gradient compression support #225
Conversation
|
Hi @vycezhong , thank you very much for your contribution and the detailed documentation! We will start to review the new features soon. Eventually, we want to make sure the original functionality does not break, and the compression benchmarks work as expected. |
6d4ee79
to
43025a0
Compare
89eb7b0
to
a77a9d6
Compare
721b4ca
to
b2acc91
Compare
cdeb2a4
to
49950d9
Compare
|
Hello everyone, we have summaried our recent updates for three months (Mar.19 - Jun.20). https://docs.google.com/presentation/d/1Dt1Sh2ixVF8Or_Q3lzUM81F4Thj5LT8Xw6QjU1e6iwQ/edit?usp=sharing If you have time, I think you can start to review the code now. Thank you in advance! |
11a7ec0
to
7dc8d7f
Compare
* 1bit: not need to do wd mom for uncompressed gradients * 1bit: fix typo * 1bit: normal weight decay * 1bit: update * 1bit: update * misc: fix typo
This reverts commit a692fea.
* test: update mxnet * test: launch tasks entirely in python * test: auto clean temp files * test: update * test: update * test: update * test: update * test: update * test: update * test: update * test: fix natural dithering * test: update * test: update
done |
* mom: nag for uncompressed * mom: fix typo * mom: fix typo
* hotfix: revert wdmom refactor * hotfix: fix typo * hotfix: fix typo * hotfix: fix typo
gradient compression support Author: zhongyuchen <[email protected]> Signed-off-by: Yulu Jia <[email protected]>
|
Hi, It will be great for BytePS to support gradient compression because tons of gradient compression algorithms (sparsification, quantization, and low-rank decomposition) are proposed in the machine learning community. My observation is that these algorithms can indeed reduce the communication time, while the compression/decompression overhead suppresses the communication improvement. The good news is that there are solutions to the costly overhead. I am working on a framework to support gradient compression algorithms and it can reduce the compression/decompression overhead to a negligible level (< 5ms). Based on our preliminary results, the scaling factor* with 8 GPUs is >90% for ResNet50, ResNet101, and VGG16 without NCCL. If you are interested, we can have a talk about this framework design. *scaling factor is defined as f=s_n/s_1, where s_n and s_1 are the training speeds with n GPUs and 1 GPU. |
@eric-haibin-lin @vycezhong |
Hello, thanks for your interests. compression/decompression overhead is indeed an issue and we have made many efforts to reduce it. We are still a little confused about your work and we have a few questions.
|
Thanks for your reply.
|
|
Hi, |
Sorry for the late reply. For PyTorch, you can refer to this repo. |
Motivation
Currently BytePS does not fully support gradient compression. The compression it supports lies in each plugin in Python. Such design may ease the difficulty of the implementation but leads to major inabilities for more aggressive compression. This is because NCCL only supports limited reduction operations such as Sum, Prod etc but these operations are meaningless for the compressed data which have been highly bit-wisely packed. For example, for signSGD, one of the most popular methods for gradient compression due to its simplicity and effectiveness, each bit represents a signbit of an element in the original data tensor, making reduction operations like summation totally meaningless. But reduction is necessary for multi-GPU devices.
Another problem is that compared to inter-node communication, intra-node communication is not the bottleneck. Furthermore, too much compression at first will lose much information, which may cause low accuracy. So there is no need to make too radical compression before running into BytePS core in worker nodes.
Therefore, changes need to be made.
Design Overview
In light of the problems mentioned above, we propose two-level gradient compression:
intra-node: This is just an alias for the current implementation, named after its communication property. Transform FP32 tensors into FP16 on each GPU, reduce them across multi-GPUs via NCCL, and copy them to the CPU buffer waiting for next-level compression. The purpose of the compression is to reduce intra-node communication overhead introduced by multi-GPUs. Since intra-node communication is very fast, especially with NCCL, only mild compression methods will be applied, most of which is type-conversion. It is framework-specific and will be implemented in each plugin.
inter-node: Usually inter-node communication is a bottleneck, so more drastically gradient compression algorithms will be applied here. This is framework-agnostic and will be implemented in BytePS core.
It is worth mentioning that our design supports all frameworks.
Interface
Only a few changes to be made for users. Users only have to add a few LOC in the script to specify which compression algorithm to be used and the parameters needed by the algorithm. Take MXNet for example.
Here we prescribe some keys. Users can lookup documentations to determine which key should be used. Here are some common keys.
If the user's input is not correct, it will give a warning and abort.
Implementation
Parameter Data Structure
To offer users a unified interface to use, we have to address the registration problem. parameters vary from different kinds of compression algorithms. For example, topk and randomk algorithms need parameter k to be specified while onebit algorithm may need to input whether to enable scaling flag. Some parameters are optional but others are not. So parameter passing is a challenge.
We address this challenge using string-string dictionary (
std::unorded_map<std::string, std::string>for C++ ordictfor Python) as our unified data structure to pass parameters. As mentioned above, we prescribe specific strings as keys, so the dictionary will look like:{"byteps_compressor_type": "topk", "byteps_compressor_k": "3", "byteps_error_feedback_type": "vanilla"}Python
For MXNet users, the dictionary can be an attribute of ParameterDict. We can filter out those parameters by leveraging the prefix "byteps". For example,
C++
Using ctypes, we can pass the dictionary conveniently. For example,
Compressor - Development API
We want developers to develop their own gradient compression algorithms without fully understanding how BytePS works. What they only need to know is development API. We currently implement some commonly used gradient compression algorithms, but in the future, we hope more novel algorithms will be implemented under our API. We abstract compression algorithms into
compressor. TheCompressorlooks like this:In order to make less modifications to BytePS core, we want compressors to be as general as possible. In the best case, the base compressor pointer/reference can represent all kinds of compressors and only need to expose two operations to users:
CompressandDecompress. This is quite challenging because there are some optional features for gradient compression, such as error-feedback and momentum. These are two common methods to correct the bias and accelerate the training process respectively. For example, with error-feedback, before being compressed, gradients are first corrected with errors which refer to the information loss during the last compression, and then errors are re-calculated. Therefore, the workflow is different from only using vanilla gradient compression.In order to support all these features and expose a unified API at the same time, we use the decorator pattern. We regard error-feedback as an additional behavior of compressors. We want a unified API, which means compressors with error-feedback should expose the same method as those without error-feedback. But in that case we have to create a subclass for each compressor, which is too redundant. So the decorator pattern just solves our problem. We create a decorator class named
ErrorFeedbackto inheritBaseCompressorwhile at the same time also keeping a member ofBaseCompressor. For example,And the workflow is implemented in
CompressandDecompress. For example,Momentumis implemented in the same way.ErrorFeedBackandMomentumare also base classes to inherit. In this way, error-feedback and momentum becomes optional features to be added to any vanilla gradient compression algorithms.BTW, momentum is not applied to servers.
Exps
CIFAR100
End-to-End Training
We conduct the experiment in distributed training ResNet18_v2 on the CIFAR100 datasets with 4 AWS P3.16xlarge instances, each equipped with 8 V100 GPUs and 25Gbps network. The compression algorithms benchmarked here are also equipped with error-feedback and nesterov momentum. We set k = 1 for topk and k = 8 for randomk. We train it for 200 epochs.
The results show that compression can reduce up to 28.6% end-to-end training time without accuracy loss.
Slow Network
Gradient compression is more beneficial in slower network. Therefore we limit the network bandwidth to 100Mbps (both downlink and uplink) and keep all other settings not changed. The results show that we can achieve up to 6x reduciton in training time.
IMAGENET
To save time, we only tested 1bit algorithm. Topk and randomk are not guaranteed to converge on IMAGENET.
Workload Breakdown
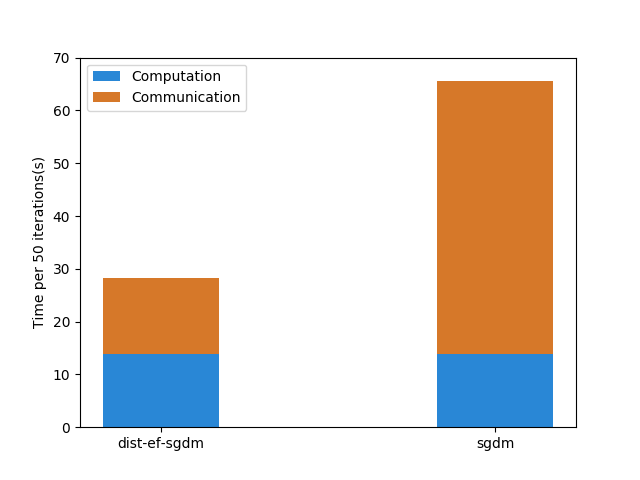
In this experiment, we measure the workload breakdown into computation and communication. We use 8 Amazon EC2 p3.2xlarge instances, each of which is shipped with one Nvidia V100 GPU and 10Gbps Ethernet. We train two CNN models: Resnet-50_v2 and VGG-16. We first measure the computation time by collecting the elapsed time of running 50 iterations (t0) on one node. Then we measure the total training time for running 50 iterations (t1) on 8 nodes. Then, we get an estimate of communication time using t1 − t0.
As the figure shows, dist-EF-SGDM can reduce communication to varying degrees. For ResNet50_v2, the drop is trivial (17.6% decrease), mainly due to the smaller model size. In contrast, a remarkable decline (73.2% decrease) occurs using dist-EF-SGDM for VGG-16, since VGG-16 has larger model size (528M).
[ResNet50_v2]
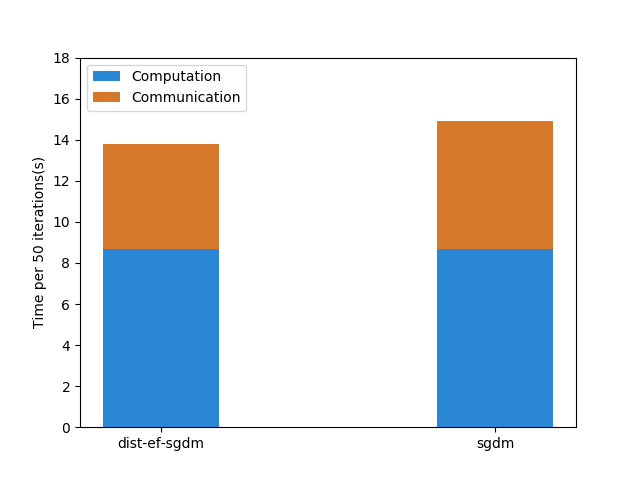
[VGG-16]
Scaling Efficiency
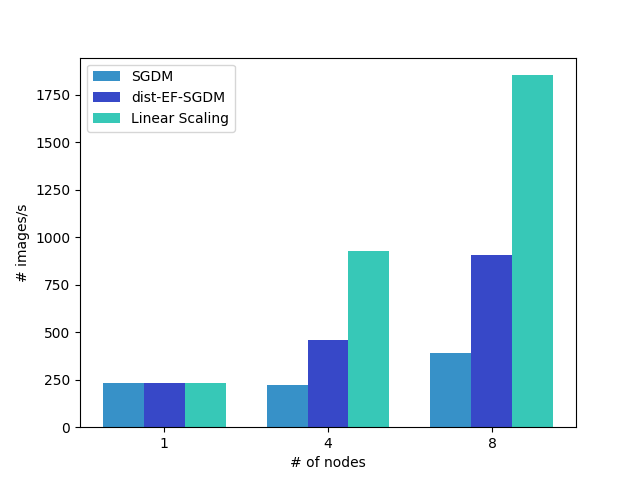
We also measure scaling efficiency when the number of nodes varies from 1 to 8. We follow the same setup as in the above experiment. The figure shows that gradient compression improves the scaling efficiency. The efficiency gain in gradient compression is much higher for VGG-16 than ResNet-50_v2, since ResNet50_v2 has smaller communication overhead.
[ResNet50_v2]
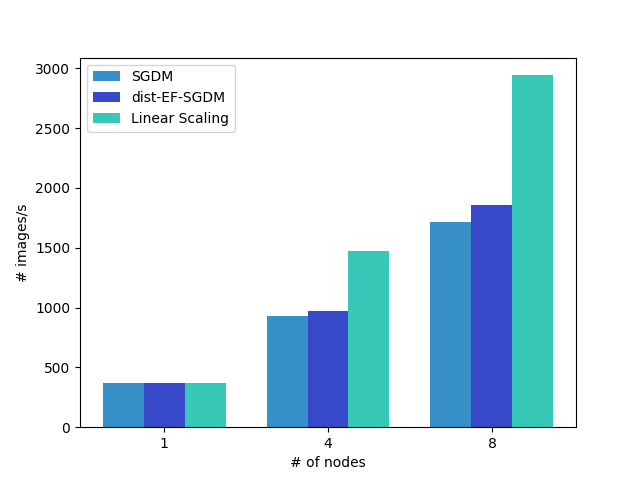
[VGG-16]
The above two sub-experiments were conducted 2 months ago. There have been large updates since then. So the results are a little outdated. They are just for reference.
End-to-End Training
Finally, we train ResNet50_v2 and VGG-16 end-to-end to measure total reduction in training time. For such large batch training, warmup and linear scaling learning rate
are used to avoid generalization gap. We set the number of warmup epochs to 5. We also leverage cosine annealing strategy for learning rate decay. For ResNet50_v2 we use 8 AWS EC2 P3.16xlarge instances while for VGG-16, we use 4 AWS EC2 P3.16xlarge.
[ResNet50_v2]
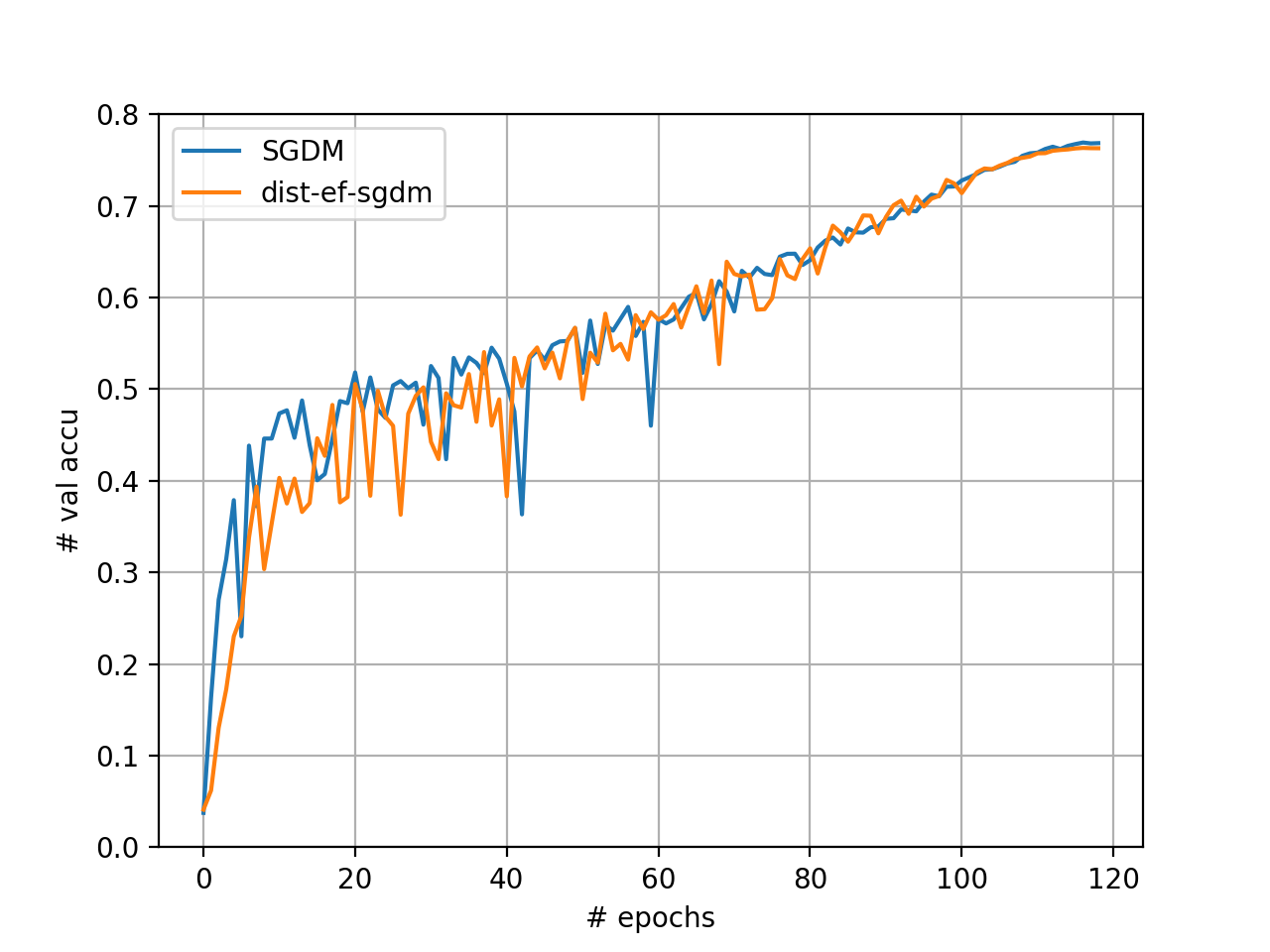
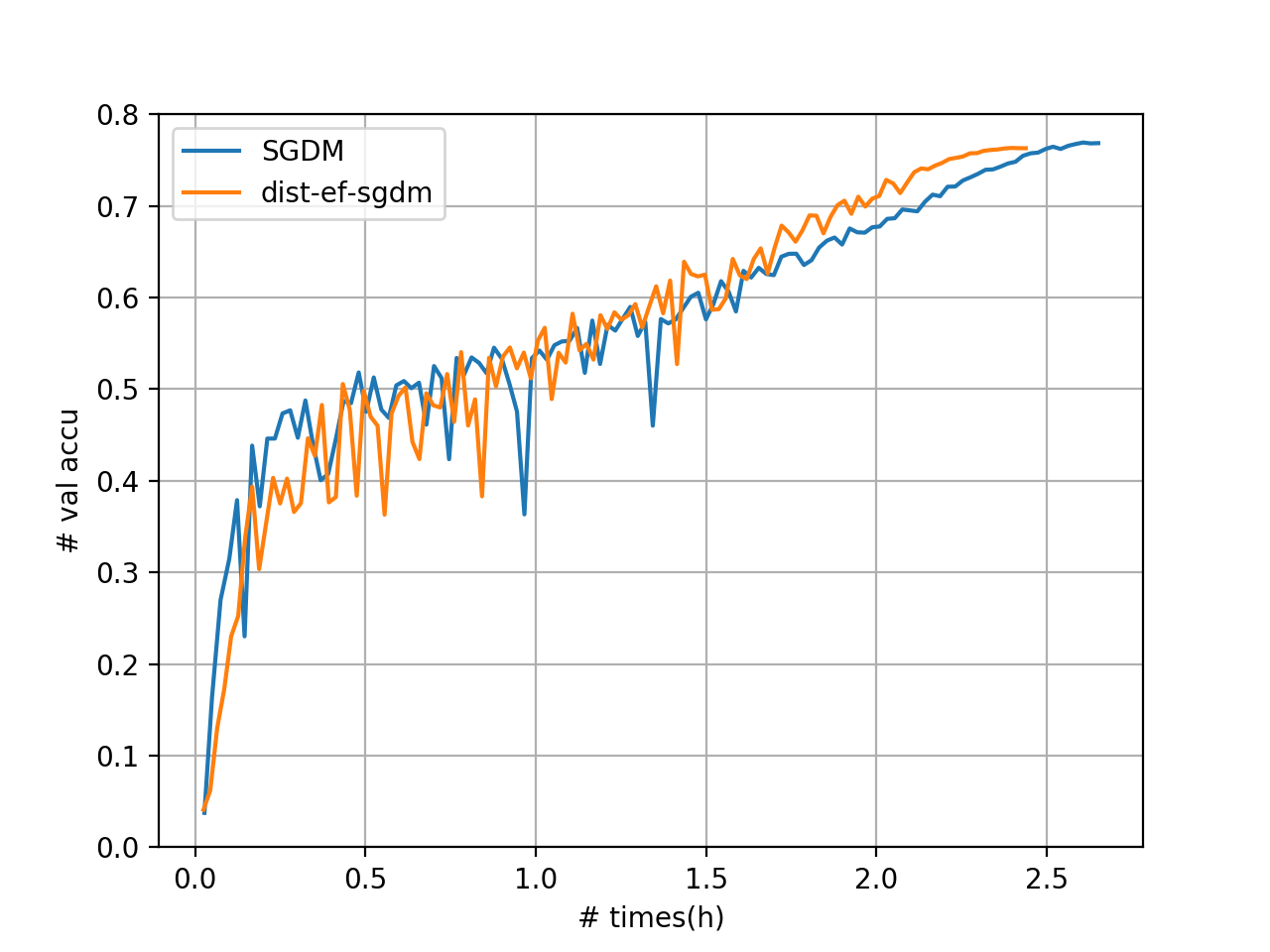
As the figure shows, we reduce the trianing time by 8.0% without accuracy loss for ResNet50_v2.
[VGG-16]
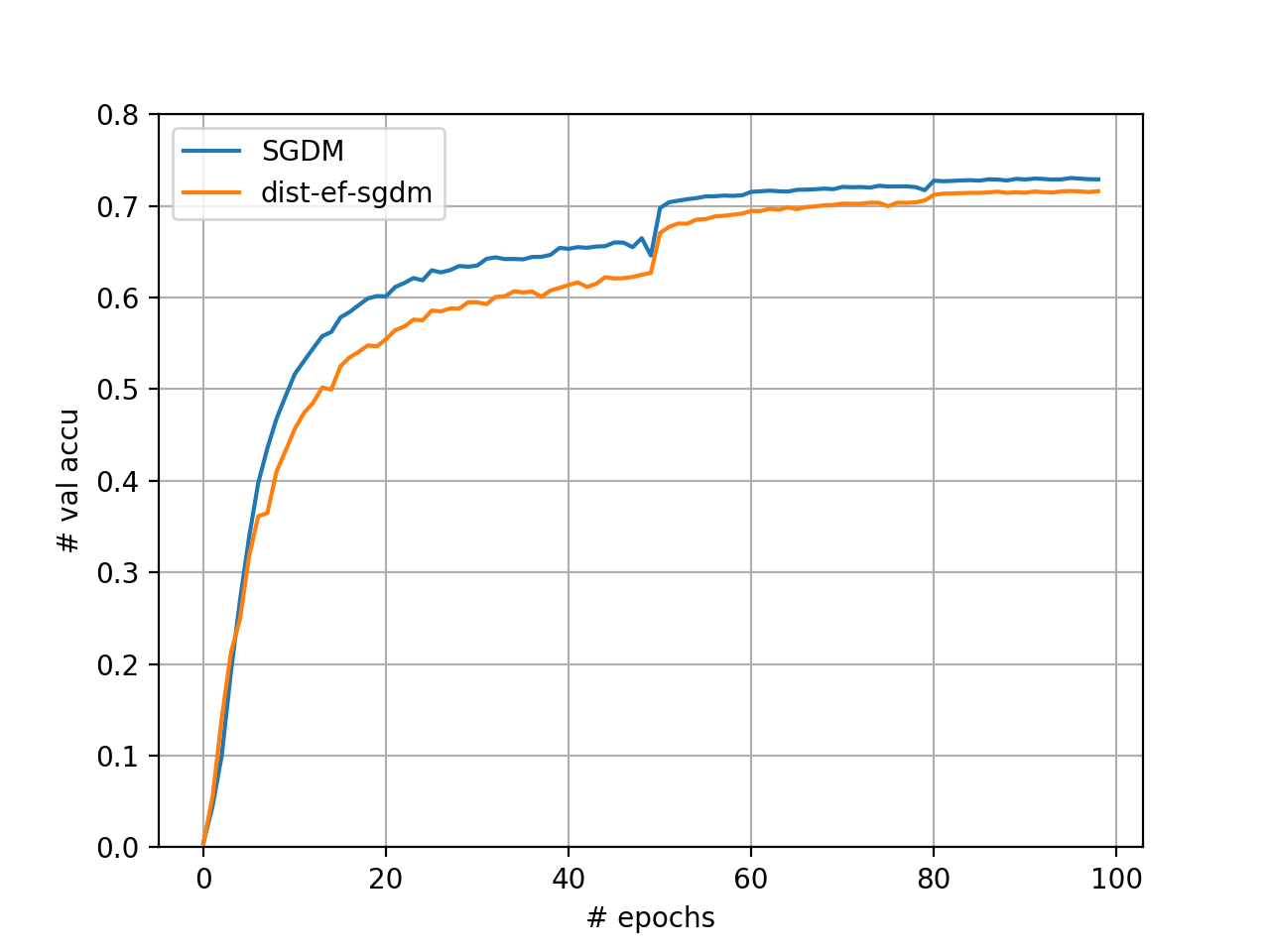
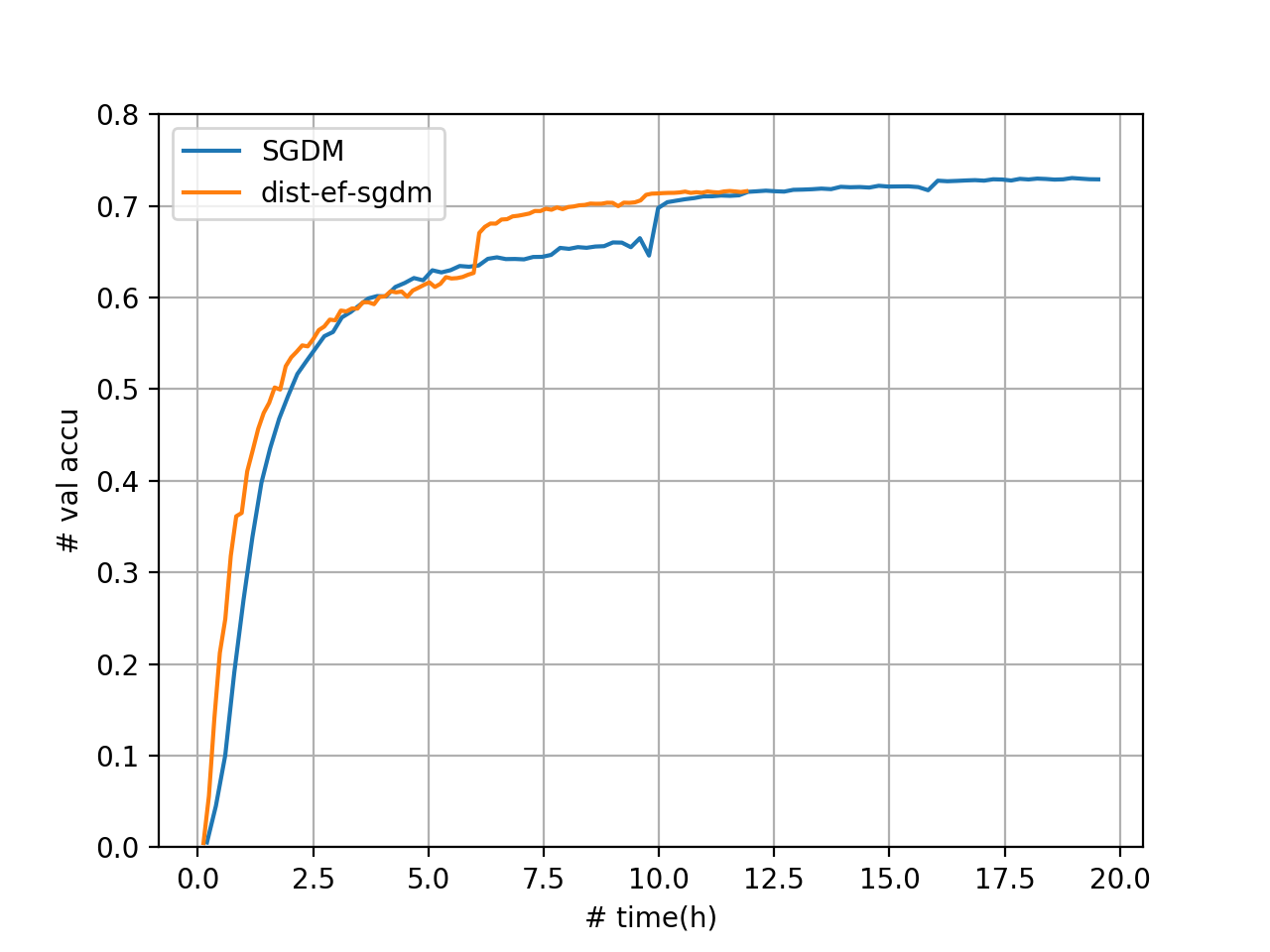
The above figure shows that our implementation of dist-EF-SGDM reduces the training time for 100 epochs by 39.04% compared to the full-precision SGDM. We note that there is a small gap in accuracy between dist-EF-SGDM and SGDM. We will investigate this problem in the future.
TODO
Precautions
ps-liteshould change one LOC. see the PR here. Relax Size Check dmlc/ps-lite#168Acknowledgement
Thanks @eric-haibin-lin @szhengac for guidance! They have been giving many valuable suggestions!