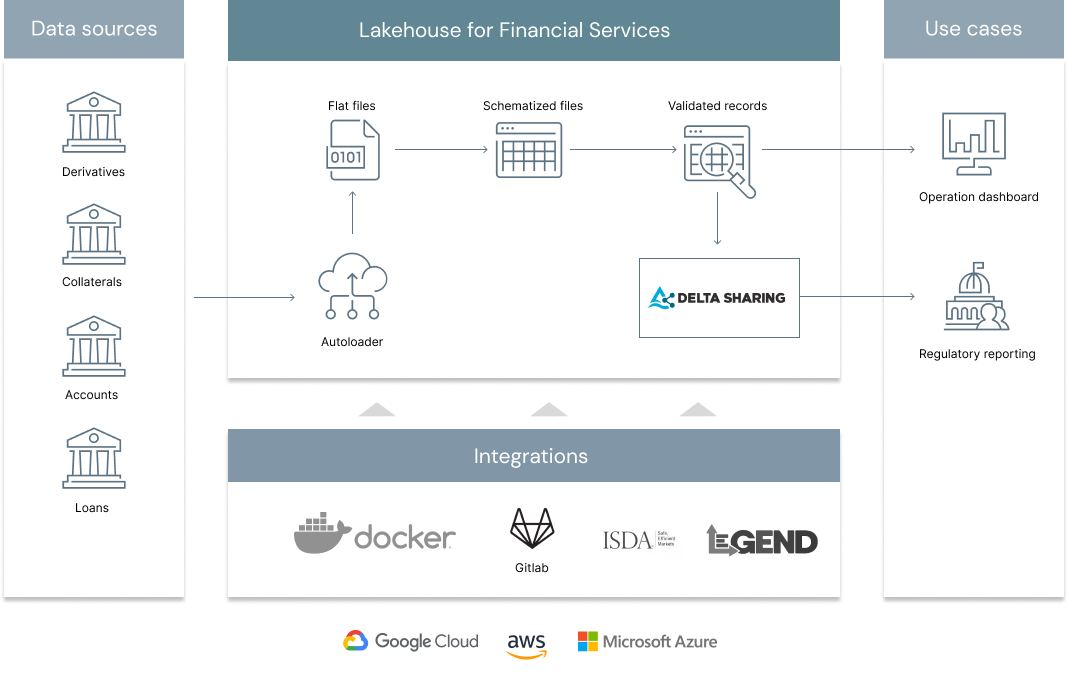
In addition to the JDBC connectivity enabled to Databricks from the legend-engine itself, this project helps organizations define data models that can be converted into efficient data pipelines, ensuring data being queried is of high quality and availability. Raw data can be ingested as stream or batch and processed in line with the business semantics defined from the Legend interface. Domain specific language defined in Legend Studio can be interpreted as a series of Spark SQL operations, helping analysts create Delta Lake tables that not only guarantees schema definition but also complies with expectations, derivations and constraints defined by business analysts.
Please check docker folder for basic installation (tested on AWS EC2), notebook for getting started example and pure model for a sample project.
© 2022 Databricks, Inc. All rights reserved. The source in this notebook is provided subject to the Databricks License [https://databricks.com/db-license-source]. All included or referenced third party libraries are subject to the licenses set forth below.
| library | description | license | source |
|---|---|---|---|
| PyYAML | Reading Yaml files | MIT | https://github.com/yaml/pyyaml |
| legend-delta | Legend delta | Apache2 | https://pypi.org/project/legend-delta/ |