Home
The initial scope of the Adapter was the import of FHIR Resources into DHIS2 Tracker by using FHIR Subscriptions. This approach has been discussed on the first integration workshop between DHIS2 and HL7-FHIR. The current state and supported features of the Adapter can also found in the linked presentation slide.
In order to eliminate the need of a FHIR server, also FHIR interfaces that use the functionality of the existing import and export will be supported. This simplifies the integration of the adapter into non FHIR server use cases.
The import and export of clinical data works on the basis of a domain specific business rule engine that decides about transformations of patient related clinical data to questionnaire-like structures (DHIS2 Tracker Programs and their Program Stages). It is optimized for national FHIR profiles that are based on standard coding systems like LOINC, SNOMED CT, CVX and others or even on national coding systems (e.g. national coding system for immunization). A specific DHIS 2 FHIR profile that allows the mapping of all Tracker Program items is not yet available. Even if the standard configuration of the adapter contains just the rules to map a DHIS 2 Tracked Entity Type to a FHIR Patient, the adapter can also be configured to perform a mapping to a different FHIR Resource (e.g. to FHIR Practitioner).
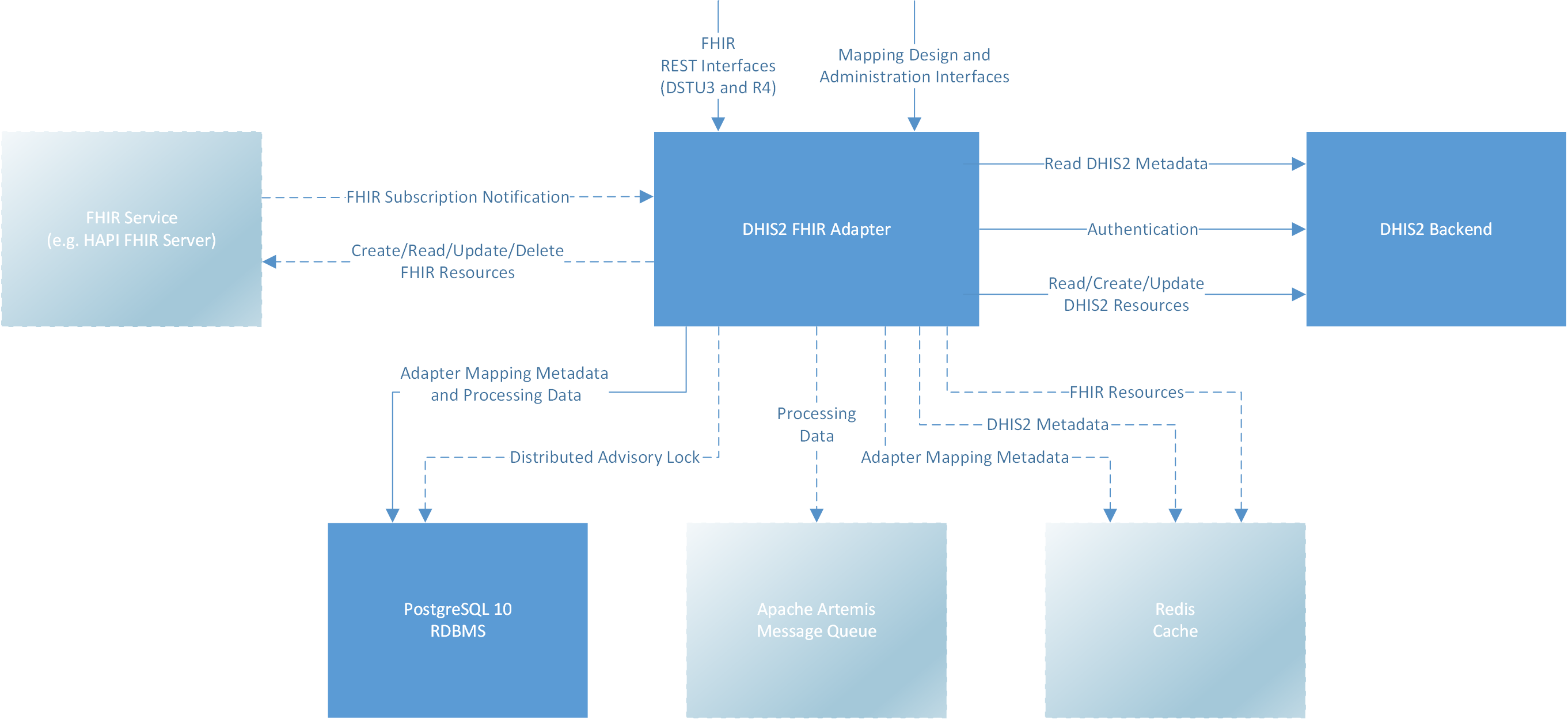
The image above shows the high level architecture of the DHIS2 FHIR Adapter. Optional components and connections are shown with dashed lines.
The Adapter receives FHIR subscription notifications from one or more FHIR Servers (e.g. HAPI FHIR JPA Server) when there are created or updated resources. The Adapter queues the notifications internally and retrieves new data from the FHIR Server as soon as possible. The Adapter may retrieve more data from the FHIR Server when needed (e.g. FHIR organization resources). To perform transformations to DHIS2 there are configured rules and transformations. Rules and transformations may use reusable Javascript code snippets. In order to identify already created DHIS2 tracked entity instances, a kind of national identifier must be provided by the FHIR patient resource (or any other FHIR resource that is mapped to a DHIS2 tracked entity type).
The Adapter uses a database to store mapping data and temporary processing data. In order to avoid conflicting tasks on more than one Adapter instance in a clustered environment (not required when just FHIR REST interfaces are used), locking is performed by using PostgreSQL Advisory Locks. Since there may be more created and updated FHIR resources than the Adapter and the DHIS2 backend (depending on the hardware sizing) can process at the same time, the Adapter queues all FHIR notifications until it is able to process them. The queue is also used to retry failed transformations (e.g. DHIS2 backend could not be reached). In a non-clustered environment the embedded Apache Artemis message queuing system can be used (not required when just FHIR REST interfaces are used). In a clustered environment an external Apache Artemis message queuing system to which all Adapter instances are connected must be installed. The Adapter supports three different caches (Adapter mapping metadata to avoid database accesses, DHIS2 metadata to avoid DHIS2 backend accesses and FHIR resources to avoid accesses to FHIR endpoints of FHIR servers). Each of the three caches can be configured individually. The cache can be disabled, can be stored in memory (Caffeine cache implementation) or on a caching server (Redis cache).
The rules that are used for the import are also used for the export of DHIS2 resources to a FHIR server. Also the FHIR REST interfaces provide the data based on these rules.