This repository trains an Encoder-Decoder seq2seq model with Bidirection-GRU, Fasttext word embedding, Attention mechanism, K-Beam search for Chinese to English Neural machine translation, and it is evaluated by BLEU score.
The dataset is based on the UM-Corpus , which is a Large English-Chinese Parallel Corpus for Statistical Machine Translation. It provides two million English-Chinese aligned corpus categorized into eight different text domains, covering several topics and text genres, including: Education, Laws, Microblog , News, Science, Spoken, Subtitles, and Thesis[1].
The UM-Corpus can be downloaded from https://nlp2ct.cis.umac.mo/um-corpus/um-corpus-license.html
To avoid OOM error on server, here in this repository we only use the Microblog set for trainning and Twitter set for testing. The Microblog training data file includes 5,000 Bilingual sentences, and the Twitter testing data file includes 66 Bilingual sentences. Both files are encoded in UTF-8.
Here we use a Java implementation tool - Stanford Word Segmenter to preform tokenization on the raw dataset[2](available from https://nlp.stanford.edu/software/segmenter.html#Download).
For English, the segmenter splits the punctuation and separates some affixes like possessives.
For Chinese, which is standardly written without spaces between words, the segmenter splits texts into a sequence of words according to some word segmentation standard.
For Chinese sentences, we covert exotic words to lowercase, then trim the text and remove non-letter characters.
For English sentences, we first turn the text from Unicode to plain ASCII, which is subsequently converted to lowercase. After that, we trim the text and eliminate non-letter characters. As the target language, each English sentence is added with a start and an end token to help the model identify when to start and stop the predication.
Each text is transformed into a sequence of integers, each integer being the index of a token in the dictionary. Only top num_words-1 most frequent words will be taken into account. The num_words was set to 160000 for Chinese(input language) vocabulary and 80000 for English(target language) vocabulary by default[3][11]. (In Microblog data there are only 13756 Chinese tokens, and 11113 English tokens with zero padding.)
In order to convert the dataset into matrices, we need to zero pad the sentences to a fixed-length format, by utilizing the max-length of sentences in the dataset or truncating sentences with a user-defined max_length (e.g., 35, since 91% sentences have the length less than or equal to 35 in Mircoblog set). In this way we can also reduce the memory consumption.
Since we will use Keras functional API to create the model, it requires to specify the encoder_inputs, decoder_inputs, and decoder_outputs before the training. The decoder_outputs is the same as decoder_inputs but offset by one timestep[5].
Note: in this case, decoder_outputs are one-hot encoded, thus it may cause high memory consumption problem.
In the code we use a flag to switch from using the pre_trained fasttext word_embedding(by default) to training a fasttext model.
The pre_trained fasttext word vectors[4](available from https://fasttext.cc/docs/en/crawl-vectors.html) were trained on Common Crawl and Wikipedia using fastText. These models were trained using CBOW with position-weights, in dimension 300, with character n-grams of length 5, a window of size 5 and 10 negatives.
If the flag is switched to 1, we train a fasttext model from gensim on the Microblog data in dimension 100, with a window of size 10, min_count of number 5, skip-gram set to True, iteration of number 20 and 10 negatives.
No matter the flag is set to 1 or 0, we need to customize the embeddings by mapping the vectors to the vocabulary based on the Microblog dataset.
We use Keras funtional API to creat a Bidirection-GRU with word embedding and Attention mechnism encoder-decoder Seq2seq model[5][6][7][8]. The model framework is shown below:

The total number of parameters is 24,235,213 including trainable parameters 16,774,513 and non-trainable parameters 7,460,700.
- We use fit_generator() instead of the fit() method because our data is too large to fit into the memory[7]. After shuffling the Microblog dataset, we create training and validation sets using an 80%-20% split. As a result, there are 4000 bilingual sentences for training and 1000 for validation.
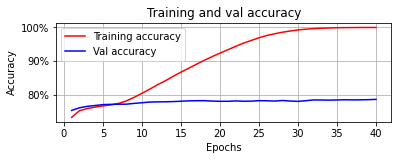
- The network is trained with a batch-size of 32(compromised on the memory consumption and the time), an optimizer of adam and a loss function of categorical_crossentropy for a total of 40 epochs.
- The training accuracy converges to 0.9996 and the val accuracy reaches 0.7869.
- The loss and accuracy history are plotted as below:

- Here it shows an attention heatmap plotting example:




{kind=link}
{kind=link}
{kind=link}
{kind=link}
The decoder will generate the predicted translation using k beam search strategy[9](k = 3 by default).
We evaluate the predicted translations by BLEU score[10].
The average BLEU score for random 1000 validation set is 48.10.
The average BLEU score for 66 Twitter testing set (after re-trained the model on the whole Mircoblog set) is 54.17.
From the predicted translations we can see sometimes the prediction is really good, because the decoder can generate the same or very closed meaning compared to the original sentence, but some other times it might not produce a decent translation. However, giving the fact that the number of training sample is just 5000(2.08% of the whole UM-Corpus), it is a resonable result. Moreover, judging from the BLEU score of the Statistical Machine Translation on UM-Corpus is 28.67[1], it's already a big progress.
- In the UM-Corpus, we can see some sentence have a particularly uncommon length(for example 264), which may cause problems such as memory exhausted if we use it as the max-length for zeor-padding, and low accuaracy for long sentence if we truncate the sentence with a small length, so these long sentences should be split further.
- We use only Mircoblog set in UM-Corpus to reduce the memory and time consumption of training as the serve cannot fit the model for the whole dataset, and it already takes more than one day to train an epoch on the serve for only a part of the dataset, but it will be worthwhile testing on the full scale dataset.
- Using Keras functional API is easy to setup the model but it requires to specify the decoder_outputs with one-hot encoding which may run into high memory consumption problem as the size of target vocabulay increases, so it's better to seek to another way to setup the model.
- Start the StanfordCoreNLPServer.ipynb : For data segmentation.
- NMT_Microblog_ZH_to_EN_Bi_GRU_+Attention+Fasttext_word_embedding+k_Beam_search+_BLEU_score.ipynb : For Data Pre-Processing, model setup, training and testing the model.
[1] Liang Tian, Derek F. Wong, Lidia S. Chao, Paulo Quaresma, Francisco Oliveira, Shuo Li, Yiming Wang, Yi Lu, "UM-Corpus: A Large English-Chinese Parallel Corpus for Statistical Machine Translation". Proceedings of the 9th International Conference on Language Resources and Evaluation (LREC'14), Reykjavik, Iceland, 2014.
[2] Huihsin Tseng, Pichuan Chang, Galen Andrew, Daniel Jurafsky and Christopher Manning. 2005. A Conditional Random Field Word Segmenter. In Fourth SIGHAN Workshop on Chinese Language Processing.
[3] Sutskever I, Vinyals O, Le Q V. Sequence to sequence learning with neural networks[C]//Advances in neural information processing systems. 2014: 3104-3112.
[4] Grave E, Bojanowski P, Gupta P, et al. Learning word vectors for 157 languages[J]. arXiv preprint arXiv:1802.06893, 2018.
[5] A ten-minute introduction to sequence-to-sequence learning in Keras
[6] TensorFlow Core - Neural machine translation with attention
[7] Implementing neural machine translation using keras
[8] thushv89/attention_keras
[9] How to Implement a Beam Search Decoder for Natural Language Processing
[10] Calculate BLEU score in Python
[11] Using Tokenizer with num_words #8092