{kind=link}
Moonweb: LLM Chat Tool
Welcome to Moonweb, a web chat tool developed with Rust, Dioxus, and Candle frameworks that supports a variety of open-source Large Language Models (LLMs). This project aims to provide a dynamic and flexible platform for integrating and testing different LLMs.
Features
- Multi-Model Support: Seamless integration of various open-source LLMs.
- Dynamic Model Loading: Supports dynamic loading and unloading of models at runtime.
- Independent Process Isolation: Each model runs in an independent process, providing services through ipc_channel, ensuring stability and responsiveness.
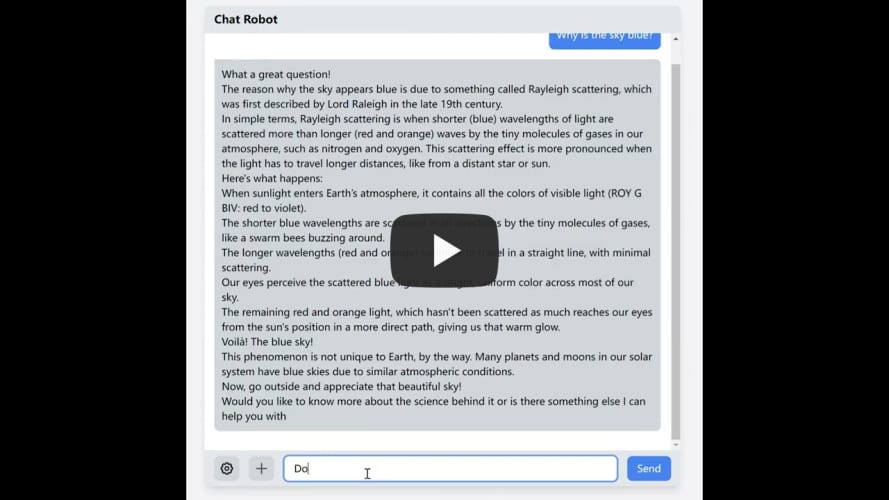
- Web Interface: A responsive and user-friendly web interface built with the Dioxus framework. It supports SSE(Server send event).
- Open Source: Fully open source, encouraging community contributions and customization.
The model services that have been implemented are as follows:
- meta-llama/Meta-Llama-3-8B-Instruct
- lmms-lab/llama3-llava-next-8b
- Qwen/Qwen2-7B-Instruct
- Qwen/Qwen2-1.5B-Instruct
- microsoft/Phi-3-medium-4k-instruct
Quick Start
-
Install Rust: Ensure that Rust is installed on your system. Visit the Rust official website for installation instructions.
-
Install Dioxus: dioxus is a react and vue like web framework. Visit the document of dioxus.
-
Clone the Repository: Clone the Moonweb project to your local machine using Git.
git clone https://github.com/ Lyn-liyuan/moonweb.git
-
Build the Project: Navigate to the project directory and build the project using Cargo.
cd moonweb
cargo build- Run the Services: Start the LLM model services.
If you want to use the load command to start model services in the models directory, you need to compile these services first. Navigate to the directories containing the Cargo.toml files and execute cargo build --release to compile these services. After the compilation is complete, set the program in the server.config file to the executable file of the compiled model service.
Before compiling the pyworker model service, you need to specify the Python interpreter used by the Python code via the environment variable PYO3_PYTHON. You can activate the Python environment with conda activate my_env and set the environment variable using export PYO3_PYTHON=$(which python).
cargo run –-release -- --server master- Build the Web : Compile rust to WASM.
dx build --releaseArchitecture Overview
- Frontend: The web interface built with Dioxus, responsible for displaying chat content and user input.
- Backend: Rust backend services that handle web requests and communicate with LLM model services.
- Model Services: Each LLM model runs as an independent process, communicating with the backend service via ipc_channel.
Model Integration
To integrate a new LLM model, follow these steps:
- Create a model service process that implements ipc_channel communication.
- Edit the server.config file and add the server config to the servers field.
- Use web interface send /load model_id to robot.
Update Records
- June 25, 2024: Implement dynamic loading of model services. The model service can be an independent program. As long as it complies with the IPC communication specification, the service can be started through the /load model_id command on the web page.
- July 2, 2024: Added qwen2 model, supported python as model service, and implemented Qwen/Qwen-7B-Instruct model service with python.
- July 4, 2024: Implement the /unload command to stop the model service process. For example, enter /unload Qwen/Qwen2-1.5B-Instruct in the text box of the web interface to stop the corresponding model process.
- July 6, 2024: To start the HTTP server using axum, you no longer need to use dx serve to start the server. Use the highlight.js library to add syntax highlighting functionality.
- July 11, 2024: To implement the llava model server.
Contributing
We welcome contributions in any form, including but not limited to:
- Code submissions
- Feature requests
- Bug reports
- Documentation improvements
License
This project is licensed under the "MIT License".
Contact
- Project Maintainer: [LYN]
- Email: [[email protected]]
- GitHub: @LYN