WO2021207827A1 - Antibody constructs binding 4-1bb and folate receptor alpha and uses thereof - Google Patents
Antibody constructs binding 4-1bb and folate receptor alpha and uses thereof Download PDFInfo
- Publication number
- WO2021207827A1 WO2021207827A1 PCT/CA2021/050481 CA2021050481W WO2021207827A1 WO 2021207827 A1 WO2021207827 A1 WO 2021207827A1 CA 2021050481 W CA2021050481 W CA 2021050481W WO 2021207827 A1 WO2021207827 A1 WO 2021207827A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- antibody
- antigen
- sequence
- antibody construct
- binding domain
- Prior art date
Links
- 230000027455 binding Effects 0.000 title claims abstract description 703
- 102000010451 Folate receptor alpha Human genes 0.000 title claims description 11
- 108050001931 Folate receptor alpha Proteins 0.000 title claims description 11
- 108010037274 Member 9 Tumor Necrosis Factor Receptor Superfamily Proteins 0.000 title description 3
- 102000011769 Member 9 Tumor Necrosis Factor Receptor Superfamily Human genes 0.000 title description 3
- 239000000427 antigen Substances 0.000 claims abstract description 541
- 108091007433 antigens Proteins 0.000 claims abstract description 516
- 102000036639 antigens Human genes 0.000 claims abstract description 516
- 206010028980 Neoplasm Diseases 0.000 claims abstract description 83
- 230000004048 modification Effects 0.000 claims abstract description 75
- 238000012986 modification Methods 0.000 claims abstract description 75
- 201000011510 cancer Diseases 0.000 claims abstract description 43
- 238000011282 treatment Methods 0.000 claims abstract description 38
- 101001023230 Homo sapiens Folate receptor alpha Proteins 0.000 claims abstract description 34
- 102100035139 Folate receptor alpha Human genes 0.000 claims abstract description 26
- 101000851370 Homo sapiens Tumor necrosis factor receptor superfamily member 9 Proteins 0.000 claims abstract description 20
- 102100036856 Tumor necrosis factor receptor superfamily member 9 Human genes 0.000 claims abstract description 20
- 239000012636 effector Substances 0.000 claims abstract description 16
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 226
- 102000004196 processed proteins & peptides Human genes 0.000 claims description 219
- 229920001184 polypeptide Polymers 0.000 claims description 216
- 101710117290 Aldo-keto reductase family 1 member C4 Proteins 0.000 claims description 152
- 150000001413 amino acids Chemical class 0.000 claims description 120
- 238000000034 method Methods 0.000 claims description 113
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 95
- 241000282414 Homo sapiens Species 0.000 claims description 83
- 108010047041 Complementarity Determining Regions Proteins 0.000 claims description 82
- 150000007523 nucleic acids Chemical class 0.000 claims description 59
- 102000039446 nucleic acids Human genes 0.000 claims description 54
- 108020004707 nucleic acids Proteins 0.000 claims description 54
- 238000006467 substitution reaction Methods 0.000 claims description 45
- 239000012634 fragment Substances 0.000 claims description 40
- 238000004519 manufacturing process Methods 0.000 claims description 31
- 108060003951 Immunoglobulin Proteins 0.000 claims description 26
- 102000018358 immunoglobulin Human genes 0.000 claims description 26
- 239000003814 drug Substances 0.000 claims description 25
- 239000013598 vector Substances 0.000 claims description 24
- 230000007423 decrease Effects 0.000 claims description 16
- 229940079593 drug Drugs 0.000 claims description 16
- 230000015572 biosynthetic process Effects 0.000 claims description 14
- NFGXHKASABOEEW-UHFFFAOYSA-N 1-methylethyl 11-methoxy-3,7,11-trimethyl-2,4-dodecadienoate Chemical compound COC(C)(C)CCCC(C)CC=CC(C)=CC(=O)OC(C)C NFGXHKASABOEEW-UHFFFAOYSA-N 0.000 claims description 11
- 239000008194 pharmaceutical composition Substances 0.000 claims description 11
- 238000002360 preparation method Methods 0.000 claims description 11
- 230000001270 agonistic effect Effects 0.000 claims description 9
- 108010054477 Immunoglobulin Fab Fragments Proteins 0.000 claims description 7
- 102000001706 Immunoglobulin Fab Fragments Human genes 0.000 claims description 7
- 238000012258 culturing Methods 0.000 claims description 7
- 108010088751 Albumins Proteins 0.000 claims description 6
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 claims description 6
- 102000008394 Immunoglobulin Fragments Human genes 0.000 claims description 5
- 239000004472 Lysine Substances 0.000 claims description 5
- OVBPIULPVIDEAO-LBPRGKRZSA-N folic acid Chemical compound C=1N=C2NC(N)=NC(=O)C2=NC=1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 OVBPIULPVIDEAO-LBPRGKRZSA-N 0.000 claims description 5
- 238000003780 insertion Methods 0.000 claims description 5
- 230000037431 insertion Effects 0.000 claims description 5
- 108010021625 Immunoglobulin Fragments Proteins 0.000 claims description 4
- 235000019152 folic acid Nutrition 0.000 claims description 4
- 239000011724 folic acid Substances 0.000 claims description 4
- 108010067060 Immunoglobulin Variable Region Proteins 0.000 claims description 3
- 108010003723 Single-Domain Antibodies Proteins 0.000 claims description 3
- 102000017727 Immunoglobulin Variable Region Human genes 0.000 claims description 2
- 239000013628 high molecular weight specie Substances 0.000 claims description 2
- 102220476699 Interleukin-1 receptor-associated kinase 3_F83A_mutation Human genes 0.000 claims 6
- 102100024952 Protein CBFA2T1 Human genes 0.000 claims 6
- 229940014144 folate Drugs 0.000 claims 3
- 102220032372 rs104895229 Human genes 0.000 claims 3
- 102000009027 Albumins Human genes 0.000 claims 2
- 102220032022 rs66677059 Human genes 0.000 claims 2
- 102220504823 Acetylcholine receptor subunit alpha_S73N_mutation Human genes 0.000 claims 1
- 102200007335 rs1554292444 Human genes 0.000 claims 1
- 102220082637 rs61743884 Human genes 0.000 claims 1
- 102220061206 rs786203134 Human genes 0.000 claims 1
- 102000005962 receptors Human genes 0.000 abstract description 12
- 108020003175 receptors Proteins 0.000 abstract description 12
- 230000003432 anti-folate effect Effects 0.000 abstract 1
- 229940127074 antifolate Drugs 0.000 abstract 1
- 239000004052 folic acid antagonist Substances 0.000 abstract 1
- 210000004027 cell Anatomy 0.000 description 195
- 235000001014 amino acid Nutrition 0.000 description 119
- 229940024606 amino acid Drugs 0.000 description 107
- 108090000623 proteins and genes Proteins 0.000 description 59
- 102000004169 proteins and genes Human genes 0.000 description 54
- 235000018102 proteins Nutrition 0.000 description 53
- 125000005647 linker group Chemical group 0.000 description 41
- 239000000203 mixture Substances 0.000 description 39
- 230000000694 effects Effects 0.000 description 36
- 108090000015 Mesothelin Proteins 0.000 description 35
- 102000003735 Mesothelin Human genes 0.000 description 34
- 241000699666 Mus <mouse, genus> Species 0.000 description 34
- 101001012157 Homo sapiens Receptor tyrosine-protein kinase erbB-2 Proteins 0.000 description 29
- 102100030086 Receptor tyrosine-protein kinase erbB-2 Human genes 0.000 description 29
- -1 alanine (Ala or A) Chemical class 0.000 description 28
- 210000004881 tumor cell Anatomy 0.000 description 28
- 210000001744 T-lymphocyte Anatomy 0.000 description 24
- 102100023144 Zinc transporter ZIP6 Human genes 0.000 description 24
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 24
- 230000014509 gene expression Effects 0.000 description 24
- 238000003571 reporter gene assay Methods 0.000 description 23
- 101000979342 Homo sapiens Nuclear factor NF-kappa-B p105 subunit Proteins 0.000 description 22
- 102100023050 Nuclear factor NF-kappa-B p105 subunit Human genes 0.000 description 22
- 125000000539 amino acid group Chemical group 0.000 description 21
- 230000006870 function Effects 0.000 description 21
- 241000894007 species Species 0.000 description 19
- 101000685848 Homo sapiens Zinc transporter ZIP6 Proteins 0.000 description 18
- 125000003729 nucleotide group Chemical group 0.000 description 16
- 238000000746 purification Methods 0.000 description 16
- 108010032595 Antibody Binding Sites Proteins 0.000 description 15
- 238000003556 assay Methods 0.000 description 15
- 238000000684 flow cytometry Methods 0.000 description 15
- 239000002773 nucleotide Substances 0.000 description 15
- 238000012360 testing method Methods 0.000 description 15
- 238000012575 bio-layer interferometry Methods 0.000 description 14
- 201000010099 disease Diseases 0.000 description 14
- 125000001570 methylene group Chemical group [H]C([H])([*:1])[*:2] 0.000 description 14
- 102000040430 polynucleotide Human genes 0.000 description 14
- 108091033319 polynucleotide Proteins 0.000 description 14
- 239000002157 polynucleotide Substances 0.000 description 14
- 238000003501 co-culture Methods 0.000 description 13
- 239000000243 solution Substances 0.000 description 13
- 241001465754 Metazoa Species 0.000 description 12
- 102100032101 Tumor necrosis factor ligand superfamily member 9 Human genes 0.000 description 12
- 238000005516 engineering process Methods 0.000 description 12
- 230000035772 mutation Effects 0.000 description 12
- 229940049595 antibody-drug conjugate Drugs 0.000 description 11
- 239000003795 chemical substances by application Substances 0.000 description 11
- 150000001875 compounds Chemical class 0.000 description 11
- 239000000463 material Substances 0.000 description 11
- 239000000126 substance Substances 0.000 description 11
- 108020004705 Codon Proteins 0.000 description 10
- 241000283973 Oryctolagus cuniculus Species 0.000 description 10
- 239000011230 binding agent Substances 0.000 description 10
- 208000035475 disorder Diseases 0.000 description 10
- 210000002865 immune cell Anatomy 0.000 description 10
- 238000002198 surface plasmon resonance spectroscopy Methods 0.000 description 10
- 229950005972 urelumab Drugs 0.000 description 10
- 108010082808 4-1BB Ligand Proteins 0.000 description 9
- 241000699670 Mus sp. Species 0.000 description 9
- 102100034922 T-cell surface glycoprotein CD8 alpha chain Human genes 0.000 description 9
- 238000007792 addition Methods 0.000 description 9
- 230000013595 glycosylation Effects 0.000 description 9
- 238000006206 glycosylation reaction Methods 0.000 description 9
- 239000003053 toxin Substances 0.000 description 9
- 231100000765 toxin Toxicity 0.000 description 9
- 108700012359 toxins Proteins 0.000 description 9
- 229950003520 utomilumab Drugs 0.000 description 9
- 108010087819 Fc receptors Proteins 0.000 description 8
- 102000009109 Fc receptors Human genes 0.000 description 8
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 8
- 238000011198 co-culture assay Methods 0.000 description 8
- 238000005755 formation reaction Methods 0.000 description 8
- 238000001727 in vivo Methods 0.000 description 8
- 238000002347 injection Methods 0.000 description 8
- 239000007924 injection Substances 0.000 description 8
- 210000000822 natural killer cell Anatomy 0.000 description 8
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 8
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 7
- 235000004279 alanine Nutrition 0.000 description 7
- 238000004458 analytical method Methods 0.000 description 7
- 239000000611 antibody drug conjugate Substances 0.000 description 7
- 238000011319 anticancer therapy Methods 0.000 description 7
- 230000000295 complement effect Effects 0.000 description 7
- 238000001938 differential scanning calorimetry curve Methods 0.000 description 7
- 238000002474 experimental method Methods 0.000 description 7
- 229950009929 farletuzumab Drugs 0.000 description 7
- 238000009472 formulation Methods 0.000 description 7
- 230000001976 improved effect Effects 0.000 description 7
- 238000004895 liquid chromatography mass spectrometry Methods 0.000 description 7
- 208000020816 lung neoplasm Diseases 0.000 description 7
- 210000004962 mammalian cell Anatomy 0.000 description 7
- 229950007243 mirvetuximab Drugs 0.000 description 7
- 230000001225 therapeutic effect Effects 0.000 description 7
- 206010006187 Breast cancer Diseases 0.000 description 6
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 6
- XUJNEKJLAYXESH-REOHCLBHSA-N L-Cysteine Chemical compound SC[C@H](N)C(O)=O XUJNEKJLAYXESH-REOHCLBHSA-N 0.000 description 6
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 6
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 6
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 6
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 6
- 206010058467 Lung neoplasm malignant Diseases 0.000 description 6
- 206010061535 Ovarian neoplasm Diseases 0.000 description 6
- 102100038437 Sodium-dependent phosphate transport protein 2B Human genes 0.000 description 6
- 210000004899 c-terminal region Anatomy 0.000 description 6
- 230000001413 cellular effect Effects 0.000 description 6
- 230000000875 corresponding effect Effects 0.000 description 6
- 235000018417 cysteine Nutrition 0.000 description 6
- 229940127089 cytotoxic agent Drugs 0.000 description 6
- 238000013461 design Methods 0.000 description 6
- 238000000338 in vitro Methods 0.000 description 6
- 239000003446 ligand Substances 0.000 description 6
- 210000004072 lung Anatomy 0.000 description 6
- 238000013507 mapping Methods 0.000 description 6
- 229930182817 methionine Natural products 0.000 description 6
- 229960002087 pertuzumab Drugs 0.000 description 6
- 229920000642 polymer Polymers 0.000 description 6
- 210000004986 primary T-cell Anatomy 0.000 description 6
- 238000004445 quantitative analysis Methods 0.000 description 6
- 229960000575 trastuzumab Drugs 0.000 description 6
- FUOOLUPWFVMBKG-UHFFFAOYSA-N 2-Aminoisobutyric acid Chemical compound CC(C)(N)C(O)=O FUOOLUPWFVMBKG-UHFFFAOYSA-N 0.000 description 5
- 241000894006 Bacteria Species 0.000 description 5
- 208000026310 Breast neoplasm Diseases 0.000 description 5
- SHZGCJCMOBCMKK-UHFFFAOYSA-N D-mannomethylose Natural products CC1OC(O)C(O)C(O)C1O SHZGCJCMOBCMKK-UHFFFAOYSA-N 0.000 description 5
- 108020004414 DNA Proteins 0.000 description 5
- 241000196324 Embryophyta Species 0.000 description 5
- PNNNRSAQSRJVSB-SLPGGIOYSA-N Fucose Natural products C[C@H](O)[C@@H](O)[C@H](O)[C@H](O)C=O PNNNRSAQSRJVSB-SLPGGIOYSA-N 0.000 description 5
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 5
- SHZGCJCMOBCMKK-DHVFOXMCSA-N L-fucopyranose Chemical compound C[C@@H]1OC(O)[C@@H](O)[C@H](O)[C@@H]1O SHZGCJCMOBCMKK-DHVFOXMCSA-N 0.000 description 5
- 239000005089 Luciferase Substances 0.000 description 5
- 108091028043 Nucleic acid sequence Proteins 0.000 description 5
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 5
- 230000021736 acetylation Effects 0.000 description 5
- 238000006640 acetylation reaction Methods 0.000 description 5
- 230000003213 activating effect Effects 0.000 description 5
- 239000002246 antineoplastic agent Substances 0.000 description 5
- 150000001720 carbohydrates Chemical class 0.000 description 5
- 230000021615 conjugation Effects 0.000 description 5
- 238000010276 construction Methods 0.000 description 5
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 5
- 238000012217 deletion Methods 0.000 description 5
- 230000037430 deletion Effects 0.000 description 5
- 229960005501 duocarmycin Drugs 0.000 description 5
- 229930184221 duocarmycin Natural products 0.000 description 5
- 102000006815 folate receptor Human genes 0.000 description 5
- 108020005243 folate receptor Proteins 0.000 description 5
- 230000001900 immune effect Effects 0.000 description 5
- 238000001990 intravenous administration Methods 0.000 description 5
- 150000002632 lipids Chemical class 0.000 description 5
- 230000002503 metabolic effect Effects 0.000 description 5
- 230000004044 response Effects 0.000 description 5
- 230000011664 signaling Effects 0.000 description 5
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 5
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 4
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 4
- 102100027211 Albumin Human genes 0.000 description 4
- 231100000729 Amatoxin Toxicity 0.000 description 4
- 150000008574 D-amino acids Chemical class 0.000 description 4
- AOJJSUZBOXZQNB-TZSSRYMLSA-N Doxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-TZSSRYMLSA-N 0.000 description 4
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 4
- 108010002350 Interleukin-2 Proteins 0.000 description 4
- 102000000588 Interleukin-2 Human genes 0.000 description 4
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 4
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 4
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 4
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 4
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 description 4
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 4
- 102100040678 Programmed cell death protein 1 Human genes 0.000 description 4
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 4
- 108060008683 Tumor Necrosis Factor Receptor Proteins 0.000 description 4
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 4
- 239000002253 acid Substances 0.000 description 4
- 230000004913 activation Effects 0.000 description 4
- 238000010171 animal model Methods 0.000 description 4
- 238000013459 approach Methods 0.000 description 4
- 108010044540 auristatin Proteins 0.000 description 4
- 210000003719 b-lymphocyte Anatomy 0.000 description 4
- 239000000872 buffer Substances 0.000 description 4
- 238000004113 cell culture Methods 0.000 description 4
- 238000007385 chemical modification Methods 0.000 description 4
- 238000003776 cleavage reaction Methods 0.000 description 4
- 238000013270 controlled release Methods 0.000 description 4
- XVOYSCVBGLVSOL-UHFFFAOYSA-N cysteic acid Chemical compound OC(=O)C(N)CS(O)(=O)=O XVOYSCVBGLVSOL-UHFFFAOYSA-N 0.000 description 4
- 238000002022 differential scanning fluorescence spectroscopy Methods 0.000 description 4
- 238000010494 dissociation reaction Methods 0.000 description 4
- 230000005593 dissociations Effects 0.000 description 4
- 230000004927 fusion Effects 0.000 description 4
- 210000000987 immune system Anatomy 0.000 description 4
- 238000001802 infusion Methods 0.000 description 4
- 230000002401 inhibitory effect Effects 0.000 description 4
- 230000005764 inhibitory process Effects 0.000 description 4
- 230000003993 interaction Effects 0.000 description 4
- 230000003834 intracellular effect Effects 0.000 description 4
- 210000003292 kidney cell Anatomy 0.000 description 4
- 239000012528 membrane Substances 0.000 description 4
- 210000004379 membrane Anatomy 0.000 description 4
- 210000000581 natural killer T-cell Anatomy 0.000 description 4
- 230000026731 phosphorylation Effects 0.000 description 4
- 238000006366 phosphorylation reaction Methods 0.000 description 4
- 230000004481 post-translational protein modification Effects 0.000 description 4
- 230000001323 posttranslational effect Effects 0.000 description 4
- 230000002265 prevention Effects 0.000 description 4
- 230000008569 process Effects 0.000 description 4
- 239000000047 product Substances 0.000 description 4
- 238000000159 protein binding assay Methods 0.000 description 4
- 230000001105 regulatory effect Effects 0.000 description 4
- 238000011160 research Methods 0.000 description 4
- 230000007017 scission Effects 0.000 description 4
- QFJCIRLUMZQUOT-HPLJOQBZSA-N sirolimus Chemical compound C1C[C@@H](O)[C@H](OC)C[C@@H]1C[C@@H](C)[C@H]1OC(=O)[C@@H]2CCCCN2C(=O)C(=O)[C@](O)(O2)[C@H](C)CC[C@H]2C[C@H](OC)/C(C)=C/C=C/C=C/[C@@H](C)C[C@@H](C)C(=O)[C@H](OC)[C@H](O)/C(C)=C/[C@@H](C)C(=O)C1 QFJCIRLUMZQUOT-HPLJOQBZSA-N 0.000 description 4
- 239000011780 sodium chloride Substances 0.000 description 4
- 230000009870 specific binding Effects 0.000 description 4
- 238000002560 therapeutic procedure Methods 0.000 description 4
- 238000013519 translation Methods 0.000 description 4
- 102000003298 tumor necrosis factor receptor Human genes 0.000 description 4
- WOWDZACBATWTAU-FEFUEGSOSA-N (2s)-2-[[(2s)-2-(dimethylamino)-3-methylbutanoyl]amino]-n-[(3r,4s,5s)-1-[(2s)-2-[(1r,2r)-3-[[(1s,2r)-1-hydroxy-1-phenylpropan-2-yl]amino]-1-methoxy-2-methyl-3-oxopropyl]pyrrolidin-1-yl]-3-methoxy-5-methyl-1-oxoheptan-4-yl]-n,3-dimethylbutanamide Chemical compound CC(C)[C@H](N(C)C)C(=O)N[C@@H](C(C)C)C(=O)N(C)[C@@H]([C@@H](C)CC)[C@H](OC)CC(=O)N1CCC[C@H]1[C@H](OC)[C@@H](C)C(=O)N[C@H](C)[C@@H](O)C1=CC=CC=C1 WOWDZACBATWTAU-FEFUEGSOSA-N 0.000 description 3
- BFSVOASYOCHEOV-UHFFFAOYSA-N 2-diethylaminoethanol Chemical compound CCN(CC)CCO BFSVOASYOCHEOV-UHFFFAOYSA-N 0.000 description 3
- STQGQHZAVUOBTE-UHFFFAOYSA-N 7-Cyan-hept-2t-en-4,6-diinsaeure Natural products C1=2C(O)=C3C(=O)C=4C(OC)=CC=CC=4C(=O)C3=C(O)C=2CC(O)(C(C)=O)CC1OC1CC(N)C(O)C(C)O1 STQGQHZAVUOBTE-UHFFFAOYSA-N 0.000 description 3
- 239000004475 Arginine Substances 0.000 description 3
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 3
- 101710183938 Barstar Proteins 0.000 description 3
- 102100032912 CD44 antigen Human genes 0.000 description 3
- 241000282472 Canis lupus familiaris Species 0.000 description 3
- 102000004127 Cytokines Human genes 0.000 description 3
- 108090000695 Cytokines Proteins 0.000 description 3
- 238000002965 ELISA Methods 0.000 description 3
- 102000004190 Enzymes Human genes 0.000 description 3
- 108090000790 Enzymes Proteins 0.000 description 3
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 3
- 241000233866 Fungi Species 0.000 description 3
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 3
- 239000004471 Glycine Substances 0.000 description 3
- 241000238631 Hexapoda Species 0.000 description 3
- 101000868273 Homo sapiens CD44 antigen Proteins 0.000 description 3
- 101000716102 Homo sapiens T-cell surface glycoprotein CD4 Proteins 0.000 description 3
- 101000638251 Homo sapiens Tumor necrosis factor ligand superfamily member 9 Proteins 0.000 description 3
- 108700005091 Immunoglobulin Genes Proteins 0.000 description 3
- 108090001005 Interleukin-6 Proteins 0.000 description 3
- 102000004889 Interleukin-6 Human genes 0.000 description 3
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 3
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 3
- HNDVDQJCIGZPNO-YFKPBYRVSA-N L-histidine Chemical compound OC(=O)[C@@H](N)CC1=CN=CN1 HNDVDQJCIGZPNO-YFKPBYRVSA-N 0.000 description 3
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 3
- LRQKBLKVPFOOQJ-YFKPBYRVSA-N L-norleucine Chemical compound CCCC[C@H]([NH3+])C([O-])=O LRQKBLKVPFOOQJ-YFKPBYRVSA-N 0.000 description 3
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 3
- 102100029193 Low affinity immunoglobulin gamma Fc region receptor III-A Human genes 0.000 description 3
- 241000124008 Mammalia Species 0.000 description 3
- 229930126263 Maytansine Natural products 0.000 description 3
- 206010061902 Pancreatic neoplasm Diseases 0.000 description 3
- 239000004365 Protease Substances 0.000 description 3
- 108091006576 SLC34A2 Proteins 0.000 description 3
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 3
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 3
- 102100036011 T-cell surface glycoprotein CD4 Human genes 0.000 description 3
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 3
- 239000004473 Threonine Substances 0.000 description 3
- ZMANZCXQSJIPKH-UHFFFAOYSA-N Triethylamine Chemical compound CCN(CC)CC ZMANZCXQSJIPKH-UHFFFAOYSA-N 0.000 description 3
- 230000008484 agonism Effects 0.000 description 3
- QWCKQJZIFLGMSD-UHFFFAOYSA-N alpha-aminobutyric acid Chemical compound CCC(N)C(O)=O QWCKQJZIFLGMSD-UHFFFAOYSA-N 0.000 description 3
- 230000009435 amidation Effects 0.000 description 3
- 238000007112 amidation reaction Methods 0.000 description 3
- 230000009830 antibody antigen interaction Effects 0.000 description 3
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 3
- 235000009697 arginine Nutrition 0.000 description 3
- 235000009582 asparagine Nutrition 0.000 description 3
- 229960001230 asparagine Drugs 0.000 description 3
- 235000003704 aspartic acid Nutrition 0.000 description 3
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 3
- 229910052799 carbon Inorganic materials 0.000 description 3
- 239000000969 carrier Substances 0.000 description 3
- 238000010367 cloning Methods 0.000 description 3
- 239000002299 complementary DNA Substances 0.000 description 3
- 201000000464 cone-rod dystrophy 2 Diseases 0.000 description 3
- 239000013078 crystal Substances 0.000 description 3
- 125000004122 cyclic group Chemical group 0.000 description 3
- 230000001086 cytosolic effect Effects 0.000 description 3
- 230000001472 cytotoxic effect Effects 0.000 description 3
- STQGQHZAVUOBTE-VGBVRHCVSA-N daunorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(C)=O)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 STQGQHZAVUOBTE-VGBVRHCVSA-N 0.000 description 3
- 230000003247 decreasing effect Effects 0.000 description 3
- 238000001212 derivatisation Methods 0.000 description 3
- 238000000113 differential scanning calorimetry Methods 0.000 description 3
- 229930188854 dolastatin Natural products 0.000 description 3
- 239000003937 drug carrier Substances 0.000 description 3
- 239000000975 dye Substances 0.000 description 3
- 229940088598 enzyme Drugs 0.000 description 3
- MHMNJMPURVTYEJ-UHFFFAOYSA-N fluorescein-5-isothiocyanate Chemical compound O1C(=O)C2=CC(N=C=S)=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 MHMNJMPURVTYEJ-UHFFFAOYSA-N 0.000 description 3
- 230000022244 formylation Effects 0.000 description 3
- 238000006170 formylation reaction Methods 0.000 description 3
- 230000002068 genetic effect Effects 0.000 description 3
- 235000013922 glutamic acid Nutrition 0.000 description 3
- 239000004220 glutamic acid Substances 0.000 description 3
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 3
- 235000004554 glutamine Nutrition 0.000 description 3
- 229930004094 glycosylphosphatidylinositol Natural products 0.000 description 3
- 230000036541 health Effects 0.000 description 3
- 229930187626 hemiasterlin Natural products 0.000 description 3
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 3
- 210000004408 hybridoma Anatomy 0.000 description 3
- 230000002163 immunogen Effects 0.000 description 3
- 229940072221 immunoglobulins Drugs 0.000 description 3
- 238000000099 in vitro assay Methods 0.000 description 3
- 238000007914 intraventricular administration Methods 0.000 description 3
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 3
- 229960000310 isoleucine Drugs 0.000 description 3
- 210000003734 kidney Anatomy 0.000 description 3
- 230000000670 limiting effect Effects 0.000 description 3
- 239000002502 liposome Substances 0.000 description 3
- 201000005202 lung cancer Diseases 0.000 description 3
- 201000005296 lung carcinoma Diseases 0.000 description 3
- 208000015486 malignant pancreatic neoplasm Diseases 0.000 description 3
- 229950003135 margetuximab Drugs 0.000 description 3
- WKPWGQKGSOKKOO-RSFHAFMBSA-N maytansine Chemical compound CO[C@@H]([C@@]1(O)C[C@](OC(=O)N1)([C@H]([C@@H]1O[C@@]1(C)[C@@H](OC(=O)[C@H](C)N(C)C(C)=O)CC(=O)N1C)C)[H])\C=C\C=C(C)\CC2=CC(OC)=C(Cl)C1=C2 WKPWGQKGSOKKOO-RSFHAFMBSA-N 0.000 description 3
- 229960005558 mertansine Drugs 0.000 description 3
- 230000003647 oxidation Effects 0.000 description 3
- 238000007254 oxidation reaction Methods 0.000 description 3
- 201000002528 pancreatic cancer Diseases 0.000 description 3
- 208000008443 pancreatic carcinoma Diseases 0.000 description 3
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 3
- 238000012545 processing Methods 0.000 description 3
- ZAHRKKWIAAJSAO-UHFFFAOYSA-N rapamycin Natural products COCC(O)C(=C/C(C)C(=O)CC(OC(=O)C1CCCCN1C(=O)C(=O)C2(O)OC(CC(OC)C(=CC=CC=CC(C)CC(C)C(=O)C)C)CCC2C)C(C)CC3CCC(O)C(C3)OC)C ZAHRKKWIAAJSAO-UHFFFAOYSA-N 0.000 description 3
- 230000009467 reduction Effects 0.000 description 3
- 238000012552 review Methods 0.000 description 3
- 150000003839 salts Chemical class 0.000 description 3
- 229960002930 sirolimus Drugs 0.000 description 3
- 238000010561 standard procedure Methods 0.000 description 3
- 229910052717 sulfur Inorganic materials 0.000 description 3
- 239000006228 supernatant Substances 0.000 description 3
- 238000001356 surgical procedure Methods 0.000 description 3
- 208000024891 symptom Diseases 0.000 description 3
- 238000003786 synthesis reaction Methods 0.000 description 3
- 230000009885 systemic effect Effects 0.000 description 3
- 210000001519 tissue Anatomy 0.000 description 3
- 230000004614 tumor growth Effects 0.000 description 3
- 239000004474 valine Substances 0.000 description 3
- LGNCNVVZCUVPOT-FUVGGWJZSA-N (2s)-2-[[(2r,3r)-3-[(2s)-1-[(3r,4s,5s)-4-[[(2s)-2-[[(2s)-2-(dimethylamino)-3-methylbutanoyl]amino]-3-methylbutanoyl]-methylamino]-3-methoxy-5-methylheptanoyl]pyrrolidin-2-yl]-3-methoxy-2-methylpropanoyl]amino]-3-phenylpropanoic acid Chemical compound CC(C)[C@H](N(C)C)C(=O)N[C@@H](C(C)C)C(=O)N(C)[C@@H]([C@@H](C)CC)[C@H](OC)CC(=O)N1CCC[C@H]1[C@H](OC)[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 LGNCNVVZCUVPOT-FUVGGWJZSA-N 0.000 description 2
- MFRNYXJJRJQHNW-DEMKXPNLSA-N (2s)-2-[[(2r,3r)-3-methoxy-3-[(2s)-1-[(3r,4s,5s)-3-methoxy-5-methyl-4-[methyl-[(2s)-3-methyl-2-[[(2s)-3-methyl-2-(methylamino)butanoyl]amino]butanoyl]amino]heptanoyl]pyrrolidin-2-yl]-2-methylpropanoyl]amino]-3-phenylpropanoic acid Chemical compound CN[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(=O)N(C)[C@@H]([C@@H](C)CC)[C@H](OC)CC(=O)N1CCC[C@H]1[C@H](OC)[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 MFRNYXJJRJQHNW-DEMKXPNLSA-N 0.000 description 2
- VYEWZWBILJHHCU-OMQUDAQFSA-N (e)-n-[(2s,3r,4r,5r,6r)-2-[(2r,3r,4s,5s,6s)-3-acetamido-5-amino-4-hydroxy-6-(hydroxymethyl)oxan-2-yl]oxy-6-[2-[(2r,3s,4r,5r)-5-(2,4-dioxopyrimidin-1-yl)-3,4-dihydroxyoxolan-2-yl]-2-hydroxyethyl]-4,5-dihydroxyoxan-3-yl]-5-methylhex-2-enamide Chemical compound N1([C@@H]2O[C@@H]([C@H]([C@H]2O)O)C(O)C[C@@H]2[C@H](O)[C@H](O)[C@H]([C@@H](O2)O[C@@H]2[C@@H]([C@@H](O)[C@H](N)[C@@H](CO)O2)NC(C)=O)NC(=O)/C=C/CC(C)C)C=CC(=O)NC1=O VYEWZWBILJHHCU-OMQUDAQFSA-N 0.000 description 2
- KQODQNJLJQHFQV-MKWZWQCGSA-N (e,4s)-4-[[(2s)-3,3-dimethyl-2-[[(2s)-3-methyl-2-(methylamino)-3-(1-methylindol-3-yl)butanoyl]amino]butanoyl]-methylamino]-2,5-dimethylhex-2-enoic acid Chemical class C1=CC=C2C(C(C)(C)[C@@H](C(=O)N[C@H](C(=O)N(C)[C@H](\C=C(/C)C(O)=O)C(C)C)C(C)(C)C)NC)=CN(C)C2=C1 KQODQNJLJQHFQV-MKWZWQCGSA-N 0.000 description 2
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 2
- VBICKXHEKHSIBG-UHFFFAOYSA-N 1-monostearoylglycerol Chemical compound CCCCCCCCCCCCCCCCCC(=O)OCC(O)CO VBICKXHEKHSIBG-UHFFFAOYSA-N 0.000 description 2
- FJHBVJOVLFPMQE-QFIPXVFZSA-N 7-Ethyl-10-Hydroxy-Camptothecin Chemical compound C1=C(O)C=C2C(CC)=C(CN3C(C4=C([C@@](C(=O)OC4)(O)CC)C=C33)=O)C3=NC2=C1 FJHBVJOVLFPMQE-QFIPXVFZSA-N 0.000 description 2
- 102100033793 ALK tyrosine kinase receptor Human genes 0.000 description 2
- 101710168331 ALK tyrosine kinase receptor Proteins 0.000 description 2
- BUROJSBIWGDYCN-GAUTUEMISA-N AP 23573 Chemical compound C1C[C@@H](OP(C)(C)=O)[C@H](OC)C[C@@H]1C[C@@H](C)[C@H]1OC(=O)[C@@H]2CCCCN2C(=O)C(=O)[C@](O)(O2)[C@H](C)CC[C@H]2C[C@H](OC)/C(C)=C/C=C/C=C/[C@@H](C)C[C@@H](C)C(=O)[C@H](OC)[C@H](O)/C(C)=C/[C@@H](C)C(=O)C1 BUROJSBIWGDYCN-GAUTUEMISA-N 0.000 description 2
- GUBGYTABKSRVRQ-XLOQQCSPSA-N Alpha-Lactose Chemical compound O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@H]1O[C@@H]1[C@@H](CO)O[C@H](O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-XLOQQCSPSA-N 0.000 description 2
- PAYRUJLWNCNPSJ-UHFFFAOYSA-N Aniline Chemical compound NC1=CC=CC=C1 PAYRUJLWNCNPSJ-UHFFFAOYSA-N 0.000 description 2
- 108010063104 Apoptosis Regulatory Proteins Proteins 0.000 description 2
- 102000010565 Apoptosis Regulatory Proteins Human genes 0.000 description 2
- 102100021569 Apoptosis regulator Bcl-2 Human genes 0.000 description 2
- 102100022718 Atypical chemokine receptor 2 Human genes 0.000 description 2
- 108010077805 Bacterial Proteins Proteins 0.000 description 2
- 206010005003 Bladder cancer Diseases 0.000 description 2
- 241000283690 Bos taurus Species 0.000 description 2
- 102100032367 C-C motif chemokine 5 Human genes 0.000 description 2
- 102000017420 CD3 protein, epsilon/gamma/delta subunit Human genes 0.000 description 2
- 108050005493 CD3 protein, epsilon/gamma/delta subunit Proteins 0.000 description 2
- 102100032937 CD40 ligand Human genes 0.000 description 2
- 101100495352 Candida albicans CDR4 gene Proteins 0.000 description 2
- 241000282465 Canis Species 0.000 description 2
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical compound [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 2
- 102100024423 Carbonic anhydrase 9 Human genes 0.000 description 2
- 102100025475 Carcinoembryonic antigen-related cell adhesion molecule 5 Human genes 0.000 description 2
- 241000282693 Cercopithecidae Species 0.000 description 2
- 108010055166 Chemokine CCL5 Proteins 0.000 description 2
- 102000011022 Chorionic Gonadotropin Human genes 0.000 description 2
- 108010062540 Chorionic Gonadotropin Proteins 0.000 description 2
- 206010009944 Colon cancer Diseases 0.000 description 2
- 241000699802 Cricetulus griseus Species 0.000 description 2
- 102000016607 Diphtheria Toxin Human genes 0.000 description 2
- 108010053187 Diphtheria Toxin Proteins 0.000 description 2
- 102100030751 Eomesodermin homolog Human genes 0.000 description 2
- 102100031940 Epithelial cell adhesion molecule Human genes 0.000 description 2
- 241000588724 Escherichia coli Species 0.000 description 2
- LYCAIKOWRPUZTN-UHFFFAOYSA-N Ethylene glycol Chemical compound OCCO LYCAIKOWRPUZTN-UHFFFAOYSA-N 0.000 description 2
- 241000206602 Eukaryota Species 0.000 description 2
- 108010021468 Fc gamma receptor IIA Proteins 0.000 description 2
- 108010021472 Fc gamma receptor IIB Proteins 0.000 description 2
- 102000018233 Fibroblast Growth Factor Human genes 0.000 description 2
- 108050007372 Fibroblast Growth Factor Proteins 0.000 description 2
- 241000205062 Halobacterium Species 0.000 description 2
- 101710154606 Hemagglutinin Proteins 0.000 description 2
- 241000282412 Homo Species 0.000 description 2
- 101000690301 Homo sapiens Aldo-keto reductase family 1 member C4 Proteins 0.000 description 2
- 101000834898 Homo sapiens Alpha-synuclein Proteins 0.000 description 2
- 101000678892 Homo sapiens Atypical chemokine receptor 2 Proteins 0.000 description 2
- 101000914324 Homo sapiens Carcinoembryonic antigen-related cell adhesion molecule 5 Proteins 0.000 description 2
- 101001064167 Homo sapiens Eomesodermin homolog Proteins 0.000 description 2
- 101000851181 Homo sapiens Epidermal growth factor receptor Proteins 0.000 description 2
- 101000853002 Homo sapiens Interleukin-25 Proteins 0.000 description 2
- 101000623901 Homo sapiens Mucin-16 Proteins 0.000 description 2
- 101001128431 Homo sapiens Myeloid-derived growth factor Proteins 0.000 description 2
- 101000611936 Homo sapiens Programmed cell death protein 1 Proteins 0.000 description 2
- 101001116548 Homo sapiens Protein CBFA2T1 Proteins 0.000 description 2
- 101000652359 Homo sapiens Spermatogenesis-associated protein 2 Proteins 0.000 description 2
- 108010073807 IgG Receptors Proteins 0.000 description 2
- DGAQECJNVWCQMB-PUAWFVPOSA-M Ilexoside XXIX Chemical compound C[C@@H]1CC[C@@]2(CC[C@@]3(C(=CC[C@H]4[C@]3(CC[C@@H]5[C@@]4(CC[C@@H](C5(C)C)OS(=O)(=O)[O-])C)C)[C@@H]2[C@]1(C)O)C)C(=O)O[C@H]6[C@@H]([C@H]([C@@H]([C@H](O6)CO)O)O)O.[Na+] DGAQECJNVWCQMB-PUAWFVPOSA-M 0.000 description 2
- 102000006496 Immunoglobulin Heavy Chains Human genes 0.000 description 2
- 108010019476 Immunoglobulin Heavy Chains Proteins 0.000 description 2
- 102000013462 Interleukin-12 Human genes 0.000 description 2
- 108010065805 Interleukin-12 Proteins 0.000 description 2
- 102000003812 Interleukin-15 Human genes 0.000 description 2
- 108090000172 Interleukin-15 Proteins 0.000 description 2
- 102100030703 Interleukin-22 Human genes 0.000 description 2
- 102100037792 Interleukin-6 receptor subunit alpha Human genes 0.000 description 2
- 208000008839 Kidney Neoplasms Diseases 0.000 description 2
- AHLPHDHHMVZTML-BYPYZUCNSA-N L-Ornithine Chemical compound NCCC[C@H](N)C(O)=O AHLPHDHHMVZTML-BYPYZUCNSA-N 0.000 description 2
- ONIBWKKTOPOVIA-BYPYZUCNSA-N L-Proline Chemical compound OC(=O)[C@@H]1CCCN1 ONIBWKKTOPOVIA-BYPYZUCNSA-N 0.000 description 2
- 150000008575 L-amino acids Chemical class 0.000 description 2
- GUBGYTABKSRVRQ-QKKXKWKRSA-N Lactose Natural products OC[C@H]1O[C@@H](O[C@H]2[C@H](O)[C@@H](O)C(O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@H]1O GUBGYTABKSRVRQ-QKKXKWKRSA-N 0.000 description 2
- 108060001084 Luciferase Proteins 0.000 description 2
- 102000029749 Microtubule Human genes 0.000 description 2
- 108091022875 Microtubule Proteins 0.000 description 2
- 102100023123 Mucin-16 Human genes 0.000 description 2
- 241001529936 Murinae Species 0.000 description 2
- 108091007491 NSP3 Papain-like protease domains Proteins 0.000 description 2
- 108700020796 Oncogene Proteins 0.000 description 2
- AHLPHDHHMVZTML-UHFFFAOYSA-N Orn-delta-NH2 Natural products NCCCC(N)C(O)=O AHLPHDHHMVZTML-UHFFFAOYSA-N 0.000 description 2
- UTJLXEIPEHZYQJ-UHFFFAOYSA-N Ornithine Natural products OC(=O)C(C)CCCN UTJLXEIPEHZYQJ-UHFFFAOYSA-N 0.000 description 2
- 101710093908 Outer capsid protein VP4 Proteins 0.000 description 2
- 101710135467 Outer capsid protein sigma-1 Proteins 0.000 description 2
- 206010033128 Ovarian cancer Diseases 0.000 description 2
- KDLHZDBZIXYQEI-UHFFFAOYSA-N Palladium Chemical compound [Pd] KDLHZDBZIXYQEI-UHFFFAOYSA-N 0.000 description 2
- 108090000526 Papain Proteins 0.000 description 2
- 108091005804 Peptidases Proteins 0.000 description 2
- 102000035195 Peptidases Human genes 0.000 description 2
- 206010035226 Plasma cell myeloma Diseases 0.000 description 2
- 241000288906 Primates Species 0.000 description 2
- 101710089372 Programmed cell death protein 1 Proteins 0.000 description 2
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 2
- 206010060862 Prostate cancer Diseases 0.000 description 2
- 208000000236 Prostatic Neoplasms Diseases 0.000 description 2
- 101710176177 Protein A56 Proteins 0.000 description 2
- 108010076504 Protein Sorting Signals Proteins 0.000 description 2
- 101000762949 Pseudomonas aeruginosa (strain ATCC 15692 / DSM 22644 / CIP 104116 / JCM 14847 / LMG 12228 / 1C / PRS 101 / PAO1) Exotoxin A Proteins 0.000 description 2
- 241000700159 Rattus Species 0.000 description 2
- 206010038389 Renal cancer Diseases 0.000 description 2
- 108091006938 SLC39A6 Proteins 0.000 description 2
- 229920002684 Sepharose Polymers 0.000 description 2
- 208000000453 Skin Neoplasms Diseases 0.000 description 2
- 108050003877 Sodium-dependent phosphate transport protein 2B Proteins 0.000 description 2
- 229920002472 Starch Polymers 0.000 description 2
- 208000005718 Stomach Neoplasms Diseases 0.000 description 2
- 230000006044 T cell activation Effects 0.000 description 2
- 108091008874 T cell receptors Proteins 0.000 description 2
- 102000016266 T-Cell Antigen Receptors Human genes 0.000 description 2
- 208000024770 Thyroid neoplasm Diseases 0.000 description 2
- 108060008682 Tumor Necrosis Factor Proteins 0.000 description 2
- 102100040247 Tumor necrosis factor Human genes 0.000 description 2
- YJQCOFNZVFGCAF-UHFFFAOYSA-N Tunicamycin II Natural products O1C(CC(O)C2C(C(O)C(O2)N2C(NC(=O)C=C2)=O)O)C(O)C(O)C(NC(=O)C=CCCCCCCCCC(C)C)C1OC1OC(CO)C(O)C(O)C1NC(C)=O YJQCOFNZVFGCAF-UHFFFAOYSA-N 0.000 description 2
- 208000007097 Urinary Bladder Neoplasms Diseases 0.000 description 2
- 244000000188 Vaccinium ovalifolium Species 0.000 description 2
- 241000251539 Vertebrata <Metazoa> Species 0.000 description 2
- 101710097851 Zinc transporter ZIP6 Proteins 0.000 description 2
- IEDXPSOJFSVCKU-HOKPPMCLSA-N [4-[[(2S)-5-(carbamoylamino)-2-[[(2S)-2-[6-(2,5-dioxopyrrolidin-1-yl)hexanoylamino]-3-methylbutanoyl]amino]pentanoyl]amino]phenyl]methyl N-[(2S)-1-[[(2S)-1-[[(3R,4S,5S)-1-[(2S)-2-[(1R,2R)-3-[[(1S,2R)-1-hydroxy-1-phenylpropan-2-yl]amino]-1-methoxy-2-methyl-3-oxopropyl]pyrrolidin-1-yl]-3-methoxy-5-methyl-1-oxoheptan-4-yl]-methylamino]-3-methyl-1-oxobutan-2-yl]amino]-3-methyl-1-oxobutan-2-yl]-N-methylcarbamate Chemical compound CC[C@H](C)[C@@H]([C@@H](CC(=O)N1CCC[C@H]1[C@H](OC)[C@@H](C)C(=O)N[C@H](C)[C@@H](O)c1ccccc1)OC)N(C)C(=O)[C@@H](NC(=O)[C@H](C(C)C)N(C)C(=O)OCc1ccc(NC(=O)[C@H](CCCNC(N)=O)NC(=O)[C@@H](NC(=O)CCCCCN2C(=O)CCC2=O)C(C)C)cc1)C(C)C IEDXPSOJFSVCKU-HOKPPMCLSA-N 0.000 description 2
- 150000007513 acids Chemical class 0.000 description 2
- 239000013543 active substance Substances 0.000 description 2
- 210000005006 adaptive immune system Anatomy 0.000 description 2
- 239000003708 ampul Substances 0.000 description 2
- 239000012491 analyte Substances 0.000 description 2
- 229940124650 anti-cancer therapies Drugs 0.000 description 2
- 239000007864 aqueous solution Substances 0.000 description 2
- 125000004429 atom Chemical group 0.000 description 2
- 230000001580 bacterial effect Effects 0.000 description 2
- 239000008228 bacteriostatic water for injection Substances 0.000 description 2
- WPYMKLBDIGXBTP-UHFFFAOYSA-N benzoic acid Chemical compound OC(=O)C1=CC=CC=C1 WPYMKLBDIGXBTP-UHFFFAOYSA-N 0.000 description 2
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 2
- UCMIRNVEIXFBKS-UHFFFAOYSA-N beta-alanine Chemical compound NCCC(O)=O UCMIRNVEIXFBKS-UHFFFAOYSA-N 0.000 description 2
- 229960002685 biotin Drugs 0.000 description 2
- 235000020958 biotin Nutrition 0.000 description 2
- 239000011616 biotin Substances 0.000 description 2
- 230000000903 blocking effect Effects 0.000 description 2
- 210000004369 blood Anatomy 0.000 description 2
- 239000008280 blood Substances 0.000 description 2
- 210000004556 brain Anatomy 0.000 description 2
- 229930195731 calicheamicin Natural products 0.000 description 2
- 235000014633 carbohydrates Nutrition 0.000 description 2
- 230000003915 cell function Effects 0.000 description 2
- 239000001913 cellulose Substances 0.000 description 2
- 229920002678 cellulose Polymers 0.000 description 2
- JROFGZPOBKIAEW-HAQNSBGRSA-N chembl3120215 Chemical compound N1C=2C(OC)=CC=CC=2C=C1C(=C1C(N)=NC=NN11)N=C1[C@H]1CC[C@H](C(O)=O)CC1 JROFGZPOBKIAEW-HAQNSBGRSA-N 0.000 description 2
- 239000003153 chemical reaction reagent Substances 0.000 description 2
- 238000002512 chemotherapy Methods 0.000 description 2
- 238000004587 chromatography analysis Methods 0.000 description 2
- 230000009137 competitive binding Effects 0.000 description 2
- 238000004132 cross linking Methods 0.000 description 2
- 230000016396 cytokine production Effects 0.000 description 2
- 231100000433 cytotoxic Toxicity 0.000 description 2
- 239000002254 cytotoxic agent Substances 0.000 description 2
- 231100000599 cytotoxic agent Toxicity 0.000 description 2
- 229960000975 daunorubicin Drugs 0.000 description 2
- 238000001514 detection method Methods 0.000 description 2
- 238000011161 development Methods 0.000 description 2
- 230000018109 developmental process Effects 0.000 description 2
- 239000003085 diluting agent Substances 0.000 description 2
- 239000000539 dimer Substances 0.000 description 2
- VSJKWCGYPAHWDS-UHFFFAOYSA-N dl-camptothecin Natural products C1=CC=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)C5(O)CC)C4=NC2=C1 VSJKWCGYPAHWDS-UHFFFAOYSA-N 0.000 description 2
- 231100000673 dose–response relationship Toxicity 0.000 description 2
- 229960004679 doxorubicin Drugs 0.000 description 2
- 230000009977 dual effect Effects 0.000 description 2
- 230000002708 enhancing effect Effects 0.000 description 2
- 102000052116 epidermal growth factor receptor activity proteins Human genes 0.000 description 2
- 108700015053 epidermal growth factor receptor activity proteins Proteins 0.000 description 2
- 150000002148 esters Chemical class 0.000 description 2
- 230000001747 exhibiting effect Effects 0.000 description 2
- 239000013604 expression vector Substances 0.000 description 2
- 229940126864 fibroblast growth factor Drugs 0.000 description 2
- GNBHRKFJIUUOQI-UHFFFAOYSA-N fluorescein Chemical compound O1C(=O)C2=CC=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 GNBHRKFJIUUOQI-UHFFFAOYSA-N 0.000 description 2
- 108091006047 fluorescent proteins Proteins 0.000 description 2
- 102000034287 fluorescent proteins Human genes 0.000 description 2
- 230000033581 fucosylation Effects 0.000 description 2
- 108020001507 fusion proteins Proteins 0.000 description 2
- 102000037865 fusion proteins Human genes 0.000 description 2
- BTCSSZJGUNDROE-UHFFFAOYSA-N gamma-aminobutyric acid Chemical compound NCCCC(O)=O BTCSSZJGUNDROE-UHFFFAOYSA-N 0.000 description 2
- 210000004602 germ cell Anatomy 0.000 description 2
- 239000011521 glass Substances 0.000 description 2
- RWSXRVCMGQZWBV-WDSKDSINSA-N glutathione Chemical compound OC(=O)[C@@H](N)CCC(=O)N[C@@H](CS)C(=O)NCC(O)=O RWSXRVCMGQZWBV-WDSKDSINSA-N 0.000 description 2
- 239000000185 hemagglutinin Substances 0.000 description 2
- 238000004128 high performance liquid chromatography Methods 0.000 description 2
- 102000054751 human RUNX1T1 Human genes 0.000 description 2
- 229940084986 human chorionic gonadotropin Drugs 0.000 description 2
- 238000009396 hybridization Methods 0.000 description 2
- 230000003053 immunization Effects 0.000 description 2
- 230000002998 immunogenetic effect Effects 0.000 description 2
- 230000016784 immunoglobulin production Effects 0.000 description 2
- 239000007943 implant Substances 0.000 description 2
- 238000010874 in vitro model Methods 0.000 description 2
- 238000010348 incorporation Methods 0.000 description 2
- 239000004615 ingredient Substances 0.000 description 2
- 238000007912 intraperitoneal administration Methods 0.000 description 2
- 238000000111 isothermal titration calorimetry Methods 0.000 description 2
- 201000010982 kidney cancer Diseases 0.000 description 2
- 239000008101 lactose Substances 0.000 description 2
- 239000007788 liquid Substances 0.000 description 2
- 201000007270 liver cancer Diseases 0.000 description 2
- 210000005229 liver cell Anatomy 0.000 description 2
- 208000014018 liver neoplasm Diseases 0.000 description 2
- 210000002540 macrophage Anatomy 0.000 description 2
- HQKMJHAJHXVSDF-UHFFFAOYSA-L magnesium stearate Chemical compound [Mg+2].CCCCCCCCCCCCCCCCCC([O-])=O.CCCCCCCCCCCCCCCCCC([O-])=O HQKMJHAJHXVSDF-UHFFFAOYSA-L 0.000 description 2
- 239000003550 marker Substances 0.000 description 2
- 230000001404 mediated effect Effects 0.000 description 2
- 238000002844 melting Methods 0.000 description 2
- 230000008018 melting Effects 0.000 description 2
- ANZJBCHSOXCCRQ-FKUXLPTCSA-N mertansine Chemical compound CO[C@@H]([C@@]1(O)C[C@H](OC(=O)N1)[C@@H](C)[C@@H]1O[C@@]1(C)[C@@H](OC(=O)[C@H](C)N(C)C(=O)CCS)CC(=O)N1C)\C=C\C=C(C)\CC2=CC(OC)=C(Cl)C1=C2 ANZJBCHSOXCCRQ-FKUXLPTCSA-N 0.000 description 2
- 108020004999 messenger RNA Proteins 0.000 description 2
- 125000001360 methionine group Chemical group N[C@@H](CCSC)C(=O)* 0.000 description 2
- 239000011859 microparticle Substances 0.000 description 2
- 210000004688 microtubule Anatomy 0.000 description 2
- 238000001823 molecular biology technique Methods 0.000 description 2
- 108010093470 monomethyl auristatin E Proteins 0.000 description 2
- 108010059074 monomethylauristatin F Proteins 0.000 description 2
- 201000000050 myeloid neoplasm Diseases 0.000 description 2
- YOHYSYJDKVYCJI-UHFFFAOYSA-N n-[3-[[6-[3-(trifluoromethyl)anilino]pyrimidin-4-yl]amino]phenyl]cyclopropanecarboxamide Chemical compound FC(F)(F)C1=CC=CC(NC=2N=CN=C(NC=3C=C(NC(=O)C4CC4)C=CC=3)C=2)=C1 YOHYSYJDKVYCJI-UHFFFAOYSA-N 0.000 description 2
- 239000002105 nanoparticle Substances 0.000 description 2
- 229960003104 ornithine Drugs 0.000 description 2
- 210000001672 ovary Anatomy 0.000 description 2
- 229940055729 papain Drugs 0.000 description 2
- 235000019834 papain Nutrition 0.000 description 2
- 230000006320 pegylation Effects 0.000 description 2
- 238000002823 phage display Methods 0.000 description 2
- 239000000546 pharmaceutical excipient Substances 0.000 description 2
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 2
- 230000006337 proteolytic cleavage Effects 0.000 description 2
- 210000003289 regulatory T cell Anatomy 0.000 description 2
- 230000001177 retroviral effect Effects 0.000 description 2
- 229960001302 ridaforolimus Drugs 0.000 description 2
- 239000000523 sample Substances 0.000 description 2
- FSYKKLYZXJSNPZ-UHFFFAOYSA-N sarcosine Chemical compound C[NH2+]CC([O-])=O FSYKKLYZXJSNPZ-UHFFFAOYSA-N 0.000 description 2
- 230000003248 secreting effect Effects 0.000 description 2
- 210000002966 serum Anatomy 0.000 description 2
- 201000000849 skin cancer Diseases 0.000 description 2
- 239000011734 sodium Substances 0.000 description 2
- 229910052708 sodium Inorganic materials 0.000 description 2
- 239000007787 solid Substances 0.000 description 2
- 239000002904 solvent Substances 0.000 description 2
- 239000008107 starch Substances 0.000 description 2
- 235000019698 starch Nutrition 0.000 description 2
- 238000007920 subcutaneous administration Methods 0.000 description 2
- 239000000829 suppository Substances 0.000 description 2
- 230000004083 survival effect Effects 0.000 description 2
- 239000000725 suspension Substances 0.000 description 2
- 230000008685 targeting Effects 0.000 description 2
- 238000001757 thermogravimetry curve Methods 0.000 description 2
- 201000002510 thyroid cancer Diseases 0.000 description 2
- 238000001890 transfection Methods 0.000 description 2
- 230000009261 transgenic effect Effects 0.000 description 2
- 230000007704 transition Effects 0.000 description 2
- 229930184737 tubulysin Natural products 0.000 description 2
- MEYZYGMYMLNUHJ-UHFFFAOYSA-N tunicamycin Natural products CC(C)CCCCCCCCCC=CC(=O)NC1C(O)C(O)C(CC(O)C2OC(C(O)C2O)N3C=CC(=O)NC3=O)OC1OC4OC(CO)C(O)C(O)C4NC(=O)C MEYZYGMYMLNUHJ-UHFFFAOYSA-N 0.000 description 2
- 238000010798 ubiquitination Methods 0.000 description 2
- 230000034512 ubiquitination Effects 0.000 description 2
- 201000005112 urinary bladder cancer Diseases 0.000 description 2
- 239000003981 vehicle Substances 0.000 description 2
- 238000011179 visual inspection Methods 0.000 description 2
- JFCFGYGEYRIEBE-YVLHJLIDSA-N wob38vs2ni Chemical compound CO[C@@H]([C@@]1(O)C[C@H](OC(=O)N1)[C@@H](C)[C@@H]1O[C@@]1(C)[C@@H](OC(=O)[C@H](C)N(C)C(=O)CCC(C)(C)S)CC(=O)N1C)\C=C\C=C(C)\CC2=CC(OC)=C(Cl)C1=C2 JFCFGYGEYRIEBE-YVLHJLIDSA-N 0.000 description 2
- FDKWRPBBCBCIGA-REOHCLBHSA-N (2r)-2-azaniumyl-3-$l^{1}-selanylpropanoate Chemical compound [Se]C[C@H](N)C(O)=O FDKWRPBBCBCIGA-REOHCLBHSA-N 0.000 description 1
- BVAUMRCGVHUWOZ-ZETCQYMHSA-N (2s)-2-(cyclohexylazaniumyl)propanoate Chemical compound OC(=O)[C@H](C)NC1CCCCC1 BVAUMRCGVHUWOZ-ZETCQYMHSA-N 0.000 description 1
- MRTPISKDZDHEQI-YFKPBYRVSA-N (2s)-2-(tert-butylamino)propanoic acid Chemical compound OC(=O)[C@H](C)NC(C)(C)C MRTPISKDZDHEQI-YFKPBYRVSA-N 0.000 description 1
- NPDBDJFLKKQMCM-SCSAIBSYSA-N (2s)-2-amino-3,3-dimethylbutanoic acid Chemical compound CC(C)(C)[C@H](N)C(O)=O NPDBDJFLKKQMCM-SCSAIBSYSA-N 0.000 description 1
- MSECZMWQBBVGEN-LURJTMIESA-N (2s)-2-azaniumyl-4-(1h-imidazol-5-yl)butanoate Chemical compound OC(=O)[C@@H](N)CCC1=CN=CN1 MSECZMWQBBVGEN-LURJTMIESA-N 0.000 description 1
- UYEGXSNFZXWSDV-BYPYZUCNSA-N (2s)-3-(2-amino-1h-imidazol-5-yl)-2-azaniumylpropanoate Chemical compound OC(=O)[C@@H](N)CC1=CNC(N)=N1 UYEGXSNFZXWSDV-BYPYZUCNSA-N 0.000 description 1
- MZOFCQQQCNRIBI-VMXHOPILSA-N (3s)-4-[[(2s)-1-[[(2s)-1-[[(1s)-1-carboxy-2-hydroxyethyl]amino]-4-methyl-1-oxopentan-2-yl]amino]-5-(diaminomethylideneamino)-1-oxopentan-2-yl]amino]-3-[[2-[[(2s)-2,6-diaminohexanoyl]amino]acetyl]amino]-4-oxobutanoic acid Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCCN MZOFCQQQCNRIBI-VMXHOPILSA-N 0.000 description 1
- CNTMOLDWXSVYKD-PSRNMDMQSA-N (e,4s)-4-[[(2s)-3,3-dimethyl-2-[[(2s)-3-methyl-2-(methylamino)-3-phenylbutanoyl]amino]butanoyl]-methylamino]-2,5-dimethylhex-2-enoic acid Chemical compound OC(=O)C(/C)=C/[C@H](C(C)C)N(C)C(=O)[C@H](C(C)(C)C)NC(=O)[C@@H](NC)C(C)(C)C1=CC=CC=C1 CNTMOLDWXSVYKD-PSRNMDMQSA-N 0.000 description 1
- UKAUYVFTDYCKQA-UHFFFAOYSA-N -2-Amino-4-hydroxybutanoic acid Natural products OC(=O)C(N)CCO UKAUYVFTDYCKQA-UHFFFAOYSA-N 0.000 description 1
- GEYOCULIXLDCMW-UHFFFAOYSA-N 1,2-phenylenediamine Chemical compound NC1=CC=CC=C1N GEYOCULIXLDCMW-UHFFFAOYSA-N 0.000 description 1
- FONKWHRXTPJODV-DNQXCXABSA-N 1,3-bis[2-[(8s)-8-(chloromethyl)-4-hydroxy-1-methyl-7,8-dihydro-3h-pyrrolo[3,2-e]indole-6-carbonyl]-1h-indol-5-yl]urea Chemical compound C1([C@H](CCl)CN2C(=O)C=3NC4=CC=C(C=C4C=3)NC(=O)NC=3C=C4C=C(NC4=CC=3)C(=O)N3C4=CC(O)=C5NC=C(C5=C4[C@H](CCl)C3)C)=C2C=C(O)C2=C1C(C)=CN2 FONKWHRXTPJODV-DNQXCXABSA-N 0.000 description 1
- WEYNBWVKOYCCQT-UHFFFAOYSA-N 1-(3-chloro-4-methylphenyl)-3-{2-[({5-[(dimethylamino)methyl]-2-furyl}methyl)thio]ethyl}urea Chemical compound O1C(CN(C)C)=CC=C1CSCCNC(=O)NC1=CC=C(C)C(Cl)=C1 WEYNBWVKOYCCQT-UHFFFAOYSA-N 0.000 description 1
- HAWSQZCWOQZXHI-FQEVSTJZSA-N 10-Hydroxycamptothecin Chemical compound C1=C(O)C=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)[C@]5(O)CC)C4=NC2=C1 HAWSQZCWOQZXHI-FQEVSTJZSA-N 0.000 description 1
- VGONTNSXDCQUGY-RRKCRQDMSA-N 2'-deoxyinosine Chemical group C1[C@H](O)[C@@H](CO)O[C@H]1N1C(N=CNC2=O)=C2N=C1 VGONTNSXDCQUGY-RRKCRQDMSA-N 0.000 description 1
- OGNSCSPNOLGXSM-UHFFFAOYSA-N 2,4-diaminobutyric acid Chemical compound NCCC(N)C(O)=O OGNSCSPNOLGXSM-UHFFFAOYSA-N 0.000 description 1
- MIJDSYMOBYNHOT-UHFFFAOYSA-N 2-(ethylamino)ethanol Chemical compound CCNCCO MIJDSYMOBYNHOT-UHFFFAOYSA-N 0.000 description 1
- WVHGJJRMKGDTEC-WCIJHFMNSA-N 2-[(1R,4S,8R,10S,13S,16S,27R,34S)-34-[(2S)-butan-2-yl]-8,22-dihydroxy-13-[(2R,3S)-3-hydroxybutan-2-yl]-2,5,11,14,27,30,33,36,39-nonaoxo-27lambda4-thia-3,6,12,15,25,29,32,35,38-nonazapentacyclo[14.12.11.06,10.018,26.019,24]nonatriaconta-18(26),19(24),20,22-tetraen-4-yl]acetamide Chemical class CC[C@H](C)[C@@H]1NC(=O)CNC(=O)[C@@H]2Cc3c([nH]c4cc(O)ccc34)[S@](=O)C[C@H](NC(=O)CNC1=O)C(=O)N[C@@H](CC(N)=O)C(=O)N1C[C@H](O)C[C@H]1C(=O)N[C@@H]([C@@H](C)[C@H](C)O)C(=O)N2 WVHGJJRMKGDTEC-WCIJHFMNSA-N 0.000 description 1
- BGFTWECWAICPDG-UHFFFAOYSA-N 2-[bis(4-chlorophenyl)methyl]-4-n-[3-[bis(4-chlorophenyl)methyl]-4-(dimethylamino)phenyl]-1-n,1-n-dimethylbenzene-1,4-diamine Chemical compound C1=C(C(C=2C=CC(Cl)=CC=2)C=2C=CC(Cl)=CC=2)C(N(C)C)=CC=C1NC(C=1)=CC=C(N(C)C)C=1C(C=1C=CC(Cl)=CC=1)C1=CC=C(Cl)C=C1 BGFTWECWAICPDG-UHFFFAOYSA-N 0.000 description 1
- PBSPQZHJEDTHTL-UHFFFAOYSA-N 2-benzoylpentanoic acid Chemical compound CCCC(C(O)=O)C(=O)C1=CC=CC=C1 PBSPQZHJEDTHTL-UHFFFAOYSA-N 0.000 description 1
- AOJJSUZBOXZQNB-VTZDEGQISA-N 4'-epidoxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-VTZDEGQISA-N 0.000 description 1
- WOVKYSAHUYNSMH-RRKCRQDMSA-N 5-bromodeoxyuridine Chemical compound C1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C(Br)=C1 WOVKYSAHUYNSMH-RRKCRQDMSA-N 0.000 description 1
- ODHCTXKNWHHXJC-VKHMYHEASA-N 5-oxo-L-proline Chemical compound OC(=O)[C@@H]1CCC(=O)N1 ODHCTXKNWHHXJC-VKHMYHEASA-N 0.000 description 1
- SLXKOJJOQWFEFD-UHFFFAOYSA-N 6-aminohexanoic acid Chemical compound NCCCCCC(O)=O SLXKOJJOQWFEFD-UHFFFAOYSA-N 0.000 description 1
- CJIJXIFQYOPWTF-UHFFFAOYSA-N 7-hydroxycoumarin Natural products O1C(=O)C=CC2=CC(O)=CC=C21 CJIJXIFQYOPWTF-UHFFFAOYSA-N 0.000 description 1
- FUXVKZWTXQUGMW-FQEVSTJZSA-N 9-Aminocamptothecin Chemical compound C1=CC(N)=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)[C@]5(O)CC)C4=NC2=C1 FUXVKZWTXQUGMW-FQEVSTJZSA-N 0.000 description 1
- 230000005730 ADP ribosylation Effects 0.000 description 1
- 102100031585 ADP-ribosyl cyclase/cyclic ADP-ribose hydrolase 1 Human genes 0.000 description 1
- MNFPZBOQEWMBOK-UHFFFAOYSA-N AS-I-145 Chemical compound C1=CC=CC2=C(CCCl)C(NC(=O)C3=CC=4C=C(C(=C(OC)C=4N3)OC)OC)=CC(N)=C21 MNFPZBOQEWMBOK-UHFFFAOYSA-N 0.000 description 1
- KVLFRAWTRWDEDF-IRXDYDNUSA-N AZD-8055 Chemical compound C1=C(CO)C(OC)=CC=C1C1=CC=C(C(=NC(=N2)N3[C@H](COCC3)C)N3[C@H](COCC3)C)C2=N1 KVLFRAWTRWDEDF-IRXDYDNUSA-N 0.000 description 1
- 108010022752 Acetylcholinesterase Proteins 0.000 description 1
- 102000012440 Acetylcholinesterase Human genes 0.000 description 1
- 102000005869 Activating Transcription Factors Human genes 0.000 description 1
- 208000010507 Adenocarcinoma of Lung Diseases 0.000 description 1
- 208000036832 Adenocarcinoma of ovary Diseases 0.000 description 1
- 101710137115 Adenylyl cyclase-associated protein 1 Proteins 0.000 description 1
- 108010000239 Aequorin Proteins 0.000 description 1
- 102000002260 Alkaline Phosphatase Human genes 0.000 description 1
- 108020004774 Alkaline Phosphatase Proteins 0.000 description 1
- 108700028369 Alleles Proteins 0.000 description 1
- 102100035248 Alpha-(1,3)-fucosyltransferase 4 Human genes 0.000 description 1
- 102100032959 Alpha-actinin-4 Human genes 0.000 description 1
- 101710115256 Alpha-actinin-4 Proteins 0.000 description 1
- 102100023635 Alpha-fetoprotein Human genes 0.000 description 1
- 108010027164 Amanitins Proteins 0.000 description 1
- QGZKDVFQNNGYKY-UHFFFAOYSA-O Ammonium Chemical compound [NH4+] QGZKDVFQNNGYKY-UHFFFAOYSA-O 0.000 description 1
- 102000052587 Anaphase-Promoting Complex-Cyclosome Apc3 Subunit Human genes 0.000 description 1
- 108700004606 Anaphase-Promoting Complex-Cyclosome Apc3 Subunit Proteins 0.000 description 1
- 101100524547 Arabidopsis thaliana RFS5 gene Proteins 0.000 description 1
- 101100208111 Arabidopsis thaliana TRX5 gene Proteins 0.000 description 1
- 241000203069 Archaea Species 0.000 description 1
- 241000205042 Archaeoglobus fulgidus Species 0.000 description 1
- 102100022716 Atypical chemokine receptor 3 Human genes 0.000 description 1
- 241000271566 Aves Species 0.000 description 1
- 108090001008 Avidin Proteins 0.000 description 1
- 102100035526 B melanoma antigen 1 Human genes 0.000 description 1
- 108010008014 B-Cell Maturation Antigen Proteins 0.000 description 1
- 102000006942 B-Cell Maturation Antigen Human genes 0.000 description 1
- 102100038080 B-cell receptor CD22 Human genes 0.000 description 1
- 102100024222 B-lymphocyte antigen CD19 Human genes 0.000 description 1
- 102100022005 B-lymphocyte antigen CD20 Human genes 0.000 description 1
- WOVKYSAHUYNSMH-UHFFFAOYSA-N BROMODEOXYURIDINE Natural products C1C(O)C(CO)OC1N1C(=O)NC(=O)C(Br)=C1 WOVKYSAHUYNSMH-UHFFFAOYSA-N 0.000 description 1
- 102100021663 Baculoviral IAP repeat-containing protein 5 Human genes 0.000 description 1
- 102100032412 Basigin Human genes 0.000 description 1
- 101150017888 Bcl2 gene Proteins 0.000 description 1
- 239000005711 Benzoic acid Substances 0.000 description 1
- 102100026189 Beta-galactosidase Human genes 0.000 description 1
- 102100037086 Bone marrow stromal antigen 2 Human genes 0.000 description 1
- 102100031172 C-C chemokine receptor type 1 Human genes 0.000 description 1
- 101710149814 C-C chemokine receptor type 1 Proteins 0.000 description 1
- 102100031151 C-C chemokine receptor type 2 Human genes 0.000 description 1
- 101710149815 C-C chemokine receptor type 2 Proteins 0.000 description 1
- 101710149863 C-C chemokine receptor type 4 Proteins 0.000 description 1
- 102100035875 C-C chemokine receptor type 5 Human genes 0.000 description 1
- 101710149870 C-C chemokine receptor type 5 Proteins 0.000 description 1
- 102100036301 C-C chemokine receptor type 7 Human genes 0.000 description 1
- 102100036305 C-C chemokine receptor type 8 Human genes 0.000 description 1
- 102100036842 C-C motif chemokine 19 Human genes 0.000 description 1
- 102100021943 C-C motif chemokine 2 Human genes 0.000 description 1
- 101710155857 C-C motif chemokine 2 Proteins 0.000 description 1
- 102100036846 C-C motif chemokine 21 Human genes 0.000 description 1
- 102100028990 C-X-C chemokine receptor type 3 Human genes 0.000 description 1
- 102100031650 C-X-C chemokine receptor type 4 Human genes 0.000 description 1
- 102100031658 C-X-C chemokine receptor type 5 Human genes 0.000 description 1
- 102100025618 C-X-C chemokine receptor type 6 Human genes 0.000 description 1
- 102100025248 C-X-C motif chemokine 10 Human genes 0.000 description 1
- 101710098275 C-X-C motif chemokine 10 Proteins 0.000 description 1
- 108700012439 CA9 Proteins 0.000 description 1
- 102100024217 CAMPATH-1 antigen Human genes 0.000 description 1
- 102100032976 CCR4-NOT transcription complex subunit 6 Human genes 0.000 description 1
- 108010029697 CD40 Ligand Proteins 0.000 description 1
- 101150013553 CD40 gene Proteins 0.000 description 1
- 108010065524 CD52 Antigen Proteins 0.000 description 1
- 102100022002 CD59 glycoprotein Human genes 0.000 description 1
- 102100025221 CD70 antigen Human genes 0.000 description 1
- 102100035793 CD83 antigen Human genes 0.000 description 1
- 101150108242 CDC27 gene Proteins 0.000 description 1
- HAWSQZCWOQZXHI-UHFFFAOYSA-N CPT-OH Natural products C1=C(O)C=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)C5(O)CC)C4=NC2=C1 HAWSQZCWOQZXHI-UHFFFAOYSA-N 0.000 description 1
- 108010021064 CTLA-4 Antigen Proteins 0.000 description 1
- 229940045513 CTLA4 antagonist Drugs 0.000 description 1
- 101100005789 Caenorhabditis elegans cdk-4 gene Proteins 0.000 description 1
- 101100180402 Caenorhabditis elegans jun-1 gene Proteins 0.000 description 1
- 241000345998 Calamus manan Species 0.000 description 1
- OYPRJOBELJOOCE-UHFFFAOYSA-N Calcium Chemical compound [Ca] OYPRJOBELJOOCE-UHFFFAOYSA-N 0.000 description 1
- 241000282836 Camelus dromedarius Species 0.000 description 1
- KLWPJMFMVPTNCC-UHFFFAOYSA-N Camptothecin Natural products CCC1(O)C(=O)OCC2=C1C=C3C4Nc5ccccc5C=C4CN3C2=O KLWPJMFMVPTNCC-UHFFFAOYSA-N 0.000 description 1
- 102100025570 Cancer/testis antigen 1 Human genes 0.000 description 1
- 102100039510 Cancer/testis antigen 2 Human genes 0.000 description 1
- 102100025473 Carcinoembryonic antigen-related cell adhesion molecule 6 Human genes 0.000 description 1
- 102000014914 Carrier Proteins Human genes 0.000 description 1
- 102100026548 Caspase-8 Human genes 0.000 description 1
- 108090000538 Caspase-8 Proteins 0.000 description 1
- 241000700198 Cavia Species 0.000 description 1
- 102000000844 Cell Surface Receptors Human genes 0.000 description 1
- 108010001857 Cell Surface Receptors Proteins 0.000 description 1
- 102100025064 Cellular tumor antigen p53 Human genes 0.000 description 1
- 102000009410 Chemokine receptor Human genes 0.000 description 1
- 108050000299 Chemokine receptor Proteins 0.000 description 1
- 108010012236 Chemokines Proteins 0.000 description 1
- 102000019034 Chemokines Human genes 0.000 description 1
- 241000282552 Chlorocebus aethiops Species 0.000 description 1
- 108090000317 Chymotrypsin Proteins 0.000 description 1
- 208000001333 Colorectal Neoplasms Diseases 0.000 description 1
- 208000035473 Communicable disease Diseases 0.000 description 1
- 102100025680 Complement decay-accelerating factor Human genes 0.000 description 1
- 102100032768 Complement receptor type 2 Human genes 0.000 description 1
- 241000557626 Corvus corax Species 0.000 description 1
- 241000699800 Cricetinae Species 0.000 description 1
- 241000938605 Crocodylia Species 0.000 description 1
- 241000195493 Cryptophyta Species 0.000 description 1
- 108010009392 Cyclin-Dependent Kinase Inhibitor p16 Proteins 0.000 description 1
- 102100026234 Cytokine receptor common subunit gamma Human genes 0.000 description 1
- 102100039498 Cytotoxic T-lymphocyte protein 4 Human genes 0.000 description 1
- IGXWBGJHJZYPQS-SSDOTTSWSA-N D-Luciferin Chemical compound OC(=O)[C@H]1CSC(C=2SC3=CC=C(O)C=C3N=2)=N1 IGXWBGJHJZYPQS-SSDOTTSWSA-N 0.000 description 1
- FBPFZTCFMRRESA-KVTDHHQDSA-N D-Mannitol Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-KVTDHHQDSA-N 0.000 description 1
- FDKWRPBBCBCIGA-UWTATZPHSA-N D-Selenocysteine Natural products [Se]C[C@@H](N)C(O)=O FDKWRPBBCBCIGA-UWTATZPHSA-N 0.000 description 1
- 229920002271 DEAE-Sepharose Polymers 0.000 description 1
- 102000053602 DNA Human genes 0.000 description 1
- XPDXVDYUQZHFPV-UHFFFAOYSA-N Dansyl Chloride Chemical compound C1=CC=C2C(N(C)C)=CC=CC2=C1S(Cl)(=O)=O XPDXVDYUQZHFPV-UHFFFAOYSA-N 0.000 description 1
- WEAHRLBPCANXCN-UHFFFAOYSA-N Daunomycin Natural products CCC1(O)CC(OC2CC(N)C(O)C(C)O2)c3cc4C(=O)c5c(OC)cccc5C(=O)c4c(O)c3C1 WEAHRLBPCANXCN-UHFFFAOYSA-N 0.000 description 1
- 206010011878 Deafness Diseases 0.000 description 1
- CYCGRDQQIOGCKX-UHFFFAOYSA-N Dehydro-luciferin Natural products OC(=O)C1=CSC(C=2SC3=CC(O)=CC=C3N=2)=N1 CYCGRDQQIOGCKX-UHFFFAOYSA-N 0.000 description 1
- 101100216227 Dictyostelium discoideum anapc3 gene Proteins 0.000 description 1
- 102100024746 Dihydrofolate reductase Human genes 0.000 description 1
- 206010061818 Disease progression Diseases 0.000 description 1
- 101100074338 Drosophila melanogaster lectin-37Db gene Proteins 0.000 description 1
- 101150029707 ERBB2 gene Proteins 0.000 description 1
- 102100025137 Early activation antigen CD69 Human genes 0.000 description 1
- 108010013369 Enteropeptidase Proteins 0.000 description 1
- 102100029727 Enteropeptidase Human genes 0.000 description 1
- 108010055196 EphA2 Receptor Proteins 0.000 description 1
- 102100030340 Ephrin type-A receptor 2 Human genes 0.000 description 1
- HTIJFSOGRVMCQR-UHFFFAOYSA-N Epirubicin Natural products COc1cccc2C(=O)c3c(O)c4CC(O)(CC(OC5CC(N)C(=O)C(C)O5)c4c(O)c3C(=O)c12)C(=O)CO HTIJFSOGRVMCQR-UHFFFAOYSA-N 0.000 description 1
- 108010066687 Epithelial Cell Adhesion Molecule Proteins 0.000 description 1
- 102100036725 Epithelial discoidin domain-containing receptor 1 Human genes 0.000 description 1
- 241000283086 Equidae Species 0.000 description 1
- 241000283073 Equus caballus Species 0.000 description 1
- HKVAMNSJSFKALM-GKUWKFKPSA-N Everolimus Chemical compound C1C[C@@H](OCCO)[C@H](OC)C[C@@H]1C[C@@H](C)[C@H]1OC(=O)[C@@H]2CCCCN2C(=O)C(=O)[C@](O)(O2)[C@H](C)CC[C@H]2C[C@H](OC)/C(C)=C/C=C/C=C/[C@@H](C)C[C@@H](C)C(=O)[C@H](OC)[C@H](O)/C(C)=C/[C@@H](C)C(=O)C1 HKVAMNSJSFKALM-GKUWKFKPSA-N 0.000 description 1
- 102000007665 Extracellular Signal-Regulated MAP Kinases Human genes 0.000 description 1
- 108010007457 Extracellular Signal-Regulated MAP Kinases Proteins 0.000 description 1
- 108010014173 Factor X Proteins 0.000 description 1
- 241000282324 Felis Species 0.000 description 1
- 241000282326 Felis catus Species 0.000 description 1
- 108090000382 Fibroblast growth factor 6 Proteins 0.000 description 1
- 102100028075 Fibroblast growth factor 6 Human genes 0.000 description 1
- 102100037362 Fibronectin Human genes 0.000 description 1
- 108010067306 Fibronectins Proteins 0.000 description 1
- BJGNCJDXODQBOB-UHFFFAOYSA-N Fivefly Luciferin Natural products OC(=O)C1CSC(C=2SC3=CC(O)=CC=C3N=2)=N1 BJGNCJDXODQBOB-UHFFFAOYSA-N 0.000 description 1
- PXGOKWXKJXAPGV-UHFFFAOYSA-N Fluorine Chemical compound FF PXGOKWXKJXAPGV-UHFFFAOYSA-N 0.000 description 1
- 102100027581 Forkhead box protein P3 Human genes 0.000 description 1
- GYHNNYVSQQEPJS-UHFFFAOYSA-N Gallium Chemical compound [Ga] GYHNNYVSQQEPJS-UHFFFAOYSA-N 0.000 description 1
- 108010010803 Gelatin Proteins 0.000 description 1
- 108700004714 Gelonium multiflorum GEL Proteins 0.000 description 1
- 241000193385 Geobacillus stearothermophilus Species 0.000 description 1
- 108091010837 Glial cell line-derived neurotrophic factor Proteins 0.000 description 1
- 102100041003 Glutamate carboxypeptidase 2 Human genes 0.000 description 1
- 108010051815 Glutamyl endopeptidase Proteins 0.000 description 1
- 108010024636 Glutathione Proteins 0.000 description 1
- 108010070675 Glutathione transferase Proteins 0.000 description 1
- 102000003886 Glycoproteins Human genes 0.000 description 1
- 108090000288 Glycoproteins Proteins 0.000 description 1
- 102100032530 Glypican-3 Human genes 0.000 description 1
- 102100030595 HLA class II histocompatibility antigen gamma chain Human genes 0.000 description 1
- 102000006354 HLA-DR Antigens Human genes 0.000 description 1
- 108010058597 HLA-DR Antigens Proteins 0.000 description 1
- 108010072471 HTI-286 Proteins 0.000 description 1
- 241000204933 Haloferax volcanii Species 0.000 description 1
- 101150046249 Havcr2 gene Proteins 0.000 description 1
- 102100031573 Hematopoietic progenitor cell antigen CD34 Human genes 0.000 description 1
- 102100029100 Hematopoietic prostaglandin D synthase Human genes 0.000 description 1
- 102100034458 Hepatitis A virus cellular receptor 2 Human genes 0.000 description 1
- 102100026122 High affinity immunoglobulin gamma Fc receptor I Human genes 0.000 description 1
- 101000777636 Homo sapiens ADP-ribosyl cyclase/cyclic ADP-ribose hydrolase 1 Proteins 0.000 description 1
- 101001022185 Homo sapiens Alpha-(1,3)-fucosyltransferase 4 Proteins 0.000 description 1
- 101000971171 Homo sapiens Apoptosis regulator Bcl-2 Proteins 0.000 description 1
- 101000678890 Homo sapiens Atypical chemokine receptor 3 Proteins 0.000 description 1
- 101000874316 Homo sapiens B melanoma antigen 1 Proteins 0.000 description 1
- 101000884305 Homo sapiens B-cell receptor CD22 Proteins 0.000 description 1
- 101000980825 Homo sapiens B-lymphocyte antigen CD19 Proteins 0.000 description 1
- 101000897405 Homo sapiens B-lymphocyte antigen CD20 Proteins 0.000 description 1
- 101000740785 Homo sapiens Bone marrow stromal antigen 2 Proteins 0.000 description 1
- 101000777558 Homo sapiens C-C chemokine receptor type 10 Proteins 0.000 description 1
- 101000716065 Homo sapiens C-C chemokine receptor type 7 Proteins 0.000 description 1
- 101000716063 Homo sapiens C-C chemokine receptor type 8 Proteins 0.000 description 1
- 101000716070 Homo sapiens C-C chemokine receptor type 9 Proteins 0.000 description 1
- 101000713106 Homo sapiens C-C motif chemokine 19 Proteins 0.000 description 1
- 101000713085 Homo sapiens C-C motif chemokine 21 Proteins 0.000 description 1
- 101000916050 Homo sapiens C-X-C chemokine receptor type 3 Proteins 0.000 description 1
- 101000922348 Homo sapiens C-X-C chemokine receptor type 4 Proteins 0.000 description 1
- 101000922405 Homo sapiens C-X-C chemokine receptor type 5 Proteins 0.000 description 1
- 101000856683 Homo sapiens C-X-C chemokine receptor type 6 Proteins 0.000 description 1
- 101100165850 Homo sapiens CA9 gene Proteins 0.000 description 1
- 101000897400 Homo sapiens CD59 glycoprotein Proteins 0.000 description 1
- 101000934356 Homo sapiens CD70 antigen Proteins 0.000 description 1
- 101000946856 Homo sapiens CD83 antigen Proteins 0.000 description 1
- 101000856237 Homo sapiens Cancer/testis antigen 1 Proteins 0.000 description 1
- 101000889345 Homo sapiens Cancer/testis antigen 2 Proteins 0.000 description 1
- 101000914326 Homo sapiens Carcinoembryonic antigen-related cell adhesion molecule 6 Proteins 0.000 description 1
- 101000914321 Homo sapiens Carcinoembryonic antigen-related cell adhesion molecule 7 Proteins 0.000 description 1
- 101000721661 Homo sapiens Cellular tumor antigen p53 Proteins 0.000 description 1
- 101000856022 Homo sapiens Complement decay-accelerating factor Proteins 0.000 description 1
- 101000941929 Homo sapiens Complement receptor type 2 Proteins 0.000 description 1
- 101000934374 Homo sapiens Early activation antigen CD69 Proteins 0.000 description 1
- 101000920667 Homo sapiens Epithelial cell adhesion molecule Proteins 0.000 description 1
- 101000861452 Homo sapiens Forkhead box protein P3 Proteins 0.000 description 1
- 101000892862 Homo sapiens Glutamate carboxypeptidase 2 Proteins 0.000 description 1
- 101001014668 Homo sapiens Glypican-3 Proteins 0.000 description 1
- 101001082627 Homo sapiens HLA class II histocompatibility antigen gamma chain Proteins 0.000 description 1
- 101000777663 Homo sapiens Hematopoietic progenitor cell antigen CD34 Proteins 0.000 description 1
- 101000913074 Homo sapiens High affinity immunoglobulin gamma Fc receptor I Proteins 0.000 description 1
- 101001103039 Homo sapiens Inactive tyrosine-protein kinase transmembrane receptor ROR1 Proteins 0.000 description 1
- 101000599951 Homo sapiens Insulin-like growth factor I Proteins 0.000 description 1
- 101001046683 Homo sapiens Integrin alpha-L Proteins 0.000 description 1
- 101000935043 Homo sapiens Integrin beta-1 Proteins 0.000 description 1
- 101000935040 Homo sapiens Integrin beta-2 Proteins 0.000 description 1
- 101000599852 Homo sapiens Intercellular adhesion molecule 1 Proteins 0.000 description 1
- 101001057504 Homo sapiens Interferon-stimulated gene 20 kDa protein Proteins 0.000 description 1
- 101001055144 Homo sapiens Interleukin-2 receptor subunit alpha Proteins 0.000 description 1
- 101001055222 Homo sapiens Interleukin-8 Proteins 0.000 description 1
- 101000971533 Homo sapiens Killer cell lectin-like receptor subfamily G member 1 Proteins 0.000 description 1
- 101000777628 Homo sapiens Leukocyte antigen CD37 Proteins 0.000 description 1
- 101000878605 Homo sapiens Low affinity immunoglobulin epsilon Fc receptor Proteins 0.000 description 1
- 101000917858 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor III-A Proteins 0.000 description 1
- 101000917839 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor III-B Proteins 0.000 description 1
- 101001137987 Homo sapiens Lymphocyte activation gene 3 protein Proteins 0.000 description 1
- 101000916644 Homo sapiens Macrophage colony-stimulating factor 1 receptor Proteins 0.000 description 1
- 101000578784 Homo sapiens Melanoma antigen recognized by T-cells 1 Proteins 0.000 description 1
- 101000961414 Homo sapiens Membrane cofactor protein Proteins 0.000 description 1
- 101000946889 Homo sapiens Monocyte differentiation antigen CD14 Proteins 0.000 description 1
- 101001133056 Homo sapiens Mucin-1 Proteins 0.000 description 1
- 101000623900 Homo sapiens Mucin-13 Proteins 0.000 description 1
- 101001133081 Homo sapiens Mucin-2 Proteins 0.000 description 1
- 101000972284 Homo sapiens Mucin-3A Proteins 0.000 description 1
- 101000972286 Homo sapiens Mucin-4 Proteins 0.000 description 1
- 101000934338 Homo sapiens Myeloid cell surface antigen CD33 Proteins 0.000 description 1
- 101001024605 Homo sapiens Next to BRCA1 gene 1 protein Proteins 0.000 description 1
- 101001103036 Homo sapiens Nuclear receptor ROR-alpha Proteins 0.000 description 1
- 101000595923 Homo sapiens Placenta growth factor Proteins 0.000 description 1
- 101000617725 Homo sapiens Pregnancy-specific beta-1-glycoprotein 2 Proteins 0.000 description 1
- 101001117317 Homo sapiens Programmed cell death 1 ligand 1 Proteins 0.000 description 1
- 101000842302 Homo sapiens Protein-cysteine N-palmitoyltransferase HHAT Proteins 0.000 description 1
- 101001109419 Homo sapiens RNA-binding protein NOB1 Proteins 0.000 description 1
- 101000738771 Homo sapiens Receptor-type tyrosine-protein phosphatase C Proteins 0.000 description 1
- 101100420560 Homo sapiens SLC39A6 gene Proteins 0.000 description 1
- 101000604039 Homo sapiens Sodium-dependent phosphate transport protein 2B Proteins 0.000 description 1
- 101000617130 Homo sapiens Stromal cell-derived factor 1 Proteins 0.000 description 1
- 101000831007 Homo sapiens T-cell immunoreceptor with Ig and ITIM domains Proteins 0.000 description 1
- 101000934346 Homo sapiens T-cell surface antigen CD2 Proteins 0.000 description 1
- 101000980827 Homo sapiens T-cell surface glycoprotein CD1a Proteins 0.000 description 1
- 101000716149 Homo sapiens T-cell surface glycoprotein CD1b Proteins 0.000 description 1
- 101000716124 Homo sapiens T-cell surface glycoprotein CD1c Proteins 0.000 description 1
- 101000934341 Homo sapiens T-cell surface glycoprotein CD5 Proteins 0.000 description 1
- 101000946843 Homo sapiens T-cell surface glycoprotein CD8 alpha chain Proteins 0.000 description 1
- 101000914484 Homo sapiens T-lymphocyte activation antigen CD80 Proteins 0.000 description 1
- 101000648265 Homo sapiens Thymocyte selection-associated high mobility group box protein TOX Proteins 0.000 description 1
- 101000819111 Homo sapiens Trans-acting T-cell-specific transcription factor GATA-3 Proteins 0.000 description 1
- 101001050288 Homo sapiens Transcription factor Jun Proteins 0.000 description 1
- 101000611023 Homo sapiens Tumor necrosis factor receptor superfamily member 6 Proteins 0.000 description 1
- 101000851376 Homo sapiens Tumor necrosis factor receptor superfamily member 8 Proteins 0.000 description 1
- 101000730644 Homo sapiens Zinc finger protein PLAGL2 Proteins 0.000 description 1
- 108010001336 Horseradish Peroxidase Proteins 0.000 description 1
- PMMYEEVYMWASQN-DMTCNVIQSA-N Hydroxyproline Chemical compound O[C@H]1CN[C@H](C(O)=O)C1 PMMYEEVYMWASQN-DMTCNVIQSA-N 0.000 description 1
- 206010021143 Hypoxia Diseases 0.000 description 1
- 101150088952 IGF1 gene Proteins 0.000 description 1
- XDXDZDZNSLXDNA-TZNDIEGXSA-N Idarubicin Chemical compound C1[C@H](N)[C@H](O)[C@H](C)O[C@H]1O[C@@H]1C2=C(O)C(C(=O)C3=CC=CC=C3C3=O)=C3C(O)=C2C[C@@](O)(C(C)=O)C1 XDXDZDZNSLXDNA-TZNDIEGXSA-N 0.000 description 1
- XDXDZDZNSLXDNA-UHFFFAOYSA-N Idarubicin Natural products C1C(N)C(O)C(C)OC1OC1C2=C(O)C(C(=O)C3=CC=CC=C3C3=O)=C3C(O)=C2CC(O)(C(C)=O)C1 XDXDZDZNSLXDNA-UHFFFAOYSA-N 0.000 description 1
- 102000009490 IgG Receptors Human genes 0.000 description 1
- 102100026120 IgG receptor FcRn large subunit p51 Human genes 0.000 description 1
- 101710177940 IgG receptor FcRn large subunit p51 Proteins 0.000 description 1
- 229940076838 Immune checkpoint inhibitor Drugs 0.000 description 1
- 102000009786 Immunoglobulin Constant Regions Human genes 0.000 description 1
- 108010009817 Immunoglobulin Constant Regions Proteins 0.000 description 1
- 102100039615 Inactive tyrosine-protein kinase transmembrane receptor ROR1 Human genes 0.000 description 1
- 102100037852 Insulin-like growth factor I Human genes 0.000 description 1
- 102100022339 Integrin alpha-L Human genes 0.000 description 1
- 102100025304 Integrin beta-1 Human genes 0.000 description 1
- 102100025390 Integrin beta-2 Human genes 0.000 description 1
- 102100037877 Intercellular adhesion molecule 1 Human genes 0.000 description 1
- 102100026720 Interferon beta Human genes 0.000 description 1
- 102100037850 Interferon gamma Human genes 0.000 description 1
- 108010047761 Interferon-alpha Proteins 0.000 description 1
- 102000006992 Interferon-alpha Human genes 0.000 description 1
- 108090000467 Interferon-beta Proteins 0.000 description 1
- 108010074328 Interferon-gamma Proteins 0.000 description 1
- 102100027268 Interferon-stimulated gene 20 kDa protein Human genes 0.000 description 1
- 108090000174 Interleukin-10 Proteins 0.000 description 1
- 108090000176 Interleukin-13 Proteins 0.000 description 1
- 102000007482 Interleukin-13 Receptor alpha2 Subunit Human genes 0.000 description 1
- 108010085418 Interleukin-13 Receptor alpha2 Subunit Proteins 0.000 description 1
- 102100020793 Interleukin-13 receptor subunit alpha-2 Human genes 0.000 description 1
- 108050003558 Interleukin-17 Proteins 0.000 description 1
- 102000013691 Interleukin-17 Human genes 0.000 description 1
- 102000003810 Interleukin-18 Human genes 0.000 description 1
- 108090000171 Interleukin-18 Proteins 0.000 description 1
- 102000013264 Interleukin-23 Human genes 0.000 description 1
- 108010065637 Interleukin-23 Proteins 0.000 description 1
- 102100033493 Interleukin-3 receptor subunit alpha Human genes 0.000 description 1
- 108090000978 Interleukin-4 Proteins 0.000 description 1
- 108010002616 Interleukin-5 Proteins 0.000 description 1
- 102000004890 Interleukin-8 Human genes 0.000 description 1
- 102100026236 Interleukin-8 Human genes 0.000 description 1
- 108090001007 Interleukin-8 Proteins 0.000 description 1
- 108010002335 Interleukin-9 Proteins 0.000 description 1
- 102100021457 Killer cell lectin-like receptor subfamily G member 1 Human genes 0.000 description 1
- 101150105104 Kras gene Proteins 0.000 description 1
- SNDPXSYFESPGGJ-BYPYZUCNSA-N L-2-aminopentanoic acid Chemical compound CCC[C@H](N)C(O)=O SNDPXSYFESPGGJ-BYPYZUCNSA-N 0.000 description 1
- ZGUNAGUHMKGQNY-ZETCQYMHSA-N L-alpha-phenylglycine zwitterion Chemical compound OC(=O)[C@@H](N)C1=CC=CC=C1 ZGUNAGUHMKGQNY-ZETCQYMHSA-N 0.000 description 1
- RHGKLRLOHDJJDR-BYPYZUCNSA-N L-citrulline Chemical compound NC(=O)NCCC[C@H]([NH3+])C([O-])=O RHGKLRLOHDJJDR-BYPYZUCNSA-N 0.000 description 1
- XIGSAGMEBXLVJJ-YFKPBYRVSA-N L-homocitrulline Chemical compound NC(=O)NCCCC[C@H]([NH3+])C([O-])=O XIGSAGMEBXLVJJ-YFKPBYRVSA-N 0.000 description 1
- UKAUYVFTDYCKQA-VKHMYHEASA-N L-homoserine Chemical compound OC(=O)[C@@H](N)CCO UKAUYVFTDYCKQA-VKHMYHEASA-N 0.000 description 1
- QEFRNWWLZKMPFJ-ZXPFJRLXSA-N L-methionine (R)-S-oxide Chemical compound C[S@@](=O)CC[C@H]([NH3+])C([O-])=O QEFRNWWLZKMPFJ-ZXPFJRLXSA-N 0.000 description 1
- QEFRNWWLZKMPFJ-UHFFFAOYSA-N L-methionine sulphoxide Natural products CS(=O)CCC(N)C(O)=O QEFRNWWLZKMPFJ-UHFFFAOYSA-N 0.000 description 1
- SNDPXSYFESPGGJ-UHFFFAOYSA-N L-norVal-OH Natural products CCCC(N)C(O)=O SNDPXSYFESPGGJ-UHFFFAOYSA-N 0.000 description 1
- ZFOMKMMPBOQKMC-KXUCPTDWSA-N L-pyrrolysine Chemical compound C[C@@H]1CC=N[C@H]1C(=O)NCCCC[C@H]([NH3+])C([O-])=O ZFOMKMMPBOQKMC-KXUCPTDWSA-N 0.000 description 1
- 102000017578 LAG3 Human genes 0.000 description 1
- 101150030213 Lag3 gene Proteins 0.000 description 1
- 102100031586 Leukocyte antigen CD37 Human genes 0.000 description 1
- NNJVILVZKWQKPM-UHFFFAOYSA-N Lidocaine Chemical compound CCN(CC)CC(=O)NC1=C(C)C=CC=C1C NNJVILVZKWQKPM-UHFFFAOYSA-N 0.000 description 1
- 241000209510 Liliopsida Species 0.000 description 1
- 102100038007 Low affinity immunoglobulin epsilon Fc receptor Human genes 0.000 description 1
- 102100029204 Low affinity immunoglobulin gamma Fc region receptor II-a Human genes 0.000 description 1
- 102100029205 Low affinity immunoglobulin gamma Fc region receptor II-b Human genes 0.000 description 1
- 101710099301 Low affinity immunoglobulin gamma Fc region receptor III-A Proteins 0.000 description 1
- DDWFXDSYGUXRAY-UHFFFAOYSA-N Luciferin Natural products CCc1c(C)c(CC2NC(=O)C(=C2C=C)C)[nH]c1Cc3[nH]c4C(=C5/NC(CC(=O)O)C(C)C5CC(=O)O)CC(=O)c4c3C DDWFXDSYGUXRAY-UHFFFAOYSA-N 0.000 description 1
- 102100034709 Lymphocyte cytosolic protein 2 Human genes 0.000 description 1
- 101710195102 Lymphocyte cytosolic protein 2 Proteins 0.000 description 1
- 206010025323 Lymphomas Diseases 0.000 description 1
- 102000001291 MAP Kinase Kinase Kinase Human genes 0.000 description 1
- 108060006687 MAP kinase kinase kinase Proteins 0.000 description 1
- 102000043131 MHC class II family Human genes 0.000 description 1
- 108091054438 MHC class II family Proteins 0.000 description 1
- 241000282567 Macaca fascicularis Species 0.000 description 1
- 108010048043 Macrophage Migration-Inhibitory Factors Proteins 0.000 description 1
- 102100028198 Macrophage colony-stimulating factor 1 receptor Human genes 0.000 description 1
- 102100037791 Macrophage migration inhibitory factor Human genes 0.000 description 1
- 101710175625 Maltose/maltodextrin-binding periplasmic protein Proteins 0.000 description 1
- 229930195725 Mannitol Natural products 0.000 description 1
- 102100028389 Melanoma antigen recognized by T-cells 1 Human genes 0.000 description 1
- 102000018697 Membrane Proteins Human genes 0.000 description 1
- 108010052285 Membrane Proteins Proteins 0.000 description 1
- 102100039373 Membrane cofactor protein Human genes 0.000 description 1
- 102100025096 Mesothelin Human genes 0.000 description 1
- 206010027476 Metastases Diseases 0.000 description 1
- 241000203407 Methanocaldococcus jannaschii Species 0.000 description 1
- 241001302042 Methanothermobacter thermautotrophicus Species 0.000 description 1
- 241000243190 Microsporidia Species 0.000 description 1
- 102000004232 Mitogen-Activated Protein Kinase Kinases Human genes 0.000 description 1
- 108090000744 Mitogen-Activated Protein Kinase Kinases Proteins 0.000 description 1
- ZOKXTWBITQBERF-UHFFFAOYSA-N Molybdenum Chemical compound [Mo] ZOKXTWBITQBERF-UHFFFAOYSA-N 0.000 description 1
- 102100035877 Monocyte differentiation antigen CD14 Human genes 0.000 description 1
- 102100034256 Mucin-1 Human genes 0.000 description 1
- 102100023124 Mucin-13 Human genes 0.000 description 1
- 102100034263 Mucin-2 Human genes 0.000 description 1
- 102100022497 Mucin-3A Human genes 0.000 description 1
- 102100022693 Mucin-4 Human genes 0.000 description 1
- 108010063954 Mucins Proteins 0.000 description 1
- 102000015728 Mucins Human genes 0.000 description 1
- 101100381525 Mus musculus Bcl6 gene Proteins 0.000 description 1
- 101100335081 Mus musculus Flt3 gene Proteins 0.000 description 1
- 101100260032 Mus musculus Tbx21 gene Proteins 0.000 description 1
- 101100370002 Mus musculus Tnfsf14 gene Proteins 0.000 description 1
- 102100025243 Myeloid cell surface antigen CD33 Human genes 0.000 description 1
- 102100031789 Myeloid-derived growth factor Human genes 0.000 description 1
- OVBPIULPVIDEAO-UHFFFAOYSA-N N-Pteroyl-L-glutaminsaeure Natural products C=1N=C2NC(N)=NC(=O)C2=NC=1CNC1=CC=C(C(=O)NC(CCC(O)=O)C(O)=O)C=C1 OVBPIULPVIDEAO-UHFFFAOYSA-N 0.000 description 1
- GXCLVBGFBYZDAG-UHFFFAOYSA-N N-[2-(1H-indol-3-yl)ethyl]-N-methylprop-2-en-1-amine Chemical compound CN(CCC1=CNC2=C1C=CC=C2)CC=C GXCLVBGFBYZDAG-UHFFFAOYSA-N 0.000 description 1
- 102000019148 NF-kappaB-inducing kinase activity proteins Human genes 0.000 description 1
- 108040008091 NF-kappaB-inducing kinase activity proteins Proteins 0.000 description 1
- RHGKLRLOHDJJDR-UHFFFAOYSA-N Ndelta-carbamoyl-DL-ornithine Natural products OC(=O)C(N)CCCNC(N)=O RHGKLRLOHDJJDR-UHFFFAOYSA-N 0.000 description 1
- 102100024964 Neural cell adhesion molecule L1 Human genes 0.000 description 1
- 102000007999 Nuclear Proteins Human genes 0.000 description 1
- 108010089610 Nuclear Proteins Proteins 0.000 description 1
- 239000004677 Nylon Substances 0.000 description 1
- KUIFHYPNNRVEKZ-VIJRYAKMSA-N O-(N-acetyl-alpha-D-galactosaminyl)-L-threonine Chemical compound OC(=O)[C@@H](N)[C@@H](C)O[C@H]1O[C@H](CO)[C@H](O)[C@H](O)[C@H]1NC(C)=O KUIFHYPNNRVEKZ-VIJRYAKMSA-N 0.000 description 1
- 206010030155 Oesophageal carcinoma Diseases 0.000 description 1
- 108091034117 Oligonucleotide Proteins 0.000 description 1
- 108020005187 Oligonucleotide Probes Proteins 0.000 description 1
- 108010038807 Oligopeptides Proteins 0.000 description 1
- 102000015636 Oligopeptides Human genes 0.000 description 1
- 102000043276 Oncogene Human genes 0.000 description 1
- 240000007594 Oryza sativa Species 0.000 description 1
- 235000007164 Oryza sativa Nutrition 0.000 description 1
- 206010061328 Ovarian epithelial cancer Diseases 0.000 description 1
- 102000038030 PI3Ks Human genes 0.000 description 1
- 108091007960 PI3Ks Proteins 0.000 description 1
- 108060006580 PRAME Proteins 0.000 description 1
- 102000036673 PRAME Human genes 0.000 description 1
- 102100034640 PWWP domain-containing DNA repair factor 3A Human genes 0.000 description 1
- 108050007154 PWWP domain-containing DNA repair factor 3A Proteins 0.000 description 1
- 235000019483 Peanut oil Nutrition 0.000 description 1
- 241001494479 Pecora Species 0.000 description 1
- 108010092528 Phosphate Transport Proteins Proteins 0.000 description 1
- 102000016462 Phosphate Transport Proteins Human genes 0.000 description 1
- 102100021768 Phosphoserine aminotransferase Human genes 0.000 description 1
- 108010004729 Phycoerythrin Proteins 0.000 description 1
- 102100035194 Placenta growth factor Human genes 0.000 description 1
- 239000004743 Polypropylene Substances 0.000 description 1
- 239000004793 Polystyrene Substances 0.000 description 1
- ZLMJMSJWJFRBEC-UHFFFAOYSA-N Potassium Chemical compound [K] ZLMJMSJWJFRBEC-UHFFFAOYSA-N 0.000 description 1
- 102100024216 Programmed cell death 1 ligand 1 Human genes 0.000 description 1
- 102100040120 Prominin-1 Human genes 0.000 description 1
- 108010072866 Prostate-Specific Antigen Proteins 0.000 description 1
- 102100035703 Prostatic acid phosphatase Human genes 0.000 description 1
- 102100030616 Protein-cysteine N-palmitoyltransferase HHAT Human genes 0.000 description 1
- 108010071563 Proto-Oncogene Proteins c-fos Proteins 0.000 description 1
- 102000007568 Proto-Oncogene Proteins c-fos Human genes 0.000 description 1
- 241000589517 Pseudomonas aeruginosa Species 0.000 description 1
- 241000589540 Pseudomonas fluorescens Species 0.000 description 1
- 241000589776 Pseudomonas putida Species 0.000 description 1
- 241000205156 Pyrococcus furiosus Species 0.000 description 1
- 241000522615 Pyrococcus horikoshii Species 0.000 description 1
- 239000012614 Q-Sepharose Substances 0.000 description 1
- 102100022491 RNA-binding protein NOB1 Human genes 0.000 description 1
- 241000700157 Rattus norvegicus Species 0.000 description 1
- 101000852966 Rattus norvegicus Interleukin-1 receptor-like 1 Proteins 0.000 description 1
- 102000004278 Receptor Protein-Tyrosine Kinases Human genes 0.000 description 1
- 108090000873 Receptor Protein-Tyrosine Kinases Proteins 0.000 description 1
- 101710100969 Receptor tyrosine-protein kinase erbB-3 Proteins 0.000 description 1
- 102100029986 Receptor tyrosine-protein kinase erbB-3 Human genes 0.000 description 1
- 102100029981 Receptor tyrosine-protein kinase erbB-4 Human genes 0.000 description 1
- 101710100963 Receptor tyrosine-protein kinase erbB-4 Proteins 0.000 description 1
- 102100037422 Receptor-type tyrosine-protein phosphatase C Human genes 0.000 description 1
- 108020004511 Recombinant DNA Proteins 0.000 description 1
- 108700008625 Reporter Genes Proteins 0.000 description 1
- AUNGANRZJHBGPY-SCRDCRAPSA-N Riboflavin Chemical compound OC[C@@H](O)[C@@H](O)[C@@H](O)CN1C=2C=C(C)C(C)=CC=2N=C2C1=NC(=O)NC2=O AUNGANRZJHBGPY-SCRDCRAPSA-N 0.000 description 1
- 108091028664 Ribonucleotide Proteins 0.000 description 1
- 108010039491 Ricin Proteins 0.000 description 1
- 241000283984 Rodentia Species 0.000 description 1
- 108010077895 Sarcosine Proteins 0.000 description 1
- VYPSYNLAJGMNEJ-UHFFFAOYSA-N Silicium dioxide Chemical compound O=[Si]=O VYPSYNLAJGMNEJ-UHFFFAOYSA-N 0.000 description 1
- 101150031731 Slc39a6 gene Proteins 0.000 description 1
- 241000256251 Spodoptera frugiperda Species 0.000 description 1
- 108010090804 Streptavidin Proteins 0.000 description 1
- 102100021669 Stromal cell-derived factor 1 Human genes 0.000 description 1
- 229930006000 Sucrose Natural products 0.000 description 1
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 1
- 241000282887 Suidae Species 0.000 description 1
- NINIDFKCEFEMDL-UHFFFAOYSA-N Sulfur Chemical compound [S] NINIDFKCEFEMDL-UHFFFAOYSA-N 0.000 description 1
- 108010002687 Survivin Proteins 0.000 description 1
- 102100035721 Syndecan-1 Human genes 0.000 description 1
- 102100024834 T-cell immunoreceptor with Ig and ITIM domains Human genes 0.000 description 1
- 102100025237 T-cell surface antigen CD2 Human genes 0.000 description 1
- 102100024219 T-cell surface glycoprotein CD1a Human genes 0.000 description 1
- 102100025244 T-cell surface glycoprotein CD5 Human genes 0.000 description 1
- 102100027222 T-lymphocyte activation antigen CD80 Human genes 0.000 description 1
- 108700012920 TNF Proteins 0.000 description 1
- 102100033082 TNF receptor-associated factor 3 Human genes 0.000 description 1
- 108010000449 TNF-Related Apoptosis-Inducing Ligand Receptors Proteins 0.000 description 1
- 102000002259 TNF-Related Apoptosis-Inducing Ligand Receptors Human genes 0.000 description 1
- 102000013530 TOR Serine-Threonine Kinases Human genes 0.000 description 1
- 108010065917 TOR Serine-Threonine Kinases Proteins 0.000 description 1
- QJJXYPPXXYFBGM-LFZNUXCKSA-N Tacrolimus Chemical compound C1C[C@@H](O)[C@H](OC)C[C@@H]1\C=C(/C)[C@@H]1[C@H](C)[C@@H](O)CC(=O)[C@H](CC=C)/C=C(C)/C[C@H](C)C[C@H](OC)[C@H]([C@H](C[C@H]2C)OC)O[C@@]2(O)C(=O)C(=O)N2CCCC[C@H]2C(=O)O1 QJJXYPPXXYFBGM-LFZNUXCKSA-N 0.000 description 1
- FEWJPZIEWOKRBE-UHFFFAOYSA-N Tartaric Acid Chemical class [H+].[H+].[O-]C(=O)C(O)C(O)C([O-])=O FEWJPZIEWOKRBE-UHFFFAOYSA-N 0.000 description 1
- CBPNZQVSJQDFBE-FUXHJELOSA-N Temsirolimus Chemical compound C1C[C@@H](OC(=O)C(C)(CO)CO)[C@H](OC)C[C@@H]1C[C@@H](C)[C@H]1OC(=O)[C@@H]2CCCCN2C(=O)C(=O)[C@](O)(O2)[C@H](C)CC[C@H]2C[C@H](OC)/C(C)=C/C=C/C=C/[C@@H](C)C[C@@H](C)C(=O)[C@H](OC)[C@H](O)/C(C)=C/[C@@H](C)C(=O)C1 CBPNZQVSJQDFBE-FUXHJELOSA-N 0.000 description 1
- 102100038126 Tenascin Human genes 0.000 description 1
- 108010008125 Tenascin Proteins 0.000 description 1
- 241000589499 Thermus thermophilus Species 0.000 description 1
- RYYWUUFWQRZTIU-UHFFFAOYSA-N Thiophosphoric acid Chemical class OP(O)(S)=O RYYWUUFWQRZTIU-UHFFFAOYSA-N 0.000 description 1
- 108090000190 Thrombin Proteins 0.000 description 1
- 108010000499 Thromboplastin Proteins 0.000 description 1
- IQFYYKKMVGJFEH-XLPZGREQSA-N Thymidine Chemical compound O=C1NC(=O)C(C)=CN1[C@@H]1O[C@H](CO)[C@@H](O)C1 IQFYYKKMVGJFEH-XLPZGREQSA-N 0.000 description 1
- 102100028788 Thymocyte selection-associated high mobility group box protein TOX Human genes 0.000 description 1
- 102100030859 Tissue factor Human genes 0.000 description 1
- 102100021386 Trans-acting T-cell-specific transcription factor GATA-3 Human genes 0.000 description 1
- 102000040945 Transcription factor Human genes 0.000 description 1
- 108091023040 Transcription factor Proteins 0.000 description 1
- 102100023132 Transcription factor Jun Human genes 0.000 description 1
- 108020004566 Transfer RNA Proteins 0.000 description 1
- YZCKVEUIGOORGS-NJFSPNSNSA-N Tritium Chemical compound [3H] YZCKVEUIGOORGS-NJFSPNSNSA-N 0.000 description 1
- 108090000631 Trypsin Proteins 0.000 description 1
- 102000004142 Trypsin Human genes 0.000 description 1
- 102100040245 Tumor necrosis factor receptor superfamily member 5 Human genes 0.000 description 1
- 102100040403 Tumor necrosis factor receptor superfamily member 6 Human genes 0.000 description 1
- 102100036857 Tumor necrosis factor receptor superfamily member 8 Human genes 0.000 description 1
- 102100033254 Tumor suppressor ARF Human genes 0.000 description 1
- 102100027212 Tumor-associated calcium signal transducer 2 Human genes 0.000 description 1
- 206010054094 Tumour necrosis Diseases 0.000 description 1
- 108091008605 VEGF receptors Proteins 0.000 description 1
- 102100033177 Vascular endothelial growth factor receptor 2 Human genes 0.000 description 1
- 101150035873 ZIP6 gene Proteins 0.000 description 1
- 102100032571 Zinc finger protein PLAGL2 Human genes 0.000 description 1
- 108091006550 Zinc transporters Proteins 0.000 description 1
- 230000001594 aberrant effect Effects 0.000 description 1
- 238000010521 absorption reaction Methods 0.000 description 1
- 229940022698 acetylcholinesterase Drugs 0.000 description 1
- 230000010933 acylation Effects 0.000 description 1
- 238000005917 acylation reaction Methods 0.000 description 1
- 239000002671 adjuvant Substances 0.000 description 1
- 229950004955 adozelesin Drugs 0.000 description 1
- BYRVKDUQDLJUBX-JJCDCTGGSA-N adozelesin Chemical compound C1=CC=C2OC(C(=O)NC=3C=C4C=C(NC4=CC=3)C(=O)N3C[C@H]4C[C@]44C5=C(C(C=C43)=O)NC=C5C)=CC2=C1 BYRVKDUQDLJUBX-JJCDCTGGSA-N 0.000 description 1
- 238000001042 affinity chromatography Methods 0.000 description 1
- 239000007801 affinity label Substances 0.000 description 1
- 239000000556 agonist Substances 0.000 description 1
- 108010026331 alpha-Fetoproteins Proteins 0.000 description 1
- VREFGVBLTWBCJP-UHFFFAOYSA-N alprazolam Chemical compound C12=CC(Cl)=CC=C2N2C(C)=NN=C2CN=C1C1=CC=CC=C1 VREFGVBLTWBCJP-UHFFFAOYSA-N 0.000 description 1
- 230000004075 alteration Effects 0.000 description 1
- 125000003277 amino group Chemical group 0.000 description 1
- 229960002684 aminocaproic acid Drugs 0.000 description 1
- 230000003444 anaesthetic effect Effects 0.000 description 1
- 238000013103 analytical ultracentrifugation Methods 0.000 description 1
- 230000033115 angiogenesis Effects 0.000 description 1
- 238000005571 anion exchange chromatography Methods 0.000 description 1
- 150000001450 anions Chemical class 0.000 description 1
- 229940045799 anthracyclines and related substance Drugs 0.000 description 1
- 239000003242 anti bacterial agent Substances 0.000 description 1
- 230000000692 anti-sense effect Effects 0.000 description 1
- 229940088710 antibiotic agent Drugs 0.000 description 1
- 230000010056 antibody-dependent cellular cytotoxicity Effects 0.000 description 1
- 230000000890 antigenic effect Effects 0.000 description 1
- 239000012062 aqueous buffer Substances 0.000 description 1
- 230000010516 arginylation Effects 0.000 description 1
- 235000010233 benzoic acid Nutrition 0.000 description 1
- 108010005774 beta-Galactosidase Proteins 0.000 description 1
- 108091008324 binding proteins Proteins 0.000 description 1
- 229950006844 bizelesin Drugs 0.000 description 1
- 238000006664 bond formation reaction Methods 0.000 description 1
- 101150061829 bre-3 gene Proteins 0.000 description 1
- 229950004398 broxuridine Drugs 0.000 description 1
- 244000309464 bull Species 0.000 description 1
- 239000011575 calcium Substances 0.000 description 1
- 229910052791 calcium Inorganic materials 0.000 description 1
- HXCHCVDVKSCDHU-LULTVBGHSA-N calicheamicin Chemical class C1[C@H](OC)[C@@H](NCC)CO[C@H]1O[C@H]1[C@H](O[C@@H]2C\3=C(NC(=O)OC)C(=O)C[C@](C/3=C/CSSSC)(O)C#C\C=C/C#C2)O[C@H](C)[C@@H](NO[C@@H]2O[C@H](C)[C@@H](SC(=O)C=3C(=C(OC)C(O[C@H]4[C@@H]([C@H](OC)[C@@H](O)[C@H](C)O4)O)=C(I)C=3C)OC)[C@@H](O)C2)[C@@H]1O HXCHCVDVKSCDHU-LULTVBGHSA-N 0.000 description 1
- 229940127093 camptothecin Drugs 0.000 description 1
- 230000005907 cancer growth Effects 0.000 description 1
- 238000002619 cancer immunotherapy Methods 0.000 description 1
- 238000005251 capillar electrophoresis Methods 0.000 description 1
- 239000002775 capsule Substances 0.000 description 1
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 1
- 150000001732 carboxylic acid derivatives Chemical group 0.000 description 1
- 238000005277 cation exchange chromatography Methods 0.000 description 1
- 150000001768 cations Chemical class 0.000 description 1
- 230000020411 cell activation Effects 0.000 description 1
- 239000006143 cell culture medium Substances 0.000 description 1
- 230000022131 cell cycle Effects 0.000 description 1
- 230000011712 cell development Effects 0.000 description 1
- 238000002737 cell proliferation kit Methods 0.000 description 1
- 108091092356 cellular DNA Proteins 0.000 description 1
- 230000004640 cellular pathway Effects 0.000 description 1
- 210000003169 central nervous system Anatomy 0.000 description 1
- 208000019065 cervical carcinoma Diseases 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 239000002738 chelating agent Substances 0.000 description 1
- 150000005829 chemical entities Chemical class 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 210000004978 chinese hamster ovary cell Anatomy 0.000 description 1
- 238000011098 chromatofocusing Methods 0.000 description 1
- 230000002759 chromosomal effect Effects 0.000 description 1
- 229960002376 chymotrypsin Drugs 0.000 description 1
- 238000002983 circular dichroism Methods 0.000 description 1
- 229960002173 citrulline Drugs 0.000 description 1
- 235000013477 citrulline Nutrition 0.000 description 1
- 230000035071 co-translational protein modification Effects 0.000 description 1
- 239000011248 coating agent Substances 0.000 description 1
- 238000000576 coating method Methods 0.000 description 1
- 210000001072 colon Anatomy 0.000 description 1
- 208000029742 colonic neoplasm Diseases 0.000 description 1
- 230000001609 comparable effect Effects 0.000 description 1
- 239000012141 concentrate Substances 0.000 description 1
- 239000000470 constituent Substances 0.000 description 1
- 239000000356 contaminant Substances 0.000 description 1
- 239000000599 controlled substance Substances 0.000 description 1
- 238000012937 correction Methods 0.000 description 1
- ATDGTVJJHBUTRL-UHFFFAOYSA-N cyanogen bromide Chemical compound BrC#N ATDGTVJJHBUTRL-UHFFFAOYSA-N 0.000 description 1
- 150000001945 cysteines Chemical class 0.000 description 1
- 239000000824 cytostatic agent Substances 0.000 description 1
- 230000001085 cytostatic effect Effects 0.000 description 1
- 230000006378 damage Effects 0.000 description 1
- 230000001934 delay Effects 0.000 description 1
- 230000017858 demethylation Effects 0.000 description 1
- 238000010520 demethylation reaction Methods 0.000 description 1
- 210000004443 dendritic cell Anatomy 0.000 description 1
- 239000005549 deoxyribonucleoside Substances 0.000 description 1
- 239000005547 deoxyribonucleotide Substances 0.000 description 1
- 125000002637 deoxyribonucleotide group Chemical group 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 229910052805 deuterium Inorganic materials 0.000 description 1
- 239000008121 dextrose Substances 0.000 description 1
- 238000000502 dialysis Methods 0.000 description 1
- 238000002050 diffraction method Methods 0.000 description 1
- 230000029087 digestion Effects 0.000 description 1
- 108020001096 dihydrofolate reductase Proteins 0.000 description 1
- 230000000447 dimerizing effect Effects 0.000 description 1
- 230000003467 diminishing effect Effects 0.000 description 1
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 1
- 230000005750 disease progression Effects 0.000 description 1
- PMMYEEVYMWASQN-UHFFFAOYSA-N dl-hydroxyproline Natural products OC1C[NH2+]C(C([O-])=O)C1 PMMYEEVYMWASQN-UHFFFAOYSA-N 0.000 description 1
- OFDNQWIFNXBECV-VFSYNPLYSA-N dolastatin 10 Chemical class CC(C)[C@H](N(C)C)C(=O)N[C@@H](C(C)C)C(=O)N(C)[C@@H]([C@@H](C)CC)[C@H](OC)CC(=O)N1CCC[C@H]1[C@H](OC)[C@@H](C)C(=O)N[C@H](C=1SC=CN=1)CC1=CC=CC=C1 OFDNQWIFNXBECV-VFSYNPLYSA-N 0.000 description 1
- 239000002552 dosage form Substances 0.000 description 1
- 231100000371 dose-limiting toxicity Toxicity 0.000 description 1
- 229940126534 drug product Drugs 0.000 description 1
- VQNATVDKACXKTF-XELLLNAOSA-N duocarmycin Chemical class COC1=C(OC)C(OC)=C2NC(C(=O)N3C4=CC(=O)C5=C([C@@]64C[C@@H]6C3)C=C(N5)C(=O)OC)=CC2=C1 VQNATVDKACXKTF-XELLLNAOSA-N 0.000 description 1
- 238000002296 dynamic light scattering Methods 0.000 description 1
- 238000001493 electron microscopy Methods 0.000 description 1
- 239000003995 emulsifying agent Substances 0.000 description 1
- 239000000839 emulsion Substances 0.000 description 1
- 238000005538 encapsulation Methods 0.000 description 1
- 230000002255 enzymatic effect Effects 0.000 description 1
- 108010087914 epidermal growth factor receptor VIII Proteins 0.000 description 1
- 229960001904 epirubicin Drugs 0.000 description 1
- 210000002919 epithelial cell Anatomy 0.000 description 1
- 150000002170 ethers Chemical class 0.000 description 1
- 241001233957 eudicotyledons Species 0.000 description 1
- 210000003527 eukaryotic cell Anatomy 0.000 description 1
- 229960004887 ferric hydroxide Drugs 0.000 description 1
- 210000003754 fetus Anatomy 0.000 description 1
- 239000000835 fiber Substances 0.000 description 1
- 235000013312 flour Nutrition 0.000 description 1
- 239000012530 fluid Substances 0.000 description 1
- 229910052731 fluorine Inorganic materials 0.000 description 1
- 239000011737 fluorine Substances 0.000 description 1
- 229960000304 folic acid Drugs 0.000 description 1
- 101150046266 foxo gene Proteins 0.000 description 1
- 230000005714 functional activity Effects 0.000 description 1
- 125000000524 functional group Chemical group 0.000 description 1
- 230000002538 fungal effect Effects 0.000 description 1
- 229910052733 gallium Inorganic materials 0.000 description 1
- 229960003692 gamma aminobutyric acid Drugs 0.000 description 1
- 230000006251 gamma-carboxylation Effects 0.000 description 1
- 206010017758 gastric cancer Diseases 0.000 description 1
- 210000001035 gastrointestinal tract Anatomy 0.000 description 1
- 239000008273 gelatin Substances 0.000 description 1
- 229920000159 gelatin Polymers 0.000 description 1
- 235000019322 gelatine Nutrition 0.000 description 1
- 235000011852 gelatine desserts Nutrition 0.000 description 1
- 238000002523 gelfiltration Methods 0.000 description 1
- 239000008103 glucose Substances 0.000 description 1
- 229960003180 glutathione Drugs 0.000 description 1
- YQEMORVAKMFKLG-UHFFFAOYSA-N glycerine monostearate Natural products CCCCCCCCCCCCCCCCCC(=O)OC(CO)CO YQEMORVAKMFKLG-UHFFFAOYSA-N 0.000 description 1
- SVUQHVRAGMNPLW-UHFFFAOYSA-N glycerol monostearate Natural products CCCCCCCCCCCCCCCCC(=O)OCC(O)CO SVUQHVRAGMNPLW-UHFFFAOYSA-N 0.000 description 1
- 230000012010 growth Effects 0.000 description 1
- 239000001963 growth medium Substances 0.000 description 1
- 150000003278 haem Chemical group 0.000 description 1
- 238000003306 harvesting Methods 0.000 description 1
- 201000010536 head and neck cancer Diseases 0.000 description 1
- 208000014829 head and neck neoplasm Diseases 0.000 description 1
- 210000002443 helper t lymphocyte Anatomy 0.000 description 1
- 231100000304 hepatotoxicity Toxicity 0.000 description 1
- 238000005734 heterodimerization reaction Methods 0.000 description 1
- 210000003630 histaminocyte Anatomy 0.000 description 1
- 238000002744 homologous recombination Methods 0.000 description 1
- 230000006801 homologous recombination Effects 0.000 description 1
- 229940088597 hormone Drugs 0.000 description 1
- 239000005556 hormone Substances 0.000 description 1
- 238000001794 hormone therapy Methods 0.000 description 1
- 230000028996 humoral immune response Effects 0.000 description 1
- 150000007857 hydrazones Chemical class 0.000 description 1
- 229910052739 hydrogen Inorganic materials 0.000 description 1
- 150000002431 hydrogen Chemical group 0.000 description 1
- 239000001257 hydrogen Substances 0.000 description 1
- 230000002209 hydrophobic effect Effects 0.000 description 1
- 125000001165 hydrophobic group Chemical group 0.000 description 1
- WGCNASOHLSPBMP-UHFFFAOYSA-N hydroxyacetaldehyde Natural products OCC=O WGCNASOHLSPBMP-UHFFFAOYSA-N 0.000 description 1
- 150000002443 hydroxylamines Chemical class 0.000 description 1
- 230000033444 hydroxylation Effects 0.000 description 1
- 238000005805 hydroxylation reaction Methods 0.000 description 1
- 229960002591 hydroxyproline Drugs 0.000 description 1
- 230000007954 hypoxia Effects 0.000 description 1
- 229960000908 idarubicin Drugs 0.000 description 1
- 238000003384 imaging method Methods 0.000 description 1
- 239000012274 immune-checkpoint protein inhibitor Substances 0.000 description 1
- 238000002649 immunization Methods 0.000 description 1
- 238000003018 immunoassay Methods 0.000 description 1
- 230000006054 immunological memory Effects 0.000 description 1
- 238000009169 immunotherapy Methods 0.000 description 1
- 230000001965 increasing effect Effects 0.000 description 1
- 229910052738 indium Inorganic materials 0.000 description 1
- APFVFJFRJDLVQX-UHFFFAOYSA-N indium atom Chemical compound [In] APFVFJFRJDLVQX-UHFFFAOYSA-N 0.000 description 1
- 239000000411 inducer Substances 0.000 description 1
- 230000001939 inductive effect Effects 0.000 description 1
- 208000015181 infectious disease Diseases 0.000 description 1
- 108040003607 interleukin-13 receptor activity proteins Proteins 0.000 description 1
- 108040002039 interleukin-15 receptor activity proteins Proteins 0.000 description 1
- 102000008616 interleukin-15 receptor activity proteins Human genes 0.000 description 1
- 108040001304 interleukin-17 receptor activity proteins Proteins 0.000 description 1
- 102000053460 interleukin-17 receptor activity proteins Human genes 0.000 description 1
- 108040002014 interleukin-18 receptor activity proteins Proteins 0.000 description 1
- 102000008625 interleukin-18 receptor activity proteins Human genes 0.000 description 1
- 108010074108 interleukin-21 Proteins 0.000 description 1
- 108010074109 interleukin-22 Proteins 0.000 description 1
- 108040006852 interleukin-4 receptor activity proteins Proteins 0.000 description 1
- 108040006858 interleukin-6 receptor activity proteins Proteins 0.000 description 1
- 210000004347 intestinal mucosa Anatomy 0.000 description 1
- 238000007918 intramuscular administration Methods 0.000 description 1
- 238000007913 intrathecal administration Methods 0.000 description 1
- 230000026045 iodination Effects 0.000 description 1
- 238000006192 iodination reaction Methods 0.000 description 1
- PNDPGZBMCMUPRI-UHFFFAOYSA-N iodine Chemical compound II PNDPGZBMCMUPRI-UHFFFAOYSA-N 0.000 description 1
- 238000005342 ion exchange Methods 0.000 description 1
- 150000002500 ions Chemical class 0.000 description 1
- 229960004768 irinotecan Drugs 0.000 description 1
- UWKQSNNFCGGAFS-XIFFEERXSA-N irinotecan Chemical compound C1=C2C(CC)=C3CN(C(C4=C([C@@](C(=O)OC4)(O)CC)C=4)=O)C=4C3=NC2=CC=C1OC(=O)N(CC1)CCC1N1CCCCC1 UWKQSNNFCGGAFS-XIFFEERXSA-N 0.000 description 1
- IEECXTSVVFWGSE-UHFFFAOYSA-M iron(3+);oxygen(2-);hydroxide Chemical compound [OH-].[O-2].[Fe+3] IEECXTSVVFWGSE-UHFFFAOYSA-M 0.000 description 1
- 238000002955 isolation Methods 0.000 description 1
- 230000000155 isotopic effect Effects 0.000 description 1
- 150000004715 keto acids Chemical class 0.000 description 1
- ZNOVTXRBGFNYRX-ABLWVSNPSA-N levomefolic acid Chemical compound C1NC=2NC(N)=NC(=O)C=2N(C)C1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 ZNOVTXRBGFNYRX-ABLWVSNPSA-N 0.000 description 1
- 235000007635 levomefolic acid Nutrition 0.000 description 1
- 239000011578 levomefolic acid Substances 0.000 description 1
- 229960004194 lidocaine Drugs 0.000 description 1
- 230000007056 liver toxicity Effects 0.000 description 1
- 230000004807 localization Effects 0.000 description 1
- 238000004020 luminiscence type Methods 0.000 description 1
- HWYHZTIRURJOHG-UHFFFAOYSA-N luminol Chemical compound O=C1NNC(=O)C2=C1C(N)=CC=C2 HWYHZTIRURJOHG-UHFFFAOYSA-N 0.000 description 1
- 201000005249 lung adenocarcinoma Diseases 0.000 description 1
- 210000005265 lung cell Anatomy 0.000 description 1
- 201000009546 lung large cell carcinoma Diseases 0.000 description 1
- RVFGKBWWUQOIOU-NDEPHWFRSA-N lurtotecan Chemical compound O=C([C@]1(O)CC)OCC(C(N2CC3=4)=O)=C1C=C2C3=NC1=CC=2OCCOC=2C=C1C=4CN1CCN(C)CC1 RVFGKBWWUQOIOU-NDEPHWFRSA-N 0.000 description 1
- 229950002654 lurtotecan Drugs 0.000 description 1
- 210000001165 lymph node Anatomy 0.000 description 1
- 210000004698 lymphocyte Anatomy 0.000 description 1
- 239000008176 lyophilized powder Substances 0.000 description 1
- 125000003588 lysine group Chemical group [H]N([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])(N([H])[H])C(*)=O 0.000 description 1
- 229940124302 mTOR inhibitor Drugs 0.000 description 1
- ZLNQQNXFFQJAID-UHFFFAOYSA-L magnesium carbonate Chemical compound [Mg+2].[O-]C([O-])=O ZLNQQNXFFQJAID-UHFFFAOYSA-L 0.000 description 1
- 239000001095 magnesium carbonate Substances 0.000 description 1
- 229910000021 magnesium carbonate Inorganic materials 0.000 description 1
- 235000019359 magnesium stearate Nutrition 0.000 description 1
- 239000003628 mammalian target of rapamycin inhibitor Substances 0.000 description 1
- 210000005075 mammary gland Anatomy 0.000 description 1
- 239000000594 mannitol Substances 0.000 description 1
- 235000010355 mannitol Nutrition 0.000 description 1
- 238000004949 mass spectrometry Methods 0.000 description 1
- 230000008774 maternal effect Effects 0.000 description 1
- 239000011159 matrix material Substances 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 239000002609 medium Substances 0.000 description 1
- 201000001441 melanoma Diseases 0.000 description 1
- 210000005033 mesothelial cell Anatomy 0.000 description 1
- 230000009401 metastasis Effects 0.000 description 1
- MYWUZJCMWCOHBA-VIFPVBQESA-N methamphetamine Chemical compound CN[C@@H](C)CC1=CC=CC=C1 MYWUZJCMWCOHBA-VIFPVBQESA-N 0.000 description 1
- 229920012128 methyl methacrylate acrylonitrile butadiene styrene Polymers 0.000 description 1
- 230000011987 methylation Effects 0.000 description 1
- 238000007069 methylation reaction Methods 0.000 description 1
- LSDPWZHWYPCBBB-UHFFFAOYSA-O methylsulfide anion Chemical compound [SH2+]C LSDPWZHWYPCBBB-UHFFFAOYSA-O 0.000 description 1
- 238000012737 microarray-based gene expression Methods 0.000 description 1
- 239000003094 microcapsule Substances 0.000 description 1
- 239000002480 mineral oil Substances 0.000 description 1
- 235000010446 mineral oil Nutrition 0.000 description 1
- 108091005601 modified peptides Proteins 0.000 description 1
- 229910052750 molybdenum Inorganic materials 0.000 description 1
- 239000011733 molybdenum Substances 0.000 description 1
- 210000002200 mouth mucosa Anatomy 0.000 description 1
- 238000000569 multi-angle light scattering Methods 0.000 description 1
- 238000012243 multiplex automated genomic engineering Methods 0.000 description 1
- 210000000066 myeloid cell Anatomy 0.000 description 1
- ZTLGJPIZUOVDMT-UHFFFAOYSA-N n,n-dichlorotriazin-4-amine Chemical compound ClN(Cl)C1=CC=NN=N1 ZTLGJPIZUOVDMT-UHFFFAOYSA-N 0.000 description 1
- OHDXDNUPVVYWOV-UHFFFAOYSA-N n-methyl-1-(2-naphthalen-1-ylsulfanylphenyl)methanamine Chemical compound CNCC1=CC=CC=C1SC1=CC=CC2=CC=CC=C12 OHDXDNUPVVYWOV-UHFFFAOYSA-N 0.000 description 1
- 239000007922 nasal spray Substances 0.000 description 1
- 229940097496 nasal spray Drugs 0.000 description 1
- 239000006199 nebulizer Substances 0.000 description 1
- 239000013642 negative control Substances 0.000 description 1
- CTMCWCONSULRHO-UHQPFXKFSA-N nemorubicin Chemical compound C1CO[C@H](OC)CN1[C@@H]1[C@H](O)[C@H](C)O[C@@H](O[C@@H]2C3=C(O)C=4C(=O)C5=C(OC)C=CC=C5C(=O)C=4C(O)=C3C[C@](O)(C2)C(=O)CO)C1 CTMCWCONSULRHO-UHQPFXKFSA-N 0.000 description 1
- 229950010159 nemorubicin Drugs 0.000 description 1
- 210000003061 neural cell Anatomy 0.000 description 1
- 230000007935 neutral effect Effects 0.000 description 1
- 210000000440 neutrophil Anatomy 0.000 description 1
- 229910052757 nitrogen Inorganic materials 0.000 description 1
- 210000004882 non-tumor cell Anatomy 0.000 description 1
- 229920001778 nylon Polymers 0.000 description 1
- 239000003921 oil Substances 0.000 description 1
- 235000019198 oils Nutrition 0.000 description 1
- 239000002751 oligonucleotide probe Substances 0.000 description 1
- 210000000056 organ Anatomy 0.000 description 1
- 230000002611 ovarian Effects 0.000 description 1
- 208000013371 ovarian adenocarcinoma Diseases 0.000 description 1
- 201000006588 ovary adenocarcinoma Diseases 0.000 description 1
- 230000002018 overexpression Effects 0.000 description 1
- 150000002923 oximes Chemical class 0.000 description 1
- 229910052760 oxygen Inorganic materials 0.000 description 1
- 102000002574 p38 Mitogen-Activated Protein Kinases Human genes 0.000 description 1
- 108010068338 p38 Mitogen-Activated Protein Kinases Proteins 0.000 description 1
- 239000006179 pH buffering agent Substances 0.000 description 1
- 229910052763 palladium Inorganic materials 0.000 description 1
- 230000001575 pathological effect Effects 0.000 description 1
- 230000007170 pathology Effects 0.000 description 1
- 230000037361 pathway Effects 0.000 description 1
- 239000000312 peanut oil Substances 0.000 description 1
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 description 1
- 239000003208 petroleum Substances 0.000 description 1
- 229940124531 pharmaceutical excipient Drugs 0.000 description 1
- 239000000825 pharmaceutical preparation Substances 0.000 description 1
- 230000000144 pharmacologic effect Effects 0.000 description 1
- NBIIXXVUZAFLBC-UHFFFAOYSA-K phosphate Chemical compound [O-]P([O-])([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-K 0.000 description 1
- 239000002953 phosphate buffered saline Substances 0.000 description 1
- PTMHPRAIXMAOOB-UHFFFAOYSA-N phosphoramidic acid Chemical class NP(O)(O)=O PTMHPRAIXMAOOB-UHFFFAOYSA-N 0.000 description 1
- 230000000704 physical effect Effects 0.000 description 1
- 239000006187 pill Substances 0.000 description 1
- 239000013612 plasmid Substances 0.000 description 1
- 239000004033 plastic Substances 0.000 description 1
- 229920003023 plastic Polymers 0.000 description 1
- 229920001481 poly(stearyl methacrylate) Polymers 0.000 description 1
- 229920002401 polyacrylamide Polymers 0.000 description 1
- 238000002264 polyacrylamide gel electrophoresis Methods 0.000 description 1
- 229920001155 polypropylene Polymers 0.000 description 1
- 229920002223 polystyrene Polymers 0.000 description 1
- 239000004800 polyvinyl chloride Substances 0.000 description 1
- 229920000915 polyvinyl chloride Polymers 0.000 description 1
- 239000011591 potassium Substances 0.000 description 1
- 229910052700 potassium Inorganic materials 0.000 description 1
- 239000000843 powder Substances 0.000 description 1
- 238000001556 precipitation Methods 0.000 description 1
- 230000013823 prenylation Effects 0.000 description 1
- MFDFERRIHVXMIY-UHFFFAOYSA-N procaine Chemical compound CCN(CC)CCOC(=O)C1=CC=C(N)C=C1 MFDFERRIHVXMIY-UHFFFAOYSA-N 0.000 description 1
- 229960004919 procaine Drugs 0.000 description 1
- 238000004393 prognosis Methods 0.000 description 1
- 210000001236 prokaryotic cell Anatomy 0.000 description 1
- 230000002035 prolonged effect Effects 0.000 description 1
- 230000001737 promoting effect Effects 0.000 description 1
- QQONPFPTGQHPMA-UHFFFAOYSA-N propylene Natural products CC=C QQONPFPTGQHPMA-UHFFFAOYSA-N 0.000 description 1
- 125000004805 propylene group Chemical group [H]C([H])([H])C([H])([*:1])C([H])([H])[*:2] 0.000 description 1
- 108010043671 prostatic acid phosphatase Proteins 0.000 description 1
- 235000019833 protease Nutrition 0.000 description 1
- 235000004252 protein component Nutrition 0.000 description 1
- 230000012846 protein folding Effects 0.000 description 1
- 238000001742 protein purification Methods 0.000 description 1
- 230000004850 protein–protein interaction Effects 0.000 description 1
- 230000002797 proteolythic effect Effects 0.000 description 1
- 230000002685 pulmonary effect Effects 0.000 description 1
- 229940043131 pyroglutamate Drugs 0.000 description 1
- 230000006340 racemization Effects 0.000 description 1
- 230000002285 radioactive effect Effects 0.000 description 1
- 239000012857 radioactive material Substances 0.000 description 1
- 238000001959 radiotherapy Methods 0.000 description 1
- 235000012950 rattan cane Nutrition 0.000 description 1
- 230000009257 reactivity Effects 0.000 description 1
- 230000008707 rearrangement Effects 0.000 description 1
- 230000010837 receptor-mediated endocytosis Effects 0.000 description 1
- 238000010188 recombinant method Methods 0.000 description 1
- 230000001603 reducing effect Effects 0.000 description 1
- 238000006722 reduction reaction Methods 0.000 description 1
- 230000002829 reductive effect Effects 0.000 description 1
- 239000011347 resin Substances 0.000 description 1
- 229920005989 resin Polymers 0.000 description 1
- 230000000284 resting effect Effects 0.000 description 1
- PYWVYCXTNDRMGF-UHFFFAOYSA-N rhodamine B Chemical compound [Cl-].C=12C=CC(=[N+](CC)CC)C=C2OC2=CC(N(CC)CC)=CC=C2C=1C1=CC=CC=C1C(O)=O PYWVYCXTNDRMGF-UHFFFAOYSA-N 0.000 description 1
- 239000002342 ribonucleoside Substances 0.000 description 1
- 239000002336 ribonucleotide Substances 0.000 description 1
- 125000002652 ribonucleotide group Chemical group 0.000 description 1
- 235000009566 rice Nutrition 0.000 description 1
- 238000007363 ring formation reaction Methods 0.000 description 1
- VHXNKPBCCMUMSW-FQEVSTJZSA-N rubitecan Chemical compound C1=CC([N+]([O-])=O)=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)[C@]5(O)CC)C4=NC2=C1 VHXNKPBCCMUMSW-FQEVSTJZSA-N 0.000 description 1
- 229950009213 rubitecan Drugs 0.000 description 1
- CVHZOJJKTDOEJC-UHFFFAOYSA-N saccharin Chemical compound C1=CC=C2C(=O)NS(=O)(=O)C2=C1 CVHZOJJKTDOEJC-UHFFFAOYSA-N 0.000 description 1
- 235000002020 sage Nutrition 0.000 description 1
- 210000003296 saliva Anatomy 0.000 description 1
- 229940043230 sarcosine Drugs 0.000 description 1
- 238000012216 screening Methods 0.000 description 1
- 229940055619 selenocysteine Drugs 0.000 description 1
- ZKZBPNGNEQAJSX-UHFFFAOYSA-N selenocysteine Natural products [SeH]CC(N)C(O)=O ZKZBPNGNEQAJSX-UHFFFAOYSA-N 0.000 description 1
- 235000016491 selenocysteine Nutrition 0.000 description 1
- 230000035945 sensitivity Effects 0.000 description 1
- 210000000717 sertoli cell Anatomy 0.000 description 1
- 239000008159 sesame oil Substances 0.000 description 1
- 235000011803 sesame oil Nutrition 0.000 description 1
- 108091006024 signal transducing proteins Proteins 0.000 description 1
- 102000034285 signal transducing proteins Human genes 0.000 description 1
- 239000000741 silica gel Substances 0.000 description 1
- 229910002027 silica gel Inorganic materials 0.000 description 1
- 238000009097 single-agent therapy Methods 0.000 description 1
- 238000002741 site-directed mutagenesis Methods 0.000 description 1
- 238000004513 sizing Methods 0.000 description 1
- 235000020183 skimmed milk Nutrition 0.000 description 1
- 150000003384 small molecules Chemical class 0.000 description 1
- RYYKJJJTJZKILX-UHFFFAOYSA-M sodium octadecanoate Chemical compound [Na+].CCCCCCCCCCCCCCCCCC([O-])=O RYYKJJJTJZKILX-UHFFFAOYSA-M 0.000 description 1
- 238000007614 solvation Methods 0.000 description 1
- XNZLMZRIGGHITK-VKXBZTRUSA-N soravtansine Chemical compound CO[C@@H]([C@@]1(O)C[C@H](OC(=O)N1)[C@@H](C)[C@@H]1O[C@@]1(C)[C@@H](OC(=O)[C@H](C)N(C)C(=O)CCC(C)(C)SSCC[C@@H](C(O)=O)S(O)(=O)=O)CC(=O)N1C)\C=C\C=C(C)\CC2=CC(OC)=C(Cl)C1=C2.CO[C@@H]([C@@]1(O)C[C@H](OC(=O)N1)[C@@H](C)[C@@H]1O[C@@]1(C)[C@@H](OC(=O)[C@H](C)N(C)C(=O)CCC(C)(C)SSCC[C@H](C(O)=O)S(O)(=O)=O)CC(=O)N1C)\C=C\C=C(C)\CC2=CC(OC)=C(Cl)C1=C2 XNZLMZRIGGHITK-VKXBZTRUSA-N 0.000 description 1
- 239000003549 soybean oil Substances 0.000 description 1
- 235000012424 soybean oil Nutrition 0.000 description 1
- 210000000952 spleen Anatomy 0.000 description 1
- 238000007619 statistical method Methods 0.000 description 1
- 239000008227 sterile water for injection Substances 0.000 description 1
- 230000004936 stimulating effect Effects 0.000 description 1
- 230000000638 stimulation Effects 0.000 description 1
- 201000011549 stomach cancer Diseases 0.000 description 1
- 239000005720 sucrose Substances 0.000 description 1
- 235000000346 sugar Nutrition 0.000 description 1
- 230000019635 sulfation Effects 0.000 description 1
- 238000005670 sulfation reaction Methods 0.000 description 1
- 125000000542 sulfonic acid group Chemical group 0.000 description 1
- 239000011593 sulfur Substances 0.000 description 1
- 239000013589 supplement Substances 0.000 description 1
- 238000013268 sustained release Methods 0.000 description 1
- 239000012730 sustained-release form Substances 0.000 description 1
- 210000004243 sweat Anatomy 0.000 description 1
- 238000010189 synthetic method Methods 0.000 description 1
- 239000003826 tablet Substances 0.000 description 1
- QJJXYPPXXYFBGM-SHYZHZOCSA-N tacrolimus Natural products CO[C@H]1C[C@H](CC[C@@H]1O)C=C(C)[C@H]2OC(=O)[C@H]3CCCCN3C(=O)C(=O)[C@@]4(O)O[C@@H]([C@H](C[C@H]4C)OC)[C@@H](C[C@H](C)CC(=C[C@@H](CC=C)C(=O)C[C@H](O)[C@H]2C)C)OC QJJXYPPXXYFBGM-SHYZHZOCSA-N 0.000 description 1
- 101150047061 tag-72 gene Proteins 0.000 description 1
- 239000000454 talc Substances 0.000 description 1
- 229910052623 talc Inorganic materials 0.000 description 1
- 235000002906 tartaric acid Nutrition 0.000 description 1
- 210000001138 tear Anatomy 0.000 description 1
- 229910052713 technetium Inorganic materials 0.000 description 1
- GKLVYJBZJHMRIY-UHFFFAOYSA-N technetium atom Chemical compound [Tc] GKLVYJBZJHMRIY-UHFFFAOYSA-N 0.000 description 1
- 229960000235 temsirolimus Drugs 0.000 description 1
- QFJCIRLUMZQUOT-UHFFFAOYSA-N temsirolimus Natural products C1CC(O)C(OC)CC1CC(C)C1OC(=O)C2CCCCN2C(=O)C(=O)C(O)(O2)C(C)CCC2CC(OC)C(C)=CC=CC=CC(C)CC(C)C(=O)C(OC)C(O)C(C)=CC(C)C(=O)C1 QFJCIRLUMZQUOT-UHFFFAOYSA-N 0.000 description 1
- 229910052716 thallium Inorganic materials 0.000 description 1
- BKVIYDNLLOSFOA-UHFFFAOYSA-N thallium Chemical compound [Tl] BKVIYDNLLOSFOA-UHFFFAOYSA-N 0.000 description 1
- 229940124597 therapeutic agent Drugs 0.000 description 1
- 229960004072 thrombin Drugs 0.000 description 1
- 230000000699 topical effect Effects 0.000 description 1
- 229960000303 topotecan Drugs 0.000 description 1
- UCFGDBYHRUNTLO-QHCPKHFHSA-N topotecan Chemical compound C1=C(O)C(CN(C)C)=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)[C@]5(O)CC)C4=NC2=C1 UCFGDBYHRUNTLO-QHCPKHFHSA-N 0.000 description 1
- FGMPLJWBKKVCDB-UHFFFAOYSA-N trans-L-hydroxy-proline Natural products ON1CCCC1C(O)=O FGMPLJWBKKVCDB-UHFFFAOYSA-N 0.000 description 1
- 238000010361 transduction Methods 0.000 description 1
- 230000026683 transduction Effects 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
- 238000003146 transient transfection Methods 0.000 description 1
- 230000005945 translocation Effects 0.000 description 1
- 102000027257 transmembrane receptors Human genes 0.000 description 1
- 108091008578 transmembrane receptors Proteins 0.000 description 1
- 230000032258 transport Effects 0.000 description 1
- 150000003626 triacylglycerols Chemical class 0.000 description 1
- 239000013638 trimer Substances 0.000 description 1
- 229910052722 tritium Inorganic materials 0.000 description 1
- 239000012588 trypsin Substances 0.000 description 1
- 229960001322 trypsin Drugs 0.000 description 1
- 238000013060 ultrafiltration and diafiltration Methods 0.000 description 1
- ORHBXUUXSCNDEV-UHFFFAOYSA-N umbelliferone Chemical compound C1=CC(=O)OC2=CC(O)=CC=C21 ORHBXUUXSCNDEV-UHFFFAOYSA-N 0.000 description 1
- HFTAFOQKODTIJY-UHFFFAOYSA-N umbelliferone Natural products Cc1cc2C=CC(=O)Oc2cc1OCC=CC(C)(C)O HFTAFOQKODTIJY-UHFFFAOYSA-N 0.000 description 1
- 210000002700 urine Anatomy 0.000 description 1
- 235000013311 vegetables Nutrition 0.000 description 1
- 230000003442 weekly effect Effects 0.000 description 1
- 238000009736 wetting Methods 0.000 description 1
- 239000000080 wetting agent Substances 0.000 description 1
- 229910052724 xenon Inorganic materials 0.000 description 1
- FHNFHKCVQCLJFQ-UHFFFAOYSA-N xenon atom Chemical compound [Xe] FHNFHKCVQCLJFQ-UHFFFAOYSA-N 0.000 description 1
Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2878—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the NGF-receptor/TNF-receptor superfamily, e.g. CD27, CD30, CD40, CD95
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/32—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against translation products of oncogenes
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/24—Immunoglobulins specific features characterized by taxonomic origin containing regions, domains or residues from different species, e.g. chimeric, humanized or veneered
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/31—Immunoglobulins specific features characterized by aspects of specificity or valency multispecific
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/33—Crossreactivity, e.g. for species or epitope, or lack of said crossreactivity
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/35—Valency
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/52—Constant or Fc region; Isotype
- C07K2317/522—CH1 domain
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/52—Constant or Fc region; Isotype
- C07K2317/524—CH2 domain
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/52—Constant or Fc region; Isotype
- C07K2317/526—CH3 domain
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/55—Fab or Fab'
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/567—Framework region [FR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
- C07K2317/62—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments comprising only variable region components
- C07K2317/622—Single chain antibody (scFv)
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/71—Decreased effector function due to an Fc-modification
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/75—Agonist effect on antigen
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/94—Stability, e.g. half-life, pH, temperature or enzyme-resistance
Definitions
- 4-1BB is a member of the TNF receptor superfamily that is expressed on several types of immune cells including, but not limited to, activated T cells, NK and NKT cells, regulatory T cells, dendritic cells, B cells, and stimulated mast cells. Resting T cells do not express high levels of 4-1BB; it is upregulated after activation through the T cell receptor (TCR). Also known as CD137 or TNFRSF9, 4-1BB is expressed on non-immune cells as well, including populations of neural cells found in the brain (Bartkowiak and Curran (2015), Front. Oncol. 5:117).
- 4-1BB is a transmembrane receptor that is activated by binding to its ligand (4-1BBL or CD137L), which is expressed on cells such as macrophages and activated B cells. Once activated, 4-1BB functions to promote division and survival of T cells, enhance the effector function of activated T cells, and generate immunological memory.
- 4-1BB and 4-1BB agonists in particular have become an attractive target for the development of cancer immunotherapies.
- 4-1BB targeting therapies including anti-4-1BB antibodies alone, or in combination with tumor-targeting antibodies, checkpoint inhibitors, or chemotherapy.
- the majority of these clinical trials have been carried out using the anti-4-1BB antibody urelumab.
- urelumab is a human IgG4 antibody currently in a number of Phase 1 and Phase 2 clinical trials designed to examine efficacy in treatment of cancers.
- urelumab administration is limited to doses of 0.1 mg/kg, as higher doses resulted in severe liver toxicity (Segal et al, Clin Cancer Res. 2017 Apr 15;23(8): 1929-1936).
- Utomilumab developed by Pfizer, is a human IgG2 antibody that is currently in various Phase 1, Phase 2 and Phase 3 clinical trials, also designed to assess efficacy in treatment of cancers. Although utomilumab does not appear to induce dose-limiting toxi cities, early clinical data indicated that its effectiveness as a monotherapy did not appear to be significant (Makkouk, et al. (2016) European Journal of Cancer 54: 112-119).
- One aspect of the present disclosure relates to an antibody construct comprising: a first 4-1BB-antigen binding domain derived from an agonistic anti-4-1BB antibody, and a first folate receptor alpha (FR ⁇ )-antigen binding domain in scFv format comprising a heavy chain variable domain (VH) sequence comprising the three heavy chain CDR sequences of antibody 8K22 and a light chain variable domain (VL) sequence comprising the three light chain CDR sequences of antibody 8K22, and further comprising one or more amino acid modifications in the VH domain and/or in the VL domain of antibody 8K22 that improve the biophysical properties of the antibody construct, wherein the first 4-1BB-antigen binding domain and the first FR ⁇ -antigen binding domain are linked directly or indirectly to a scaffold.
- VH heavy chain variable domain
- VL light chain variable domain
- Another aspect of the present disclosure relates to an antibody construct comprising a first 4-1BB antigen-binding domain derived from an agonistic anti-4-1BB antibody, and a first folate receptor- ⁇ (FR ⁇ ) antigen -binding domain in a Fab format comprising a heavy chain variable domain (VH) comprising the three heavy chain CDR sequences of antibody 8K22 and a light chain variable domain (VL) comprising the three light chain CDR sequences of antibody 8K22, wherein the first 4-1BB antigen-binding domain and the first FR ⁇ antigen- binding domain are linked directly or indirectly to a scaffold.
- VH heavy chain variable domain
- VL light chain variable domain
- Another aspect of the present disclosure relates to an antibody construct comprising: a) a first 4-1BB antigen-binding domain derived from an agonistic anti-4-1BB antibody, and b) a first folate receptor- ⁇ (FR ⁇ ) antigen-binding domain comprising a heavy chain variable domain (VH) comprising the three heavy chain CDR sequences of antibody 2L16 and a light chain variable domain (VL) comprising the three light chain CDR sequences of antibody 2L16, wherein the first 4-1BB antigen-binding domain and the first FR ⁇ antigen-binding domain are linked directly or indirectly to a scaffold.
- FR ⁇ folate receptor- ⁇
- Another aspect of the present disclosure relates to an antibody construct or antigen- binding fragment thereof, that specifically binds to folate receptor- ⁇ (FR ⁇ ), comprising: a heavy chain variable domain (VH) sequence comprising three heavy chain CDRs and a light chain variable domain (VL) sequence comprising three light chain CDRs, wherein the heavy chain CDRs and the light chain CDRs are from antibody 2L16.
- VH heavy chain variable domain
- VL light chain variable domain
- Another aspect of the present disclosure relates to pharmaceutical composition comprising the antibody constructs described herein.
- Another aspect of the present disclosure relates to one or more nucleic acids encoding the antibody constructs described herein.
- Another aspect of the present disclosure relates to one or more vectors comprising the one or more nucleic acids encoding the antibody constructs described herein.
- Another aspect of the present disclosure relates to an isolated cell comprising the one or more nucleic acids encoding the antibody constructs described herein, or the one or more vectors comprising the one or more nucleic acids.
- Another aspect of the present disclosure relates to a method of preparing the antibody constructs described herein, comprising culturing the isolated cells described herein under conditions suitable for expressing the antibody construct, and purifying the antibody construct.
- Another aspect of the present disclosure relates to method of treating a subject having a cancer, comprising administering to the subject an effective amount of the antibody constructs described herein.
- Another aspect of the present disclosure relates to use of an effective amount of the antibody construct described herein for the treatment of cancer in a subject in need thereof.
- Another aspect of the present disclosure relates to use of the antibody constructs described herein in the preparation of a medicament for the treatment of cancer.
- Figure 1 depicts exemplary antibody formats.
- Figure 1A provides a representation of a naturally-occurring antibody format (FSA format);
- Figure 1B provides a representation of a one-armed antibody format (OAA) where the anti gen -binding domain is in the Fab format;
- Figure 1C provides a representation of a one-armed antibody format (OAA) where the antigen- binding domain is in the scFv format;
- Figure ID provides a representation of a bivalent antibody format where one antigen-binding domain is in the scFv format and the other is in a Fab format (also referred to as a hybrid format);
- Figure IE provides a representation of a bivalent antibody format where both antigen-binding domains are in the scFv format (also referred to as a dual scFv format).
- Figure 2 depicts a number of additional exemplary formats contemplated for the 4-1BB x TAA antibody constructs described herein.
- Figure 2A provides an example of a 1 x 1 format, where the antibody construct comprises one 4-1BB binding domain (depicted here as 4-1BB ligand), and one TAA antigen-binding domain (depicted here in the Fab format).
- Figure 2B provides an example of a 2 x 1 format, where the antibody construct comprises two 4-1BB antigen-binding domains (both depicted here in the Fab format), and one TAA antigen-binding domain (depicted here in the scFv format).
- Figure 2C provides an example of a 2 x 2 format, where the antibody construct comprises two 4-1BB antigen-binding domains (both depicted here in the Fab format), and two TAA antigen-binding domains (both depicted here in the scFv format).
- Figure 2D provides another example of a 1 x 1 format, where the antibody construct comprises one 4-1BB binding domain (depicted here in the Fab format), and one TAA antigen- binding domain (depicted here in the scFv format).
- Figure 2E provides another example of a 2 x 1 format, where the antibody construct comprises two 4-1BB antigen-binding domains (both depicted here in the Fab format), and one TAA anti gen -binding domain (depicted here in the scFv format), linked to one of the 4-1BB antigen-binding domains.
- Figure 2F provides another example of a 1 x 1 format, where the antibody construct comprises one 4-1BB binding domain (depicted here in the Fab format), and one TAA antigen-binding domain (depicted here in the scFv format); this type of antibody construct is also referred to as a hybrid format.
- Figure 2G provides another example of a 1 x 1 format, where the antibody construct comprises one 4- 1BB binding domain (depicted here in the Fab format), and one TAA antigen-binding domain (depicted here in the scFv format), linked to the 4-1BB antigen-binding domain.
- the representations in Figure 2 are exemplary only, and it is to be understood that although the 4- 1BB antigen-binding domains are depicted in the Fab format here, they may also be in the scFv or sdAb format, or if there are two 4-1BB antigen-binding domains, they may be in different formats or may bind to different epitopes of 4-1BB .
- TAA antigen- binding domains are depicted here in the scFv format, they may also be in the Fab or sdAb format, or if there are two TAA antigen-binding domains, they may be in different formats, or may bind to different TAAs.
- Figure 3 depicts the formats of exemplary 4-1BB x HER2 antibody constructs that were constructed as described in Example 1.
- Figure 4 shows the ability of 4-1BB x HER2 antibody constructs in different formats and controls to activate 4-1BB in a co-culture experiment using 4-1BB-NFkB-Luciferase Jurkat reporter cells and SKOV3 or MDA-MB-468 tumour cells. Shown is the amount of luminescence induced by each antibody construct: v16675 (Figure 4A); v16679 ( Figure 4B); v15534 ( Figure 4C); v16601 ( Figure 4D); v16605 (Figure 4E); v19353 ( Figure 4F); v1040 (Figure 4G); v16992 ( Figure 4H); and v12952 ( Figure 41).
- Figure 5 shows the ability of 4-1BB x HER2 antibody constructs in different formats and controls to activate 4-1BB in a primary CD4+ T cell co-culture experiment with and without SKBR3 tumour cells. Production of IL-2 by the T cells was measured by ELISA.
- Figure 6 compares the ability of 4-1BB x HER2 antibody construct v16679, the 4-1BB antibody v12592, the 4-1BB x HER2 anticalin construct v19353, and the negative control antibody v13725 to stimulate IFN ⁇ production in an assay in which CD4 + , CD8 + or pan-T cells were co-cultured with HER2 + SKBR3 cells.
- Figure 7 depicts the ability of chimeric 4-1BB antibodies to stimulate 4-1BB activity in a 4-1BB-NF-KB reporter gene assay when crosslinked with an anti-Fc antibody.
- the four columns for each variant correspond (in order right-to-left) to the concentrations of antibody construct tested: 2.5 ⁇ g/ml, 0.833 ⁇ g/ml, 0.277 ⁇ g/ml, 0.092 ⁇ g/ml.
- Figure 8 shows the constructs used for domain-mapping of antibody binding to 4-1BB.
- Figure 8A shows the human, dog and dog-human chimeric 4-1BB constructs;
- Figure 8B shows the full-length transmembrane human 4-1BB and the truncated human domain 3 and 4 construct.
- Figure 9 shows the ability of chimeric 4-1BB antibodies and controls to bind to human and dog 4-1BB. The results are shown for v12592 in Figure 9A; for v12593 in Figure 9B; for v20022 in Figure 9C; for v20023 in Figure 9D; for v20025 in Figure 9E; for v20029 in Figure 9F; for v20032 in Figure 9G; for v20036 in Figure 9H, and for v20037 in Figure 91.
- Figure 10 depicts the ability of chimeric antibodies to bind to various 4-1BB proteins expressed in 293E6 cells.
- Figure 11A shows the ability of chimeric antibodies to bind to cynomolgus 4-1BB.
- Figure 11B depicts the ability of these chimeric antibodies to bind to mouse 4-1BB.
- Figure 12 shows the sequences of the mouse heavy chain variable domain CDRs of A) 1C8, B) 1G1 and C) 5G8 ported onto a human framework, as well as mouse light chain variable domain CDRs of D) 1C8, E) 1G1 and F) 5G8 ported onto a human framework.
- the sequences are numbered according to Rabat and the CDRs were assigned with the AbM definition and are identified by
- Figure 13 depicts the SPR sensorgrams of representative humanized 4-1BB antibodies derived from mouse 1C8 antibody.
- Figure 14 depicts the SPR sensorgrams of representative humanized 4-1BB antibodies derived from mouse 1G1 antibody.
- Figure 15 depicts the SPR sensorgrams of representative humanized 4-1BB antibodies derived from mouse 5G8 antibody.
- Figure 16A depicts the ability of humanized 4-1BB antibodies derived from 1C8 to bind cells expressing 4-1BB as measured by flow cytometry.
- Figure 16B depicts the ability of humanized 4-1BB antibodies derived from 1G1 to bind cells expressing 4-1BB as measured by flow cytometry.
- Figure 16C depicts the ability of humanized 4-1BB antibodies derived from 5G8 to bind cells expressing 4-1BB as measured by flow cytometry.
- Figure 17 depicts the DSC thermograms of humanized antibodies derived from 1C8.
- Figure 18 depicts the DSC thermograms of humanized antibodies derived from 1G1.
- Figure 19 depicts the DSC thermograms of humanized antibodies derived from 5G8.
- Figure 20 depicts the LC-MS profile of a representative purified humanized antibody derived from 1C8.
- Figure 21A shows the ability of humanized 4-1BB antibodies derived from 1C8 to stimulate 4-1BB activity in the 4-1BB-NF-KB-1UC reporter assay.
- Figure 21B shows the ability of humanized 4-1BB antibodies derived from 1G1 to stimulate 4-1BB activity in the 4-1BB- NF-KB-1UC reporter assay.
- Figure 21C shows the ability of humanized 4-1BB antibodies derived from 5G8 to stimulate 4-1BB activity in the 4-1BB-NF-KB-1UC reporter assay.
- Figure 22 depicts the formats of exemplary 4-1BB x TAA antibody constructs prepared as described in Example 17.
- Figure 23A depicts the ability of 4-1BB x MSLN antibody constructs v22329 and v22639 to stimulate 4-1BB activity in a co-culture experiments using 4-1BB-NF-KB- Luciferase Jurkat reporter cells and MSLN high H226 tumour cells or MSLN low A549 cells.
- Figure 23B depicts the ability of 4-1BB x MSLN antibody constructs v22353 and v22630 to stimulate 4-1BB activity in the same assay.
- Figure 24 shows the ability of the 4-1BB x FR ⁇ antibody construct v22638 to stimulate 4-1BB activity in the 4-1BB-NF-KB-Luciferase Jurkat reporter cell co-culture assay.
- Figure 25A shows the ability of the 4-1BB x NaPi2b construct v22345 to enhance IFN ⁇ production by CD8 cells when co-cultured with tumor cells expressing NaPi2b at different levels.
- Figure 25B shows the ability of the 4-1BB x MSLN construct v22630 to enhance IFN ⁇ production by CD8 cells when in co-culture with various tumor cells expressing MSLN at varying levels.
- Figure 25C shows the ability of the 4-1BB x FR ⁇ construct v22638 to enhance IFN ⁇ production by CD8 T cells when in co-culture with various tumor cells expressing FR ⁇ at varying levels.
- Figure 25D shows that the control 4-1BB monospecific antibody v12592 is unable to enhance IFN ⁇ production by CD8 T cells when in co-culture with various tumor cells expressing varying levels of TAA.
- Figure 26 shows the formats of exemplary 4-1BB x FR ⁇ antibody constructs prepared as described in Example 20.
- the scFv orientation depicted in this Figure is for illustration only; the scFvs in the constructs may be in VH-VL or VL-VH orientation as described in Table 11
- Figure 27 depicts the ability of 4-1BB x FR ⁇ antibody constructs to bind to 4-1BB- expressing Jurkat cells as measured by flow cytometry.
- Figure 27A shows the data for antibody constructs having a 4-1BB paratope derived from mouse antibody 1C8; Figure 27B from mouse antibody 2E8; Figure 27C from mouse antibody 4E6; Figure 27D from mouse antibody 5G8; Figure 27E from mouse antibody 6B3, and Figure 27F from antibody MOR7480.1.
- Figure 28 depicts the ability of the 4-1BB x FR ⁇ antibody constructs to bind to FR ⁇ expressed on 293E cells as measured by flow cytometry.
- Figure 28A depicts the ability of v23656, v23657, v23658, v23659, and v23660 to bind to cells;
- Figure 28B depicts the ability of v23661, v23662, v23663, v23664, and v23665 to bind to cells, and
- Figure 28C depicts the ability of v23651, v17721, and IgG1 to bind to cells.
- Figure 29A depicts the ability of 4-1BB x FR ⁇ antibody constructs having FR ⁇ paratope 8K22 to stimulate IFN ⁇ production in a CD8+ T cell co-culture assay with FR ⁇ high IGROV1 cells or FR ⁇ low A549 cells.
- Figure 29B depicts the ability of 4-1BB x FR ⁇ antibody constructs having FR ⁇ paratope 1H06 to stimulate IFN ⁇ production in a CD8+ T cell co-culture assay.
- Figure 29C depicts the ability of monospecific 4-1BB antibodies v20022, v20036 or v12592 and the monospecific FR ⁇ antibody v17721 to stimulate IFN ⁇ production in the CD8+ T cell co-culture assay.
- Figure 30A and Figure 30B depict UPLC-SEC and Caliper profiles, respectively, of purified parental chimeric 8K22 variant 23820
- Figure 30C and Figure 30D depict UPLC-SEC and Caliper profiles, respectively, of purified representative humanized 8K22 variant 23807.
- Figure 31A depicts the BLI sensorgrams for the parental chimeric 8K22 antibody v23820 and two representative humanized 8K22 antibodies v23801 and v23807 in the supernatant.
- Figure 31B depicts the BLI sensorgrams for the parental chimeric 8K22 antibody v23820 and the two representative humanized 8K22 antibodies v23801 and v23807 after purification.
- Figure 32A depicts the DSC thermograms of purified representative humanized 8K22 antibodies exhibiting a single transition.
- Figure 32B depicts the DSC thermograms of purified representative humanized 8K22 antibodies exhibiting a two-state transition.
- Figure 33A depicts the LC/MS profile of purified representative humanized 8K22 antibody v23801.
- Figure 33B depicts the LC/MS profile of purified representative humanized 8K22 antibody v23807.
- Figure 34 depicts the DSC thermograms of antibodies having 8K22 binding arms.
- Figure 35A depicts the BLI sensorgram for v29675;
- Figure 35B depicts the BLI sensorgram for v29677;
- Figure 35C depicts the BLI sensorgram for v29680.
- Figure 36 depicts representations of the additional 4-1BB x FR ⁇ bispecific antibodies prepared and tested as described in Example 33.
- Figure 37 depicts the ability of various 4-1BB x FR ⁇ bispecific antibodies to stimulate IFN ⁇ production in a primary T cell humour cell co-culture assay with IGROV1 cells.
- Figure 38A depicts the ability of 4-1BB x FR ⁇ bispecific antibodies to activate 4-1BB in an NF ⁇ B reporter gene assay with IGROV1 cells.
- Figure 38B depicts the ability of 4-1BB x FR ⁇ bispecific antibodies to activate 4-1BB in an NF ⁇ B reporter gene assay with A431 cells.
- Figure 38C depicts the ability of 4-1BB x FR ⁇ bispecific antibodies to activate 4-1BB in an NF ⁇ B reporter gene assay with HCC827 cells.
- Figure 38D depicts the ability of 4-1BB x FR ⁇ bispecific antibodies to activate 4-1BB in an NF ⁇ B reporter gene assay with OVKATE cells.
- Figure 38E depicts the ability of 4-1BB x FR ⁇ bispecific antibodies to activate 4-1BB in an NF ⁇ B reporter gene assay with OVCAR3 cells.
- Figure 38F depicts the ability of 4-1BB x FR ⁇ bispecific antibodies to activate 4-1BB in an NF ⁇ B reporter gene assay with H661 cells.
- Figure 38G depicts the ability of 4-1BB x FR ⁇ bispecific antibodies to activate 4-1BB in an NF ⁇ B reporter gene assay with H441 cells.
- Figure 38H depicts the ability of 4-1BB x FR ⁇ bispecific antibodies to activate 4-1BB in an NF ⁇ B reporter gene assay with H1975 cells.
- Figure 39A demonstrates the ability of the mouse anti 4-1BB paratope 1C8 to bind to cyno 4-1BB;
- Figure 39D demonstrates the ability of the humanized anti-4-1BB paratope 1C8 to bind to cyno 4-1BB.
- Figure 39B demonstrates the ability of the mouse anti 4-1BB paratope 1G1 to bind to cyno 4-1BB;
- Figure 39E demonstrates the ability of the humanized anti-4-1BB paratope 1G1 to bind to cyno 4-1BB.
- Figure 39C demonstrates the ability of the mouse anti 4- 1BB paratope 5G8 to bind to cyno 4-1BB
- Figure 39F demonstrates the ability of the humanized anti-4-1BB paratope 5G8 to bind to cyno 4-1BB.
- Figure 40A shows the sequence of the rabbit heavy chain variable domain CDRs of 8K22 ported onto a human framework
- Figure 40B shows the sequence of the rabbit light chain variable domain CDRs of 8K22 ported onto a human framework.
- the sequences are numbered according to Rabat and the CDRs were assigned with the AbM definition and are identified by "*"
- Figure 41A and Figure 41B depict DSC thermograms of variant 31332 and 31586, respectively.
- Figure 42A, Figure 42B, and Figure 42C depict BLI sensorgrams for variants 31332, 31586, and 31588, respectively.
- Figure 43A depicts the UPLC-SEC profde for variant 31586 at day 0 and day 14 after high temperature treatment
- Figure 43B depicts the UPLC-SEC profde for variant 31588 at day 0 and day 14 after high temperature treatment.
- Figure 44A, Figure 44B, Figure 44C, and Figure 44D depict exemplary formats of various 4-1BB x FR ⁇ antibody constructs, 31946, 32681, 33568, and 32693, respectively.
- Figure 45A depicts the LC/MS analysis of variant 33568
- Figure 45B depicts the LC/MS analysis of variant 33569.
- Figure 46A shows the alignment of the sequence of the 2L16 rabbit heavy chain variable domain with the closest human Germline and subsequent grafting of the CDRs of 2L16 onto a human framework
- Figure 46B shows the alignment of the sequence of the 2L16 rabbit light chain variable domain with the closest human Germline and subsequent grafting of the CDRs of 2L16 onto a human framework.
- the sequences are numbered according to Rabat and the CDRs were assigned with the AbM definition and are identified in bold text.
- Figures 47A and 47C show the UPLC-SEC profiles for the parental chimeric antibody v30048 and a representative humanized variant, v32680, respectively.
- Figures 47B and 47D show the Caliper results for the parental chimeric antibody v30048 and a representative humanized variant, v32680, respectively.
- Figure 48A shows the BLI results for the C-terminal rabbit parental chimeric scFv v30048 while the BLI results for two representative 1G1 x humanized 2L16 antibodies, v31946 and v32681, are shown in Figure 48B and Figure 48C, respectively.
- Figure 49A depicts a thermogram for variant 31946;
- Figure 49B depicts a thermogram for variant 32681.
- Figure 50A depicts the LC/MS profile for v32681
- Figure 50B depicts the LC/MS profile for v31946.
- Figure 51A provides the BLI sensorgram for a representative bispecific antibody variant 31946;
- Figure 51B provides the BLI sensorgram for the Parent Fab antibody 32680;
- Figure 51C provides the BLI sensorgram for variant 33570, and
- Figure 5 ID provides the BLI sensorgram for the variant 33571.
- Figure 52A depicts the ability of variants 16952, 30048, and 30335 to activate 4-1BB in an NF ⁇ B reporter gene assay
- Figure 52B depicts the ability of variants 31946, 32680, and 32681 to activate 4-1BB in an NF ⁇ B reporter gene assay
- Figure 52C depicts the ability of variants 32683, 32685, and 32686 to activate 4-1BB in an NF ⁇ B reporter gene assay
- Figure 52D depicts the ability of variants 32687, 32688, and 32693 to activate 4-1BB in an NF ⁇ B reporter gene assay.
- Figure 53 depicts the ability of 1G1 x humanized 2L16 bispecific antibody constructs to stimulate 4-1BB activity in an NF ⁇ B reporter gene assay.
- Figure 54 depicts the ability of a modified 1G1 x 8K22 bispecific antibody to stimulate 4-1BB activity in an NF ⁇ B reporter gene assay.
- Figure 55A depicts the ability of a modified 1G1 x 8K22 bispecific antibody to stimulate 4-1BB activity in an NF ⁇ B reporter gene assay in co-culture with IGROV1 cells.
- Figure 55B depicts the ability of a modified 1G1 x 8K22 bispecific antibody to stimulate 4- 1BB activity in an NF ⁇ B reporter gene assay in co-culture with HCC1954 cells.
- Figure 55C depicts the ability of a modified 1G1 x 8K22 bispecific antibody to stimulate 4-1BB activity in an NF ⁇ B reporter gene assay in co-culture with NCI-N87 cells.
- Figure 55D depicts the ability of a modified 1G1 x 8K22 bispecific antibody to stimulate 4-1BB activity in an NF ⁇ B reporter gene assay in co-culture with SK-BR-3 cells.
- Figure 55E depicts the ability of a modified 1G1 x 8K22 bispecific antibody to stimulate 4-1BB activity in an NF ⁇ B reporter gene assay in co- culture with NCI-H226 cells.
- Figure 55F depicts the ability of a modified 1G1 x 8K22 bispecific antibody to stimulate 4-1BB activity in an NF ⁇ B reporter gene assay in co-culture with JIMT-1 cells.
- Figure 55G depicts the ability of a modified 1G1 x 8K22 bispecific antibody to stimulate 4-1BB activity in an NF ⁇ B reporter gene assay in co-culture with NCI-H661 cells.
- the identification of variants in the legend is the same for Figures 55A-G and is shown once on each page.
- Figure 56A depicts the ability of a 1G1 x humanized 8K22 bispecific antibody to reduce tumor volume in mice bearing wild-type MC38 mouse tumor cells.
- Figure 56B depicts the ability of a 1G1 x humanized 8K22 bispecific antibody to reduce tumor volume in mice bearing MC38 mouse tumor cells engineered to overexpress human FR ⁇ .
- the arrows represent timepoints at which test articles were administered.
- the present disclosure relates to 4-1BB x folate receptor a (FR ⁇ ) antibody constructs that specifically bind to a 4-1BB extracellular domain (ECD) and to FR ⁇ .
- the 4-1BB x FR ⁇ antibody constructs may be capable of conditionally enhancing the activity of T cells within a tumor.
- the 4-1BB x FR ⁇ antibody constructs are capable of promoting conditional agonism of 4-1BB.
- the 4-1BB x FR ⁇ antibody constructs may be more effective in activating 4-1BB on T cells in the presence of FR ⁇ -expressing cells compared to a monospecific, monovalent anti-4-1BB antibody, as measured by cytokine production.
- the 4-1BB x FR ⁇ antibody constructs may be used to treat cancer.
- 4-1BB x FR ⁇ antibody constructs wherein the FR ⁇ antigen-binding domain is derived from the anti-FR ⁇ antibody 8K22, is in an scFv format and comprises one or more amino acid modifications that improve the biophysical properties of the antigen-binding construct.
- 4-1BB x FR ⁇ antibody constructs wherein the FR ⁇ antigen-binding domain is derived from the anti-FR ⁇ antibody 8K22 and is in the Fab format.
- the present disclosure further provides 4-1BB x FR ⁇ antibody constructs comprising an anti-FR ⁇ antigen-binding domain is derived from the anti-FR ⁇ antibody 2L16.
- the latter antigen-binding constructs may be in a number of different formats as described generally herein.
- the present disclosure further provides antibody sequences that specifically bind 4- 1BB (anti-4-1BB antibody sequences). These anti-4-1BB antibody sequences may be used in the preparation of monospecific, bispecific, or multispecific antibody constructs that bind to 4- 1BB (4-1BB antibody constructs). These monospecific, bispecific, or multispecific 4-1BB antibody constructs may also be used in the treatment of cancer, either alone or in combination with other anti-cancer therapies.
- novel antibody sequences that specifically bind FR ⁇ (anti-FR ⁇ antibody sequences).
- the novel antibody sequence is derived from the 2L16 paratope.
- These anti-FR ⁇ antibody sequences may be used in the preparation of monospecific, bispecific, or multispecific antibody constructs that bind to FR ⁇ (FR ⁇ antibody constructs).
- These monospecific, bispecific, or multispecific FR ⁇ antibody constructs may also be used in the treatment of cancer, either alone or in combination with other anti-cancer therapies.
- any concentration range, percentage range, ratio range, or integer range is to be understood to include the value of any integer within the recited range and, when appropriate, fractions thereof (such as one tenth and one hundredth of an integer), unless otherwise indicated.
- “about” means ⁇ 1%, 2%, 3%, 4%, 5%, 6%, 7%, 8%, 9% or 10% of the indicated range, value, sequence, or structure, unless otherwise indicated.
- the terms “a” and “an” as used herein refer to “one or more" of the enumerated components unless otherwise indicated or dictated by its context.
- the use of the alternative should be understood to mean either one, both, or any combination thereof of the alternatives.
- compositions, use or method denotes that additional elements and/or method steps may be present, but that these additions do not materially affect the manner in which the recited composition, method or use functions.
- Consisting of when used herein in connection with a composition, use or method, excludes the presence of additional elements and/or method steps.
- a composition, use or method described herein as comprising certain elements and/or steps may also, in certain embodiments consist essentially of those elements and/or steps, and in other embodiments consist of those elements and/or steps, whether or not these embodiments are specifically referred to.
- amino acid names and atom names are used as defined by the Protein DataBank (PDB) (www.pdb.org), which is based on the IUPAC nomenclature (IUPAC Nomenclature and Symbolism for Amino Acids and Peptides (residue names, atom names etc.), Eur. J. Biochem, 138, 9-37 (1984) together with their corrections in Eur. J. Biochem., 152, 1 (1985).
- the term “amino acid residue” is primarily intended to indicate an amino acid residue contained in the group consisting of the 20 naturally occurring amino acids, i.e.
- alanine (Ala or A), cysteine (Cys or C), aspartic acid (Asp or D), glutamic acid (Glu or E), phenylalanine (Phe or F), glycine (Gly or G), histidine (His or H), isoleucine (lie or I), lysine (Lys or K), leucine (Leu or L), methionine (Met or M), asparagine (Asn or N), proline (Pro or P), glutamine (Gin or Q), arginine (Arg or R), serine (Ser or S), threonine (Thr or T), valine (Val or V), tryptophan (Trp or W), and tyrosine (Tyr or Y) residues.
- an “antibody” refers to a polypeptide substantially encoded by an immunoglobulin gene or immunoglobulin genes, or one or more fragments thereof, which specifically bind an analyte (antigen).
- the recognized immunoglobulin genes include the kappa, lambda, alpha, gamma, delta, epsilon and mu constant region genes, as well as the myriad immunoglobulin variable region genes. Light chains are classified as either kappa or lambda.
- Heavy chains are classified as gamma, mu, alpha, delta, or epsilon, which in turn define the immunoglobulin isotypes, IgG, IgM, IgA, IgD, and IgE, respectively.
- the antibody can belong to one of a number of subtypes, for instance, the human IgG can belong to the IgG1, IgG2, IgG3, or IgG4 subtypes.
- An exemplary immunoglobulin (antibody) structural unit is composed of two pairs of polypeptide chains, each pair having one immunoglobulin “light” (about 25 kD) and one immunoglobulin “heavy” chain (about 50-70 kD).
- This type of immunoglobulin or antibody structural unit is considered to be “naturally occurring,” or in a “naturally occurring format.”
- the term “light chain” includes a full-length light chain and fragments thereof having sufficient variable domain sequence to confer binding specificity.
- a full-length light chain includes a variable domain, VL, and a constant domain, CL.
- the variable domain of the light chain is at the amino-terminus of the polypeptide.
- Light chains include kappa chains and lambda chains.
- a full-length heavy chain includes a variable domain, VH, a hinge region, and constant domains, CH1, CH2, and CH3, optionally a CH4 domain.
- the VH domain is at the amino-terminus of the polypeptide, and the CH domains are at the carboxyl-terminus, with the CH3 (or CH4 where present) domain being closest to the carboxy-terminus of the polypeptide.
- Heavy chains can be of any isotype, including IgG (including IgG1, IgG2, IgG3 and IgG4 subclasses), IgA (including IgA1 and IgA2 subclasses), IgM, IgD and IgE.
- the term “variable region” or “variable domain” refers to a portion of the light and/or heavy chains of an antibody generally responsible for antigen recognition, typically including approximately the amino -terminal 120 to 130 amino acids in the heavy chain (VH) and about 100 to 110 amino terminal amino acids in the light chain (VL).
- antigen e.g., a polypeptide, polynucleotide, carbohydrate, lipid, chemical moiety, or combinations thereof (e.g., phosphorylated or glycosylated polypeptides, etc.).
- an antibody e.g., a polypeptide, polynucleotide, carbohydrate, lipid, chemical moiety, or combinations thereof (e.g., phosphorylated or glycosylated polypeptides, etc.).
- phosphorylated or glycosylated polypeptides etc.
- an “antigen-binding domain” is that portion of an antibody that is capable of specifically binding to an epitope or antigen.
- the epitope- or antigen-binding function of an antibody can be performed by fragments of an antibody in a naturally occurring format.
- antigen-binding domains include (i) a Fab fragment, a monovalent fragment consisting of the VH, VL, CH1 and CL domains; (ii) a F(ab')2 fragment, a bivalent fragment comprising two Fab fragments linked by a disulfide bridge at the hinge region; (iii) a Fd fragment consisting of the VH and CH1 domains; (iv) a Fv fragment consisting of the VH and VL domains of a single arm of an antibody, (v) a sdAb fragment (Ward et al, (1989) Nature 341 :544-546), which comprises a single variable domain; and (vi) an isolated complementarity determining region (CDR).
- a Fab fragment a monovalent fragment consisting of the VH, VL, CH1 and CL domains
- F(ab')2 fragment a bivalent fragment comprising two Fab fragments linked by a disulfide bridge at the hinge region
- Exemplary formats of the antigen-binding domains described herein include but are not limited to the Fab, scFv, VHH, or sdAb formats.
- methods of converting between types of antigen-binding domains are known in the art (see, for example, methods for converting an scFv to a Fab format described in Zhou et al (2012) Mol Cancer Ther 11:1167-1476).
- an antibody is available in a format that includes an antigen-binding domain that is an scFv, but it is desired that the antibody construct comprise an antigen-binding domain in a Fab format, one of skill in the art would be able to make such conversion, and vice-versa.
- a “Fab fragment” (also referred to as fragment antigen-binding, Fab format) includes the constant domain (CL) sequences of the light chain and the constant domain 1 (CH1) of the heavy chain along with the variable domains VL and VH on the light and heavy chains, respectively.
- the variable domains comprise the CDRs, which are involved in antigen-binding.
- Fab' fragments differ from Fab fragments by the addition of a few amino acid residues at the C-terminus of the heavy chain CH1 domain, including one or more cysteines from the antibody hinge region.
- a “single-chain Fv” or “scFv” format includes the VH and VL domains of an antibody in a single polypeptide chain.
- the scFv polypeptide may optionally further comprise a polypeptide linker between the VH and VL domains which enables the scFv to form a desired structure for antigen binding.
- a “single domain antibody” or “sdAb” format refers to a single immunoglobulin domain.
- the sdAb may be, for example, of camelid origin. Camelid antibodies lack light chains and their antigen-binding sites consist of a single domain, termed a “VHH.”
- An sdAb comprises three CDR/hypervariable loops that form the anti gen -binding site: CDR1, CDR2 and CDR3. SdAbs are fairly stable and can be expressed as a fusion with the Fc region of an antibody (see, for example, Harmsen MM, De Haard HJ (2007) “Properties, production, and applications of camelid single-domain antibody fragments,” Appl. Microbiol Biotechnol. 77(1): 13-22).
- Antibodies bind to an “epitope” on an antigen.
- the epitope is the localized site on the antigen that is recognized and bound by the antibody.
- Epitopes can include a few amino acids, e.g., 5 or 6, or more, e.g., 20 or more amino acids.
- the epitope includes non- protein components, e.g., from a carbohydrate, nucleic acid, or lipid.
- the epitope is a three-dimensional moiety.
- the epitope can be comprised of consecutive amino acids, or amino acids from different parts of the protein that are brought into proximity by protein folding (e.g., a discontinuous epitope). The same is true for other types of target molecules that form three-dimensional structures.
- An epitope may be determined by obtaining an X-ray crystal structure of an antibody: antigen complex and determining which residues on the antigen are within a specified distance of residues on the antibody of interest, wherein the specified distance is, 5 ⁇ or less, e.g., 5 ⁇ , 4A, 3 ⁇ , 2 ⁇ , 1 ⁇ or less, or any distance in between.
- the epitope is defined as a stretch of 8 or more contiguous amino acid residues along the antigen sequence in which at least 50%, 70% or 85% of the residues are within the specified distance of the antibody or binding protein in the X-ray crystal structure.
- Mapping of epitopes recognized by antibodies can also be performed as described in detail in “Epitope Mapping Protocols” (Methods in Molecular Biology) by Glenn E. Morris ISBN-089603-375-9 (1996), and in “Epitope Mapping: A Practical Approach” Practical Approach Series, 248 by Olwyn M. R. Westwood, Frank C. Hay. (2001).
- X-ray co-crystallography, cryogenic electron microscopy, array-based oligo-peptide scanning, site-directed mutagenesis mapping, hydrogen-deuterium exchange, cross-linking coupled mass spectrometry may be used to determine or map epitopes. These methods are well-known in the art.
- binding agent refers to a binding agent’s ability to discriminate between possible partners in the environment in which binding is to occur.
- a binding agent may be an antibody, antibody construct or antigen-binding domain, for example.
- a binding agent that interacts with one particular target when other potential targets are present is said to “bind specifically” to the target with which it interacts.
- specific binding is assessed by detecting or determining degree of association between the binding agent and its partner; in some embodiments, specific binding is assessed by detecting or determining degree of dissociation of a binding agent-partner complex; in some embodiments, specific binding is assessed by detecting or determining ability of the binding agent to compete an alternative interaction between its partner and another entity.
- specific binding is assessed by performing such detections or determinations across a range of concentrations.
- the term “specifically binds” as used herein in relation to antigen-binding domains, antibodies or antibody constructs means that the antigen-binding domains, antibodies or antibody constructs bind to their target antigen with no or insignificant binding to other antigens.
- a “complementarity determining region” or “CDR” is an amino acid sequence that contributes to antigen-binding specificity and affinity.
- “Framework” regions (FR) can aid in maintaining the proper conformation of the CDRs to promote binding between the antigen- binding region and an antigen.
- framework regions can be located in antibodies between CDRs.
- the variable regions typically exhibit the same general structure of relatively conserved framework regions (FR) joined by three hyper variable regions, also known as CDRs.
- the CDRs from the variable domains of the heavy chain and light chain typically are aligned by the framework regions, which can enable binding to a specific epitope.
- both light and heavy chain variable domains typically comprise the domains FR1, CDR1, FR2, CDR2, FR3, CDR3, and FR4.
- the assignment of amino acids to each domain is typically in accordance with the definitions of Rabat Sequences of Proteins of Immunological Interest (National Institutes of Health, Bethesda, Md. (1987 and 1991)), unless stated otherwise.
- the three heavy chain CDRs are referred to herein as HCDR1, HCDR2, and HCDR3, while the three light chain CDRs are referred to as LCDR1, LCDR2, and LCDR3.
- CDRs may refer to all three heavy chain CDRs, or all three light chain CDRs (or both all heavy and all light chain CDRs, if appropriate). CDRs provide the majority of contact residues for the binding of the antibody to the antigen or epitope. Often, the three heavy chain CDRs and the three light chain CDRs are required to bind antigen. However, in some instances, even a single variable domain can confer binding specificity to the antigen. Furthermore, as is known in the art, in some cases, antigen-binding may also occur through a combination of a minimum of one or more CDRs selected from the VH and/or VL domains, for example HCDR3.
- CDR sequences are in common use, including those described by Rabat et al. (1983, Sequences of Proteins of Immunological Interest, NIH Publication No. 369-847, Bethesda, MD), by Chothia et al. (1987, J Mol Biol, 196:901-917), as well as the IMGT, AbM (University of Bath) and Contact (MacCallum R. M., and Martin A. C. R. and Thornton J. M, (1996), Journal of Molecular Biology, 262 (5), 732-745) definitions.
- CDR definitions according to Rabat, Chothia, IMGT, AbM and Contact are provided in Table A below.
- VH includes the disclosure of the associated (inherent) heavy chain CDRs (HCDRs) as defined by any of the known numbering systems.
- disclosure herein of a VH includes the disclosure of the associated (inherent) heavy chain CDRs (HCDRs) as defined by any of the known numbering systems.
- Table A Common CDR Definitions 1
- Chimeric antibody refers to an antibody whose amino acid sequence includes VH and VL sequences that are found in a first species and constant domain sequences that are found in a second species, different from the first species.
- a chimeric antibody has murine VH and VL sequences linked to human constant domain sequences.
- “Humanized” forms of non-human (e.g., rodent) antibodies are antibodies that contain minimal sequence derived from non-human immunoglobulin.
- humanized antibodies are human immunoglobulins (recipient antibody) in which residues from a hypervariable region of the recipient are replaced by residues from a hypervariable region of a non-human species (donor antibody) such as mouse, rat, rabbit or nonhuman primate having the desired specificity, affinity, or capacity.
- donor antibody such as mouse, rat, rabbit or nonhuman primate having the desired specificity, affinity, or capacity.
- framework region (FR) residues of the human immunoglobulin are replaced by corresponding non-human residues.
- humanized antibodies may comprise residues that are not found in the recipient antibody or in the donor antibody. These modifications are made to further refine antibody performance.
- the humanized antibody will comprise substantially all of at least one, and typically two, variable domains, in which all or substantially all of the hypervariable regions correspond to those of a non-human immunoglobulin and all or substantially all of the FRs are those of a human immunoglobulin sequence.
- the humanized antibody optionally also will comprise at least a portion of an immunoglobulin constant region (Fc), typically that of a human immunoglobulin.
- Fc immunoglobulin constant region
- CDR-grafted antibody refers to an antibody whose amino acid sequence comprises heavy and light chain variable region sequences from one species but in which the sequences of one or more of the CDR sequences of VH and/or VL sequences are replaced with CDR sequences of another species, such as antibodies having mouse VH and VL sequences in which one or more of the mouse CDRs (e.g., HCDR3) has been replaced with human CDR sequences.
- a “CDR-grafted antibody” may also refer to antibodies having human VH and VL regions in which one or more of the human CDRs (e.g., CDR3) has been replaced with mouse CDR sequences.
- a first antibody, or an antigen-binding portion thereof “competes” for binding to a target with a second antibody, or an antigen-binding portion thereof, when binding of the second antibody with the target is detectably decreased in the presence of the first antibody compared to the binding of the second antibody in the absence of the first antibody.
- the alternative, where the binding of the first antibody to the target is also detectably decreased in the presence of the second antibody can, but need not be the case. That is, a second antibody can inhibit the binding of a first antibody to the target without that first antibody inhibiting the binding of the second antibody to the target.
- each antibody detectably inhibits the binding of the other antibody to its cognate epitope or ligand, whether to the same, greater, or lesser extent, the antibodies are said to “cross -compete” with each other for binding of their respective epitope(s).
- competing and cross -competing antibodies are encompassed by the present disclosure.
- the term “competitor” antibody can be applied to the first or second antibody as can be determined by one of skill in the art.
- the presence of the competitor antibody reduces binding of the second antibody to the target by at least 10%, e.g., at least any of 20%, 30%, 40%, 50%, 60%, 70%, 80%, or more, e.g., so that binding of the second antibody to target is undetectable in the presence of the first (competitor) antibody.
- K D dissociation constant
- K d dissociation constant
- ligand-protein interactions refer to, but are not limited to protein-protein interactions or antibody-antigen interactions.
- the K D measures the propensity of two proteins complexed together (e.g. AB) to dissociate reversibly into constituent components (A+B), and is defined as the ratio of the rate of dissociation, also called the “off-rate (k off )”, to the association rate, or “on-rate (k on )”
- K D equals k 0fl /k on and is expressed as a molar concentration (M).
- K D values for antigen-binding constructs can be determined using methods well established in the art.
- One method for determining the K D of an antigen-binding construct is by using surface plasmon resonance (SPR), typically using a biosensor system such as a Biacore® system.
- ITC Isothermal titration calorimetry
- the OctetTM system may also be used to measure the affinity of antibodies for a target antigen.
- conditional agonism is intended to refer to the ability of the 4-1BB x TAA antibody constructs or 4-1BB x FR ⁇ antibody constructs to agonize 4- 1BB activity in immune cells such as for example, T cells or NK cells, predominantly when the immune cells are in the proximity of TAA or FR ⁇ expressing cells.
- conditional agonism refers to the ability of the 4-1BB x TAA antibody constructs or 4-1BB x FR ⁇ antibody constructs to agonize 4-1BB activity in immune cells only when the immune cells are in the proximity of TAA or FR ⁇ expressing cells.
- amino acid modifications includes, but is not limited to, amino acid insertions, deletions, substitutions, chemical modifications, physical modifications, and rearrangements.
- amino acid modification is an amino acid substitution.
- the amino acid residues for the immunoglobulin heavy and light chains may be numbered according to several conventions including Rabat (as described in Rabat and Wu, 1991; Kabat et al, Sequences of proteins of immunological interest. 5th Edition - US Department of Health and Human Services, NIH publication no. 91-3242, p 647 (1991)), IMGT (as set forth in Lefranc, M.-P., et al. IMGT®, the international ImMunoGeneTics information system® Nucl. Acids Res, 37, D1006-D1012 (2009), and Lefranc, M.-P., IMGT, the International ImMunoGeneTics Information System, Cold Spring Harb Protoc.
- Rabat as described in Rabat and Wu, 1991; Kabat et al, Sequences of proteins of immunological interest. 5th Edition - US Department of Health and Human Services, NIH publication no. 91-3242, p 647 (1991)
- IMGT as
- Antibody construct refers to a polypeptide or a set of polypeptides that specifically bind to an epitope or antigen and include one or more immunoglobulin structural features.
- an antibody construct is a polypeptide or set of polypeptides whose amino acid sequence includes elements characteristic of an antigen- binding domain (e.g., an antibody light chain or variable region or one or more complementarity determining regions (“CDRs”) thereof, or an antibody heavy chain or variable region or one more CDRs thereof, optionally in presence of one or more framework regions).
- an antibody construct is or comprises an antibody in a naturally occurring format.
- the term “antibody construct” encompasses a protein having a binding domain which is homologous or largely homologous to an immunoglobulin- binding domain.
- an antibody construct comprises a fragment of a naturally occurring antibody including at least one antigen-binding domain.
- the antibody construct may further comprise a binding domain that is other than an antigen-binding domain, for example a ligand for a target protein.
- an “antibody construct” encompasses polypeptides having an antigen-binding domain that shows at least 99% sequence identity with an immunoglobulin binding domain.
- an “antibody construct” is any polypeptide having a binding domain that shows at least 70%, 75%, 80%, 85%, 90%, 95% or 98% sequence identity with an immunoglobulin binding domain, for example a reference immunoglobulin binding domain.
- An “antibody construct” may have an amino acid sequence identical to that of an antibody (or a fragment thereof, e.g., an antigen-binding fragment thereof) that is found in a natural source.
- an “antigen-binding fragment” of an antibody includes a fragment of an antibody having an antigen-binding domain with the required specificity.
- an antigen-binding fragment includes antibody fragments, derivatives, functional equivalents and homologues of antibodies, humanized antibodies, including any polypeptide comprising an immunoglobulin binding domain, whether natural or wholly or partially synthetic. Chimeric molecules comprising an immunoglobulin binding domain, or equivalent, fused to another polypeptide are also included.
- An antibody construct may be monospecific, bispecific, or multispecific, and may bind to at least one distinct target, antigen or epitope.
- Antibody constructs can be prepared in many formats, and exemplary antibody construct formats are described in Figures 1 and 2, and elsewhere throughout the application.
- the term “antibody construct” as used herein is meant to encompass monospecific, bispecific, or multispecific antibody constructs.
- a “monospecific” antibody construct is a species of antibody construct that binds to one target, antigen, or epitope.
- Monospecific antibody constructs may comprise one or more antigen- binding domains, each binding to the same epitope.
- Monospecific antibody constructs may be monovalent (i.e. having only one arm or paratope), bivalent (i.e.
- a “bispecific” antibody construct is a species of antibody construct that targets two different antigens or epitopes.
- a bispecific antibody construct can have two antigen-binding domains, although, in some embodiments, a bispecific antibody construct may have more than two antigen-binding domains, provided that no more than two unique epitopes are recognized by the antigen-binding domains. The two or more antigen-binding domains of a bispecific antibody construct will bind to two different epitopes, which can reside on the same or different molecular targets.
- the bispecific antibody construct is referred to herein as “biparatopic.”
- the monospecific or bispecific antibody constructs are in a naturally occurring format, also referred to herein as a full-sized antibody (FSA) format.
- FSA full-sized antibody
- the monospecific or bispecific antibody construct has the same format as a naturally occurring IgG, IgA, IgM, IgD, or IgE antibody.
- a multispecific antibody construct can include three or more antigen-binding domains, each capable of binding to a different target or epitope.
- the multispecific antibody construct comprises a format that is the same as a naturally occurring IgG, IgA, IgM, IgD, or IgE antibody, but further includes one or more additional antigen- binding domains.
- an antibody construct may have structural elements characteristic of chimeric or humanized antibodies or may have amino acid sequences derived from chimeric or humanized antibodies. In some embodiments, an antibody construct may have structural elements characteristic of a human antibody.
- antibody constructs capable of binding to the extracellular domain (ECD) of 4-1BB and to a tumor-associated antigen (TAA), for example FR ⁇ . Also described herein are antibody constructs comprising sequences that specifically bind to the ECD of 4-1BB. Antibody constructs comprising sequences that specifically bind to folate receptor alpha (FR ⁇ ) are also described herein.
- ECD extracellular domain
- TAA tumor-associated antigen
- FR ⁇ folate receptor alpha
- Antibody constructs capable of binding to the ECD of 4-1BB and to a TAA comprise a 4-1BB binding domain that binds to a 4-1BB ECD and a TAA antigen-binding domain, wherein the 4-1BB binding domain and the TAA antigen-binding domain are linked directly or indirectly to a scaffold.
- the 4-1BB x TAA antibody constructs described herein are bispecific antibody constructs that bind to two distinct targets.
- the 4-1BB x TAA antibody construct may be a multispecific antibody construct where the 4-1BB x TAA antibody construct binds to 4-1BB and to two or more distinct TAAs.
- the scaffold is an Fc construct.
- the scaffold is an Fc construct with modifications that reduce its ability to mediate effector function.
- the 4-1BB x TAA antibody constructs are capable of binding to 4-1BB-expressing cells. In some embodiments, the 4-1BB x TAA antibody constructs are capable of binding to TAAs expressed on the surface of cancer cells. In some embodiments, the 4-1BB x TAA antibody constructs are capable of activating 4-1BB signalling in 4-1BB-expressing cells. In some embodiments, the 4-1BB x TAA antibody constructs are capable of enhancing CD3 -stimulated T cell activation.
- 4-1BB (also known as TNFRSF9 or CD137) is a member of the TNF receptor superfamily.
- Human 4-1BB is a 255 amino acid protein (Accession Nos. NM 001561 and UniProt Q07011 for mRNA and polypeptide sequences respectively).
- the complete human 4- 1BB amino acid sequence is provided in SEQ ID NO:79.
- the sequence shown in SEQ ID NO:l includes a signal sequence (amino acid residues 1-23), an extracellular domain (ECD, amino acid residues 23-187), a transmembrane region (amino acids 188 to 213), and an intracellular domain (amino acids 214 to 255) (Bitra et al. J. Biol. Chem. (2016) 293(26) 9958 -9969).
- the 4-1BB receptor is expressed on the cell surface in monomeric and dimeric forms and likely trimerizes with 4-1BB ligand to allow signalling.
- the structure of mammalian 4-1BB protein consists of four Cysteine-Rich Domains (CRDs) which show homology to other TNFR superfamily members.
- CRDl consists of amino acids 24 to 45, and both the mouse and human 4-1BB lack a disulphide found in other TNFR superfamily members.
- CRD2 and CRD3 extend from amino acids 47 to 86 and 87 to 118, respectively, and are the domains that contact 4-1BBL (Bitra et al, supra).
- CRD4 is comprised of amino acids 119 to 159 and is followed by a short stalk region comprised on amino acids 160 to the transmembrane domain at amino acid 187 (with reference to SEQ ID NO:79).
- CRDl, CRD2, CRD3 and CDR4 are also referred to herein as domains 1, 2, 3, and 4, respectively.
- the 4-1BB x TAA antibody construct comprises one 4-1BB binding domain. In some embodiments, the 4-1BB x TAA antibody construct may comprise more than one 4-1BB-binding domain. In certain embodiments, the 4-1BB x TAA antibody construct comprises two 4-1BB-binding domains, and a TAA antigen-binding domain, wherein the 4-1BB-binding domain and the TAA antigen-binding domain are linked directly or indirectly to a scaffold.
- the 4-1BB x TAA antibody construct comprises two 4-1BB-binding domains, and a TAA antigen-binding domain, wherein the 4- lBB-binding domain and the TAA anti gen -binding domain are linked directly or indirectly to a scaffold, and wherein at least one of the 4-1BB-binding domains is a 4-1BB antigen-binding domain.
- each 4-1BB antigen-binding domain may bind to the same epitope of the ECD of 4-1BB, or they may bind to different epitopes of the ECD of 4- 1BB.
- the 4-1BB x TAA antibody construct comprises a 4-1BB binding domain that is an antigen-binding domain, and a TAA antigen-binding domain.
- the 4-1BB x TAA antibody construct comprises three or more 4-1BB-binding domains that bind to the ECD of 4-1BB.
- the three or more 4-1BB-binding domains include at least one 4-1BB antigen-binding domain.
- the three or more 4-1BB-binding domains include at least two 4-1BB antigen- binding domains. In the latter embodiment, the two 4-1BB antigen-binding domains may bind to the same epitope of 4-1BB, or they may bind to different epitopes of 4-1BB.
- the 4-1BB antigen-binding domains may be in scFv, Fab or sdAb formats.
- the 4-1BB antigen-binding domain of the 4-1BB x TAA antibody construct is in a Fab format.
- the 4-1BB antigen-binding domain is in a scFv format.
- the 4-1BB x TAA antibody construct comprises more than one 4-1BB antigen-binding domain, wherein at least one 4-1BB antigen-binding domain is in a Fab format.
- at least two of the antigen-binding domains are in the Fab format.
- the 4-1BB x TAA antibody construct comprises a 4-1BB-binding domain that binds to the ECD of 4-1BB.
- the 4-1BB x TAA antibody construct comprises a 4-1BB-binding domain that can bind to an ECD of human 4-1BB.
- Suitable 4- lBB-binding domains include naturally occurring molecules such as ligands or 4-1BB-binding fragments thereof. Examples of such molecules include 4-1BB ligand (see NP_003802.1, for example), also known as TNFSF9 or CD137L.
- the antibody construct comprises a 4-1BB-binding domain that binds to a 4-1BB ligand and a TAA antigen- binding domain, wherein the 4-1BB-binding domain and the TAA antigen-binding domain are linked directly or indirectly to a scaffold.
- the 4-1BB x TAA antibody construct comprises a 4-1BB-binding domain that is an antigen-binding domain.
- Antigen- binding domains can be constructed from the sequences of antibodies that bind to the ECD of 4-1BB. Suitable antibodies include those that are known in the art, commercially available, or those that are identified and prepared according to methods well known in the art and described herein.
- 4-1BB antigen-binding domains may be constructed from mouse, human, humanized, or chimeric anti-4-1BB antibodies. In some embodiments, the 4-1BB antigen-binding domain is derived from an agonistic anti-4-1BB antibody.
- Agonistic anti-4-1BB antibodies bind to 4- 1BB and are able to stimulate 4-1BB signalling activity.
- 4-1BB signalling activity refers to at least one of the activities that can be exhibited by 4-1BB in vitro or in vivo. For example, these activities may include stimulation of cytokine release from T or NK cells, or an increase in metabolic activity by T or NK cells, or enhancement of cytotoxic activity by T or NK cells.
- utomilumab (described in WO2012/032433, Pfizer), urelumab (described in W02004/010947 and W02005/035584, BMS), and the antibodies described in WO 2018/156740 (Macrogenics), US 8,337,850 (Pfizer), US 2018/0258177 (Eutilex) W02017/077085 (Cancer Research Technologies), and WO2006126835 (University of Ulsan).
- Urelumab and utomilumab are exemplary agonistic anti-4-1BB antibodies.
- the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain that can compete with one of the antibodies described in the preceding paragraph for binding to an epitope of 4-1BB ECD.
- the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain that can compete with utomilumab for binding to an epitope of 4-1BB ECD.
- the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain that can compete with urelumab for binding to an epitope of 4-1BB ECD.
- the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain that can compete with the anti-4-1BB antibodies described in US 8,337,850 for binding to an epitope of 4-1BB ECD.
- the 4-1BB x TAA antibody construct comprises a 4-1BB antigen- binding domain that can compete with the anti-4-1BB antibodies described in US 2018/0258177 for binding to an epitope of 4-1BB ECD.
- the 4- 1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain that can compete with the anti-4-1BB antibodies described in WO2018/156740 for binding to an epitope of 4- 1BB ECD.
- the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain that binds to the same epitope of 4-1BB ECD as utomilumab, or urelumab, or any one of the anti-4-1BB antibodies described in US 8,337,850, US 2018/0258177 or WO2018/156740.
- the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain that binds to a 4-1BB ECD other than domain 3 or domain 4.
- the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain that binds to an epitope at least partially within amino acid residues 24-85 of the mature 4-1BB protein (SEQ ID NO:79).
- the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain that binds to domain 1 of 4-1BB.
- the 4-1BB x TAA antibody construct comprises a4-1BB antigen-binding domain that binds to domain 2 of 4-1BB.
- the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain that binds to domain 3 of 4-1BB.
- the 4-1BB x TAA antibody construct comprises a4-1BB antigen-binding domain that binds to domain 4 of 4-1BB.
- the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain that binds to the ECD of human and cynomolgus 4-1BB.
- the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain that comprises at least one, two, or all three heavy chain CDRs and/or at least one, two, or all three light chain CDRs of urelumab, utomilumab, or any one of the anti- 4-1BB antibodies described in US 8,337,850, US 2018/0258177 or WO2018/156740.
- the 4-1BB x TAA antibody construct comprises a 4-1BB antigen- binding domain that comprises at least one, two, or all three heavy chain CDRs and at least one, two, or all three light chain CDRs of urelumab, utomilumab, or any one of the anti -4-1BB antibodies described in US 8,337,850, US 2018/0258177 or WO2018/156740.
- the 4-1BB x TAA construct comprises a 4-1BB antigen-binding domain comprising a VH sequence that is at least about 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, or 100% identical to the VH sequence of urelumab, utomilumab, or any one of the anti-4-1BB antibodies described in US 8,337,850, US 2018/0258177 or WO2018/156740.
- the specific VH and VL sequences of MOR7480.1, one of the antibodies described in US 8,337,850, are provided as SEQ ID NOs: 71 and 72, respectively, in Table 15.
- the CDRs of MOR7480.1 are provided in Table B below.
- VH, VL and CDR sequences of the other 4-1BB antigen- binding domains described above can readily be determined by one of skill in the art with reference to the disclosures of US 8,337,850, US 2018/0258177, WO2018/156740 W02004/010947, W02005/035584, US 2018/0258177, W02017/077085, or
- VH, VL and CDR sequences of antibodies that bind 4-1BB are described below and in Table 13; these antibodies are identified as 1B2, 1C3, 1C8, 1G1, 2A7, 2E8, 2H9, 3D7, 3H1, 3E7, 3G4, 4B11, 4E6, 4F9, 4G10, 5E2, 5G8, and 6B3.
- the 4-1BB x TAA antibody construct comprises a4-1BB antigen-binding domain comprising a VH sequence and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence and VL sequence of any one of antibodies 1B2, 1C3, 1C8, 1G1, 2A7, 2E8, 2H9, 3D7, 3H1, 3E7, 3G4, 4B11, 4E6, 4F9, 4G10, 5E2, 5G8, or 6B3 as set forth in Table 13.
- the 4-1BB x TAA antibody construct comprises a 4- 1BB antigen-binding domain comprising a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of antibody 1B2 as set forth in Table 13 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 1B2 as set forth in Table 13.
- the 4-1BB x TAA antibody construct comprises a4-1BB antigen-binding domain comprising a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of antibody 1C3 as set forth in Table 13 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 1C3 as set forth in Table 13.
- the 4-1BB x TAA antibody construct comprises a4-1BB antigen-binding domain comprising a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of antibody 1C8 as set forth in Table 13 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 1C8 as set forth in Table 13.
- the 4-1BB x TAA antibody construct comprises a 4- 1BB antigen-binding domain comprising a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of antibody 1G1 as set forth in Table 13 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 1G1 as set forth in Table 13.
- the 4-1BB x TAA antibody construct comprises a4-1BB antigen-binding domain comprising a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of antibody 2A7 as set forth in Table 13 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 2A7 as set forth in Table 13.
- the 4-1BB x TAA antibody construct comprises a4-1BB antigen-binding domain comprising a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of antibody 2E8 as set forth in Table 13 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 2E8 as set forth in Table 13.
- the 4-1BB x TAA antibody construct comprises a 4- 1BB antigen-binding domain comprising a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of antibody 2H9 as set forth in Table 13 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 2H9 as set forth in Table 13.
- the 4-1BB x TAA antibody construct comprises a4-1BB antigen-binding domain comprising a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of antibody 3D7 as set forth in Table 13 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 3D7 as set forth in Table 13.
- the 4-1BB x TAA antibody construct comprises a4-1BB antigen-binding domain comprising a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of antibody 3H1 as set forth in Table 13 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 3H1 as set forth in Table 13.
- the 4-1BB x TAA antibody construct comprises a 4- 1BB antigen-binding domain comprising a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of antibody 3E7 as set forth in Table 13 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 3E7 as set forth in Table 13.
- the 4-1BB x TAA antibody construct comprises a4-1BB antigen-binding domain comprising a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of antibody 3G4 as set forth in Table 13 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 3G4 as set forth in Table 13.
- the 4-1BB x TAA antibody construct comprises a4-1BB antigen-binding domain comprising a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of antibody 4B11 as set forth in Table 13 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 4B11 as set forth in Table 13.
- the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain comprising a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of antibody 4E6 as set forth in Table 13 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 4E6 as set forth in Table 13.
- the 4-1BB x TAA antibody construct comprises a4-1BB antigen-binding domain comprising a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of antibody 4F9 as set forth in Table 13 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 4F9 as set forth in Table 13.
- the 4-1BB x TAA antibody construct comprises a4-1BB antigen-binding domain comprising a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of antibody 4G10 as set forth in Table 13 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 4G10 as set forth in Table 13.
- the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain comprising a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of antibody 5E2 as set forth in Table 13 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 5E2 as set forth in Table 13.
- the 4-1BB x TAA antibody construct comprises a4-1BB antigen-binding domain comprising a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of antibody 5G8 as set forth in Table 13 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 5G8 as set forth in Table 13.
- the 4-1BB x TAA antibody construct comprises a4-1BB antigen-binding domain comprising a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of antibody 6B3 as set forth in Table 13 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 6B3 as set forth in Table 13.
- the 4-1BB x TAA antibody construct comprises the heavy chain CDRs and light chain CDRs of one of the antibodies listed in Table 13. The CDRs of these antibodies can be found in Table 18.
- the 4-1BB x TAA antibody construct comprises the heavy chain CDRs and light chain CDRs of any one of antibodies 1C3, 1C8, 1G1, 2E8, 3E7, 4E6, 5G8, or 6B3, described in Table 13.
- the 4-1BB x TAA antibody construct comprises the heavy chain CDRs and light chain CDRs of any one of anti-4-1BB antibodies 1G1, 1C8, or 5G8.
- the 4-1BB x TAA antibody construct comprises the 3 heavy chain CDRs and the 3 light chain CDRs of anti -4-1BB antibody 1G1.
- the 4-1BB x TAA antibody construct comprises the heavy chain CDRs and light chain CDRs of any one of anti-4-1BB antibodies 1G1, 1C8, or 5G8, wherein one or more CDRs comprise at least one amino acid substitution that improves the affinity of the anti-4-1BB antigen-binding domain for human 4-1BB.
- the 4-1BB x TAA antibody construct comprises three heavy chain CDRs and three light chain CDRs of anti-4-1BB antibody 1C8, wherein one or more CDRs comprise at least one amino acid substitution that improves the affinity of the antibody for human 4-1BB.
- the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain comprising a humanized VH sequence and a humanized VL sequence of any one of antibodies 1B2, 1C3, 1C8, 1G1, 2A7, 2E8, 2H9, 3D7, 3H1, 3E7, 3G4, 4B11, 4E6, 4F9, 4G10, 5E2, 5G8, or 6B3.
- Several exemplary humanized VH and VL sequences are described in Table 14 and have been used in the construction of several 4-1BB antibody constructs comprising humanized VH and VL sequences based on the mouse VH and VL sequences of anti-4-1BB antibodies 1C8, 1G1, and 5G8.
- the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain comprising a humanized VH sequence and humanized VL sequence of antibody 1C8.
- the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28726, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variants 28726.
- the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28727, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28727.
- the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28728, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28728.
- the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28730, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28730.
- the 4-1BB x TAA antibody construct comprises a construct having three heavy chain CDRs and three light chain CDRs comprising at least one amino acid substitution that improves the affinity of the 4-1BB antigen-binding domain for human 4-1BB, and comprises a humanized VH sequence and humanized VL sequence of anti-4-1BB antibody 1C8.
- the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain comprising a humanized VH sequence and humanized VL sequence of antibody 1G1.
- the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28683, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variants 28683.
- the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28684, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28684.
- the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28685, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28685.
- the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28686, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28686.
- the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28687, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28687.
- the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28688, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28688.
- the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28689, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28689.
- the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28690, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28690.
- the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28691, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28691.
- the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28692, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28692.
- the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28693, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28693.
- the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28694, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28694.
- the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain comprising a humanized VH sequence and humanized VL sequence of antibody 5C8.
- the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28700, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variants 28700.
- the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28704, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28704.
- the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28705, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28705.
- the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28706, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of 28706.
- the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28711, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28711.
- the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28712 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28712.
- the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28713, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28713.
- the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28696, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28696.
- the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28697, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28697.
- the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28698, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28698.
- the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28701, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28701.
- the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28702, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28702.
- the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28703, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28703.
- the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28707, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28707.
- the 4-1BB x TAA antibody construct comprises the heavy chain CDRs and light chain CDRs of any one of the humanized antibodies v28726, v28727,
- the CDRs of these antibodies can be found in Table 18.
- the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain, and a TAA antigen -binding domain, wherein the 4-1BB-binding domain and the TAA antigen-binding domain are linked directly or indirectly to a scaffold, and the 4-1BB antigen-binding domain comprises one, two, or three heavy chain CDRs and/or one, two, or three light chain CDRs of v28726, v28727, v28728, v28730, v20022, v28700, v28704, V28705, v28706, v28711, v28712, v28713, v20036, v28696, v28697, v28698, v28701,
- the 4-1BB x TAA antibody construct comprises a 4- lBB-binding domain that is capable of binding to an ECD of human 4-1BB and is cyno cross- reactive.
- the term “cyno cross-reactive” as used herein is meant to describe binding domains that bind to a target from one species (for example, human or mouse) and are able also to bind to the same target expressed in a cynomolgus monkey.
- the antibody construct comprises a 4-1BB-binding domain that can bind to an ECD of mouse 4-1BB.
- the 4-1BB x TAA antibody constructs described herein comprise a 4-1BB- binding domain that binds to a 4-1BB extracellular domain (4-1BB ECD), and a tumor- associated antigen (TAA) antigen binding domain that binds to a TAA, wherein the 4-1BB- binding domain and the TAA antigen binding domain are linked directly or indirectly to a scaffold.
- the 4-1BB x TAA antibody construct comprises a first TAA antigen-binding domain and a second TAA antigen-binding domain linked directly or indirectly to a scaffold.
- tumor-associated antigen refers to an antigen that is expressed by cancer cells.
- a tumor-associated antigen may or may not be expressed by normal cells (non-tumor cells).
- normal cells non-tumor cells
- TAA-specific antigen When a TAA is not expressed by normal cells (i.e. when it is unique to tumor cells) it may also be referred to as a “tumor-specific antigen.”
- TAA tumor-associated antigen
- TAA tumor-associated antigen
- TAAs may be antigens that are normally present at low levels on normal cells but which are expressed at higher levels on tumor cells. Those TAAs of greatest clinical interest are differentially expressed compared to the corresponding normal tissue and allow for a preferential recognition of tumor cells by specific T-cells or immunoglobulins. In some embodiments, TAAs may be membrane-bound antigens, or antigens that are localized on the surface of a tumor cell.
- the 4-1BB x TAA antibody construct comprises a TAA antigen-binding domain that binds to a TAA that is expressed at high levels in tumor cells.
- the tumor cells may express the TAA at greater than about 1 million copies per cell.
- the 4-1BB x TAA antibody construct comprises at least one TAA antigen-binding domain that binds to a TAA that is expressed at medium levels in tumor cells.
- the tumor cells may express the TAA at greater than about 100,000 to about 1 million copies per cell.
- the 4-1BB x TAA antibody construct comprises at least one TAA antigen-binding domain that binds to a TAA that is expressed at low levels in tumor cells.
- the tumor cells may express the TAA at less than about 100,000 copies per cell.
- the 4-1BB x TAA antibody construct binds to a TAA that is expressed at higher levels on tumor cells than on normal cells.
- the 4-1BB x TAA antibody construct binds to a TAA that is expressed on a breast cancer cell, a lung cancer cell, an ovarian cancer cell, a colon cancer cell, a skin cancer cell, a bladder cancer cell, a lymphoma or leukemic cell, a kidney cancer cell, a pancreatic cancer cell, a stomach cancer cell, an oesophageal cancer cell, a prostate cancer cell, a thyroid cancer cell or other non-liver cancer cell.
- the 4-1BB x TAA antibody construct may comprise varying numbers of TAA antigen-binding domains. Accordingly, in certain embodiments, the 4-1BB x TAA antibody construct comprises a 4-1BB-binding domain and a TAA antigen-binding domain, wherein the 4-1BB-binding domains and the TAA antigen-binding domains are linked directly or indirectly to a scaffold. In other embodiments, the 4-1BB x TAA antibody construct comprises two 4- lBB-binding domains and one TAA antigen-binding domain, wherein the 4-1BB-binding domains and the TAA antigen-binding domains are linked directly or indirectly to a scaffold.
- the 4-1BB x TAA antibody construct comprises one or more 4- lBB-binding domains, and two TAA antigen-binding domains, wherein the 4-1BB-binding domains and the TAA antigen-binding domains are linked directly or indirectly to a scaffold.
- each TAA antigen-binding domain may bind to the same epitope of one TAA, or to different epitopes of the same TAA, or to different TAAs.
- the TAA antigen-binding domains may be in scFv, Fab or sdAb formats.
- the TAA antigen-binding domain of the 4-1BB x TAA antibody construct is in a Fab format.
- the TAA antigen-binding domain is in a scFv format.
- the 4-1BB x TAA antibody construct comprises more than one TAA antigen-binding domain, wherein at least one TAA antigen-binding domain is in an scFv format.
- at least two of the antigen-binding domains are in the scFv format.
- the 4-1BB x TAA antibody construct comprises a TAA antigen-binding domain that binds to a TAA selected from, but not limited to, carbonic anhydrase IX, alpha-fetoprotein (AFP), alpha-actinin-4, A3, antigen specific for A33 antibody, ALK (anaplastic lymphoma receptor tyrosine kinase), ART-4, B7, B7-H4, Ba 733, BAGE, BCMA, BrE3 -antigen, CA125, CAMEL, CAP-1, CASP-8/m, CCL19, CCL21, CD1, CDla, CD2, CD3, CD4, CD5, CD8, CD11A, CD14, CD15, CD16, CD18, CD19, CD20, CD21, CD22, CD23, CD25, CD29, CD30, CD32b, CD33, CD37, CD38, CD40, CD40L, CD44, CD45, CD46, CD52, CD54, CD55, CD
- a TAA selected
- the 4-1BB x TAA antibody constructs described herein comprise a 4-1BB-binding domain that binds to a 4-1BB extracellular domain (4-1BB ECD), and a TAA antigen-binding domain that binds to folate receptor (FR ⁇ ), wherein the first 4- lBB-binding domain and the TAA antigen binding domain are linked directly or indirectly to a scaffold.
- 4-1BB ECD 4-1BB extracellular domain
- FR ⁇ folate receptor
- the 4-1BB x TAA antibody constructs described herein comprise a 4-1BB-binding domain that binds to a 4-1BB extracellular domain (4-1BB ECD), and a tumor-associated antigen (TAA)-antigen binding domain that binds to Solute Carrier Family 34 Member 2 (SLC34A2, NaPi2b), wherein the first 4-1BB-binding domain and the TAA antigen binding domain are linked directly or indirectly to a scaffold.
- 4-1BB ECD 4-1BB extracellular domain
- TAA tumor-associated antigen-antigen binding domain that binds to Solute Carrier Family 34 Member 2 (SLC34A2, NaPi2b)
- the 4-1BB x TAA antibody constructs described herein comprise a 4-1BB-binding domain that binds to a 4-1BB extracellular domain (4-1BB ECD), and a tumor-associated antigen (TAA)- antigen binding domain that binds to HER2, wherein the first 4-1BB-binding domain and the TAA antigen binding domain are linked directly or indirectly to a scaffold.
- 4-1BB ECD 4-1BB extracellular domain
- TAA tumor-associated antigen
- the 4-1BB x TAA antibody constructs described herein comprise a 4-1BB-binding domain that binds to a 4-1BB extracellular domain (4-1BB ECD), and a tumor-associated antigen (TAA)- antigen binding domain that binds to mesothelin, wherein the first 4-1BB-binding domain and the TAA antigen binding domain are linked directly or indirectly to a scaffold.
- 4-1BB ECD 4-1BB extracellular domain
- TAA tumor-associated antigen
- the 4-1BB x TAA antibody constructs described herein comprise a 4-1BB- binding domain that binds to a 4-1BB extracellular domain (4-1BB ECD), and a tumor- associated antigen (TAA)-antigen binding domain that binds to Solute Carrier Family 39 Member 6 (SLC3A6, LIV-1), wherein the first 4-1BB-binding domain and the TAA antigen binding domain are linked directly or indirectly to a scaffold.
- 4-1BB ECD 4-1BB extracellular domain
- TAA tumor- associated antigen-antigen binding domain that binds to Solute Carrier Family 39 Member 6 (SLC3A6, LIV-1)
- the TAA antigen-binding domains may be constructed from the sequences of known antibodies directed against TAAs. Many such antibodies are known in the art and may be commercially obtained from a number of sources. For example, a variety of antibody secreting hybridoma lines are available from the American Type Culture Collection (ATCC, Manassas, Va.) In addition, a number of antibodies against various TAAs have been deposited at the ATCC and/or have published variable domain sequences and may be used to prepare the TAA antigen-binding domains of the antibody constructs. The skilled artisan will appreciate that antibody sequences or antibody-secreting hybridomas against various TAAs may be obtained by a simple search of the ATCC, NCBI, and/or USPTO databases. Alternatively, antibodies that specifically bind to a desired TAA may be generated according to methods known in the art and described elsewhere herein.
- the 4-1BB x TAA antibody construct is a 4-1BB x FR ⁇ antibody construct comprising a 4-1BB antigen-binding domain and a FR ⁇ antigen-binding domain wherein the 4-1BB binding domain and the FR ⁇ antigen-binding domain are linked directly or indirectly to a scaffold.
- FR ⁇ is a member of the folate receptor family which functions to bind folic acid and transports 5-methyltetrahydrofolate into cells.
- FR ⁇ is also known as folate receptor 1, FOLR, FOLR1, FBP or MOv18 and is expressed in normal cells as well as tumor cells as a secreted protein that exists in soluble form or is anchored to the membrane of cells through a glycosyl-phosphatidylinositol (GPI) linkage.
- GPI glycosyl-phosphatidylinositol
- FR ⁇ antigen-binding domains may be derived from anti-FR ⁇ antibodies known in the art, including but not limited to: farletuzumab (Morphotek, described in W02004/003388 and W02005/080431), mirvetuximab (ImmunoGen, described in WO2011106528).
- Other anti-FR ⁇ antibodies are described in US 8,388,972 (Advanced Accelerator Applications), WO2018/098277 (Eisai R&D Management Co.), US 9,695,237 (Kyowa Hakko Kirin Co.), WO2015/196167 (Bioalliance), W02016/079076 (Roche), and WO2018/071597 (Sutro).
- the 4-1BB x TAA antibody construct comprises a FR ⁇ antigen-binding domain that can compete with farletuzumab for binding to an epitope of FR ⁇ .
- the 4-1BB x TAA antibody construct comprises a FR ⁇ antigen- binding domain that can compete with mirvetuximab for binding to an epitope of FR ⁇ .
- the 4-1BB x TAA antibody construct comprises a FR ⁇ antigen-binding domain that can compete for binding to an epitope of FR ⁇ with any one of the anti-FR ⁇ antibodies described in US 8,388,972, WO2018/098277, US 9,695,237, WO2015/196167, WO2016/079076, or WO2018/071597.
- the 4-1BB x TAA antibody construct comprises a FR ⁇ antigen-binding domain that binds to the same epitope of FR ⁇ as farletuzumab or mirvetuximab, or any one of the FR ⁇ antibodies described in US 8,388,972, WO2018/098277, US 9,695,237, WO2015/196167, WO2016/079076, or WO2018/071597.
- the 4-1BB x TAA antibody construct comprises an FR ⁇ antigen-binding domain that comprises at least one, two, or all three heavy chain CDRs and/or at least one, two, or all three light chain CDRs of farletuzumab, mirvetuximab, or any one of the anti-FR ⁇ antibodies described in US 8,388,972, WO2018/098277, US 9,695,237, WO2015/196167, W02016/079076, or WO2018/071597.
- the 4- 1BB x TAA antibody construct comprises a FR ⁇ antigen-binding domain that comprises at least one, two, or all three heavy chain CDRs and at least one, two, or all three light chain CDRs of farletuzumab, mirvetuximab, or any one of the anti-FR ⁇ antibodies described in US 8,388,972, WO2018/098277, US 9,695,237, WO2015/196167, WO2016/079076, or WO2018/071597.
- the 4-1BB x TAA construct comprises a FR ⁇ antigen-binding domain comprising a VH sequence that is at least about 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, or 100% identical to the VH sequence of farletuzumab, mirvetuximab, or any one of the anti-FR ⁇ antibodies described in US 8,388,972, WO2018/098277, US 9,695,237, WO2015/196167, WO2016/079076, or WO2018/071597.
- FR ⁇ antigen-binding domains may be derived from novel antibodies that are generated according to methods known in the art.
- the 4-1BB x FR ⁇ antibody construct comprises a FR ⁇ antigen-binding domain having a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of antibody 8K22 or 1H06 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 8K22 or 1H06.
- the CDRs of these antibodies are provided in Table 18.
- the 4-1BB x TAA antibody construct comprises the heavy chain CDRs and light chain CDRs of antibody 8K22 or 1H06.
- the 4-1BB x FR ⁇ antibody construct comprises a FR ⁇ antigen- binding domain having a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of antibody 2L16 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 2L16.
- the 4-1BB x TAA antibody construct comprises the heavy chain rabbit CDRs and light chain rabbit CDRs of anti-FR ⁇ antibody 2L16 as provided in Table 47.
- the 4-1BB x TAA antibody construct comprises the heavy chain humanized CDRs and light chain humanized CDRs of anti-FR ⁇ antibody 2L16 as provided in Table 47.
- the 4-1BB x FR ⁇ antibody construct comprises a first folate receptor alpha (FR ⁇ )-antigen binding domain in scFv format comprising a heavy chain variable domain (VH) sequence having at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% sequence identity to the VH sequence of antibody 8K22 and comprising the three heavy chain CDR sequences of antibody 8K22 and a light chain variable domain (VL) sequence having at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% sequence identity to the VL sequence of antibody 8K22 and comprising the three light chain CDR sequences of antibody 8K22, and further comprising one or more amino acid modifications that improve the biophysical properties of the antibody construct in the VH domain and/or in the VL domain of antibody 8K22.
- VH heavy chain variable
- the 4-1BB x FR ⁇ antibody construct comprises a 4-1BB antigen-binding domain comprising the CDRs of any one of the humanized antibodies v28726, V28727, v28728, v28730, v28700, v28704, v28705, v28706, v28711, v28712, v28713,
- the 4-1BB x FR ⁇ antibody construct comprises a 4-1BB antigen-binding domain comprising the CDRs of any one of the humanized antibodies v28726, v28727, v28728, v28730, v28700, v28704, v28705, v28706, v28711, v28712, v28713, v28696, v28697, v28698, v28701, v28702, v28703, v28707,
- the 4-1BB x FR ⁇ antibody construct comprises a 4-1BB antigen- binding domain comprising the CDRs of any one of the humanized antibodies v28726, v28727, V28728, v28730, v28700, v28704, v28705, v28706, v28711, v28712, v28713, v28696,
- the 4-1BB x FR ⁇ antibody construct comprises a 4-1BB antigen-binding domain comprising the CDRs of any one of the humanized anti-4-1BB antibodies 1G1, 1C8, or 5G8, and a FR ⁇ antigen-binding domain comprising the CDRs of anti-FR ⁇ antibody 2L16.
- the 4-1BB x FR ⁇ antibody construct comprises a 4-1BB antigen-binding domain comprising the CDRs of any one of the humanized anti-4-1BB antibodies 1G1, 1C8, or 5G8, and a FR ⁇ antigen-binding domain comprising a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of antibody 2L16 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 2L16.
- the 4-1BB x FR ⁇ antibody construct comprises the heavy chain CDRs and light chain CDRs of any one of anti-4-1BB antibodies 1G1, 1C8, or 5G8.
- the 4-1BB x FR ⁇ antibody construct comprises the 3 heavy chain CDRs and the 3 light chain CDRs of anti-4-1BB antibody 1G1 and the 3 heavy chain CDRs and the 3 light chain CDRs of antibody 8K22 or 2L16.
- the 4-1BB x TAA antibody construct comprises the heavy chain CDRs and light chain CDRs of any one of anti-4-1BB antibodies 1G1, 1C8, or 5G8, wherein one or more CDRs comprise at least one amino acid substitution that improves the affinity of the antibody for human 4-1BB and the 3 heavy chain CDRs and the 3 light chain CDRs of antibody 8K22 or 2L16.
- the 4-1 BB x TAA antibody construct comprises three heavy chain CDRs and three light chain CDRs of anti-4-1BB antibody 1C8, wherein one or more CDRs comprise at least one amino acid substitution that improves the affinity of the antibody for human 4-1BB and the 3 heavy chain CDRs and the 3 light chain CDRs of antibody 8K22 or 2L16.
- the biophysical properties of the 4-1BB x FR ⁇ antibody construct may be improved according to methods known in the art. Such biophysical properties may include improved thermal stability with respect to a reference construct or improved species homogeneity during production. Species homogeneity can be measured as a decrease in high molecular weight species during production. [00158] Improved thermal stability may be measured according to methods known in the art. The thermal stability of antibody constructs or scFvs, Fabs, CH3, or CH2 domains thereof can be determined as absolute numbers or in comparison to a reference construct.
- the melting temperature of each domain is indicative of its thermal stability and can be measured using techniques such as differential scanning calorimetry (Chen et al (2003) Pharm Res 20:1952-60; Ghirlando et al (1999) Immunol Lett 68:47-52), and differential scanning fluorimetry (Niesen et al. (2007) Nature Protocols 2(9): 2212-21).
- the latter methods provide a measure of thermal stability in terms of “melting temperature” or Tm.
- the thermal stability of domains of the antibody construct can be measured using circular dichroism (Murray et al. (2002) J. Chromatogr Sci 40:343-9).
- the thermal stability of the domain, or antibodies comprising the domain is measured by differential scanning calorimetry (DSC).
- the thermal stability of the domain, or antibodies comprising the domain is measured by differential scanning fluorimetry (DSF). In one embodiment, the thermal stability of the domain, or antibodies comprising the domain is measured by DSC or DSF.
- the reference construct may vary. For example, if the domain of interest is an scFv with amino acid modifications designed to improve thermal stability of the scFv, the reference construct may be an scFv without the amino acid modifications.
- HMW species typically include undesired dimers, trimers and higher order aggregates of the antibody constructs.
- the physical properties (i.e . amino acid sequence) of certain domains of the antibody construct may result in amounts of HMW species that are undesirable.
- Methods of assessing the sequence and structure of these domains to identify amino acid modifications that could result in a decrease in HMW species are known in the art. In general, such amino acid modifications include replacing certain surface hydrophobic residues with hydrophilic residues or alanine.
- antibody constructs have no greater than about 10% to about 15% HMW species with respect to total amount of species obtained after purification of antibody constructs from cellular supernatants. In some embodiments, antibody constructs have no greater than about 10% HMW species with respect to total amount of species obtained after purification of antibody constructs from cellular supernatants.
- the 4-1BB x FR ⁇ antibody construct comprises a 4-1BB antigen-binding domain comprising the CDRs of any one of the humanized anti-4-1BB antibodies 1G1, 1C 8, or 5G8, and a humanized VH sequence and humanized VL sequence of anti-FR ⁇ antibody 2L16, wherein the humanized VH sequence and/or the humanized VL sequence comprises one or more amino acid modifications that improve the affinity of the 2L16 antibody for human FR ⁇ , or improve the biophysical properties of the 4-1BB x FR ⁇ antibody construct.
- the one or more amino acid modifications may include changes in the linker sequence between the VH and VL sequences where the anti-FR ⁇ antigen-binding domain is in the scFv format.
- Changes in the linker sequence may includes use of different amino acid sequences, or different linker lengths for example.
- the 4-1BB antigen- binding domain is in the Fab format and the anti-FR ⁇ antigen-binding domain is in the scFv format.
- the one or more amino acid modifications that improve the biophysical properties of the 4-1BB x FR ⁇ antibody construct are selected from those shown in the table below, wherein the numbering of amino acid residues is according to Rabat:
- the 4-1BB x FR ⁇ antibody construct comprises a 4-1BB antigen-binding domain comprising the CDRs of any one of the humanized anti-4-1BB antibodies 1G1, 1C 8, or 5G8, and a humanized VH sequence and humanized VL sequence of anti-FR ⁇ antibody 8K22, wherein the humanized VH sequence and/or the humanized VL sequence comprises one or more amino acid modifications that improve the affinity of the 8K22 antibody for human FR ⁇ , or improve the biophysical properties of the 4-1BB x FR ⁇ antibody construct.
- the 4-1BB antigen-binding domain is in the Fab format and the anti-FR ⁇ antigen-binding domain is in the scFv format.
- the one or more amino acid modifications may include changes in the linker sequence between the VH and VL sequences. Changes in the linker sequence may includes use of different amino acid sequences, or different linker lengths for example. Suitable linker sequences and lengths can readily be determined by one of skill in the art, given common general knowledge.
- the one or more amino acid modifications that improve the biophysical properties of the 4-1BB x FR ⁇ antibody construct are selected from those shown in the table below, wherein the numbering of residues is according to Rabat:
- Table C3 Modifications in 8K22 scFv sequence to improve biophysical properties of antibody constructs having an 8K22 scFv SLC34A2/NaPi2b antigen-binding domains
- the 4-1BB x TAA antibody construct is a 4-1BB x NaPi2b antibody construct comprising a 4-1BB anti gen -binding domain and aNaPi2b antigen-binding domain wherein the 4-1BB binding domain and the NaPi2b antigen-binding domain are linked directly or indirectly to a scaffold.
- SLC34A2 is a pH-sensitive sodium-dependent phosphate transporter. Also known as NaPi2b as well as NAPI-3B, NAPI-IIb, NPTIIb, this protein is expressed in some normal epithelial cells in the lung, gut and mammary gland and has a function in transporting phosphate ions. NaPi2b is found highly expressed on tumor cells, primarily in lung and ovarian cancers (Lin K et al, Clin Cancer Res. 2015 Nov 15;21(22):5139-50). NaPi2b is a multispan membrane protein, with extracellular domains of 14, 129, 57 and 6 amino acids. The polypeptide sequence of this protein is described in NCBI Reference Sequence: NP_001171470.1 and UniProt 095436, and provided herein as SEQ ID NO:81.
- NaPi2b antigen-binding domains may be derived from antibodies known in the art, including but not limited to: lifastuzumab (Genentech, Seattle Genetics, described in WO2011/066503), MX-35 (Ludwig Institute, described in W02009/097128), and the antibodies described by Mersana Therapeutics in US2017/0266311.
- NaPi2b antigen-binding domains may be derived from novel antibodies that are generated according to methods known in the art and described elsewhere herein.
- the 4-1BB x TAA antibody construct comprises an NaPi2b antigen-binding domain that can compete with lifastuzumab for binding to an epitope of NaPi2b.
- the 4-1BB x TAA antibody construct comprises an NaPi2b antigen-binding domain that can compete with MX-35 for binding to an epitope of NaPi2b.
- the 4-1BB x TAA antibody construct comprises an NaPi2b antigen- binding domain that can compete for binding to an epitope of NaPi2b with any one of the anti- NaPi2b antibodies described in WO2011/066503, W02009/097128, or US2017/0266311.
- the 4-1BB x TAA antibody construct comprises an NaPi2b antigen-binding domain that binds to the same epitope of NaPi2b as lifastuzumab or MX-35, or any one of the anti-NaPi2b antibodies described in WO2011/066503, W02009/097128, or US2017/0266311.
- the 4-1BB x TAA antibody construct comprises an NaPi2b antigen-binding domain that comprises at least one, two, or all three heavy chain CDRs and/or at least one, two, or all three light chain CDRs of lifastuzumab or MX-35, or any one of the anti-NaPi2b antibodies described in WO2011/066503, W02009/097128, orUS2017/0266311.
- the 4-1BB x TAA antibody construct comprises an NaPi2b antigen-binding domain that comprises at least one, two, or all three heavy chain CDRs and at least one, two, or all three light chain CDRs of lifastuzumab or MX-35, or any one of the anti- NaPi2b antibodies described in WO2011/066503, W02009/097128, or US2017/0266311.
- the 4-1BB x TAA construct comprises an NaPi2b antigen-binding domain comprising a VH sequence that is at least about 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, or 100% identical to the VH sequence of lifastuzumab or MX-35, or any one of the anti-NaPi2b antibodies described in WO2011/066503, W02009/097128, or US2017/0266311.
- the specific sequences of the CDRs of exemplary anti-NaPi2b antibodies are described in Table D; the VH and VL sequences of these antibodies are found in Table 17.
- Other anti-NaPi2b antibody sequences can readily be determined by one of skill in the art with reference to the disclosures ofWO2011/066503, W02009/097128, or US2017/0266311.
- NaPi2b antigen-binding domains may be derived from novel antibodies that are generated according to methods known in the art.
- the 4-1BB x TAA antibody construct is a 4-1BB x HER2 antibody construct comprising a 4-1BB antigen-binding domain and a HER2 antigen-binding domain wherein the 4-1BB binding domain and the HER2 antigen-binding domain are linked directly or indirectly to a scaffold.
- HER2 also known as ErbB2 is a receptor protein tyrosine kinase which belongs to the human epidermal growth factor receptor (HER) family which includes EGFR, HER2, HER3 and HER4 receptors.
- the extracellular (ecto) domain of HER2 comprises four domains, Domain I (ECD1, amino acid residues from about 1-195), Domain II (ECD2, amino acid residues from about 196-319), Domain III (ECD3, amino acid residues from about 320- 488), and Domain IV (ECD4, amino acid residues from about 489-630) (residue numbering without signal peptide). See Garrett et al. Mol. Cell. 11 : 495-505 (2003), Cho et al.
- HER2 antigen-binding domains may be derived from antibodies known in the art, including but not limited to: trastuzumab (Genentech, described for example in US 5,821,337, and US 6,528,624), or pertuzumab (Genentech, US 7,862,217).
- the online Therapeutic Antibodies Database (Tabs, hosted by Craic Computing LLC, tabs.craic.com) identifies many additional anti-HER2 antibodies that provide suitable sequences for preparing the anti-HER2 antigen-binding domains of the 4-1BB x TAA antibody construct.
- the 4-1BB x TAA antibody construct comprises a HER2 antigen-binding domain that can compete with trastuzumab for binding to an epitope of HER2.
- the 4-1BB x TAA antibody construct comprises a HER2 antigen- binding domain that can compete with pertuzumab for binding to an epitope of HER2.
- the 4-1BB x TAA antibody construct comprises aHER2 antigen-binding domain that can compete for binding to an epitope of HER2 with any one of the anti-HER2 antibodies described in US 5,821,337, US 6,528,624, or US 7,862,217.
- the 4-1BB x TAA antibody construct comprises a HER2 antigen-binding domain that binds to the same epitope of HER2 as trastuzumab or pertuzumab, or any one of the anti-HER2 antibodies described in US 5,821,337, US 6,528,624, or US
- the 4-1BB x TAA antibody construct comprises a HER2 antigen-binding domain that comprises at least one, two, or all three heavy chain CDRs and/or at least one, two, or all three light chain CDRs of trastuzumab or pertuzumab or margetuximab, or any one of the anti-HER2 antibodies described in US 5,821,337, US 6,528,624, or US
- the 4-1BB x TAA antibody construct comprises HER2 antigen-binding domain that comprises at least one, two, or all three heavy chain CDRs and at least one, two, or all three light chain CDRs of trastuzumab or pertuzumab or margetuximab, or any one of the anti-HER2 antibodies described in US 5,821,337, US 6,528,624, or US
- the 4-1BB x TAA construct comprises a HER2 antigen- binding domain comprising a VH sequence that is at least about 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, or 100% identical to the VH sequence of trastuzumab or pertuzumab or margetuximab, or any one of the anti-HER2 antibodies described in US 5,821,337, US 6,528,624, or US 7,862,217.
- the specific sequences of the CDRs of exemplary anti-HER2 antibodies are described in Table E; the VH and VL sequences of these antibodies are found in Table 17.
- Other anti-HER2 antibody sequences can readily be determined by one of skill in the art with reference at least to the disclosures of WO2011/066503, W02009/097128, or US2017/0266311.
- HER2 antigen-binding domains may be derived from novel antibodies that are generated according to methods known in the art.
- the 4-1BB x TAA antibody construct is a 4-1BB x LIV-1 antibody construct comprising a 4-1BB antigen-binding domain and a LIV-1 antigen-binding domain wherein the 4-1BB binding domain and the LIV-1 antigen-binding domain are linked directly or indirectly to a scaffold.
- SLC39A6 also known as LIV-1 or ZIP6, belongs to a family of proteins that function as zinc transporters. It is expressed at low levels on normal cells throughout the body but is expressed at high levels on some tumor cells, particularly breast cancers (Takatani- Nakase et al, (2016) Biomed Res Clin Prac 1:71-75).
- the polypeptide sequence of LIV-1 is described in UniProt Accession Number Q13433 and included herein as SEQ ID NO:83.
- LIV-1 antigen-binding domains may be derived from antibodies known in the art, including but not limited to those described in WO 2012/078688 (Seattle Genetics), WO 2004/067564 (Abbvie), and WO 2001/055178 (Genentech). Other antibodies that bind to LIV- 1 are described in US2008/0175839.
- the 4-1BB x TAA antibody construct comprises a LIV-1 antigen-binding domain that can compete for binding to an epitope of LIV-1 with any one of the antibodies described in WO 2012/078688, WO 2004/067564, WO 2001/055178, or US2008/0175839.
- the 4-1BB x TAA antibody construct comprises a LIV-1 that can compete for binding to an epitope of LIV-1 with any one of the anti-LIV-1 antibodies described in WO 2012/078688, WO 2004/067564, WO 2001/055178, or US2008/0175839.
- the 4-1BB x TAA antibody construct comprises a LIV- 1 antigen-binding domain that binds to the same epitope of LIV-1 as any one of the anti-LIV- 1 antibodies described in WO 2012/078688, WO 2004/067564, WO 2001/055178, or US2008/0175839.
- the 4-1BB x TAA antibody construct comprises an LIV-1 antigen-binding domain that comprises at least one, two, or all three heavy chain CDRs and/or at least one, two, or all three light chain CDRs of any one of the anti-LIV-1 antibodies described in WO 2012/078688, WO 2004/067564, WO 2001/055178, or US2008/0175839.
- the 4-1BB x TAA antibody construct comprises an LIV-1 antigen- binding domain that comprises at least one, two, or all three heavy chain CDRs and at least one, two, or all three light chain CDRs of any one of the anti-LIV-1 antibodies described in WO 2012/078688, WO 2004/067564, WO 2001/055178, or US2008/0175839.
- the 4-1BB x TAA construct comprises a LIV-1 antigen-binding domain comprising a VH sequence that is at least about 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, or 100% identical to the VH sequence of any one of the anti-LIV-1 antibodies described in WO 2012/078688, WO 2004/067564, WO 2001/055178, or US2008/0175839.
- the specific sequences of the CDRs, VHs, and VLs for exemplary anti-LIV-1 antibodies are described in the disclosures of WO2011/066503, W02009/097128, or US2017/0266311.
- LIV-1 antigen-binding domains may be derived from novel antibodies that are generated according to methods known in the art and described elsewhere herein.
- Mesothelin (MSLN) antigen-binding domains may be derived from novel antibodies that are generated according to methods known in the art and described elsewhere herein.
- the 4-1BB x TAA antibody construct is a 4-1BB x MSLN antibody construct comprising a 4-1BB antigen-binding domain and a MSLN antigen-binding domain wherein the 4-1BB binding domain and the MSLN antigen-binding domain are linked directly or indirectly to a scaffold.
- MSLN Mesothelin
- CAK antigen also known as CAK antigen or Pre-pro-megakaryocyte- potentiating factor
- SEQ ID NO: 84 The polypeptide sequence of mesothelin is described in UniProt Accession Number Q13421 and included herein as SEQ ID NO: 84.
- MSLN antigen-binding domains may be derived from anti-MSLN antibodies known in the art, including but not limited to: anetumab (Bayer, described in W02009/068204), 6A4/BMS-986148 (BMS, described in W02009/045957), or the Mab Designs anti-MSLN antibody described in W02018/060480.
- the 4-1BB x TAA antibody construct comprises a MSLN antigen-binding domain that competes for binding with anetumab for binding to MSLN.
- the 4-1BB x TAA antibody construct comprises a MSLN antigen-binding domain that competes for binding with 6A4/BMS-986148 for binding to MSLN.
- the 4-1BB x TAA antibody construct comprises a MSLN antigen-binding domain that competes for binding with the Mab Designs anti-MSLN antibody for binding to MSLN.
- the 4-1BB x TAA antibody construct comprises a MSLN antigen-binding domain that binds to the same epitope as anetumab for binding to MSLN.
- the 4-1BB x TAA antibody construct comprises a MSLN antigen-binding domain that binds to the same epitope as 6A4/BMS-986148 for binding to MSLN.
- the 4-1BB x TAA antibody construct comprises a MSLN antigen-binding domain that binds to the same epitope as the Mab Designs anti-MSLN antibody for binding to MSLN.
- the 4-1BB x TAA antibody construct comprises a MSLN antigen-binding domain that comprises at least one, two, or all three heavy chain CDRs and/or at least one, two, or all three light chain CDRs of any one of the anti-MSLN antibodies described in W02009/068204, W02009/045957, or WO2018/060480.
- the 4-1BB x TAA antibody construct comprises a MSLN antigen-binding domain that comprises at least one, two, or all three heavy chain CDRs and at least one, two, or all three light chain CDRs of any one of the anti-MSLN antibodies described in W02009/068204, W02009/045957, or WO2018/060480.
- the 4-1BB x TAA construct comprises a MSLN antigen-binding domain comprising a VH sequence that is at least about 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, or 100% identical to the VH sequence of any one of the anti-MSLN antibodies described in W02009/068204, W02009/045957, or W02018/060480.
- the specific sequences of the CDRs of exemplary anti-MSLN antibodies are described in Table F; the VH and VL sequences of these antibodies are found in Table 17.
- Other anti-MSLN antibody sequences can readily be determined by one of skill in the art with reference to the disclosures of W02009/068204, W02009/045957, or WO2018/060480.
- the 4-1BB x TAA antibody construct comprises a 4-1BB binding domain that binds to a 4-1BB ECD and a TAA antigen-binding domain, wherein the first 4-1BB binding domain and the TAA antigen-binding domain are linked directly or indirectly to a scaffold.
- Direct linkage of the 4-1BB-binding domain and the TAA antigen- binding domain results when each of these domains is directly linked to the scaffold, without linkers.
- the 4-1BB-binding domain is linked to the scaffold without a linker and the TAA antigen-binding domain is also linked to the scaffold without a linker.
- Methods of accomplishing direct linkage are known in the art and include recombinant DNA methodology and/or chemical conjugation, for example.
- Indirect linkage can be achieved by using a linker to link one or both of the 4- lBB-binding domain and the TAA antigen-binding domain to the scaffold.
- the 4-1BB-binding domain is linked to the scaffold with a linker and the TAA antigen-binding domain is also linked to the scaffold with a linker.
- one of the 4-1BB-binding domain and the TAA antigen-binding domain is linked to the scaffold with a linker and the other is directly linked to the scaffold without a linker.
- the 4-1BB-binding domain is linked to the scaffold with a linker, and the TAA antigen-binding domain is linked to the 4-1BB-binding domain with a linker. In the latter embodiment, the TAA antigen-binding domain is considered to be indirectly linked to the scaffold. In an alternate embodiment, the TAA antigen-binding domain is linked to the scaffold with a linker, and the 4-1BB-binding domain is linked to the TAA antigen-binding domain with a linker. In the latter embodiment, the 4-1BB-binding domain is considered to be indirectly linked to the scaffold.
- linker may be a linker peptide, a linker polypeptide, or a non -polypeptide linker.
- the antibody constructs described herein include a 4-1BB- binding domain and a TAA antigen-binding domain that are each operatively linked to a linker polypeptide wherein the linker polypeptides are capable of forming a complex or interface with each other.
- the linker polypeptides are capable of forming a covalent linkage with each other.
- the spatial conformation of the constructs with the linker polypeptides is similar to the relative spatial conformation of the paratopes of a F(ab’)2 fragment generated by papain digestion, albeit in the context of an antibody construct with two antigen-binding domains.
- the linker polypeptides are selected from IgG1 , IgG2, IgG3, or IgG4 hinge regions. [00193] In some embodiments, the linker polypeptides are selected such that they maintain the relative spatial conformation of the paratopes of a F(ab’) fragment and are capable of forming a covalent bond equivalent to the disulphide bond in the core hinge of IgG. Suitable linker polypeptides include IgG hinge regions such as, for example those from IgG1, IgG2, or IgG4. Modified versions of these exemplary linkers can also be used. For example, modifications to improve the stability of the IgG4 hinge are known in the art (see for example, Labrijn et al. (2009) Nature Biotechnology 27, 767 - 771).
- a number of suitable scaffolds are known in the art, including peptides, polypeptides, polymers, nanoparticles or other chemical entities.
- the scaffold is an Fc construct.
- a number of scaffolds based on alternate protein or molecular domains are known in the art and can be used to form selective pairs of two different target- binding polypeptides. Examples of such alternate domains include the cohesin-dockerin scaffolds described International Patent Publication No. W02008/097817, and the split albumin scaffolds described in WO 2012/116453 and WO 2014/012082.
- a further example is the leucine zipper domains such as Fos and Jun that selectively pair together [S A Kostelny et al.
- the linker polypeptides are operatively linked to scaffolds other than an Fc.
- scaffolds based on alternate protein or molecular domains are known in the art and can be used to form selective pairs of two different target- binding polypeptides. Examples of such alternate domains are the split albumin scaffolds described in WO 2012/116453 and WO 2014/012082.
- a further example is the leucine zipper domains such as Fos and Jun that selectively pair together [S A Kostelny, M S Cole, and J Y Tso. Formation of a bispecific antibody by the use of leucine zippers. J Immunol 1992 148:1547-53; Bemd J. Wranik, Erin L.
- the 4-1BB- binding domain and/or the TAA antigen-binding domain of the antibody construct may be linked directly or indirectly to the scaffold by genetic fusion.
- the 4-1BB-binding domain and/or the TAA antigen- binding domain of the antibody construct may be linked to the scaffold by chemical conjugation.
- the antibody construct described herein comprises a 4- lBB-binding domain, and a tumor-associated antigen (TAA)-antigen binding domain, wherein the first 4-1BB-binding domain and the TAA antigen binding domain are linked directly or indirectly to an Fc construct.
- TAA tumor-associated antigen
- Fc or “Fc construct” as used herein refers to a C-terminal region of an immunoglobulin heavy chain that contains at least a portion of the constant region (also referred to as an “Fc domain” or “Fc region”), including the CH3 domain.
- the term includes native sequence Fc regions and variant Fc regions. Unless otherwise specified herein, numbering of amino acid residues in the Fc region or constant region is according to the EU numbering system, also called the EU index, as described in Edelman, G.M. et al, Proc. Natl. Acad. USA, 63, 78-85 (1969).
- a “dimeric Fc construct” comprises two Fc polypeptides.
- An “Fc polypeptide” of a dimeric Fc construct refers to one of the two polypeptides forming the construct, i.e. a polypeptide comprising C-terminal constant regions of an immunoglobulin heavy chain that is capable of stable self-association.
- the Fc polypeptides are derived from heavy chain isotypes including IgG, IgA, IgM, IgD, and IgE.
- the Fc polypeptides may also be derived from the heavy chain subtypes IgG1, IgG2, IgG3, IgG4, IgA1, or IgA2.
- the Fc construct is a human Fc construct.
- the Fc construct is a human IgG Fc construct. In other embodiments, the Fc construct is a human IgG1 Fc construct.
- Each Fc polypeptide comprises a CH3 sequence and may optionally comprise a CH2 sequence. In some embodiments, each Fc polypeptide comprises a CH3 sequences having one or more amino acid modifications. In some embodiments, each Fc polypeptide comprises a CH2 sequence comprises one or more amino acid modifications. In some embodiments, an Fc construct is composed of a single polypeptide, for example where the Fc polypeptides are linked by a linker. In other embodiments, the Fc construct is a heterodimeric Fc construct, wherein the Fc polypeptides that make up the Fc construct have different CH3 or CH2 sequences.
- the scaffold is a heterodimeric Fc construct comprising CH3 sequence modifications that promote the formation of a heterodimeric Fc construct compared to a homodimeric Fc, as described in International Patent Application No. PCT/CA2011/001238 or International Patent Application No. PCT/CA2012/050780, the entire disclosure of each of which is hereby incorporated by reference in its entirety for all purposes.
- Table G provides the amino acid sequence of the human IgG1 Fc sequence, corresponding to amino acids 231 to 447 of the full-length human IgG1 heavy chain.
- the CH3 sequence comprises amino acid 341-447 of the full-length human IgG1 heavy chain.
- an Fc includes two contiguous heavy chain sequences or Fc polypeptide sequences (A and B) that are capable of dimerizing.
- one or both sequences of these sequences may include one or more mutations or modifications at the following locations: L351, F405, Y407, T366, K392, T394, T350, S400, and/or N390, using EU numbering.
- an Fc may include a mutant sequence as shown in Table G.
- an Fc may include the mutations of Variant 1 A-B.
- an Fc may include the mutations of Variant 2 A-B.
- an Fc may include the mutations of Variant 3 A-B.
- an Fc may include the mutations of Variant 4 A-B.
- an Fc may include the mutations of Variant 5 A-B.
- Additional methods for modifying the Fc polypeptides of the Fc construct to promote heterodimeric Fc formation include, for example, those described in International Patent Publication No. WO 96/027011 (knobs into holes), in Gunasekaran et al. (Gunasekaran K. et al. (2010) J Biol Chem. 285, 19637-46, electrostatic design to achieve selective heterodimerization), in Davis et al. (Davis, JH. et al.
- Labrijn et al [Efficient generation of stable bispecific IgG1 by controlled Fab-arm exchange.
- Labrijn AF Meesters JI, de Goeij BE, van den Bremer ET, Neijssen J, van Kampen MD, Strumane K, Verploegen S, Kundu A, Gramer MJ, van Berkel PH, van de Winkel JG, Schuurman J, Parren PW. ProcNatl Acad Sci U S A. 2013 Mar 26;110(13):5145-50.
- the scaffold is an Fc construct wherein each Fc polypeptide of the Fc construct comprises a CH2 sequence and a CH3 sequence.
- a CH2 sequence of an Fc is amino acids 231-340 of the sequence shown in Table B.
- FcRs Fc receptors
- Fc receptor and “FcR” are used to describe a receptor that binds to the Fc region of an antibody.
- an FcR can be a native sequence human FcR.
- an FcR is one which binds an IgG antibody (a gamma receptor) and includes receptors of the Fc ⁇ RI, Fc ⁇ RII, and Fc ⁇ RIII subclasses, including allelic variants and alternatively spliced forms of these receptors.
- Fc ⁇ RII receptors include Fc ⁇ RIIA (an “activating receptor”) and Fc ⁇ RIIB (an “inhibiting receptor”), which have similar amino acid sequences that differ primarily in the cytoplasmic domains thereof.
- Immunoglobulins of other isotypes can also be bound by certain FcRs (see, e.g., Janeway et al, Immuno Biology: the immune system in health and disease, (Elsevier Science Ltd., NY) (4th ed., 1999)).
- Activating receptor Fc ⁇ RIIA contains an immunoreceptor tyrosine-based activation motif (ITAM) in its cytoplasmic domain.
- Inhibiting receptor Fc ⁇ RIIB contains an immunoreceptor tyrosine-based inhibition motif (ITIM) in its cytoplasmic domain (reviewed in Daeron, Annu. Rev. Immunol. 15:203-234 (1997)).
- FcRs are reviewed in Ravetch and Kinet, Annu. Rev.
- FcR neonatal receptor
- Modifications in the CH2 sequence can affect the binding of FcRs to the Fc construct.
- a number of amino acid modifications in the Fc region are known in the art for selectively altering the affinity of the Fc for different Fcgamma receptors.
- the Fc comprises one or more modifications to promote selective binding of Fc-gamma receptors.
- S239D/I332E/A330L S239D/I332E (Lazar GA, Dang W, Karki S, et al. Proc Natl Acad Sci U S A. 2006 Mar 14;103(11):4005-10);
- S239D/S267E, S267E/L328F (Chu SY, Vostiar I, Karki S, et al. Mol Immunol. 2008 Sep;45(15):3926-33); S239D/D265S/S298A/I332E, S239E/S298A/K326A/A327H, G237F/S298A/A330L/I3 32, S239D/I332E/S298A, S239D/K326E/A330L/I332E/S298A, G236A/S239D/D270L/ I332E, S239E/S267E/H268D, L234F/S267E/N325L, G237F/V266L/S267D and other mutations listed in WO2011/120134 and WO2011/120135, herein incorporated by reference.
- the heterodimeric Fc comprises Fc polypeptides having CH2 sequences comprising one or more asymmetric amino acid modifications. Exemplary asymmetric amino acid modifications are described in International Patent Application No. PCT/CA2014/050507. In one embodiment the heterodimeric Fc comprises Fc polypeptides having the amino acid substitutions L234A, L235A, and D265S which reduce Fc ⁇ R binding.
- the Fc construct includes amino acid modifications that improve its ability to mediate effector function.
- modifications are known in the art and include afucosylation, or engineering of the affinity of the Fc towards an activating receptor, mainly Fc ⁇ RIIIa for ADCC, and towards C1q for CDC.
- the Fc of the antibody constructs or antibody constructs can be fully afucosylated (meaning they contain no detectable fucose) or they can be partially afucosylated, meaning that the TAA presentation inducer in bispecific antibody format contains less than 95%, less than 85%, less than 75%, less than 65%, less than 55%, less than 45%, less than 35%, less than 25%, less than 15% or less than 5% of the amount of fucose normally detected for a similar antibody produced by a mammalian expression system.
- the antibody constructs described herein can include a dimeric Fc that comprises one or more amino acid modifications as noted in Table H that confer improved effector function.
- the construct can be afucosylated to improve effector function.
- Fc modifications reducing Fc ⁇ R and/or complement binding and/or effector function are known in the art.
- Various publications describe strategies that have been used to engineer antibodies with reduced or silenced effector activity (see Strohl, WR (2009), Curr Opin Biotech 20:685-691, and Strohl, WR and Strohl LM, “Antibody Fc engineering for optimal antibody performance” In Therapeutic Antibody Engineering, Cambridge: Woodhead Publishing (2012), pp 225-249). These strategies include reduction of effector function through modification of glycosylation, use of IgG2/IgG4 scaffolds, or the introduction of mutations in the hinge or CH2 regions of the Fc.
- the Fc comprises at least one amino acid modification identified in Table I. In some embodiments, the Fc comprises amino acid modification of at least one of L234, L235, or D265. In some embodiments, the Fc comprises amino acid modification at L234, L235 and D265. In some embodiments, the Fc comprises the amino acid modifications L234A, L235A and D265S.
- the 4-1BB-binding domain may be linked to the N-terminus of one of the Fc polypeptides. In other embodiments, the 4-1BB- binding domain may be linked to the C-terminus of one of the Fc polypeptides.
- the 4-1BB x TAA antibody construct can comprise a 4-1BB-binding domain linked to the N-terminus of one of the Fc polypeptides and another 4-1BB-binding domain linked to the N-terminus of the other Fc polypeptide. In yet other embodiments, the 4-1BB x TAA antibody construct can comprise a 4-1BB-binding domain that is linked to the C-terminus of one of the Fc polypeptides.
- the 4-1BB x TAA antibody construct can comprise a 4-1BB-binding domain linked to the C-terminus of one of the Fc polypeptides and another 4-1BB-binding domain linked to the C-terminus of the other Fc polypeptide.
- the TAA antigen- binding domain may be linked to the N-terminus of one of the Fc polypeptides. In other embodiments, the TAA antigen-binding domain may be linked to the C-terminus of one of the Fc polypeptides. In certain embodiments, the 4-1BB x TAA antibody construct can comprise a TAA antigen-binding domain linked to the N-terminus of one of the Fc polypeptides and another TAA antigen-binding domain linked to the N-terminus of the other Fc polypeptide.
- the 4-1BB x TAA can comprise a TAA antigen-binding domain that is linked to the C-terminus of one of the Fc polypeptides.
- the 4-1BB x TAA antibody construct can comprise a TAA antigen-binding domain linked to the C-terminus of one of the Fc polypeptides and another TAA antigen-binding domain linked to the C- terminus of the other Fc polypeptide.
- the 4-1BB x TAA antibody constructs described herein comprise a 4-1BB- binding domain and a TAA antigen-binding domain wherein the 4-1BB-binding domain and the TAA antigen-binding domain are linked directly or indirectly to a scaffold.
- these 4-1BB x TAA antibody constructs may be constructed in many formats; exemplary, non-limiting formats are described below.
- the 4-1BB-binding domain of the 4-1BB x TAA antibody construct is a 4-1BB antigen-binding domain
- the 4-1BB antigen-binding domain may be in Fab format, scFv format, or sdAb format.
- the antibody construct comprises a 4-1BB antigen-binding domain that is in the Fab format, and a TAA antigen- binding domain, wherein the 4-1BB antigen-binding domain and the TAA antigen-binding domain are linked directly or indirectly to a scaffold.
- the antibody construct comprises a 4-1BB antigen-binding domain that is in the scFv format, and a TAA antigen-binding domain, wherein the 4-1BB antigen-binding domain and the TAA antigen- binding domain are linked directly or indirectly to a scaffold.
- the antibody construct comprises a 4-1BB antigen-binding domain that is in the sdAb format, and a TAA antigen-binding domain, wherein the 4-1BB antigen-binding domain and the TAA antigen- binding domain are linked directly or indirectly to a scaffold.
- the 4-1BB antigen-binding domain is linked to the N-terminus of the scaffold and the TAA antigen-binding domain is linked to the C-terminus of the scaffold. In other embodiments, both the 4-1BB antigen-binding domain and the TAA antigen-binding domain are linked to the N-terminus of the scaffold.
- the scaffold is an Fc construct.
- the 4-1BB x TAA antibody construct comprises a first 4-1BB antigen-binding domain linked to the N-terminus of a first Fc polypeptide, a second 4-1BB antigen-binding domain linked to the N-terminus of a second Fc polypeptide, and a TAA antigen-binding domain linked to the C-terminus of the first Fc polypeptide.
- the first and second 4-1BB antigen-binding domains are both in the Fab format and the TAA antigen-binding domain is in the scFv format.
- Figure 2B provides a representation of an exemplary construct related to these embodiments, where the TAA antigen-binding domain is in the scFv format.
- the first and second 4-1BB antigen-binding domains are both in the Fab format and the TAA antigen-binding domain is also in the Fab format.
- the 4-1BB x TAA antibody construct is a 4-1BB x FR ⁇ antibody construct comprising a first 4-1BB 1G1 antigen-binding domain linked to the N- terminus of a first Fc polypeptide, a second 4-1BB 1G1 antigen-binding domain linked to the N-terminus of a second Fc polypeptide, and an anti FR ⁇ 8K22 antigen-binding domain linked to the C-terminus of the first Fc polypeptide.
- the anti-FR ⁇ 8K22 antigen-binding domain is in scFv format.
- the anti-FR ⁇ 8K22 antigen-binding domain is in scFv format and comprises one or more amino acid modifications to improve its biophysical properties.
- the 4-1BB x TAA antibody construct is a 4-1BB x FR ⁇ antibody construct comprising a first 4-1BB 1G1 antigen-binding domain linked to the N- terminus of a first Fc polypeptide, a second 4-1BB 1G1 antigen-binding domain linked to the N-terminus of a second Fc polypeptide, and an anti FR ⁇ 8K22 antigen-binding domain linked to the C-terminus of the first Fc polypeptide, where the anti-FR ⁇ 8K22 antigen-binding domain is in Fab format.
- the anti-FR ⁇ 8K22 antigen-binding domain and the 1G1 antigen-binding domains comprises amino acid substitutions that promote correct pairing of the 8K22 light chain with the 8K22 heavy chain and correct pairing between 1G1 light chain and the 1G1 heavy chain.
- correct pairing between heavy and light chains is enabled through use of CrossMab technology.
- the 4-1BB x TAA antibody construct is a 4-1BB x FR ⁇ antibody construct comprising a first 4-1BB 1G1 antigen-binding domain linked to the N- terminus of a first Fc polypeptide, a second 4-1BB 1G1 antigen-binding domain linked to the N-terminus of a second Fc polypeptide, and an anti FR ⁇ 2L16 antigen-binding domain linked to the C-terminus of the first Fc polypeptide.
- the anti-FR ⁇ 2L16 antigen-binding domain is in scFv format.
- the anti-FR ⁇ 2L16 antigen-binding domain is in scFv format and comprises one or more amino acid modifications to improve its biophysical properties.
- the 4-1BB x TAA antibody construct is a 4-1BB x FR ⁇ antibody construct comprising a first 4-1BB 1G1 antigen-binding domain linked to the N- terminus of a first Fc polypeptide, a second 4-1BB 1G1 antigen-binding domain linked to the N-terminus of a second Fc polypeptide, and an anti FR ⁇ 2L16 antigen-binding domain linked to the C-terminus of the first Fc polypeptide, where the anti-FR ⁇ 2L16 antigen-binding domain is in Fab format.
- the anti-FR ⁇ 2L16 antigen-binding domain and the 1G1 antigen-binding domains comprises amino acid substitutions that promote correct pairing of the 2L16 light chain with the 2L16 heavy chain and correct pairing between 1G1 light chain and the 1G1 heavy chain.
- correct pairing between heavy and light chains is enabled through use of CrossMab technology.
- the 4-1BB x TAA antibody construct is a 4-1BB x FR ⁇ antibody construct comprising a first 4-1BB 1C8 antigen-binding domain linked to the N- terminus of a first Fc polypeptide, a second 4-1BB 1C8 antigen-binding domain linked to the N-terminus of a second Fc polypeptide, where the first and second 4-1BB antigen-binding domains comprise one or more CDRs comprising at least one amino acid substitution that improves the affinity of the antibody for human 4-1BB, and an anti FR ⁇ 8K22 antigen-binding domain linked to the C-terminus of the first Fc polypeptide.
- the anti- FR ⁇ 8K22 antigen-binding domain is in scFv format. In an alternate embodiment, the anti- FR ⁇ 8K22 antigen-binding domain is in scFv format and comprises one or more amino acid modifications to improve its biophysical properties.
- the 4-1BB x TAA antibody construct is a 4-1BB x FR ⁇ antibody construct comprising a first 4-1BB 1C8 antigen-binding domain linked to the N- terminus of a first Fc polypeptide, a second 4-1BB 1C8 antigen-binding domain linked to the N-terminus of a second Fc polypeptide, where the first and second 4-1BB antigen-binding domains comprise one or more CDRs comprising at least one amino acid substitution that improves the affinity of the antibody for human 4-1BB, and an anti FR ⁇ 2L16 antigen-binding domain linked to the C-terminus of the first Fc polypeptide.
- the anti- FR ⁇ 2L16 antigen-binding domain is in scFv format. In an alternate embodiment, the anti- FR ⁇ 2L16 antigen-binding domain is in scFv format and comprises one or more amino acid modifications to improve its biophysical properties.
- the 4-1BB x TAA antibody construct comprises a first 4-1BB antigen-binding domain linked to the N-terminus of a first Fc polypeptide, a second 4-1BB antigen-binding domain linked to the N-terminus of a second Fc polypeptide, a first TAA antigen-binding domain linked to the C-terminus of the first Fc polypeptide, and a second TAA linked to the C-terminus of the second Fc polypeptide.
- the first and second 4-1BB antigen-binding domains are both in the Fab format and the first and second TAA antigen-binding domain are both in the scFv format.
- Figure 2C provides a representation of an exemplary construct related to these embodiments.
- the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain linked to the N-terminus of one of the Fc polypeptides of the Fc construct, and a first TAA antigen-binding domain linked to the C-terminus of the same Fc polypeptide.
- the 4-1BB antigen-binding domain is in the Fab format and the TAA antigen-binding domain is in the scFv format.
- Figure 2D provides a representation of an exemplary construct related to these embodiments.
- the 4-1BB x TAA antibody construct comprises a first 4-1BB antigen-binding domain linked to the N- terminus of a first Fc polypeptide, a second 4-1BB antigen-binding domain linked to the N- terminus of a second Fc polypeptide, and a TAA antigen-binding domain linked to the N- terminus of the VH domain of the first 4-1BB antigen-binding domain.
- the first and second 4-1BB antigen-binding domains are both in the Fab format and the TAA antigen-binding domain is in the scFv format.
- Figure 2E provides a representation of an exemplary construct related to these embodiments.
- the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain linked to the N-terminus of a first Fc polypeptide, and a TAA anti gen -binding domain linked to the N-terminus of the second Fc polypeptide.
- the 4-1BB antigen-binding domains are both in the Fab format and the TAA antigen-binding domain is in the scFv format.
- Figure 2F provides a representation of an exemplary construct related to these embodiments.
- the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain linked to the N-terminus of one of the Fc polypeptides of the Fc construct and a TAA antigen-binding domain linked to the N- terminus of the VH region of the 4-1BB antigen-binding domain.
- the 4-1BB antigen-binding domain is in the Fab format and the TAA antigen-binding domain is in the scFv format.
- Figure 2G provides a representation of an exemplary construct related to these embodiments.
- the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain linked to the N-terminus of one of the Fc polypeptides of the Fc construct, a TAA antigen-binding domain linked to the C- terminus of the same Fc polypeptide, and a TAA antigen-binding domain linked to the C- terminus of the second Fc polypeptide.
- the 4-1BB antigen-binding domain is in the Fab format and the TAA antigen-binding domains are in the scFv format.
- Figure 2G provides a representation of an exemplary construct related to these embodiments.
- the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain linked to the N-terminus of one of the Fc polypeptides of the Fc construct, and a TAA antigen-binding domain linked to the C-terminus of the second Fc polypeptide.
- the 4-1BB antigen- binding domain is in the Fab format and the TAA antigen-binding domain is in the scFv format.
- the 4-1BB x TAA antibody construct comprises a 4-1BB- binding domain that is a 4-1BB ligand, the 4-1BB ligand linked to the C-terminus of one of the Fc polypeptides of an Fc construct, and a TAA antigen-binding domain that is in a Fab format, linked to the N-terminus of the other Fc polypeptide of the Fc construct.
- the 4-1BB x TAA antibody constructs provided herein can bind 4-1BB and a TAA with a range of affinities.
- the affinity or avidity of an antibody for an antigen can be determined experimentally using methods known in the art (see, for example, Berzofsky, et al, “Antibody-Antigen Interactions,” In Fundamental Immunology, Paul, W. E., Ed., Raven Press: New York, N.Y. (1984); Kuby, Janis Immunology, W.H. Freeman and Company: New York, N.Y. (1992); and methods described herein).
- the measured affinity of a particular antibody-antigen interaction can vary if measured under different conditions (e.g., salt concentration, pH).
- measurements of affinity and other antigen-binding parameters are preferably made with standardized solutions of antibody and antigen, and a standardized buffer, such as the buffer described herein.
- the affinity, KD IS a ratio of k on /k off .
- a K D in the micromolar range is considered low affinity for monospecific bivalent antibodies.
- a K D in the picomolar range is considered high affinity for monospecific bivalent antibodies.
- the affinity of an antibody measured as a monovalent binder is generally lower than that measured as a bivalent binder.
- the 4- 1 BB x TAA antibody construct comprises a 4- 1 BB antigen-binding domain that has an KD for human 4-1BB between about 15nM and 100nM, about 15nM and 200nM, or about 15nM and 500nM, between about 100pM and I ⁇ M, measured as a monovalent binder.
- the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain that has an KD for human 4-1BB between about InM and about 100OnM, or between about 10nM to about 500nM, or between about 20nM and about 400nM measured as a monovalent binder.
- the 4-1BB x TAA antibody construct comprises a TAA antigen-binding domain having a KD for the TAA of between about O.lnM to about 50nM, or about InM to about 20nM, or about InM to about 10nM.
- the KD may be measured by a number of known methods, for example SPR, as described elsewhere herein.
- the term “about” means ⁇ 10% of the value for KD identified in each range.
- the 4-1BB x TAA antibody construct binds to one or more TAA-expressing cell lines as determined by for example, ELISA, BiaCoreTM, and/or flow cytometry, or as described in the Examples.
- the TAA-expressing cell line is an ovarian adenocarcinoma cell line, such as, for example, IGROV1, SKOV3, or OVCAR3.
- the TAA-expressing cell line is a lung carcinoma cell line.
- the lung carcinoma cell line is a lung squamous cell line such as H226; or a lung adenocarcinoma cell line such as H441, HCC827, H1573, H1975, or H1563; or a lung carcinoma cell line such as H1299, or a lung large cell carcinoma such as H661.
- the TAA-expressing cell line is a HER2-expressing cell line such as SKBr3, a FR ⁇ -expressing cell line, a LIV-l-expressing cell line, an NaPi2b-expressing cell line, or a mesothelin-expressing cell line.
- the 4-1BB x TAA antibody construct may be able to stimulate 4-1BB activity in T cells as measured by cytokine production, in the presence of TAA expressing cells.
- the TAA-expressing cell expresses the TAA on the cell surface at greater than about 500,000 molecules per cell, as measured by quantitative flow cytometry or other quantitative method.
- the TAA-expressing cell expresses the TAA on the cell surface at greater than about 300,000 molecules per cell, as measured by quantitative flow cytometry or other quantitative method.
- the TAA-expressing cell expresses the TAA on the cell surface at greater than about 100,000 molecules per cell, as measured by quantitative flow cytometry or other quantitative method.
- the TAA-expressing cell expresses the TAA on the cell surface at greater than about 50,000 molecules per cell, as measured by quantitative flow cytometry or other quantitative method. In some embodiments, the TAA-expressing cell expresses the TAA on the cell surface at between about 100,000 and 500,000 molecules per cell, as measured by quantitative flow cytometry or other quantitative method. In some embodiments, the TAA- expressing cell expresses the TAA on the cell surface at between about 50,000 and 500,000 molecules per cell, as measured by quantitative flow cytometry or other quantitative method.
- the 4-1BB x TAA antibody construct binds to 4-1BB- expressing cells as determined by the methods described above.
- the 4- lBB-expressing cells are primary T, NK or NKT cells, activated primary T, NK or NKT cells, regulatory T cells, or T, NKT or NKT cells extracted from tumours
- the 4-1BB x TAA antibody constructs described herein may be capable of stimulating 4-1BB signalling in 4-1BB expressing cells. Methods of testing for 4-1BB activity are known in the art.
- an NF-KB reporter gene assay as described in the examples may be used to assess the ability of the 4-1BB x TAA antibody constructs to promote NF-KB activation and translocation to the nucleus, subsequently driving reporter gene expression.
- a primary T cell coculture assay as described in the examples may be employed to assess the ability of the 4-1BB x TAA antibody constructs to stimulate T cell activation by measuring the increase or decrease in the production of a cytokine (such as IL-2, IL-4, IL-5, IL-6, IL-9, IL-10, IL-12, IL-13, IL-15, IL-21, IL-22, IL-35, IFN-g, TNF-a, TGF-b), increase or decrease in the expression of chemokine receptors (CXCR3, CXCR5, CXCR6, CCR1, CCR2, CCR4, CCR5, CCR7, CCR8, CCR9, CCR10), increase or decrease in expression of key transcription factors (Tbet, GATA
- Activity in the primary T cell assay could also be assessed by examining increase or decrease in total cellular DNA contents (by measuring incorporation of 3 H-thymidine, bromodeoxyuridine or analogous trackers) or by increase or decrease in levels of a tracking dye which is able to determine number of divisions in assays where the cells are labelled with the dye (CFDA-SE, Cell Tracker Violet, PKH26).
- CFDA-SE Cell Tracker Violet
- the present disclosure further provides antibody constructs or antigen-binding fragments thereof that specifically bind to 4-1BB ECD (4-1BB antibody constructs).
- these 4-1BB antibody constructs comprise VH and VL sequences as set forth in Tables 13 and 14, and the CDR sequences of these VH and VL sequences can be found in Table 18.
- the 4-1BB antibody construct is capable of agonizing 4- 1BB activity as described elsewhere herein.
- the 4-1BB antibody construct binds to any one of CRD1, CRD2, CRD3, or CDR4 of human 4-1BB.
- a 4-1BB antibody construct or antigen-binding fragment thereof comprises a heavy chain variable sequence comprising three heavy chain CDRs and a light chain variable sequence comprising three light chain CDRs, wherein the heavy chain CDRs and the light chain CDRs are from any one of antibodies 1G1, 1B2, 1C3, 1C8, 2A7, 2E8, 2H9, 3D7, 3H1, 3E7, 3G4, 4B11, 4E6, 4F9, 4G10, 5E2, 5G8, or 6B3 and the 4-1BB antibody construct binds to human 4-1BB.
- the 4-1BB antibody construct or antigen-binding fragment comprises a heavy chain variable (VH) sequence comprising three CDRs and a light chain variable (VL) sequence comprising three CDRs, wherein the heavy chain CDRs and the light chain CDRs are from any one of antibodies 1G1, 1C3, 1C8, 2E8, 3E7, 4E6, 5G8, or 6B3, and the 4-1BB antibody construct binds to human 4- 1BB.
- VH heavy chain variable
- VL light chain variable
- the 4-1BB antibody construct comprises VH and VL sequences that are human or humanized.
- the 4-1BB antibody construct comprises a VH sequence and a VL sequence having at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% sequence identity to the VH and VL sequences of any one of variants v28726, v28727, V28728, v28730, v28700, v28704, v28705, v28706, v28711, v28712, v28713, v28696, V28697, v28698, v28701, v28702, v28703, v28707, v28683, v28684, v28685, v28686, V28687, v28688, v28689, v28690, v28691, v28692, v28694, or v28695.
- the anti-4-1BB CDR, VH and VL sequences may be used to construct various formats of antibody constructs as is known in the art. For example, these sequences may be used to construct Fab fragments or scFvs, which may be linked to a scaffold such as an Fc or other scaffolds as described herein. Exemplary formats for antibody constructs comprising these CDR, VH and VL sequences are depicted in Figure 1.
- the antibody constructs may be monovalent, bivalent or multivalent. In some embodiments, the antibody constructs are monospecific. In some embodiments, the antibody constructs are monospecific and in the naturally occurring format (FSA).
- anti-4-1BB VH and VL sequences as set forth in Tables 13, 14 and the anti- 4-1BB CDR sequences found in Table 18 may further be used in the construction of bispecific or multispecific antibodies, such as the 4-1BB x TAA antibody constructs described here, or other antibody constructs comprising at least one antigen-binding domain that binds to the ECD of 4-1BB.
- the 4-1BB antibody constructs in monovalent form bind human 4-1BB with a KD for 4-1BB between about 15nM and 100nM, about 15nM and 200nM, or about 15nM and 500nM, between about 100pM and 1 ⁇ M.
- the 4-1BB antibody construct in monovalent form comprises a 4-1BB antigen-binding domain that has an KD for human 4-1BB between about InM and about 1000nM, or between about 10nM to about 500nM, or between about 20nM and about 400nM.
- the KD may be measured by a number of known methods, for example SPR, as described elsewhere herein.
- the term “about” means ⁇ 10% of the value for KD identified in each range. In a related embodiment, the term “about” means ⁇ 20% of the value for KD as measured by SPR.
- the present disclosure further provides antibody constructs or antigen-binding fragments thereof that specifically bind to FR ⁇ (FR ⁇ antibody constructs).
- FR ⁇ antibody constructs comprise VH and VL sequences as set forth in Tables 17, 20, and 48 and the CDR sequences of these VH and VL sequences can be found in Tables 18 and 47.
- the FR ⁇ antibody constructs bind to human FR ⁇ .
- the FR ⁇ antibody constructs comprise a heavy chain variable sequence comprising three heavy chain CDRs and a light chain comprising three light chain CDRs, wherein the heavy chain CDRs and the light chain CDRs are from antibody 8K22 or antibody 1H06.
- the FR ⁇ antibody constructs comprise a heavy chain variable sequence comprising three heavy chain CDRs and a light chain comprising three light chain CDRs, wherein the heavy chain CDRs and the light chain CDRs are from antibody 2L16.
- the FR ⁇ antibody constructs comprise VH and VL sequences that are human or humanized.
- the FR ⁇ antibody construct comprises a VH sequence and a VL sequence having at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% sequence identity to the VH and VL sequences of any one of variants 23794, 23795, 23796, 23797, 23798, 23799, 23800, 23801, 23802, 23803, 23804, 23805, 23806, 23807, 23808, 23809, 23810, 23811, 23812, 23813, 23814, 23815, 23816, 23817, or 23818, derived from the 8K22 antibody.
- the FR ⁇ antibody constructs comprise humanized VH and VL sequences comprising the heavy chain CDRs and the light chain CDRs of antibody 1H06.
- the FR ⁇ antibody construct comprises a VH sequence and a VL sequence having at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% sequence identity to the VH and VL sequences as set forth in SEQ ID NOs:804 and 805, in SEQ ID NOs:806 and 805, in SEQ ID NOs:807 and 805, or in SEQ ID NOs:808 and 805.
- humanized FR ⁇ antibody constructs comprise a humanized FR ⁇ Fab domain that is more stable that than of the parental Fab from which the humanized Fab domain is derived.
- the humanized FR ⁇ Fab domain can exhibit a Tm that is up to 10°C higher than that of the parental Fab.
- the humanized FR ⁇ Fab domain can exhibit a Tm that is up to 5°C higher than that of the parental Fab.
- the FR ⁇ antibody construct has a binding affinity or KD for human FR ⁇ ranging from 100pM to 100nM. In some embodiments, the FR ⁇ antibody construct has a binding affinity or KD for human FR ⁇ ranging from 10pM to 100nM. In related embodiments, the FR ⁇ antibody construct has a KD for human FR ⁇ ranging from InM to 50nM. In additional related embodiments, the affinity of the FR ⁇ antibody constructs for human FR ⁇ is measured by Bio-layer interferometry (BLI).
- BBI Bio-layer interferometry
- These anti-FR ⁇ CDR, VH and VL sequences described in Tables 17, 18, 20, 47 and 48 may be used to construct various formats of antibody constructs as is known in the art. For example, these sequences may be used to construct Fab fragments or scFvs, which may be linked to a scaffold such as an Fc or other scaffold as described herein. Exemplary formats for antibody constructs comprising these CDR, VH and VL sequences are depicted in Figure 1.
- the antibody constructs may be monovalent, bivalent or multivalent. In some embodiments, the antibody constructs are monospecific. In some embodiments, the antibody constructs are monospecific and in the naturally occurring format (FSA).
- anti-FR ⁇ VH and VL sequences as set forth in Tables 17, 20, 48 and the anti-FR ⁇ CDR sequences found in Table 18 and Table 47 may further be used in the construction of bispecific or multispecific antibodies, such as the 4-1BB x FR ⁇ antibody constructs described here, or other antibody constructs comprising at least one antigen-binding domain that binds to the FR ⁇ .
- FR ⁇ antibody constructs described herein may be prepared, tested and used as described elsewhere herein.
- the 4-1BB x TAA antibody constructs, 4-1BB x FR ⁇ antibody constructs, FR ⁇ antibody constructs and 4-1BB antibody constructs described herein may be produced using recombinant methods and compositions, e.g., as described in U.S. Patent No. 4,816,567. This method and other methods for producing these constructs are described as follows.
- nucleic acids may encode the amino acid sequences corresponding to the 4-1BB x TAA antibody constructs or the 4-1BB antibody constructs.
- the 4-1BB x TAA antibody construct comprises two different Fabs
- One such technology is Cross-Mab in which Fabs binding to two different targets are fused to an Fc. CL and CH1 domains and VH and VL domains are switched, e.g., CH1 is fused in-line with VL, while CL is fused in-line with VH.
- nucleic acid encoding the antibody constructs described herein relate to one or more vectors (e.g., expression vectors) comprising nucleic acid encoding the antibody constructs described herein.
- the nucleic acid encoding the antibody construct is included in a multi cistronic vector.
- each polypeptide chain of the antibody construct is encoded by a separate vector. It is further contemplated that combinations of vectors may comprise nucleic acid encoding a single antibody construct.
- a host cell comprises (e.g., has been transformed with): (1) a vector comprising a nucleic acid that encodes an amino acid sequence comprising the VL of the antigen-binding domain and an amino acid sequence comprising the VH of the antigen-binding domain, or (2) a first vector comprising a nucleic acid that encodes an amino acid sequence comprising the VL of the antigen-binding domain and a second vector comprising a nucleic acid that encodes an amino acid sequence comprising the VH of the antigen-binding domain.
- the host cell is eukaryotic, e.g. a Chinese Hamster Ovary (CHO) cell, or human embryonic kidney (HEK) cell, or lymphoid cell (e.g., Y0, NSO, Sp20 cell).
- CHO Chinese Hamster Ovary
- HEK human embryonic kidney
- lymphoid cell e.g., Y0, NSO, Sp20 cell.
- Certain embodiments relate to a method of making an antibody construct, wherein the method comprises culturing a host cell comprising nucleic acid encoding the antibody construct, as described above, under conditions suitable for expression of the antibody construct, and optionally recovering the antibody construct from the host cell (or host cell culture medium).
- nucleic acid encoding an antibody construct is isolated and inserted into one or more vectors for further cloning and/or expression in a host cell.
- nucleic acid may be readily isolated and sequenced using conventional procedures (e.g., by using oligonucleotide probes that are capable of binding specifically to genes encoding the heavy and light chains of the antibody construct).
- substantially purified refers to a construct described herein, or variant thereof, that may be substantially or essentially free of components that normally accompany or interact with the protein as found in its naturally occurring environment, i.e. a native cell, or host cell in the case of recombinantly produced construct.
- a construct that is substantially free of cellular material includes preparations of protein having less than about 30%, less than about 25%, less than about 20%, less than about 15%, less than about 10%, less than about 5%, less than about 4%, less than about 3%, less than about 2%, or less than about 1% (by dry weight) of contaminating protein.
- the protein in certain embodiments is present at about 30%, about 25%, about 20%, about 15%, about 10%, about 5%, about 4%, about 3%, about 2%, or about 1% or less of the dry weight of the cells.
- the protein in certain embodiments, is present in the culture medium at about 5 g/L, about 4 g/L, about 3 g/L, about 2 g/L, about 1 g/L, about 750 mg/L, about 500 mg/L, about 250 mg/L, about 100 mg/L, about 50 mg/L, about 10 mg/L, or about 1 mg/L or less of the dry weight of the cells.
- the term “substantially purified” as applied to a construct comprising a heteromultimer Fc and produced by the methods described herein has a purity level of at least about 30%, at least about 35%, at least about 40%, at least about 45%, at least about 50%, at least about 55%, at least about 60%, at least about 65%, at least about 70%, specifically, a purity level of at least about 75%, 80%, 85%, and more specifically, a purity level of at least about 90%, a purity level of at least about 95%, a purity level of at least about 99% or greater as determined by appropriate methods such as SDS/PAGE analysis, RP- HPLC, SEC, and capillary electrophoresis.
- Suitable host cells for cloning or expression of antibody construct-encoding vectors include prokaryotic or eukaryotic cells described herein.
- a “recombinant host cell” or “host cell” refers to a cell that includes an exogenous polynucleotide, regardless of the method used for insertion, for example, direct uptake, transduction, f-mating, or other methods known in the art to create recombinant host cells.
- the exogenous polynucleotide may be maintained as anonintegrated vector, for example, a plasmid, or alternatively, may be integrated into the host genome.
- the term “eukaryote” refers to organisms belonging to the phylogenetic domain Eucarya such as animals (including but not limited to, mammals, insects, reptiles, birds, etc.), cibates, plants (including but not limited to, monocots, dicots, algae, etc.), fungi, yeasts, flagellates, microsporidia, protists, and the like.
- prokaryote refers to prokaryotic organisms.
- a non-eukaryotic organism can belong to the Eubacteria (including but not limited to,
- Archaea including but not limited to, Methanococcus jannaschii, Methanobacterium thermoautotrophicum, Halobacterium such as Haloferax volcanii and Halobacterium species NRC-1, Archaeoglobus fulgidus
- an antibody construct may be produced in bacteria, in particular when glycosylation and Fc effector function are not needed.
- antigen-binding construct fragments and polypeptides see, e.g., U.S. Pat. Nos. 5,648,237, 5,789,199, and 5,840,523. (See also Charlton, Methods in Molecular Biology Vol. 248 (B.K.C. Lo, ed., Humana Press, Totowa, N.J., 2003), pp. 245-254, describing expression of antibody fragments in E. coli.)
- the antigen-binding construct may be isolated from the bacterial cell paste in a soluble fraction and can be further purified.
- eukaryotic microbes such as filamentous fungi or yeast are suitable cloning or expression hosts for Antibody construct-encoding vectors, including fungi and yeast strains whose glycosylation pathways have been “humanized,” resulting in the production of an antigen-binding construct with a partially or fully human glycosylation pattern. See Gemgross, Nat. Biotech. 22:1409-1414 (2004), and Li et al.. Nat. Biotech. 24:210-215 (2006).
- Suitable host cells for the expression of glycosylated antigen-binding constructs are also derived from multicellular organisms (invertebrates and vertebrates). Examples of invertebrate cells include plant and insect cells. Numerous baculoviral strains have been identified which may be used in conjunction with insect cells, particularly for transfection of Spodoptera frugiperda cells.
- Plant cell cultures can also be utilized as hosts. See, e.g., U.S. Pat. Nos. 5,959,177, 6,040,498, 6,420,548, 7,125,978, and 6,417,429 (describing PLANTIBODIESTM technology for producing antigen-binding constructs in transgenic plants).
- Vertebrate cells may also be used as hosts.
- mammalian cell lines that are adapted to grow in suspension may be useful.
- useful mammalian host cell lines are monkey kidney CV1 line transformed by SV40 (COS-7); human embryonic kidney line (293 or 293 cells as described, e.g., in Graham et al., J. Gen Virol. 36:59 (1977)); baby hamster kidney cells (BHK); mouse sertoli cells (TM4 cells as described, e.g., in Mather, Biol. Reprod.
- monkey kidney cells (CV1); African green monkey kidney cells (VERO-76); human cervical carcinoma cells (HELA); canine kidney cells (MDCK; buffalo rat liver cells (BRL 3 A); human lung cells (W138); human liver cells (Hep G2); mouse mammary tumor (MMT 060562); TRI cells, as described, e.g., in Mather et al ., Annals N.Y. Acad. Sci. 383:44-68 (1982); MRC 5 cells; and FS4 cells.
- Other useful mammalian host cell lines include Chinese hamster ovary (CHO) cells, including DHFR CHO cells (Urlaub et al, Proc. Natl. Acad. Sci.
- the antibody constructs described herein are produced in stable mammalian cells, by a method comprising: transfecting at least one stable mammalian cell with: nucleic acid encoding the antibody construct, in a predetermined ratio; and expressing the nucleic acid in the at least one mammalian cell.
- the predetermined ratio of nucleic acid is determined in transient transfection experiments to determine the relative ratio of input nucleic acids that results in the highest percentage of the antigen-binding construct in the expressed product.
- the expression product of the stable mammalian cell comprises a larger percentage of the desired glycosylated antigen-binding construct as compared to the monomeric heavy or light chain polypeptides, or other antibodies.
- the antibody constructs can be purified or isolated after expression.
- Proteins may be isolated or purified in a variety of ways known to those skilled in the art. Standard purification methods include chromatographic techniques, including ion exchange, hydrophobic interaction, affinity, sizing or gel filtration, and reversed-phase, carried out at atmospheric pressure or at high pressure using systems such as FPLC and HPLC. Purification methods also include electrophoretic, immunological, precipitation, dialysis, and chromatofocusing techniques. Ultrafiltration and diafiltration techniques, in conjunction with protein concentration, are also useful. As is well known in the art, a variety of natural proteins bind Fc and antibodies, and these proteins can used for purification of antigen-binding constructs.
- the bacterial proteins A and G bind to the Fc region.
- the bacterial protein L binds to the Fab region of some antibodies.
- Purification can often be enabled by a particular fusion partner.
- antibodies may be purified using glutathione resin if a GST fusion is employed, Ni +2 affinity chromatography if a His-tag is employed, or immobilized anti-flag antibody if a flag-tag is used.
- suitable purification techniques see, e.g. incorporated entirely by reference Protein Purification: Principles and Practice, 3 rd Ed., Scopes, Springer-Verlag, NY, 1994, incorporated entirely by reference.
- the degree of purification necessary will vary depending on the use of the antigen-binding constructs. In some instances, no purification is necessary.
- the antibody constructs may be purified using Anion Exchange Chromatography including, but not limited to, chromatography on Q-sepharose, DEAE sepharose, poros HQ, poros DEAF, Toyopearl Q, Toyopearl QAE, Toyopearl DEAE, Resource/Source Q and DEAE, Fractogel Q and DEAE columns.
- Anion Exchange Chromatography including, but not limited to, chromatography on Q-sepharose, DEAE sepharose, poros HQ, poros DEAF, Toyopearl Q, Toyopearl QAE, Toyopearl DEAE, Resource/Source Q and DEAE, Fractogel Q and DEAE columns.
- the antibody constructs are purified using Cation Exchange Chromatography including, but not limited to, SP-sepharose, CM sepharose, poros HS, poros CM, Toyopearl SP, Toyopearl CM, Resource/Source S and CM, Fractogel S and CM columns and their equivalents and comparables.
- Cation Exchange Chromatography including, but not limited to, SP-sepharose, CM sepharose, poros HS, poros CM, Toyopearl SP, Toyopearl CM, Resource/Source S and CM, Fractogel S and CM columns and their equivalents and comparables.
- the antibody constructs are expressed using cell-free translation or expression systems. Suitable systems are known in the art, such as for example the method described by Stech et al, in Nature Scientific Reports 7:12030, or those described by Gregorio et al, in Methods Protoc. 20192:24.
- the antibody constructs can be chemically synthesized using techniques known in the art (e.g., see Creighton, 1983, Proteins: Structures and Molecular Principles, W. H. Freeman & Co., N.Y and Hunkapiller et al, Nature, 310:105-111 (1984)).
- a polypeptide corresponding to a fragment of a polypeptide can be synthesized by use of a peptide synthesizer.
- nonclassical amino acids or chemical amino acid analogs can be introduced as a substitution or addition into the polypeptide sequence.
- Non-classical amino acids include, but are not limited to, to the D-isomers of the common amino acids, 2,4diaminobutyric acid, alpha-amino isobutyric acid, 4-aminobutyric acid, Abu, 2-amino butyric acid, g-Abu, eAhx, 6-amino hexanoic acid, Aib, 2-amino isobutyric acid, 3-amino propionic acid, ornithine, norleucine, norvaline, hydroxyproline, sarcosine, citrulline, homocitrulline, cysteic acid, t-butylglycine, t-butylalanine, phenylglycine, cyclohexylalanine, b-alanine, fluoro-amino acids, designer amino acids such as a-methyl amino acids, C a-methyl amino acids, N a-methyl amino acids, and amino acid analogs in general. Furthermore, the
- the antibody constructs described herein are differentially modified during or after translation.
- modified refers to any changes made to a given polypeptide, such as changes to the length of the polypeptide, the amino acid sequence, chemical structure, co-translational modification, or post-translational modification of a polypeptide.
- post-translationally modified refers to any modification of a natural or non-natural amino acid that occurs to such an amino acid after it has been incorporated into a polypeptide chain.
- the term encompasses, by way of example only, co-translational in vivo modifications, co-translational in vitro modifications (such as in a cell-free translation system), post-translational in vivo modifications, and post-translational in vitro modifications.
- the antibody constructs may comprise a modification that is: glycosylation, acetylation, phosphorylation, amidation, derivatization by known protecting/blocking groups, proteolytic cleavage or linkage to an antibody molecule or antigen- binding construct or other cellular ligand, or a combination of these modifications.
- the antibody construct is chemically modified by known techniques, including but not limited, to specific chemical cleavage by cyanogen bromide, trypsin, chymotrypsin, papain, V8 protease, NaBFLq acetylation, formylation, oxidation, reduction; and metabolic synthesis in the presence of tunicamycin.
- antigen-binding constructs include, for example, N-linked or O-linked carbohydrate chains, processing of N- terminal or C-terminal ends), attachment of chemical moieties to the amino acid backbone, chemical modifications of N-linked or O-linked carbohydrate chains, and addition or deletion of an N-terminal methionine residue as a result of procaryotic host cell expression.
- the antigen- binding constructs described herein are modified with a detectable label, such as an enzymatic, fluorescent, isotopic or affinity label to allow for detection and isolation of the protein.
- examples of suitable enzyme labels include horseradish peroxidase, alkaline phosphatase, beta-galactosidase, or acetylcholinesterase;
- examples of suitable prosthetic group complexes include streptavidin biotin and avidin/biotin;
- examples of suitable fluorescent materials include umbelliferone, fluorescein, fluorescein isothiocyanate, rhodamine, dichlorotriazinylamine fluorescein, dansyl chloride or phycoerythrin;
- an example of a luminescent material includes luminol;
- examples of bioluminescent materials include luciferase, luciferin, and aequorin;
- examples of suitable radioactive material include iodine, carbon, sulfur, tritium, indium, technetium, thallium, gallium, palladium, molybdenum, xenon, fluorine.
- antigen-binding constructs described herein may be attached to macrocyclic chelators that associate with radiometal ions.
- the antibody constructs described herein may be modified by either natural processes, such as post-translational processing, or by chemical modification techniques which are well known in the art.
- the same type of modification may be present in the same or varying degrees at several sites in a given polypeptide.
- polypeptides from antigen-binding constructs described herein are branched, for example, as a result of ubiquitination, and in some embodiments are cyclic, with or without branching. Cyclic, branched, and branched cyclic polypeptides are a result from post-translation natural processes or made by synthetic methods.
- Modifications include acetylation, acylation, ADP-ribosylation, amidation, covalent attachment of flavin, covalent attachment of a heme moiety, covalent attachment of a nucleotide or nucleotide derivative, covalent attachment of a lipid or lipid derivative, covalent attachment of phosphotidylinositol, cross-linking, cyclization, disulfide bond formation, demethylation, formation of covalent cross-links, formation of cysteine, formation of pyroglutamate, formylation, gamma-carboxylation, glycosylation, GPI anchor formation, hydroxylation, iodination, methylation, myristylation, oxidation, pegylation, proteolytic processing, phosphorylation, prenylation, racemization, selenoylation, sulfation, transfer-RNA mediated addition of amino acids to proteins such as arginylation, and ubiquitination.
- antigen-binding constructs described herein may be attached to solid supports, which are particularly useful for immunoassays or purification of polypeptides that are bound by, that bind to, or associate with proteins described herein.
- solid supports include, but are not limited to, glass, cellulose, polyacrylamide, nylon, polystyrene, polyvinyl chloride or polypropylene.
- the antibody constructs described herein can be further modified (i.e., by the covalent attachment of various types of molecules) such that covalent attachment does not interfere with or affect the ability of the 4-1BB x TAA antibody construct to bind to 4-1BB or to the TAA, or affect the ability of the 4-1BB antibody construct to bind to 4-1BB, or negatively affect the stability of these antibody constructs.
- the 4-1BB antibody constructs and FR ⁇ antibody constructs may be modified by covalent attachment such that their stability or ability to bind to their target is not significantly affected.
- Such modifications include, for example, but not by way of limitation, glycosylation, acetylation, pegylation, phosphorylation, amidation, derivatization by known protecting/blocking groups, proteolytic cleavage, linkage to a cellular ligand or other protein, etc. Any of numerous chemical modifications can be carried out by known techniques, including, but not limited to, specific chemical cleavage, acetylation, formylation, metabolic synthesis of tunicamycin, etc.
- Certain embodiments contemplate conjugation of the antibody construct to a drug moiety, for example, a toxin, a chemotherapeutic agent, an immune modulator, or a radioisotope.
- a drug moiety for example, a toxin, a chemotherapeutic agent, an immune modulator, or a radioisotope.
- ADCs antibody drug conjugates
- Examples include methods described in U.S. Patent No. 8,624,003 (pot method), U.S. Patent No. 8,163,888 (one-step), and U.S. Patent No. 5,208,020 (two-step method). See also, Antibody-Drug Conjugates, Series: Methods in Molecular Biology, Laurent Ducry (Ed.), Humana Press, 2013.
- the drug moiety of the ADCs is typically a compound or moiety having a cytostatic or cytotoxic effect.
- the drug comprised by the ADC is a cytotoxic agent.
- cytotoxic agent refers to a substance that inhibits or prevents the function of cells and/or causes destruction of cells.
- radioactive isotopes for example, 211 At, 131 1, 125 I, 90 Y, 186 Re, 188 Re, 153 Sm, 212 Bi, 32 P and 177 LU
- chemotherapeutic agents for example, 211 At, 131 1, 125 I, 90 Y, 186 Re, 188 Re, 153 Sm, 212 Bi, 32 P and 177 LU
- chemotherapeutic agents for example, 211 At, 131 1, 125 I, 90 Y, 186 Re, 188 Re, 153 Sm, 212 Bi, 32 P and 177 LU
- chemotherapeutic agents for example, 211 At, 131 1, 125 I, 90 Y, 186 Re, 188 Re, 153 Sm, 212 Bi, 32 P and 177 LU
- toxins such as small molecule toxins or enzymatically active toxins of bacterial, fungal, plant or animal origin, including fragments and/or variants thereof.
- toxins may also be considered as chemotherapeut
- toxins include, but are not limited to, maytansines, auristatins, dolastatins, tubulysins, hemiasterlins, calicheamicins, duocarmycins, pyrrolobenzodiazapenes, amatoxins, camptothecins, Pseudomonas exotoxin (PE), diphtheria toxin (DT), deglycosylated ricin A (dgA) and gelonin.
- maytansines auristatins, dolastatins, tubulysins, hemiasterlins, calicheamicins, duocarmycins, pyrrolobenzodiazapenes, amatoxins, camptothecins, Pseudomonas exotoxin (PE), diphtheria toxin (DT), deglycosylated ricin A (dgA) and gelonin.
- PE Pseudomonas exotoxi
- the drug comprised by the ADCs is a microtubule disrupting agent or a DNA modifying agent.
- toxins that are microtubule disrupting agents include, but are not limited to, maytansines, auristatins, dolastatins, tubulysins, hemiasterlins, and analogs and derivatives thereof.
- toxins that are DNA modifying agents include, but are not limited to, calicheamicins and other enediyne antibiotics, duocarmycins, pyrrolobenzodiazapenes, amatoxins, camptothecins, and analogs and derivatives thereof.
- Exemplary maytansinoids include DM1 (mertansine, emtansine, N2'-deacetyl- N 2 '-(3-mercapto-l -oxopropyl)maytansine), DM3 (N 2 '-deacetyl-N 2 '-(4-mercapto- 1 - oxopentyl)maytansine) and DM4 (ravtansine, soravtansine, N 2 '-deacetyl-N 2 '-(4-methyl-4- mercapto-l-oxopentyl)maytansine) (see U.S. Patent Application Publication No. US 2009/0202536).
- Exemplary dolastatins and auristatins include auristatin E (also known in the art as a derivative of dolastatin-10) and auristatin F, and analogs and derivatives thereof.
- Auristatin analogs include, for example, esters formed between auristatin E and a keto acid.
- auristatin E can be reacted with paraacetyl benzoic acid or benzoylvaleric acid to produce auristatin EB (AEB) and auristatin EVB (AEVB), respectively.
- auristatin F phenylenediamine AFP
- MMAF monomethylauristatin F
- MMAE monomethylauristatin E
- Exemplary hemiasterlins and hemiasterlin analogs and derivatives include those described in International Publication Nos. WO 1996/33211 and WO 2004/026293; U.S. Patent No. 7,579,323 (which describes the hemiasterlin analog, HTI-286) and International Publication No. WO 2014/144871.
- Exemplary calicheamycins and calicheamycin analogs and derivatives include those described in International Publication No. WO 2015/063680, and U.S. Patent Nos. 5,773,001; 5,714,586 and 5,770,701).
- duocarmycins and duocarmycin analogs and derivatives include naturally-occurring duocarmycins such as duocarmycins A, Bl, B2, C1, C2, D and SA, as well as CC-1065, and analogs and derivatives such as adozelesin, bizelesin and centanamycin.
- Other calicheamicin analogs and derivatives are described in U.S. Patent Nos. 4,912,227; 5,070,092; 5,084,468; 5,332,837; 5,641,780; 5,739,350 and 8,889,868.
- Exemplary pyrrolobenzodiazapenes include various PBD dimers such as those described in U.S. Patent Nos. 6,884,799; 7,049,311; 7,511,032; 7,528,126; 7,557,099 and 9,056,914, and in International Publication Nos. WO 2007/085930, WO 2009/016516, WO 2011/130598, WO 2011/130613 and WO 2011/130616, and U.S. Patent Application Publication No. US 2011/0256157.
- Exemplary amatoxins include a-Amanitin, b-Amanitin, g-Amanitin and e- Amanitin, and analogs and derivatives thereof.
- Various amatoxins and amatoxin analogues have been described (see, for example, European Patent No. EP 1 859 811, U.S. Patent No. 9,233,173 and International Publication No. WO 2014/043403).
- Exemplary camptothecins include irinotecan (CPT-11), SN-38 (7-ethyl- 10-hydroxy-camptothecin), 10-hydroxy camptothecin, topotecan, lurtotecan, 9- aminocamptothecin and 9-nitrocamptothecin.
- CPT analogs and derivatives include 7-butyl-10-amino-camptothecin and 7-butyl-9-amino-10,ll-methylenedioxy- camptothecin (see U.S. Patent Application Publication No. US 2005/0209263) and aniline containing derivatives of these compounds as described in Burke et al, 2009, Bioconj. Chem.
- the drug comprised by the ADC is a chemotherapeutic agent.
- the drug comprised by the ADC is an anthracycline, such as doxorubicin, epirubicin, idarubicin, daunorubicin (also known as daunomycin), nemorubicin or an analog or derivative thereof. Derivatization of daunorubicin and doxorubicin for conjugation to antibodies has been described (see, for example, Kratz et al, 2006, Current Med. Chem. 13:477-523, and U.S. Patent No. 6,630,579).
- Rapalogs are considered to be compounds that are structurally related to rapamycin that retain mTOR inhibiting activity and include, for example, esters, ethers, oximes, hydrazones, and hydroxylamines of rapamycin, as well as compounds in which functional groups on the rapamycin core structure have been modified, for example, by reduction or oxidation.
- Exemplary rapalogs include, but are not limited to, temsirolimus (CC1779), tacrolimus (FK-506), everolimus (RAD001), deforolimus (AP23573), AZD8055 (AstraZeneca), and OSI-027 (OSI).
- the selected drug may be conjugated to the antibody construct with or without a linker by any of a variety of methods known in the art.
- drugs are conjugated to cysteine or lysine residues in the antibody construct via a linker, which may be cleavable or non-cleavable.
- linker which may be cleavable or non-cleavable. Exemplary methods and linkers are provided in Antibody-Drug Conjugates, Series: Methods in Molecular Biology, Laurent Ducry (Ed.), Humana Press, 2013.
- the antibody construct may be expressed as fusion proteins comprising a tag to facilitate purification and/or testing etc.
- a tag is any added series of amino acids which are provided in a protein at either the C- terminus, the N-terminus, or internally that contributes to the identification or purification of the protein.
- Suitable tags include but are not limited to tags known to those skilled in the art to be useful in purification and/or testing such as albumin binding domain (ABD), His tag, FLAG tag, glutathione-s-transferase, hemagglutinin (HA) and maltose binding protein.
- Such tagged proteins can also be engineered to comprise a cleavage site, such as a thrombin, enterokinase or factor X cleavage site, for ease of removal of the tag before, during or after purification.
- a cleavage site such as a thrombin, enterokinase or factor X cleavage site
- antibodies to a specific antigen of interest may be generated by standard techniques and used as a basis for the preparation of antigen-binding domains of the 4-1BB x TAA antibody constructs, for example for preparing 4-1BB, FR ⁇ , NaPi2B, HER2, or mesothelin or LIV1 antigen-binding domains.
- an antibody to an antigen can be prepared by immunizing the purified antigen into rabbits, preparing serum from blood of the rabbits and absorbing the sera to a normal plasma fraction to produce an antibody specific to the antigen.
- Monoclonal antibody preparations to the antigen may be prepared by injecting the purified protein into mice, harvesting the spleen and lymph node cells, fusing these cells with mouse myeloma cells and using the resultant hybridoma cells to produce the monoclonal antibody. Both of these methods are well-known in the art. In some embodiments, antibodies resulting from these methods may be humanized as described elsewhere herein.
- human antibodies can be generated.
- transgenic animals e.g., mice
- transgenic animals e.g., mice
- transgenic animals e.g., mice
- phage display technology can be used to produce human antibodies and antibody fragments in vitro, from immunoglobulin variable (V) domain gene repertoires from unimmunized donors.
- V immunoglobulin variable
- Phage display can be performed in a variety of formats; for their review see, e.g., Johnson and Chiswell, 1993, Current Opinion in Structural Biology 3:564-571.
- Human antibodies may also be generated by in vitro activated B cells (see U.S. Pat. Nos. 5,567,610 and 5,229,275). Novel antibody sequences may also be generated de novo using platforms such as the HuTargTM platform (Innovative Targeting Solutions Inc., Vancouver Canada).
- the ability of the 4-1BB x TAA antibody constructs to bind to 4-1BB and the TAA can be tested according to methods known in the art including antigen-binding assays or cell binding assays.
- Antigen-binding assays are carried out by incubating the antibody construct with antigen (4-1BB or TAA), either purified, or in a mixture and assessing the amount of 4-1BB x TAA antibody construct bound to the antigen, compared to controls.
- the amount of 4-1BB x TAA antibody construct bound to the antigen can by assessed by ELISA, or SPR (surface plasmon resonance), for example.
- Cell binding assays are carried out by incubating the antibody construct with cells that express 4-1BB or the TAA of interest (such cells are commercially available).
- the amount of 4-1BB x TAA antibody construct bound to the cells can be assessed by flow cytometry, for example, and compared to binding observed in the presence of controls. Methods for carrying out these types of assays are well known in the art. Similar methods may be used to assess the ability of 4-1BB antibody constructs to bind to 4- 1BB. Likewise, the ability of FR ⁇ antibody constructs to bind to purified FR ⁇ or FR ⁇ expressed on cells may be determined.
- the 4-1BB x TAA antibody constructs or 4-1BB antibody constructs may also be tested to determine if they promote activation of cells expressing 4-1BB.
- Suitable assays include the co-culture assays described in the examples, such as the NF-icB-luciferase/4-1BB- expressing Jurkat cell assay, or the primary T cell co-culture assay. TAA expressing cell lines suitable for use in these assays are readily identified by one of skill in the art.
- a number of cell line may be used, for example but not limited to IGROV1, OVCAR3, OVKATE, NCI-H441, NCI-H661, NCI-H1975, or HCC827.
- These FR ⁇ -expressing cell lines can be divided into FR ⁇ high , FR ⁇ mid and FR ⁇ low based on numbers of receptor expressed in these cells as measured by binding of a reference antibody to these cells via, for example, quantitative flow cytometry experiments.
- FR ⁇ high cells may express greater than about 300,000 - 500,000 FR ⁇ molecules per cell, FR ⁇ mid between about 100,000 - 200,000 and about 300,000 - 500,000 FR ⁇ molecules per cell and FR ⁇ low below about 100,000 - 200,000 FR ⁇ molecules per cell.
- FR ⁇ neg cells are those where binding of a reference antibody to FR ⁇ cannot be detected by flow cytometry.
- In vivo efficacy of the 4-1BB x TAA antibody constructs, 4-1BB antibody constructs, or FR ⁇ antibody constructs may also be evaluated by standard techniques. For example, the effect of the antibody constructs on tumor growth can be examined in various tumor models.
- Suitable animal models are known in the art to test the ability of candidate therapies to treat cancers, such as, for example, breast cancers or gastric cancers. Some models are commercially available. Suitable models include syngeneic or xenograft models (see below).
- the construct to be tested is generally administered after the tumor has been established in the animal, but in some cases, the construct can be administered with the cell line. The volume of the tumor, survival of the animal and/or a response which may correlate with function is monitored in order to determine if the construct is able to treat the tumor.
- the construct may be administered intravenously (i.v.), intraperitoneally (i.p.) or subcutaneously (s.c.). Dosing schedules and amounts vary but can be readily determined by the skilled person.
- An exemplary dosage would be 10 mg/kg once weekly.
- Tumor growth can be monitored by standard procedures. For example, when labelled tumor cells have been used, tumor growth may be monitored by appropriate imaging techniques. For solid tumors, tumor size may also be measured by caliper.
- Other responses which may be indicative of efficacy of the construct may include increases or decreases in systemic or localized cytokine or chemokine responses (such as but not limited to IFN ⁇ , IL-2, TNFa, CXCL8, IP-10, RANTES), increases or decreases in the number of immune cells (such as T, NK, NKT, B, DCs, Macrophages, Neutrophils), increase or decrease of the expression of key surface, intracellular or nuclear proteins on or in either the immune cells (such as but not limited to PD1, Tim3, Lag3, 4-1BB, CD163, EOMES, TOX) or on the surface of the tumour (PDL1). It is further contemplated that these responses can also be assessed in in vitro assays such as the immune cell co-
- In vivo mouse tumour models may be syngeneic or xenograft models. Syngeneic models involve grafting a tumour from one mouse to another where the genetic background of the two mice is sufficiently close that the recipient mouse immune system does not reject the tumour (Teicher, BA Tumor models in cancer research, Springer 2011). This can be done either directly from mouse to mouse, or via a cell line that is stable in culture. The cell lines can be engineered using standard molecular biology techniques to express the TAA if they do not naturally, which enables control over expression levels. [00316] Xenograft tumour models involve the grafting of a tumour from another species (usually human) into a mouse.
- mice which are suitable for engraftment of human tumour cells are NSGTM, NOGTM and NRG mice, which have combined either Prkdc scid or Ragl -/- with IL2rg mutations on a NOD background (Morton et al, Cancer Research 2016;76:21 pp6153-6158). These mice can be implanted with human tumours, but lack an adaptive immune system.
- the human tumour cells can come from cells which are stable in cell culture (such as OVCAR3, HCC827, IGROV1 or H1975) or from patients which have had their tumours removed.
- the immune system can be then be recapitulated by addition of either PBMC, T cells or CD34 + HSC from human donors. These immune cells can then reconstitute the host with T cells to act as effectors during an experiment.
- the 4-1BB epitopes bound by the 4-1BB antibody constructs or the epitopes bound by the FR ⁇ antibody constructs described herein can be determined by standard competitive binding analysis (Fendly et al, Cancer Research 50: 1550-1558 (1990)).
- cross-blocking studies may be done on antibodies by direct fluorescence on intact cells engineered to express 4-1BB using suitable methods to quantitate fluorescence.
- Each test antibody is conjugated with fluorescein isothiocyanate (FITC), using established procedures (Wofsy et al, Selected Methods in Cellular Immunology, p. 287, Mishel and Schiigi (eds.) San Francisco: W.J. Freeman Co. (1980)).
- FITC fluorescein isothiocyanate
- Antibodies are considered to share an epitope if each blocked binding of the other by 40% or greater in comparison to an irrelevant antibody control and at the same antibody concentration. Using this assay, one of ordinary skill in the art can identify other antibodies that bind to the same epitope as those described herein. Deletion analysis may be conducted to identify the approximate location in the polypeptide sequence of 4-1BB of the antigenic epitopes. In a similar manner, the epitopes bound by the TAA antigen-binding domains of the 4-1BB x TAA antibody construct, or the FR ⁇ antibody construct may also be identified.
- compositions comprising an antibody construct described herein and a pharmaceutically acceptable carrier.
- pharmaceutically acceptable means approved by a regulatory agency of the Federal or a state government or listed in the U.S. Pharmacopeia or other generally recognized pharmacopeia for use in animals, and more particularly in humans.
- carrier refers to a diluent, adjuvant, excipient, vehicle, or combination thereof, with which the construct is administered.
- Such pharmaceutical carriers can be sterile liquids, such as water and oils, including those of petroleum, animal, vegetable or synthetic origin, such as peanut oil, soybean oil, mineral oil, sesame oil and the like.
- the carrier is a man-made carrier not found in nature.
- Water can be used as a carrier when the pharmaceutical composition is administered intravenously.
- Saline solutions and aqueous dextrose and glycerol solutions can also be employed as liquid carriers, particularly for injectable solutions.
- Suitable pharmaceutical excipients include starch, glucose, lactose, sucrose, gelatin, malt, rice, flour, chalk, silica gel, sodium stearate, glycerol monostearate, talc, sodium chloride, dried skim milk, glycerol, propylene, glycol, water, ethanol and the like.
- the composition if desired, can also contain minor amounts of wetting or emulsifying agents, or pH buffering agents. Examples of suitable pharmaceutical carriers are described in “Remington's Pharmaceutical Sciences” by E. W. Martin.
- compositions may be in the form of solutions, suspensions, emulsion, tablets, pills, capsules, powders, sustained-release formulations and the like.
- the composition may be formulated as a suppository, with traditional binders and carriers such as triglycerides.
- Oral formulations may include standard carriers such as pharmaceutical grades of mannitol, lactose, starch, magnesium stearate, sodium saccharine, cellulose, magnesium carbonate, and the like.
- compositions will contain a therapeutically effective amount of the antibody construct, together with a suitable amount of carrier so as to provide the form for proper administration to a patient.
- the formulation should suit the mode of administration.
- the composition comprising the antibody construct is formulated in accordance with routine procedures as a pharmaceutical composition adapted for intravenous administration to human beings.
- compositions for intravenous administration are solutions in sterile isotonic aqueous buffer.
- the composition may also include a solubilizing agent and a local anaesthetic such as lignocaine to ease pain at the site of the injection.
- the ingredients are supplied either separately or mixed together in unit dosage form, for example, as a dry lyophilized powder or water free concentrate in a hermetically sealed container such as an ampoule or sachette indicating the quantity of active agent.
- composition is to be administered by infusion, it can be dispensed with an infusion bottle containing sterile pharmaceutical grade water or saline.
- an ampoule of sterile water for injection or saline can be provided so that the ingredients may be mixed prior to administration.
- compositions described herein are formulated as neutral or salt forms.
- Pharmaceutically acceptable salts include those formed with anions such as those derived from hydrochloric, phosphoric, acetic, oxalic, tartaric acids, etc., and those formed with cations such as those derived from sodium, potassium, ammonium, calcium, ferric hydroxide isopropylamine, triethylamine, 2-ethylamino ethanol, histidine, procaine, and the like.
- a method of treating a cancer comprising administering to a subject in which such treatment, prevention or amelioration is desired, a 4- 1BB x TAA antibody construct described herein, in an amount effective to treat or ameliorate the cancer.
- a method of using the 4-1BB x TAA antibody construct in the preparation of a medicament for the treatment, prevention, or amelioration of cancer in a subject may be used for the treatment of cancer in a subject in need thereof.
- the 4-1BB antibody construct and FR ⁇ antibody constructs may also be used in the treatment of cancer as described below.
- the 4-1BB x TAA antibody construct, 4-1BB antibody construct, or FR ⁇ antibody construct may be used in a subject to treat, prevent or ameliorate a cancer selected from breast cancer, bladder cancer, colorectal cancer, head and neck cancer, liver cancer, lung cancer, ovarian cancer, pancreatic cancer, skin cancer, prostate cancer, kidney cancer or thyroid cancer.
- the 4-1BB x TAA antibody construct may be used to treat, prevent or ameliorate lung or ovarian cancers in a subject.
- the 4-1BB x TAA antibody construct may be used in the treatment of solid tumors.
- the construct may be used to treat, prevent or ameliorate lung or ovarian cancers in a subject.
- the construct may be used to treat, prevent or ameliorate lung cancer in a subject.
- the term “subject” refers to an animal, in some embodiments a mammal, which is the object of treatment, observation or experiment.
- An animal may be a human, a non -human primate, a companion animal (e.g., dogs, cats, and the like), farm animal (e.g., cows, sheep, pigs, horses, and the like) or a laboratory animal (e.g., rats, mice, guinea pigs, and the like).
- mammal as used herein includes but is not limited to humans, non- human primates, canines, felines, murines, bovines, equines, and porcines.
- Treatment refers to clinical intervention in an attempt to alter the natural course of the individual or cell being treated, and can be performed during the course of clinical pathology. Desirable effects of treatment include preventing recurrence of disease, alleviation of symptoms, diminishing of any direct or indirect pathological consequences of the disease, preventing metastasis, decreasing the rate of disease progression, amelioration or palliation of the disease state, and remission or improved prognosis.
- the 4-1BB x TAA antibody constructs described herein are used to delay development of a disease or disorder in a subject.
- 4-1BB x TAA antibody constructs and methods described herein effect tumor regression in a subject.
- the 4-1BB x TAA antibody constructs and methods described herein effect inhibition of tumor/cancer growth in a subject.
- the term “effective amount” as used herein refers to that amount of antibody construct being administered, which will accomplish the goal of the recited method, e.g., relieve to some extent one or more of the symptoms of the disease, condition or disorder being treated.
- the amount of the composition described herein which will be effective in the treatment, inhibition and prevention of a disease or disorder associated with aberrant expression and/or activity of a therapeutic protein can be determined by standard clinical techniques.
- in vitro assays may optionally be employed to help identify optimal dosage ranges.
- the precise dose to be employed in the formulation will also depend on the route of administration, and the seriousness of the disease or disorder, and should be decided according to the judgment of the practitioner and each patient's circumstances.
- Effective doses are extrapolated from dose-response curves derived from in vitro or animal model test systems.
- “Therapeutically effective amount,” as used herein, is meant an amount that produces the desired effect for which it is administered. In some embodiments, the term refers to an amount that is sufficient, when administered to a population suffering from or susceptible to a disease, disorder, and/or condition in accordance with a therapeutic dosing regimen, to treat the disease, disorder, and/or condition. In some embodiments, a therapeutically effective amount is one that reduces the incidence and/or severity of, and/or delays onset of, one or more symptoms of the disease, disorder, and/or condition.
- a therapeutically effective amount does not in fact require successful treatment be achieved in a particular individual. Rather, a therapeutically effective amount may be that amount that provides a particular desired pharmacological response in a significant number of subjects when administered to patients in need of such treatment.
- reference to a therapeutically effective amount may be a reference to an amount as measured in one or more specific tissues (e.g., a tissue affected by the disease, disorder or condition) or fluids (e.g., blood, saliva, serum, sweat, tears, urine, etc.).
- tissue e.g., a tissue affected by the disease, disorder or condition
- fluids e.g., blood, saliva, serum, sweat, tears, urine, etc.
- a therapeutically effective amount of a particular agent or therapy may be formulated and/or administered in a single dose.
- a therapeutically effective agent may be formulated and/or administered in a plurality of doses, for example, as part of a dosing regimen.
- the 4-1BB x TAA antibody construct can be administered to a subject.
- Various delivery systems are known and can be used to administer an antibody construct formulation described herein, e.g., encapsulation in liposomes, microparticles, microcapsules, recombinant cells capable of expressing the compound, receptor-mediated endocytosis (see, e.g., Wu and Wu, J. Biol. Chem. 262:4429-4432 (1987)), construction of anucleic acid as part of a retroviral or other vector, etc.
- Methods of introduction include but are not limited to intradermal, intramuscular, intraperitoneal, intravenous, subcutaneous, intranasal, epidural, and oral routes.
- the compounds or compositions may be administered by any convenient route, for example by infusion or bolus injection, by absorption through epithelial or mucocutaneous linings (e.g., oral mucosa, rectal and intestinal mucosa, etc.) and may be administered together with other biologically active agents. Administration can be systemic or local.
- Pulmonary administration can also be employed, e.g., by use of an inhaler or nebulizer, and formulation with an aerosolizing agent.
- the antibody constructs, or compositions described herein may be administered locally to the area in need of treatment; this may be achieved by, for example, and not by way of limitation, local infusion during surgery, topical application, e.g., in conjunction with a wound dressing after surgery, by injection, by means of a catheter, by means of a suppository, or by means of an implant, said implant being of a porous, non- porous, or gelatinous material, including membranes, such as sialastic membranes, or fibers.
- care must be taken to use materials to which the protein does not absorb.
- the antibody constructs or composition can be delivered in a vesicle, in particular a liposome (see Langer, Science 249:1527-1533 (1990); Treat et al, in Liposomes in the Therapy of Infectious Disease and Cancer, Lopez-Berestein and Fidler (eds.), Liss, New York, pp. 353-365 (1989); Lopez-Berestein, ibid., pp. 317-327; see generally ibid.)
- the antibody constructs or composition can be delivered in a controlled release system.
- a pump may be used (see Langer, supra; Sefton, CRC Crit. Ref. Biomed. Eng. 14:201 (1987); Buchwald et al, Surgery 88:507 (1980); Saudek et al, N. Engl. J. Med. 321:574 (1989)).
- polymeric materials can be used (see Medical Applications of Controlled Release, Langer and Wise (eds.), CRC Pres., Boca Raton, Fla.
- a controlled release system can be placed in proximity of the therapeutic target, e.g., the brain, thus requiring only a fraction of the systemic dose (see, e.g., Goodson, in Medical Applications of Controlled Release, vol. 2, pp. 115-138 (1984)).
- the nucleic acid in a specific embodiment comprising a nucleic acid encoding the antibody constructs described herein, can be administered in vivo to promote expression of its encoded protein, by constructing it as part of an appropriate nucleic acid expression vector and administering it so that it becomes intracellular, e.g., by use of a retroviral vector (see U.S. Pat. No.
- a nucleic acid can be introduced intracellularly and incorporated within host cell DNA for expression, by homologous recombination.
- the amount of the antibody construct which will be effective in the treatment, inhibition or prevention of a disease or disorder can be determined by standard clinical techniques.
- in vitro assays may optionally be employed to help identify optimal dosage ranges.
- the precise dose to be employed in the formulation will also depend on the route of administration, and the seriousness of the disease or disorder, and should be decided according to the judgment of the practitioner and each patient’s circumstances. Effective doses are extrapolated from dose-response curves derived from in vitro or animal model test systems.
- the antibody constructs described herein may be administered alone or in combination with other alternate forms of treatments or anti-cancer therapy (e.g., radiation therapy, chemotherapy, hormonal therapy, immunotherapy, bispecific antibodies, and anti- tumor agents). Generally, administration of products of a species origin or species reactivity (in the case of antibodies) that is the same species as that of the patient is preferred.
- treatments or anti-cancer therapy e.g., radiation therapy, chemotherapy, hormonal therapy, immunotherapy, bispecific antibodies, and anti- tumor agents.
- administration of products of a species origin or species reactivity in the case of antibodies that is the same species as that of the patient is preferred.
- the antibody construct may be used in the treatment of a patient who has undergone one or more alternate forms of anti-cancer therapy. In some embodiments, the patient has relapsed or failed to respond to one or more alternate forms of anti-cancer therapy. In other embodiments, the antibody construct is administered to a patient in combination with one or more alternate forms of anti-cancer therapy. In other embodiments, the antibody construct is administered to a patient that has become refractory to treatment with one or more alternate forms of anti-cancer therapy.
- kits comprising one or more antibody constructs. Individual components of the kit would be packaged in separate containers and, associated with such containers, can be a notice in the form prescribed by a governmental agency regulating the manufacture, use or sale of pharmaceuticals or biological products, which notice reflects approval by the agency of manufacture, use or sale.
- the kit may optionally contain instructions or directions outlining the method of use or administration regimen for the antibody construct.
- the container means may itself be an inhalant, syringe, pipette, eye dropper, or other such like apparatus, from which the solution may be administered to a subject or applied to and mixed with the other components of the kit.
- kits described herein also may comprise an instrument for assisting with the administration of the composition to a patient.
- an instrument may be an inhalant, nasal spray device, syringe, pipette, forceps, measured spoon, eye dropper or similar medically approved delivery vehicle.
- Certain embodiments relate to an article of manufacture containing materials useful for treatment of a patient as described herein.
- the article of manufacture comprises a container and a label or package insert on or associated with the container.
- Suitable containers include, for example, bottles, vials, syringes, intravenous solution bags, etc.
- the containers may be formed from a variety of materials such as glass or plastic.
- the container holds a composition comprising the antibody construct which is by itself or combined with another composition effective for treating the patient and may have a sterile access port (for example the container may be an intravenous solution bag or a vial having a stopper pierceable by a hypodermic injection needle).
- the label or package insert indicates that the composition is used for treating the condition of choice.
- the article of manufacture may comprise (a) a first container with a composition contained therein, wherein the composition comprises an antibody construct described herein; and (b) a second container with a composition contained therein, wherein the composition in the second container comprises a further cytotoxic or otherwise therapeutic agent.
- the article of manufacture may further comprise a package insert indicating that the compositions can be used to treat a particular condition.
- the article of manufacture may further comprise a second (or third) container comprising a pharmaceutically-acceptable buffer, such as bacteriostatic water for injection (BWFI), phosphate-buffered saline, Ringer’s solution and dextrose solution.
- BWFI bacteriostatic water for injection
- phosphate-buffered saline such as bacteriostatic water for injection (BWFI), phosphate-buffered saline, Ringer’s solution and dextrose solution.
- BWFI bacteriostatic water for injection
- the article of manufacture may optionally further include other materials desirable from
- the antibody constructs comprise at least one polypeptide. Certain embodiments relate to polynucleotides encoding such polypeptides described herein.
- isolated means an agent (e.g., a polypeptide or polynucleotide) that has been identified and separated and/or recovered from a component of its natural cell culture environment. Contaminant components of its natural environment are materials that would interfere with diagnostic or therapeutic uses for the antibody construct, and may include enzymes, hormones, and other proteinaceous or non-proteinaceous solutes. Isolated also refers to an agent that has been synthetically produced, e.g., via human intervention.
- polypeptide “peptide” and “protein” are used interchangeably herein to refer to a polymer of amino acid residues. That is, a description directed to a polypeptide applies equally to a description of a peptide and a description of a protein, and vice versa.
- the terms apply to naturally occurring amino acid polymers as well as amino acid polymers in which one or more amino acid residues is a non-naturally encoded amino acid.
- the terms encompass amino acid chains of any length, including full-length proteins, wherein the amino acid residues are linked by covalent peptide bonds.
- amino acid refers to naturally occurring and non-naturally occurring amino acids, as well as amino acid analogs and amino acid mimetics that function in a manner similar to the naturally occurring amino acids.
- Naturally encoded amino acids are the 20 common amino acids (alanine, arginine, asparagine, aspartic acid, cysteine, glutamine, glutamic acid, glycine, histidine, isoleucine, leucine, lysine, methionine, phenylalanine, proline, serine, threonine, tryptophan, tyrosine, and valine) and pyrrolysine and selenocysteine.
- Amino acid analogs refers to compounds that have the same basic chemical structure as a naturally occurring amino acid, i.e., a carbon that is bound to a hydrogen, a carboxyl group, an amino group, and an R group, such as, homoserine, norleucine, methionine sulfoxide, methionine methyl sulfonium.
- Such analogs have modified R groups (such as, norleucine) or modified peptide backbones, but retain the same basic chemical structure as a naturally occurring amino acid.
- Reference to an amino acid includes, for example, naturally occurring proteogenic L-amino acids; D-amino acids, chemically modified amino acids such as amino acid variants and derivatives; naturally occurring non-proteogenic amino acids such as b- alanine, ornithine, etc.; and chemically synthesized compounds having properties known in the art to be characteristic of amino acids.
- non-naturally occurring amino acids include, but are not limited to, a-methyl amino acids (e.g.
- a-methyl alanine D-amino acids, histidine-like amino acids (e.g., 2-amino-histidine, b-hydroxy-histidine, homohistidine), amino acids having an extra methylene in the side chain (“homo” amino acids), and amino acids in which a carboxylic acid functional group in the side chain is replaced with a sulfonic acid group (e.g., cysteic acid).
- non-natural amino acids including synthetic non- native amino acids, substituted amino acids, or one or more D-amino acids into the antibody constructs described herein may be advantageous in a number of different ways.
- D-amino acid- containing peptides, etc. exhibit increased stability in vitro or in vivo compared to L-amino acid-containing counterparts.
- the construction of peptides, etc., incorporating D-amino acids can be particularly useful when greater intracellular stability is desired or required.
- D-peptides, etc. are resistant to endogenous peptidases and proteases, thereby providing improved bioavailability of the molecule, and prolonged lifetimes in vivo when such properties are desirable.
- D-peptides, etc. cannot be processed efficiently for major histocompatibility complex class II -restricted presentation to T helper cells, and are therefore, less likely to induce humoral immune responses in the whole organism.
- Amino acids may be referred to herein by either their commonly known three letter symbols or by the one-letter symbols recommended by the IUPAC-IUB Biochemical Nomenclature Commission. Nucleotides, likewise, may be referred to by their commonly accepted single-letter codes.
- polynucleotides encoding polypeptides of the antibody constructs.
- the term “polynucleotide” or “nucleotide sequence” is intended to indicate a consecutive stretch of two or more nucleotide molecules.
- the nucleotide sequence may be of genomic, cDNA, RNA, semisynthetic or synthetic origin, or any combination thereof.
- nucleotide sequence or “nucleic acid sequence” is intended to indicate a consecutive stretch of two or more nucleotide molecules.
- the nucleotide sequence can be of genomic, cDNA, RNA, semisynthetic or synthetic origin, or any combination thereof.
- Cell “host cell”, “cell line” and “cell culture” are used interchangeably herein and all such terms should be understood to include progeny resulting from growth or culturing of a cell.
- Transformation and “transfection” are used interchangeably to refer to the process of introducing a nucleic acid sequence into a cell.
- nucleic acid refers to deoxyribonucleotides, deoxyribonucleosides, ribonucleosides, or ribonucleotides and polymers thereof in either single- or double-stranded form. Unless specifically limited, the term encompasses nucleic acids containing known analogues of natural nucleotides that have similar binding properties as the reference nucleic acid and are metabolized in a manner similar to naturally occurring nucleotides.
- oligonucleotide analogs including PNA (peptidonucleic acid), analogs of DNA used in antisense technology (phosphorothioates, phosphoroamidates, and the like).
- PNA peptidonucleic acid
- analogs of DNA used in antisense technology phosphorothioates, phosphoroamidates, and the like.
- a particular nucleic acid sequence also implicitly encompasses conservatively modified variants thereof (including but not limited to, degenerate codon substitutions) and complementary sequences as well as the sequence explicitly indicated.
- degenerate codon substitutions may be achieved by generating sequences in which the third position of one or more selected (or all) codons is substituted with mixed-base and/or deoxyinosine residues (Batzer et al., Nucleic Acid Res. 19:5081 (1991); Ohtsuka et al., J. Biol. Chem. 260:2605-2608 (1985); Rossolini et
- “Conservatively modified variants” applies to both amino acid and nucleic acid sequences. With respect to particular nucleic acid sequences, “conservatively modified variants” refers to those nucleic acids which encode identical or essentially identical amino acid sequences, or where the nucleic acid does not encode an amino acid sequence, to essentially identical sequences. Because of the degeneracy of the genetic code, a large number of functionally identical nucleic acids encode any given protein. For instance, the codons GCA, GCC, GCG and GCU all encode the amino acid alanine. Thus, at every position where an alanine is specified by a codon, the codon can be altered to any of the corresponding codons described without altering the encoded polypeptide.
- nucleic acid variations are “silent variations,” which are one species of conservatively modified variations. Every nucleic acid sequence herein that encodes a polypeptide also encompasses every possible silent variation of the nucleic acid.
- each codon in a nucleic acid except AUG, which is ordinarily the only codon for methionine, and TGG, which is ordinarily the only codon for tryptophan
- TGG which is ordinarily the only codon for tryptophan
- amino acid sequences one of ordinary skill in the art will recognize that individual substitutions, deletions or additions to a nucleic acid, peptide, polypeptide, or protein sequence which alters, adds or deletes a single amino acid or a small percentage of amino acids in the encoded sequence is a “conservatively modified variant” where the alteration results in the deletion of an amino acid, addition of an amino acid, or substitution of an amino acid with a chemically similar amino acid.
- Conservative substitution tables providing functionally similar amino acids are known to those of ordinary skill in the art. Such conservatively modified variants are in addition to and do not exclude polymorphic variants, interspecies homologs, and alleles described herein.
- the following eight groups each contain amino acids that are conservative substitutions for one another: 1) Alanine (A), Glycine (G); 2) Aspartic acid (D), Glutamic acid (E); 3) Asparagine (N), Glutamine (Q); 4) Arginine (R), Lysine (K); 5) Isoleucine (I), Leucine (L), Methionine (M), Valine (V); 6) Phenylalanine (F), Tyrosine (Y), Tryptophan (W); 7) Serine (S), Threonine (T); and [0139] 8) Cysteine (C), Methionine (M) (see, e.g., Creighton, Proteins: Structures and Molecular Properties (W H Freeman & Co.; 2nd edition
- nucleic acids or polypeptide sequences refers to two or more sequences or subsequences that are the same. Sequences are “substantially identical” if they have a percentage of amino acid residues or nucleotides that are the same (i.e., about 60% identity, about 65%, about 70%, about 75%, about 80%, about 85%, about 90%, or about 95% identity over a specified region), when compared and aligned for maximum correspondence over a comparison window, or designated region as measured using one of the following sequence comparison algorithms (or other algorithms available to persons of ordinary skill in the art) or by manual alignment and visual inspection. This definition also refers to the complement of a test sequence.
- the identity can exist over a region that is at least about 50 amino acids or nucleotides in length, or over a region that is 75-100 amino acids or nucleotides in length, or, where not specified, across the entire sequence of a polynucleotide or polypeptide.
- a polynucleotide encoding a polypeptide described herein, including homologs from species other than human, may be obtained by a process comprising the steps of screening a library under stringent hybridization conditions with a labeled probe having a polynucleotide sequence described herein or a fragment thereof, and isolating full- length cDNA and genomic clones containing said polynucleotide sequence. Such hybridization techniques are well known to the skilled artisan.
- sequence comparison typically one sequence acts as a reference sequence, to which test sequences are compared.
- test and reference sequences are entered into a computer, subsequence coordinates are designated, if necessary, and sequence algorithm program parameters are designated. Default program parameters can be used, or alternative parameters can be designated.
- sequence comparison algorithm then calculates the percent sequence identities for the test sequences relative to the reference sequence, based on the program parameters.
- a “comparison window”, as used herein, includes reference to a segment of any one of the number of contiguous positions selected from the group consisting of from 20 to 600, usually about 50 to about 200, more usually about 100 to about 150 in which a sequence may be compared to a reference sequence of the same number of contiguous positions after the two sequences are optimally aligned.
- Methods of alignment of sequences for comparison are known to those of ordinary skill in the art.
- Optimal alignment of sequences for comparison can be conducted, including but not limited to, by the local homology algorithm of Smith and Waterman (1970) Adv. Appl. Math. 2:482c, by the homology alignment algorithm of Needleman and Wunsch (1970) J. Mol. Biol.
- BLAST and BLAST 2.0 algorithms are described in Altschul et al. (1997) Nuc. Acids Res. 25:3389-3402, and Altschul et al. (1990) J. Mol. Biol. 215:403-410, respectively.
- Software for performing BLAST analyses is publicly available through the National Center for Biotechnology Information available at the World Wide Web at ncbi.nlm.nih.gov.
- the BLAST algorithm parameters W, T, and X determine the sensitivity and speed of the alignment.
- W wordlength
- E expectation
- B B-BLAST algorithm
- E expectation
- the BLAST algorithm is typically performed with the “low complexity” fdter turned off.
- the BLAST algorithm also performs a statistical analysis of the similarity between two sequences (see, e.g., Karlin and Altschul (1993) Proc. Natl. Acad. Sci. USA 90:5873-5787).
- One measure of similarity provided by the BLAST algorithm is the smallest sum probability (P(N)), which provides an indication of the probability by which a match between two nucleotide or amino acid sequences would occur by chance.
- P(N) the smallest sum probability
- a nucleic acid is considered similar to a reference sequence if the smallest sum probability in a comparison of the test nucleic acid to the reference nucleic acid is less than about 0.2, or less than about 0.01, or less than about 0.001.
- engine As used herein, the term “engineer,” and grammatical variations thereof is considered to include any manipulation of a peptide backbone or the post-translational modifications of a naturally occurring or recombinant polypeptide or fragment thereof. Engineering includes modifications of the amino acid sequence, of the glycosylation pattern, or of the side chain group of individual amino acids, as well as combinations of these approaches. The engineered proteins are expressed and produced by standard molecular biology techniques.
- a derivative, or a variant of a polypeptide is said to share “homology” or be “homologous” with the polypeptide if the amino acid sequences of the derivative or variant has at least 50% identity with a 100 amino acid sequence from the original polypeptide.
- the derivative or variant is at least 75% the same as that of either the polypeptide or a fragment of the polypeptide having the same number of amino acid residues as the derivative.
- the derivative or variant is at least 85%, 90%, 95% or 99% the same as that of either the polypeptide or a fragment of the polypeptide having the same number of amino acid residues as the derivative.
- an antibody construct comprises an amino acid sequence that is at least 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, or 100% identical to a relevant amino acid sequence or fragment thereof set forth in the Tables or Accession Numbers disclosed herein.
- an isolated antibody construct comprises an amino acid sequence encoded by a polynucleotide that is at least 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, or 100% identical to a relevant nucleotide sequence or fragment thereof set forth in Tables or Accession Numbers disclosed herein.
- An antibody construct comprising: a) a first 4-1BB-binding domain that binds to a 4-1BB extracellular domain (4-1BB ECD), and b) a tumor-associated antigen (TAA) antigen binding domain (TAA antigen-binding domain) that binds to a TAA, wherein the first 4-1BB-binding domain and the TAA antigen-binding domain are linked directly or indirectly to a scaffold.
- TAA tumor-associated antigen
- A2 The antibody construct according to embodiment Al, wherein the first 4-1BB binding domain is a first 4-1BB antigen-binding domain or a 4-1BB ligand.
- A7 The antibody construct according to embodiment A5 or A6, wherein the first epitope of 4-1BB ECD is the same as the second epitope of 4-1BB ECD.
- A8 The antibody construct according to embodiment A5 or A6, wherein the first epitope of 4-1BB ECD is different from the second epitope of 4-1BB ECD.
- A9 The antibody construct according to any one of embodiments A4 to A8, wherein the first or second 4-1BB antigen-binding domain binds to human and cynomolgus 4-1BB.
- A10 The antibody construct according to any one of embodiments A4 to A9, wherein the 4-1BB antigen-binding domain binds to domain 1 or domain 2 of 4-1BB.
- A11 The antibody construct according to any one of embodiments A4 to A9, wherein the 4-1BB antigen-binding domain binds to other than domains 3 and 4 or 4-1BB.
- first 4-1BB-binding domain is a first 4-1BB antigen-binding domain comprising a heavy chain variable sequence comprising three CDRs and light chain variable sequence comprising three CDRs and the heavy chain variable sequence and the light chain variable sequence is from any one of variants v28726, v28727, v28728, v28730, v20022, v28700, v28704,
- A13 The antibody construct according to any one of embodiments A4 to A12, wherein the first 4-1BB antigen-binding domain and/or the second 4-1BB antigen-binding domain are in a Fab format.
- A14 The antibody construct according to any one of embodiments A4 to A12, wherein one of the first 4-1BB antigen-binding domain or the second 4-1BB antigen-binding domain is in an scFv format.
- TAA antigen-binding domain is a folate receptor- ⁇ (FR ⁇ ) antigen-binding domain, a Solute Carrier Family 34 Member 2 (NaPi2b) antigen-binding domain, aHER2 antigen-binding domain, a mesothelin antigen-binding domain, or a Solute Carrier Family 39 Member 6 (LIV-1) antigen-binding domain.
- FR ⁇ folate receptor- ⁇
- NaPi2b Solute Carrier Family 34 Member 2
- HER2 antigen-binding domain a HER2 antigen-binding domain
- mesothelin antigen-binding domain a Solute Carrier Family 39 Member 6 (LIV-1) antigen-binding domain.
- A16 The antibody construct according to any one of embodiments A1 to A15 wherein the TAA antigen-binding domain is a FR ⁇ antigen-binding domain.
- A17 The antibody construct according to embodiment A16, wherein the FR ⁇ antigen- binding domain comprises the three heavy chain CDRs and the three light chain CDRs of antibody 8K22 or 1H06.
- A18 The antibody construct according to embodiment A17, wherein the FR ⁇ antigen- binding domain is a human or humanized antigen-binding domain.
- A19 The antibody construct according to any one of embodiments A1 to A18, wherein the TAA antigen-binding domain is in an scFv format.
- A20 The antibody construct according to any one of embodiments A1 to A18, wherein the TAA antigen-binding domain is in a Fab format.
- A21 The antibody construct according to any one of embodiments A1 to A20, wherein the scaffold is a dimeric Fc construct having a first Fc polypeptide and a second Fc polypeptide, each Fc polypeptide comprising a CH3 sequence, or wherein the scaffold is a linker or an albumin polypeptide.
- A22 The antibody construct according to embodiment A21, wherein the scaffold is a heterodimeric Fc construct having a first Fc polypeptide that is different from the second Fc polypeptide, and wherein the CH3 sequences of the first Fc polypeptide and the second Fc polypeptide comprise amino acid substitutions that promote the formation of a heterodimeric Fc.
- A23 The antibody construct according to embodiment A22, wherein: a) one Fc polypeptide comprises the amino acid substitutions T350V_L351Y_F405A_Y407V and the other Fc polypeptide comprises the amino acid substitutions T350V T366L K392L_T394W; b) one Fc polypeptide comprises the amino acid substitutions T350V_T366L_K392M_T394W and the other Fc polypeptide comprises the amino acid substitutions T350V_L351 Y_F405 A_Y407V; c) one Fc polypeptide comprises the amino acid substitutions L351Y_F405A_Y407V and the other Fc polypeptide comprises the amino acid substitutions T366L K392M T394W; d) one Fc polypeptide comprises the amino acid substitutions L351Y_F405A_Y407V and the other Fc polypeptide comprises the amino acid substitutions T366L K392L T39
- A24 The antibody construct according to any one of embodiments A21to A23, further comprising one or more amino acid modifications that reduce effector function.
- A25 The antibody construct according to any one of embodiments A21 to A24, wherein the first 4-1BB antigen-binding domain is linked to the N terminus of the first Fc polypeptide, and the TAA antigen-binding domain is linked to the C terminus of the first Fc polypeptide.
- the antibody construct according to embodiment A25, further comprising a second 4- 1BB antigen-binding domain is linked to the N terminus of the second Fc polypeptide.
- An antibody construct or antigen-binding fragment thereof, that specifically binds to 4-1BB, comprising: a heavy chain variable sequence comprising three CDRs and light chain variable sequence comprising three CDRs and the heavy chain variable sequence and the light chain variable sequence is from any one of variants v28726, v28727, v28728, v28730, V20022, v28700, v28704, v28705, v28706, v28711, v28712, v28713, v20036, v28696, V28697, v28698, v28701, v28702, v28703, v28707, v20023, v28683, v28684, v28685, V28686, v28687, v28688, v28689, v28690, v28691, v28692, v28694, or v28995.
- A28 The antibody construct according to embodiment A27, comprising a VH sequence and a VL sequence having at least 85% sequence identity to the VH and VL sequences of any one of variants v28726, v28727, v28728, v28730, v20022, v28700, v28704, v28705, V28706, v28711, v28712, v28713, v20036, v28696, v28697, v28698, v28701, v28702, V28703, v28707, v20023, v28683, v28684, v28685, v28686, v28687, v28688, v28689, V28690, v28691, v28692, v28694, or v28995.
- A29 The antibody construct according to any one of embodiments A1 to A28, conjugated to a drug.
- a pharmaceutical composition comprising the antibody construct of any one of embodiments A1 to A29.
- A31 One or more nucleic acids encoding the antibody construct according to any one of embodiments A1 to A28.
- One or more vectors comprising the one or more nucleic acids according to embodiment A31.
- A33 An isolated cell comprising the one or more nucleic acid according to embodiment A31, or the one or more vectors according to embodiment A32.
- A34 A method of preparing the antibody construct according to any one of embodiments A1 to A29, comprising culturing the isolated cell of embodiment A33 under conditions suitable for expressing the antibody construct, and purifying the antibody construct.
- a method of treating a subject having a cancer comprising administering to the subject an effective amount of the antibody construct according to any one of embodiments A1 to A29.
- An antibody construct comprising: a) a first 4-1BB-binding domain that binds to a 4-1BB extracellular domain (4-1BB ECD), and b) a first tumor-associated antigen (TAA) antigen binding domain (TAA antigen- binding domain) that binds to a TAA, wherein the first 4-1BB-binding domain and the first TAA antigen-binding domain are linked directly or indirectly to a scaffold.
- TAA tumor-associated antigen
- the first 4-1BB antigen-binding domain comprises: a) a heavy chain variable domain comprising the three heavy chain CDRs of antibody 1C3, and a light chain variable domain comprising the three light chain CDRs of antibody 1C3; b) a heavy chain variable domain comprising the three heavy chain CDRs of antibody 1C8, and a light chain variable domain comprising the three light chain CDRs of antibody 1C8; c) a heavy chain variable domain comprising the three heavy chain CDRs of antibody 1G1, and a light chain variable domain comprising the three light chain CDRs of antibody 1G1; d) a heavy chain variable domain comprising the three heavy chain CDRs of antibody 2E8, and a light chain variable domain comprising the three light chain CDRs of antibody 2E8; e) a heavy chain variable domain comprising the three heavy chain CDRs of antibody 3E7, and a light chain variable domain comprising the three light chain CDRs of antibody 3
- the first 4-1BB antigen- binding domain comprises: a) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v28726 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v28726; b) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v28727 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v28727; c) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v28728 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v28728; d) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v28730 and a light chain variable domain (VH) sequence that is at least 85% identical to the
- TAA antigen-binding domain is a folate receptor- ⁇ (FR ⁇ ) antigen-binding domain, a Solute Carrier Family 34 Member 2 (NaPi2b) antigen-binding domain, aHER2 antigen-binding domain, a mesothelin antigen-binding domain, or a Solute Carrier Family 39 Member 6 (LIV-1) antigen-binding domain.
- FR ⁇ folate receptor- ⁇
- NaPi2b Solute Carrier Family 34 Member 2
- HER2 antigen-binding domain a HER2 antigen-binding domain
- mesothelin antigen-binding domain a Solute Carrier Family 39 Member 6 (LIV-1) antigen-binding domain.
- the antibody construct according to embodiment B15, wherein the FR ⁇ antigen- binding domain comprises: a) a heavy chain variable domain comprising the three heavy chain CDRs of antibody 8K22, and a light chain variable domain comprising the three light chain CDRs of antibody 8K22; or b) heavy chain variable domain comprising the three heavy chain CDRs of antibody 1H06, and a light chain variable domain comprising the three light chain CDRs of antibody 1H06.
- the FR ⁇ antigen- binding domain comprises: a) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v23794 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v23794; b) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v23795 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v23795; c) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v23796 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v23796; d) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v23797 and a light chain variable domain (V
- one Fc polypeptide comprises the amino acid substitutions
- T350V_T366L_K392M_T394W and the other Fc polypeptide comprises the amino acid substitutions T350V_L351 Y_F405 A_Y407V; c) one Fc polypeptide comprises the amino acid substitutions L351Y_F405A_Y407V and the other Fc polypeptide comprises the amino acid substitutions T366L K392M T394W; d) one Fc polypeptide comprises the amino acid substitutions L351Y_F405A_Y407V and the other Fc polypeptide comprises the amino acid substitutions T366L K392L T394W; or e) one Fc polypeptide comprises the amino acid substitutions L351Y_S400E_F405A_Y407V and the other Fc polypeptide comprises the amino acid substitutions T366I_N390R_K392M_T394W, wherein the numbering of residues is according to the EU numbering system.
- the antibody construct according to any one of embodiments B1 to B25 comprising a first 4-1BB antigen-binding domain linked to the N terminus of the first Fc polypeptide, a second 4-1BB antigen-binding domain linked to the N terminus of the second Fc polypeptide, a first TAA antigen-binding domain linked to the C terminus of the first Fc polypeptide and a second TAA antigen-binding domain linked to the C terminus of the second Fc polypeptide.
- the antibody construct according to any one of embodiments B1 to B25 comprising a first 4-1BB antigen-binding domain linked to the N terminus of the first Fc polypeptide or to the N terminus of the second Fc polypeptide, a first TAA antigen-binding domain linked to the C terminus of the first Fc polypeptide and a second TAA antigen-binding domain linked to the C terminus of the second Fc polypeptide.
- first and second 4- 1BB antigen-binding domain comprises a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v28614 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v28614, and the first and/or second FR ⁇ antigen-binding domain comprises a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v23807 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v23807.
- VH heavy chain variable domain
- VL light chain variable domain
- the antibody construct according to embodiment B32 comprising a first heavy chain polypeptide sequence as set forth in SEQ ID NO:353, a second heavy chain polypeptide sequence as set forth in SEQ ID NO:349, and a light chain polypeptide sequence as set forth in SEQ ID NO:346.
- a pharmaceutical composition comprising the antibody construct of any one of embodiments B1 to B33.
- B37 One or more vectors comprising the one or more nucleic acids according to embodiment B36.
- B38 An isolated cell comprising the one or more nucleic acid according to embodiment B36, or the one or more vectors according to embodiment B37.
- a method of treating a subject having a cancer comprising administering to the subject an effective amount of the antibody construct according to any one of embodiments B1 to B34.
- C1 An antibody construct or antigen-binding fragment thereof, that specifically binds to 4-1BB, comprising: a heavy chain variable sequence comprising three heavy chain CDRs and a light chain variable sequence comprising three light chain CDRs, wherein the heavy chain CDRs and the light chain CDRs are from any one of antibodies 1G1, 1B2, 1C3, 1C8, 2A7, 2E8, 2H9, 3D7, 3H1, 3E7, 3G4, 4B11, 4E6, 4F9, 4G10, 5E2, 5G8, or 6B3.
- the antibody construct according to embodiment C2 comprising a heavy chain variable (VH) sequence comprising three CDRs and a light chain variable (VL) sequence comprising three CDRs, wherein the heavy chain CDRs and the light chain CDRs are from any one of antibodies 1G1, 1C3, 1C8, 2E8, 3E7, 4E6, 5G8, or 6B3.
- VH heavy chain variable
- VL light chain variable
- KD binding affinity
- C15 One or more vectors comprising the one or more nucleic acids according to embodiment C14.
- C16 An isolated cell comprising the one or more nucleic acids according to embodiment C14, or the one or more vectors according to embodiment C15.
- C17 A method of preparing the antibody construct according to any one of embodiments C1 to C12, comprising culturing the isolated cell of embodiment C16 under conditions suitable for expressing the antibody construct, and purifying the antibody construct.
- C18 A method of treating a subject having a cancer, comprising administering to the subject an effective amount of the antibody construct according to any one of embodiments C1 to C12.
- C19 Use of an effective amount of the antibody construct according to any one of embodiments C1 to C12 for the treatment of cancer in a subject in need thereof.
- An antibody construct or antigen-binding fragment thereof, that specifically binds to FR ⁇ comprising: a heavy chain variable (VH) sequence comprising three CDRs and a light chain variable (VL) sequence comprising three CDRs, wherein the heavy chain CDRs and the light chain CDRs are from antibody 8K22 or 1H06.
- VH heavy chain variable
- VL light chain variable
- anti-FR ⁇ antibody or antigen-binding fragment according to embodiment Dl, wherein the antibody or antigen-binding fragment thereof is or comprises a humanized antibody.
- the anti-FR ⁇ antibody or antigen-binding fragment according to embodiment Dl or D2 comprising a VH sequence and a VL sequence having at least 85% sequence identity to the VH and VL sequences of any one of variants 23794, 23795, 23796, 23797, 23798, 23799, 23800, 23801, 23802, 23803, 23804, 23805, 23806, 23807, 23808, 23809, 23810, 23811, 23812, 23813, 23814, 23815, 23816, 23817, or 23818.
- the anti-FR ⁇ antibody or antigen-binding fragment according to any one of embodiments D1 to D4, wherein the antibody or antigen-binding fragment has a binding affinity (KD) for a human FR ⁇ molecule of between about 100pM to about 100nM.
- KD binding affinity
- anti-FR ⁇ antibody or antigen-binding fragment according to any one of embodiments D1 to D8, wherein the antibody fragment is a Fab fragment, a Fab' fragment, a F(ab')2 fragment, a Fv fragment, a scFv fragment, a single domain antibody, or a diabody.
- a pharmaceutical composition comprising the antibody construct of any one of embodiments D1 to D10.
- D12 One or more nucleic acids encoding the antibody construct according to any one of embodiments D1 to D9.
- a method of preparing the antibody construct according to any one of embodiments D1 to D10 comprising culturing the isolated cell of embodiment D14 under conditions suitable for expressing the antibody construct, and purifying the antibody construct.
- An antibody construct comprising: a) a first 4-1BB-antigen binding domain derived from an agonistic anti-4-1BB antibody, and b) a first folate receptor alpha (FR ⁇ )-antigen binding domain in scFv format comprising a heavy chain variable domain (VH) sequence comprising the three heavy chain CDR sequences of antibody 8K22 and a light chain variable domain (VL) sequence comprising the three light chain CDR sequences of antibody 8K22, and further comprising one or more amino acid modifications in the VH domain and/or in the VL domain of antibody 8K22 that improve the biophysical properties of the antibody construct, wherein the first 4-1BB-antigen binding domain and the first FR ⁇ - anti gen binding domain are linked directly or indirectly to a scaffold.
- VH heavy chain variable domain
- VL light chain variable domain
- the first 4-1BB antigen binding domain comprises: a) a heavy chain variable domain (VH) comprising the three heavy chain CDRs of antibody 1G1, and a light chain variable domain (VL) comprising the three light chain CDRs of antibody 1G1, b) a heavy chain variable domain comprising the three heavy chain CDRs of antibody 5G8, and a light chain variable domain comprising the three light chain CDRs of antibod1 5G8, or c) a heavy chain variable domain comprising the three heavy chain CDRs of antibody 1C8, and a light chain variable domain comprising the three light chain CDRs of antibody 1C8.
- VH heavy chain variable domain
- VL light chain variable domain
- the first 4-1BB-antigen binding domain comprises: a) a heavy chain variable domain (VH) comprising the three heavy chain CDRs of antibody 1G1 and is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO:46, and a light chain variable domain (VL) comprising the three light chain CDRs of antibody 1G1 and is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO:58, b) a heavy chain variable domain comprising the three heavy chain CDRs of antibody and is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO:62, and a light chain variable domain comprising the three light chain CDRs of antibody 5G8 and is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO: 64, or c) a heavy chain variable domain comprising the three heavy chain CDRs of antibody 1C8 and is at least 90% identical to the amino acid sequence as set forth in SEQ
- E15 The antibody construct according to any one of embodiments E10 to E14, wherein the first 4-1BB-antigen-binding domain and the second 4-1BB-antigen-binding domain are in a Fab format.
- E16 The antibody construct according to any one of embodiments E1 to E15, wherein the scaffold is a dimeric Fc construct having a first Fc polypeptide and a second Fc polypeptide, each Fc polypeptide comprising a CH3 sequence, or wherein the scaffold is a linker or an albumin polypeptide.
- T350V_T366L_K392M_T394W and the other Fc polypeptide comprises the amino acid substitutions T350V_L351 Y_F405 A_Y407V; c) one Fc polypeptide comprises the amino acid substitutions L351Y_F405A_Y407V and the other Fc polypeptide comprises the amino acid substitutions T366L K392M T394W; d) one Fc polypeptide comprises the amino acid substitutions L351Y_F405A_Y407V and the other Fc polypeptide comprises the amino acid substitutions T366L K392L T394W; or e) one Fc polypeptide comprises the amino acid substitutions L351Y_S400E_F405A_Y407V and the other Fc polypeptide comprises the amino acid substitutions T366I_N390R_K392M_T394W, wherein the numbering of residues in the Fc polypeptide is according to the EU numbering
- E19 The antibody construct according to any one of embodiments E16 to E18, further comprising one or more amino acid modifications that reduce effector function.
- E20 The antibody construct according to embodiment E19, wherein the one or more amino acid modifications are L234A, L235A and D265S, wherein the numbering of residues is according to the EU numbering system.
- E21 The antibody construct according to any one of embodiments E1 to E20, wherein the first 4-1BB antigen-binding domain is linked to the N terminus of the first Fc polypeptide, and the first TAA antigen-binding domain is linked to the C terminus of the second Fc polypeptide.
- E22 The antibody construct according to any one of embodiments E12 to E21, wherein the first 4-1BB antigen-binding domain is linked to the N terminus of the first Fc polypeptide, the first FR ⁇ antigen-binding domain is linked to the C terminus of the second Fc polypeptide, and the second 4-1BB antigen-binding domain is linked to the N terminus of the second Fc polypeptide.
- a pharmaceutical composition comprising the antibody construct of any one of embodiments E1 to E25.
- E1 to E25 comprising culturing the isolated cell of embodiment E29 under conditions suitable for expressing the antibody construct, and purifying the antibody construct.
- E31. A method of treating a subj ect having a cancer, comprising administering to the subject an effective amount of the antibody construct according to any one of embodiments
- An antibody construct comprising a) a first 4-1BB antigen-binding domain derived from an agonistic anti-4-1BB antibody, and b) a first folate receptor- ⁇ (FR ⁇ ) antigen-binding domain in a Fab format comprising a heavy chain variable domain (VH) comprising the three heavy chain CDR sequences of antibody 8K22 and a light chain variable domain (VL) comprising the three light chain CDR sequences of antibody 8K22, wherein the first 4-1BB antigen-binding domain and the first FR ⁇ antigen-binding domain are linked directly or indirectly to a scaffold.
- VH heavy chain variable domain
- VL light chain variable domain
- E36 The antibody construct according to embodiment E35, wherein the construct comprises the polypeptide sequences of variant 33568, or variant 33569.
- a pharmaceutical composition comprising the antibody construct of embodiment E35 or E36.
- a method of preparing the antibody construct according to embodiment E35 or E36 comprising culturing the isolated cell of embodiment E41 under conditions suitable for expressing the antibody construct, and purifying the antibody construct.
- An antibody construct comprising: a) a first 4-1BB antigen-binding domain derived from an agonistic anti-4-1BB antibody, and b) a first folate receptor- ⁇ (FR ⁇ ) antigen-binding domain comprising a heavy chain variable domain (VH) comprising the three heavy chain CDR sequences of antibody 2L16 and a light chain variable domain (VL) comprising the three light chain CDR sequences of antibody 2L16, wherein the first 4-1BB antigen-binding domain and the first FR ⁇ antigen-binding domain are linked directly or indirectly to a scaffold.
- FR ⁇ folate receptor- ⁇
- the antibody construct according to embodiment F1 wherein the first FR ⁇ antigen- binding domain comprises: a) a VH domain comprising the three heavy chain CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO: 804, and a VL domain comprising the three light chain CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO: 805; b) a VH domain comprising the three heavy chain CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO: 806, and a VL domain comprising the three light chain CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO: 805, c) a VH domain comprising the three heavy chain CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as
- the antibody construct according to embodiment F3, wherein the first FR ⁇ antigen- binding domain comprises the sequence as set forth in SEQ ID NO:819, SEQ ID NO:820, SEQ ID NO:821, or SEQ ID NO:822.
- the antibody construct according to embodiment F4 wherein the first FR ⁇ antigen- binding domain further comprises one or more amino acid modifications in the VH sequence or VL sequence of antibody 2L16 that improve the biophysical properties of the antibody construct.
- VH heavy chain variable domain
- VL light chain variable domain
- the first 4-1BB antigen-binding domain comprises: a) a heavy chain variable domain (VH) comprising the three heavy chain CDRs of antibody 1G1 and is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO:46, and a light chain variable domain (VL) comprising the three light chain CDRs of antibody 1G1 and is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO:58, b) a heavy chain variable domain comprising the three heavy chain CDRs of antibody and is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO:62, and a light chain variable domain comprising the three light chain CDRs of antibody 5G8 and is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO: 64, or c) a heavy chain variable domain comprising the three heavy chain CDRs of antibody 1C8 and is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO:
- F13 The antibody construct according to embodiment F12, wherein the first 4-1BB- antigen-binding domain and the second 4-1BB-antigen-binding domain are in a Fab format.
- F14 The antibody construct according to embodiment F12 or F13, wherein the second 4- 1BB antigen-binding domain is the same as the first 4-1BB antigen-binding domain.
- F15 The antibody construct according to embodiment F14, wherein the first 4-1BB antigen-binding domain and/or the second 4-1BB antigen-binding domain are in a Fab format.
- F18 The antibody construct according to embodiment F17, wherein: a) one Fc polypeptide comprises the amino acid substitutions T350V_L351Y_F405A_Y407V and the other Fc polypeptide comprises the amino acid substitutions
- T350V_T366L_K392M_T394W and the other Fc polypeptide comprises the amino acid substitutions T350V_L351 Y_F405 A_Y407V; c) one Fc polypeptide comprises the amino acid substitutions L351Y_F405A_Y407V and the other Fc polypeptide comprises the amino acid substitutions T366L K392M T394W; d) one Fc polypeptide comprises the amino acid substitutions L351Y_F405A_Y407V and the other Fc polypeptide comprises the amino acid substitutions T366L K392L T394W; or e) one Fc polypeptide comprises the amino acid substitutions L351Y_S400E_F405A_Y407V and the other Fc polypeptide comprises the amino acid substitutions T366I_N390R_K392M_T394W, wherein the numbering of residues in the Fc polypeptide is according to the EU numbering
- F21 The antibody construct according to any one of embodiments F1 to F20, wherein the first 4-1BB antigen-binding domain is linked to the N terminus of the first Fc polypeptide, and the first FR ⁇ antigen-binding domain is linked to the C terminus of the first Fc polypeptide.
- F22 The antibody construct according to any one of embodiments F1 to F21, wherein the first 4-1BB antigen-binding domain is linked to the N terminus of the first Fc polypeptide, and the first FR ⁇ antigen-binding domain is linked to the C terminus of the second Fc polypeptide.
- the antibody construct according to any one of embodiments F1 to F24 comprising a first 4-1BB antigen-binding domain linked to the N terminus of the first Fc polypeptide or to the N terminus of the second Fc polypeptide, a first FR ⁇ antigen-binding domain linked to the C terminus of the first Fc polypeptide and a second FR ⁇ antigen-binding domain linked to the C terminus of the second Fc polypeptide.
- F27 The antibody construct according to any one of embodiments F1 to F26, conjugated to a drug.
- F28 A pharmaceutical composition comprising the antibody construct of any one of embodiments F1 to F27.
- F29 One or more nucleic acids encoding the antibody construct according to any one of embodiments F1 to F26.
- F31 An isolated cell comprising the one or more nucleic acid according to embodiment F29, or the one or more vectors according to embodiment F30.
- a method of preparing the antibody construct according to any one of embodiments F1 to F27 comprising culturing the isolated cell of embodiment F31 under conditions suitable for expressing the antibody construct, and purifying the antibody construct.
- a method of treating a subject having a cancer comprising administering to the subject an effective amount of the antibody construct according to any one of embodiments F1 to F27.
- F36 The antibody construct according to any one of embodiments F1 to F27, for use in the treatment of cancer in a subject.
- F37 An antibody construct or antigen-binding fragment thereof, that specifically binds to folate receptor- ⁇ (FR ⁇ ), comprising: a heavy chain variable domain (VH) sequence comprising three heavy chain CDRs and a light chain variable domain (VL) sequence comprising three light chain CDRs, wherein the heavy chain CDRs and the light chain CDRs are from antibody 2L16.
- VH heavy chain variable domain
- VL light chain variable domain
- the antibody construct according to embodiment F37 or F38 comprising: a) a VH domain comprising the three heavy chain CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO: 804, and a VL domain comprising the three light chain CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO: 805; b) a VH domain comprising the three heavy chain CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO: 806, and a VL domain comprising the three light chain CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO: 805, c) a VH domain comprising the three heavy chain CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO:
- F42 The antibody construct according to any one of embodiments F37 to F41, wherein the antibody or antigen-binding fragment is a monoclonal antibody.
- F43 The antibody construct according to any one of embodiments F37 to F42, wherein the antibody fragment is a Fab fragment, a Fab' fragment, a F(ab')2 fragment, a Fv fragment, a scFv fragment, a single domain antibody, or a diabody.
- F44 The antibody construct according to any one of embodiments F37 to F43, conjugated to a drug.
- F46 One or more nucleic acids encoding the antibody construct according to any one of embodiments F37 to F43.
- F48 An isolated cell comprising the one or more nucleic acids according to embodiment F46, or the one or more vectors according to embodiment F47.
- F50 A method of treating a subject having a cancer, comprising administering to the subject an effective amount of the antibody construct according to any one of embodiments F37 to F43.
- F51 Use of an effective amount of the antibody construct according to any one of F37 to F43, for the treatment of cancer in a subject in need thereof.
- EXAMPLE 1 Design and Preparation of Exemplary 4-1BB x HER2 bispecific antibody constructs
- a number of exemplary bispecific antibody constructs (or bispecific antibodies) targeting 4-1BB and the TAA HER2, as well as controls were constructed as described below.
- the antibodies and controls were prepared in different exemplary formats, as described in Figure 2. These antibody constructs were prepared in order to allow examination of the potential for conditional agonism of 4-1BB, and the optimal format for activity of the 4-1BB x HER2 constructs.
- Het FcA having the amino acid substitutions T350V/L351Y/F405A/Y407V
- Het FcB having the amino acid substitutions T350V/T366L/K392L/T394W
- Variants having these sets of amino acid substitutions are referred to in Table 1 as having “Het Fc” modifications.
- Variants in Table 1 noted as having “FcKO” have the following CH2 amino acid substitutions which knock out Fc ⁇ R binding: L234A, L235A and D265S. Amino acid residues in the Fc region are identified according to the EU index.
- bivalent, trivalent and tetravalent antibody constructs were made, all having three polypeptide chains constructs - one heavy chain containing Het FcA mutations, a second heavy chain containing Het FcB mutations and a single light chain.
- the heavy chains were constructed in a series of formats, all of which were comprised of one or two anti-4-1BB antigen-binding domains in the Fab format and a single anti-HER2 antigen-binding domain in the scFv format. These heavy chain formats are described below from N-terminus to C- terminus:
- Table 1 provides a description of the 4-1BB x HER2 bispecific antibody constructs that were prepared. The number of 4-1BB-targeting domains and HER2 -targeting domains are indicated in the “Format” column. For example, in Table 1, 1 x 1 indicates that the bispecific antibody construct has one 4-1BB binding domain and one HER2 binding domain, 2 x 1 indicates that the bispecific antibody construct has two 4-1BB binding domains and one HER2 binding domain, etc.
- the formats of the specific bispecific antibody constructs described below are also represented in Figure 3.
- Table 1 Exemplary bispecific antibody constructs targeting 4-1BB and HER2
- VH and VL sequences used to construct the 4-1BB antigen-binding domains of the constructs are provided in Table 15, as are the scFv sequences used to construct HER2 scFv containing constructs.
- Table X, Table XI and Table X2 identify the clones that make up each of the antibody constructs.
- the polypeptide sequences of each clone can be found in Table Y, Table Y1 or Table Y2.
- heavy chain vectors having a 5’-EcoRl restriction site - signal peptide - heavy chain clone terminating at G446 (EU numbering) of CH3 - TGA stop - BamHl cutsite-3’ were ligated into a pTT5 vector to produce heavy chain expression vectors.
- Light chain vectors, having a 5’-EcoRI cut site -signal peptide - light chain- TGA stop - BamHl cutsite-3’ were ligated into apTT5 vector (Durocher Y et al, Nucl. Acids Res. 2002; 30, No.2 e9) to produce light chain expression vectors.
- the resulting heavy and light chain expression vectors were sequenced to confirm correct reading frame and sequence of the coding DNA.
- One of two signal peptides was used, either an artificially designed sequence, MRPTW AWWLFL VLLL ALW AP ARG [SEQ ID NO:l], Barash S et al, Biochem and Biophys Res. Comm. 2002; 294, 835-842) or the HLA-A signal peptide M AVM APRTLVLLLS GAL ALT QTW AG [SEQ ID NO:2],
- CHO-3E7 cells were cultured at 37°C in FreeStyleTM F17 medium (Thermo Fisher, Watham, MA) supplemented with 4 mM glutamine (GE Life Sciences, Marlborough, MA) and 0.1% KoliphorP188 (Sigma Aldrich, St. Louis, MO).
- a total volume of 200 ml was transfected with a total of 200 mg DNA (100 ⁇ g of variant DNA and lOO ⁇ g of GFP/AKT/stuffer DNA) using PEI-max (Polyscience, Philadelphia, PA) at a DNA:PEI ratio of 1:4 (W/W). Twenty-four hours after the addition of the DNA-PEI mixture, 0.5mM valproic acid (final concentration) + 1% w/v Tryptone (final concentration) + 1x antibiotic/antimycotics (GE Life Sciences, Marlborough, MA) were added to the cells which were then transferred to 32°C and incubated for 7 days prior to harvesting.
- Clarified supernatant samples were incubated in batch with MabSelectTM SuReTM resin (GE Healthcare, Chicago, IL) cleaned with NaOH and equilibrated in DPBS. Resin was poured into cleaned columns, the columns were washed with DPBS and protein eluted with 100 mM sodium citrate buffer pH 3.0. The eluted antibodies were pH adjusted by adding 10% (v/v) 1M HEPES pH 8 to yield a final pH of 6-7. Samples were buffer exchanged into PBS and aseptically filtered. Protein was quantified based on A280 nm (NanoDropTM). Endotoxin levels were determined using the Endosafe® Portable system (Charles River, Wilmington, MA). For samples above 0.1 EU/mg, these underwent endotoxin removal with the Proteus NoEndoTM Spin columns (Charles River, Wilmington, MA).
- Endotoxin levels were determined by the LAL (limulus amebocyte lysate) assay using the Endosafe® Portable Test System (PTS, Charles River, Wilmington, MA). Protein was quantified based on A280 nm (Nanodrop) post protein-A and SEC.
- UPLC-SEC was performed using a Waters Acquity BEH200 SEC column (2.5 mL, 4.6 x 150 mm, stainless steel, 1.7 ⁇ m particles) (Waters LTD, Mississauga, ON) set to 30°C and mounted on a Waters Acquity UPLC H-Class Bio system with a PDA detector.
- Run times consisted of 7 min and a total volume per injection of 2.8 mL with a running buffer of DPBS or DPBS with 0.02% Tween 20 pH 7.4 at 0.4 ml/min. E1ution was monitored by UV absorbance in the range 210-500 nm, and chromatograms were extracted at 280 nm. Peak integration was performed using Empower 3 software.
- the deglycosylated protein samples were analyzed by intact LC-MS using an Agilent 1100 HPLC system coupled to an LTQ-Orbitrap XL mass spectrometer (ThermoFisher , Waltham, MA) via an Ion Max electrospray source.
- the samples (5 ⁇ g) were injected onto a 2.1 x 30 mm Poros R2 reverse phase column (Applied Biosystems) and resolved using the following gradient conditions: 0-3 min: 20% solvent B; 3-6 min: 20-90% solvent B; 6-7 min: 90-20% Solvent B; 7-9 min: 20% solvent B.
- Solvent A was degassed 0.1% formic acid aq. and solvent B was degassed acetonitrile.
- the flow rate was 3 mL/min.
- the flow was split post- column to direct 100 ⁇ L/mL into the electrospray interface.
- the column was heated to 82.5°C and solvents were heated pre-column to 80 ° C to improve protein peak shape.
- the LTQ-Orbitrap XL was calibrated using ThermoFisher Scientific’s LTQ Positive Ion ESI calibration solution (caffeine, MRFA and Ultramark 1621), and tuned for optimal detection of larger proteins (>50kDa) using a 1 mg/mL solution of lactalbumin.
- the cone voltage (source fragmentation setting) was approximately 40 V
- the FT resolution was 7,500
- the scan range was m/z 400-4,000.
- the LC-MS system was evaluated for IgG sample analysis using a deglycosylated IgG standard (Waters IgG standard) as well as a deglycosyated antibody standard mix (25:75 half: full sized antibody).
- a deglycosylated IgG standard Waters IgG standard
- a deglycosyated antibody standard mix 25:75 half: full sized antibody.
- the raw protein LC-MS data were first opened in QualBrowser, the spectrum viewing module of XcaliburTM (Thermo Fisher, Waltham, MA) and converted to be compatible with MassLynxTM using DatabridgeTM, a file conversion program provided by Waters.
- the converted protein spectra were viewed in the Spectrum module of MassLynxTM and deconvoluted using MaxEnt 1.
- the apparent amount of each antibody species in each sample was determined from their peak heights in the resulting molecular weight profiles. In the majority of cases, the antibodies comprised >95% of the desired construct, with no major glycovariants.
- EXAMPLE 2 Ability of 4-1BB x HER2 bispecific antibody constructs to bind to 4-1BB and HER2 as assessed by Surface Plasmon Resonance (SPR)
- a surface plasmon resonance (SPR) binding assay for determination of 4-1BB binding affinity to 4-1BB antibody variants was carried out on BiacoreTM T200 instrument (GE Healthcare, Mississauga, ON, Canada) with PBS-T (PBS + 0.05% (v/v) Tween 20) running buffer (with 0.5 M EDTA stock solution added to 3.0 mM final concentration) at a temperature of 25 ° C.
- CM5 Series S sensor chip, BiacoreTM amine coupling kit (NHS, EDC and 1 M ethanolamine), and 10 mM sodium acetate buffers were all purchased from GE Healthcare.
- PBS running buffer with 0.05% Tween20 (PBS-T) was purchased from Teknova Inc. (Hollister, CA).
- Goat polyclonal anti-human Fc antibody was purchased from Jackson ImmunoResearch Laboratories Inc. (West Grove, PA).
- the cleavage reaction was mixture was subsequently applied to a 1 mL HiTrap Ni Sepharose Excel (GE Heathcare) column equilibrated in dPBS and the column washed with 5xCV dPBS.
- the cleaved 41BB protein was collected in the flow-thru fractions. Residual Fc was removed using Protein A purification by applying the protein sample to mAh Select SuRe by gravity. The flow-through was applied to a Superdex 200 10/30 column equilibrated in dPBS. Fractions corresponding to the major 41BB product were collected and used for SPR.
- the anti-human Fc surface was prepared on a CM5 Series S sensorchip by standard amine coupling methods as described by the manufacturer (GE Healthcare). Briefly, immediately after EDC/NHS activation, a 25 ⁇ g/mL solution of anti-human Fc in 10 mM NaOAc pH 4.5 was injected at a flow rate of 10 ⁇ L/min for 420s until approximately 2000 resonance units (RUs) were immobilized on all four flow cells. The remaining active groups were quenched by a 420s injection of 1M ethanolamine at 10 ⁇ L/min.
- Antibodies for analysis were captured onto the anti-Fc surface by injecting 5 ⁇ g/mL solutions at a flow rate of 10 ⁇ L/min for 60s.
- 5 ⁇ g/mL solutions were injected at a flow rate of 10 ⁇ L/min for 60s.
- a blank buffer control was sequentially injected at 40 ⁇ L/min for 180s with a 600s dissociation phase, resulting in a set of sensorgrams with a buffer blank reference.
- Experiments were performed at a constant temperature of 25°C.
- the anti-human Fc surfaces were regenerated to prepare for the next injection cycle by one pulse of 10mM Glycine/HCl pH 1.5 for 120 s at 40 ⁇ L/min.
- Blank-subtracted sensorgrams were analyzed using BiacoreTM T200 Evaluation Software v3.0. The blank-subtracted sensorgrams were then fit to the 1:1 Langmuir binding model.
- An anti-Fc capture chip was prepared in the same way as above, then antibodies for analysis at 50 ⁇ g/ml were injected into the chip at a flow rate of 10 ⁇ l/min for 60s.
- antibodies for analysis at 50 ⁇ g/ml were injected into the chip at a flow rate of 10 ⁇ l/min for 60s.
- five concentrations of a two-fold dilution series of HER2 (having recombinant human Her-2 amino acids 23-652; eBioscience) starting at 40nM (for both supernatant and purified antibody runs) with a blank buffer control were sequentially injected at 50 ⁇ L/min for 180s with a 1800s dissociation phase, resulting in a set of sensorgrams with a buffer blank reference.
- Experiments were performed at a constant temperature of 25 °C.
- the anti -human Fc surfaces were regenerated to prepare for the next injection cycle by one pulse of 10mM Glycine/HCl pH 1.5 for 120 s at 40 ⁇ L/min.
- Blank-subtracted sensorgrams were analyzed using BiacoreTM T200 Evaluation Software v3.0. The blank-subtracted sensorgrams were then fit to the 1:1 Langmuir binding model to obtain the ka, kd and KD values shown in Table 2 below.
- EXAMPLE 3 Ability of 4-1BB x HER2 bispecific antibody constructs to stimulate 4- 1BB activity in an NF-kB-Luciferase reporter assay
- NF ⁇ B 1UC2P/4-1BB Thaw-and-Use Jurkat cells (Promega) were thawed at 37°C according to manufacturer’s instructions and diluted with 5.8 mL of Assay Buffer. A volume of 20 ⁇ L of the reporter cell suspension at approximately 1x10 6 cells/mL ( ⁇ 2x10 4 cells) was added to each well containing the variant/effector-cell mixture.
- the positive control 4-1BB x HER2 bispecific antibody v19353 showed intermediate potency - higher than v16601 and v16605 but lower than v16675 and v16679.
- v19353 (having a lipocalin 4-1BB binding domain) showed low activity, as given by maximal RLU, compared to the antibody-based 4-1BB agonists.
- 4-1BB monospecific control variant v12592 showed low activity at lower concentrations, with activity increasing with concentration; however, activity of this antibody was not increased in the presence of SKOV3 cells compared to MDA-MD-468 cells.
- Control variant v1040 showed no activity in activating 4-1BB, suggesting that there was no direct effect of the HER2 binding arm on the experiment, v 16992 similarly showed no effect of a non- binding control antibody.
- constructs with two anti-4-1BB binding arms showed greater activity than constructs with one anti-4-1BB arm.
- the constructs with a Her2- binding site close to the 4-1BB binding site appeared less active than the constructs with the Her2 binding site distal from the 4-1BB binding site (eg. v16605 and v 16679).
- T cells in co-culture with tumour cells.
- cytokines such as IFN ⁇ or IL-2
- IL-2 is also a key cytokine produced by T cells after activation which promotes their survival and correlates with activation of T cells.
- This experiment examined the ability of 4-1BB x HER2 antibodies to enhance the activation of T cells as measured by IL-2 production, where the T cells have been activated by a sub-optimal amount of anti-CD3 antibody.
- Bispecific 4-1BB x HER2 antibody variants 16601, 16605, 16675, and 16679 were tested in this example, along with the control variants 1040, 12592, and a human IgG1 negative control.
- the assay was carried out as described below, using CD4+ T cells.
- 96 well plates were coated with anti-CD3 by adding 100 ⁇ l 1 ⁇ g/ml UCHT1 to wells. The plate was then incubated overnight at 4°C. Blood was obtained from healthy donors, centrifuged at 1500rpm for 5 minutes and plasma discarded. The blood was then diluted in PBS, layered over FicollTM and centrifuged at 2000rpm for 20 minutes at room temperature. The interface layer of PBMC was then taken, washed with PBS to remove platelets, and resuspended.
- Cells were then counted, diluted to 5 x 10 7 cells per ml in PBS 2% FBS ImM EDTA, and CD4+ T cell enrichment cocktail (Stemcell Technologies) added at 50 ⁇ l/ml cells. The cells were then left at room temperature for 10 minutes. EasySepTM D magnetic particles (Stemcell Technologies) were then added at 100 ⁇ l/ml cells, mixed and left at room temperature for 5 minutes. The cells were then diluted to a volume of 10ml using PBS/2% FCS/lmM EDTA and placed into an EasySepTM magnet. Non-selected cells were then decanted, and placed into a fresh tube in an EasySepTM magnet, and those cells decanted into a fresh tube.
- CD4+ T cells were then washed twice in RPMI-1640 10% FCS 1% Penicillin- Streptomycin and diluted to 10 6 cells/ml and 100 ⁇ l added per well to a 96 well plate that had been pre-coated with anti-CD3 (UCHT1).
- SKBR3 cells were obtained, diluted to 2 x 10 5 cells/ml and 50 ⁇ l added to wells.
- Antibody samples were also diluted to 40nM in RPMI-1640 10% FCS 1% Penicillin-Streptomycin and 50 ⁇ l of the resulting solution added per well (10nM final concentration). In some cases, antibodies were cross-linked using an anti-Fc antibody. The plate was then incubated for three days at 37°C in a 5% CO 2 atmosphere, and supernatants taken for analysis of IL-2 concentrations by ELISA.
- EXAMPLE 5 Comparison of activation of T cells by v16679, v19353 and v12592 as measured by IFN-g production
- SKBR3 tumor cells were cultured in RPMI 10% FCS, treated with 0.05% Trypsin-EDTA (Invitrogen) to remove them from the plate, collected and counted. After centrifugation, the tumor cells were resuspended in assay media at a concentration of 10 6 cells per ml. 10 4 tumor cells (10 ⁇ l) were added per well according to each condition. Artificial APCs (aAPC/CHO-K1 cells, Promega) were collected using cell dissociation buffer and counted. These cells expressed anti-CD3 (0KT3) and PD-L1 on the surface of the cell and were used to stimulate the T cells in a non-specific manner.
- Trypsin-EDTA Invitrogen
- the artificial APC cells were resuspended in assay media at a concentration of 10 6 cells per ml.
- T cells were thawed, pelleted, counted and resuspended in assay media at a concentration of 2 x 10 6 cells per ml.
- CD8+ T cells, CD4+ T cells and pan-T cells were purchased from BioIVT, Westbury, NY, USA or Stemcell, Vancouver, BC, Canada.
- mice were immunized with human 4-1BB-His protein or a mixture of human 4-1BB-His and mouse 4-1BB-Fc (Aero Biosystems, Newark, DE), and spleens taken and dissociated to obtain single cells. Splenocytes were then fused with a myeloma partner line to create hybridomas. The hybridoma cells were cloned by limiting dilution and the supernatants taken for screening.
- Antibodies binding to human, cynomolgus ( Macaca fascicularis ) and/or mouse (Mus musculus) 4-1BB were identified by ELISA.
- 96-well plates were coated by adding 100 ⁇ l of a 0.1 ⁇ g/ml solution of human, cynomolgus or mouse 4-1BB in carbonate buffer (pH 9.6) overnight at 4°C.
- the wells were then blocked by using 3% skim milk powder in PBS for 1 hour at room temperature, followed by addition of neat hybridoma supernatant (100 ⁇ l/well) at 37°C for 1 hour with shaking.
- the antibody was then detected using 1:10000 goat anti-mouse IgG/IgM (H+L)-HRP, 100 ⁇ l/well in PBS 0.05% Tween-20 for 1 hour at 37°C with shaking.
- the presence of HRP in the well was then detected using TMB substrate (50 ⁇ l/well) for 3 minutes in the dark, followed by addition of 50 ⁇ l 1M HC1 to stop the reaction.
- the plate was then read at 450nm.
- Antibodies were also counter-screened to exclude antibodies that bound to TNF superfamily members 0x40 and CD40 and GITR, using the same method.
- RNA from hybridoma cells were washed once in cold phosphate-buffered saline (pH 7.4) and immediately processed through the RNeasy Plus Micro Kit (QIAgen). Total RNA was eluted in nuclease-free water and mRNA converted to cDNA using AMY reverse transcriptase (NEB), primed with oligo(dT2o).
- NEB AMY reverse transcriptase
- a nested PCR reaction was then performed on these unique sequences using V - segment family and J-segment family-specific primers. The resulting amplicons were then cloned into pTT5-based expression plasmids (National Research Council, Montreal, QC). Unique heavy chain sequences and light chain sequences emerging from a single hybridoma sample were co-expressed in HEK293-6E cells (National Research Council) in all possible combinations to determine the correct heavy and light chain pairing. Antibodies produced were assayed for binding to antigen that was transiently expressed on HEK293 cells.
- the 18 chimeric mouse-human 4-1BB antibodies were produced by transfection of two plasmids into HEK293-6E cells, one plasmid containing the heavy chain and the other plasmid containing the light chain.
- the antibody levels within the supernatant were quantified using an OctetTM RED96 (ForteBio) with a Protein A tip, and the supernatants used immediately in assays.
- the supernatants were also purified using Protein A.
- cells were first removed from the antibody supernatants by centrifuging at 100Orcf for 15 minutes.
- Protein A GravitrapTM columns were then prepared by equilibration using 10ml PBS, followed by application of antibody supernatant in batches of 10ml. Once all of the supernatant had flowed through the column, the column was washed twice, each time with 10ml PBS.
- E1ution of the antibody was performed by the addition of 3ml 0.1M glycine-HCl, pH 2.7. The eluted antibody sample was then neutralized using 1M Tris-HCl, pH 9.
- the antibody samples were loaded into a VivaspinTM 30kDa MWCO protein concentrator spin column (GE Healthcare). The columns were then spun at 3000rcf for 7 minutes to concentrate the antibody. 4ml PBS was then added to the column to exchange buffers, and the column was then spun again, to exchange buffers into PBS. The antibody levels in the resulting solution were then measured using 260nm/280nm absorbance ratio using a NanodropTM S pectrophotometer (Thermofisher) .
- EXAMPLE 7 Activity of chimeric 4-1BB antibodies in 4-1BB NF-kB-Luciferase reporter assay
- This experiment was set up in a manner similar to that described in Example 3, except that antibody supernatants were used in place of bispecific antibodies, and no tumour cells were used.
- the antibody supernatants were diluted in Assay Buffer (RPMI (Gibco)/l% FBS (Gibco)) to 5000ng/ml, 1666ng/ml, 554ng/ml and 184ng/ml.
- Rabbit-anti-human IgG Fc (Thermofisher) polyclonal secondary antibody was then added to a concentration of 15000ng/ml and the antibody mixture left at room temperature. [00419] After 45 minutes, 30 ⁇ l of the antibody mix was added to wells.
- v12592 was diluted either in supernatant (ESN) or RPMI.
- ESN supernatant
- RPMI supernatant
- the negative control was v16992 diluted in ESN.
- 4-1BB Thaw-and-use Jurkat cells (Promega) were then added, followed by a 5 hour incubation and then Bio-GloTM reagent (Promega) was added, as described in Example 3. The data was acquired and analyzed as in Example 3.
- the chimeric antibodies were tested for binding to human 4-1BB, dog 4-1BB and a chimeric human-dog 4-1BB protein.
- the human-dog 4-1BB protein included a set of mutations within domain 4 that modified human 4-1BB to dog.
- the pTT5 vectors containing the 4-1BB expression constructs were then produced and purified in a manner similar to the antibodies in Example 1, except a 500ml culture volume was used. Caliper results indicated that human, dog and chimeric human-dog 4-1BB constructs were prepared in substantially pure form.
- a soluble antigen binding ELISA was performed to assess antibodies for their ability to bind outside of 4-1BB domain 4. The goal was to determine if samples have differential binding to hybrid or chimeric human-dog 4-1BB versus human 4-1BB to suggest whether or not binding is outside of domain 4. However, if the tested antibodies were able to bind to dog 4-1BB assessment of binding to domain 4 by this method would not be accomplished.
- Soluble human, dog or human-dog 4-1BB-Fc proteins were prepared in PBS pH
- Antibody samples were then diluted in assay buffer (2% w/v skim milk powder in PBS) to 10 ⁇ g/mL final or used neat if samples were below 10 ⁇ g/mL. Directly in assay plates, samples were serially diluted five times 1:8 in duplicate in assay buffer with a final volume of 50 ⁇ L/well. Similarly, control antibodies were prepared and diluted in assay buffer. For wells containing no antibody sample, assay buffer was added at 50 ⁇ L/well. The plates were then covered with a lid, sealed with parafilm, and incubated overnight at 4°C. The next day, plates were washed with the plate washer as previously and tapped dry.
- assay buffer 2% w/v skim milk powder in PBS
- Peroxidase AffiniPure goat anti -human F(ab') 2 (Jackson ImmunoResearch, West Grove, PA) was prepared in assay buffer at 0.4 ⁇ g/mL.
- Peroxidase AffiniPure goat anti- human Fc (Jackson ImmunoResearch, West Grove, PA) was prepared in assay buffer at 1 ⁇ g/mL. Both secondaries were added at 50 ⁇ L/well and plates were incubated at room temperature for 30 minutes. The plates were washed and dried as previous and TMB substrate (Cell Signaling Technology, Danvers, MA) was added at 50 ⁇ L/well.
- v20022, 20025, v20032, v20036 and v20037 showed equal binding on human and human-dog chimeric 4-1BB, suggesting that all these antibodies bound outside domain 4 (amino acids 115-156).
- MOR7480.1-IgG1 variant 12592
- v12593 a version of Urelumab with an IgG1 Fc, similar to the tested antibodies, bound human and human-dog chimeric 4-1BB equally, suggesting that its binding domain also lies outside amino acids 115-156.
- v20027 did not show binding in this experiment and was excluded from future analysis. Domain binding of antibodies using truncated 4-1BB proteins
- Constructs were synthesized having either full-length human 4-1BB (residues 24-255) or extracellular domains 3 and 4 (residues 86-255) along with the native human transmembrane and intracellular parts of 4-1BB.
- Full-length mouse 4-1BB was also cloned. All vectors also contained the native signal peptide (MGNSCYNIVATLLLVLNFERTRS, SEQ ID NO:42) and were run through SignalP 4.1 (www.cbs.dtu.dk/services/SignalP/) to predict the successful cleavage of the signal peptide. All constructs were synthesized in the form 3’-EcoRI-4-1BB-BamHI-5’ and cloned into an EcoRI-BamHI digested pTT5 vector.
- v20022, v20023, v20025, v20029, v20032, v20036 and v20037 antibodies did not show binding to cells transfected with the domain 3 and 4 only construct, suggesting that all of the antibodies bind outside of those domains, and bind to an epitope at least partially within amino acids 24-85 of the mature 4-1BB protein. This data reinforces the conclusions of the human-dog chimera experiment, that v20022, v20025, v20029, v20036 and v20037 do not bind domain 4.
- HEK293-6e cells (National Research Council Canada, Montreal, QB) were cultured in 293 Freestyle Media (ThermoFisher, Watham, MA). with 1% FBS (Coming, Coming, NY) in 250mL Erlenmeyer flasks (Coming, Coming, NY) at 37 °C, 5% CO2 in a humidified incubator with rotation at 115 rpm. Before transfection, HEK293-6e cells were re-suspended to 1 x 10 6 cells/mL in fresh 293 Freestyle media.
- Cells were then transfected using 293fectinTM transfection reagent (Thermo Fisher, Watham, MA) at a ratio of l ⁇ g DNA/10 6 cells in Opti- MEMTM Reduced Serum Medium (Thermo Fisher, Watham, MA).
- Cells were transfected with pTT5 DNA vectors containing either full length cynomolgus monkey 4-1BB with a flag-tag (CL#11070 SEQ ID NO:43), mouse 4-1BB-flag (CL#11063 SEQ ID NO:44) as shown in Table 5, or vector containing GFP as a control for transfection efficiency.
- the cells were incubated for 24 hours at 37 °C, 5% CO2 in a humidified incubator with rotation at 115 rpm.
- Antibody samples were prepared at concentrations of neat, 1:4 and 1:16 final in PBS pH 7.4 (Thermo Fisher, Watham, MA) + 2% FBS in Eppendorf tubes and 30 pi of antibody mix was added to wells of a 384-well black optical bottom plate (ThermoFisher). v12592 was used as a positive control for binding to Cynomolgus 4-1BB, and human IgG1 as a negative control.
- Anti-mouse 4-1BB antibody LOB12.3 BioXCell, West Riverside, NH
- its respective rat IgG1 isotype control R&D Systems, Minneapolis, MN
- a cell mixture of transfected HEK293-6e cells (10,000 cells per 30 ⁇ L), VybrantTM DyeCycleTM Violet nuclear stain at 2 ⁇ M final (Thermo Fisher) and Goat anti Human IgG Fc A647 at 0.6 ⁇ g/mL (Jackson ImmunoResearch, Westgrove, PA) was prepared. The cells were vortexed briefly to mix added to wells at 30 ⁇ L/well. The plate was incubated at room temperature for 3 hours before scanning. Data analysis was performed on the Celllnsight CX5 with the HCS high content screening platform (ThermoFisher), using BioApplication “CellViability” with a 10x objective.
- Samples were scanned on the 385 nm channel to visualize nuclear staining and 650nm channel to assess cell binding.
- the mean object average fluorescence intensity of A647 was measured on channel 2 to determine binding intensity. This intensity was then divided by the intensity of staining seen in the GFP- transfected wells to give a fold binding induced by the antibody.
- Antibodies were then assembled such that each humanized heavy chain was paired with each of the humanized light chains, making a total of twelve humanized variants each for 1C8 and 1G1, and 16 variants for 5G8, (Table 6).
- the amino acid sequences for each of the humanized heavy chains and humanized light chains are provided in Table 14.
- Table 6 Humanized 1C8, 1G1 and 5G8 variants and their composition.
- each of the humanized 1C8, 1G1 and 5G8 VH and VL sequences described in Table 6 as well as the parental mouse VH and VL sequences were used to prepare humanized antibodies in the naturally occurring, or FSA antibody format, containing two identical full- length heavy chains and two identical kappa light chains.
- Table X identifies the clones that make up each of the antibody constructs.
- the polypeptide sequences of each clone can be found in Table Y.
- variable domain sequences were mouse (SEQ ID NOs:7, 9, 35 (VH) and 8, 10, 36 (VL)) and constant domain sequences were human (SEQ ID NOs:68 and 67 correspondingly). These sequences were reverse translated to DNA, codon optimized for mammalian expression, and gene synthesized.
- the heavy and light chains of antibody variants were expressed in 100 mL CHO cultures and purified as described in Example 1. Following protein-A purification, purity of samples was assessed by non-reducing and reducing High Throughput Protein Express assay as described in Example 1.
- Yields of protein post protein-A purification were in the range of -3.5-9 mg for humanized 1C8 variants, -4.5-9.5 mg for humanized 1G1 variants and -4.5-8 mg for humanized 5G8 variants.
- Non-reducing and reducing LabChip post protein-A reflected single species corresponding to full size antibody and intact heavy and light chains in all cases (data not shown). Endotoxin levels were within the specifications.
- UPLC-SEC analysis of protein A purified humanized 1C8 antibody variants was reflective of high species homogeneity in the case of variants 28717, 28719, 28720, 28721 (data not shown).
- UPLC-SEC profiles of all other humanized 1C8 variants (data not shown) reflected good homogeneity, as judged by the presence of small peaks (likely reflective of aggregates) and shoulder to the main peak (possibly reflective of different antibody conformation).
- UPLC-SEC analysis of protein A purified humanized 1G1 antibody variants was reflective of high species homogeneity for variants 28683, 28684, 28685 and 28686.
- UPLC-SEC profiles of all other humanized 1G1 variants reflected slightly lower homogeneity (data not shown).
- UPLC-SEC analysis of protein A purified humanized 5G8 antibody variants showed good species homogeneity for all variants.
- UPLC-SEC analysis was repeated for final pools of samples post SEC purification and these samples showed homogeneity in the range of 99.2-100.0 % (data not shown).
- EXAMPLE 12 Binding of humanized 1C8, 1G1 and 5G8 antibodies to human 4-1BB by SPR
- Protein material post protein-A or SEC was assessed for binding to human 4- 1BB.
- the antigen-binding affinity was determined by SPR as described in Example 2.
- Figure 13 provides SPR sensorgrams for the parental chimera and representative humanized variants that were able to bind human 4-1BB.
- Jurkat T cells engineered to stably express human 4-1BB were used to measure binding of antibodies to human 4-1BB.
- Antibodies were diluted in 50 ⁇ l FB (PBS 2% FCS) 1:3 from stock in wells of a 96 V-well plate, and cells added on top. The cells were then left on ice for 30 minutes for the antibodies to bind. The cells were then washed twice in FB, and then incubated in 50 ⁇ l FB containing 2gg/ml goat anti-human Alexa647 antibody (Jackson Immunoresearch).
- the cells were then left on ice for a further 20 minutes, washed twice in FB, resuspended in 100 ⁇ l FB and analysed on a BD FortessaTM X20.
- the subsequent data fdes were analysed using FlowJoTM and Prism 7 (GraphPad) using a four-parameter non-linear regression.
- Figure 16A, 16B and 16C depict the ability of the 1 C8, 1 G1 and 5G8 humanized antibodies, respectively, to bind to 4-1BB-expressing Jurkat T cells. Similar to the SPR results, antibodies which derive from the 1C8 paratope bound poorly, including the parental antibody, v20022. The original mouse 1G1 paratope, v20023, bound well to 4-1BB as would be expected from the SPR results. The humanized antibodies based on the 1G1 paratope also bound well, and there was little drop in binding seen as a result of humanization. Similarly, 5G8 antibodies also bound well, with some antibodies displaying greater binding to 4-1BB when compared to the parental mouse-human chimeric antibody v20036.
- the thermal stability of humanized 1C8, 1G1 and 5G8 antibody variants was measured using DSC as follows. 400 ⁇ L of purified samples primarily at concentrations of 0.4 mg/mL in PBS were used for DSC analysis with a VP-Capillary DSC (GE Healthcare, Chicago, IL). At the start of each DSC run, 5 buffer blank injections were performed to stabilize the baseline, and a buffer injection was placed before each sample injection for referencing. Each sample was scanned from 20 to 100 ° C at a 60 ° C/hr rate, with low feedback, 8 sec filter, 3 or 5 min pre-scan thermostat, and 70 psi nitrogen pressure. The resulting thermograms were referenced and analyzed using Origin 7 software to determine melting temperature (Tm) as an indicator of thermal stability.
- Tm melting temperature
- Fab Tm values of select variants are 9 ⁇ 11°C higher than the Tm of the parental mouse chimera v20023.
- Figure 18 shows the corresponding DSC thermograms of the 1G1 variants that were tested.
- Fab Tm values of select variants are ⁇ 7-9°C higher than the Tm of the parental mouse chimera v20036.
- Figure 19 shows the corresponding DSC thermograms of the 5G8 variants that were tested.
- EXAMPLE 15 Purity assessment of humanized 1C8, 1G1 and 5G8 antibody variants
- EXAMPLE 16 Activation of 4-1BB by humanized antibodies
- EXAMPLE 17 Generation of additional 4-1BB x TAA antibody constructs
- bispecific antibody constructs were prepared in a similar format to the most active 4-1BB x HER2 bispecific constructs with two 4-1BB Fab and one TAA scFv at the C-terminus of the Fc, as shown in Figure 2B.
- these bispecific antibody constructs comprised a human IgG1 heterodimeric Fc having CH3 domain amino acid substitutions Het FcA and Het FcB, which drive association of the two component Fc polypeptides.
- Bispecific antibody constructs noted as “FcKO” included the following CH2 mutations designed to knock out or reduce Fc ⁇ R binding: L234A, L235A and D265S.
- Table 9 summarizes the antibody constructs that were prepared and Figure 22 provides a representation of the formats of these antibody constructs.
- Control constructs 17717 (mirvetuximab), 17449 (farletuzumab), 18490 (RG7787), and 18993 (lifastuzumab) for each TAA paratope are also depicted in Figure 22 and are described in Example 18.
- Table 15 The sequences of the scFvs used to construct the anti-TAA arm of the antibody constructs are provided in Table 16.
- Table X identifies the clones that make up each of the antibody constructs.
- the polypeptide sequences of each clone can be found in Table Y.
- Antibodies were produced by transfecting CHO-2E7 cells, and purified using Protein A and prep-SEC, as described in Example 1. After purification, the antibodies were checked for purity and lack of aggregation using LC/MS and UPLC-SEC.
- MSLN mesothelin
- NaPi2b NaPi2b
- FR ⁇ surface protein FR ⁇ surface protein
- IGROV1, OVCAR3, H441, H661, H226, H1975 and A549 tumor cells were cultured in RPMI 10% FCS in 10cm 3 plates. These cell lines were chosen due to RNA data suggesting that they would be a representative set of Ovarian and Lung cell lines expressing high, medium or low MSLN, NaPi2b and FR ⁇ .
- Cell dissociation buffer (Invitrogen) was added, and cells removed from the plate with mechanical means if necessary, using either a pipette or a cell scraper. Cells were left on ice with a pre-determined excess level of conjugated antibody, to ensure that the cells in the suspension are completely labelled.
- a series of beads with pre- determined levels of anti -human coating antibody were used as standards (816; Bangs Laboratories). Numbers of receptor per cell were calculated by comparing the level of AlexaFluor647 fluorescence on the tumour cells to a standard curve constructed using the calibration beads.
- Table 10 provides the results of surface TAA quantification and identifies tumour cell lines with high, medium and low expression of TAAs MSLN, FR ⁇ and NaPi2b.
- EXAMPLE 19 Ability of 4-1BB x TAA bispecific antibody constructs to stimulate 4- 1BB activity
- Figure 24 shows the activity of the 4-1BB x FR ⁇ antibody v22638 on 4-1BB reporter cells in co-culture with a series of tumour lines representing a range of expression.
- 4-1BB reporter cells were cultured in presence of v22638 and tumour cells with greater than -150,000 FR ⁇ proteins per cell (IGROV1, H441, H661) an activation of the reporter genes was seen.
- tumour cells with lower levels of FR ⁇ such as the H1299 cells
- no activation of 4-1BB was seen.
- the ability of 4-1BB x FR ⁇ construct v22638 to stimulate 4-1BB activity appeared to be dependent on the level of FR ⁇ expression by tumour cells in this co-culture experiment.
- v22638 showed activity on FR ⁇ high IGROV1 cells and FR ⁇ mid H441 and H661 cells but did not show activity on FR ⁇ low A549 or H1975 cells.
- CD8+ T cells were cultured with IGROV1, OVCAR3, H441, H661, H226, H1975 or A549 tumor cells and aAPC/CHO-K1 cells. After four days, supernatants were taken and IFN ⁇ measured by HTRF. GraphPad Prism v7 was used for data analysis, using the non-linear four-parameter model.
- bispecific antibodies induced cytokine production by T cells when in co-culture with tumour cells expressing the cross-linking tumour antigen.
- the 4-1BB x MSLN antibody v22630 induced IFN ⁇ production by T cells when co-cultured with H226 cells which express high levels of MSLN, but not other tumour cells which express ⁇ 300,000 MSLN molecules/cell ( Figure 25B).
- v22638, which is a bispecific antibody targeting 4-1BB and FR ⁇ shows activity on T cells in co-culture with IGROV1, OVCAR3 and H441 cells, suggesting a similar cut-off for expression of -200,000 FR ⁇ molecules/cell ( Figure 25C).
- the NaPi2b x 4-1BB antibody construct v22345 was able to enhance IFN ⁇ production by T cells co-cultured with NaPi2b high IGROV1 or OVCAR3 cells and NaPi2b mid H441 cells, but not NaPi2b mid-low H661, H226, A549 or H1975 cells. This suggests that a cut-off of -200,000-300,000 NaPi2b molecules/cell is required for function in vitro (Figure 25 A). No effect of v12592, the parental 4-1BB antibody without a TAA cross- linking arm, was seen on the T cells in co-culture with any of the tumour cell lines, suggesting that cross-linking via the TAA arm was absolutely required for activity (Figure 25D).
- Additional 4-1BB x FR ⁇ antibody constructs were prepared according to the methods described in Example 1. Table 11 describes the compositions of these additional 4-1BB x FR ⁇ antibodies, while Figure 26 provides a representation of the formats of exemplary antibodies.
- These 4-1BB x FR ⁇ antibody constructs were constructed using a subset of the mouse anti-4-1BB paratopes described in Example 7 that were shown to be agonistic to 4-1BB, and the anti-FR ⁇ paratopes mirvetuximab, rabbit paratope 1H06, and rabbit paratope 8K22.
- FR ⁇ paratopes 1H06 and 8K22 are novel rabbit anti-FR ⁇ paratopes generated as described in Example 23.
- Table 11 Composition of 4-1BB x FRa antibodies
- Table X identifies the clones that make up each of the antibody constructs.
- the polypeptide sequences of each clone can be found in Table Y.
- EXAMPLE 21 Characterization of 4-1BB x FR ⁇ antibody constructs binding to 4-1BB and FR ⁇
- Variants purified by SEC were assessed for binding to human 4-1BB.
- the antigen-binding affinity was determined by SPR according to the method described in Example 2. A summary of the SPR binding data is provided in Table 12.
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Organic Chemistry (AREA)
- Immunology (AREA)
- Medicinal Chemistry (AREA)
- Life Sciences & Earth Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Genetics & Genomics (AREA)
- Molecular Biology (AREA)
- Biophysics (AREA)
- Biochemistry (AREA)
- General Chemical & Material Sciences (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Oncology (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Pharmacology & Pharmacy (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Peptides Or Proteins (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
Abstract
Described herein are antibody constructs comprising a 4- 1BB binding domain and an anti-Folate Receptor a (FRα) antigen- binding domain, wherein the 4-1BB-binding domain and the FRα antigen-binding domain are linked directly or indirectly to a scaffold. The scaffold may be an Fc construct with modifications that reduce its ability to mediate effector function. The antibody constructs are used in the treatment of a subject having cancer.
Description
ANTIBODY CONSTRUCTS BINDING 4-1BB AND FOLATE RECEPTOR ALPHA
AND USES THEREOF
BACKGROUND
[001] 4-1BB is a member of the TNF receptor superfamily that is expressed on several types of immune cells including, but not limited to, activated T cells, NK and NKT cells, regulatory T cells, dendritic cells, B cells, and stimulated mast cells. Resting T cells do not express high levels of 4-1BB; it is upregulated after activation through the T cell receptor (TCR). Also known as CD137 or TNFRSF9, 4-1BB is expressed on non-immune cells as well, including populations of neural cells found in the brain (Bartkowiak and Curran (2015), Front. Oncol. 5:117). 4-1BB is a transmembrane receptor that is activated by binding to its ligand (4-1BBL or CD137L), which is expressed on cells such as macrophages and activated B cells. Once activated, 4-1BB functions to promote division and survival of T cells, enhance the effector function of activated T cells, and generate immunological memory.
[002] Given its pivotal role in modulating T cell function, 4-1BB and 4-1BB agonists in particular have become an attractive target for the development of cancer immunotherapies. In fact, a number of clinical trials have examined the efficacy of different 4-1BB targeting therapies, including anti-4-1BB antibodies alone, or in combination with tumor-targeting antibodies, checkpoint inhibitors, or chemotherapy. The majority of these clinical trials have been carried out using the anti-4-1BB antibody urelumab. Developed by Bristol-Myers Squibb, urelumab is a human IgG4 antibody currently in a number of Phase 1 and Phase 2 clinical trials designed to examine efficacy in treatment of cancers. However, urelumab administration is limited to doses of 0.1 mg/kg, as higher doses resulted in severe liver toxicity (Segal et al, Clin Cancer Res. 2017 Apr 15;23(8): 1929-1936).
[003] Utomilumab, developed by Pfizer, is a human IgG2 antibody that is currently in various Phase 1, Phase 2 and Phase 3 clinical trials, also designed to assess efficacy in treatment of cancers. Although utomilumab does not appear to induce dose-limiting toxi cities, early clinical data indicated that its effectiveness as a monotherapy did not appear to be significant (Makkouk, et al. (2016) European Journal of Cancer 54: 112-119).
[004] This background information is provided for the purpose of making known information believed by the applicant to be of possible relevance to the present disclosure. No admission
is necessarily intended, nor should be construed, that any of the preceding information constitutes prior art against the claimed invention(s).
SUMMARY
[005] Described herein are bispecific antibody constructs binding 4-1BB and tumor- associated antigens and uses thereof. One aspect of the present disclosure relates to an antibody construct comprising: a first 4-1BB-antigen binding domain derived from an agonistic anti-4-1BB antibody, and a first folate receptor alpha (FRα)-antigen binding domain in scFv format comprising a heavy chain variable domain (VH) sequence comprising the three heavy chain CDR sequences of antibody 8K22 and a light chain variable domain (VL) sequence comprising the three light chain CDR sequences of antibody 8K22, and further comprising one or more amino acid modifications in the VH domain and/or in the VL domain of antibody 8K22 that improve the biophysical properties of the antibody construct, wherein the first 4-1BB-antigen binding domain and the first FRα-antigen binding domain are linked directly or indirectly to a scaffold.
[006] Another aspect of the present disclosure relates to an antibody construct comprising a first 4-1BB antigen-binding domain derived from an agonistic anti-4-1BB antibody, and a first folate receptor-α (FRα) antigen -binding domain in a Fab format comprising a heavy chain variable domain (VH) comprising the three heavy chain CDR sequences of antibody 8K22 and a light chain variable domain (VL) comprising the three light chain CDR sequences of antibody 8K22, wherein the first 4-1BB antigen-binding domain and the first FRα antigen- binding domain are linked directly or indirectly to a scaffold.
[007] Another aspect of the present disclosure relates to an antibody construct comprising: a) a first 4-1BB antigen-binding domain derived from an agonistic anti-4-1BB antibody, and b) a first folate receptor-α (FRα) antigen-binding domain comprising a heavy chain variable domain (VH) comprising the three heavy chain CDR sequences of antibody 2L16 and a light chain variable domain (VL) comprising the three light chain CDR sequences of antibody 2L16, wherein the first 4-1BB antigen-binding domain and the first FRα antigen-binding domain are linked directly or indirectly to a scaffold.
[008] Another aspect of the present disclosure relates to an antibody construct or antigen- binding fragment thereof, that specifically binds to folate receptor-α (FRα), comprising: a heavy chain variable domain (VH) sequence comprising three heavy chain CDRs and a light
chain variable domain (VL) sequence comprising three light chain CDRs, wherein the heavy chain CDRs and the light chain CDRs are from antibody 2L16.
[009] Another aspect of the present disclosure relates to pharmaceutical composition comprising the antibody constructs described herein.
[0010] Another aspect of the present disclosure relates to one or more nucleic acids encoding the antibody constructs described herein.
[0011] Another aspect of the present disclosure relates to one or more vectors comprising the one or more nucleic acids encoding the antibody constructs described herein.
[0012] Another aspect of the present disclosure relates to an isolated cell comprising the one or more nucleic acids encoding the antibody constructs described herein, or the one or more vectors comprising the one or more nucleic acids.
[0013] Another aspect of the present disclosure relates to a method of preparing the antibody constructs described herein, comprising culturing the isolated cells described herein under conditions suitable for expressing the antibody construct, and purifying the antibody construct.
[0014] Another aspect of the present disclosure relates to method of treating a subject having a cancer, comprising administering to the subject an effective amount of the antibody constructs described herein.
[0015] Another aspect of the present disclosure relates to use of an effective amount of the antibody construct described herein for the treatment of cancer in a subject in need thereof.
[0016] Another aspect of the present disclosure relates to use of the antibody constructs described herein in the preparation of a medicament for the treatment of cancer.
BRIEF DESCRIPTION OF THE FIGURES
[0017] These and other features of the claimed invention(s) will become more apparent in the following detailed description in which reference is made to the appended drawings.
[0018] Figure 1 depicts exemplary antibody formats. Figure 1A provides a representation of a naturally-occurring antibody format (FSA format); Figure 1B provides a representation of a one-armed antibody format (OAA) where the anti gen -binding domain is in the Fab format; Figure 1C provides a representation of a one-armed antibody format (OAA) where the antigen-
binding domain is in the scFv format; Figure ID provides a representation of a bivalent antibody format where one antigen-binding domain is in the scFv format and the other is in a Fab format (also referred to as a hybrid format); and Figure IE provides a representation of a bivalent antibody format where both antigen-binding domains are in the scFv format (also referred to as a dual scFv format).
[0019] Figure 2 depicts a number of additional exemplary formats contemplated for the 4-1BB x TAA antibody constructs described herein. Figure 2A provides an example of a 1 x 1 format, where the antibody construct comprises one 4-1BB binding domain (depicted here as 4-1BB ligand), and one TAA antigen-binding domain (depicted here in the Fab format). Figure 2B provides an example of a 2 x 1 format, where the antibody construct comprises two 4-1BB antigen-binding domains (both depicted here in the Fab format), and one TAA antigen-binding domain (depicted here in the scFv format). Figure 2C provides an example of a 2 x 2 format, where the antibody construct comprises two 4-1BB antigen-binding domains (both depicted here in the Fab format), and two TAA antigen-binding domains (both depicted here in the scFv format). Figure 2D provides another example of a 1 x 1 format, where the antibody construct comprises one 4-1BB binding domain (depicted here in the Fab format), and one TAA antigen- binding domain (depicted here in the scFv format). Figure 2E provides another example of a 2 x 1 format, where the antibody construct comprises two 4-1BB antigen-binding domains (both depicted here in the Fab format), and one TAA anti gen -binding domain (depicted here in the scFv format), linked to one of the 4-1BB antigen-binding domains. Figure 2F provides another example of a 1 x 1 format, where the antibody construct comprises one 4-1BB binding domain (depicted here in the Fab format), and one TAA antigen-binding domain (depicted here in the scFv format); this type of antibody construct is also referred to as a hybrid format. Figure 2G provides another example of a 1 x 1 format, where the antibody construct comprises one 4- 1BB binding domain (depicted here in the Fab format), and one TAA antigen-binding domain (depicted here in the scFv format), linked to the 4-1BB antigen-binding domain. The representations in Figure 2 are exemplary only, and it is to be understood that although the 4- 1BB antigen-binding domains are depicted in the Fab format here, they may also be in the scFv or sdAb format, or if there are two 4-1BB antigen-binding domains, they may be in different formats or may bind to different epitopes of 4-1BB . Likewise, although the TAA antigen- binding domains are depicted here in the scFv format, they may also be in the Fab or sdAb format, or if there are two TAA antigen-binding domains, they may be in different formats, or may bind to different TAAs.
[0020] Figure 3 depicts the formats of exemplary 4-1BB x HER2 antibody constructs that were constructed as described in Example 1.
[0021] Figure 4 shows the ability of 4-1BB x HER2 antibody constructs in different formats and controls to activate 4-1BB in a co-culture experiment using 4-1BB-NFkB-Luciferase Jurkat reporter cells and SKOV3 or MDA-MB-468 tumour cells. Shown is the amount of luminescence induced by each antibody construct: v16675 (Figure 4A); v16679 (Figure 4B); v15534 (Figure 4C); v16601 (Figure 4D); v16605 (Figure 4E); v19353 (Figure 4F); v1040 (Figure 4G); v16992 (Figure 4H); and v12952 (Figure 41).
[0022] Figure 5 shows the ability of 4-1BB x HER2 antibody constructs in different formats and controls to activate 4-1BB in a primary CD4+ T cell co-culture experiment with and without SKBR3 tumour cells. Production of IL-2 by the T cells was measured by ELISA.
[0023] Figure 6 compares the ability of 4-1BB x HER2 antibody construct v16679, the 4-1BB antibody v12592, the 4-1BB x HER2 anticalin construct v19353, and the negative control antibody v13725 to stimulate IFNγ production in an assay in which CD4+, CD8+ or pan-T cells were co-cultured with HER2+ SKBR3 cells.
[0024] Figure 7 depicts the ability of chimeric 4-1BB antibodies to stimulate 4-1BB activity in a 4-1BB-NF-KB reporter gene assay when crosslinked with an anti-Fc antibody. The four columns for each variant correspond (in order right-to-left) to the concentrations of antibody construct tested: 2.5μg/ml, 0.833μg/ml, 0.277μg/ml, 0.092μg/ml.
[0025] Figure 8 shows the constructs used for domain-mapping of antibody binding to 4-1BB. Figure 8A shows the human, dog and dog-human chimeric 4-1BB constructs; Figure 8B shows the full-length transmembrane human 4-1BB and the truncated human domain 3 and 4 construct.
[0026] Figure 9 shows the ability of chimeric 4-1BB antibodies and controls to bind to human and dog 4-1BB. The results are shown for v12592 in Figure 9A; for v12593 in Figure 9B; for v20022 in Figure 9C; for v20023 in Figure 9D; for v20025 in Figure 9E; for v20029 in Figure 9F; for v20032 in Figure 9G; for v20036 in Figure 9H, and for v20037 in Figure 91.
[0027] Figure 10 depicts the ability of chimeric antibodies to bind to various 4-1BB proteins expressed in 293E6 cells.
[0028] Figure 11A shows the ability of chimeric antibodies to bind to cynomolgus 4-1BB. Figure 11B depicts the ability of these chimeric antibodies to bind to mouse 4-1BB.
[0029] Figure 12 shows the sequences of the mouse heavy chain variable domain CDRs of A) 1C8, B) 1G1 and C) 5G8 ported onto a human framework, as well as mouse light chain variable domain CDRs of D) 1C8, E) 1G1 and F) 5G8 ported onto a human framework. The sequences are numbered according to Rabat and the CDRs were assigned with the AbM definition and are identified by
[0030] Figure 13 depicts the SPR sensorgrams of representative humanized 4-1BB antibodies derived from mouse 1C8 antibody.
[0031] Figure 14 depicts the SPR sensorgrams of representative humanized 4-1BB antibodies derived from mouse 1G1 antibody.
[0032] Figure 15 depicts the SPR sensorgrams of representative humanized 4-1BB antibodies derived from mouse 5G8 antibody.
[0033] Figure 16A depicts the ability of humanized 4-1BB antibodies derived from 1C8 to bind cells expressing 4-1BB as measured by flow cytometry. Figure 16B depicts the ability of humanized 4-1BB antibodies derived from 1G1 to bind cells expressing 4-1BB as measured by flow cytometry. Figure 16C depicts the ability of humanized 4-1BB antibodies derived from 5G8 to bind cells expressing 4-1BB as measured by flow cytometry.
[0034] Figure 17 depicts the DSC thermograms of humanized antibodies derived from 1C8.
[0035] Figure 18 depicts the DSC thermograms of humanized antibodies derived from 1G1.
[0036] Figure 19 depicts the DSC thermograms of humanized antibodies derived from 5G8.
[0037] Figure 20 depicts the LC-MS profile of a representative purified humanized antibody derived from 1C8.
[0038] Figure 21A shows the ability of humanized 4-1BB antibodies derived from 1C8 to stimulate 4-1BB activity in the 4-1BB-NF-KB-1UC reporter assay. Figure 21B shows the ability of humanized 4-1BB antibodies derived from 1G1 to stimulate 4-1BB activity in the 4-1BB- NF-KB-1UC reporter assay. Figure 21C shows the ability of humanized 4-1BB antibodies derived from 5G8 to stimulate 4-1BB activity in the 4-1BB-NF-KB-1UC reporter assay.
[0039] Figure 22 depicts the formats of exemplary 4-1BB x TAA antibody constructs prepared as described in Example 17.
[0040] Figure 23A depicts the ability of 4-1BB x MSLN antibody constructs v22329 and v22639 to stimulate 4-1BB activity in a co-culture experiments using 4-1BB-NF-KB- Luciferase Jurkat reporter cells and MSLNhigh H226 tumour cells or MSLNlow A549 cells. Figure 23B depicts the ability of 4-1BB x MSLN antibody constructs v22353 and v22630 to stimulate 4-1BB activity in the same assay.
[0041] Figure 24 shows the ability of the 4-1BB x FRα antibody construct v22638 to stimulate 4-1BB activity in the 4-1BB-NF-KB-Luciferase Jurkat reporter cell co-culture assay.
[0042] Figure 25A shows the ability of the 4-1BB x NaPi2b construct v22345 to enhance IFNγ production by CD8 cells when co-cultured with tumor cells expressing NaPi2b at different levels. Figure 25B shows the ability of the 4-1BB x MSLN construct v22630 to enhance IFNγ production by CD8 cells when in co-culture with various tumor cells expressing MSLN at varying levels. Figure 25C shows the ability of the 4-1BB x FRα construct v22638 to enhance IFNγ production by CD8 T cells when in co-culture with various tumor cells expressing FRα at varying levels. Figure 25D shows that the control 4-1BB monospecific antibody v12592 is unable to enhance IFNγ production by CD8 T cells when in co-culture with various tumor cells expressing varying levels of TAA.
[0043] Figure 26 shows the formats of exemplary 4-1BB x FRα antibody constructs prepared as described in Example 20. The scFv orientation depicted in this Figure is for illustration only; the scFvs in the constructs may be in VH-VL or VL-VH orientation as described in Table 11
[0044] Figure 27 depicts the ability of 4-1BB x FRα antibody constructs to bind to 4-1BB- expressing Jurkat cells as measured by flow cytometry. Figure 27A shows the data for antibody constructs having a 4-1BB paratope derived from mouse antibody 1C8; Figure 27B from mouse antibody 2E8; Figure 27C from mouse antibody 4E6; Figure 27D from mouse antibody 5G8; Figure 27E from mouse antibody 6B3, and Figure 27F from antibody MOR7480.1.
[0045] Figure 28 depicts the ability of the 4-1BB x FRα antibody constructs to bind to FRα expressed on 293E cells as measured by flow cytometry. Figure 28A depicts the ability of
v23656, v23657, v23658, v23659, and v23660 to bind to cells; Figure 28B depicts the ability of v23661, v23662, v23663, v23664, and v23665 to bind to cells, and Figure 28C depicts the ability of v23651, v17721, and IgG1 to bind to cells.
[0046] Figure 29A depicts the ability of 4-1BB x FRα antibody constructs having FRα paratope 8K22 to stimulate IFNγ production in a CD8+ T cell co-culture assay with FRαhigh IGROV1 cells or FRαlow A549 cells. Figure 29B depicts the ability of 4-1BB x FRα antibody constructs having FRα paratope 1H06 to stimulate IFNγ production in a CD8+ T cell co-culture assay. Figure 29C depicts the ability of monospecific 4-1BB antibodies v20022, v20036 or v12592 and the monospecific FRα antibody v17721 to stimulate IFNγ production in the CD8+ T cell co-culture assay.
[0047] Figure 30A and Figure 30B depict UPLC-SEC and Caliper profiles, respectively, of purified parental chimeric 8K22 variant 23820, while Figure 30C and Figure 30D depict UPLC-SEC and Caliper profiles, respectively, of purified representative humanized 8K22 variant 23807.
[0048] Figure 31A depicts the BLI sensorgrams for the parental chimeric 8K22 antibody v23820 and two representative humanized 8K22 antibodies v23801 and v23807 in the supernatant. Figure 31B depicts the BLI sensorgrams for the parental chimeric 8K22 antibody v23820 and the two representative humanized 8K22 antibodies v23801 and v23807 after purification.
[0049] Figure 32A depicts the DSC thermograms of purified representative humanized 8K22 antibodies exhibiting a single transition. Figure 32B depicts the DSC thermograms of purified representative humanized 8K22 antibodies exhibiting a two-state transition.
[0050] Figure 33A depicts the LC/MS profile of purified representative humanized 8K22 antibody v23801. Figure 33B depicts the LC/MS profile of purified representative humanized 8K22 antibody v23807.
[0051] Figure 34 depicts the DSC thermograms of antibodies having 8K22 binding arms.
[0052] Figure 35A depicts the BLI sensorgram for v29675; Figure 35B depicts the BLI sensorgram for v29677; Figure 35C depicts the BLI sensorgram for v29680.
[0053] Figure 36 depicts representations of the additional 4-1BB x FRα bispecific antibodies prepared and tested as described in Example 33.
[0054] Figure 37 depicts the ability of various 4-1BB x FRα bispecific antibodies to stimulate IFNγ production in a primary T cell humour cell co-culture assay with IGROV1 cells.
[0055] Figure 38A depicts the ability of 4-1BB x FRα bispecific antibodies to activate 4-1BB in an NFκB reporter gene assay with IGROV1 cells. Figure 38B depicts the ability of 4-1BB x FRα bispecific antibodies to activate 4-1BB in an NFκB reporter gene assay with A431 cells. Figure 38C depicts the ability of 4-1BB x FRα bispecific antibodies to activate 4-1BB in an NFκB reporter gene assay with HCC827 cells. Figure 38D depicts the ability of 4-1BB x FRα bispecific antibodies to activate 4-1BB in an NFκB reporter gene assay with OVKATE cells. Figure 38E depicts the ability of 4-1BB x FRα bispecific antibodies to activate 4-1BB in an NFκB reporter gene assay with OVCAR3 cells. Figure 38F depicts the ability of 4-1BB x FRα bispecific antibodies to activate 4-1BB in an NFκB reporter gene assay with H661 cells. Figure 38G depicts the ability of 4-1BB x FRα bispecific antibodies to activate 4-1BB in an NFκB reporter gene assay with H441 cells. Figure 38H depicts the ability of 4-1BB x FRα bispecific antibodies to activate 4-1BB in an NFκB reporter gene assay with H1975 cells.
[0056] Figure 39A demonstrates the ability of the mouse anti 4-1BB paratope 1C8 to bind to cyno 4-1BB; Figure 39D demonstrates the ability of the humanized anti-4-1BB paratope 1C8 to bind to cyno 4-1BB. Figure 39B demonstrates the ability of the mouse anti 4-1BB paratope 1G1 to bind to cyno 4-1BB; Figure 39E demonstrates the ability of the humanized anti-4-1BB paratope 1G1 to bind to cyno 4-1BB. Figure 39C demonstrates the ability of the mouse anti 4- 1BB paratope 5G8 to bind to cyno 4-1BB; Figure 39F demonstrates the ability of the humanized anti-4-1BB paratope 5G8 to bind to cyno 4-1BB.
[0057] Figure 40A shows the sequence of the rabbit heavy chain variable domain CDRs of 8K22 ported onto a human framework; Figure 40B shows the sequence of the rabbit light chain variable domain CDRs of 8K22 ported onto a human framework. The sequences are numbered according to Rabat and the CDRs were assigned with the AbM definition and are identified by "*"
[0058] Figure 41A and Figure 41B depict DSC thermograms of variant 31332 and 31586, respectively.
[0059] Figure 42A, Figure 42B, and Figure 42C depict BLI sensorgrams for variants 31332, 31586, and 31588, respectively.
[0060] Figure 43A depicts the UPLC-SEC profde for variant 31586 at day 0 and day 14 after high temperature treatment, while Figure 43B depicts the UPLC-SEC profde for variant 31588 at day 0 and day 14 after high temperature treatment.
[0061] Figure 44A, Figure 44B, Figure 44C, and Figure 44D depict exemplary formats of various 4-1BB x FRα antibody constructs, 31946, 32681, 33568, and 32693, respectively.
[0062] Figure 45A depicts the LC/MS analysis of variant 33568, while Figure 45B depicts the LC/MS analysis of variant 33569.
[0063] Figure 46A shows the alignment of the sequence of the 2L16 rabbit heavy chain variable domain with the closest human Germline and subsequent grafting of the CDRs of 2L16 onto a human framework; Figure 46B shows the alignment of the sequence of the 2L16 rabbit light chain variable domain with the closest human Germline and subsequent grafting of the CDRs of 2L16 onto a human framework. The sequences are numbered according to Rabat and the CDRs were assigned with the AbM definition and are identified in bold text.
[0064] Figures 47A and 47C show the UPLC-SEC profiles for the parental chimeric antibody v30048 and a representative humanized variant, v32680, respectively. Figures 47B and 47D show the Caliper results for the parental chimeric antibody v30048 and a representative humanized variant, v32680, respectively.
[0065] Figure 48A shows the BLI results for the C-terminal rabbit parental chimeric scFv v30048 while the BLI results for two representative 1G1 x humanized 2L16 antibodies, v31946 and v32681, are shown in Figure 48B and Figure 48C, respectively.
[0066] Figure 49A depicts a thermogram for variant 31946; Figure 49B depicts a thermogram for variant 32681.
[0067] Figure 50A depicts the LC/MS profile for v32681, while Figure 50B depicts the LC/MS profile for v31946.
[0068] Figure 51A provides the BLI sensorgram for a representative bispecific antibody variant 31946; Figure 51B provides the BLI sensorgram for the Parent Fab antibody 32680;
Figure 51C provides the BLI sensorgram for variant 33570, and Figure 5 ID provides the BLI sensorgram for the variant 33571.
[0069] Figure 52A depicts the ability of variants 16952, 30048, and 30335 to activate 4-1BB in an NFκB reporter gene assay; Figure 52B depicts the ability of variants 31946, 32680, and 32681 to activate 4-1BB in an NFκB reporter gene assay; Figure 52C depicts the ability of variants 32683, 32685, and 32686 to activate 4-1BB in an NFκB reporter gene assay; and Figure 52D depicts the ability of variants 32687, 32688, and 32693 to activate 4-1BB in an NFκB reporter gene assay.
[0070] Figure 53 depicts the ability of 1G1 x humanized 2L16 bispecific antibody constructs to stimulate 4-1BB activity in an NFκB reporter gene assay.
[0071] Figure 54 depicts the ability of a modified 1G1 x 8K22 bispecific antibody to stimulate 4-1BB activity in an NFκB reporter gene assay.
[0072] Figure 55A depicts the ability of a modified 1G1 x 8K22 bispecific antibody to stimulate 4-1BB activity in an NFκB reporter gene assay in co-culture with IGROV1 cells. Figure 55B depicts the ability of a modified 1G1 x 8K22 bispecific antibody to stimulate 4- 1BB activity in an NFκB reporter gene assay in co-culture with HCC1954 cells. Figure 55C depicts the ability of a modified 1G1 x 8K22 bispecific antibody to stimulate 4-1BB activity in an NFκB reporter gene assay in co-culture with NCI-N87 cells. Figure 55D depicts the ability of a modified 1G1 x 8K22 bispecific antibody to stimulate 4-1BB activity in an NFκB reporter gene assay in co-culture with SK-BR-3 cells. Figure 55E depicts the ability of a modified 1G1 x 8K22 bispecific antibody to stimulate 4-1BB activity in an NFκB reporter gene assay in co- culture with NCI-H226 cells. Figure 55F depicts the ability of a modified 1G1 x 8K22 bispecific antibody to stimulate 4-1BB activity in an NFκB reporter gene assay in co-culture with JIMT-1 cells. Figure 55G depicts the ability of a modified 1G1 x 8K22 bispecific antibody to stimulate 4-1BB activity in an NFκB reporter gene assay in co-culture with NCI-H661 cells. The identification of variants in the legend is the same for Figures 55A-G and is shown once on each page.
[0073] Figure 56A depicts the ability of a 1G1 x humanized 8K22 bispecific antibody to reduce tumor volume in mice bearing wild-type MC38 mouse tumor cells. Figure 56B depicts the ability of a 1G1 x humanized 8K22 bispecific antibody to reduce tumor volume in mice bearing
MC38 mouse tumor cells engineered to overexpress human FRα. In both Figures 56A and 56B, the arrows represent timepoints at which test articles were administered.
DETAILED DESCRIPTION
[0074] The present disclosure relates to 4-1BB x folate receptor a (FRα) antibody constructs that specifically bind to a 4-1BB extracellular domain (ECD) and to FRα. In some embodiments, the 4-1BB x FRα antibody constructs may be capable of conditionally enhancing the activity of T cells within a tumor. In some embodiments, the 4-1BB x FRα antibody constructs are capable of promoting conditional agonism of 4-1BB. In some embodiments, the 4-1BB x FRα antibody constructs may be more effective in activating 4-1BB on T cells in the presence of FRα -expressing cells compared to a monospecific, monovalent anti-4-1BB antibody, as measured by cytokine production. In related embodiments, the 4-1BB x FRα antibody constructs may be used to treat cancer.
[0075] More specifically, described herein are 4-1BB x FRα antibody constructs wherein the FRα antigen-binding domain is derived from the anti-FRα antibody 8K22, is in an scFv format and comprises one or more amino acid modifications that improve the biophysical properties of the antigen-binding construct. Also described herein are 4-1BB x FRα antibody constructs wherein the FRα antigen-binding domain is derived from the anti-FRα antibody 8K22 and is in the Fab format. The present disclosure further provides 4-1BB x FRα antibody constructs comprising an anti-FRα antigen-binding domain is derived from the anti-FRα antibody 2L16. The latter antigen-binding constructs may be in a number of different formats as described generally herein.
[0076] The present disclosure further provides antibody sequences that specifically bind 4- 1BB (anti-4-1BB antibody sequences). These anti-4-1BB antibody sequences may be used in the preparation of monospecific, bispecific, or multispecific antibody constructs that bind to 4- 1BB (4-1BB antibody constructs). These monospecific, bispecific, or multispecific 4-1BB antibody constructs may also be used in the treatment of cancer, either alone or in combination with other anti-cancer therapies.
[0077] Further provided are novel antibody sequences that specifically bind FRα (anti-FRα antibody sequences). In one embodiment the novel antibody sequence is derived from the 2L16 paratope. These anti-FRα antibody sequences may be used in the preparation of monospecific, bispecific, or multispecific antibody constructs that bind to FRα (FRα antibody
constructs). These monospecific, bispecific, or multispecific FRα antibody constructs may also be used in the treatment of cancer, either alone or in combination with other anti-cancer therapies.
Definitions
[0078] Unless defined otherwise, all technical and scientific terms used herein have the same meaning as is commonly understood by one of skill in the art to which the claimed subject matter belongs. In the event that there are a plurality of definitions for terms herein, those in this section prevail. Where reference is made to a URL or other such identifier or address, it is understood that such identifiers can change and particular information on the internet can come and go, but equivalent information can be found by searching the internet. Reference thereto evidences the availability and public dissemination of such information.
[0079] It is to be understood that the foregoing general description and the following detailed description are exemplary and explanatory only and are not restrictive of any subject matter claimed. In this application, the use of the singular includes the plural unless specifically stated otherwise.
[0080] In the present description, any concentration range, percentage range, ratio range, or integer range is to be understood to include the value of any integer within the recited range and, when appropriate, fractions thereof (such as one tenth and one hundredth of an integer), unless otherwise indicated. As used herein, "about" means ± 1%, 2%, 3%, 4%, 5%, 6%, 7%, 8%, 9% or 10% of the indicated range, value, sequence, or structure, unless otherwise indicated. It should be understood that the terms "a" and "an" as used herein refer to "one or more" of the enumerated components unless otherwise indicated or dictated by its context. The use of the alternative (e.g., "or") should be understood to mean either one, both, or any combination thereof of the alternatives.
[0081] As used herein, the terms “include,” “have,” “contain,” “comprise,” and grammatical variations thereof are used synonymously. These terms are inclusive or open-ended and do not exclude additional, unrecited elements and/or method steps. The term “consisting essentially of’ when used herein in connection with a composition, use or method, denotes that additional elements and/or method steps may be present, but that these additions do not materially affect the manner in which the recited composition, method or use functions. The term “consisting of’ when used herein in connection with a composition, use or method, excludes the presence
of additional elements and/or method steps. A composition, use or method described herein as comprising certain elements and/or steps may also, in certain embodiments consist essentially of those elements and/or steps, and in other embodiments consist of those elements and/or steps, whether or not these embodiments are specifically referred to.
[0082] It is also to be understood that the positive recitation of a feature in one embodiment serves as a basis for excluding the feature in a particular embodiment. For example, where a list of options is presented for a given embodiment or claim, it is to be understood that one or more option may be deleted from the list and the shortened list may form an alternative embodiment, whether or not such an alternative embodiment is specifically referred to.
[0083] The section headings used herein are for organizational purposes only and are not to be construed as limiting the subject matter described. All documents, or portions of documents, cited in the application including, but not limited to, patents, patent applications, articles, books, manuals, and treatises are hereby expressly incorporated by reference in their entirety for any purpose.
[0084] It is to be understood that the methods and compositions described herein are not limited to the particular methodology, protocols, cell lines, constructs, and reagents described herein and as such may vary. It is also to be understood that the terminology used herein is for the purpose of describing particular embodiments only and is not intended to limit the scope of the methods and compositions described herein.
[0085] All publications and patents mentioned herein are incorporated herein by reference in their entirety for the purpose of describing and disclosing, for example, the constructs and methodologies that are described in the publications, which might be used in connection with the methods, compositions and compounds described herein. The publications discussed herein are provided solely for their disclosure prior to the fding date of the present application. Nothing herein is to be construed as an admission that the inventors described herein are not entitled to antedate such disclosure by virtue of prior invention or for any other reason.
[0086] In the present application, amino acid names and atom names (e.g. N, O, C, etc.) are used as defined by the Protein DataBank (PDB) (www.pdb.org), which is based on the IUPAC nomenclature (IUPAC Nomenclature and Symbolism for Amino Acids and Peptides (residue names, atom names etc.), Eur. J. Biochem, 138, 9-37 (1984) together with their corrections in Eur. J. Biochem., 152, 1 (1985). The term “amino acid residue” is primarily intended to indicate
an amino acid residue contained in the group consisting of the 20 naturally occurring amino acids, i.e. alanine (Ala or A), cysteine (Cys or C), aspartic acid (Asp or D), glutamic acid (Glu or E), phenylalanine (Phe or F), glycine (Gly or G), histidine (His or H), isoleucine (lie or I), lysine (Lys or K), leucine (Leu or L), methionine (Met or M), asparagine (Asn or N), proline (Pro or P), glutamine (Gin or Q), arginine (Arg or R), serine (Ser or S), threonine (Thr or T), valine (Val or V), tryptophan (Trp or W), and tyrosine (Tyr or Y) residues.
[0087] Terms understood by those in the art of antibody technology are each given the meaning acquired in the art, unless expressly defined differently herein. Antibodies are known to have variable regions, a hinge region, and constant domains. Immunoglobulin structure and function are reviewed, for example, in Harlow et al, Eds., Antibodies: A Laboratory Manual, Chapter 14 (Cold Spring Harbor Laboratory, Cold Spring Harbor, 1988).
[0088] As used herein, the terms “antibody” and “immunoglobulin” are used interchangeably. An “antibody” refers to a polypeptide substantially encoded by an immunoglobulin gene or immunoglobulin genes, or one or more fragments thereof, which specifically bind an analyte (antigen). The recognized immunoglobulin genes include the kappa, lambda, alpha, gamma, delta, epsilon and mu constant region genes, as well as the myriad immunoglobulin variable region genes. Light chains are classified as either kappa or lambda. Heavy chains are classified as gamma, mu, alpha, delta, or epsilon, which in turn define the immunoglobulin isotypes, IgG, IgM, IgA, IgD, and IgE, respectively. Further, the antibody can belong to one of a number of subtypes, for instance, the human IgG can belong to the IgG1, IgG2, IgG3, or IgG4 subtypes.
[0089] An exemplary immunoglobulin (antibody) structural unit is composed of two pairs of polypeptide chains, each pair having one immunoglobulin “light” (about 25 kD) and one immunoglobulin “heavy” chain (about 50-70 kD). This type of immunoglobulin or antibody structural unit is considered to be “naturally occurring,” or in a “naturally occurring format.” The term “light chain” includes a full-length light chain and fragments thereof having sufficient variable domain sequence to confer binding specificity. A full-length light chain includes a variable domain, VL, and a constant domain, CL. The variable domain of the light chain is at the amino-terminus of the polypeptide. Light chains include kappa chains and lambda chains. The term “heavy chain” includes a full-length heavy chain and fragments thereof having sufficient variable region sequence to confer binding specificity. A full-length heavy chain includes a variable domain, VH, a hinge region, and constant domains, CH1, CH2, and CH3, optionally a CH4 domain. The VH domain is at the amino-terminus of the polypeptide, and the
CH domains are at the carboxyl-terminus, with the CH3 (or CH4 where present) domain being closest to the carboxy-terminus of the polypeptide. Heavy chains can be of any isotype, including IgG (including IgG1, IgG2, IgG3 and IgG4 subclasses), IgA (including IgA1 and IgA2 subclasses), IgM, IgD and IgE. The term “variable region” or “variable domain” refers to a portion of the light and/or heavy chains of an antibody generally responsible for antigen recognition, typically including approximately the amino -terminal 120 to 130 amino acids in the heavy chain (VH) and about 100 to 110 amino terminal amino acids in the light chain (VL).
[0090] The terms “antigen,” “immunogen,” “antibody target,” “target analyte,” and like terms are used herein to refer to a molecule, compound, or complex that is recognized by an antibody, i.e. can be specifically bound by the antibody. The term can refer to a molecule that can be specifically recognized by an antibody, e.g., a polypeptide, polynucleotide, carbohydrate, lipid, chemical moiety, or combinations thereof (e.g., phosphorylated or glycosylated polypeptides, etc.). One of skill will understand that the term does not indicate that the molecule is immunogenic in every context, but simply indicates that it can be targeted by an antibody.
[0091] An “antigen-binding domain” is that portion of an antibody that is capable of specifically binding to an epitope or antigen. The epitope- or antigen-binding function of an antibody can be performed by fragments of an antibody in a naturally occurring format. Examples of antigen-binding domains include (i) a Fab fragment, a monovalent fragment consisting of the VH, VL, CH1 and CL domains; (ii) a F(ab')2 fragment, a bivalent fragment comprising two Fab fragments linked by a disulfide bridge at the hinge region; (iii) a Fd fragment consisting of the VH and CH1 domains; (iv) a Fv fragment consisting of the VH and VL domains of a single arm of an antibody, (v) a sdAb fragment (Ward et al, (1989) Nature 341 :544-546), which comprises a single variable domain; and (vi) an isolated complementarity determining region (CDR). Exemplary formats of the antigen-binding domains described herein include but are not limited to the Fab, scFv, VHH, or sdAb formats. Furthermore, methods of converting between types of antigen-binding domains are known in the art (see, for example, methods for converting an scFv to a Fab format described in Zhou et al (2012) Mol Cancer Ther 11:1167-1476). Thus, if an antibody is available in a format that includes an antigen-binding domain that is an scFv, but it is desired that the antibody construct comprise an antigen-binding domain in a Fab format, one of skill in the art would be able to make such conversion, and vice-versa.
[0092] A “Fab fragment” (also referred to as fragment antigen-binding, Fab format) includes the constant domain (CL) sequences of the light chain and the constant domain 1 (CH1) of the heavy chain along with the variable domains VL and VH on the light and heavy chains, respectively. The variable domains comprise the CDRs, which are involved in antigen-binding. Fab' fragments differ from Fab fragments by the addition of a few amino acid residues at the C-terminus of the heavy chain CH1 domain, including one or more cysteines from the antibody hinge region.
[0093] A “single-chain Fv” or “scFv” format includes the VH and VL domains of an antibody in a single polypeptide chain. The scFv polypeptide may optionally further comprise a polypeptide linker between the VH and VL domains which enables the scFv to form a desired structure for antigen binding. For a review of scFvs see Pluckthun in The Pharmacology of Monoclonal Antibodies , vol. 113, Rosenburg and Moore eds., Springer-Verlag, New York, pp. 269-315 (1994).
[0094] A “single domain antibody” or “sdAb” format refers to a single immunoglobulin domain. The sdAb may be, for example, of camelid origin. Camelid antibodies lack light chains and their antigen-binding sites consist of a single domain, termed a “VHH.” An sdAb comprises three CDR/hypervariable loops that form the anti gen -binding site: CDR1, CDR2 and CDR3. SdAbs are fairly stable and can be expressed as a fusion with the Fc region of an antibody (see, for example, Harmsen MM, De Haard HJ (2007) “Properties, production, and applications of camelid single-domain antibody fragments,” Appl. Microbiol Biotechnol. 77(1): 13-22).
[0095] Antibodies bind to an “epitope” on an antigen. The epitope is the localized site on the antigen that is recognized and bound by the antibody. Epitopes can include a few amino acids, e.g., 5 or 6, or more, e.g., 20 or more amino acids. In some cases, the epitope includes non- protein components, e.g., from a carbohydrate, nucleic acid, or lipid. In some cases, the epitope is a three-dimensional moiety. Thus, for example, where the target is a protein, the epitope can be comprised of consecutive amino acids, or amino acids from different parts of the protein that are brought into proximity by protein folding (e.g., a discontinuous epitope). The same is true for other types of target molecules that form three-dimensional structures.
[0096] An epitope may be determined by obtaining an X-ray crystal structure of an antibody: antigen complex and determining which residues on the antigen are within a specified
distance of residues on the antibody of interest, wherein the specified distance is, 5Å or less, e.g., 5 Å, 4A, 3 Å, 2Å, 1Å or less, or any distance in between. In some embodiments, the epitope is defined as a stretch of 8 or more contiguous amino acid residues along the antigen sequence in which at least 50%, 70% or 85% of the residues are within the specified distance of the antibody or binding protein in the X-ray crystal structure. Mapping of epitopes recognized by antibodies can also be performed as described in detail in “Epitope Mapping Protocols” (Methods in Molecular Biology) by Glenn E. Morris ISBN-089603-375-9 (1996), and in “Epitope Mapping: A Practical Approach” Practical Approach Series, 248 by Olwyn M. R. Westwood, Frank C. Hay. (2001). For example, X-ray co-crystallography, cryogenic electron microscopy, array-based oligo-peptide scanning, site-directed mutagenesis mapping, hydrogen-deuterium exchange, cross-linking coupled mass spectrometry, may be used to determine or map epitopes. These methods are well-known in the art.
[0097] The term “specifically binds” as used herein, refers to a binding agent’s ability to discriminate between possible partners in the environment in which binding is to occur. A binding agent may be an antibody, antibody construct or antigen-binding domain, for example. A binding agent that interacts with one particular target when other potential targets are present is said to “bind specifically” to the target with which it interacts. In some embodiments, specific binding is assessed by detecting or determining degree of association between the binding agent and its partner; in some embodiments, specific binding is assessed by detecting or determining degree of dissociation of a binding agent-partner complex; in some embodiments, specific binding is assessed by detecting or determining ability of the binding agent to compete an alternative interaction between its partner and another entity. In some embodiments, specific binding is assessed by performing such detections or determinations across a range of concentrations. The term “specifically binds” as used herein in relation to antigen-binding domains, antibodies or antibody constructs means that the antigen-binding domains, antibodies or antibody constructs bind to their target antigen with no or insignificant binding to other antigens.
[0098] A “complementarity determining region” or “CDR” is an amino acid sequence that contributes to antigen-binding specificity and affinity. “Framework” regions (FR) can aid in maintaining the proper conformation of the CDRs to promote binding between the antigen- binding region and an antigen. Structurally, framework regions can be located in antibodies between CDRs. The variable regions typically exhibit the same general structure of relatively
conserved framework regions (FR) joined by three hyper variable regions, also known as CDRs. The CDRs from the variable domains of the heavy chain and light chain typically are aligned by the framework regions, which can enable binding to a specific epitope. From N- terminal to C-terminal, both light and heavy chain variable domains typically comprise the domains FR1, CDR1, FR2, CDR2, FR3, CDR3, and FR4. The assignment of amino acids to each domain is typically in accordance with the definitions of Rabat Sequences of Proteins of Immunological Interest (National Institutes of Health, Bethesda, Md. (1987 and 1991)), unless stated otherwise. Typically, there are three heavy chain and three light chain CDRs (or CDR regions) in the variable portion of an immunoglobulin. The three heavy chain CDRs are referred to herein as HCDR1, HCDR2, and HCDR3, while the three light chain CDRs are referred to as LCDR1, LCDR2, and LCDR3. Thus, “CDRs” as used herein may refer to all three heavy chain CDRs, or all three light chain CDRs (or both all heavy and all light chain CDRs, if appropriate). CDRs provide the majority of contact residues for the binding of the antibody to the antigen or epitope. Often, the three heavy chain CDRs and the three light chain CDRs are required to bind antigen. However, in some instances, even a single variable domain can confer binding specificity to the antigen. Furthermore, as is known in the art, in some cases, antigen-binding may also occur through a combination of a minimum of one or more CDRs selected from the VH and/or VL domains, for example HCDR3.
[0099] A number of different definitions of the CDR sequences are in common use, including those described by Rabat et al. (1983, Sequences of Proteins of Immunological Interest, NIH Publication No. 369-847, Bethesda, MD), by Chothia et al. (1987, J Mol Biol, 196:901-917), as well as the IMGT, AbM (University of Bath) and Contact (MacCallum R. M., and Martin A. C. R. and Thornton J. M, (1996), Journal of Molecular Biology, 262 (5), 732-745) definitions. By way of example, CDR definitions according to Rabat, Chothia, IMGT, AbM and Contact are provided in Table A below. Accordingly, as would be readily apparent to one skilled in the art, the exact numbering and placement of CDRs may differ based on the numbering system employed. However, it is to be understood that the disclosure herein of a VH includes the disclosure of the associated (inherent) heavy chain CDRs (HCDRs) as defined by any of the known numbering systems. Similarly, disclosure herein of a VH includes the disclosure of the associated (inherent) heavy chain CDRs (HCDRs) as defined by any of the known numbering systems.
Table A: Common CDR Definitions1

1 Either the Kabat or Chothia numbering system may be used for HCDR2, HCDR3 and the light chain CDRs for all definitions except Contact, which uses Chothia numbering
2 Using Kabat numbering. The position in the Kabat numbering scheme that demarcates the end of the Chothia and IMGT CDR-H1 loop varies depending on the length of the loop because Kabat places insertions outside of those CDR definitions at positions 35A and 35B. However, the IMGT and Chothia CDR-H1 loop can be unambiguously defined using Chothia numbering. CDR-H1 definitions using Chothia numbering: Kabat H31-H35, Chothia H26-H32, AbM H26-H35, IMGT H26-H33, Contact H30-H35.
[00100] Throughout this specification, amino acid residues in VH and VL sequences are numbered according to the Kabat scheme, unless otherwise indicated.
[00101] “Chimeric antibody,” as used herein, refers to an antibody whose amino acid sequence includes VH and VL sequences that are found in a first species and constant domain sequences that are found in a second species, different from the first species. In many embodiments, a chimeric antibody has murine VH and VL sequences linked to human constant domain sequences.
[00102] “Humanized” forms of non-human (e.g., rodent) antibodies are antibodies that contain minimal sequence derived from non-human immunoglobulin. For the most part, humanized antibodies are human immunoglobulins (recipient antibody) in which residues from a hypervariable region of the recipient are replaced by residues from a hypervariable region of a non-human species (donor antibody) such as mouse, rat, rabbit or nonhuman primate having the desired specificity, affinity, or capacity. In some instances, framework region (FR) residues of the human immunoglobulin are replaced by corresponding non-human residues. Furthermore, humanized antibodies may comprise residues that are not found in the recipient
antibody or in the donor antibody. These modifications are made to further refine antibody performance. In general, the humanized antibody will comprise substantially all of at least one, and typically two, variable domains, in which all or substantially all of the hypervariable regions correspond to those of a non-human immunoglobulin and all or substantially all of the FRs are those of a human immunoglobulin sequence. The humanized antibody optionally also will comprise at least a portion of an immunoglobulin constant region (Fc), typically that of a human immunoglobulin. For further details, see Jones et al., Nature 321:522-525 (1986); Riechmann et al, Nature 332:323-329 (1988); and Presta, Curr. Op. Struct. Biol. 2:593-596 (1992).
[00103] “CDR-grafted antibody,” or “CDR-ported antibody” as used herein, refers to an antibody whose amino acid sequence comprises heavy and light chain variable region sequences from one species but in which the sequences of one or more of the CDR sequences of VH and/or VL sequences are replaced with CDR sequences of another species, such as antibodies having mouse VH and VL sequences in which one or more of the mouse CDRs (e.g., HCDR3) has been replaced with human CDR sequences. Likewise, a “CDR-grafted antibody” may also refer to antibodies having human VH and VL regions in which one or more of the human CDRs (e.g., CDR3) has been replaced with mouse CDR sequences.
[00104] As used herein, a first antibody, or an antigen-binding portion thereof, “competes” for binding to a target with a second antibody, or an antigen-binding portion thereof, when binding of the second antibody with the target is detectably decreased in the presence of the first antibody compared to the binding of the second antibody in the absence of the first antibody. The alternative, where the binding of the first antibody to the target is also detectably decreased in the presence of the second antibody, can, but need not be the case. That is, a second antibody can inhibit the binding of a first antibody to the target without that first antibody inhibiting the binding of the second antibody to the target. However, where each antibody detectably inhibits the binding of the other antibody to its cognate epitope or ligand, whether to the same, greater, or lesser extent, the antibodies are said to “cross -compete” with each other for binding of their respective epitope(s). Both competing and cross -competing antibodies are encompassed by the present disclosure. The term “competitor” antibody can be applied to the first or second antibody as can be determined by one of skill in the art. In some cases, the presence of the competitor antibody (e.g., the first antibody) reduces binding of the second antibody to the target by at least 10%, e.g., at least any of 20%, 30%, 40%, 50%, 60%,
70%, 80%, or more, e.g., so that binding of the second antibody to target is undetectable in the presence of the first (competitor) antibody.
[00105] The term “dissociation constant (KD or Kd )" as used herein, is intended to refer to the equilibrium dissociation constant of a particular ligand-protein interaction. As used herein, ligand-protein interactions refer to, but are not limited to protein-protein interactions or antibody-antigen interactions. The KD measures the propensity of two proteins complexed together (e.g. AB) to dissociate reversibly into constituent components (A+B), and is defined as the ratio of the rate of dissociation, also called the “off-rate (koff)”, to the association rate, or “on-rate (kon)” Thus, KD equals k0fl/kon and is expressed as a molar concentration (M). It follows that the smaller the KD, the stronger the affinity of binding, and thus a decrease in KD indicates an increase in affinity. Therefore, a KD of 1 mM indicates weak binding affinity compared to a KD of 1 nM. Affinity is sometimes measured in terms of a KA or R,. which is the reciprocal of the KD or Kd. KD values for antigen-binding constructs can be determined using methods well established in the art. One method for determining the KD of an antigen-binding construct is by using surface plasmon resonance (SPR), typically using a biosensor system such as a Biacore® system. Isothermal titration calorimetry (ITC) is another method that can be used to measure KD. The Octet™ system may also be used to measure the affinity of antibodies for a target antigen.
[00106] As used herein, the term “conditional agonism” is intended to refer to the ability of the 4-1BB x TAA antibody constructs or 4-1BB x FRα antibody constructs to agonize 4- 1BB activity in immune cells such as for example, T cells or NK cells, predominantly when the immune cells are in the proximity of TAA or FRα expressing cells. In one embodiment, conditional agonism” refers to the ability of the 4-1BB x TAA antibody constructs or 4-1BB x FRα antibody constructs to agonize 4-1BB activity in immune cells only when the immune cells are in the proximity of TAA or FRα expressing cells.
[00107] The term “amino acid modifications” as used herein includes, but is not limited to, amino acid insertions, deletions, substitutions, chemical modifications, physical modifications, and rearrangements. In some embodiments, the amino acid modification is an amino acid substitution.
[00108] The amino acid residues for the immunoglobulin heavy and light chains may be numbered according to several conventions including Rabat (as described in Rabat and Wu,
1991; Kabat et al, Sequences of proteins of immunological interest. 5th Edition - US Department of Health and Human Services, NIH publication no. 91-3242, p 647 (1991)), IMGT (as set forth in Lefranc, M.-P., et al. IMGT®, the international ImMunoGeneTics information system® Nucl. Acids Res, 37, D1006-D1012 (2009), and Lefranc, M.-P., IMGT, the International ImMunoGeneTics Information System, Cold Spring Harb Protoc. 2011 Jun 1; 2011(6)), 1JPT (as described in Katja Faelber, Daniel Kirchhofer, Leonard Presta, Robert F Kelley, Yves A Muller, The 1.85 A resolution crystal structures of tissue factor in complex with humanized fab d3h44 and of free humanized fab d3h44: revisiting the solvation of antigen combining sitesl, Journal of Molecular Biology, Volume 313, Issue 1, Pages 83-97,) and EU (according to the EU index as in Kabat referring to the numbering of the EU antibody (Edelman et al, 1969, Proc Natl Acad Sci USA 63:78-85)). Kabat numbering is used herein for the VH, CH1, CL, and VL domains unless otherwise indicated. EU numbering is used herein for the CH3 and CH2 domains, and the hinge region unless otherwise indicated.
Antibody constructs
[00109] “Antibody construct,” as used herein, refers to a polypeptide or a set of polypeptides that specifically bind to an epitope or antigen and include one or more immunoglobulin structural features. In general, an antibody construct is a polypeptide or set of polypeptides whose amino acid sequence includes elements characteristic of an antigen- binding domain (e.g., an antibody light chain or variable region or one or more complementarity determining regions (“CDRs”) thereof, or an antibody heavy chain or variable region or one more CDRs thereof, optionally in presence of one or more framework regions). In some embodiments, an antibody construct is or comprises an antibody in a naturally occurring format. In some embodiments, the term “antibody construct” encompasses a protein having a binding domain which is homologous or largely homologous to an immunoglobulin- binding domain. In some embodiments, an antibody construct comprises a fragment of a naturally occurring antibody including at least one antigen-binding domain. In some embodiments, the antibody construct may further comprise a binding domain that is other than an antigen-binding domain, for example a ligand for a target protein.
[00110] In particular embodiments, an “antibody construct” encompasses polypeptides having an antigen-binding domain that shows at least 99% sequence identity with an immunoglobulin binding domain. In some embodiments, an “antibody construct” is any polypeptide having a binding domain that shows at least 70%, 75%, 80%, 85%, 90%, 95% or
98% sequence identity with an immunoglobulin binding domain, for example a reference immunoglobulin binding domain. An “antibody construct” may have an amino acid sequence identical to that of an antibody (or a fragment thereof, e.g., an antigen-binding fragment thereof) that is found in a natural source. An “antigen-binding fragment” of an antibody includes a fragment of an antibody having an antigen-binding domain with the required specificity. Thus, an antigen-binding fragment includes antibody fragments, derivatives, functional equivalents and homologues of antibodies, humanized antibodies, including any polypeptide comprising an immunoglobulin binding domain, whether natural or wholly or partially synthetic. Chimeric molecules comprising an immunoglobulin binding domain, or equivalent, fused to another polypeptide are also included.
[00111] An antibody construct may be monospecific, bispecific, or multispecific, and may bind to at least one distinct target, antigen or epitope. Antibody constructs can be prepared in many formats, and exemplary antibody construct formats are described in Figures 1 and 2, and elsewhere throughout the application. The term “antibody construct” as used herein is meant to encompass monospecific, bispecific, or multispecific antibody constructs. A “monospecific” antibody construct is a species of antibody construct that binds to one target, antigen, or epitope. Monospecific antibody constructs may comprise one or more antigen- binding domains, each binding to the same epitope. Monospecific antibody constructs may be monovalent (i.e. having only one arm or paratope), bivalent (i.e. having two arms or paratopes, both binding to the same epitope) or multivalent (i.e. having multiple arms or paratopes, all binding to the same epitope). A “bispecific” antibody construct is a species of antibody construct that targets two different antigens or epitopes. In general, a bispecific antibody construct can have two antigen-binding domains, although, in some embodiments, a bispecific antibody construct may have more than two antigen-binding domains, provided that no more than two unique epitopes are recognized by the antigen-binding domains. The two or more antigen-binding domains of a bispecific antibody construct will bind to two different epitopes, which can reside on the same or different molecular targets. Where the two different epitopes reside on the same molecular target, the bispecific antibody construct is referred to herein as “biparatopic.” In some embodiments, the monospecific or bispecific antibody constructs are in a naturally occurring format, also referred to herein as a full-sized antibody (FSA) format. In other words, in the latter embodiment, the monospecific or bispecific antibody construct has the same format as a naturally occurring IgG, IgA, IgM, IgD, or IgE antibody.
[00112] A multispecific antibody construct can include three or more antigen-binding domains, each capable of binding to a different target or epitope. In some embodiments, the multispecific antibody construct comprises a format that is the same as a naturally occurring IgG, IgA, IgM, IgD, or IgE antibody, but further includes one or more additional antigen- binding domains.
[00113] In some embodiments, an antibody construct may have structural elements characteristic of chimeric or humanized antibodies or may have amino acid sequences derived from chimeric or humanized antibodies. In some embodiments, an antibody construct may have structural elements characteristic of a human antibody.
[00114] Described herein are antibody constructs capable of binding to the extracellular domain (ECD) of 4-1BB and to a tumor-associated antigen (TAA), for example FRα. Also described herein are antibody constructs comprising sequences that specifically bind to the ECD of 4-1BB. Antibody constructs comprising sequences that specifically bind to folate receptor alpha (FRα) are also described herein.
Antibody constructs that bind to 4-1BB and to a TAA (4-1BB x TAA antibody constructs)
[00115] Antibody constructs capable of binding to the ECD of 4-1BB and to a TAA comprise a 4-1BB binding domain that binds to a 4-1BB ECD and a TAA antigen-binding domain, wherein the 4-1BB binding domain and the TAA antigen-binding domain are linked directly or indirectly to a scaffold. Accordingly, in certain embodiments, the 4-1BB x TAA antibody constructs described herein are bispecific antibody constructs that bind to two distinct targets. In certain other embodiments, the 4-1BB x TAA antibody construct may be a multispecific antibody construct where the 4-1BB x TAA antibody construct binds to 4-1BB and to two or more distinct TAAs. In related embodiments, the scaffold is an Fc construct. In certain embodiments, the scaffold is an Fc construct with modifications that reduce its ability to mediate effector function.
[00116] In some embodiments, the 4-1BB x TAA antibody constructs are capable of binding to 4-1BB-expressing cells. In some embodiments, the 4-1BB x TAA antibody constructs are capable of binding to TAAs expressed on the surface of cancer cells. In some embodiments, the 4-1BB x TAA antibody constructs are capable of activating 4-1BB signalling
in 4-1BB-expressing cells. In some embodiments, the 4-1BB x TAA antibody constructs are capable of enhancing CD3 -stimulated T cell activation.
4-lBB-binding domains
[00117] 4-1BB (also known as TNFRSF9 or CD137) is a member of the TNF receptor superfamily. Human 4-1BB is a 255 amino acid protein (Accession Nos. NM 001561 and UniProt Q07011 for mRNA and polypeptide sequences respectively). The complete human 4- 1BB amino acid sequence is provided in SEQ ID NO:79. The sequence shown in SEQ ID NO:l includes a signal sequence (amino acid residues 1-23), an extracellular domain (ECD, amino acid residues 23-187), a transmembrane region (amino acids 188 to 213), and an intracellular domain (amino acids 214 to 255) (Bitra et al. J. Biol. Chem. (2018) 293(26) 9958 -9969).
[00118] The 4-1BB receptor is expressed on the cell surface in monomeric and dimeric forms and likely trimerizes with 4-1BB ligand to allow signalling. The structure of mammalian 4-1BB protein consists of four Cysteine-Rich Domains (CRDs) which show homology to other TNFR superfamily members. CRDl consists of amino acids 24 to 45, and both the mouse and human 4-1BB lack a disulphide found in other TNFR superfamily members. CRD2 and CRD3 extend from amino acids 47 to 86 and 87 to 118, respectively, and are the domains that contact 4-1BBL (Bitra et al, supra). CRD4 is comprised of amino acids 119 to 159 and is followed by a short stalk region comprised on amino acids 160 to the transmembrane domain at amino acid 187 (with reference to SEQ ID NO:79). CRDl, CRD2, CRD3 and CDR4 are also referred to herein as domains 1, 2, 3, and 4, respectively.
[00119] In one embodiment, the 4-1BB x TAA antibody construct comprises one 4-1BB binding domain. In some embodiments, the 4-1BB x TAA antibody construct may comprise more than one 4-1BB-binding domain. In certain embodiments, the 4-1BB x TAA antibody construct comprises two 4-1BB-binding domains, and a TAA antigen-binding domain, wherein the 4-1BB-binding domain and the TAA antigen-binding domain are linked directly or indirectly to a scaffold. In related embodiments, the 4-1BB x TAA antibody construct comprises two 4-1BB-binding domains, and a TAA antigen-binding domain, wherein the 4- lBB-binding domain and the TAA anti gen -binding domain are linked directly or indirectly to a scaffold, and wherein at least one of the 4-1BB-binding domains is a 4-1BB antigen-binding domain. In related embodiments, where the 4-1BB x TAA antibody construct comprises two or more 4-1BB antigen-binding domains, each 4-1BB antigen-binding domain may bind to the
same epitope of the ECD of 4-1BB, or they may bind to different epitopes of the ECD of 4- 1BB. In other embodiments, the 4-1BB x TAA antibody construct comprises a 4-1BB binding domain that is an antigen-binding domain, and a TAA antigen-binding domain.
[00120] In yet other embodiments, the 4-1BB x TAA antibody construct comprises three or more 4-1BB-binding domains that bind to the ECD of 4-1BB. In one embodiment, the three or more 4-1BB-binding domains include at least one 4-1BB antigen-binding domain. In one embodiment, the three or more 4-1BB-binding domains include at least two 4-1BB antigen- binding domains. In the latter embodiment, the two 4-1BB antigen-binding domains may bind to the same epitope of 4-1BB, or they may bind to different epitopes of 4-1BB.
[00121] The 4-1BB antigen-binding domains may be in scFv, Fab or sdAb formats. Thus, in one embodiment, the 4-1BB antigen-binding domain of the 4-1BB x TAA antibody construct is in a Fab format. In alternate embodiments, the 4-1BB antigen-binding domain is in a scFv format. In additional embodiments, the 4-1BB x TAA antibody construct comprises more than one 4-1BB antigen-binding domain, wherein at least one 4-1BB antigen-binding domain is in a Fab format. In other embodiments where the 4-1BB x TAA comprises more than one 4-1BB antigen-binding domain, at least two of the antigen-binding domains are in the Fab format.
[00122] The 4-1BB x TAA antibody construct comprises a 4-1BB-binding domain that binds to the ECD of 4-1BB. In certain embodiments, the 4-1BB x TAA antibody construct comprises a 4-1BB-binding domain that can bind to an ECD of human 4-1BB. Suitable 4- lBB-binding domains include naturally occurring molecules such as ligands or 4-1BB-binding fragments thereof. Examples of such molecules include 4-1BB ligand (see NP_003802.1, for example), also known as TNFSF9 or CD137L. Thus, in one embodiment, the antibody construct comprises a 4-1BB-binding domain that binds to a 4-1BB ligand and a TAA antigen- binding domain, wherein the 4-1BB-binding domain and the TAA antigen-binding domain are linked directly or indirectly to a scaffold.
[00123] As indicated above, in some embodiments, the 4-1BB x TAA antibody construct comprises a 4-1BB-binding domain that is an antigen-binding domain. Antigen- binding domains can be constructed from the sequences of antibodies that bind to the ECD of 4-1BB. Suitable antibodies include those that are known in the art, commercially available, or those that are identified and prepared according to methods well known in the art and described
herein. 4-1BB antigen-binding domains may be constructed from mouse, human, humanized, or chimeric anti-4-1BB antibodies. In some embodiments, the 4-1BB antigen-binding domain is derived from an agonistic anti-4-1BB antibody. Agonistic anti-4-1BB antibodies bind to 4- 1BB and are able to stimulate 4-1BB signalling activity. 4-1BB signalling activity refers to at least one of the activities that can be exhibited by 4-1BB in vitro or in vivo. For example, these activities may include stimulation of cytokine release from T or NK cells, or an increase in metabolic activity by T or NK cells, or enhancement of cytotoxic activity by T or NK cells.
[00124] Numerous antibodies that bind human 4-1BB are known in the art, for example and not limited to, utomilumab (described in WO2012/032433, Pfizer), urelumab (described in W02004/010947 and W02005/035584, BMS), and the antibodies described in WO 2018/156740 (Macrogenics), US 8,337,850 (Pfizer), US 2018/0258177 (Eutilex) W02017/077085 (Cancer Research Technologies), and WO2006126835 (University of Ulsan). Urelumab and utomilumab are exemplary agonistic anti-4-1BB antibodies.
[00125] In one embodiment, the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain that can compete with one of the antibodies described in the preceding paragraph for binding to an epitope of 4-1BB ECD. In one embodiment, the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain that can compete with utomilumab for binding to an epitope of 4-1BB ECD. In another embodiment, the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain that can compete with urelumab for binding to an epitope of 4-1BB ECD. In yet another embodiment, the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain that can compete with the anti-4-1BB antibodies described in US 8,337,850 for binding to an epitope of 4-1BB ECD. In a still further embodiment, the 4-1BB x TAA antibody construct comprises a 4-1BB antigen- binding domain that can compete with the anti-4-1BB antibodies described in US 2018/0258177 for binding to an epitope of 4-1BB ECD. In a still further embodiment, the 4- 1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain that can compete with the anti-4-1BB antibodies described in WO2018/156740 for binding to an epitope of 4- 1BB ECD. In other embodiments, the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain that binds to the same epitope of 4-1BB ECD as utomilumab, or urelumab, or any one of the anti-4-1BB antibodies described in US 8,337,850, US 2018/0258177 or WO2018/156740.
[00126] In one embodiment, the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain that binds to a 4-1BB ECD other than domain 3 or domain 4. In another embodiment, the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain that binds to an epitope at least partially within amino acid residues 24-85 of the mature 4-1BB protein (SEQ ID NO:79). In one embodiment, the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain that binds to domain 1 of 4-1BB. In another embodiment, the 4-1BB x TAA antibody construct comprises a4-1BB antigen-binding domain that binds to domain 2 of 4-1BB. In one embodiment, the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain that binds to domain 3 of 4-1BB. In one embodiment, the 4-1BB x TAA antibody construct comprises a4-1BB antigen-binding domain that binds to domain 4 of 4-1BB.
[00127] In some embodiments, the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain that binds to the ECD of human and cynomolgus 4-1BB.
[00128] In one embodiment, the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain that comprises at least one, two, or all three heavy chain CDRs and/or at least one, two, or all three light chain CDRs of urelumab, utomilumab, or any one of the anti- 4-1BB antibodies described in US 8,337,850, US 2018/0258177 or WO2018/156740. In an alternate embodiment, the 4-1BB x TAA antibody construct comprises a 4-1BB antigen- binding domain that comprises at least one, two, or all three heavy chain CDRs and at least one, two, or all three light chain CDRs of urelumab, utomilumab, or any one of the anti -4-1BB antibodies described in US 8,337,850, US 2018/0258177 or WO2018/156740. In other embodiments, the 4-1BB x TAA construct comprises a 4-1BB antigen-binding domain comprising a VH sequence that is at least about 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, or 100% identical to the VH sequence of urelumab, utomilumab, or any one of the anti-4-1BB antibodies described in US 8,337,850, US 2018/0258177 or WO2018/156740. The specific VH and VL sequences of MOR7480.1, one of the antibodies described in US 8,337,850, are provided as SEQ ID NOs: 71 and 72, respectively, in Table 15. The CDRs of MOR7480.1 are provided in Table B below. The VH, VL and CDR sequences of the other 4-1BB antigen- binding domains described above can readily be determined by one of skill in the art with reference to the disclosures of US 8,337,850, US 2018/0258177, WO2018/156740 W02004/010947, W02005/035584, US 2018/0258177, W02017/077085, or
WO2006126835.
Table B: MOR7480.1 CDRs

[00129] Additional VH, VL and CDR sequences of antibodies that bind 4-1BB are described below and in Table 13; these antibodies are identified as 1B2, 1C3, 1C8, 1G1, 2A7, 2E8, 2H9, 3D7, 3H1, 3E7, 3G4, 4B11, 4E6, 4F9, 4G10, 5E2, 5G8, and 6B3. In one embodiment, the 4-1BB x TAA antibody construct comprises a4-1BB antigen-binding domain comprising a VH sequence and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence and VL sequence of any one of antibodies 1B2, 1C3, 1C8, 1G1, 2A7, 2E8, 2H9, 3D7, 3H1, 3E7, 3G4, 4B11, 4E6, 4F9, 4G10, 5E2, 5G8, or 6B3 as set forth in Table 13. In one embodiment, the 4-1BB x TAA antibody construct comprises a 4- 1BB antigen-binding domain comprising a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of antibody 1B2 as set forth in Table 13 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 1B2 as set forth in Table 13. In one embodiment, the 4-1BB x TAA antibody construct comprises a4-1BB antigen-binding domain comprising a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of antibody 1C3 as set forth in Table 13 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 1C3 as set forth in Table 13. In one embodiment, the 4-1BB x TAA antibody construct comprises a4-1BB antigen-binding domain comprising a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of antibody 1C8 as set forth in Table 13 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 1C8 as set forth in Table 13. In one embodiment, the 4-1BB x TAA antibody construct comprises a 4- 1BB antigen-binding domain comprising a VH sequence that is at least 85%, 90%, 95%, 96%,
97%, 98%, or 99% identical to the VH sequence of antibody 1G1 as set forth in Table 13 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 1G1 as set forth in Table 13. In one embodiment, the 4-1BB x TAA antibody construct comprises a4-1BB antigen-binding domain comprising a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of antibody 2A7 as set forth in Table 13 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 2A7 as set forth in Table 13. In one embodiment, the 4-1BB x TAA antibody construct comprises a4-1BB antigen-binding domain comprising a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of antibody 2E8 as set forth in Table 13 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 2E8 as set forth in Table 13. In one embodiment, the 4-1BB x TAA antibody construct comprises a 4- 1BB antigen-binding domain comprising a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of antibody 2H9 as set forth in Table 13 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 2H9 as set forth in Table 13. In one embodiment, the 4-1BB x TAA antibody construct comprises a4-1BB antigen-binding domain comprising a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of antibody 3D7 as set forth in Table 13 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 3D7 as set forth in Table 13. In one embodiment, the 4-1BB x TAA antibody construct comprises a4-1BB antigen-binding domain comprising a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of antibody 3H1 as set forth in Table 13 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 3H1 as set forth in Table 13. In one embodiment, the 4-1BB x TAA antibody construct comprises a 4- 1BB antigen-binding domain comprising a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of antibody 3E7 as set forth in Table 13 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 3E7 as set forth in Table 13. In one embodiment, the 4-1BB x TAA antibody construct comprises a4-1BB antigen-binding domain comprising a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of antibody 3G4 as set forth in Table 13 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 3G4 as set forth in Table 13. In one embodiment, the 4-1BB x TAA antibody construct comprises a4-1BB antigen-binding domain
comprising a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of antibody 4B11 as set forth in Table 13 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 4B11 as set forth in Table 13. In one embodiment, the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain comprising a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of antibody 4E6 as set forth in Table 13 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 4E6 as set forth in Table 13. In one embodiment, the 4-1BB x TAA antibody construct comprises a4-1BB antigen-binding domain comprising a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of antibody 4F9 as set forth in Table 13 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 4F9 as set forth in Table 13. In one embodiment, the 4-1BB x TAA antibody construct comprises a4-1BB antigen-binding domain comprising a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of antibody 4G10 as set forth in Table 13 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 4G10 as set forth in Table 13. In one embodiment, the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain comprising a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of antibody 5E2 as set forth in Table 13 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 5E2 as set forth in Table 13. In one embodiment, the 4-1BB x TAA antibody construct comprises a4-1BB antigen-binding domain comprising a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of antibody 5G8 as set forth in Table 13 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 5G8 as set forth in Table 13. In one embodiment, the 4-1BB x TAA antibody construct comprises a4-1BB antigen-binding domain comprising a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of antibody 6B3 as set forth in Table 13 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 6B3 as set forth in Table 13.
[00130] In one embodiment, the 4-1BB x TAA antibody construct comprises the heavy chain CDRs and light chain CDRs of one of the antibodies listed in Table 13. The CDRs of these antibodies can be found in Table 18. In related embodiments, the 4-1BB x TAA antibody
construct comprises the heavy chain CDRs and light chain CDRs of any one of antibodies 1C3, 1C8, 1G1, 2E8, 3E7, 4E6, 5G8, or 6B3, described in Table 13. In one embodiment, the 4-1BB x TAA antibody construct comprises the heavy chain CDRs and light chain CDRs of any one of anti-4-1BB antibodies 1G1, 1C8, or 5G8. In one embodiment, the 4-1BB x TAA antibody construct comprises the 3 heavy chain CDRs and the 3 light chain CDRs of anti -4-1BB antibody 1G1. In one embodiment, the 4-1BB x TAA antibody construct comprises the heavy chain CDRs and light chain CDRs of any one of anti-4-1BB antibodies 1G1, 1C8, or 5G8, wherein one or more CDRs comprise at least one amino acid substitution that improves the affinity of the anti-4-1BB antigen-binding domain for human 4-1BB. In one embodiment, the 4-1BB x TAA antibody construct comprises three heavy chain CDRs and three light chain CDRs of anti-4-1BB antibody 1C8, wherein one or more CDRs comprise at least one amino acid substitution that improves the affinity of the antibody for human 4-1BB.
[00131] In one embodiment, the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain comprising a humanized VH sequence and a humanized VL sequence of any one of antibodies 1B2, 1C3, 1C8, 1G1, 2A7, 2E8, 2H9, 3D7, 3H1, 3E7, 3G4, 4B11, 4E6, 4F9, 4G10, 5E2, 5G8, or 6B3. Several exemplary humanized VH and VL sequences are described in Table 14 and have been used in the construction of several 4-1BB antibody constructs comprising humanized VH and VL sequences based on the mouse VH and VL sequences of anti-4-1BB antibodies 1C8, 1G1, and 5G8.
[00132] In one embodiment, the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain comprising a humanized VH sequence and humanized VL sequence of antibody 1C8. In a related embodiment, the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28726, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variants 28726. In another embodiment, the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28727, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28727. In another embodiment, the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28728, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28728. In another embodiment, the 4-1BB x TAA antibody construct comprises a
VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28730, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28730. In one embodiment, the 4-1BB x TAA antibody construct comprises a construct having three heavy chain CDRs and three light chain CDRs comprising at least one amino acid substitution that improves the affinity of the 4-1BB antigen-binding domain for human 4-1BB, and comprises a humanized VH sequence and humanized VL sequence of anti-4-1BB antibody 1C8.
[00133] In one embodiment, the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain comprising a humanized VH sequence and humanized VL sequence of antibody 1G1. In a related embodiment, the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28683, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variants 28683. In another embodiment, the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28684, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28684. In another embodiment, the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28685, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28685. In another embodiment, the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28686, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28686. In another embodiment, the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28687, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28687. In another embodiment, the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28688, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28688. In another embodiment, the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28689, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28689. In another embodiment, the 4-1BB x TAA
antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28690, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28690. In another embodiment, the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28691, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28691. In another embodiment, the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28692, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28692. In another embodiment, the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28693, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28693. In another embodiment, the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28694, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28694.
[00134] In one embodiment, the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain comprising a humanized VH sequence and humanized VL sequence of antibody 5C8. In a related embodiment, the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28700, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variants 28700. In another embodiment, the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28704, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28704. In another embodiment, the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28705, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28705. In another embodiment, the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28706, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of 28706. In another embodiment, the 4-1BB x TAA
antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28711, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28711. In another embodiment, the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28712 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28712. In another embodiment, the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28713, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28713. In another embodiment, the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28696, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28696. In another embodiment, the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28697, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28697. In another embodiment, the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28698, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28698. In another embodiment, the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28701, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28701. In another embodiment, the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28702, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28702. In another embodiment, the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28703, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28703. In another embodiment, the 4-1BB x TAA antibody construct comprises a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of v28707, and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of variant 28707.
[00135] In one embodiment, the 4-1BB x TAA antibody construct comprises the heavy chain CDRs and light chain CDRs of any one of the humanized antibodies v28726, v28727,
V28728, v28730, , v28700, v28704, v28705, v28706, v28711, v28712, v28713, , v28696,
V28697, v28698, v28701, v28702, v28703, v28707, , v28683, v28684, v28685, v28686, v28687, v28688, v28689, v28690, v28691, v28692, v28694, and v28695. The CDRs of these antibodies can be found in Table 18.
[00136] In other embodiments, the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain, and a TAA antigen -binding domain, wherein the 4-1BB-binding domain and the TAA antigen-binding domain are linked directly or indirectly to a scaffold, and the 4-1BB antigen-binding domain comprises one, two, or three heavy chain CDRs and/or one, two, or three light chain CDRs of v28726, v28727, v28728, v28730, v20022, v28700, v28704, V28705, v28706, v28711, v28712, v28713, v20036, v28696, v28697, v28698, v28701,
V28702, v28703, v28707, v20023, v28683, v28684, v28685, v28686, v28687, v28688,
V28689, v28690, v28691, v28692, v28694, and v28695.
[00137] In other embodiments, the 4-1BB x TAA antibody construct comprises a 4- lBB-binding domain that is capable of binding to an ECD of human 4-1BB and is cyno cross- reactive. The term “cyno cross-reactive” as used herein is meant to describe binding domains that bind to a target from one species (for example, human or mouse) and are able also to bind to the same target expressed in a cynomolgus monkey. In some embodiments, the antibody construct comprises a 4-1BB-binding domain that can bind to an ECD of mouse 4-1BB.
TAAs and TAA antigen-binding domains
[00138] The 4-1BB x TAA antibody constructs described herein comprise a 4-1BB- binding domain that binds to a 4-1BB extracellular domain (4-1BB ECD), and a tumor- associated antigen (TAA) antigen binding domain that binds to a TAA, wherein the 4-1BB- binding domain and the TAA antigen binding domain are linked directly or indirectly to a scaffold. In some embodiments, the 4-1BB x TAA antibody construct comprises a first TAA antigen-binding domain and a second TAA antigen-binding domain linked directly or indirectly to a scaffold.
[00139] As used herein “tumor-associated antigen” or “TAA” refers to an antigen that is expressed by cancer cells. A tumor-associated antigen may or may not be expressed by normal cells (non-tumor cells). When a TAA is not expressed by normal cells (i.e. when it is
unique to tumor cells) it may also be referred to as a “tumor-specific antigen.” When a TAA is not unique to a tumor cell, it is also expressed on a normal cell under conditions that fail to induce a state of immunologic tolerance to the antigen. The expression of the antigen on the tumor may occur under conditions that enable the immune system to respond to the antigen. TAAs may be antigens that are normally present at low levels on normal cells but which are expressed at higher levels on tumor cells. Those TAAs of greatest clinical interest are differentially expressed compared to the corresponding normal tissue and allow for a preferential recognition of tumor cells by specific T-cells or immunoglobulins. In some embodiments, TAAs may be membrane-bound antigens, or antigens that are localized on the surface of a tumor cell.
[00140] In one embodiment, the 4-1BB x TAA antibody construct comprises a TAA antigen-binding domain that binds to a TAA that is expressed at high levels in tumor cells. For example, the tumor cells may express the TAA at greater than about 1 million copies per cell. In another embodiment, the 4-1BB x TAA antibody construct comprises at least one TAA antigen-binding domain that binds to a TAA that is expressed at medium levels in tumor cells. For example, the tumor cells may express the TAA at greater than about 100,000 to about 1 million copies per cell. In one embodiment, the 4-1BB x TAA antibody construct comprises at least one TAA antigen-binding domain that binds to a TAA that is expressed at low levels in tumor cells. For example, the tumor cells may express the TAA at less than about 100,000 copies per cell. In one embodiment, the 4-1BB x TAA antibody construct binds to a TAA that is expressed at higher levels on tumor cells than on normal cells.
[00141] In some embodiments the 4-1BB x TAA antibody construct binds to a TAA that is expressed on a breast cancer cell, a lung cancer cell, an ovarian cancer cell, a colon cancer cell, a skin cancer cell, a bladder cancer cell, a lymphoma or leukemic cell, a kidney cancer cell, a pancreatic cancer cell, a stomach cancer cell, an oesophageal cancer cell, a prostate cancer cell, a thyroid cancer cell or other non-liver cancer cell.
[00142] The 4-1BB x TAA antibody construct may comprise varying numbers of TAA antigen-binding domains. Accordingly, in certain embodiments, the 4-1BB x TAA antibody construct comprises a 4-1BB-binding domain and a TAA antigen-binding domain, wherein the 4-1BB-binding domains and the TAA antigen-binding domains are linked directly or indirectly to a scaffold. In other embodiments, the 4-1BB x TAA antibody construct comprises two 4- lBB-binding domains and one TAA antigen-binding domain, wherein the 4-1BB-binding
domains and the TAA antigen-binding domains are linked directly or indirectly to a scaffold. In still other embodiments, the 4-1BB x TAA antibody construct comprises one or more 4- lBB-binding domains, and two TAA antigen-binding domains, wherein the 4-1BB-binding domains and the TAA antigen-binding domains are linked directly or indirectly to a scaffold. In related embodiments, where the antibody construct comprises two or more TAA antigen- binding domains, each TAA antigen-binding domain may bind to the same epitope of one TAA, or to different epitopes of the same TAA, or to different TAAs.
[00143] The TAA antigen-binding domains may be in scFv, Fab or sdAb formats. Thus, in one embodiment, the TAA antigen-binding domain of the 4-1BB x TAA antibody construct is in a Fab format. In alternate embodiments, the TAA antigen-binding domain is in a scFv format. In additional embodiments, the 4-1BB x TAA antibody construct comprises more than one TAA antigen-binding domain, wherein at least one TAA antigen-binding domain is in an scFv format. In other embodiments where the 4-1BB x TAA comprises more than one TAA antigen-binding domain, at least two of the antigen-binding domains are in the scFv format.
[00144] In one embodiment, the 4-1BB x TAA antibody construct comprises a TAA antigen-binding domain that binds to a TAA selected from, but not limited to, carbonic anhydrase IX, alpha-fetoprotein (AFP), alpha-actinin-4, A3, antigen specific for A33 antibody, ALK (anaplastic lymphoma receptor tyrosine kinase), ART-4, B7, B7-H4, Ba 733, BAGE, BCMA, BrE3 -antigen, CA125, CAMEL, CAP-1, CASP-8/m, CCL19, CCL21, CD1, CDla, CD2, CD3, CD4, CD5, CD8, CD11A, CD14, CD15, CD16, CD18, CD19, CD20, CD21, CD22, CD23, CD25, CD29, CD30, CD32b, CD33, CD37, CD38, CD40, CD40L, CD44, CD45, CD46, CD52, CD54, CD55, CD59, CD64, CD66a-e, CD67, CD70, CD70L, CD74, CD79a, CD79b, CD80, CD83, CD95, CD123, CD126, CD132, CD133, CD138, CD147, CD154, CD171, CDC27, CDK-4/m, CDKN2A, CSF1R, CTLA-4, CXCR4, CXCR7, CXCL12, HIF- la, colon-specific antigen-p (CSAp), CEA, CEACAM5, CEACAM6, c-Met, DAM, DL3, EGFR, EGFRvIII, EGP-1 (TROP-2), EGP-2, ELF2-M, Ep-CAM, EphA2, fibroblast growth factor (FGF), Fit- 1 , Flt-3, folate receptor, G250 antigen, GAGE, GD2, gp100, GPC3, GRO- 13, HLA-DR, HM1.24, human chorionic gonadotropin (HCG) and its subunits, HER2/neu, HMGB-1, hypoxia inducible factor (HIF-1), HSP70-2M, HST-2, la, IGF-1R, IFN-gamma, IFN-alpha, IFN-beta, IFN-X, IL-4R, IL-6R, IL-13R, IL13Ralpha2, IL-15R, IL-17R, IL-18R, IL-2, IL-6, IL-8, IL-12, IL-15, IL-17, IL-18, IL-23, IL-25, insulin-like growth factor-1 (IGF- 1), KC4-antigen, KS-1 -antigen, KS1-4, Le-Y, LDR/FUT, macrophage migration inhibitory
factor (MIF), MAGE, MAGE-3, MART-1, MART-2, mCRP, MCP-1, melanoma glycoprotein, mesothelin, MIP-1A, MIP-1B, MIF, MUC1, MUC2, MUC3, MUC4, MUC5ac, MUC13, MUC16, MUM-1/2, MUM-3, NaPi2B, NCA66, NCA95, NCA90, NY-ESO-1, PAM4 antigen, pancreatic cancer mucin, PD-1, PD-1 receptor, placental growth factor, p53, PLAGL2, prostatic acid phosphatase, PSA, PRAME, PSMA, P1GF, ILGF, ILGF-1R, IL-6, IL-25, RS5, RANTES, ROR1, T101, SAGE, 5100, survivin, survivin-2B, TAC, TAG-72, tenascin, TRAG- 3, TRAIL receptors, TGFp, TNF-alpha, Tn antigen, Thomson-Friedenreich antigens, tumor necrosis antigens, VEGFR, ED-B fibronectin, WT-1, 17-1 A- antigen, complement factors C3, C3a, C3b, C5a, C5, an angiogenesis marker, bcl-2, bcl-6, Kras, an oncogene marker and an oncogene product (see, e.g., Sensi et al., Clin Cancer Res 2006, 12:5023-32; Parmiani et al, J Immunol 2007, 178:1975-79; Novellino et al. Cancer Immunol Immunother 2005, 54:187- 207).
[00145] In one embodiment, the 4-1BB x TAA antibody constructs described herein comprise a 4-1BB-binding domain that binds to a 4-1BB extracellular domain (4-1BB ECD), and a TAA antigen-binding domain that binds to folate receptor (FRα), wherein the first 4- lBB-binding domain and the TAA antigen binding domain are linked directly or indirectly to a scaffold. In one embodiment, the 4-1BB x TAA antibody constructs described herein comprise a 4-1BB-binding domain that binds to a 4-1BB extracellular domain (4-1BB ECD), and a tumor-associated antigen (TAA)-antigen binding domain that binds to Solute Carrier Family 34 Member 2 (SLC34A2, NaPi2b), wherein the first 4-1BB-binding domain and the TAA antigen binding domain are linked directly or indirectly to a scaffold. In one embodiment, the 4-1BB x TAA antibody constructs described herein comprise a 4-1BB-binding domain that binds to a 4-1BB extracellular domain (4-1BB ECD), and a tumor-associated antigen (TAA)- antigen binding domain that binds to HER2, wherein the first 4-1BB-binding domain and the TAA antigen binding domain are linked directly or indirectly to a scaffold. In one embodiment, the 4-1BB x TAA antibody constructs described herein comprise a 4-1BB-binding domain that binds to a 4-1BB extracellular domain (4-1BB ECD), and a tumor-associated antigen (TAA)- antigen binding domain that binds to mesothelin, wherein the first 4-1BB-binding domain and the TAA antigen binding domain are linked directly or indirectly to a scaffold. In one embodiment, the 4-1BB x TAA antibody constructs described herein comprise a 4-1BB- binding domain that binds to a 4-1BB extracellular domain (4-1BB ECD), and a tumor- associated antigen (TAA)-antigen binding domain that binds to Solute Carrier Family 39
Member 6 (SLC3A6, LIV-1), wherein the first 4-1BB-binding domain and the TAA antigen binding domain are linked directly or indirectly to a scaffold.
[00146] The TAA antigen-binding domains may be constructed from the sequences of known antibodies directed against TAAs. Many such antibodies are known in the art and may be commercially obtained from a number of sources. For example, a variety of antibody secreting hybridoma lines are available from the American Type Culture Collection (ATCC, Manassas, Va.) In addition, a number of antibodies against various TAAs have been deposited at the ATCC and/or have published variable domain sequences and may be used to prepare the TAA antigen-binding domains of the antibody constructs. The skilled artisan will appreciate that antibody sequences or antibody-secreting hybridomas against various TAAs may be obtained by a simple search of the ATCC, NCBI, and/or USPTO databases. Alternatively, antibodies that specifically bind to a desired TAA may be generated according to methods known in the art and described elsewhere herein.
FRa antigen-binding domains
[00147] In one embodiment, the 4-1BB x TAA antibody construct is a 4-1BB x FRα antibody construct comprising a 4-1BB antigen-binding domain and a FRα antigen-binding domain wherein the 4-1BB binding domain and the FRα antigen-binding domain are linked directly or indirectly to a scaffold.
[00148] FRα is a member of the folate receptor family which functions to bind folic acid and transports 5-methyltetrahydrofolate into cells. FRα is also known as folate receptor 1, FOLR, FOLR1, FBP or MOv18 and is expressed in normal cells as well as tumor cells as a secreted protein that exists in soluble form or is anchored to the membrane of cells through a glycosyl-phosphatidylinositol (GPI) linkage. FRα is further described in Cheung et al. (2016) Oncotarget 7:52553-52574. The polypeptide sequence of this protein is described in GenBank Accession No. AAB05827.1 and UniProt P15328, and provided here as SEQ ID NO:80.
[00149] FRα antigen-binding domains may be derived from anti-FRα antibodies known in the art, including but not limited to: farletuzumab (Morphotek, described in W02004/003388 and W02005/080431), mirvetuximab (ImmunoGen, described in WO2011106528). Other anti-FRα antibodies are described in US 8,388,972 (Advanced Accelerator Applications), WO2018/098277 (Eisai R&D Management Co.), US 9,695,237
(Kyowa Hakko Kirin Co.), WO2015/196167 (Bioalliance), W02016/079076 (Roche), and WO2018/071597 (Sutro).
[00150] In one embodiment, the 4-1BB x TAA antibody construct comprises a FRα antigen-binding domain that can compete with farletuzumab for binding to an epitope of FRα. In another embodiment, the 4-1BB x TAA antibody construct comprises a FRα antigen- binding domain that can compete with mirvetuximab for binding to an epitope of FRα. In still other embodiments, the 4-1BB x TAA antibody construct comprises a FRα antigen-binding domain that can compete for binding to an epitope of FRα with any one of the anti-FRα antibodies described in US 8,388,972, WO2018/098277, US 9,695,237, WO2015/196167, WO2016/079076, or WO2018/071597.
[00151] In other embodiments, the 4-1BB x TAA antibody construct comprises a FRα antigen-binding domain that binds to the same epitope of FRα as farletuzumab or mirvetuximab, or any one of the FRα antibodies described in US 8,388,972, WO2018/098277, US 9,695,237, WO2015/196167, WO2016/079076, or WO2018/071597.
[00152] In one embodiment, the 4-1BB x TAA antibody construct comprises an FRα antigen-binding domain that comprises at least one, two, or all three heavy chain CDRs and/or at least one, two, or all three light chain CDRs of farletuzumab, mirvetuximab, or any one of the anti-FRα antibodies described in US 8,388,972, WO2018/098277, US 9,695,237, WO2015/196167, W02016/079076, or WO2018/071597. In an alternate embodiment, the 4- 1BB x TAA antibody construct comprises a FRα antigen-binding domain that comprises at least one, two, or all three heavy chain CDRs and at least one, two, or all three light chain CDRs of farletuzumab, mirvetuximab, or any one of the anti-FRα antibodies described in US 8,388,972, WO2018/098277, US 9,695,237, WO2015/196167, WO2016/079076, or WO2018/071597. In other embodiments, the 4-1BB x TAA construct comprises a FRα antigen-binding domain comprising a VH sequence that is at least about 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, or 100% identical to the VH sequence of farletuzumab, mirvetuximab, or any one of the anti-FRα antibodies described in US 8,388,972, WO2018/098277, US 9,695,237, WO2015/196167, WO2016/079076, or WO2018/071597. The specific sequences of the CDRs for mirvetuximab and farletuzumab are described in Table C and the VH and VL sequences of these antibodies are provided in Table 17; the others can readily be determined
by one of skill in the art with reference to the disclosures of US 8,388,972, WO2018/098277, US 9,695,237, WO2015/196167, WO2016/079076, or WO2018/071597.
Table C: CDR sequences of exemplary anti-FRa antibodies

[00153] Alternatively, FRα antigen-binding domains may be derived from novel antibodies that are generated according to methods known in the art.
[00154] Additional anti-FRα antibody VH and VL sequences are provided in Table 17. In one embodiment, the 4-1BB x FRα antibody construct comprises a FRα antigen-binding domain having a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of antibody 8K22 or 1H06 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 8K22 or 1H06. The CDRs of these antibodies are provided in Table 18. In one embodiment, the 4-1BB x TAA
antibody construct comprises the heavy chain CDRs and light chain CDRs of antibody 8K22 or 1H06. In one embodiment, the 4-1BB x FRα antibody construct comprises a FRα antigen- binding domain having a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of antibody 2L16 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 2L16. In another embodiment, the 4-1BB x TAA antibody construct comprises the heavy chain rabbit CDRs and light chain rabbit CDRs of anti-FRα antibody 2L16 as provided in Table 47. In another embodiment, the 4-1BB x TAA antibody construct comprises the heavy chain humanized CDRs and light chain humanized CDRs of anti-FRα antibody 2L16 as provided in Table 47. In some embodiments, the 4-1BB x FRα antibody construct comprises a first folate receptor alpha (FRα)-antigen binding domain in scFv format comprising a heavy chain variable domain (VH) sequence having at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% sequence identity to the VH sequence of antibody 8K22 and comprising the three heavy chain CDR sequences of antibody 8K22 and a light chain variable domain (VL) sequence having at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% sequence identity to the VL sequence of antibody 8K22 and comprising the three light chain CDR sequences of antibody 8K22, and further comprising one or more amino acid modifications that improve the biophysical properties of the antibody construct in the VH domain and/or in the VL domain of antibody 8K22.
[00155] In one embodiment, the 4-1BB x FRα antibody construct comprises a 4-1BB antigen-binding domain comprising the CDRs of any one of the humanized antibodies v28726, V28727, v28728, v28730, v28700, v28704, v28705, v28706, v28711, v28712, v28713,
V28696, v28697, v28698, v28701, v28702, v28703, v28707, v28683, v28684, v28685,
V28686, v28687, v28688, v28689, v28690, v28691, v28692, v28694, and v28695 and a FRα antigen-binding domain linked to scaffold. In one embodiment, the 4-1BB x FRα antibody construct comprises a 4-1BB antigen-binding domain comprising the CDRs of any one of the humanized antibodies v28726, v28727, v28728, v28730, v28700, v28704, v28705, v28706, v28711, v28712, v28713, v28696, v28697, v28698, v28701, v28702, v28703, v28707,
V28683, v28684, v28685, v28686, v28687, v28688, v28689, v28690, v28691, v28692, v28694, and v28695 and a FRα antigen-binding domain comprising the CDRs of 8K22 or 1H06. In other embodiments, the 4-1BB x FRα antibody construct comprises a 4-1BB antigen- binding domain comprising the CDRs of any one of the humanized antibodies v28726, v28727, V28728, v28730, v28700, v28704, v28705, v28706, v28711, v28712, v28713, v28696,
V28697, v28698, v28701, v28702, v28703, v28707, v28683, v28684, v28685, v28686,
v28687, v28688, v28689, v28690, v28691, v28692, v28694, and v28695 and a FRα antigen- binding domain comprising the CDRs of anti-FRα antibody 2L16. In still other embodiments, the 4-1BB x FRα antibody construct comprises a 4-1BB antigen-binding domain comprising the CDRs of any one of the humanized anti-4-1BB antibodies 1G1, 1C8, or 5G8, and a FRα antigen-binding domain comprising the CDRs of anti-FRα antibody 2L16. In yet other embodiments, the 4-1BB x FRα antibody construct comprises a 4-1BB antigen-binding domain comprising the CDRs of any one of the humanized anti-4-1BB antibodies 1G1, 1C8, or 5G8, and a FRα antigen-binding domain comprising a VH sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VH sequence of antibody 2L16 and a VL sequence that is at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% identical to the VL sequence of antibody 2L16.
[00156] In one embodiment, the 4-1BB x FRα antibody construct comprises the heavy chain CDRs and light chain CDRs of any one of anti-4-1BB antibodies 1G1, 1C8, or 5G8. In one embodiment, the 4-1BB x FRα antibody construct comprises the 3 heavy chain CDRs and the 3 light chain CDRs of anti-4-1BB antibody 1G1 and the 3 heavy chain CDRs and the 3 light chain CDRs of antibody 8K22 or 2L16. In one embodiment, the 4-1BB x TAA antibody construct comprises the heavy chain CDRs and light chain CDRs of any one of anti-4-1BB antibodies 1G1, 1C8, or 5G8, wherein one or more CDRs comprise at least one amino acid substitution that improves the affinity of the antibody for human 4-1BB and the 3 heavy chain CDRs and the 3 light chain CDRs of antibody 8K22 or 2L16. In one embodiment, the 4-1 BB x TAA antibody construct comprises three heavy chain CDRs and three light chain CDRs of anti-4-1BB antibody 1C8, wherein one or more CDRs comprise at least one amino acid substitution that improves the affinity of the antibody for human 4-1BB and the 3 heavy chain CDRs and the 3 light chain CDRs of antibody 8K22 or 2L16.
[00157] In embodiments where the anti-FRα antigen-binding domain is in the scFv format, the biophysical properties of the 4-1BB x FRα antibody construct may be improved according to methods known in the art. Such biophysical properties may include improved thermal stability with respect to a reference construct or improved species homogeneity during production. Species homogeneity can be measured as a decrease in high molecular weight species during production.
[00158] Improved thermal stability may be measured according to methods known in the art. The thermal stability of antibody constructs or scFvs, Fabs, CH3, or CH2 domains thereof can be determined as absolute numbers or in comparison to a reference construct. The melting temperature of each domain is indicative of its thermal stability and can be measured using techniques such as differential scanning calorimetry (Chen et al (2003) Pharm Res 20:1952-60; Ghirlando et al (1999) Immunol Lett 68:47-52), and differential scanning fluorimetry (Niesen et al. (2007) Nature Protocols 2(9): 2212-21). The latter methods provide a measure of thermal stability in terms of “melting temperature” or Tm. Alternatively, the thermal stability of domains of the antibody construct can be measured using circular dichroism (Murray et al. (2002) J. Chromatogr Sci 40:343-9). In one embodiment, the thermal stability of the domain, or antibodies comprising the domain is measured by differential scanning calorimetry (DSC). In one embodiment, the thermal stability of the domain, or antibodies comprising the domain is measured by differential scanning fluorimetry (DSF). In one embodiment, the thermal stability of the domain, or antibodies comprising the domain is measured by DSC or DSF. The reference construct may vary. For example, if the domain of interest is an scFv with amino acid modifications designed to improve thermal stability of the scFv, the reference construct may be an scFv without the amino acid modifications.
[00159] In general, for efficiency in preparing the antibody constructs described herein, it is desired to minimize the amount of high molecular weight (HMW) species produced during expression and purification of the antibody constructs, typically from host cells, thus improving species homogeneity. HMW species typically include undesired dimers, trimers and higher order aggregates of the antibody constructs. In some cases, the physical properties ( i.e . amino acid sequence) of certain domains of the antibody construct may result in amounts of HMW species that are undesirable. Methods of assessing the sequence and structure of these domains to identify amino acid modifications that could result in a decrease in HMW species are known in the art. In general, such amino acid modifications include replacing certain surface hydrophobic residues with hydrophilic residues or alanine. Several methods can be used to assess the amount of HMW species including but not limited to UPLC-SEC (Hong et al. (2012) 35: 2923-2950), light angle scattering (multi-angle light scattering or dynamic light scattering) (Hawe et al. (2009) Eur J Pharm Sci 38:79-87; Sahin, Roberts (2012) Methods Mol Biol 899:403-423), or Analytical Ultra Centrifugation (Berkowitz (2006) AAPS J. 8: E590-E605). In some embodiments, antibody constructs have no greater than about 10% to about 15% HMW species with respect to total amount of species obtained after purification of antibody constructs
from cellular supernatants. In some embodiments, antibody constructs have no greater than about 10% HMW species with respect to total amount of species obtained after purification of antibody constructs from cellular supernatants.
[00160] In some embodiments, the 4-1BB x FRα antibody construct comprises a 4-1BB antigen-binding domain comprising the CDRs of any one of the humanized anti-4-1BB antibodies 1G1, 1C 8, or 5G8, and a humanized VH sequence and humanized VL sequence of anti-FRα antibody 2L16, wherein the humanized VH sequence and/or the humanized VL sequence comprises one or more amino acid modifications that improve the affinity of the 2L16 antibody for human FRα, or improve the biophysical properties of the 4-1BB x FRα antibody construct. The one or more amino acid modifications may include changes in the linker sequence between the VH and VL sequences where the anti-FRα antigen-binding domain is in the scFv format. Changes in the linker sequence may includes use of different amino acid sequences, or different linker lengths for example. In related embodiments, the 4-1BB antigen- binding domain is in the Fab format and the anti-FRα antigen-binding domain is in the scFv format. In some embodiments, the one or more amino acid modifications that improve the biophysical properties of the 4-1BB x FRα antibody construct are selected from those shown in the table below, wherein the numbering of amino acid residues is according to Rabat:
Table C2: Modifications in 2L16 scFv sequence to improve biophysical properties of antibody constructs having a 2L16 scFv

[00161] In other embodiments, the 4-1BB x FRα antibody construct comprises a 4-1BB antigen-binding domain comprising the CDRs of any one of the humanized anti-4-1BB antibodies 1G1, 1C 8, or 5G8, and a humanized VH sequence and humanized VL sequence of anti-FRα antibody 8K22, wherein the humanized VH sequence and/or the humanized VL sequence comprises one or more amino acid modifications that improve the affinity of the 8K22 antibody for human FRα, or improve the biophysical properties of the 4-1BB x FRα antibody construct. In related embodiments, the 4-1BB antigen-binding domain is in the Fab format and the anti-FRα antigen-binding domain is in the scFv format. In embodiments where the anti-FRα antigen-binding domain is in the scFv format, the one or more amino acid modifications may include changes in the linker sequence between the VH and VL sequences. Changes in the linker sequence may includes use of different amino acid sequences, or different linker lengths for example. Suitable linker sequences and lengths can readily be determined by one of skill in the art, given common general knowledge. In some embodiments, the one or more amino acid modifications that improve the biophysical properties of the 4-1BB x FRα antibody construct are selected from those shown in the table below, wherein the numbering of residues is according to Rabat:
Table C3: Modifications in 8K22 scFv sequence to improve biophysical properties of antibody constructs having an 8K22 scFv
 SLC34A2/NaPi2b antigen-binding domains
SLC34A2/NaPi2b antigen-binding domains
[00162] In one embodiment, the 4-1BB x TAA antibody construct is a 4-1BB x NaPi2b antibody construct comprising a 4-1BB anti gen -binding domain and aNaPi2b antigen-binding domain wherein the 4-1BB binding domain and the NaPi2b antigen-binding domain are linked directly or indirectly to a scaffold.
[00163] SLC34A2 is a pH-sensitive sodium-dependent phosphate transporter. Also known as NaPi2b as well as NAPI-3B, NAPI-IIb, NPTIIb, this protein is expressed in some normal epithelial cells in the lung, gut and mammary gland and has a function in transporting phosphate ions. NaPi2b is found highly expressed on tumor cells, primarily in lung and ovarian cancers (Lin K et al, Clin Cancer Res. 2015 Nov 15;21(22):5139-50). NaPi2b is a multispan membrane protein, with extracellular domains of 14, 129, 57 and 6 amino acids. The polypeptide sequence of this protein is described in NCBI Reference Sequence: NP_001171470.1 and UniProt 095436, and provided herein as SEQ ID NO:81.
[00164] NaPi2b antigen-binding domains may be derived from antibodies known in the art, including but not limited to: lifastuzumab (Genentech, Seattle Genetics, described in WO2011/066503), MX-35 (Ludwig Institute, described in W02009/097128), and the antibodies described by Mersana Therapeutics in US2017/0266311. Alternatively, NaPi2b antigen-binding domains may be derived from novel antibodies that are generated according to methods known in the art and described elsewhere herein.
[00165] In one embodiment, the 4-1BB x TAA antibody construct comprises an NaPi2b antigen-binding domain that can compete with lifastuzumab for binding to an epitope of NaPi2b. In another embodiment, the 4-1BB x TAA antibody construct comprises an NaPi2b antigen-binding domain that can compete with MX-35 for binding to an epitope of NaPi2b. In still other embodiments, the 4-1BB x TAA antibody construct comprises an NaPi2b antigen- binding domain that can compete for binding to an epitope of NaPi2b with any one of the anti- NaPi2b antibodies described in WO2011/066503, W02009/097128, or US2017/0266311.
[00166] In other embodiments, the 4-1BB x TAA antibody construct comprises an NaPi2b antigen-binding domain that binds to the same epitope of NaPi2b as lifastuzumab or MX-35, or any one of the anti-NaPi2b antibodies described in WO2011/066503, W02009/097128, or US2017/0266311.
[00167] In one embodiment, the 4-1BB x TAA antibody construct comprises an NaPi2b antigen-binding domain that comprises at least one, two, or all three heavy chain CDRs and/or at least one, two, or all three light chain CDRs of lifastuzumab or MX-35, or any one of the anti-NaPi2b antibodies described in WO2011/066503, W02009/097128, orUS2017/0266311. In an alternate embodiment, the 4-1BB x TAA antibody construct comprises an NaPi2b antigen-binding domain that comprises at least one, two, or all three heavy chain CDRs and at least one, two, or all three light chain CDRs of lifastuzumab or MX-35, or any one of the anti- NaPi2b antibodies described in WO2011/066503, W02009/097128, or US2017/0266311. In other embodiments, the 4-1BB x TAA construct comprises an NaPi2b antigen-binding domain comprising a VH sequence that is at least about 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, or 100% identical to the VH sequence of lifastuzumab or MX-35, or any one of the anti-NaPi2b antibodies described in WO2011/066503, W02009/097128, or US2017/0266311. The specific sequences of the CDRs of exemplary anti-NaPi2b antibodies are described in Table D; the VH and VL sequences of these antibodies are found in Table 17. Other anti-NaPi2b antibody sequences can readily be determined by one of skill in the art with reference to the disclosures ofWO2011/066503, W02009/097128, or US2017/0266311.
Table I): CDR sequences of exemplary anti-NaPi2b antibodies


[00168] Alternatively, NaPi2b antigen-binding domains may be derived from novel antibodies that are generated according to methods known in the art.
HER2 antigen-binding domains
[00169] In one embodiment, the 4-1BB x TAA antibody construct is a 4-1BB x HER2 antibody construct comprising a 4-1BB antigen-binding domain and a HER2 antigen-binding domain wherein the 4-1BB binding domain and the HER2 antigen-binding domain are linked directly or indirectly to a scaffold.
[00170] HER2 (also known as ErbB2) is a receptor protein tyrosine kinase which belongs to the human epidermal growth factor receptor (HER) family which includes EGFR, HER2, HER3 and HER4 receptors. The extracellular (ecto) domain of HER2 comprises four domains, Domain I (ECD1, amino acid residues from about 1-195), Domain II (ECD2, amino acid residues from about 196-319), Domain III (ECD3, amino acid residues from about 320- 488), and Domain IV (ECD4, amino acid residues from about 489-630) (residue numbering without signal peptide). See Garrett et al. Mol. Cell. 11 : 495-505 (2003), Cho et al. Nature 421 : 756-760 (2003), Franklin et al. Cancer Cell 5:317-328 (2004), Tse et al. Cancer Treat Rev. 2012 Apr;38(2): 133-42 (2012), or Plowman et al. Proc. Natl. Acad. Sci. 90:1746-1750 (1993). The polypeptide sequence of HER2 is described in UniProt P04626 and included herein as SEQ ID NO: 82.
[00171] HER2 antigen-binding domains may be derived from antibodies known in the art, including but not limited to: trastuzumab (Genentech, described for example in US 5,821,337, and US 6,528,624), or pertuzumab (Genentech, US 7,862,217). The online Therapeutic Antibodies Database (Tabs, hosted by Craic Computing LLC, tabs.craic.com) identifies many additional anti-HER2 antibodies that provide suitable sequences for preparing the anti-HER2 antigen-binding domains of the 4-1BB x TAA antibody construct.
[00172] In one embodiment, the 4-1BB x TAA antibody construct comprises a HER2 antigen-binding domain that can compete with trastuzumab for binding to an epitope of HER2.
In another embodiment, the 4-1BB x TAA antibody construct comprises a HER2 antigen- binding domain that can compete with pertuzumab for binding to an epitope of HER2. In still other embodiments, the 4-1BB x TAA antibody construct comprises aHER2 antigen-binding domain that can compete for binding to an epitope of HER2 with any one of the anti-HER2 antibodies described in US 5,821,337, US 6,528,624, or US 7,862,217.
[00173] In other embodiments, the 4-1BB x TAA antibody construct comprises a HER2 antigen-binding domain that binds to the same epitope of HER2 as trastuzumab or pertuzumab, or any one of the anti-HER2 antibodies described in US 5,821,337, US 6,528,624, or US
7,862,217.
[00174] In one embodiment, the 4-1BB x TAA antibody construct comprises a HER2 antigen-binding domain that comprises at least one, two, or all three heavy chain CDRs and/or at least one, two, or all three light chain CDRs of trastuzumab or pertuzumab or margetuximab, or any one of the anti-HER2 antibodies described in US 5,821,337, US 6,528,624, or US
7,862,217. In an alternate embodiment, the 4-1BB x TAA antibody construct comprises HER2 antigen-binding domain that comprises at least one, two, or all three heavy chain CDRs and at least one, two, or all three light chain CDRs of trastuzumab or pertuzumab or margetuximab, or any one of the anti-HER2 antibodies described in US 5,821,337, US 6,528,624, or US
7,862,217. In other embodiments, the 4-1BB x TAA construct comprises a HER2 antigen- binding domain comprising a VH sequence that is at least about 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, or 100% identical to the VH sequence of trastuzumab or pertuzumab or margetuximab, or any one of the anti-HER2 antibodies described in US 5,821,337, US 6,528,624, or US 7,862,217. The specific sequences of the CDRs of exemplary anti-HER2 antibodies are described in Table E; the VH and VL sequences of these antibodies are found in Table 17. Other anti-HER2 antibody sequences can readily be determined by one of skill in the art with reference at least to the disclosures of WO2011/066503, W02009/097128, or US2017/0266311.
Table E: CDR sequences of exemplary anti-HER2 antibodies


[00175] Alternatively, HER2 antigen-binding domains may be derived from novel antibodies that are generated according to methods known in the art.
SLC39A6/LIV-1 antigen-binding domains
[00176] In one embodiment, the 4-1BB x TAA antibody construct is a 4-1BB x LIV-1 antibody construct comprising a 4-1BB antigen-binding domain and a LIV-1 antigen-binding domain wherein the 4-1BB binding domain and the LIV-1 antigen-binding domain are linked directly or indirectly to a scaffold.
[00177] SLC39A6, also known as LIV-1 or ZIP6, belongs to a family of proteins that function as zinc transporters. It is expressed at low levels on normal cells throughout the body but is expressed at high levels on some tumor cells, particularly breast cancers (Takatani- Nakase et al, (2016) Biomed Res Clin Prac 1:71-75). The polypeptide sequence of LIV-1 is described in UniProt Accession Number Q13433 and included herein as SEQ ID NO:83.
[00178] LIV-1 antigen-binding domains may be derived from antibodies known in the art, including but not limited to those described in WO 2012/078688 (Seattle Genetics), WO
2004/067564 (Abbvie), and WO 2001/055178 (Genentech). Other antibodies that bind to LIV- 1 are described in US2008/0175839.
[00179] In one embodiment, the 4-1BB x TAA antibody construct comprises a LIV-1 antigen-binding domain that can compete for binding to an epitope of LIV-1 with any one of the antibodies described in WO 2012/078688, WO 2004/067564, WO 2001/055178, or US2008/0175839. In another embodiment, the 4-1BB x TAA antibody construct comprises a LIV-1 that can compete for binding to an epitope of LIV-1 with any one of the anti-LIV-1 antibodies described in WO 2012/078688, WO 2004/067564, WO 2001/055178, or US2008/0175839.
[00180] In other embodiments, the 4-1BB x TAA antibody construct comprises a LIV- 1 antigen-binding domain that binds to the same epitope of LIV-1 as any one of the anti-LIV- 1 antibodies described in WO 2012/078688, WO 2004/067564, WO 2001/055178, or US2008/0175839.
[00181] In one embodiment, the 4-1BB x TAA antibody construct comprises an LIV-1 antigen-binding domain that comprises at least one, two, or all three heavy chain CDRs and/or at least one, two, or all three light chain CDRs of any one of the anti-LIV-1 antibodies described in WO 2012/078688, WO 2004/067564, WO 2001/055178, or US2008/0175839. In an alternate embodiment, the 4-1BB x TAA antibody construct comprises an LIV-1 antigen- binding domain that comprises at least one, two, or all three heavy chain CDRs and at least one, two, or all three light chain CDRs of any one of the anti-LIV-1 antibodies described in WO 2012/078688, WO 2004/067564, WO 2001/055178, or US2008/0175839. In other embodiments, the 4-1BB x TAA construct comprises a LIV-1 antigen-binding domain comprising a VH sequence that is at least about 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, or 100% identical to the VH sequence of any one of the anti-LIV-1 antibodies described in WO 2012/078688, WO 2004/067564, WO 2001/055178, or US2008/0175839. The specific sequences of the CDRs, VHs, and VLs for exemplary anti-LIV-1 antibodies are described in the disclosures of WO2011/066503, W02009/097128, or US2017/0266311.
[00182] Alternatively, LIV-1 antigen-binding domains may be derived from novel antibodies that are generated according to methods known in the art and described elsewhere herein.
Mesothelin (MSLN) antigen-binding domains
[00183] In one embodiment, the 4-1BB x TAA antibody construct is a 4-1BB x MSLN antibody construct comprising a 4-1BB antigen-binding domain and a MSLN antigen-binding domain wherein the 4-1BB binding domain and the MSLN antigen-binding domain are linked directly or indirectly to a scaffold.
[00184] Mesothelin (MSLN), also known as CAK antigen or Pre-pro-megakaryocyte- potentiating factor, is expressed in normal lung mesothelial cells and at low levels in other normal organs. Mesothelin is expressed at high levels in ovarian and lung cancers. The polypeptide sequence of mesothelin is described in UniProt Accession Number Q13421 and included herein as SEQ ID NO: 84.
[00185] MSLN antigen-binding domains may be derived from anti-MSLN antibodies known in the art, including but not limited to: anetumab (Bayer, described in W02009/068204), 6A4/BMS-986148 (BMS, described in W02009/045957), or the Mab Designs anti-MSLN antibody described in W02018/060480.
[00186] In one embodiment, the 4-1BB x TAA antibody construct comprises a MSLN antigen-binding domain that competes for binding with anetumab for binding to MSLN. In another embodiment, the 4-1BB x TAA antibody construct comprises a MSLN antigen-binding domain that competes for binding with 6A4/BMS-986148 for binding to MSLN. In yet another embodiment, the 4-1BB x TAA antibody construct comprises a MSLN antigen-binding domain that competes for binding with the Mab Designs anti-MSLN antibody for binding to MSLN.
[00187] In some embodiments, the 4-1BB x TAA antibody construct comprises a MSLN antigen-binding domain that binds to the same epitope as anetumab for binding to MSLN. In another embodiment, the 4-1BB x TAA antibody construct comprises a MSLN antigen-binding domain that binds to the same epitope as 6A4/BMS-986148 for binding to MSLN. In yet another embodiment, the 4-1BB x TAA antibody construct comprises a MSLN antigen-binding domain that binds to the same epitope as the Mab Designs anti-MSLN antibody for binding to MSLN.
[00188] In one embodiment, the 4-1BB x TAA antibody construct comprises a MSLN antigen-binding domain that comprises at least one, two, or all three heavy chain CDRs and/or at least one, two, or all three light chain CDRs of any one of the anti-MSLN antibodies
described in W02009/068204, W02009/045957, or WO2018/060480. In an alternate embodiment, the 4-1BB x TAA antibody construct comprises a MSLN antigen-binding domain that comprises at least one, two, or all three heavy chain CDRs and at least one, two, or all three light chain CDRs of any one of the anti-MSLN antibodies described in W02009/068204, W02009/045957, or WO2018/060480. In other embodiments, the 4-1BB x TAA construct comprises a MSLN antigen-binding domain comprising a VH sequence that is at least about 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, or 100% identical to the VH sequence of any one of the anti-MSLN antibodies described in W02009/068204, W02009/045957, or W02018/060480. The specific sequences of the CDRs of exemplary anti-MSLN antibodies are described in Table F; the VH and VL sequences of these antibodies are found in Table 17. Other anti-MSLN antibody sequences can readily be determined by one of skill in the art with reference to the disclosures of W02009/068204, W02009/045957, or WO2018/060480.
Table F: CDR sequences of an exemplary anti-MSLN antibody RG7787

Scaffolds
[00189] As described herein, the 4-1BB x TAA antibody construct comprises a 4-1BB binding domain that binds to a 4-1BB ECD and a TAA antigen-binding domain, wherein the first 4-1BB binding domain and the TAA antigen-binding domain are linked directly or indirectly to a scaffold. Direct linkage of the 4-1BB-binding domain and the TAA antigen-
binding domain results when each of these domains is directly linked to the scaffold, without linkers. Thus, in one embodiment, the 4-1BB-binding domain is linked to the scaffold without a linker and the TAA antigen-binding domain is also linked to the scaffold without a linker. Methods of accomplishing direct linkage are known in the art and include recombinant DNA methodology and/or chemical conjugation, for example.
[00190] Indirect linkage can be achieved by using a linker to link one or both of the 4- lBB-binding domain and the TAA antigen-binding domain to the scaffold. Accordingly, in one embodiment, the 4-1BB-binding domain is linked to the scaffold with a linker and the TAA antigen-binding domain is also linked to the scaffold with a linker. In other embodiments, one of the 4-1BB-binding domain and the TAA antigen-binding domain is linked to the scaffold with a linker and the other is directly linked to the scaffold without a linker. In still other embodiments, the 4-1BB-binding domain is linked to the scaffold with a linker, and the TAA antigen-binding domain is linked to the 4-1BB-binding domain with a linker. In the latter embodiment, the TAA antigen-binding domain is considered to be indirectly linked to the scaffold. In an alternate embodiment, the TAA antigen-binding domain is linked to the scaffold with a linker, and the 4-1BB-binding domain is linked to the TAA antigen-binding domain with a linker. In the latter embodiment, the 4-1BB-binding domain is considered to be indirectly linked to the scaffold.
Linkers and linker polypeptides
[00191] As indicated above, in some embodiments, indirect linkage of the 4-1BB- binding domains and the TAA antigen-binding domain to the scaffold is accomplished by the use of linkers. The linker may be a linker peptide, a linker polypeptide, or a non -polypeptide linker. In some embodiments, the antibody constructs described herein include a 4-1BB- binding domain and a TAA antigen-binding domain that are each operatively linked to a linker polypeptide wherein the linker polypeptides are capable of forming a complex or interface with each other. In some embodiments, the linker polypeptides are capable of forming a covalent linkage with each other. The spatial conformation of the constructs with the linker polypeptides is similar to the relative spatial conformation of the paratopes of a F(ab’)2 fragment generated by papain digestion, albeit in the context of an antibody construct with two antigen-binding domains.
[00192] In one embodiment, the linker polypeptides are selected from IgG1 , IgG2, IgG3, or IgG4 hinge regions.
[00193] In some embodiments, the linker polypeptides are selected such that they maintain the relative spatial conformation of the paratopes of a F(ab’) fragment and are capable of forming a covalent bond equivalent to the disulphide bond in the core hinge of IgG. Suitable linker polypeptides include IgG hinge regions such as, for example those from IgG1, IgG2, or IgG4. Modified versions of these exemplary linkers can also be used. For example, modifications to improve the stability of the IgG4 hinge are known in the art (see for example, Labrijn et al. (2009) Nature Biotechnology 27, 767 - 771).
[00194] A number of suitable scaffolds are known in the art, including peptides, polypeptides, polymers, nanoparticles or other chemical entities. In one embodiment, the scaffold is an Fc construct. A number of scaffolds based on alternate protein or molecular domains are known in the art and can be used to form selective pairs of two different target- binding polypeptides. Examples of such alternate domains include the cohesin-dockerin scaffolds described International Patent Publication No. W02008/097817, and the split albumin scaffolds described in WO 2012/116453 and WO 2014/012082. A further example is the leucine zipper domains such as Fos and Jun that selectively pair together [S A Kostelny et al. J Immunol 1992 148:1547-53; Bemd J. Wranik, et al. J. Biol. Chem. 2012 287: 43331- 43339], Alternately, other selectively pairing molecular pairs such as the bamase barstar pair [Deyev, et al. (2003). Nat Biotechnol 21, 1486-1492], or split fluorescent protein pairs [WO 2011135040] can also be employed.
[00195] In other embodiments, the linker polypeptides are operatively linked to scaffolds other than an Fc. A number of scaffolds based on alternate protein or molecular domains are known in the art and can be used to form selective pairs of two different target- binding polypeptides. Examples of such alternate domains are the split albumin scaffolds described in WO 2012/116453 and WO 2014/012082. A further example is the leucine zipper domains such as Fos and Jun that selectively pair together [S A Kostelny, M S Cole, and J Y Tso. Formation of a bispecific antibody by the use of leucine zippers. J Immunol 1992 148:1547-53; Bemd J. Wranik, Erin L. Christensen, Gabriele Schaefer, Janet K. Jackman, Andrew C. Vendel, and Dan Eaton. LUZ-Y, a Novel Platform for the Mammalian Cell Production of Full-length IgG-bispecific Antibodies J. Biol. Chem. 2012287: 43331-43339], Alternately, other selectively pairing molecular pairs such as the bamase barstar pair [Deyev, S. M., Waibel, R., Lebedenko, E. N., Schubiger, A. P., and Pldckthun, A. (2003). Design of multivalent complexes using the bamase*barstar module. Nat Biotechnol 21, 1486-1492],
DNA strand pairs [Zahida N. Chaudri, Michael Bartlet-Jones, George Panayotou, Thomas Klonisch, Ivan M. Roitt, Torben Lund, Peter J. Delves, Dual specificity antibodies using a double-stranded oligonucleotide bridge, FEBS Leters, Volume 450, Issues 1-2, 30 April 1999, Pages 23-26], split fluorescent protein pairs [Ulrich Brinkmann, Alexander Haas. Fluorescent antibody fusion protein, its production and use, WO 2011135040 Al] can also be employed.
[00196] In embodiments where the scaffold is a peptide or polypeptide, the 4-1BB- binding domain and/or the TAA antigen-binding domain of the antibody construct may be linked directly or indirectly to the scaffold by genetic fusion. In other embodiments, where the scaffold is a polymer or nanoparticle, the 4-1BB-binding domain and/or the TAA antigen- binding domain of the antibody construct may be linked to the scaffold by chemical conjugation.
[00197] In one embodiment, the antibody construct described herein comprises a 4- lBB-binding domain, and a tumor-associated antigen (TAA)-antigen binding domain, wherein the first 4-1BB-binding domain and the TAA antigen binding domain are linked directly or indirectly to an Fc construct.
[00198] The term “Fc” or “Fc construct” as used herein refers to a C-terminal region of an immunoglobulin heavy chain that contains at least a portion of the constant region (also referred to as an “Fc domain” or “Fc region”), including the CH3 domain. The term includes native sequence Fc regions and variant Fc regions. Unless otherwise specified herein, numbering of amino acid residues in the Fc region or constant region is according to the EU numbering system, also called the EU index, as described in Edelman, G.M. et al, Proc. Natl. Acad. USA, 63, 78-85 (1969).
[00199] A “dimeric Fc construct” comprises two Fc polypeptides. An “Fc polypeptide” of a dimeric Fc construct refers to one of the two polypeptides forming the construct, i.e. a polypeptide comprising C-terminal constant regions of an immunoglobulin heavy chain that is capable of stable self-association. The Fc polypeptides are derived from heavy chain isotypes including IgG, IgA, IgM, IgD, and IgE. The Fc polypeptides may also be derived from the heavy chain subtypes IgG1, IgG2, IgG3, IgG4, IgA1, or IgA2. In some embodiments, the Fc construct is a human Fc construct. In some embodiments, the Fc construct is a human IgG Fc construct. In other embodiments, the Fc construct is a human IgG1 Fc construct.
[00200] Each Fc polypeptide comprises a CH3 sequence and may optionally comprise a CH2 sequence. In some embodiments, each Fc polypeptide comprises a CH3 sequences having one or more amino acid modifications. In some embodiments, each Fc polypeptide comprises a CH2 sequence comprises one or more amino acid modifications. In some embodiments, an Fc construct is composed of a single polypeptide, for example where the Fc polypeptides are linked by a linker. In other embodiments, the Fc construct is a heterodimeric Fc construct, wherein the Fc polypeptides that make up the Fc construct have different CH3 or CH2 sequences.
CH3 sequence modifications
[00201] In certain embodiments, the scaffold is a heterodimeric Fc construct comprising CH3 sequence modifications that promote the formation of a heterodimeric Fc construct compared to a homodimeric Fc, as described in International Patent Application No. PCT/CA2011/001238 or International Patent Application No. PCT/CA2012/050780, the entire disclosure of each of which is hereby incorporated by reference in its entirety for all purposes.
[00202] Table G provides the amino acid sequence of the human IgG1 Fc sequence, corresponding to amino acids 231 to 447 of the full-length human IgG1 heavy chain. The CH3 sequence comprises amino acid 341-447 of the full-length human IgG1 heavy chain.
[00203] Typically, an Fc includes two contiguous heavy chain sequences or Fc polypeptide sequences (A and B) that are capable of dimerizing. In some embodiments, one or both sequences of these sequences may include one or more mutations or modifications at the following locations: L351, F405, Y407, T366, K392, T394, T350, S400, and/or N390, using EU numbering. In some embodiments, an Fc may include a mutant sequence as shown in Table G. In some embodiments, an Fc may include the mutations of Variant 1 A-B. In some embodiments, an Fc may include the mutations of Variant 2 A-B. In some embodiments, an Fc may include the mutations of Variant 3 A-B. In some embodiments, an Fc may include the mutations of Variant 4 A-B. In some embodiments, an Fc may include the mutations of Variant 5 A-B.
Table G: IgGl Fc sequences
 _
_

[00204] Additional methods for modifying the Fc polypeptides of the Fc construct to promote heterodimeric Fc formation are known in the art and include, for example, those described in International Patent Publication No. WO 96/027011 (knobs into holes), in Gunasekaran et al. (Gunasekaran K. et al. (2010) J Biol Chem. 285, 19637-46, electrostatic design to achieve selective heterodimerization), in Davis et al. (Davis, JH. et al. (2010) Prot Eng Des Sel ;23(4): 195-202, strand exchange engineered domain (SEED) technology), and in Labrijn et al [Efficient generation of stable bispecific IgG1 by controlled Fab-arm exchange. Labrijn AF, Meesters JI, de Goeij BE, van den Bremer ET, Neijssen J, van Kampen MD, Strumane K, Verploegen S, Kundu A, Gramer MJ, van Berkel PH, van de Winkel JG, Schuurman J, Parren PW. ProcNatl Acad Sci U S A. 2013 Mar 26;110(13):5145-50.
CH2 sequence modifications
[00205] In some embodiments, the scaffold is an Fc construct wherein each Fc polypeptide of the Fc construct comprises a CH2 sequence and a CH3 sequence. One example of a CH2 sequence of an Fc is amino acids 231-340 of the sequence shown in Table B. Several effector functions are mediated by Fc receptors (FcRs), which bind to the Fc of an antibody.
[00206] The terms “Fc receptor” and “FcR” are used to describe a receptor that binds to the Fc region of an antibody. For example, an FcR can be a native sequence human FcR. Generally, an FcR is one which binds an IgG antibody (a gamma receptor) and includes receptors of the FcγRI, FcγRII, and FcγRIII subclasses, including allelic variants and alternatively spliced forms of these receptors. FcγRII receptors include FcγRIIA (an “activating
receptor”) and FcγRIIB (an “inhibiting receptor”), which have similar amino acid sequences that differ primarily in the cytoplasmic domains thereof. Immunoglobulins of other isotypes can also be bound by certain FcRs (see, e.g., Janeway et al, Immuno Biology: the immune system in health and disease, (Elsevier Science Ltd., NY) (4th ed., 1999)). Activating receptor FcγRIIA contains an immunoreceptor tyrosine-based activation motif (ITAM) in its cytoplasmic domain. Inhibiting receptor FcγRIIB contains an immunoreceptor tyrosine-based inhibition motif (ITIM) in its cytoplasmic domain (reviewed in Daeron, Annu. Rev. Immunol. 15:203-234 (1997)). FcRs are reviewed in Ravetch and Kinet, Annu. Rev. Immunol 9:457-92 (1991); Capel et al, Immunomethods 4:25-34 (1994); and de Haas et al, J. Lab. Clin. Med. 126:330-41 (1995). Other FcRs, including those to be identified in the future, are encompassed by the term “FcR” herein. The term also includes the neonatal receptor, FcRn, which is responsible for the transfer of maternal IgGs to the fetus (Guyer et al, J. Immunol. 117:587 (1976); and Kim et al, J. Immunol. 24:249 (1994)).
[00207] Modifications in the CH2 sequence can affect the binding of FcRs to the Fc construct. A number of amino acid modifications in the Fc region are known in the art for selectively altering the affinity of the Fc for different Fcgamma receptors. In some aspects, the Fc comprises one or more modifications to promote selective binding of Fc-gamma receptors.
[00208] Exemplary mutations that alter the binding of FcRs to the Fc are listed below:
S298A/E333A/K334A, S298A/E333A/K334A/K326A (Lu Y, Vemes JM, ChiangN, et al. J Immunol Methods. 2011 Feb 28;365(l-2): 132-41);
F243L/R292P/Y300L/V305I/P396L, F243 L/R292P/Y300L/L235 V/P396L (Stavenhagen JB, Gorlatov S, Tuaillon N, et al. Cancer Res. 2007 Sep 15;67(18):8882- 90; Nordstrom JL, Gorlatov S, Zhang W, et al. Breast Cancer Res. 2011 Nov 30;13(6):R123);
F243L (Stewart R, Thom G, Levens M, et al. Protein Eng Des Sel. 2011 Sep;24(9):671- 8.)
S298A/E333A/K334A (Shields RL, Namenuk AK, Hong K, et al. J Biol Chem. 2001 Mar 2;276(9):6591-604);
S239D/I332E/A330L, S239D/I332E (Lazar GA, Dang W, Karki S, et al. Proc Natl Acad Sci U S A. 2006 Mar 14;103(11):4005-10);
S239D/S267E, S267E/L328F (Chu SY, Vostiar I, Karki S, et al. Mol Immunol. 2008 Sep;45(15):3926-33);
S239D/D265S/S298A/I332E, S239E/S298A/K326A/A327H, G237F/S298A/A330L/I3 32, S239D/I332E/S298A, S239D/K326E/A330L/I332E/S298A, G236A/S239D/D270L/ I332E, S239E/S267E/H268D, L234F/S267E/N325L, G237F/V266L/S267D and other mutations listed in WO2011/120134 and WO2011/120135, herein incorporated by reference.
[00209] Therapeutic Antibody Engineering (by William R. Strohl and Lila M. Strohl, Woodhead Publishing series in Biomedicine No 11, ISBN 1 907568 37 9, Oct 2012) lists mutations on page 283.
[00210] In some embodiments, the heterodimeric Fc comprises Fc polypeptides having CH2 sequences comprising one or more asymmetric amino acid modifications. Exemplary asymmetric amino acid modifications are described in International Patent Application No. PCT/CA2014/050507. In one embodiment the heterodimeric Fc comprises Fc polypeptides having the amino acid substitutions L234A, L235A, and D265S which reduce FcγR binding.
Additional modifications to improve effector function
[00211] In some embodiments, the Fc construct includes amino acid modifications that improve its ability to mediate effector function. Such modifications are known in the art and include afucosylation, or engineering of the affinity of the Fc towards an activating receptor, mainly FcγRIIIa for ADCC, and towards C1q for CDC.
[00212] Methods of producing antibody Fc regions with little or no fucose on the Fc glycosylation site (Asn 297 EU numbering) without altering the amino acid sequence are well known in the art. The GlymaX® technology (ProBioGen AG) is based on the introduction of a gene for an enzyme which deflects the cellular pathway of fucose biosynthesis into cells used for antibody Fc region production. This prevents the addition of the sugar “fucose” to the N- linked antibody carbohydrate part by cells, (von Horsten et al. (2010) Gly cobiology. 20 (12):1607-18). Another approach to obtaining antibody constructs having Fc constructs with lowered levels of fucosylation can be found in U.S. Patent No. 8,409,572, which teaches selecting cell lines for antibody production based on their ability to yield lower levels of fucosylation on antibodies. In some embodiments, the Fc of the antibody constructs or antibody constructs can be fully afucosylated (meaning they contain no detectable fucose) or they can be partially afucosylated, meaning that the TAA presentation inducer in bispecific antibody format contains less than 95%, less than 85%, less than 75%, less than 65%, less than
55%, less than 45%, less than 35%, less than 25%, less than 15% or less than 5% of the amount of fucose normally detected for a similar antibody produced by a mammalian expression system.
[00213] Thus, in some embodiments, the antibody constructs described herein can include a dimeric Fc that comprises one or more amino acid modifications as noted in Table H that confer improved effector function. In some embodiments, the construct can be afucosylated to improve effector function.
Table H: CH2 domains and effector function engineering

[00214] Fc modifications reducing FcγR and/or complement binding and/or effector function are known in the art. Various publications describe strategies that have been used to engineer antibodies with reduced or silenced effector activity (see Strohl, WR (2009), Curr Opin Biotech 20:685-691, and Strohl, WR and Strohl LM, “Antibody Fc engineering for optimal antibody performance” In Therapeutic Antibody Engineering, Cambridge: Woodhead Publishing (2012), pp 225-249). These strategies include reduction of effector function through modification of glycosylation, use of IgG2/IgG4 scaffolds, or the introduction of mutations in the hinge or CH2 regions of the Fc. For example, U.S. Patent Publication No. 2011/0212087 (Strohl), International Patent Publication No. WO 2006/105338 (Xencor), U.S. Patent Publication No. 2012/0225058 (Xencor), U.S. Patent Publication No. 2012/0251531 (Genentech), and Strop et al ((2012) J. Mol. Biol. 420: 204-219) describe specific modifications to reduce FcγR or complement binding to the Fc.
[00215] Specific, non-limiting examples of known amino acid modifications to reduce FcγR or complement binding to the Fc include those identified in Table I.
Table I: Modifications to reduce FcyR or complement binding to the Fc

[00216] In some embodiments, the Fc comprises at least one amino acid modification identified in Table I. In some embodiments, the Fc comprises amino acid modification of at least one of L234, L235, or D265. In some embodiments, the Fc comprises amino acid modification at L234, L235 and D265. In some embodiments, the Fc comprises the amino acid modifications L234A, L235A and D265S.
[00217] In embodiments where the scaffold is an Fc, the 4-1BB-binding domain may be linked to the N-terminus of one of the Fc polypeptides. In other embodiments, the 4-1BB- binding domain may be linked to the C-terminus of one of the Fc polypeptides. In certain embodiments, the 4-1BB x TAA antibody construct can comprise a 4-1BB-binding domain linked to the N-terminus of one of the Fc polypeptides and another 4-1BB-binding domain linked to the N-terminus of the other Fc polypeptide. In yet other embodiments, the 4-1BB x TAA antibody construct can comprise a 4-1BB-binding domain that is linked to the C-terminus
of one of the Fc polypeptides. In certain embodiments, the 4-1BB x TAA antibody construct can comprise a 4-1BB-binding domain linked to the C-terminus of one of the Fc polypeptides and another 4-1BB-binding domain linked to the C-terminus of the other Fc polypeptide.
[00218] In additional embodiments where the scaffold is an Fc, the TAA antigen- binding domain may be linked to the N-terminus of one of the Fc polypeptides. In other embodiments, the TAA antigen-binding domain may be linked to the C-terminus of one of the Fc polypeptides. In certain embodiments, the 4-1BB x TAA antibody construct can comprise a TAA antigen-binding domain linked to the N-terminus of one of the Fc polypeptides and another TAA antigen-binding domain linked to the N-terminus of the other Fc polypeptide. In yet other embodiments, the 4-1BB x TAA can comprise a TAA antigen-binding domain that is linked to the C-terminus of one of the Fc polypeptides. In certain embodiments, the 4-1BB x TAA antibody construct can comprise a TAA antigen-binding domain linked to the C-terminus of one of the Fc polypeptides and another TAA antigen-binding domain linked to the C- terminus of the other Fc polypeptide.
[00219] As would be understood by one of skill in the art, in some embodiments combinations of the above linkages are also possible. Specific exemplary combinations are described as follows.
Formats of antibody constructs 4-1BB x TAA antibody constructs
[00220] The 4-1BB x TAA antibody constructs described herein comprise a 4-1BB- binding domain and a TAA antigen-binding domain wherein the 4-1BB-binding domain and the TAA antigen-binding domain are linked directly or indirectly to a scaffold. As is known in the art, these 4-1BB x TAA antibody constructs may be constructed in many formats; exemplary, non-limiting formats are described below.
[00221] In embodiments where the 4-1BB-binding domain of the 4-1BB x TAA antibody construct is a 4-1BB antigen-binding domain, the 4-1BB antigen-binding domain may be in Fab format, scFv format, or sdAb format. In one embodiment, the antibody construct comprises a 4-1BB antigen-binding domain that is in the Fab format, and a TAA antigen- binding domain, wherein the 4-1BB antigen-binding domain and the TAA antigen-binding domain are linked directly or indirectly to a scaffold. In another embodiment, the antibody construct comprises a 4-1BB antigen-binding domain that is in the scFv format, and a TAA
antigen-binding domain, wherein the 4-1BB antigen-binding domain and the TAA antigen- binding domain are linked directly or indirectly to a scaffold. In one embodiment, the antibody construct comprises a 4-1BB antigen-binding domain that is in the sdAb format, and a TAA antigen-binding domain, wherein the 4-1BB antigen-binding domain and the TAA antigen- binding domain are linked directly or indirectly to a scaffold. In some of these embodiments, the 4-1BB antigen-binding domain is linked to the N-terminus of the scaffold and the TAA antigen-binding domain is linked to the C-terminus of the scaffold. In other embodiments, both the 4-1BB antigen-binding domain and the TAA antigen-binding domain are linked to the N-terminus of the scaffold.
[00222] In some embodiments, the scaffold is an Fc construct. In one such embodiment, the 4-1BB x TAA antibody construct comprises a first 4-1BB antigen-binding domain linked to the N-terminus of a first Fc polypeptide, a second 4-1BB antigen-binding domain linked to the N-terminus of a second Fc polypeptide, and a TAA antigen-binding domain linked to the C-terminus of the first Fc polypeptide. In some embodiments, the first and second 4-1BB antigen-binding domains are both in the Fab format and the TAA antigen-binding domain is in the scFv format. Figure 2B provides a representation of an exemplary construct related to these embodiments, where the TAA antigen-binding domain is in the scFv format. In related embodiments, the first and second 4-1BB antigen-binding domains are both in the Fab format and the TAA antigen-binding domain is also in the Fab format.
[00223] In one embodiment, the 4-1BB x TAA antibody construct is a 4-1BB x FRα antibody construct comprising a first 4-1BB 1G1 antigen-binding domain linked to the N- terminus of a first Fc polypeptide, a second 4-1BB 1G1 antigen-binding domain linked to the N-terminus of a second Fc polypeptide, and an anti FRα 8K22 antigen-binding domain linked to the C-terminus of the first Fc polypeptide. In related embodiments, the anti-FRα 8K22 antigen-binding domain is in scFv format. In an alternate embodiment, the anti-FRα 8K22 antigen-binding domain is in scFv format and comprises one or more amino acid modifications to improve its biophysical properties.
[00224] In one embodiment, the 4-1BB x TAA antibody construct is a 4-1BB x FRα antibody construct comprising a first 4-1BB 1G1 antigen-binding domain linked to the N- terminus of a first Fc polypeptide, a second 4-1BB 1G1 antigen-binding domain linked to the N-terminus of a second Fc polypeptide, and an anti FRα 8K22 antigen-binding domain linked to the C-terminus of the first Fc polypeptide, where the anti-FRα 8K22 antigen-binding domain
is in Fab format. In an alternate embodiment, the anti-FRα 8K22 antigen-binding domain and the 1G1 antigen-binding domains comprises amino acid substitutions that promote correct pairing of the 8K22 light chain with the 8K22 heavy chain and correct pairing between 1G1 light chain and the 1G1 heavy chain. In other embodiments, correct pairing between heavy and light chains is enabled through use of CrossMab technology.
[00225] In one embodiment, the 4-1BB x TAA antibody construct is a 4-1BB x FRα antibody construct comprising a first 4-1BB 1G1 antigen-binding domain linked to the N- terminus of a first Fc polypeptide, a second 4-1BB 1G1 antigen-binding domain linked to the N-terminus of a second Fc polypeptide, and an anti FRα 2L16 antigen-binding domain linked to the C-terminus of the first Fc polypeptide. In related embodiments, the anti-FRα 2L16 antigen-binding domain is in scFv format. In an alternate embodiment, the anti-FRα 2L16 antigen-binding domain is in scFv format and comprises one or more amino acid modifications to improve its biophysical properties.
[00226] In one embodiment, the 4-1BB x TAA antibody construct is a 4-1BB x FRα antibody construct comprising a first 4-1BB 1G1 antigen-binding domain linked to the N- terminus of a first Fc polypeptide, a second 4-1BB 1G1 antigen-binding domain linked to the N-terminus of a second Fc polypeptide, and an anti FRα 2L16 antigen-binding domain linked to the C-terminus of the first Fc polypeptide, where the anti-FRα 2L16 antigen-binding domain is in Fab format. In an alternate embodiment, the anti-FRα 2L16 antigen-binding domain and the 1G1 antigen-binding domains comprises amino acid substitutions that promote correct pairing of the 2L16 light chain with the 2L16 heavy chain and correct pairing between 1G1 light chain and the 1G1 heavy chain. In other embodiments, correct pairing between heavy and light chains is enabled through use of CrossMab technology.
[00227] In one embodiment, the 4-1BB x TAA antibody construct is a 4-1BB x FRα antibody construct comprising a first 4-1BB 1C8 antigen-binding domain linked to the N- terminus of a first Fc polypeptide, a second 4-1BB 1C8 antigen-binding domain linked to the N-terminus of a second Fc polypeptide, where the first and second 4-1BB antigen-binding domains comprise one or more CDRs comprising at least one amino acid substitution that improves the affinity of the antibody for human 4-1BB, and an anti FRα 8K22 antigen-binding domain linked to the C-terminus of the first Fc polypeptide. In related embodiments, the anti- FRα 8K22 antigen-binding domain is in scFv format. In an alternate embodiment, the anti-
FRα 8K22 antigen-binding domain is in scFv format and comprises one or more amino acid modifications to improve its biophysical properties.
[00228] In one embodiment, the 4-1BB x TAA antibody construct is a 4-1BB x FRα antibody construct comprising a first 4-1BB 1C8 antigen-binding domain linked to the N- terminus of a first Fc polypeptide, a second 4-1BB 1C8 antigen-binding domain linked to the N-terminus of a second Fc polypeptide, where the first and second 4-1BB antigen-binding domains comprise one or more CDRs comprising at least one amino acid substitution that improves the affinity of the antibody for human 4-1BB, and an anti FRα 2L16 antigen-binding domain linked to the C-terminus of the first Fc polypeptide. In related embodiments, the anti- FRα 2L16 antigen-binding domain is in scFv format. In an alternate embodiment, the anti- FRα 2L16 antigen-binding domain is in scFv format and comprises one or more amino acid modifications to improve its biophysical properties.
[00229] In other embodiments where the scaffold is an Fc construct, the 4-1BB x TAA antibody construct comprises a first 4-1BB antigen-binding domain linked to the N-terminus of a first Fc polypeptide, a second 4-1BB antigen-binding domain linked to the N-terminus of a second Fc polypeptide, a first TAA antigen-binding domain linked to the C-terminus of the first Fc polypeptide, and a second TAA linked to the C-terminus of the second Fc polypeptide. In some embodiments, the first and second 4-1BB antigen-binding domains are both in the Fab format and the first and second TAA antigen-binding domain are both in the scFv format. Figure 2C provides a representation of an exemplary construct related to these embodiments.
[00230] In other embodiments where the scaffold is an Fc construct, the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain linked to the N-terminus of one of the Fc polypeptides of the Fc construct, and a first TAA antigen-binding domain linked to the C-terminus of the same Fc polypeptide. In some embodiments, the 4-1BB antigen-binding domain is in the Fab format and the TAA antigen-binding domain is in the scFv format. Figure 2D provides a representation of an exemplary construct related to these embodiments.
[00231] In still other embodiments where the scaffold is an Fc construct, the 4-1BB x TAA antibody construct comprises a first 4-1BB antigen-binding domain linked to the N- terminus of a first Fc polypeptide, a second 4-1BB antigen-binding domain linked to the N- terminus of a second Fc polypeptide, and a TAA antigen-binding domain linked to the N- terminus of the VH domain of the first 4-1BB antigen-binding domain. In some embodiments,
the first and second 4-1BB antigen-binding domains are both in the Fab format and the TAA antigen-binding domain is in the scFv format. Figure 2E provides a representation of an exemplary construct related to these embodiments.
[00232] In other embodiments where the scaffold is an Fc construct, the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain linked to the N-terminus of a first Fc polypeptide, and a TAA anti gen -binding domain linked to the N-terminus of the second Fc polypeptide. In some embodiments, the 4-1BB antigen-binding domains are both in the Fab format and the TAA antigen-binding domain is in the scFv format. Figure 2F provides a representation of an exemplary construct related to these embodiments.
[00233] In other embodiments where the scaffold is an Fc construct, the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain linked to the N-terminus of one of the Fc polypeptides of the Fc construct and a TAA antigen-binding domain linked to the N- terminus of the VH region of the 4-1BB antigen-binding domain. In some embodiments, the 4-1BB antigen-binding domain is in the Fab format and the TAA antigen-binding domain is in the scFv format. Figure 2G provides a representation of an exemplary construct related to these embodiments.
[00234] In further embodiments where the scaffold is an Fc construct, the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain linked to the N-terminus of one of the Fc polypeptides of the Fc construct, a TAA antigen-binding domain linked to the C- terminus of the same Fc polypeptide, and a TAA antigen-binding domain linked to the C- terminus of the second Fc polypeptide. In some embodiments, the 4-1BB antigen-binding domain is in the Fab format and the TAA antigen-binding domains are in the scFv format. Figure 2G provides a representation of an exemplary construct related to these embodiments.
[00235] In yet other embodiments where the scaffold is an Fc construct, the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain linked to the N-terminus of one of the Fc polypeptides of the Fc construct, and a TAA antigen-binding domain linked to the C-terminus of the second Fc polypeptide. In some embodiments, the 4-1BB antigen- binding domain is in the Fab format and the TAA antigen-binding domain is in the scFv format.
[00236] In one embodiment, the 4-1BB x TAA antibody construct comprises a 4-1BB- binding domain that is a 4-1BB ligand, the 4-1BB ligand linked to the C-terminus of one of the
Fc polypeptides of an Fc construct, and a TAA antigen-binding domain that is in a Fab format, linked to the N-terminus of the other Fc polypeptide of the Fc construct.
Functional activity of the 4-1BB x TAA antibody constructs
[00237] The 4-1BB x TAA antibody constructs provided herein can bind 4-1BB and a TAA with a range of affinities. The affinity or avidity of an antibody for an antigen can be determined experimentally using methods known in the art (see, for example, Berzofsky, et al, “Antibody-Antigen Interactions,” In Fundamental Immunology, Paul, W. E., Ed., Raven Press: New York, N.Y. (1984); Kuby, Janis Immunology, W.H. Freeman and Company: New York, N.Y. (1992); and methods described herein).
[00238] The measured affinity of a particular antibody-antigen interaction can vary if measured under different conditions (e.g., salt concentration, pH). Thus, measurements of affinity and other antigen-binding parameters are preferably made with standardized solutions of antibody and antigen, and a standardized buffer, such as the buffer described herein. The affinity, KD IS a ratio of kon/koff. Generally, a KD in the micromolar range is considered low affinity for monospecific bivalent antibodies. Generally, a KD in the picomolar range is considered high affinity for monospecific bivalent antibodies. As is known in the art, the affinity of an antibody measured as a monovalent binder, is generally lower than that measured as a bivalent binder.
[00239] In some embodiments, the 4- 1 BB x TAA antibody construct comprises a 4- 1 BB antigen-binding domain that has an KD for human 4-1BB between about 15nM and 100nM, about 15nM and 200nM, or about 15nM and 500nM, between about 100pM and IμM, measured as a monovalent binder. In additional embodiments, the 4-1BB x TAA antibody construct comprises a 4-1BB antigen-binding domain that has an KD for human 4-1BB between about InM and about 100OnM, or between about 10nM to about 500nM, or between about 20nM and about 400nM measured as a monovalent binder. In other embodiments, the 4-1BB x TAA antibody construct comprises a TAA antigen-binding domain having a KD for the TAA of between about O.lnM to about 50nM, or about InM to about 20nM, or about InM to about 10nM. The KD may be measured by a number of known methods, for example SPR, as described elsewhere herein. As used in this section, the term “about” means ± 10% of the value for KD identified in each range.
[00240] In some embodiments, the 4-1BB x TAA antibody construct binds to one or more TAA-expressing cell lines as determined by for example, ELISA, BiaCore™, and/or flow cytometry, or as described in the Examples. In certain embodiments, the TAA-expressing cell line is an ovarian adenocarcinoma cell line, such as, for example, IGROV1, SKOV3, or OVCAR3. In certain embodiments, the TAA-expressing cell line is a lung carcinoma cell line. In certain embodiments, the lung carcinoma cell line is a lung squamous cell line such as H226; or a lung adenocarcinoma cell line such as H441, HCC827, H1573, H1975, or H1563; or a lung carcinoma cell line such as H1299, or a lung large cell carcinoma such as H661. In some embodiments the TAA-expressing cell line is a HER2-expressing cell line such as SKBr3, a FRα-expressing cell line, a LIV-l-expressing cell line, an NaPi2b-expressing cell line, or a mesothelin-expressing cell line.
[00241] In some embodiments, the 4-1BB x TAA antibody construct may be able to stimulate 4-1BB activity in T cells as measured by cytokine production, in the presence of TAA expressing cells. In some embodiments, the TAA-expressing cell expresses the TAA on the cell surface at greater than about 500,000 molecules per cell, as measured by quantitative flow cytometry or other quantitative method. In some embodiments, the TAA-expressing cell expresses the TAA on the cell surface at greater than about 300,000 molecules per cell, as measured by quantitative flow cytometry or other quantitative method. In some embodiments, the TAA-expressing cell expresses the TAA on the cell surface at greater than about 100,000 molecules per cell, as measured by quantitative flow cytometry or other quantitative method. In some embodiments, the TAA-expressing cell expresses the TAA on the cell surface at greater than about 50,000 molecules per cell, as measured by quantitative flow cytometry or other quantitative method. In some embodiments, the TAA-expressing cell expresses the TAA on the cell surface at between about 100,000 and 500,000 molecules per cell, as measured by quantitative flow cytometry or other quantitative method. In some embodiments, the TAA- expressing cell expresses the TAA on the cell surface at between about 50,000 and 500,000 molecules per cell, as measured by quantitative flow cytometry or other quantitative method.
[00242] In some embodiments, the 4-1BB x TAA antibody construct binds to 4-1BB- expressing cells as determined by the methods described above. In some embodiments, the 4- lBB-expressing cells are primary T, NK or NKT cells, activated primary T, NK or NKT cells, regulatory T cells, or T, NKT or NKT cells extracted from tumours
[00243] In some embodiments, the 4-1BB x TAA antibody constructs described herein may be capable of stimulating 4-1BB signalling in 4-1BB expressing cells. Methods of testing for 4-1BB activity are known in the art. For example, an NF-KB reporter gene assay as described in the examples may be used to assess the ability of the 4-1BB x TAA antibody constructs to promote NF-KB activation and translocation to the nucleus, subsequently driving reporter gene expression. As another example, a primary T cell coculture assay as described in the examples may be employed to assess the ability of the 4-1BB x TAA antibody constructs to stimulate T cell activation by measuring the increase or decrease in the production of a cytokine (such as IL-2, IL-4, IL-5, IL-6, IL-9, IL-10, IL-12, IL-13, IL-15, IL-21, IL-22, IL-35, IFN-g, TNF-a, TGF-b), increase or decrease in the expression of chemokine receptors (CXCR3, CXCR5, CXCR6, CCR1, CCR2, CCR4, CCR5, CCR7, CCR8, CCR9, CCR10), increase or decrease in expression of key transcription factors (Tbet, GATA3, FOXP3, EOMES, TOX), increase or decrease in metabolic activity or proteins regulating metabolic activity, increase or decrease in expression of anti- or pro-apoptotic proteins (Bcl2, Bcl-Xl, Bim, Mcll), increase or decrease in expression of surface markers (PD1, TIGIT, LAG3, ICOS, CD45RA, CD45RO, CD44, CD69, CD44, KLRG1), increase or decrease in the ability of T cells to kill tumour cells, or the phosphorylation, localization or activity of signaling proteins (Akt/PkB, PI3K, CD3zeta, LAT, SLP76, IKK, NFκB, TRAF family, MEK, MEKK, NIK, ERK, p38 MAPK, c-fos, c-jun, ATF, Foxo) or proteins regulating cell cycle (CyclinD3, p27kipl). This could be assessed either at the level of protein, mRNA or chromosomal availability. Activity in the primary T cell assay could also be assessed by examining increase or decrease in total cellular DNA contents (by measuring incorporation of 3H-thymidine, bromodeoxyuridine or analogous trackers) or by increase or decrease in levels of a tracking dye which is able to determine number of divisions in assays where the cells are labelled with the dye (CFDA-SE, Cell Tracker Violet, PKH26). These assays are well known to one of skill in the art, and in many cases, reagents and kits for carrying out these assays are commercially available, such as for example, CellTracker ™Violet BMQC Dye (ThermoFisher Scientific) or CellTrace™ Violet Cell proliferation Kit, ThermoFisher Scientific/Invitrogen™.
4-1BB antibody constructs
[00244] The present disclosure further provides antibody constructs or antigen-binding fragments thereof that specifically bind to 4-1BB ECD (4-1BB antibody constructs). In some embodiments, these 4-1BB antibody constructs comprise VH and VL sequences as set forth in
Tables 13 and 14, and the CDR sequences of these VH and VL sequences can be found in Table 18. In certain embodiments, the 4-1BB antibody construct is capable of agonizing 4- 1BB activity as described elsewhere herein. In some embodiments the 4-1BB antibody construct binds to any one of CRD1, CRD2, CRD3, or CDR4 of human 4-1BB.
[00245] In one embodiment, a 4-1BB antibody construct or antigen-binding fragment thereof, comprises a heavy chain variable sequence comprising three heavy chain CDRs and a light chain variable sequence comprising three light chain CDRs, wherein the heavy chain CDRs and the light chain CDRs are from any one of antibodies 1G1, 1B2, 1C3, 1C8, 2A7, 2E8, 2H9, 3D7, 3H1, 3E7, 3G4, 4B11, 4E6, 4F9, 4G10, 5E2, 5G8, or 6B3 and the 4-1BB antibody construct binds to human 4-1BB. In some embodiments, the 4-1BB antibody construct or antigen-binding fragment comprises a heavy chain variable (VH) sequence comprising three CDRs and a light chain variable (VL) sequence comprising three CDRs, wherein the heavy chain CDRs and the light chain CDRs are from any one of antibodies 1G1, 1C3, 1C8, 2E8, 3E7, 4E6, 5G8, or 6B3, and the 4-1BB antibody construct binds to human 4- 1BB.
[00246] In certain embodiments, the 4-1BB antibody construct comprises VH and VL sequences that are human or humanized. In other embodiments, the 4-1BB antibody construct comprises a VH sequence and a VL sequence having at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% sequence identity to the VH and VL sequences of any one of variants v28726, v28727, V28728, v28730, v28700, v28704, v28705, v28706, v28711, v28712, v28713, v28696, V28697, v28698, v28701, v28702, v28703, v28707, v28683, v28684, v28685, v28686, V28687, v28688, v28689, v28690, v28691, v28692, v28694, or v28695.
[00247] The anti-4-1BB CDR, VH and VL sequences may be used to construct various formats of antibody constructs as is known in the art. For example, these sequences may be used to construct Fab fragments or scFvs, which may be linked to a scaffold such as an Fc or other scaffolds as described herein. Exemplary formats for antibody constructs comprising these CDR, VH and VL sequences are depicted in Figure 1. The antibody constructs may be monovalent, bivalent or multivalent. In some embodiments, the antibody constructs are monospecific. In some embodiments, the antibody constructs are monospecific and in the naturally occurring format (FSA).
[00248] The anti-4-1BB VH and VL sequences as set forth in Tables 13, 14 and the anti- 4-1BB CDR sequences found in Table 18 may further be used in the construction of bispecific or multispecific antibodies, such as the 4-1BB x TAA antibody constructs described here, or other antibody constructs comprising at least one antigen-binding domain that binds to the ECD of 4-1BB.
[00249] In some embodiments, the 4-1BB antibody constructs in monovalent form bind human 4-1BB with a KD for 4-1BB between about 15nM and 100nM, about 15nM and 200nM, or about 15nM and 500nM, between about 100pM and 1μM. In additional embodiments, the 4-1BB antibody construct in monovalent form comprises a 4-1BB antigen-binding domain that has an KD for human 4-1BB between about InM and about 1000nM, or between about 10nM to about 500nM, or between about 20nM and about 400nM. As indicated above, the KD may be measured by a number of known methods, for example SPR, as described elsewhere herein. As used in this section, the term “about” means ± 10% of the value for KD identified in each range. In a related embodiment, the term “about” means ± 20% of the value for KD as measured by SPR.
[00250] The 4-1BB antibody constructs described herein may be prepared, tested and used as described elsewhere herein. FRα antibody constructs
[00251] The present disclosure further provides antibody constructs or antigen-binding fragments thereof that specifically bind to FRα (FRα antibody constructs). These FRα antibody constructs comprise VH and VL sequences as set forth in Tables 17, 20, and 48 and the CDR sequences of these VH and VL sequences can be found in Tables 18 and 47. In one embodiment, the FRα antibody constructs bind to human FRα.
[00252] In some embodiments, the FRα antibody constructs comprise a heavy chain variable sequence comprising three heavy chain CDRs and a light chain comprising three light chain CDRs, wherein the heavy chain CDRs and the light chain CDRs are from antibody 8K22 or antibody 1H06. In other embodiments, the FRα antibody constructs comprise a heavy chain variable sequence comprising three heavy chain CDRs and a light chain comprising three light chain CDRs, wherein the heavy chain CDRs and the light chain CDRs are from antibody 2L16.
[00253] In certain embodiments, the FRα antibody constructs comprise VH and VL sequences that are human or humanized. In related embodiments, the FRα antibody construct comprises a VH sequence and a VL sequence having at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% sequence identity to the VH and VL sequences of any one of variants 23794, 23795, 23796, 23797, 23798, 23799, 23800, 23801, 23802, 23803, 23804, 23805, 23806, 23807, 23808, 23809, 23810, 23811, 23812, 23813, 23814, 23815, 23816, 23817, or 23818, derived from the 8K22 antibody.
[00254] In other embodiments, the FRα antibody constructs comprise humanized VH and VL sequences comprising the heavy chain CDRs and the light chain CDRs of antibody 1H06.
[00255] In still other embodiments, the FRα antibody construct comprises a VH sequence and a VL sequence having at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% sequence identity to the VH and VL sequences as set forth in SEQ ID NOs:804 and 805, in SEQ ID NOs:806 and 805, in SEQ ID NOs:807 and 805, or in SEQ ID NOs:808 and 805.
[00256] In some embodiments, humanized FRα antibody constructs comprise a humanized FRα Fab domain that is more stable that than of the parental Fab from which the humanized Fab domain is derived. In related embodiments, the humanized FRα Fab domain can exhibit a Tm that is up to 10°C higher than that of the parental Fab. In some embodiments, the humanized FRα Fab domain can exhibit a Tm that is up to 5°C higher than that of the parental Fab.
[00257] In certain embodiments, the FRα antibody construct has a binding affinity or KD for human FRα ranging from 100pM to 100nM. In some embodiments, the FRα antibody construct has a binding affinity or KD for human FRα ranging from 10pM to 100nM. In related embodiments, the FRα antibody construct has a KD for human FRα ranging from InM to 50nM. In additional related embodiments, the affinity of the FRα antibody constructs for human FRα is measured by Bio-layer interferometry (BLI).
[00258] These anti-FRα CDR, VH and VL sequences described in Tables 17, 18, 20, 47 and 48 may be used to construct various formats of antibody constructs as is known in the art. For example, these sequences may be used to construct Fab fragments or scFvs, which may be linked to a scaffold such as an Fc or other scaffold as described herein. Exemplary formats for antibody constructs comprising these CDR, VH and VL sequences are depicted in Figure 1.
The antibody constructs may be monovalent, bivalent or multivalent. In some embodiments, the antibody constructs are monospecific. In some embodiments, the antibody constructs are monospecific and in the naturally occurring format (FSA).
[00259] The anti-FRα VH and VL sequences as set forth in Tables 17, 20, 48 and the anti-FRα CDR sequences found in Table 18 and Table 47 may further be used in the construction of bispecific or multispecific antibodies, such as the 4-1BB x FRα antibody constructs described here, or other antibody constructs comprising at least one antigen-binding domain that binds to the FRα.
[00260] The FRα antibody constructs described herein may be prepared, tested and used as described elsewhere herein.
Methods of Preparing the Antibody Constructs
[00261] The 4-1BB x TAA antibody constructs, 4-1BB x FRα antibody constructs, FRα antibody constructs and 4-1BB antibody constructs described herein may be produced using recombinant methods and compositions, e.g., as described in U.S. Patent No. 4,816,567. This method and other methods for producing these constructs are described as follows.
[00262] Certain embodiments thus relate to one or more nucleic acids encoding an antibody construct described herein. Such nucleic acids may encode the amino acid sequences corresponding to the 4-1BB x TAA antibody constructs or the 4-1BB antibody constructs. In some cases, where the 4-1BB x TAA antibody construct comprises two different Fabs, it may be necessary to employ one of several technologies that promote correct pairing of light chains between the different Fabs. One such technology is Cross-Mab in which Fabs binding to two different targets are fused to an Fc. CL and CH1 domains and VH and VL domains are switched, e.g., CH1 is fused in-line with VL, while CL is fused in-line with VH. This technology is described in Klein et al, 2016. MABS, 8(6): 1010-1020. Other examples of light chain pairing solutions are known in the art and described, for example, in International Patent Publication Nos. WO 2014/082179, WO 2015/181805, and WO 2017/059551.
[00263] Certain embodiments relate to one or more vectors (e.g., expression vectors) comprising nucleic acid encoding the antibody constructs described herein. In some embodiments, the nucleic acid encoding the antibody construct is included in a multi cistronic vector. In other embodiments, each polypeptide chain of the antibody construct is encoded by
a separate vector. It is further contemplated that combinations of vectors may comprise nucleic acid encoding a single antibody construct.
[00264] Certain embodiments relate to host cells comprising such nucleic acid or one or more vectors comprising the nucleic acid. In some embodiments, for example, where the antibody construct is a multispecific or bispecific antibody, a host cell comprises (e.g., has been transformed with): (1) a vector comprising a nucleic acid that encodes an amino acid sequence comprising the VL of the antigen-binding domain and an amino acid sequence comprising the VH of the antigen-binding domain, or (2) a first vector comprising a nucleic acid that encodes an amino acid sequence comprising the VL of the antigen-binding domain and a second vector comprising a nucleic acid that encodes an amino acid sequence comprising the VH of the antigen-binding domain. In some embodiments, the host cell is eukaryotic, e.g. a Chinese Hamster Ovary (CHO) cell, or human embryonic kidney (HEK) cell, or lymphoid cell (e.g., Y0, NSO, Sp20 cell).
[00265] Certain embodiments relate to a method of making an antibody construct, wherein the method comprises culturing a host cell comprising nucleic acid encoding the antibody construct, as described above, under conditions suitable for expression of the antibody construct, and optionally recovering the antibody construct from the host cell (or host cell culture medium).
[00266] For recombinant production of the antibody construct, nucleic acid encoding an antibody construct, e.g., as described above, is isolated and inserted into one or more vectors for further cloning and/or expression in a host cell. Such nucleic acid may be readily isolated and sequenced using conventional procedures (e.g., by using oligonucleotide probes that are capable of binding specifically to genes encoding the heavy and light chains of the antibody construct).
[00267] The term “substantially purified” refers to a construct described herein, or variant thereof, that may be substantially or essentially free of components that normally accompany or interact with the protein as found in its naturally occurring environment, i.e. a native cell, or host cell in the case of recombinantly produced construct. In certain embodiments, a construct that is substantially free of cellular material includes preparations of protein having less than about 30%, less than about 25%, less than about 20%, less than about 15%, less than about 10%, less than about 5%, less than about 4%, less than about 3%, less
than about 2%, or less than about 1% (by dry weight) of contaminating protein. When the construct is recombinantly produced by the host cells, the protein in certain embodiments is present at about 30%, about 25%, about 20%, about 15%, about 10%, about 5%, about 4%, about 3%, about 2%, or about 1% or less of the dry weight of the cells. When the construct is recombinantly produced by the host cells, the protein, in certain embodiments, is present in the culture medium at about 5 g/L, about 4 g/L, about 3 g/L, about 2 g/L, about 1 g/L, about 750 mg/L, about 500 mg/L, about 250 mg/L, about 100 mg/L, about 50 mg/L, about 10 mg/L, or about 1 mg/L or less of the dry weight of the cells.
[00268] In certain embodiments, the term “substantially purified” as applied to a construct comprising a heteromultimer Fc and produced by the methods described herein, has a purity level of at least about 30%, at least about 35%, at least about 40%, at least about 45%, at least about 50%, at least about 55%, at least about 60%, at least about 65%, at least about 70%, specifically, a purity level of at least about 75%, 80%, 85%, and more specifically, a purity level of at least about 90%, a purity level of at least about 95%, a purity level of at least about 99% or greater as determined by appropriate methods such as SDS/PAGE analysis, RP- HPLC, SEC, and capillary electrophoresis.
[00269] Suitable host cells for cloning or expression of antibody construct-encoding vectors include prokaryotic or eukaryotic cells described herein.
[00270] A “recombinant host cell” or “host cell” refers to a cell that includes an exogenous polynucleotide, regardless of the method used for insertion, for example, direct uptake, transduction, f-mating, or other methods known in the art to create recombinant host cells. The exogenous polynucleotide may be maintained as anonintegrated vector, for example, a plasmid, or alternatively, may be integrated into the host genome.
[00271] As used herein, the term “eukaryote” refers to organisms belonging to the phylogenetic domain Eucarya such as animals (including but not limited to, mammals, insects, reptiles, birds, etc.), cibates, plants (including but not limited to, monocots, dicots, algae, etc.), fungi, yeasts, flagellates, microsporidia, protists, and the like.
[00272] As used herein, the term “prokaryote” refers to prokaryotic organisms. For example, a non-eukaryotic organism can belong to the Eubacteria (including but not limited to,
Escherichia coli, Thermus thermophilus, Bacillus stearothermophilus, Pseudomonas fluorescens, Pseudomonas aeruginosa, Pseudomonas putida, and the like) phylogenetic
domain, or the Archaea (including but not limited to, Methanococcus jannaschii, Methanobacterium thermoautotrophicum, Halobacterium such as Haloferax volcanii and Halobacterium species NRC-1, Archaeoglobus fulgidus, Pyrococcus furiosus, Pyrococcus horikoshii, Aeuropyrum pernix, and the like) phylogenetic domain.
[00273] For example, an antibody construct may be produced in bacteria, in particular when glycosylation and Fc effector function are not needed. For expression of antigen-binding construct fragments and polypeptides in bacteria, see, e.g., U.S. Pat. Nos. 5,648,237, 5,789,199, and 5,840,523. (See also Charlton, Methods in Molecular Biology Vol. 248 (B.K.C. Lo, ed., Humana Press, Totowa, N.J., 2003), pp. 245-254, describing expression of antibody fragments in E. coli.) After expression, the antigen-binding construct may be isolated from the bacterial cell paste in a soluble fraction and can be further purified.
[00274] In addition to prokaryotes, eukaryotic microbes such as filamentous fungi or yeast are suitable cloning or expression hosts for Antibody construct-encoding vectors, including fungi and yeast strains whose glycosylation pathways have been “humanized,” resulting in the production of an antigen-binding construct with a partially or fully human glycosylation pattern. See Gemgross, Nat. Biotech. 22:1409-1414 (2004), and Li et al.. Nat. Biotech. 24:210-215 (2006).
[00275] Suitable host cells for the expression of glycosylated antigen-binding constructs are also derived from multicellular organisms (invertebrates and vertebrates). Examples of invertebrate cells include plant and insect cells. Numerous baculoviral strains have been identified which may be used in conjunction with insect cells, particularly for transfection of Spodoptera frugiperda cells.
[00276] Plant cell cultures can also be utilized as hosts. See, e.g., U.S. Pat. Nos. 5,959,177, 6,040,498, 6,420,548, 7,125,978, and 6,417,429 (describing PLANTIBODIES™ technology for producing antigen-binding constructs in transgenic plants).
[00277] Vertebrate cells may also be used as hosts. For example, mammalian cell lines that are adapted to grow in suspension may be useful. Other examples of useful mammalian host cell lines are monkey kidney CV1 line transformed by SV40 (COS-7); human embryonic kidney line (293 or 293 cells as described, e.g., in Graham et al., J. Gen Virol. 36:59 (1977)); baby hamster kidney cells (BHK); mouse sertoli cells (TM4 cells as described, e.g., in Mather, Biol. Reprod. 23:243-251 (1980)); monkey kidney cells (CV1); African green monkey
kidney cells (VERO-76); human cervical carcinoma cells (HELA); canine kidney cells (MDCK; buffalo rat liver cells (BRL 3 A); human lung cells (W138); human liver cells (Hep G2); mouse mammary tumor (MMT 060562); TRI cells, as described, e.g., in Mather et al ., Annals N.Y. Acad. Sci. 383:44-68 (1982); MRC 5 cells; and FS4 cells. Other useful mammalian host cell lines include Chinese hamster ovary (CHO) cells, including DHFR CHO cells (Urlaub et al, Proc. Natl. Acad. Sci. USA 77:4216 (1980)); and myeloma cell lines such as Y0, NS0 and Sp2/0. For a review of certain mammalian host cell lines suitable for antigen- binding construct production, see, e.g., Yazaki and Wu , Methods in Molecular Biology, Vol. 248 (B.K.C. Lo, ed., Humana Press, Totowa, N.J.), pp. 255-268 (2003).
[00278] In some embodiments, the antibody constructs described herein are produced in stable mammalian cells, by a method comprising: transfecting at least one stable mammalian cell with: nucleic acid encoding the antibody construct, in a predetermined ratio; and expressing the nucleic acid in the at least one mammalian cell. In some embodiments, the predetermined ratio of nucleic acid is determined in transient transfection experiments to determine the relative ratio of input nucleic acids that results in the highest percentage of the antigen-binding construct in the expressed product.
[00279] In some embodiments, in the method of producing an antibody construct in stable mammalian cells, the expression product of the stable mammalian cell comprises a larger percentage of the desired glycosylated antigen-binding construct as compared to the monomeric heavy or light chain polypeptides, or other antibodies.
[00280] If required, the antibody constructs can be purified or isolated after expression. Proteins may be isolated or purified in a variety of ways known to those skilled in the art. Standard purification methods include chromatographic techniques, including ion exchange, hydrophobic interaction, affinity, sizing or gel filtration, and reversed-phase, carried out at atmospheric pressure or at high pressure using systems such as FPLC and HPLC. Purification methods also include electrophoretic, immunological, precipitation, dialysis, and chromatofocusing techniques. Ultrafiltration and diafiltration techniques, in conjunction with protein concentration, are also useful. As is well known in the art, a variety of natural proteins bind Fc and antibodies, and these proteins can used for purification of antigen-binding constructs. For example, the bacterial proteins A and G bind to the Fc region. Likewise, the bacterial protein L binds to the Fab region of some antibodies. Purification can often be enabled by a particular fusion partner. For example, antibodies may be purified using
glutathione resin if a GST fusion is employed, Ni+2 affinity chromatography if a His-tag is employed, or immobilized anti-flag antibody if a flag-tag is used. For general guidance in suitable purification techniques, see, e.g. incorporated entirely by reference Protein Purification: Principles and Practice, 3rd Ed., Scopes, Springer-Verlag, NY, 1994, incorporated entirely by reference. The degree of purification necessary will vary depending on the use of the antigen-binding constructs. In some instances, no purification is necessary.
[00281] In certain embodiments, the antibody constructs may be purified using Anion Exchange Chromatography including, but not limited to, chromatography on Q-sepharose, DEAE sepharose, poros HQ, poros DEAF, Toyopearl Q, Toyopearl QAE, Toyopearl DEAE, Resource/Source Q and DEAE, Fractogel Q and DEAE columns.
[00282] In some embodiments, the antibody constructs are purified using Cation Exchange Chromatography including, but not limited to, SP-sepharose, CM sepharose, poros HS, poros CM, Toyopearl SP, Toyopearl CM, Resource/Source S and CM, Fractogel S and CM columns and their equivalents and comparables.
[00283] In some embodiments, the antibody constructs are expressed using cell-free translation or expression systems. Suitable systems are known in the art, such as for example the method described by Stech et al, in Nature Scientific Reports 7:12030, or those described by Gregorio et al, in Methods Protoc. 20192:24.
[00284] In addition, the antibody constructs can be chemically synthesized using techniques known in the art (e.g., see Creighton, 1983, Proteins: Structures and Molecular Principles, W. H. Freeman & Co., N.Y and Hunkapiller et al, Nature, 310:105-111 (1984)). For example, a polypeptide corresponding to a fragment of a polypeptide can be synthesized by use of a peptide synthesizer. Furthermore, if desired, nonclassical amino acids or chemical amino acid analogs can be introduced as a substitution or addition into the polypeptide sequence. Non-classical amino acids include, but are not limited to, to the D-isomers of the common amino acids, 2,4diaminobutyric acid, alpha-amino isobutyric acid, 4-aminobutyric acid, Abu, 2-amino butyric acid, g-Abu, eAhx, 6-amino hexanoic acid, Aib, 2-amino isobutyric acid, 3-amino propionic acid, ornithine, norleucine, norvaline, hydroxyproline, sarcosine, citrulline, homocitrulline, cysteic acid, t-butylglycine, t-butylalanine, phenylglycine, cyclohexylalanine, b-alanine, fluoro-amino acids, designer amino acids such as a-methyl
amino acids, C a-methyl amino acids, N a-methyl amino acids, and amino acid analogs in general. Furthermore, the amino acid can be D (dextrorotary) or L (levorotary).
Post-translational modifications
[00285] In certain embodiments, the antibody constructs described herein are differentially modified during or after translation.
[00286] The term “modified,” as used herein, refers to any changes made to a given polypeptide, such as changes to the length of the polypeptide, the amino acid sequence, chemical structure, co-translational modification, or post-translational modification of a polypeptide.
[00287] The term “post-translationally modified” refers to any modification of a natural or non-natural amino acid that occurs to such an amino acid after it has been incorporated into a polypeptide chain. The term encompasses, by way of example only, co-translational in vivo modifications, co-translational in vitro modifications (such as in a cell-free translation system), post-translational in vivo modifications, and post-translational in vitro modifications.
[00288] In some embodiments, the antibody constructs may comprise a modification that is: glycosylation, acetylation, phosphorylation, amidation, derivatization by known protecting/blocking groups, proteolytic cleavage or linkage to an antibody molecule or antigen- binding construct or other cellular ligand, or a combination of these modifications. In some embodiments, the antibody construct is chemically modified by known techniques, including but not limited, to specific chemical cleavage by cyanogen bromide, trypsin, chymotrypsin, papain, V8 protease, NaBFLq acetylation, formylation, oxidation, reduction; and metabolic synthesis in the presence of tunicamycin.
[00289] Additional optional post-translational modifications of antigen-binding constructs include, for example, N-linked or O-linked carbohydrate chains, processing of N- terminal or C-terminal ends), attachment of chemical moieties to the amino acid backbone, chemical modifications of N-linked or O-linked carbohydrate chains, and addition or deletion of an N-terminal methionine residue as a result of procaryotic host cell expression. The antigen- binding constructs described herein are modified with a detectable label, such as an enzymatic, fluorescent, isotopic or affinity label to allow for detection and isolation of the protein. In certain embodiments, examples of suitable enzyme labels include horseradish peroxidase,
alkaline phosphatase, beta-galactosidase, or acetylcholinesterase; examples of suitable prosthetic group complexes include streptavidin biotin and avidin/biotin; examples of suitable fluorescent materials include umbelliferone, fluorescein, fluorescein isothiocyanate, rhodamine, dichlorotriazinylamine fluorescein, dansyl chloride or phycoerythrin; an example of a luminescent material includes luminol; examples of bioluminescent materials include luciferase, luciferin, and aequorin; and examples of suitable radioactive material include iodine, carbon, sulfur, tritium, indium, technetium, thallium, gallium, palladium, molybdenum, xenon, fluorine.
[00290] In some embodiments, antigen-binding constructs described herein may be attached to macrocyclic chelators that associate with radiometal ions.
[00291] In some embodiments, the antibody constructs described herein may be modified by either natural processes, such as post-translational processing, or by chemical modification techniques which are well known in the art. In certain embodiments, the same type of modification may be present in the same or varying degrees at several sites in a given polypeptide. In certain embodiments, polypeptides from antigen-binding constructs described herein are branched, for example, as a result of ubiquitination, and in some embodiments are cyclic, with or without branching. Cyclic, branched, and branched cyclic polypeptides are a result from post-translation natural processes or made by synthetic methods. Modifications include acetylation, acylation, ADP-ribosylation, amidation, covalent attachment of flavin, covalent attachment of a heme moiety, covalent attachment of a nucleotide or nucleotide derivative, covalent attachment of a lipid or lipid derivative, covalent attachment of phosphotidylinositol, cross-linking, cyclization, disulfide bond formation, demethylation, formation of covalent cross-links, formation of cysteine, formation of pyroglutamate, formylation, gamma-carboxylation, glycosylation, GPI anchor formation, hydroxylation, iodination, methylation, myristylation, oxidation, pegylation, proteolytic processing, phosphorylation, prenylation, racemization, selenoylation, sulfation, transfer-RNA mediated addition of amino acids to proteins such as arginylation, and ubiquitination. (See, for instance, PROTEINS— STRUCTURE AND MOLECULAR PROPERTIES, 2nd Ed., T. E. Creighton, W. H. Freeman and Company, New York (1993); POST-TRANSLATIONAL COVALENT MODIFICATION OF PROTEINS, B. C. Johnson, Ed., Academic Press, New York, μgs. 1-12 (1983); Seifter et al, Meth. Enzymol. 182:626-646 (1990); Rattan et al, Ann. N.Y. Acad. Sci. 663:48-62 (1992)).
[00292] In certain embodiments, antigen-binding constructs described herein may be attached to solid supports, which are particularly useful for immunoassays or purification of polypeptides that are bound by, that bind to, or associate with proteins described herein. Such solid supports include, but are not limited to, glass, cellulose, polyacrylamide, nylon, polystyrene, polyvinyl chloride or polypropylene.
Additional optional modifications
[00293] In one embodiment, the antibody constructs described herein can be further modified (i.e., by the covalent attachment of various types of molecules) such that covalent attachment does not interfere with or affect the ability of the 4-1BB x TAA antibody construct to bind to 4-1BB or to the TAA, or affect the ability of the 4-1BB antibody construct to bind to 4-1BB, or negatively affect the stability of these antibody constructs. Similarly, the 4-1BB antibody constructs and FRα antibody constructs may be modified by covalent attachment such that their stability or ability to bind to their target is not significantly affected. Such modifications include, for example, but not by way of limitation, glycosylation, acetylation, pegylation, phosphorylation, amidation, derivatization by known protecting/blocking groups, proteolytic cleavage, linkage to a cellular ligand or other protein, etc. Any of numerous chemical modifications can be carried out by known techniques, including, but not limited to, specific chemical cleavage, acetylation, formylation, metabolic synthesis of tunicamycin, etc.
[00294] Certain embodiments contemplate conjugation of the antibody construct to a drug moiety, for example, a toxin, a chemotherapeutic agent, an immune modulator, or a radioisotope. Numerous methods of preparing antibody drug conjugates (ADCs) are known in the art. Examples include methods described in U.S. Patent No. 8,624,003 (pot method), U.S. Patent No. 8,163,888 (one-step), and U.S. Patent No. 5,208,020 (two-step method). See also, Antibody-Drug Conjugates, Series: Methods in Molecular Biology, Laurent Ducry (Ed.), Humana Press, 2013.
[00295] The drug moiety of the ADCs is typically a compound or moiety having a cytostatic or cytotoxic effect. In some embodiments, the drug comprised by the ADC is a cytotoxic agent. The term “cytotoxic agent” as used herein refers to a substance that inhibits or prevents the function of cells and/or causes destruction of cells. The term is intended to include radioactive isotopes (for example, 211At, 1311, 125I, 90Y, 186Re, 188Re, 153Sm, 212Bi, 32P and 177LU), chemotherapeutic agents, and toxins such as small molecule toxins or enzymatically active toxins of bacterial, fungal, plant or animal origin, including fragments
and/or variants thereof. One skilled in the art will appreciate that some of these categories of drugs overlap and are thus not intended to be mutually exclusive. For example, toxins may also be considered as chemotherapeutic agents in the sense that they are chemical compounds that may be used to treat cancer. In some embodiments, the drug comprised by the ADC is an analog or derivative of a naturally occurring toxin. Examples of such naturally occurring toxins include, but are not limited to, maytansines, auristatins, dolastatins, tubulysins, hemiasterlins, calicheamicins, duocarmycins, pyrrolobenzodiazapenes, amatoxins, camptothecins, Pseudomonas exotoxin (PE), diphtheria toxin (DT), deglycosylated ricin A (dgA) and gelonin.
[00296] In certain embodiments, the drug comprised by the ADCs is a microtubule disrupting agent or a DNA modifying agent. Examples of toxins that are microtubule disrupting agents include, but are not limited to, maytansines, auristatins, dolastatins, tubulysins, hemiasterlins, and analogs and derivatives thereof. Examples of toxins that are DNA modifying agents include, but are not limited to, calicheamicins and other enediyne antibiotics, duocarmycins, pyrrolobenzodiazapenes, amatoxins, camptothecins, and analogs and derivatives thereof.
[00297] Exemplary maytansinoids include DM1 (mertansine, emtansine, N2'-deacetyl- N2'-(3-mercapto-l -oxopropyl)maytansine), DM3 (N2'-deacetyl-N2'-(4-mercapto- 1 - oxopentyl)maytansine) and DM4 (ravtansine, soravtansine, N2'-deacetyl-N2'-(4-methyl-4- mercapto-l-oxopentyl)maytansine) (see U.S. Patent Application Publication No. US 2009/0202536). Other examples of naturally occurring, synthetic and semi-synthetic maytansinoids are described in Cassady et al, 2004, Chem. Pharm. Bull., 52(1): 1-26, and in U.S. Patent Nos.4, 256, 746; 4,361,650; 4,307,016; 4,294,757; 4,424,219; 4,331,598; 4,364,866; 4,313,946; 4,315,929; 4,362,663; 4,322,348 and 4,371,533.
[00298] Exemplary dolastatins and auristatins include auristatin E (also known in the art as a derivative of dolastatin-10) and auristatin F, and analogs and derivatives thereof. Auristatin analogs include, for example, esters formed between auristatin E and a keto acid. For example, auristatin E can be reacted with paraacetyl benzoic acid or benzoylvaleric acid to produce auristatin EB (AEB) and auristatin EVB (AEVB), respectively. Other typical auristatins include auristatin F phenylenediamine (AFP), monomethylauristatin F (MMAF) and monomethylauristatin E (MMAE). The synthesis and structure of exemplary auristatins are described in U.S. Patent Nos. 6,884,869; 7,098,308; 7,256,257; 7,423,116; 7,498,298 and 7,745,394. Other examples of auristatin analogs, in particular analogs suitable for conjugation
via the C-terminus of the drug molecule, include those described in International Publication Nos. WO 2002/088172 and WO 2016/041082.
[00299] Exemplary hemiasterlins and hemiasterlin analogs and derivatives include those described in International Publication Nos. WO 1996/33211 and WO 2004/026293; U.S. Patent No. 7,579,323 (which describes the hemiasterlin analog, HTI-286) and International Publication No. WO 2014/144871.
[00300] Exemplary calicheamycins and calicheamycin analogs and derivatives include those described in International Publication No. WO 2015/063680, and U.S. Patent Nos. 5,773,001; 5,714,586 and 5,770,701).
[00301] Exemplary duocarmycins and duocarmycin analogs and derivatives include naturally-occurring duocarmycins such as duocarmycins A, Bl, B2, C1, C2, D and SA, as well as CC-1065, and analogs and derivatives such as adozelesin, bizelesin and centanamycin. Other calicheamicin analogs and derivatives are described in U.S. Patent Nos. 4,912,227; 5,070,092; 5,084,468; 5,332,837; 5,641,780; 5,739,350 and 8,889,868.
[00302] Exemplary pyrrolobenzodiazapenes (PBD) include various PBD dimers such as those described in U.S. Patent Nos. 6,884,799; 7,049,311; 7,511,032; 7,528,126; 7,557,099 and 9,056,914, and in International Publication Nos. WO 2007/085930, WO 2009/016516, WO 2011/130598, WO 2011/130613 and WO 2011/130616, and U.S. Patent Application Publication No. US 2011/0256157.
[00303] Exemplary amatoxins include a-Amanitin, b-Amanitin, g-Amanitin and e- Amanitin, and analogs and derivatives thereof. Various amatoxins and amatoxin analogues have been described (see, for example, European Patent No. EP 1 859 811, U.S. Patent No. 9,233,173 and International Publication No. WO 2014/043403).
[00304] Exemplary camptothecins (CPT) include irinotecan (CPT-11), SN-38 (7-ethyl- 10-hydroxy-camptothecin), 10-hydroxy camptothecin, topotecan, lurtotecan, 9- aminocamptothecin and 9-nitrocamptothecin. Other examples of CPT analogs and derivatives include 7-butyl-10-amino-camptothecin and 7-butyl-9-amino-10,ll-methylenedioxy- camptothecin (see U.S. Patent Application Publication No. US 2005/0209263) and aniline containing derivatives of these compounds as described in Burke et al, 2009, Bioconj. Chem. 20(6): 1242-1250 and Sharkey et al, 2012, Mol. Cancer Ther. 11:224-234.
[00305] In certain embodiments, the drug comprised by the ADC is a chemotherapeutic agent. In some embodiments, the drug comprised by the ADC is an anthracycline, such as doxorubicin, epirubicin, idarubicin, daunorubicin (also known as daunomycin), nemorubicin or an analog or derivative thereof. Derivatization of daunorubicin and doxorubicin for conjugation to antibodies has been described (see, for example, Kratz et al, 2006, Current Med. Chem. 13:477-523, and U.S. Patent No. 6,630,579).
[00306] Additional examples of drugs for use in the ADCs include mTOR inhibitors such as rapamycin (sirolimus) and analogs thereof (“rapalogs”). Rapalogs are considered to be compounds that are structurally related to rapamycin that retain mTOR inhibiting activity and include, for example, esters, ethers, oximes, hydrazones, and hydroxylamines of rapamycin, as well as compounds in which functional groups on the rapamycin core structure have been modified, for example, by reduction or oxidation. Exemplary rapalogs include, but are not limited to, temsirolimus (CC1779), tacrolimus (FK-506), everolimus (RAD001), deforolimus (AP23573), AZD8055 (AstraZeneca), and OSI-027 (OSI).
[00307] The selected drug may be conjugated to the antibody construct with or without a linker by any of a variety of methods known in the art. Typically, drugs are conjugated to cysteine or lysine residues in the antibody construct via a linker, which may be cleavable or non-cleavable. Exemplary methods and linkers are provided in Antibody-Drug Conjugates, Series: Methods in Molecular Biology, Laurent Ducry (Ed.), Humana Press, 2013.
[00308] In some embodiments, the antibody construct may be expressed as fusion proteins comprising a tag to facilitate purification and/or testing etc. As referred to herein, a "tag" is any added series of amino acids which are provided in a protein at either the C- terminus, the N-terminus, or internally that contributes to the identification or purification of the protein. Suitable tags include but are not limited to tags known to those skilled in the art to be useful in purification and/or testing such as albumin binding domain (ABD), His tag, FLAG tag, glutathione-s-transferase, hemagglutinin (HA) and maltose binding protein. Such tagged proteins can also be engineered to comprise a cleavage site, such as a thrombin, enterokinase or factor X cleavage site, for ease of removal of the tag before, during or after purification.
Methods of generating antibodies
[00309] If desired, antibodies to a specific antigen of interest may be generated by standard techniques and used as a basis for the preparation of antigen-binding domains of the 4-1BB x TAA antibody constructs, for example for preparing 4-1BB, FRα, NaPi2B, HER2, or mesothelin or LIV1 antigen-binding domains. Briefly, an antibody to an antigen can be prepared by immunizing the purified antigen into rabbits, preparing serum from blood of the rabbits and absorbing the sera to a normal plasma fraction to produce an antibody specific to the antigen. Monoclonal antibody preparations to the antigen may be prepared by injecting the purified protein into mice, harvesting the spleen and lymph node cells, fusing these cells with mouse myeloma cells and using the resultant hybridoma cells to produce the monoclonal antibody. Both of these methods are well-known in the art. In some embodiments, antibodies resulting from these methods may be humanized as described elsewhere herein.
[00310] As an alternative to humanization, human antibodies can be generated. For example, transgenic animals (e.g., mice) can be used that are capable, upon immunization, of producing a full repertoire of human antibodies in the absence of endogenous immunoglobulin production. See, e.g., Jakobovits et al, 1993, Proc. Natl. Acad. Sci. USA 90:2551; Jakobovits et al, 1993, Nature 362:255-258; Bruggermann et al., 1993, Year in Immuno. 7:33; and U.S. Pat. Nos. 5,591,669; 5,589,369; 5,545,807; 6,075,181; 6,150,584; 6,657,103; and 6,713,610.
[00311] Alternatively, phage display technology (see, e.g., McCafferty et al, 1990, Nature 348:552-553) can be used to produce human antibodies and antibody fragments in vitro, from immunoglobulin variable (V) domain gene repertoires from unimmunized donors. Phage display can be performed in a variety of formats; for their review see, e.g., Johnson and Chiswell, 1993, Current Opinion in Structural Biology 3:564-571. Human antibodies may also be generated by in vitro activated B cells (see U.S. Pat. Nos. 5,567,610 and 5,229,275). Novel antibody sequences may also be generated de novo using platforms such as the HuTarg™ platform (Innovative Targeting Solutions Inc., Vancouver Canada).
[00312] The affinity of antibodies for an antigen may be altered according to methods known in the art (see for example, Tabasinezhad et al. (2019) Immunology Letters (212): 106- 113).
Testing the antibody constructs
The ability of the 4-1BB x TAA antibody constructs to bind to 4-1BB and the TAA can be tested according to methods known in the art including antigen-binding assays or cell binding assays. Antigen-binding assays are carried out by incubating the antibody construct with antigen (4-1BB or TAA), either purified, or in a mixture and assessing the amount of 4-1BB x TAA antibody construct bound to the antigen, compared to controls. The amount of 4-1BB x TAA antibody construct bound to the antigen can by assessed by ELISA, or SPR (surface plasmon resonance), for example. Cell binding assays are carried out by incubating the antibody construct with cells that express 4-1BB or the TAA of interest (such cells are commercially available). The amount of 4-1BB x TAA antibody construct bound to the cells can be assessed by flow cytometry, for example, and compared to binding observed in the presence of controls. Methods for carrying out these types of assays are well known in the art. Similar methods may be used to assess the ability of 4-1BB antibody constructs to bind to 4- 1BB. Likewise, the ability of FRα antibody constructs to bind to purified FRα or FRα expressed on cells may be determined.
[00313] The 4-1BB x TAA antibody constructs or 4-1BB antibody constructs may also be tested to determine if they promote activation of cells expressing 4-1BB. Suitable assays include the co-culture assays described in the examples, such as the NF-icB-luciferase/4-1BB- expressing Jurkat cell assay, or the primary T cell co-culture assay. TAA expressing cell lines suitable for use in these assays are readily identified by one of skill in the art. For example, to assess the ability of a 4-1BB x FRα antibody construct to promote activation of 4-1BB in the presence of cells expressing FRα, a number of cell line may be used, for example but not limited to IGROV1, OVCAR3, OVKATE, NCI-H441, NCI-H661, NCI-H1975, or HCC827. These FRα-expressing cell lines can be divided into FRαhigh, FRαmid and FRαlow based on numbers of receptor expressed in these cells as measured by binding of a reference antibody to these cells via, for example, quantitative flow cytometry experiments. In some embodiments, FRαhigh cells may express greater than about 300,000 - 500,000 FRα molecules per cell, FRαmid between about 100,000 - 200,000 and about 300,000 - 500,000 FRα molecules per cell and FRαlow below about 100,000 - 200,000 FRα molecules per cell. In some embodiments, FRαneg cells are those where binding of a reference antibody to FRα cannot be detected by flow cytometry.
[00314] In vivo efficacy of the 4-1BB x TAA antibody constructs, 4-1BB antibody constructs, or FRα antibody constructs may also be evaluated by standard techniques. For example, the effect of the antibody constructs on tumor growth can be examined in various tumor models. Several suitable animal models are known in the art to test the ability of candidate therapies to treat cancers, such as, for example, breast cancers or gastric cancers. Some models are commercially available. Suitable models include syngeneic or xenograft models (see below). The construct to be tested is generally administered after the tumor has been established in the animal, but in some cases, the construct can be administered with the cell line. The volume of the tumor, survival of the animal and/or a response which may correlate with function is monitored in order to determine if the construct is able to treat the tumor. The construct may be administered intravenously (i.v.), intraperitoneally (i.p.) or subcutaneously (s.c.). Dosing schedules and amounts vary but can be readily determined by the skilled person. An exemplary dosage would be 10 mg/kg once weekly. Tumor growth can be monitored by standard procedures. For example, when labelled tumor cells have been used, tumor growth may be monitored by appropriate imaging techniques. For solid tumors, tumor size may also be measured by caliper. Other responses which may be indicative of efficacy of the construct may include increases or decreases in systemic or localized cytokine or chemokine responses (such as but not limited to IFNγ, IL-2, TNFa, CXCL8, IP-10, RANTES), increases or decreases in the number of immune cells (such as T, NK, NKT, B, DCs, Macrophages, Neutrophils), increase or decrease of the expression of key surface, intracellular or nuclear proteins on or in either the immune cells (such as but not limited to PD1, Tim3, Lag3, 4-1BB, CD163, EOMES, TOX) or on the surface of the tumour (PDL1). It is further contemplated that these responses can also be assessed in in vitro assays such as the immune cell co-culture assays described herein and in the Examples in order to test the activity of candidate 4-1BB x TAA antibody constructs.
[00315] In vivo mouse tumour models may be syngeneic or xenograft models. Syngeneic models involve grafting a tumour from one mouse to another where the genetic background of the two mice is sufficiently close that the recipient mouse immune system does not reject the tumour (Teicher, BA Tumor models in cancer research, Springer 2011). This can be done either directly from mouse to mouse, or via a cell line that is stable in culture. The cell lines can be engineered using standard molecular biology techniques to express the TAA if they do not naturally, which enables control over expression levels.
[00316] Xenograft tumour models involve the grafting of a tumour from another species (usually human) into a mouse. The mouse would normally reject the tumour as non-self, but is engineered to lack a functional adaptive immune system by a set of mutations which prevent T, B and NK cell development and impair myeloid cell function. Common strains of mice which are suitable for engraftment of human tumour cells are NSG™, NOG™ and NRG mice, which have combined either Prkdcscidor Ragl-/- with IL2rg mutations on a NOD background (Morton et al, Cancer Research 2016;76:21 pp6153-6158). These mice can be implanted with human tumours, but lack an adaptive immune system. The human tumour cells can come from cells which are stable in cell culture (such as OVCAR3, HCC827, IGROV1 or H1975) or from patients which have had their tumours removed. The immune system can be then be recapitulated by addition of either PBMC, T cells or CD34+ HSC from human donors. These immune cells can then reconstitute the host with T cells to act as effectors during an experiment.
Competitive Binding Analyses and Epitope Mapping of antibody sequences
[00317] The 4-1BB epitopes bound by the 4-1BB antibody constructs or the epitopes bound by the FRα antibody constructs described herein can be determined by standard competitive binding analysis (Fendly et al, Cancer Research 50: 1550-1558 (1990)). For example, for 4-1BB, cross-blocking studies may be done on antibodies by direct fluorescence on intact cells engineered to express 4-1BB using suitable methods to quantitate fluorescence. Each test antibody is conjugated with fluorescein isothiocyanate (FITC), using established procedures (Wofsy et al, Selected Methods in Cellular Immunology, p. 287, Mishel and Schiigi (eds.) San Francisco: W.J. Freeman Co. (1980)). Antibodies are considered to share an epitope if each blocked binding of the other by 40% or greater in comparison to an irrelevant antibody control and at the same antibody concentration. Using this assay, one of ordinary skill in the art can identify other antibodies that bind to the same epitope as those described herein. Deletion analysis may be conducted to identify the approximate location in the polypeptide sequence of 4-1BB of the antigenic epitopes. In a similar manner, the epitopes bound by the TAA antigen-binding domains of the 4-1BB x TAA antibody construct, or the FRα antibody construct may also be identified.
Pharmaceutical compositions
[00318] Certain embodiments relate to pharmaceutical compositions comprising an antibody construct described herein and a pharmaceutically acceptable carrier.
[00319] The term “pharmaceutically acceptable” means approved by a regulatory agency of the Federal or a state government or listed in the U.S. Pharmacopeia or other generally recognized pharmacopeia for use in animals, and more particularly in humans.
[00320] The term “carrier” refers to a diluent, adjuvant, excipient, vehicle, or combination thereof, with which the construct is administered. Such pharmaceutical carriers can be sterile liquids, such as water and oils, including those of petroleum, animal, vegetable or synthetic origin, such as peanut oil, soybean oil, mineral oil, sesame oil and the like. In some aspects, the carrier is a man-made carrier not found in nature. Water can be used as a carrier when the pharmaceutical composition is administered intravenously. Saline solutions and aqueous dextrose and glycerol solutions can also be employed as liquid carriers, particularly for injectable solutions. Suitable pharmaceutical excipients include starch, glucose, lactose, sucrose, gelatin, malt, rice, flour, chalk, silica gel, sodium stearate, glycerol monostearate, talc, sodium chloride, dried skim milk, glycerol, propylene, glycol, water, ethanol and the like. The composition, if desired, can also contain minor amounts of wetting or emulsifying agents, or pH buffering agents. Examples of suitable pharmaceutical carriers are described in “Remington's Pharmaceutical Sciences” by E. W. Martin.
[00321] The pharmaceutical compositions may be in the form of solutions, suspensions, emulsion, tablets, pills, capsules, powders, sustained-release formulations and the like. The composition may be formulated as a suppository, with traditional binders and carriers such as triglycerides. Oral formulations may include standard carriers such as pharmaceutical grades of mannitol, lactose, starch, magnesium stearate, sodium saccharine, cellulose, magnesium carbonate, and the like.
[00322] Pharmaceutical compositions will contain a therapeutically effective amount of the antibody construct, together with a suitable amount of carrier so as to provide the form for proper administration to a patient. The formulation should suit the mode of administration.
[00323] In certain embodiments, the composition comprising the antibody construct is formulated in accordance with routine procedures as a pharmaceutical composition adapted for intravenous administration to human beings. Typically, compositions for intravenous administration are solutions in sterile isotonic aqueous buffer. Where necessary, the composition may also include a solubilizing agent and a local anaesthetic such as lignocaine to ease pain at the site of the injection. Generally, the ingredients are supplied either separately or
mixed together in unit dosage form, for example, as a dry lyophilized powder or water free concentrate in a hermetically sealed container such as an ampoule or sachette indicating the quantity of active agent. Where the composition is to be administered by infusion, it can be dispensed with an infusion bottle containing sterile pharmaceutical grade water or saline. Where the composition is administered by injection, an ampoule of sterile water for injection or saline can be provided so that the ingredients may be mixed prior to administration.
[00324] In certain embodiments, the compositions described herein are formulated as neutral or salt forms. Pharmaceutically acceptable salts include those formed with anions such as those derived from hydrochloric, phosphoric, acetic, oxalic, tartaric acids, etc., and those formed with cations such as those derived from sodium, potassium, ammonium, calcium, ferric hydroxide isopropylamine, triethylamine, 2-ethylamino ethanol, histidine, procaine, and the like.
Methods of using the antibody constructs
[00325] In certain embodiments, provided is a method of treating a cancer comprising administering to a subject in which such treatment, prevention or amelioration is desired, a 4- 1BB x TAA antibody construct described herein, in an amount effective to treat or ameliorate the cancer. In other embodiments, there is provided a method of using the 4-1BB x TAA antibody construct in the preparation of a medicament for the treatment, prevention, or amelioration of cancer in a subject. In additional embodiments, the 4-1BB x TAA antibody constructs may be used for the treatment of cancer in a subject in need thereof. The 4-1BB antibody construct and FRα antibody constructs may also be used in the treatment of cancer as described below.
[00326] In some embodiments, the 4-1BB x TAA antibody construct, 4-1BB antibody construct, or FRα antibody construct may be used in a subject to treat, prevent or ameliorate a cancer selected from breast cancer, bladder cancer, colorectal cancer, head and neck cancer, liver cancer, lung cancer, ovarian cancer, pancreatic cancer, skin cancer, prostate cancer, kidney cancer or thyroid cancer. In specific embodiments, the 4-1BB x TAA antibody construct may be used to treat, prevent or ameliorate lung or ovarian cancers in a subject. In certain embodiments, the 4-1BB x TAA antibody construct may be used in the treatment of solid tumors. In embodiments where the 4-1BB x TAA is a 4-1BB x FRα antibody construct, the construct may be used to treat, prevent or ameliorate lung or ovarian cancers in a subject.
In embodiments where the 4-1BB x TAA is a 4-1BB x NaPi2b antibody construct, the construct may be used to treat, prevent or ameliorate lung cancer in a subject.
[00327] The term “subject” refers to an animal, in some embodiments a mammal, which is the object of treatment, observation or experiment. An animal may be a human, a non -human primate, a companion animal (e.g., dogs, cats, and the like), farm animal (e.g., cows, sheep, pigs, horses, and the like) or a laboratory animal (e.g., rats, mice, guinea pigs, and the like).
[00328] The term “mammal” as used herein includes but is not limited to humans, non- human primates, canines, felines, murines, bovines, equines, and porcines.
[00329] “Treatment” or “treat” refers to clinical intervention in an attempt to alter the natural course of the individual or cell being treated, and can be performed during the course of clinical pathology. Desirable effects of treatment include preventing recurrence of disease, alleviation of symptoms, diminishing of any direct or indirect pathological consequences of the disease, preventing metastasis, decreasing the rate of disease progression, amelioration or palliation of the disease state, and remission or improved prognosis. In some embodiments, the 4-1BB x TAA antibody constructs described herein are used to delay development of a disease or disorder in a subject. In one embodiment, 4-1BB x TAA antibody constructs and methods described herein effect tumor regression in a subject. In one embodiment, the 4-1BB x TAA antibody constructs and methods described herein effect inhibition of tumor/cancer growth in a subject.
[00330] The term “effective amount” as used herein refers to that amount of antibody construct being administered, which will accomplish the goal of the recited method, e.g., relieve to some extent one or more of the symptoms of the disease, condition or disorder being treated. The amount of the composition described herein which will be effective in the treatment, inhibition and prevention of a disease or disorder associated with aberrant expression and/or activity of a therapeutic protein can be determined by standard clinical techniques. In addition, in vitro assays may optionally be employed to help identify optimal dosage ranges. The precise dose to be employed in the formulation will also depend on the route of administration, and the seriousness of the disease or disorder, and should be decided according to the judgment of the practitioner and each patient's circumstances. Effective doses are extrapolated from dose-response curves derived from in vitro or animal model test systems.
[00331] “Therapeutically effective amount,” as used herein, is meant an amount that produces the desired effect for which it is administered. In some embodiments, the term refers to an amount that is sufficient, when administered to a population suffering from or susceptible to a disease, disorder, and/or condition in accordance with a therapeutic dosing regimen, to treat the disease, disorder, and/or condition. In some embodiments, a therapeutically effective amount is one that reduces the incidence and/or severity of, and/or delays onset of, one or more symptoms of the disease, disorder, and/or condition. Those of ordinary skill in the art will appreciate that the term “therapeutically effective amount” does not in fact require successful treatment be achieved in a particular individual. Rather, a therapeutically effective amount may be that amount that provides a particular desired pharmacological response in a significant number of subjects when administered to patients in need of such treatment. In some embodiments, reference to a therapeutically effective amount may be a reference to an amount as measured in one or more specific tissues (e.g., a tissue affected by the disease, disorder or condition) or fluids (e.g., blood, saliva, serum, sweat, tears, urine, etc.). Those of ordinary skill in the art will appreciate that, in some embodiments, a therapeutically effective amount of a particular agent or therapy may be formulated and/or administered in a single dose. In some embodiments, a therapeutically effective agent may be formulated and/or administered in a plurality of doses, for example, as part of a dosing regimen.
[00332] The 4-1BB x TAA antibody construct can be administered to a subject. Various delivery systems are known and can be used to administer an antibody construct formulation described herein, e.g., encapsulation in liposomes, microparticles, microcapsules, recombinant cells capable of expressing the compound, receptor-mediated endocytosis (see, e.g., Wu and Wu, J. Biol. Chem. 262:4429-4432 (1987)), construction of anucleic acid as part of a retroviral or other vector, etc. Methods of introduction include but are not limited to intradermal, intramuscular, intraperitoneal, intravenous, subcutaneous, intranasal, epidural, and oral routes. The compounds or compositions may be administered by any convenient route, for example by infusion or bolus injection, by absorption through epithelial or mucocutaneous linings (e.g., oral mucosa, rectal and intestinal mucosa, etc.) and may be administered together with other biologically active agents. Administration can be systemic or local. In addition, in certain embodiments, it is desirable to introduce the antibody construct compositions described herein into the central nervous system by any suitable route, including intraventricular and intrathecal injection; intraventricular injection may be facilitated by an intraventricular catheter, for example, attached to a reservoir, such as an Ommaya reservoir. Pulmonary administration can
also be employed, e.g., by use of an inhaler or nebulizer, and formulation with an aerosolizing agent.
[00333] In a specific embodiment, it is desirable to administer the antibody constructs, or compositions described herein locally to the area in need of treatment; this may be achieved by, for example, and not by way of limitation, local infusion during surgery, topical application, e.g., in conjunction with a wound dressing after surgery, by injection, by means of a catheter, by means of a suppository, or by means of an implant, said implant being of a porous, non- porous, or gelatinous material, including membranes, such as sialastic membranes, or fibers. Preferably, when administering a protein, including an antibody construct, described herein, care must be taken to use materials to which the protein does not absorb.
[00334] In another embodiment, the antibody constructs or composition can be delivered in a vesicle, in particular a liposome (see Langer, Science 249:1527-1533 (1990); Treat et al, in Liposomes in the Therapy of Infectious Disease and Cancer, Lopez-Berestein and Fidler (eds.), Liss, New York, pp. 353-365 (1989); Lopez-Berestein, ibid., pp. 317-327; see generally ibid.)
[00335] In yet another embodiment, the antibody constructs or composition can be delivered in a controlled release system. In one embodiment, a pump may be used (see Langer, supra; Sefton, CRC Crit. Ref. Biomed. Eng. 14:201 (1987); Buchwald et al, Surgery 88:507 (1980); Saudek et al, N. Engl. J. Med. 321:574 (1989)). In another embodiment, polymeric materials can be used (see Medical Applications of Controlled Release, Langer and Wise (eds.), CRC Pres., Boca Raton, Fla. (1974); Controlled Drug Bioavailability, Drug Product Design and Performance, Smolen and Ball (eds.), Wiley, New York (1984); Ranger and Peppas, J., Macromol. Sci. Rev. Macromol. Chem. 23:61 (1983); see also Levy et al., Science 228:190 (1985); During et al., Ann. Neurol. 25:351 (1989); Howard et al., J. Neurosurg. 71:105 (1989)). In yet another embodiment, a controlled release system can be placed in proximity of the therapeutic target, e.g., the brain, thus requiring only a fraction of the systemic dose (see, e.g., Goodson, in Medical Applications of Controlled Release, vol. 2, pp. 115-138 (1984)).
[00336] In a specific embodiment comprising a nucleic acid encoding the antibody constructs described herein, the nucleic acid can be administered in vivo to promote expression of its encoded protein, by constructing it as part of an appropriate nucleic acid expression vector and administering it so that it becomes intracellular, e.g., by use of a retroviral vector (see U.S.
Pat. No. 4,980,286), or by direct injection, or by use of microparticle bombardment (e.g., a gene gun; Biolistic, Dupont), or coating with lipids or cell-surface receptors or transfecting agents, or by administering it in linkage to a homeobox-like peptide which is known to enter the nucleus (see e.g., Joliot et al, Proc. Natl. Acad. Sci. USA 88:1864-1868 (1991)), etc. Alternatively, a nucleic acid can be introduced intracellularly and incorporated within host cell DNA for expression, by homologous recombination.
[00337] The amount of the antibody construct which will be effective in the treatment, inhibition or prevention of a disease or disorder can be determined by standard clinical techniques. In addition, in vitro assays may optionally be employed to help identify optimal dosage ranges. The precise dose to be employed in the formulation will also depend on the route of administration, and the seriousness of the disease or disorder, and should be decided according to the judgment of the practitioner and each patient’s circumstances. Effective doses are extrapolated from dose-response curves derived from in vitro or animal model test systems.
[00338] The antibody constructs described herein may be administered alone or in combination with other alternate forms of treatments or anti-cancer therapy (e.g., radiation therapy, chemotherapy, hormonal therapy, immunotherapy, bispecific antibodies, and anti- tumor agents). Generally, administration of products of a species origin or species reactivity (in the case of antibodies) that is the same species as that of the patient is preferred.
[00339] In some embodiments, the antibody construct may be used in the treatment of a patient who has undergone one or more alternate forms of anti-cancer therapy. In some embodiments, the patient has relapsed or failed to respond to one or more alternate forms of anti-cancer therapy. In other embodiments, the antibody construct is administered to a patient in combination with one or more alternate forms of anti-cancer therapy. In other embodiments, the antibody construct is administered to a patient that has become refractory to treatment with one or more alternate forms of anti-cancer therapy.
Kits and Articles of Manufacture
[00340] Also described herein are kits comprising one or more antibody constructs. Individual components of the kit would be packaged in separate containers and, associated with such containers, can be a notice in the form prescribed by a governmental agency regulating the manufacture, use or sale of pharmaceuticals or biological products, which notice reflects
approval by the agency of manufacture, use or sale. The kit may optionally contain instructions or directions outlining the method of use or administration regimen for the antibody construct.
[00341] When one or more components of the kit are provided as solutions, for example an aqueous solution, or a sterile aqueous solution, the container means may itself be an inhalant, syringe, pipette, eye dropper, or other such like apparatus, from which the solution may be administered to a subject or applied to and mixed with the other components of the kit.
[00342] The components of the kit may also be provided in dried or lyophilized form and the kit can additionally contain a suitable solvent for reconstitution of the lyophilized components. Irrespective of the number or type of containers, the kits described herein also may comprise an instrument for assisting with the administration of the composition to a patient. Such an instrument may be an inhalant, nasal spray device, syringe, pipette, forceps, measured spoon, eye dropper or similar medically approved delivery vehicle.
[00343] Certain embodiments relate to an article of manufacture containing materials useful for treatment of a patient as described herein. The article of manufacture comprises a container and a label or package insert on or associated with the container. Suitable containers include, for example, bottles, vials, syringes, intravenous solution bags, etc. The containers may be formed from a variety of materials such as glass or plastic. The container holds a composition comprising the antibody construct which is by itself or combined with another composition effective for treating the patient and may have a sterile access port (for example the container may be an intravenous solution bag or a vial having a stopper pierceable by a hypodermic injection needle). The label or package insert indicates that the composition is used for treating the condition of choice. In some embodiments, the article of manufacture may comprise (a) a first container with a composition contained therein, wherein the composition comprises an antibody construct described herein; and (b) a second container with a composition contained therein, wherein the composition in the second container comprises a further cytotoxic or otherwise therapeutic agent. In such embodiments, the article of manufacture may further comprise a package insert indicating that the compositions can be used to treat a particular condition. Alternatively, or additionally, the article of manufacture may further comprise a second (or third) container comprising a pharmaceutically-acceptable buffer, such as bacteriostatic water for injection (BWFI), phosphate-buffered saline, Ringer’s solution and dextrose solution. The article of manufacture may optionally further include other
materials desirable from a commercial and user standpoint, including other buffers, diluents, fdters, needles, and syringes.
Polypeptides and Polynucleotides
[00344] As described herein, the antibody constructs comprise at least one polypeptide. Certain embodiments relate to polynucleotides encoding such polypeptides described herein.
[00345] The antibody constructs, polypeptides and polynucleotides described herein are typically isolated. As used herein, “isolated” means an agent (e.g., a polypeptide or polynucleotide) that has been identified and separated and/or recovered from a component of its natural cell culture environment. Contaminant components of its natural environment are materials that would interfere with diagnostic or therapeutic uses for the antibody construct, and may include enzymes, hormones, and other proteinaceous or non-proteinaceous solutes. Isolated also refers to an agent that has been synthetically produced, e.g., via human intervention.
[00346] The terms “polypeptide,” “peptide” and “protein” are used interchangeably herein to refer to a polymer of amino acid residues. That is, a description directed to a polypeptide applies equally to a description of a peptide and a description of a protein, and vice versa. The terms apply to naturally occurring amino acid polymers as well as amino acid polymers in which one or more amino acid residues is a non-naturally encoded amino acid. As used herein, the terms encompass amino acid chains of any length, including full-length proteins, wherein the amino acid residues are linked by covalent peptide bonds.
[00347] The term “amino acid” refers to naturally occurring and non-naturally occurring amino acids, as well as amino acid analogs and amino acid mimetics that function in a manner similar to the naturally occurring amino acids. Naturally encoded amino acids are the 20 common amino acids (alanine, arginine, asparagine, aspartic acid, cysteine, glutamine, glutamic acid, glycine, histidine, isoleucine, leucine, lysine, methionine, phenylalanine, proline, serine, threonine, tryptophan, tyrosine, and valine) and pyrrolysine and selenocysteine. Amino acid analogs refers to compounds that have the same basic chemical structure as a naturally occurring amino acid, i.e., a carbon that is bound to a hydrogen, a carboxyl group, an amino group, and an R group, such as, homoserine, norleucine, methionine sulfoxide, methionine methyl sulfonium. Such analogs have modified R groups (such as, norleucine) or modified peptide backbones, but retain the same basic chemical structure as a naturally
occurring amino acid. Reference to an amino acid includes, for example, naturally occurring proteogenic L-amino acids; D-amino acids, chemically modified amino acids such as amino acid variants and derivatives; naturally occurring non-proteogenic amino acids such as b- alanine, ornithine, etc.; and chemically synthesized compounds having properties known in the art to be characteristic of amino acids. Examples of non-naturally occurring amino acids include, but are not limited to, a-methyl amino acids (e.g. a-methyl alanine), D-amino acids, histidine-like amino acids (e.g., 2-amino-histidine, b-hydroxy-histidine, homohistidine), amino acids having an extra methylene in the side chain (“homo” amino acids), and amino acids in which a carboxylic acid functional group in the side chain is replaced with a sulfonic acid group (e.g., cysteic acid). The incorporation of non-natural amino acids, including synthetic non- native amino acids, substituted amino acids, or one or more D-amino acids into the antibody constructs described herein may be advantageous in a number of different ways. D-amino acid- containing peptides, etc., exhibit increased stability in vitro or in vivo compared to L-amino acid-containing counterparts. Thus, the construction of peptides, etc., incorporating D-amino acids can be particularly useful when greater intracellular stability is desired or required. More specifically, D-peptides, etc., are resistant to endogenous peptidases and proteases, thereby providing improved bioavailability of the molecule, and prolonged lifetimes in vivo when such properties are desirable. Additionally, D-peptides, etc., cannot be processed efficiently for major histocompatibility complex class II -restricted presentation to T helper cells, and are therefore, less likely to induce humoral immune responses in the whole organism.
[00348] Amino acids may be referred to herein by either their commonly known three letter symbols or by the one-letter symbols recommended by the IUPAC-IUB Biochemical Nomenclature Commission. Nucleotides, likewise, may be referred to by their commonly accepted single-letter codes.
[00349] Also included herein are polynucleotides encoding polypeptides of the antibody constructs. The term “polynucleotide” or “nucleotide sequence” is intended to indicate a consecutive stretch of two or more nucleotide molecules. The nucleotide sequence may be of genomic, cDNA, RNA, semisynthetic or synthetic origin, or any combination thereof.
[00350] The term “nucleotide sequence” or “nucleic acid sequence” is intended to indicate a consecutive stretch of two or more nucleotide molecules. The nucleotide sequence can be of genomic, cDNA, RNA, semisynthetic or synthetic origin, or any combination thereof.
[00351] “Cell”, “host cell”, “cell line” and “cell culture” are used interchangeably herein and all such terms should be understood to include progeny resulting from growth or culturing of a cell. “Transformation” and “transfection” are used interchangeably to refer to the process of introducing a nucleic acid sequence into a cell.
[00352] The term “nucleic acid” refers to deoxyribonucleotides, deoxyribonucleosides, ribonucleosides, or ribonucleotides and polymers thereof in either single- or double-stranded form. Unless specifically limited, the term encompasses nucleic acids containing known analogues of natural nucleotides that have similar binding properties as the reference nucleic acid and are metabolized in a manner similar to naturally occurring nucleotides. Unless specifically limited otherwise, the term also refers to oligonucleotide analogs including PNA (peptidonucleic acid), analogs of DNA used in antisense technology (phosphorothioates, phosphoroamidates, and the like). Unless otherwise indicated, a particular nucleic acid sequence also implicitly encompasses conservatively modified variants thereof (including but not limited to, degenerate codon substitutions) and complementary sequences as well as the sequence explicitly indicated. Specifically, degenerate codon substitutions may be achieved by generating sequences in which the third position of one or more selected (or all) codons is substituted with mixed-base and/or deoxyinosine residues (Batzer et al., Nucleic Acid Res. 19:5081 (1991); Ohtsuka et al., J. Biol. Chem. 260:2605-2608 (1985); Rossolini et al, Mol. Cell. Probes 8:91-98 (1994)).
[00353] “Conservatively modified variants” applies to both amino acid and nucleic acid sequences. With respect to particular nucleic acid sequences, “conservatively modified variants” refers to those nucleic acids which encode identical or essentially identical amino acid sequences, or where the nucleic acid does not encode an amino acid sequence, to essentially identical sequences. Because of the degeneracy of the genetic code, a large number of functionally identical nucleic acids encode any given protein. For instance, the codons GCA, GCC, GCG and GCU all encode the amino acid alanine. Thus, at every position where an alanine is specified by a codon, the codon can be altered to any of the corresponding codons described without altering the encoded polypeptide. Such nucleic acid variations are “silent variations,” which are one species of conservatively modified variations. Every nucleic acid sequence herein that encodes a polypeptide also encompasses every possible silent variation of the nucleic acid. One of ordinary skill in the art will recognize that each codon in a nucleic acid (except AUG, which is ordinarily the only codon for methionine, and TGG, which is ordinarily
the only codon for tryptophan) can be modified to yield a functionally identical molecule. Accordingly, each silent variation of a nucleic acid that encodes a polypeptide is implicit in each described sequence.
[00354] As to amino acid sequences, one of ordinary skill in the art will recognize that individual substitutions, deletions or additions to a nucleic acid, peptide, polypeptide, or protein sequence which alters, adds or deletes a single amino acid or a small percentage of amino acids in the encoded sequence is a “conservatively modified variant” where the alteration results in the deletion of an amino acid, addition of an amino acid, or substitution of an amino acid with a chemically similar amino acid.
[00355] Conservative substitution tables providing functionally similar amino acids are known to those of ordinary skill in the art. Such conservatively modified variants are in addition to and do not exclude polymorphic variants, interspecies homologs, and alleles described herein. The following eight groups each contain amino acids that are conservative substitutions for one another: 1) Alanine (A), Glycine (G); 2) Aspartic acid (D), Glutamic acid (E); 3) Asparagine (N), Glutamine (Q); 4) Arginine (R), Lysine (K); 5) Isoleucine (I), Leucine (L), Methionine (M), Valine (V); 6) Phenylalanine (F), Tyrosine (Y), Tryptophan (W); 7) Serine (S), Threonine (T); and [0139] 8) Cysteine (C), Methionine (M) (see, e.g., Creighton, Proteins: Structures and Molecular Properties (W H Freeman & Co.; 2nd edition (December 1993).
[00356] The term “identical” in the context of two or more nucleic acids or polypeptide sequences, refers to two or more sequences or subsequences that are the same. Sequences are “substantially identical” if they have a percentage of amino acid residues or nucleotides that are the same (i.e., about 60% identity, about 65%, about 70%, about 75%, about 80%, about 85%, about 90%, or about 95% identity over a specified region), when compared and aligned for maximum correspondence over a comparison window, or designated region as measured using one of the following sequence comparison algorithms (or other algorithms available to persons of ordinary skill in the art) or by manual alignment and visual inspection. This definition also refers to the complement of a test sequence. The identity can exist over a region that is at least about 50 amino acids or nucleotides in length, or over a region that is 75-100 amino acids or nucleotides in length, or, where not specified, across the entire sequence of a polynucleotide or polypeptide. A polynucleotide encoding a polypeptide described herein, including homologs from species other than human, may be obtained by a process comprising the steps of screening a library under stringent hybridization conditions with a labeled probe
having a polynucleotide sequence described herein or a fragment thereof, and isolating full- length cDNA and genomic clones containing said polynucleotide sequence. Such hybridization techniques are well known to the skilled artisan.
[00357] For sequence comparison, typically one sequence acts as a reference sequence, to which test sequences are compared. When using a sequence comparison algorithm, test and reference sequences are entered into a computer, subsequence coordinates are designated, if necessary, and sequence algorithm program parameters are designated. Default program parameters can be used, or alternative parameters can be designated. The sequence comparison algorithm then calculates the percent sequence identities for the test sequences relative to the reference sequence, based on the program parameters.
[00358] A “comparison window”, as used herein, includes reference to a segment of any one of the number of contiguous positions selected from the group consisting of from 20 to 600, usually about 50 to about 200, more usually about 100 to about 150 in which a sequence may be compared to a reference sequence of the same number of contiguous positions after the two sequences are optimally aligned. Methods of alignment of sequences for comparison are known to those of ordinary skill in the art. Optimal alignment of sequences for comparison can be conducted, including but not limited to, by the local homology algorithm of Smith and Waterman (1970) Adv. Appl. Math. 2:482c, by the homology alignment algorithm of Needleman and Wunsch (1970) J. Mol. Biol. 48:443, by the search for similarity method of Pearson and Lipman (1988) Proc. Nat’l. Acad. Sci. USA 85:2444, by computerized implementations of these algorithms (GAP, BESTFIT, FASTA, and TFASTA in the Wisconsin Genetics Software Package, Genetics Computer Group, 575 Science Dr., Madison, Wis.), or by manual alignment and visual inspection (see, e.g., Ausubel et al, Current Protocols in Molecular Biology (1995 supplement)).
[00359] One example of an algorithm that is suitable for determining percent sequence identity and sequence similarity are the BLAST and BLAST 2.0 algorithms, which are described in Altschul et al. (1997) Nuc. Acids Res. 25:3389-3402, and Altschul et al. (1990) J. Mol. Biol. 215:403-410, respectively. Software for performing BLAST analyses is publicly available through the National Center for Biotechnology Information available at the World Wide Web at ncbi.nlm.nih.gov. The BLAST algorithm parameters W, T, and X determine the sensitivity and speed of the alignment. The BLASTN program (for nucleotide sequences) uses as defaults a wordlength (W) of 11, an expectation (E) or 10, M=5, N=-4 and a comparison of
both strands. For amino acid sequences, the BLASTP program uses as defaults a wordlength of 3, and expectation (E) of 10, and the BLOSUM62 scoring matrix (see Henikoff and Henikoff (1992) Proc. Natl. Acad. Sci. USA 89: 10915) alignments (B) of 50, expectation (E) of 10, M=5, N=-4, and a comparison of both strands. The BLAST algorithm is typically performed with the “low complexity” fdter turned off.
[00360] The BLAST algorithm also performs a statistical analysis of the similarity between two sequences (see, e.g., Karlin and Altschul (1993) Proc. Natl. Acad. Sci. USA 90:5873-5787). One measure of similarity provided by the BLAST algorithm is the smallest sum probability (P(N)), which provides an indication of the probability by which a match between two nucleotide or amino acid sequences would occur by chance. For example, a nucleic acid is considered similar to a reference sequence if the smallest sum probability in a comparison of the test nucleic acid to the reference nucleic acid is less than about 0.2, or less than about 0.01, or less than about 0.001.
[00361] As used herein, the term “engineer,” and grammatical variations thereof is considered to include any manipulation of a peptide backbone or the post-translational modifications of a naturally occurring or recombinant polypeptide or fragment thereof. Engineering includes modifications of the amino acid sequence, of the glycosylation pattern, or of the side chain group of individual amino acids, as well as combinations of these approaches. The engineered proteins are expressed and produced by standard molecular biology techniques.
[00362] A derivative, or a variant of a polypeptide is said to share “homology” or be “homologous” with the polypeptide if the amino acid sequences of the derivative or variant has at least 50% identity with a 100 amino acid sequence from the original polypeptide. In certain embodiments, the derivative or variant is at least 75% the same as that of either the polypeptide or a fragment of the polypeptide having the same number of amino acid residues as the derivative. In various embodiments, the derivative or variant is at least 85%, 90%, 95% or 99% the same as that of either the polypeptide or a fragment of the polypeptide having the same number of amino acid residues as the derivative.
[00363] In some aspects, an antibody construct comprises an amino acid sequence that is at least 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, or 100% identical to a relevant amino acid sequence or fragment thereof set forth in the Tables or Accession Numbers disclosed
herein. In some aspects, an isolated antibody construct comprises an amino acid sequence encoded by a polynucleotide that is at least 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, or 100% identical to a relevant nucleotide sequence or fragment thereof set forth in Tables or Accession Numbers disclosed herein.
Embodiments
Al. An antibody construct comprising: a) a first 4-1BB-binding domain that binds to a 4-1BB extracellular domain (4-1BB ECD), and b) a tumor-associated antigen (TAA) antigen binding domain (TAA antigen-binding domain) that binds to a TAA, wherein the first 4-1BB-binding domain and the TAA antigen-binding domain are linked directly or indirectly to a scaffold.
A2. The antibody construct according to embodiment Al, wherein the first 4-1BB binding domain is a first 4-1BB antigen-binding domain or a 4-1BB ligand.
A3. The antibody construct according to embodiment A2, wherein the first 4-1BB antigen-binding domain binds to a first epitope of 4-1BB ECD.
A4. The antibody construct according to any one of embodiments Al to A3, further comprising a second 4-1BB binding domain.
A5. The antibody construct according to embodiment A4, wherein the second 4-1BB binding domain is a second 4-1BB antigen-binding domain.
A6. The antibody construct according to embodiment A5, wherein the second 4-1BB antigen-binding domain binds to a second epitope of 4-1BB ECD.
A7. The antibody construct according to embodiment A5 or A6, wherein the first epitope of 4-1BB ECD is the same as the second epitope of 4-1BB ECD.
A8. The antibody construct according to embodiment A5 or A6, wherein the first epitope of 4-1BB ECD is different from the second epitope of 4-1BB ECD.
A9. The antibody construct according to any one of embodiments A4 to A8, wherein the first or second 4-1BB antigen-binding domain binds to human and cynomolgus 4-1BB.
A10. The antibody construct according to any one of embodiments A4 to A9, wherein the 4-1BB antigen-binding domain binds to domain 1 or domain 2 of 4-1BB.
A11. The antibody construct according to any one of embodiments A4 to A9, wherein the 4-1BB antigen-binding domain binds to other than domains 3 and 4 or 4-1BB.
A12. The antibody construct according to any one of embodiments A1 to A9, wherein the first 4-1BB-binding domain is a first 4-1BB antigen-binding domain comprising a heavy chain variable sequence comprising three CDRs and light chain variable sequence comprising three CDRs and the heavy chain variable sequence and the light chain variable sequence is from any one of variants v28726, v28727, v28728, v28730, v20022, v28700, v28704,
V28705, v28706, v28711, v28712, v28713, v20036, v28696, v28697, v28698, v28701, V28702, v28703, v28707, v20023, v28683, v28684, v28685, v28686, v28687, v28688, V28689, v28690, v28691, v28692, v28694, or v28995.
A13. The antibody construct according to any one of embodiments A4 to A12, wherein the first 4-1BB antigen-binding domain and/or the second 4-1BB antigen-binding domain are in a Fab format.
A14. The antibody construct according to any one of embodiments A4 to A12, wherein one of the first 4-1BB antigen-binding domain or the second 4-1BB antigen-binding domain is in an scFv format.
A15. The antibody construct according to any one of embodiments A1 to A14, wherein the TAA antigen-binding domain is a folate receptor-α (FRα) antigen-binding domain, a Solute Carrier Family 34 Member 2 (NaPi2b) antigen-binding domain, aHER2 antigen-binding domain, a mesothelin antigen-binding domain, or a Solute Carrier Family 39 Member 6 (LIV-1) antigen-binding domain.
A16. The antibody construct according to any one of embodiments A1 to A15 wherein the TAA antigen-binding domain is a FRα antigen-binding domain.
A17. The antibody construct according to embodiment A16, wherein the FRα antigen- binding domain comprises the three heavy chain CDRs and the three light chain CDRs of antibody 8K22 or 1H06.
A18. The antibody construct according to embodiment A17, wherein the FRα antigen- binding domain is a human or humanized antigen-binding domain.
A19. The antibody construct according to any one of embodiments A1 to A18, wherein the TAA antigen-binding domain is in an scFv format.
A20. The antibody construct according to any one of embodiments A1 to A18, wherein the TAA antigen-binding domain is in a Fab format.
A21. The antibody construct according to any one of embodiments A1 to A20, wherein the scaffold is a dimeric Fc construct having a first Fc polypeptide and a second Fc polypeptide, each Fc polypeptide comprising a CH3 sequence, or wherein the scaffold is a linker or an albumin polypeptide.
A22. The antibody construct according to embodiment A21, wherein the scaffold is a heterodimeric Fc construct having a first Fc polypeptide that is different from the second Fc polypeptide, and wherein the CH3 sequences of the first Fc polypeptide and the second Fc polypeptide comprise amino acid substitutions that promote the formation of a heterodimeric Fc.
A23. The antibody construct according to embodiment A22, wherein: a) one Fc polypeptide comprises the amino acid substitutions T350V_L351Y_F405A_Y407V and the other Fc polypeptide comprises the amino acid substitutions T350V T366L K392L_T394W; b) one Fc polypeptide comprises the amino acid substitutions T350V_T366L_K392M_T394W and the other Fc polypeptide comprises the amino acid substitutions T350V_L351 Y_F405 A_Y407V; c) one Fc polypeptide comprises the amino acid substitutions L351Y_F405A_Y407V and the other Fc polypeptide comprises the amino acid substitutions T366L K392M T394W; d) one Fc polypeptide comprises the amino acid substitutions L351Y_F405A_Y407V and the other Fc polypeptide comprises the amino acid substitutions T366L K392L T394W; or e) one Fc polypeptide comprises the amino acid substitutions L351Y_S400E_F405A_Y407V and the other Fc polypeptide comprises the amino acid substitutions T366I_N390R_K392M_T394W,
wherein the numbering of residues is according to the EU numbering system.
A24. The antibody construct according to any one of embodiments A21to A23, further comprising one or more amino acid modifications that reduce effector function.
A25. The antibody construct according to any one of embodiments A21 to A24, wherein the first 4-1BB antigen-binding domain is linked to the N terminus of the first Fc polypeptide, and the TAA antigen-binding domain is linked to the C terminus of the first Fc polypeptide.
A26. The antibody construct according to embodiment A25, further comprising a second 4- 1BB antigen-binding domain is linked to the N terminus of the second Fc polypeptide.
A27. An antibody construct or antigen-binding fragment thereof, that specifically binds to 4-1BB, comprising: a heavy chain variable sequence comprising three CDRs and light chain variable sequence comprising three CDRs and the heavy chain variable sequence and the light chain variable sequence is from any one of variants v28726, v28727, v28728, v28730, V20022, v28700, v28704, v28705, v28706, v28711, v28712, v28713, v20036, v28696, V28697, v28698, v28701, v28702, v28703, v28707, v20023, v28683, v28684, v28685, V28686, v28687, v28688, v28689, v28690, v28691, v28692, v28694, or v28995.
A28. The antibody construct according to embodiment A27, comprising a VH sequence and a VL sequence having at least 85% sequence identity to the VH and VL sequences of any one of variants v28726, v28727, v28728, v28730, v20022, v28700, v28704, v28705, V28706, v28711, v28712, v28713, v20036, v28696, v28697, v28698, v28701, v28702, V28703, v28707, v20023, v28683, v28684, v28685, v28686, v28687, v28688, v28689, V28690, v28691, v28692, v28694, or v28995.
A29. The antibody construct according to any one of embodiments A1 to A28, conjugated to a drug.
A30. A pharmaceutical composition comprising the antibody construct of any one of embodiments A1 to A29.
A31. One or more nucleic acids encoding the antibody construct according to any one of embodiments A1 to A28.
A32. One or more vectors comprising the one or more nucleic acids according to embodiment A31.
A33. An isolated cell comprising the one or more nucleic acid according to embodiment A31, or the one or more vectors according to embodiment A32.
A34. A method of preparing the antibody construct according to any one of embodiments A1 to A29, comprising culturing the isolated cell of embodiment A33 under conditions suitable for expressing the antibody construct, and purifying the antibody construct.
A35. A method of treating a subject having a cancer, comprising administering to the subject an effective amount of the antibody construct according to any one of embodiments A1 to A29.
A36. Use of an effective amount of the antibody construct according to any one of embodiments A1 to A29 for the treatment of cancer in a subject in need thereof.
A37. Use of the antibody construct according to any one of embodiments A1 to A29 in the preparation of a medicament for the treatment of cancer.
A38. The antibody construct according to any one of embodiments A1 to A29, for use in the treatment of cancer in a subject.
Bl. An antibody construct comprising: a) a first 4-1BB-binding domain that binds to a 4-1BB extracellular domain (4-1BB ECD), and b) a first tumor-associated antigen (TAA) antigen binding domain (TAA antigen- binding domain) that binds to a TAA, wherein the first 4-1BB-binding domain and the first TAA antigen-binding domain are linked directly or indirectly to a scaffold.
B2. The antibody construct according to embodiment Bl, wherein the first 4-1BB binding domain is a first 4-1BB antigen-binding domain.
B3. The construct according to embodiment Bl or B2, wherein the first 4-1BB antigen- binding domain is derived from an agonistic anti-4-1BB antibody.
B4. The construct according to any one of embodiments B1 to B3, wherein: a) the first 4-1BB antigen-binding domain in monovalent form has an KD for human 4- 1BB between about IμM and 100pM; and/or b) the 4-1BB x TAA antibody construct binds to one or more TAA-expressing cell lines as determined by flow cytometry; and/or c) the 4-1BB x TAA antibody construct binds to human 4-1BB as measured by SPR and binds to the TAA as measured by SPR; and/or d) the 4-1BB x TAA antibody construct stimulates 4-1BB activity in T cells as measured by cytokine production, in the presence of TAA expressing cells; and/or e) the 4-1BB x TAA antibody construct binds to 4-1BB-expressing cells and binds to TAA-expressing cells as measured by flow cytometry; and/or f) the 4-1BB x TAA antibody constructs are capable of stimulating 4-1BB signalling in 4-1BB-expressing cells in the presence of TAA-expressing cells.
B5. The antibody construct according to any one of embodiments B1 to B4, wherein the first 4-1BB antigen-binding domain comprises: a) a heavy chain variable domain comprising the three heavy chain CDRs of antibody 1C3, and a light chain variable domain comprising the three light chain CDRs of antibody 1C3; b) a heavy chain variable domain comprising the three heavy chain CDRs of antibody 1C8, and a light chain variable domain comprising the three light chain CDRs of antibody 1C8; c) a heavy chain variable domain comprising the three heavy chain CDRs of antibody 1G1, and a light chain variable domain comprising the three light chain CDRs of antibody 1G1; d) a heavy chain variable domain comprising the three heavy chain CDRs of antibody 2E8, and a light chain variable domain comprising the three light chain CDRs of antibody 2E8; e) a heavy chain variable domain comprising the three heavy chain CDRs of antibody 3E7, and a light chain variable domain comprising the three light chain CDRs of antibody 3E7; f) a heavy chain variable domain comprising the three heavy chain CDRs of antibody 4E6, and a light chain variable domain comprising the three light chain CDRs of antibody 4E6; g) a heavy chain variable domain comprising the three heavy chain CDRs of antibody 5G8, and a light chain variable domain comprising the three light chain CDRs of antibody 5G8; or h) a heavy chain variable domain comprising the three heavy chain CDRs of antibody 6B3, and a light chain variable domain comprising the three light chain CDRs of antibody 6B3.
B6. The antibody construct according to any one of embodiments B1 to B5, wherein the first 4-1BB antigen-binding domain is a human or humanized antigen-binding domain.
B7. The antibody construct according to embodiment B6, wherein the first 4-1BB antigen- binding domain comprises: a) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v28726 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v28726; b) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v28727 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v28727; c) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v28728 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v28728; d) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v28730 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v28730; e) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v28700 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v28700; f) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v28704 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v28704; g) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v28705 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v28705; h) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v28706 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v28706; i) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v28711 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v28711;
j) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v28712 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v28712; k) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v28713 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v28713; l) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v28696 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v28696; m) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v28697 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v28697; n) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v28698 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v28698; o) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v28701 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v28701; p) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v28702 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v28702; q) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v28703 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v28703; r) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v28707 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v28707; s) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v28683 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v28683; t) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v28684 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v28684;
u) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v28685 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v28685; v) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v28686 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v28686; w) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v28687 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v28687; x) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v28688 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v28688; y) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v28689 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v28689; z) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v28690 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v28690; aa) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v28691 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v28691; ab) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v28692 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v28692; ac) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v28694 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v28694; or ad) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v28695 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v28695.
B8. The antibody construct according to any one of embodiments B1 to B7, further comprising a second 4-1BB binding domain.
B9. The antibody construct according to any one of embodiments B1 to B8, wherein the second 4-1BB binding domain is a second 4-1BB antigen-binding domain.
B10. The antibody construct according to embodiment B9, wherein the second 4-1BB antigen-binding domain is the same as the first 4-1BB antigen-binding domain.
B11. The antibody construct according to embodiment B10, wherein the first 4-1BB antigen-binding domain and/or the second 4-1BB antigen-binding domain are in a Fab format.
B12. The antibody construct according to any one of embodiments B1 to B11, wherein the TAA antigen-binding domain is a folate receptor-α (FRα) antigen-binding domain, a Solute Carrier Family 34 Member 2 (NaPi2b) antigen-binding domain, aHER2 antigen-binding domain, a mesothelin antigen-binding domain, or a Solute Carrier Family 39 Member 6 (LIV-1) antigen-binding domain.
B13. The antibody construct according to any one of embodiments B1 to B12, wherein the antibody construct comprises a second TAA antigen-binding domain.
B14. The antibody construct according to embodiment B13, wherein the first and second TAA antigen-binding domain bind to the same TAA.
B15. The antibody construct according to any one of embodiments B1 to B14, wherein the first TAA antigen-binding domain is a FRα antigen-binding domain.
B16. The antibody construct according to embodiment B15, wherein the FRα antigen- binding domain comprises: a) a heavy chain variable domain comprising the three heavy chain CDRs of antibody 8K22, and a light chain variable domain comprising the three light chain CDRs of antibody 8K22; or b) heavy chain variable domain comprising the three heavy chain CDRs of antibody 1H06, and a light chain variable domain comprising the three light chain CDRs of antibody 1H06.
B17. The antibody construct according to embodiment B16, wherein the FRα antigen- binding domain is a human or humanized antigen-binding domain.
B18. The antibody construct according to embodiment B17, wherein the FRα antigen- binding domain comprises:
a) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v23794 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v23794; b) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v23795 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v23795; c) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v23796 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v23796; d) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v23797 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v23797; e) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v23798 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v23798; f) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v23799 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v23799; g) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v23800 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v23800; h) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v23801 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v23801; i) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v23802 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v23802; j) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v23803 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v23803; k) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v23804 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v23804;
l) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v23805 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v23805; m) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v23806 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v23806; n) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v23807 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v23807; o) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v23808 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v23808; p) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v23809 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v23809; q) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v23810 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v23810; r) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v23811 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v23811; s) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v23812 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v23812; t) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v23813 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v23813; u) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v23814 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v23814; v) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v23815 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v23815;
w) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v23816 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v23816; x) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v23817 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v23817; or y) a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v23818 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v23818.
B19. The antibody construct according to any one of embodiments B1 to B18, wherein the TAA antigen-binding domain is in an scFv format.
B20. The antibody construct according to any one of embodiments B1 to B18, wherein the TAA antigen-binding domain is in a Fab format.
B21. The antibody construct according to any one of embodiments B1 to B20, wherein the scaffold is a dimeric Fc construct having a first Fc polypeptide and a second Fc polypeptide, each Fc polypeptide comprising a CH3 sequence, or wherein the scaffold is a linker or an albumin polypeptide.
B22. The antibody construct according to embodiment B21, wherein the scaffold is a heterodimeric Fc construct having a first Fc polypeptide that is different from the second Fc polypeptide, and wherein the CH3 sequences of the first Fc polypeptide and the second Fc polypeptide comprise amino acid substitutions that promote the formation of a heterodimeric Fc.
B23. The antibody construct according to embodiment B22, wherein: a) one Fc polypeptide comprises the amino acid substitutions T350V_L351Y_F405A_Y407V and the other Fc polypeptide comprises the amino acid substitutions
T350 V_T366L_K392L_T394 W; b) one Fc polypeptide comprises the amino acid substitutions
T350V_T366L_K392M_T394W and the other Fc polypeptide comprises the amino acid substitutions T350V_L351 Y_F405 A_Y407V; c) one Fc polypeptide comprises the amino acid substitutions L351Y_F405A_Y407V and the other Fc polypeptide comprises the amino acid substitutions T366L K392M T394W;
d) one Fc polypeptide comprises the amino acid substitutions L351Y_F405A_Y407V and the other Fc polypeptide comprises the amino acid substitutions T366L K392L T394W; or e) one Fc polypeptide comprises the amino acid substitutions L351Y_S400E_F405A_Y407V and the other Fc polypeptide comprises the amino acid substitutions T366I_N390R_K392M_T394W, wherein the numbering of residues is according to the EU numbering system.
B24. The antibody construct according to any one of embodiments B21 or B23, further comprising one or more amino acid modifications that reduce effector function.
B25. The antibody construct according to embodiment B24, wherein the one or more amino acid modifications are L234A, L235A and D265S, wherein the numbering of residues is according to the EU numbering system.
B26. The antibody construct according to any one of embodiments B1 to B25, wherein the first 4-1BB antigen-binding domain is linked to the N terminus of the first Fc polypeptide, and the first TAA antigen-binding domain is linked to the C terminus of the first Fc polypeptide.
B27. The antibody construct according to any one of embodiments B1 to B25, wherein the first 4-1BB antigen-binding domain is linked to the N terminus of the first Fc polypeptide, and the first TAA antigen-binding domain is linked to the C terminus of the second Fc polypeptide
B28. The antibody construct according to embodiment B26 or B27, further comprising a second 4-1BB antigen-binding domain linked to the N terminus of the second Fc polypeptide.
B29. The antibody construct according to any one of embodiments B1 to B25, comprising a first 4-1BB antigen-binding domain linked to the N terminus of the first Fc polypeptide, a second 4-1BB antigen-binding domain linked to the N terminus of the second Fc polypeptide, a first TAA antigen-binding domain linked to the C terminus of the first Fc polypeptide and a second TAA antigen-binding domain linked to the C terminus of the second Fc polypeptide.
B30. The antibody construct according to any one of embodiments B1 to B25, comprising a first 4-1BB antigen-binding domain linked to the N terminus of the first Fc polypeptide or to the N terminus of the second Fc polypeptide, a first TAA antigen-binding domain linked to
the C terminus of the first Fc polypeptide and a second TAA antigen-binding domain linked to the C terminus of the second Fc polypeptide.
B31. The antibody construct according to any one of embodiments B1 to B30, wherein the first and or second 4-1BB antigen-binding domain comprises a heavy chain variable domain comprising the three heavy chain CDRs of antibody 1G1, and a light chain variable domain comprising the three light chain CDRs of antibody 1G1, and the first and/or second FRα antigen-binding domain comprises a heavy chain variable domain comprising the three heavy chain CDRs of antibody 8K22, and a light chain variable domain comprising the three light chain CDRs of antibody 8K22.
B32. The antibody construct according to embodiment B31, wherein the first and second 4- 1BB antigen-binding domain comprises a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v28614 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v28614, and the first and/or second FRα antigen-binding domain comprises a heavy chain variable domain (VH) sequence that is at least 85% identical to the VH sequence of v23807 and a light chain variable domain (VL) sequence that is at least 85% identical to the VL sequence of v23807.
B33. The antibody construct according to embodiment B32, comprising a first heavy chain polypeptide sequence as set forth in SEQ ID NO:353, a second heavy chain polypeptide sequence as set forth in SEQ ID NO:349, and a light chain polypeptide sequence as set forth in SEQ ID NO:346.
B34. The antibody construct according to any one of embodiments B1 to B33, conjugated to a drug.
B35. A pharmaceutical composition comprising the antibody construct of any one of embodiments B1 to B33.
B36. One or more nucleic acids encoding the antibody construct according to any one of embodiments B1 to B34.
B37. One or more vectors comprising the one or more nucleic acids according to embodiment B36.
B38. An isolated cell comprising the one or more nucleic acid according to embodiment B36, or the one or more vectors according to embodiment B37.
B39. A method of preparing the antibody construct according to any one of embodiments B1 to B34, comprising culturing the isolated cell of embodiment B38 under conditions suitable for expressing the antibody construct, and purifying the antibody construct.
B40. A method of treating a subject having a cancer, comprising administering to the subject an effective amount of the antibody construct according to any one of embodiments B1 to B34.
B41. Use of an effective amount of the antibody construct according to any one of embodiments B1 to B34 for the treatment of cancer in a subject in need thereof.
B42. Use of the antibody construct according to any one of embodiments B1 to B34 in the preparation of a medicament for the treatment of cancer.
B43. The antibody construct according to any one of embodiments B1 to B34, for use in the treatment of cancer in a subject. C1. An antibody construct or antigen-binding fragment thereof, that specifically binds to 4-1BB, comprising: a heavy chain variable sequence comprising three heavy chain CDRs and a light chain variable sequence comprising three light chain CDRs, wherein the heavy chain CDRs and the light chain CDRs are from any one of antibodies 1G1, 1B2, 1C3, 1C8, 2A7, 2E8, 2H9, 3D7, 3H1, 3E7, 3G4, 4B11, 4E6, 4F9, 4G10, 5E2, 5G8, or 6B3.
C2. The antibody construct according to embodiment C1, wherein the antibody construct agonizes 4-1BB.
C3. The antibody construct according to embodiment C2, comprising a heavy chain variable (VH) sequence comprising three CDRs and a light chain variable (VL) sequence comprising three CDRs, wherein the heavy chain CDRs and the light chain CDRs are from any one of antibodies 1G1, 1C3, 1C8, 2E8, 3E7, 4E6, 5G8, or 6B3.
C4. The antibody construct according to any one of embodiments C1 to C3, wherein the antibody or antigen-binding fragment is or comprises a humanized antibody.
C5. The antibody construct according to embodiment C1 or C2, comprising a VH sequence and a VL sequence having at least 85% sequence identity to the VH and VL sequences of any one of variants v28726, v28727, v28728, v28730, v28700, v28704, v28705, V28706, v28711, v28712, v28713, v28696, v28697, v28698, v28701, v28702, v28703, V28707, v28683, v28684, v28685, v28686, v28687, v28688, v28689, v28690, v28691, V28692, v28694, or v28695.
C6. The antibody construct according to any one of embodiments C1 to C5, wherein the antibody or antigen-binding fragment has a binding affinity (KD) for a human 4-1BB molecule of about 10nM to about 500nM.
C7. The antibody construct according to any one of embodiments C1 to C6, wherein the antibody or antigen-binding fragment binds to an epitope within the extracellular domain of human 4-1BB polypeptide.
C8. The antibody construct according to any one of embodiments C1 to C7, wherein the antibody construct includes immunoglobulin constant domains, wherein the constant domains are from an IgG1 or a variant thereof, an IgG2 or a variant thereof, an IgG4 or a variant thereof, an IgA or a variant thereof, an IgE or a variant thereof, an IgM or a variant thereof, or an IgD or a variant thereof.
C9. The antibody construct according to any one of embodiments C1 to C8, wherein the antibody is or comprises a human IgG1.
C10. The antibody construct according to any one of embodiments C1 to C9, wherein the antibody or antigen-binding fragment is a monoclonal antibody.
C11. The antibody construct according to any one of embodiments C1 to C7, wherein the antibody fragment is a Fab fragment, a Fab' fragment, a F(ab')2 fragment, a Fv fragment, a scFv fragment, a single domain antibody, or a diabody.
C12. The antibody construct according to any one of embodiments C1 to C11, conjugated to a drug.
C13. A pharmaceutical composition comprising the antibody construct of any one of embodiments C1 to C12.
C14. One or more nucleic acids encoding the antibody construct according to any one of embodiments C1 to C11.
C15. One or more vectors comprising the one or more nucleic acids according to embodiment C14. C16. An isolated cell comprising the one or more nucleic acids according to embodiment C14, or the one or more vectors according to embodiment C15.
C17. A method of preparing the antibody construct according to any one of embodiments C1 to C12, comprising culturing the isolated cell of embodiment C16 under conditions suitable for expressing the antibody construct, and purifying the antibody construct. C18. A method of treating a subject having a cancer, comprising administering to the subject an effective amount of the antibody construct according to any one of embodiments C1 to C12. C19. Use of an effective amount of the antibody construct according to any one of embodiments C1 to C12 for the treatment of cancer in a subject in need thereof.
C20. Use of the antibody construct according to any one of embodiments C1 to C12 in the preparation of a medicament for the treatment of cancer.
C21. The antibody construct according to any one of embodiments C1 to C12, for use in the treatment of cancer in a subject.
D1. An antibody construct or antigen-binding fragment thereof, that specifically binds to FRα, comprising: a heavy chain variable (VH) sequence comprising three CDRs and a light chain variable (VL) sequence comprising three CDRs, wherein the heavy chain CDRs and the light chain CDRs are from antibody 8K22 or 1H06.
D2. The anti-FRα antibody or antigen-binding fragment according to embodiment Dl, wherein the antibody or antigen-binding fragment thereof is or comprises a humanized antibody.
D3. The anti-FRα antibody or antigen-binding fragment according to embodiment Dl or D2, comprising a VH sequence and a VL sequence having at least 85% sequence identity to the VH and VL sequences of any one of variants 23794, 23795, 23796, 23797, 23798, 23799,
23800, 23801, 23802, 23803, 23804, 23805, 23806, 23807, 23808, 23809, 23810, 23811, 23812, 23813, 23814, 23815, 23816, 23817, or 23818.
D4. The anti-FRα antibody or antigen-binding fragment according to embodiment D1 or D2, comprising a VH sequence having at least 85% sequence identity to the VH sequence as set forth in SEQ ID NO:300 and a VL sequence having at least 85% sequence identity to the VL sequence as set forth in SEQ ID NO:301.
D5. The anti-FRα antibody or antigen-binding fragment according to any one of embodiments D1 to D4, wherein the antibody or antigen-binding fragment has a binding affinity (KD) for a human FRα molecule of between about 100pM to about 100nM.
D6. The anti-FRα antibody or antigen-binding fragment according to any one of embodiments D1 to D5, wherein the antibody includes an immunoglobulin constant domain, wherein the constant domain is selected from an IgG1 or a variant thereof, an IgG2 or a variant thereof, an IgG4 or a variant thereof, an IgA or a variant thereof, an IgE or a variant thereof, an IgM or a variant thereof, and an IgD or a variant thereof.
D7. The anti-FRα antibody or antigen-binding fragment according to any one of embodiments D1 to D6, wherein the antibody is or comprises a human IgG1.
D8. The anti-FRα antibody or antigen-binding fragment according to any one of embodiments D1 to D7, wherein the antibody or antigen-binding fragment is a monoclonal antibody.
D9. The anti-FRα antibody or antigen-binding fragment according to any one of embodiments D1 to D8, wherein the antibody fragment is a Fab fragment, a Fab' fragment, a F(ab')2 fragment, a Fv fragment, a scFv fragment, a single domain antibody, or a diabody.
D10. The antibody construct according to any one of embodiments D1 to D9, conjugated to a drug.
Dll. A pharmaceutical composition comprising the antibody construct of any one of embodiments D1 to D10.
D12. One or more nucleic acids encoding the antibody construct according to any one of embodiments D1 to D9.
D13. One or more vectors comprising the one or more nucleic acids according to embodiment D12.
D14. An isolated cell comprising the one or more nucleic acids according to embodiment D12, or the one or more vectors according to embodiment D13.
D15. A method of preparing the antibody construct according to any one of embodiments D1 to D10, comprising culturing the isolated cell of embodiment D14 under conditions suitable for expressing the antibody construct, and purifying the antibody construct.
D16. A method of treating a subject having a cancer, comprising administering to the subject an effective amount of the antibody construct according to any one of embodiments D1 to D10.
D17. Use of an effective amount of the antibody construct according to any one of embodiments D1 to D10 for the treatment of cancer in a subject in need thereof.
D18. Use of the antibody construct according to any one of embodiments D1 to D10 in the preparation of a medicament for the treatment of cancer.
D19. The antibody construct according to any one of embodiments D1 to D10, for use in the treatment of cancer in a subject.
E1. An antibody construct comprising: a) a first 4-1BB-antigen binding domain derived from an agonistic anti-4-1BB antibody, and b) a first folate receptor alpha (FRα)-antigen binding domain in scFv format comprising a heavy chain variable domain (VH) sequence comprising the three heavy chain CDR sequences of antibody 8K22 and a light chain variable domain (VL) sequence comprising the three light chain CDR sequences of antibody 8K22, and further comprising one or more amino acid modifications in the VH domain and/or in the VL domain of antibody 8K22 that improve the biophysical properties of the antibody construct, wherein the first 4-1BB-antigen binding domain and the first FRα- anti gen binding domain are linked directly or indirectly to a scaffold.
E2. The antibody construct according to embodiment E1, wherein the one or more amino acid modifications increase the thermal stability of the first FRα antigen-binding domain.
E3. The antibody construct according to embodiment E1 or E2, wherein the one or more amino acid modifications result in a decrease in the amount of high molecular weight species of the antibody construct during production.
E4. The antibody construct according to any one of embodiments E1 to E3, wherein the one or more amino acid modifications comprise amino acid substitution at one or more of residues Y67, F83, Y49, and V15 of the VL sequence of antibody 8K22, wherein the numbering of residues is according to the Kabat numbering system.
E5. The antibody construct according to any one of embodiments E1 to E4, wherein the one or more amino acid modifications comprise insertion of lysine (K) at position 75 of the VH sequence of antibody 8K22, wherein the numbering of residues is according to the Kabat numbering system.
E6. The antibody construct according to any one of embodiments E1 to E5, wherein the one or more amino acid modifications comprise amino acid substitution at one or more of residues 153, L108, V89, and Q105, in the VH sequence of antibody 8K22 wherein the numbering of residues is according to the Kabat numbering system.
E7. The antibody construct according to embodiment E4, wherein the one or more amino acid modifications in the VH sequence and/or the VL sequence of 8K22 comprise: a) F83A or F83D in the VL sequence, b) V 15P or V 15T in the VL sequence, c) F83A in the VL sequence, I48V, A49S, A63V, S73N, and V78L in the VH sequence, and insertion of lysine at residue 75 of the VH sequence, d) 153 S in the VH sequence, e) V89T in the VH sequence f) Q105D or Q105E in the VH sequence, g) F83A in the VL sequence and L108T in the VH sequence, h) F83A in the VL sequence and I53S in the VH sequence, i) F83A in the VL sequence and L108T and I53S in the VH sequence, j) F83A and Y67S in the VL sequence, k) F83A and Y67S in the VL sequence, and L108T in the VH sequence, or l) F83A and Y67S in the VL sequence, and L108T and I53S in the VH sequence.
E8. The antibody construct according to embodiment E7, wherein the first FRα-antigen binding domain comprises the VH sequence and the VL sequence of variant 31588, 31586, 31594, or 31595.
E9. The antibody construct according to embodiment E8, wherein the first FRα-antigen binding domain comprises the sequence as set forth in SEQ ID NO: 831.
E10. The antibody construct according to any one of embodiments E1 to E9, further comprising a second 4-1BB-antigen-binding domain, linked directly or indirectly to the scaffold.
E1l. The antibody construct according to embodiment E10, wherein the first 4-1BB- antigen-binding domain is different from the second 4- lBB-anti gen-binding domain.
E12. The antibody construct according to embodiment E10 or E11, wherein the first 4- lBB-anti gen-binding domain is the same as the second 4- lBB-anti gen-binding domain.
E13. The antibody construct according to any one of embodiments E1 to E12, wherein the first 4-1BB antigen binding domain comprises: a) a heavy chain variable domain (VH) comprising the three heavy chain CDRs of antibody 1G1, and a light chain variable domain (VL) comprising the three light chain CDRs of antibody 1G1, b) a heavy chain variable domain comprising the three heavy chain CDRs of antibody 5G8, and a light chain variable domain comprising the three light chain CDRs of antibod1 5G8, or c) a heavy chain variable domain comprising the three heavy chain CDRs of antibody 1C8, and a light chain variable domain comprising the three light chain CDRs of antibody 1C8.
E14. The antibody construct according to any one of embodiments E1 to E12, wherein the first 4-1BB-antigen binding domain comprises: a) a heavy chain variable domain (VH) comprising the three heavy chain CDRs of antibody 1G1 and is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO:46, and a light chain variable domain (VL) comprising the three light chain CDRs of antibody 1G1 and is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO:58, b) a heavy chain variable domain comprising the three heavy chain CDRs of antibody and is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO:62, and a light chain variable domain comprising the three light chain CDRs of antibody 5G8 and is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO: 64, or c) a heavy chain variable domain comprising the three heavy chain CDRs of antibody 1C8 and is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO:53,
and a light chain variable domain comprising the three light chain CDRs of antibody 1C8 and is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO:48.
E15. The antibody construct according to any one of embodiments E10 to E14, wherein the first 4-1BB-antigen-binding domain and the second 4-1BB-antigen-binding domain are in a Fab format.
E16. The antibody construct according to any one of embodiments E1 to E15, wherein the scaffold is a dimeric Fc construct having a first Fc polypeptide and a second Fc polypeptide, each Fc polypeptide comprising a CH3 sequence, or wherein the scaffold is a linker or an albumin polypeptide.
E17. The antibody construct according to embodiment E16, wherein the scaffold is a heterodimeric Fc construct having a first Fc polypeptide that is different from the second Fc polypeptide, and wherein the CH3 sequences of the first Fc polypeptide and the second Fc polypeptide comprise amino acid substitutions that promote the formation of a heterodimeric Fc.
E18. The antibody construct according to embodiment E17, wherein: a) one Fc polypeptide comprises the amino acid substitutions T350V_L351Y_F405A_Y407V and the other Fc polypeptide comprises the amino acid substitutions
T350 V_T366L_K392L_T394 W; b) one Fc polypeptide comprises the amino acid substitutions
T350V_T366L_K392M_T394W and the other Fc polypeptide comprises the amino acid substitutions T350V_L351 Y_F405 A_Y407V; c) one Fc polypeptide comprises the amino acid substitutions L351Y_F405A_Y407V and the other Fc polypeptide comprises the amino acid substitutions T366L K392M T394W; d) one Fc polypeptide comprises the amino acid substitutions L351Y_F405A_Y407V and the other Fc polypeptide comprises the amino acid substitutions T366L K392L T394W; or e) one Fc polypeptide comprises the amino acid substitutions L351Y_S400E_F405A_Y407V and the other Fc polypeptide comprises the amino acid substitutions T366I_N390R_K392M_T394W, wherein the numbering of residues in the Fc polypeptide is according to the EU numbering system.
E19. The antibody construct according to any one of embodiments E16 to E18, further comprising one or more amino acid modifications that reduce effector function.
E20. The antibody construct according to embodiment E19, wherein the one or more amino acid modifications are L234A, L235A and D265S, wherein the numbering of residues is according to the EU numbering system.
E21. The antibody construct according to any one of embodiments E1 to E20, wherein the first 4-1BB antigen-binding domain is linked to the N terminus of the first Fc polypeptide, and the first TAA antigen-binding domain is linked to the C terminus of the second Fc polypeptide.
E22. The antibody construct according to any one of embodiments E12 to E21, wherein the first 4-1BB antigen-binding domain is linked to the N terminus of the first Fc polypeptide, the first FRα antigen-binding domain is linked to the C terminus of the second Fc polypeptide, and the second 4-1BB antigen-binding domain is linked to the N terminus of the second Fc polypeptide.
E23. The antibody construct according to embodiment E1, wherein the first 4-1BB antigen- binding domain and the second 4-1BB antigen-binding domain comprise the VH amino acid sequence as set forth in SEQ ID NO:46 and the VL amino acid sequence as set forth in SEQ ID NO:54, and the first FRα-antigen-binding domain comprises the sequence as set forth in SEQ ID NO: 831.
E24. The antibody construct according to embodiment E23, comprising the polypeptide sequences of variant 31588.
E25. The antibody construct according to any one of embodiments E1 to E24, conjugated to a drug.
E26. A pharmaceutical composition comprising the antibody construct of any one of embodiments E1 to E25.
E27. One or more nucleic acids encoding the antibody construct according to any one of embodiments E1 to E24.
E28. One or more vectors comprising the one or more nucleic acids according to embodiment E27.
E29. An isolated cell comprising the one or more nucleic acids according to embodiment E27, or the one or more vectors according to embodiment E28.
E30. A method of preparing the antibody construct according to any one of embodiments
E1 to E25, comprising culturing the isolated cell of embodiment E29 under conditions suitable for expressing the antibody construct, and purifying the antibody construct.
E31. A method of treating a subj ect having a cancer, comprising administering to the subject an effective amount of the antibody construct according to any one of embodiments
E1 to E25.
E32. Use of an effective amount of the antibody construct according to any one of embodiments E1 to E25 for the treatment of cancer in a subject in need thereof.
E33. Use of the antibody construct according to any one of embodiments E1 to E25 in the preparation of a medicament for the treatment of cancer.
E34. The antibody construct according to any one of embodiments E1 to E25, for use in the treatment of cancer in a subject.
E35. An antibody construct comprising a) a first 4-1BB antigen-binding domain derived from an agonistic anti-4-1BB antibody, and b) a first folate receptor-α (FRα) antigen-binding domain in a Fab format comprising a heavy chain variable domain (VH) comprising the three heavy chain CDR sequences of antibody 8K22 and a light chain variable domain (VL) comprising the three light chain CDR sequences of antibody 8K22, wherein the first 4-1BB antigen-binding domain and the first FRα antigen-binding domain are linked directly or indirectly to a scaffold.
E36. The antibody construct according to embodiment E35, wherein the construct comprises the polypeptide sequences of variant 33568, or variant 33569.
E37. The antibody construct according to embodiment E35, conjugated to a drug.
E38. A pharmaceutical composition comprising the antibody construct of embodiment E35 or E36.
E39. One or more nucleic acids encoding the antibody construct according to embodiment E35.
E40. One or more vectors comprising the one or more nucleic acids according to embodiment E39.
E41. An isolated cell comprising the one or more nucleic acids according to embodiment E39, or the one or more vectors according to embodiment E40.
E42. A method of preparing the antibody construct according to embodiment E35 or E36, comprising culturing the isolated cell of embodiment E41 under conditions suitable for expressing the antibody construct, and purifying the antibody construct.
E43. A method of treating a subject having a cancer, comprising administering to the subject an effective amount of the antibody construct according to embodiment E35 or E36.
E44. Use of an effective amount of the antibody construct to embodiment E35 or E36 for the treatment of cancer in a subject in need thereof.
E45. Use of the antibody construct according to embodiment E35 or E36 in the preparation of a medicament for the treatment of cancer.
E46. The antibody construct according to embodiment E35 or E36, for use in the treatment of cancer in a subject. F1. An antibody construct comprising: a) a first 4-1BB antigen-binding domain derived from an agonistic anti-4-1BB antibody, and b) a first folate receptor-α (FRα) antigen-binding domain comprising a heavy chain variable domain (VH) comprising the three heavy chain CDR sequences of antibody 2L16 and a light chain variable domain (VL) comprising the three light chain CDR sequences of antibody 2L16, wherein the first 4-1BB antigen-binding domain and the first FRα antigen-binding domain are linked directly or indirectly to a scaffold.
F2. The antibody construct according to embodiment F1, wherein the first FRα antigen- binding domain comprises: a) a VH domain comprising the three heavy chain CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO: 804, and a VL domain comprising the three light chain CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO: 805; b) a VH domain comprising the three heavy chain CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO: 806, and a VL domain comprising the three light chain CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO: 805, c) a VH domain comprising the three heavy chain CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO: 807, and a VL domain comprising the three light chain CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO: 805; or
d) a VH domain comprising the three heavy chain CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO:808, and a VL domain comprising the three light chain CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO: 805.
F3. The antibody construct according to embodiment F1 or F2, wherein the first FRα antigen-binding domain is in an scFv format.
F4. The antibody construct according to embodiment F3, wherein the first FRα antigen- binding domain comprises the sequence as set forth in SEQ ID NO:819, SEQ ID NO:820, SEQ ID NO:821, or SEQ ID NO:822.
F5. The antibody construct according to embodiment F4, wherein the first FRα antigen- binding domain further comprises one or more amino acid modifications in the VH sequence or VL sequence of antibody 2L16 that improve the biophysical properties of the antibody construct.
F6. The antibody construct according to embodiment F1 or F2, wherein the first FRα antigen-binding domain is in a Fab format.
F7. The antibody construct according to any one of embodiments F1 to F6, further comprising a second FRα antigen-binding domain.
F8. The antibody construct according to embodiment F7, wherein the first and second FRα antigen-binding domains are the same.
F9. The antibody construct according to embodiment F7, wherein the first and second FRα antigen-binding domains are different.
F10. The antibody construct according to any one of embodiments F1 to F9, wherein the first 4-1BB antigen binding domain comprises: a) a heavy chain variable domain (VH) comprising the three heavy chain CDRs of antibody 1G1, and a light chain variable domain (VL) comprising the three light chain CDRs of antibody 1G1, b) a heavy chain variable domain comprising the three heavy chain CDRs of antibody 5G8, and a light chain variable domain comprising the three light chain CDRs of antibody 5G8, or c) a heavy chain variable domain comprising the three heavy chain CDRs of antibody 1C8, and a light chain variable domain comprising the three light chain CDRs of antibody 1C8.
F11. The antibody construct according to any one of embodiments F1 to F10, wherein the first 4-1BB antigen-binding domain comprises: a) a heavy chain variable domain (VH) comprising the three heavy chain CDRs of antibody 1G1 and is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO:46, and a light chain variable domain (VL) comprising the three light chain CDRs of antibody 1G1 and is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO:58, b) a heavy chain variable domain comprising the three heavy chain CDRs of antibody and is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO:62, and a light chain variable domain comprising the three light chain CDRs of antibody 5G8 and is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO: 64, or c) a heavy chain variable domain comprising the three heavy chain CDRs of antibody 1C8 and is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO:53, and a light chain variable domain comprising the three light chain CDRs of antibody 1C8 and is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO:48. F12. The antibody construct according to any one of embodiments F1 to F11, further comprising a second 4-1BB antigen-binding domain.
F13. The antibody construct according to embodiment F12, wherein the first 4-1BB- antigen-binding domain and the second 4-1BB-antigen-binding domain are in a Fab format. F14. The antibody construct according to embodiment F12 or F13, wherein the second 4- 1BB antigen-binding domain is the same as the first 4-1BB antigen-binding domain. F15. The antibody construct according to embodiment F14, wherein the first 4-1BB antigen-binding domain and/or the second 4-1BB antigen-binding domain are in a Fab format. F16. The antibody construct according to any one of embodiments F1 to F15, wherein the scaffold is a dimeric Fc construct having a first Fc polypeptide and a second Fc polypeptide, each Fc polypeptide comprising a CH3 sequence, or wherein the scaffold is a linker or an albumin polypeptide. F17. The antibody construct according to embodiment F16, wherein the scaffold is a heterodimeric Fc construct having a first Fc polypeptide that is different from the second Fc polypeptide, and wherein the CH3 sequences of the first Fc polypeptide and the second Fc polypeptide comprise amino acid substitutions that promote the formation of a heterodimeric Fc. F18. The antibody construct according to embodiment F17, wherein:
a) one Fc polypeptide comprises the amino acid substitutions T350V_L351Y_F405A_Y407V and the other Fc polypeptide comprises the amino acid substitutions
T350 V_T366L_K392L_T394 W; b) one Fc polypeptide comprises the amino acid substitutions
T350V_T366L_K392M_T394W and the other Fc polypeptide comprises the amino acid substitutions T350V_L351 Y_F405 A_Y407V; c) one Fc polypeptide comprises the amino acid substitutions L351Y_F405A_Y407V and the other Fc polypeptide comprises the amino acid substitutions T366L K392M T394W; d) one Fc polypeptide comprises the amino acid substitutions L351Y_F405A_Y407V and the other Fc polypeptide comprises the amino acid substitutions T366L K392L T394W; or e) one Fc polypeptide comprises the amino acid substitutions L351Y_S400E_F405A_Y407V and the other Fc polypeptide comprises the amino acid substitutions T366I_N390R_K392M_T394W, wherein the numbering of residues in the Fc polypeptide is according to the EU numbering system. F19. The antibody construct according to any one of embodiments F16 to F18, further comprising one or more amino acid modifications that reduce effector function.
F20. The antibody construct according to embodiment F19, wherein the one or more amino acid modifications are L234A, L235A and D265S, wherein the numbering of residues is according to the EU numbering system.
F21. The antibody construct according to any one of embodiments F1 to F20, wherein the first 4-1BB antigen-binding domain is linked to the N terminus of the first Fc polypeptide, and the first FRα antigen-binding domain is linked to the C terminus of the first Fc polypeptide.
F22. The antibody construct according to any one of embodiments F1 to F21, wherein the first 4-1BB antigen-binding domain is linked to the N terminus of the first Fc polypeptide, and the first FRα antigen-binding domain is linked to the C terminus of the second Fc polypeptide.
F23. The antibody construct according to embodiment F21 or F22, further comprising a second 4-1BB antigen-binding domain linked to the N terminus of the second Fc polypeptide. F24. The antibody construct according to any one of embodiments F1 to F23, comprising a first 4-1BB antigen-binding domain linked to the N terminus of the first Fc polypeptide, a second 4-1BB antigen-binding domain linked to the N terminus of the second Fc polypeptide,
a first FRα antigen-binding domain linked to the C terminus of the first Fc polypeptide and a second FRα antigen-binding domain linked to the C terminus of the second Fc polypeptide. F25. The antibody construct according to any one of embodiments F1 to F24, comprising a first 4-1BB antigen-binding domain linked to the N terminus of the first Fc polypeptide or to the N terminus of the second Fc polypeptide, a first FRα antigen-binding domain linked to the C terminus of the first Fc polypeptide and a second FRα antigen-binding domain linked to the C terminus of the second Fc polypeptide.
F26. The antibody construct according to embodiment F1, wherein the construct comprises the polypeptide sequences of any one of variants 31946, 32687, 32686, or 32688.
F27. The antibody construct according to any one of embodiments F1 to F26, conjugated to a drug.
F28. A pharmaceutical composition comprising the antibody construct of any one of embodiments F1 to F27.
F29. One or more nucleic acids encoding the antibody construct according to any one of embodiments F1 to F26.
F30. One or more vectors comprising the one or more nucleic acids according to embodiment F29.
F31. An isolated cell comprising the one or more nucleic acid according to embodiment F29, or the one or more vectors according to embodiment F30.
F32. A method of preparing the antibody construct according to any one of embodiments F1 to F27, comprising culturing the isolated cell of embodiment F31 under conditions suitable for expressing the antibody construct, and purifying the antibody construct.
F33. A method of treating a subject having a cancer, comprising administering to the subject an effective amount of the antibody construct according to any one of embodiments F1 to F27.
F34. Use of an effective amount of the antibody construct according to any one of embodiments F1 to F27 for the treatment of cancer in a subject in need thereof.
F35. Use of the antibody construct according to any one of embodiments F1 to F27 in the preparation of a medicament for the treatment of cancer.
F36. The antibody construct according to any one of embodiments F1 to F27, for use in the treatment of cancer in a subject.
F37. An antibody construct or antigen-binding fragment thereof, that specifically binds to folate receptor-α (FRα), comprising: a heavy chain variable domain (VH) sequence comprising three heavy chain CDRs and a light chain variable domain (VL) sequence
comprising three light chain CDRs, wherein the heavy chain CDRs and the light chain CDRs are from antibody 2L16.
F38. The antibody construct according to embodiment F37, wherein the antibody or antigen-binding fragment is or comprises a humanized antibody.
F39. The antibody construct according to embodiment F37 or F38, comprising: a) a VH domain comprising the three heavy chain CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO: 804, and a VL domain comprising the three light chain CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO: 805; b) a VH domain comprising the three heavy chain CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO: 806, and a VL domain comprising the three light chain CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO: 805, c) a VH domain comprising the three heavy chain CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO: 807, and a VL domain comprising the three light chain CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO: 805; or d) a VH domain comprising the three heavy chain CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO:808, and a VL domain comprising the three light chain CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO: 805.
F40. The antibody construct according to any one of embodiments F37 to F39, wherein the antibody construct includes immunoglobulin constant domains, wherein the constant domains are from an IgG1 or a variant thereof, an IgG2 or a variant thereof, an IgG4 or a variant thereof, an IgA or a variant thereof, an IgE or a variant thereof, an IgM or a variant thereof, or an IgD or a variant thereof.
F41. The antibody construct according to any one of embodiments F37 to F40, wherein the antibody is or comprises a human IgG1.
F42. The antibody construct according to any one of embodiments F37 to F41, wherein the antibody or antigen-binding fragment is a monoclonal antibody.
F43. The antibody construct according to any one of embodiments F37 to F42, wherein the antibody fragment is a Fab fragment, a Fab' fragment, a F(ab')2 fragment, a Fv fragment, a scFv fragment, a single domain antibody, or a diabody.
F44. The antibody construct according to any one of embodiments F37 to F43, conjugated to a drug.
F45. A pharmaceutical composition comprising the antibody construct of any one of embodiments F37 to F44.
F46. One or more nucleic acids encoding the antibody construct according to any one of embodiments F37 to F43.
F47. One or more vectors comprising the one or more nucleic acids according to embodiment F46.
F48. An isolated cell comprising the one or more nucleic acids according to embodiment F46, or the one or more vectors according to embodiment F47.
F49. A method of preparing the antibody construct according to any one of embodiments F37 to F43, comprising culturing the isolated cell of embodiment F48 under conditions suitable for expressing the antibody construct, and purifying the antibody construct.
F50. A method of treating a subject having a cancer, comprising administering to the subject an effective amount of the antibody construct according to any one of embodiments F37 to F43.
F51. Use of an effective amount of the antibody construct according to any one of F37 to F43, for the treatment of cancer in a subject in need thereof.
F52. Use of the antibody construct according to any one of embodiments F37 to F43, in the preparation of a medicament for the treatment of cancer.
F53. The antibody construct according to any one of embodiments F37 to F43, for use in the treatment of cancer in a subject.
EXAMPLES
[00364] Below are examples of specific embodiments related to the antibody constructs described herein. The examples are offered for illustrative purposes only, and are not intended to limit the scope of the disclosure in any way. Efforts have been made to ensure accuracy with respect to numbers used (e.g., amounts, temperatures, etc.), but some experimental error and deviation should, of course, be allowed for.
[00365] The practice of the present disclosure will employ, unless otherwise indicated, conventional methods of protein chemistry, biochemistry, recombinant DNA techniques and pharmacology, within the skill of the art. Such techniques are explained fully in the literature. See, e.g., T.E. Creighton, Proteins: Structures and Molecular Properties (W.H. Freeman and Company, 1993); A.L. Lehninger, Biochemistry (Worth Publishers, Inc., current addition); Sambrook, et al., Molecular Cloning: A Laboratory Manual (2nd Edition, 1989); Methods In Enzymology (S. Colowick and N. Kaplan eds., Academic Press, Inc.); Remington's Pharmaceutical Sciences , 18th Edition (Easton, Pennsylvania: Mack Publishing Company, 1990); Carey and Sundberg Advanced Organic Chemistry 3rd Ed. (Plenum Press) Vols A and B(1992).
EXAMPLE 1: Design and Preparation of Exemplary 4-1BB x HER2 bispecific antibody constructs
[00366] A number of exemplary bispecific antibody constructs (or bispecific antibodies) targeting 4-1BB and the TAA HER2, as well as controls were constructed as described below. The antibodies and controls were prepared in different exemplary formats, as described in Figure 2. These antibody constructs were prepared in order to allow examination of the potential for conditional agonism of 4-1BB, and the optimal format for activity of the 4-1BB x HER2 constructs.
Design of exemplary bispeciflc antibody constructs targeting 4-1BB and HER2
[00367] Bispecific antibody constructs were prepared in a format in which the HER2 antigen-binding domain was an scFv and the 4-1BB antigen-binding domain was a Fab. Constructs, including controls, comprised an IgG1 Fc, unless otherwise indicated (see Table 1). These bispecific antibody constructs comprised a human IgG1 heterodimeric Fc having sets of CH3 domain amino acid substitutions promoting the formation of a heterodimeric Fc. These sets of amino acid substitutions are referred to herein as Het FcA (having the amino acid substitutions T350V/L351Y/F405A/Y407V) and Het FcB having the amino acid substitutions T350V/T366L/K392L/T394W). Variants having these sets of amino acid substitutions are referred to in Table 1 as having “Het Fc” modifications. Variants in Table 1 noted as having “FcKO” have the following CH2 amino acid substitutions which knock out FcγR binding: L234A, L235A and D265S. Amino acid residues in the Fc region are identified according to the EU index.
[00368] Bivalent, trivalent and tetravalent antibody constructs were made, all having three polypeptide chains constructs - one heavy chain containing Het FcA mutations, a second heavy chain containing Het FcB mutations and a single light chain. The heavy chains were constructed in a series of formats, all of which were comprised of one or two anti-4-1BB antigen-binding domains in the Fab format and a single anti-HER2 antigen-binding domain in the scFv format. These heavy chain formats are described below from N-terminus to C- terminus:
- VL-VH-VH-CH 1 -hinge-CH2-CH3
- VH-CH 1 -hinge -CH2 -CH3 - VL- VH
- VH-CH 1 -hinge -CH2 -CH3
- VL-VH-hinge-CH2-CH3
[00369] Table 1 provides a description of the 4-1BB x HER2 bispecific antibody constructs that were prepared. The number of 4-1BB-targeting domains and HER2 -targeting domains are indicated in the “Format” column. For example, in Table 1, 1 x 1 indicates that the bispecific antibody construct has one 4-1BB binding domain and one HER2 binding domain, 2 x 1 indicates that the bispecific antibody construct has two 4-1BB binding domains and one HER2 binding domain, etc. The formats of the specific bispecific antibody constructs described below are also represented in Figure 3.
Table 1: Exemplary bispecific antibody constructs targeting 4-1BB and HER2


[00370] The VH and VL sequences used to construct the 4-1BB antigen-binding domains of the constructs are provided in Table 15, as are the scFv sequences used to construct HER2 scFv containing constructs. Table X, Table XI and Table X2 identify the clones that make up each of the antibody constructs. The polypeptide sequences of each clone can be found in Table Y, Table Y1 or Table Y2.
Production of 4-1BB x HER2 bispecific antibodies
[00371] To allow the production of bispecific antibodies, heavy chain vectors having a 5’-EcoRl restriction site - signal peptide - heavy chain clone terminating at G446 (EU numbering) of CH3 - TGA stop - BamHl cutsite-3’, were ligated into a pTT5 vector to produce heavy chain expression vectors. Light chain vectors, having a 5’-EcoRI cut site -signal peptide - light chain- TGA stop - BamHl cutsite-3’, were ligated into apTT5 vector (Durocher Y et al, Nucl. Acids Res. 2002; 30, No.2 e9) to produce light chain expression vectors. The resulting heavy and light chain expression vectors were sequenced to confirm correct reading frame and sequence of the coding DNA. One of two signal peptides was used, either an artificially designed sequence, MRPTW AWWLFL VLLL ALW AP ARG [SEQ ID NO:l], Barash S et al, Biochem and Biophys Res. Comm. 2002; 294, 835-842) or the HLA-A signal peptide M AVM APRTLVLLLS GAL ALT QTW AG [SEQ ID NO:2],
[00372] The heavy and light chains of variants, were expressed in 200 ml cultures of CHO-3E7 cells. CHO-3E7 cells, at a density of 1.7 - 2 x 106 cells /ml, were cultured at 37°C in FreeStyle™ F17 medium (Thermo Fisher, Watham, MA) supplemented with 4 mM glutamine (GE Life Sciences, Marlborough, MA) and 0.1% KoliphorP188 (Sigma Aldrich, St. Louis,
MO). A total volume of 200 ml was transfected with a total of 200 mg DNA (100μg of variant DNA and lOOμg of GFP/AKT/stuffer DNA) using PEI-max (Polyscience, Philadelphia, PA) at a DNA:PEI ratio of 1:4 (W/W). Twenty-four hours after the addition of the DNA-PEI mixture, 0.5mM valproic acid (final concentration) + 1% w/v Tryptone (final concentration) + 1x antibiotic/antimycotics (GE Life Sciences, Marlborough, MA) were added to the cells which were then transferred to 32°C and incubated for 7 days prior to harvesting.
[00373] Clarified supernatant samples were incubated in batch with MabSelect™ SuRe™ resin (GE Healthcare, Chicago, IL) cleaned with NaOH and equilibrated in DPBS. Resin was poured into cleaned columns, the columns were washed with DPBS and protein eluted with 100 mM sodium citrate buffer pH 3.0. The eluted antibodies were pH adjusted by adding 10% (v/v) 1M HEPES pH 8 to yield a final pH of 6-7. Samples were buffer exchanged into PBS and aseptically filtered. Protein was quantified based on A280 nm (NanoDrop™). Endotoxin levels were determined using the Endosafe® Portable system (Charles River, Wilmington, MA). For samples above 0.1 EU/mg, these underwent endotoxin removal with the Proteus NoEndo™ Spin columns (Charles River, Wilmington, MA).
[00374] Post protein-A purification, samples were either buffer exchanged into DPBS and aseptically filtered or, depending on their homogeneity assessed by UPLC-SEC, subjected to SEC purification. Samples were loaded onto a Superdex 200 10/30 Increase column (GE Healthcare Life Sciences, Marlborough, MA) on an Akta Avant 25 chromatography system (GE Healthcare Life Sciences, Marlborough, MA) in DBPS with a flow rate of 0.5 mL/min. Fractions of eluted protein were collected based on A280 nm and the fractions were assessed by non-reducing and reducing High Throughput Protein Express assay using Caliper LabChip GXII (Perkin E1mer, Waltham, MA). Procedures were carried out according to HT Protein Express LabChip User Guide version2 LabChip GXII User Manual, with the following modifications, antibody samples, at either 2 μl or 5 μl (concentration range 5-2000 ng/μl), were added to separate wells in 96 well plates (BioRad, Hercules, CA) along with 7 μl of HT Protein Express Sample Buffer (Perkin E1mer # 760328). Antibody samples were then denatured at 70°C for 15 mins. The LabChip instrument was operated using the HT Protein Express Chip (Perkin E1mer, Waltham, MA) and the Ab-200 assay setting.
[00375] Endotoxin levels were determined by the LAL (limulus amebocyte lysate) assay using the Endosafe® Portable Test System (PTS, Charles River, Wilmington, MA). Protein was quantified based on A280 nm (Nanodrop) post protein-A and SEC.
[00376] UPLC-SEC was performed using a Waters Acquity BEH200 SEC column (2.5 mL, 4.6 x 150 mm, stainless steel, 1.7 μm particles) (Waters LTD, Mississauga, ON) set to 30°C and mounted on a Waters Acquity UPLC H-Class Bio system with a PDA detector. Run times consisted of 7 min and a total volume per injection of 2.8 mL with a running buffer of DPBS or DPBS with 0.02% Tween 20 pH 7.4 at 0.4 ml/min. E1ution was monitored by UV absorbance in the range 210-500 nm, and chromatograms were extracted at 280 nm. Peak integration was performed using Empower 3 software.
Purity assessment of bispecific antibodies by LC/MS
[00377] The apparent purity of the variants was assessed using mass spectrometry after purification and non-denaturating deglycosylation as described below.
[00378] As the antibody contained Fc N-linked glycans only, the samples were treated with only one enzyme, N-glycosidase F (PNGase-F). The purified samples were de- glycosylated with PNGaseF as follows: 0.1U PNGaseF/μg of antibody in 50mM Tris-HCl pH 7.0, overnight incubation at 37°C, final protein concentration of 0.48 mg/mL. After deglycosylation, the samples were stored at 4°C prior to LC-MS analysis.
[00379] The deglycosylated protein samples were analyzed by intact LC-MS using an Agilent 1100 HPLC system coupled to an LTQ-Orbitrap XL mass spectrometer (ThermoFisher , Waltham, MA) via an Ion Max electrospray source. The samples (5 μg) were injected onto a 2.1 x 30 mm Poros R2 reverse phase column (Applied Biosystems) and resolved using the following gradient conditions: 0-3 min: 20% solvent B; 3-6 min: 20-90% solvent B; 6-7 min: 90-20% Solvent B; 7-9 min: 20% solvent B. Solvent A was degassed 0.1% formic acid aq. and solvent B was degassed acetonitrile. The flow rate was 3 mL/min. The flow was split post- column to direct 100μL/mL into the electrospray interface. The column was heated to 82.5°C and solvents were heated pre-column to 80°C to improve protein peak shape. Prior to analysis, the LTQ-Orbitrap XL was calibrated using ThermoFisher Scientific’s LTQ Positive Ion ESI calibration solution (caffeine, MRFA and Ultramark 1621), and tuned for optimal detection of larger proteins (>50kDa) using a 1 mg/mL solution of lactalbumin. The cone voltage (source fragmentation setting) was approximately 40 V, the FT resolution was 7,500 and the scan range was m/z 400-4,000. The LC-MS system was evaluated for IgG sample analysis using a deglycosylated IgG standard (Waters IgG standard) as well as a deglycosyated antibody standard mix (25:75 half: full sized antibody).
[00380] For each LC-MS analysis the mass spectra acquired across the antibody peak (typically 3.6-4.1 minutes) were summed and the entire multiply charged ion envelope (m/z 1,400-4,000) was deconvoluted into a molecular weight profde using the MaxEnt 1 module of MassLynx™, the instrument control and data analysis software (Waters LTD, Missassaugua, ON). Briefly, the raw protein LC-MS data were first opened in QualBrowser, the spectrum viewing module of Xcalibur™ (Thermo Fisher, Waltham, MA) and converted to be compatible with MassLynx™ using Databridge™, a file conversion program provided by Waters. The converted protein spectra were viewed in the Spectrum module of MassLynx™ and deconvoluted using MaxEnt 1. The apparent amount of each antibody species in each sample was determined from their peak heights in the resulting molecular weight profiles. In the majority of cases, the antibodies comprised >95% of the desired construct, with no major glycovariants.
EXAMPLE 2: Ability of 4-1BB x HER2 bispecific antibody constructs to bind to 4-1BB and HER2 as assessed by Surface Plasmon Resonance (SPR)
[00381] To check the production and characteristics of the 4-1BB x HER2 bispecific antibodies described in Example 1, the ability of these antibodies to bind to human 4-1BB and HER2 was assessed by SPR. 4-1BB x HER2 bispecific variants 16601, 16605, 16675, 16679 were assessed, as well as the control antibody variant 19353 (trastuzumab, having two anticalin domains at the C-termini of both heavy chains that bind to 4-1BB).
Binding of 4-1BB to antibodies by SPR
[00382] A surface plasmon resonance (SPR) binding assay for determination of 4-1BB binding affinity to 4-1BB antibody variants was carried out on Biacore™ T200 instrument (GE Healthcare, Mississauga, ON, Canada) with PBS-T (PBS + 0.05% (v/v) Tween 20) running buffer (with 0.5 M EDTA stock solution added to 3.0 mM final concentration) at a temperature of 25°C. CM5 Series S sensor chip, Biacore™ amine coupling kit (NHS, EDC and 1 M ethanolamine), and 10 mM sodium acetate buffers were all purchased from GE Healthcare. PBS running buffer with 0.05% Tween20 (PBS-T) was purchased from Teknova Inc. (Hollister, CA). Goat polyclonal anti-human Fc antibody was purchased from Jackson ImmunoResearch Laboratories Inc. (West Grove, PA).
[00383] The SPR binding of antibodies to 4-1BB antigen occurred in two steps: an indirect capture of antibodies onto the anti-human Fc-specific polyclonal antibody surface,
followed by the injection of five concentrations of purified human monomeric 4-1BB (SEQ ID NO:70). Monomeric 4-1BB protein was produced by cleaving a 4-1BB-Fc fusion protein (v16730). 4-1BB-Fc was expressed and purified with Protein A in the same manner to antibodies in Example 1 above. The construct was made with a factor Xa cleavage site between the 4-1BB and the Fc, and with a 10xHis tag at the c-term of the Fc.
[00384] v16730 in dPBS was buffer exchanged into Factor Xa cleavage buffer (20 mM
Tris, 100 mM NaCl, 2 mM CaC12 pH 8) using a 5 mL Zeba spin column (ThermoFisher) and cleaved with 0.45% (w/w) of Factor Xa (New England Biolabs, Whitby, ON, Canada) overnight at room temp. The cleavage reaction was stopped by adding 0.372 μM final concentration of 1,5-Dansyl-Glu-Gly-Arg-chloromethyl ketone (Calbiochem, San Diego, California, USA) as an inhibitor. Satisfactory cleavage was verified by NR+R SDS-PAGE. The cleavage reaction was mixture was subsequently applied to a 1 mL HiTrap Ni Sepharose Excel (GE Heathcare) column equilibrated in dPBS and the column washed with 5xCV dPBS. The cleaved 41BB protein was collected in the flow-thru fractions. Residual Fc was removed using Protein A purification by applying the protein sample to mAh Select SuRe by gravity. The flow-through was applied to a Superdex 200 10/30 column equilibrated in dPBS. Fractions corresponding to the major 41BB product were collected and used for SPR.
[00385] The anti-human Fc surface was prepared on a CM5 Series S sensorchip by standard amine coupling methods as described by the manufacturer (GE Healthcare). Briefly, immediately after EDC/NHS activation, a 25 μg/mL solution of anti-human Fc in 10 mM NaOAc pH 4.5 was injected at a flow rate of 10 μL/min for 420s until approximately 2000 resonance units (RUs) were immobilized on all four flow cells. The remaining active groups were quenched by a 420s injection of 1M ethanolamine at 10 μL/min.
[00386] Antibodies for analysis were captured onto the anti-Fc surface by injecting 5 μg/mL solutions at a flow rate of 10 μL/min for 60s. Using single-cycle kinetics, five concentrations of a two-fold dilution series of 4-1BB starting at 40nM (for both supernatant and purified antibody runs) with a blank buffer control were sequentially injected at 40 μL/min for 180s with a 600s dissociation phase, resulting in a set of sensorgrams with a buffer blank reference. Experiments were performed at a constant temperature of 25°C. The anti-human Fc surfaces were regenerated to prepare for the next injection cycle by one pulse of 10mM Glycine/HCl pH 1.5 for 120 s at 40 μL/min. Blank-subtracted sensorgrams were analyzed using
Biacore™ T200 Evaluation Software v3.0. The blank-subtracted sensorgrams were then fit to the 1:1 Langmuir binding model.
Binding of HER2 to antibodies by SPR
[00387] An anti-Fc capture chip was prepared in the same way as above, then antibodies for analysis at 50μg/ml were injected into the chip at a flow rate of 10μl/min for 60s. Using single-cycle kinetics, five concentrations of a two-fold dilution series of HER2 (having recombinant human Her-2 amino acids 23-652; eBioscience) starting at 40nM (for both supernatant and purified antibody runs) with a blank buffer control were sequentially injected at 50μL/min for 180s with a 1800s dissociation phase, resulting in a set of sensorgrams with a buffer blank reference. Experiments were performed at a constant temperature of 25 °C. The anti -human Fc surfaces were regenerated to prepare for the next injection cycle by one pulse of 10mM Glycine/HCl pH 1.5 for 120 s at 40 μL/min. Blank-subtracted sensorgrams were analyzed using Biacore™ T200 Evaluation Software v3.0. The blank-subtracted sensorgrams were then fit to the 1:1 Langmuir binding model to obtain the ka, kd and KD values shown in Table 2 below.
Table 2: Ability of bispecific antibody constructs to bind to target

[00388] Table 2 shows that the antibodies in different formats are still able to bind to their targets with similar affinity regardless of format. Variants with C-terminal Trastuzumab scFv, v16605 and v16679, showed about a 2-3 fold drop in KD compared to antibodies with N-terminal scFv, but this was judged to be a minor change and not expected to affect function. All 4-1BB antibodies showed similar KD values, with the anti-4-1BB anticalin v19353 showing a lower affinity for 4-1BB compared to the antibodies.
EXAMPLE 3: Ability of 4-1BB x HER2 bispecific antibody constructs to stimulate 4- 1BB activity in an NF-kB-Luciferase reporter assay
[00389] To test the ability of bispecific 4-1BB x HER2 antibodies to stimulate 4-1BB activity in the presence of a tumor cell expressing HER2, a reporter-gene assay was used as a
measure of signaling downstream of 4-1BB to aNF-kB reporter driving luciferase. The 4-1BB x HER2 bispecific antibodies tested included variants 16675, 16679, 15534, 16601, and 16605. Control constructs 19353, 1040, 16992, and 12952 were also tested.
[00390] The ability of bispecific antibodies to activate 4-1BB in the context of HER2+ tumour cells was measured using a co-culture assay. This assay used Jurkat cells engineered to express 4-1BB and a luciferase reporter gene driven by an NF-kB site. This assay measures signaling from 4-1BB on the surface of the cell down to the nucleus. Two different tumour lines were used; SKOV3, which express a high level of HER2, and MDA-MB-468 which express a low level of HER2. If the activation of 4-1BB is HER2 dependent, activation should be seen in co-culture with SKOV3 cells and not MDA-MB-468 cells.
[00391] The day prior to the assay white, TC-treated, polystyrene, 384-well plates (Coming) were treated with 40 μL/well of OKT3, mouse-anti-human-CD3 antibody (Biolegend) at 5 μg/mL in phosphate buffered saline (PBS) (Gibco). The plate was sealed to the plate lid by wrapping in parafdm. The plate was incubated overnight at 4°C. The next day, the contents of the plate were aspirated, and the plate was washed with 3 changes of distilled water (120μL/well) using a 405HT ELISA plate washer (Biotek). The plate was then ready for use in the assay.
[00392] Bispecific antibodies were diluted in Assay Buffer (RPMI (Gibco)/l% FBS (Gibco)) to 400 nM (final assay concentration 100 nM). A volume of 15 μL was pipetted into the well of a 384-well plate treated with OKT3 as above receiving the top concentration of the variant. A volume of 5μL was pipetted into a volume of 10μL Assay Buffer in the next well for the second highest concentration well and mixed to give a 3-fold dilution. This was repeated for the transfer from the second highest well to the third highest until the lowest concentration well, where the residual 5μL volume was removed. 10μL of either SKOV3 or MDA-MB-468 tumour cells, at a density of 2x106 cells/mL, was then added to give 2x104 cells/well. NFκB 1UC2P/4-1BB Thaw-and-Use Jurkat cells (Promega) were thawed at 37°C according to manufacturer’s instructions and diluted with 5.8 mL of Assay Buffer. A volume of 20 μL of the reporter cell suspension at approximately 1x106 cells/mL (~2x104 cells) was added to each well containing the variant/effector-cell mixture.
[00393] The co-cultured cells with variants were then incubated at 37°C in a 5% CO2 atmosphere for 5 hours and then equilibrated to room temperature on the benchtop for
10 minutes. A volume of 40 μL of Bio-Glo™ (Promega) luciferase substrate reagent was added to each well of the plate and incubated for 10 minutes at room temperature. The plate was scanned on the Synergy™ Hl(Biotek) multi-mode plate reader in luminescence mode. Data was analysed using Prism 7 (GraphPad) and four-parameter variable slope nonlinear fit.
Results
[00394] All variants having a 4-1BB binding arm induced dose-dependent NF-kB signalling downstream of 4-1BB as measured by production of luciferase in this assay when co-cultured with SKOV-3 cells (Figure 4A to 41). In comparison, variants having activity showed lower activity on MDA-MD-468 cells, suggesting that the presence of HER2 on the surface of the SKOV-3 cells induced cross-linking of the antibodies and enhanced 4-1BB signalling. The lowest activation of 4-1BB was seen with the v16601 variant. v16605 and v16675 showed higher activity. v16679 showed highest activity, as determined by greatest potency (EC50) and activity (max RLU). The positive control 4-1BB x HER2 bispecific antibody v19353 showed intermediate potency - higher than v16601 and v16605 but lower than v16675 and v16679. However, v19353 (having a lipocalin 4-1BB binding domain) showed low activity, as given by maximal RLU, compared to the antibody-based 4-1BB agonists. 4-1BB monospecific control variant v12592 showed low activity at lower concentrations, with activity increasing with concentration; however, activity of this antibody was not increased in the presence of SKOV3 cells compared to MDA-MD-468 cells. Control variant v1040 showed no activity in activating 4-1BB, suggesting that there was no direct effect of the HER2 binding arm on the experiment, v 16992 similarly showed no effect of a non- binding control antibody. A summary of the results in provided in Table 3.
Table 3: Activity of 4-1BB x HER2 bispecific antibody constructs

[00395] From this data, it appeared that constructs with two anti-4-1BB binding arms showed greater activity than constructs with one anti-4-1BB arm. The constructs with a Her2- binding site close to the 4-1BB binding site (eg. v 16601 and v 16675) appeared less active than
the constructs with the Her2 binding site distal from the 4-1BB binding site (eg. v16605 and v 16679).
EXAMPLE 4: Primary T cell-tumour co-culture assay
[00396] The activity of the 4-1BB x HER2 constructs was also compared using primary
T cells in co-culture with tumour cells. To look at activation of T cells, and the effects of 4- 1BB more broadly, production of cytokines such as IFNγ or IL-2 by T cells was used as a proxy for enhanced T cell activation and function. IL-2 is also a key cytokine produced by T cells after activation which promotes their survival and correlates with activation of T cells. This experiment examined the ability of 4-1BB x HER2 antibodies to enhance the activation of T cells as measured by IL-2 production, where the T cells have been activated by a sub-optimal amount of anti-CD3 antibody. Bispecific 4-1BB x HER2 antibody variants 16601, 16605, 16675, and 16679, were tested in this example, along with the control variants 1040, 12592, and a human IgG1 negative control. The assay was carried out as described below, using CD4+ T cells.
[00397] Ahead of the experiment, 96 well plates were coated with anti-CD3 by adding 100μl 1μg/ml UCHT1 to wells. The plate was then incubated overnight at 4°C. Blood was obtained from healthy donors, centrifuged at 1500rpm for 5 minutes and plasma discarded. The blood was then diluted in PBS, layered over Ficoll™ and centrifuged at 2000rpm for 20 minutes at room temperature. The interface layer of PBMC was then taken, washed with PBS to remove platelets, and resuspended. Cells were then counted, diluted to 5 x 107 cells per ml in PBS 2% FBS ImM EDTA, and CD4+ T cell enrichment cocktail (Stemcell Technologies) added at 50μl/ml cells. The cells were then left at room temperature for 10 minutes. EasySep™ D magnetic particles (Stemcell Technologies) were then added at 100μl/ml cells, mixed and left at room temperature for 5 minutes. The cells were then diluted to a volume of 10ml using PBS/2% FCS/lmM EDTA and placed into an EasySep™ magnet. Non-selected cells were then decanted, and placed into a fresh tube in an EasySep™ magnet, and those cells decanted into a fresh tube.
[00398] CD4+ T cells were then washed twice in RPMI-1640 10% FCS 1% Penicillin- Streptomycin and diluted to 106 cells/ml and 100μl added per well to a 96 well plate that had been pre-coated with anti-CD3 (UCHT1). SKBR3 cells were obtained, diluted to 2 x 105 cells/ml and 50μl added to wells. Antibody samples were also diluted to 40nM in RPMI-1640
10% FCS 1% Penicillin-Streptomycin and 50μl of the resulting solution added per well (10nM final concentration). In some cases, antibodies were cross-linked using an anti-Fc antibody. The plate was then incubated for three days at 37°C in a 5% CO2 atmosphere, and supernatants taken for analysis of IL-2 concentrations by ELISA.
Results
[00399] Similar to the 4-1BB NF-kB reporter gene assay, the greatest IL-2 production was seen with v16679, with v16675 and v16605 showing equal levels of IL-2 (Figure 5, left panel). Without SKBR3 cells in the culture, no increase in IL-2 production was seen as a result of any of the 4-1BB bispecifics. v12592 cross-linked by anti-Fc was used as a positive control and represents the level of signaling induced by a fully cross-linked antibody (Figure 5, right panel). This data indicated that of the variants tested, v16679 (having the format described in Figure 2B) was able to induce a level of 4-1BB signaling in the T cells in excess of that stimulated by v12592.
EXAMPLE 5: Comparison of activation of T cells by v16679, v19353 and v12592 as measured by IFN-g production
[00400] As v 16679 appeared to be the most active 4-1BB x HER2 bispecific in both the reporter-gene assay as well as the primary T cell-tumour co-culture, the ability of this variant to stimulate cytokine production by T cells in co-culture with SKBR3 cells was compared to the positive control constructs v19353 and v12592. In this experiment, IFNγ production was used as a measure of T cell activation as described below.
[00401] 4-1BB x HER2 bispecific antibodies were prepared at 150nM in assay media
(RPMI containing 5% human AB serum with 1% penicillin-streptomycin (Gibco)). 20μl of diluted antibodies at 150nM was then added to the top concentration well of a sterile 384-well cell culture plate (Thermo Scientific), and then the antibodies serially diluted 1:3 to generate the lower antibody concentrations.
[00402] SKBR3 tumor cells were cultured in RPMI 10% FCS, treated with 0.05% Trypsin-EDTA (Invitrogen) to remove them from the plate, collected and counted. After centrifugation, the tumor cells were resuspended in assay media at a concentration of 106 cells per ml. 104 tumor cells (10μl) were added per well according to each condition. Artificial APCs (aAPC/CHO-K1 cells, Promega) were collected using cell dissociation buffer and counted.
These cells expressed anti-CD3 (0KT3) and PD-L1 on the surface of the cell and were used to stimulate the T cells in a non-specific manner. After centrifugation, the artificial APC cells were resuspended in assay media at a concentration of 106 cells per ml. T cells were thawed, pelleted, counted and resuspended in assay media at a concentration of 2 x 106 cells per ml. CD8+ T cells, CD4+ T cells and pan-T cells were purchased from BioIVT, Westbury, NY, USA or Stemcell, Vancouver, BC, Canada.
[00403] aAPC/CHO-K1 and CD8+, CD4+ T cells or pan-T cells, each from separate donors, were then mixed in 1 :2 ratio and 30μl of cell mixture added to the 384 well plate along with the 10μl SKBR3 tumour cells. The plate was then incubated for 37°C in a 5% CO2 atmosphere.
[00404] After four days, supernatant was collected to perform Homogenous Time Resolved Fluorescence ELISA (HTRF™). Either 5μl supernatants, 5μl serially diluted IFNγ standards or 5μl PBS were added to wells of a white round-bottom 384 shallow-well plate (Thermo Scientific). Anti-IFNγ-Cryptate antibody (Cisbio, Bedford, MA) and anti-IFNγ-XL (Cisbio, Bedford, MA) antibody were diluted 20-fold in detection buffer #3 (Cisbio, Bedford, MA), and 2μl of each diluted antibody mixed with 11 μl PBS per well. 15μl of this antibody cocktail was added to wells of the 384 well plate alongside the 5μl experimental supernatant or standards. The plate was then sealed and left overnight at room temperature. The next day, the plate was read at 665 and 620nm on a Biotek reader and values reported as ratio of 665nm/620nm readings, after correcting for the plate absorption using PBS-only wells. IFNγ concentrations were calculated using the standard curve. GraphPad Prism v7 was used for data analysis, using the non-linear four-parameter model.
Results
The results are shown in Figure 6 with multiple independent CD4 and CD8 T cell donors as well as a single pan-T cell donor. This was done to test if the response was only found in a small number of donors. Across all CD4, CD8 and pan-T cell donors, v 16679 showed a dose- dependent increase in IFNγ production by T cells in co-culture with SKBR3 cells. v16679 also showed much greater maximal cytokine production and higher potency compared to v19353. v12592 was not active in this experiment, and did not show activity greater than that seen by the negative control v13725, suggesting that v16679 is active in conditions where v12592 is not.
EXAMPLE 6: Generation of antibodies which bind 4-1BB and preparation of mouse- human chimeric antibodies
[00405] Additional antibodies targeting 4-1BB were generated by ImmunoPrecise (Victoria, Canada) using their proprietary RapidPrime immunization strategy to immunize mice.
[00406] Briefly, Balb/c and NZB/W mice were immunized with human 4-1BB-His protein or a mixture of human 4-1BB-His and mouse 4-1BB-Fc (Aero Biosystems, Newark, DE), and spleens taken and dissociated to obtain single cells. Splenocytes were then fused with a myeloma partner line to create hybridomas. The hybridoma cells were cloned by limiting dilution and the supernatants taken for screening.
[00407] Antibodies binding to human, cynomolgus ( Macaca fascicularis ) and/or mouse (Mus musculus) 4-1BB were identified by ELISA. 96-well plates were coated by adding 100μl of a 0.1μg/ml solution of human, cynomolgus or mouse 4-1BB in carbonate buffer (pH 9.6) overnight at 4°C. The wells were then blocked by using 3% skim milk powder in PBS for 1 hour at room temperature, followed by addition of neat hybridoma supernatant (100μl/well) at 37°C for 1 hour with shaking. The antibody was then detected using 1:10000 goat anti-mouse IgG/IgM (H+L)-HRP, 100μl/well in PBS 0.05% Tween-20 for 1 hour at 37°C with shaking. The presence of HRP in the well was then detected using TMB substrate (50μl/well) for 3 minutes in the dark, followed by addition of 50μl 1M HC1 to stop the reaction. The plate was then read at 450nm. Antibodies were also counter-screened to exclude antibodies that bound to TNF superfamily members 0x40 and CD40 and GITR, using the same method.
Results
Twenty-four antibodies binding to human 4-1BB were taken forward to be sequenced and further characterized. Some of these antibodies also bound to cynomolgus or mouse 4-1BB.
Antibody Recovery
[00408] The twenty-four antibodies selected by ELISA were then sequenced to obtain full VH and VL sequences. To prepare RNA from hybridoma cells, cells were washed once in cold phosphate-buffered saline (pH 7.4) and immediately processed through the RNeasy Plus Micro Kit (QIAgen). Total RNA was eluted in nuclease-free water and mRNA converted to cDNA using AMY reverse transcriptase (NEB), primed with oligo(dT2o).
[00409] Initial PCR of heavy and light chain antibody-coding sequences was performed using primers and methods modified from Babcook et al. (Proc Natl Acad Sci USA 1996 Jul 23; 93(15): 7843) and von Boehmer et al. (Nat Protoc. 2016 Oct; 11(10): 1908), with cDNA as the nucleic acid template. PCR products were cloned into the pCRTOP04 vector using the Zero Blunt™ TOPO™ PCR Cloning kit (Thermofisher Scientific) and transformed into E. cloni™ cells (Lucigen). Antibiotic-resistant clones were sequenced and analyzed for unique antibody-coding sequences.
[00410] A nested PCR reaction was then performed on these unique sequences using V - segment family and J-segment family-specific primers. The resulting amplicons were then cloned into pTT5-based expression plasmids (National Research Council, Montreal, QC). Unique heavy chain sequences and light chain sequences emerging from a single hybridoma sample were co-expressed in HEK293-6E cells (National Research Council) in all possible combinations to determine the correct heavy and light chain pairing. Antibodies produced were assayed for binding to antigen that was transiently expressed on HEK293 cells.
Results
[00411] Of the 24 antibodies initially identified as binding to human 4-1BB, a total of 18 paired antibody VH and VL sequences (shown in Table 13) were obtained from the hybridomas and cloned into the pTT5 vector as human-mouse chimeric antibodies, with mouse VH and VL domains and a human IgG1 Fc. Mouse VH domains were cloned in frame with a human CH1-hinge-CH2-CH3 construct, and mouse VL domains cloned in frame with the human kappa CL domain.
Expression of 4-1BB chimeric antibodies
[00412] The 18 chimeric mouse-human 4-1BB antibodies were produced by transfection of two plasmids into HEK293-6E cells, one plasmid containing the heavy chain and the other plasmid containing the light chain.
[00413] HEK293-6E cells were split 1:10 72 hours prior to transfection to ensure growth-phase cells. These cells were then counted and resuspended at 106 cellsml"1 in OptiMEM™ (Thermofisher). A transfection mix was made by mixing 30μl 293fectin™ (Thermofisher) and 1.5ml OptiMEM™. This mix was then incubated at room temperature. After five minutes, 1.5ml OptiMEM™ and 15μg of each of the plasmids containing the antibody heavy or light chains in the pTT5 vector were added. This mix was then left at room
temperature for 20 minutes, and then added dropwise to cells, with a total volume of 3ml. Cells were then left at 37C in a 5% CO2 atmosphere in a shaking incubator at 120rpm for five days.
[00414] In some cases, the antibody levels within the supernatant were quantified using an Octet™ RED96 (ForteBio) with a Protein A tip, and the supernatants used immediately in assays.
[00415] The supernatants were also purified using Protein A. To purify the antibodies, cells were first removed from the antibody supernatants by centrifuging at 100Orcf for 15 minutes. Protein A Gravitrap™ columns were then prepared by equilibration using 10ml PBS, followed by application of antibody supernatant in batches of 10ml. Once all of the supernatant had flowed through the column, the column was washed twice, each time with 10ml PBS.
E1ution of the antibody was performed by the addition of 3ml 0.1M glycine-HCl, pH 2.7. The eluted antibody sample was then neutralized using 1M Tris-HCl, pH 9.
[00416] To concentrate the antibody sample and perform a buffer exchange, the antibody samples were loaded into a Vivaspin™ 30kDa MWCO protein concentrator spin column (GE Healthcare). The columns were then spun at 3000rcf for 7 minutes to concentrate the antibody. 4ml PBS was then added to the column to exchange buffers, and the column was then spun again, to exchange buffers into PBS. The antibody levels in the resulting solution were then measured using 260nm/280nm absorbance ratio using a Nanodrop™ S pectrophotometer (Thermofisher) .
EXAMPLE 7: Activity of chimeric 4-1BB antibodies in 4-1BB NF-kB-Luciferase reporter assay
[00417] To test the ability of chimeric mouse-human 4-1BB antibodies to stimulate 4- 1BB activation and downstream signaling, a reporter gene assay was used. The cells used in this experiment produce luciferase under the control of the NF-kB promoter when signaling is induced by ligation of the 4-1BB receptor.
[00418] This experiment was set up in a manner similar to that described in Example 3, except that antibody supernatants were used in place of bispecific antibodies, and no tumour cells were used. The antibody supernatants were diluted in Assay Buffer (RPMI (Gibco)/l% FBS (Gibco)) to 5000ng/ml, 1666ng/ml, 554ng/ml and 184ng/ml. Rabbit-anti-human IgG Fc (Thermofisher) polyclonal secondary antibody was then added to a concentration of 15000ng/ml and the antibody mixture left at room temperature.
[00419] After 45 minutes, 30μl of the antibody mix was added to wells. If the concentration of antibody in the supernatant was below 5000ng/ml, supernatants were diluted from neat (v20023, v20025, v20028, v22033, v22034). As a positive control, v12592 was diluted either in supernatant (ESN) or RPMI. The negative control was v16992 diluted in ESN. 4-1BB Thaw-and-use Jurkat cells (Promega) were then added, followed by a 5 hour incubation and then Bio-Glo™ reagent (Promega) was added, as described in Example 3. The data was acquired and analyzed as in Example 3.
Results
[00420] Eight antibodies induced the production of luciferase: v20021 , v20022, v20023, v20025, v20029, v20032, v20036, v20037 suggesting that they agonise 4-1BB (Figure 7). These antibodies were then purified from supernatant and taken forward to assess which 4- 1BB domains they bound to.
EXAMPLE 8: Determination of 4-1BB domain binding
[00421] To determine which domains of human 4-1BB the chimeric antibodies recognized, the chimeric antibodies were tested for binding to human 4-1BB, dog 4-1BB and a chimeric human-dog 4-1BB protein. The human-dog 4-1BB protein included a set of mutations within domain 4 that modified human 4-1BB to dog.
Preparation of human, dog and human-dog 4-1BB
[00422] To generate expression constructs for soluble human, dog and human-dog chimeric 4-1BB, synthesized DNA having 4-1BB ECD-TEV-IgG1 hinge-CH2-CH3-10xHis was made. Table 4 below provides the sequences of these constructs and Figure 8A provides a representation of the 4-1BB portion of these constructs. Both dog and human 4-1BB extracellular domain included residues 24-186 of the 4-1BB protein sequence taken from Uniprot (IDs E2R1R9 and Q07011 for dog and human 4-1BB, respectively). The mutations in the human-dog chimera to mimic dog 4-1BB in domain 4 wereK115Q, C121R, R134Q, R154S and V156A (described in WO2012/032433).
Table 4: 4-1BB domain-binding constructs


[00423] The pTT5 vectors containing the 4-1BB expression constructs were then produced and purified in a manner similar to the antibodies in Example 1, except a 500ml culture volume was used. Caliper results indicated that human, dog and chimeric human-dog 4-1BB constructs were prepared in substantially pure form.
Domain-mapping of 4-1BB antibodies by ELISA
[00424] A soluble antigen binding ELISA was performed to assess antibodies for their ability to bind outside of 4-1BB domain 4. The goal was to determine if samples have differential binding to hybrid or chimeric human-dog 4-1BB versus human 4-1BB to suggest whether or not binding is outside of domain 4. However, if the tested antibodies were able to bind to dog 4-1BB assessment of binding to domain 4 by this method would not be accomplished.
[00425] Soluble human, dog or human-dog 4-1BB-Fc proteins were prepared in PBS pH
7.4 (Thermo Fisher, Whetham, MA) at 400 ng/mL. 4-1BB-Fc proteins were added at 50 μL/well to wells of a 96-well flat bottom ELISA plates (Coming 3368). The plates were covered by a lid, sealed with parafilm, and left overnight at 4°C. The next day, the plates were washed three times with 300μL/well distilled water using a BioTek 405 HT microplate washer (BioTek, Winooski, VT) and tapped to dry. Wells were then blocked by adding 200 μL/well
blocking buffer (2% w/v skim milk powder in PBS) and left at room temperature for 1 hour. The plates were washed as previously and tapped to dry. Antibody samples were then diluted in assay buffer (2% w/v skim milk powder in PBS) to 10 μg/mL final or used neat if samples were below 10 μg/mL. Directly in assay plates, samples were serially diluted five times 1:8 in duplicate in assay buffer with a final volume of 50 μL/well. Similarly, control antibodies were prepared and diluted in assay buffer. For wells containing no antibody sample, assay buffer was added at 50 μL/well. The plates were then covered with a lid, sealed with parafilm, and incubated overnight at 4°C. The next day, plates were washed with the plate washer as previously and tapped dry. For detection of sample binding to soluble antigen, Peroxidase AffiniPure goat anti -human F(ab')2 (Jackson ImmunoResearch, West Grove, PA) was prepared in assay buffer at 0.4 μg/mL. For detection of coated antigen, Peroxidase AffiniPure goat anti- human Fc (Jackson ImmunoResearch, West Grove, PA) was prepared in assay buffer at 1 μg/mL. Both secondaries were added at 50 μL/well and plates were incubated at room temperature for 30 minutes. The plates were washed and dried as previous and TMB substrate (Cell Signaling Technology, Danvers, MA) was added at 50 μL/well. After incubation at room temperature for ten minutes, the reaction was neutralized with 1M HC1 (VWR, Radnor, PA). The plate absorbance at OD450 was scanned on the BioTek Synergy™ H1 plate reader (BioTek, Winooski, VT).
Results
[00426] As shown in Figures 9A to Figure 91, all chimeric antibodies tested were able to bind human 4-1BB. However, v20023 and v20029 also bound dog 4-1BB, suggesting that the domain binding of those two antibodies cannot be assessed by this method. The remaining antibodies did not bind dog 4-1BB.
[00427] v20022, 20025, v20032, v20036 and v20037 showed equal binding on human and human-dog chimeric 4-1BB, suggesting that all these antibodies bound outside domain 4 (amino acids 115-156). MOR7480.1-IgG1 (variant 12592), as expected, showed a reduction of binding to dog-human chimeric 4-1BB compared to human 4-1BB, suggesting that its binding domain is within the amino acids 115-156. v12593, a version of Urelumab with an IgG1 Fc, similar to the tested antibodies, bound human and human-dog chimeric 4-1BB equally, suggesting that its binding domain also lies outside amino acids 115-156. v20027 did not show binding in this experiment and was excluded from future analysis.
Domain binding of antibodies using truncated 4-1BB proteins
[00428] As some of the antibodies were cross-reactive to dog 4-1BB, another method was required to determine to which domain antibodies bound. As an alternative, truncated transmembrane 4-1BB constructs were made, where 4-1BB domains 3 and 4 only would be expressed. Figure 8B provides a representation of the truncated transmembrane 4-1BB constructs that were made.
Construction of 4-1BB domain vectors
[00429] Constructs were synthesized having either full-length human 4-1BB (residues 24-255) or extracellular domains 3 and 4 (residues 86-255) along with the native human transmembrane and intracellular parts of 4-1BB. Full-length mouse 4-1BB was also cloned. All vectors also contained the native signal peptide (MGNSCYNIVATLLLVLNFERTRS, SEQ ID NO:42) and were run through SignalP 4.1 (www.cbs.dtu.dk/services/SignalP/) to predict the successful cleavage of the signal peptide. All constructs were synthesized in the form 3’-EcoRI-4-1BB-BamHI-5’ and cloned into an EcoRI-BamHI digested pTT5 vector.
[00430] To test binding of antibodies to 4-1BB, 293E6 cells were transfected as before, except that all human 4-1BB constructs were co-transfected with mouse 4-1BB, to act as a carrier protein. Twenty-four hours after transfection, 2x105 cells were labelled with 2.5μg of antibody for one hour on ice, and then analysed by flow cytometry using a Attune cytometer (ThermoFisher, Waltham, Massachusetts, U.S.). The antibodies had been pre-complexed with Zenon-Alexa-647 reagent (ThermoFisher) using manufacturer’s instructions.
Results
[00431] The results of this experiment are shown in Figure 10. All antibodies showed binding to cells transfected with human 4-1BB and to cells transfected with human and mouse 4-1BB. Variant 16992, an anti-RSV antibody, was used as a negative control. As expected, v12592 showed binding to cells transfected with the 4-1BB domain 3 and 4 only construct (amino acids 86-255), as its hypothesized binding domain is between amino acids 115 and 156 (domain 4). v20022, v20023, v20025, v20029, v20032, v20036 and v20037 antibodies did not show binding to cells transfected with the domain 3 and 4 only construct, suggesting that all of the antibodies bind outside of those domains, and bind to an epitope at least partially within amino acids 24-85 of the mature 4-1BB protein. This data reinforces the conclusions of the
human-dog chimera experiment, that v20022, v20025, v20029, v20036 and v20037 do not bind domain 4.
EXAMPLE 9: Binding of chimeric anti-4-1BB antibodies to Cynomolgus and Mouse 4- 1BB
[00432] To assess the binding of v20022, v20023, v20025, v20029, v20032, v20036 and v20037 to native transmembrane Cynomolgus ( Macaca fascicularis ) and Mouse (Mus musculus ) 4-1BB, a homogeneous cell binding assay was performed using the Celllnsight CX5 platform (Thermo Fisher, Watham, MA). This experiment used cells transiently expressing either Cynomolgus or mouse 4-1BB.
[00433] To prepare cells for transfection, suspension HEK293-6e cells (National Research Council Canada, Montreal, QB) were cultured in 293 Freestyle Media (ThermoFisher, Watham, MA). with 1% FBS (Coming, Coming, NY) in 250mL Erlenmeyer flasks (Coming, Coming, NY) at 37 °C, 5% CO2 in a humidified incubator with rotation at 115 rpm. Before transfection, HEK293-6e cells were re-suspended to 1 x 106 cells/mL in fresh 293 Freestyle media. Cells were then transfected using 293fectin™ transfection reagent (Thermo Fisher, Watham, MA) at a ratio of lμg DNA/106 cells in Opti- MEM™ Reduced Serum Medium (Thermo Fisher, Watham, MA). Cells were transfected with pTT5 DNA vectors containing either full length cynomolgus monkey 4-1BB with a flag-tag (CL#11070 SEQ ID NO:43), mouse 4-1BB-flag (CL#11063 SEQ ID NO:44) as shown in Table 5, or vector containing GFP as a control for transfection efficiency. The cells were incubated for 24 hours at 37 °C, 5% CO2 in a humidified incubator with rotation at 115 rpm.
Table 5: Cynomolgus or mouse 4-1BB sequences


[00434] Antibody samples were prepared at concentrations of neat, 1:4 and 1:16 final in PBS pH 7.4 (Thermo Fisher, Watham, MA) + 2% FBS in Eppendorf tubes and 30 pi of antibody mix was added to wells of a 384-well black optical bottom plate (ThermoFisher). v12592 was used as a positive control for binding to Cynomolgus 4-1BB, and human IgG1 as a negative control. Anti-mouse 4-1BB antibody LOB12.3 (BioXCell, West Lebanon, NH) and its respective rat IgG1 isotype control (R&D Systems, Minneapolis, MN) were used as controls for mouse binding. A cell mixture of transfected HEK293-6e cells (10,000 cells per 30 μL), Vybrant™ DyeCycle™ Violet nuclear stain at 2 μM final (Thermo Fisher) and Goat anti Human IgG Fc A647 at 0.6 μg/mL (Jackson ImmunoResearch, Westgrove, PA) was prepared. The cells were vortexed briefly to mix added to wells at 30 μL/well. The plate was incubated at room temperature for 3 hours before scanning. Data analysis was performed on the Celllnsight CX5 with the HCS high content screening platform (ThermoFisher), using BioApplication “CellViability” with a 10x objective. Samples were scanned on the 385 nm channel to visualize nuclear staining and 650nm channel to assess cell binding. The mean object average fluorescence intensity of A647 was measured on channel 2 to determine binding intensity. This intensity was then divided by the intensity of staining seen in the GFP- transfected wells to give a fold binding induced by the antibody.
Results
[00435] All antibodies with the exception of v20020 (1B2) and v20031 (4B1) appeared to bind Cynomolgus 4-1BB (Figure 11A). v12952 was used as a positive control for cyno 4- 1BB binding, with hlgG1 being its matched isotype control, which does not show binding. No antibodies bound mouse 4-1BB (Figure 11B). LOB12.3 was used as a positive control for binding to mouse 4-1BB, with the Rat IgG being a matched isotype control, which does not show binding.
EXAMPLE 10: Humanization of mouse 5G8, 1G1 and 1C8 VH and VL sequences
[00436] Humanized versions of three of the mouse anti-human 4-1BB antibodies generated in Example 6 were prepared as described below.
[00437] Humanization of mouse 1C8, 1G1 and 5G8 variable light (VL) and variable heavy (VH) domains was performed as follows. Sequence alignment of mouse 1C8 VH and VL sequences to respective human germlines identified IGHV3-66*03 and IGKV1D-33*01 among the closest as well as relatively frequent germlines in humans. Sequence alignment of mouse 1G1 VH and VL sequences to respective human germlines identified IGHV3-48*03 and IGKV3-11*01 among the closest, as well as relatively frequent germlines in humans. Sequence alignment of mouse 5G8 VH and VL sequences to respective human germlines identified IGHV4-59*08 and IGKV1-16*01 among the closest, as well as relatively frequent germlines in humans. CDRs, identified according to AbM definition (see Table A), were ported onto the framework of these selected human germlines. Figure 12 provides the sequences of the resulting VH (Figures 12 A-C) and VL sequences (Figure 12 D-F). Back mutations to mouse residues in such generated sequence, at positions judged to likely be important for the retention of binding affinity to human 4-1BB, were included in such way to create several humanized sequences in which next one builds on the previous one, and where the first humanized sequence contains minimal number of back mutations or no back mutations.
[00438] For 1C8 this process led to four variable heavy chain humanized sequences and three variable light chain humanized sequences. For 1G1 this process led to three variable heavy chain humanized sequences and four variable light chain humanized sequences. For 5G8 this process led to four variable heavy chain humanized sequences and four variable light chain humanized sequences. Full heavy chain sequence containing humanized heavy chain variable domain (VH) and hlgG1 heavy chain constant domains (CH1, hinge, CH2, CH3), as well as full light chain sequence containing humanized light chain variable domain (VL) and human kappa light chain constant domain (kappa CL) were created for 1C8, 1G1 and 5G8. Antibodies were then assembled such that each humanized heavy chain was paired with each of the humanized light chains, making a total of twelve humanized variants each for 1C8 and 1G1, and 16 variants for 5G8, (Table 6). The amino acid sequences for each of the humanized heavy chains and humanized light chains are provided in Table 14.
Table 6: Humanized 1C8, 1G1 and 5G8 variants and their composition.


Production of humanized antibodies
[00439] Each of the humanized 1C8, 1G1 and 5G8 VH and VL sequences described in Table 6 as well as the parental mouse VH and VL sequences were used to prepare humanized antibodies in the naturally occurring, or FSA antibody format, containing two identical full- length heavy chains and two identical kappa light chains. Table X identifies the clones that make up each of the antibody constructs. The polypeptide sequences of each clone can be found in Table Y.
[00440] Each of the humanized VH domain sequences (SEQ ID NOs:45, 46, 47, 51, 52,
53, 56, 57, 61, 62, and 63) was appended to the human CH1-hinge-CH2-CH3 domain sequence of IGHG1*01 (SEQ ID NO:68) to obtain a protein sequence for four humanized 1C8, three humanized 1G1 and four humanized 5G8 full heavy chain sequences. Each of the humanized VL domain sequences (SEQ ID NOs:48, 49, 50, 54, 55, 58, 59, 60, 64, 65, and 66) was appended to the human kappa CL sequence of IGKC*01 (SEQ ID NO:67) to obtain a protein sequence for three humanized 1C8, four humanized 1G1 and four humanized 5G8 full light chain sequences. In a similar manner, 1C8, 1G1 and 5G8 mouse-human parental antibody chimera heavy and light chain sequences were assembled, with the difference that variable domain sequences were mouse (SEQ ID NOs:7, 9, 35 (VH) and 8, 10, 36 (VL)) and constant domain sequences were human (SEQ ID NOs:68 and 67 correspondingly). These sequences
were reverse translated to DNA, codon optimized for mammalian expression, and gene synthesized.
[00441] All mouse-human parental and humanized full heavy and full light chain sequences were preceded by a signal peptide which is an artificially designed sequence MRPTWAWWLFLVLLLALWAPARG [SEQ ID NO:l] (ref: Barash S et al, Biochem and Biophys Res. Comm. 2002; 294, 835-842). For all parental and humanized heavy and light chains, vector inserts were prepared as described in Example 1 and cloned into pTT5 to produce expression vectors.
[00442] The heavy and light chains of antibody variants were expressed in 100 mL CHO cultures and purified as described in Example 1. Following protein-A purification, purity of samples was assessed by non-reducing and reducing High Throughput Protein Express assay as described in Example 1.
[00443] Post protein-A purification, samples were either buffer exchanged into DPBS and aseptically filtered or, depending on their homogeneity assessed by UPLC-SEC, subjected to SEC purification as described in Example 1.
Results
[00444] Yields of protein post protein-A purification were in the range of -3.5-9 mg for humanized 1C8 variants, -4.5-9.5 mg for humanized 1G1 variants and -4.5-8 mg for humanized 5G8 variants. Non-reducing and reducing LabChip post protein-A reflected single species corresponding to full size antibody and intact heavy and light chains in all cases (data not shown). Endotoxin levels were within the specifications.
EXAMPLE 11: Biophysical assessment of purified humanized 1C8, 1G1 and 5G8 antibodies
[00445] Samples of humanized antibody variants were subj ected to UPLC-SEC in order to assess species homogeneity following protein-A purification. UPLC-SEC was performed as described in Example 1.
Results
[00446] UPLC-SEC analysis of protein A purified humanized 1C8 antibody variants was reflective of high species homogeneity in the case of variants 28717, 28719, 28720, 28721
(data not shown). UPLC-SEC profiles of all other humanized 1C8 variants (data not shown) reflected good homogeneity, as judged by the presence of small peaks (likely reflective of aggregates) and shoulder to the main peak (possibly reflective of different antibody conformation).
[00447] UPLC-SEC analysis of protein A purified humanized 1G1 antibody variants was reflective of high species homogeneity for variants 28683, 28684, 28685 and 28686. UPLC-SEC profiles of all other humanized 1G1 variants reflected slightly lower homogeneity (data not shown).
[00448] UPLC-SEC analysis of protein A purified humanized 5G8 antibody variants showed good species homogeneity for all variants. UPLC-SEC analysis was repeated for final pools of samples post SEC purification and these samples showed homogeneity in the range of 99.2-100.0 % (data not shown).
EXAMPLE 12: Binding of humanized 1C8, 1G1 and 5G8 antibodies to human 4-1BB by SPR
[00449] To compare the ability of the humanized antibodies to bind human 4-1BB, the affinity of humanized antibodies was compared to the parental chimeric antibodies by Surface Plasmon Resonance (SPR).
[00450] Protein material post protein-A or SEC was assessed for binding to human 4- 1BB. The antigen-binding affinity was determined by SPR as described in Example 2.
Results
[00451] As can be seen from Table 7 (shown in Example 13), SPR binding assay performed on the humanized 1C8 variants revealed that four of the humanized 1C8 antibody variants (v28726, v28727, v28728, v28730) bound h4-1BB with comparable affinity to the parental chimera antibody (variant v20022) and eight variants did not bind h4-1BB. These variants have in common humanized 1C8 heavy chains H5 and H6 in combination with humanized 1C8 light chains LI, L2 or L3. Humanized 1C8 light chains LI and L2 also do not bind 4-1BB when in combination with humanized 1C8 heavy chain H7. These results suggest that back mutations to mouse residues at specific positions incorporated in humanized 1C8 heavy chain H8 as well as into humanized 1C8 light chain L3 are important to maintain CDR conformations such that binding to h4-1BB can be retained. Figure 13 provides SPR
sensorgrams for the parental chimera and representative humanized variants that were able to bind human 4-1BB.
[00452] As can be seen from Table 7, SPR binding assay performed on the humanized 1G1 variants revealed that all humanized 1G1 antibody variants bound h4-1BB with affinity within 2-fold of the KD of the parental chimera antibody (variant v20023). This suggests that the frameworks of humanized 1G1 heavy and light chain without back mutations to mouse residues are sufficient to maintain the CDR conformations necessary for binding to h4-1BB. Figure 14 provides SPR sensorgrams for the parental chimera and representative humanized variants that were able to bind human 4-1BB.
[00453] SPR binding assay performed on the humanized 5G8 variants showed, as can be seen in Table 7 and Figure 15, that seven humanized 5G8 antibody variants (v28700, v28704, v28705, v28706, v28711, v28712, v28713) bound h4-1BB with affinity within 2-fold of the KD of the parental chimera antibody (variant v20036). Seven humanized 5G8 variants bound h4-1BB with 2-3x decreased affinity compared to the KD of the parental chimera antibody (v28696, v28697, v28698, v28701, v28702, v28703, v28707) and two variants did not bind h4-1BB. These two variants have in common humanized light chain L1. The seven 5G8 variants with slightly decreased affinity to 4-1BB have in common humanized heavy chain H1 or H2, or humanized heavy chain H3 or H4 in combination with humanized light chain 1. The results for humanized 5G8 antibody suggest that the back mutations to mouse residues at specific positions incorporated into L2, as well as into H3 are necessary to maintain the required CDR conformations to bind h4-1BB with a KD comparable to the parental chimera variant v20036.
EXAMPLE 13: Comparison of binding of humanized variants by flow cytometry
[00454] To examine binding of antibodies to native cell-surface expressed 4-1BB, a flow cytometry binding assay was carried out as described below.
[00455] Jurkat T cells engineered to stably express human 4-1BB were used to measure binding of antibodies to human 4-1BB. Antibodies were diluted in 50μl FB (PBS 2% FCS) 1:3 from stock in wells of a 96 V-well plate, and cells added on top. The cells were then left on ice for 30 minutes for the antibodies to bind. The cells were then washed twice in FB, and then incubated in 50μl FB containing 2gg/ml goat anti-human Alexa647 antibody (Jackson Immunoresearch). The cells were then left on ice for a further 20 minutes, washed twice in FB,
resuspended in 100μl FB and analysed on a BD Fortessa™ X20. The subsequent data fdes were analysed using FlowJo™ and Prism 7 (GraphPad) using a four-parameter non-linear regression.
Results
[00456] Figure 16A, 16B and 16C depict the ability of the 1 C8, 1 G1 and 5G8 humanized antibodies, respectively, to bind to 4-1BB-expressing Jurkat T cells. Similar to the SPR results, antibodies which derive from the 1C8 paratope bound poorly, including the parental antibody, v20022. The original mouse 1G1 paratope, v20023, bound well to 4-1BB as would be expected from the SPR results. The humanized antibodies based on the 1G1 paratope also bound well, and there was little drop in binding seen as a result of humanization. Similarly, 5G8 antibodies also bound well, with some antibodies displaying greater binding to 4-1BB when compared to the parental mouse-human chimeric antibody v20036.
[00457] The results of the SPR and flow cytometry assays are summarized in Table 7 below.
Table 7: Antigen binding assessment of the humanized antibody variants by SPR


DNB=did not bind ND=not tested
NF=no fit (for 4-parameter nonlinear regression model)
EXAMPLE 14: Thermal stability assessment of humanized antibodies
[00458] In order to fully characterize humanized 1C8, 1G1 and 5G8 variants with affinity to human 4-1BB, the thermal stability of select antibody samples was assessed by differential scanning calorimetry (DSC) as described below.
[00459] The thermal stability of humanized 1C8, 1G1 and 5G8 antibody variants was measured using DSC as follows. 400 μL of purified samples primarily at concentrations of 0.4 mg/mL in PBS were used for DSC analysis with a VP-Capillary DSC (GE Healthcare, Chicago, IL). At the start of each DSC run, 5 buffer blank injections were performed to stabilize the baseline, and a buffer injection was placed before each sample injection for referencing. Each sample was scanned from 20 to 100°C at a 60°C/hr rate, with low feedback, 8 sec filter, 3 or 5 min pre-scan thermostat, and 70 psi nitrogen pressure. The resulting thermograms were referenced and analyzed using Origin 7 software to determine melting temperature (Tm) as an indicator of thermal stability.
Results
[00460] The results are shown in Table 8 below.
Table 8: Thermal stability of humanized antibodies


[00461] As can be seen in Table 8, determined Fab Tm values of select humanized 1C8 antibody variants are ~4-6°C higher compared to the parental mouse chimera v20022. Figure 17 shows the corresponding DSC thermograms of the 1C8 variants that were tested.
[00462] For humanized 1G1 antibody variants, as can be seen from Table 8, determined
Fab Tm values of select variants are 9~11°C higher than the Tm of the parental mouse chimera v20023. Figure 18 shows the corresponding DSC thermograms of the 1G1 variants that were tested.
[00463] For humanized 5G8 antibody variants, as can be seen from Table 8, determined
Fab Tm values of select variants are ~7-9°C higher than the Tm of the parental mouse chimera v20036. Figure 19 shows the corresponding DSC thermograms of the 5G8 variants that were tested.
EXAMPLE 15: Purity assessment of humanized 1C8, 1G1 and 5G8 antibody variants
[00464] The apparent purity of the humanized antibody variants prepared as described in Example 10 was assessed using mass spectrometry after non-denaturating deglycosylation. Samples of humanized variants were prepared and analyzed by LCMS as described in Example 1
Results
[00465] All humanized 1C8, 1G1 and 5G8 antibody variants were of 100% species purity. A representative LC-MS profde for one of the 1C8 humanized antibodies is shown in Figure 20.
EXAMPLE 16: Activation of 4-1BB by humanized antibodies
[00466] To determine if the humanized antibodies retained functionality post- humanization, they were tested in the 4-1BB NF-kB reporter gene assay according to the method described in Example 3.
Results
[00467] As seen in Figure 21A, 1C8 showed a slight drop in potency compared to the parental v20022 antibody, as expected from the slight drop in binding seen in Figure 16A. Similar to the flow cytometric binding in Figure 16B, 1G1 retained functionality, with antibodies showing similar potency to the parental chimeric 4-1BB antibody v20023 (Figure 21B). The humanized antibodies based on 5G8, similar to those based on 1C8, showed a slight decrease in potency compared to the parental antibody (Figure 21C).
EXAMPLE 17: Generation of additional 4-1BB x TAA antibody constructs
[00468] The experiments described in Examples 1-3 identified a format in which 4-1BB x HER2 antibodies were able to cross-link 4-1BB and stimulate downstream 4-1BB signaling and the production of cytokine by T cells. To determine if this effect was specific to HER2 targeting or HER2-expressing tumours or if it can be also transferred to other tumour- associated antigens, 4-1BB x mesothelin (MSLN), 4-1BB x NaPi2b and 4-1BB x FRα antibodies were prepared.
Design of 4- IBB x MSLN, 4- IBB x NaPi2b and 4- IBB x FRa bispecific antibodies
[00469] To allow testing of different tumour-associated antigens, bispecific antibody constructs were prepared in a similar format to the most active 4-1BB x HER2 bispecific constructs with two 4-1BB Fab and one TAA scFv at the C-terminus of the Fc, as shown in Figure 2B. Like the 4-1BB x HER2 bispecific antibody constructs described in Example 1, these bispecific antibody constructs comprised a human IgG1 heterodimeric Fc having CH3 domain amino acid substitutions Het FcA and Het FcB, which drive association of the two component Fc polypeptides. Bispecific antibody constructs noted as “FcKO” included the following CH2 mutations designed to knock out or reduce FcγR binding: L234A, L235A and D265S. Table 9 summarizes the antibody constructs that were prepared and Figure 22 provides a representation of the formats of these antibody constructs. Control constructs 17717 (mirvetuximab), 17449 (farletuzumab), 18490 (RG7787), and 18993 (lifastuzumab) for each TAA paratope are also depicted in Figure 22 and are described in Example 18.
Table 9: Description of 4-1BB x TAA antibodies


[00470] The sequences corresponding to the VH and VL of MOR7480.1 are provided in
Table 15. The sequences of the scFvs used to construct the anti-TAA arm of the antibody constructs are provided in Table 16. Table X identifies the clones that make up each of the antibody constructs. The polypeptide sequences of each clone can be found in Table Y.
Production of 4-1BB x TAA antibodies
[00471] To allow the production of bispecific antibodies, constructs were made in a similar manner to Example 1.
Production and purification of bispecific antibodies
Antibodies were produced by transfecting CHO-2E7 cells, and purified using Protein A and prep-SEC, as described in Example 1. After purification, the antibodies were checked for purity and lack of aggregation using LC/MS and UPLC-SEC.
EXAMPLE 18: Quantification of surface TAA protein on tumor cells
[00472] To determine what threshold of TAA expression is required on the tumour in order to stimulate 4-1BB signaling in T cells, the levels of mesothelin (MSLN), NaPi2b and FRα surface protein were measured in several tumour cell lines. This was achieved using quantitative flow cytometry using a set of beads with known levels of antibody bound as described below.
[00473] IGROV1, OVCAR3, H441, H661, H226, H1975 and A549 tumor cells were cultured in RPMI 10% FCS in 10cm3 plates. These cell lines were chosen due to RNA data
suggesting that they would be a representative set of Ovarian and Lung cell lines expressing high, medium or low MSLN, NaPi2b and FRα. Cell dissociation buffer (Invitrogen) was added, and cells removed from the plate with mechanical means if necessary, using either a pipette or a cell scraper. Cells were left on ice with a pre-determined excess level of conjugated antibody, to ensure that the cells in the suspension are completely labelled. A series of beads with pre- determined levels of anti -human coating antibody were used as standards (816; Bangs Laboratories). Numbers of receptor per cell were calculated by comparing the level of AlexaFluor647 fluorescence on the tumour cells to a standard curve constructed using the calibration beads.
[00474] For conjugation with Alexa Fluor 647, antibodies were buffer exchanged into sodium bicarbonate buffer pH 8.4 using 40kDa Zeba columns. An aliquot of each of the buffer exchanged material was then reacted with 10eq. of NHS -Alexa Fluor 647 (Thermofisher A20006, 10mM). Each reaction was allowed to proceed protected from light at room temperature for 90 minutes. Following incubation, each reaction was then purified using a 40kDa Zeba column, pre-equilibrated with PBS pH7.4. Conjugation was confirmed by SEC chromatography (Ex: 650nm, Em: 665nm). SEC analysis also estimated the amount of unpurified NHS -Alexa Fluor 647.

Results
[00475] Table 10 provides the results of surface TAA quantification and identifies tumour cell lines with high, medium and low expression of TAAs MSLN, FRα and NaPi2b.
Table 10: Surface TAA quantification on tumor cell lines


EXAMPLE 19: Ability of 4-1BB x TAA bispecific antibody constructs to stimulate 4- 1BB activity
[00476] To test the ability of bispecific 4-1BB x MSLN, 4-1BB x NaPi2b and 4-1BB x FRα antibodies to stimulate 4-1BB activity in the presence of a tumor cell, a co-culture reporter gene assay was employed.
4-1BB NF-kB-Luciferase reporter assay
[00477] This experiment was undertaken similarly to the experiment in Example 3, except either H226, H661, H441, H1975, IGROV1, H1299 or A549 tumour cells were used. Briefly, NFκB-1UC2P/4-1BB Jurkat cells were mixed with tumour cells in CD3-coated plates and left for 5 hours. The production of luciferase was then measured using Bio-Glo™ substrate. Data was analyzed using Prism 7 (GraphPad) and four-parameter variable slope nonlinear fit.
Results
[00478] The results are shown in Figures 23A and 23B. 4-1BB x MSLN antibodies showed activity on H226 cells, but not A549 cells. v12592, which is a similar format antibody to the bispecific antibody construct but without the C-terminal anti-TAA scFv, does not show activity in this experiment on any of the cell lines, suggesting that crosslinking via the TAA may be necessary in order to function.
[00479] Figure 24 shows the activity of the 4-1BB x FRα antibody v22638 on 4-1BB reporter cells in co-culture with a series of tumour lines representing a range of expression. When the 4-1BB reporter cells were cultured in presence of v22638 and tumour cells with greater than -150,000 FRα proteins per cell (IGROV1, H441, H661) an activation of the reporter genes was seen. In co-culture with tumour cells with lower levels of FRα, such as the H1299 cells, no activation of 4-1BB was seen. The ability of 4-1BB x FRα construct v22638 to stimulate 4-1BB activity appeared to be dependent on the level of FRα expression by tumour
cells in this co-culture experiment. v22638 showed activity on FRαhigh IGROV1 cells and FRαmid H441 and H661 cells but did not show activity on FRαlow A549 or H1975 cells.
Primary T cell-Tumour co-culture assay
[00480] Similar to Example 5, CD8+ T cells were cultured with IGROV1, OVCAR3, H441, H661, H226, H1975 or A549 tumor cells and aAPC/CHO-K1 cells. After four days, supernatants were taken and IFNγ measured by HTRF. GraphPad Prism v7 was used for data analysis, using the non-linear four-parameter model.
Results
[00481] Similar to the results seen with the reporter gene assay, bispecific antibodies induced cytokine production by T cells when in co-culture with tumour cells expressing the cross-linking tumour antigen. The 4-1BB x MSLN antibody v22630 induced IFNγ production by T cells when co-cultured with H226 cells which express high levels of MSLN, but not other tumour cells which express <300,000 MSLN molecules/cell (Figure 25B). v22638, which is a bispecific antibody targeting 4-1BB and FRα shows activity on T cells in co-culture with IGROV1, OVCAR3 and H441 cells, suggesting a similar cut-off for expression of -200,000 FRα molecules/cell (Figure 25C). The NaPi2b x 4-1BB antibody construct v22345 was able to enhance IFNγ production by T cells co-cultured with NaPi2bhigh IGROV1 or OVCAR3 cells and NaPi2bmid H441 cells, but not NaPi2bmid-low H661, H226, A549 or H1975 cells. This suggests that a cut-off of -200,000-300,000 NaPi2b molecules/cell is required for function in vitro (Figure 25 A). No effect of v12592, the parental 4-1BB antibody without a TAA cross- linking arm, was seen on the T cells in co-culture with any of the tumour cell lines, suggesting that cross-linking via the TAA arm was absolutely required for activity (Figure 25D).
EXAMPLE 20: Preparation of Additional 4-1BB x FRα antibodies
[00482] Additional 4-1BB x FRα antibody constructs (antibodies) were prepared according to the methods described in Example 1. Table 11 describes the compositions of these additional 4-1BB x FRα antibodies, while Figure 26 provides a representation of the formats of exemplary antibodies. These 4-1BB x FRα antibody constructs were constructed using a subset of the mouse anti-4-1BB paratopes described in Example 7 that were shown to be agonistic to 4-1BB, and the anti-FRα paratopes mirvetuximab, rabbit paratope 1H06, and
rabbit paratope 8K22. FRα paratopes 1H06 and 8K22 are novel rabbit anti-FRα paratopes generated as described in Example 23.
Table 11: Composition of 4-1BB x FRa antibodies

[00483] Table X identifies the clones that make up each of the antibody constructs. The polypeptide sequences of each clone can be found in Table Y.
[00484] The expressed and purified antibodies were then tested as described in Examples 21 and 22.
EXAMPLE 21: Characterization of 4-1BB x FRα antibody constructs binding to 4-1BB and FRα
[00485] To test the ability of the 4-1BB x FRα antibody constructs produced in Example 20 to bind 4-1BB, the affinity of these constructs for human 4-1BB was measured by SPR and by flow cytometry.
SPR
[00486] Variants purified by SEC were assessed for binding to human 4-1BB. The antigen-binding affinity was determined by SPR according to the method described in Example 2. A summary of the SPR binding data is provided in Table 12.
Table 12: Binding data for 4-1BB x FRa bispecific antibodies

[00487] All of the 4-1BB x FRα antibodies tested showed binding to 4-1BB, and had a KD representing affinity that was between approximately 20-100 fold lower than the control anti-4-1BB antibody MOR7480.1 (v12592) as measured by SPR.
Binding of 4-1BB x FRa antibody constructs to 4-lBB-expressing Jurkat T cells by flow cytometry
[00488] To examine binding of these antibodies to native cell surface-expressed 4-1BB, a flow cytometry binding assay was carried out.
[00489] Jurkat T cells engineered to stably express human 4-1BB were used to measure binding of antibodies to human 4-1BB. Antibodies were diluted in 50μl FB (PBS 2% FCS) 1:3 from stock in wells of a 96 V-well plate, and cells added on top. The cells were then left on ice for 30 minutes for the antibodies to bind. The cells were then washed twice in FB, and incubated in 50μl FB containing 2μg/ml goat anti-human Alexa647 antibody (Jackson Immunoresearch). The cells were then left on ice for a further 20 minutes, washed twice in FB, resuspended in 100μl FB and analysed on a BD Fortessa™ X20. The subsequent data fries were analysed using FlowJo™ and Prism™ 7 (GraphPad) using a four-parameter non-linear regression.
Results
[00490] All variants except v23663 showed binding. Similar to the SPR results, the antibodies tested in this experiment showed lower affinity compared to v12592 (Figure 27A to 27F). Figure 27F shows the results for the control variant 22638, a 4-1BB x FRα bispecific antibody with MOR7480.1 (4-1BB) and mirvetuximab (FRα) paratopes.
Binding of 4-1BB x FRa antibody constructs to FRa expressed on 293E cells by flow cytometry
[00491] To examine binding of antibodies to FRα expressed on the cell surface, 293E cells were transiently transfected with full-length FRα (SEQ ID NO: 80). Antibodies were diluted in 50μl FB (PBS 2% FCS) 1:3 from stock in wells of a 96 V-well plate, and cells added on top. The cells were then left on ice for 30 minutes for the antibodies to bind. The cells were then washed twice in FB, and incubated in 50 μl FB containing 2μg/ml goat anti-human Alexa647 antibody (Jackson Immunoresearch). The cells were then left on ice for a further 20 minutes, washed twice in FB, resuspended in 100μl FB and analyzed on a BD Fortessa™ X20. The subsequent data files were analyzed using FlowJo™ and Prism 7 (GraphPad).
The results are shown in Figure 28 and demonstrate that all antibodies showed binding to FRα. Sample containing the 8K22 scFv (Figure 28A) showed higher binding than the 1H06 scFv (Figure 28B), suggesting that it is of higher affinity as an scFv. Antibodies containing a mirvetuximab scFv (Figure 28C) showed intermediate binding between 8K22 and 1H06, suggesting that its affinity is between the two.
EXAMPLE 22: Activation of T cells by 4-1BB x FRα bispecific antibodies
[00492] After confirmation of binding of 4-1BB x FRα antibodies to both 4-1BB and FRα, the bispecific antibodies were examined in a primary T cell activity assay. The experiment looked at the ability of 4-1BB to stimulate the production of IFNγ by T cells in the culture. Co-culture of T cells with tumour cells allowed the investigation of crosslinking of the 4-1BB antibodies by TAA on tumour cells. IGROV1 cells were chosen due to their high expression of FRα, and A549 for low expression of FRα.
[00493] The method used was similar to that used in Example 5. Bispecific antibodies, CD8+ T cells and either IGROV1 or A549 tumour cells were cultured together with aAPC/CHO-K1 cells. After four days, supernatants were taken and IFNγ measured by HTRF.
Results
[00494] All 4-1BB x FRα antibodies stimulated IFNγ production by T cells when in co- culture with FRαhigh IGROV1 cells (Figure 29A and 29B). In culture with FRαlow A549 cells, there was no effect of the 4-1BB x FRα antibodies seen on the T cells, suggesting that this cell line may not express FRα at a level sufficient for the 4-1BB x FRα antibodies to stimulate IFNγ production by T cells. In the absence of a tumour-targeting arm, 4-1BB monospecific antibodies v12592, v20022 and v20036 could not stimulate cytokine production when in culture with IGROV1 or A549 cells (Figure 29C). v22368 acted as a positive control and comparator.
[00495] It was also found that 4-1BB antibody affinity did not affect the response of the T cells in this experiment. The difference in activity between the antibodies may be due to the difference in binding between the 1H06 and 8K22 scFvs (8K22 demonstrated greater binding to FRα by flow cytometry than did 1H06, and also showed greater activity in stimulating IFNγ production).
EXAMPLE 23: Generation of rabbit antibodies that bind human FRα
[00496] Antibodies to Folate receptor alpha (FRα) were raised in rabbits immunized with soluble HIS tagged human folate receptor 1 antigen (FRα-HIS, AcroBiosy stems Cat# F01-H82E2). The 8K22 and 1H06 paratopes described in Example 20 were identified by the method described here.
[00497] Briefly, New Zealand white rabbits were given a primary injection followed by 4 additional boosts of the FRα-HIS antigen mixed with adjuvant. Each of the boosts were separated by 14 days. Anti human FRα antibodies titers were determined by FACs using transiently expressing human FRα CHO cells to choose which animal to harvest for B cells.
Recovery of B cells and discovery of anti-human FRa antibodies by SLAM:
[00498] Immunized rabbits with desired titers about 100,000 were sacrificed, and the spleens harvested. The lymphoid cells were dissociated by grinding in FACs buffer (PBS 2% FBS) to release the cells from the tissues. The cells were pelleted and then suspended for 1 min in 5 ml of BD Pharm Lyse to lyse red blood cells. Equal volume of FACs buffer was added to neutralize the Pharm Lyse and the resultant lymphocyte sample was pelleted and suspended in FACs buffer.
[00499] The lymphocyte suspension was then stained with anti -rabbit IgG Alexa-Fluor 647 to identify IgG+ B cells. After 30 min of staining, IgG+ B cells were sorted on a FACS Aria (BD Biosciences) and counted. Using the Selected Lymphocyte Antibody Method (SLAM) (Proc Natl Acad Sci U S A. 1996 Jul 23; 93(15): 7843-7848. John Babcook et al), B cells were plated at different densities ranging from single cell up to 50 cells in a 384 well plate, expanded in culture for 7 days and the supernatants harvested to detect for anti-human FRα antibodies. The 384 well plates were frozen down in a -80 C freezer.
[00500] Supernatants were screened for human FRα specific monoclonal antibodies by ELISA. 384 well ELISA plates were coated with 25μL/well of human FRα-HIS (2μg/mL) in PBS, then incubated at 4°C overnight. After incubation, the plates were washed with water 2 times. 90μL/well Blocking Buffer (2% skim milk, PBS) were added and the plates incubated at room temperature for 1 hour. After incubation, the plates were washed and 12.5μL/well of antibody containing supernatants + 12.5 μl Blocking Buffer, and positive and negative controls were added and the plates incubated at room temperature for 2 hours.
[00501] After incubation, the plates were washed, 25 μl of 0.4 ug/ml goat anti-rabbit IgG Fc-HRP detection antibody was added to each well and the plates were incubated at room temperature for 1 hour. After the incubation, the plates were washed and 25 μl of TMB were added and the plates allowed to develop for about 10 minutes (until negative control wells barely started to show color). Then 25 μl stop solution (IN HCL) were added to each well and the plates read on an ELISA plate reader at wavelength 450nm.
Sequencing of anti-human FRa monoclonal antibodies:
[00502] Wells containing antibodies of desired characteristics were treated with RNA lysis buffer (Qiagen RNeasy) for molecular rescue of antibody heavy and light chains. Initial PCR of heavy and light chain antibody-coding sequences was performed using primers and methods modified from Babcook et al. (Proc Natl Acad Sci USA 1996 Jul 23; 93(15): 7843) and von Boehmer et al. (Nat Protoc. 2016 Oct; 11(10): 1908), with cDNA as the nucleic acid template. PCR products were cloned into the pCRTOP04 vector using the Zero Blunt™ TOPO™ PCR Cloning kit (Thermofisher Scientific) and transformed into E. cloni™ cells (Lucigen). Antibiotic-resistant clones were sequenced and analyzed for unique antibody- coding sequences.
[00503] A nested PCR reaction was then performed on these unique sequences using V- segment family and J-segment family-specific primers. The resulting amplicons were then cloned into pTT5-based expression plasmids (National Research Council of Canada). Unique heavy chain sequences and light chain sequences emerging from a single well sample were co- expressed in HEK293-6E cells (National Research Council of Canada) in all possible combinations to determine the correct heavy and light chain pairing. Antibodies produced were assayed for binding to antigen that was transiently expressed on HEK293 cells.
EXAMPLE 24: Humanization of rabbit 8K22 VH and VL Sequences
[00504] A rabbit anti-human folate receptor alpha (anti-hFRα) antibody, 8K22, which was generated as described in Example 23, was humanized as described below.
[00505] Sequence alignment of rabbit 8K22 VH and VL sequences to respective human germline sequences identified IGHV3-66*01 and IGKVI-39*01 as the closest, as well as frequent, human germline sequences. CDRs according to the AbM definition (<https://www.bioinf.org.Uk/abs/#cdrdef>) were ported onto the framework of these selected human germline sequences as shown in Figure 40. Back mutations to rabbit residues in the resultant sequences at positions judged likely to be important for the retention of binding affinity to antigen, hFRα, were included creating several humanized sequences in which generated sequences for the most part built on the previous sequence, and where the first humanized sequence (H1 and L1, Table 19) contained the minimal number of back mutations. None of the variants modified the CDRs of the 8K22 antibody as defined by the AbM method.
[00506] This process provided five variable heavy chain humanized sequences and five variable light chain humanized sequences. Full heavy chain sequences containing humanized heavy chain variable domain (VH) and hlgG1 heavy chain constant domains (CH1, hinge, CH2, CH3), and full light chain sequence containing humanized light chain variable domain (VL) and human kappa light chain constant domain (kappa CL) were assembled. Monoclonal antibody (mAh) variants were then assembled such that each of the humanized heavy chains was paired with each of the humanized light chains, providing a total of twenty-five humanized variants to be evaluated experimentally (Table 19).
EXAMPLE 25: Humanized 8K22 Antibody Production
[00507] The humanized 8K22 antibodies described in Example 24 and Table 19 were prepared as follows.
[00508] Each of the humanized 8K22 constructs, as well as the parental 8K22 construct, were in the naturally occurring or FSA format, containing two identical full-length heavy chains and two identical kappa light chains. The amino acid sequences of each of the antibody variable heavy chains and variable light chains are provided in Table 20. Each of the humanized VH domain sequences (SEQ ID NOs: 307, 308, 309, 310 and 312) was appended to the human CH1-hinge-CH2-CH3 domain sequence of IGHG1*01 (SEQ ID NO: 318) to provide five humanized 8K22 full heavy chain sequences. Each of the humanized VL domain sequences (SEQ ID NOs: 313, 314, 315, 316 and 317) was appended to the human kappa CL sequence of IGKC*01 (SEQ ID NO:67) to provide five humanized 8K22 light chain sequences. In a similar manner, 8K22 rabbit-human parental antibody chimera heavy and light chain sequences were assembled, with the difference that variable domain sequences were rabbit (SEQ ID NOs:298 (VH) and 299 (VL)) and constant domain sequences were human (SEQ ID NOs: 318 (CH1- hinge-CH2-CH3 chain) and 67 (CL sequence of IGKC*01)). These sequences were reverse translated to DNA, codon optimized for mammalian expression and gene synthesized. The humanized VH and VL sequences are provided in Table 20.
[00509] Heavy chain vector inserts comprising a signal peptide (artificially designed sequence: MRPTWAWWLFLVLLLALWAPARG (SEQ ID NO:l) (Barash et al, (2002), Biochem and Biophys Res. Comm., 294:835-842)) and the heavy chain clone terminating at G446 (EU numbering) of CH3 were ligated into a pTT5 vector to produce heavy chain expression vectors. Light chain vector inserts comprising the same signal peptide were ligated into a pTT5 vector to produce light chain expression vectors. The resulting heavy and light chain expression vectors were sequenced to confirm correct reading frame and sequence of the coding DNA.
[00510] The heavy and light chains of the antibody variants were expressed in 400 ml cultures of CHO-3E7 cells. Briefly, CHO-3E7 cells, at a density of 1.7-2 x 106 cells /ml, viability >95%, were cultured at 37°C in FreeStyle™ F17 medium (ThermoFisher, Watham, MA) supplemented with 4 mM glutamine (GE Life Sciences, Marlborogh, MA) and 0.1% Pluronic® F-68 (Gibco, Life Technologies). A total volume of 400ml was transfected with a total of 400ug DNA (200ug of antibody DNA and 200ug of GFP/AKT/stuffer DNA) using PEI-max (Polyscience, Philadelphia, PA) at a DNA:PEI ratio of 1 :4 (W/W). Twenty -four hours after the addition of the DNA-PEI mixture, 0.5mM valproic acid (final concentration) + 1% w/v Tryptone (final concentration) + 1x antibiotic/antimycotics (GE Life Sciences,
Marlborogh, MA) were added to the cells, which were then transferred to 32°C and incubated for 9 days prior to harvesting. The parental 8K22 rabbit-human antibody chimera was expressed in a similar manner in a 1L culture.
[00511] Clarified supernatant samples were incubated in batch with mAb Select SuRe resin (GE Healthcare, Chicago, IL) cleaned-in-place (CIP’d) with NaOH and equilibrated in Dulbecco’s PBS (DPBS). Resin was poured into CIP’d columns, the columns were washed with DPBS and protein eluted with 100 mM sodium citrate buffer pH 3.0. The eluted fractions were pH adjusted by adding 10% (v/v) 1M HEPES pH 8 to yield a final pH of 6-7. Samples were buffer exchanged into PBS and aseptically filtered. Protein was quantitated based on absorbance at 280nm (A280 nm) (in instances where precipitation was present upon sample neutralization, these samples were centrifuged briefly prior to A280nm measurements). Endotoxin levels were determined using the Endosafe® Portable system (Charles River, Wilmington, MA). Samples having endotoxin above 0.2 EU/mg underwent endotoxin removal with the NoEndo™ Spin columns (Viva Products Inc., Littleton, MA). Parental 8K22 rabbit- human antibody chimera variant was further purified by preparatory SEC chromatography (Superdex 20026/60) in DPBS mobile phase following protein-A purification.
[00512] Following purification, purity of samples was assessed by non-reducing and reducing High Throughput Protein Express assay using Caliper LabChip® GXII (Perkin
E1mer, Waltham, MA). Procedures were carried out according to HT Protein Express LabChip® User Guide version 2 with the following modifications. Antibody samples, at either 2pl or 5μl (concentration range 5-2000 ng/μl), were added to separate wells in 96 well plates (BioRad, Hercules, CA) along with 7μl of HT Protein Express Sample Buffer (Perkin E1mer # 760328). Antibody samples were then denatured at 70°C for 15 mins. The LabChip® instrument was operated using the HT Protein Express Chip (Perkin E1mer, Waltham, MA) and the Ab-200 assay sehing.
Results
[00513] Yield post protein-A purification across the twenty-five humanized 8K22 antibody variants ranged from ~ 10-30 mg (or -25-75 mg/L). Figure 30B and 30D shows the Caliper result for the parental chimeric antibody v23820 and a representative humanized variant, v23807. As shown in Figure 30D, on a representative humanized antibody sample, non-reducing (NR) and reducing (R) Caliper reflected a single species corresponding to full-
size antibody and intact heavy and light chains, which was the case with all humanized variants. Small levels of precipitation were observed upon sample neutralization following protein-A elution, for the following variants: 23804, 2805, 23807, 23808, 23814, 23816, 23817, 23818, including the parental chimera, v23820. Comparison with protein samples of similar titers that did not result in any precipitation, suggested that levels of precipitation observed were relatively negligible, since the resulting yields for these two types of samples were comparable. Some of the humanized 8K22 antibody samples required endotoxin removal following protein - A purification. Endotoxin removal was carried out for two out of twenty-five humanized 8K22 antibody samples and resulted in successful reduction of endotoxin levels to the necessary specifications.
EXAMPLE 26: Quality Assessment of Purified Humanized 8K22 Antibodies
[00514] Samples of humanized 8K22 antibody variants were subjected to UPLC-SEC in order to assess species homogeneity following protein-A purification or following preparatory SEC purification in the case of parental chimera antibody, v23820.
[00515] UPLC-SEC was performed using a Waters Acquity BEH200 SEC column (2.5 mL, 4.6 x 150 mm, stainless steel, 1.7 μm particles) (Waters LTD, Mississauga, ON) set to 30°C and mounted on a Waters Acquity UPLC H-Class Bio system with a photodiode array (PDA) detector. Run times consisted of 7 min and a total volume per injection of 2.8 mL with a running buffer of DPBS with 0.02% Tween 20 pH 7.4 at 0.4 ml/min. E1ution was monitored by UV absorbance in the range 210-500 nm, and chromatograms were extracted at 280 nm. Peak integration was performed using Waters Empower 3 software.
Results
[00516] As shown in Figures 30A (for the parental chimera v23820) and 30C (for a representative humanized antibody), UPLC-SEC profile for the representative humanized antibody sample reflected high species homogeneity, comparable to the purified parental chimera antibody sample. The parental chimera contained higher molecular weight species following protein-A purification (not shown), which were removed by preparatory SEC. The rest of the humanized 8K22 antibody samples had similar profiles to those of the representative humanized antibody sample.
EXAMPLE 27: Affinity Assessment of Humanized 8K22 Antibodies for hFRα
[00517] To determine whether the humanization process affected the affinity of the humanized variants for their target, the ability of the humanized 8K22 antibody variants to bind the hFRα antigen was assessed by Bio-layer interferometry (BLI).
[00518] Supernatant material post-harvest was screened for binding to the hFRα, followed by the binding assay repeat on the purified antibody samples for selected variants.
[00519] Antigen binding was assessed using the Octet RED96 system by cycling through the following steps: loading of antibodies (0.9 μg/mL) onto AHC biosensors over 200s; stabilization of baseline for 60s; association to recombinant His-tagged human FRα (Acrobiosystem) at multiple relevant concentrations spanning the expected KD for 500s; dissociation was recorded for 1200 s; and regeneration was performed by cycling 3 times between 10 mM glycine pH 1.5 (15 s) and the assay buffer (15 s) before proceeding to the next antibody. The assay buffer used was KB buffer (kinetics buffer, composed of PBS pH 7.4, 0.1% BSA, 0.02 % Tween 20, 0.05% sodium azide) supplemented with 0.06% Tween 20. The experiment was conducted at 25°C with a shake speed of 1000 rpm.
[00520] Data analysis was performed using the ‘Data analysis software 9.0’ (ForteBio). The reference-subtracted binding curves were globally fitted to the 1:1 interaction model to generate the binding kinetic parameters kon, koff, and the dissociation constant KD.
Results
[00521] The results are shown in Table 21 and Figure 31. Figure 31A shows the BLI sensorgrams for the parental chimeric antibody v23820, and two representative humanized antibodies, v23801 and v23807 using supernatants. Figure 31B shows the BLI sensorgrams for the parental chimeric antibody v23820, and two representative humanized antibodies, v23801 and v23807 using purified antibodies. Screening of antibody supernatants for binding to hFRα distinguished a top group (Group A) of humanized 8K22 antibody variants (variants 23798, 23804, 23806, 23807, 23809, 23814, 23816 and 23817) with minor reduction in affinity, within ~2-fold, compared to that of the parental chimera antibody. Obtained KD values ranged from ~ 14 nM to 9.3nM, with KD of the parental chimera antibody (variant 23820) determined to be 5.9 nM. The majority of the humanized 8K22 antibody variants were characterized by greater than 2-fold and up to 4-fold reduced affinity compared to that of the
parental chimera mAh; these are referred to as Group B variants. Variants 23795, 23800, 23810, 23803 and 23813 exhibited a further decrease in affinity, ~5-6 fold compared to the parental chimera mAh; these variants are referred to as Group C variants. Differences in determined KD values between humanized 8K22 antibody variants primarily stemmed from differences in Koff values.
[00522] BLI binding assay on purified antibody samples was consequently performed for the variants that exhibited up to ~4-fold reduction in affinity as determined in the assay performed on the supernatant material. Absolute KD values obtained in this assay, performed on purified material, were systematically lower than those obtained in the assay performed on the supernatant material, due to higher Kon values ( koff values were largely comparable to those obtained in the assay performed on the supernatant material), however the relative ranking of 8K22 humanized variants was very similar. Differences in the placement within Groups A, B and C were observed for variants 23809 and 23816 (from Group A to Group B), as well as for the variants 23794 and 23818 (from Group B to Group A).
[00523] Variants 23804, 23806, 23807, 23814 and 23817 emerged as the top tier performing variants, with respect to the retention of the affinity to hFRα within 2-fold upon humanization, as determined by both binding assays, performed on supernatant and purified sample material. These variants have L3 or L5 humanized light chains in common, which differ from the rest of the three humanized light chains by the presence of the two amino acid back substitutions to rabbit residues in the FR loop. Data obtained in these binding assays suggests that these two particular amino acid residues are important for retaining parental chimera-like antigen binding affinity in humanized variants. Secondary determinants of the top tier antibody variants that emerged are the presence of H1 or H4 humanized heavy chains.
EXAMPLE 28: Thermal Stability Assessment of Humanized 8K22 Antibodies
[00524] The thermal stability of humanized 8K22 antibody variants was assessed by differential scanning calorimetry (DSC) as described below.
[00525] 400 μL of purified samples primarily at concentrations of 0.4 mg/mL in PBS were used for DSC analysis with a VP-Capillary DSC (GE Healthcare, Chicago, IL). At the start of each DSC run, 5 buffer blank injections were performed to stabilize the baseline, and a buffer injection was placed before each sample injection for referencing. Each sample was scanned from 20 °C to 100°C at a 60° C/hr rate, with low feedback, 8 sec filter, 3 min pre-scan
thermostat, and 70 psi nitrogen pressure. The resulting thermograms were referenced and analyzed using Origin 7 software (OriginLab Corporation, Northampton, MA) to determine melting temperature (Tm) as an indicator of thermal stability.
Results
[00526] Fab Tm values were determined for the humanized 8K22 antibody variants that exhibited lower than ~5-6-fold reduction in antigen affinity compared to the parental chimera antibody. Determined Fab Tm values for the characterized humanized variants, were comparable or up to 10°C higher than that of the parental chimera antibody, ranging from ~70°C to ~81.0°C (Table 22). As can be seen in Table 22 and Figure 32 (thermograms of representative variants), aside from commonly observed single transition profiles (Figure 32A) humanized 8K22 antibody variants (variants 23796, 23798, 23801 and 23818) exhibited two- state transition profiles (Figure 32B) and some exhibited weakly pronounced two-state transition profiles (variants 23802, 23814, 23815, 23816, 23817) (Figure 32B). Whereas such profiles are not generally characteristic of kappa Fabs, they are sometimes observed and are likely reflective of uncooperative melting of Fab domain, i.e. constant and variable domains unfolding separately.
[00527] Humanized variants with the lowest determined Fab Tm values have in common presence of the two amino acid back substitutions to rabbit residues in the FR loop of the humanized light chain, whereas the variants with the highest Tm values have in common the amino acid back substitution to rabbit residue at a position in the variable domain of the humanized light chain that is in contact with the constant domain of that chain. No particular trends were identified in terms of the particular heavy and light chain composition of the variants that could explain the differences in the transition profiles (single or two-state) observed between some of the variants.
EXAMPLE 29: Purity Assessment of Humanized 8K22 Antibodies
[00528] The apparent purity of the antibody variants was assessed using mass spectrometry after protein A purification (Example 25) and non-denaturating deglycosylation.
[00529] As the antibody variant samples contained Fc N-linked glycans only, the samples were treated with only one enzyme, N-glycosidase F (PNGase-F). The purified samples were de-glycosylated with PNGaseF as follows: 0.1U PNGaseF/μg of antibody in
50mM Tris-HCl pH 7.0, overnight incubation at 37°C, final protein concentration of 0.48 mg/mL. After deglycosylation, the samples were stored at 4°C prior to LC-MS analysis.
[00530] The deglycosylated protein samples were analyzed by intact LC-MS using an Agilent 1100 HPLC system coupled to an LTQ-Orbitrap™ XL mass spectrometer (ThermoFisher, Waltham, MA) (tuned for optimal detection of larger proteins (>50kDa)) via an Ion Max electrospray source. The samples were injected onto a 2.1 x 30 mm Poros R2 reverse phase column (Applied Biosystems) and resolved using a 0.1% formic acid aq/acetonitrile (degassed) linear gradient consisting of increasing concentration (20-90%) of acetonitrile. The column was heated to 82.5°C and solvents were heated pre-column to 80°C to improve protein peak shape. The cone voltage (source fragmentation setting) was approximately 40 V, the FT resolution setting was 7,500 and the scan range was m/z 400-4,000. The LC-MS system was evaluated for IgG sample analysis using a deglycosylated IgG standard (Waters IgG standard) as well as a deglycosylated mAh standard mix (25:75 half full sized mAh). For each LC-MS analysis, the mass spectra acquired across the antibody peak (typically 3.6-4.3 minutes) were summed and the entire multiply charged ion envelope (m/z 1,400-4,000) was deconvoluted into a molecular weight profile using the MaxEnt 1 module of MassLynx, the instrument control and data analysis software (Waters, Milford, MA). The apparent amount of each antibody species in each sample was determined from peak heights in the resulting molecular weight profiles.
Results
[00531] All characterized humanized 8K22 antibody variants were of 100% species purity, exemplified by the LC/MS profile of the two representative humanized antibody samples in Figure 33. Figure 33A depicts the LC/MS profile for v23801, while Figure 33B depicts the LC/MS profile for v23807. In LC/MS profiles of all samples, a peak at ~+422Da was present. This peak also was observed in the standard sample run, suggesting it may be a system contaminant and not a sample contaminant.
EXAMPLE 30: Conversion of Fab 8K22 to scFv
[00532] The VH and VL sequences of the humanized anti -human folate receptor alpha (anti-hFRα) antibody 8K22 variant 23807 (H4L3), described in Examples 24 and 25, was converted from Fab format to scFv format as described below. This was done to facilitate the
production of anti-4-1BB x anti-FRα bispecific antibodies in the 2 x 1 format described in Example 1 and Figure 2B.
Design of 8K22 scFvs
[00533] A number of 8K22 scFvs were designed in which the order of the VH and VL domains was varied, the length of the linker between the two domains was varied, or the effect of including a stabilizing disulfide bridge was assessed. The 8K22 scFvs were prepared and tested in one-armed antibody format as described in Example 1 and Figure 1C. For most designs, the 8K22 scFvs were fused to the C-terminus of the Fc, but in some cases the 8K22 scFvs were fused to the N-terminus of the Fc. A summary of the 8K22 scFvs designed is found in Table 23. The sequences for the 8K22 scFv portion of each variant is found in Table 27 in Example 32.
Table 23: scFv conversion

[00534] In more detail, humanized 8K22 variable light (VL) and variable heavy (VH) domains were converted to an scFv as follows: The VL (SEQ ID NO: 316) and VH (SEQ ID NO: 310) amino acid sequences were generated according to Kabat definitions. The VL and VH sequences were combined as a single sequence separated by a short linker sequence. The
linker sequence was either (G4S)3 (short, GGGGS GGGGS GGGGS , SEQ ID NO:320) or (G4S)4 (long, GGGGS GGGGS GGGGS GGGGS , SEQ ID NO:321). The order of the domains was either VL-linker-VH or VH-linker-VL (see “Orientation” column in Table 23) where VL- VH indicates the VL sequence precedes the VH sequence and is connected by a short linker. VH-VL indicates the VH sequence precedes the VL sequence and is connected by a short linker. A stabilization disulfide between the VL and VH was introduced in some variants at position VL - G100C and VH - G44C according to the Kabat numbering system. This is denoted in Table 23 under the Disulfide column with Yes. The scFv designs used are described in table 23. For example, v29683 - C-term VH-(short)-VL + disulphide is fused to the C- terminus of the Fc by the VH domain, followed by a (G4S)3 linker, and VL domain. The VH and VL domain contain a disulfide bond at VL - G100C and VH - G44C. The variants were constructed in a One-armed format generated using the heterodimeric Fc design described in Example 17.
[00535] Each of the 8K22 scFv sequences described in Table 23 were fused to an Fc sequence having the Het FcA mutations, as described in Example 17, at either the N-terminus or C-terminus. If fused to the N-terminus of Het FcA a short Ala-Ala linker was included between the scFv and the hinge of Het FcA. If fused to the C-terminus of the Het FcA a short Gly-Gly-Gly-Gly (SEQ ID NO:336) linker was included between the Het FcA and the scFv. In all constructs the cysteine located in the upper hinge at position Kabat: 233 was mutated to SER. These sequences were reverse translated to DNA, codon optimized for mammalian expression, and gene synthesized.
[00536] All parent (humanized 8K22) and scFv converted sequences were preceded by the artificially designed signal peptide sequence MRPTWAWWLFLVLLLALWAPARG [SEQ ID NO:l] (ref: Barash S et al., Biochem and Biophys Res. Comm. 2002; 294, 835-842). For all parental and scFv converted chains, vector inserts were prepared as described in Example 1 and cloned into the pTT5 expression vector.
EXAMPLE 31: Production of Fc-fused 8K22 scFv variants
[00537] Variants described in Example 30 were prepared under transient mammalian expression conditions and subsequently purified and characterized for stability and antigen binding. Samples of Fc-fused 8K22 scFv variants post protein-A were subjected to UPLC-SEC to assess the amount of high molecular species. Further, thermal stability of 8K22 scFv in Fc-
fused 8K22 scFv variants was assessed by differential scanning calorimetry (DSC) as described below. This was performed to identify the optimal design for an 8K22 scFv.
Method
[00538] The two different heavy chains in Fc-fused scFv variants and heavy and light chains in Fab containing (29675 and 29686) antibody variants were co-expressed in 200 mL CHO cultures and purified as described in Example 1. Following protein-A purification, purity of samples was assessed by non-reducing and reducing High Throughput Protein Express assay (LabChip) as described in Example 1.
[00539] Post protein-A purification, samples were either buffer exchanged into DPBS (Dulbecco’s PBS) and aseptically filtered or, depending on their homogeneity assessed by UPLC-SEC, subjected to SEC purification as described in Example 1. UPLC-SEC was performed as described in Example 1.
[00540] Final purified samples were analyzed with DSC to determine their thermal stability. DSC experiments were performed as described in Example 14.
Results
[00541] Yields of variant post protein-A were in the range of 85 - 109 mg/L for the Fc- fused 8K22 scFv variants. Non-reducing and reducing LabChip post protein-A reflected a predominant species of the desired molecular weight.
[00542] As can be seen on Table 24, UPLC-SEC profiles showed a variety of homogeneity in the different variants. Some variants contained high molecular weight (HWM) species (ie dimers, trimers, higher order aggregates) of up to 56%, v29676. Variants with a (G4S)4 linker (v29677, v29680 and v29681) had the lowest measured HMW species, 21-34%. With v29680 having the lowest measured HMW species at 21.8% All samples had the HMW species removed with preparative SEC.
Table 24: High molecular weight species in Fc-fused 8K22 scFv samples


[00543] Figure 34 shows the DSC thermograms of the Fc-fused 8K22 scFv antibodies tested. The Tm values, corresponding to the scFv portion of the Ab, determined from the thermograms are shown in Table 25 below.
Table 25: Thermal stability of 8K22 scFv in Fc-fused variants
 [00544] Each peak on the thermogram corresponds to a thermal transition. There are three expected thermal transitions: Fab/scFv, CH2 (~71°C) and CH3 (~80°C). The transition of the Fab reflects cooperative melting of the VH-VL and CH1 -CL domains. The expected transition of the scFv would correspond to the melting of the VH-VL domains. Some scFvs do not undergo cooperative melting and two transitions were observed. In these cases the lower Tm is reported in Table 25. The 8K22 Fab transition overlaps with the CH2 domain transition and therefore only 2 transition peaks are observed in the thermogram for 8K22 parent Fab antibody variants. As can be seen in Figure 34, three distinct transitions can be observed for all variants which contain an 8K22 scFv. The Tm of the 8K22 scFv was 10-15°C lower than the parent Fab antibody. The engineered disulfide bond increases the Tm of the scFv between 1- 6.5°C. Of the scFvs having a disulfide bond, the scFv of v29683 and v29684 had the highest thermal stability. Of the scFvs without a disulfide bond, the scFv of v29679 had the highest thermal stability.
[00544] Each peak on the thermogram corresponds to a thermal transition. There are three expected thermal transitions: Fab/scFv, CH2 (~71°C) and CH3 (~80°C). The transition of the Fab reflects cooperative melting of the VH-VL and CH1 -CL domains. The expected transition of the scFv would correspond to the melting of the VH-VL domains. Some scFvs do not undergo cooperative melting and two transitions were observed. In these cases the lower Tm is reported in Table 25. The 8K22 Fab transition overlaps with the CH2 domain transition and therefore only 2 transition peaks are observed in the thermogram for 8K22 parent Fab antibody variants. As can be seen in Figure 34, three distinct transitions can be observed for all variants which contain an 8K22 scFv. The Tm of the 8K22 scFv was 10-15°C lower than the parent Fab antibody. The engineered disulfide bond increases the Tm of the scFv between 1- 6.5°C. Of the scFvs having a disulfide bond, the scFv of v29683 and v29684 had the highest thermal stability. Of the scFvs without a disulfide bond, the scFv of v29679 had the highest thermal stability.
EXAMPLE 32: Binding of Fc-fused 8K22 scFv antibodies to human FRα by Bio-layer interferometry
[00545] To assess the ability of the Fc-fused 8K22 scFv antibodies to retain Fab-like binding to human FRα, the affinity of scFv converted antibodies described in Example 31 were compared to the parental chimeric antibodies described in Examples 24 and 25 by Bio-layer interferometry (BLI).
[00546] Post SEC protein material described in Example 31 was assessed for binding to human FRα. Binding was measured by Bio-layer interferometry (BLI) using the Octet RED 96 (ForteBio) as described in Example 27. All parameters remained the same except for the dissociation phase which was recorded for 1500s.
Results
The KDs measured for each Fc-fused 8K22 scFv variant are provided in Table 26.
Table 26: Binding of Fc-fused 8K22 scFv variants to hFRa


[00547] As can be seen from Table 26, the BLI binding assay performed on the Fc-fused 8K22 scFv variants revealed that all scFv variants bound to hFRα with an affinity that was within 2-fold of the Parent Fab antibody. Figure 35 provides BLI sensorgrams for the Parent Fab antibody (Figure 35A) and two representative Fc-fused scFv variants (Figure 35B and 35C) that were able to bind human FRα. These results suggest that the conversion to the scFv format and addition of the disulfide bond did not impact the binding to the antigen and that the location of the scFv, N-term or C-term, also had no effect on binding.
Table 27: 8K22 scFv amino acid sequences of variants


EXAMPLE 33: Generation of 4-1BBxFRα bispecific antibodies utilising humanized paratopes
[00548] Additional 4-1BB x FRα antibody constructs (antibodies) v31330, v31331, v31332, v31333, v31334, and v31335 were designed to assess the effect of format on the ability of these 4-1BB x FRα bispecific constructs to conditionally activate 4-1BB. Figure 36 provides a representation of the formats of the antibodies tested in this example. These 4-1BB x FRα antibody constructs were prepared using the humanised anti-4-1BB paratope 1G1 corresponding to variant 28684 (H1L2), described in Example 10, and the anti-FRα humanised paratope 8K22 based on variant 23807 (H4L3) converted into an scFv, described in Example 30. Table XI identifies the clones that make up each of the antibody constructs. The polypeptide sequences of each clone can be found in Table Yl.
[00549] Antibodies were expressed and purified as described in Example 1. Purified antibodies were then tested as described in subsequent examples.
EXAMPLE 34: Activity of humanised 4-1BB x FRα bispecifics in a primary T cell: tumour co-culture assay
[00550] The antibodies described in the previous example were tested in a primary T celktumour co-culture assay to assess their ability to activate 4-1BB, according to methods previously described in Example 22. Briefly, CD8+ T cells were placed into wells of a 384- well plate with IGROV1 tumour cells and aAPC/CHO-K1 cells and samples of antibodies.
[00551] After four days, supernatants were taken and the concentration of IFNγ measured by MesoScale Discovery (MSD) U-Plex IFNγ 384-well assay kit (Meso Scale Diagnostics, Rockville, MD). Prior to use, the MSD plates were blocked by adding 50μl Diluent 100 (Meso Scale Diagnostics, Rockville, MD) to wells of aMA6000384-well SA plate for 30 minutes at room temperature. The blocking solution was then removed and 10μl of capture antibody added to each well (228μl of biotylated IFNγ capture antibody diluted in 3.77 ml Diluent 100). The plate was left at 4°C overnight, and then washed three times with PBS 0.05% Tween-20.
[00552] Tissue culture supernatant samples were diluted 1:20 with Diluent 43 (Meso Scale Diagnostics) and 5 μL of the diluted supernatant was placed into wells containing 5 μL of Diluent 43. The plate was left at room temperature for an hour to allow binding, then washed three times with PBS 0.05% Tween-20. SULFO-TAG IFNγ detection antibody (MesoScale Diagnostics) was diluted 100X in Diluent 3 and 10 μl of the resulting solution was added to each well, and the plate incubated for a further hour. The plate was then washed three times in PBS 0.05% Tween-20. 40μl of MSD GOLD Read buffer was added to each well, and the plate read on a MesoSector R600 instrument (MesoScale Diagonistics). The amount of IFNγ in each sample was calculated according to a standard curve generated from recombinant IFNγ (R&D System).
Results
[00553] As can be seen from Figure 37, 4-1BB x FRα bispecific antibodies showed induction of IFNγ in co-culture with IGROV1 cells. Samples v31332, v31362 and v31330 which have two 4-1BB binding domains showed both the highest potency and highest activity, as shown by the total production of IFNγ. v31332, v31362 and v31330 also showed higher activity than v30335, a monospecific 4-1BB antibody that is not reliant on Fc-mediated crosslinking. Samples with only a single 4-1BB binding arm (v31333, v31334 and v31335) induced production of IFNγ in dose-dependent manner, but total production of cytokine was lower than seen for samples with two 4-1BB binding arms. v31331, despite having two 4-1BB binding domains, showed activity similar to antibodies with a single 4-1BB binding domain (v31333, v31334 and v31335), suggesting that the 4-1BB and FRα binding domains on the same arm of v31331 may result in a geometry that prevents engagement of both 4-1BB and FRα simultaneously, reducing activity to that seen with a single 4-1BB arm.
[00554] Two antibodies were used as control antibodies for non-specific activity, v 16952, which does not bind mammalian proteins, and v31354, which contains the same 4- 1BB binding domains and same format as v31332 but does not bind FRα did not show any activity in this experiment, suggesting that the IFNg production seen in this experiment was due to 4-1BB costimulation and clustering of the 4-1BB antibody via FRα.
EXAMPLE 35: Activation of 4-1BB by 4-1BB x FRα bispecific antibodies in co-culture with Lung and Ovarian cell lines
[00555] The 4-1BB x FRα antibodies described in Example 33 were assessed for induction of 4-1BB signalling in co-culture with lung and ovarian cancer cell lines. The assay was carried out using the NFκB reporter gene assay described in Example 3, but with the tumour cell lines described in Table 28 below:
Table 28: Ovarian and lung cell lines

[00556] Cell lines were obtained from ATCC (Manassas, Virginia, USA), with the exception of OVKATE (Japanese Collection of Research Bioresources Cell Bank, Osaka, Japan) and IGROV1 (National Cancer Institute, Bethesda, Maryland, USA). Cells were assigned as FRαhigh, FRαmid and FRαlow based on binding of v17717 directly conjugated to Alexa647 by flow cytometry, as described in Example 18.
Results
[00557] Similar to previous experiments, IGROV 1 cells in co-culture with Jurkat T cells with a 4-1BB NFκB reporter system showed activation by 4-1BB x FRα antibodies in a dose- dependent manner (Figure 38A). 4-1BB x FRα antibodies with two 4-1BB binding domains (v31332, v31330 and v31362) showed greater activity than antibodies only having a single 4-
1BB binding domain (v31333, v31334 and v31335) (Figure 38A-H). The exception was v31331, which has two 4-1BB binding domains but had similar activity to v31333, v31334 and v31335. v31331 may only be able to engage a single 4-1BB on the Jurkat at the same time as the FRα on the tumour cell, potentially due to the proximity of the 4-1BB and FRα binding pockets.
[00558] Activity on cell lines derived from patients with either Ovarian or Lung cancers were also tested. These cell lines also expressed different levels of FRα, enabling the examination of the effect of FRα level on activity. The maximal activity and potency were higher when the antibodies were in co-culture with FRαhigh cells and correlated with levels of FRα on the surface of the tumour cells (Figure 38A-H). However, the relative activity on the antibodies did not change, with the highest potency and activity seen from v31332, v31330 and v31362 compared to the other antibodies. Activity was also seen in co-culture with FRα- positive Ovarian and Lung cancer cell lines of diverse origin. On FRαlow cell lines, activity could be seen but was lower than seen with the monospecific 4-1BB antibody v30335.
EXAMPLE 36: Ability of selected anti-4-1BB paratopes to bind to 4-1BB from cynomolgus (cyno) monkeys
[00559] The ability of select humanized antibodies to bind cyno 4-1BB by SPR was assessed and compared to that of the parent mouse paratopes 1C8, 1G1, and 5G8. Cyno cross- reactivity of these antibodies had been assessed using a homogeneous cell binding assay as described in Example 9; in this experiment cyno cross-reactivity was assessed using SPR. The SPR method used was similar to the one described in Example 2, except that SEC-purified Cyno 4-1BB-His (Aero Biosystems) was used in place of the human 4-1BB. The antibodies tested are described in Table 29 below:
Table 29: Antibodies tested

Results
[00560] Binding of cyno 4-1BB to both v20023 and v28684 was similar, suggesting that the 1G1 paratope bound cyno 4-1BB before and after humanization. The 1C8 paratope, similar
to seen with human 4-1BB, lost some binding after humanization as can be seen in the difference between v20022 and v28727. In contrast to Figure 11 A where v20036 appeared to bind cyno 4-1BB, by SPR v20036 binds poorly to cyno 4-1BB. The discrepancy between Figure 11 A and the data in Figure 39 is likely due to the inability of the method used in Figure 11 A to discriminate between antibodies which bind well and antibodies which bind poorly to cyno 4-1BB.
EXAMPLE 37: Preparation of modified 4-1BB x FRα bispecific antibody constructs
[00561] One ofthe4-1BBx FRα bispecific antibodies described in Example 33, v31332, was engineered to improve its biophysical properties. Variant 31332 included humanized 4- 1BB antigen binding domains based on the 1G1 antibody (H1L2) in Fab format and a humanized FRα antigen binding domain based on the 8K22 antibody (H4L3) in scFv format. Identification of amino acid residues in the anti-FRα scFv portion of the bispecific antibody that could be modified to improve biophysical properties of the antibody was carried out as described below. These properties include increased thermal stability of modified antigen- binding domains of the bispecific antibody, as measured by thermal stability of the modified antigen-binding domain, and/or an increase in species homogeneity of the bispecific antibody, as measured by a decrease in the amount of high molecular weight (HMW) species.
[00562] A homology model for the 8K22 scFv was prepared to identify surface residues that could be modified to improve stability. Select hydrophobic residues were replaced with hydrophilic or Ala residues. In the parent sequence variant 31332 according to the Rabat number scheme there is a gap between position 74 and 76 in the VH domain of 8K22. One proposed modification is an insertion of a Lys after position 74. This new Lys would be numbered as K75. In one variant the linker between the VL and VH domains was replaced with VEGGSGGSGGSGGSGGVD [SEQ ID NO:982], A list of the modifications tested is given in Table 30. The numbering of amino acid residues is according to Rabat.
Table 30: Modified Residues


[00563] All modifications were tried independently, and in some cases up to 7 modifications were combined making a total of 21 variants to be tested (Table 31). Sequences of the scFv portion of each variant are shown below and the sequence of the scFv portion of variant 31332 is set forth in SEQ ID NO:850; sequences of each modified VH and VL region are provided in Table 48.
Table 31: Modifications in the 8K22 scFv portion of 4-1BB x FRa bispecific antibodies
 Production of bispecific antibodies
Production of bispecific antibodies
[00564] Each of the 4-1BB x FRα bispecific antibodies (also referred to here as 1G1- 8K22 antibodies) described in Table 30 were designed as in a 2 x 1 format with a C-terminal 8K22 scFv paratope as depicted in Figure 2B. Heavy chain sequences containing humanized 1G1 heavy chain variable domain (VH) and hlgG1 heavy chain constant domains (CH1, hinge, CH2, CH3) followed by a GGGG [SEQ ID NO:336] linker and a 8K22 heavy chain variable domain (VH) and light chain variable domain (VL) connected by a (G4S)3 linker (short, GGGGS GGGGS GGGGS , [SEQ ID NO: 320]), were assembled.
[00565] Heavy chain vector inserts comprising a signal peptide (artificially designed sequence: MRPTWAWWLFLVLLLALWAPARG (SEQ ID NO:l) (Barash et al, (2002), Biochem and Biophys Res. Comm., 294:835-842)) and the heavy chain clone terminating at G446 (EU numbering) of CH3, or in the case of a C-terminal 8K22 scFv the heavy chain clone terminated at K127 of VL. Clones were ligated into a pTT5 vector to produce heavy chain expression vectors having a 5’-EcoRl restriction site and a BamHl cutsite-3’. Light chain vector inserts comprising the same signal peptide and cut sites were ligated into a pTT5 vector to produce light chain expression vectors. These sequences were reverse translated to DNA, codon optimized for mammalian expression and gene synthesized. These bispecific antibody constructs comprised a human IgG1 heterodimeric Fc having CH3 domain amino acid substitutions Het FcA (T350V/L351Y/F405A/Y407V) and Het FcB (T350V/T366L/K392L/T394W), which drive association of the two component Fc polypeptides. Bispecific antibody constructs also included the FcKO CH2 mutations designed to knock out or reduce FcγR binding: L234A, L235A and D265S Amino acid residues in the Fc region are identified according to the EU index. The resulting heavy and light chain expression vectors were sequenced to confirm correct reading frame and sequence of the coding DNA. Table X2 identifies the clones that make up each of the antibody constructs. The polypeptide sequences of each clone can be found in Table Y2.
[00566] The heavy and light chains of the antibody variants were expressed in 250 ml cultures of CHO-3E7 cells. Briefly, CHO-3E7 cells, at a density of 1.7-2 x 106 cells /ml, viability >95%, were cultured at 37°C in FreeStyle™ F17 medium (ThermoFisher, Watham, MA) supplemented with 4 mM glutamine (GE Life Sciences, Marlborogh, MA) and 0.1% Pluronic® F-68 (Gibco, Life Technologies). A total volume of 250ml was transfected with a total of 250ug DNA (125ug of antibody DNA and 125ug of GFP/AKT/stuffer DNA) using
PEI-max (Polyscience, Philadelphia, PA) at a DNA:PEI ratio of 1 :4 (W/W). Twenty -four hours after the addition of the DNA-PEI mixture, 0.25mM valproic acid (final concentration) + 1% w/v Tryptone (final concentration) + 1x antibiotic/antimycotics (GE Life Sciences, Marlborogh, MA) were added to the cells, which were then transferred to 32°C and incubated for 9 days prior to harvesting.
[00567] Clarified supernatant samples were incubated in batch with mAh Select SuRe resin (GE Healthcare, Chicago, IL) cleaned-in-place (CIP’d) with NaOH and equilibrated in Dulbecco’s PBS (DPBS). Resin was poured into CIP’d columns, the columns were washed with DPBS and protein eluted with 100 mM sodium citrate buffer pH 3.0. The eluted fractions were pH adjusted by adding 10% (v/v) 1M HEPES pH 8 to yield a final pH of 6-7. Samples were buffer exchanged into PBS and aseptically filtered. Protein was quantitated based on absorbance at 280nm (A280 nm) (in instances where precipitation was present upon sample neutralization, these samples were centrifuged briefly prior to A280nm measurements). Endotoxin levels were determined using the Endosafe® Portable system (Charles River, Wilmington, MA). Samples having endotoxin above 0.2 EU/mg underwent endotoxin removal with the NoEndo™ Spin columns (Viva Products Inc., Littleton, MA). All variants were further purified by preparatory SEC chromatography (Superdex 200 26/60) in DPBS mobile phase following protein A purification.
[00568] Following purification, purity of samples was assessed by non-reducing and reducing High Throughput Protein Express assay using Caliper LabChip® GXII (Perkin
E1mer, Waltham, MA). Procedures were carried out according to HT Protein Express LabChip® User Guide version 2 with the following modifications. Antibody samples, at either 2pl or 5μl (concentration range 5-2000 ng/μl), were added to separate wells in 96 well plates (BioRad, Hercules, CA) along with 7μl of HT Protein Express Sample Buffer (Perkin E1mer # 760328). Antibody samples were then denatured at 70°C for 15 mins. The LabChip® instrument was operated using the HT Protein Express Chip (Perkin E1mer, Waltham, MA) and the Ab-200 assay setting.
[00569] Post protein A purification, samples were either buffer exchanged into DPBS and aseptically filtered or, depending on their homogeneity assessed by UPLC-SEC, subjected to SEC purification as described in Example 2.
Results
[00570] Yields of protein post protein A purification were in the range of 29-71 mg/L for the 1G1-8K22 variants. Non-reducing and reducing LabChip post protein A reflected single species corresponding to full size antibody and intact heavy and light chains in all cases (data not shown). Endotoxin levels were within the specifications.
EXAMPLE 38: Characterization of modified 1G1-8K22 bispecific antibodies
[00571] The bispecific antibodies described in Example 37 were characterized to assess species homogeneity after protein A purification, thermal stability of the 8K22 scFv, binding of the 8K22 scFv to FRα, and high temperature stability.
Biophysical assessment of 1G1-8K22 bispecific antibodies
[00572] Samples of antibody variants generated in Example 37 were subj ected to UPLC -
SEC in order to assess species homogeneity following protein A purification.
[00573] UPLC-SEC was performed using a Waters Acquity BEH200 SEC column (2.5 mL, 4.6 x 150 mm, stainless steel, 1.7 μm particles) (Waters LTD, Mississauga, ON) set to 30°C and mounted on a Waters Acquity UPLC H-Class Bio system with a photodiode array (PDA) detector. Run times consisted of 7 min and a total volume per injection of 2.8 mL with a running buffer of DPBS with 0.02% Tween 20 pH 7.4 at 0.4 ml/min. E1ution was monitored by UV absorbance in the range 210-500 nm, and chromatograms were extracted at 280 nm. Peak integration was performed using Waters Empower 3 software. HMW species was determined by calculating the % total peak area which eluted before the peak corresponding to the monodispersed sample (~2.7 min).
Results
[00574] The results are shown in Table 32 below.
Table 32: Species homogeneity of modified 1G1-8K22 bispecific variants, % high molecular weight species


[00575] UPLC-SEC analysis of protein A purified modified 1G1-8K22 bispecific antibody variants was reflective of high species homogeneity in the case of variants v31586, v31588, v31594 and v31595. UPLC-SEC profiles of all other stabilized 1G1-8K22 variants reflected lower homogeneity and greater high molecular weight species.
Thermal Stability of modified 1G1-8K22 bispecific antibodies
[00576] In order to determine the effects of the modifications on the thermal stability of the 8K22 scFv. the thermal stability of modified 1G1-8K22 antibody variants was assessed by differential scanning calorimetry (DSC) as described in Example 14.
[00577] 400 μL of purified samples from example 37 primarily at concentrations of 0.4 mg/mL in PBS were used for DSC analysis with a VP-Capillary DSC (GE Healthcare, Chicago, IL). At the start of each DSC run, 5 buffer blank injections were performed to stabilize the baseline, and a buffer injection was placed before each sample injection for referencing. Each sample was scanned from 20 °C to 100°C at a 60° C/hr rate, with low feedback, 8 sec filter, 3 min pre-scan thermostat, and 70 psi nitrogen pressure. The resulting thermograms were referenced and analyzed using Origin 7 software (OriginLab Corporation, Northampton, MA) to determine melting temperature (Tm) as an indicator of thermal stability.
Results
[00578] The results are shown in Table 33 below.
Table 33: Thermal stability of modified 1G1-8K22 bispecific variants

[00579] As can be seen in Table 33, determined scFv Tm of variants v31586, v31588, v31589, v31600, v31601, v31602, v30604, v31605 and v31606 were ~5-11°C higher compared to the parental scFv v31332. Figure 41 shows the corresponding DSC thermograms of the parental 1G1-8K22 bispecific antibody variant 31332 (Figure 41A) and modified variant 31586 (Figure 41B). As can be seen from Table 33, the modified variant with increased scFv Tm values have in common presence of the F83A amino acid substitution. This suggests that this position is important for the stability of the scFv.
Binding of modified 1G1-8K22 bispecific antibodies
[00580] To compare the ability of the modified 1G1-8K22 antibodies to bind human FR«. the affinity of these antibodies was compared to the parental antibody by Bio-layer interferometry (BLI).
[00581] Protein material post SEC of select samples were assessed for binding to human FRα. Antigen binding was assessed using the Octet RED96 system by cycling through the following steps: loading of antibodies (0.9 μg/mL) onto AHC biosensors over 200s; stabilization of baseline for 60s; association to recombinant His-tagged human FRα (Acrobiosystem) at multiple relevant concentrations spanning the expected KD for 500s; dissociation was recorded for 1200 s; and regeneration was performed by cycling 3 times between 10 mM glycine pH 1.5 (15 s) and the assay buffer (15 s) before proceeding to the next antibody. The assay buffer used was KB buffer (kinetics buffer, composed of PBS pH 7.4, 0.1% BSA, 0.02 % Tween 20, 0.05% sodium azide) supplemented with 0.06% Tween 20. The experiment was conducted at 25°C with a shake speed of 1000 rpm.
[00582] Data analysis was performed using the ‘Data analysis software 9.0’ (ForteBio). The reference-subtracted binding curves were globally fitted to the 1:1 interaction model to generate the binding kinetic parameters kon, koff, and the dissociation constant KD.
Results
[00583] scFv KD values were determined for modified 1G1-8K22 bsAb variants that exhibited aggregates <21% and Tm >54°C. As can be seen from Table 34, BLI assay performed on selected modified 1G1-8K22 bispecific antibody variants revealed a top group of modified scFv 1G1-8K22 bsAb variants (variants 31586, 31587, 31588, 31589, 31593, 31596, 31597, 31600, 31601, 31605) with affinity within 2-fold of the KD of the parental scFv (v31332). Obtained KD values ranged from ~9 nM to 21 nM. Variants with mutation I53S located in CDR H2 (v31591, v31602, v31604, v31606) exhibited reduced affinity, > 2-fold of the KD of the parental scFv. These results suggest that residue 153 S is involved in binding to hFRα.
Table 34: Binding of select modified 1G1-8K22 bispecific variants to hFRa


[00584] As can be seen from Table 34, the BLI binding assay revealed that most scFv variants bound to hFRα within 2-fold of the Parent scFv of variant 31332. Several variants, v31591, v31602, 31604, v31606, had affinity reduced by >2-fold. The variants with reduced binding all contain mutations located in the CDRs. Figure 42 provides BLI sensorgrams for the parental 1G1-8K22 bispecific (Figure 42A, v31332) and representative stabilized variants (Figure 42B, v31586, and Figure 42C, v31588) that were able to bind human FRα.
High temperature stability of 1 G1-8K22 bispecific antibodies
[00585] In order to determine the long-term stability of 1 G1 -8K22 bispecific antibodies, the samples were incubated at high temperature as described below.
[00586] Select post-SEC purified variants (v31332, v31586, v31588, v31602) were incubated as follows: 1 mg/mL of 1G1-8K22 bispecific antibody in PBS for 14 days at 40°C. Samples were obtained at day 0, 3, 7, 10, and 14 and frozen at -80°C. Time points were assessed by UPLC-SEC and by non-reducing and reducing High Throughput Protein Express assay as described in Examples 37 and as described for Biophysical assessment of the 1G1-8K22 bispecific antibodies above.
Results
[00587] As can be seen from Table 35, high temperature incubation revealed that three variants (v31332, v31588 and v31602) were stable at 40°C and exhibited no more than 0.1% loss of monomer species. The variant v31586 had a 13.8% loss of monomer species. As can be seen in Figure 43 this loss of monomer coincides with an increase in lower molecular weight species suggesting an increased rate of degradation.
Table 35: High temperature stability of selected 1G1-8K22 bispecific variants

[00588] In summary, several 1G1-8K22 bispecific variants having improved biophysical properties compared to the parent variant 31332 were identified. These variants included v31588, v31586, and 31602 which all exhibited a lower percentage of HMW species after protein A purification and improved thermal stability compared to the parent variant 31332 while maintaining binding to human FRα.
EXAMPLE 39: Production of a 4-1BB x FRα bispecific antibody construct having an anti-FRα antigen-binding domain in a Fab format
[00589] Additional 4-1BB x FRα bispecific antibodies having an anti-FRα antigen- binding domain in the Fab format were designed and prepared. These trivalent bispecific antibodies were in a 2x1 format where the anti FRα binding portion of the antibody was in a Fab format. The bispecific antibodies prepared are also referred to here as 1G1-8K22 (Fab) bispecific antibodies as they included the humanized anti-4-1BB paratope 1G1 (H1L2) and the humanized anti FRα paratope 8K22 (H4L3). Two different 1G1-8K22 (Fab) bispecific antibodies, variants 33568 and 33569, were generated with a C-terminal 8K22 antigen-binding domain in a Fab format where the 8K22 Fab portion and the 1G1 Fab portions of the bispecific antibody incorporated amino acid substitutions in their CH1 and CL domains to drive correct pairing of heavy and light chains. A representation of the format of these bispecific antibodies is depicted in Figure 44C. The samples were subsequently produced as described below.
[00590] In more detail, the trivalent 2x1 1G1-8K22 (Fab) bispecific antibodies, v33568 and v33569, were designed with two 1G1 4-1BB antigen-binding domains as Fabs and one
8K22 FRα antigen binding domain as a Fab. The two anti-4-1BB Fabs were appended to a hinge-CH2-CH3 domain sequence of IGHG1*01, the 8K22 paratope was connected to the C- terminus of one Fc through a short GGGG linker to a VH-CH1 domain. The 8K22 humanized VL sequences were appended to the human CL (kappa) domain to generate the light chain Fab sequence. Variant 33568 and v33569 each contained a different set of mutations located in the CH1 and CL domains to drive the correct pairing between the heavy and light chains of the 4- 1BB paratopes and between the heavy and light chains of the 8K22 paratopes. These mutations are shown in Table 36 and Table 37 below. The Fc region of these bispecific antibodies included the Het Fc and FcKO amino acid substitutions described in Example 1 and elsewhere.
Table 36: Light chain pairing design for 1G1-8K22 bispecific antibody v33568

Table 37: Light chain pairing design for 1G1-8K22 bispecific antibody v33568

[00591] These amino acid sequences were reverse translated to DNA, codon optimized for mammalian expression and gene synthesized.
[00592] The trivalent antibody constructs were made, all having four polypeptide chains - one heavy chain containing Het FcA mutations, a second heavy chain containing Het FcB mutations, a 1G1 light chain, and a 8K22 Fab light chain (see representation in Figure 44C). Heavy chain vector inserts comprising a signal peptide (artificially designed sequence: MRPTWAWWLFLVLLLALWAPARG (SEQ ID NO:l) (Barash et al, (2002), Biochem
and Biophys Res. Comm., 294:835-842)) and the heavy chain clone terminating at G446 (EU numbering) of CH3, or in the case of a 8K22 Fab the upper hinge was included to residue T225 (EU numbering), were ligated into a pTT5 vector to produce heavy chain expression vectors having a 5’-EcoRl restriction site and a BamHl cutsite-3’. Light chain vector inserts comprising the same signal peptide and cut sites were ligated into a pTT5 vector to produce light chain expression vectors. The resulting heavy and light chain expression vectors were sequenced to confirm correct reading frame and sequence of the coding DNA.
[00593] The heavy and light chains of the antibody variants were expressed in 20 ml cultures of CHO-3E7 cells. Briefly, CHO-3E7 cells, at a density of 1.7-2 x 106 cells /ml, viability >95%, were cultured at 37°C in FreeStyle™ F17 medium (ThermoFisher, Watham, MA) supplemented with 4 mM glutamine (GE Life Sciences, Marlborogh, MA) and 0.1% Pluronic® F-68 (Gibco, Life Technologies). A total volume of 20ml was transfected with a total of 20ug DNA (10ug of antibody DNA and 10ug of GFP/AKT/stuffer DNA) using PEI- max (Polyscience, Philadelphia, PA) at a DNA:PEI ratio of 1:4 (W/W). Samples were expressed in different heavy chain and light chain ratios to identify ratios resulting in optimal expression of correctly-paired heavy and light chains. Twenty-four hours after the addition of the DNA-PEI mixture, 0.25mM valproic acid (final concentration) + 1% w/v Tryptone (final concentration) + 1x antibiotic/antimycotics (GE Life Sciences, Marlborogh, MA) were added to the cells, which were then transferred to 32°C and incubated for 9 days prior to harvesting.
[00594] CHO cultures were purified as described in Example 1. Post protein A purification, samples were buffer exchanged into DPBS (Dulbecco’s PBS). Samples were assessed by UPLC-SEC, UPLC-SEC was performed as described in Example 2. Purity of samples was assessed by non-reducing and reducing High Throughput Protein Express assay (LabChip) as described in Example 1 and by LC-MS analysis as follows.
[00595] As the antibody variant samples contained Fc N-linked glycans only, the samples were treated with only one enzyme, N-glycosidase F (PNGase-F). The purified samples were de-glycosylated with PNGaseF as follows: 0.1U PNGaseF/μg of antibody in 50mM Tris-HCl pH 7.0, overnight incubation at 37°C, final protein concentration of 0.48 mg/mL. After deglycosylation, the samples were stored at 4°C prior to LC-MS analysis.
[00596] The deglycosylated protein samples were analyzed by intact LC-MS using an Agilent 1100 HPLC system coupled to an LTQ-Orbitrap™ XL mass spectrometer
(ThermoFisher, Waltham, MA) (tuned for optimal detection of larger proteins (>50kDa)) via an Ion Max electrospray source. The samples were injected onto a 2.1 x 30 mm Poros R2 reverse phase column (Applied Biosystems) and resolved using a 0.1% formic acid aq/acetonitrile (degassed) linear gradient consisting of increasing concentration (20-90%) of acetonitrile. The column was heated to 82.5°C and solvents were heated pre-column to 80°C to improve protein peak shape. The cone voltage (source fragmentation sehing) was approximately 40 V, the FT resolution sehing was 7,500 and the scan range was m/z 400-4,000. The LC-MS system was evaluated for IgG sample analysis using a deglycosylated IgG standard (Waters IgG standard) as well as a deglycosylated mAb standard mix (25:75 half full sized mAb). For each LC-MS analysis, the mass spectra acquired across the antibody peak (typically 3.6-4.3 minutes) were summed and the entire multiply charged ion envelope (m/z 1,400-4,000) was deconvoluted into a molecular weight profde using the MaxEnt 1 module of MassLynx, the instrument control and data analysis software (Waters, Milford, MA). The apparent amount of each antibody species in each sample was determined from peak heights in the resulting molecular weight profdes.
Results
[00597] A ratio of heavy and light chain DNA of 6.5: 18.5:25:50 for HC1 :HC2:LC1 :LC2 respectively resulted in optimal production of v33568, while a ratio of 12.5:12.5:50:25 for HC1:HC2:LC1:LC2 respectively resulted in optimal production of v33569. Yield of protein post protein A purification was ~45 mg/L for v33568 and was ~57 mg/L for v33569. Non- reducing and reducing LabChip post protein A reflected a major species corresponding to full size antibody and intact heavy and light chains with some half antibody present (data not shown) at the top DNA ratio for both v33568 and v33569. UPLC-SEC profile for the 1G1- 8K22 v33568 antibody sample reflected high species homogeneity 92.5% and v33569 had a species homogeneity of 75.5% with presence of both higher and lower molecular weight species, as shown in Table 38.
Table 38: Expression of 1G1-8K22 bispecific antibodies
 [00598] As seen in Figure 45 A, LC-MS analysis demonstrated that v33568 had a high purity of 92% of desired bispecific antibody species with 5.6% Het FcB half-antibody and 1.7% homodimeric Het FcB. and in Figure 45B, v33569 had a purity of 81% of desired bispecific antibody species with 15% of Het FcB half-antibody and 3% of homodimeric Het FcB. The light chain pairing designs were successful in producing the desired bispecific antibody species.
[00598] As seen in Figure 45 A, LC-MS analysis demonstrated that v33568 had a high purity of 92% of desired bispecific antibody species with 5.6% Het FcB half-antibody and 1.7% homodimeric Het FcB. and in Figure 45B, v33569 had a purity of 81% of desired bispecific antibody species with 15% of Het FcB half-antibody and 3% of homodimeric Het FcB. The light chain pairing designs were successful in producing the desired bispecific antibody species.
EXAMPLE 40: Identification and Humanization of a novel rabbit anti-FRα antibody
[00599] A rabbit anti-human folate receptor alpha (anti-hFRα) antibody, 2L16, was generated as described in Example 23, and humanized as described below.
[00600] Sequence alignment of rabbit 2L16 VH and VL sequences to respective human germline sequences identified IGHV3-66*01 and IGKVI-39*01 as the closest, as well as frequent, human germline sequences. CDRs were ported onto the framework of these selected human germline sequences as shown in Figure 46. IGHJ4*01 was used for the joining sequence in the VH domain and IGKJ4*01 was used for the joining sequence in the VL domain. Back mutations to rabbit residues were added in the resultant sequences at positions judged likely to be important to create several humanized sequences.
[00601] This process identified four 2L16 variable heavy chain humanized sequences, H2, H2c, H2e, and H2g, and one light chain humanized sequence, LI. These humanized sequences were used to construct a number of 4-1BB x FRα bispecific antibodies in 2x1 format as described in the following Example.
EXAMPLE 41: Production of bispecific 4-1BB x FRα antibodies having a humanized 2L16 antigen-binding domain
[00602] The humanized sequences described in Example 40 were used to assemble 4- 1BB x FRα bispecific antibodies as described below.
[00603] Sequences containing a humanized 1G1 (binding to 4-1BB) heavy chain variable domain (VH) and hlgG1 heavy chain constant domains (CH1, hinge, CH2, CH3) followed by a GGGG linker and a 2L16 light chain variable domain (CL) and human kappa light chain constant domain (kappa CL) were assembled (VH(lG1)-CH1-hinge-CH2-CH3- VL(2L16)-CL). An additional sequence containing a 2L16 humanized heavy chain variable domain (VH) and hlgG1 heavy chain constant domains (CH1) was generated (VH(2L16)-
CH1). These sequences were used to construct variants where the 2L16 paratope was in the Fab format (see exemplary construct v32681 in Figure 44B). Bispecific variants were then assembled such that each humanized 2L16 heavy chain H2, H2c, H2e, or H2g sequence, was paired with the humanized light chain LI in a Fab format, providing a total of four variants to be evaluated experimentally (see Table 39). An additional variant was constructed in which the 2L16 paratope was in the scFv format (see Figure 44A). To ensure the orientation did not affect the affinity of the 2L16 paratope, a one-armed antibody format was generated as a binding control using the H2gL1 combination (see Figure 44D).
Table 39: VH and VL Composition of Humanized 2L 16 antibody portion ofbispeciflc 4- IBB x FRa Variants

[00604] The humanized 2L16 antibodies described in Example 40 and Table 39 were prepared as follows.
[00605] Each of the humanized 2L16 constructs, as well as the parental 2L16 construct, were in bispecific antibody format in which two 1G1 4-1BB antigen binding domains were Fabs and one 2L16 FRα antigen binding domain (2L16) as a Fab. The two anti-4-1BB Fabs were appended to a hinge-CH2-CH3 domain sequence of IGHG1*01, the 2L16 paratope was connected to the C-terminus of one Fc through a short GGGG linker to a VL-CL (kappa) domain. The 2L16 humanized VH sequences (SEQ ID NOs:) were appended to the human CH1 domain to generate the heavy chain Fab fragment. The amino acid sequences of each of the antibody variable heavy chains and variable light chain are provided in Table 48. In a similar manner, 2L16 rabbit-human parental antibody chimera heavy and light chain sequences were assembled in a 2x1 bispecific format with the 2L16 paratope as a scFv in a VH to VL format as described in Examples. These sequences were reverse translated to DNA, codon optimized for mammalian expression and gene synthesized. The humanized VH and VL
sequences are provided in Table 48. These bispecific antibody constructs comprised the HetFc A and B mutations to generate a human IgG1 heterodimer in addition to the FcKO mutations.
[00606] The trivalent antibody constructs were made, all having four polypeptide chains
- one heavy chain containing Het FcA mutations, a second heavy chain containing Het FcB mutations, a 1G1 light chain and in the case of 2L16 Fab a VH-CH1 chain. The heavy chains were constructed in a series of formats, all of which were comprised of one antigen-binding domains in the Fab format and a single anti-FRα antigen-binding domain in the scFv or Fab format. These heavy chain formats are described below from N-terminus to C-terminus:
- VH( 1 G1 )-CH1 -hinge-CH2-CH3-VL(2L 16)-CL
- VH( 1 G1 )-CH1 -hinge-CH2-CH3
- VH( 1 G1 )-CH1 -hinge-CH2-CH3-VH(2L 16 rabbit)-VL(2L16 rabbit)
[00607] Heavy chain vector inserts comprising a signal peptide (artificially designed sequence: MRPTWAWWLFLVLLLALWAPARG (SEQ ID NO:l) (Barash et al, (2002), Biochem and Biophys Res. Comm., 294:835-842)) and the heavy chain clone terminating at G446 (EU numbering) of CH3, or C126 of CL in the case of a 2L16 Fab, were ligated into a pTT5 vector to produce heavy chain expression vectors having a 5’-EcoRl restriction site and a BamHl cutsite-3’. Light chain vector inserts comprising the same signal peptide and cut sites were ligated into a pTT5 vector to produce light chain expression vectors. In the case of 2L16 Fab a VH-CH1 chain vector inserts comprising the same signal peptide and cut sites were ligated into a pTT5 vector. The resulting heavy and light chain expression vectors were sequenced to confirm correct reading frame and sequence of the coding DNA.
[00608] The heavy and light chains of antibody variants were expressed in 250 mL CHO cultures and purified as described in Example 1. The parental 2L16 rabbit -human antibody chimera v30048 was expressed in a similar manner in a 1L culture. Following protein A purification, purity of samples was assessed by non-reducing and reducing High Throughput Protein Express assay as described in Example 1. The bispecific 4-1BB x FRα antibody variants having the humanized 2L16 VH and VL sequences described above are referred to as 1G1 x humanized 2L16 antibodies or antibody variants.
Results
[00609] Yield post protein A purification across the five 1G1 x humanized 2L16 antibody variants ranged from ~ 14-18 mg (or -50-90 mg/L). Figures 47B and 47D show the Caliper results for the parental chimeric antibody v30048 and a representative humanized variant, v32680, respectively. As shown in Figure 47D, on the representative humanized antibody v32680, non-reducing (NR) and reducing (R) Caliper reflected a single species corresponding to full-size antibody and intact heavy and light chains, which was the case with all humanized variants. All humanized antibodies were produced with sufficient quantity and purity to further characterize.
EXAMPLE 42: Assessment of Purified 1G1 x Humanized 2L16 Antibodies
[00610] 1 G1 x humanized 2L 16 antibodies having humanized 2L 16 paratopes produced as described in Example 41 were assessed for species homogeneity of the antibody, affinity and thermal stability of the humanized 2L16 paratope portion of the antibody to FRα, and purity of the antibody as described below.
Species homogeneity
[00611] Samples of 1G1 x humanized 2L16 antibody variants produced in Example 41 were subjected to UPLC-SEC in order to assess species homogeneity following protein A purification or following preparatory SEC purification.
[00612] UPLC-SEC was performed as described in Example 38.
Results
[00613] As shown in Figures 47A (for the parental chimera v30048) and 47C (for a representative humanized antibody v32680), UPLC-SEC profile for the v32680 antibody sample reflected high species homogeneity, comparable to the purified parental chimera antibody sample. The parental chimera contained higher molecular weight species following protein A purification (not shown), which were removed by preparatory SEC. The rest of the 1G1 x humanized 2L16 antibody samples had similar profiles to those of the representative humanized antibody sample.
Affinity of 1G1 x Humanized 2L16 Antibodies for hFRa
[00614] To determine whether the humanization process affected the affinity of the humanized variants for their target, the ability of the 1G1 x humanized 2L16 antibody variants to bind the hFRα antigen was assessed by Bio-layer interferometry (BLI).
[00615] Protein material post SEC of select samples were assessed for binding to human FRα. The antigen-binding affinity was determined by BLI as described in Example 38.
Results
[00616] The results are shown in Table 40 and Figure 48.
Table 40: Affinity and Thermal Stability of 2L16 paratope portion of 1G1 x Humanized 2L16 antibody Variants

[00617] Figure 48 shows the BLI results for the C-terminal rabbit parental chimeric scFv v30048 and two representative 1G1 x humanized 2L16 antibodies, v31946 and v32681, Figure 48B and Figure 48C, respectively using purified antibodies.
[00618] Variants 32681, 32683, and 32685 emerged as the top tier performing variants, with respect to the retention of the affinity to hFRα within 5 -fold upon humanization, as determined by binding assays with purified sample material. The heavy chain was sensitive to the back mutations in the framework region and required the set of back mutations used in 32681, 32683, and 32685 to retain parental binding. Comparing the binding between humanized 2L16 paratope fused at the N-terminus, v32693, and C-terminus v32685 demonstrated a difference of affinity of less than 2-fold. This suggests that the orientation of the 2L16 paratope had minimal effects on the affinity for the FRα paratope for human FRα.
Thermal Stability of Humanized 2L16 Antibodies
[00619] The thermal stability of 1G1 x humanized 2L16 antibody variants was assessed by differential scanning calorimetry (DSC) as described in Example 38.
Results
[00620] Figure 49 depicts thermograms of two representative variants 31946 and 32681 in Figure 49A and Figure 49B, respectively. Each peak on the thermogram corresponds to a thermal transition. There are four expected thermal transitions: 2L16 Fab, 1G1 Fab (~80°C),
CH2 (~71°C) and CH3 (~80°C). The transition of the Fab reflects cooperative melting of the VH-VL and CH1-CL domains. Tm values were determined for the humanized 2L16 scFv or Fab portions of the bispecific 1G1 x humanized 2L16 antibodies. As shown in Table 40 above, the Tms for the Fabs were 81-82°C. In the case of variant 31946 with a2L16 scFv, the transition occurs at a similar temperature as the CH2 domain. In the case of variants with 2L16 Fabs, the transition occurs at a similar temperature as the CH3 domain and 1G1 Fab. In these cases, only two transition peaks were observed on the thermogram.
[00621] All the 2L 16 Fabs have aTmof 81-82°C suggesting these humanized sequences are stable to thermal stress.
Purity Assessment of 1G1 x Humanized 2L16 Antibodies
[00622] The apparent purity of the 1G1 x humanized 2L16 antibody variants was assessed using mass spectrometry after protein A purification and non-denaturating deglycosylation as described in Example 39.
Results
[00623] The characterized 1G1 x humanized 2L16 antibody variants contained 84-93% species purity of the desired bispecific antibody, exemplified by the LC/MS profile of the two representative humanized antibody samples in Figure 50. Figure 50A depicts the LC/MS profile for v32681, while Figure 50B depicts the LC/MS profile for v31946. The LC/MS profile of v32681 contains a peak at 167 kDa which corresponds to a species lacking the 2L16 heavy chain fragment. The LC/MS profile of v31946 contains two extra peaks at ~96 kDa and 195 kDa which correspond to the MW of the larger half antibody and homodimer. All variants contained decon artifact peaks which are artifacts produced during the analysis of the mass spectra.
[00624] In summary, the humanized 2L16 VH and VL sequences identified and tested here exhibited properties making them suitable for use in preparing the 4-1BB x FRα antibodies described herein.
EXAMPLE 43: Modification of 2L16 scFv domain arrangements
[00625] The VH and VL sequences of the humanized 2L16 (H2L1) Fab portion of variant 32680 described in Examples 41 and 42, were converted from Fab format to scFv
format with different orientations and linkers as described below to prepare additional bispecific 1G1 x humanized 2L16 antibodies. This was done to facilitate the production of optimized anti-4-1BB x anti-FRα bispecific antibodies in the 2 x 1 format with a 2L16 scFv.
Design of 2L16 scFv portion of bispecific 1G1 x humanized 2L16 antibodies
[00626] A number of 2L16 scFvs were designed in which the order of the VH and VL domains was varied, the length of the linker between the two domains was varied. The 2L16 scFvs were prepared and tested in a 2 x 1 bispecific 1G1 x humanized 2L16 antibody format that was the same type of format as for v31946 as described in Example 41 and depicted in Figure 44A. The 2L16 scFvs were fused to the C-terminus of the Fc in a manner similar to v31946. A summary of the 2L16 scFvs designed is found in Table 41. The sequences for the 2L16 scFv portion of each variant are identified in Table 41.
Table 41: 2L16 scFv domain arrangements in 1G1 x humanized 2L16 antibodies

[00627] Bispecific 1G1 x humanized 2L16 antibodies in a 2x1 format described in Table 41 were constructed as described in Example 37 and produced as described below.
Production and characterization of 1G1 x humanized 2L16 antibodies with 2L16 paratope in scFv format
[00628] Variants v32680, v31946, v32687, v32686, and v32688 were prepared using transient mammalian expression conditions and subsequently purified and characterized for stability and antigen binding. Samples of bispecific lG1x humanized 2L16 antibodies with 2L16 scFv antigen-binding domains were subjected to UPLC-SEC after protein A purification to assess the amount of high molecular weight (HMW) species. Further, thermal stability of the 2L16 scFv in these bispecific antibodies was assessed by differential scanning calorimetry (DSC) as described below. This was performed to identify the optimal design for an 2L16 scFv in the context of a 1G1 humanized 2L16 antibody.
Method
[00629] The bispecific antibody variants were co-expressed in 250 mL CHO cultures and purified as described in Example 37. Following protein A purification, purity of samples was assessed by non-reducing and reducing High Throughput Protein Express assay (LabChip) as described in Example 37.
[00630] Post protein A purification, samples were either buffer exchanged into DPBS (Dulbecco’s PBS) and aseptically filtered or, depending on their homogeneity assessed by UPLC-SEC, subjected to SEC purification as described in Example 37. UPLC-SEC was performed as described in Example 38.
[00631] The thermal stability of bispecific antibody variants was assessed by differential scanning calorimetry (DSC) as described in Example 38.
Results
[00632] The results are shown in Table 42. Yields of variant post protein A were in the range of 36-66 mg/L for the bispecific antibody variants. Non-reducing and reducing LabChip post protein A reflected a predominant species of the desired molecular weight.
[00633] As can be seen in Table 42, UPLC-SEC profdes showed a variety of homogeneity in the different variants. Some variants contained high molecular weight (HWM) species (i.e. dimers, trimers, higher order aggregates) of up to 41%, v32687. v31946 had the lowest measured HMW species at 15.6% with a (G4S)3 linker. All samples had the HMW species removed with preparative SEC.
Table 42: High molecular weight species in Fc-fused 2L16 scFv samples

[00634] Figure 49 shows sample DSC thermograms of v31946 and v32681, see Figure 49A and Figure 49B, respectively. The Tm values corresponding to the scFv portion of the bispecific antibody determined from the thermograms are shown in Table 42 above.
[00635] Each peak on the thermogram corresponds to a thermal transition. There are four expected thermal transitions: 1G1 Fab (~80°C), 2L16 Fab/scFv, CH2 (~71°C) and CH3 (~80°C). The transition of the Fab reflects cooperative melting of the VH-VL and CH1 -CL domains. The expected transition of the scFv would correspond to the melting of the VH-VL domains. The 2L16 scFv transition overlaps with the CH2 domain transition and therefore only 2 transition peaks are observed in the thermogram for the 1G1 x humanized 2L16 bispecific antibody variants with a 2L16 scFv. As can be seen in Figure 49A, v31946 contains a small shoulder at ~61°C that may correspond to part or all of the 2L16 scFv transition. As the thermal transition overlaps significantly with the CH2 domain obtaining a precise Tm is not possible. The Tm of the 2L16 scFv was ~20°C lower than the parent Fab antibody.
Binding of the 2L16 scFv portion of 1G1 x humanized 2L16 antibodies to human FRa by Bio-layer interferometry
[00636] To assess the ability of the 2L16 scFv portion of 1G1 x humanized 2L16 antibodies to retain Fab-like binding to human FRα, the affinity of these antibodies was compared to the parental antibody variant 32680 by Bio-layer interferometry (BLI).
[00637] Post SEC protein material described above was assessed for binding to human FRα. Binding was measured by Bio-layer interferometry (BLI) using the Octet RED 96 (ForteBio) as described in Example 38. All parameters remained the same except for the dissociation phase which was recorded for 1500s.
Results
The KDs measured for the 2L16 scFv portion of each 1G1 humanized 2L16 antibody are provided in Table 43.
Table 43: Binding of 2L16 scFv portion of each 1G1 humanized 2L16 antibody to hFRa

[00638] As can be seen from Table 43, the BLI binding assay performed on the antibody variants revealed that all 2L16 scFv variants bound to hFRα with an affinity that was within 2-
fold of the Parent Fab antibody. Figure 51 provides BLI sensorgrams for the Parent Fab antibody (Figure 51B) and one representative bispecific antibody variant 31946 (Figure 51 A) that were able to bind human FRα. These results suggest that the conversion to the scFv did not impact the binding to the antigen and that the location or fusion of the scFv to the C- terminus had no effect on binding.
EXAMPLE 44: Ability of 4-1BB x FRα 2L16 bispecific antibody constructs to stimulate 4-1BB activity in an NF-kB-Luciferase reporter assay
[00639] To test the ability of bispecific 4-1BB x FRα antibodies to stimulate 4-1BB activity in the presence of a tumor cell expressing FRα, a reporter-gene assay was used as a measure of signaling downstream of 4-1BB to a NF-kB reporter driving luciferase. The bispecific antibody variants tested included the 1G1 x humanized 2L16 antibodies 31946, 32686, 32687, and 32688 having the 2L16 paratope in scFv format (described in Example 43) and 32680, 32681, 32683, and 32685, having the 2L16 paratope in Fab format.
[00640] The ability of bispecific antibodies to activate 4-1BB in the context of FRα+ tumour cells was measured using a co-culture assay. This assay used Jurkat cells engineered to express 4-1BB and a luciferase reporter gene driven by an NF-kB site. This assay measures signaling from 4-1BB on the surface of the cell down to the nucleus. IGROV1 cells were used as a FRα+ tumour cell line.
[00641] The day prior to the assay white, TC-treated, polystyrene, 384-well plates (Coming) were treated with 40 μL/well OKT3, mouse-anti-human-CD3 antibody (Biolegend) at 5 μg/mL in phosphate buffered saline (PBS) (Gibco). The plate was sealed to the plate lid by wrapping in parafilm. The plate was incubated overnight at 4°C. The next day, the contents of the plate were aspirated, and the plate was washed with 3 changes of distilled water (120μL/well) using a 405HT ELISA plate washer (Biotek). The plate was then ready for use in the assay.
[00642] Bispecific antibodies were diluted in Assay Buffer (RPMI (Gibco)/l% FBS (Gibco)) to 40 nM (final assay concentration 20 nM). A volume of 30 μL was pipetted into the well of a white, TC-treated, polystyrene, 384-well plate (Coming) receiving the top concentration of the variant. A volume of 10μL was pipetted into a volume of 20μL Assay Buffer in the next well for the second highest concentration well and mixed to give a 3-fold
dilution. This was repeated for the transfer from the second highest well to the third highest until the lowest concentration well, where the residual 10μL volume was removed.
[00643] 8.0E6 IGROV1 tumor cells were harvested and resuspended at a density of 2.0E6 cells/mL. NFκB 1UC2P/4-1BB Thaw-and-Use Jurkat cells (Promega) were thawed at 37C according to manufacturer’s instructions and 1.60E7 total cells were resuspended at 4.0E6 cells/mL in assay buffer. The tumor cells and Jurkat cells were then mixed in equal volume, washed, and resuspended in an equivalent volume of Assay Buffer. 20uL of cell suspension was added to each well containing the variants and 20uL of media was added to media-only wells. The co-cultured cells with variants were then incubated at 37°C in a 5% CO2 atmosphere for 6 hours and then equilibrated to room temperature on the benchtop for 10 minutes. A volume of 40μL of Bio-Glo™ (Promega) luciferase substrate reagent was added to each well of the plate and incubated for 10 minutes at room temperature. The plate was scanned on the Synergy™ Hl(Biotek) multi-mode plate reader in luminescence mode. Data was analysed using Prism 7 (GraphPad) and four-parameter variable slope nonlinear fit.
Results
[00644] The results are shown in Figures 52A-D. Negative non-binding control antibody v16952 did not show any activation of the 4-1BB RGA cells, nor did the monospecific 2L16 FRα antibody v32693. Positive control monospecific anti-4-1BB antibody v30335 induced luciferase expression by the Jurkat reporter cells. v30048, a construct containing the original rabbit 2L16 scFv showed higher potency compared to that shown by v30335. The 1G1 x humanized 2L16 scFv variants all showed activity, with v32686 the most potent.
EXAMPLE 45: Preparation of additional 1G1 x humanized 2L16 antibodies having a 2L16 scFv
[00645] The 2L16 Fab portion of 1G1 x humanized 2L16 variants 32681 and 32685 (comprising humanized sequences H2cL1 and H2gL1, respectively) described in Example 41 were converted from Fab format to scFv format as described below. This was done to facilitate the production of the high affinity optimized anti-4-1BB x anti-FRα bispecific antibodies in the 2 x 1 format described in Example 43 and Figure 2B.
Design and production of humanized 2L16 scFv
[00646] The two humanized 2L16 Fab portions of variants 32681 and 32685 (H2cL1 and H2gL1), were converted into a scFv format and expressed and purified described in Example 43. New variant 33570 is the same as variant 32681 but with a 2L16 scFv instead of Fab, and new variant 33571 is the same as variant 32685 but with a 2L16 scFv instead of Fab. The purified material was assessed for binding to human FRα. Binding was measured by Bio- layer interferometry (BLI) using the Octet RED 96 (ForteBio) as described in Example 43. All parameters remained the same except for the dissociation phase which was recorded for 1500s.
Results
[00647] Yields of variant antibodies post protein A were ~75 mg/L. Non-reducing and reducing LabChip post protein A reflected a predominant species of the desired molecular weight.
[00648] As can be seen in Table 44, UPLC-SEC profiles showed a variety of homogeneity in the different variants. Both variants contained 23% high molecular weight (HMW) species (ie dimers, trimers, higher order aggregates). In both cases, the HMW species was removed by preparative SEC. Both of the variants were high affinity binders with a measured affinity of 0.1 -0.2 nM. BLI sensorgrams for these two variants are shown in Figure
51C and 5 ID.
Table 44: Optimized 2L16 scFv

EXAMPLE 46: Modification of 1G1 x humanized 2L16 bispecific antibodies
[00649] To improve the biophysical properties of the lG1x humanized 2L16 bispecific antibodies described in Example 45, having a 2L16 scFv, several mutations were identified on the 2L16 scFv paratope that could potentially improve the thermal stability and/or species homogeneity of the bispecific antibody.
[00650] A homology model for the 2L16 scFv was prepared to identify surface and buried residues. Select hydrophobic residues were replaced with hydrophilic or Ala residues. Select VH-VL interface residues were replaced to optimize the interface interactions and select
buried residues were with alternative hydrophobic residues to improve packing. In some variants the linker between the VL and VH domains was replaced with an alternative linker shown in Table 45. A list of the potential mutations is shown in Table 46.
Table 45: Modifications in 2L16 scFv sequence to improve biophysical properties of antibody constructs having a 2L16 scFv

[00651] All mutations were tried independently, and in combinations up to 4, making a total of 21 modified variants (Table 46). Sequences of the scFv portion of each variant are referenced below; sequences of each modified VH and VL region are provided in Table 48.
Table 46: Modified 1G1-2L16 bispeciflc variants and their composition


[00652] Each of the modifications described in Table 46 was incorporated into a 1G1 x humanized 2L16 bispecific antibody in 2 x 1 format having a C-terminal 2L16 scFv.
[00653] All sequences will be preceded by a signal peptide which is an artificially designed sequence MRPTWAWWLFLVLLLALWAPARG [SEQ ID NO:l] (ref: Barash S et al, Biochem and Biophys Res. Comm. 2002; 294, 835-842). For all parental and humanized heavy and light chains, vector inserts will be prepared as described in Example 37 and cloned into pTT5 to produce expression vectors.
[00654] The heavy and light chains of antibody variants will be expressed in 250 mL CHO cultures and purified as described in Example 37. Following protein A purification, purity of samples will be assessed by non-reducing and reducing High Throughput Protein Express assay as described in Example 37.
[00655] Post protein A purification, samples will be either buffer exchanged into DPBS and aseptically filtered or, depending on their homogeneity assessed by UPLC-SEC, subjected to SEC purification as described in Example 38.
[00656] DSC experiments will be performed as described in Example 38 on samples generated above. The Tm for the scFv should be the first transition observed in the thermograph. Purified protein material of select samples will be assessed for binding to human FRα. The antigen-binding affinity will determined by BLI as described in Example 38.
EXAMPLE 47: Production of modified of 1G1 x humanized 2L16 bispecific antibodies
[00657] The bispecific antibodies described in Example 46 were produced and characterized to assess species homogeneity after protein A purification, thermal stability of the 2L16 scFv, binding of the 2L16 scFv to FRα, and high temperature stability.
Production of modified antibodies
[00658] The modifications for each variant described in Table 46 were incorporated into a 1G1 x humanized 2L16 bispecific antibody in 2 x 1 format having a C-terminal 2L16 scFv as follows.
[00659] All sequences were preceded by a signal peptide which is an artificially designed sequence MRPTWAWWLFLVLLLALWAPARG [SEQ ID NO:l] (ref: Barash S et
al., Biochem and Biophys Res. Comm. 2002; 294, 835-842). For all parental and humanized heavy and light chains, vector inserts were prepared as described in Example 37 and cloned into pTT5 to produce expression vectors.
[00660] The heavy and light chains of variants were expressed in 250 mL CHO cultures and purified as described in Example 37. Following protein A purification, purity of samples was assessed by non-reducing and reducing High Throughput Protein Express assay as described in Example 37.
[00661] Post protein A purification, samples were either buffer exchanged into DPBS and aseptically filtered or, depending on their homogeneity assessed by UPLC-SEC, subjected to SEC purification as described in Example 38.
[00662] DSC measurements were performed as described in Example 38 on samples generated above. The Tm for the scFv was the first transition observed in the thermograph. Purified protein material of select samples was assessed for binding to human FRα. The antigen -binding affinity was determined by BLI as described in Example 38.
[00663] High temperature stability was determined on a select set of variants as described in Example 38.
Results
[00664] Yields of protein post protein A purification were in the range of 26-54 mg/L for the 1G1-2L16 variants. Non-reducing and reducing LabChip post protein A reflected the predominant species corresponding to full size antibody and intact heavy and light chains in all cases (data not shown). Endotoxin levels were within the specifications.
[00665] The results for the species homogeneity after protein A purification based on UPLC-SEC, thermal stability and binding to FRα are shown in Table 50 as are the measurements for thermal stability and FRα-binding.
Table 50: Species homogeneity of modified 1 G1-2L16 bispecific variants, % high molecular weight species

 N/D - no data measured due to the high level of aggregates
N/D - no data measured due to the high level of aggregates
[00666] As can be seen in Table 50, the majority of variants had similar HMWS compared to the parent, v31946. Three variants, v33711, v33715, and v33730, had the amount of aggregates improve to <10% compared to the parent v31946. The thermal stability of v33707, v33728, v33731, and v33903 increased by at least 1°C. Additionally, v33707 and v33731 had reduced amount of aggregates form under thermal stress compared to the parent. Several of the variants lost their affinity suggesting that these modifications impacted the structure of the CDRs. v33705 and v33730 had the greatest improvement in the HMW species but had no detectable binding to FRα.
[00667] In summary the majority of variants only provided a minor improvement in biophysical properties compared to the parent variant v31946. The variants with the most improved biophysical profile while maintain FRα binding were v33711 and v33731.
EXAMPLE 48: Ability of 1G1 x humanized 2L16 scFv bispecific antibody constructs to stimulate 4-1BB activity in an NF-kB-Luciferase reporter assay
[00668] The 1G1 x humanized 2L16 antibodies 33570 and 33571 having the 2L16 paratope in scFv format described in Example 45 were tested to assess their ability to stimulate 4-1BB activity according to the method described in Example 44 with the following exceptions.
[00669] 384-well plates were treated with 30 μL/well OKT3, mouse-anti -human-CD3 antibody (Biolegend) at 5 μg/mL in phosphate buffered saline (PBS) (Gibco) instead of 40 μL.
[00670]4.26E6 IGROV1 tumor cells were harvested and resuspended at a density of 1.0E6 cells/mL. NFκB 1UC2P/4-1BB Thaw-and-Use Jurkat cells (Promega) were thawed at 37°C according to manufacturer’s instructions and 8.51E6 total cells were resuspended at 2.0E6 cells/mL in assay buffer. The tumor cells and Jurkat cells were then mixed in equal volume, washed, and resuspended in an equivalent volume of Assay Buffer. 20uL of cell suspension was added to each well containing the variants and 20uL of media was added to media-only wells. 20uL of cell suspension was also added to 20uL of Assay Buffer in no-variant wells. The co-cultured cells with or without variants were then incubated at 37°C in a 5% CO2 atmosphere for 6 hours and then equilibrated to room temperature on the benchtop for 10 minutes. A volume of 40μL of Bio-Glo™ (Promega) luciferase substrate reagent was added to each well
of the plate and incubated for 10 minutes at room temperature. The plate was scanned on the Synergy™ Hl(Biotek) multi -mode plate reader in luminescence mode. Data were analysed using Prism 9 (GraphPad) and four-parameter variable slope nonlinear fit.
Results
[00671] The results are shown in Figure 53. Two antibodies were used as control antibodies for non-specific activity. v16981, which does not bind mammalian proteins, did not show activity in this assay. v31354, which contains the same 4-1BB binding domains and same format as v33570 and v33571, but does not bind FRα, showed minimal activity. Positive control monospecific anti-4-1BB antibody v30335 induced luciferase expression by the Jurkat reporter cells. The 1G1 x humanized 2L16 scFv variants, v33570 and v33571, both showed activity with higher potency compared to that shown by v30335.
EXAMPLE 49: Ability of a modified 1G1-8K22 bispecific antibody to stimulate 4-1BB activity in an NF-kB-Luciferase reporter assay
[00672] The ability of the modified 1G1-8K22 antibody 31588 (described in Example 37) to stimulate 4-1BB activity in the presence of a tumor cell expressing FRα was determined using the NF-kB-Luciferase reporter gene assay described in previous examples. The assay was carried out as described in Example 48.
Results
[00673] The results are shown in Figure 54. Two antibodies were used as control antibodies for non-specific activity, v 16981, which does not bind mammalian proteins, did not show activity in this assay. v31354, which contains the same 4-1BB binding domains and same format as v31588, but does not bind FRα, showed minimal activity. Positive control monospecific anti- 4-1BB antibody v30335 induced luciferase expression by the Jurkat reporter cells. The modified 1G1-8K22 variant, v31588, showed activity with higher potency compared to that shown by v30335.
EXAMPLE 50: Quantitation of surface FRα on tumor cells
[00674] The levels of FRα surface protein were measured in several tumor cell lines by quantitative flow cytometry using a set of beads with known levels of antibody. Anti-FRα antibody v17717 was used, conjugated to AlexaFluor647 as described below. Tumor cell lines
were chosen based on mRNA expression data suggesting that they would represent cell lines expressing varying levels of FRα expression.
[00675] Variant 17717 was conjugated to Alexa Fluor 647 as follows. Variant 17717 was buffer exchanged into sodium bicarbonate buffer pH 8.4 using 40kDa Zeba columns. The antibody was then reacted with 10eq. of NHS-Alexa Fluor 647 (Thermofisher A20006, 10mM). Each reaction was allowed to proceed protected from light at room temperature for 90 minutes. Following incubation, each reaction was then purified using a 40kDa Zeba column, pre-equilibrated with PBS pH7.4. Conjugation was confirmed by SEC chromatography (Excitation: 650nm, Emission: 665nm).
[00676] Cell lines were obtained from ATCC (Manassas, Virginia, USA), with the exception of JIMT-1 (German Collection of Microorganisms and Cell Culture, Braunschweig, Germany) and IGROV1 (National Cancer Institute, Bethesda, Maryland, USA). IGROV-1, NCI-N87, HCC1954, NCI-H226, andNCI-H661 tumor cells were cultured in RPMI (Gibco)/10% FBS in T175 flasks. JIMT-1 tumor cells were cultured in DMEM (Gibco)/10% FBS in T175 flasks. SK-BR-3 tumor cells were cultured in McCoy’s 5A (Gibco)/10% FBS in T175 flasks. Cell lines were maintained in culture for up to one month post-thaw and harvested at 90% confluency. Cell dissociation buffer (Invitrogen) was added, and cells removed from the plate with mechanical means if necessary, using either a pipette or a cell scraper. Cells were left on ice for one hour with 15 μg/mL of mirvetuximab analog variant 17717 conjugated to AlexaFluor647.The concentration of 15 μg/mL was pre-determined to be a saturating concentration of conjugated antibody, to ensure that the cells in the suspension were completely labelled. A series of beads with pre-determined levels of anti-human coating antibody were used as standards (816; Bangs Laboratories). Numbers of receptor per cell were calculated by comparing the level of AlexaFluor647 fluorescence on the tumor cells to a standard curve constructed using the calibration beads.
Results
[00677] Table 51 provides the results of surface TAA quantitation and identifies tumor cell lines with varying levels of expression of FRα.
Table 51: Surface TAA quantitation on tumor cell lines


EXAMPLE 51: Activation of 4-1BB by a modified 1G1-8K22 bispecific antibody in co- culture with cell lines expressing different levels of FRα
[00678] The ability of the modified bispecific 1G1-8K22 antibody variant 31588, described in Example 37, to stimulate 4-1BB activity in co-culture with tumor cells expressing different levels of FRα was determined. The assay was performed as described in Example 48, with the following exceptions.
[00679] The tumor cell lines tested are shown in the table below and express FRα at the levels assessed in Example 50.
Table 52: Tumor Cell lines

Plates were prepared as described in Example 48, as were the bispecific antibodies and controls.
[00680] Tumor cells were harvested and resuspended at a density of 1.0E6 cells/mL. NFκB luc2P/4-1BB Thaw-and-Use Jurkat cells (Promega) were thawed at 37°C according to manufacturer’s instructions and were resuspended at 2.0E6 cells/mL in assay buffer. The tumor cells and Jurkat cells were then mixed in equal volume, washed, and resuspended in an equivalent volume of Assay Buffer. 20uL of cell suspension was added to each well containing the variants and 20μL of media was added to media-only wells. 20uL of cell suspension was also added to 20μL of Assay Buffer in no-variant wells. The co-cultured
cells with or without variants were then incubated at 37°C in a 5% CO2 atmosphere for 6 hours and then equilibrated to room temperature on the benchtop for 10 minutes. A volume of 40μL of Bio-Glo™ (Promega) luciferase substrate reagent was added to each well of the plate and incubated for 10 minutes at room temperature. The plate was scanned on the Synergy™ Hl(Biotek) multi-mode plate reader in luminescence mode. Data were analysed using Prism 9 (GraphPad) and four-parameter variable slope nonlinear fit.
Results
[00681] The results are shown in Figures 55A-G. Two antibodies were used as control antibodies for non-specific activity. v16981, which does not bind mammalian proteins, did not show activity in all cell lines assayed. v31354, which contains the same 4-1BB binding domains and same format as v31588, but does not bind FRα, showed minimal activity in all cell lines assayed. Positive control monospecific anti-4-1BB antibody v30335, a urelumab analog, induced luciferase expression by the Jurkat reporter cells, regardless of FRα expression. In cell lines with greater than -60,000 FRα proteins per cell (IGROV1 and HCC1954, Fig. 55 A and B), the modified 1G1-8K22 variant, v31588, showed activity with higher potency compared to that shown by v30335. In cell lines with greater than -10,000, but less than -60,000 FRα proteins per cell (NCI-N87 and SK-BR-3, Fig. 55C and D), the modified 1G1-8K22 variant, v31588, showed activity with higher potency compared to that shown by v31354, but less than that shown by v30335. In cell lines with less than -10,000 FRα proteins per cell (NCI-H226, NCI-H661, and JIMT-1, Fig. 55E, F, and G), the modified 1G1-8K22 variant, v31588, showed similar activity as was observed with v31354.
EXAMPLE 52: Bispecific 4-1BB x FRα variant shows anti-tumor activity in a transgenic mouse model
[00682] The purpose of the experiment was to determine the anti-tumor activity of a 4- 1BB x FRα bispecific antibody in human FRα expressing tumors compared to a monospecific anti-4-1BB Urelumab analog in a transgenic mouse tumor model expressing human 4-1BB and FRα. Immunocompetent mice expressing chimeric human 4-1BB on a C57B1/6 mouse background (Shanghai Model Organism Center; Strain name: C57BL/6J- Tnfrsf9eml(TNFRSF9)Smoc) were engrafted with wild type MC38 mouse tumor cells (Parental MC38) or engineered MC38 cells stably expressing full-length human FRα (hFRα #32 MC38). When tumors reached a mean tumor volume of about 80 mm3 mice were randomized into treatment groups of either: Phosphate buffered saline vehicle control (v!7891); 4-1BB x
FRα bispecific antibody (v33520); or urelumab analog antibody (v30335). Variant 33520 is the same bispecific antibody as v31588 and is composed of heavy and light chains having the same amino acid sequences as variant 31588. All test articles were administered at 10 mg/kg, intravenously, once per week for 4 weeks. Tumor growth in mice was monitored over a period of 53 days.
Results:
[00683] The effect of the test articles in mice engrafted with wild-type MC38 mouse tumor cells is shown in Figure 56A and the effect of the test articles in mice engrafted with hFRα #32 MC38 is shown in Figure 56B. In mice bearing parental MC38 tumors v33520 showed minimal anti-tumor activity; tumor growth was similar to vehicle control (v17891). Treatment with the urelumab analog v30335 was associated with acute and unexplained toxicity, and effects of v30335 on tumor growth could not be established. In mice bearing human FRα-expressing MC38 tumors treatment with v33520 rapidly decreased tumor volume to undetectable levels compared to control vehicle treated tumors, and the anti-tumor activity of v33520 was retained for the duration of the study. Treatment with urelumab analog v30335 appeared to be less effective than v33520 but the comparison is confounded by acute and unexplained toxicity observed following v30335 administration. No adverse events were observed in animals treated with v33520 in either parental or human FRα-expressing tumor models.
[00684] Collectively, the data indicate that the 4-1BB x FRα bispecific antibody had significant anti-tumor activity in a mouse model expressing human FRα but limited activity in tumors that do not express FRα.
Tables 13-22, 47, 48, and 49
Table 13: Recovered anti-human 4- IBB antibody sequences


Table 14. Amino acid and DNA sequences of heavy and light chain humanized 1C8, 1G1 and 5G8




Table 15: Sequences used in the construction of 4-1BB x HER2 antibodies

Table 16: Sequences used in the preparation of additional 4- IBB x TAA bispecific antibody constructs



t
-to *.
























Table 19: VH and VL Composition of Humanized 8K22 antibody Variants

Table 20. Amino acid sequences of heavy and light chain humanized 8K22


Table 21: Antigen binding assessment of the humanized 8K22 antibody variants by Octet

ND-not determined
Table 22: Thermal stability assessment of the humanized 8K22 antibody variants by DSC

ND-not determined, ‘exhibited two-state transition
Table 47: Human and rabbit CDRs of anti-FRa antibody 2L16*
 those of the parent rabbit antibody, both versions of the CDR are provided and identified accordingly.
those of the parent rabbit antibody, both versions of the CDR are provided and identified accordingly.
Table 48: Anti-FRa VH and VL sequences





Table 49: scFv sequences



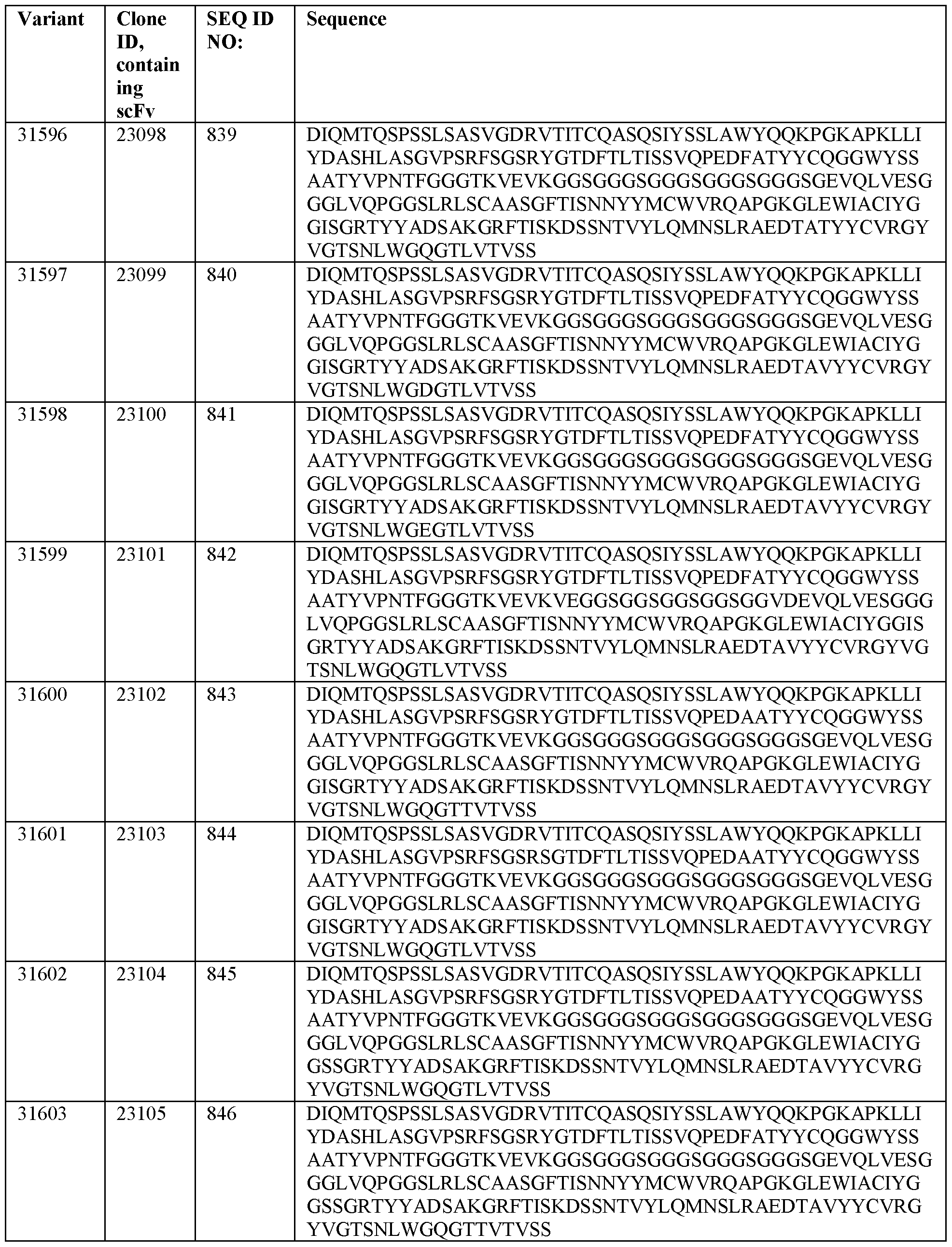



 Table X: Variant Clone Composition
Table X: Variant Clone Composition



Table XI: Variant Clone Composition

* N-terminus heavy chain attached to a C-terminus light chain
** This clone is a heavy chain Fab. It should pair with the C-terminus light chain of the H1 clone
Table X2: Variant Clone Composition



*hybrid chain with heavy and light chain sequences; includes VL, CL attached to C- terminus of heavy chain
Table Y: Sequences











































































Table Yl: Sequences




Table Y2: Sequences

















[00685] The disclosures of all patents, patent applications, publications and database entries referenced in this specification are hereby specifically incorporated by reference in their entirety to the same extent as if each such individual patent, patent application, publication and database entry were specifically and individually indicated to be incorporated by reference.
[00686] Modifications of the specific embodiments described herein that would be apparent to those skilled in the art are intended to be included within the scope of the following claims.
Claims
1. An antibody construct comprising: a) a first 4-1BB-antigen binding domain derived from an agonistic anti -4-1BB antibody, and b) a first folate receptor alpha (FRα)-antigen binding domain in scFv format comprising a heavy chain variable domain (VH) sequence having at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% sequence identity to the VH sequence of antibody 8K22 and comprising the three heavy chain CDR sequences of antibody 8K22 and a light chain variable domain (VL) sequence having at least 85%, 90%, 95%, 96%, 97%, 98%, or 99% sequence identity to the VL sequence of antibody 8K22 comprising the three light chain CDR sequences of antibody 8K22, and further comprising one or more amino acid modifications in the VH domain and/or in the VL domain of antibody 8K22 that improve the biophysical properties of the antibody construct, wherein the first 4-1BB-antigen binding domain and the first FRα-antigen binding domain are linked directly or indirectly to a scaffold.
2. The antibody construct according to claim 1, wherein the one or more amino acid modifications increase the thermal stability of the first FRα antigen-binding domain.
3. The antibody construct according to claim 1 or 2, wherein the one or more amino acid modifications result in a decrease in the amount of high molecular weight species of the antibody construct during production.
4. The antibody construct according to any one of claims 1 to 3, wherein the one or more amino acid modifications comprise amino acid substitution at one or more of residues Y67, F83, Y49, and VI 5 of the VL sequence of antibody 8K22, wherein the numbering of residues is according to the Rabat numbering system.
5. The antibody construct according to any one of claims 1 to 4, wherein the one or more amino acid modifications comprise insertion of lysine (K) at position 75 of the
VH sequence of antibody 8K22, wherein the numbering of residues is according to the Kabat numbering system.
6. The antibody construct according to any one of claims 1 to 5, wherein the one or more amino acid modifications comprise amino acid substitution at one or more of residues 153, L108, V89, and Q105, in the VH sequence of antibody 8K22 wherein the numbering of residues is according to the Kabat numbering system.
7. The antibody construct according to claim 4, wherein the one or more amino acid modifications in the VH sequence and/or the VL sequence of 8K22 comprise: a) F83 A or F83D in the VL sequence, b) VI 5P or VI 5T in the VL sequence, c) F83 A in the VL sequence, I48V, A49S, A63 V, S73N, and V78L in the VH sequence, and insertion of lysine at residue 75 of the VH sequence, d) 153 S in the VH sequence, e) V89T in the VH sequence f) Q 105D or Q 105E in the VH sequence, g) F83A in the VL sequence and L108T in the VH sequence, h) F83A in the VL sequence and 153 S in the VH sequence, i) F83A in the VL sequence and L108T and I53S in the VH sequence, j) F83A and Y67S in the VL sequence, k) F83A and Y67S in the VL sequence, and L108T in the VH sequence, or l) F83A and Y67S in the VL sequence, and L108T and I53S in the VH sequence.
8. The antibody construct according to claim 7, wherein the first FRα-antigen binding domain comprises the VH sequence and the VL sequence of variant 31588, 31586, 31594, or 31595.
9. The antibody construct according to claim 8, wherein the first FRα-antigen binding domain comprises the sequence as set forth in SEQ ID NO:831.
10. The antibody construct according to any one of claims 1 to 9, further comprising a second 4-1BB-antigen-binding domain, linked directly or indirectly to the scaffold.
11. The antibody construct according to claim 10, wherein the first 4-1BB-antigen- binding domain is different from the second 4- lBB-anti gen-binding domain.
12. The antibody construct according to claim 10 or 11, wherein the first 4-1BB- anti gen-binding domain is the same as the second 4-1BB-antigen-binding domain.
13. The antibody construct according to any one of claims 1 to 12, wherein the first 4- 1BB antigen binding domain comprises: a) a heavy chain variable domain (VH) comprising the three heavy chain complementarity-determining regions (CDRs) of antibody 1G1, and a light chain variable domain (VL) comprising the three light chain CDRs of antibody 1G1, b) a heavy chain variable domain comprising the three heavy chain CDRs of antibody 5G8, and a light chain variable domain comprising the three light chain CDRs of antibody 5G8, or c) a heavy chain variable domain comprising the three heavy chain CDRs of antibody 1C8, and a light chain variable domain comprising the three light chain CDRs of antibody 1C8.
14. The antibody construct according to any one of claims 1 to 12, wherein the first 4- lBB-antigen binding domain comprises: a) a heavy chain variable domain (VH) comprising the three heavy chain CDRs of antibody 1G1 and is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO:46, and a light chain variable domain (VL) comprising the three light chain CDRs of antibody 1G1 and is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO:58, b) a heavy chain variable domain comprising the three heavy chain CDRs of antibody and is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO:62, and a light chain variable domain comprising the three
light chain CDRs of antibody 5G8 and is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO: 64, or c) a heavy chain variable domain comprising the three heavy chain CDRs of antibody 1C8 and is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO:53, and a light chain variable domain comprising the three light chain CDRs of antibody 1C8 and is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO:48.
15. The antibody construct according to any one of claims 10 to 14, wherein the first 4- lBB-antigen-binding domain and the second 4- lBB-anti gen-binding domain are in a Fab format.
16. The antibody construct according to any one of claims 1 to 15, wherein the scaffold is a dimeric Fc construct having a first Fc polypeptide and a second Fc polypeptide, each Fc polypeptide comprising a CH3 sequence, or wherein the scaffold is a linker or an albumin polypeptide.
17. The antibody construct according to claim 16, wherein the scaffold is a heterodimeric Fc construct having a first Fc polypeptide that is different from the second Fc polypeptide, and wherein the CH3 sequences of the first Fc polypeptide and the second Fc polypeptide comprise amino acid substitutions that promote the formation of a heterodimeric Fc.
18. The antibody construct according to claim 17, wherein: a) one Fc polypeptide comprises the amino acid substitutions T350V_L351Y_F405A_Y407V and the other Fc polypeptide comprises the amino acid substitutions T350V_T366L_K392L_T394W; b) one Fc polypeptide comprises the amino acid substitutions T350V_T366L_K392M_T394W and the other Fc polypeptide comprises the amino acid substitutions T350V_L351 Y_F405A_Y407V;
c) one Fc polypeptide comprises the amino acid substitutions
L351Y F405A Y407V and the other Fc polypeptide comprises the amino acid substitutions T366L K392M T394W; d) one Fc polypeptide comprises the amino acid substitutions
L351Y F405A Y407V and the other Fc polypeptide comprises the amino acid substitutions T366L K392L T394W; or e) one Fc polypeptide comprises the amino acid substitutions L351Y_S400E_F405A_Y407V and the other Fc polypeptide comprises the amino acid substitutions T366I N390R K392M T394W, wherein the numbering of residues in the Fc polypeptide is according to the EU numbering system.
19. The antibody construct according to any one of claims 16 to 18, further comprising one or more amino acid modifications that reduce effector function.
20. The antibody construct according to claim 19, wherein the one or more amino acid modifications are L234A, L235A and D265S, wherein the numbering of residues is according to the EU numbering system.
21. The antibody construct according to any one of claims 1 to 20, wherein the first 4- 1BB antigen-binding domain is linked to the N terminus of the first Fc polypeptide, and the first TAA antigen -binding domain is linked to the C terminus of the second Fc polypeptide.
22. The antibody construct according to any one of claims 12 to 21, wherein the first 4- 1BB antigen-binding domain is linked to the N terminus of the first Fc polypeptide, the first FRα antigen-binding domain is linked to the C terminus of the second Fc polypeptide, and the second 4-1BB antigen-binding domain is linked to the N terminus of the second Fc polypeptide.
23. The antibody construct according to claim 10, wherein the first 4-1BB antigen- binding domain and the second 4-1BB antigen-binding domain comprise the VH
amino acid sequence as set forth in SEQ ID NO:46 and the VL amino acid sequence as set forth in SEQ ID NO:54, and the first FRα-antigen-binding domain comprises the sequence as set forth in SEQ ID NO:831.
24. The antibody construct according to claim 23, comprising the polypeptide sequences of variant 31588.
25. The antibody construct according to any one of claims 1 to 24, conjugated to a drug.
26. A pharmaceutical composition comprising the antibody construct of any one of claims 1 to 25.
27. One or more nucleic acids encoding the antibody construct according to any one of claims 1 to 24.
28. One or more vectors comprising the one or more nucleic acids according to claim 27.
29. An isolated cell comprising the one or more nucleic acids according to claim 27, or the one or more vectors according to claim 28.
30. A method of preparing the antibody construct according to any one of claims 1 to 25, comprising culturing the isolated cell of claim 29 under conditions suitable for expressing the antibody construct, and purifying the antibody construct.
31. A method of treating a subject having a cancer, comprising administering to the subject an effective amount of the antibody construct according to any one of claims 1 to 25.
32. Use of an effective amount of the antibody construct according to any one of claims 1 to 25 for the treatment of cancer in a subject in need thereof.
33. Use of the antibody construct according to any one of claims 1 to 25 in the preparation of a medicament for the treatment of cancer.
34. The antibody construct according to any one of claims 1 to 25, for use in the treatment of cancer in a subject.
35. An antibody construct comprising a) a first 4-1BB antigen-binding domain derived from an agonistic anti -4-1BB antibody, and b) a first folate receptor-a (FRα) antigen-binding domain in a Fab format comprising a heavy chain variable domain (VH) comprising the three heavy chain CDR sequences of antibody 8K22 and a light chain variable domain (VL) comprising the three light chain CDR sequences of antibody 8K22, wherein the first 4-1BB antigen-binding domain and the first FRα antigen-binding domain are linked directly or indirectly to a scaffold.
36. The antibody construct according to claim 35, wherein the construct comprises the polypeptide sequences of variant 33568, or variant 33569.
37. The antibody construct according to claim 35, conjugated to a drug.
38. A pharmaceutical composition comprising the antibody construct of claim 35 or 36.
39. One or more nucleic acids encoding the antibody construct according to claim 35 or 36.
40. One or more vectors comprising the one or more nucleic acids according to claim 39.
41. An isolated cell comprising the one or more nucleic acids according to claim 39 or the one or more vectors according to claim 40.
42. A method of preparing the antibody construct according to claim 35 or 36, comprising culturing the isolated cell of claim 41 under conditions suitable for expressing the antibody construct, and purifying the antibody construct.
43. A method of treating a subject having a cancer, comprising administering to the subject an effective amount of the antibody construct according to claim 35 or 36.
44. Use of an effective amount of the antibody construct to claim 35 or 36 for the treatment of cancer in a subject in need thereof.
45. Use of the antibody construct according to claim 35 or 36 in the preparation of a medicament for the treatment of cancer.
46. The antibody construct according to claim 35 or 36, for use in the treatment of cancer in a subject.
47. An antibody construct comprising: a) a first 4-1BB antigen-binding domain derived from an agonistic anti-4-1BB antibody, and b) a first folate receptor-a (FRα) antigen-binding domain comprising a heavy chain variable domain (VH) comprising the three heavy chain CDR sequences of antibody 2L16 and a light chain variable domain (VL) comprising the three light chain CDR sequences of antibody 2L16, wherein the first 4-1BB antigen-binding domain and the first FRα antigen-binding domain are linked directly or indirectly to a scaffold.
48. The antibody construct according to claim 47, wherein the first FRα antigen-binding domain comprises: a) a VH domain comprising the three heavy chain CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO: 804, and a VL domain comprising the three light chain CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO: 805; b) a VH domain comprising the three heavy chain CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO: 806, and a VL domain comprising the three light chain
CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO:805, c) a VH domain comprising the three heavy chain CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO: 807, and a VL domain comprising the three light chain CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO: 805; or d) a VH domain comprising the three heavy chain CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO: 808, and a VL domain comprising the three light chain CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO:805.
49. The antibody construct according to claim 47 or 48, wherein the first FRα antigen- binding domain is in an scFv format.
50. The antibody construct according to claim 49, wherein the first FRα antigen-binding domain comprises the sequence as set forth in SEQ ID NO:819, SEQ ID NO:820, SEQ ID NO:821, or SEQ ID NO:822.
51. The antibody construct according to claim 50, wherein the first FRα antigen-binding domain further comprises one or more amino acid modifications in the VH sequence or VL sequence of antibody 2L16 that improve the biophysical properties of the antibody construct.
52. The antibody construct according to claim 47 or 48, wherein the first FRα antigen- binding domain is in a Fab format.
53. The antibody construct according to any one of claims 47 to 52, further comprising a second FRα antigen-binding domain.
54. The antibody construct according to claim 53, wherein the first and second FRα antigen-binding domains are the same.
55. The antibody construct according to claim 53, wherein the first and second FRα antigen-binding domains are different.
56. The antibody construct according to any one of claims 47 to 55, wherein the first 4- 1BB antigen binding domain comprises: a) a heavy chain variable domain (VH) comprising the three heavy chain CDRs of antibody 1G1, and a light chain variable domain (VL) comprising the three light chain CDRs of antibody 1G1, b) a heavy chain variable domain comprising the three heavy chain CDRs of antibody 5G8, and a light chain variable domain comprising the three light chain CDRs of antibody 5G8, or c) a heavy chain variable domain comprising the three heavy chain CDRs of antibody 1C8, and a light chain variable domain comprising the three light chain CDRs of antibody 1C8.
57. The antibody construct according to any one of claims 47 to 56, wherein the first 4- 1BB antigen-binding domain comprises: a) a heavy chain variable domain (VH) comprising the three heavy chain CDRs of antibody 1G1 and is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO:46, and a light chain variable domain (VL) comprising the three light chain CDRs of antibody 1G1 and is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO:58, b) a heavy chain variable domain comprising the three heavy chain CDRs of antibody and is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO:62, and a light chain variable domain comprising the three light chain CDRs of antibody 5G8 and is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO: 64, or
c) a heavy chain variable domain comprising the three heavy chain CDRs of antibody 1C8 and is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO:53, and a light chain variable domain comprising the three light chain CDRs of antibody 1C8 and is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO:48.
58. The antibody construct according to any one of claims 47 to 57, further comprising a second 4-1BB antigen-binding domain.
59. The antibody construct according to claim 58, wherein the first 4-1BB-antigen- binding domain and the second 4-1BB-antigen-binding domain are in a Fab format.
60. The antibody construct according to claim 58 or 59, wherein the second 4-1BB antigen-binding domain is the same as the first 4-1BB antigen-binding domain.
61. The antibody construct according to claim 60, wherein the first 4-1BB antigen- binding domain and/or the second 4-1BB antigen-binding domain are in a Fab format.
62. The antibody construct according to any one of claims 47 to 61, wherein the scaffold is a dimeric Fc construct having a first Fc polypeptide and a second Fc polypeptide, each Fc polypeptide comprising a CH3 sequence, or wherein the scaffold is a linker or an albumin polypeptide.
63. The antibody construct according to claim 62, wherein the scaffold is a heterodimeric Fc construct having a first Fc polypeptide that is different from the second Fc polypeptide, and wherein the CH3 sequences of the first Fc polypeptide and the second Fc polypeptide comprise amino acid substitutions that promote the formation of a heterodimeric Fc.
64. The antibody construct according to claim 63, wherein:
a) one Fc polypeptide comprises the amino acid substitutions T350V_L351Y_F405A_Y407V and the other Fc polypeptide comprises the amino acid sub stitutions T350 V_T366L K392L T394W; b) one Fc polypeptide comprises the amino acid substitutions T350V_T366L_K392M_T394W and the other Fc polypeptide comprises the amino acid substitutions T350V_L351 Y_F405 A_Y407 V; c) one Fc polypeptide comprises the amino acid substitutions
L351Y F405A Y407V and the other Fc polypeptide comprises the amino acid substitutions T366L K392M T394W; d) one Fc polypeptide comprises the amino acid substitutions
L351Y F405A Y407V and the other Fc polypeptide comprises the amino acid substitutions T366L K392L T394W; or e) one Fc polypeptide comprises the amino acid substitutions L351Y_S400E_F405A_Y407V and the other Fc polypeptide comprises the amino acid sub stitutions T366I_N390R_K392M_T394W, wherein the numbering of residues in the Fc polypeptide is according to the EU numbering system.
65. The antibody construct according to any one of claims 62 to 64, further comprising one or more amino acid modifications that reduce effector function.
66. The antibody construct according to claim 65, wherein the one or more amino acid modifications are L234A, L235A and D265S, wherein the numbering of residues is according to the EU numbering system.
67. The antibody construct according to any one of claims 47 to 66, wherein the first 4- 1BB antigen-binding domain is linked to the N terminus of the first Fc polypeptide, and the first FRα antigen -binding domain is linked to the C terminus of the first Fc polypeptide.
68. The antibody construct according to any one of claims 47 to 67, wherein the first 4- 1BB antigen-binding domain is linked to the N terminus of the first Fc polypeptide,
and the first FRα antigen -binding domain is linked to the C terminus of the second Fc polypeptide
69. The antibody construct according to claim 67 or 68, further comprising a second 4- 1BB antigen-binding domain linked to the N terminus of the second Fc polypeptide.
70. The antibody construct according to any one of claims 47 to 69, comprising a first 4-1BB antigen-binding domain linked to the N terminus of the first Fc polypeptide, a second 4-1BB antigen-binding domain linked to the N terminus of the second Fc polypeptide, a first FRα antigen-binding domain linked to the C terminus of the first Fc polypeptide and a second FRα antigen-binding domain linked to the C terminus of the second Fc polypeptide.
71. The antibody construct according to any one of claims 47 to 70, comprising a first 4-1BB antigen-binding domain linked to the N terminus of the first Fc polypeptide or to the N terminus of the second Fc polypeptide, a first FRα antigen-binding domain linked to the C terminus of the first Fc polypeptide and a second FRα antigen-binding domain linked to the C terminus of the second Fc polypeptide.
72. The antibody construct according to claim 47, wherein the construct comprises the polypeptide sequences of any one of variants 31946, 32687, 32686, and 32688.
73. The antibody construct according to any one of claims 47 to 72, conjugated to a drug.
74. A pharmaceutical composition comprising the antibody construct of any one of claims 47 to 73.
75. One or more nucleic acids encoding the antibody construct according to any one of claims 47 to 72.
76. One or more vectors comprising the one or more nucleic acids according to claim 75.
77. An isolated cell comprising the one or more nucleic acid according to claim 75, or the one or more vectors according to claim 76.
78. A method of preparing the antibody construct according to any one of claims 47 to 73, comprising culturing the isolated cell of claim 77 under conditions suitable for expressing the antibody construct, and purifying the antibody construct.
79. A method of treating a subject having a cancer, comprising administering to the subject an effective amount of the antibody construct according to any one of claims 47 to 73.
80. Use of an effective amount of the antibody construct according to any one of claims 47 to 73, for the treatment of cancer in a subject in need thereof.
81. Use of the antibody construct according to any one of claims 47 to 73, in the preparation of a medicament for the treatment of cancer.
82. The antibody construct according to any one of claims 47 to 73, for use in the treatment of cancer in a subject.
83. An antibody construct or antigen-binding fragment thereof, that specifically binds to folate receptor-a (FRα), comprising: a heavy chain variable domain (VH) sequence comprising three heavy chain complementarity-determining regions (CDRs) and a light chain variable domain (VL) sequence comprising three light chain CDRs, wherein the heavy chain CDRs and the light chain CDRs are from antibody 2L16.
84. The antibody construct according to claim 83, wherein the antibody or antigen- binding fragment is or comprises a humanized antibody.
85. The antibody construct according to claim 83 or 84, comprising: a) a VH domain comprising the three heavy chain CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO:804, and a VL domain comprising the three light
chain CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO:805; b) a VH domain comprising the three heavy chain CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO:806, and a VL domain comprising the three light chain CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO:805, c) a VH domain comprising the three heavy chain CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO:807, and a VL domain comprising the three light chain CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO:805; or d) a VH domain comprising the three heavy chain CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO:808, and a VL domain comprising the three light chain CDRs of antibody 2L16 and having a sequence that is at least 90% identical to the amino acid sequence as set forth in SEQ ID NO:805.
86. The antibody construct according to any one of claims 83 to 85, wherein the antibody construct includes immunoglobulin constant domains, wherein the constant domains are from an IgG1 or a variant thereof, an IgG2 or a variant thereof, an IgG4 or a variant thereof, an IgA or a variant thereof, an IgE or a variant thereof, an IgM or a variant thereof, or an IgD or a variant thereof.
87. The antibody construct according to any one of claims 83 to 86, wherein the antibody comprises a human IgG1.
88. The antibody construct according to any one of claims 83 to 87, wherein the antibody or antigen-binding fragment is a monoclonal antibody.
89. The antibody construct according to any one of claims 83 to 88, wherein the antibody fragment is a Fab fragment, a Fab' fragment, a F(ab')2 fragment, a Fv fragment, a scFv fragment, a single domain antibody, or a diabody.
90. The antibody construct according to any one of claims 83 to 89, conjugated to a drug.
91. A pharmaceutical composition comprising the antibody construct of any one of claims 83 to 90.
92. One or more nucleic acids encoding the antibody construct according to any one of claims 83 to 89.
93. One or more vectors comprising the one or more nucleic acids according to claim 92.
94. An isolated cell comprising the one or more nucleic acids according to claim 92 or the one or more vectors according to claim 93.
95. A method of preparing the antibody construct according to any one of claims 83 to 90, comprising culturing the isolated cell of claim 94 under conditions suitable for expressing the antibody construct, and purifying the antibody construct.
96. A method of treating a subject having a cancer, comprising administering to the subject an effective amount of the antibody construct according to any one of claims 83 to 90.
97. Use of an effective amount of the antibody construct according to any one of 83 to 90, for the treatment of cancer in a subject in need thereof.
98. Use of the antibody construct according to any one of claims 83 to 90, in the preparation of a medicament for the treatment of cancer.
99. The antibody construct according to any one of claims 83 to 90, for use in the treatment of cancer in a subject.
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CA3146977A CA3146977A1 (en) | 2020-04-15 | 2021-04-09 | Antibody constructs binding 4-1bb and folate receptor alpha and uses thereof |
| US17/919,109 US20230265202A1 (en) | 2020-04-15 | 2021-04-09 | Antibody constructs binding 4-1bb and folate receptor alpha and uses thereof |
| EP21788244.8A EP4136122A4 (en) | 2020-04-15 | 2021-04-09 | Antibody constructs binding 4-1bb and folate receptor alpha and uses thereof |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US202063010497P | 2020-04-15 | 2020-04-15 | |
| US63/010,497 | 2020-04-15 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| WO2021207827A1 true WO2021207827A1 (en) | 2021-10-21 |
| WO2021207827A8 WO2021207827A8 (en) | 2022-12-01 |
Family
ID=78083545
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/CA2021/050481 WO2021207827A1 (en) | 2020-04-15 | 2021-04-09 | Antibody constructs binding 4-1bb and folate receptor alpha and uses thereof |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US20230265202A1 (en) |
| EP (1) | EP4136122A4 (en) |
| CA (1) | CA3146977A1 (en) |
| WO (1) | WO2021207827A1 (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2024083925A3 (en) * | 2022-10-18 | 2024-05-30 | Tubulis Gmbh | Novel anti-napi2b antibodies and antibody-drug-conjugates based thereon, therapeutic methods and uses thereof |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2005080431A2 (en) * | 2004-02-12 | 2005-09-01 | Morphotek, Inc. | Monoclonal antibodies that specifically bind to folate receptor alpha |
| WO2018156740A1 (en) * | 2017-02-24 | 2018-08-30 | Macrogenics, Inc. | Bispecific binding molecules that are capable of binding cd137 and tumor antigens, and uses thereof |
| WO2020073131A1 (en) * | 2018-10-10 | 2020-04-16 | Zymeworks Inc. | Antibody constructs binding 4-1bb and tumor-associated antigens and uses thereof |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR102426765B1 (en) * | 2016-04-22 | 2022-07-29 | 엘리게이터 바이오사이언스 에이비 | Novel bispecific polypeptide for CD137 |
-
2021
- 2021-04-09 WO PCT/CA2021/050481 patent/WO2021207827A1/en active Search and Examination
- 2021-04-09 EP EP21788244.8A patent/EP4136122A4/en active Pending
- 2021-04-09 US US17/919,109 patent/US20230265202A1/en active Pending
- 2021-04-09 CA CA3146977A patent/CA3146977A1/en active Pending
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2005080431A2 (en) * | 2004-02-12 | 2005-09-01 | Morphotek, Inc. | Monoclonal antibodies that specifically bind to folate receptor alpha |
| WO2018156740A1 (en) * | 2017-02-24 | 2018-08-30 | Macrogenics, Inc. | Bispecific binding molecules that are capable of binding cd137 and tumor antigens, and uses thereof |
| WO2020073131A1 (en) * | 2018-10-10 | 2020-04-16 | Zymeworks Inc. | Antibody constructs binding 4-1bb and tumor-associated antigens and uses thereof |
Non-Patent Citations (1)
| Title |
|---|
| See also references of EP4136122A4 * |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2024083925A3 (en) * | 2022-10-18 | 2024-05-30 | Tubulis Gmbh | Novel anti-napi2b antibodies and antibody-drug-conjugates based thereon, therapeutic methods and uses thereof |
Also Published As
| Publication number | Publication date |
|---|---|
| EP4136122A1 (en) | 2023-02-22 |
| WO2021207827A8 (en) | 2022-12-01 |
| US20230265202A1 (en) | 2023-08-24 |
| CA3146977A1 (en) | 2021-10-21 |
| EP4136122A4 (en) | 2024-05-15 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11845795B2 (en) | NKp46 binding proteins | |
| US20230052369A1 (en) | Antibody constructs binding 4-1bb and tumor-associated antigens and uses thereof | |
| CN112912397A (en) | anti-CD 3 antibodies and uses thereof | |
| US20210395388A1 (en) | Antigen-Binding Constructs Targeting HER2 | |
| JP2023517753A (en) | Antibody that binds to B7H4 | |
| US20230062624A1 (en) | Cd3/cd38 t cell retargeting hetero-dimeric immunoglobulins and methods of their production | |
| US20230121511A1 (en) | Method for producing multispecific antigen-binding molecules | |
| JP2021510064A (en) | Cytotoxic Tocyte Therapeutic Agent | |
| KR20230120665A (en) | Anti-HLA-G Antibodies and Uses Thereof | |
| JP2021528973A (en) | Anti-STEAP1 antigen-binding protein | |
| US10836833B2 (en) | Cell engaging binding molecules | |
| US20230357398A1 (en) | Novel human antibodies binding to human cd3 epsilon | |
| EP4155318A1 (en) | Bispecific antibody and use thereof | |
| US20230265202A1 (en) | Antibody constructs binding 4-1bb and folate receptor alpha and uses thereof | |
| WO2023160376A1 (en) | Antibodies and variants thereof against human b7-h3 | |
| WO2018039107A1 (en) | Binding molecules specific for notch4 and uses thereof | |
| CN118922448A (en) | CD3 specific deimmunized antibodies | |
| TW202436358A (en) | Fap/4-1bb/cd40 binding molecules and pharmaceutical uses thereof | |
| CN117986371A (en) | Antibodies that bind CD123 and gamma-delta T cell receptors |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 21788244 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 3146977 Country of ref document: CA |
|
| DPE1 | Request for preliminary examination filed after expiration of 19th month from priority date (pct application filed from 20040101) | ||
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2021788244 Country of ref document: EP Effective date: 20221115 |