旋转矩阵用9自由度描述三自由度旋转,冗余;旋转向量和欧拉角是紧凑的,但是有奇异性。
四元数是一种紧凑+非奇异表达。三维旋转可以用单位四元数表示。
四元数拥有一个实部+3个虚部。
单应矩阵(Homography)描述两个平面之间的映射关系。需要4对匹配点(八点法)。

特征点共面or纯旋转情况发生退化。
F为基础矩阵,E为本质矩阵,都由对极约束定义
由于旋转平移各自有3个自由度,但同时考虑尺度不确定,因此E为5自由度。由此,说明最少需要五点来求解。但E内部为非线性性质,求解线性方程会比较麻烦,因此只考虑尺度等价性质,使用9-1=8点法求解。
八点法求解得到E后,后续可通过SVD分解得到R,t。分解时容易有4组解,但是带入深度后只会保留一组正确解。

- 径向畸变(分为桶形和枕形畸变):透镜形状导致。下文中的k。
- 切向畸变:相机组装过程透镜和成像平面没有严格平行。下文中的p。
其中,畸变模型还分为:针孔畸变模型、鱼眼畸变模型
- 针孔畸变模型一般包含:k1,k2,p1,p2,k3.
- 鱼眼畸变模型:鱼眼相机的设计引入了畸变,因此鱼眼相机所成影像存在畸变,其中径向畸变非常严重,因此其畸变模型主要考虑径向畸变。鱼眼模型的分析有多种多样,不详细展开,一般OpenCV用多项式模型近似表示,对于入射角theta,使用如下共识表达:


参考资料:https://codeantenna.com/a/w6CmtokJwn
RANSAC全称:随机采样一致算法。
-
高斯牛顿(Gauss Newton):将f(x)进行一阶泰勒展开,使用J.T*J作为了二阶Hessian矩阵的近似。
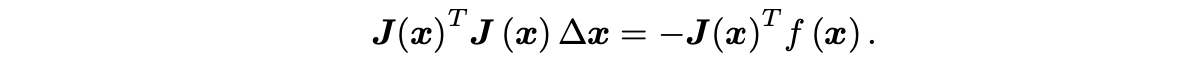
-
LM:信赖区域方法。使用一下公式判断梯度的近似效果(真实下降值与梯度推导下降值之比):
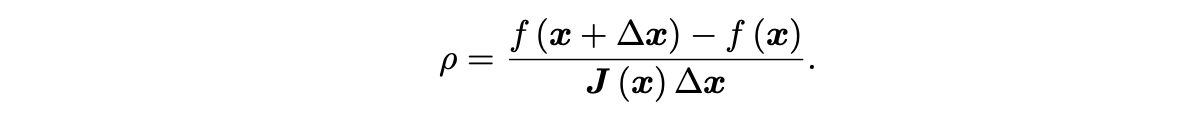
当其值接近1,意味着近似效果好。当其值大于1,说明实际下降效果很好,可以放大半径,反之,缩小半径。
LM的常用形式之一:
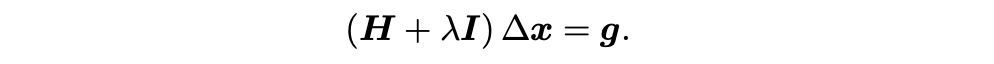
labmda接近0时,类似高斯牛顿法,二次型近似不错;labmda变大,接近最速下降(1阶梯度)。
-
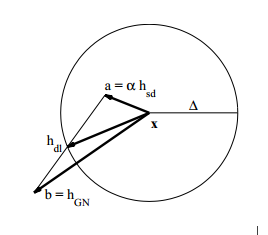
Dog Leg: 以信赖域为中心。高斯牛顿法的步长在信赖域中,用高斯牛顿;最速下降的步长在信赖域之外,用归一化到信赖域的最速下降;高斯牛顿法超出信赖域,牛顿法没有超出,找到一个比例,使得两者的加权和在信赖域上。 $$ \left{\begin{array}{ll} \text { if }\left|h_{g n}\right| \leq \Delta & h_{d l}=h_{g n} \ \text { else if }\left|\alpha h_{s d}\right| \geq \Delta & h_{d l}=\frac{\Delta}{\left|h_{s d}\right|} h_{s d} \ \text { else } & h_{d l}=\alpha h_{s d}+\beta\left(h_{g n}-\alpha h_{s d}\right) \ & \text { 选择 } \beta \text { 使得 }\left|h_{d l}\right|=\Delta \end{array}\right. $$




- Huber: $\rho(s)=\left{\begin{array}{ll}s & s \leq 1 \ 2 \sqrt{s}-1 & s>1\end{array}\right.$
- SoftLOneLoss:
$\rho(s)=2(\sqrt{1+s}-1)$ - Cauchy:
$\rho(s)=\log (1+s)$ - Acrtan:
$\rho(s)=\arctan (s)$ - Tolerrant:
$\rho(s, a, b)=b \log \left(1+e^{(s-a) / b}\right)-b \log \left(1+e^{-a / b}\right)$
激光雷达畸变产生的原因:1.激光点云数据不是瞬时同时完成;2.激光点云获取时机器人正在运动。
- TODO 补充
- Schur 消元,利用H稀疏特性,先求解路标的坐标再求解相机位姿。
ORB = Oriented Fast + BRIEF
尺度不变通过金字塔实现,旋转不变通过灰度质心实现。
Harris角点的优点
- 计算简单
- 提取的点特征均匀且合理
- 稳定:Harris算子对图像旋转、亮度变化、噪声影响和视点变换不敏感
Harris 算子的局限性
- 对尺度很敏感,不具有尺度不变性
梯度消失与梯度爆炸其实是一种情况。两种情况下梯度消失经常出现,一是在深层网络中,二是采用了不合适的损失函数,比如sigmoid(sigmoid容易导致梯度消失)。
解决方案:1.微调+预训练;2.权重正则化;3.调整激活函数;4.BatchNorm;5.残差结构
权重正则化:L1正则化与L2正则化
-
正则化(Regularization) 是机器学习中对原始损失函数引入额外信息,以便防止过拟合和提高模型泛化性能的一类方法的统称。也就是目标函数变成了原始损失函数+额外项,常用的额外项一般有两种,英文称作ℓ1−normℓ1−norm和ℓ2−normℓ2−norm,中文称作L1正则化和L2正则化,或者L1范数和L2范数(实际是L2范数的平方)。
-
L1正则化可以使得参数稀疏化,即得到的参数是一个稀疏矩阵,可以用于特征选择。
- 稀疏性,说白了就是模型的很多参数是0。通常机器学习中特征数量很多,例如文本处理时,如果将一个词组(term)作为一个特征,那么特征数量会达到上万个(bigram)。在预测或分类时,那么多特征显然难以选择,但是如果代入这些特征得到的模型是一个稀疏模型,很多参数是0,表示只有少数特征对这个模型有贡献,绝大部分特征是没有贡献的,即使去掉对模型也没有什么影响,此时我们就可以只关注系数是非零值的特征。这相当于对模型进行了一次特征选择,只留下一些比较重要的特征,提高模型的泛化能力,降低过拟合的可能。
-
L2正则化可以防止模型过拟合(overfitting);一定程度上,L1也可以防止过拟合。
-
L1对模型权值的绝对值之和约束,L2的模型权值的平方和约束!
-
L1容易得到稀疏的解,L2容易得到平滑的解。
因为深层神经网络在做非线性变换前的激活输入值(就是那个x=WU+B,U是输入)随着网络深度加深或者在训练过程中,其分布逐渐发生偏移或者变动,之所以训练收敛慢,所以这导致反向传播时低层神经网络的梯度消失,这是训练深层神经网络收敛越来越慢的.
BN就是通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布 ,其实就是把越来越偏的分布强制拉回比较标准的分布,这样使得激活输入值落在非线性函数对输入比较敏感的区域,这样输入的小变化就会导致损失函数较大的变化,记住“保持数据同分布”即可。

-
回归问题L1 loss、L2 loss
L1损失与L2损失的区别:L2损失的收敛速度更快,但是受到离群点的影响更大
-
分类问题:交叉熵损失
BGD:batch gradient descent,使用整个batch的数据计算梯度。优点是梯度下降比较稳定,缺点是太耗时。
SGD(随机梯度下降法):是一种使用梯度去迭代更新权重参数使目标函数最小化的方法。每次更新只选取一个mini-batch,计算速度大大提高,但是每一步的下降不一定都是最优的,会有震荡。
mini-batch(MBGD):小批量梯度下降算法是折中方案,选取训练集中一个小批量样本(一般是2的倍数,如32,64,128等)计算,这样可以保证训练过程更稳定,而且采用批量训练方法也可以利用矩阵计算的优势。这是目前最常用的梯度下降算法。
随机梯度下降(SGD):随机梯度下降算法是另外一个极端,损失函数是针对训练集中的一个训练样本计算的,又称为在线学习,即得到了一个样本,就可以执行一次参数更新。所以其收敛速度会快一些,但是有可能出现目标函数值震荡现象,因为高频率的参数更新导致了高方差。
动量梯度下降(momentum):引入一个指数加权平均的知识点。可以使得梯度方向不变的维度上速度变快,梯度方向有所改变的维度上的更新速度变慢,这样就可以加快收敛并减小震荡。
RMSprop:更新权重的时候,使用除根号的方法,可以使较大的梯度大幅度变小,而较小的梯度小幅度变小,这样就可以使较大梯度方向上的波动小下来,那么整个梯度下降的过程中摆动就会比较小
Adam:Adam算法结合了Momentum和RMSprop梯度下降法,是一种极其常见的学习算法,被证明能有效适用于不同神经网络,适用于广泛的结构。
参考资料:Deep-Learning-Interview-Book
sigmoid(容易出现梯度消失)、ReLU、Tanh
其它一些函数:
softmax(用于分类任务):
- TODO
- TODO
- Instant Neural Graphics Primitives with a Multiresolution Hash Encoding
- TensoRF: Tensorial Radiance Fields
- R2L
- Ha—Nerf
- Nerf in the wild: 没开源,复现性能困难
- Neus: 难以加速
- Neural RGB-D Surface Reconstruction
- Learning Object-Compositional Neural Radiance Field for Editable Scene Rendering
HDR-NeRF
- NeRF in the dark
引入先验
- pixelNeRF
- Putting NeRF on a Diet
- MipNeRF
- BARF
- NeRF--
- GNeRF
- self-calibration neural radiance field
- Deblur NeRF
TODO
TODO
TODO
vim使用