WO2014007596A1 - 다계층 비디오 부호화 방법 및 장치, 다계층 비디오 복호화 방법 및 장치 - Google Patents
다계층 비디오 부호화 방법 및 장치, 다계층 비디오 복호화 방법 및 장치 Download PDFInfo
- Publication number
- WO2014007596A1 WO2014007596A1 PCT/KR2013/006058 KR2013006058W WO2014007596A1 WO 2014007596 A1 WO2014007596 A1 WO 2014007596A1 KR 2013006058 W KR2013006058 W KR 2013006058W WO 2014007596 A1 WO2014007596 A1 WO 2014007596A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- unit
- scalable extension
- information
- extension type
- video
- Prior art date
Links
- 238000000034 method Methods 0.000 title claims abstract description 52
- 230000002123 temporal effect Effects 0.000 claims description 13
- 230000005540 biological transmission Effects 0.000 claims description 8
- 230000003044 adaptive effect Effects 0.000 claims description 5
- 230000000153 supplemental effect Effects 0.000 claims description 5
- 238000005192 partition Methods 0.000 description 146
- 230000009466 transformation Effects 0.000 description 56
- 238000010586 diagram Methods 0.000 description 24
- 238000006243 chemical reaction Methods 0.000 description 19
- 230000001419 dependent effect Effects 0.000 description 5
- 239000000284 extract Substances 0.000 description 5
- 108091000069 Cystinyl Aminopeptidase Proteins 0.000 description 4
- 102100020872 Leucyl-cystinyl aminopeptidase Human genes 0.000 description 4
- 230000007423 decrease Effects 0.000 description 3
- 238000013139 quantization Methods 0.000 description 3
- 230000011218 segmentation Effects 0.000 description 3
- 238000004891 communication Methods 0.000 description 2
- 238000007906 compression Methods 0.000 description 2
- 230000006835 compression Effects 0.000 description 2
- 238000013144 data compression Methods 0.000 description 2
- 230000011664 signaling Effects 0.000 description 2
- 238000000638 solvent extraction Methods 0.000 description 2
- 238000013500 data storage Methods 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 238000000605 extraction Methods 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 238000005457 optimization Methods 0.000 description 1
- 238000011426 transformation method Methods 0.000 description 1
- 230000001131 transforming effect Effects 0.000 description 1
Images

























Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/169—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding
- H04N19/188—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being a video data packet, e.g. a network abstraction layer [NAL] unit
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/169—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding
- H04N19/17—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object
- H04N19/176—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object the region being a block, e.g. a macroblock
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/169—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding
- H04N19/187—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being a scalable video layer
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/30—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using hierarchical techniques, e.g. scalability
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/46—Embedding additional information in the video signal during the compression process
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/597—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding specially adapted for multi-view video sequence encoding
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/70—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals characterised by syntax aspects related to video coding, e.g. related to compression standards
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/20—Servers specifically adapted for the distribution of content, e.g. VOD servers; Operations thereof
- H04N21/23—Processing of content or additional data; Elementary server operations; Server middleware
- H04N21/234—Processing of video elementary streams, e.g. splicing of video streams or manipulating encoded video stream scene graphs
- H04N21/2343—Processing of video elementary streams, e.g. splicing of video streams or manipulating encoded video stream scene graphs involving reformatting operations of video signals for distribution or compliance with end-user requests or end-user device requirements
- H04N21/234327—Processing of video elementary streams, e.g. splicing of video streams or manipulating encoded video stream scene graphs involving reformatting operations of video signals for distribution or compliance with end-user requests or end-user device requirements by decomposing into layers, e.g. base layer and one or more enhancement layers
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/20—Servers specifically adapted for the distribution of content, e.g. VOD servers; Operations thereof
- H04N21/23—Processing of content or additional data; Elementary server operations; Server middleware
- H04N21/236—Assembling of a multiplex stream, e.g. transport stream, by combining a video stream with other content or additional data, e.g. inserting a URL [Uniform Resource Locator] into a video stream, multiplexing software data into a video stream; Remultiplexing of multiplex streams; Insertion of stuffing bits into the multiplex stream, e.g. to obtain a constant bit-rate; Assembling of a packetised elementary stream
Definitions
- the present invention relates to a method and apparatus for encoding and decoding video composed of multiple layers such as scalable video and multiview video, and more particularly, to a high level syntax structure for signaling of multilayer video. .
- image data is encoded by a codec according to a predetermined data compression standard, for example, the Moving Picture Expert Group (MPEG) standard, and then stored in an information storage medium in the form of a bitstream or transmitted through a communication channel.
- MPEG Moving Picture Expert Group
- Scalable video coding is a video compression method for appropriately adjusting and transmitting information in response to various communication networks and terminals.
- Scalable video coding provides a video encoding method capable of adaptively serving various transmission networks and various receiving terminals using a single video stream.
- Multi-view video coding Multiview Video Coding
- video is encoded according to a limited coding scheme based on a macroblock having a predetermined size.
- the technical problem to be solved by the present invention is to provide a structure of the NAL unit for signaling scalable extension type information of multi-layer video, such as multi-view video and scalable video.
- scalable extension type information for scalable extension of multilayer video is added to a VPS NAL unit including VPS (Video Parameter Set) information about information commonly applied to multilayer video.
- VPS Video Parameter Set
- scalable extension type information related to multilayer video may be signaled using a VPS NAL unit.
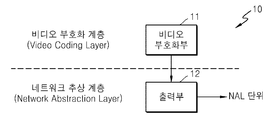
- FIG. 1 is a block diagram illustrating a configuration of an apparatus for encoding a multilayer video, according to an exemplary embodiment.
- FIG. 2 illustrates a multilayer video according to an embodiment.
- FIG. 3 illustrates NAL units including encoded data of a multilayer video, according to an embodiment.
- 4A and 4B are diagrams illustrating an example of a header of a NAL unit according to an embodiment.
- FIG. 5 is a diagram illustrating a VPS NAL unit including scalable extension type information (SET) of a multilayer video according to an embodiment.
- SET scalable extension type information
- FIG. 6 illustrates a scalable extension type table according to an embodiment.
- FIG. 7A illustrates a VPS NAL unit including scalable extension type information (SET) of a multilayer video according to another embodiment.
- SET scalable extension type information
- FIG 7B illustrates NAL units other than VPS NAL units according to another embodiment.
- FIG. 8 is a diagram illustrating a NAL unit header for scalable extension according to another embodiment of the present invention.
- FIG. 9 illustrates a first sub-layer index (Sub-LID0) 82, a second sub-layer index (Sub-LID1) 83, and a third sub-layer index according to SET 81 of the NAL unit header of FIG. 8.
- FIG. 10 is a flowchart of a multilayer video encoding method, according to an embodiment.
- FIG. 11 is a block diagram illustrating a configuration of a multilayer video decoding apparatus, according to an embodiment.
- FIG. 12 is a flowchart illustrating a multilayer video decoding method, according to an embodiment.
- FIG. 13 is a block diagram of a video encoding apparatus based on coding units having a tree structure, according to an embodiment of the present invention.
- FIG. 14 is a block diagram of a video decoding apparatus based on coding units having a tree structure, according to an embodiment of the present invention.
- 16 is a block diagram of an image encoder based on coding units, according to an embodiment of the present invention.
- 17 is a block diagram of an image decoder based on coding units, according to an embodiment of the present invention.
- FIG. 18 is a diagram of deeper coding units according to depths, and partitions, according to an embodiment of the present invention.
- FIG. 19 illustrates a relationship between a coding unit and transformation units, according to an embodiment of the present invention.
- 21 is a diagram of deeper coding units according to depths, according to an embodiment of the present invention.
- 22, 23, and 24 illustrate a relationship between coding units, prediction units, and transformation units, according to an embodiment of the present invention.
- FIG. 25 illustrates a relationship between coding units, prediction units, and transformation units, according to encoding mode information of Table 2.
- FIG. 25 illustrates a relationship between coding units, prediction units, and transformation units, according to encoding mode information of Table 2.
- a multi-layer video encoding method includes: encoding the multi-layer video; Generating NAL units for each data unit by dividing the encoded multilayer video according to data units; And scalable expansion for scalable expansion of the multilayer video in a VPS NAL unit including VPS (Video Parameter Set) information about information commonly applied to the multilayer video among the transmission unit data for each data unit. And adding the type information.
- VPS Video Parameter Set
- a multilayer video encoding apparatus may include a video encoder that encodes the multilayer video;
- the NPS (Network Adaptive Layer) units are generated for each data unit by dividing the encoded multilayer video according to a data unit, and the VPS (Regarding information commonly applied to the multilayer video among transmission unit data for each data unit)
- a multi-layer video decoding method includes receiving network adaptive layer (NAL) units generated by dividing an encoded multi-layer video by data units; Obtaining a VPS NAL unit including video parameter set (VPS) information about information commonly applied to the multilayer video among the received NAL units; And obtaining scalable extension type information for scalable extension of the multilayer video from the VPS NAL unit.
- NAL network adaptive layer
- VPS video parameter set
- the multilayer video decoding apparatus receives NAL units generated by dividing an encoded multilayer video for each data unit, and applies the same to the multilayer video among the received NAL units.
- a receiver which obtains a VPS NAL unit including VPS (Video Parameter Set) information about the information, and obtains scalable extension type information for scalable extension of the multilayer video from the VPS NAL unit;
- a video decoder configured to determine a scalable extension type applied to each data unit included in the multilayer video based on the obtained scalable extension type information, and to decode the multilayer video.
- FIGS. 1 to 13. 13 to 25 a method of encoding encoding and a multilayer video decoding of a multilayer video according to an embodiment will be described with reference to FIGS. 1 to 13. 13 to 25, a video encoding method and a video decoding method based on coding units having a tree structure according to an embodiment are disclosed.
- FIG. 1 is a block diagram illustrating a configuration of an apparatus for encoding a multilayer video, according to an exemplary embodiment.
- the multilayer video encoding apparatus 10 includes a video encoder 11 and an output unit 12.
- the video encoder 11 receives and encodes a multilayer video.
- the video encoder 11 corresponds to a video coding layer that handles the input video encoding process itself.
- the video encoder 11 may encode each picture included in the multilayer video based on coding units having a tree structure.
- the output unit 12 corresponds to a network abstraction layer (NAL) that adds and outputs encoded multilayer video data and additional information to a transmission data unit according to a predetermined format.
- the transmission data unit may be a NAL unit.
- the output unit 12 outputs the NAL unit by including multilayer video data and additional information in the NAL unit.
- FIG. 2 illustrates a multilayer video according to an embodiment.
- the multilayer video encoding apparatus 10 may include various spatial resolutions, various quality, various frame rates, A scalable bitstream may be output by encoding multilayer image sequences having different views. That is, the multilayer video encoding apparatus 10 may generate and output a scalable video bitstream by encoding an input image according to various scalable extension types (SET).
- Scalable extension types include temporal, spatial, image quality, multi-point scalability, and combinations of such scalability.
- a bitstream is called scalable if it can be separated from the bitstream into valid substreams.
- the spatially scalable bitstream includes substreams of various resolutions.
- the spatially scalable bitstream may be divided into substreams having different resolutions such as QVGA, VGA, WVGA, and the like.
- a temporally scalable bitstream includes substreams having various frame rates.
- a temporally scalable bitstream may be divided into substreams having a frame rate of 7.5 Hz, a frame rate of 15 Hz, a frame rate of 30 Hz, and a frame rate of 60 Hz.
- Image quality scalable bitstreams can be divided into substreams having different qualities according to the Coarse-Grained Scalability (CGS) method, the Medium-Grained Scalability (MGS) method, and the Fine-Grained Scalability (GFS) method. Can be.
- CGS Coarse-Grained Scalability
- MCS Medium-Grained Scalability
- GFS Fine-Grained Scalability
- a multiview scalable bitstream includes substreams of different views within one bitstream.
- a bitstream includes a left image and a right image.
- the scalable bitstream may include substreams related to encoded data of a multiview image and a depth map.
- the scalable video bitstream may include substreams in which at least one of temporal, spatial, image quality, and multi-view scalability is encoded with a multi-layer image sequence composed of different images.
- the image sequence 21 of the first layer, the image sequence 22 of the second layer, and the image sequence 23 of the nth (n is an integer) layer may be image sequences having at least one of a resolution, an image quality, and a viewpoint. have.
- an image sequence of one layer among the image sequence 21 of the first layer, the image sequence 22 of the second layer, and the image sequence 23 of the nth (n is an integer) layer may be an image sequence of the base layer.
- the video sequences of other layers may be the video sequences of the enhancement layer.
- the image sequence 21 of the first layer may include images of a first view
- the image sequence 22 of the second layer may include images of a second view
- the image sequence 23 of the nth layer may include an nth view.
- the image sequence 21 of the first layer is the left view image of the base layer
- the image sequence 22 of the second layer is the right view image of the base layer
- the image sequence 23 of the nth layer is It may be a right view image.
- the present invention is not limited to the above-described example, and the image sequences 21, 22, and 23 having different scalable extension types may be image sequences having different image attributes.
- FIG. 3 illustrates NAL units including encoded data of a multilayer video, according to an embodiment.
- the output unit 12 outputs NAL units including encoded multilayer video data and additional information.
- the video parameter set (hereinafter referred to as "VPS") includes information applied to the multilayer video sequences 32, 33, and 34 included in the multilayer video.
- a NAL unit including information about the VPS is called a VPS NAL unit 31.
- the VPS NAL unit 31 includes a common syntax element shared by the multilayer video sequences 32, 33, and 34, information about an operation point, and a profile to prevent unnecessary information from being transmitted. Includes essential information about the operating point needed during the session negotiation phase, such as (profile) or level.
- the VPS NAL unit 31 according to an embodiment includes information about a scalable extension type (hereinafter referred to as "SET") for scalable expansion of a multilayer video.
- the SET is information for determining a scalable type applied to the multilayer image sequences 32, 33, and 34 included in the multilayer video.
- the SET is a scalable extension that represents one of the scalable extension type tables that includes combinations of scalable extension types applicable to the multilayer video sequences 32, 33, 34 included in the multilayer video.
- Type table index The VPS NAL unit 31 may further include a hierarchical index indicating one of combinations of scalable extension types included in the scalable extension type table indicated by the scalable extension type table index.
- the layer index information is included in the SPS NAL units 32a, 33a, 34a including the sequence parameter set (SPS) information of each layer, or the PPS (Picture) of each layer. It may be included in the PPS NAL units 32b, 33b, and 34b including Parameter Set) information.
- the SPS includes information commonly applied to an image sequence of one layer.
- Each of the SPS NALs 32a, 33a, 34a including the SPS includes information commonly applied to each of the image sequences 32, 33, 34.
- the PPS includes information that is commonly applied to pictures of one layer.
- Each of the PPS NALs 32b, 33b, 34B including such a PPS includes information commonly applied to pictures of the same layer.
- the PPS may include information about an encoding mode of an entire picture, for example, an entropy encoding mode and an initial value of a quantization parameter in a picture unit. PPS need not be generated for every picture. That is, when there is no PPS, a PPS NAL unit including information on the set PPS may be generated by using a previously existing PPS and newly setting the PPS when information included in the PPS needs to be updated. have.
- the slice segment includes encoded data of at least one maximum coding unit, and the slice segment may be included in the slice segment NALs 32c, 33c, and 34c and transmitted.
- one video includes multiple layers of image sequences 32, 33, and 34.
- the SPS of each layer includes the SPS identifier (sequence_parameter_set_id), and the sequence including the PPS can be identified by designating the SPS identifier in the PPS.
- the PPS includes a PPS identifier (picture_parameter_set_id), and the PPS identifier may be included in the slice segment to identify which PPS the slice segment uses.
- the SPS identifier and the layer information used for the slice segment may be identified using the SPS identifier included in the PPS indicated by the PPS identifier of the slice segment.
- the SPS identifier (sequence_parameter_set_id) of the first layer SPS NAL 32a has a value of zero.
- the first layer PPS NAL 32b included in the first layer image sequence 32 includes an SPS identifier (sequence_parameter_set_id) having a value of zero.
- the PPS identifier (picture_parameter_set_id) of the first layer PPS NAL 32b has a value of zero.
- the first layer slice segment NAL 32c referring to the first layer PPS NAL 32b has a PPS identifier (picture_parameter_set_id) having a value of zero.
- FIG. 3 illustrates an example of configuring one VPS
- a VPS identifier (video_parameter_set_id) may be included in the SPS NAL unit.
- the VPS identifier (video_parameter_set_id) of the VPS NAL 31 has a value of 0, the SPS NALs 32a, 33a, and 34a included in one multilayer video have a VPS identifier (0).
- video_parameter_set_id may be included.
- 4A and 4B are diagrams illustrating an example of a header of a NAL unit according to an embodiment.
- the NAL unit header has a total length of 2 bytes.
- the numbers 0 through 7 in FIG. 4B mean each bit included in 2 bytes.
- the NAL unit header is a bit for identifying the NAL unit, forbidden_zero_bit (F) 41 having a value of 0, an nal unit type (hereinafter referred to as "NUT" 42) 42 indicating the type of the NAL unit, and for future use.
- the identifier NUT 42 and the reserved area 43 may each consist of 6 bits, and the temporal identifier (TID: temporal ID) 44 may consist of 3 bits.
- the output unit 12 may use the future use of the areas of the VPS NAL unit header. For example, an area of the reserved area 43 and a temporal ID 44 may be used.
- FIG. 5 is a diagram illustrating a VPS NAL unit including scalable extension type information (SET) of a multilayer video according to an embodiment.
- SET scalable extension type information
- a header of a NAL unit for scalable extension of a multilayer video is a forbidden_zero_bit (F) having a value of 0 as a bit for identification of a NAL unit and an identifier indicating a type of a NAL unit.
- F forbidden_zero_bit
- the corresponding NAL unit is Instantaneous Decoding Refresh (IDR) picture, Clean Random Access (CRA) picture, VPS, SPS, PPS, Supplemental Enhancement Information (SEI), Adaptive Parameter Set (APS) Parameter Set), which may be identified as a NAL unit including information of a reserved NAL unit, which is reserved for future expansion, or an undefined NAL unit.
- IDR Instantaneous Decoding Refresh
- CRA Clean Random Access
- VPS Clean Random Access
- SPS SPS
- PPS Supplemental Enhancement Information
- SEI Supplemental Enhancement Information
- APS Adaptive Parameter Set
- Table 1 is a table showing types of NAL units according to Nal_unit_type (NUT) according to an embodiment.
- nal_unit_type Name of nal_unit_type Content of NAL unit and RBSP syntax structure 0 1 TRAIL_N TRAIL_R Coded slice segment of a non-TSA, non-STSA trailing picture slice_segment_layer_rbsp () 2 3 TSA_N TSA_R Coded slice segment of a TSA picture slice_segment_layer_rbsp () 4 5 STSA_N STSA_R Coded slice segment of an STSA picture slice_segment_layer_rbsp () 6 7 RADL_N RADL_R Coded slice segment of a RADL picture slice_segment_layer_rbsp () 8 9 RASL_N RASL_R Coded slice segment of a RASL picture slice_segment_layer_rbsp () 10 12 14 RSV_VCL_N10 RSV_VCL_N12 RSV_VCL_N14 Reserved non-IRAP sub
- RSV_VCL31 Reserved non-IRAP VCL NAL unit types 32 VPS_NUT Video parameter set video_parameter_set_rbsp () 33 SPS_NUT Sequence parameter set seq_parameter_set_rbsp () 34 PPS_NUT Picture parameter set pic_parameter_set_rbsp () 35 AUD_NUT Access unit delimiter access_unit_delimiter_rbsp () 36 EOS_NUT End of sequence end_of_seq_rbsp () 37 EOB_NUT End of bitstream end_of_bitstream_rbsp () 38 FD_NUT Filler data filler_data_rbsp () 39 40 PREFIX_SEI_NUT SUFFIX_SEI_NUT Supplemental enhancement information sei_rbsp () 41..47 RSV_NVCL41 .. RSV_NVCL47 Reserved
- nal_unit_type of a NAL unit including a VPS may be set to 32.
- the scalable extension type information of the multilayer video according to an embodiment may be included in NAL units reserved for future use, that is, nal_unit_type having NAL units having a value of 41-47.
- the present invention is not limited thereto, and the type of the NAL unit according to nal_unit_type may be changed.
- Scalable extension type information (SET) 51 corresponds to a scalable extension type table index that indicates one of the scalable extension type tables that includes combinations of scalable extension types applicable to multilayer video.
- the layer index information (LID) 52 indicates one of combinations of the scalable extension types included in the scalable extension type table indicated by the scalable extension type table index.
- FIG. 6 illustrates a scalable extension type table according to an embodiment.
- one scalable extension type table may be defined.
- SET 51 is a specific value k
- one scalable extension type table as shown in FIG. 6 is defined.
- the Dependent flag indicates whether the data of the current layer is an independent layer referring to data of another layer or a dependent layer referring to data of another layer. If the Dependent flag is 0, data of the current layer is an independent layer. When the dependent flag is 0, it indicates that the images of each layer included in the multilayer video are encoded / decoded independently of each other.
- the reference layer ID indicates an identifier (layer ID) of a layer referred to by data of the current layer.
- the dependency ID indicates an identifier of a layer on which data of the current layer depends.
- the Quality ID indicates the image quality of the image included in the multilayer video. View ID represents a viewpoint of an image included in a multilayer video.
- Temporal ID is a temporal identifier for temporal scalability of an image included in a multilayer video.
- FIG. 6 illustrates a scalable extension type table in which the SET 51 has a specific value of k.
- the SET 51 when the SET 51 is composed of M bits, the SET 51 may have a maximum of 2 ⁇ . It can have M values. Therefore, up to 2 ⁇ M scalable extension type tables may be predefined according to the value of SET 51.
- the scalable extension type table as shown in FIG. 6 may be predefined in the video encoding apparatus and the video decoding apparatus, and may be pre-defined from the video encoding apparatus to the video decoding apparatus through the SPS, PPS, and Supplemental Enhancement Information (SEI) messages. Can be sent.
- SEI message may also be transmitted in a NAL unit having a predetermined nal unit type.
- FIG. 7A illustrates a VPS NAL unit including scalable extension type information (SET) of a multilayer video according to another embodiment.
- 7B illustrates NAL units other than VPS NAL units according to another embodiment.
- SET scalable extension type information
- scalable extension type information (SET) 71 for determining the scalable extension type table is included in the VPS NAL unit, and the scalable extension is included in the other NAL units except for the VPS NAL unit.
- Layer index information (LID) 72 indicating a scalable extension type applied to data included in a current NAL unit among a plurality of combinations of scalable extension types included in the type table may be included.
- the scalable extension type information (SET) 51 included in the VPS NAL unit includes one of scalable extension type tables including combinations of scalable extension types applicable to multi-layer video. Corresponds to the scalable extension type table index.
- the layer index information LID may be included in an SPS NAL unit including SPS information of each layer, or may be included in PPS NAL units including PPS information of each layer. .
- the layer index information (LID) is included in the SPS NAL unit, it is possible to apply different scalable extension types for each sequence.
- layer index information (LID) is included in the PPS NAL unit, it is possible to apply different scalable extension types for each picture.
- FIG. 8 is a diagram illustrating a NAL unit header for scalable extension according to another embodiment of the present invention.
- the NAL unit redefines an area of a reserved area and a temporal ID, which is to be used for future expansion, to expand the scalable extension type information. It may include.
- the NAL unit may include scalable extension type information indicating whether a scalable type applied to each data unit is applied by setting the sequence, picture, and slice unit in addition to the VPS.
- the NAL unit header may include a SET 81 composed of M bits, a first sub-layer index (Sub-LID0) 82, and a second sub-layer index (Sub-LID1). ) And a third sub-layer index (Sub_LID2) 84.
- SET 81 extends to which scalable first sub-layer index (Sub-LID0) 82, second sub-layer index (Sub-LID1) 83, and third sub-layer index (Sub_LID2) 84 are respectively scalable. Scalable index information for determining whether a type is indicated.
- SET 81 includes a plurality of first sub-layer indexes (Sub-LID0) 82, second sub-layer indexes (Sub-LID1) 83, and third sub-layer indexes (Sub_LID2) 84.
- the information may be information for determining which of the scalable extension type information corresponds to.
- FIG. 9 illustrates a first sub-layer index (Sub-LID0) 82, a second sub-layer index (Sub-LID1) 83, and a third sub-layer index according to SET 81 of the NAL unit header of FIG. 8.
- the first sub-layer index (Sub-LID0) 82, the second sub-layer index (Sub-LID1) 83, and the third sub-layer index (Sub_LID2) may indicate which scalable extension type information represents a value. For example, when the SET 81 has a value of 1, the value of the first sub-layer index (Sub-LID0) 82 represents the view information (view ID), and the second sub-layer index (Sub-LID1). ) 83 indicates dependency ID, and the third sub-layer index Sub_LID2 84 indicates quality scalability information quality_id.
- FIG. 9 illustrates the case where three sublayer indexes are included, the present invention is not limited thereto, and the sublayer index may be extended to indicate three or more scalable extension type information within a range of available bits.
- the scalable extension type information indicated by each sub-layer index may also be changed according to the SET 81.
- FIG. 10 is a flowchart of a multilayer video encoding method, according to an embodiment.
- multi-layer video is multi-layer video sequences in which at least one of temporal, spatial, image quality, and multi-view scalability is composed of different images.
- the output unit 12 classifies the encoded multilayer video according to data units and generates NAL units for each data unit.
- the output unit 12 may generate the slice segment NAL unit including the encoded information of the slice unit for each slice unit included in the multilayer video.
- the output unit 12 may generate a PPS NAL unit including information about a PPS that is commonly applied to pictures included in the multilayer video.
- the output unit 12 may generate an SPS NAL unit including information on an SPS commonly applied to an image sequence of a predetermined layer included in the multilayer video.
- the output unit 12 may generate a VPS NAL unit including information about a VPS commonly applied to multilayer video.
- the output unit 12 may add scalable extension type information for scalable expansion of the multilayer video to the VPS NAL unit.
- the output unit 12 includes SET information corresponding to a scalable extension type table index indicating one of scalable extension type tables including combinations of scalable extension types applicable to multi-layer video.
- layer index information indicating one of combinations of the scalable extension types included in the scalable extension type table indicated by the scalable extension type table index in the VPS NAL unit.
- the output unit 12 includes only the SET information in the VPS NAL unit, and includes the layer index information (LID) in the SPS NAL unit including the SPS information of each layer, or the PPS including the PPS information of each layer. It may be included in the layer index information (LID) in the NAL unit.
- LID layer index information
- FIG. 11 is a block diagram illustrating a configuration of a multilayer video decoding apparatus, according to an embodiment.
- the multilayer video decoding apparatus 1100 includes a receiver 1110 and a video decoder 1120.
- the receiver 1110 receives a NAL unit of a network abstraction layer and identifies a VPS NAL unit including scalable extension type information according to embodiments of the present invention.
- the VPS NAL unit may be determined using nal_unit_type (NUT), which is an identifier indicating the type of the NAL unit.
- Scalable extension type information according to embodiments of the present invention may be included in a reserved area of a VPS NAL unit.
- the receiver 1110 indicates one of scalable extension type tables including combinations of scalable extension types applicable to current multi-layer video by parsing a VPS NAL unit including scalable extension type information.
- Layer index information (LID) indicating one of a combination of the SET information corresponding to the scalable extension type table index and the scalable extension type included in the scalable extension type table indicated by the scalable extension type table index may be obtained. .
- the receiver 1110 may acquire only SET information from a VPS NAL unit and may obtain layer index information (LID) from another NAL unit other than the VPS NAL unit. That is, the receiver 1110 obtains layer index information (LID) for determining the scalable extension type applied to the images included in the current sequence from the SPS NAL unit including the SPS information of each layer, or includes the PPS information. Layer index information (LID) for determining a scalable extension type applied to pictures from a PPS NAL unit may be obtained.
- LID layer index information
- the video decoder 1120 determines the scalable extension type applied to the images included in the multilayer video based on the SET information and the LID information, and decodes the multilayer video.
- the video decoder 1120 may decode the multilayer video based on coding units having a tree structure. The decoding process of the multilayer video based on the coding unit of the tree structure will be described later.
- FIG. 12 is a flowchart illustrating a multilayer video decoding method, according to an embodiment.
- the receiver 1110 receives NAL units generated by dividing an encoded multilayer video by data units.
- the receiver 1110 obtains a VPS NAL unit including VPS information among the received NAL units.
- the VPS NAL unit may be determined using nal_unit_type (NUT), which is an identifier indicating the type of the NAL unit.
- NUT nal_unit_type
- the receiver 1110 obtains scalable extension type information for scalable extension of multilayer video from a VPS NAL unit.
- the receiver 1110 indicates one of scalable extension type tables including combinations of scalable extension types applicable to current multi-layer video by parsing a VPS NAL unit including scalable extension type information.
- Layer index information (LID) indicating one of a combination of the SET information corresponding to the scalable extension type table index and the scalable extension type included in the scalable extension type table indicated by the scalable extension type table index may be obtained.
- the receiver 1110 may acquire only SET information from a VPS NAL unit and may obtain layer index information (LID) from another NAL unit other than the VPS NAL unit.
- the receiver 1110 obtains layer index information (LID) for determining the scalable extension type applied to the images included in the current sequence from the SPS NAL unit including the SPS information of each layer, or includes the PPS information.
- Layer index information (LID) for determining a scalable extension type applied to pictures from a PPS NAL unit may be obtained.
- the video decoder 1120 determines the scalable extension type applied to the images included in the multilayer video based on the SET information and the LID information, and decodes the multilayer video.
- the encoding method and the video decoding method based on coding units having a tree structure described below include a video encoder 11 of the video encoding apparatus 10 of FIG. 1 and a video decoder 1120 of the video decoding apparatus 1100 of FIG. 11. It relates to a process of encoding / decoding pictures included in a multilayer video performed at.
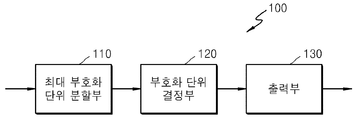
- FIG. 13 is a block diagram of a video encoding apparatus 100 based on coding units having a tree structure, according to an embodiment of the present invention.
- the video encoding apparatus 100 including video prediction based on coding units having a tree structure may include a maximum coding unit splitter 110, a coding unit determiner 120, and an outputter 130.
- the video encoding apparatus 100 that includes video prediction based on coding units having a tree structure is abbreviated as “video encoding apparatus 100”.
- the maximum coding unit splitter 110 may partition the current picture based on the maximum coding unit that is a coding unit of the maximum size for the current picture of the image. If the current picture is larger than the maximum coding unit, image data of the current picture may be split into at least one maximum coding unit.
- the maximum coding unit may be a data unit having a size of 32x32, 64x64, 128x128, 256x256, or the like, and may be a square data unit having a square of two horizontal and vertical sizes.
- the image data may be output to the coding unit determiner 120 for at least one maximum coding unit.
- the coding unit according to an embodiment may be characterized by a maximum size and depth.
- the depth indicates the number of times the coding unit is spatially divided from the maximum coding unit, and as the depth increases, the coding unit for each depth may be split from the maximum coding unit to the minimum coding unit.
- the depth of the largest coding unit is the highest depth and the minimum coding unit may be defined as the lowest coding unit.
- the maximum coding unit decreases as the depth increases, the size of the coding unit for each depth decreases, and thus, the coding unit of the higher depth may include coding units of a plurality of lower depths.
- the image data of the current picture may be divided into maximum coding units according to the maximum size of the coding unit, and each maximum coding unit may include coding units divided by depths. Since the maximum coding unit is divided according to depths, image data of a spatial domain included in the maximum coding unit may be hierarchically classified according to depths.
- the maximum depth and the maximum size of the coding unit that limit the total number of times of hierarchically dividing the height and the width of the maximum coding unit may be preset.
- the coding unit determiner 120 encodes at least one divided region obtained by dividing the region of the largest coding unit for each depth, and determines a depth at which the final encoding result is output for each of the at least one divided region. That is, the coding unit determiner 120 encodes the image data in coding units according to depths for each maximum coding unit of the current picture, and selects a depth at which the smallest coding error occurs to determine the coding depth. The determined coded depth and the image data for each maximum coding unit are output to the outputter 130.
- Image data in the largest coding unit is encoded based on coding units according to depths according to at least one depth less than or equal to the maximum depth, and encoding results based on the coding units for each depth are compared. As a result of comparing the encoding error of the coding units according to depths, a depth having the smallest encoding error may be selected. At least one coding depth may be determined for each maximum coding unit.
- the coding unit is divided into hierarchically and the number of coding units increases.
- a coding error of each data is measured, and whether or not division into a lower depth is determined. Therefore, even in the data included in one largest coding unit, since the encoding error for each depth is different according to the position, the coding depth may be differently determined according to the position. Accordingly, one or more coding depths may be set for one maximum coding unit, and data of the maximum coding unit may be partitioned according to coding units of one or more coding depths.
- the coding unit determiner 120 may determine coding units having a tree structure included in the current maximum coding unit.
- the coding units having a tree structure according to an embodiment include coding units having a depth determined as a coding depth among all deeper coding units included in the maximum coding unit.
- the coding unit of the coding depth may be hierarchically determined according to the depth in the same region within the maximum coding unit, and may be independently determined for the other regions.
- the coded depth for the current region may be determined independently of the coded depth for the other region.
- the maximum depth according to an embodiment is an index related to the number of divisions from the maximum coding unit to the minimum coding unit.
- the first maximum depth according to an embodiment may represent the total number of divisions from the maximum coding unit to the minimum coding unit.
- the second maximum depth according to an embodiment may represent the total number of depth levels from the maximum coding unit to the minimum coding unit. For example, when the depth of the largest coding unit is 0, the depth of the coding unit obtained by dividing the largest coding unit once may be set to 1, and the depth of the coding unit divided twice may be set to 2. In this case, if the coding unit divided four times from the maximum coding unit is the minimum coding unit, since depth levels of 0, 1, 2, 3, and 4 exist, the first maximum depth is set to 4 and the second maximum depth is set to 5. Can be.
- Predictive encoding and transformation of the largest coding unit may be performed. Similarly, prediction encoding and transformation are performed based on depth-wise coding units for each maximum coding unit and for each depth less than or equal to the maximum depth.
- encoding including prediction encoding and transformation should be performed on all the coding units for each depth generated as the depth deepens.
- the prediction encoding and the transformation will be described based on the coding unit of the current depth among at least one maximum coding unit.
- the video encoding apparatus 100 may variously select a size or shape of a data unit for encoding image data.
- the encoding of the image data is performed through prediction encoding, transforming, entropy encoding, and the like.
- the same data unit may be used in every step, or the data unit may be changed in steps.
- the video encoding apparatus 100 may select not only a coding unit for encoding the image data, but also a data unit different from the coding unit in order to perform predictive encoding of the image data in the coding unit.
- prediction encoding may be performed based on a coding unit of a coding depth, that is, a more strange undivided coding unit, according to an embodiment.
- a more strange undivided coding unit that is the basis of prediction coding is referred to as a 'prediction unit'.
- the partition in which the prediction unit is divided may include a data unit in which at least one of the prediction unit and the height and the width of the prediction unit are divided.
- the partition may be a data unit in which the prediction unit of the coding unit is split, and the prediction unit may be a partition having the same size as the coding unit.
- the partition type includes not only symmetric partitions in which the height or width of the prediction unit is divided by a symmetrical ratio, but also partitions divided in an asymmetrical ratio, such as 1: n or n: 1, by a geometric form It may optionally include partitioned partitions, arbitrary types of partitions, and the like.
- the prediction mode of the prediction unit may be at least one of an intra mode, an inter mode, and a skip mode.
- the intra mode and the inter mode may be performed on partitions having sizes of 2N ⁇ 2N, 2N ⁇ N, N ⁇ 2N, and N ⁇ N.
- the skip mode may be performed only for partitions having a size of 2N ⁇ 2N.
- the encoding may be performed independently for each prediction unit within the coding unit to select a prediction mode having the smallest encoding error.
- the video encoding apparatus 100 may perform conversion of image data of a coding unit based on not only a coding unit for encoding image data, but also a data unit different from the coding unit.
- the transformation may be performed based on a transformation unit having a size smaller than or equal to the coding unit.
- the transformation unit may include a data unit for intra mode and a transformation unit for inter mode.
- the transformation unit in the coding unit is also recursively divided into smaller transformation units, so that the residual data of the coding unit is determined according to the tree structure according to the transformation depth. Can be partitioned according to the conversion unit.
- a transform depth indicating a number of divisions between the height and the width of the coding unit divided to the transform unit may be set. For example, if the size of the transform unit of the current coding unit of size 2Nx2N is 2Nx2N, the transform depth is 0, the transform depth 1 if the size of the transform unit is NxN, and the transform depth 2 if the size of the transform unit is N / 2xN / 2. Can be. That is, the transformation unit having a tree structure may also be set for the transformation unit according to the transformation depth.
- the encoded information for each coded depth requires not only the coded depth but also prediction related information and transformation related information. Accordingly, the coding unit determiner 120 may determine not only the coded depth that generated the minimum coding error, but also a partition type obtained by dividing a prediction unit into partitions, a prediction mode for each prediction unit, and a size of a transformation unit for transformation.
- a method of determining a coding unit, a prediction unit / partition, and a transformation unit according to a tree structure of a maximum coding unit according to an embodiment will be described in detail with reference to FIGS. 15 to 25.
- the coding unit determiner 120 may measure a coding error of coding units according to depths using a Lagrangian Multiplier-based rate-distortion optimization technique.
- the output unit 130 outputs the image data of the maximum coding unit encoded based on the at least one coded depth determined by the coding unit determiner 120 and the information about the encoding modes according to depths in the form of a bit stream.
- the encoded image data may be a result of encoding residual data of the image.
- the information about the encoding modes according to depths may include encoding depth information, partition type information of a prediction unit, prediction mode information, size information of a transformation unit, and the like.
- the coded depth information may be defined using depth-specific segmentation information indicating whether to encode to a coding unit of a lower depth without encoding to the current depth. If the current depth of the current coding unit is a coding depth, since the current coding unit is encoded in a coding unit of the current depth, split information of the current depth may be defined so that it is no longer divided into lower depths. On the contrary, if the current depth of the current coding unit is not the coding depth, encoding should be attempted using the coding unit of the lower depth, and thus split information of the current depth may be defined to be divided into coding units of the lower depth.
- encoding is performed on the coding unit divided into the coding units of the lower depth. Since at least one coding unit of a lower depth exists in the coding unit of the current depth, encoding may be repeatedly performed for each coding unit of each lower depth, and recursive coding may be performed for each coding unit of the same depth.
- coding units having a tree structure are determined in one largest coding unit and information about at least one coding mode should be determined for each coding unit of a coding depth, information about at least one coding mode may be determined for one maximum coding unit. Can be.
- the coding depth may be different for each location, and thus information about the coded depth and the coding mode may be set for the data.
- the output unit 130 may allocate encoding information about a corresponding coding depth and an encoding mode to at least one of a coding unit, a prediction unit, and a minimum unit included in the maximum coding unit. .
- the minimum unit according to an embodiment is a square data unit having a size obtained by dividing the minimum coding unit, which is the lowest coding depth, into four divisions.
- the minimum unit according to an embodiment may be a square data unit having a maximum size that may be included in all coding units, prediction units, partition units, and transformation units included in the maximum coding unit.
- the encoding information output through the output unit 130 may be classified into encoding information according to depth coding units and encoding information according to prediction units.
- the encoding information for each coding unit according to depth may include prediction mode information and partition size information.
- the encoding information transmitted for each prediction unit includes information about an estimation direction of the inter mode, information about a reference image index of the inter mode, information about a motion vector, information about a chroma component of an intra mode, and information about an inter mode of an intra mode. And the like.
- Information about the maximum size and information about the maximum depth of the coding unit defined for each picture, slice, or GOP may be inserted into a header, a sequence parameter set, or a picture parameter set of the bitstream.
- the information on the maximum size of the transform unit and the minimum size of the transform unit allowed for the current video may also be output through a header, a sequence parameter set, a picture parameter set, or the like of the bitstream.
- a coding unit according to depths is a coding unit having a size in which a height and a width of a coding unit of one layer higher depth are divided by half. That is, if the size of the coding unit of the current depth is 2Nx2N, the size of the coding unit of the lower depth is NxN.
- the current coding unit having a size of 2N ⁇ 2N may include up to four lower depth coding units having a size of N ⁇ N.
- the video encoding apparatus 100 determines a coding unit having an optimal shape and size for each maximum coding unit based on the size and the maximum depth of the maximum coding unit determined in consideration of the characteristics of the current picture. Coding units may be configured. In addition, since each of the maximum coding units may be encoded in various prediction modes and transformation methods, an optimal coding mode may be determined in consideration of image characteristics of coding units having various image sizes.
- the video encoding apparatus may adjust the coding unit in consideration of the image characteristics while increasing the maximum size of the coding unit in consideration of the size of the image, thereby increasing image compression efficiency.
- FIG. 2 is a block diagram of a video decoding apparatus based on coding units having a tree structure, according to an embodiment of the present invention.
- a video decoding apparatus 200 including video prediction based on coding units having a tree structure includes a receiver 210, image data and encoding information extractor 220, and image data decoder 230. do.
- the video decoding apparatus 200 that includes video prediction based on coding units having a tree structure is abbreviated as “video decoding apparatus 200”.
- Definition of various terms such as a coding unit, a depth, a prediction unit, a transformation unit, and information about various encoding modes for a decoding operation of the video decoding apparatus 200 according to an embodiment may refer to the video encoding apparatus 100 of FIG. 1. Same as described above with reference.
- the receiver 210 receives and parses a bitstream of an encoded video.
- the image data and encoding information extractor 220 extracts image data encoded for each coding unit from the parsed bitstream according to coding units having a tree structure for each maximum coding unit, and outputs the encoded image data to the image data decoder 230.
- the image data and encoding information extractor 220 may extract information about a maximum size of a coding unit of the current picture from a header, a sequence parameter set, or a picture parameter set for the current picture.
- the image data and encoding information extractor 220 extracts information about a coded depth and an encoding mode for the coding units having a tree structure for each maximum coding unit, from the parsed bitstream.
- the extracted information about the coded depth and the coding mode is output to the image data decoder 230. That is, the image data of the bit string may be divided into maximum coding units so that the image data decoder 230 may decode the image data for each maximum coding unit.
- the information about the coded depth and the encoding mode for each largest coding unit may be set with respect to one or more coded depth information, and the information about the coding mode according to the coded depths may include partition type information, prediction mode information, and transformation unit of the corresponding coding unit. May include size information and the like.
- split information for each depth may be extracted as the coded depth information.
- the information about the coded depth and the encoding mode according to the maximum coding units extracted by the image data and the encoding information extractor 220 may be encoded according to the depth according to the maximum coding unit, as in the video encoding apparatus 100 according to an embodiment.
- the image data and the encoding information extractor 220 may determine the predetermined data.
- Information about a coded depth and an encoding mode may be extracted for each unit. If the information about the coded depth and the coding mode of the maximum coding unit is recorded for each of the predetermined data units, the predetermined data units having the information about the same coded depth and the coding mode are inferred as data units included in the same maximum coding unit. Can be.
- the image data decoder 230 reconstructs the current picture by decoding image data of each maximum coding unit based on the information about the coded depth and the encoding mode for each maximum coding unit. That is, the image data decoder 230 may decode the encoded image data based on the read partition type, the prediction mode, and the transformation unit for each coding unit among the coding units having the tree structure included in the maximum coding unit. Can be.
- the decoding process may include a prediction process including intra prediction and motion compensation, and an inverse transform process.
- the image data decoder 230 may perform intra prediction or motion compensation according to each partition and prediction mode for each coding unit based on partition type information and prediction mode information of the prediction unit of the coding unit for each coding depth. .
- the image data decoder 230 may read transform unit information having a tree structure for each coding unit, and perform inverse transform based on the transformation unit for each coding unit, for inverse transformation for each largest coding unit. Through inverse transformation, the pixel value of the spatial region of the coding unit may be restored.
- the image data decoder 230 may determine the coded depth of the current maximum coding unit by using the split information for each depth. If the split information indicates that the split information is no longer split at the current depth, the current depth is the coded depth. Therefore, the image data decoder 230 may decode the coding unit of the current depth using the partition type, the prediction mode, and the transformation unit size information of the prediction unit with respect to the image data of the current maximum coding unit.
- the image data decoder 230 It may be regarded as one data unit to be decoded in the same encoding mode.
- the decoding of the current coding unit may be performed by obtaining information about an encoding mode for each coding unit determined in this way.
- the video decoding apparatus 200 may obtain information about a coding unit that generates a minimum coding error by recursively encoding each maximum coding unit in the encoding process, and use the same to decode the current picture. That is, decoding of encoded image data of coding units having a tree structure determined as an optimal coding unit for each maximum coding unit can be performed.
- the image data can be efficiently used according to the coding unit size and the encoding mode that are adaptively determined according to the characteristics of the image by using the information about the optimum encoding mode transmitted from the encoding end. Can be decoded and restored.
- a size of a coding unit may be expressed by a width x height, and may include 32x32, 16x16, and 8x8 from a coding unit having a size of 64x64.
- Coding units of size 64x64 may be partitioned into partitions of size 64x64, 64x32, 32x64, and 32x32, coding units of size 32x32 are partitions of size 32x32, 32x16, 16x32, and 16x16, and coding units of size 16x16 are 16x16.
- Coding units of size 8x8 may be divided into partitions of size 8x8, 8x4, 4x8, and 4x4, into partitions of 16x8, 8x16, and 8x8.
- the resolution is set to 1920x1080, the maximum size of the coding unit is 64, and the maximum depth is 2.
- the resolution is set to 1920x1080, the maximum size of the coding unit is 64, and the maximum depth is 3.
- the resolution is set to 352x288, the maximum size of the coding unit is 16, and the maximum depth is 1.
- the maximum depth illustrated in FIG. 15 represents the total number of divisions from the maximum coding unit to the minimum coding unit.
- the maximum size of the coding size is relatively large not only to improve the coding efficiency but also to accurately shape the image characteristics. Accordingly, the video data 310 or 320 having a higher resolution than the video data 330 may be selected to have a maximum size of 64.
- the coding unit 315 of the video data 310 is divided twice from a maximum coding unit having a long axis size of 64, and the depth is deepened by two layers, so that the long axis size is 32, 16. Up to coding units may be included.
- the coding unit 335 of the video data 330 is divided once from coding units having a long axis size of 16, and the depth is deepened by one layer to increase the long axis size to 8. Up to coding units may be included.
- the coding unit 325 of the video data 320 is divided three times from the largest coding unit having a long axis size of 64, and the depth is three layers deep, so that the long axis size is 32, 16. , Up to 8 coding units may be included. As the depth increases, the expressive power of the detailed information may be improved.
- 16 is a block diagram of an image encoder based on coding units, according to an embodiment of the present invention.
- the image encoder 400 includes operations performed by the encoding unit determiner 120 of the video encoding apparatus 100 to encode image data. That is, the intra predictor 410 performs intra prediction on the coding unit of the intra mode among the current frame 405, and the motion estimator 420 and the motion compensator 425 are the current frame 405 of the inter mode. And the inter frame estimation and the motion compensation using the reference frame 495.
- Data output from the intra predictor 410, the motion estimator 420, and the motion compensator 425 is output as a quantized transform coefficient through the transform unit 430 and the quantization unit 440.
- the quantized transform coefficients are reconstructed into the data of the spatial domain through the inverse quantizer 460 and the inverse transformer 470, and the data of the reconstructed spatial domain is post-processed through the deblocking unit 480 and the offset adjusting unit 490. And output to the reference frame 495.
- the quantized transform coefficients may be output to the bitstream 455 via the entropy encoder 450.
- the intra predictor 410, the motion estimator 420, the motion compensator 425, and the transform unit may be components of the image encoder 400.
- quantizer 440, entropy encoder 450, inverse quantizer 460, inverse transform unit 470, deblocking unit 480, and offset adjuster 490 all have the maximum depth for each largest coding unit. In consideration of this, operations based on each coding unit among the coding units having a tree structure should be performed.
- the intra predictor 410, the motion estimator 420, and the motion compensator 425 partition each coding unit among coding units having a tree structure in consideration of the maximum size and the maximum depth of the current maximum coding unit.
- a prediction mode, and the transform unit 430 should determine the size of a transform unit in each coding unit among the coding units having a tree structure.
- 17 is a block diagram of an image decoder based on coding units, according to an embodiment of the present invention.
- the bitstream 505 is parsed through the parsing unit 510, and the encoded image data to be decoded and information about encoding necessary for decoding are parsed.
- the encoded image data is output as inverse quantized data through the entropy decoding unit 520 and the inverse quantization unit 530, and the image data of the spatial domain is restored through the inverse transformation unit 540.
- the intra prediction unit 550 performs intra prediction on the coding unit of the intra mode, and the motion compensator 560 uses the reference frame 585 together to apply the coding unit of the inter mode. Perform motion compensation for the
- Data in the spatial region that has passed through the intra predictor 550 and the motion compensator 560 may be post-processed through the deblocking unit 570 and the offset adjusting unit 580 and output to the reconstructed frame 595.
- the post-processed data through the deblocking unit 570 and the offset adjusting unit 580 may be output as the reference frame 585.
- step-by-step operations after the parser 510 of the image decoder 500 may be performed.
- the parser 510, the entropy decoder 520, the inverse quantizer 530, and the inverse transform unit 540 which are components of the image decoder 500, may be used.
- the intra predictor 550, the motion compensator 560, the deblocking unit 570, and the offset adjuster 580 must all perform operations based on coding units having a tree structure for each maximum coding unit. .
- the intra predictor 550 and the motion compensator 560 determine partitions and prediction modes for each coding unit having a tree structure, and the inverse transform unit 540 must determine the size of the transform unit for each coding unit. .
- FIG. 18 is a diagram of deeper coding units according to depths, and partitions, according to an embodiment of the present invention.
- the video encoding apparatus 100 according to an embodiment and the video decoding apparatus 200 according to an embodiment use hierarchical coding units to consider image characteristics.
- the maximum height, width, and maximum depth of the coding unit may be adaptively determined according to the characteristics of the image, and may be variously set according to a user's request. According to the maximum size of the preset coding unit, the size of the coding unit for each depth may be determined.
- the hierarchical structure 600 of a coding unit illustrates a case in which a maximum height and a width of a coding unit are 64 and a maximum depth is three.
- the maximum depth indicates the total number of divisions from the maximum coding unit to the minimum coding unit. Since the depth deepens along the vertical axis of the hierarchical structure 600 of the coding unit according to an embodiment, the height and the width of the coding unit for each depth are divided.
- a prediction unit and a partition on which the prediction encoding of each depth-based coding unit is shown along the horizontal axis of the hierarchical structure 600 of the coding unit are illustrated.
- the coding unit 610 has a depth of 0 as the largest coding unit of the hierarchical structure 600 of the coding unit, and the size, ie, the height and width, of the coding unit is 64x64.
- a depth along the vertical axis includes a coding unit 620 of depth 1 having a size of 32x32, a coding unit 630 of depth 2 having a size of 16x16, and a coding unit 640 of depth 3 having a size of 8x8.
- the coding unit 640 of 3 is a minimum coding unit.
- Prediction units and partitions of the coding unit are arranged along the horizontal axis for each depth. That is, if the coding unit 610 of size 64x64 having a depth of zero is a prediction unit, the prediction unit may include a partition 610 of size 64x64, partitions 612 of size 64x32, and size included in the coding unit 610 of size 64x64. 32x64 partitions 614, 32x32 partitions 616.
- the prediction unit of the coding unit 620 having a size of 32x32 having a depth of 1 includes a partition 620 of size 32x32, partitions 622 of size 32x16 and a partition of size 16x32 included in the coding unit 620 of size 32x32. 624, partitions 626 of size 16x16.
- the prediction unit of the coding unit 630 of size 16x16 having a depth of 2 includes a partition 630 of size 16x16, partitions 632 of size 16x8, and a partition of size 8x16 included in the coding unit 630 of size 16x16. 634, partitions 636 of size 8x8.
- the prediction unit of the coding unit 640 of size 8x8 having a depth of 3 includes a partition 640 of size 8x8, partitions 642 of size 8x4 and a partition of size 4x8 included in the coding unit 640 of size 8x8. 644, partitions 646 of size 4x4.
- the coding unit 640 of size 8x8 having a depth of 3 is a minimum coding unit and a coding unit of the lowest depth.
- the coding unit determiner 120 of the video encoding apparatus 100 may determine a coding depth of the maximum coding unit 610.
- the number of deeper coding units according to depths for including data having the same range and size increases as the depth increases. For example, four coding units of depth 2 are required for data included in one coding unit of depth 1. Therefore, in order to compare the encoding results of the same data for each depth, each of the coding units having one depth 1 and four coding units having four depths 2 should be encoded.
- encoding may be performed for each prediction unit of a coding unit according to depths along a horizontal axis of the hierarchical structure 600 of the coding unit, and a representative coding error, which is the smallest coding error at a corresponding depth, may be selected. .
- a depth deeper along the vertical axis of the hierarchical structure 600 of the coding unit the encoding may be performed for each depth, and the minimum coding error may be searched by comparing the representative coding error for each depth.
- the depth and the partition in which the minimum coding error occurs in the maximum coding unit 610 may be selected as the coding depth and the partition type of the maximum coding unit 610.
- FIG. 19 illustrates a relationship between a coding unit and transformation units, according to an embodiment of the present invention.
- the video encoding apparatus 100 encodes or decodes an image in coding units having a size smaller than or equal to the maximum coding unit for each maximum coding unit.
- the size of a transformation unit for transformation in the encoding process may be selected based on a data unit that is not larger than each coding unit.
- the 32x32 size conversion unit 720 is The conversion can be performed.
- the data of the 64x64 coding unit 710 is transformed into 32x32, 16x16, 8x8, and 4x4 transform units of 64x64 size or less, and then encoded, and the transform unit having the least error with the original is selected. Can be.
- the output unit 130 of the video encoding apparatus 100 is information about an encoding mode, and information about a partition type 800 and information 810 about a prediction mode for each coding unit of each coded depth.
- the information 820 about the size of the transformation unit may be encoded and transmitted.
- the information about the partition type 800 is a data unit for predictive encoding of the current coding unit and indicates information about a partition type in which the prediction unit of the current coding unit is divided.
- the current coding unit CU_0 of size 2Nx2N may be any one of a partition 802 of size 2Nx2N, a partition 804 of size 2NxN, a partition 806 of size Nx2N, and a partition 808 of size NxN. It can be divided and used.
- the information 800 about the partition type of the current coding unit represents one of a partition 802 of size 2Nx2N, a partition 804 of size 2NxN, a partition 806 of size Nx2N, and a partition 808 of size NxN. It is set to.
- Information 810 relating to the prediction mode indicates the prediction mode of each partition. For example, through the information 810 about the prediction mode, whether the partition indicated by the information 800 about the partition type is performed in one of the intra mode 812, the inter mode 814, and the skip mode 816 is performed. Whether or not can be set.
- the information about the transform unit size 820 indicates whether to transform the current coding unit based on the transform unit.
- the transform unit may be one of a first intra transform unit size 822, a second intra transform unit size 824, a first inter transform unit size 826, and a second inter transform unit size 828. have.
- the image data and encoding information extractor 210 of the video decoding apparatus 200 may include information about a partition type 800, information 810 about a prediction mode, and transformation for each depth-based coding unit. Information 820 about the unit size may be extracted and used for decoding.
- 21 is a diagram of deeper coding units according to depths, according to an embodiment of the present invention.
- Segmentation information may be used to indicate a change in depth.
- the split information indicates whether a coding unit of a current depth is split into coding units of a lower depth.
- the prediction unit 910 for predictive encoding of the coding unit 900 having depth 0 and 2N_0x2N_0 size includes a partition type 912 having a size of 2N_0x2N_0, a partition type 914 having a size of 2N_0xN_0, a partition type 916 having a size of N_0x2N_0, and a N_0xN_0 It may include a partition type 918 of size. Although only partitions 912, 914, 916, and 918 in which the prediction unit is divided by a symmetrical ratio are illustrated, as described above, the partition type is not limited thereto, and asymmetric partitions, arbitrary partitions, geometric partitions, and the like. It may include.
- prediction coding For each partition type, prediction coding must be performed repeatedly for one 2N_0x2N_0 partition, two 2N_0xN_0 partitions, two N_0x2N_0 partitions, and four N_0xN_0 partitions.
- prediction encoding For partitions having a size 2N_0x2N_0, a size N_0x2N_0, a size 2N_0xN_0, and a size N_0xN_0, prediction encoding may be performed in an intra mode and an inter mode. The skip mode may be performed only for prediction encoding on partitions having a size of 2N_0x2N_0.
- the depth 0 is changed to 1 and split (920), and the encoding is repeatedly performed on the depth 2 and the coding units 930 of the partition type having the size N_0xN_0.
- the prediction unit 940 for predictive encoding of the coding unit 930 having a depth of 1 and a size of 2N_1x2N_1 includes a partition type 942 having a size of 2N_1x2N_1, a partition type 944 having a size of 2N_1xN_1, and a partition type having a size of N_1x2N_1.
- 946, a partition type 948 of size N_1 ⁇ N_1 may be included.
- the depth 1 is changed to the depth 2 and divided (950), and repeatedly for the depth 2 and the coding units 960 of the size N_2xN_2.
- the encoding may be performed to search for a minimum encoding error.
- depth-based coding units may be set until depth d-1, and split information may be set up to depth d-2. That is, when encoding is performed from the depth d-2 to the depth d-1 to the depth d-1, the prediction encoding of the coding unit 980 of the depth d-1 and the size 2N_ (d-1) x2N_ (d-1)
- the prediction unit for 990 is a partition type 992 of size 2N_ (d-1) x2N_ (d-1), partition type 994 of size 2N_ (d-1) xN_ (d-1), size A partition type 996 of N_ (d-1) x2N_ (d-1) and a partition type 998 of size N_ (d-1) xN_ (d-1) may be included.
- one partition 2N_ (d-1) x2N_ (d-1), two partitions 2N_ (d-1) xN_ (d-1), two sizes N_ (d-1) x2N_ Prediction encoding is repeatedly performed for each partition of (d-1) and four partitions of size N_ (d-1) xN_ (d-1), so that a partition type having a minimum encoding error may be searched. .
- the coding unit CU_ (d-1) of the depth d-1 is no longer
- the encoding depth of the current maximum coding unit 900 may be determined as the depth d-1, and the partition type may be determined as N_ (d-1) xN_ (d-1) without going through a division process into lower depths.
- split information is not set for the coding unit 952 having the depth d-1.
- the data unit 999 may be referred to as a 'minimum unit' for the current maximum coding unit.
- the minimum unit may be a square data unit having a size obtained by dividing the minimum coding unit, which is the lowest coding depth, into four divisions.
- the video encoding apparatus 100 compares the encoding errors for each depth of the coding unit 900, selects a depth at which the smallest encoding error occurs, and determines a coding depth.
- the partition type and the prediction mode may be set to the encoding mode of the coded depth.
- the depth with the smallest error can be determined by comparing the minimum coding errors for all depths of depths 0, 1, ..., d-1, d, and can be determined as the coding depth.
- the coded depth, the partition type of the prediction unit, and the prediction mode may be encoded and transmitted as information about an encoding mode.
- the coding unit since the coding unit must be split from the depth 0 to the coded depth, only the split information of the coded depth is set to '0', and the split information for each depth except the coded depth should be set to '1'.
- the image data and encoding information extractor 220 of the video decoding apparatus 200 may extract information about a coding depth and a prediction unit for the coding unit 900 and use the same to decode the coding unit 912. Can be.
- the video decoding apparatus 200 may identify a depth having split information of '0' as a coding depth using split information for each depth, and may use the decoding depth by using information about an encoding mode for a corresponding depth. have.
- 22, 23, and 24 illustrate a relationship between a coding unit, a prediction unit, and a transformation unit, according to an embodiment of the present invention.
- the coding units 1010 are coding units according to coding depths determined by the video encoding apparatus 100 according to an embodiment with respect to the maximum coding unit.
- the prediction unit 1060 is partitions of prediction units of each coding depth of each coding depth among the coding units 1010, and the transformation unit 1070 is transformation units of each coding depth for each coding depth.
- the depth-based coding units 1010 have a depth of 0
- the coding units 1012 and 1054 have a depth of 1
- the coding units 1014, 1016, 1018, 1028, 1050, and 1052 have depths.
- coding units 1020, 1022, 1024, 1026, 1030, 1032, and 1048 have a depth of three
- coding units 1040, 1042, 1044, and 1046 have a depth of four.
- partitions 1014, 1016, 1022, 1032, 1048, 1050, 1052, and 1054 of the prediction units 1060 are obtained by splitting coding units. That is, partitions 1014, 1022, 1050, and 1054 are partition types of 2NxN, partitions 1016, 1048, and 1052 are partition types of Nx2N, and partitions 1032 are partition types of NxN. Prediction units and partitions of the coding units 1010 according to depths are smaller than or equal to each coding unit.
- the image data of the part 1052 of the transformation units 1070 is transformed or inversely transformed into a data unit having a smaller size than the coding unit.
- the transformation units 1014, 1016, 1022, 1032, 1048, 1050, 1052, and 1054 are data units having different sizes or shapes when compared to corresponding prediction units and partitions among the prediction units 1060. That is, the video encoding apparatus 100 according to an embodiment and the video decoding apparatus 200 according to an embodiment may be intra prediction / motion estimation / motion compensation operations and transform / inverse transform operations for the same coding unit. Each can be performed on a separate data unit.
- coding is performed recursively for each coding unit having a hierarchical structure for each largest coding unit to determine an optimal coding unit.
- coding units having a recursive tree structure may be configured.
- the encoding information may include split information about a coding unit, partition type information, prediction mode information, and transformation unit size information. Table 2 below shows an example that can be set in the video encoding apparatus 100 and the video decoding apparatus 200 according to an embodiment.
- Segmentation information 0 (coding for coding units of size 2Nx2N of current depth d) Split information 1 Prediction mode Partition type Transformation unit size Iterative coding for each coding unit of lower depth d + 1 Intra interskip (2Nx2N only) Symmetric Partition Type Asymmetric Partition Type Conversion unit split information 0 Conversion unit split information 1 2Nx2N2NxNNx2NNxN 2NxnU2NxnDnLx2NnRx2N 2Nx2N NxN (symmetric partition type) N / 2xN / 2 (asymmetric partition type)
- the output unit 130 of the video encoding apparatus 100 outputs encoding information about coding units having a tree structure
- the encoding information extraction unit of the video decoding apparatus 200 according to an embodiment 220 may extract encoding information about coding units having a tree structure from the received bitstream.
- the split information indicates whether the current coding unit is split into coding units of a lower depth. If the split information of the current depth d is 0, partition type information, prediction mode, and transform unit size information are defined for the coded depth because the depth in which the current coding unit is no longer divided into the lower coding units is a coded depth. Can be. If it is to be further split by the split information, encoding should be performed independently for each coding unit of the divided four lower depths.
- the prediction mode may be represented by one of an intra mode, an inter mode, and a skip mode.
- Intra mode and inter mode can be defined in all partition types, and skip mode can be defined only in partition type 2Nx2N.
- the partition type information indicates the symmetric partition types 2Nx2N, 2NxN, Nx2N and NxN, in which the height or width of the prediction unit is divided by the symmetrical ratio, and the asymmetric partition types 2NxnU, 2NxnD, nLx2N, nRx2N, which are divided by the asymmetrical ratio.
- the asymmetric partition types 2NxnU and 2NxnD are divided into heights 1: 3 and 3: 1, respectively, and the asymmetric partition types nLx2N and nRx2N are divided into 1: 3 and 3: 1 widths, respectively.
- the conversion unit size may be set to two kinds of sizes in the intra mode and two kinds of sizes in the inter mode. That is, if the transformation unit split information is 0, the size of the transformation unit is set to the size 2Nx2N of the current coding unit. If the transform unit split information is 1, a transform unit having a size obtained by dividing the current coding unit may be set. In addition, if the partition type for the current coding unit having a size of 2Nx2N is a symmetric partition type, the size of the transform unit may be set to NxN, and if the asymmetric partition type is N / 2xN / 2.
- Encoding information of coding units having a tree structure may be allocated to at least one of a coding unit, a prediction unit, and a minimum unit unit of a coding depth.
- the coding unit of the coding depth may include at least one prediction unit and at least one minimum unit having the same encoding information.
- the encoding information held by each adjacent data unit is checked, it may be determined whether the adjacent data units are included in the coding unit having the same coding depth.
- the coding unit of the corresponding coding depth may be identified by using the encoding information held by the data unit, the distribution of the coded depths within the maximum coding unit may be inferred.
- the encoding information of the data unit in the depth-specific coding unit adjacent to the current coding unit may be directly referred to and used.
- the prediction coding when the prediction coding is performed by referring to the neighboring coding unit, the data adjacent to the current coding unit in the coding unit according to depths is encoded by using the encoding information of the adjacent coding units according to depths.
- the neighboring coding unit may be referred to by searching.
- FIG. 25 illustrates a relationship between coding units, prediction units, and transformation units, according to encoding mode information of Table 2.
- FIG. 25 illustrates a relationship between coding units, prediction units, and transformation units, according to encoding mode information of Table 2.
- the maximum coding unit 1300 includes coding units 1302, 1304, 1306, 1312, 1314, 1316, and 1318 of a coded depth. Since one coding unit 1318 is a coding unit of a coded depth, split information may be set to zero.
- the partition type information of the coding unit 1318 having a size of 2Nx2N is partition type 2Nx2N 1322, 2NxN 1324, Nx2N 1326, NxN 1328, 2NxnU 1332, 2NxnD 1334, nLx2N (1336). And nRx2N 1338.
- the transform unit split information (TU size flag) is a type of transform index, and a size of a transform unit corresponding to the transform index may be changed according to a prediction unit type or a partition type of a coding unit.
- the partition type information is set to one of the symmetric partition types 2Nx2N 1322, 2NxN 1324, Nx2N 1326, and NxN 1328
- the conversion unit partition information is 0, a conversion unit of size 2Nx2N ( 1342 is set, and if the transform unit split information is 1, a transform unit 1344 of size NxN may be set.
- the partition type information is set to one of the asymmetric partition types 2NxnU (1332), 2NxnD (1334), nLx2N (1336), and nRx2N (1338), if the conversion unit partition information (TU size flag) is 0, a conversion unit of size 2Nx2N ( 1352 is set, and if the transform unit split information is 1, a transform unit 1354 of size N / 2 ⁇ N / 2 may be set.
- the conversion unit partitioning information (TU size flag) described above with reference to FIG. 25 is a flag having a value of 0 or 1, but the conversion unit partitioning information according to an embodiment is not limited to a 1-bit flag and is set to 0 according to a setting. , 1, 2, 3., etc., and may be divided hierarchically.
- the transformation unit partition information may be used as an embodiment of the transformation index.
- the size of the transformation unit actually used may be expressed.
- the video encoding apparatus 100 may encode maximum transform unit size information, minimum transform unit size information, and maximum transform unit split information.
- the encoded maximum transform unit size information, minimum transform unit size information, and maximum transform unit split information may be inserted into the SPS.
- the video decoding apparatus 200 may use the maximum transform unit size information, the minimum transform unit size information, and the maximum transform unit split information to use for video decoding.
- the maximum transform unit split information is defined as 'MaxTransformSizeIndex'
- the minimum transform unit size is 'MinTransformSize'
- the transform unit split information is 0,
- the minimum transform unit possible in the current coding unit is defined as 'RootTuSize'.
- the size 'CurrMinTuSize' can be defined as in relation (1) below.
- 'RootTuSize' which is a transform unit size when the transform unit split information is 0, may indicate a maximum transform unit size that can be adopted in the system. That is, according to relation (1), 'RootTuSize / (2 ⁇ MaxTransformSizeIndex)' is a transformation obtained by dividing 'RootTuSize', which is the size of the transformation unit when the transformation unit division information is 0, by the number of times corresponding to the maximum transformation unit division information. Since the unit size is 'MinTransformSize' is the minimum transform unit size, a smaller value among them may be the minimum transform unit size 'CurrMinTuSize' possible in the current coding unit.
- the maximum transform unit size RootTuSize may vary depending on a prediction mode.
- RootTuSize may be determined according to the following relation (2).
- 'MaxTransformSize' represents the maximum transform unit size
- 'PUSize' represents the current prediction unit size.
- RootTuSize min (MaxTransformSize, PUSize) ......... (2)
- 'RootTuSize' which is a transform unit size when the transform unit split information is 0, may be set to a smaller value among the maximum transform unit size and the current prediction unit size.
- 'RootTuSize' may be determined according to Equation (3) below.
- 'PartitionSize' represents the size of the current partition unit.
- RootTuSize min (MaxTransformSize, PartitionSize) ........... (3)
- the conversion unit size 'RootTuSize' when the conversion unit split information is 0 may be set to a smaller value among the maximum conversion unit size and the current partition unit size.
- the current maximum conversion unit size 'RootTuSize' according to an embodiment that changes according to the prediction mode of the partition unit is only an embodiment, and a factor determining the current maximum conversion unit size is not limited thereto.
- the maximum coding unit including the coding units of the tree structure described above with reference to FIGS. 13 to 25 may be a coding block tree, a block tree, a root block tree, a coding tree, a coding root, or It may also be called variously as a tree trunk.
- the invention can also be embodied as computer readable code on a computer readable recording medium.
- the computer-readable recording medium includes all kinds of recording devices in which data that can be read by a computer system is stored. Examples of computer-readable recording media include ROM, RAM, CD-ROM, magnetic tape, floppy disk, optical data storage device, and the like.
- the computer readable recording medium can also be distributed over network coupled computer systems so that the computer readable code is stored and executed in a distributed fashion.
Landscapes
- Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Compression Or Coding Systems Of Tv Signals (AREA)
Abstract
Description
| nal_unit_type | Name of nal_unit_type | Content of NAL unit and RBSP syntax structure |
| 0 1 | TRAIL_N TRAIL_R | Coded slice segment of a non-TSA, non-STSA trailing picture slice_segment_layer_rbsp( ) |
| 2 3 | TSA_N TSA_R | Coded slice segment of a TSA picture slice_segment_layer_rbsp( ) |
| 4 5 | STSA_N STSA_R | Coded slice segment of an STSA picture slice_segment_layer_rbsp( ) |
| 6 7 | RADL_N RADL_R | Coded slice segment of a RADL picture slice_segment_layer_rbsp( ) |
| 8 9 | RASL_N RASL_R | Coded slice segment of a RASL picture slice_segment_layer_rbsp( ) |
| 10 12 14 | RSV_VCL_N10 RSV_VCL_N12 RSV_VCL_N14 | Reserved non-IRAP sub-layer non-reference VCL NAL unit types |
| 11 13 15 | RSV_VCL_R11 RSV_VCL_R13 RSV_VCL_R15 | Reserved non-IRAP sub-layer reference VCL NAL unit types |
| 16 17 18 | BLA_W_LP BLA_W_RADL BLA_N_LP | Coded slice segment of a BLA picture slice_segment_layer_rbsp( ) |
| 19 20 | IDR_W_RADL IDR_N_LP | Coded slice segment of an IDR picture slice_segment_layer_rbsp( ) |
| 21 | CRA_NUT | Coded slice segment of a CRA picture slice_segment_layer_rbsp( ) |
| 22 23 | RSV_IRAP_VCL22 RSV_IRAP_VCL23 | Reserved IRAP VCL NAL unit types |
| 24..31 | RSV_VCL24.. RSV_VCL31 | Reserved non-IRAP VCL NAL unit types |
| 32 | VPS_NUT | Video parameter set video_parameter_set_rbsp( ) |
| 33 | SPS_NUT | Sequence parameter set seq_parameter_set_rbsp( ) |
| 34 | PPS_NUT | Picture parameter set pic_parameter_set_rbsp( ) |
| 35 | AUD_NUT | Access unit delimiter access_unit_delimiter_rbsp( ) |
| 36 | EOS_NUT | End of sequence end_of_seq_rbsp( ) |
| 37 | EOB_NUT | End of bitstream end_of_bitstream_rbsp( ) |
| 38 | FD_NUT | Filler data filler_data_rbsp( ) |
| 39 40 | PREFIX_SEI_NUT SUFFIX_SEI_NUT | Supplemental enhancement information sei_rbsp( ) |
| 41..47 | RSV_NVCL41.. RSV_NVCL47 | Reserved |
| 분할 정보 0 (현재 심도 d의 크기 2Nx2N의 부호화 단위에 대한 부호화) | 분할 정보 1 | ||||
| 예측 모드 | 파티션 타입 | 변환 단위 크기 | 하위 심도 d+1의 부호화 단위들마다 반복적 부호화 | ||
| 인트라 인터스킵 (2Nx2N만) | 대칭형 파티션 타입 | 비대칭형 파티션 타입 | 변환 단위 분할 정보 0 | 변환 단위 분할 정보 1 | |
| 2Nx2N2NxNNx2NNxN | 2NxnU2NxnDnLx2NnRx2N | 2Nx2N | NxN (대칭형 파티션 타입) N/2xN/2 (비대칭형 파티션 타입) | ||
Claims (15)
- 다계층 비디오 부호화 방법에 있어서,상기 다계층 비디오를 부호화하는 단계;상기 부호화된 다계층 비디오를 데이터 단위에 따라 구분하여 데이터 단위별 NAL(Network Adaptive Layer) 단위들을 생성하는 단계; 및상기 데이터 단위별 전송 단위 데이터들 중 상기 다계층 비디오에 공통적으로 적용되는 정보에 관한 VPS(Video Parameter Set) 정보를 포함하는 VPS NAL 단위에, 상기 다계층 비디오의 스케일러블 확장을 위한 스케일러블 확장 유형 정보를 부가하는 단계를 포함하는 것을 특징으로 하는 다계층 비디오 부호화 방법.
- 제 1항에 있어서,상기 NAL 단위들을 생성하는 단계는상기 다계층 비디오에 포함된 슬라이스 단위별로, 슬라이스 단위의 부호화된 정보를 포함하는 슬라이스 세그먼트 NAL 단위를 생성하는 단계;상기 다계층 비디오에 포함된 픽처들에 공통적으로 적용되는 PPS(Picture Parameter Set)에 관한 정보를 포함하는 PPS NAL 단위를 생성하는 단계;상기 다계층 비디오에 포함된 소정 계층의 영상 시퀀스에 공통적으로 적용되는 SPS(Sequence Parameter Set)에 관한 정보를 포함하는 SPS NAL 단위를 생성하는 단계; 및상기 소정 계층의 영상 시퀀스의 집합인 다계층 비디오에 공통적으로 적용되는 상기 VPS에 관한 정보를 포함하는 상기 VPS NAL 단위를 생성하는 단계를 포함하는 것을 특징으로 하는 다계층 비디오 부호화 방법.
- 제 1항에 있어서,상기 스케일러블 확장 유형 정보를 부가하는 단계는상기 다계층 비디오에 적용가능한 스케일러블 확장 유형의 조합들을 포함하는 스케일러블 확장 유형 테이블들 중 하나를 나타내는 스케일러블 확장 유형 테이블 인덱스 및 상기 스케일러블 확장 유형 테이블 인덱스가 가리키는 상기 스케일러블 확장 유형 테이블에 포함된 상기 스케일러블 확장 유형의 조합들 중 하나를 나타내는 계층 인덱스를 상기 VPS NAL 단위의 헤더에 부가하는 단계를 포함하는 것을 특징으로 하는 다계층 비디오 부호화 방법.
- 제 1항에 있어서,상기 스케일러블 확장 유형 정보를 부가하는 단계는상기 다계층 비디오에 적용가능한 스케일러블 확장 유형의 조합들을 포함하는 스케일러블 확장 유형 테이블들 중 하나를 나타내는 스케일러블 확장 유형 테이블 인덱스를 상기 VPS NAL 단위의 헤더에 부가하는 단계를 포함하며,상기 PPS NAL 단위에 적용된 스케일러블 확장 유형을 나타내기 위하여, 상기 PPS NAL 단위는 상기 스케일러블 확장 유형 테이블 인덱스가 가리키는 상기 스케일러블 확장 유형 테이블에 포함된 상기 스케일러블 확장 유형의 조합들 중 하나를 나타내는 계층 인덱스를 더 포함하는 것을 특징으로 하는 다계층 비디오 부호화 방법.
- 제 1항에 있어서,상기 스케일러블 확장 유형 정보를 부가하는 단계는상기 다계층 비디오에 적용가능한 스케일러블 확장 유형의 조합들을 포함하는 스케일러블 확장 유형 테이블들 중 하나를 나타내는 스케일러블 확장 유형 테이블 인덱스를 상기 VPS NAL 단위의 헤더에 부가하는 단계를 포함하며,상기 SPS NAL 단위에 적용된 스케일러블 확장 유형을 나타내기 위하여, 상기 SPS NAL 단위는 상기 스케일러블 확장 유형 테이블 인덱스가 가리키는 상기 스케일러블 확장 유형 테이블에 포함된 상기 스케일러블 확장 유형의 조합들 중 하나를 나타내는 계층 인덱스를 더 포함하는 것을 특징으로 하는 다계층 비디오 부호화 방법.
- 제 1항에 있어서,상기 스케일러블 확장 유형 정보는시간적 스케일러빌러티, 화질적 스케일러빌러티, 공간적 스케일러빌러티 및 시점 정보 중 적어도 하나를 포함하는 것을 특징으로 하는 다계층 비디오 부호화 방법.
- 제 1항에 있어서,상기 스케일러블 확장 유형 정보는상기 다계층 비디오에 적용가능한 스케일러블 확장 유형의 조합들을 포함하는 스케일러블 확장 유형 테이블들 중 하나를 나타내는 스케일러블 확장 유형 테이블 인덱스이며,상기 스케일러블 확장 유형 테이블은 SEI(Supplemental Enhancement Information) 메시지에 포함되어 전송되는 것을 특징으로 하는 다계층 비디오 부호화 방법.
- 다계층 비디오 부호화 장치에 있어서,상기 다계층 비디오를 부호화하는 비디오 부호화부;상기 부호화된 다계층 비디오를 데이터 단위에 따라 구분하여 데이터 단위별 NAL(Network Adaptive Layer) 단위들을 생성하고, 상기 데이터 단위별 전송 단위 데이터들 중 상기 다계층 비디오에 공통적으로 적용되는 정보에 관한 VPS(Video Parameter Set) 정보를 포함하는 VPS NAL 단위에, 상기 다계층 비디오의 스케일러블 확장을 위한 스케일러블 확장 유형 정보를 부가하는 출력부를 포함하는 것을 특징으로 하는 다계층 비디오 부호화 장치.
- 다계층 비디오 복호화 방법에 있어서,부호화된 다계층 비디오를 데이터 단위별로 구분하여 생성된 NAL(Network Adaptive Layer) 단위들을 수신하는 단계;상기 수신된 NAL 단위들 중 상기 다계층 비디오에 공통적으로 적용되는 정보에 관한 VPS(Video Parameter Set) 정보를 포함하는 VPS NAL 단위를 획득하는 단계; 및상기 VPS NAL 단위로부터 상기 다계층 비디오의 스케일러블 확장을 위한 스케일러블 확장 유형 정보를 획득하는 단계를 포함하는 것을 특징으로 하는 다계층 비디오 복호화 방법.
- 제 9항에 있어서,상기 NAL 단위들은상기 다계층 비디오에 포함된 슬라이스 단위별로, 슬라이스 단위의 부호화된 정보를 포함하는 슬라이스 세그먼트 NAL 단위, 상기 다계층 비디오에 포함된 픽처들에 공통적으로 적용되는 PPS(Picture Parameter Set)에 관한 정보를 포함하는 PPS NAL 단위, 상기 다계층 비디오에 포함된 소정 계층의 영상 시퀀스에 공통적으로 적용되는 SPS(Sequence Parameter Set)에 관한 정보를 포함하는 SPS NAL 단위 및 상기 VPS NAL 단위를 포함하며,상기 슬라이스 세그먼트 NAL 단위, 상기 PPS NAL 단위, 상기 SPS NAL 단위 및 상기 VPS NAL 단위는 상기 NAL 단위의 헤더에 포함된 NAL 단위 식별자(nal unit type)을 통해 식별되는 것을 특징으로 하는 다계층 비디오 복호화 방법.
- 제 9항에 있어서,상기 스케일러블 확장 유형 정보를 획득하는 단계는상기 VPS NAL 단위의 헤더로부터, 상기 다계층 비디오에 적용가능한 스케일러블 확장 유형의 조합들을 포함하는 스케일러블 확장 유형 테이블들 중 하나를 나타내는 스케일러블 확장 유형 테이블 인덱스 및 상기 스케일러블 확장 유형 테이블 인덱스가 가리키는 상기 스케일러블 확장 유형 테이블에 포함된 상기 스케일러블 확장 유형의 조합들 중 하나를 나타내는 계층 인덱스를 획득하는 것을 특징으로 하는 다계층 비디오 복호화 방법.
- 제 9항에 있어서,상기 스케일러블 확장 유형 정보를 획득하는 단계는상기 VPS NAL 단위의 헤더로부터, 상기 다계층 비디오에 적용가능한 스케일러블 확장 유형의 조합들을 포함하는 스케일러블 확장 유형 테이블들 중 하나를 나타내는 스케일러블 확장 유형 테이블 인덱스를 획득하는 단계; 및상기 다계층 비디오에 포함된 픽처들에 공통적으로 적용되는 PPS(Picture Parameter Set)에 관한 정보를 포함하는 PPS NAL 단위로부터, 상기 스케일러블 확장 유형 테이블 인덱스가 가리키는 상기 스케일러블 확장 유형 테이블에 포함된 상기 스케일러블 확장 유형의 조합들 중 하나를 나타내는 계층 인덱스를 획득하고, 상기 획득된 계층 인덱스를 이용하여 상기 픽처들에 적용된 스케일러블 확장 유형을 결정하는 단계를 더 포함하는 것을 특징으로 하는 다계층 비디오 복호화 방법.
- 제 9항에 있어서,상기 스케일러블 확장 유형 정보를 획득하는 단계는상기 VPS NAL 단위의 헤더로부터, 상기 다계층 비디오에 적용가능한 스케일러블 확장 유형의 조합들을 포함하는 스케일러블 확장 유형 테이블들 중 하나를 나타내는 스케일러블 확장 유형 테이블 인덱스를 획득하는 단계; 및상기 다계층 비디오에 포함된 소정 계층의 영상 시퀀스에 공통적으로 적용되는 SPS(Sequence Parameter Set)에 관한 정보를 포함하는 SPS NAL 단위로부터, 상기 스케일러블 확장 유형 테이블 인덱스가 가리키는 상기 스케일러블 확장 유형 테이블에 포함된 상기 스케일러블 확장 유형의 조합들 중 하나를 나타내는 계층 인덱스를 획득하고, 상기 획득된 계층 인덱스를 이용하여 상기 소정 계층의 영상 시퀀스에 적용된 스케일러블 확장 유형을 결정하는 단계를 더 포함하는 것을 특징으로 하는 다계층 비디오 복호화 방법.
- 제 9항에 있어서,상기 스케일러블 확장 유형 정보는상기 다계층 비디오에 적용가능한 스케일러블 확장 유형의 조합들을 포함하는 스케일러블 확장 유형 테이블들 중 하나를 나타내는 스케일러블 확장 유형 테이블 인덱스이며,상기 스케일러블 확장 유형 테이블은 SEI(Supplemental Enhancement Information) 메시지에 포함되어 전송되는 것을 특징으로 하는 다계층 비디오 복호화 방법.
- 다계층 비디오 복호화 장치에 있어서,부호화된 다계층 비디오를 데이터 단위별로 구분하여 생성된 NAL(Network Adaptive Layer) 단위들을 수신하고, 상기 수신된 NAL 단위들 중 상기 다계층 비디오에 공통적으로 적용되는 정보에 관한 VPS(Video Parameter Set) 정보를 포함하는 VPS NAL 단위를 획득하며, 상기 VPS NAL 단위로부터 상기 다계층 비디오의 스케일러블 확장을 위한 스케일러블 확장 유형 정보를 획득하는 수신부; 및상기 획득된 스케일러블 확장 유형 정보에 기초하여 상기 다계층 비디오에 포함된 상기 데이터 단위별로 적용된 스케일러블 확장 유형을 결정하고, 상기 다계층 비디오를 복호화하는 비디오 복호화부를 포함하는 것을 특징으로 하는 다계층 비디오 복호화 장치.
Priority Applications (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| IN77MUN2015 IN2015MN00077A (ko) | 2012-07-06 | 2013-07-08 | |
| US14/413,154 US10116947B2 (en) | 2012-07-06 | 2013-07-08 | Method and apparatus for coding multilayer video to include scalable extension type information in a network abstraction layer unit, and method and apparatus for decoding multilayer video |
| JP2015520072A JP6050489B2 (ja) | 2012-07-06 | 2013-07-08 | 多階層ビデオ符号化方法及びその装置、並びに多階層ビデオ復号化方法及びその装置 |
| CN201380046648.6A CN104620587B (zh) | 2012-07-06 | 2013-07-08 | 用于对多层视频进行编码的方法和设备以及用于对多层视频进行解码的方法和设备 |
| EP13813869.8A EP2871567A4 (en) | 2012-07-06 | 2013-07-08 | METHOD AND APPARATUS FOR ENCODING MULTILAYER VIDEO, AND METHOD AND APPARATUS FOR DECODING MULTILAYER VIDEO |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201261668666P | 2012-07-06 | 2012-07-06 | |
| US61/668,666 | 2012-07-06 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2014007596A1 true WO2014007596A1 (ko) | 2014-01-09 |
Family
ID=49882280
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/KR2013/006058 WO2014007596A1 (ko) | 2012-07-06 | 2013-07-08 | 다계층 비디오 부호화 방법 및 장치, 다계층 비디오 복호화 방법 및 장치 |
Country Status (7)
| Country | Link |
|---|---|
| US (1) | US10116947B2 (ko) |
| EP (1) | EP2871567A4 (ko) |
| JP (1) | JP6050489B2 (ko) |
| KR (1) | KR102180470B1 (ko) |
| CN (1) | CN104620587B (ko) |
| IN (1) | IN2015MN00077A (ko) |
| WO (1) | WO2014007596A1 (ko) |
Families Citing this family (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9648352B2 (en) * | 2012-09-24 | 2017-05-09 | Qualcomm Incorporated | Expanded decoding unit definition |
| US9794558B2 (en) * | 2014-01-08 | 2017-10-17 | Qualcomm Incorporated | Support of non-HEVC base layer in HEVC multi-layer extensions |
| US10178397B2 (en) * | 2014-03-24 | 2019-01-08 | Qualcomm Incorporated | Generic use of HEVC SEI messages for multi-layer codecs |
| US10785492B2 (en) * | 2014-05-30 | 2020-09-22 | Arris Enterprises Llc | On reference layer and scaled reference layer offset parameters for inter-layer prediction in scalable video coding |
| CN106658225B (zh) * | 2016-10-31 | 2019-11-26 | 日立楼宇技术(广州)有限公司 | 视频扩展码设置及视频播放方法和系统 |
| CN108616748A (zh) * | 2017-01-06 | 2018-10-02 | 科通环宇(北京)科技有限公司 | 一种码流及其封装方法、解码方法及装置 |
| ES2981568T3 (es) | 2019-01-09 | 2024-10-09 | Huawei Tech Co Ltd | Señalización indicadora de nivel de subimagen en codificación de vídeo |
| US11245899B2 (en) * | 2019-09-22 | 2022-02-08 | Tencent America LLC | Method and system for single loop multilayer coding with subpicture partitioning |
| BR112022023367A2 (pt) | 2020-05-22 | 2022-12-20 | Bytedance Inc | Método de processamento de vídeo, aparelho de processamento de dados vídeo, e, meios de armazenamento e de gravação legível por computador não transitório |
| JP2023526661A (ja) | 2020-05-22 | 2023-06-22 | バイトダンス インコーポレイテッド | 適合出力サブビットストリームの生成技術 |
| WO2021252533A1 (en) | 2020-06-09 | 2021-12-16 | Bytedance Inc. | Sub-bitstream extraction of multi-layer video bitstreams |
| GB2599171A (en) * | 2020-09-29 | 2022-03-30 | Canon Kk | Method and apparatus for encapsulating video data into a file |
| CN115134432B (zh) * | 2021-03-22 | 2023-09-12 | 中国科学院沈阳自动化研究所 | 一种多工业通信协议自适应快速解析方法 |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR100908062B1 (ko) * | 2006-09-07 | 2009-07-15 | 엘지전자 주식회사 | 비디오 신호의 디코딩/인코딩 방법 및 장치 |
| JP2010016910A (ja) * | 2005-03-18 | 2010-01-21 | Sharp Corp | 空間的にスケーラブルなビデオ符号化のために、低い複雑さでブロッキング歪を低減するための方法およびシステム |
| KR20100014553A (ko) * | 2007-04-25 | 2010-02-10 | 엘지전자 주식회사 | 비디오 신호의 인코딩/디코딩 방법 및 장치 |
| US20110064146A1 (en) * | 2009-09-16 | 2011-03-17 | Qualcomm Incorporated | Media extractor tracks for file format track selection |
Family Cites Families (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7929610B2 (en) | 2001-03-26 | 2011-04-19 | Sharp Kabushiki Kaisha | Methods and systems for reducing blocking artifacts with reduced complexity for spatially-scalable video coding |
| US8175168B2 (en) | 2005-03-18 | 2012-05-08 | Sharp Laboratories Of America, Inc. | Methods and systems for picture up-sampling |
| CN101518086B (zh) * | 2006-07-20 | 2013-10-30 | 汤姆森特许公司 | 在多视图视频编码中用信号通知视图可分级性的方法和装置 |
| EP2127395B1 (en) * | 2007-01-10 | 2016-08-17 | Thomson Licensing | Video encoding method and video decoding method for enabling bit depth scalability |
| EP3484123A1 (en) | 2007-01-12 | 2019-05-15 | University-Industry Cooperation Group Of Kyung Hee University | Packet format of network abstraction layer unit, and algorithm and apparatus for video encoding and decoding using the format |
| JP2010520697A (ja) | 2007-03-02 | 2010-06-10 | エルジー エレクトロニクス インコーポレイティド | ビデオ信号のデコーディング/エンコーディング方法及び装置 |
| CN101669367A (zh) | 2007-03-02 | 2010-03-10 | Lg电子株式会社 | 用于解码/编码视频信号的方法及设备 |
| US20100142613A1 (en) * | 2007-04-18 | 2010-06-10 | Lihua Zhu | Method for encoding video data in a scalable manner |
| EP2153661A2 (en) * | 2007-05-16 | 2010-02-17 | Thomson Licensing | Methods and apparatus for the use of slice groups in encoding multi-view video coding (mvc) information |
| WO2010073513A1 (ja) * | 2008-12-26 | 2010-07-01 | 日本ビクター株式会社 | 画像符号化装置、画像符号化方法およびそのプログラム、ならびに画像復号装置、画像復号方法およびそのプログラム |
| CA2824741C (en) | 2011-01-14 | 2016-08-30 | Vidyo, Inc. | Improved nal unit header |
| US9451252B2 (en) * | 2012-01-14 | 2016-09-20 | Qualcomm Incorporated | Coding parameter sets and NAL unit headers for video coding |
| PL2842318T3 (pl) | 2012-04-13 | 2017-06-30 | Ge Video Compression, Llc | Kodowanie obrazu z małym opóźnieniem |
| US9716892B2 (en) * | 2012-07-02 | 2017-07-25 | Qualcomm Incorporated | Video parameter set including session negotiation information |
| US9462287B2 (en) * | 2013-01-04 | 2016-10-04 | Dolby International Ab | Implicit signaling of scalability dimension identifier information in a parameter set |
-
2013
- 2013-07-08 EP EP13813869.8A patent/EP2871567A4/en not_active Ceased
- 2013-07-08 WO PCT/KR2013/006058 patent/WO2014007596A1/ko active Application Filing
- 2013-07-08 JP JP2015520072A patent/JP6050489B2/ja not_active Expired - Fee Related
- 2013-07-08 KR KR1020130079906A patent/KR102180470B1/ko active IP Right Grant
- 2013-07-08 US US14/413,154 patent/US10116947B2/en not_active Expired - Fee Related
- 2013-07-08 CN CN201380046648.6A patent/CN104620587B/zh not_active Expired - Fee Related
- 2013-07-08 IN IN77MUN2015 patent/IN2015MN00077A/en unknown
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2010016910A (ja) * | 2005-03-18 | 2010-01-21 | Sharp Corp | 空間的にスケーラブルなビデオ符号化のために、低い複雑さでブロッキング歪を低減するための方法およびシステム |
| KR100908062B1 (ko) * | 2006-09-07 | 2009-07-15 | 엘지전자 주식회사 | 비디오 신호의 디코딩/인코딩 방법 및 장치 |
| KR20100014553A (ko) * | 2007-04-25 | 2010-02-10 | 엘지전자 주식회사 | 비디오 신호의 인코딩/디코딩 방법 및 장치 |
| US20110064146A1 (en) * | 2009-09-16 | 2011-03-17 | Qualcomm Incorporated | Media extractor tracks for file format track selection |
Non-Patent Citations (1)
| Title |
|---|
| BOYCE, JILL ET AL.: "High level syntax hooks for future extensions", JOINT COLLABORATIVE TEAM ON VIDEO CODING (JCT-VC) OF ITU-T SG16 WP3 AND ISO/IEC JTC1/SC29/WGL 18TH MEETING, 1 February 2012 (2012-02-01), SAN JOSE, CA, USA, XP030111415 * |
Also Published As
| Publication number | Publication date |
|---|---|
| JP6050489B2 (ja) | 2016-12-21 |
| US10116947B2 (en) | 2018-10-30 |
| CN104620587A (zh) | 2015-05-13 |
| EP2871567A4 (en) | 2016-01-06 |
| KR102180470B1 (ko) | 2020-11-19 |
| CN104620587B (zh) | 2018-04-03 |
| JP2015526018A (ja) | 2015-09-07 |
| EP2871567A1 (en) | 2015-05-13 |
| KR20140007292A (ko) | 2014-01-17 |
| US20150172679A1 (en) | 2015-06-18 |
| IN2015MN00077A (ko) | 2015-10-16 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2014007596A1 (ko) | 다계층 비디오 부호화 방법 및 장치, 다계층 비디오 복호화 방법 및 장치 | |
| WO2013077665A1 (ko) | 복호화기의 버퍼 관리를 위한 영상 부호화 방법 및 장치, 그 영상 복호화 방법 및 장치 | |
| WO2013157797A1 (ko) | 다계층 비디오 부호화 방법 및 장치, 다계층 비디오 복호화 방법 및 장치 | |
| WO2014109607A1 (ko) | 멀티 레이어 비디오 부호화 방법 및 장치, 멀티 레이어 비디오 복호화 방법 및 장치 | |
| WO2016200100A1 (ko) | 적응적 가중치 예측을 위한 신택스 시그널링을 이용하여 영상을 부호화 또는 복호화하는 방법 및 장치 | |
| WO2013005969A2 (ko) | 비디오 데이터의 재생 상태 식별을 위한 비디오 데이터의 다중화 방법 및 장치, 역다중화 방법 및 장치 | |
| WO2014051410A1 (ko) | 랜덤 액세스를 위한 비디오 부호화 방법 및 장치, 비디오 복호화 방법 및 장치 | |
| WO2013005963A2 (ko) | 콜로케이티드 영상을 이용한 인터 예측을 수반하는 비디오 부호화 방법 및 그 장치, 비디오 복호화 방법 및 그 장치 | |
| WO2013005968A2 (ko) | 계층적 구조의 데이터 단위를 이용한 엔트로피 부호화 방법 및 장치, 복호화 방법 및 장치 | |
| WO2011129620A2 (ko) | 트리 구조에 따른 부호화 단위에 기초한 비디오 부호화 방법과 그 장치, 및 비디오 복호화 방법 및 그 장치 | |
| WO2013162258A1 (ko) | 다시점 비디오 부호화 방법 및 장치, 다시점 비디오 복호화 방법 및 장치 | |
| WO2014007524A1 (ko) | 비디오의 엔트로피 부호화 방법 및 장치, 비디오의 엔트로피 복호화 방법 및 장치 | |
| WO2012093891A2 (ko) | 계층적 구조의 데이터 단위를 이용한 비디오의 부호화 방법 및 장치, 그 복호화 방법 및 장치 | |
| WO2011071308A2 (en) | Method and apparatus for encoding video by motion prediction using arbitrary partition, and method and apparatus for decoding video by motion prediction using arbitrary partition | |
| WO2011087297A2 (en) | Method and apparatus for encoding video by using deblocking filtering, and method and apparatus for decoding video by using deblocking filtering | |
| WO2012124961A2 (ko) | 영상의 부호화 방법 및 장치, 그 복호화 방법 및 장치 | |
| WO2011021839A2 (en) | Method and apparatus for encoding video, and method and apparatus for decoding video | |
| WO2013005962A2 (ko) | 단일화된 참조가능성 확인 과정을 통해 인트라 예측을 수반하는 비디오 부호화 방법 및 그 장치, 비디오 복호화 방법 및 그 장치 | |
| WO2013115572A1 (ko) | 계층적 데이터 단위의 양자화 파라메터 예측을 포함하는 비디오 부호화 방법 및 장치, 비디오 복호화 방법 및 장치 | |
| WO2014163456A1 (ko) | 멀티 레이어 비디오의 복호화 방법 및 장치, 멀티 레이어 비디오의 부호화 방법 및 장치 | |
| WO2014116047A1 (ko) | 비디오 부호화 방법 및 장치, 비디오 복호화 방법 및 장치 | |
| WO2013066051A1 (ko) | 변환 계수 레벨의 엔트로피 부호화 및 복호화를 위한 컨텍스트 모델 결정 방법 및 장치 | |
| WO2011053020A2 (en) | Method and apparatus for encoding residual block, and method and apparatus for decoding residual block | |
| WO2015056955A1 (ko) | 다시점 비디오 부호화 방법 및 장치, 다시점 비디오 복호화 방법 및 장치 | |
| WO2013002586A2 (ko) | 영상의 인트라 예측 부호화, 복호화 방법 및 장치 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 13813869 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2015520072 Country of ref document: JP Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 14413154 Country of ref document: US |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2013813869 Country of ref document: EP |