Here at Tobiko Data, we love SQL and think about it a lot. This isn’t surprising since we’re on a mission to simplify the process of developing, deploying, and maintaining SQL data pipelines.
We express our love and vision for SQL in the open-source solutions we build - SQLGlot and SQLMesh. The foundational principle behind these products is the ability to understand SQL semantically.
In the following sections, I’m going to explain what semantic understanding is and how it unlocks some cool capabilities which lead to improved user experiences and increased productivity when using SQL.
If you're already familiar with the concept of semantic understanding, then skip ahead to the Applications section.
Semantic Understanding
Let’s start by considering the following SQL query:
1 2 3 | |
A person completely unfamiliar with SQL sees just a sequence of words. Even then, such a person immediately notices that words are arranged in a certain way and some of the words like SELECT, FROM, and WHERE might hold a special meaning. It’s immediately obvious that there is a structure to it and there should be some rules that set this sequence of words apart from any other arbitrarily formed sequence of words.
Such arrangements of words that follow a specific set of rules are referred to as syntax.
In programming languages like SQL, the rules are well defined. This means that for every possible sequence of words it’s easy to tell whether such sequence is syntactically correct in the context of a given language or not.
This is not unlike human languages, which also follow certain rules, though such rules are less strict and not as rigorously-defined. When we humans interpret a language, we extract meaning from the sequences of words that are arranged in a way that is familiar to us in order to interpret and react to it accordingly.
Similarly, computers also need to extract meaning from sequences of words when they are input into the system. When the words are arranged properly, the computer can “recognize” the user’s intention and transform the words into a series of executable steps.
This ability to extract and interpret the meaning behind a syntactically correct sequence of words is called semantic understanding.
Usually, the process of semantic understanding involves parsing the input text using syntactic rules and transforming it into a tree-like data structure called Abstract Syntax Tree, or AST for short.
For example, the query I provided at the beginning of this section can have the following AST representation:
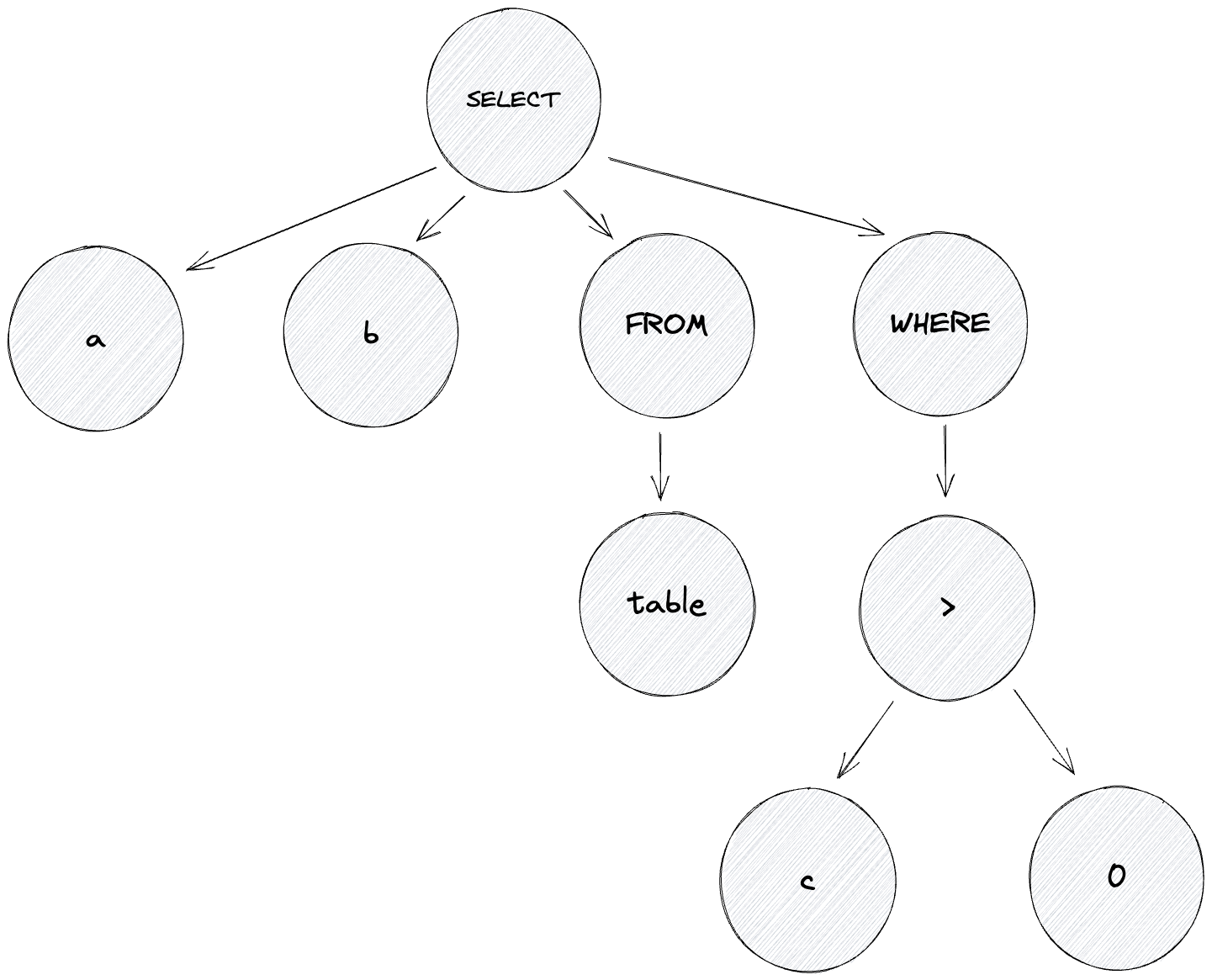 Figure 1: Abstract Syntax Tree derived from a SQL query
Figure 1: Abstract Syntax Tree derived from a SQL query
SQLGlot’s main purpose is to parse an input SQL query written in any of the 19 (at the time of writing) supported dialects and produce a tree-like data structure like the one above.
Databases and query engines like Apache Spark, Snowflake and BigQuery use the AST representation of SQL queries and statements provided by a user to insert, update, delete, and fetch data records. This, however, is not the only possible application for the syntax tree.
Applications
In SQLMesh, we use AST for all sorts of features that improve user experience and boost productivity. In this section, I’m going to highlight some of the most exciting ones.
Discovery of Upstream Dependencies
Due to the lack of semantic understanding, tools like dbt require their users to use special macros (eg. {{ ref() }} and {{ source() }}) in their SQL queries in order to inform the platform about upstream dependencies:
1 2 | |
This approach pollutes the code base, making it less readable and harder to maintain. Additionally, such macros are outside the scope of any SQL syntax, so additional tools become necessary for editing and navigating the code base. It’s also error-prone, since forgetting to use the special macro leads to an incorrect dependency graph and unexpected results during evaluation.
Thanks to the syntax tree, SQLMesh’s users don’t need to explicitly point out references to tables produced by upstream dependencies. Users write SQL as usual, while SQLMesh extracts all table references and constructs the dependency graph without requiring any guidance from a user. One less thing to think about and the code remains clean with just SQL in it.
Column-level Lineage
By traversing the syntax tree, we can also extract information about columns, their types, and dependencies between them.
Looking at the diagram above (Figure 1), we can see that it’s quite easy to build an algorithm which returns a list of projections for a given SELECT query.
Combining this with the existing dependency graph for pipelines, we can link individual projections and produce the following visualization:
 Figure 2: Column-level lineage in SQLMesh
Figure 2: Column-level lineage in SQLMesh
Transpilation
The syntax tree can also be viewed as a universal representation of any SQL dialect out there. We can use it as an intermediate state into which a query can be parsed, and from which another query can be produced.
If we parse any supported SQL dialect into AST and use it to generate a new SQL query in any other supported dialect, then we get a powerful tool capable of converting queries of one dialect to another.
For example, queries written for Snowflake can be evaluated in DuckDB, Apache Spark, BigQuery, etc. and vice versa. Thus, you can write a query once and then run it anywhere.
Thanks to transpilation, SQLMesh is able to run unit tests for any SQL query in DuckDB without requiring a connection to the underlying data warehouse. Because of semantic understanding, it can also extract and test individual Common Table Expressions (CTE) within the larger query.
Detection of Breaking Changes
Last but not least, the semantic understanding powers SQLMesh’s ability to detect breaking changes made to SQL queries. I cover this topic in greater detail in my other post.
Conclusion
While we have made significant progress, we have only just begun to tap into the vast potential of semantic understanding. Many more exciting developments and innovations are ahead of us. Fully automated data contracts, query linting and optimization, detection of similar pipelines to name a few.
Join our Slack community to chat about SQL and innovations around it.