Human mind is great at learning from very few examples. If you show a child two-three pictures of an animal(say a rhino), the child is able to learn very quickly what a rhino looks like and is easily able to distinguish between a rhino and a dog. Deep learning has given SOTA performance on many visual recognition tasks but these deep learning models require humongous amount of labelled data and many iterations to achieve the performance. Keeping in mind how easily human brain is able to learn there has been a rise in research in the fields of "Zero-Shot and Few-Shot-Learning".
According the Tom Mitchell machine learning is defined as follows : "A computer program is said to learn from experience E with respect to some classes of task T and performance measure P if its performance can improve with E on T measured by P."
Few shot learning(FSL): It is a type of machine learning problem(specified by E, T and P), where E contains only a limited number of examples with supervised information for the target T.
Putting it simply the experience E i.e my training data has very few samples and we want a model which is able to generalize well on test samples by using the limited samples in training. Few Shot Learning, the ability to learn from few labeled samples. Concretely, few-shot classification learns classifiers given only a few labeled examples of each class.
The few shot learning is formulated as a N way K way classification problem, where K is the number of labeled samples per class, and N is the number of classes to classify among.

Q) What does eminem's "Lose Yourself" lyrics have to do with one shot learning?
Answer : Consider these lines in the lyrics "If you had one shot opportunity to seize everything you ever wanted", in refernce to FSL it is saying that "My Model has One shot(meaning I have only one image per class in training data)".
The gist of it is that the model has to learn for one example per class thus rendering the type of learning as one shot learning. There are many ways to solve the problem for FSL such as Meta Learning,Embedding learning and Generative modelling.
In this project I used Relation Networks which use the concept of embedding learning. But before dwelling into working of embedding learning and Relation networks let me first tell the problem defintion
Problem Definition : Given few images of paintings drawn by varied artist we have to learn to classify which artist drew that painting.
Luckily I didn't had to scrape the painting data on my own it was available on kaggle datasets. The data has in total paintings from 50 artists and each artist had varied number of paintings belonging to them. So I decided to create a super unofficial few shot dataset here's how I did it.

- First I decided that I'm going to keep 40 classes in train set and the remaining test set.
- I found out which class had the least amount of paintings( it was 23),so I decided that each class will have randomly selected 20 samples and Viola you have your own few shot dataset.
Relation networks use the concept of embedding learning. It is defined as follows :- Embedding learning embeds each sample to a lower-dimensional space Z, such that similar samples are close together while dissimilar samples can be more easily differentiated. In this lower-dimensional Z, one can then construct a smaller hypothesis space H˜ which subsequently requires fewer training samples. Basically it means we are going to embed our data into lower dimensional space in which our similar instances are closer to each other. The aim of relation networks is to o learn a transferrable deep metric for comparing the relation between images (few-shot learning), or between images and class descriptions (zero-shot learning).
The relation networks consist of two stages a embedding stage and a relation stage.
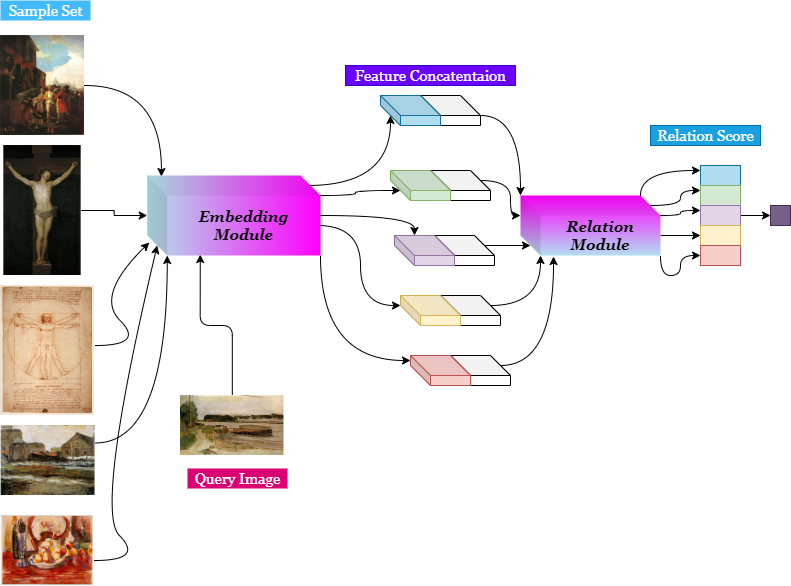
The above figure shows setting for 5-way 1 shot classification i.e 5 classes and 1 image per class.
- Embedding module : The embedding module take input images from the query set and the sample test and generates the corresponding feature maps. Then these feature maps are concatenated depth wise i.e for the above diagram the each feature map generated from the images in sample set is concatenated with the feature map generated from the query image.
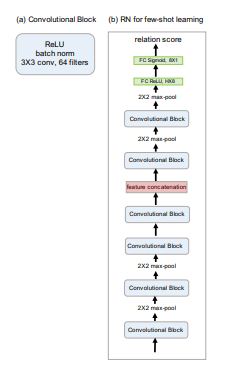
The embedding module consists of 4 convolutional blocks where each convolutional block contains a 64-filter 3 × 3 convolution, a batch normalisation and a ReLU activation. The first two convolutional blocks also contain a MaxPooling layer with kernel size 2x2.
- Relation module : The concatenated feature maps generated from the embedding module are then passed to relation module which produces a score between range of 0 to 1 indicating the similarity between the images.
The relation module consists of two convolutional blocks and two fully-connected layers. Each of convolutional block is a 3×3convolution with 64 filters followed by batch normalisation, ReLU non-linearity and 2 × 2 max-pooling. The output size of last max pooling layer is H = 64. The two fully-connected layers are 8 and 1 dimensional, respectively. All fully-connected layers are ReLU except the output layer is Sigmoid in order to generate relation scores in a reasonable range for all versions of our network architecture.
The below image shows the network architecture
- I trained my model for 5000 episodes and I got the accuracy for only 41% pretty bad right ? Here are few reasons
- Variability of Data,if you take a look at the paintings there's a lot variability
- Less training episodes(the paper trains the model of 500000 episodes for omniglot data)
- Less size of embedding space.
-
The aim of this project was not to attain SOTA benchmark because it's not possible as I randomly sampled the data myself drawing inspiration from two of the famous FSL datasets the omniglot dataset and miniImagenet.
-
Here are some visualizations from the Embedding module.
IMAGE FROM SAMPLE SET

OUTPUT OF THE EMBEDDING MODULE

Pretty good right you can see the patterns for trees and houses in some of the feature maps, thus more training would have been better for the net to generalize well
IMAGE FROM QUERY SET

OUTPUT OF EMBEDDING MODULE FOR THE QUERY IMAGE

- Things you can do to improve accuracy.
- Increase the embedding layer size
- Train for more time.
- Instead of framing it as 5-way-1-shot task,frame it as 5-way-5-shot task i.e 5 samples per class, this will help model to learn more.
- Do not Normalize the images during preprocessing and maybe instead of using 128x128 as the size use higher sizes of images
- Learning to Compare: Relation Network for Few-Shot Learning : https://arxiv.org/pdf/1904.05046.pdf
- Generalizing from a Few Examples: A Survey on Few-Shot Learning : https://arxiv.org/pdf/1904.05046.pdf
- Youtube channel for Few shot learning(Massimiliano Patacchiola) : https://www.youtube.com/channel/UC6AxKVw2y_b3ab-esLdK0_g
- Python 3.6
- PyTorch
- Numpy
- Matplotlib