![]()
Research into multimodalities is pivotal for advancing Artificial General Intelligence (AGI). Previous studies have delved into the capabilities of models trained using contrastive losses. Notably, successful models such as CLIP and BLIP have exerted substantial influence. However, their application predominantly focuses on tasks such as Image-Text Retrieval, Visual Question Answering, or Conditional Generation. Classification, despite being a fundamental task, has received comparatively limited attention. Thus, in this project, we demonstrate a practical implementation of a classification task using pretrained models. It is our hope that the examples provided in this repository will inspire further exploration and innovation.
To illustrate, consider training a BlipMLDecoderClassifier with a learning rate of 0.01. Execute the following command:
python3 train.py \
--model_name blip_ml_decoder \
--learning_rate 1e-2The model weights will be stored at ./checkpoints/blip_ml_decoder_large_bce_v1_lr0.01_bs256_seed3407_loss.pth.
It is important to note that using a batch size of 256 with the BlipMLDecoderClassifier requires a GPU with at least 24 GB of memory. Additionally, our experiments were conducted on a two-GPU system, where part of the model was allocated to the second GPU. If you are operating on a machine with a single GPU, consider using alternative models such as the BlipClassifier, which is the default model choice.
After training your model, you can proceed to make predictions. For instance, to use the previously trained model for inference, execute the command below:
python3 predict.py \
--checkpoint_path ./checkpoints/blip_ml_decoder_large_bce_v1_lr0.01_bs256_seed3407_loss.pthThe output of the models will be saved in a .csv file.
Links: Dataset on Kaggle


-
Router
- Description: Utilizes a router module to dynamically assign weights to different modalities, adapting to the task requirements.
- Diagram:

-
Boosting- Description: Currently ineffective, this strategy requires further development and optimization.

-
Naive
- Description: The original BLIP model effectively extracts features from multiple modalities without complex modifications.
-
Ensembling
- Description: Combines base classifiers that use both unimodal and multimodal features to improve prediction accuracy.
-
Boosting- Description: This strategy is still under development as it has not yet proven effective.
-
Graph Attention Transformer (GAT)
- Description: Employs Graph Neural Networks (GNNs) to model the relationships between labels, enhancing multilabel classification tasks.
-
ML-Decoder [3]
- Description: Focuses on learning robust representations by leveraging embeddings, facilitating effective decoding in complex scenarios.
- Diagram:
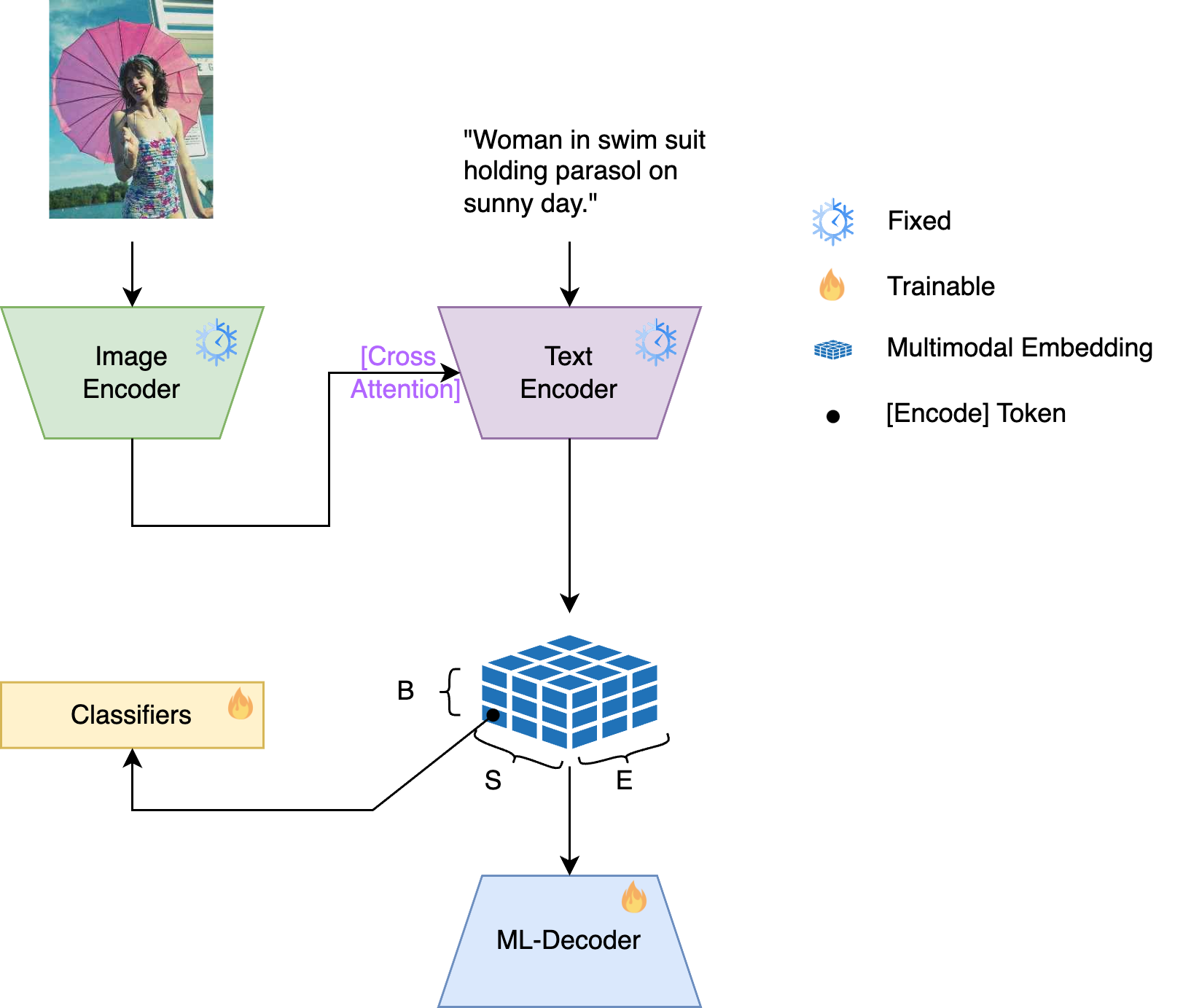

- Binary Cross Entropy Loss with Logits (Default)
- Smoothing Loss
- Binary Focal Loss with Logits
- Angular Additive Margin (AAM) Loss with Logits [4]
- ZLPR Loss with Logits [5]
To optimize the effectiveness of unimodal classifiers, initial warmups are conducted until these classifiers plateau in performance improvements. Subsequently, a router is used to allocate weights to each classifier, thereby enhancing overall performance. If a unimodal classifier excels independently, it often overshadows improvements in classifiers using different modalities. Hence, unimodal warmups are essential for optimizing CLIP-based models.
In scenarios with limited computational resources, it is advisable to initially extract embeddings, followed by the application of MLDecoder for sequential learning. This approach allows for the scaling of batch sizes to extremely large quantities, accommodating thousands of samples in a single batch.
├── MultiCLIP/
│ ├── checkpoints/*.pth
│ ├── data/*.jpg
│ ├── figures/*.jpg
│ ├── models/*
│ ├── multi_clip/
│ │ ├── models/
│ │ │ ├── __init__.py
│ │ │ ├── blip_classifier.py
│ │ │ ├── clip_classifier.py
│ │ │ ├── config.py
│ │ │ ├── gat.py
│ │ │ ├── ml_decoder.py
│ │ │ └── router.py
│ │ ├── processors/
│ │ │ ├── __init__.py
│ │ │ ├── blip_processor.py
│ │ │ └── clip_processor.py
│ │ ├── trainers/
│ │ │ ├── __init__.py
│ │ │ ├── base_trainer.py
│ │ │ ├── boost_trainer.py
│ │ │ ├── clip_trainer.py
│ │ │ ├── head_trainer.py
│ │ │ └── ml_decoder_trainer.py
│ │ ├── utils/
│ │ │ ├── __init__.py
│ │ │ ├── inference_func.py
│ │ │ ├── label_encoder.py
│ │ │ ├── losses.py
│ │ │ ├── metrics.py
│ │ │ ├── predict_func.py
│ │ │ └── tools.py
│ │ ├── __init__.py
│ │ └── datasets.py
│ ├── .gitignore
│ ├── LICENSE
│ ├── label_encoder.npy
│ ├── predict.py
│ ├── README.md
│ ├── test.csv
│ ├── train_boost.py
│ ├── train.csv
│ └── train.py
└───
<style> ol { counter-reset: list-counter; list-style: none; padding-left: 0; } ol li { counter-increment: list-counter; margin-bottom: 10px; } ol li::before { content: "[" counter(list-counter) "] "; font-weight: bold; } </style>
- Radford, Alec, et al. "Learning transferable visual models from natural language supervision." International conference on machine learning. PMLR, 2021.
- Li, Junnan, et al. "Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation." International conference on machine learning. PMLR, 2022.
- Ridnik, Tal, et al. "Ml-decoder: Scalable and versatile classification head." Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2023.
- Deng, Jiankang, et al. "Arcface: Additive angular margin loss for deep face recognition." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019.
- Su, Jianlin, et al. "Zlpr: A novel loss for multi-label classification." arXiv preprint arXiv:2208.02955 (2022).