- Dependencies
- Project Introduction
- Instructions for running the scripts
- Project Structure
- File Descriptions
- Results
- Licensing, Authors, and Acknowledgements
The code should run with no issues using Python versions 3. Other libraries used in this project are:
- numpy
- pandas
- flask
- nltk
- pickle
- matplotlib
- scikit-learn
- sqlalchemy
The task of this project is to analyze disaster messages from Figure Eight and build a Machine Learning model that classifies disaster messages. The data set contains real messages that were sent during disaster events. A machine learning pipeline is created to categorize these events so that one can send the messages to an appropriate disaster relief agency. The project also includes a web app where an emergency worker can input a new message and get classification results in several categories.
-
Run the following commands in the project's root directory to set up your database and model. s
- To run ETL pipeline that cleans data and stores in database
python data/process_data.py data/disaster_messages.csv data/disaster_categories.csv data/DisasterResponse.db - To run ML pipeline that trains classifier and saves
python models/train_classifier.py data/DisasterResponse.db models/classifier.pkl
- To run ETL pipeline that cleans data and stores in database
-
Run the following command in the app's directory to run your web app.
python run.py
-
app folder
- templates folder
- go.html
- master.html
- run.py
- templates folder
-
data folder
- disaster_categories.csv
- disaster_messages.csv
- DisasterResponse.db
- process_data.py
-
models folder
- classifier.pkl
- train_classifier.py
-
jupyter notebooks folder
- categories.csv
- messages.csv
- ETL Pipeline Preparation.ipynb
- ML Pipeline Preparation.ipynb
-
sample images folder
-
README.md
-
The
app foldercontains files necessary for the functioning of the Web app. The templates folder contains two html files (go.htmlis used to render the information about the training data in the form of bar graphs and the classification results into 36 different categories whilemaster.htmlis used to render the Web page). Therun.pyfile runs the flask Web app. -
The
data foldercontains two csv files (disaster_messages.csv contains disaster messages and disaster_categories.csv contains 36 different categories into which disaster messages can be classified) and a sql database fileDisasterResponse.dbthat contains the cleaned and processed disaster messages for training the classification model. Theprocess_data.pyscript merges the two csv files into a single file, cleans the disaster messages and stores the cleaned/processed messages into a sql database. -
The
train_classifier.pyscript inside themodels foldercontains the code to load the cleaned disaster messages from the sql database, creates new features (number of words in each message, number of characters in each message, number of non stopwords in each message), builds Machine Learning Pipeline, performs GridSearchCV to find the best hyperparameter for the classification model, evaluates the trained model on test set and then saves the trained model as a pickle file to deploy on the Web app. Theclassifier.pklfile contains the trained model as pickle file. -
The
jupyter notebooksfolder contains two jupyter notebooks.ETL Pipeline Preparation.ipynbnotebook performs Extract, Load and Transform task on the messages and categories csv files after merging these two files. Theprocess_data.pyscript is prepared using ETL notebook.ML Pipeline Preparation.ipynbcontains Machine Learning Pipeline to classify disaster messages into 36 different categories. Thetrain_classifier.pyscript is prepared using this notebook. -
The
sample_imagesfolder contains the images of visualizations from the ETL notebook and the working Web app for the purpose of quick demonstration in the results section below.
Some visualizations from this project
-
Number of messages in each genre
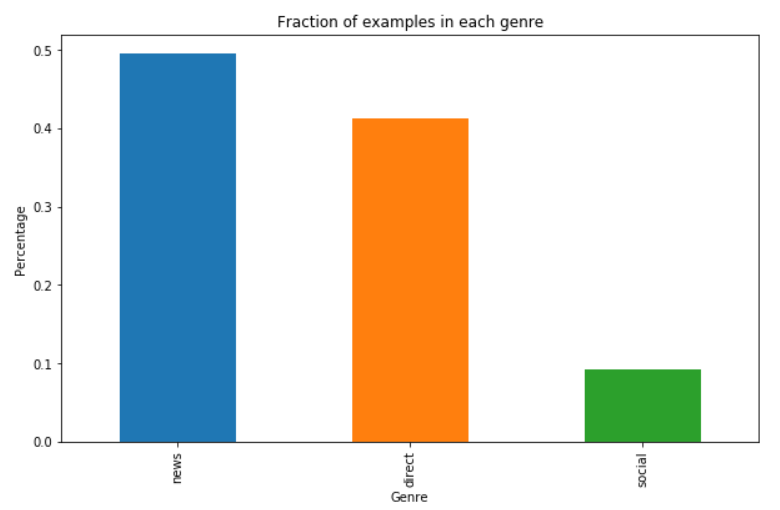
-
Number of messages in each category
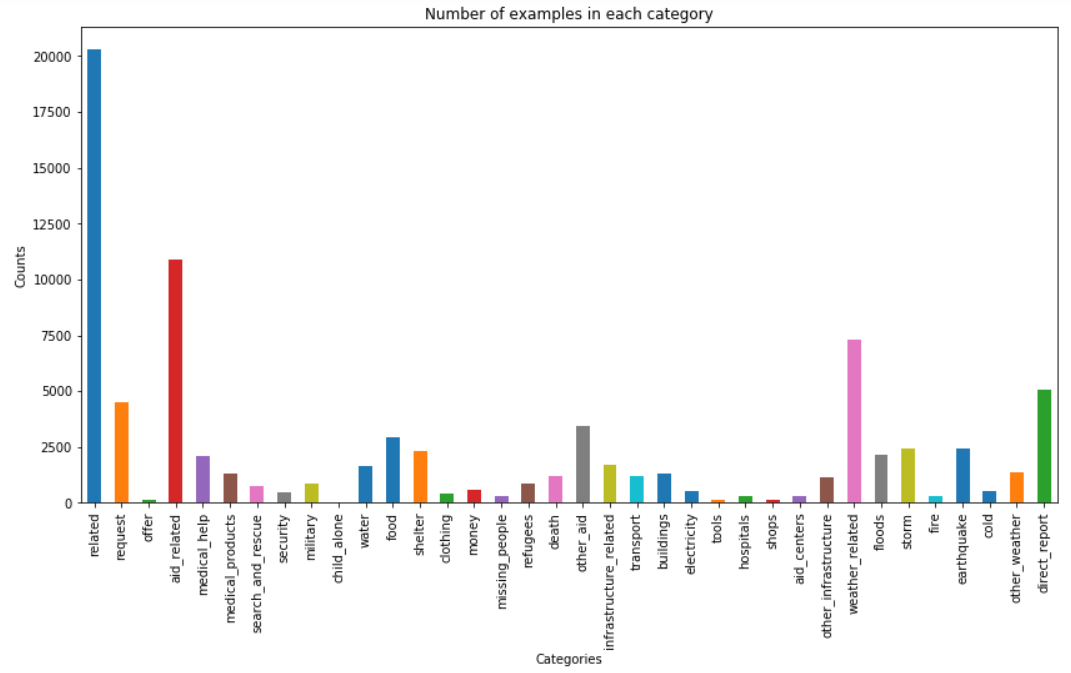
-
Web app interface
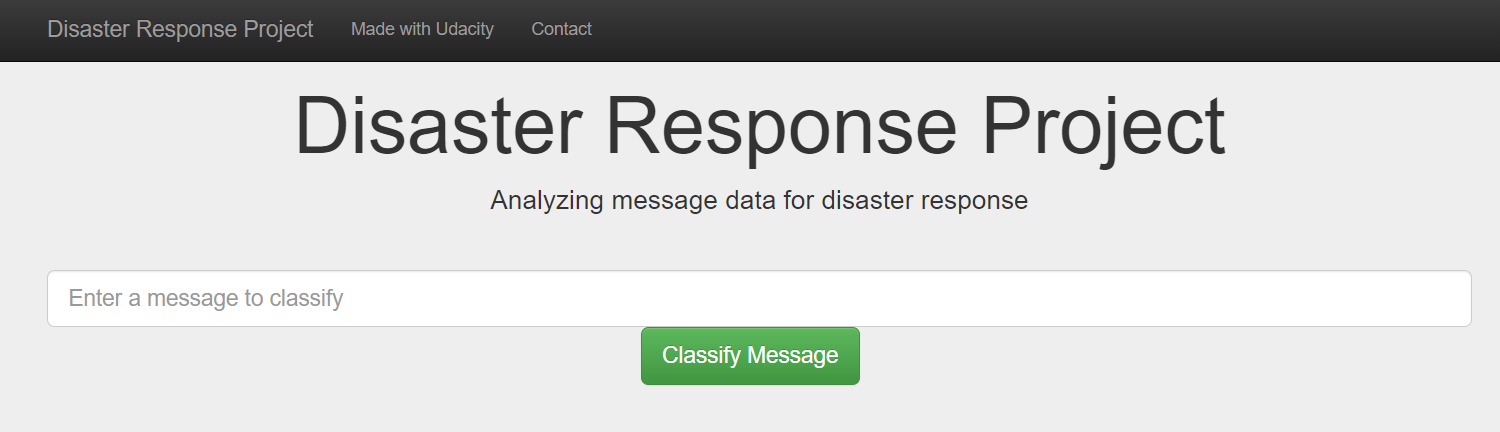
-
Directing message to web app for classification

-
Classification result of above message

-
Statistics of word and character counts of messages in the training data







Must give credit to Udacity for the data and python 3 notebook.