This model can be used for Binary Classification tasks and will be used below as a stock movement classifier (UP/DOWN).
- Getting started
- How to use the Adv-ASLTM model?
- Reproduce Results from paper (Coming soon)
The project is all about reproducing a working version of Adversarial Attention Based LSTM for TensorFlow 2. This new version is available in AdvALSTM.py with the object AdvLSTM.
More details of my version below.
I finally updated the author's code for it to run with TensorFlow 2.x and compare my results with his. The updated code is available in the folder original_code_updated .
│ AdvALSTM.py
│ preprocessing.py
│ replicate_result.py
├───data
│ └───stocknet-dataset
│ └───price
│ │ trading_dates.csv
│ ├───ourpped/
│ └───raw/
└───original_code_updated
evaluator.py
load.py
pred_lstm.py
__init__.py
- TensorFlow : 2.9.2
Download the AdvASLTM.py file and place it in your project folder.
from AdvLSTM import AdvLSTMTo create a AdvLSTM model, use :
model = AdvLSTM(
units,
epsilon,
beta,
learning_rate = 1E-2,
dropout = None,
l2 = None,
attention = True,
hinge = True,
adversarial_training = True,
random_perturbations = False)The AdvLSTM object is a subclass of tf.keras.Model. So you can easily train it as you would normally do with a TensorFlow 2 model :
model.fit(
X_train, y_train,
validation_data = (X_validation, y_validation),
epochs = 200,
batch_size = 1024
)The model only accepts:
- y : labelled as binary classes (0 or 1), even when using Hinge loss !
(nb_sequences, )
- x : sequences of length T, with n features.
(nb_sequences, T, n)
class AdvALSTM.AdvALSTM(**params):
__init__(self, units, epsilon = 1E-3, beta = 5E-2, learning_rate = 1E-2, dropout = None, l2 = None, attention = True, hinge = True, adversarial_training = True, random_perturbations = False)-
units : int (required)
Specify the number of units of the layers (Dense, LSTM and Temporal Attention) contained in the model.
-
epsilon : float (optional, default : 1E-3)
-
beta : float (optional, default : 5E-2). If
adversarial_training = True: Epsilon and Beta are used in the adversarial loss. Epsilon define the l2 norm of the perturbations that used to generate the Adversarial Examples :
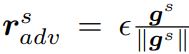
Beta is then used to weight the Adversarial loss generated with the Adversarial example following the formula below :

-
learning_rate : float (optional, default : 1E-2). Define the learning rate used to initialize the Adam optimizer used for training.
-
dropout : float (optional, default : 0.0).
-
l2 : float (optional, default : 1E-2). Define l2 regularization parameter
-
attention : boolean (optional, default : True). If
True, the model will use the TemporalAttention layer after the LSTM layer to generate the Latent Space representation. IfFalse, the model will take the last hidden state of the LSTM (withreturn_sequences = False) -
hinge : boolean (optional, default : True). If
True, the model will uses the Hinge loss to perform training. IfFalse, the model use the Binary Cross-Entropy loss. -
adversarial_training : boolean (optional, default : True). If
True, the model will generate an Adversarial Loss from the Adversarial Example that will be added to the global loss. IfFalse, the model will be training without adversarial example and loss. -
random_perturbations : boolean (optional, default : False). Define how the perturbations are created. If
False(default), the perturbations are generated following the paper guidelines with :
gis computed withtape.gradient(loss(y, y_pred), e). IfTrue, the perturbations are randomly generated instead of being gradient oriented.gis computed withtf.random.normal(...)


The Adversarial Attentive LSTM is based on an Attentive LSTM is used to generate a latent space vector that is used as a 1D-representation of a 2D-input sequence (here, the last T technical indicators of a given stock).
This Attentive LSTM use a Temporal Attention Layer that "summarize" the hidden states of the LSTM following the temporal importance detected by the Neural Network. This layer keeps the last hidden states and append it to the attentive output.
Following the Attentive LSTM, we get $e_^{s}$ the latent space representation of the input sequence.
We pass it through the classifier to get $\hat{y}_^{s}$ which it then used to calculate the first loss.
This first loss is derived with respect to $e_^{s}$. It gives the "direction" to follow to maximize the loss by adding perturbations. We use this derivative to calculate
![]()
![]()
This Adversarial Example is then passed to the classifier to receive a second loss (Adversarial Loss) as below :

With