
Running Apache Kafka on Kubernetes at Shopify
In the Beginning, There Was the Data Center
![]() Shopify is a leading multi-channel commerce platform that powers over 600,000 businesses in approximately 175 countries. We first adopted Apache Kafka as our data bus for reliable messaging in 2014 and mainly used it for collecting events and log aggregation across the systems.
Shopify is a leading multi-channel commerce platform that powers over 600,000 businesses in approximately 175 countries. We first adopted Apache Kafka as our data bus for reliable messaging in 2014 and mainly used it for collecting events and log aggregation across the systems.
In that first year, our primary focus was building trust in the platform with our data analysts and developers by automating all aspects of cluster management, creating the proper in-house tooling needed for our daily operations, and helping them use it with minimum friction. Initially, our deployment was a single regional Kafka cluster in each of our data centers and one aggregate cluster for our data warehouse. The regional clusters would mirror their data to the aggregate using Kafka’s mirrormaker.

Apache Kafka deployment in the data center
Fast forward to 2016, and we’re managing many multi-tenant clusters in all our regions. These clusters are the backbone of our data superhighway — delivering billions of messages every day to our data warehouse and other application-specific Kafka consumers. Chef provisioned, configured and managed our Kafka infrastructure in the data center. We deploy a configuration change to all clusters at once by updating one or more files in our Chef GitHub repository.
Moving to the Cloud
In 2017, Shopify started moving some services from our data centers to the cloud. We took on the task of migrating our Kafka infrastructure to the cloud with zero downtime. Our target was to achieve reliable cluster deployment with predictable and scalable performance and do all this without sacrificing ease of use and security. Migration was a three-step process:
- Deploy one regional Kafka cluster in each cloud region we use, and deploy an aggregate Kafka cluster in one of the regions.
- Mirror all regional clusters in the data center and in the cloud to both aggregate clusters in the data center and in the cloud. This guarantees both aggregate clusters will have the same data.
- Move Kafka clients (both producers and consumers) from the data center clusters and configure them to point to the cloud clusters.
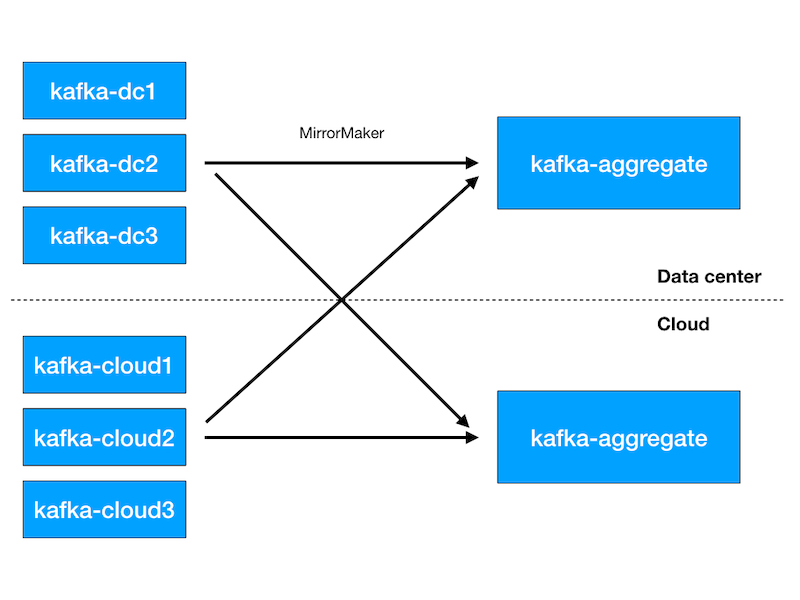
Apache Kafka deployment during our move to the cloud
By the time we migrated all clients to the cloud clusters, the regional clusters in the data center had zero incoming traffic and we could safely shut them down. That was followed by a safe shutdown of the aggregate Kafka cluster in the data center as no more clients were reading from it.
Virtual-Machines or Kubernetes?
We compared running Kafka brokers in Google Cloud Platform (GCP) as Virtual Machines (VM) vs. running it in containers managed by Kubernetes and we decided to use Kubernetes for the following reasons.
The first option using GCP VMs is closer in concept to how we managed physical machines in the data center. There, we have full control of the individual servers, but we also need to write our own tooling to monitor, manage the state of the cluster as a whole, and execute deployments in a way that we do not impact Kafka availability. For example, we can’t perform a configuration change and restart all Kafka brokers at once —this results in a service outage.
Kubernetes, on the other hand, offers abstract constructs to manage a set of containers together as a stateless or stateful cluster. Kubernetes manages a set of Pods. Each Pod is a set of functionally related containers deployed together on a server called a Node. To manage a stateful set of nodes like a Kafka cluster, we used Kubernetes StatefulSets to control deployment and scaling of containers with an ordered and graceful deployment of changes including guarantees to prevent compromising the overall service availability. And to implement our own custom behavior that’s not provided by Kubernetes, we extended it using Custom Resources and Controllers, an extension for Kubernetes API to create user-defined resources and implement actions when these resources are updated.
This is an example of a Kubernetes StatefulSet template used to configure a Kafka cluster of 30 nodes:
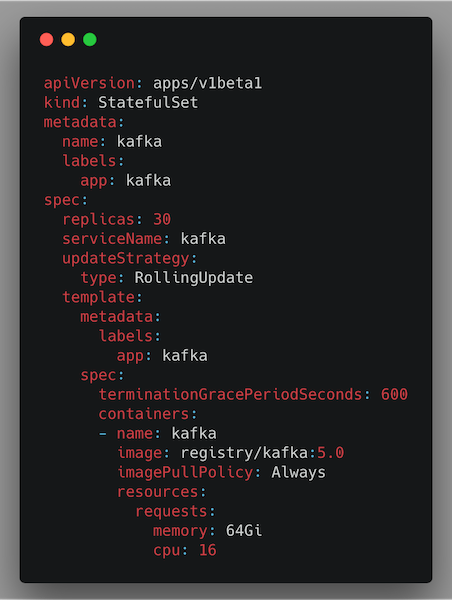
Kubernetes StatefulSet template
Containerizing Kafka
Running Kafka in a docker container is straightforward, the simplest setup is for the Kafka server configuration to be stored in a Kubernetes ConfigMap and to mount the configuration file in the container by referencing the proper configMap key. But… pulling a third party Kafka image is risky since depending on a Kafka image from an external registry risks application failure if the image is changed or removed! We highly recommend hosting your own container registry and building your own Kafka image. In a critical software environment where you want to minimize sources of failures, it’s more reliable to build the image yourself and host it in your own registry, giving you more control on its content and availability.
Best Practices
Our Kafka Pods contain the Kafka container itself and another resource-monitoring container. Kafka isn’t friendly with frequent server restarts because restarting a Kafka broker or container means terabytes of data shuffling around the cluster. Restarting many brokers at the same time risks having offline-partitions and consequently data-loss. These are some of the best practices we learned and implemented to tune the cluster availability:
- Node Affinity and Taints: Schedules Kafka containers on nodes with the required specifications. Taints guarantees that other applications can’t use nodes required for Kafka containers.
- Inter-pod Affinity and Anti-Affinity prevents the Kubernetes scheduler from scheduling two Kafka containers on the same node.
- Persistent Volumes is persistent storage for Kafka pods and guarantees that a Pod always mounts the same disk volume when it restarts.
- Kubernetes Custom Resources extends Kubernetes functionality; we use to automate and manage Kafka Topic provisioning, cluster discovery, and SSL certificate distribution.
- Kafka broker’s rack-awareness reduces the impact of a single Kubernetes zone failure by mapping Kafka containers to multiple Kubernetes zones
- Readiness Probe guarantees how fast we roll configuration changes to cluster nodes.
We successfully migrated all our Kafka clusters to the cloud. We run multiple regional Kafka clusters and an aggregate one to mirror all other clusters before feeding its data into our data warehouse. Today, we stream billions of events daily across all clusters — these events are key to our developers, data analysts, and data scientists to build a world-class, data-driven commerce platform.
If you are excited about working on similar systems join our Production-Engineering team at Shopify here: Careers at Shopify