Training a pair of competing RL agents to play Tennis using MADDPG algorithm.
The environment requires the agents to learn both competitive and cooperative strategies in order to maximize their respective cummulative rewards.

- Set-up: Two-player game where agents control rackets to bounce ball over a net.
- Goal: The agents must bounce ball between one another while not dropping or sending ball out of bounds.
- Agents: The environment contains two agent linked to a single Brain named TennisBrain. After training you can attach another Brain named MyBrain to one of the agent to play against your trained model.
- Agent Reward Function (independent):
- +0.1 To agent when hitting ball over net.
- -0.01 To agent who let ball hit their ground, or hit ball out of bounds.
- Brains: One Brain with the following observation/action space.
- Vector Observation space: 8 variables corresponding to position and velocity of ball and racket.
- Vector Action space: (Continuous) Size of 2, corresponding to movement toward net or away from net, and jumping.
- Visual Observations: None.
- Reset Parameters: One, corresponding to size of ball.
- Benchmark Mean Reward: 2.5
The project was built with the following configuration:
- Ubuntu 16.04
- CUDA 10.0
- CUDNN 7.4
- Python 3.6 (currently ml-agents unity package does not work with python=3.7)
- Pytorch 1.0
Though not tested, the project can still be expected to work out of the box for most reasonably deviant configurations.
- Create separate virtual environment for the project using the provided
environment.ymlfile
conda env create -f environment.yml
conda activate tennis
- Clone the repository (if you haven't already!)
git clone https://github.com/1jsingh/rl_tennis.git
cd rl_tennis-
Download the environment from one of the links below. You need only select the environment that matches your operating system:
- Linux: click here
- Mac OSX: click here
(For AWS) If you'd like to train the agent on AWS (and have not enabled a virtual screen), then please use this link to obtain the "headless" version of the environment. You will not be able to watch the agent without enabling a virtual screen, but you will be able to train the agent. (To watch the agent, you should follow the instructions to enable a virtual screen, and then download the environment for the Linux operating system above.)
-
Place the downloaded file in the
unity_envsdirectory and unzip it.
mkdir unity_envs && cd unity_envs
unzip Tennis_Linux.zip
- Follow along with
maddpg/Tennis-maddpg.ipynbto train your own RL agent.
Besides the MADDPG algorithm the repo also contains 2 other solutions for the Tennis Unity environment:
maddpg: implementation of the MADDPG algorithm consisting independent but centralized critic for each agent with access to combined action and observation states of all agents.ddpg: single ddpg agent with shared actor and critic model for the 2 playersddpg_multi: separate DDPG agents with independent actor and critic modelsunity_envs: directory for downloading and storing the unity envs for your systemtrained_models: directory for storing trained models
The Multi Agent Deep Deterministic Policy Gradient (MADDPG) algorithm consists of multiple agents with separate actor and critic models. Unlike multiple DDPG models (refer ddpg_multi), MADDPG requires that all critics have access to the combined action and observation space of all agents. Doing so, enables the agents to coordinate in a much more sophisticated fashion than independent DDPG agents.
For comparison purposes, the repo also contains 2 separate solutions to the tennis unity environment
- DDPG : Using the fact that environment is highly symmetrical, this solution tries to use the same DDPG agent for both the players.
- DDPG-multi: This is the standard point of comparison to the MADDPG algorithm. The solution consists of using separate and decentralized DDPG agents for the 2 players.
-
MADDPG
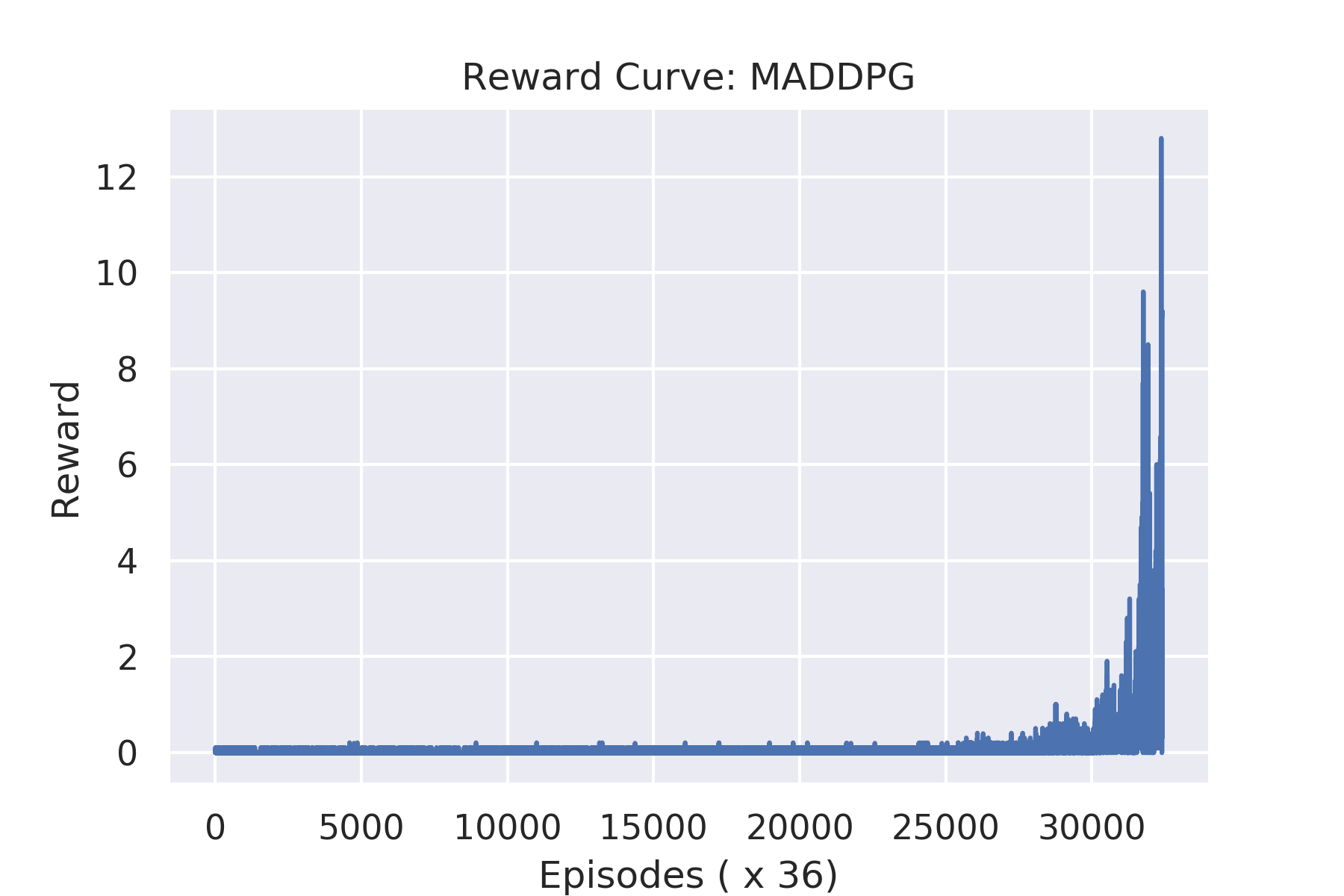
-
DDPG-multi: multiple DDPG agents with independent actor and critic models
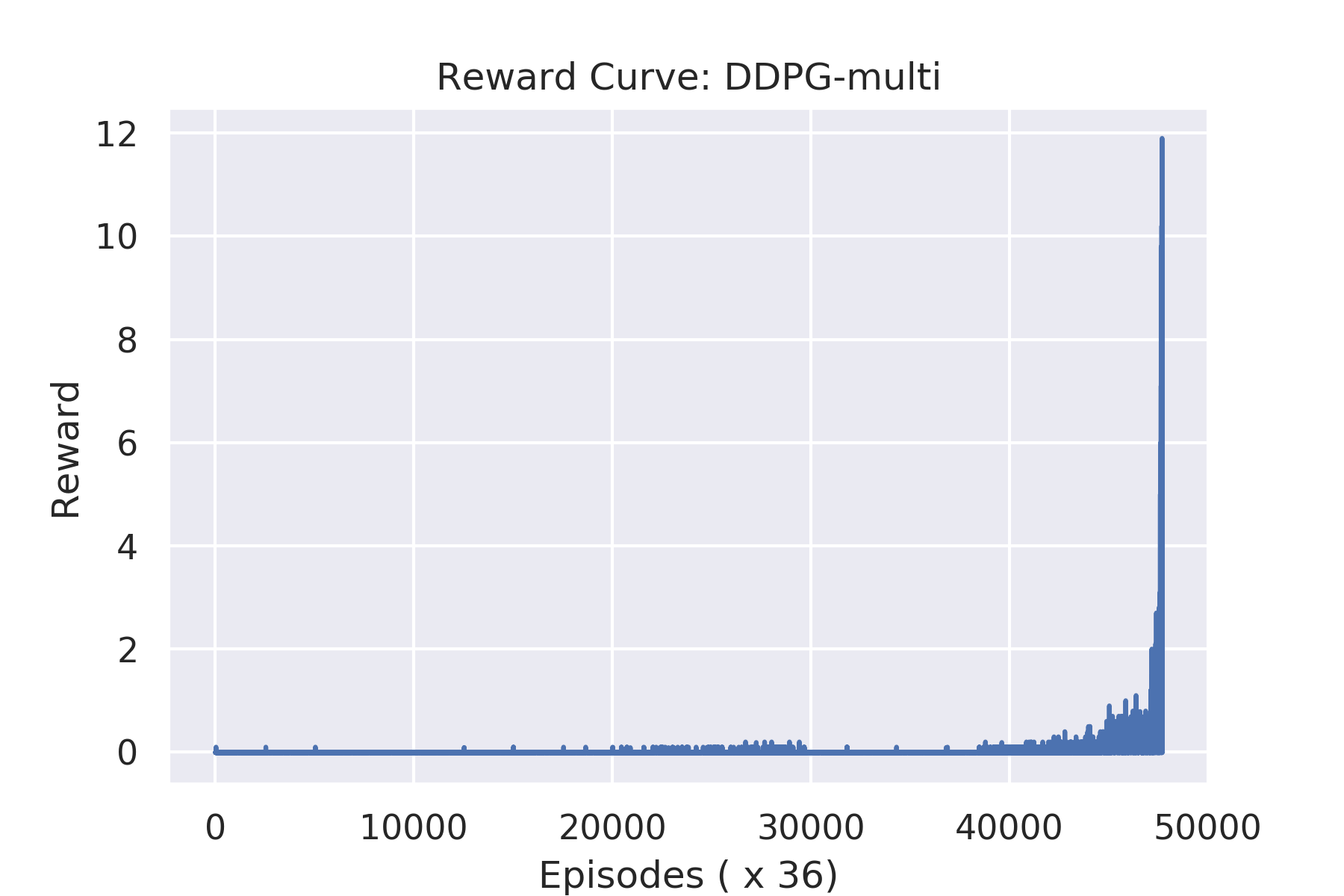


Note: MADDPG agent learns faster than independent DDPG agents
- Lowe, Ryan, et al. "Multi-agent actor-critic for mixed cooperative-competitive environments." Advances in Neural Information Processing Systems. 2017.
- Learning to Cooperate, Compete, and Communicate: https://openai.com/blog/learning-to-cooperate-compete-and-communicate/