forked from ray-project/ray
-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Revert "Revert "[serve] Integrate and Document Bring-Your-Own Gradio …
…Applications"" (ray-project#27662) Signed-off-by: Stefan van der Kleij <[email protected]>
- Loading branch information
Showing
13 changed files
with
402 additions
and
366 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,12 @@ | ||
| #!/usr/bin/env bash | ||
|
|
||
| # Installs serve dependencies ("ray[serve]") on top of minimal install | ||
|
|
||
| # Get script's directory: https://stackoverflow.com/a/246128 | ||
| SCRIPT_DIR=$( cd -- "$( dirname -- "${BASH_SOURCE[0]}" )" &> /dev/null && pwd ) | ||
|
|
||
| # Installs minimal dependencies | ||
| "$SCRIPT_DIR"/install-minimal.sh | ||
|
|
||
| # Installs serve dependencies | ||
| python -m pip install -U "ray[serve]" |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,123 @@ | ||
| # Scaling your Gradio app with Ray Serve | ||
|
|
||
| In this guide, we will show you how to scale up your [Gradio](https://gradio.app/) application using Ray Serve. Keeping the internal architecture of your Gradio app intact (no changes), we simply wrap the app within Ray Serve as a deployment and scale it to access more resources. | ||
| ## Dependencies | ||
|
|
||
| To follow this tutorial, you will need Ray Serve and Gradio. If you haven't already, install them by running: | ||
| ```console | ||
| $ pip install "ray[serve]" | ||
| $ pip install gradio | ||
| ``` | ||
| For this tutorial, we will use Gradio apps that run text summarization and generation models and use [HuggingFace's Pipelines](https://huggingface.co/docs/transformers/main_classes/pipelines) to access these models. **Note that you can substitute this Gradio app for any Gradio app of your own!** | ||
|
|
||
| First, let's install the transformers module. | ||
| ```console | ||
| $ pip install transformers | ||
| ``` | ||
|
|
||
| ## Quickstart: Deploy your Gradio app with Ray Serve | ||
|
|
||
| This section shows you an easy way to deploy your app onto Ray Serve. First, create a new Python file named `demo.py`. Second, import `GradioServer` from Ray Serve to deploy your Gradio app later, `gradio`, and `transformers.pipeline` to load text summarization models. | ||
| ```{literalinclude} ../../../../python/ray/serve/examples/doc/gradio-integration.py | ||
| :start-after: __doc_import_begin__ | ||
| :end-before: __doc_import_end__ | ||
| ``` | ||
|
|
||
| Then, we construct the (optional) Gradio app `io`. This application takes in text and uses the [T5 Small](https://huggingface.co/t5-small) text summarization model loaded using [HuggingFace's Pipelines](https://huggingface.co/docs/transformers/main_classes/pipelines) to summarize that text. | ||
| :::{note} | ||
| Remember you can substitute this with your own Gradio app if you want to try scaling up your own Gradio app! | ||
| ::: | ||
| ```{literalinclude} ../../../../python/ray/serve/examples/doc/gradio-integration.py | ||
| :start-after: __doc_gradio_app_begin__ | ||
| :end-before: __doc_gradio_app_end__ | ||
| ``` | ||
|
|
||
| ### Deploying Gradio Server | ||
| In order to deploy your Gradio app onto Ray Serve, you need to wrap your Gradio app in a Serve [deployment](serve-key-concepts-deployment). `GradioServer` acts as that wrapper. It serves your Gradio app remotely on Ray Serve so that it can process and respond to HTTP requests. | ||
|
|
||
| Replicas in a deployment are copies of your program running on Ray Serve, where each replica runs on a separate Ray cluster node's worker process. More replicas scales your deployment by serving more client requests. By wrapping your application in `GradioServer`, you can increase the number of replicas of your application or increase the number of CPUs and/or GPUs available to each replica. | ||
|
|
||
| :::{note} | ||
| `GradioServer` is simply `GradioIngress` but wrapped in a Serve deployment. You can use `GradioServer` for the simple wrap-and-deploy use case, but as you will see in the next section, you can use `GradioIngress` to define your own Gradio Server for more customized use cases. | ||
| ::: | ||
|
|
||
| Using either the example app `io` we created above or an existing Gradio app (of type `Interface`, `Block`, `Parallel`, etc.), wrap it in your Gradio Server. | ||
|
|
||
| ```{literalinclude} ../../../../python/ray/serve/examples/doc/gradio-integration.py | ||
| :start-after: __doc_app_begin__ | ||
| :end-before: __doc_app_end__ | ||
| ``` | ||
|
|
||
| Finally, deploy your Gradio Server! Run the following in your terminal: | ||
| ```console | ||
| $ serve run demo:app | ||
| ``` | ||
|
|
||
| Now you can access your Gradio app at `https://localhost:8000`! This is what it should look like: | ||
| 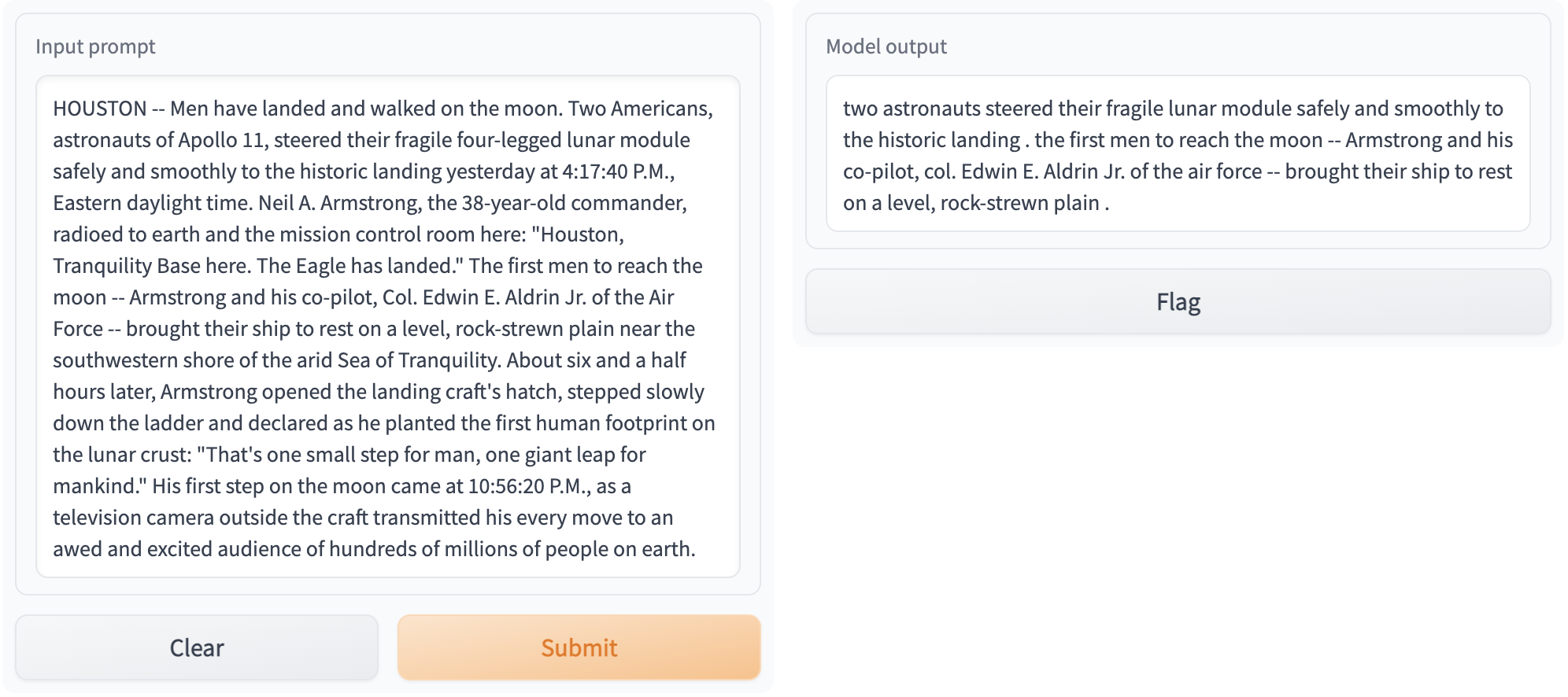 | ||
|
|
||
| See [Putting Ray Serve Deployment Graphs in Production](https://docs.ray.io/en/master/serve/production.html#id1) for more information on how to deploy your app in production. | ||
|
|
||
|
|
||
| ## Parallelizing models with Ray Serve | ||
| You can run multiple models in parallel with Ray Serve by utilizing the [deployment graph](serve-model-composition-deployment-graph) in Ray Serve. | ||
|
|
||
| ### Original Approach | ||
| Suppose you want to run the following program. | ||
|
|
||
| 1. Take two text generation models, [`gpt2`](https://huggingface.co/gpt2) and [`EleutherAI/gpt-neo-125M`](https://huggingface.co/EleutherAI/gpt-neo-125M). | ||
| 2. Run the two models on the same input text, such that the generated text has a minimum length of 20 and maximum length of 100. | ||
| 3. Display the outputs of both models using Gradio. | ||
|
|
||
| This is how you would do it normally: | ||
|
|
||
| ```{literalinclude} ../../../../python/ray/serve/examples/doc/gradio-original.py | ||
| :start-after: __doc_code_begin__ | ||
| :end-before: __doc_code_end__ | ||
| ``` | ||
|
|
||
| ### Parallelize using Ray Serve | ||
|
|
||
| With Ray Serve, we can parallelize the two text generation models by wrapping each model in a separate Ray Serve [deployment](serve-key-concepts-deployment). Deployments are defined by decorating a Python class or function with `@serve.deployment`, and they usually wrap the models that you want to deploy on Ray Serve to handle incoming requests. | ||
|
|
||
| Let's walk through a few steps to achieve parallelism. First, let's import our dependencies. Note that we need to import `GradioIngress` instead of `GradioServer` like before since we're now building a customized `MyGradioServer` that can run models in parallel. | ||
|
|
||
| ```{literalinclude} ../../../../python/ray/serve/examples/doc/gradio-integration-parallel.py | ||
| :start-after: __doc_import_begin__ | ||
| :end-before: __doc_import_end__ | ||
| ``` | ||
|
|
||
| Then, let's wrap our `gpt2` and `EleutherAI/gpt-neo-125M` models in Serve deployments, named `TextGenerationModel`. | ||
| ```{literalinclude} ../../../../python/ray/serve/examples/doc/gradio-integration-parallel.py | ||
| :start-after: __doc_models_begin__ | ||
| :end-before: __doc_models_end__ | ||
| ``` | ||
|
|
||
| Next, instead of simply wrapping our Gradio app in a `GradioServer` deployment, we can build our own `MyGradioServer` that reroutes the Gradio app so that it runs the `TextGenerationModel` deployments: | ||
|
|
||
| ```{literalinclude} ../../../../python/ray/serve/examples/doc/gradio-integration-parallel.py | ||
| :start-after: __doc_gradio_server_begin__ | ||
| :end-before: __doc_gradio_server_end__ | ||
| ``` | ||
|
|
||
| Lastly, we link everything together: | ||
| ```{literalinclude} ../../../../python/ray/serve/examples/doc/gradio-integration-parallel.py | ||
| :start-after: __doc_app_begin__ | ||
| :end-before: __doc_app_end__ | ||
| ``` | ||
|
|
||
| :::{note} | ||
| This will bind your two text generation models (wrapped in Serve deployments) to `MyGradioServer._d1` and `MyGradioServer._d2`, forming a [deployment graph](serve-model-composition-deployment-graph). Thus, we have built our Gradio Interface `io` such that it calls `MyGradioServer.fanout()`, which simply sends requests to your two text generation models that are deployed on Ray Serve. | ||
| ::: | ||
|
|
||
| Now, you can run your scalable app, and the two text generation models will run in parallel on Ray Serve. | ||
| Run your Gradio app with the following command: | ||
|
|
||
| ```console | ||
| $ serve run demo:app | ||
| ``` | ||
|
|
||
| Access your Gradio app at `https://localhost:8000`, and you should see the following interactive interface: | ||
| 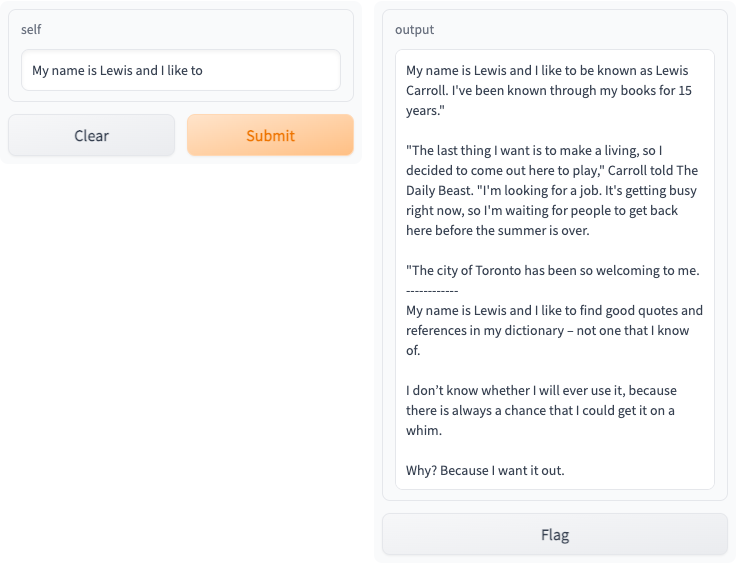 | ||
|
|
||
| See [Putting Ray Serve Deployment Graphs in Production](https://docs.ray.io/en/master/serve/production.html#id1) for more information on how to deploy your app in production. |
Oops, something went wrong.