This repository is a comparitive study of Vanilla GAN, LSGAN, DCGAN, and WGAN for MNIST dataset on both tensorflow and pytorch frameworks.
In 2014, Goodfellow et al. presented a method for training generative models called Generative Adversarial Networks (GANs for short). In a GAN, there are two different neural networks. Our first network is a traditional classification network, called the discriminator. We will train the discriminator to take images, and classify them as being real (belonging to the training set) or fake (not present in the training set). Our other network, called the generator, will take random noise as input and transform it using a neural network to produce images. The goal of the generator is to fool the discriminator into thinking the images it produced are real.
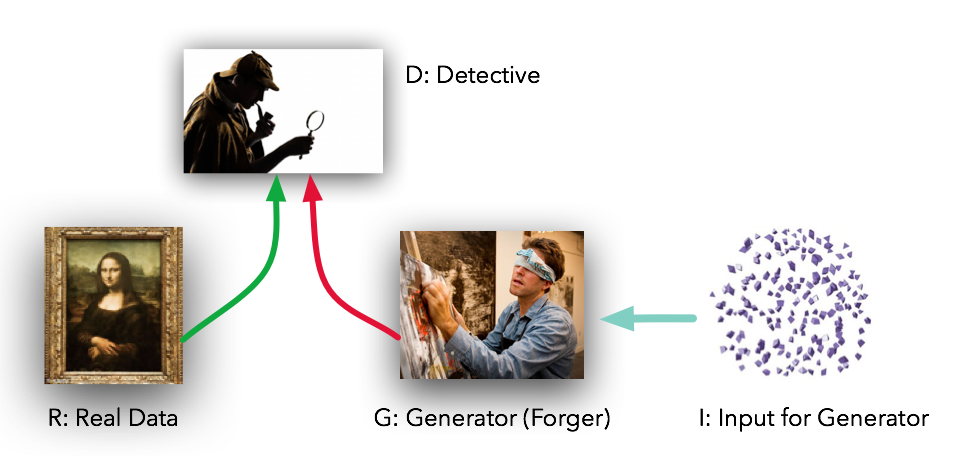
Since 2014, GANs have exploded into a huge research area, with massive workshops, and hundreds of new papers. Compared to other approaches for generative models, they often produce the highest quality samples but are some of the most difficult and finicky models to train (see this github repo that contains a set of 17 hacks that are useful for getting models working). Improving the stabiilty and robustness of GAN training is an open research question, with new papers coming out every day! For a more recent tutorial on GANs, see here. There is also some even more recent exciting work that changes the objective function to Wasserstein distance and yields much more stable results across model architectures: WGAN, WGAN-GP.
GANs are not the only way to train a generative model! For other approaches to generative modeling check out the deep generative model chapter of the Deep Learning book. Another popular way of training neural networks as generative models is Variational Autoencoders (co-discovered here and here). Variational autoencoders combine neural networks with variational inference to train deep generative models. These models tend to be far more stable and easier to train but currently don't produce samples that are as pretty as GANs.

Both Generator and Discriminator are stacked fully-connected layers in case of Vanilla GAN and Convolutional in case of DCGAN
This loss function is from the original paper by Goodfellow et al.. It can be thought as minimax game between generator and discriminator where generator () trying to fool the discriminator (
), and the discriminator trying to correctly classify real vs. fake.
where are samples from the input data,
are the random noise samples,
are the generated images using the neural network generator
, and
is the output of the discriminator, specifying the probability of an input being real. In Goodfellow et al., they analyze this minimax game and show how it relates to minimizing the Jensen-Shannon divergence between the training data distribution and the generated samples from
To optimize this minimax game, we will aternate between taking gradient descent steps on the objective for , and gradient ascent steps on the objective for
:
- update the generator (
) to minimize the probability of the discriminator making the correct choice.
- update the discriminator (
) to maximize the probability of the discriminator making the correct choice.
While these updates are useful for analysis, they do not perform well in practice. Instead, we will use a different objective when we update the generator: maximize the probability of the discriminator making the incorrect choice. This small change helps to allevaiate problems with the generator gradient vanishing when the discriminator is confident. This is the standard update used in most GAN papers, and was used in the original paper from Goodfellow et al..
Here, We will alternate the following updates:
- Update the generator (
- Update the discriminator (
It is more stable alternative to the original GAN loss function.
Algorithm from WGAN paper.

A system with anaconda and jupyter notebook installed is required.
PyTorch 0.3
TensorFlow r1.7
numpy 1.4.2
matplotlib
Change to any directory you want to download the project to.
git clone https://github.com/divyanshj16/GANs.git
cd GANs
jupyter notebookSince the dataset is small this can run even on CPU in reasonable time. The GPU provides big boost to the DCGAN part.






