Sistema de Recomendação fornece sugestões a usuários, ajudando-os a tomar decisões em meio a uma grande quantidade de opções. Esses sistemas desempenham um papel fundamental em diversas áreas, desde o comércio eletrônico até o streaming de conteúdo, personalizando a experiência do usuário e facilitando a descoberta de novos itens de interesse. Existem diferentes tipos de sistemas de recomendação, cada um projetado para atender a necessidades específicas. Aqui estão alguns dos tipos básicos:
- Recomedacao nao personalizada
- Recomendacao baseado em conteudo
- Filtragem colaborativa
- Recomendacao Hibrida
Sasaki.Corp, uma empresa que fornece serviços de jogos e vídeos via streaming, decide aumentar a eficiência na entrega de conteúdos e aprimorar a experiência do usuário do serviço Animeflix. Com esse objetivo, ela sugeriu à equipe de dados uma versão beta de um sistema de recomendação capaz de oferecer sugestões personalizadas aos usuários desse serviço. O projeto ainda está em desenvolvimento, com o codinome #DataGlowUp.
O objetivo da análise é compreender como os usuários interagem, por meio de um conjunto de dados contendo as avaliações de cada usuário (ratings) e outro conjunto de dados com os títulos dos animes (anime), juntamente com informações sobre o site. A intenção é identificar padrões de comportamento para que possamos recomendar itens mais adequados a cada usuário.
Os conjuntos de dados possuem as características descritas a seguir: rating e anime, respectivamente.


Como visto, enfrentamos alguns problemas no conjunto de dados, como valores ausentes (NaN) e avaliações negativas. Os valores negativos foram atribuídos à parte responsável pela geração dos dados, explicando que esses valores foram imputados nos campos sem avaliação, considerando-se que, se necessário, poderiam ser transformados em NaN ou 0, uma vez que as avaliações variam de 1 a 10.
Seguindo essa recomendação, a equipe de Data Science optou, inicialmente, por substituir esses valores por NaN, entendendo que valores NaN podem fornecer mais informações para análises de matriz de preferências. No caso dos valores NaN no conjunto de dados de Anime, na coluna de gêneros, eles foram substituídos por 'No Class', a princípio
Para o nosso dataset de anime temos as seguintes caracteristicas para os tipo de
- Generos de desenho
| Genre | Count |
|---|---|
| Comedy | 3193 |
| Action | 2845 |
| Sci-Fi | 1986 |

- Types
| Types | Count |
|---|---|
| TV | 134583 |
| OVA | 8959 |
| Movie | 6744 |

- Ratings
| Rating | Count |
|---|---|
| 8.0 | 1646019 |
| 7.0 | 1375287 |
| 9.0 | 1254096 |

- Esparsidade é um conceito que utilizamos para medir quantos dados estão faltando no nosso dataset para entendermos o usuário. Os usuários não costumam avaliar a maioria dos itens que você tem no seu sistema de recomendação.
- A overall sparsity (OS) pode ser calculada como:

onde ratings é o número de avaliações dadas, users é o número de usuários no sistema e items é o número de itens no catálogo. Quanto menos avaliações tivermos dos usuários, maior será a esparsidade.
Exemplo:
- Poucas avaliações preenchidas:
$OS \rightarrow 100%$ (alta esparsidade) - Muitas avaliações preenchidas:
$OS \rightarrow 0%$ (baixa esparsidade)
No nosso dataset temos um total de 99% de esparcidade, isso corrobora a ideia inicial que a maioria do nosso catalogo nao esta sendo avaliado pelo nossos usarios( grafico abaixo mostra o quao esparco esta o nosso dataset)

- Usuário com poucas avaliações:
$USS(\mathbf{u}) \rightarrow 100%$ - Itens com muitas avaliações:
$ISS(\mathbf{i}) \rightarrow 0%$
Com esses calculos chegamos na conclusao tambem que a os nossos usuarios nao avaliam os nosso animes e a quase na sua totalidade dos titulos tambem nao sao avaliados
-
ISS
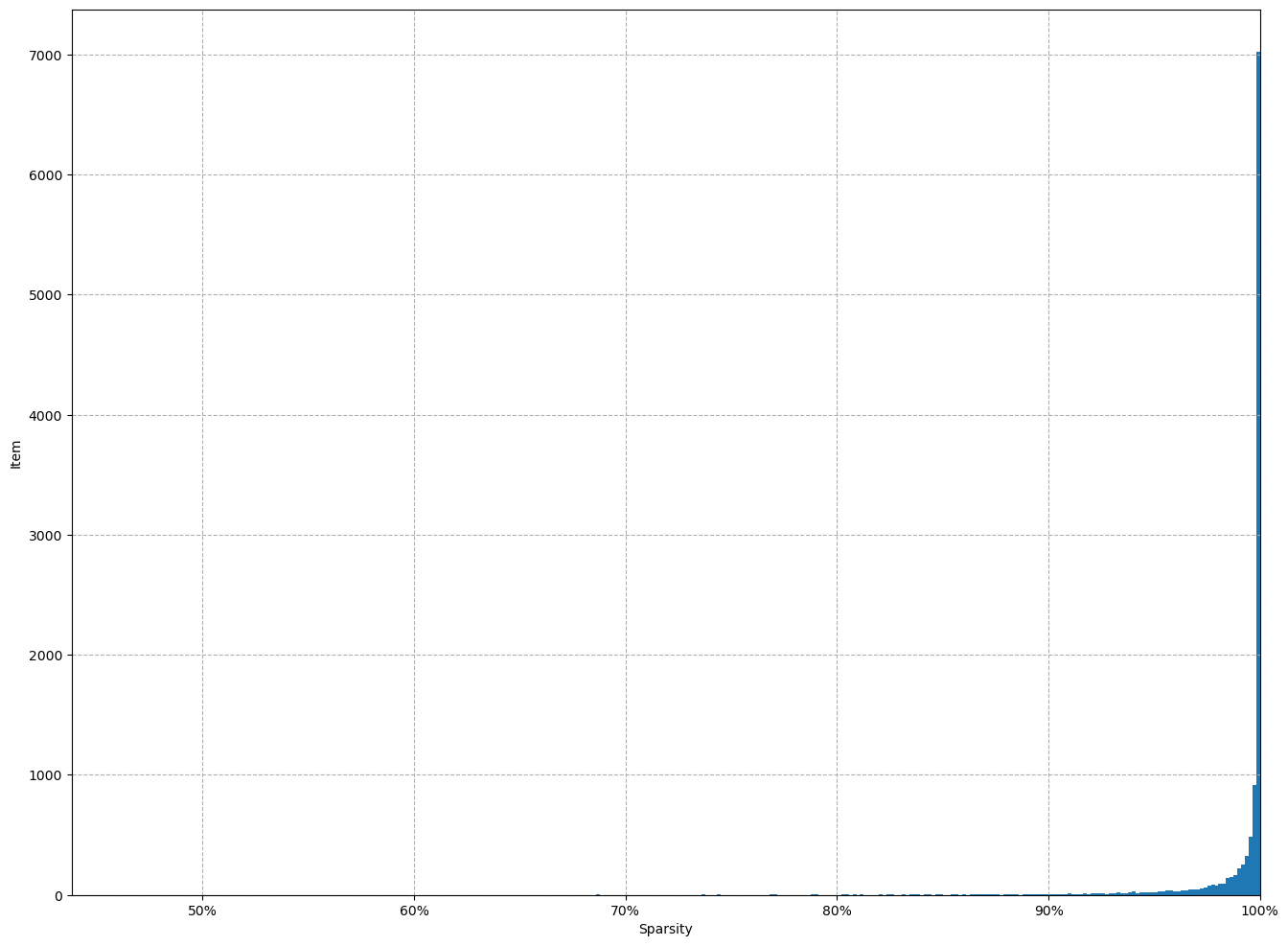
-
USS
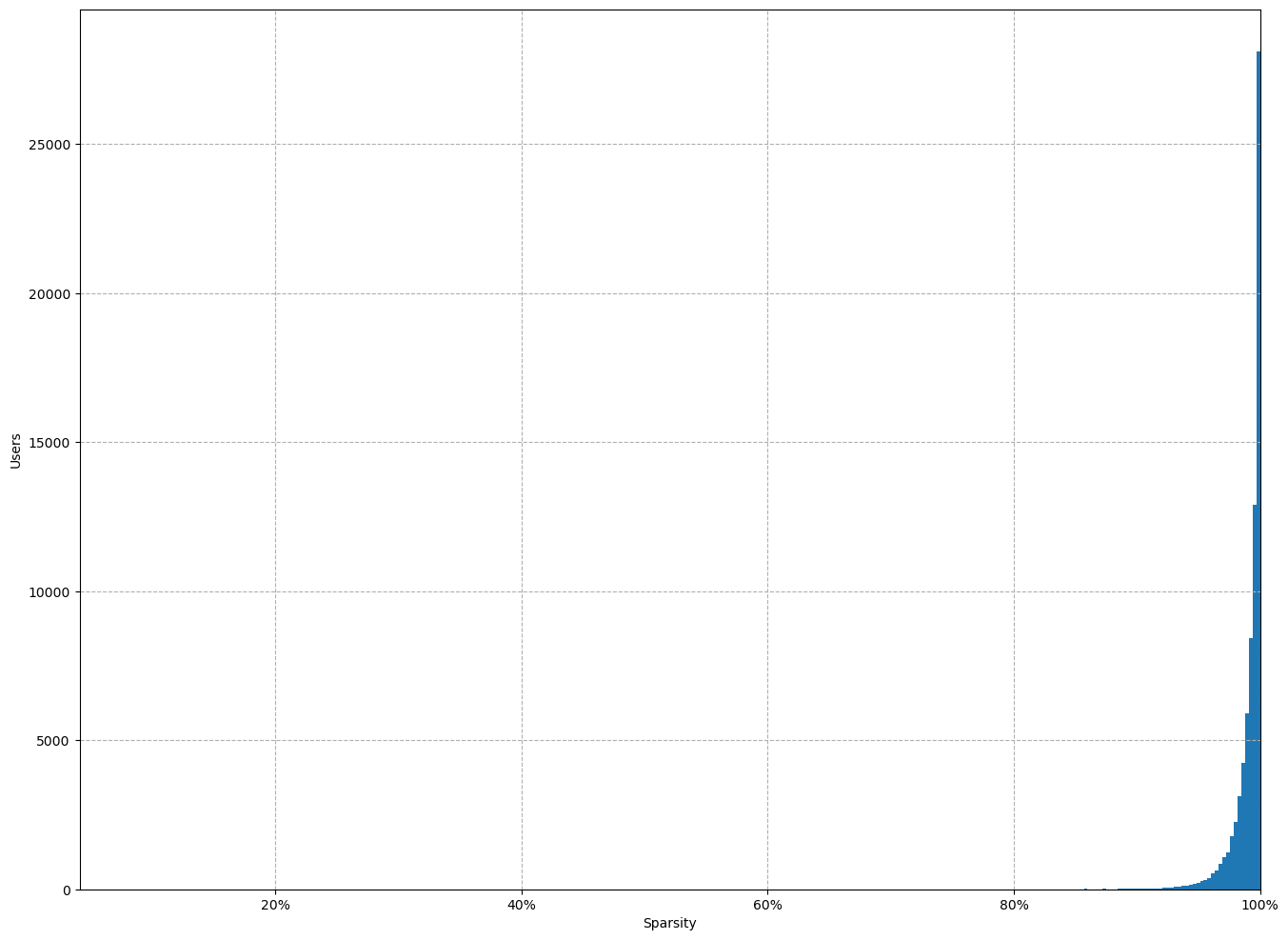


E com isso tambem consiguimos entender melhor quais sao as preferencias dos usuarios e conseguindo gerear assim duas matriz uma de preferencia com 0,1, e outra de similaridade com valores entre 0 a 1, onde valores mais proximos a 1 sao itens mais similares
-
Matrix preferencia
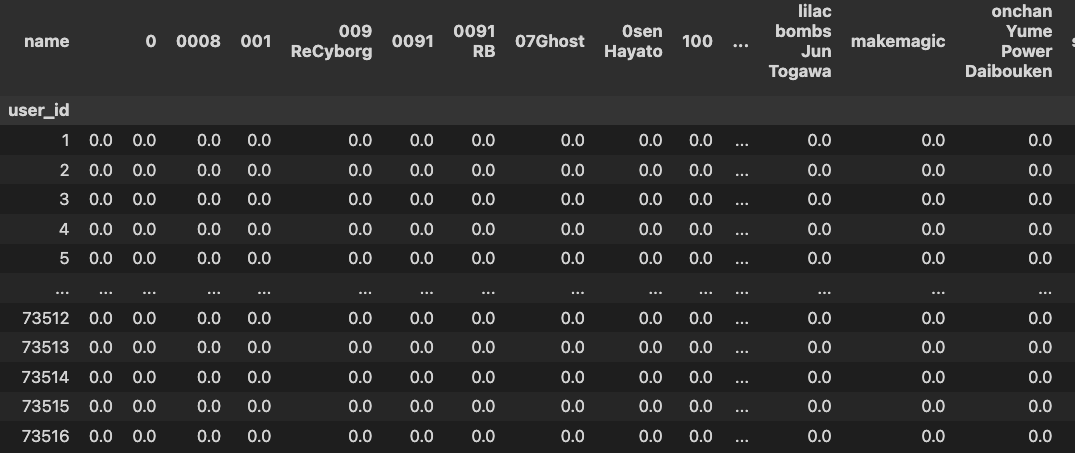
-
Matriz similaridade entre os titulos


Com isso dados fornecidos conseguimos chegar em algumas recommendacoes para
-
Top mais avaliado
Titulo Score Death Note 39340 Sword Art Online 30582 Shingeki no Kyojin 29583 Code Geass Hangyaku no Lelouch 27717 Elfen Lied 27506 Angel Beats 27183 Naruto 25925 -
Indicacao caso fosse pelo type: Exemplo TV
Titulo Score Death Note 30582 Shingeki no Kyojin 29583 Code Geass Hangyaku no Lelouch 27717
-
Recomendacao por item: Exemplo Naruto
Titulo Score Naruto 1.000 Death Note 0.551 Fullmetal Alchemist 0.477 Bleach 0.471 -
Recomendacao para os 200 usuarios mais avaliaram o nossos catalogos
Titulo Score Naruto 1.000 Naruto Movie 1 0.798 Naruto Movie 2 0.776 Soul Eater 0.772 Naruto Shippuuden Movie 1 0.762
- Inserir datas nos campo rating( quando foi dado) ou no campo do anime ( quando foi lancado)
- Colocar feedbacks, conseguindo assim gerar recomendacoes usando palavras chaves e ou sentimento
- Classificao de nota de 1 a 5 ou no sistema 1 para nao gostei, 2 para gostei, 3 para amei
- Para reduzir esparcidade, sugere-se que o feedback seja intrinseco.
- Usando esses dois sistemas podemos depois comparar se houve melhora na esparcidade para podermos assim gerar as recomendacoes de maneira mais assertiva
- email: [email protected]
- linkedIn:https://www.linkedin.com/in/chen-yen-pin/