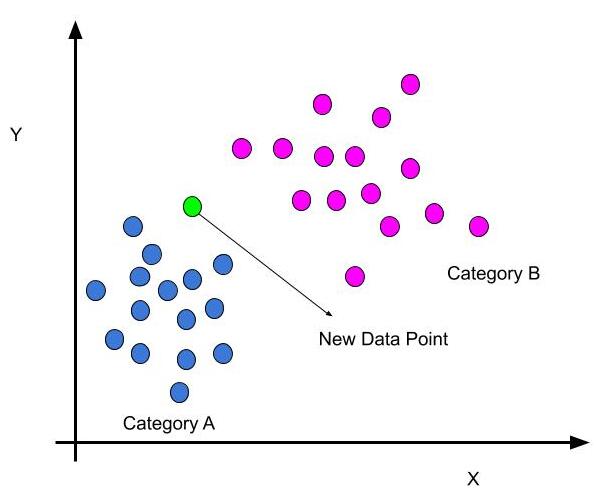
- K-Nearest Neighbors (KNN) is a simple and intuitive supervised machine learning algorithm used for classification and regression tasks.
- It is based on the idea that objects (data points) that are close to each other in a feature space are likely to belong to the same class or have similar numeric values.
- In KNN, the "K" represents the number of nearest neighbors used to make predictions.
KNN uses Euclidean distance for measuring the straight-line distance between two points in a multidimensional space.
In the context of KNN, the Euclidean distance is used to quantify the similarity (or dissimilarity) between data points when determining the K nearest neighbors.
The Euclidean distance between two points, A and B, in a two-dimensional space (2D) with coordinates (x1, y1) and (x2, y2) can be calculated as:
In a multidimensional space (nD), where each data point consists of n features (attributes), the Euclidean distance between two data points,A and B can be calculated as:
from math import sqrt
plot1 = [1,3]
plot2 = [2,5]
euclidean_distance = sqrt( (plot1[0]-plot2[0]) + (plot1[1]-plot2[1]) )
import numpy as np
plot1 = [1,3]
plot2 = [2,5]
eucildean_distance = np.linalg.norm(np.array(plot1)-np.array(plot2))
The second method is mainly used for computing large datasets and its mainly used in KNN algorithm. It takes lesser computing time compared to the First method.