├── rpc-framework-consumer -> 服务消费者测试
├── rpc-framework-core -> rpc核心实现逻辑模块
├── rpc-framework-interface -> 远程服务接口
├── rpc-framework-provider -> 服务提供者测试
└── rpc-framework-spring-starter -> spring-starter接入类
└─core
├─client -> 客户端相关类(请求处理、启动加载)
├─common -> 通用模块
│ ├─annotations -> 项目注解包
│ ├─cache -> 项目全局缓存
│ ├─config -> 项目配置(服务端、客户端属性配置)
│ ├─constants -> 项目常量
│ ├─event -> 事件监听机制
│ │ ├─data
│ │ └─listener
│ ├─exception -> 全局异常
│ └─utils -> 项目工具包
├─dispatcher -> 服务端请求解耦
├─filter -> 责任链模式过滤请求
│ ├─client
│ └─server
├─proxy -> 动态代理
│ └─jdk
├─registry -> 注册中心
│ └─zookeeper
├─router -> 路由选择负载均衡
├─serialize -> 序列化与反序列化
│ ├─fastjson
│ ├─hessian
│ ├─jdk
│ ├─kryo
│ └─rpc
├─server -> 服务端相关类(请求处理、启动加载)
└─spi -> SPI自定义加载类
└─jdk
在项目模块的resouces文件下,有 rpc.properties 文件,用于配置Consumer(服务消费者)与Provider(服务提供者)的基本属性
- Consumer基本配置
# 注册中心地址
rpc.registerAddr=localhost:2181
# 注册中心类型
rpc.registerType=zookeeper
# 应用名
rpc.applicationName=rpc-consumer
# 动态代理类型
rpc.proxyType=jdk
# 路由策略类型
rpc.router=rotate
# 序列化类型
rpc.clientSerialize=fastJson
# 请求超时时间
rpc.client.default.timeout=3000
# 最大发送数据包
rpc.client.max.data.size=4096- Provider基本配置
# 服务提供者端口号
rpc.serverPort=9093
# 服务提供者名称
rpc.applicationName=rpc-provider
# 注册中心地址
rpc.registerAddr=localhost:2181
# 注册中心类型
rpc.registerType=zookeeper
# 序列化类型
rpc.serverSerialize=fastJson
# 服务端异步处理队列大小
rpc.server.queue.size=513
# 服务端线程池大小
rpc.server.biz.thread.nums=257
# 服务端最大连接数
rpc.server.max.connection=100
# 服务端可接收数据包最大值
rpc.server.max.data.size=4096- 基于Netty搭建了一套简单的服务端和客户端通信模型。
- 通过自定义协议体RpcProtocol的方式来解决网络粘包和拆包的问题。
- 封装了统一的代理接口,合理引入了JDK代理来实现网络传输的功能。
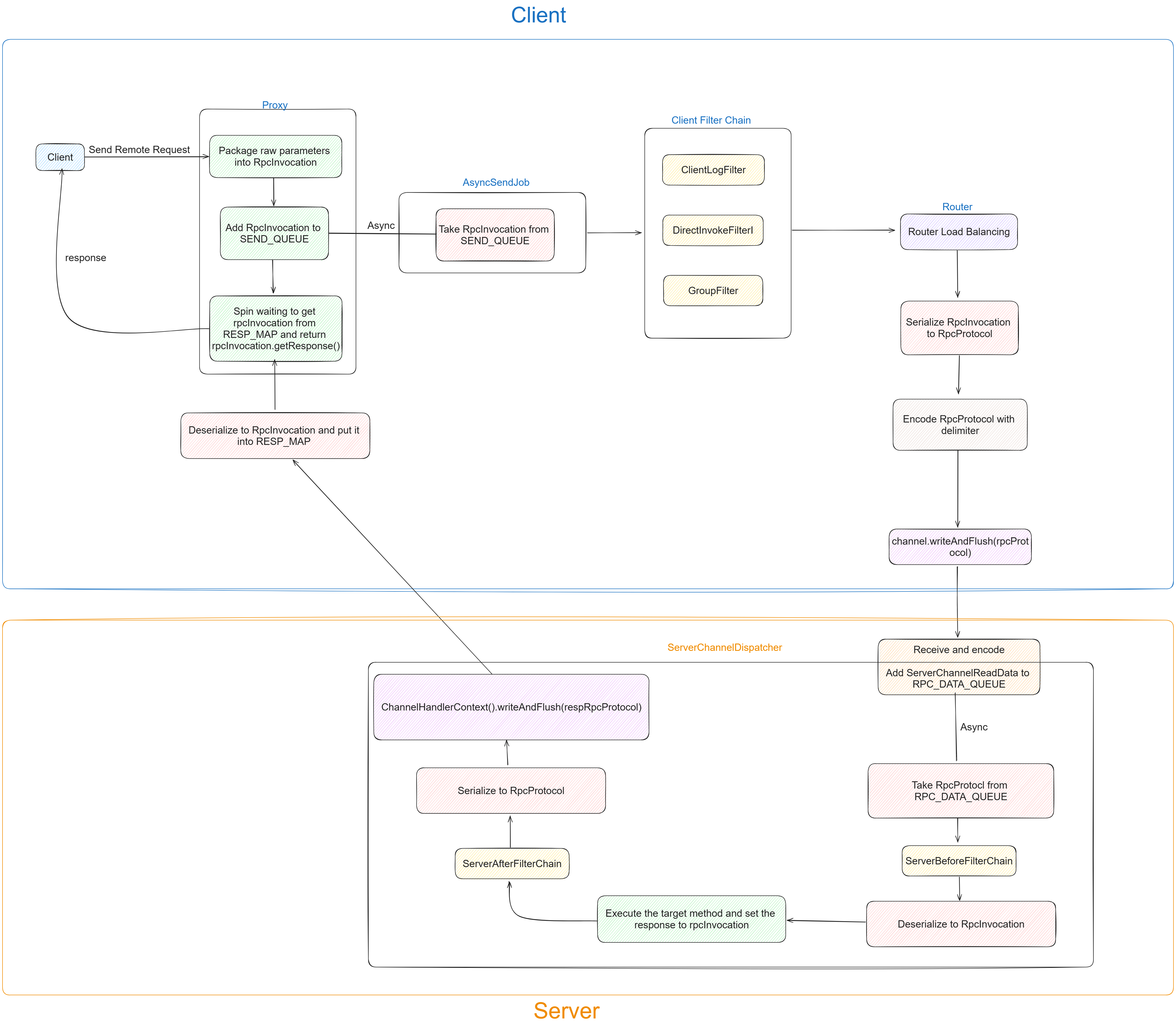
- 客户端通过队列消费的异步设计来实现消息发送,通过uuid来标示请求线程和响应线程之间的数据匹配问题。

采用JDK类代理,执行的逻辑为:将请求方法放入SEND_QUEUE队列中,自旋等待结果响应结果(从RESP_MAP中取出)
关键代码如下:
// 放入阻塞队列中
SEND_QUEUE.add(rpcInvocation);
RESP_MAP.put(rpcInvocation.getUuid(), OBJECT);
// 自旋
while (...) {
Object object = RESP_MAP.get(rpcInvocation.getUuid());
if (object instanceof RpcInvocation) {
return rpcInvocationResp.getResponse();
}
}-
Client启动时会开启一个异步线程阻塞队列,等待接收代理类放入的RpcInvocation,并将其顺序发送给对应Server
asyncSendJob.start(); // 异步线程 run代码:真正执行网络通信的操作 RpcInvocation rpcInvocation = SEND_QUEUE.take(); // 阻塞等待接收代理类放入RpcInvocation ChannelFuture channelFuture = ConnectionHandler.getChannelFuture(rpcInvocation); if (channelFuture != null) { Channel channel = channelFuture.channel(); // 如果出现服务端中断的情况需要兼容下 if (channel.isOpen()) { RpcProtocol rpcProtocol = new RpcProtocol(CLIENT_SERIALIZE_FACTORY.serialize(rpcInvocation)); channel.writeAndFlush(rpcProtocol); } }
-
Client先通过代理类为RpcInvocation(RpcProtocol中content的具体实现)设置必要的参数,
- 如:目标服务、目标方法、参数、UUID等,其中UUID是为了保证Client接收结果时判断一致
代理类还有如下几点核心操作:
- 将该uuid放入一个结果集map中,key为uuid,value为NULL对象
- 将封装好的RpcInvocation类放入阻塞队列中
- 最后代理类开始自旋一定时间,从结果集map中通过uuid获取其value:RpcInvocation,从中获取response结果
-
异步线程阻塞队列阻塞式地获取到RpcInvocation后,将其再次封装为RpcProtocol(包含有magicNumber、content、contentLength),经过Encoder编码后发送给Server
-
Server收到后进行Decode解码,ServerHandler将解码后的结果转为RpcProtocol,并获取其content,将content再转为RpcInvocation类。从该类中获取对应的目标服务属性,通过该属性从map(专门用来保存已经注册的服务信息)中找到对应服务,再通过目标方法属性从服务中找到对应的方法,并invoke执行得到返回结果。
注意,之前传递的RpcInvocation类的response为空,为它set返回结果。
最后将完整的RpcInvocation再次封装为RpcProtocol类并通过Encoder编码发送给Client
-
Client通过Decoder将数据包解码,经由ClientHandler将解码后的结果转为RpcProtocol,再将其cotent转为RpcInvocation,通过之前的结果集map判断请求与响应是否一致。若一致,则将其放入结果集map,此时自旋等待的代理类便可从中取到RpcInvocation,并返回给Client。

Zookeeper注册节点结果

先定义一个rpc的根节点,接着是不同的服务名称(例如:com.poldroc.UserService)作为二级节点,在二级节点下划分了provider和consumer节点。provider下存放的数据以ip+端口的格式存储,consumer下边存放具体的服务调用服务名与地址。
/rpc/com.poldroc.rpc.framework.core.server.DataService/provider/127.0.0.1:9093
添加Zookeeper注册中心后
核心代码
server = new Server();
// 初始化当前服务提供者的基本信息
server.initServerConfig();
// 加载RPC监听器
RpcListenerLoader rpcListenerLoader = new RpcListenerLoader();
rpcListenerLoader.init();
for (String beanName : beanMap.keySet()) {
Object bean = beanMap.get(beanName);
// 获取每个Bean的ARpcService注解,用于获取一些配置信息
ARpcService aRpcService = bean.getClass().getAnnotation(ARpcService.class);
ServiceWrapper dataServiceServiceWrapper = new ServiceWrapper(bean, aRpcService.group());
dataServiceServiceWrapper.setServiceToken(aRpcService.serviceToken());
dataServiceServiceWrapper.setLimit(aRpcService.limit());
// RPC服务暴露给RPC框架,以便客户端可以调用
server.exportService(dataServiceServiceWrapper);
LOGGER.info(">>>>>>>>>>>>>>> [rpc] {} export success! >>>>>>>>>>>>>>> ",beanName);
}
ApplicationShutdownHook.registryShutdownHook();
// 启动服务端
server.startApplication();-
在
initServerConfig初始化配置的方法中-
加载服务器配置:
ServerConfig serverConfig = PropertiesBootstrap.loadServerConfigFromLocal(); this.setServerConfig(serverConfig); SERVER_CONFIG = serverConfig;
这段代码从
PropertiesBootstrap类中的loadServerConfigFromLocal方法中加载服务器配置。获取到的ServerConfig对象然后通过setServerConfig方法设置为当前实例,并存储在SERVER_CONFIG字段中。 -
初始化服务端通道分发器:
SERVER_CHANNEL_DISPATCHER.init(SERVER_CONFIG.getServerQueueSize(), SERVER_CONFIG.getServerBizThreadNums());
通过提供从加载的服务器配置获取的队列大小和业务线程数,初始化服务器通道调度程序。
-
初始化序列化:
String serverSerialize = serverConfig.getServerSerialize(); EXTENSION_LOADER.loadExtension(SerializeFactory.class); LinkedHashMap<String, Class> serializeFactoryClassMap = EXTENSION_LOADER_CLASS_CACHE.get(SerializeFactory.class.getName()); Class serializeFactoryClass = serializeFactoryClassMap.get(serverSerialize); SERVER_SERIALIZE_FACTORY = (SerializeFactory) serializeFactoryClass.newInstance();
根据配置的序列化类型,初始化序列化机制。它加载
SerializeFactory扩展,根据配置的序列化类型检索相应的类,并实例化该类的对象,将其设置为SERVER_SERIALIZE_FACTORY。 -
初始化过滤器链:
EXTENSION_LOADER.loadExtension(ServerFilter.class); LinkedHashMap<String, Class> serverFilterClassMap = EXTENSION_LOADER_CLASS_CACHE.get(ServerFilter.class.getName()); ServerBeforeFilterChain serverBeforeFilterChain = new ServerBeforeFilterChain(); ServerAfterFilterChain serverAfterFilterChain = new ServerAfterFilterChain(); for (String key : serverFilterClassMap.keySet()) { // ... } SERVER_AFTER_FILTER_CHAIN = serverAfterFilterChain; SERVER_BEFORE_FILTER_CHAIN = serverBeforeFilterChain;
通过使用
EXTENSION_LOADER加载服务器过滤器,根据它们的处理顺序(在处理之前或之后)使用SPI注解来区分。然后将过滤器添加到适当的过滤器链(ServerBeforeFilterChain和ServerAfterFilterChain),并将它们设置为SERVER_BEFORE_FILTER_CHAIN和SERVER_AFTER_FILTER_CHAIN字段。
-
-
rpcListenerLoader.init()加载服务更新监听器、服务注销监听器、服务节点数据变化监听器 -
在
exportService方法中,将将服务实现的接口名和服务实现类的映射关系存入PROVIDER_CLASS_MAP,将服务提供者添加到PROVIDER_URL_SET中ServiceUrl类是配置类,基于其进行存储
// 将服务实现的接口名和服务实现类的映射关系存入缓存 PROVIDER_CLASS_MAP.put(interfaceClass.getName(), serviceBean); ServiceUrl serviceUrl = new ServiceUrl(); serviceUrl.setServiceName(interfaceClass.getName()); serviceUrl.setApplicationName(serverConfig.getApplicationName()); // 设置服务提供者的IP地址和端口号 serviceUrl.addParameter(HOST, CommonUtils.getIpAddress()); serviceUrl.addParameter(PORT, String.valueOf(serverConfig.getServerPort())); serviceUrl.addParameter(GROUP, String.valueOf(serviceWrapper.getGroup())); serviceUrl.addParameter(LIMIT, String.valueOf(serviceWrapper.getLimit())); serviceUrl.addParameter(WEIGHT, String.valueOf(serviceWrapper.getWeight())); PROVIDER_URL_SET.add(serviceUrl);
-
在
startApplication方法中,调用batchExportUrl方法,开启异步任务,从PROVIDER_URL_SET中获取serviceUrl,进行服务注册REGISTRY_SERVICE.register(serviceUrl);其中registerService由ZookeeperRegister实现
/** * 在zooKeeper中注册服务提供者 * 注册该服务 -> 本质是在Zookeeper中建立相应的节点 * @param sUrl 服务url */ @Override public void register(ServiceUrl sUrl) { if (!this.zkClient.existNode(ROOT)) { // 首先检查根路径是否存在,如果不存在则创建它 zkClient.createPersistentData(ROOT, ""); } // 构建URL字符串并使用临时节点在zooKeeper中创建服务提供者的路径 String urlStr = ServiceUrl.buildProviderUrlStr(sUrl); if (!zkClient.existNode(getProviderPath(sUrl))) { zkClient.createTemporaryData(getProviderPath(sUrl), urlStr); } else { zkClient.deleteNode(getProviderPath(sUrl)); zkClient.createTemporaryData(getProviderPath(sUrl), urlStr); } super.register(sUrl); // -> PROVIDER_URL_SET.add(url); }
核心代码
client = new Client();
// RpcReference用于实现JDK代理
RpcReference rpcReference = client.initClientApplication();
// // 订阅对应类型的服务,以便接收服务提供者的变更通知
client.doSubscribeService(field.getType());
ConnectionHandler.setBootstrap(client.getBootstrap());
// 连接RPC服务端
client.doConnectServer();
client.startClient();-
在
initClientApplication方法中,除了进行Bootstrap等与Netty相关的初始化操作外,还进行了事件监听器的初始化、spi扩展的加载、代理工厂初始化 -
在
doSubscribeService方法中,初始化ZookeeperRegister,定义ServiceUrl。根据此ServiceUrl订阅相应的服务/** * 启动服务之前需要预先订阅对应的服务 * * @param serviceBean */ public void doSubscribeService(Class serviceBean) { log.info("doSubscribeService start ====> serviceBean Name:{}", serviceBean.getName()); if (ABSTRACT_REGISTER == null) { try { // 使用自定义的SPI机制去加载配置 EXTENSION_LOADER.loadExtension(RegistryService.class); Map<String, Class> registerMap = EXTENSION_LOADER_CLASS_CACHE.get(RegistryService.class.getName()); Class registerClass = registerMap.get(clientConfig.getRegisterType()); // 通过反射创建注册中心对象 ABSTRACT_REGISTER = (AbstractRegister) registerClass.newInstance(); } catch (Exception e) { throw new RuntimeException("registryServiceType unKnow,error is ", e); } } ServiceUrl url = new ServiceUrl(); url.setApplicationName(clientConfig.getApplicationName()); url.setServiceName(serviceBean.getName()); url.addParameter(HOST, CommonUtils.getIpAddress()); Map<String, String> result = ABSTRACT_REGISTER.getServiceWeightMap(serviceBean.getName()); URL_MAP.put(serviceBean.getName(), result); // 把客户端的信息注册到注册中心 ABSTRACT_REGISTER.subscribe(url); // 订阅该服务 -> 本质是在Zookeeper中建立相应的节点 // register方法中除了建立节点,还需要将url添加到SUBSCRIBE_SERVICE_LIST中 // -> SUBSCRIBE_SERVICE_LIST.add(url.getServiceName()); }
-
在
doConnectServer方法中,提前与所有已注册的服务建立连接,并监听这些服务的变化(上线、下线、更改等)- 监听事件参照
2.3 - ConnectionHandler建立连接逻辑参照
2.4
/** * 开始和各个provider建立连接 * 客户端和服务提供端建立连接的时候,会触发 */ public void doConnectServer() { log.info("======== doConnectServer start ========"); // 遍历名为 SUBSCRIBE_SERVICE_LIST 的服务列表,这些服务列表是之前使用 doSubscribeService 方法订阅的服务 for (ServiceUrl providerUrl : SUBSCRIBE_SERVICE_LIST) { // 从注册中心获取其 IP 地址列表 List<String> providerIps = ABSTRACT_REGISTER.getProviderIps(providerUrl.getServiceName()); for (String providerIp : providerIps) { try { // 循环遍历每个 IP 地址,调用 ConnectionHandler.connect 方法来与服务提供者建立连接 ConnectionHandler.connect(providerUrl.getServiceName(), providerIp); } catch (InterruptedException e) { log.error("[doConnectServer] connect fail ", e); } } ServiceUrl url = new ServiceUrl(); url.addParameter("servicePath", providerUrl.getServiceName() + "/provider"); url.addParameter("providerIps", com.alibaba.fastjson.JSON.toJSONString(providerIps)); // 客户端在此新增一个订阅的功能 ABSTRACT_REGISTER.doAfterSubscribe(url); } }
- 监听事件参照
-
在
startClient中,开启发送线程,专门从事将数据包发送给服务端,起到一个解耦的效果
订阅之后开启监听事件,主要用于监听已注册服务的变化
-
RpcListenerLoader: 用于注册与管理监听器。当事件发生时,调用相应的监听器回调方法RpcEvent为发生事件接口,RpcListener为事件监听器接口监听器加载器类中主要方法有:
// 监听器注册 public static void registerListener(RpcListener rpcListener) {rpcListenerList.add(rpcListener);} // 监听器初始化 public void init() { registerListener(new ServiceUpdateListener()); registerListener(new ServiceDestroyListener()); registerListener(new ProviderNodeDataChangeListener()); } // 将RPC事件发送给注册的RPC监听器 public static void sendEvent(RpcEvent rpcEvent){ // 调用监听器的回调方法处理事件数据 rpcListener.callBack(rpcEvent.getData()); }
sendEvent方法实现如下:
public static void sendEvent(RpcEvent rpcEvent) { log.info("======== sendEvent ========"); // 检查rpcListenerList是否为空或为空列表 if (CommonUtils.isEmptyList(rpcListenerList)) { return; } // 遍历注册的监听器列表 for (RpcListener<?> rpcListener : rpcListenerList) { // 获取监听器的泛型类型参数 Class<?> type = getInterfaceT(rpcListener); // 如果监听器的泛型类型参数与RPC事件的类型相同 if (type != null && type.equals(rpcEvent.getClass())) { // 将事件放入线程池中执行 eventThreadPool.execute(new Runnable() { @Override public void run() { try { log.info("sendEvent callBack: {} ", rpcEvent.getData()); // 调用监听器的回调方法处理事件数据 rpcListener.callBack(rpcEvent.getData()); } catch (Exception e) { e.printStackTrace(); } } }); } } }
-
主要监听逻辑位于
ZookeeperRegister中的watchChildNodeData方法,如下:当监听的Zookeeper服务Node发生变化时,触发Watcher事件,Watcher内调用ListenerLoader方法(事件为方法参数),由ListenerLoader寻找对应的Listener(通过传入的事件与Listener泛型上的事件对比)。
URLChangeWrapper对应为发生变化的URL包装类:包括serviceName与providerUrlList
public void watchChildNodeData(String newServerNodePath) { zkClient.watchChildNodeData(newServerNodePath, new Watcher() { @Override public void process(WatchedEvent watchedEvent) { log.info("[watchChildNodeData ]" + watchedEvent); String path = watchedEvent.getPath(); log.info("收到子节点" + path + "数据变化"); List<String> childrenDataList = zkClient.getChildrenData(path); if (CommonUtils.isEmptyList(childrenDataList)) { watchChildNodeData(path); return; } SUrlChangeWrapper urlChangeWrapper = new SUrlChangeWrapper(); Map<String, String> nodeDetailInfoMap = new HashMap<>(); for (String providerAddress : childrenDataList) { String nodeDetailInfo = zkClient.getNodeData(path + "/" + providerAddress); nodeDetailInfoMap.put(providerAddress, nodeDetailInfo); } urlChangeWrapper.setNodeDataUrl(nodeDetailInfoMap); urlChangeWrapper.setProviderUrl(childrenDataList); urlChangeWrapper.setServiceName(path.split("/")[2]); RpcEvent rpcEvent = new RpcUpdateEvent(urlChangeWrapper); RpcListenerLoader.sendEvent(rpcEvent); // 收到回调之后再注册一次监听,这样能保证一直都收到消息 watchChildNodeData(path); for (String providerAddress : childrenDataList) { watchNodeDataChange(path + "/" + providerAddress); } } }); }
按照单一职责的设计原则,将与连接有关的功能都统一封装在了一起。
主要用于Netty在客户端与服务端之间建立连接、断开连接、按照服务名获取连接等操作。
-
建立连接逻辑如下:
connect方法// 将服务提供者的 IP 地址拆分成 IP 和端口号 String[] providerAddress = providerIp.split(":"); String ip = providerAddress[0]; Integer port = Integer.parseInt(providerAddress[1]); // 关键代码:创建ChannelFuture,即与目的服务简历底层通信连接 // 使用 bootstrap 对象建立与服务提供者的连接,这是一个同步操作,会等待连接建立完成 ChannelFuture channelFuture = bootstrap.connect(ip, port).sync(); ProviderNodeInfo providerNodeInfo = ServiceUrl.buildURLFromUrlStr(providerURLInfo); // 创建 ChannelFutureWrapper 对象,将来可以从这个对象中获取与服务端的连接 ChannelFutureWrapper channelFutureWrapper = new ChannelFutureWrapper(); channelFutureWrapper.setChannelFuture(channelFuture); channelFutureWrapper.setHost(ip); channelFutureWrapper.setPort(port); channelFutureWrapper.setWeight(providerNodeInfo.getWeight()); channelFutureWrapper.setGroup(providerNodeInfo.getGroup()); // 将服务提供者的 IP 地址添加到 SERVER_ADDRESS 集合中,用于跟踪已连接的服务提供者 SERVER_ADDRESS.add(providerIp); // 获取与特定服务名称关联的连接信息列表 List<ChannelFutureWrapper> channelFutureWrappers = CONNECT_MAP.get(providerServiceName); // 如果列表为空,则创建一个新的空列表 if (CommonUtils.isEmptyList(channelFutureWrappers)) { channelFutureWrappers = new ArrayList<>(); } // 将新建立的连接信息添加到与服务名称关联的连接信息列表中,并将更新后的列表存储回 CONNECT_MAP 中 channelFutureWrappers.add(channelFutureWrapper); // 将连接添加到CONNECT_MAP中 // 连接CONNECT_MAP -> key:需要调用的serviceName // -> value:与多个服务提供者建立的连接,为List CONNECT_MAP.put(providerServiceName, channelFutureWrappers); // 为服务提供者构建一个 Selector 对象,Selector 对象中存储了该服务提供者对应的服务名称 Selector selector = new Selector(); selector.setProviderServiceName(providerServiceName); // 刷新路由信息 // SERVICE_ROUTER_MAP.put(selector.getProviderServiceName(), arr); ROUTER.refreshRouterArr(selector);
-
获取连接逻辑如下:
getChannelFuture方法每个服务可以有多个服务提供者(对应于多个物理机器)
负载均衡策略:默认走随机策略获取ChannelFuture
String providerServiceName = rpcInvocation.getTargetServiceName(); ChannelFutureWrapper[] channelFutureWrappers = SERVICE_ROUTER_MAP.get(providerServiceName); List<ChannelFutureWrapper> channelFutureWrappersList = new ArrayList<>(channelFutureWrappers.length); for (int i = 0; i < channelFutureWrappers.length; i++) { channelFutureWrappersList.add(channelFutureWrappers[i]); } //在客户端会做分组的过滤操作 //这里不能用Arrays.asList 因为它所生成的list是一个不可修改的list CLIENT_FILTER_CHAIN.doFilter(channelFutureWrappersList, rpcInvocation); Selector selector = new Selector(); selector.setProviderServiceName(providerServiceName); selector.setChannelFutureWrappers(channelFutureWrappers); ChannelFuture channelFuture = ROUTER.select(selector).getChannelFuture(); return channelFuture;
同一个服务可能对应着多个服务提供者,因此当客户端请求服务时,需要通过负载均衡策略从中选择一个合适的服务提供者。
实现了随机路由和轮询路由 两大类
基于 SERVICE_ROUTER_MAP 实现
public static Map<String, ChannelFutureWrapper[]> SERVICE_ROUTER_MAP = new ConcurrentHashMap<>();- key为服务提供者名字,value为对应的连接数组
SERVICE_ROUTER_MAP集合的内部存储结构如下:

com.poldroc.rpc.framework.core.router.RandomRouterImpl
自定义随机选取逻辑,将转化后的连接数组存入 SERVICE_ROUTER_MAP 中
虽然是随机选取,但是权重值越大,被选取的次数也会越多
默认初始情况下weight值为100
com.poldroc.rpc.framework.core.router.RotateRouterImpl
直接按照添加的先后顺序获取连接,将转化后的连接数组存入 SERVICE_ROUTER_MAP 中
从SERVICE_ROUTER_MAP中按照服务的key查询到对应的服务调用顺序数组,接下来就是对该数组进行轮询获取连接,ChannelFutureRefWrapper类就是专门实现轮训效果,
它的本质就是通过取模计算:
public class ChannelFuturePollingRef {
private AtomicLong referenceTimes = new AtomicLong(0);
public ChannelFutureWrapper getChannelFutureWrapper(ChannelFutureWrapper[] arr){
long i = referenceTimes.getAndIncrement();
int index = (int) (i % arr.length);
return arr[index];
}
}每个服务提供者在注册服务时默认的权重初始值为100。当该值被修改后,触发权重更新事件,修改对应的 SERVICE_ROUTER_MAP
该更新事件也是通过Watcher与自定义的监听事件机制实现,参考 2.3
com.poldroc.rpc.framework.core.router.RandomRouterImpl#updateWeight
/**
* 更新特定服务的服务提供者权重
* @param sUrl 服务地址
*/
@Override
public void updateWeight(ServiceUrl sUrl) {
// 服务节点的权重
List<ChannelFutureWrapper> channelFutureWrappers = CONNECT_MAP.get(sUrl.getServiceName());
// 根据每个服务提供者的权重计算一个权重数组
Integer[] weightArr = createWeightArr(channelFutureWrappers);
// 根据权重数组生成一个随机数组
Integer[] randomArr = createRandomArr(weightArr);
// 根据随机数组生成一个调用顺序数组
ChannelFutureWrapper[] arr = new ChannelFutureWrapper[randomArr.length];
for (int i = 0; i < randomArr.length; i++) {
arr[i] = channelFutureWrappers.get(randomArr[i]);
}
// 更新路由器的映射,使用新的有序数组更新该服务
SERVICE_ROUTER_MAP.put(sUrl.getServiceName(), arr);
}引入多种序列化策略,由用户自行配置与选择对应的策略
- Hessian2
- Kryo
- JDK
- FastJson
创建序列化工厂接口,定义接口方法:serialize与deserialize(均为范型方法)
具体的序列化策略去实现该工厂类。
- SerializeFactory
- FastJsonSerializeFactory
- HessianSerializeFactory
- KryoSerializeFactory
- JdkSerializeFactory
序列化策略在Server与Client初始化时从配置文件中加载
目前我们Rpc框架的基本设计架构如下图所示,除了简单的客户端发送请求抵达服务端之外,还新增了以下几个角色:
- 代理层 (根据配置生成不同的动态代理类);
- 路由层 (根据配置选用不同的负载均衡方法);
- 注册中心层(根据配置接入多种注册中心,通过引入第三者来实现“协调”的效果);
- 序列化层(根据配置采用不同的序列化框架,传输协议的统一)。

暂时来看,请求的基本功能算是比较完善了,但是在实际的开发使用过程中可能还会存在以下问题:
- 对client的请求做鉴权;
- 分组管理服务;
- 如何实现基于ip直连的方式访问server端?
- 调用过程中需要记录下调用的相关日志信息。
对应解释如下:
对client的请求做鉴权
随着互联网业务的不断扩展,服务的种类开始变得越来越丰富,其中就有可能会出现一些比较注重安全方面的服务信息,例如查询账户信息服务、查询身份证信息服务、查询工资流水服务等等,这些服务都有一个共同点,就是私密性强,调用时候需要做安全防范。所以我尝试在Rpc框架内部加入对服务鉴权的操作,通过鉴权来提高一定的安全性。
具体的思路大概是:请求抵达服务端调用具体方法之前,先对其调用凭证进行判断操作,如果凭证不一致则抛出异常。

分组管理服务

如何实现基于ip直连的方式访问server端
按照指定ip访问的方式请求server端是我们在测试阶段会比较常见的方式,例如服务部署之后,发现2个名字相同的服务,面对相同的请求参数,在两个服务节点中返回的结果却不一样,此时就可以通过指定请求ip来进行debug诊断。

用过程中需要记录下调用的相关日志信息
每次请求都最好能有一次请求调用的记录,方便开发者调试。日志的内容一般会关注以下几个点:调用方信息,请求的具体服务的哪个方法,请求时间。
传统模式中,客户端需要在发送请求之前,逐个的调用过滤请求的方法;服务端在接受请求之前,也需要逐个调用过滤请求的方法
这种模式下,代码耦合度高,且扩展性差。
而采用责任链模式可以带来:
- 发送者与接收方的处理对象类之间解耦。
- 封装每个处理对象,处理类的最小封装原则。
- 可以任意添加处理对象,调整处理对象之间的顺序,提高了维护性和可拓展性,可以根据需求新增处理类,满足开闭原则。
- 增强了对象职责指派的灵活性,当流程发生变化的时候,可以动态地改变链内的调动次序可动态的新增或者删除。
- 责任链简化了对象之间的连接。每个对象只需保持一个指向其后继者的引用,不需保持其他所有处理者的引用,这避免了使用众多的 if 或者 if···else 语句。
- 责任分担。每个类只需要处理自己该处理的工作,不该处理的传递给下一个对象完成,明确各类的责任范围,符合类的单一职责原则。
├── Filter.java
├── ClientFilter.java -> 继承Filter接口
├── ServerFilter.java -> 继承Filter接口
├── client
│ ├── ClientFilterChain.java -> 客户端过滤链
│ ├── ClientLogFilterImpl.java -> 日志过滤器实现类
│ ├── DirectInvokeFilterImpl.java -> IP过滤器实现类
│ └── GroupFilterImpl.java -> 分组过滤器实现类
└── server
├── ServerFilterChain.java -> 服务器过滤链
├── ServerLogFilterImpl.java -> 日志过滤器实现类
└── ServerTokenFilterImpl.java -> Token安全校验过滤器实现类
- 首先创建Filter接口,然后分别创建服务器与客户端对应的接口,继承Filter接口
- 分别创建服务器与客户端过滤链,用于存放过滤器实现类,并遍历过滤器实现类集合,执行过滤方法
- 依次实现过滤器实现类
客户端的责任链插入位置
com.poldroc.rpc.framework.core.client.ConnectionHandler#getChannelFuture选择在这里插入的原因是,客户端在获取到目标方的channel集合之后需要进行筛选过滤,最终才会发起真正的请求。
服务端的责任链插入位置
com.poldroc.rpc.framework.core.server.ServerHandler#channelRead在 ChannelInboundHandlerAdapter 内部加入过滤链说明此事请求数据已经落入到了server端的业务线程池中,接下来需要通过责任链的每一个环节进行校对,最终确认是否可以执行目标函数。
后续引入限流组件会将服务端过滤器划分为了前置过滤器和后置过滤器
是一种通过外界配置来加载具体代码内容的技术手段
引入SPI技术的目的是希望可以通过配置化的方式来引入自定义插件部分,例如自定义负载均衡策略、自定义序列化算法技术、自定义代理工厂等等。通常常见的实现思路是:在统一规定的文件目录底下,新建一份文件,并在该文件内部定义好需要加载的类,让核心程序在不做内部源代码修改的条件下可以引入执行的代码逻辑。业界常见的SPI机制大体分为了两种类型:
- JDK内部自带的SPI机制;
- 自定义实现的SPI机制。
这块的具体设计思路其实比较简单,通过当前Class的类加载器去加载META-INF/rpc/目录底下以类路径命名的资源文件,并且将它们放入一个LinkedHashMap中。核心代码 如下:
package com.poldroc.rpc.framework.core.spi;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
import java.util.Enumeration;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
/**
* 自定义SPI扩展加载器
*
* @author Poldroc
* @date 2023/9/28
*/
public class ExtensionLoader {
/**
* 扩展加载器目录前缀
*/
public static String EXTENSION_LOADER_DIR_PREFIX = "META-INF/rpc/";
/**
* 扩展加载器缓存
* key: 扩展加载器接口
* value: 扩展加载器实例
*/
public static Map<String, LinkedHashMap<String, Class>> EXTENSION_LOADER_CLASS_CACHE = new ConcurrentHashMap<>();
/**
* 加载指定接口的扩展加载器
*
* @param clazz 扩展加载器接口
*/
public void loadExtension(Class clazz) throws IOException, ClassNotFoundException {
// 参数校验
if (clazz == null) {
throw new IllegalArgumentException("class is null!");
}
// 获取扩展加载器配置文件路径
String spiFilePath = EXTENSION_LOADER_DIR_PREFIX + clazz.getName();
// 获取类加载器
ClassLoader classLoader = this.getClass().getClassLoader();
// 获取所有匹配的扩展文件的URL枚举
Enumeration<URL> enumeration = classLoader.getResources(spiFilePath);
// 遍历所有匹配的扩展文件
while (enumeration.hasMoreElements()) {
// 获取下一个扩展文件的URL
URL url = enumeration.nextElement();
// 获取扩展文件的输入流
InputStreamReader inputStreamReader = new InputStreamReader(url.openStream());
// 获取扩展文件的缓冲读取器
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
// 读取扩展文件的每一行
String line;
// 存储扩展类信息
LinkedHashMap<String, Class> classMap = new LinkedHashMap<>();
// 遍历扩展文件的每一行
while ((line = bufferedReader.readLine()) != null) {
// 如果配置中加入了#开头则表示忽略该类无需进行加载
if (line.startsWith("#")) {
continue;
}
// 按照=分割扩展类信息
String[] lineArr = line.split("=");
// 获取扩展类名
String implClassName = lineArr[0];
// 获取扩展接口名
String interfaceName = lineArr[1];
// 将扩展类信息存入classMap
classMap.put(implClassName, Class.forName(interfaceName));
}
// 只会触发class文件的加载,而不会触发对象的实例化
if (EXTENSION_LOADER_CLASS_CACHE.containsKey(clazz.getName())) {
// 支持开发者自定义配置,将新加载的信息合并到已有缓存中
EXTENSION_LOADER_CLASS_CACHE.get(clazz.getName()).putAll(classMap);
} else {
// 将新加载的信息存入缓存
EXTENSION_LOADER_CLASS_CACHE.put(clazz.getName(), classMap);
}
}
}
}在需要加载资源时(初始化序列化框架、初始化过滤链、初始化路由策略、初始化注册中心),使用SPI加载类去实现
从而避免了在代码中通过switch语句以硬编码的方式选择资源
基本使用:
// 初始化路由策略
EXTENSION_LOADER.loadExtension(Router.class);
String routerStrategy = clientConfig.getRouterStrategy();
LinkedHashMap<String, Class> routerMap = EXTENSION_LOADER_CLASS_CACHE.get(Router.class.getName());
Class routerClass = routerMap.get(routerStrategy);
if (routerClass == null) {
throw new RuntimeException("no match routerStrategy for " + routerStrategy);
}
ROUTER = (Router) routerClass.newInstance();至此,整套框架的大致模型如下:

例如当客户端发起一个dataService.sendData方法的时候,实际上会通过一个代理对象帮其将参数封装好,然后经过一系列的过滤链二次包装,再通过路由层计算好实际应该发送的目标机器,最后通过序列化层将其转换为字节数组,通过netty底层将其从网络通道发送到目标服务节点上。
- 如何使用阻塞队列对高并发请求的一个削弱
- 业务线程池的引入保证请求的处理吞吐能力
- 异步调用的简单实现
NIO线程常见的阻塞情况,一共两大类:
-
无意识:在ChannelHandler中编写了可能导致NIO线程阻塞的代码,但是用户没有意识到,包括但不限于查询各种数据存储器的操作、第三方服务的远程调用、中间件服务的调用、等待锁等。
-
有意识:用户知道有耗时逻辑需要额外处理,但是在处理过程中翻车了,比如主动切换耗时逻辑到业务线程池或者业务的消息队列做处理时发生阻塞,最典型的有对方是阻塞队列,锁竞争激烈导致耗时,或者投递异步任务给消息队列时异机房的网络耗时,或者任务队列满了导致等待,等等。
服务端接收到消息之后
-
需要对消息进行解码,使字节序列变为消息对象。
-
将消息对象与上下文传入ServerHandler中进行进一步处理。
可能某个业务Handler处理流程非常耗时,如查询数据库。为了避免线程被长时间占用,采用异步消费进行处理
客户端通过动态代理层封装RpcInvocation对象并将其放入SEND_QUEUE队列后,需要同步阻塞等待最终处理的响应结果
- 可以将此处改为同步与异步两种方式
-
对于服务端:
当请求抵达服务器时,将其直接丢入业务阻塞队列中,然后开辟一个新的线程,从阻塞队列中循环获取Handler请求任务。
将获取到的任务对象交付于业务线程池进行消费处理。
-
对于客户端:
在RpcReferenceWrapper中设置一个isAsync字段,用于判断是否为异步。
若该字段为True,则在动态代理层中,不需要同步阻塞等待响应结果,直接返回null即可。
- 单独设计一条独立的队列用于接收请求
单独使用一条堵塞队列用于接收请求,然后在队尾由业务线程池来负责消费请求数据。这样即使请求出现了堆积,也是堆积在一条我们比较能轻易操作的队列当中。
首先定义一个请求分发器ServerChannelDispatcher,这个分发器的内部存有一条阻塞队列 RPC_DATA_QUEUE。 另外分发器的内部还有一个线程对象ServerJobCoreHandle专门负责将队列的数据读出,然后提及到业务线程池去执行。
核心代码
package com.poldroc.rpc.framework.core.dispatcher;
import com.poldroc.rpc.framework.core.common.RpcInvocation;
import com.poldroc.rpc.framework.core.common.RpcProtocol;
import com.poldroc.rpc.framework.core.server.ServerChannelReadData;
import java.lang.reflect.Method;
import java.util.concurrent.*;
import static com.poldroc.rpc.framework.core.common.cache.CommonServerCache.*;
/**
* 服务器通道分发器
* @author Poldroc
* @date 2023/10/4
*/
public class ServerChannelDispatcher {
/**
* 阻塞队列
*/
private BlockingQueue<ServerChannelReadData> RPC_DATA_QUEUE;
/**
* 业务线程池
*/
private ExecutorService executorService;
public ServerChannelDispatcher() {
}
/**
* 初始化 阻塞队列和业务线程池
* @param queueSize
* @param bizThreadNums
*/
public void init(int queueSize, int bizThreadNums) {
RPC_DATA_QUEUE = new ArrayBlockingQueue<>(queueSize);
// 初始化业务线程池
// 线程池的核心线程数,最大线程数目,空闲线程存活时间,时间单位,阻塞队列
executorService = new ThreadPoolExecutor(bizThreadNums, bizThreadNums,
// 非核心线程在执行完任务后立即被销毁,不会保持空闲
0L, TimeUnit.MILLISECONDS,
new ArrayBlockingQueue<>(512));
}
/**
* 将数据放入阻塞队列
* @param serverChannelReadData
*/
public void add(ServerChannelReadData serverChannelReadData) {
RPC_DATA_QUEUE.add(serverChannelReadData);
}
/**
* 专门负责将队列的数据读出,然后提及到业务线程池去执行
*/
class ServerJobCoreHandle implements Runnable {
/**
* 可以实现并发处理多个请求,每个请求都在独立的线程中执行,以提高服务器的处理能力
*/
@Override
public void run() {
while (true) {
try {
// 阻塞式获取数据 如果队列为空,线程将阻塞等待,直到有数据可用
ServerChannelReadData serverChannelReadData = RPC_DATA_QUEUE.take();
// 取出一个 ServerChannelReadData 后,将其交给 executorService 线程池中的一个线程去执行,以实现并发处理
executorService.submit(new Runnable() {
@Override
public void run() {
try {
RpcProtocol rpcProtocol = serverChannelReadData.getRpcProtocol();
// 反序列化
RpcInvocation rpcInvocation = SERVER_SERIALIZE_FACTORY.deserialize(rpcProtocol.getContent(), RpcInvocation.class);
// 执行过滤链路
SERVER_FILTER_CHAIN.doFilter(rpcInvocation);
// 执行目标方法
Object aimObject = PROVIDER_CLASS_MAP.get(rpcInvocation.getTargetServiceName());
Method[] methods = aimObject.getClass().getDeclaredMethods();
Object result = null;
// 遍历所有方法,找到目标方法,找到与客户端请求的目标方法名匹配的方法
for (Method method : methods) {
if (method.getName().equals(rpcInvocation.getTargetMethod())) {
// 如果目标方法的返回值为void,则直接调用目标方法
if (method.getReturnType().equals(Void.TYPE)) {
// 动态调用方法
method.invoke(aimObject, rpcInvocation.getArgs());
} else {
// 如果目标方法的返回值不为void,则调用目标方法,并将返回值赋值给result
result = method.invoke(aimObject, rpcInvocation.getArgs());
}
break;
}
}
rpcInvocation.setResponse(result);
// 将结果序列化
RpcProtocol respRpcProtocol = new RpcProtocol(SERVER_SERIALIZE_FACTORY.serialize(rpcInvocation));
// 将结果返回给客户端
serverChannelReadData.getChannelHandlerContext().writeAndFlush(respRpcProtocol);
} catch (Exception e) {
e.printStackTrace();
}
}
});
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
/**
* 启动数据消费
*/
public void startDataConsume() {
Thread thread = new Thread(new ServerJobCoreHandle());
thread.start();
}
}例如当我们遇到一些只需要触发接口调用,但是对于接口返回内容并不关心的这类函数,就没有必要再在代码中监听对方的消息返回行为了,此时可以采用异步发送的策略进行实现。
在底层的代理类com.poldroc.rpc.framework.core.proxy.jdk.JDKClientInvocationHandler内部实现部分加入了一个if判断,如果发送请求的部分存在async相关配置,则不会进入循环监听的逻辑代码部分,具体:
package com.poldroc.rpc.framework.core.proxy.jdk;
import com.poldroc.rpc.framework.core.client.RpcReferenceWrapper;
import com.poldroc.rpc.framework.core.common.RpcInvocation;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.util.UUID;
import java.util.concurrent.TimeoutException;
import static com.poldroc.rpc.framework.core.common.cache.CommonClientCache.RESP_MAP;
import static com.poldroc.rpc.framework.core.common.cache.CommonClientCache.SEND_QUEUE;
import static com.poldroc.rpc.framework.core.common.constants.RpcConstants.DEFAULT_TIMEOUT;
import static com.poldroc.rpc.framework.core.common.constants.RpcConstants.TIME_OUT;
/**
* 各代理工厂都统一使用
* 核心任务就是将需要调用的方法名称、服务名称,参数统统都封装好到RpcInvocation当中,然后塞入到一个队列里,并且等待服务端的数据返回
* @author Poldroc
* @date 2023/9/15
*/
public class JDKClientInvocationHandler implements InvocationHandler {
/**
* 用于锁定当前对象
*/
private final static Object OBJECT = new Object();
private RpcReferenceWrapper rpcReferenceWrapper;
private int timeOut = DEFAULT_TIMEOUT;
public JDKClientInvocationHandler(RpcReferenceWrapper rpcReferenceWrapper) {
this.rpcReferenceWrapper = rpcReferenceWrapper;
timeOut = Integer.valueOf(String.valueOf(rpcReferenceWrapper.getAttatchments().get(TIME_OUT)));
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
RpcInvocation rpcInvocation = new RpcInvocation();
rpcInvocation.setArgs(args);
rpcInvocation.setTargetServiceName(rpcReferenceWrapper.getAimClass().getName());
rpcInvocation.setTargetMethod(method.getName());
// 注入uuid,用于标识请求
rpcInvocation.setUuid(UUID.randomUUID().toString());
rpcInvocation.setAttachments(rpcReferenceWrapper.getAttatchments());
// 将请求信息放入发送队列
SEND_QUEUE.add(rpcInvocation);
if (rpcReferenceWrapper.isAsync()) {
return null;
}
// 如果不是异步调用,客户端会等待服务端的响应,同时检查是否超时
long beginTime = System.currentTimeMillis();
RESP_MAP.put(rpcInvocation.getUuid(), OBJECT);
while (System.currentTimeMillis() - beginTime < timeOut ) {
// 从响应结果集中获取响应结果
Object object = RESP_MAP.get(rpcInvocation.getUuid());
if (object instanceof RpcInvocation) {
// 如果是RpcInvocation类型,说明是服务端返回的响应结果,直接返回
return ((RpcInvocation)object).getResponse();
}
}
// 如果超时,抛出异常
throw new TimeoutException("client wait server's response timeout!");
}
}- 服务端异常返回给到调用方展示
- 客户端调用可以支持超时重试
- 服务提供方进行接口限流
设计思路是:将服务端的异常信息统一采集起来,返回给到调用方并且将堆栈记录打印。

在客户端调用服务端的时候,数据都会被封装在了一个叫做
com.poldroc.rpc.framework.core.common.RpcInvocation的代码对象中,该对象包含了请求的目标方法,请求参数,正常响应内容等字段,现在我计划给它新增一个异常信息字段Throwable e:
/**
* RPC自定义协议请求的封装类
* @author Poldroc
* @date 2023/9/12
*/
@Data
@ToString
public class RpcInvocation {
/**
* 请求的目标方法名称,例如:sayHello
*/
private String targetMethod;
/**
* 请求的目标接口名称,例如:HelloService
*/
private String targetServiceName;
/**
* 请求的参数
*/
private Object[] args;
/**
* 请求的唯一标识,用于异步调用时,标识请求和响应的对应关系
* 当请求从客户端发出的时候,会有一个uuid用于记录发出的请求,待数据返回的时候通过uuid来匹配对应的请求线程,并且返回给调用线程
*/
private String uuid;
/**
* 接口响应的数据塞入这个字段中(如果是异步调用或者void类型,这里就为空)
*/
private Object response;
/**
* 附加属性
*/
private Map<String,Object> attachments = new HashMap<>();
/**
* 主要用于记录服务端抛出的异常信息
*/
private Throwable e;
}实现流程如下:
-
RpcInvocation类中添加异常字段
private Throwable e;
-
服务端处理接收到的请求时,用try-catch进行捕获,并设置异常
// 业务异常 rpcInvocation.setE(e);
-
客户端处理器ClientHandler中,读取响应结果时,对异常进行判断。如果该字段不为空,则打印异常
if (rpcInvocation.getE() != null) { rpcInvocation.getE().printStackTrace(); }
e字段用于存储服务端抛出的异常信息,而相关的异常信息则是在服务端的com.poldroc.rpc.framework.core.dispatcher.ServerChannelDispatcher任务中进行捕获。
捕获原理:在服务端获取到目标函数和传入参数之后,需要通过反射来执行相关调用,可以在外加一层try catch去捕获该部分的异常信息
关于接口超时重试这类机制,其实建议在实际使用的时候再三斟酌下,并不是所有的接口在超时的时候都需要进行重试,面对一些非幂等性的接口调用情况,重试机制就应该谨慎使用。下边我们来深入分析下,什么样的场景适合使用重试机制。
- 目标集群中有A,B服务器,A服务器性能不佳,处理请求比较缓慢,B服务器性能优于A,所以当接口调用A出现超时之后,可以尝试重新发起调用,将请求转到B上从而获取数据结果。
- 网络因为某些特殊异常,导致突然间断,此时可以通过重试机制发起二次调用,这时候重试机制就对接口的整体可用性有了一定的保障。
听了上边的这些场景介绍,我们似乎会发现重试机制的存在还是有一定好处的,那么接下来让我们来思考下重试机制使用不当可能会导致什么情况发生:
- 对于一些对数据重复性较为敏感的接口,例如转账,下单,以及一些和金融相关的接口,当接口调用出现超时之后,并不好确认数据包是否已经抵达到目标服务,所以这类场景下对接口设置超时重试功能需要有所斟酌。
综合上述的这些因素,我在设计思路为:如果出现超时异常,默认可以发起1次重试机会,如果不想使用重试功能,可以在配置中将对应方法的重试次数设置为0。 例如下边的案例代码:
public static void main(String[] args) throws Throwable {
Client client = new Client();
RpcReference rpcReference = client.initClientApplication();
RpcReferenceWrapper<DataService> rpcReferenceWrapper = new RpcReferenceWrapper<>();
rpcReferenceWrapper.setAimClass(DataService.class);
rpcReferenceWrapper.setGroup("dev");
rpcReferenceWrapper.setServiceToken("token-a");
rpcReferenceWrapper.setTimeOut(3000);
// 超时重试次数
rpcReferenceWrapper.setRetry(0);
rpcReferenceWrapper.setAsync(false);
DataService dataService = rpcReference.get(rpcReferenceWrapper);
// 订阅服务
client.doSubscribeService(DataService.class);
ConnectionHandler.setBootstrap(client.getBootstrap());
client.doConnectServer();
client.startClient();
String result = dataService.testErrorV2();
System.out.println("结束调用");
System.out.println(result);
}大致的一个逻辑处理流程图如下图所示:

重试策略:立即重试
调用失败后立即发送二次重试,并且会把超时的请求路由到其他机器上,而不是本机尝试。
- 控制业务应用整体的连接上限;
- 单个服务请求的限流。
采用RPC服务的集群设计中,通常都是服务的消费方要比提供方更多,服务提供者有可能会同时和上百个服务调用方建立连接,所以当服务提供方的负载压力达到一定阈值的条件下就应该减少外界新访问的连接。
所以我们现在需要在原有的代码基础上加上以下实现:对服务端的要有一个统一的连接数控制,比如最大连接限制为512,当前连接数超过512则超出的部分直接拒绝。
限制服务端的总体连接数,超过指定连接数时,拒绝剩余的连接请求。
通过为ServerBootstrap设置最大连接数处理器,及时地对连接进行释放。
最大连接数在服务端的配置文件中配置。
bootstrap.handler(new MaxConnectionLimitHandler(serverConfig.getMaxConnections()));@ChannelHandler.Sharable
@Slf4j
public class MaxConnectionLimitHandler extends ChannelInboundHandlerAdapter {
/**
* 最大连接数
*/
private final int maxConnectionNums;
/**
* 当前连接数 线程安全的方式
*/
private final AtomicInteger numConnection = new AtomicInteger(0);
/**
* 子连接的Channel对象
*/
private final Set<Channel> childChannel = Collections.newSetFromMap(new ConcurrentHashMap<>());
/**
* 记录被丢弃的连接数量 这是在jdk1.8之后出现的对于AtomicLong的优化版本
*/
private final LongAdder numDroppedConnections = new LongAdder();
/**
* 用于标记是否已经调度了日志打印任务
*/
private final AtomicBoolean loggingScheduled = new AtomicBoolean(false);
public MaxConnectionLimitHandler(int maxConnectionNums) {
this.maxConnectionNums = maxConnectionNums;
}
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
Channel channel = (Channel) msg;
// 连接数加一
int conn = numConnection.incrementAndGet();
// 如果连接数小于最大连接数,将channel加入到childChannel中
if (conn > 0 && conn <= maxConnectionNums) {
this.childChannel.add(channel);
// 添加监听器,当channel关闭时,将channel从childChannel中移除,并将连接数减一
channel.closeFuture().addListener(future -> {
childChannel.remove(channel);
numConnection.decrementAndGet();
});
super.channelRead(ctx, msg);
} else {
// 递减连接计数器
numConnection.decrementAndGet();
// 避免产生大量的time_wait连接
// 设置SO_LINGER为0,表示立即关闭连接
channel.config().setOption(ChannelOption.SO_LINGER, 0);
// 强制关闭channel
channel.unsafe().closeForcibly();
// 递增丢弃连接计数器
numDroppedConnections.increment();
// 这里加入一道CAS(Compare-And-Swap)操作来确保只有一个线程安排了日志记录,并且在1秒后调度writeNumDroppedConnectionLog方法
if (loggingScheduled.compareAndSet(false, true)) {
ctx.executor().schedule(this::writeNumDroppedConnectionLog, 1, TimeUnit.SECONDS);
}
}
}
/**
* 记录连接失败的日志
*/
private void writeNumDroppedConnectionLog() {
// 将标记设置为false
loggingScheduled.set(false);
// 获取丢弃的连接数并重置计数器
final long dropped = numDroppedConnections.sumThenReset();
// 记录日志
if (dropped > 0) {
log.error("Dropped {} connections because of connection limit", dropped);
}
}
}细节注意:
- 防止高并发请求下,突然大量请求抵达服务端,但是却被告知断开链接,此时为了防止打印重复的日志,可以采用定时记录的设计思想去实现。
首先来解释下这个概念,例如UserProvider这个服务提供者,内部有多个方法对外暴露给调用方远程执行,整体的服务调用规律如下表所示:
| 服务名称 | 方法名称 | 限制并发调用次数 | 日常并发请求量 | 备注 |
|---|---|---|---|---|
| UserProvider | UserQueryService | 100 | 50 | 写DB |
| UserProvider | UserUpdateService | 40 | 20 | 写DB |
| UserProvider | UserRegistryService | 5 | 2 | 写DB |
由于业务场景中偶尔会有一些大流量的线上活动,这种规模会对现有的访问流量造成突发增加,如果不做相关的防御手段容易直接将流量压力打入到整个数据库层面,从而引发更加严重的系统危害问题。
所以限流的策略更加细粒度化是我们实现保护效果的关键思路。
限流部分的主要核心思想是采用了Semaphore的组件进行实践。
Semaphore 是 Java JDK 中提供的一种同步工具,用于控制多线程并发访问共享资源。它是一种信号量机制,可以帮助防止竞态条件,并协调多线程之间对关键代码段的访问。
它提供了acquire和tryAcquire两种方法供开发者调用,在Sem aphore的内部其实是有一个计数器,每次向它申请许可的时候如果计数器不为0,则申请通过,如果计数器为0则会处于堵塞(acquire),或者立马断开(tryAcquire),又或者等待一定时间后才断开(tryAcquire可以指定等待时间)。当资源使用完毕之后需要执行release操作,将计数器归还。
使用tryAcquire则是一种“快速响应”的解决思路,当获取申请失败后,不会堵塞当前线程,而是立马通知客户端调用异常,然后发起二次重试,路由到其他节点。至少这种策略相比于acquire来说不存在请求堆积,导致服务崩溃的风险因素。
采用 Semaphore 进行流量控制,在每一个服务进行注册时,便指定服务对应的最大连接数。
// 设置服务端的限流器
SERVER_SERVICE_SEMAPHORE_MAP.put(interfaceClass.getName(), new ServerServiceSemaphoreWrapper(serviceWrapper.getLimit()));限流部分的代码实现:
划分为了前置过滤器和后置过滤器。
- 前置过滤器:
请求数据在执行实际业务函数之前需要会经过前置过滤器的逻辑,而限流组件则是在前置过滤器的最后一环,主要负责tryAcquire环节。
当当前连接数超过最大连接数时,根据Semaphore的tryAcquire原理,会直接返回False,据此判断流量超峰,抛出异常。
/**
* 请求数据在执行实际业务函数之前需要会经过前置过滤器的逻辑,
* 而限流组件则是在前置过滤器的最后一环,主要负责tryAcquire环节
* @author Poldroc
* @date 2023/10/7
*/
@SPI("before")
@Slf4j
public class ServerServiceBeforeLimitFilterImpl implements ServerFilter {
@Override
public void doFilter(RpcInvocation rpcInvocation) {
String serviceName = rpcInvocation.getTargetServiceName();
ServerServiceSemaphoreWrapper serverServiceSemaphoreWrapper = SERVER_SERVICE_SEMAPHORE_MAP.get(serviceName);
// 从缓存中提取semaphore对象
Semaphore semaphore = serverServiceSemaphoreWrapper.getSemaphore();
// 尝试获取信号量
boolean tryResult = semaphore.tryAcquire();
// 如果获取失败,说明当前服务已经达到最大并发数,直接抛出异常
if (!tryResult) {
log.error("[ServerServiceBeforeLimitFilterImpl] {}'s max request is {},reject now", rpcInvocation.getTargetServiceName(), serverServiceSemaphoreWrapper.getMaxNums());
MaxServiceLimitRequestException rpcException = new MaxServiceLimitRequestException(rpcInvocation);
rpcInvocation.setE(rpcException);
throw rpcException;
}
}
}- 后置过滤器
当业务核心逻辑执行完毕之后,会进入到后置过滤器中,这里面可以执行relase操作,也就是对Semaphore持有资源数加1。
package com.poldroc.rpc.framework.core.filter.server;
import com.poldroc.rpc.framework.core.common.RpcInvocation;
import com.poldroc.rpc.framework.core.common.ServerServiceSemaphoreWrapper;
import com.poldroc.rpc.framework.core.common.annotations.SPI;
import com.poldroc.rpc.framework.core.filter.ServerFilter;
import static com.poldroc.rpc.framework.core.common.cache.CommonServerCache.SERVER_SERVICE_SEMAPHORE_MAP;
/**
* 当业务核心逻辑执行完毕之后,会进入到后置过滤器中,这里面可以执行relase操作
* @author Poldroc
* @date 2023/10/7
*/
@SPI("after")
public class ServerServiceAfterLimitFilterImpl implements ServerFilter {
@Override
public void doFilter(RpcInvocation rpcInvocation) {
String serviceName = rpcInvocation.getTargetServiceName();
ServerServiceSemaphoreWrapper serverServiceSemaphoreWrapper = SERVER_SERVICE_SEMAPHORE_MAP.get(serviceName);
serverServiceSemaphoreWrapper.getSemaphore().release();
}
}SpringBoot的使用率更广泛,接入难度也比较低,所以下边会采用以SpringBoot自动装配的思路去设计这个接入层的代码
接入思路
开发对应的自动装配类,并且通过引入spi文件去让Spring扫描到该装配类即可。
提供了starter的设计思路,遵循了“约定大于配置”的这种理念,只需要给对应的中间件编写好一个自动配置类以及一份spi文件,最后交给SpringBoot去扫描即可,整体难度会比较低。
-
客户端对需要调用的服务添加
@ARpcReference注解在Spring容器启动过程中,将带有此注解的字段进行构建,让它们的句柄可以指向一个代理类
这样在使用UserService和OrderService类对应的方法时候就会感觉到似乎在执行本地调用一样,降低开发者的代码编写难度。
-
服务端通过
@ARpcService注解对服务进行暴露,将其注入到Spring容器中- 该注解内部添加了
@Component注解,因此能被扫描到Spring容器中
- 该注解内部添加了
com.poldroc.rpc.framework.spring.starter.config.RpcServerAutoConfiguration
服务端自动装配流程
-
初始化服务端配置
- 从
rpc.properties中读取相关配置并写入config - 初始化线程池、队列
- 通过
SPI初始化序列化框架、过滤链 - 初始化并注册启动事件监听器
- 从
-
Spring从容器中筛选出带有
@ARpcService注解的类,以Map形式封装 -
将每一个Map中的对象封装为
ServiceWrapper对象,并从注解中提取并设置相应的属性,将service注册到注册中心 -
RPC服务暴露给RPC框架,以便客户端可以调用
-
开启服务端,准备接收任务
com.poldroc.rpc.framework.spring.starter.config.RpcClientAutoConfiguration
客户端自动装配流程
- 初始化客户端配置
- 从
rpc.properties中读取相关配置并写入config - 通过
SPI初始化动态代理
- 从
- 获取带有
@ARpcReference注解的类,从注解中提取并设置相应的属性为RpcReferenceWrapper - 获得对应代理对象,设置回Bean对象的字段中,以便应用程序可以通过这些字段访问RPC服务
- 在注册中心中订阅对应的服务