Every Data Scientist needs a methodology to solve data science’s problems. For example, let’s suppose that you are a Data Scientist and your first job is to increase sales for a company, they want to know what product they should sell on what period. You will need the correct methodology to organize your work, analyze different types of data, and solve their problem. Your customer doesn’t care about how you do your job; they only care if you will manage to do it in time.
Methodology in Data Science is the best way to organize your work, doing it better, and without losing time. Data Science Methodology is composed of 10 parts:
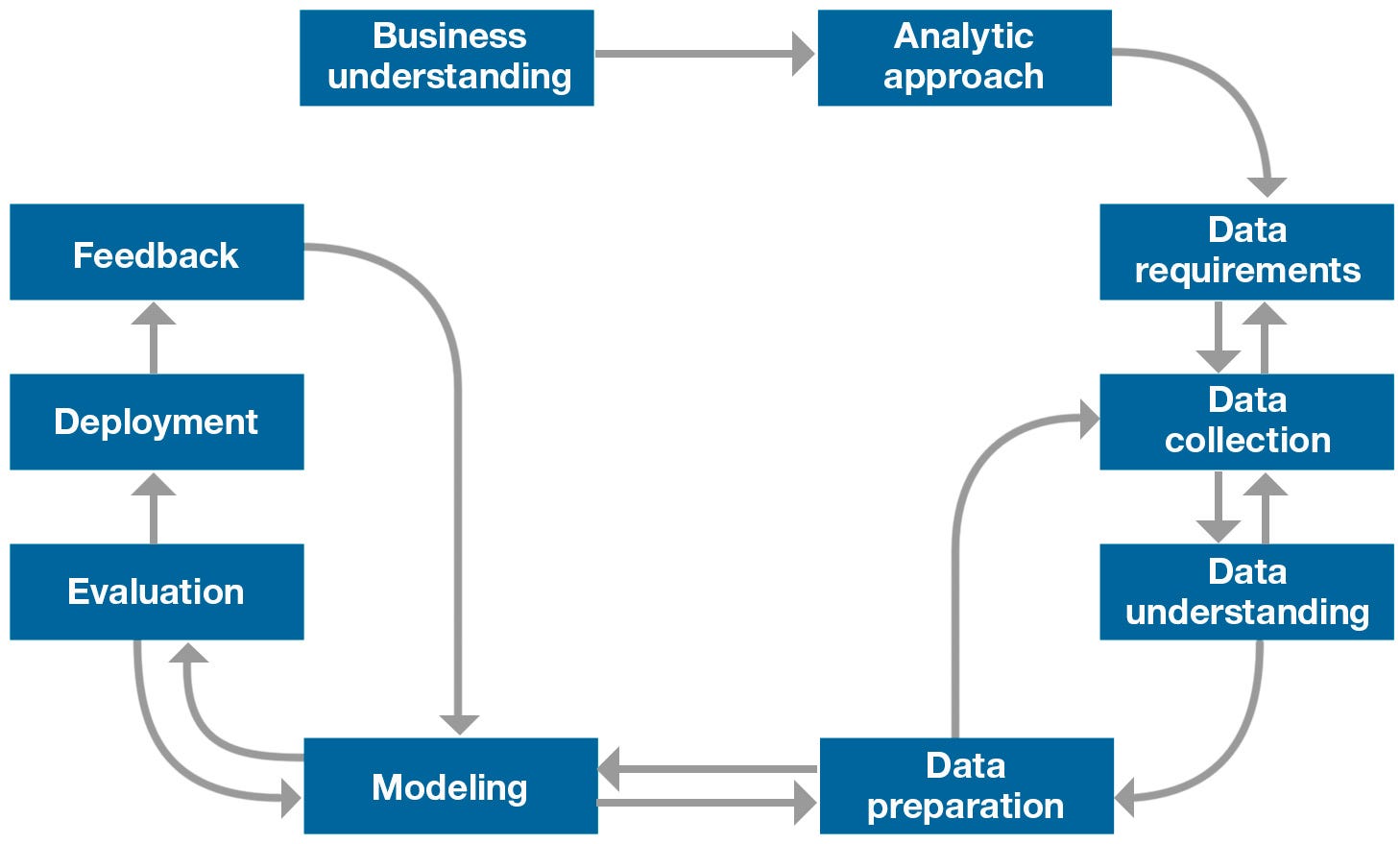
Source: IBMOpenSource_FoundationalMethologyforDataScience.PDF
In this article, there are five parts, each of which contains more steps:
1. From Problem to Approach
2. From Requirements to Collection
3. From Understanding to Preparation
4. From Modeling to Evaluation
5. From Deployment to Feedback
If we look at the chart in the last image, we see that it is highly iterative and never ends; that’s because in a real case study, we have to repeat some steps to improve the model.
Every customer’s request starts with a problem, and Data Scientists’ job is first to understand it and approach this problem with statistical and machine learning techniques.
Business Understanding: This stage is crucial because it helps to clarify the goal of the customer. In this stage, we have to ask a lot of questions to the customer about every single aspect of the problem; in this manner, we are sure that we will study data related, and at the end of this stage, we will have a list of business requirements.
Analytic Approach: Once the business problem has been clearly stated, the data scientist can define the analytic approach to solve the problem. This step entails expressing the problem in the context of statistical and machine-learning techniques, and it is essential because it helps identify what type of patterns will be needed to address the question most effectively. If the issue is to determine the probabilities of something, then a predictive model might be used; if the question is to show relationships, a descriptive approach may be required, and if our problem requires counts, then statistical analysis is the best way to solve it. For each type of approach, we can use different algorithms.
Once we have found a way to solve our problem, we will need to discover the correct data for our model.
Data Requirements: In this stage, is where we identify the necessary data content, formats, and sources for initial data collection, and we use this data inside the algorithm of the approach we chose.
Data Collection: In this stage, the data scientists identify the available data resources relevant to the problem domain. To retrieve data, we can do web scraping on a related website, or we can use repository with premade datasets ready to use. Usually, premade datasets are CSV files or Excel; anyway, if we want to collect data from any website or repository, we should use Pandas, a useful tool to download, convert, and modify datasets.
Now that the data collection stage is complete, data scientists use descriptive statistics and visualization techniques to understand data better. Data scientists, explore the dataset to understand its content, determine if additional data is necessary to fill any gaps but also to verify the quality of the data.
Data Understanding: In this stage, data scientists try to understand more about the data collected before. We have to check the type of each data and to learn more about the attributes and their names.
Data Preparation: In this stage, data scientists prepare data for modeling, which is one of the most crucial steps because the model has to be clean and without errors. In this stage, we have to be sure that the data are in the correct format for the machine learning algorithm we chose in the analytic approach stage. The dataframe has to have appropriate columns name, unified boolean value (yes, no or 1, 0). We have to pay attention to the name of each data because sometimes they might be written in different characters, but they are the same thing; for example (WaTeR, water), we can fix this making all the value of a column lowercase. Another improvement can be made by deleting data exceptions from the dataframe because of their irrelevance.
Once data are prepared for the chosen machine learning algorithm, we are ready for modeling.
Modeling: In this stage, the data scientist has the chance to understand if his work is ready to go or if it needs review. Modeling focuses on developing models that are either descriptive or predictive, and these models are based on the analytic approach that was taken statistically or through machine learning. Descriptive modeling is a mathematical process that describes real-world events and the relationships between factors responsible for them, for example, a descriptive model might examine things like: if a person did this, then they’re likely to prefer that. Predictive modeling is a process that uses data mining and probability to forecast outcomes; for example, a predictive model might be used to determine whether an email is a spam or not. For predictive modeling, data scientists use a training set that is a set of historical data in which the outcomes are already known. This step can be repeated more times until the model understands the question and answer to it.
Model Evaluation: In this stage, data scientists can evaluate the model in two ways: Hold-Out and Cross-Validation. In the Hold-Out method, the dataset is divided into three subsets: a training set as we said in the modeling stage; a validation set that is a subset used to assess the performance of the model built in the training phase; a test set is a subset to evaluate the likely future performance of a model.
Data scientists have to make the stakeholders familiar with the tool produced in different scenarios, so once the model is evaluated and the data scientist is confident it will work, it is deployed and put to the ultimate test.
Deployment: This stage, depends on the purpose of the model, and it may be rolled out to a limited group of users or in a test environment. A real case study example can be for a model destined for the healthcare system; the model can be deployed for some patients with low-risk and after for high-risk patients too.
Feedback: This stage, is usually made the most from the customer. Customers after the deployment stage can say if the model works for their purposes or not. Data scientists take this feedback and decide if they should improve the model; that’s because the process from modeling to feedback is highly iterative.
When the model meets all the requirements of the customer, our data science project is complete.
To learn more, you can visit my GitHub Page where you can find real use cases examples and more.