![]()
Here, we tracks and document reuse of artifacts in computer science (starting with the SE field).
Why is that important? Well, philosophers of science like Karl Popper tell us that the ideas we can most trust are those that have been most tried and most tested. For that reason, many of us are involved in a process that produces trusted knowledge by sharing one’s ideas, and trying out and testing others’ ideas. Scientists (like us) form communities where people do each other the courtesy of curating, clarifying, critiquing and improving a large pool of ideas.
But there's a problem. In any field, finding the leading edge of research is an on-going challenge. If no one agrees on what is the state-of-the-art then:
- Researchers cannot appease reviewers
- Educators cannot teach to the leading edge of their field
- Reseachers cannot step off from the leading edge to find even better results.
Here, we assume that the leading edge can be found amongst artifacts that are heavily reused. Our goal is to map out that leading edge and reward its contributors:
- An R-index (reuse index) score will be awarded to resaerchers that reuse the most from other sources;
- An R+-index score will be awarded to resaerchers that build the artifacts that are most reused.
We are building that map using methods that are community comprehensible, community verifiable, and
community
correctable,
- All the data used for our reuse graphs is community-collected (see About this Data, below.
- All the data can be audited at this site} and if errors are detected, issue reports can be raised in our GitHub repository (and the error corrected).
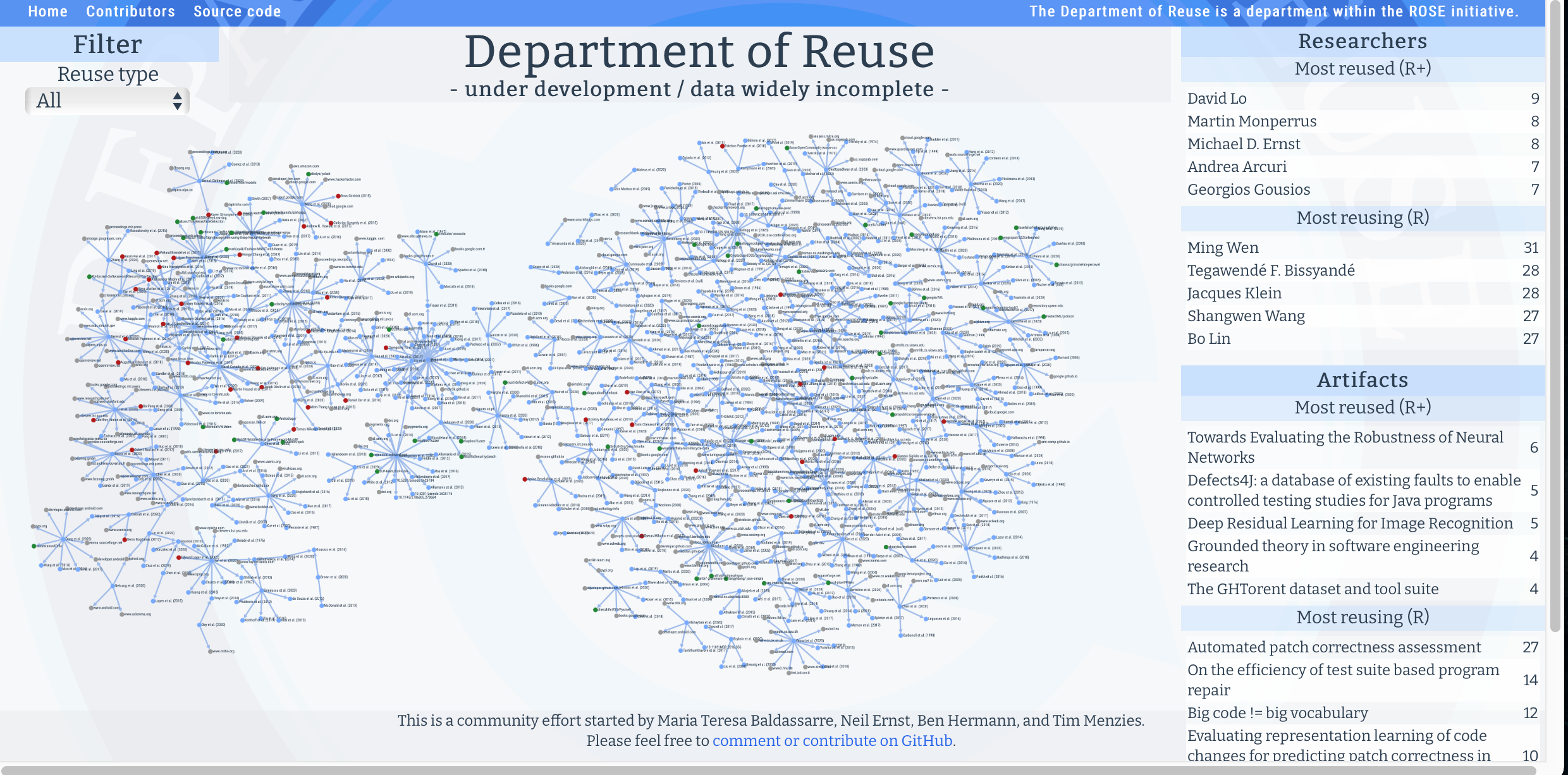
We have covered around 40% of the papers from the main technical track of the six main SE conferences (listed below).
Fron here, our short term tactical goal is to analyze 200, 2000, 5000 papers in 2021, 2022, 2023 (respectively) by which time we would have covered most of the major SE conferences in the last five years.
- If you want to help with that, see "Getting Invloved" (below).
After that, our long term strategic goal is to read 500 (ish) papers per year to keep up to date with the conferences.
- Based on results so far, then assuming each paper is read by two people, that strategic goal would be achievable by a team of twenty people working two hours per month on this task.

If that work interests you, then there are many ways you can get involved:
- If you are a researcher then
- If wish to check that we have accurately recorded your contribution, please visit please check our graph at https://reuse-dept.org.
- If you want to use this data to study the nature of science, please note that all the data iused in this site is freely and readily accessable (see About this Data, below)
- If you want to apply reuse graphs to your community, please use the tools in this repo.
- If you are interested in joining this initiative and contributing to an up-to-minute snapshot of SE research, then please
- Take our how-to-read-for-reuse tutorial;
- Then visit our control dashboard abd find an issue with no one's face on it, and assign yourself a task.
- Better yet, if you are an educator teaching a graduate SE class, then get your students to do the following three week reading assignments,

Start by telling students that understanding the current state of the art will be their challenge for the rest of their career. Using reuse graphs, it is possible for a community to find and maintain a shared understanding of that state-of-the-art. To demonstrate this, get them to:
- First, learn this reuse graph approach by performing our standard how-to-read-for-reuse tutorial;
- Then visit our control dashboard
- Find an issue with no one's face on it,
- Assign yourself a task.
- Finally, they should check someone else's reuse findings from other papers (checking in their results to our repo, of course_
As a result, students will join an international team exploring reuse in SE that will keep them informed and updated about the state-of-the-art in SE for many years to come. Also, as a side-effect, they will also see first hand the benefit of open source tools that can be shared by teams working around the globe.

At the time of this writing (August 2021) it is our judgement that there is not enough data here, yet, to do things like (e.g.) topological studies on the nature of SE science. That said, at our current rate of data collection, we should be at that stage by end 2021.
With that caveat, we note that researchers can access all the data from this project at the following places:
- The primary source of data for the website is: https://raw.githubusercontent.com/bhermann/DoR/main/department-of-reuse/src/assets/data/reuse.json
- It is composed from all the CSV files in: https://github.com/bhermann/DoR/tree/main/workflow/done
- The transformation process run as a build step is: https://github.com/bhermann/DoR/blob/main/department-of-reuse/scripts/data-transformation.ts
- There is a separate script used when checking new results to catch common mistakes: https://github.com/bhermann/DoR/blob/main/department-of-reuse/scripts/check-reuse.ts
FYI, our data was collected as follows:
-
We targeted papers from the 2020 technical programs of six major international SE conferences:
- International Software Engineering (ICSE),
- Automated Software Engineering (ASE),
- Joint European Software Engineering Conference / Foundations of Software Engineering (ESEC/FSE),
- Software Maintenance and Engineering (ICSME),
- Mining Software Repositories (MSR),
- Empirical Software Engineering and Measurement (ESEM).
- These conferences were selected using advice from prior work but our vision is to expand; for example, by looking at all top-ranked SE conferences.
-
GitHub issues were used to divide up the hundreds of papers from those conferences into “work packets" of ten papers each.
-
Reading teams were set up from software engineering research teams from around the globe in Hong Kong, Istanbul (Turkey), Victoria (Canada), Gothenburg (Sweden), Oulu (Finland), Melbourne (Australia), and Raleigh (USA).
-
Team members would assign themselves work packets and then read the papers looking for eight kinds of reuse. Of course, there any many other items being reused than those we study here (and it is an open question, worthy of future work, to check if those other items can be collected in this way).
-
Once completed, a second person (from any of our teams) would do the same and check for consistency.
-
Fleiss Kappa statistics are then computed to track the level of reader disagreement.
-
All interaction was done via the GitHub issue system,
{kind=link}