放电影30秒后对电影进行拖拽操作
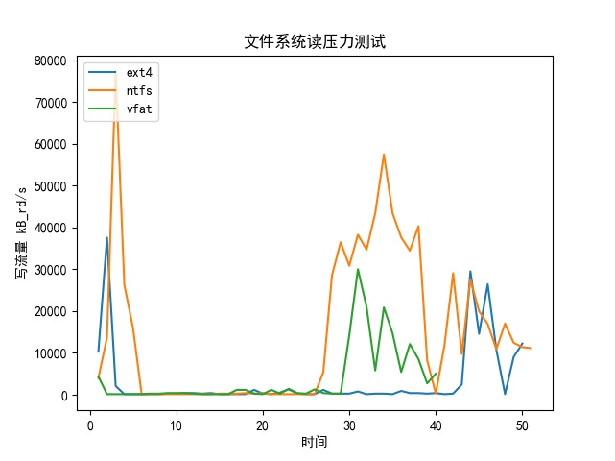
结果:
- 刚开始读取流量都较大
- NTFS每次都会读很多数据
原因分析:
- 文件播放开始会对内容进行缓存,NTFS'缓存最多
- 每次访问NTFS文件系统都是通过mount.ntfs命令
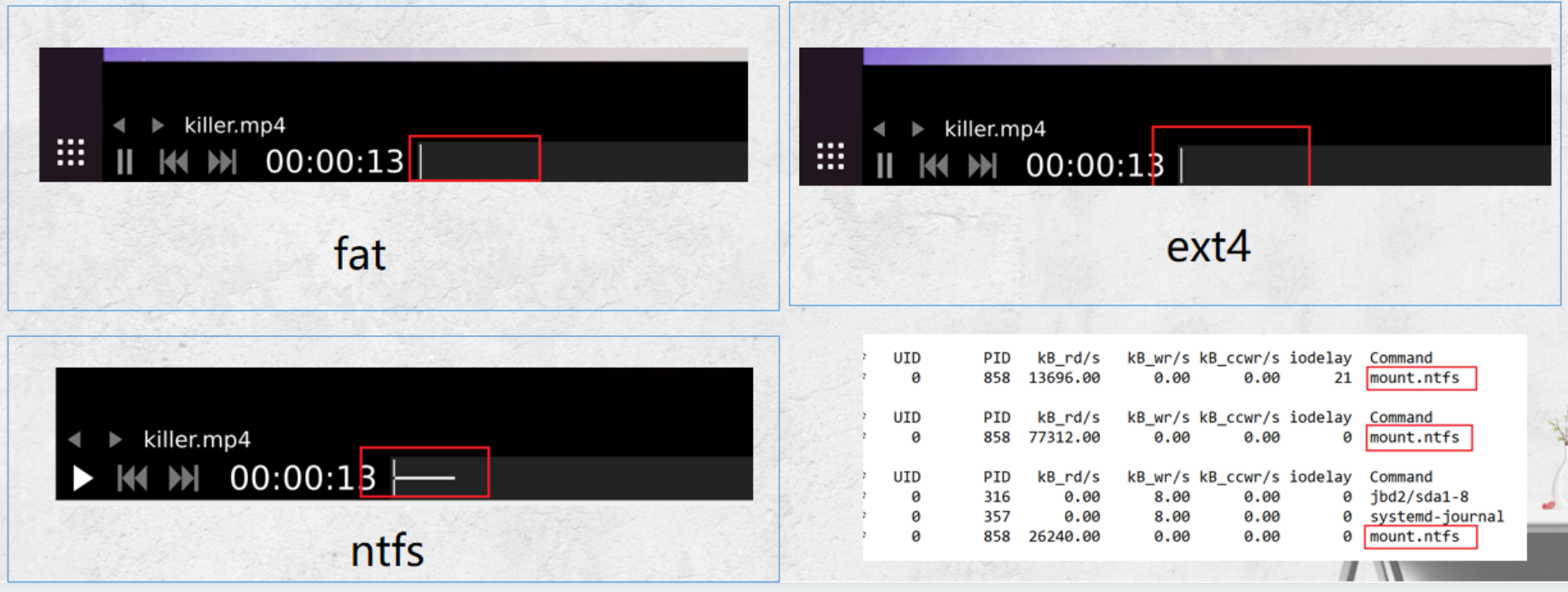
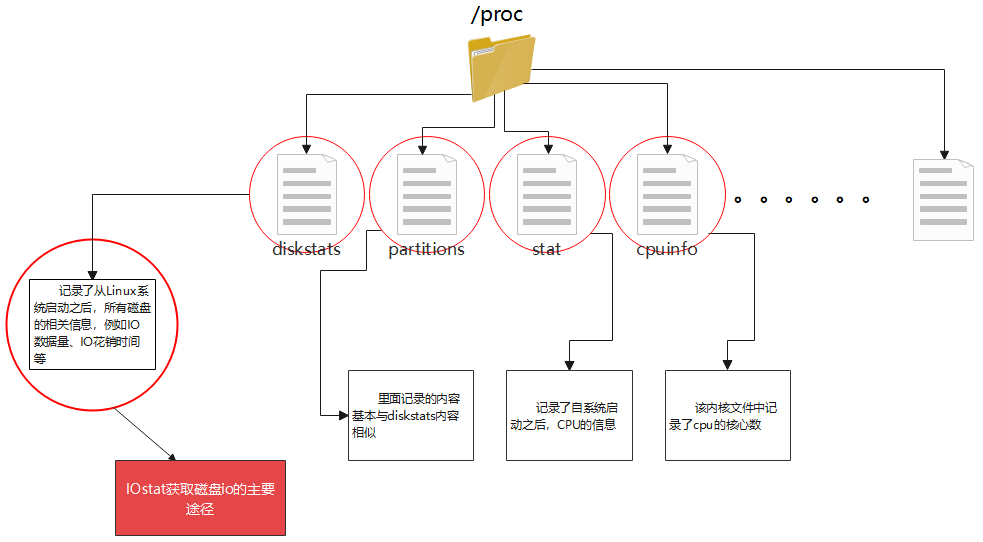
被访问的四个内核文件:/proc/diskstats、/proc/partitions、/proc/stat、/proc/cpuinfo
得出结论:IOSTAT的测试结果并不准确
内核测试:
- kprobe:监控某个内核函数
- hander_pre:监控函数被执行前执行
- hander_post:监控函数被执行后执行
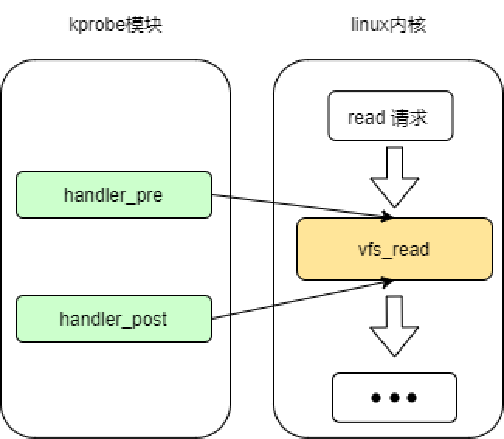
问题:不能监控单个文件的流量
-
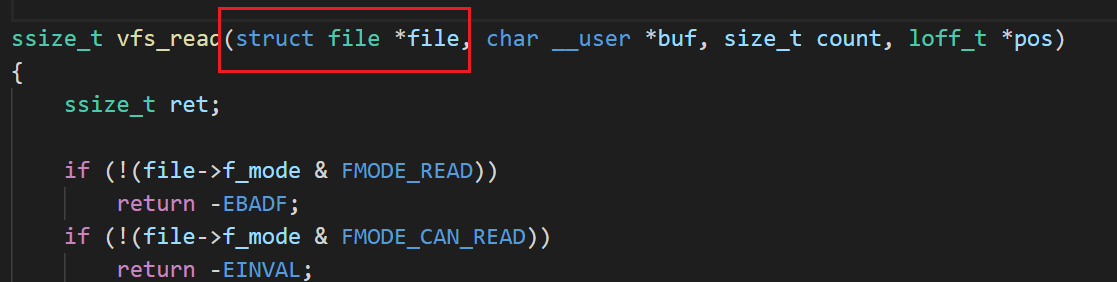
vfs_read函数分析
-
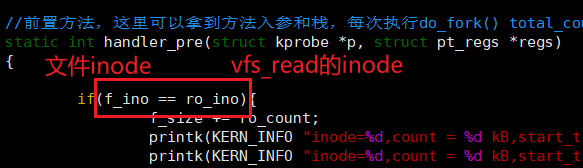
实现方式:判断inode号来监控单个文件流量
计算速率
-
记录每次read前后的时间差:Δt=t2-t1

-
单次速率=单次size/ 单次Δt
-
平均速率 = size之和/ Δt之和
内核时间
- Jiffies:精确到毫秒
- 手动测试:
- shell测试:
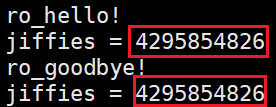
- 手动测试:
- Ktime:精确到纳秒:
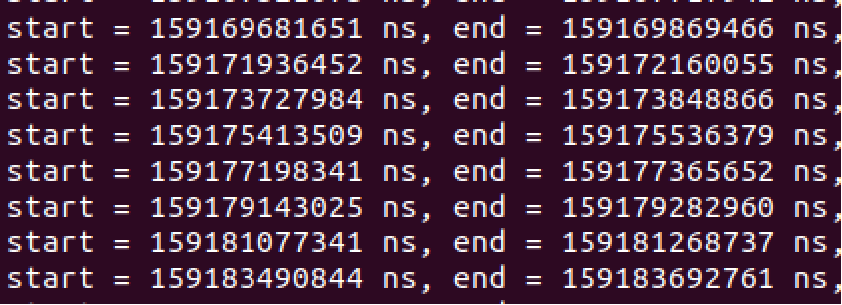
测试结果
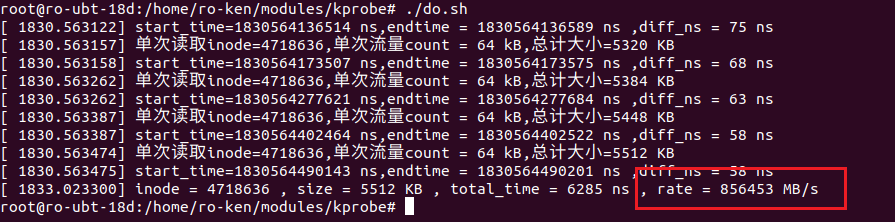
- 文件大小正常
- 时间太短
- 算出的速率太快:接近1TB/s
问题分析
-
可能是多CPU存在并发
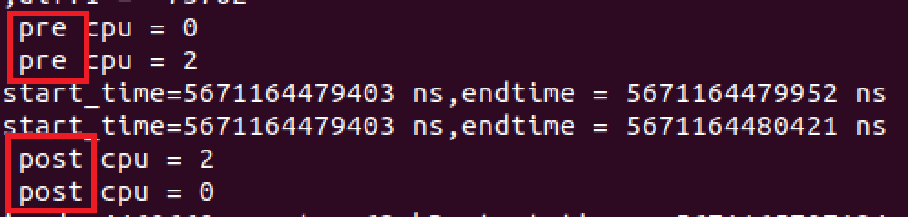
-
测量时间过短的原因
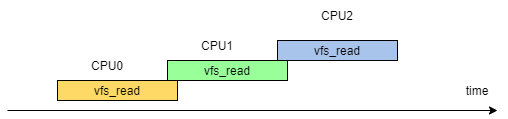
-
全局时间变量被修改
解决方案尝试:设置虚拟机为单核
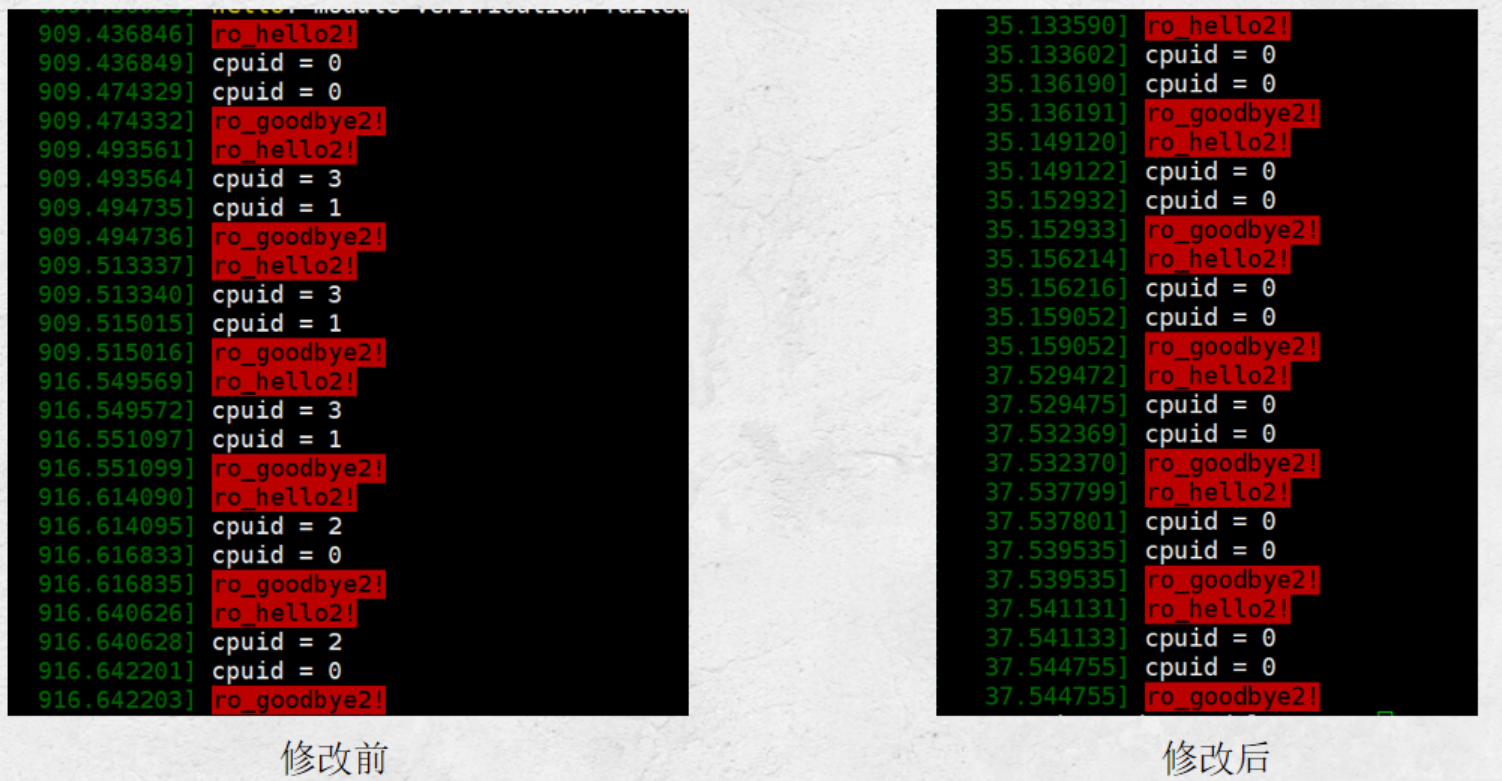
设置后,可发现执行的cpuid只有一个,即单个单核CPU在执行。
问题解决
-
把全局变量换成局部变量
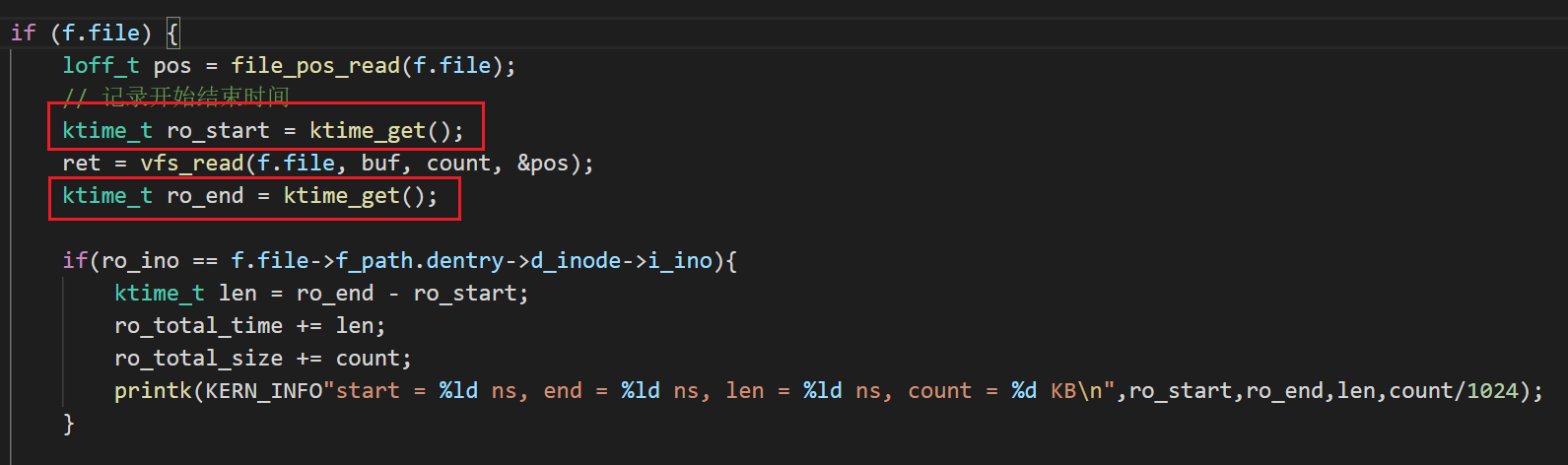
-
结果:速率回到正常水平
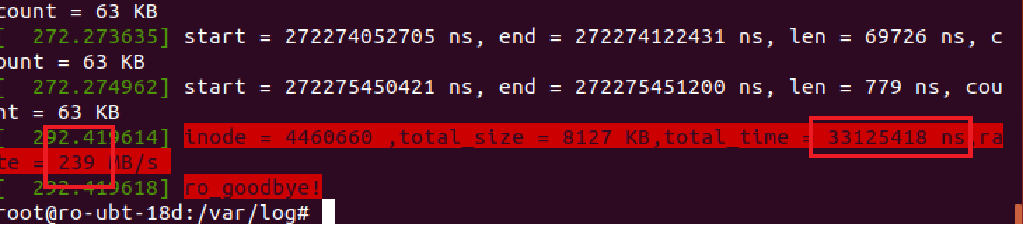
测试读取8M的图片
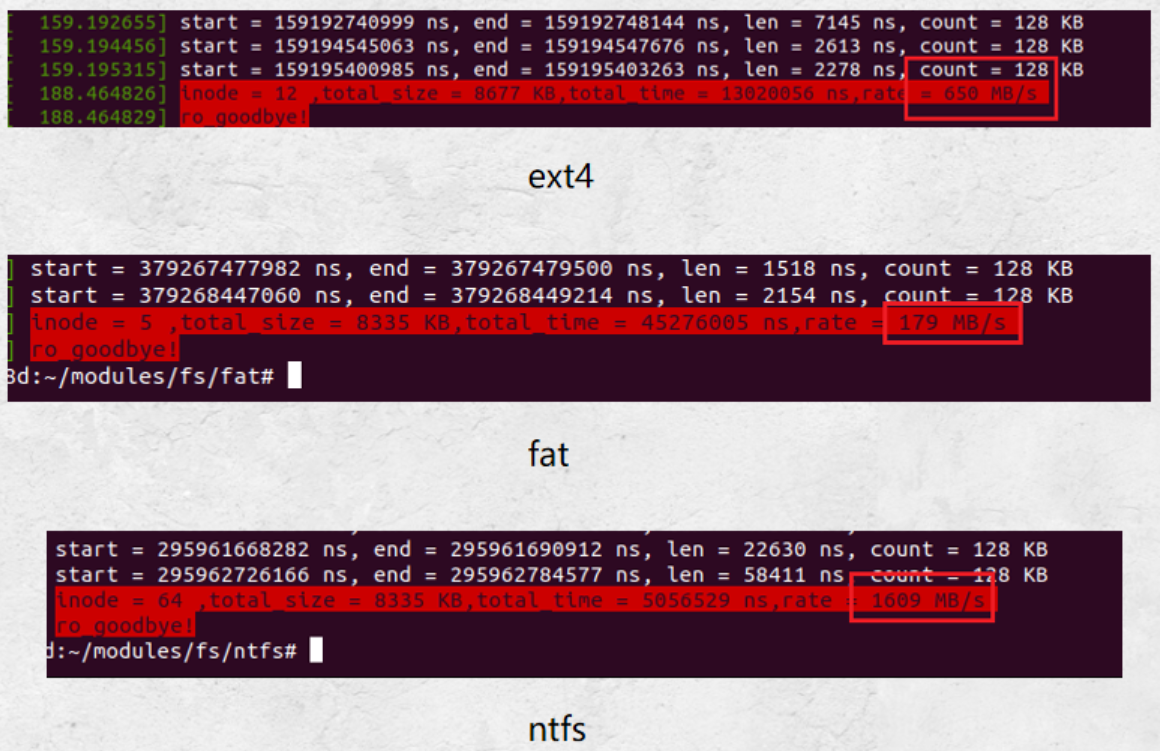
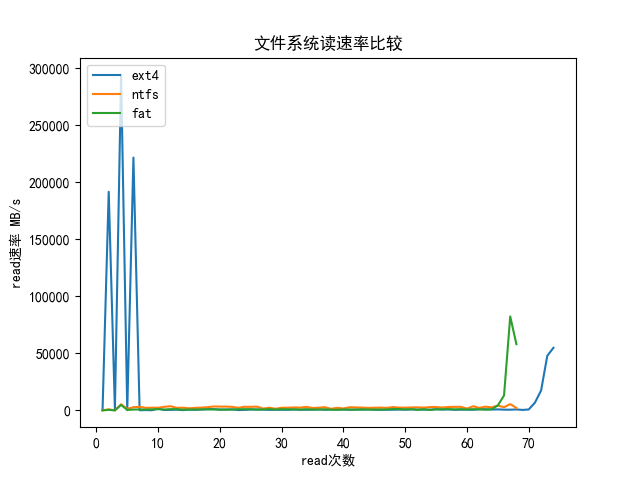
图形化展示:
- 所有数据:
- 去掉异常点:
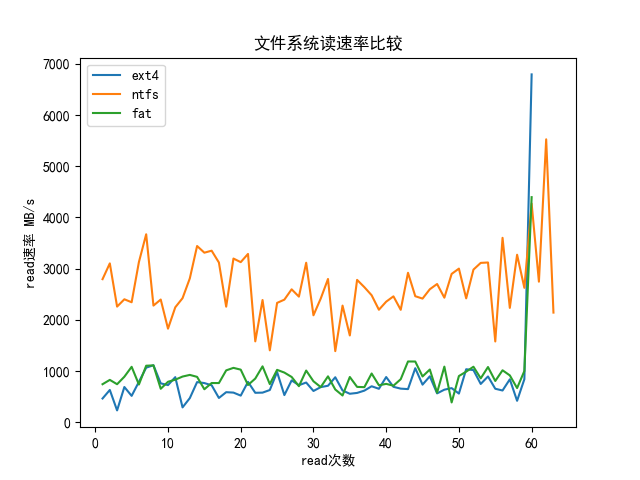
结论:
- 不同文件系统元数据读取速率差异较大
- ntfs的读取速率较快
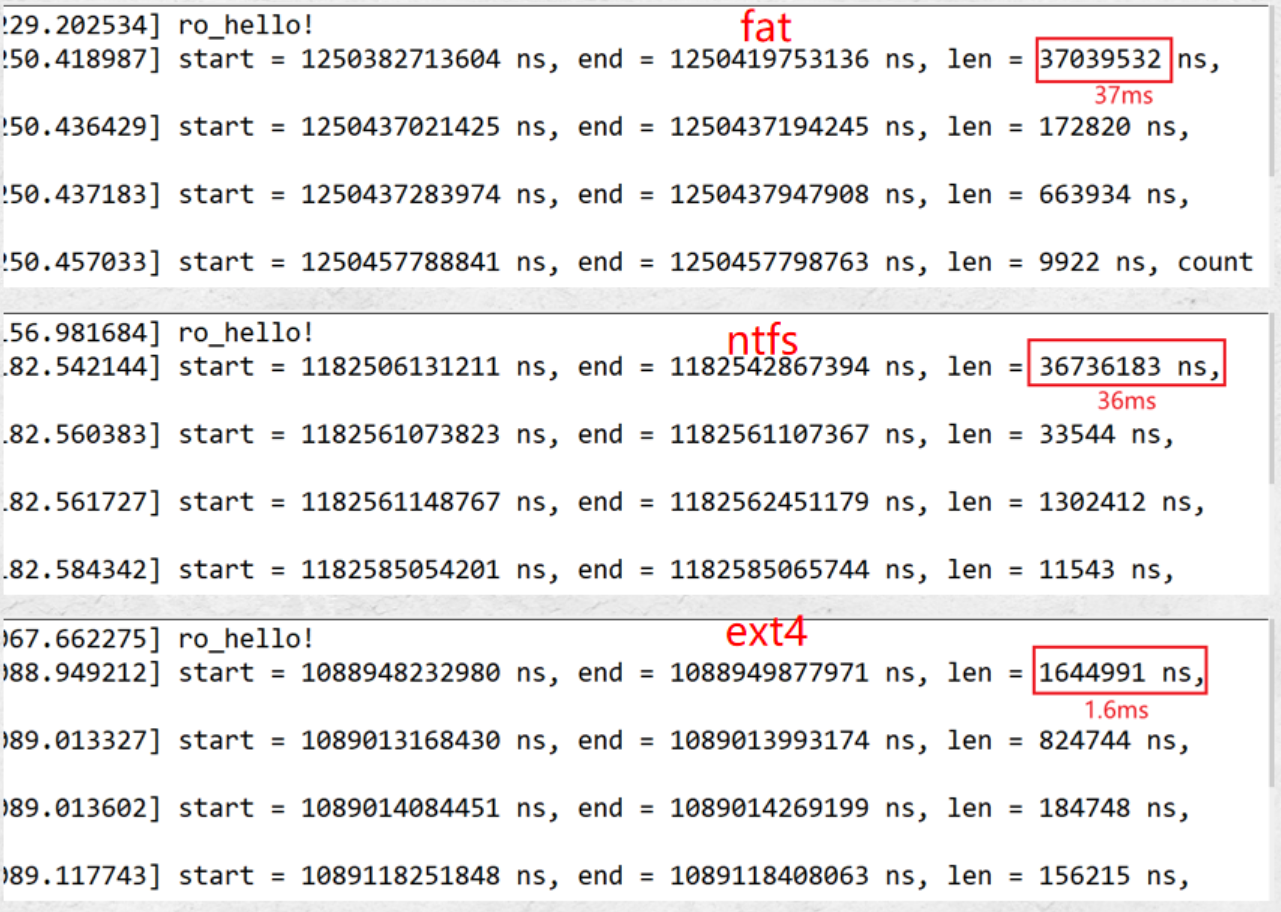
- 第一次vfs_read时间过长,中途可能发生进程调度,导致该次测试得到的时间不准确
实验改进
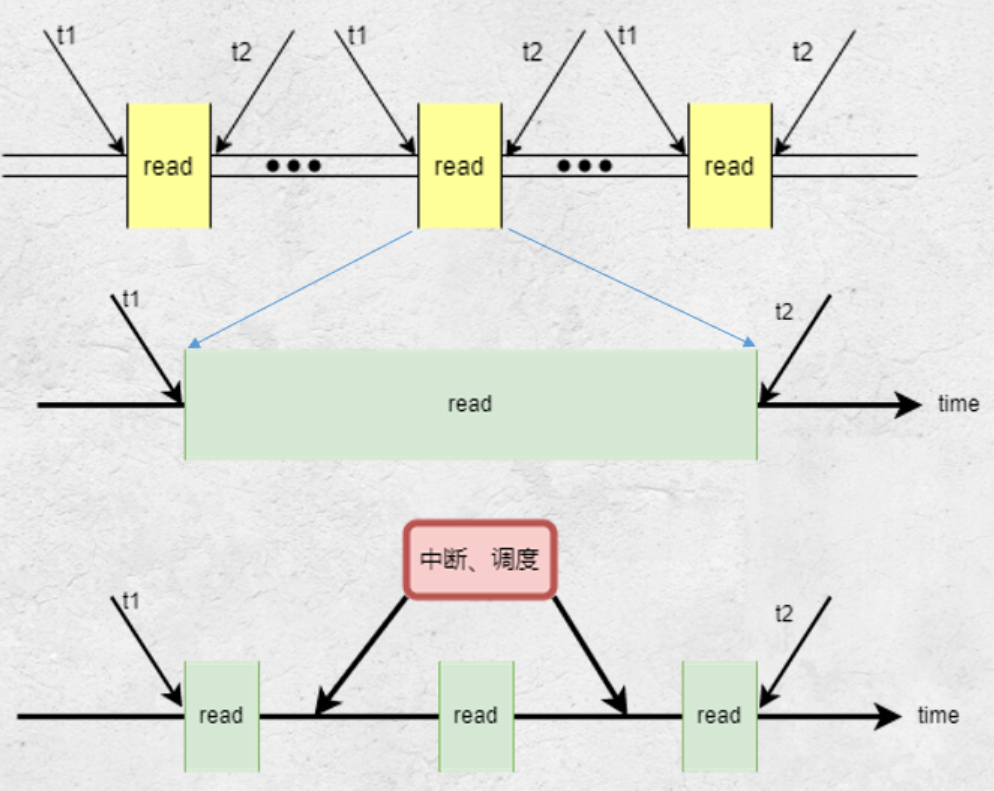
预想改进方案:关闭中断
中断函数
-
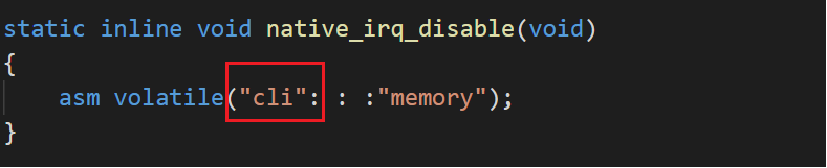
关中断
-
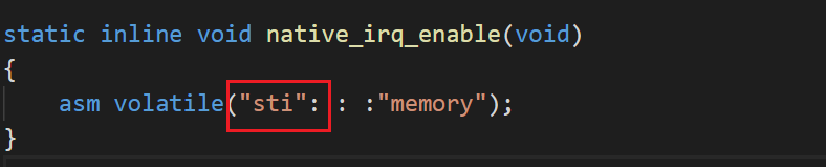
开中断
-
在模块进行测试
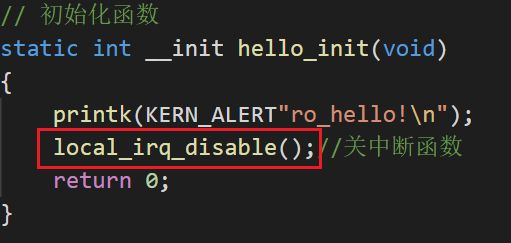
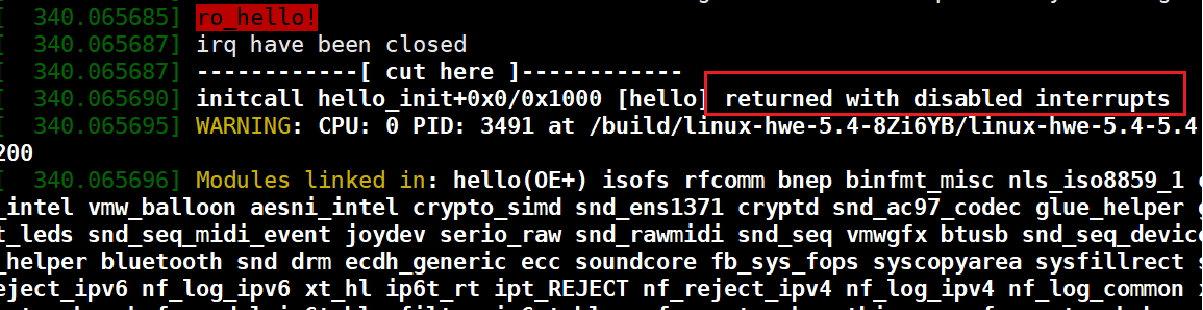
好像没有效果......
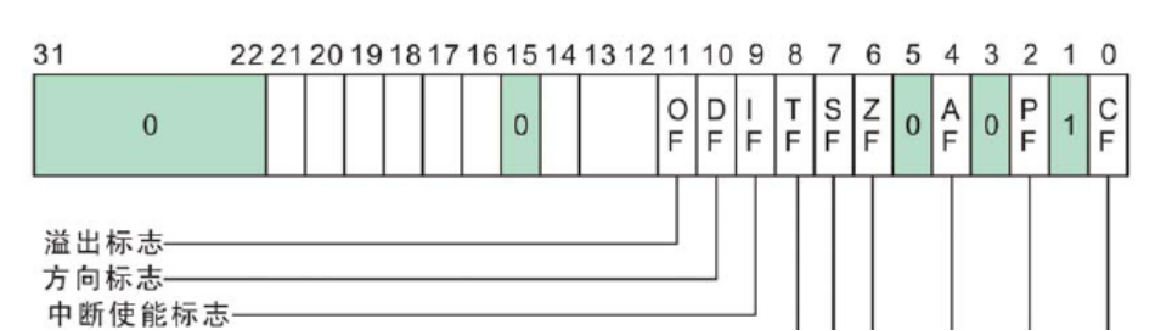
中断标志位
-
eflags结构
-
获取eflags的值
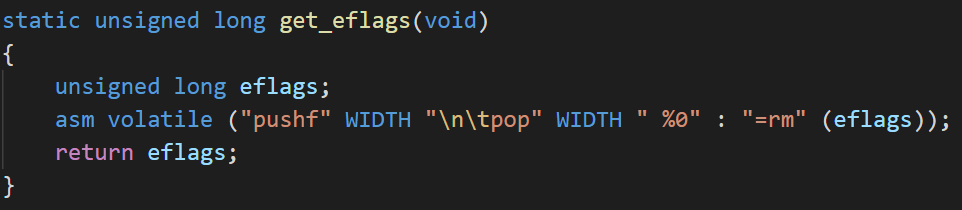
检查标志位:
-
测试代码:在关中断后监测IF标志位
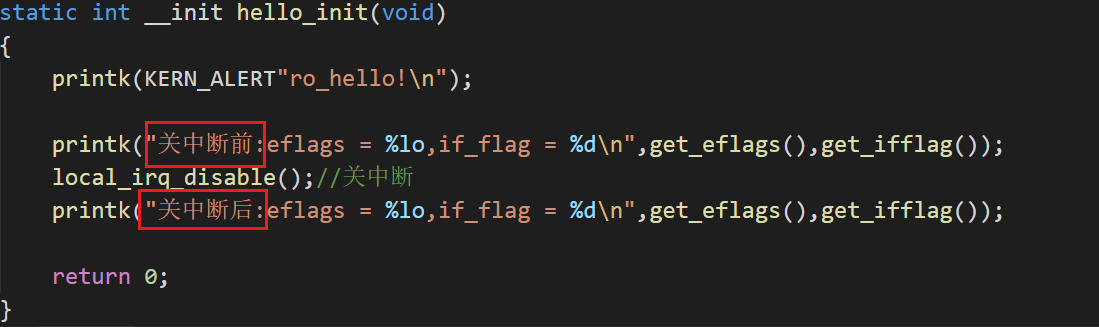
-
结果:关中断函数可以使标志位置0
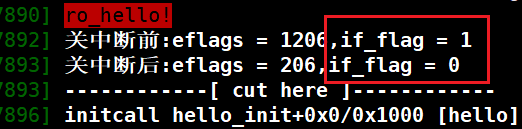
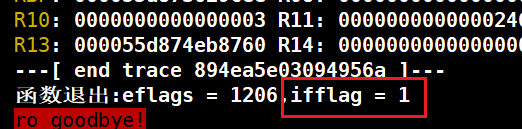
猜测:可能在其他函数打开了中断
分析
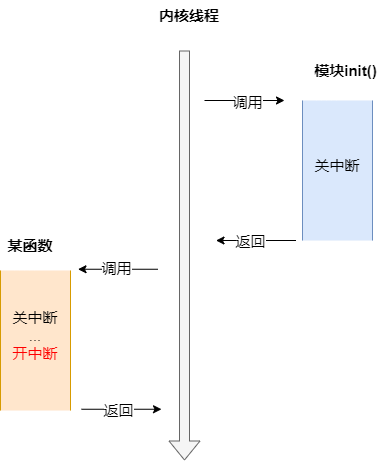
- 在模块里关闭中断
- 调用其他函数进行关开中断
- 最终中断被打开
原因分析:可能在其他函数打开了中断
论证
-
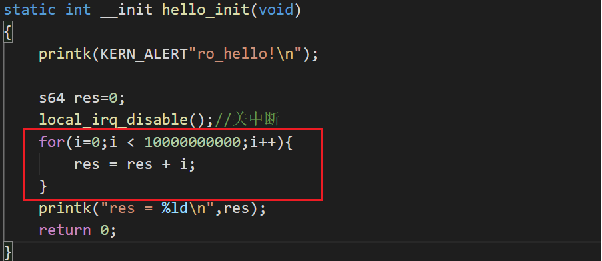
测试代码:关中断后停一下再返回
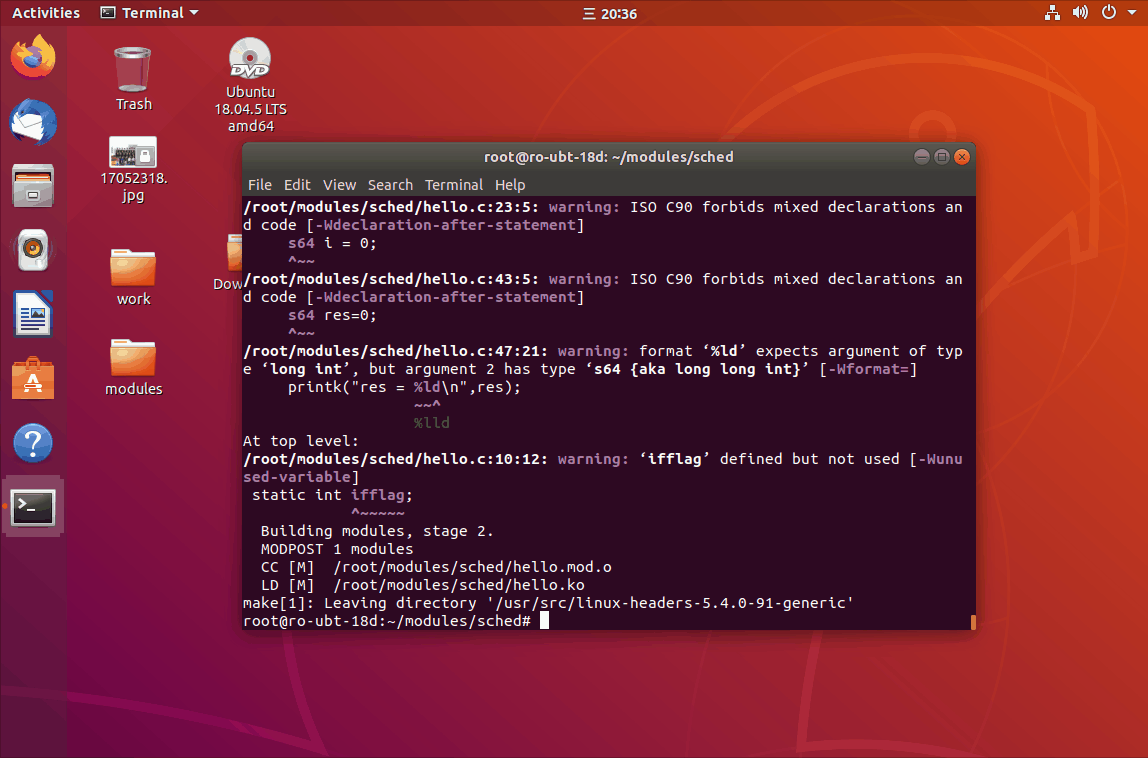
(gif插入有问题)
结论:关中断确实是有效果的。
测试时间
-
测试代码:关中断后记录时间
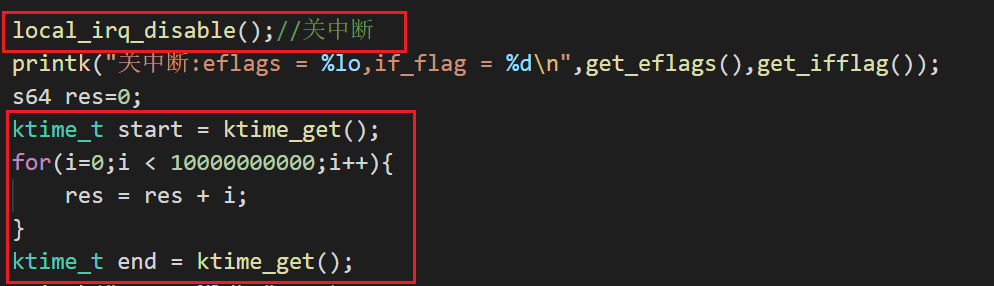
-
结果:关中断后能正确地记录时间

问题产生:ktime靠什么来记录时间?
-
底层调用函数
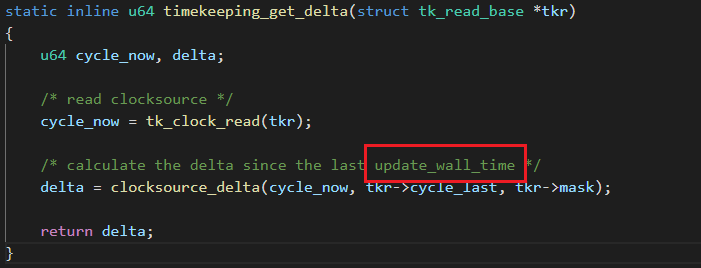
-
实时时钟RTC
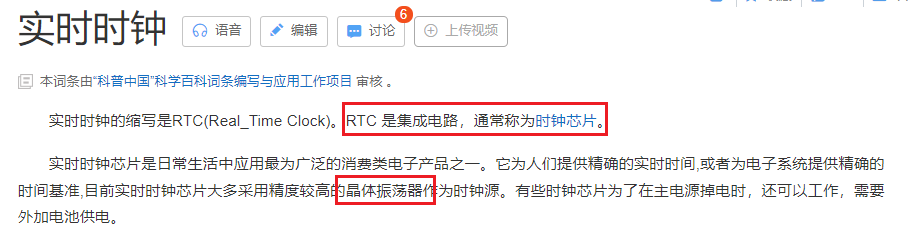
在关中断后精确测量读写时间(挖坑待填......)