# Benchee [](https://hex.pm/packages/benchee) [](https://hexdocs.pm/benchee/) [](https://inch-ci.org/github/PragTob/benchee) [](https://travis-ci.org/PragTob/benchee)
Library for easy and nice (micro) benchmarking in Elixir. It allows you to compare the performance of different pieces of code at a glance. Benchee is also versatile and extensible, relying only on functions - no macros! There are also a bunch of [plugins](#plugins) to draw pretty graphs and more!
Benchee has a nice and concise main interface, and its behavior can be altered through lots of [configuration options](#configuration):
```elixir
list = Enum.to_list(1..10_000)
map_fun = fn(i) -> [i, i * i] end
Benchee.run(%{
"flat_map" => fn -> Enum.flat_map(list, map_fun) end,
"map.flatten" => fn -> list |> Enum.map(map_fun) |> List.flatten end
}, time: 3)
```
Produces the following output on the console:
```
tobi@happy ~/github/benchee $ mix run samples/run.exs
Erlang/OTP 19 [erts-8.1] [source] [64-bit] [smp:8:8] [async-threads:10] [hipe] [kernel-poll:false]
Elixir 1.3.4
Benchmark suite executing with the following configuration:
warmup: 2.0s
time: 3.0s
parallel: 1
inputs: none specified
Estimated total run time: 10.0s
Benchmarking flat_map...
Benchmarking map.flatten...
Name ips average deviation median
map.flatten 1.04 K 0.96 ms ±21.82% 0.90 ms
flat_map 0.66 K 1.51 ms ±16.98% 1.50 ms
Comparison:
map.flatten 1.04 K
flat_map 0.66 K - 1.56x slower
```
The aforementioned [plugins](#plugins) like [benchee_html](https://github.com/PragTob/benchee_html) make it possible to generate nice looking [html reports](https://www.pragtob.info/benchee/flat_map.html) and export graphs as png images like this IPS comparison chart with standard deviation:
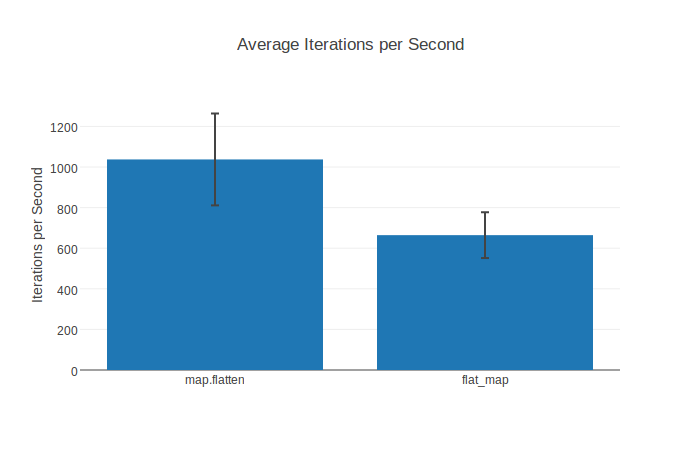
## Features
* first runs the functions for a given warmup time without recording the results, to simulate a _"warm"_ running system
* plugin/extensible friendly architecture so you can use different formatters to generate CSV and more
* well tested
* well documented
* execute benchmark jobs in parallel to gather more results in the same time, or simulate a system under load
* nicely formatted console output with units scaled to appropriate units
* provides you with lots of statistics - check the next list
Provides you with the following **statistical data**:
* **average** - average execution time (the lower the better)
* **ips** - iterations per second, aka how often can the given function be executed within one second (the higher the better)
* **deviation** - standard deviation (how much do the results vary), given as a percentage of the average (raw absolute values also available)
* **median** - when all measured times are sorted, this is the middle value (or average of the two middle values when the number of samples is even). More stable than the average and somewhat more likely to be a typical value you see. (the lower the better)
Benchee does not:
* Keep results of previous runs and compare them, if you want that have a look at [benchfella](https://github.com/alco/benchfella) or [bmark](https://github.com/joekain/bmark)
Benchee only has a small runtime dependency on `deep_merge` for merging configuration and is aimed at being the core benchmarking logic. Further functionality is provided through plugins that then pull in dependencies, such as HTML generation and CSV export. Check out the [available plugins](#plugins)!
## Installation
Add benchee to your list of dependencies in `mix.exs`:
```elixir
def deps do
[{:benchee, "~> 0.6", only: :dev}]
end
```
Install via `mix deps.get` and then happy benchmarking as described in [Usage](#usage) :)
## Usage
After installing just write a little Elixir benchmarking script:
```elixir
list = Enum.to_list(1..10_000)
map_fun = fn(i) -> [i, i * i] end
Benchee.run(%{
"flat_map" => fn -> Enum.flat_map(list, map_fun) end,
"map.flatten" => fn -> list |> Enum.map(map_fun) |> List.flatten end
}, time: 3)
```
This produces the following output:
```
tobi@happy ~/github/benchee $ mix run samples/run.exs
Erlang/OTP 19 [erts-8.1] [source] [64-bit] [smp:8:8] [async-threads:10] [hipe] [kernel-poll:false]
Elixir 1.3.4
Benchmark suite executing with the following configuration:
warmup: 2.0s
time: 3.0s
parallel: 1
inputs: none specified
Estimated total run time: 10.0s
Benchmarking flat_map...
Benchmarking map.flatten...
Name ips average deviation median
map.flatten 1.27 K 0.79 ms ±15.34% 0.76 ms
flat_map 0.85 K 1.18 ms ±6.00% 1.23 ms
Comparison:
map.flatten 1.27 K
flat_map 0.85 K - 1.49x slower
```
See [Features](#features) for a description of the different statistical values and what they mean.
If you're looking to see how to make something specific work, please refer to the [samples](https://github.com/PragTob/benchee/tree/master/samples) directory. Also, especially when wanting to extend benchee check out the [hexdocs](https://hexdocs.pm/benchee/api-reference.html).
### Configuration
Benchee takes a wealth of configuration options, in the most common `Benchee.run/2` interface these are passed as the second argument in the form of an optional keyword list:
```elixir
Benchee.run(%{"some function" => fn -> magic end}, print: [benchmarking: false])
```
The available options are the following (also documented in [hexdocs](https://hexdocs.pm/benchee/Benchee.Config.html#init/1)).
* `warmup` - the time in seconds for which a benchmark should be run without measuring times before real measurements start. This simulates a _"warm"_ running system. Defaults to 2.
* `time` - the time in seconds for how long each individual benchmark should be run and measured. Defaults to 5.
* `inputs` - a map from descriptive input names to some different input, your benchmarking jobs will then be run with each of these inputs. For this to work your benchmarking function gets the current input passed in as an argument into the function. Defaults to `nil`, aka no input specified and functions are called without an argument. See [Inputs](#inputs)
* `parallel` - each job will be executed in `parallel` number processes. Gives you more data in the same time, but also puts a load on the system interfering with benchmark results. For more on the pros and cons of parallel benchmarking [check the wiki](https://github.com/PragTob/benchee/wiki/Parallel-Benchmarking). Defaults to 1.
* `formatters` - list of formatter functions you'd like to run to output the benchmarking results of the suite when using `Benchee.run/2`. Functions need to accept one argument (which is the benchmarking suite with all data) and then use that to produce output. Used for plugins. Defaults to the builtin console formatter calling `Benchee.Formatters.Console.output/1`. See [Formatters](#formatters)
* `print` - a map from atoms to `true` or `false` to configure if the output identified by the atom will be printed during the standard Benchee benchmarking process. All options are enabled by default (true). Options are:
* `:benchmarking` - print when Benchee starts benchmarking a new job (Benchmarking name ..)
* `:configuration` - a summary of configured benchmarking options including estimated total run time is printed before benchmarking starts
* `:fast_warning` - warnings are displayed if functions are executed too fast leading to inaccurate measures
* `console` - options for the built-in console formatter. Like the `print` options they are also enabled by default:
* `:comparison` - if the comparison of the different benchmarking jobs (x times slower than) is shown
* `:unit_scaling` - the strategy for choosing a unit for durations and
counts. When scaling a value, Benchee finds the "best fit" unit (the
largest unit for which the result is at least 1). For example, 1_200_000
scales to `1.2 M`, while `800_000` scales to `800 K`. The `unit_scaling`
strategy determines how Benchee chooses the best fit unit for an entire
list of values, when the individual values in the list may have different
best fit units. There are four strategies, defaulting to `:best`:
* `:best` - the most frequent best fit unit will be used, a tie will
result in the larger unit being selected.
* `:largest` - the largest best fit unit will be used (i.e. thousand
and seconds if values are large enough)
* `:smallest` - the smallest best fit unit will be used (i.e. millisecond
and one)
* `:none` - no unit scaling will occur. Durations will be displayed in microseconds, and counts will be displayed in ones (this is equivalent to the behaviour Benchee had pre 0.5.0)
### Inputs
`:inputs` is a very useful configuration that allows you to run the same benchmarking with different inputs. Functions can have different performance characteristics on differently shaped inputs be that structure or input size.
One of such cases is comparing tail-recursive and body-recursive implementations of `map`. More information in the [repository with the benchmark](https://github.com/PragTob/elixir_playground/blob/master/bench/tco_blog_post_focussed_inputs.exs) and the [blog post](https://pragtob.wordpress.com/2016/06/16/tail-call-optimization-in-elixir-erlang-not-as-efficient-and-important-as-you-probably-think/).
```elixir
map_fun = fn(i) -> i + 1 end
inputs = %{
"Small (1 Thousand)" => Enum.to_list(1..1_000),
"Middle (100 Thousand)" => Enum.to_list(1..100_000),
"Big (10 Million)" => Enum.to_list(1..10_000_000),
}
Benchee.run %{
"map tail-recursive" =>
fn(list) -> MyMap.map_tco(list, map_fun) end,
"stdlib map" =>
fn(list) -> Enum.map(list, map_fun) end,
"map simple body-recursive" =>
fn(list) -> MyMap.map_body(list, map_fun) end,
"map tail-recursive different argument order" =>
fn(list) -> MyMap.map_tco_arg_order(list, map_fun) end
}, time: 15, warmup: 5, inputs: inputs
```
Omitting some of the output this produces the following results:
```
##### With input Big (10 Million) #####
Name ips average deviation median
map tail-recursive different argument order 5.09 196.48 ms ±9.70% 191.18 ms
map tail-recursive 3.86 258.84 ms ±22.05% 246.03 ms
stdlib map 2.87 348.36 ms ±9.02% 345.21 ms
map simple body-recursive 2.85 350.80 ms ±9.03% 349.33 ms
Comparison:
map tail-recursive different argument order 5.09
map tail-recursive 3.86 - 1.32x slower
stdlib map 2.87 - 1.77x slower
map simple body-recursive 2.85 - 1.79x slower
##### With input Middle (100 Thousand) #####
Name ips average deviation median
stdlib map 584.79 1.71 ms ±16.20% 1.67 ms
map simple body-recursive 581.89 1.72 ms ±15.38% 1.68 ms
map tail-recursive different argument order 531.09 1.88 ms ±17.41% 1.95 ms
map tail-recursive 471.64 2.12 ms ±18.93% 2.13 ms
Comparison:
stdlib map 584.79
map simple body-recursive 581.89 - 1.00x slower
map tail-recursive different argument order 531.09 - 1.10x slower
map tail-recursive 471.64 - 1.24x slower
##### With input Small (1 Thousand) #####
Name ips average deviation median
stdlib map 66.10 K 15.13 μs ±58.17% 15.00 μs
map tail-recursive different argument order 62.46 K 16.01 μs ±31.43% 15.00 μs
map simple body-recursive 62.35 K 16.04 μs ±60.37% 15.00 μs
map tail-recursive 55.68 K 17.96 μs ±30.32% 17.00 μs
Comparison:
stdlib map 66.10 K
map tail-recursive different argument order 62.46 K - 1.06x slower
map simple body-recursive 62.35 K - 1.06x slower
map tail-recursive 55.68 K - 1.19x slower
```
As you can see, the tail-recursive approach is significantly faster for the _Big_ 10 Million input while body recursion outperforms it or performs just as well on the _Middle_ and _Small_ inputs.
Therefore, I **highly recommend** using this feature and checking different realistically structured and sized inputs for the functions you benchmark!
### Formatters
Among all the configuration options, one that you probably want to use are the formatters. Formatters are functions that take one argument (the benchmarking suite with all its results) and then generate some output. You can specify multiple formatters to run for the benchmarking run.
So if you are using the [HTML plugin](https://github.com/PragTob/benchee_html) and you want to run both the console formatter and the HTML formatter this looks like this (after you installed it of course):
```elixir
list = Enum.to_list(1..10_000)
map_fun = fn(i) -> [i, i * i] end
Benchee.run(%{
"flat_map" => fn -> Enum.flat_map(list, map_fun) end,
"map.flatten" => fn -> list |> Enum.map(map_fun) |> List.flatten end
},
formatters: [
&Benchee.Formatters.HTML.output/1,
&Benchee.Formatters.Console.output/1
],
html: [file: "samples_output/my.html"],
)
```
### More expanded/verbose usage
It is important to note that the benchmarking code shown before is the convenience interface. The same benchmark in its more verbose form looks like this:
```elixir
list = Enum.to_list(1..10_000)
map_fun = fn(i) -> [i, i * i] end
Benchee.init(time: 3)
|> Benchee.benchmark("flat_map", fn -> Enum.flat_map(list, map_fun) end)
|> Benchee.benchmark("map.flatten",
fn -> list |> Enum.map(map_fun) |> List.flatten end)
|> Benchee.measure
|> Benchee.statistics
|> Benchee.Formatters.Console.output
```
This is a take on the _functional transformation_ of data applied to benchmarks here:
1. Configure the benchmarking suite to be run
2. Define the functions to be benchmarked
3. Run n benchmarks with the given configuration gathering raw run times per function
4. Generate statistics based on the raw run times
5. Format the statistics in a suitable way
6. Output the formatted statistics
This is also part of the **official API** and allows for more **fine grained control**. (It's also what Benchee does internally when you use `Benchee.run/2`).
Do you just want to have all the raw run times? Just work with the result of `Benchee.measure/1`! Just want to have the calculated statistics and use your own formatting? Grab the result of `Benchee.statistics/1`! Or, maybe you want to write to a file or send an HTTP post to some online service? Just use the `Benchee.Formatters.Console.format/1` and then send the result where you want.
This way Benchee should be flexible enough to suit your needs and be extended at will. Have a look at the [available plugins](#plugins).
## Plugins
Packages that work with Benchee to provide additional functionality.
* [benchee_html](//github.com/PragTob/benchee_html) - generate HTML including a data table and many different graphs with the possibility to export individual graphs as PNG :)
* [benchee_csv](//github.com/PragTob/benchee_csv) - generate CSV from your Benchee benchmark results so you can import them into your favorite spreadsheet tool and make fancy graphs
* [benchee_json](//github.com/PragTob/benchee_json) - export suite results as JSON to feed anywhere or feed it to your JavaScript and make magic happen :)
With the HTML plugin for instance you can get fancy graphs like this boxplot (but normal bar chart is there as well):
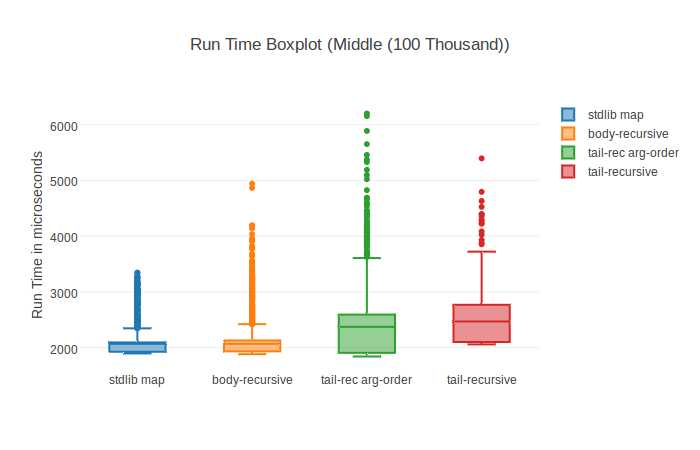
## Contributing
Contributions to Benchee are very welcome! Bug reports, documentation, spelling corrections, whole features, feature ideas, bugfixes, new plugins, fancy graphics... all of those (and probably more) are much appreciated contributions!
Please respect the [Code of Conduct](//github.com/PragTob/benchee/blob/master/CODE_OF_CONDUCT.md).
You can get started with a look at the [open issues](https://github.com/PragTob/benchee/issues).
A couple of (hopefully) helpful points:
* Feel free to ask for help and guidance on an issue/PR ("How can I implement this?", "How could I test this?", ...)
* Feel free to open early/not yet complete pull requests to get some early feedback
* When in doubt if something is a good idea open an issue first to discuss it
* In case I don't respond feel free to bump the issue/PR or ping me on other places
## Development
* `mix deps.get` to install dependencies
* `mix test` to run tests or `mix test.watch` to run them continuously while you change files
* `mix credo` or `mix credo --strict` to find code style problems (not too strict with the 80 width limit for sample output in the docs)
