📃 Paper • 🤗 Demo & Model
- [2024/01/06] We open source the LLaMA-Pro repository and Demo & Model.
- [2024/01/07] Add how to run gradio demo locally in demo
- [2024/01/18] Add the training code in open-instruct.
- [2024/02/23] We release the Mistral-Pro-8B-v0.1 with superior performance on a range of benchmarks. It enhances the code and math performance of Mistral and matches the performance of the recently dominant model, Gemma.
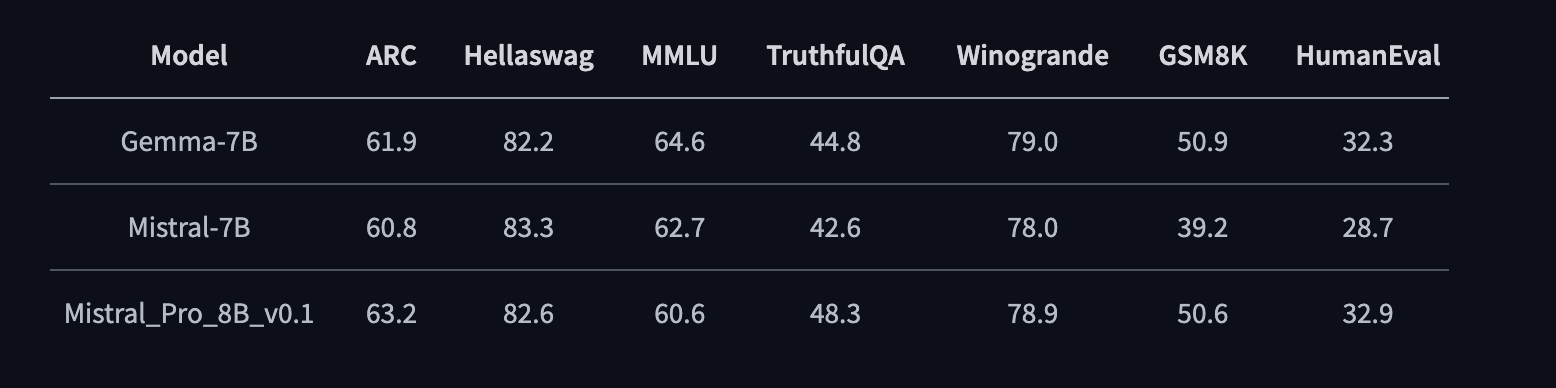
- [2024/02/23] We release the evaluation code of Mistral-Pro-8B-v0.1 in lm-evaluation-harness.
- [2024/02/23] We release MetaMath-Mistral-Pro that surpasses previous MetaMath series 7B models at both GSM8k and MATH. The evaluation is following the official MetaMath repo.
- [2024/05/08] Add the pre-train example script for cosmopedia in open-instruct.
- [2024/05/16] LLaMA Pro has been accepted to the main conference of ACL 2024!

🔥 Comprehensive Results
| Model | GSM8k Pass@1 | MATH Pass@1 |
|---|---|---|
| WizardMath-7B | 54.9 | 10.7 |
| LLaMA-2-70B | 56.8 | 13.5 |
| WizardMath-13B | 63.9 | 14.0 |
| MetaMath-7B | 66.5 | 19.8 |
| MetaMath-13B | 72.3 | 22.4 |
| MetaMath-Mistral-7B | 77.7 | 28.2 |
| MetaMath-Llemma-7B | 69.2 | 30.0 |
| 🔥 MetaMath-Mistral-Pro | 78.4 | 30.3 |
The code of instruction tuning is based on the official implementation of open-instruct.
Thanks huggingface & wisemodel for hosting our checkpoint.
The code and model in this repository is mostly developed for or derived from the paper below. Please cite it if you find the repository helpful.
@article{wu2024llama,
title={Llama pro: Progressive llama with block expansion},
author={Wu, Chengyue and Gan, Yukang and Ge, Yixiao and Lu, Zeyu and Wang, Jiahao and Feng, Ye and Luo, Ping and Shan, Ying},
journal={arXiv preprint arXiv:2401.02415},
year={2024}
}