[ADD] support Distributed Data Parallel #137
Conversation
…e updated more. (remove unnecssary code)
|
Could you run |
## Title Refactor backward in DP ## Description Followed https://github.com/KKIEEK/oslo/blob/3ca6b1aa0d87688af891f12b22837d89847680e9/oslo/torch/nn/parallel/data_parallel/distributed_data_parallel.py#L96. And committed as KKIEEK for the code ownership. Co-authored-by: KKIEEK <[email protected]>
## Title Deleted legacy code. ## Description Only newly added code written by jinwonkim93 remains. --------- Co-authored-by: KKIEEK <[email protected]>
Co-authored-by: Junhwa Song <[email protected]>
|
I think it would be better to merge |
Co-authored-by: Junhwa Song <[email protected]>
Related to #137 For now, our implementation of DDP does not support long tensor input, so I fixed it. --------- Co-authored-by: Hakjin Lee <[email protected]>
|
please resolve conflict! @jinwonkim93 |
Completed. One question is there a reason for "ALL" rather than "all"? |
|
no. I prefer |
oslo/oslo/torch/utils/__init__.py Line 5 in dcad48e |
|
I didn't add them. all the code added by DP new members. so it's okay to change them to uppercase. |
Okay. I think it is ready to merged. what do you think? |
oslo/torch/nn/parallel/data_parallel/zero/sharded_optim/bookkeeping/__init__.py
Outdated
Show resolved
Hide resolved
…eping/__init__.py Co-authored-by: Junhwa Song <[email protected]>
|
@jinwonkim93 looks good to me. |
## Title
Colossal AI-based Distributed Data Parallel with oslo interface
-
## Description
The purpose of this implementation is to enable DDP in Oslo, with the
reducer method being identical to that of Colossal AI, but adapted to
fit Oslo's interface. To enhance user experience, we replaced
model.backward() with loss.backward() and added model.zero_grad()
temporarily to the code. Any feedback is welcome :)
If you don't use model.zero_grad() there will be unexpected error.
test_data_parallel.py
```python
import os
import torch.multiprocessing as mp
import torch
from torch.nn.parallel import DistributedDataParallel as DDP
from torch import nn
from torch import optim
import torch.distributed as dist
from oslo.torch.distributed.parallel_context import ParallelContext
def setup(rank, world_size):
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "12345"
os.environ["RANK"] = str(rank)
os.environ["LOCAL_RANK"] = str(rank)
os.environ["WORLD_SIZE"] = str(world_size)
os.environ["LOCAL_WORLD_SIZE"] = str(world_size)
def cleanup():
dist.destroy_process_group()
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net1 = nn.Linear(10, 10)
self.relu = nn.ReLU()
self.net2 = nn.Linear(10, 5)
def forward(self, x):
return self.net2(self.relu(self.net1(x)))
def train(rank, world_size):
print(f"Running basic DDP example on rank {rank}.")
setup(rank, world_size)
parallel_context = ParallelContext.from_torch(data_parallel_size=world_size)
# create model and move it to GPU with id rank
model = ToyModel().to(rank)
ddp_model = DDP(model, device_ids=[rank])
loss_fn = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.001)
optimizer.zero_grad()
outputs = ddp_model(torch.zeros(20, 10).to(rank))
labels = torch.zeros(20, 5).to(rank)
loss_fn(outputs, labels).backward()
optimizer.step()
print(outputs)
cleanup()
def main(world_size):
mp.spawn(train, args=(world_size,), nprocs=world_size, join=True)
if __name__ == "__main__":
main(2)
```
test_oslo_data_parallel.py
```python
import os
import torch.multiprocessing as mp
import torch
from torch import nn
from torch import optim
import torch.distributed as dist
import oslo
from oslo.torch.distributed.parallel_context import ParallelContext
from oslo.torch.nn.parallel.data_parallel import DistributedDataParallel as DDP
def setup(rank, world_size):
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "12345"
os.environ["RANK"] = str(rank)
os.environ["LOCAL_RANK"] = str(rank)
os.environ["WORLD_SIZE"] = str(world_size)
os.environ["LOCAL_WORLD_SIZE"] = str(world_size)
def cleanup():
dist.destroy_process_group()
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net1 = nn.Linear(10, 10)
self.relu = nn.ReLU()
self.net2 = nn.Linear(10, 5)
def forward(self, x):
return self.net2(self.relu(self.net1(x)))
def train(rank, world_size):
print(f"Running oslo DDP example on rank {rank}.")
setup(rank, world_size)
parallel_context = ParallelContext.from_torch(data_parallel_size=world_size)
# create model and move it to GPU with id rank
model = ToyModel().to(rank)
ddp_model = DDP(model, parallel_context)
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
oslo.ready(ddp_model, parallel_context)
optimizer.zero_grad()
outputs = ddp_model(torch.zeros(20, 10).to(rank))
labels = torch.zeros(20, 5).to(rank)
loss = loss_fn(outputs, labels)
ddp_model.backward(loss)
optimizer.step()
print(outputs)
cleanup()
def main(world_size):
mp.spawn(train, args=(world_size,), nprocs=world_size, join=True)
if __name__ == "__main__":
main(2)
```
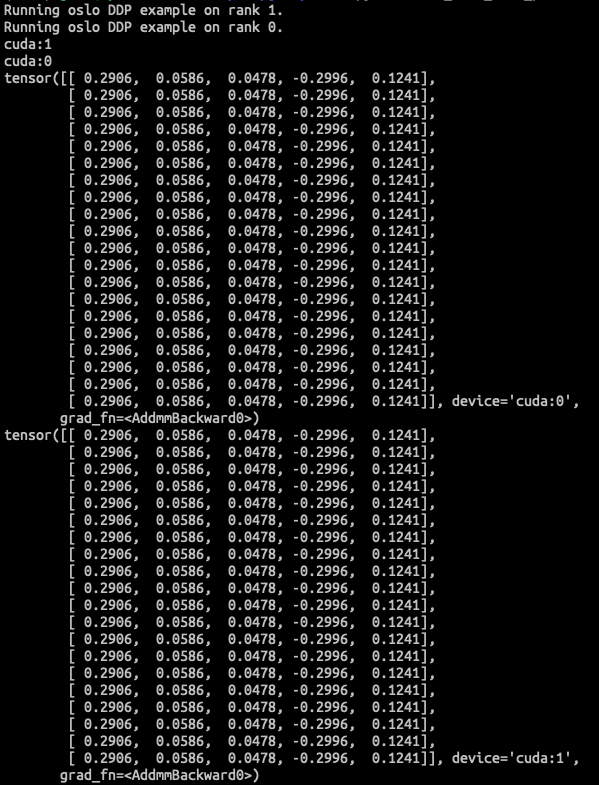
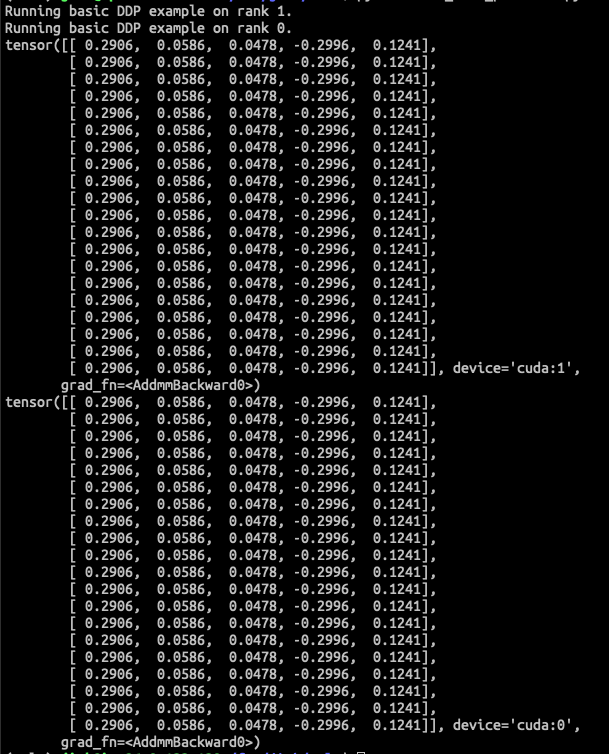
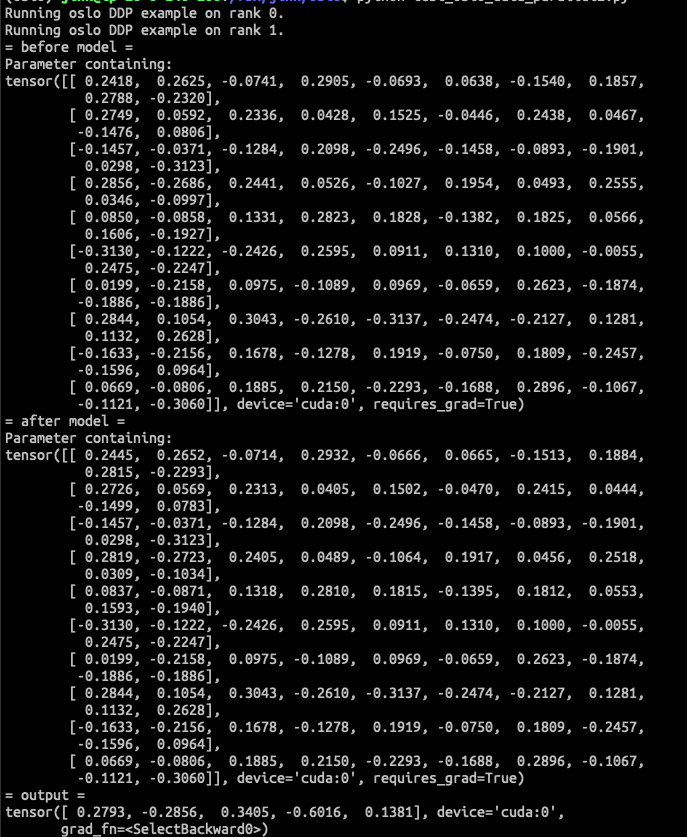
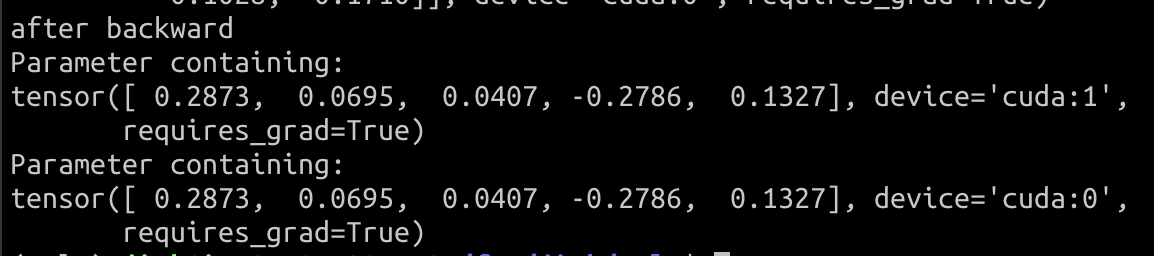
-
pytorch DDP
<img width="585" alt="ddp_before_backward"
src="https://user-images.githubusercontent.com/26476095/221404650-2525413c-ce86-44e9-bd53-897ac4077b4a.png">
<img width="577" alt="ddp_after_backward"
src="https://user-images.githubusercontent.com/26476095/221404654-ce1e2d45-9304-4d13-aa83-c5a5f8d06689.png">
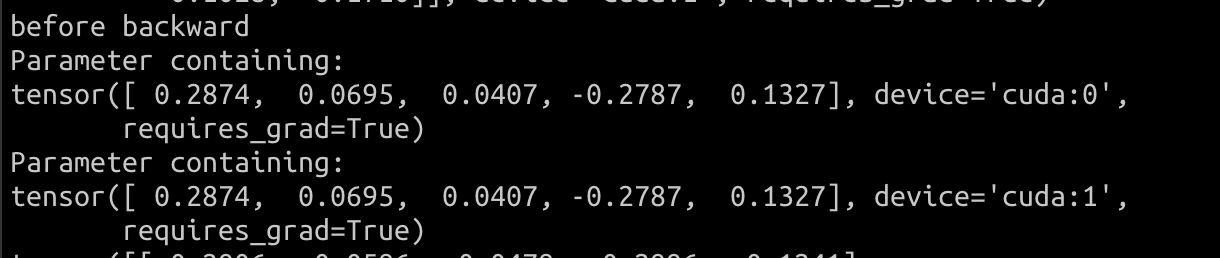
Oslo DDP
<img width="610" alt="oslo_before_backward"
src="https://user-images.githubusercontent.com/26476095/221404663-e85a0462-6fd2-4a6d-85a3-7fdcf9a5e9a7.png">
<img width="576" alt="oslo_after_backward"
src="https://user-images.githubusercontent.com/26476095/221404668-8cdee44d-3d76-4d23-adc0-68983ea7b173.png">
By checking the model's parameters, oslo DDP is working as expected.
After Cleaning
Oslo DDP
[oslo-ddp-time.log](https://github.com/EleutherAI/oslo/files/10887632/oslo-ddp-time.log)
Torch DDP
[torch-ddp-time.log](https://github.com/EleutherAI/oslo/files/10887634/torch-ddp-time.log)
## Linked Issues
- resolved #00
---------
Co-authored-by: dongsung kim <[email protected]>
Co-authored-by: Hakjin Lee <[email protected]>
Co-authored-by: KKIEEK <[email protected]>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Title
Colossal AI-based Distributed Data Parallel with oslo interface
Description
The purpose of this implementation is to enable DDP in Oslo, with the reducer method being identical to that of Colossal AI, but adapted to fit Oslo's interface. To enhance user experience, we replaced model.backward() with loss.backward() and added model.zero_grad() temporarily to the code. Any feedback is welcome :)
If you don't use model.zero_grad() there will be unexpected error.
test_data_parallel.py
test_oslo_data_parallel.py
pytorch DDP


Oslo DDP


By checking the model's parameters, oslo DDP is working as expected.
After Cleaning

Oslo DDP
oslo-ddp-time.log
Torch DDP
torch-ddp-time.log
Linked Issues