Visual Blocks is a framework that allows any platform or application to easily integrate a visual and user-friendly interface for ML creation. Visual Blocks aims to help applications & platforms accelerate many stages of the ML product cycle including pipeline authoring, model evaluation, data pipelining, model & pipeline experimentation, and more. Visual Blocks enables these behaviors through a JavaScript front-end library for low/no code editing and a separate JS library embedding the newly created experience.
If you use Visual Blocks in your research, please reference it as:
@inproceedings{Du2023Rapsai,
title = {{Rapsai: Accelerating Machine Learning Prototyping of Multimedia Applications Through Visual Programming}},
author = {Du, Ruofei and Li, Na and Jin, Jing and Carney, Michelle and Miles, Scott and Kleiner, Maria and Yuan, Xiuxiu and Zhang, Yinda and Kulkarni, Anuva and Liu, Xingyu and Sabie, Ahmed and Orts-Escolano, Sergio and Kar, Abhishek and Yu, Ping and Iyengar, Ram and Kowdle, Adarsh and Olwal, Alex},
booktitle = {Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems},
year = {2023},
publisher = {ACM},
month = {Apr.},
day = {22-29},
numpages = {23},
series = {CHI},
doi = {10.1145/3544548.3581338},
}Node Graph Editor
The node graph editor is a custom Angular component. It takes a JSON object as the specifications of nodes (i.e. their inputs, outputs, properties, etc), and output the graph structure on changes (e.g. node added, edge deleted, etc).
Library of ML Nodes
ML Nodes include Models, I/O (camera, image, mic, etc.), and Visualizations.
Runtime
The runner takes a graph json file and a list of nodes. It traverses the graph to decide the execution order. For each node execution, it loads the Angular component and uses the run function to run it.
There is a Visual Blocks Python package for use within Google Colaboratory notebooks. It allows you to register python functions defined in the notebook with Visual Blocks, and it provides an interactive UI where you can easily build ML pipelines to execute those functions along with other ML-related nodes.
Follow the steps below to get started in Colab with Visual Blocks. You can also check out the example notebooks in the directory examples/, or watch the tutorial.
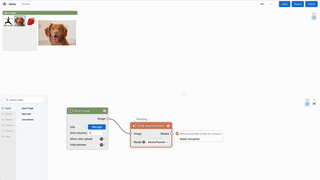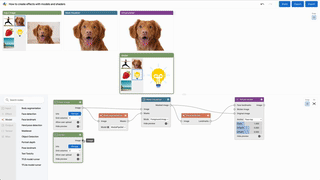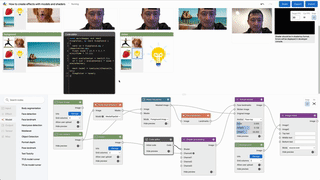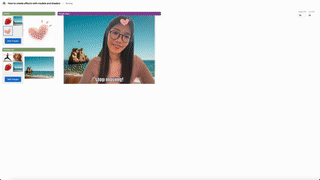
For users who are interested in creating ML pipelines through the web interface, check out pipelines/ for a comrehensive gallery of end-to-end applications including 3D photos, manuscript helper with large language models, and cartoonization.
!pip install visualblocks
The inference function should perform inference on the model of your chosen. It is your responsibility to import required packages that make the function work. For TF or TFLite models, you can find instructions on how to import and use them on TF Hub.
There are three types of inference functions supported by Visual Blocks:
- generic: Generic inference functions accept input tensors and return output tensors.
- text_to_text: Text to text inference functions accept strings and return output strings.
- text_to_tensors: Text to tensors inference functions accept strings and return output tensors.
When writing your inference function note the following:
- Args: The type of input tensors should be a list of NumPy arrays.
- Returns: The type of output tensors should be a list of NumPy arrays.
- Ensure the dimensions of the input and output NumPy arrays align with the expected tensor dimensions of your model.
For references on how to define an inference function, check out the example notebooks in the directory examples/.
If you would like to view changes made to inference functions in the Visual Blocks UI without needing to re-run the Visual Blocks server, you can use a Visual Blocks decorator.
First, import the decorator:
from visualblocks import register_vb_fnThen, decorate the inference function:
# inference_function_type could be `generic`, `text_to_text`, or `text_to_tensors`.
@register_vb_fn(type='[inference_function_type]')
def my_fn1(input_tensors):
# ...For example, to decorate a generic inference function:
@register_vb_fn(type='generic')
def my_generic_inference_function(tensors):
# ...Check out the Quick Start Style Transfer Example for reference.
If you do not use the function decorator register_vb_fn, pass each inference
function with its inference type in the visualblocks.Server() function. For
example:
# Pass each inference function in the Visual Blocks server
# when not using the decorator function
import visualblocks
server = visualblocks.Server(generic=my_fn1)
# You can also pass multiple functions:
# server = visualblocks.Server(generic=(my_fn1, my_fn2), text_to_text=(my_fn3))When using the function decorator register_vb_fn, you do not need to pass
inference functions in the Visual Blocks server. Example:
# Do not pass inference functions in the Visual Blocks server
# when using the decorator function
import visualblocks
server = visualblocks.Server()In a separate cell, call the display function to view the Visual Blocks
graphical development environment in your Colab notebook.
server.display()The registered functions can then be executed by using the corresponding type of node. For example, the registered generic inference functions can be selected in the "Colab (generic)" node, located in the "Model" category.
In Visual Blocks UI, you can click the Save to Colab button to save the
pipeline to the notebook. You can then share the notebook with others and they
will see the exact pipeline.
server.display() has to be run manually after all the
other cells have finished running.
!pip install git+https://... in a notebook will install the package straight
from the latest, unreleased source in Github. The notebooks in the
tests/ directory use this method.
The directory scripts/ contains turnkey scripts for common developer tasks such as building and uploading the Python distribution package.
One time setup:
# Install `build`.
$ python3 -m pip install --upgrade build
# Install `twine`, and make sure its binary is in your PATH.
$ python3 -m pip install twineSteps:
- Update the version number in pyproject.toml.
- Run
rm -rf buildto clean up previous builds. - Run
scripts/packageto build the package. - Run
scripts/uploadto upload the package. You need to have the username and password ready.
We are not accepting contributions to the core library at this time. The Visual Blocks team will contribute to this library.
However, we welcome community contributions of pipelines made with Visual Blocks. Please refer to pipelines/README.md to contribute your masterpiece!
This is not an officially supported Google product. As this is an experimental release aimed at starting a conversation and gauging community interest, we want to explicitly communicate a lack of guarantee for long term maintenance.