CI Monitoring Runbook
TVM's CI fails on main and PRs with unrelated changes all the time. The purpose of the rotation above is to get these failures triaged and managed quickly improve the developer experience for TVM. This page documents what to do while you are the "on-call".
Rotation Schedule (issue #11462)
These are mostly suggestions and need not be adhered to by the letter. If there are adjustments or useful information you discover during your rotation, please add them to this page.
- When is a rotation?
- Rotations last one work week, starting Monday (and extending retroactively from the end of the last rotation, so on Monday you would triage failures from the previous Saturday and Sunday) and ending on Friday at 5 PM local time.
- How to I find CI failures?
- See the CI status of TVM commits during that day: https://github.com/apache/tvm/commits/main. Failures are also messaged to the
#tvm-ci-failureschannel on Discord. An exploded view of each CI job crossed with commits is available here.
- See the CI status of TVM commits during that day: https://github.com/apache/tvm/commits/main. Failures are also messaged to the
- What do I do if there is a CI failure on
main?- Search for existing issues that match that error
- If an issue does exist, edit it or leave a comment with the new failure
- If an issue does not exist, open a new one and triage the failure.
-
Every failure on
mainshould get an issue filed or be linked to an existing issue- TVM CI issues are reported and tracked in Github (link)
- Flaky tests should use the flaky-test issue template. As the oncall you should also follow up with a PR to mark the flaky test with
@pytest.mark.xfail.
-
Every CI issue should have:
- A short snippet from the relevant logs (if possible), this makes later searching for the same issue much easier
- Someone tagged to investigate or address the issue. For test failures tag the test author. For CI infra failures, add
[ci]to the title to tag the TVM OSS team. - Some kind of mitigation or mitigation plan. Coming up with this is usually up to the triagee, though the oncall should follow up with them until a plan is in place.
-
Every failure on
- It is not your job to fix the failures! You can if you want, but the only expectation is triaging
- This is not a real on-call, if you can't check on some day then it's fine to skip it and check both days on the next. If you're going to be out for a week, arrange in
#tvm-ci-failuresto swap rotations with someone. If you find the workload too much, you can resign from the rotation or scale back your participation. - Rotations are a week long in order to make it simpler to know if you're on or not and give people time to work out their own flows.
- What is this rotation for?
- TVM developers depend on CI to merge changes with confidence that the codebase is still correct. It needs to properly test their changes and only fail if their changes do not pass the TVM test suite. As such, anything merged into the
mainbranch should always be passing all tests, so any failures onmainshould be reported and resolved.
- TVM developers depend on CI to merge changes with confidence that the codebase is still correct. It needs to properly test their changes and only fail if their changes do not pass the TVM test suite. As such, anything merged into the
- What is a flaky test?
- A flaky test is a specific test case that failed for reasons not related to the pull request (PR) that is being tested
- What is an CI infrastructure failure?
- An infra failure is any failure that happens outside of a test case (e.g. network errors, errors in CI job definitions)
Please edit this section as needed to add common failure modes
-
File an issue via the link in the failing PR run and look in the git blame history for that test to find people to tag. All flaky test issues should have at least 1 person tagged.
- The "Report flaky test shortcut" link shows up at the end of unit test steps, e.g.
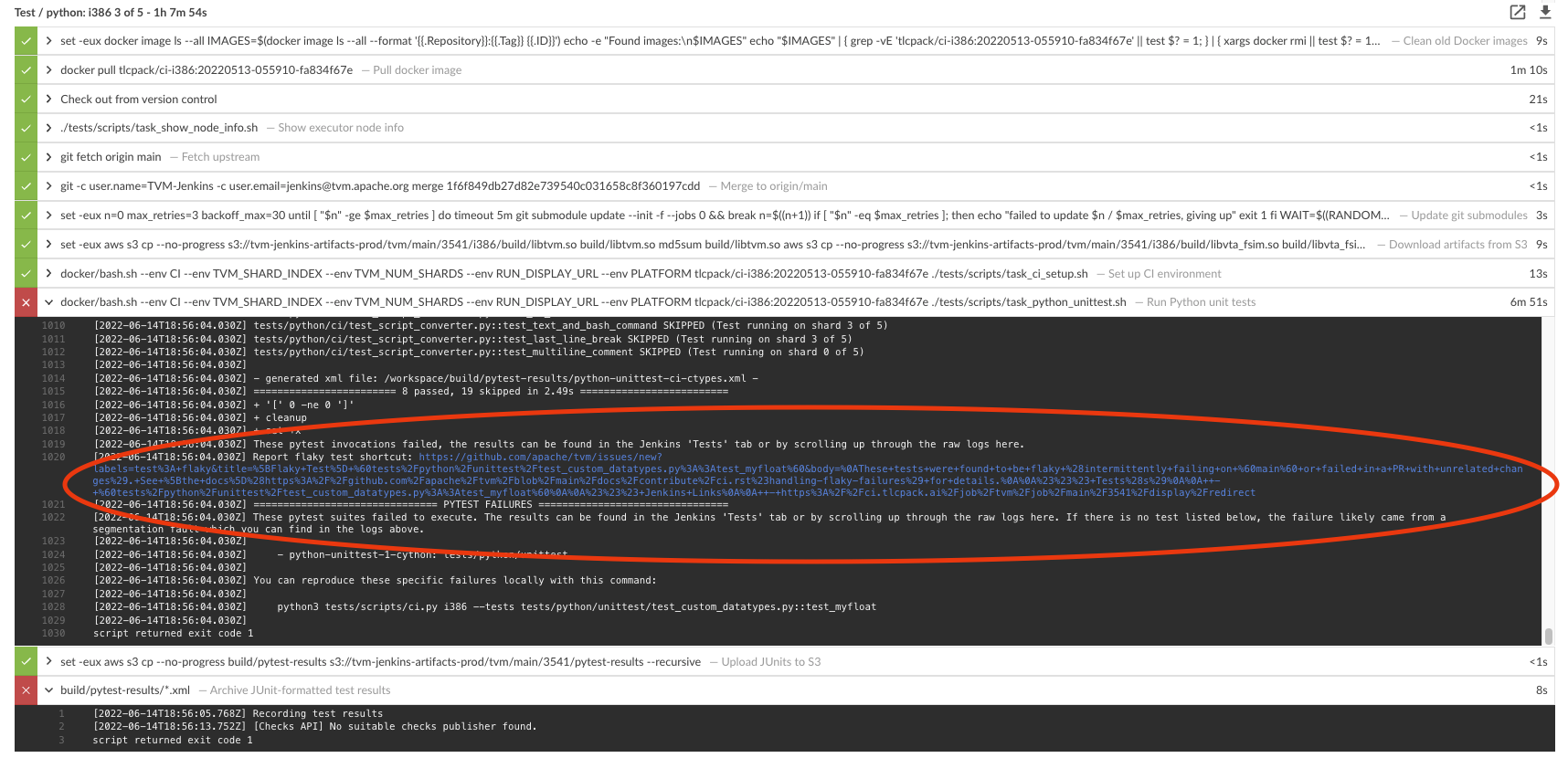
- The "Report flaky test shortcut" link shows up at the end of unit test steps, e.g.
-
Disable the flaky tests in code and submit a PR. Make sure to link the issue in the PR message
@pytest.mark.skip(reason="Disabled due to flakiness <issue link") def test_some_test_case(): ...
-
If there are two PRs (PR A and PR B) that both passed CI individually, it is possible for CI to fail when they're both merged into
mainif they made different assumptions about the codebase that don't work when mixed together. In this case, a revert of the second PR to merge is the fastest resolution.git revert <commit hash that broke CI> git commit --amend # prepend '[skip ci]' to the commit title before you submit the PR
-
Always comment on reverted PRs with the reason and next steps for the PR author (in this case, rebase and resubmit the PR)
- If a failure happens in any part of Jenkins outside of a test case, it is an infrastructure failure. File an issue with
[ci]prefixed to the title. This will auto-tag all CI maintainers.
- TVM tests are split among many nodes to enable horizontal scaling in CI. These splits are fixed in
Test.groovy.j2and occasionally need to be readjusted. See https://github.com/apache/tvm/pull/12473 for an example.
Interested in helping out? Comment on https://github.com/apache/tvm/issues/11462.