Multi-Still: A lightweight Multi-modal Cross Attention Knowledge Distillation method for real-time Emotion Recognition
😊 대회 소개
- 인간과 교감할 수 있는 인공지능을 구현하기 위한 목적으로 개최 되었습니다.
- 사람의 행동과 감정을 이해하는 기술 연구를 가능토록 하기위해 구축한 데이터셋을 활용하여 휴먼이해 인공지능 기술 연구를 확산시키고자 합니다.
- 이에 창의적은 연구를 발굴하고자 합니다.
😊 주최/주관
- 주최 : 한국전자통신연구원 (ETRI)
- 후원 : 과학정보기술통신부, 국가과학기술연구회 (NST)
- 운영 : 인공지능팩토리 (AIFactory)
😊 논문 주제
-
멀티모달 감정 데이터셋 활용 감정 인식 기술 분야
-
논문주제: Emotion Recognition in Conversation (ERC)분야
-
Multi-Still: 실시간 감정 인식을 위한 경량화된 멀티모달 교차 어텐션 지식 증류 방법
* Emotion Recognition in Conversation이란? 두 명 이상의 참여자 간의 대화(dialogue)과정에서 대화 참여자의 감정을 인식 또는 예측하기 위한 감정인식 연구분야입니다.
😊 활용 데이터: ETRI 한국어 감정 데이터셋 활용 연구
😊 Environment
python version : python3.9
OS type : WSL
requires packages: {
'numpy==1.22.3',
'pandas==1.4.2',
'torch==1.11.0+cu113',
'torchaudio==0.11.0+cu113',
'scikit-learn',
'transformers==4.18.0',
'tokenizers==0.12.1',
'soundfile==0.10.3.post1'
}
😊 Docker container run
docker container run -d -it --name multi_still --gpus all python:3.9😊 Environment Setting
git clone https://github.com/SeolRoh/Multi-Still_ETRI.git
cd Multi-Still_ETRI
bash setup.sh😊 Preprocessing
# 데이터 전처리
bash data_preprocessing.sh- 7가지 감정 레이블의 데이터 불균형 완화 전후 분포 비교

😊 Train
# 멀티모달 교사 모델 훈련
python train_crossattention.py --model_name multimodal_teacher
# 교사모델을 활용해, 데이터셋에 증류 데이터(Softmax) 추가
#--teacher_name 옵션으로 MultiModal 교사모델의 이름_epoch수를 입력한다.
#--data_path 옵션으로 softmax 데이터를 추가할 기존 데이터셋의 경로를 입력 (기본값, "data/train_preprocessed_data.json")
python Distill_knowledge.py --teacher_name multimodal_teacher_epoch4
# miniconfig.py 를 수정해서 Epoch를 포함한 하이퍼파라미터 변경
# 멀티모달 학생 모델 지식증류 훈련
python KD_train_crossattention.py --model_name multimodal_student
# 문자모달 학생 모델 지식증류 훈련
python KD_train_crossattention.py --model_name text_student --text_only True
# 음성모달 학생 모델 지식증류 훈련
python KD_train_crossattention.py --model_name audio_student --audio_only True😊 Test
# pt 파일은 훈련의 5번째 Epoch마다 생성됨. (예: 5, 10, 11....)
# 여러 파일을 테스트 하기위해 test_all파일에 복사
mkdir ckpt/test_all
cp ckpt/* ckpt/test_all/
python test.py --all
# test.py의 결과는 "result_all_model2.csv"에서 😁 Directory
- 코드 구현을 위해서는 ETRI에서 제공하는 파일(KEMDy19 & KEMDy20)과 AI Hub 감정 데이터 파일이 알맞은 위치에 있어야합니다.
+--Multi-Still_ETRI
+--KEMDy19
+--annotation
+--EDA
+--TEMP
+--wav
+--KEMDy20
+--annotation
+--wav
+--TEMP
+--IBI
+--EDA
+--models
+--module_for_clossattention
+--MultiheadAttention.py # 멀티헤드 어텐션
+--PositionalEmbedding.py # 포지셔널 임베딩
+--Transformer.py # 트랜스포머
+--multimodal.py # 멀티모달, encoding진행
+--multimodal_cross_attention.py # 음성 및 텍스트를 포함한 멀티모달 인코딩 및 크로스 어텐션
+--data (data_preprocessing.sh 실행 후 생성)
+--total_data.json # 모든 데이터셋을 전처리한 파일
+--preprocessed_data.json # 모든 데이터셋에서 음성파일이 존재하지 않는 데이터를 제거 후, 테스트데이터와 훈련 데이터를 분리한 파일
+--test_preprocessed_data.json # preprocessed_data.json에서 테스트 데이터를 추출한 파일
+--train_preprocessed_data.json # preprocessed_data.json에서 훈련 데이터를 추출한 파일
+--ckpt (train_crossattention.py, KD_train_crossattention.py 실행 후 생성)
+--test_all # 여러 모델들을 한번에 테스트할 때 복사해줄 폴더
+--*.pt # 모델 훈련 후, 5의 배수 Epoch마다 저장되는 모델 파일
+--TOTAL(Data_Preprocessing.sh 실행 후 생성) # 모든 데이터를 TOTAL 폴더에 복사한 후, 전처리 및 훈련 진행
+--hidden_states # 훈련 및 추론을 빨리 진행하기 위해, 미리 훈련된 Wav2Vec2모델에서 인코딩한 결과를 미리 저장하여 활용.
+--setup.sh # update, upgrade 및 모델 생성 시 필요한 라이브러리 설치
+--data_preprocessing.sh # 데이터 전처리 및 훈련, 테스트 데이터셋 분리 저장
+--config.py # 교사모델 훈련시 필요한 하이퍼파라미터 정의
+--Data_Balancing.py # 데이터셋 전처리 및 훈련, 테스트 데이터셋 분리 저장
+--Distill_knowledge.py # 훈련된 교사 모델을 이용해, 데이터 셋에 증류된 지식(Softmax) 데이터 추가저장
+--KD_train_crossattention.py # 증류된 지식을 통해, 학생모델을 훈련
+--KEMDy_preprocessing.py # 모든 데이터를 TOTAL 폴더로 이동 후, 데이터셋으로 가공
+--merdataset.py # 데이터를 읽고, 모델 훈련시 데이터를 제공해주는 DataLoader 파일
+--mini_config.py # 학생모델 훈련시 필요한 하이퍼파라미터 정의
+--test.py # ckpt 폴더에 저장되어 있는 모델을 테스트
+--train_crossattention.py # 크로스 어텐션 기반 교사모델을 훈련하는 파일
+--utils.py # logger, get_params 등 모델 정보를 볼 수 있는 기능 포함
😆 Base Model
| Encoder | Architecture | pretrained-weights |
|---|---|---|
| Audio Encoder | pretrained Wav2Vec 2.0 | kresnik/wav2vec2-large-xlsr-korean |
| Text Encoder | pretrained Electra | monologg/koelectra-base |
😃 Arguments
- train_crossattention.py
| Arguments | Description |
|---|---|
| --epochs | 모델 반복 훈련 수 |
| --batch | 데이터 batch 사이즈 |
| --shuffle | 훈련 데이터의 shuffle 여부 |
| --lr | 훈련시 사용할 Learning rate 값 |
| --cuda | 사용할 GPU 정의 (default="cuda:0") |
| --save | 모델의 저장 여부 |
| --model_name | 모델 저장시, 저장할 모델의 이름 |
| --text_only | 텍스트 데이터 및 인코더만 사용해서 훈련 |
| --audio_only | 오디오 데이터 및 인코더만 사용해서 훈련 |
- Distill_knowledge.py
| Arguments | Description |
|---|---|
| --cuda | 사용할 GPU 정의 (default="cuda:0") |
| --teacher_name | 지식 증류할 저장된 모델의 이름 |
| --data_path | 지식 증류할 데이터의 경로 |
- KD_train_crossattention.py
| Arguments | Description |
|---|---|
| --epochs | 모델 반복 훈련 수 |
| --batch | 데이터 batch 사이즈 |
| --shuffle | 훈련 데이터의 shuffle 여부 |
| --lr | 훈련시 사용할 Learning rate 값 |
| --cuda | 사용할 GPU 정의 (default="cuda:0") |
| --save | 모델의 저장 여부 |
| --model_name | 모델 저장시, 저장할 모델의 이름 |
| --text_only | 텍스트 데이터 및 인코더만 사용해서 훈련 |
| --audio_only | 오디오 데이터 및 인코더만 사용해서 훈련 |
- test.py
| Arguments | Description |
|---|---|
| --batch | 데이터 batch 사이즈 |
| --cuda | 사용할 GPU 정의 (default="cuda:0") |
| --model_name | 테스트할 모델의 이름(예: ckpt/[모델이름].pt) |
| --all | "ckpt/test_all" 경로 안에 있는 모든 모델 테스트 |
😀 Model Architecture
Multi-Still경량화 기술 중 하나인 지식 증류 (Knowledge Distillation)를 사용하여 실시간 감정인식을 위한 멀티모달 구조를 경량화하는 방법- 👩🏫➡👨💻 Muti-Still Architecture

- 👩🏫 Teacher Model
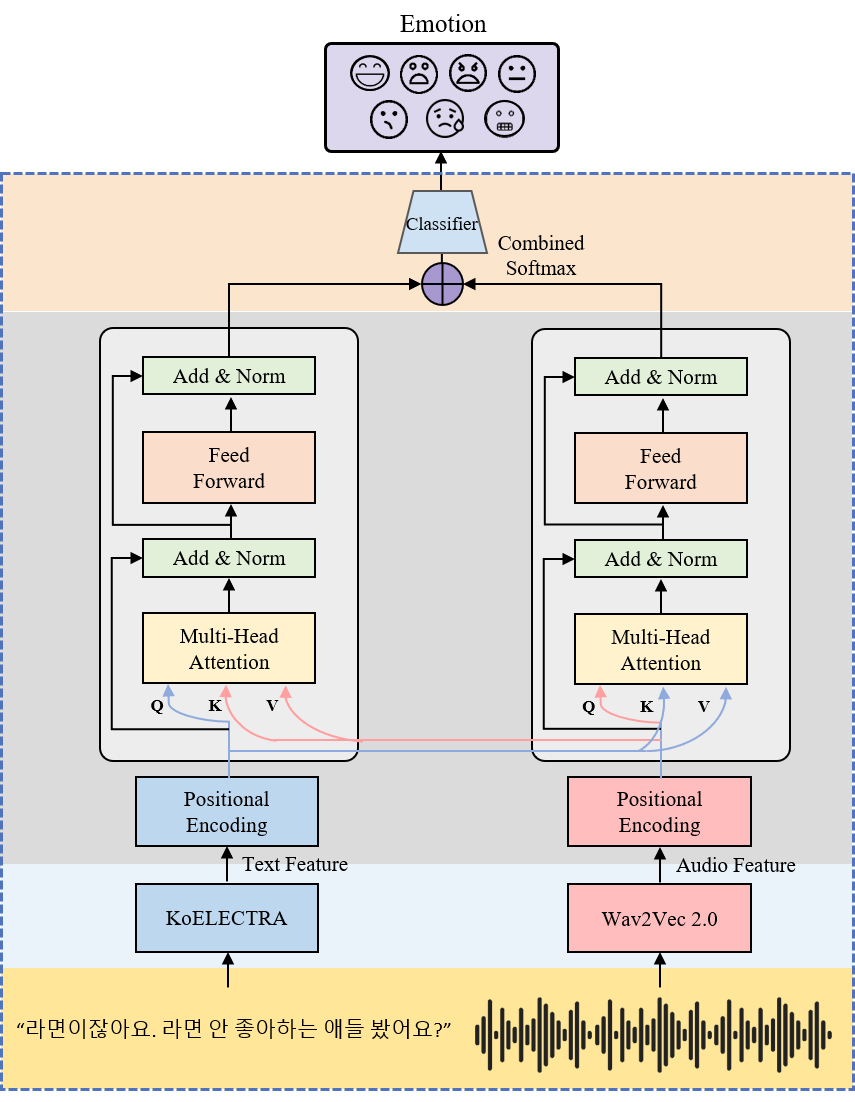


😆 Experiments
- 텍스트 모델(KoELECTRA)
- 오디오 모델(WAV2VEC 2.0)
- 교사 모델(Multimodal Cross-Attention)
- 학생모델((a)Text-OnlyStudent, (b)Audio-OnlyStudent, (c)MultimodalStudent)

🙂 References
-
[1] Xu, Peng, Xiatian Zhu, and David A. Clifton. "Multimodal learning with transformers: A survey." arXiv preprint arXiv:2206.06488 (2022).
-
[2] Tao, Jiang, Zhen Gao, and Zhaohui Guo. "Training Vision Transformers in Federated Learning with Limited Edge-Device Resources." Electronics 11.17, 2638. (2022).
-
[3] Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. ”Distilling the knowledge in a neural network.” arXiv preprint arXiv:1503.02531 2.7 (2015).
-
[4] Gou, J., Yu, B., Maybank, S. J., & Tao, D. “Knowledge distillation: A survey”. International Journal of Computer Vision, 129, 1789-1819. (2021).
-
[5] K. J. Noh and H. Jeong, “KEMDy19,” https://nanum.etri.re.kr/share/kjnoh/KEMDy19?lang=ko_KR.
-
[6] Noh, K.J.; Jeong, C.Y.; Lim, J.; Chung, S.; Kim, G.; Lim, J.M.; Jeong, H. Multi-Path and Group-Loss-Based Network for Speech Emotion Recognition in Multi-Domain Datasets. Sensors 2021, 21, 1579. https://doi.org/10.3390/s21051579.
-
[7] K. J. Noh and H. Jeong, “KEMDy20,” https://nanum.etri.re.kr/share/kjnoh/KEMDy20?lang=ko_KR.
-
[8] Thabtah, Fadi, et al. "Data imbalance in classification: Experimental evaluation." Information Sciences 513 : 429-441 (2020).
-
[9] Park Jangwon, “KoELECTRA: Pretrained ELECTRA Model for Korean”https://github.com/monologg/KoELECT RA (2020).
-
[10] Baevski, Alexei, et al. “wav2vec 2.0: A framework for self-supervised learning of speech representations”. Advances in Neural Information Processing Systems, 33, 12449-12460, (2020).
🙂 Contact
- Hyun-Ki Jo : [email protected]
- Yu-Ri Seo : [email protected]
- Seol Roh : [email protected]