- 主爬虫项目文件为Tieba文件
- 项目结构
- run_scrapy.py
启动项目的文件 - Tieba\Tieba中文件为爬虫文件,包含scrapy爬虫基本的文件,不做过多介绍
- run_scrapy.py
- 项目配置
- settings.py 的配置信息,见注释
# 开启item存储
# Configure item pipelines
# See https://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'Tieba.pipelines.TiebaPipeline': 300,
}# MYSQL数据库连接配置
MYSQL_HOST = "localhost"
MYSQL_PORT = 3306
MYSQL_USER = 'root'
MYSQL_PW = 'python'
MYSQL_DB = 'tieba'
MYSQL_CHARSET = 'utf8mb4'
# 表格名称
MYSQL_TABLE = 'sanhe'# 爬虫开始链接和总页码数
# 格式统一为这种结构https://tieba.baidu.com/f?kw=%E9%BE%99%E5%8D%8E&ie=utf-8
BASE_URL = 'https://tieba.baidu.com/f?kw=%E9%BE%99%E5%8D%8E&ie=utf-8'
TOTAL_PAGE = 100- 爬虫部分和数据保存到数据库的部分可以看具体代码及注释
- 本次分析的数据是“龙华吧”前100页共91000多条数据
虽然信息是用MySQL收集的,但是由于数据量不是很大,所以数据的分析 部分主要是用的Excel整理的,整理后的数据保存在basedata.ini中 - 数据分析的文件是analysis.py具体可视化方法见代码及注释
数据的展现形式主要是图表,使用的可视化库是pyecharts - 首先来看贴吧人的等级分布吧,等级从1-15级,分析代码如下
def bartest(self):
from pyecharts import Bar
bar = Bar('等级分布条形图',self.ftitle)
# 利用自带的解析方法把列表解析成2个关联列表
key,value = bar.cast(self.bardata)
# is_datazoom_show = 参数是用来显示下滑筛选块的,默认假
# is_label_show = 参数用来显示数值,默认假
bar.add('等级分布',key,value,is_datazoom_show=False,is_label_show=True)
# bar.show_config()
bar.render(r"pic\等级分布条形图.html")
print('成功输出Bar测试网页')
- 跟等级对应的是贴吧的头衔(每个吧的头衔名称不一样,龙华吧的有点搞笑)
具体的可视化代码如下:
def pietest(self):
from pyecharts import Pie
pie = Pie('头衔分布饼形图',self.ftitle,height=600,title_pos='left')
key,value = pie.cast(self.piedata)
pie.add('人数',key,value,is_label_show=True,is_legend_show=False,radius=[30,70])
pie.render(r'pic\头衔分布饼形图.html')
print('饼形图输出Pie测试网页')
- 看到这里,不知道有没有人会疑问,为什么我要爬“龙华吧”的帖子?
这个问题要起源于一个前段时间火了一把的人群————“三和大神”,没错,就是深圳 三和的一群人。
本来有个吧叫做“三和吧”的,但是由于那段时间这群人火了,就引起了政府的关注,可能是怕生事端, 反正这个吧就没了,只剩下一个“三和大神吧”,但是人气不怎么样,所以我就爬了“龙华吧”,因为他 们的主要交流地点还是在这里。
这都是题外话,回归主题! - 接着,从一个面积折线图来看看贴吧的人主要发帖时间
代码如下:
def linetest(self):
from pyecharts import Line
line = Line('发帖时间分布折线图',self.ftitle)
key,value = line.cast(self.linedata)
line.add('发帖人数',key,value,is_label_show=True,is_fill=True,area_opacity=0.3,is_smooth=True)
line.render(r'pic\发帖时间折线图.html')
print("折线图测试成功输出")
- 从这个发帖时间可以看出来,贴吧的人也大多是“夜猫子”,主要的发帖时间都集中在深夜,其实 这个规律在很多的社交平台都是一样的,大家都已经习惯了熬夜。
- 来看看贴吧的人群性别分布
实现代码:
def sexpietest(self):
from pyecharts import Pie
pie = Pie('性别分布饼形图',self.ftitle,height=500)
key,value = pie.cast(self.sexpiedata)
pie.add('人数',key,value,is_label_show=True,center=[50,55],rosetype='area')
pie.render(r'pic\性别分布饼形图.html')
print('性别饼形图输出成功')
- 男多女少,这个倒是一点不意外,如果换做为微博估计就反过来了。
- 再来看看发帖的来源都是什么平台
实现代码:
def fromtest(self):
from pyecharts import Pie
pie = Pie('帖子来源饼形图',self.ftitle,title_pos='center')
key,value = pie.cast(self.fromdata)
pie.add('帖子数',key,value,is_label_show=True,radius=[35,65],center=[50,55],legend_pos='left',legend_orient='vertical')
pie.render(r'pic\帖子来源饼形图.html')- 这个数据倒是挺有意思,大部分人还是使用手机端来玩贴吧的,而且这个吧的安卓用户比苹果用户多很多。
之后我会用mongodb结合一些数据分析的库来分析深圳吧的更大量的数据来看看这个地方的数据是怎么分布的。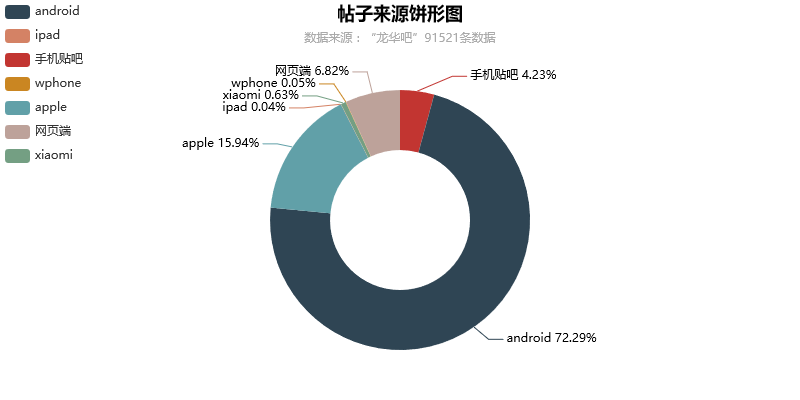
- 最后,来用一个词云图来看看贴吧中哪些人发帖最多
实现代码:

def wordcloud_1(self,imagename,cloudname,fontname):
wordlist = self.wordcloud
coloring = imread(imagename)
# 词云图的最大尺寸取决于比较图
wc = WordCloud(background_color='white',mask=coloring,stopwords=STOPWORDS,font_path=fontname,max_font_size=150,
height=800,width=600)
# 参数是一个字典
wc.generate_from_frequencies({i:int(dict(wordlist)[i]) for i in dict(wordlist)})
plt.imshow(wc)
plt.axis('off')
plt.figure()
wc.to_file(cloudname)
print("词云图生成完毕")
- 其实pyecharts也是能做词云图的,而且我在分析代码中已经做了,但是感觉太单调了,所以就用来 更加强大的词云库wordcloud来做。
- 以上就是一些用Excel的透视表整理的数据来做的基本可视化分析,其实也算不上什么分析,主要目的还是熟悉 一些新接触的库的用法。
- 后续会使用完全用Python库方式去爬取和分析一波,暂时把项目定在前程无忧的招聘信息吧。
项目链接:https://github.com/Hopetree/scrapy-51job