
Scalable AI Inference Server for CPU and GPU with Node.js
Inferenceable is a super simple, pluggable, and production-ready inference server written in Node.js. It utilizes llama.cpp and parts of llamafile C/C++ core under the hood.
- Linux
- macOS
Here is a typical installation process:
git clone https://github.com/HyperMink/inferenceable.git
cd inferenceablenpm installTo run, simply execute npm start command, and all dependencies, including required models, will be downloaded.
Tip
To use existing local models, set INFER_MODEL_CONFIG before starting
npm startThat's it! 🎉 Once all required models are downloaded, you should have your own Inferenceable running on localhost:3000
To start using Inferenceable, you do not need to configure anything; default configuration is provided. Please see config.js for detailed configuration possibilities.
export INFER_HTTP_PORT=3000
export INFER_HTTPS_PORT=443
export INFER_MAX_THREADS=4 # Max threads for llama.cpp binaries
export INFER_MAX_HTTP_WORKERS=4 # Max Node workersA fully functional UI for chat and vision is provided. You can either customize it or use a different UI.
export INFER_UI_PATH=/path/to/custom/ui-
Vision example
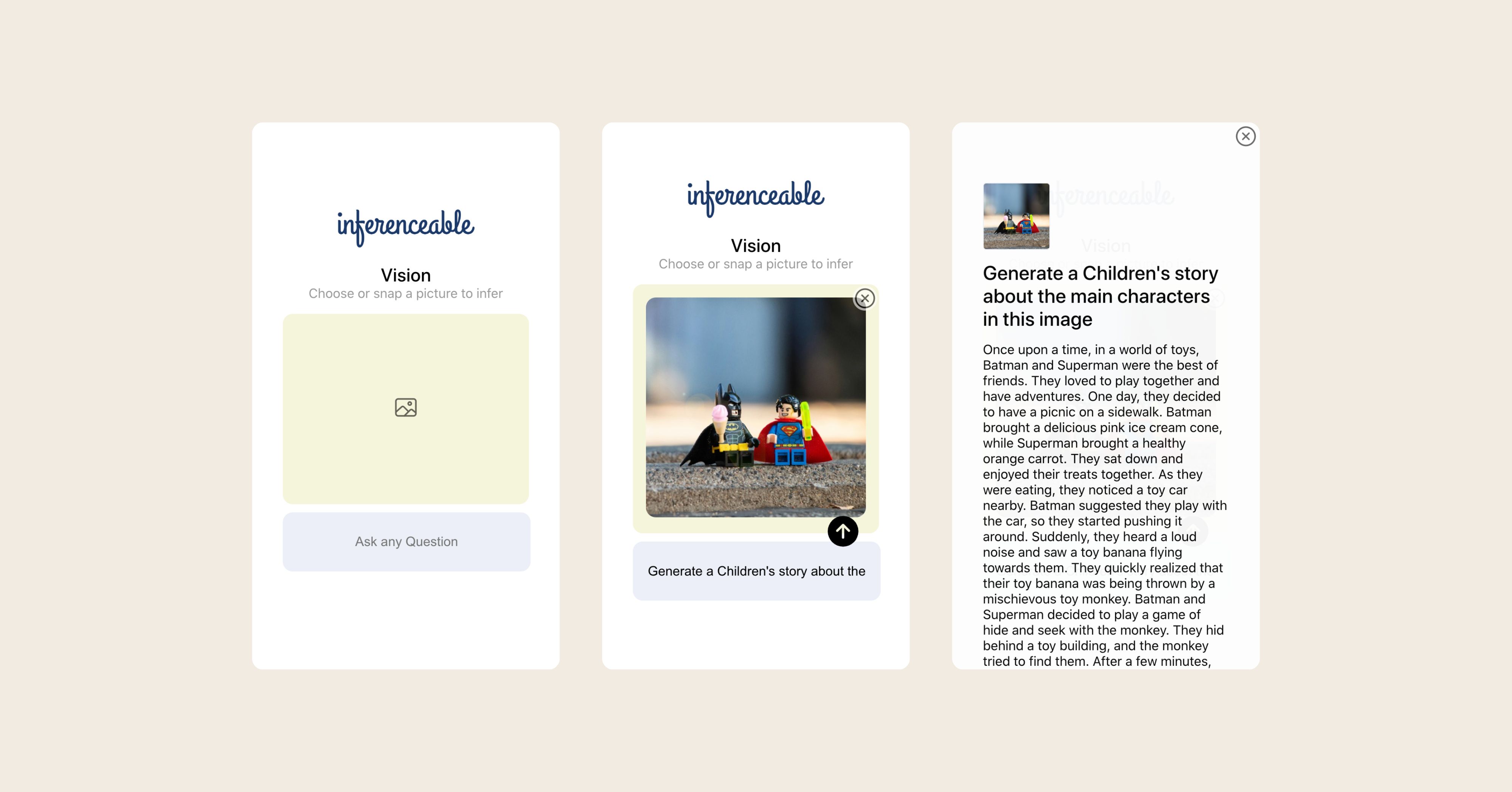
-
Chat example
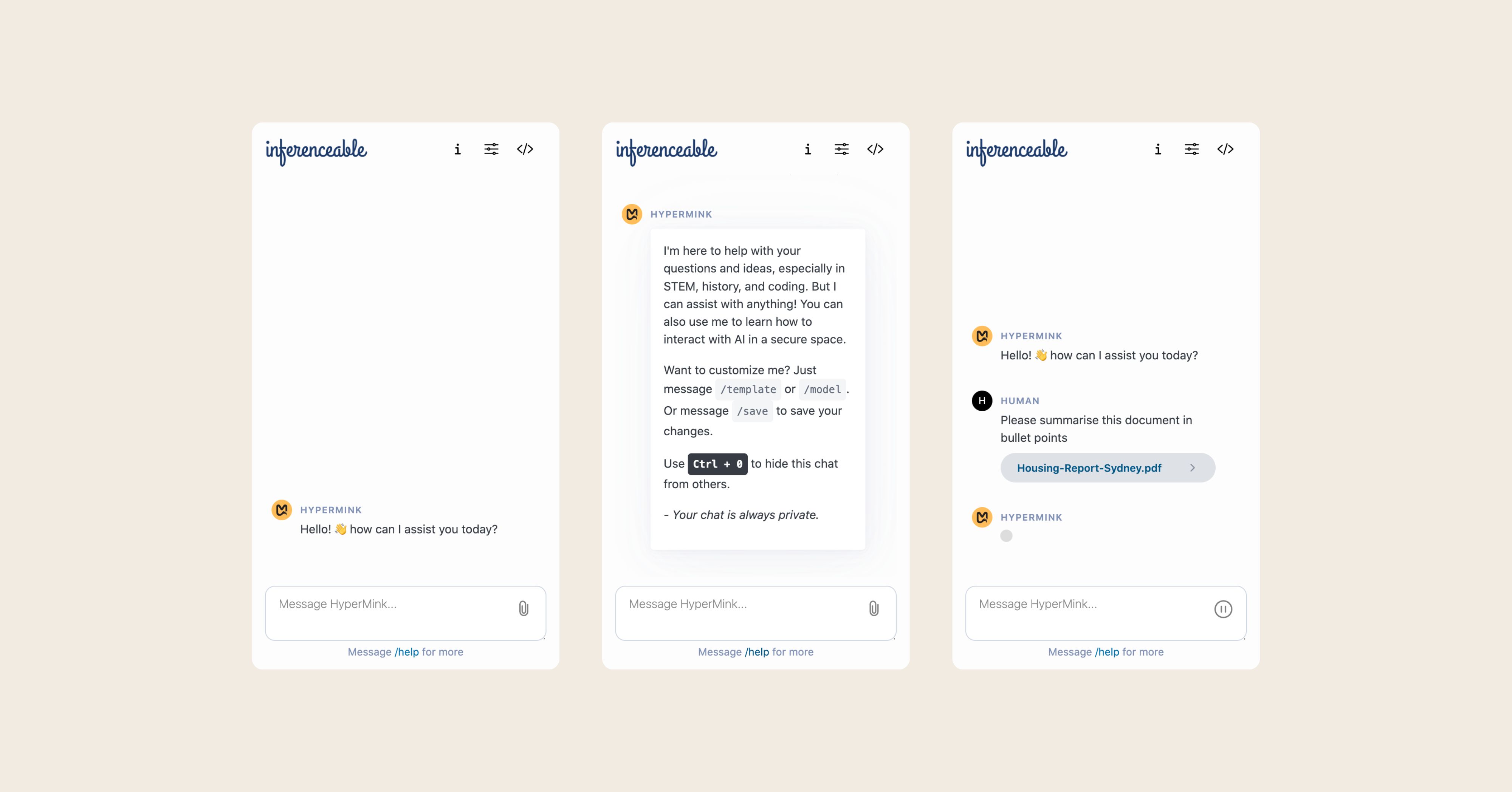
-
Timeless
A lyrical clock that tells the time in poem.


By default, all required models defined in data/models.json will be downloaded on the first start. You can provide a custom models.json by setting the environment variable INFER_MODEL_CONFIG.
export INFER_MODEL_CONFIG=my/models.jsonDefault grammar files are available in data/grammar/. You can provide any custom grammar files either by adding them to data/grammar or by setting the environment variable INFER_GRAMMAR_FILES.
Grammar files needs to be in GBNF format which is an extension of Bakus-Naur Form (BNF).
export INFER_GRAMMAR_FILES=data/grammarInferenceable comes bundled with a single custom llama.cpp binary that includes main, embedding, and llava implementations from the llama.cpp and llamafile projects. The bundled binary data/bin/inferenceable_bin is an αcτµαlly pδrταblε εxεcµταblε that should work on Linux, macOS, and Windows.
You can use your own llama.cpp builds by setting INFER_TEXT_BIN_PATH, INFER_VISION_BIN_PATH, and INFER_EMBEDDING_BIN_PATH. See config.js for details.
Inferenceable comes with pluggable Authentication, CSP, and Rate limiter. A basic implementation is provided that can be used for small-scale projects or as examples. Production installations should use purpose-built strategies.
Inferenceable uses passport.js as an authentication middleware, allowing you to plugin any authentication policy of your choice. A basic HTTP auth implementation is provided. For production, refer to passport.js strategies.
Caution
HTTP Basic Auth sends your password as plain text. If you decide to use HTTP Basic Auth in production, you must set up SSL.
export INFER_AUTH_STRATEGY=server/security/auth/basic.jsInferenceable uses helmet.js as a content security middleware. A default CSP is provided.
export INFER_CSP=server/security/csp/default.jsInferenceable uses rate-limiter-flexible as a rate limiting middleware, which lets you configure numerous strategies. A simple in-memory rate limiter is provided. For production, a range of distributed rate limiter options are available: Redis, Prisma, DynamoDB, process Memory, Cluster or PM2, Memcached, MongoDB, MySQL, and PostgreSQL.
export INFER_RATE_LIMITER=server/security/rate/memory.jsIn production, SSL is usually provided on an infrastructure level. However, for small deployments, you can set up Inferenceable to support HTTPS.
export INFER_SSL_KEY=path/to/ssl.key
export INFER_SSL_CERT=path/to/ssl.cert
Inferenceable has 2 main API endpoints: /api/infer and /api/embedding. See config.js for details.
curl -X GET http:https://localhost:3000/api -H 'Content-Type: application/json' -vcurl -X POST \
http:https://localhost:3000/api/infer \
-N \
-H 'Content-Type: application/json' \
-d '{
"prompt": "Whats the purpose of our Universe?",
"temperature": 0.3,
"n_predict": 500,
"mirostat": 2
}' \
--header "Accept: text/plain"curl -X POST \
http:https://localhost:3000/api/infer \
-N \
-H 'Content-Type: application/json' \
-d '{
"prompt": "Whats in this image?",
"temperature": 0.3,
"n_predict": 500,
"mirostat": 2,
"image_data": "'"$(base64 ./test/test.jpeg)"'"
}' \
--header "Accept: text/plain"curl -X POST \
http:https://localhost:3000/api/embedding \
-N \
-H 'Content-Type: application/json' \
-d '{
"prompt": "Your digital sanctuary, where privacy reigns supreme, is not a fortress of secrecy but a bastion of personal sovereignty."
}' \
--header "Accept: text/plain"curl -X POST \
http:https://localhost:3000/api/infer \
-N \
-H 'Content-Type: application/json' \
-d '{
"model": "Phi-3-Mini-4k",
"prompt": "Whats the purpose of our Universe?",
"temperature": 0.3,
"n_predict": 500,
"mirostat": 2
}' \
--header "Accept: text/plain"
Inferenceable is created by HyperMink. At HyperMink we believe that all humans should be the masters of their own destiny, free from unnecessary restrictions. Our commitment to putting control back in your hands drives everything we do.
Pull requests are welcome. For major changes, please open an issue first to discuss what you would like to change.