JP7128517B2 - Antisense nucleic acid with reduced side effects - Google Patents
Antisense nucleic acid with reduced side effects Download PDFInfo
- Publication number
- JP7128517B2 JP7128517B2 JP2018539601A JP2018539601A JP7128517B2 JP 7128517 B2 JP7128517 B2 JP 7128517B2 JP 2018539601 A JP2018539601 A JP 2018539601A JP 2018539601 A JP2018539601 A JP 2018539601A JP 7128517 B2 JP7128517 B2 JP 7128517B2
- Authority
- JP
- Japan
- Prior art keywords
- nucleic acid
- formula
- integer
- independently
- polynucleotide
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 102000039446 nucleic acids Human genes 0.000 title claims description 631
- 108020004707 nucleic acids Proteins 0.000 title claims description 630
- 150000007523 nucleic acids Chemical class 0.000 title claims description 625
- 230000000692 anti-sense effect Effects 0.000 title claims description 340
- 230000000694 effects Effects 0.000 title description 89
- 230000002829 reductive effect Effects 0.000 title description 11
- 102000040430 polynucleotide Human genes 0.000 claims description 321
- 108091033319 polynucleotide Proteins 0.000 claims description 321
- 239000002157 polynucleotide Substances 0.000 claims description 316
- 230000000295 complement effect Effects 0.000 claims description 236
- 125000003729 nucleotide group Chemical group 0.000 claims description 167
- 239000002773 nucleotide Substances 0.000 claims description 139
- 239000003446 ligand Substances 0.000 claims description 122
- 125000002652 ribonucleotide group Chemical group 0.000 claims description 89
- 108090000623 proteins and genes Proteins 0.000 claims description 87
- 125000002637 deoxyribonucleotide group Chemical group 0.000 claims description 86
- 230000036961 partial effect Effects 0.000 claims description 80
- 108091028664 Ribonucleotide Proteins 0.000 claims description 75
- 239000002336 ribonucleotide Substances 0.000 claims description 75
- 239000005547 deoxyribonucleotide Substances 0.000 claims description 70
- 239000002777 nucleoside Substances 0.000 claims description 64
- 108020004999 messenger RNA Proteins 0.000 claims description 63
- 230000014509 gene expression Effects 0.000 claims description 62
- 150000003833 nucleoside derivatives Chemical class 0.000 claims description 56
- 239000002253 acid Substances 0.000 claims description 53
- OVBPIULPVIDEAO-LBPRGKRZSA-N folic acid Chemical compound C=1N=C2NC(N)=NC(=O)C2=NC=1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 OVBPIULPVIDEAO-LBPRGKRZSA-N 0.000 claims description 48
- 238000000034 method Methods 0.000 claims description 47
- 239000008194 pharmaceutical composition Substances 0.000 claims description 45
- 206010028980 Neoplasm Diseases 0.000 claims description 39
- 239000005549 deoxyribonucleoside Substances 0.000 claims description 35
- 201000011510 cancer Diseases 0.000 claims description 34
- 239000011724 folic acid Substances 0.000 claims description 34
- 239000000470 constituent Substances 0.000 claims description 33
- 150000004713 phosphodiesters Chemical class 0.000 claims description 30
- 241000124008 Mammalia Species 0.000 claims description 28
- 235000019152 folic acid Nutrition 0.000 claims description 25
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 25
- OVBPIULPVIDEAO-UHFFFAOYSA-N N-Pteroyl-L-glutaminsaeure Natural products C=1N=C2NC(N)=NC(=O)C2=NC=1CNC1=CC=C(C(=O)NC(CCC(O)=O)C(O)=O)C=C1 OVBPIULPVIDEAO-UHFFFAOYSA-N 0.000 claims description 24
- 229960000304 folic acid Drugs 0.000 claims description 24
- GVJHHUAWPYXKBD-UHFFFAOYSA-N (±)-α-Tocopherol Chemical compound OC1=C(C)C(C)=C2OC(CCCC(C)CCCC(C)CCCC(C)C)(C)CCC2=C1C GVJHHUAWPYXKBD-UHFFFAOYSA-N 0.000 claims description 22
- RYYWUUFWQRZTIU-UHFFFAOYSA-K thiophosphate Chemical compound [O-]P([O-])([O-])=S RYYWUUFWQRZTIU-UHFFFAOYSA-K 0.000 claims description 20
- 102000004169 proteins and genes Human genes 0.000 claims description 19
- 150000002632 lipids Chemical class 0.000 claims description 16
- 230000035755 proliferation Effects 0.000 claims description 15
- 239000000126 substance Substances 0.000 claims description 13
- 206010061902 Pancreatic neoplasm Diseases 0.000 claims description 12
- 208000015486 malignant pancreatic neoplasm Diseases 0.000 claims description 12
- 208000008443 pancreatic carcinoma Diseases 0.000 claims description 12
- GVJHHUAWPYXKBD-IEOSBIPESA-N α-tocopherol Chemical compound OC1=C(C)C(C)=C2O[C@@](CCC[C@H](C)CCC[C@H](C)CCCC(C)C)(C)CCC2=C1C GVJHHUAWPYXKBD-IEOSBIPESA-N 0.000 claims description 12
- 230000000975 bioactive effect Effects 0.000 claims description 11
- 201000002528 pancreatic cancer Diseases 0.000 claims description 11
- 229930003799 tocopherol Natural products 0.000 claims description 11
- 239000011732 tocopherol Substances 0.000 claims description 11
- HVYWMOMLDIMFJA-DPAQBDIFSA-N cholesterol Chemical compound C1C=C2C[C@@H](O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)CCCC(C)C)[C@@]1(C)CC2 HVYWMOMLDIMFJA-DPAQBDIFSA-N 0.000 claims description 10
- PFNFFQXMRSDOHW-UHFFFAOYSA-N spermine Chemical compound NCCCNCCCCNCCCN PFNFFQXMRSDOHW-UHFFFAOYSA-N 0.000 claims description 10
- 235000010384 tocopherol Nutrition 0.000 claims description 10
- 229960001295 tocopherol Drugs 0.000 claims description 10
- 108091023037 Aptamer Proteins 0.000 claims description 8
- UKMSUNONTOPOIO-UHFFFAOYSA-N docosanoic acid Chemical compound CCCCCCCCCCCCCCCCCCCCCC(O)=O UKMSUNONTOPOIO-UHFFFAOYSA-N 0.000 claims description 8
- WIGCFUFOHFEKBI-UHFFFAOYSA-N gamma-tocopherol Natural products CC(C)CCCC(C)CCCC(C)CCCC1CCC2C(C)C(O)C(C)C(C)C2O1 WIGCFUFOHFEKBI-UHFFFAOYSA-N 0.000 claims description 7
- 150000003384 small molecules Chemical class 0.000 claims description 7
- 108010069514 Cyclic Peptides Proteins 0.000 claims description 6
- 102000001189 Cyclic Peptides Human genes 0.000 claims description 6
- OVRNDRQMDRJTHS-CBQIKETKSA-N N-Acetyl-D-Galactosamine Chemical compound CC(=O)N[C@H]1[C@@H](O)O[C@H](CO)[C@H](O)[C@@H]1O OVRNDRQMDRJTHS-CBQIKETKSA-N 0.000 claims description 6
- MBLBDJOUHNCFQT-UHFFFAOYSA-N N-acetyl-D-galactosamine Natural products CC(=O)NC(C=O)C(O)C(O)C(O)CO MBLBDJOUHNCFQT-UHFFFAOYSA-N 0.000 claims description 6
- 108700020796 Oncogene Proteins 0.000 claims description 6
- 229930003427 Vitamin E Natural products 0.000 claims description 6
- POULHZVOKOAJMA-UHFFFAOYSA-N methyl undecanoic acid Natural products CCCCCCCCCCCC(O)=O POULHZVOKOAJMA-UHFFFAOYSA-N 0.000 claims description 6
- 235000019165 vitamin E Nutrition 0.000 claims description 6
- 239000011709 vitamin E Substances 0.000 claims description 6
- 229940046009 vitamin E Drugs 0.000 claims description 6
- GUCPYIYFQVTFSI-UHFFFAOYSA-N 4-methoxybenzamide Chemical compound COC1=CC=C(C(N)=O)C=C1 GUCPYIYFQVTFSI-UHFFFAOYSA-N 0.000 claims description 5
- 235000021355 Stearic acid Nutrition 0.000 claims description 5
- LGEQQWMQCRIYKG-DOFZRALJSA-N anandamide Chemical compound CCCCC\C=C/C\C=C/C\C=C/C\C=C/CCCC(=O)NCCO LGEQQWMQCRIYKG-DOFZRALJSA-N 0.000 claims description 5
- LGEQQWMQCRIYKG-UHFFFAOYSA-N arachidonic acid ethanolamide Natural products CCCCCC=CCC=CCC=CCC=CCCCC(=O)NCCO LGEQQWMQCRIYKG-UHFFFAOYSA-N 0.000 claims description 5
- 150000001720 carbohydrates Chemical class 0.000 claims description 5
- 235000012000 cholesterol Nutrition 0.000 claims description 5
- QIQXTHQIDYTFRH-UHFFFAOYSA-N octadecanoic acid Chemical compound CCCCCCCCCCCCCCCCCC(O)=O QIQXTHQIDYTFRH-UHFFFAOYSA-N 0.000 claims description 5
- OQCDKBAXFALNLD-UHFFFAOYSA-N octadecanoic acid Natural products CCCCCCCC(C)CCCCCCCCC(O)=O OQCDKBAXFALNLD-UHFFFAOYSA-N 0.000 claims description 5
- 229940063675 spermine Drugs 0.000 claims description 5
- 239000008117 stearic acid Substances 0.000 claims description 5
- 235000021357 Behenic acid Nutrition 0.000 claims description 4
- 229940116226 behenic acid Drugs 0.000 claims description 4
- KFEVDPWXEVUUMW-UHFFFAOYSA-N docosanoic acid Natural products CCCCCCCCCCCCCCCCCCCCCC(=O)OCCC1=CC=C(O)C=C1 KFEVDPWXEVUUMW-UHFFFAOYSA-N 0.000 claims description 4
- 238000007911 parenteral administration Methods 0.000 claims description 2
- 210000004027 cell Anatomy 0.000 description 238
- 239000002585 base Substances 0.000 description 137
- 230000008685 targeting Effects 0.000 description 50
- 125000005647 linker group Chemical group 0.000 description 41
- 101100381516 Homo sapiens BCL2 gene Proteins 0.000 description 39
- 101150006308 botA gene Proteins 0.000 description 36
- 238000012360 testing method Methods 0.000 description 33
- 238000007385 chemical modification Methods 0.000 description 29
- 108020004414 DNA Proteins 0.000 description 27
- 235000000346 sugar Nutrition 0.000 description 27
- 108091032973 (ribonucleotides)n+m Chemical class 0.000 description 23
- 230000002401 inhibitory effect Effects 0.000 description 23
- 210000001519 tissue Anatomy 0.000 description 22
- 125000003835 nucleoside group Chemical group 0.000 description 21
- 230000010261 cell growth Effects 0.000 description 20
- IYMAXBFPHPZYIK-BQBZGAKWSA-N Arg-Gly-Asp Chemical compound NC(N)=NCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O IYMAXBFPHPZYIK-BQBZGAKWSA-N 0.000 description 19
- -1 arabinose sugars Chemical class 0.000 description 19
- 239000003814 drug Substances 0.000 description 17
- 235000018102 proteins Nutrition 0.000 description 17
- 150000001413 amino acids Chemical class 0.000 description 15
- 229940079593 drug Drugs 0.000 description 14
- UCSJYZPVAKXKNQ-HZYVHMACSA-N streptomycin Chemical compound CN[C@H]1[C@H](O)[C@@H](O)[C@H](CO)O[C@H]1O[C@@H]1[C@](C=O)(O)[C@H](C)O[C@H]1O[C@@H]1[C@@H](NC(N)=N)[C@H](O)[C@@H](NC(N)=N)[C@H](O)[C@H]1O UCSJYZPVAKXKNQ-HZYVHMACSA-N 0.000 description 14
- 238000000137 annealing Methods 0.000 description 13
- WEVYNIUIFUYDGI-UHFFFAOYSA-N 3-[6-[4-(trifluoromethoxy)anilino]-4-pyrimidinyl]benzamide Chemical compound NC(=O)C1=CC=CC(C=2N=CN=C(NC=3C=CC(OC(F)(F)F)=CC=3)C=2)=C1 WEVYNIUIFUYDGI-UHFFFAOYSA-N 0.000 description 12
- 229940024606 amino acid Drugs 0.000 description 12
- 235000001014 amino acid Nutrition 0.000 description 12
- 150000001875 compounds Chemical class 0.000 description 12
- 108010045325 cyclic arginine-glycine-aspartic acid peptide Proteins 0.000 description 12
- 238000002474 experimental method Methods 0.000 description 12
- 102000005962 receptors Human genes 0.000 description 11
- 108020003175 receptors Proteins 0.000 description 11
- 102000004190 Enzymes Human genes 0.000 description 10
- 108090000790 Enzymes Proteins 0.000 description 10
- 230000015572 biosynthetic process Effects 0.000 description 10
- 229940014144 folate Drugs 0.000 description 10
- 238000003757 reverse transcription PCR Methods 0.000 description 10
- 239000000758 substrate Substances 0.000 description 10
- 206010019851 Hepatotoxicity Diseases 0.000 description 9
- 102000006992 Interferon-alpha Human genes 0.000 description 9
- 108010047761 Interferon-alpha Proteins 0.000 description 9
- 150000001408 amides Chemical class 0.000 description 9
- 238000006243 chemical reaction Methods 0.000 description 9
- 231100000304 hepatotoxicity Toxicity 0.000 description 9
- 230000007686 hepatotoxicity Effects 0.000 description 9
- 239000000203 mixture Substances 0.000 description 9
- 239000000047 product Substances 0.000 description 9
- 238000002054 transplantation Methods 0.000 description 9
- 108091034117 Oligonucleotide Proteins 0.000 description 8
- 239000001963 growth medium Substances 0.000 description 8
- 210000004185 liver Anatomy 0.000 description 8
- 238000007069 methylation reaction Methods 0.000 description 8
- 102000004196 processed proteins & peptides Human genes 0.000 description 8
- 108010003415 Aspartate Aminotransferases Proteins 0.000 description 7
- 102000004625 Aspartate Aminotransferases Human genes 0.000 description 7
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 7
- 229930182555 Penicillin Natural products 0.000 description 7
- JGSARLDLIJGVTE-MBNYWOFBSA-N Penicillin G Chemical compound N([C@H]1[C@H]2SC([C@@H](N2C1=O)C(O)=O)(C)C)C(=O)CC1=CC=CC=C1 JGSARLDLIJGVTE-MBNYWOFBSA-N 0.000 description 7
- ISAKRJDGNUQOIC-UHFFFAOYSA-N Uracil Chemical compound O=C1C=CNC(=O)N1 ISAKRJDGNUQOIC-UHFFFAOYSA-N 0.000 description 7
- 239000003795 chemical substances by application Substances 0.000 description 7
- 239000012091 fetal bovine serum Substances 0.000 description 7
- 238000012986 modification Methods 0.000 description 7
- 230000004048 modification Effects 0.000 description 7
- OHDXDNUPVVYWOV-UHFFFAOYSA-N n-methyl-1-(2-naphthalen-1-ylsulfanylphenyl)methanamine Chemical compound CNCC1=CC=CC=C1SC1=CC=CC2=CC=CC=C12 OHDXDNUPVVYWOV-UHFFFAOYSA-N 0.000 description 7
- 229940049954 penicillin Drugs 0.000 description 7
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 description 7
- 125000002467 phosphate group Chemical group [H]OP(=O)(O[H])O[*] 0.000 description 7
- 229960005322 streptomycin Drugs 0.000 description 7
- 230000001629 suppression Effects 0.000 description 7
- 102100036475 Alanine aminotransferase 1 Human genes 0.000 description 6
- 108010082126 Alanine transaminase Proteins 0.000 description 6
- IAZDPXIOMUYVGZ-UHFFFAOYSA-N Dimethylsulphoxide Chemical compound CS(C)=O IAZDPXIOMUYVGZ-UHFFFAOYSA-N 0.000 description 6
- 101000971171 Homo sapiens Apoptosis regulator Bcl-2 Proteins 0.000 description 6
- NBIIXXVUZAFLBC-UHFFFAOYSA-N Phosphoric acid Chemical compound OP(O)(O)=O NBIIXXVUZAFLBC-UHFFFAOYSA-N 0.000 description 6
- 208000009956 adenocarcinoma Diseases 0.000 description 6
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical compound NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 description 6
- 238000003682 fluorination reaction Methods 0.000 description 6
- 230000006870 function Effects 0.000 description 6
- UYTPUPDQBNUYGX-UHFFFAOYSA-N guanine Chemical compound O=C1NC(N)=NC2=C1N=CN2 UYTPUPDQBNUYGX-UHFFFAOYSA-N 0.000 description 6
- 238000000338 in vitro Methods 0.000 description 6
- 238000010172 mouse model Methods 0.000 description 6
- 238000003786 synthesis reaction Methods 0.000 description 6
- 238000013518 transcription Methods 0.000 description 6
- 230000035897 transcription Effects 0.000 description 6
- 101100366880 Homo sapiens STAT3 gene Proteins 0.000 description 5
- 239000012097 Lipofectamine 2000 Substances 0.000 description 5
- 241001465754 Metazoa Species 0.000 description 5
- PYMYPHUHKUWMLA-UHFFFAOYSA-N arabinose Natural products OCC(O)C(O)C(O)C=O PYMYPHUHKUWMLA-UHFFFAOYSA-N 0.000 description 5
- SRBFZHDQGSBBOR-UHFFFAOYSA-N beta-D-Pyranose-Lyxose Natural products OC1COC(O)C(O)C1O SRBFZHDQGSBBOR-UHFFFAOYSA-N 0.000 description 5
- 238000001516 cell proliferation assay Methods 0.000 description 5
- 238000012650 click reaction Methods 0.000 description 5
- 150000002148 esters Chemical class 0.000 description 5
- 238000001890 transfection Methods 0.000 description 5
- 229930024421 Adenine Natural products 0.000 description 4
- GFFGJBXGBJISGV-UHFFFAOYSA-N Adenine Chemical compound NC1=NC=NC2=C1N=CN2 GFFGJBXGBJISGV-UHFFFAOYSA-N 0.000 description 4
- 102000016911 Deoxyribonucleases Human genes 0.000 description 4
- 108010053770 Deoxyribonucleases Proteins 0.000 description 4
- 206010025323 Lymphomas Diseases 0.000 description 4
- 241000699666 Mus <mouse, genus> Species 0.000 description 4
- 101710163270 Nuclease Proteins 0.000 description 4
- IQFYYKKMVGJFEH-XLPZGREQSA-N Thymidine Chemical compound O=C1NC(=O)C(C)=CN1[C@@H]1O[C@H](CO)[C@@H](O)C1 IQFYYKKMVGJFEH-XLPZGREQSA-N 0.000 description 4
- 229960000643 adenine Drugs 0.000 description 4
- 150000001540 azides Chemical class 0.000 description 4
- 230000037396 body weight Effects 0.000 description 4
- 238000005893 bromination reaction Methods 0.000 description 4
- 235000014633 carbohydrates Nutrition 0.000 description 4
- 125000004432 carbon atom Chemical group C* 0.000 description 4
- 238000004132 cross linking Methods 0.000 description 4
- 125000004122 cyclic group Chemical group 0.000 description 4
- 201000010099 disease Diseases 0.000 description 4
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 4
- 102000006815 folate receptor Human genes 0.000 description 4
- 108020005243 folate receptor Proteins 0.000 description 4
- 230000001939 inductive effect Effects 0.000 description 4
- 230000005764 inhibitory process Effects 0.000 description 4
- NOESYZHRGYRDHS-UHFFFAOYSA-N insulin Chemical compound N1C(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(NC(=O)CN)C(C)CC)CSSCC(C(NC(CO)C(=O)NC(CC(C)C)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CCC(N)=O)C(=O)NC(CC(C)C)C(=O)NC(CCC(O)=O)C(=O)NC(CC(N)=O)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CSSCC(NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2C=CC(O)=CC=2)NC(=O)C(CC(C)C)NC(=O)C(C)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2NC=NC=2)NC(=O)C(CO)NC(=O)CNC2=O)C(=O)NCC(=O)NC(CCC(O)=O)C(=O)NC(CCCNC(N)=N)C(=O)NCC(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC(O)=CC=3)C(=O)NC(C(C)O)C(=O)N3C(CCC3)C(=O)NC(CCCCN)C(=O)NC(C)C(O)=O)C(=O)NC(CC(N)=O)C(O)=O)=O)NC(=O)C(C(C)CC)NC(=O)C(CO)NC(=O)C(C(C)O)NC(=O)C1CSSCC2NC(=O)C(CC(C)C)NC(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CC(N)=O)NC(=O)C(NC(=O)C(N)CC=1C=CC=CC=1)C(C)C)CC1=CN=CN1 NOESYZHRGYRDHS-UHFFFAOYSA-N 0.000 description 4
- 238000005259 measurement Methods 0.000 description 4
- 210000000496 pancreas Anatomy 0.000 description 4
- 229920001515 polyalkylene glycol Polymers 0.000 description 4
- 150000008163 sugars Chemical class 0.000 description 4
- 125000004434 sulfur atom Chemical group 0.000 description 4
- 238000013519 translation Methods 0.000 description 4
- 238000012795 verification Methods 0.000 description 4
- KDCGOANMDULRCW-UHFFFAOYSA-N 7H-purine Chemical compound N1=CNC2=NC=NC2=C1 KDCGOANMDULRCW-UHFFFAOYSA-N 0.000 description 3
- 208000035657 Abasia Diseases 0.000 description 3
- 101150017888 Bcl2 gene Proteins 0.000 description 3
- 241000282412 Homo Species 0.000 description 3
- 101000826373 Homo sapiens Signal transducer and activator of transcription 3 Proteins 0.000 description 3
- 108091028043 Nucleic acid sequence Proteins 0.000 description 3
- 108091093037 Peptide nucleic acid Proteins 0.000 description 3
- CZPWVGJYEJSRLH-UHFFFAOYSA-N Pyrimidine Chemical compound C1=CN=CN=C1 CZPWVGJYEJSRLH-UHFFFAOYSA-N 0.000 description 3
- PYMYPHUHKUWMLA-LMVFSUKVSA-N Ribose Natural products OC[C@@H](O)[C@@H](O)[C@@H](O)C=O PYMYPHUHKUWMLA-LMVFSUKVSA-N 0.000 description 3
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 3
- 229910000147 aluminium phosphate Inorganic materials 0.000 description 3
- 125000003277 amino group Chemical group 0.000 description 3
- 230000000259 anti-tumor effect Effects 0.000 description 3
- 230000005907 cancer growth Effects 0.000 description 3
- 229940104302 cytosine Drugs 0.000 description 3
- 230000001085 cytostatic effect Effects 0.000 description 3
- 230000001419 dependent effect Effects 0.000 description 3
- 239000000539 dimer Substances 0.000 description 3
- 239000003797 essential amino acid Substances 0.000 description 3
- 235000020776 essential amino acid Nutrition 0.000 description 3
- 150000002224 folic acids Chemical class 0.000 description 3
- 102000051841 human STAT3 Human genes 0.000 description 3
- 208000032839 leukemia Diseases 0.000 description 3
- 238000001668 nucleic acid synthesis Methods 0.000 description 3
- 125000004430 oxygen atom Chemical group O* 0.000 description 3
- 125000006239 protecting group Chemical group 0.000 description 3
- 230000009467 reduction Effects 0.000 description 3
- 239000002342 ribonucleoside Substances 0.000 description 3
- 150000003839 salts Chemical class 0.000 description 3
- 239000007787 solid Substances 0.000 description 3
- 229910052717 sulfur Inorganic materials 0.000 description 3
- 229940035893 uracil Drugs 0.000 description 3
- OIGKWPIMJCPGGD-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 3-[2-[2-[2-(2-azidoethoxy)ethoxy]ethoxy]ethoxy]propanoate Chemical compound [N-]=[N+]=NCCOCCOCCOCCOCCC(=O)ON1C(=O)CCC1=O OIGKWPIMJCPGGD-UHFFFAOYSA-N 0.000 description 2
- SJIYVXTZWZSVLZ-QCNRFFRDSA-N 1-[(2r,3r,4r,5r)-4-hydroxy-5-(hydroxymethyl)-3-prop-2-ynoxyoxolan-2-yl]pyrimidine-2,4-dione Chemical compound C#CCO[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C=C1 SJIYVXTZWZSVLZ-QCNRFFRDSA-N 0.000 description 2
- NVHPXYIRNJFKTE-HAGHYFMRSA-N 2-[(2s,5r,8s,11s)-8-(4-aminobutyl)-5-benzyl-11-[3-(diaminomethylideneamino)propyl]-3,6,9,12,15-pentaoxo-1,4,7,10,13-pentazacyclopentadec-2-yl]acetic acid Chemical compound N1C(=O)[C@H](CC(O)=O)NC(=O)CNC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCCCN)NC(=O)[C@H]1CC1=CC=CC=C1 NVHPXYIRNJFKTE-HAGHYFMRSA-N 0.000 description 2
- ZVQAVWAHRUNNPG-LMVFSUKVSA-N 2-deoxy-alpha-D-ribopyranose Chemical group O[C@@H]1C[C@H](O)[C@H](O)CO1 ZVQAVWAHRUNNPG-LMVFSUKVSA-N 0.000 description 2
- 125000001494 2-propynyl group Chemical group [H]C#CC([H])([H])* 0.000 description 2
- OTXNTMVVOOBZCV-UHFFFAOYSA-N 2R-gamma-tocotrienol Natural products OC1=C(C)C(C)=C2OC(CCC=C(C)CCC=C(C)CCC=C(C)C)(C)CCC2=C1 OTXNTMVVOOBZCV-UHFFFAOYSA-N 0.000 description 2
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 2
- FJGRSBJPLPTKDE-QCNRFFRDSA-N 4-amino-1-[(2r,3r,4r,5r)-4-hydroxy-5-(hydroxymethyl)-3-prop-2-ynoxyoxolan-2-yl]pyrimidin-2-one Chemical compound O=C1N=C(N)C=CN1[C@H]1[C@H](OCC#C)[C@H](O)[C@@H](CO)O1 FJGRSBJPLPTKDE-QCNRFFRDSA-N 0.000 description 2
- 102100021569 Apoptosis regulator Bcl-2 Human genes 0.000 description 2
- 208000032791 BCR-ABL1 positive chronic myelogenous leukemia Diseases 0.000 description 2
- DWRXFEITVBNRMK-UHFFFAOYSA-N Beta-D-1-Arabinofuranosylthymine Natural products O=C1NC(=O)C(C)=CN1C1C(O)C(O)C(CO)O1 DWRXFEITVBNRMK-UHFFFAOYSA-N 0.000 description 2
- 201000009030 Carcinoma Diseases 0.000 description 2
- 208000010833 Chronic myeloid leukaemia Diseases 0.000 description 2
- 206010009944 Colon cancer Diseases 0.000 description 2
- 125000003603 D-ribosyl group Chemical group C1([C@H](O)[C@H](O)[C@H](O1)CO)* 0.000 description 2
- SRBFZHDQGSBBOR-IOVATXLUSA-N D-xylopyranose Chemical compound O[C@@H]1COC(O)[C@H](O)[C@H]1O SRBFZHDQGSBBOR-IOVATXLUSA-N 0.000 description 2
- 102000053602 DNA Human genes 0.000 description 2
- 102000030914 Fatty Acid-Binding Human genes 0.000 description 2
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 2
- 108091093094 Glycol nucleic acid Proteins 0.000 description 2
- 229930186217 Glycolipid Natural products 0.000 description 2
- 206010020880 Hypertrophy Diseases 0.000 description 2
- DGAQECJNVWCQMB-PUAWFVPOSA-M Ilexoside XXIX Chemical compound C[C@@H]1CC[C@@]2(CC[C@@]3(C(=CC[C@H]4[C@]3(CC[C@@H]5[C@@]4(CC[C@@H](C5(C)C)OS(=O)(=O)[O-])C)C)[C@@H]2[C@]1(C)O)C)C(=O)O[C@H]6[C@@H]([C@H]([C@@H]([C@H](O6)CO)O)O)O.[Na+] DGAQECJNVWCQMB-PUAWFVPOSA-M 0.000 description 2
- 102000004877 Insulin Human genes 0.000 description 2
- 108090001061 Insulin Proteins 0.000 description 2
- 102100034343 Integrase Human genes 0.000 description 2
- 101710203526 Integrase Proteins 0.000 description 2
- 208000008839 Kidney Neoplasms Diseases 0.000 description 2
- ODKSFYDXXFIFQN-BYPYZUCNSA-N L-arginine Chemical compound OC(=O)[C@@H](N)CCCN=C(N)N ODKSFYDXXFIFQN-BYPYZUCNSA-N 0.000 description 2
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 2
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 2
- 208000033761 Myelogenous Chronic BCR-ABL Positive Leukemia Diseases 0.000 description 2
- 241000209094 Oryza Species 0.000 description 2
- 235000007164 Oryza sativa Nutrition 0.000 description 2
- 206010033128 Ovarian cancer Diseases 0.000 description 2
- 206010061535 Ovarian neoplasm Diseases 0.000 description 2
- 229910019142 PO4 Inorganic materials 0.000 description 2
- 206010060862 Prostate cancer Diseases 0.000 description 2
- 208000000236 Prostatic Neoplasms Diseases 0.000 description 2
- 239000012980 RPMI-1640 medium Substances 0.000 description 2
- 206010038389 Renal cancer Diseases 0.000 description 2
- 102000006382 Ribonucleases Human genes 0.000 description 2
- 108010083644 Ribonucleases Proteins 0.000 description 2
- 108010017324 STAT3 Transcription Factor Proteins 0.000 description 2
- 102000004495 STAT3 Transcription Factor Human genes 0.000 description 2
- 101150099493 STAT3 gene Proteins 0.000 description 2
- 206010039491 Sarcoma Diseases 0.000 description 2
- 108091081021 Sense strand Proteins 0.000 description 2
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 2
- 208000005718 Stomach Neoplasms Diseases 0.000 description 2
- 108091046915 Threose nucleic acid Proteins 0.000 description 2
- 208000024770 Thyroid neoplasm Diseases 0.000 description 2
- 125000000217 alkyl group Chemical group 0.000 description 2
- RZFHLOLGZPDCHJ-DLQZEEBKSA-N alpha-Tocotrienol Natural products Oc1c(C)c(C)c2O[C@@](CC/C=C(/CC/C=C(\CC/C=C(\C)/C)/C)\C)(C)CCc2c1C RZFHLOLGZPDCHJ-DLQZEEBKSA-N 0.000 description 2
- 125000000539 amino acid group Chemical group 0.000 description 2
- 238000012230 antisense oligonucleotides Methods 0.000 description 2
- 125000003236 benzoyl group Chemical group [H]C1=C([H])C([H])=C(C([H])=C1[H])C(*)=O 0.000 description 2
- IQFYYKKMVGJFEH-UHFFFAOYSA-N beta-L-thymidine Natural products O=C1NC(=O)C(C)=CN1C1OC(CO)C(O)C1 IQFYYKKMVGJFEH-UHFFFAOYSA-N 0.000 description 2
- 210000004369 blood Anatomy 0.000 description 2
- 239000008280 blood Substances 0.000 description 2
- 201000008274 breast adenocarcinoma Diseases 0.000 description 2
- 230000015556 catabolic process Effects 0.000 description 2
- 238000004113 cell culture Methods 0.000 description 2
- 210000000170 cell membrane Anatomy 0.000 description 2
- 230000004663 cell proliferation Effects 0.000 description 2
- 238000006482 condensation reaction Methods 0.000 description 2
- 230000003247 decreasing effect Effects 0.000 description 2
- 238000006731 degradation reaction Methods 0.000 description 2
- 235000014113 dietary fatty acids Nutrition 0.000 description 2
- HOWGUJZVBDQJKV-UHFFFAOYSA-N docosane Chemical compound CCCCCCCCCCCCCCCCCCCCCC HOWGUJZVBDQJKV-UHFFFAOYSA-N 0.000 description 2
- 239000000975 dye Substances 0.000 description 2
- 230000012202 endocytosis Effects 0.000 description 2
- 238000006911 enzymatic reaction Methods 0.000 description 2
- 238000011156 evaluation Methods 0.000 description 2
- 229930195729 fatty acid Natural products 0.000 description 2
- 239000000194 fatty acid Substances 0.000 description 2
- 108091022862 fatty acid binding Proteins 0.000 description 2
- 150000004665 fatty acids Chemical class 0.000 description 2
- 239000000796 flavoring agent Substances 0.000 description 2
- 235000013305 food Nutrition 0.000 description 2
- 235000013355 food flavoring agent Nutrition 0.000 description 2
- 206010017758 gastric cancer Diseases 0.000 description 2
- 201000004528 gastrointestinal lymphoma Diseases 0.000 description 2
- 208000005017 glioblastoma Diseases 0.000 description 2
- 239000008187 granular material Substances 0.000 description 2
- 230000012010 growth Effects 0.000 description 2
- IPCSVZSSVZVIGE-UHFFFAOYSA-N hexadecanoic acid Chemical compound CCCCCCCCCCCCCCCC(O)=O IPCSVZSSVZVIGE-UHFFFAOYSA-N 0.000 description 2
- 229920001519 homopolymer Polymers 0.000 description 2
- 102000051711 human BCL2 Human genes 0.000 description 2
- 238000009396 hybridization Methods 0.000 description 2
- 229910052739 hydrogen Inorganic materials 0.000 description 2
- 239000001257 hydrogen Substances 0.000 description 2
- 125000002887 hydroxy group Chemical group [H]O* 0.000 description 2
- 229940125396 insulin Drugs 0.000 description 2
- 238000006192 iodination reaction Methods 0.000 description 2
- 201000010982 kidney cancer Diseases 0.000 description 2
- 229940124280 l-arginine Drugs 0.000 description 2
- 239000002609 medium Substances 0.000 description 2
- 239000012528 membrane Substances 0.000 description 2
- NBIIXXVUZAFLBC-UHFFFAOYSA-K phosphate Chemical compound [O-]P([O-])([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-K 0.000 description 2
- 239000010452 phosphate Substances 0.000 description 2
- 150000003904 phospholipids Chemical class 0.000 description 2
- 238000002360 preparation method Methods 0.000 description 2
- 235000009566 rice Nutrition 0.000 description 2
- 239000011734 sodium Substances 0.000 description 2
- 229910052708 sodium Inorganic materials 0.000 description 2
- 239000011780 sodium chloride Substances 0.000 description 2
- 239000000243 solution Substances 0.000 description 2
- 239000002904 solvent Substances 0.000 description 2
- 150000003431 steroids Chemical class 0.000 description 2
- 201000011549 stomach cancer Diseases 0.000 description 2
- KDYFGRWQOYBRFD-UHFFFAOYSA-N succinic acid Chemical compound OC(=O)CCC(O)=O KDYFGRWQOYBRFD-UHFFFAOYSA-N 0.000 description 2
- 239000004094 surface-active agent Substances 0.000 description 2
- 125000003396 thiol group Chemical group [H]S* 0.000 description 2
- 229940104230 thymidine Drugs 0.000 description 2
- RWQNBRDOKXIBIV-UHFFFAOYSA-N thymine Chemical compound CC1=CNC(=O)NC1=O RWQNBRDOKXIBIV-UHFFFAOYSA-N 0.000 description 2
- 201000002510 thyroid cancer Diseases 0.000 description 2
- 150000003611 tocopherol derivatives Chemical class 0.000 description 2
- 150000003852 triazoles Chemical class 0.000 description 2
- 210000004291 uterus Anatomy 0.000 description 2
- 210000003462 vein Anatomy 0.000 description 2
- 229940088594 vitamin Drugs 0.000 description 2
- 229930003231 vitamin Natural products 0.000 description 2
- 235000013343 vitamin Nutrition 0.000 description 2
- 239000011782 vitamin Substances 0.000 description 2
- 150000003722 vitamin derivatives Chemical class 0.000 description 2
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Chemical compound O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 2
- WGVKWNUPNGFDFJ-DQCZWYHMSA-N β-tocopherol Chemical compound OC1=CC(C)=C2O[C@@](CCC[C@H](C)CCC[C@H](C)CCCC(C)C)(C)CCC2=C1C WGVKWNUPNGFDFJ-DQCZWYHMSA-N 0.000 description 2
- GZIFEOYASATJEH-VHFRWLAGSA-N δ-tocopherol Chemical compound OC1=CC(C)=C2O[C@@](CCC[C@H](C)CCC[C@H](C)CCCC(C)C)(C)CCC2=C1 GZIFEOYASATJEH-VHFRWLAGSA-N 0.000 description 2
- KIUKXJAPPMFGSW-DNGZLQJQSA-N (2S,3S,4S,5R,6R)-6-[(2S,3R,4R,5S,6R)-3-Acetamido-2-[(2S,3S,4R,5R,6R)-6-[(2R,3R,4R,5S,6R)-3-acetamido-2,5-dihydroxy-6-(hydroxymethyl)oxan-4-yl]oxy-2-carboxy-4,5-dihydroxyoxan-3-yl]oxy-5-hydroxy-6-(hydroxymethyl)oxan-4-yl]oxy-3,4,5-trihydroxyoxane-2-carboxylic acid Chemical compound CC(=O)N[C@H]1[C@H](O)O[C@H](CO)[C@@H](O)[C@@H]1O[C@H]1[C@H](O)[C@@H](O)[C@H](O[C@H]2[C@@H]([C@@H](O[C@H]3[C@@H]([C@@H](O)[C@H](O)[C@H](O3)C(O)=O)O)[C@H](O)[C@@H](CO)O2)NC(C)=O)[C@@H](C(O)=O)O1 KIUKXJAPPMFGSW-DNGZLQJQSA-N 0.000 description 1
- NJYXSKVOTDPOAT-LMVFSUKVSA-N (2r,3r,4r)-2-fluoro-3,4,5-trihydroxypentanal Chemical compound OC[C@@H](O)[C@@H](O)[C@@H](F)C=O NJYXSKVOTDPOAT-LMVFSUKVSA-N 0.000 description 1
- ROHGEAZREAFNTO-QYVSTXNMSA-N (2r,3r,4r,5r)-5-(6-aminopurin-9-yl)-2-(hydroxymethyl)-4-prop-2-ynoxyoxolan-3-ol Chemical compound C1=NC=2C(N)=NC=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1OCC#C ROHGEAZREAFNTO-QYVSTXNMSA-N 0.000 description 1
- WDQLRUYAYXDIFW-RWKIJVEZSA-N (2r,3r,4s,5r,6r)-4-[(2s,3r,4s,5r,6r)-3,5-dihydroxy-4-[(2r,3r,4s,5s,6r)-3,4,5-trihydroxy-6-(hydroxymethyl)oxan-2-yl]oxy-6-[[(2r,3r,4s,5s,6r)-3,4,5-trihydroxy-6-(hydroxymethyl)oxan-2-yl]oxymethyl]oxan-2-yl]oxy-6-(hydroxymethyl)oxane-2,3,5-triol Chemical compound O[C@@H]1[C@@H](CO)O[C@@H](O)[C@H](O)[C@H]1O[C@H]1[C@H](O)[C@@H](O[C@H]2[C@@H]([C@@H](O)[C@H](O)[C@@H](CO)O2)O)[C@H](O)[C@@H](CO[C@H]2[C@@H]([C@@H](O)[C@H](O)[C@@H](CO)O2)O)O1 WDQLRUYAYXDIFW-RWKIJVEZSA-N 0.000 description 1
- STGXGJRRAJKJRG-JDJSBBGDSA-N (3r,4r,5r)-5-(hydroxymethyl)-3-methoxyoxolane-2,4-diol Chemical compound CO[C@H]1C(O)O[C@H](CO)[C@H]1O STGXGJRRAJKJRG-JDJSBBGDSA-N 0.000 description 1
- WRIDQFICGBMAFQ-UHFFFAOYSA-N (E)-8-Octadecenoic acid Natural products CCCCCCCCCC=CCCCCCCC(O)=O WRIDQFICGBMAFQ-UHFFFAOYSA-N 0.000 description 1
- FGYKUFVNYVMTAM-UHFFFAOYSA-N (R)-2,5,8-trimethyl-2-(4,8,12-trimethyl-trideca-3t,7t,11-trienyl)-chroman-6-ol Natural products OC1=CC(C)=C2OC(CCC=C(C)CCC=C(C)CCC=C(C)C)(C)CCC2=C1C FGYKUFVNYVMTAM-UHFFFAOYSA-N 0.000 description 1
- GJJVAFUKOBZPCB-ZGRPYONQSA-N (r)-3,4-dihydro-2-methyl-2-(4,8,12-trimethyl-3,7,11-tridecatrienyl)-2h-1-benzopyran-6-ol Chemical class OC1=CC=C2OC(CC/C=C(C)/CC/C=C(C)/CCC=C(C)C)(C)CCC2=C1 GJJVAFUKOBZPCB-ZGRPYONQSA-N 0.000 description 1
- XYGVIBXOJOOCFR-BTJKTKAUSA-N (z)-but-2-enedioic acid;8-chloro-6-(2-fluorophenyl)-1-methyl-4h-imidazo[1,5-a][1,4]benzodiazepine Chemical compound OC(=O)\C=C/C(O)=O.C12=CC(Cl)=CC=C2N2C(C)=NC=C2CN=C1C1=CC=CC=C1F XYGVIBXOJOOCFR-BTJKTKAUSA-N 0.000 description 1
- NWUYHJFMYQTDRP-UHFFFAOYSA-N 1,2-bis(ethenyl)benzene;1-ethenyl-2-ethylbenzene;styrene Chemical compound C=CC1=CC=CC=C1.CCC1=CC=CC=C1C=C.C=CC1=CC=CC=C1C=C NWUYHJFMYQTDRP-UHFFFAOYSA-N 0.000 description 1
- MXHRCPNRJAMMIM-ULQXZJNLSA-N 1-[(2r,4s,5r)-4-hydroxy-5-(hydroxymethyl)oxolan-2-yl]-5-tritiopyrimidine-2,4-dione Chemical compound O=C1NC(=O)C([3H])=CN1[C@@H]1O[C@H](CO)[C@@H](O)C1 MXHRCPNRJAMMIM-ULQXZJNLSA-N 0.000 description 1
- NHBKXEKEPDILRR-UHFFFAOYSA-N 2,3-bis(butanoylsulfanyl)propyl butanoate Chemical compound CCCC(=O)OCC(SC(=O)CCC)CSC(=O)CCC NHBKXEKEPDILRR-UHFFFAOYSA-N 0.000 description 1
- KXSKAZFMTGADIV-UHFFFAOYSA-N 2-[3-(2-hydroxyethoxy)propoxy]ethanol Chemical compound OCCOCCCOCCO KXSKAZFMTGADIV-UHFFFAOYSA-N 0.000 description 1
- BOEUHAUGJSOEDZ-UHFFFAOYSA-N 2-amino-5,6,7,8-tetrahydro-1h-pteridin-4-one Chemical compound N1CCNC2=C1C(=O)N=C(N)N2 BOEUHAUGJSOEDZ-UHFFFAOYSA-N 0.000 description 1
- OTDJAMXESTUWLO-UUOKFMHZSA-N 2-amino-9-[(2R,3R,4S,5R)-3,4-dihydroxy-5-(hydroxymethyl)-2-oxolanyl]-3H-purine-6-thione Chemical compound C12=NC(N)=NC(S)=C2N=CN1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O OTDJAMXESTUWLO-UUOKFMHZSA-N 0.000 description 1
- VBIXIAQUDWOPDT-WOUKDFQISA-N 2-amino-9-[(2r,3r,4r,5r)-4-hydroxy-5-(hydroxymethyl)-3-prop-2-ynoxyoxolan-2-yl]-3h-purin-6-one Chemical compound C1=NC=2C(=O)NC(N)=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1OCC#C VBIXIAQUDWOPDT-WOUKDFQISA-N 0.000 description 1
- YNNKKMKHXXUFLP-UHFFFAOYSA-N 2-pyrrolidin-1-yl-n-[4-[[4-[(2-pyrrolidin-1-ylacetyl)amino]phenyl]methyl]phenyl]acetamide Chemical compound C=1C=C(CC=2C=CC(NC(=O)CN3CCCC3)=CC=2)C=CC=1NC(=O)CN1CCCC1 YNNKKMKHXXUFLP-UHFFFAOYSA-N 0.000 description 1
- LQJBNNIYVWPHFW-UHFFFAOYSA-N 20:1omega9c fatty acid Natural products CCCCCCCCCCC=CCCCCCCCC(O)=O LQJBNNIYVWPHFW-UHFFFAOYSA-N 0.000 description 1
- ODADKLYLWWCHNB-UHFFFAOYSA-N 2R-delta-tocotrienol Natural products OC1=CC(C)=C2OC(CCC=C(C)CCC=C(C)CCC=C(C)C)(C)CCC2=C1 ODADKLYLWWCHNB-UHFFFAOYSA-N 0.000 description 1
- OVONXEQGWXGFJD-UHFFFAOYSA-N 4-sulfanylidene-1h-pyrimidin-2-one Chemical compound SC=1C=CNC(=O)N=1 OVONXEQGWXGFJD-UHFFFAOYSA-N 0.000 description 1
- 125000002373 5 membered heterocyclic group Chemical group 0.000 description 1
- MSTNYGQPCMXVAQ-KIYNQFGBSA-N 5,6,7,8-tetrahydrofolic acid Chemical compound N1C=2C(=O)NC(N)=NC=2NCC1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 MSTNYGQPCMXVAQ-KIYNQFGBSA-N 0.000 description 1
- WOVKYSAHUYNSMH-RRKCRQDMSA-N 5-bromodeoxyuridine Chemical compound C1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C(Br)=C1 WOVKYSAHUYNSMH-RRKCRQDMSA-N 0.000 description 1
- KDOPAZIWBAHVJB-UHFFFAOYSA-N 5h-pyrrolo[3,2-d]pyrimidine Chemical compound C1=NC=C2NC=CC2=N1 KDOPAZIWBAHVJB-UHFFFAOYSA-N 0.000 description 1
- 125000004070 6 membered heterocyclic group Chemical group 0.000 description 1
- NLLCDONDZDHLCI-UHFFFAOYSA-N 6-amino-5-hydroxy-1h-pyrimidin-2-one Chemical compound NC=1NC(=O)N=CC=1O NLLCDONDZDHLCI-UHFFFAOYSA-N 0.000 description 1
- CKOMXBHMKXXTNW-UHFFFAOYSA-N 6-methyladenine Chemical compound CNC1=NC=NC2=C1N=CN2 CKOMXBHMKXXTNW-UHFFFAOYSA-N 0.000 description 1
- VVIAGPKUTFNRDU-UHFFFAOYSA-N 6S-folinic acid Chemical class C1NC=2NC(N)=NC(=O)C=2N(C=O)C1CNC1=CC=C(C(=O)NC(CCC(O)=O)C(O)=O)C=C1 VVIAGPKUTFNRDU-UHFFFAOYSA-N 0.000 description 1
- QSBYPNXLFMSGKH-UHFFFAOYSA-N 9-Heptadecensaeure Natural products CCCCCCCC=CCCCCCCCC(O)=O QSBYPNXLFMSGKH-UHFFFAOYSA-N 0.000 description 1
- 102000007469 Actins Human genes 0.000 description 1
- 108010085238 Actins Proteins 0.000 description 1
- 206010002091 Anaesthesia Diseases 0.000 description 1
- 206010003571 Astrocytoma Diseases 0.000 description 1
- 208000010839 B-cell chronic lymphocytic leukemia Diseases 0.000 description 1
- 206010005003 Bladder cancer Diseases 0.000 description 1
- 241000283690 Bos taurus Species 0.000 description 1
- 208000003174 Brain Neoplasms Diseases 0.000 description 1
- 208000006274 Brain Stem Neoplasms Diseases 0.000 description 1
- 206010006187 Breast cancer Diseases 0.000 description 1
- 208000011691 Burkitt lymphomas Diseases 0.000 description 1
- OYPRJOBELJOOCE-UHFFFAOYSA-N Calcium Chemical compound [Ca] OYPRJOBELJOOCE-UHFFFAOYSA-N 0.000 description 1
- 102000016289 Cell Adhesion Molecules Human genes 0.000 description 1
- 108010067225 Cell Adhesion Molecules Proteins 0.000 description 1
- 208000005243 Chondrosarcoma Diseases 0.000 description 1
- 241000725101 Clea Species 0.000 description 1
- 208000001333 Colorectal Neoplasms Diseases 0.000 description 1
- 208000035473 Communicable disease Diseases 0.000 description 1
- JPVYNHNXODAKFH-UHFFFAOYSA-N Cu2+ Chemical compound [Cu+2] JPVYNHNXODAKFH-UHFFFAOYSA-N 0.000 description 1
- 229920000858 Cyclodextrin Polymers 0.000 description 1
- 206010011732 Cyst Diseases 0.000 description 1
- GZIFEOYASATJEH-UHFFFAOYSA-N D-delta tocopherol Natural products OC1=CC(C)=C2OC(CCCC(C)CCCC(C)CCCC(C)C)(C)CCC2=C1 GZIFEOYASATJEH-UHFFFAOYSA-N 0.000 description 1
- SHZGCJCMOBCMKK-UHFFFAOYSA-N D-mannomethylose Natural products CC1OC(O)C(O)C(O)C1O SHZGCJCMOBCMKK-UHFFFAOYSA-N 0.000 description 1
- WQZGKKKJIJFFOK-QTVWNMPRSA-N D-mannopyranose Chemical compound OC[C@H]1OC(O)[C@@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-QTVWNMPRSA-N 0.000 description 1
- HMFHBZSHGGEWLO-SOOFDHNKSA-N D-ribofuranose Chemical compound OC[C@H]1OC(O)[C@H](O)[C@@H]1O HMFHBZSHGGEWLO-SOOFDHNKSA-N 0.000 description 1
- 108091028709 DNA adenine Proteins 0.000 description 1
- 230000006820 DNA synthesis Effects 0.000 description 1
- 102000004163 DNA-directed RNA polymerases Human genes 0.000 description 1
- 108090000626 DNA-directed RNA polymerases Proteins 0.000 description 1
- 102000007260 Deoxyribonuclease I Human genes 0.000 description 1
- 108010008532 Deoxyribonuclease I Proteins 0.000 description 1
- 239000004375 Dextrin Substances 0.000 description 1
- 229920001353 Dextrin Polymers 0.000 description 1
- 208000006402 Ductal Carcinoma Diseases 0.000 description 1
- 239000006144 Dulbecco’s modified Eagle's medium Substances 0.000 description 1
- 238000002965 ELISA Methods 0.000 description 1
- 206010014733 Endometrial cancer Diseases 0.000 description 1
- 206010014759 Endometrial neoplasm Diseases 0.000 description 1
- 208000000461 Esophageal Neoplasms Diseases 0.000 description 1
- IAYPIBMASNFSPL-UHFFFAOYSA-N Ethylene oxide Chemical group C1CO1 IAYPIBMASNFSPL-UHFFFAOYSA-N 0.000 description 1
- 108700024394 Exon Proteins 0.000 description 1
- GHASVSINZRGABV-UHFFFAOYSA-N Fluorouracil Chemical compound FC1=CNC(=O)NC1=O GHASVSINZRGABV-UHFFFAOYSA-N 0.000 description 1
- MPJKWIXIYCLVCU-UHFFFAOYSA-N Folinic acid Chemical class NC1=NC2=C(N(C=O)C(CNc3ccc(cc3)C(=O)NC(CCC(=O)O)CC(=O)O)CN2)C(=O)N1 MPJKWIXIYCLVCU-UHFFFAOYSA-N 0.000 description 1
- PNNNRSAQSRJVSB-SLPGGIOYSA-N Fucose Natural products C[C@H](O)[C@@H](O)[C@H](O)[C@H](O)C=O PNNNRSAQSRJVSB-SLPGGIOYSA-N 0.000 description 1
- 208000002966 Giant Cell Tumor of Bone Diseases 0.000 description 1
- 208000032612 Glial tumor Diseases 0.000 description 1
- 201000010915 Glioblastoma multiforme Diseases 0.000 description 1
- 206010018338 Glioma Diseases 0.000 description 1
- 102400000322 Glucagon-like peptide 1 Human genes 0.000 description 1
- 101800000224 Glucagon-like peptide 1 Proteins 0.000 description 1
- DTHNMHAUYICORS-KTKZVXAJSA-N Glucagon-like peptide 1 Chemical compound C([C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(N)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@H](CCC(N)=O)NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@@H](NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC=1N=CNC=1)[C@@H](C)O)[C@@H](C)O)C(C)C)C1=CC=CC=C1 DTHNMHAUYICORS-KTKZVXAJSA-N 0.000 description 1
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 1
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 1
- 239000004471 Glycine Substances 0.000 description 1
- 229920000028 Gradient copolymer Polymers 0.000 description 1
- 206010053759 Growth retardation Diseases 0.000 description 1
- NYHBQMYGNKIUIF-UUOKFMHZSA-N Guanosine Chemical compound C1=NC=2C(=O)NC(N)=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O NYHBQMYGNKIUIF-UUOKFMHZSA-N 0.000 description 1
- 108091027305 Heteroduplex Proteins 0.000 description 1
- 208000002291 Histiocytic Sarcoma Diseases 0.000 description 1
- 208000017604 Hodgkin disease Diseases 0.000 description 1
- 208000021519 Hodgkin lymphoma Diseases 0.000 description 1
- 208000010747 Hodgkins lymphoma Diseases 0.000 description 1
- 101000693243 Homo sapiens Paternally-expressed gene 3 protein Proteins 0.000 description 1
- 101001094545 Homo sapiens Retrotransposon-like protein 1 Proteins 0.000 description 1
- 208000030673 Homozygous familial hypercholesterolemia Diseases 0.000 description 1
- 208000005726 Inflammatory Breast Neoplasms Diseases 0.000 description 1
- 206010021980 Inflammatory carcinoma of the breast Diseases 0.000 description 1
- 241000764238 Isis Species 0.000 description 1
- 208000022120 Jeavons syndrome Diseases 0.000 description 1
- SHZGCJCMOBCMKK-DHVFOXMCSA-N L-fucopyranose Chemical compound C[C@@H]1OC(O)[C@@H](O)[C@H](O)[C@@H]1O SHZGCJCMOBCMKK-DHVFOXMCSA-N 0.000 description 1
- 239000005639 Lauric acid Substances 0.000 description 1
- 102000003960 Ligases Human genes 0.000 description 1
- 108090000364 Ligases Proteins 0.000 description 1
- 102000011965 Lipoprotein Receptors Human genes 0.000 description 1
- 108010061306 Lipoprotein Receptors Proteins 0.000 description 1
- 102000004895 Lipoproteins Human genes 0.000 description 1
- 108090001030 Lipoproteins Proteins 0.000 description 1
- 102000003820 Lipoxygenases Human genes 0.000 description 1
- 108090000128 Lipoxygenases Proteins 0.000 description 1
- 206010058467 Lung neoplasm malignant Diseases 0.000 description 1
- 208000031422 Lymphocytic Chronic B-Cell Leukemia Diseases 0.000 description 1
- 239000004472 Lysine Substances 0.000 description 1
- 206010027406 Mesothelioma Diseases 0.000 description 1
- WXJXBKBJAKPJRN-UHFFFAOYSA-N Methanephosphonothioic acid Chemical compound CP(O)(O)=S WXJXBKBJAKPJRN-UHFFFAOYSA-N 0.000 description 1
- 108010006519 Molecular Chaperones Proteins 0.000 description 1
- 102000005431 Molecular Chaperones Human genes 0.000 description 1
- 208000034578 Multiple myelomas Diseases 0.000 description 1
- 241000699670 Mus sp. Species 0.000 description 1
- 235000021360 Myristic acid Nutrition 0.000 description 1
- OVRNDRQMDRJTHS-UHFFFAOYSA-N N-acelyl-D-glucosamine Natural products CC(=O)NC1C(O)OC(CO)C(O)C1O OVRNDRQMDRJTHS-UHFFFAOYSA-N 0.000 description 1
- OVRNDRQMDRJTHS-FMDGEEDCSA-N N-acetyl-beta-D-glucosamine Chemical compound CC(=O)N[C@H]1[C@H](O)O[C@H](CO)[C@@H](O)[C@@H]1O OVRNDRQMDRJTHS-FMDGEEDCSA-N 0.000 description 1
- MBLBDJOUHNCFQT-LXGUWJNJSA-N N-acetylglucosamine Natural products CC(=O)N[C@@H](C=O)[C@@H](O)[C@H](O)[C@H](O)CO MBLBDJOUHNCFQT-LXGUWJNJSA-N 0.000 description 1
- 208000033755 Neutrophilic Chronic Leukemia Diseases 0.000 description 1
- 208000015914 Non-Hodgkin lymphomas Diseases 0.000 description 1
- 238000000636 Northern blotting Methods 0.000 description 1
- 206010030155 Oesophageal carcinoma Diseases 0.000 description 1
- 239000005642 Oleic acid Substances 0.000 description 1
- ZQPPMHVWECSIRJ-UHFFFAOYSA-N Oleic acid Natural products CCCCCCCCC=CCCCCCCCC(O)=O ZQPPMHVWECSIRJ-UHFFFAOYSA-N 0.000 description 1
- 102000043276 Oncogene Human genes 0.000 description 1
- 101800000989 Oxytocin Proteins 0.000 description 1
- 102400000050 Oxytocin Human genes 0.000 description 1
- XNOPRXBHLZRZKH-UHFFFAOYSA-N Oxytocin Natural products N1C(=O)C(N)CSSCC(C(=O)N2C(CCC2)C(=O)NC(CC(C)C)C(=O)NCC(N)=O)NC(=O)C(CC(N)=O)NC(=O)C(CCC(N)=O)NC(=O)C(C(C)CC)NC(=O)C1CC1=CC=C(O)C=C1 XNOPRXBHLZRZKH-UHFFFAOYSA-N 0.000 description 1
- 235000021314 Palmitic acid Nutrition 0.000 description 1
- 102100025757 Paternally-expressed gene 3 protein Human genes 0.000 description 1
- 206010035226 Plasma cell myeloma Diseases 0.000 description 1
- 208000007452 Plasmacytoma Diseases 0.000 description 1
- ZLMJMSJWJFRBEC-UHFFFAOYSA-N Potassium Chemical compound [K] ZLMJMSJWJFRBEC-UHFFFAOYSA-N 0.000 description 1
- XBDQKXXYIPTUBI-UHFFFAOYSA-N Propionic acid Chemical class CCC(O)=O XBDQKXXYIPTUBI-UHFFFAOYSA-N 0.000 description 1
- 102000004005 Prostaglandin-endoperoxide synthases Human genes 0.000 description 1
- 108090000459 Prostaglandin-endoperoxide synthases Proteins 0.000 description 1
- LCTONWCANYUPML-UHFFFAOYSA-M Pyruvate Chemical compound CC(=O)C([O-])=O LCTONWCANYUPML-UHFFFAOYSA-M 0.000 description 1
- 238000012228 RNA interference-mediated gene silencing Methods 0.000 description 1
- 238000011530 RNeasy Mini Kit Methods 0.000 description 1
- 102100035123 Retrotransposon-like protein 1 Human genes 0.000 description 1
- 208000004337 Salivary Gland Neoplasms Diseases 0.000 description 1
- 206010061934 Salivary gland cancer Diseases 0.000 description 1
- 229920002305 Schizophyllan Polymers 0.000 description 1
- 206010070834 Sensitisation Diseases 0.000 description 1
- 208000021712 Soft tissue sarcoma Diseases 0.000 description 1
- 208000000389 T-cell leukemia Diseases 0.000 description 1
- 208000028530 T-cell lymphoblastic leukemia/lymphoma Diseases 0.000 description 1
- 206010042971 T-cell lymphoma Diseases 0.000 description 1
- 208000027585 T-cell non-Hodgkin lymphoma Diseases 0.000 description 1
- 208000024313 Testicular Neoplasms Diseases 0.000 description 1
- 206010057644 Testis cancer Diseases 0.000 description 1
- RYYWUUFWQRZTIU-UHFFFAOYSA-N Thiophosphoric acid Chemical compound OP(O)(S)=O RYYWUUFWQRZTIU-UHFFFAOYSA-N 0.000 description 1
- 206010045261 Type IIa hyperlipidaemia Diseases 0.000 description 1
- 206010045515 Undifferentiated sarcoma Diseases 0.000 description 1
- 208000007097 Urinary Bladder Neoplasms Diseases 0.000 description 1
- GXBMIBRIOWHPDT-UHFFFAOYSA-N Vasopressin Natural products N1C(=O)C(CC=2C=C(O)C=CC=2)NC(=O)C(N)CSSCC(C(=O)N2C(CCC2)C(=O)NC(CCCN=C(N)N)C(=O)NCC(N)=O)NC(=O)C(CC(N)=O)NC(=O)C(CCC(N)=O)NC(=O)C1CC1=CC=CC=C1 GXBMIBRIOWHPDT-UHFFFAOYSA-N 0.000 description 1
- 102000002852 Vasopressins Human genes 0.000 description 1
- 108010004977 Vasopressins Proteins 0.000 description 1
- 208000008383 Wilms tumor Diseases 0.000 description 1
- 230000003187 abdominal effect Effects 0.000 description 1
- 238000002835 absorbance Methods 0.000 description 1
- 150000001242 acetic acid derivatives Chemical class 0.000 description 1
- 150000007513 acids Chemical class 0.000 description 1
- 239000004480 active ingredient Substances 0.000 description 1
- 208000037833 acute lymphoblastic T-cell leukemia Diseases 0.000 description 1
- 125000002015 acyclic group Chemical group 0.000 description 1
- 125000002252 acyl group Chemical group 0.000 description 1
- 239000000654 additive Substances 0.000 description 1
- 230000001919 adrenal effect Effects 0.000 description 1
- 125000003342 alkenyl group Chemical group 0.000 description 1
- 150000001345 alkine derivatives Chemical class 0.000 description 1
- 125000003545 alkoxy group Chemical group 0.000 description 1
- 125000004414 alkyl thio group Chemical group 0.000 description 1
- 230000002152 alkylating effect Effects 0.000 description 1
- 229940087168 alpha tocopherol Drugs 0.000 description 1
- 229940064063 alpha tocotrienol Drugs 0.000 description 1
- HMFHBZSHGGEWLO-UHFFFAOYSA-N alpha-D-Furanose-Ribose Natural products OCC1OC(O)C(O)C1O HMFHBZSHGGEWLO-UHFFFAOYSA-N 0.000 description 1
- WQZGKKKJIJFFOK-PHYPRBDBSA-N alpha-D-galactose Chemical compound OC[C@H]1O[C@H](O)[C@H](O)[C@@H](O)[C@H]1O WQZGKKKJIJFFOK-PHYPRBDBSA-N 0.000 description 1
- DTOSIQBPPRVQHS-PDBXOOCHSA-N alpha-linolenic acid Chemical compound CC\C=C/C\C=C/C\C=C/CCCCCCCC(O)=O DTOSIQBPPRVQHS-PDBXOOCHSA-N 0.000 description 1
- 235000020661 alpha-linolenic acid Nutrition 0.000 description 1
- 229920005603 alternating copolymer Polymers 0.000 description 1
- 125000002344 aminooxy group Chemical group [H]N([H])O[*] 0.000 description 1
- 230000003321 amplification Effects 0.000 description 1
- 230000037005 anaesthesia Effects 0.000 description 1
- 230000003444 anaesthetic effect Effects 0.000 description 1
- 210000003503 anal sac Anatomy 0.000 description 1
- 238000010171 animal model Methods 0.000 description 1
- 230000001028 anti-proliverative effect Effects 0.000 description 1
- 239000000427 antigen Substances 0.000 description 1
- 102000036639 antigens Human genes 0.000 description 1
- 108091007433 antigens Proteins 0.000 description 1
- 229940045687 antimetabolites folic acid analogs Drugs 0.000 description 1
- 201000007436 apocrine adenocarcinoma Diseases 0.000 description 1
- 239000002215 arabinonucleoside Substances 0.000 description 1
- PYMYPHUHKUWMLA-WDCZJNDASA-N arabinose Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)C=O PYMYPHUHKUWMLA-WDCZJNDASA-N 0.000 description 1
- 108010072041 arginyl-glycyl-aspartic acid Proteins 0.000 description 1
- KBZOIRJILGZLEJ-LGYYRGKSSA-N argipressin Chemical compound C([C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CSSC[C@@H](C(N[C@@H](CC=2C=CC(O)=CC=2)C(=O)N1)=O)N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCN=C(N)N)C(=O)NCC(N)=O)C1=CC=CC=C1 KBZOIRJILGZLEJ-LGYYRGKSSA-N 0.000 description 1
- 125000006615 aromatic heterocyclic group Chemical group 0.000 description 1
- 125000002029 aromatic hydrocarbon group Chemical group 0.000 description 1
- 125000003710 aryl alkyl group Chemical group 0.000 description 1
- 125000003118 aryl group Chemical group 0.000 description 1
- 108010045569 atelocollagen Proteins 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 229940066595 beta tocopherol Drugs 0.000 description 1
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 1
- SQVRNKJHWKZAKO-UHFFFAOYSA-N beta-N-Acetyl-D-neuraminic acid Natural products CC(=O)NC1C(O)CC(O)(C(O)=O)OC1C(O)C(O)CO SQVRNKJHWKZAKO-UHFFFAOYSA-N 0.000 description 1
- FGYKUFVNYVMTAM-YMCDKREISA-N beta-Tocotrienol Natural products Oc1c(C)c2c(c(C)c1)O[C@@](CC/C=C(\CC/C=C(\CC/C=C(\C)/C)/C)/C)(C)CC2 FGYKUFVNYVMTAM-YMCDKREISA-N 0.000 description 1
- 235000013361 beverage Nutrition 0.000 description 1
- 125000002619 bicyclic group Chemical group 0.000 description 1
- 239000011230 binding agent Substances 0.000 description 1
- 238000010876 biochemical test Methods 0.000 description 1
- 230000001851 biosynthetic effect Effects 0.000 description 1
- 229920001400 block copolymer Polymers 0.000 description 1
- 201000011143 bone giant cell tumor Diseases 0.000 description 1
- 238000009395 breeding Methods 0.000 description 1
- 230000001488 breeding effect Effects 0.000 description 1
- 230000031709 bromination Effects 0.000 description 1
- 239000000872 buffer Substances 0.000 description 1
- 239000007853 buffer solution Substances 0.000 description 1
- 239000004067 bulking agent Substances 0.000 description 1
- 239000006227 byproduct Substances 0.000 description 1
- 239000011575 calcium Substances 0.000 description 1
- 229910052791 calcium Inorganic materials 0.000 description 1
- 239000002775 capsule Substances 0.000 description 1
- 229910052799 carbon Inorganic materials 0.000 description 1
- 239000000969 carrier Substances 0.000 description 1
- 239000003729 cation exchange resin Substances 0.000 description 1
- 125000002091 cationic group Chemical group 0.000 description 1
- 239000001913 cellulose Substances 0.000 description 1
- 229920002678 cellulose Polymers 0.000 description 1
- TZRFSLHOCZEXCC-HIVFKXHNSA-N chembl2219536 Chemical compound N1([C@H]2C[C@@H]([C@H](O2)COP(O)(=O)S[C@@H]2[C@H](O[C@H](C2)N2C3=C(C(NC(N)=N3)=O)N=C2)COP(O)(=O)S[C@@H]2[C@H](O[C@H](C2)N2C(NC(=O)C(C)=C2)=O)COP(O)(=O)S[C@@H]2[C@H](O[C@H](C2)N2C(N=C(N)C(C)=C2)=O)COP(O)(=O)S[C@@H]2[C@H](O[C@H](C2)N2C(NC(=O)C(C)=C2)=O)COP(O)(=O)S[C@@H]2[C@H](O[C@H](C2)N2C3=C(C(NC(N)=N3)=O)N=C2)COP(O)(=O)S[C@@H]2[C@H](O[C@H](C2)N2C3=NC=NC(N)=C3N=C2)COP(O)(=O)S[C@H]2[C@H]([C@@H](O[C@@H]2COP(O)(=O)S[C@H]2[C@H]([C@@H](O[C@@H]2COP(O)(=O)S[C@H]2[C@H]([C@@H](O[C@@H]2COP(O)(=O)S[C@H]2[C@H]([C@@H](O[C@@H]2COP(O)(=O)S[C@H]2[C@H]([C@@H](O[C@@H]2CO)N2C3=C(C(NC(N)=N3)=O)N=C2)OCCOC)N2C(N=C(N)C(C)=C2)=O)OCCOC)N2C(N=C(N)C(C)=C2)=O)OCCOC)N2C(NC(=O)C(C)=C2)=O)OCCOC)N2C(N=C(N)C(C)=C2)=O)OCCOC)SP(O)(=O)OC[C@H]2O[C@H](C[C@@H]2SP(O)(=O)OC[C@H]2O[C@H](C[C@@H]2SP(O)(=O)OC[C@H]2O[C@H](C[C@@H]2SP(O)(=O)OC[C@@H]2[C@H]([C@H]([C@@H](O2)N2C3=C(C(NC(N)=N3)=O)N=C2)OCCOC)SP(O)(=O)OC[C@H]2[C@@H]([C@@H]([C@H](O2)N2C(N=C(N)C(C)=C2)=O)OCCOC)SP(O)(=O)OC[C@H]2[C@@H]([C@@H]([C@H](O2)N2C3=NC=NC(N)=C3N=C2)OCCOC)SP(O)(=O)OC[C@H]2[C@@H]([C@@H]([C@H](O2)N2C(N=C(N)C(C)=C2)=O)OCCOC)SP(O)(=O)OC[C@H]2[C@H](O)[C@@H]([C@H](O2)N2C(N=C(N)C(C)=C2)=O)OCCOC)N2C(N=C(N)C(C)=C2)=O)N2C(NC(=O)C(C)=C2)=O)N2C(NC(=O)C(C)=C2)=O)C=C(C)C(N)=NC1=O TZRFSLHOCZEXCC-HIVFKXHNSA-N 0.000 description 1
- 239000003153 chemical reaction reagent Substances 0.000 description 1
- 230000001055 chewing effect Effects 0.000 description 1
- 208000032852 chronic lymphocytic leukemia Diseases 0.000 description 1
- 201000010903 chronic neutrophilic leukemia Diseases 0.000 description 1
- HGCIXCUEYOPUTN-UHFFFAOYSA-N cis-cyclohexene Natural products C1CCC=CC1 HGCIXCUEYOPUTN-UHFFFAOYSA-N 0.000 description 1
- 238000003776 cleavage reaction Methods 0.000 description 1
- 239000011248 coating agent Substances 0.000 description 1
- 208000029742 colonic neoplasm Diseases 0.000 description 1
- 239000003086 colorant Substances 0.000 description 1
- 238000004737 colorimetric analysis Methods 0.000 description 1
- 239000002299 complementary DNA Substances 0.000 description 1
- 238000002247 constant time method Methods 0.000 description 1
- 230000001276 controlling effect Effects 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 229920001577 copolymer Polymers 0.000 description 1
- JZCCFEFSEZPSOG-UHFFFAOYSA-L copper(II) sulfate pentahydrate Chemical compound O.O.O.O.O.[Cu+2].[O-]S([O-])(=O)=O JZCCFEFSEZPSOG-UHFFFAOYSA-L 0.000 description 1
- 230000008878 coupling Effects 0.000 description 1
- 238000010168 coupling process Methods 0.000 description 1
- 238000005859 coupling reaction Methods 0.000 description 1
- 210000004748 cultured cell Anatomy 0.000 description 1
- 125000005159 cyanoalkoxy group Chemical group 0.000 description 1
- 125000000753 cycloalkyl group Chemical group 0.000 description 1
- 208000031513 cyst Diseases 0.000 description 1
- DTPCFIHYWYONMD-UHFFFAOYSA-N decaethylene glycol Chemical compound OCCOCCOCCOCCOCCOCCOCCOCCOCCOCCO DTPCFIHYWYONMD-UHFFFAOYSA-N 0.000 description 1
- 230000000593 degrading effect Effects 0.000 description 1
- 235000010389 delta-tocopherol Nutrition 0.000 description 1
- BTNBMQIHCRIGOU-UHFFFAOYSA-N delta-tocotrienol Natural products CC(=CCCC(=CCCC(=CCCOC1(C)CCc2cc(O)cc(C)c2O1)C)C)C BTNBMQIHCRIGOU-UHFFFAOYSA-N 0.000 description 1
- 238000010520 demethylation reaction Methods 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 235000019425 dextrin Nutrition 0.000 description 1
- 150000001991 dicarboxylic acids Chemical class 0.000 description 1
- OZRNSSUDZOLUSN-LBPRGKRZSA-N dihydrofolic acid Chemical compound N=1C=2C(=O)NC(N)=NC=2NCC=1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 OZRNSSUDZOLUSN-LBPRGKRZSA-N 0.000 description 1
- 239000003085 diluting agent Substances 0.000 description 1
- NAGJZTKCGNOGPW-UHFFFAOYSA-K dioxido-sulfanylidene-sulfido-$l^{5}-phosphane Chemical compound [O-]P([O-])([S-])=S NAGJZTKCGNOGPW-UHFFFAOYSA-K 0.000 description 1
- 239000007884 disintegrant Substances 0.000 description 1
- 239000002552 dosage form Substances 0.000 description 1
- 231100000673 dose–response relationship Toxicity 0.000 description 1
- 238000012377 drug delivery Methods 0.000 description 1
- 239000003995 emulsifying agent Substances 0.000 description 1
- 201000003908 endometrial adenocarcinoma Diseases 0.000 description 1
- 208000029382 endometrium adenocarcinoma Diseases 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 230000002255 enzymatic effect Effects 0.000 description 1
- FGYKUFVNYVMTAM-MUUNZHRXSA-N epsilon-Tocopherol Natural products OC1=CC(C)=C2O[C@@](CCC=C(C)CCC=C(C)CCC=C(C)C)(C)CCC2=C1C FGYKUFVNYVMTAM-MUUNZHRXSA-N 0.000 description 1
- 201000004101 esophageal cancer Diseases 0.000 description 1
- 210000003238 esophagus Anatomy 0.000 description 1
- 230000003203 everyday effect Effects 0.000 description 1
- 230000001605 fetal effect Effects 0.000 description 1
- 239000007888 film coating Substances 0.000 description 1
- 238000009501 film coating Methods 0.000 description 1
- 238000000684 flow cytometry Methods 0.000 description 1
- 229960002949 fluorouracil Drugs 0.000 description 1
- 125000003929 folic acid group Chemical group 0.000 description 1
- 239000011672 folinic acid Chemical class 0.000 description 1
- 235000008191 folinic acid Nutrition 0.000 description 1
- VVIAGPKUTFNRDU-ABLWVSNPSA-N folinic acid Chemical class C1NC=2NC(N)=NC(=O)C=2N(C=O)C1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 VVIAGPKUTFNRDU-ABLWVSNPSA-N 0.000 description 1
- 201000003444 follicular lymphoma Diseases 0.000 description 1
- 230000037406 food intake Effects 0.000 description 1
- 235000003599 food sweetener Nutrition 0.000 description 1
- 238000009472 formulation Methods 0.000 description 1
- 239000003205 fragrance Substances 0.000 description 1
- 229930182830 galactose Natural products 0.000 description 1
- OTXNTMVVOOBZCV-YMCDKREISA-N gamma-Tocotrienol Natural products Oc1c(C)c(C)c2O[C@@](CC/C=C(\CC/C=C(\CC/C=C(\C)/C)/C)/C)(C)CCc2c1 OTXNTMVVOOBZCV-YMCDKREISA-N 0.000 description 1
- 235000010382 gamma-tocopherol Nutrition 0.000 description 1
- 238000003633 gene expression assay Methods 0.000 description 1
- 230000009368 gene silencing by RNA Effects 0.000 description 1
- 238000002695 general anesthesia Methods 0.000 description 1
- 239000008103 glucose Substances 0.000 description 1
- 235000013922 glutamic acid Nutrition 0.000 description 1
- 239000004220 glutamic acid Substances 0.000 description 1
- 150000004676 glycans Chemical class 0.000 description 1
- 229930182470 glycoside Natural products 0.000 description 1
- 150000002339 glycosphingolipids Chemical class 0.000 description 1
- 210000003128 head Anatomy 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 206010073071 hepatocellular carcinoma Diseases 0.000 description 1
- 231100000844 hepatocellular carcinoma Toxicity 0.000 description 1
- 125000000623 heterocyclic group Chemical group 0.000 description 1
- 150000002402 hexoses Chemical class 0.000 description 1
- 229920002674 hyaluronan Polymers 0.000 description 1
- 229960003160 hyaluronic acid Drugs 0.000 description 1
- 125000004435 hydrogen atom Chemical group [H]* 0.000 description 1
- 238000001727 in vivo Methods 0.000 description 1
- 201000004653 inflammatory breast carcinoma Diseases 0.000 description 1
- 238000001802 infusion Methods 0.000 description 1
- 102000006495 integrins Human genes 0.000 description 1
- 108010044426 integrins Proteins 0.000 description 1
- 239000000543 intermediate Substances 0.000 description 1
- 238000001361 intraarterial administration Methods 0.000 description 1
- 230000003834 intracellular effect Effects 0.000 description 1
- 238000007918 intramuscular administration Methods 0.000 description 1
- 238000007912 intraperitoneal administration Methods 0.000 description 1
- 238000001990 intravenous administration Methods 0.000 description 1
- QXJSBBXBKPUZAA-UHFFFAOYSA-N isooleic acid Natural products CCCCCCCC=CCCCCCCCCC(O)=O QXJSBBXBKPUZAA-UHFFFAOYSA-N 0.000 description 1
- 229960001691 leucovorin Drugs 0.000 description 1
- 229960004488 linolenic acid Drugs 0.000 description 1
- KQQKGWQCNNTQJW-UHFFFAOYSA-N linolenic acid Natural products CC=CCCC=CCC=CCCCCCCCC(O)=O KQQKGWQCNNTQJW-UHFFFAOYSA-N 0.000 description 1
- 239000002502 liposome Substances 0.000 description 1
- 239000007788 liquid Substances 0.000 description 1
- 201000007270 liver cancer Diseases 0.000 description 1
- 208000014018 liver neoplasm Diseases 0.000 description 1
- 244000144972 livestock Species 0.000 description 1
- 239000007937 lozenge Substances 0.000 description 1
- 239000000314 lubricant Substances 0.000 description 1
- 210000004072 lung Anatomy 0.000 description 1
- 201000005249 lung adenocarcinoma Diseases 0.000 description 1
- 201000005202 lung cancer Diseases 0.000 description 1
- 208000020816 lung neoplasm Diseases 0.000 description 1
- 210000004698 lymphocyte Anatomy 0.000 description 1
- 210000003563 lymphoid tissue Anatomy 0.000 description 1
- 159000000003 magnesium salts Chemical class 0.000 description 1
- 238000012423 maintenance Methods 0.000 description 1
- 238000004519 manufacturing process Methods 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 230000010534 mechanism of action Effects 0.000 description 1
- 201000001441 melanoma Diseases 0.000 description 1
- 208000030159 metabolic disease Diseases 0.000 description 1
- 239000002207 metabolite Substances 0.000 description 1
- 125000000956 methoxy group Chemical group [H]C([H])([H])O* 0.000 description 1
- YACKEPLHDIMKIO-UHFFFAOYSA-N methylphosphonic acid Chemical compound CP(O)(O)=O YACKEPLHDIMKIO-UHFFFAOYSA-N 0.000 description 1
- 239000000693 micelle Substances 0.000 description 1
- 108091060283 mipomersen Proteins 0.000 description 1
- 229960004778 mipomersen Drugs 0.000 description 1
- 239000000178 monomer Substances 0.000 description 1
- 150000002772 monosaccharides Chemical class 0.000 description 1
- 208000001611 myxosarcoma Diseases 0.000 description 1
- VMGAPWLDMVPYIA-HIDZBRGKSA-N n'-amino-n-iminomethanimidamide Chemical compound N\N=C\N=N VMGAPWLDMVPYIA-HIDZBRGKSA-N 0.000 description 1
- WQEPLUUGTLDZJY-UHFFFAOYSA-N n-Pentadecanoic acid Natural products CCCCCCCCCCCCCCC(O)=O WQEPLUUGTLDZJY-UHFFFAOYSA-N 0.000 description 1
- 229950006780 n-acetylglucosamine Drugs 0.000 description 1
- 210000003739 neck Anatomy 0.000 description 1
- 201000008026 nephroblastoma Diseases 0.000 description 1
- 238000003199 nucleic acid amplification method Methods 0.000 description 1
- 230000001293 nucleolytic effect Effects 0.000 description 1
- OGIAAULPRXAQEV-UHFFFAOYSA-N odn 2216 Chemical compound O=C1NC(=O)C(C)=CN1C1OC(COP(O)(=O)OC2C(OC(C2)N2C3=NC=NC(N)=C3N=C2)COP(O)(=O)OC2C(OC(C2)N2C3=C(C(NC(N)=N3)=O)N=C2)COP(O)(=O)OC2C(OC(C2)N2C(N=C(N)C=C2)=O)COP(O)(=O)OC2C(OC(C2)N2C3=NC=NC(N)=C3N=C2)COP(O)(=O)OC2C(OC(C2)N2C3=C(C(NC(N)=N3)=O)N=C2)COP(O)(=O)OC2C(OC(C2)N2C3=C(C(NC(N)=N3)=O)N=C2)COP(O)(=O)OC2C(OC(C2)N2C3=C(C(NC(N)=N3)=O)N=C2)COP(O)(=O)OC2C(OC(C2)N2C3=C(C(NC(N)=N3)=O)N=C2)COP(O)(=O)OC2C(OC(C2)N2C3=C(C(NC(N)=N3)=O)N=C2)COP(O)(O)=O)C(OP(O)(=O)OCC2C(CC(O2)N2C(N=C(N)C=C2)=O)OP(O)(=O)OCC2C(CC(O2)N2C3=C(C(NC(N)=N3)=O)N=C2)OP(O)(=O)OCC2C(CC(O2)N2C(NC(=O)C(C)=C2)=O)OP(O)(=O)OCC2C(CC(O2)N2C(N=C(N)C=C2)=O)OP(O)(=O)OCC2C(CC(O2)N2C3=C(C(NC(N)=N3)=O)N=C2)OP(O)(=O)OCC2C(CC(O2)N2C3=C(C(NC(N)=N3)=O)N=C2)OP(O)(=O)OCC2C(CC(O2)N2C3=C(C(NC(N)=N3)=O)N=C2)OP(O)(=O)OCC2C(CC(O2)N2C3=C(C(NC(N)=N3)=O)N=C2)OP(O)(=O)OCC2C(CC(O2)N2C3=C(C(NC(N)=N3)=O)N=C2)OP(O)(=O)OCC2C(CC(O2)N2C3=C(C(NC(N)=N3)=O)N=C2)O)C1 OGIAAULPRXAQEV-UHFFFAOYSA-N 0.000 description 1
- ZQPPMHVWECSIRJ-KTKRTIGZSA-N oleic acid Chemical compound CCCCCCCC\C=C/CCCCCCCC(O)=O ZQPPMHVWECSIRJ-KTKRTIGZSA-N 0.000 description 1
- 229960002969 oleic acid Drugs 0.000 description 1
- 235000021313 oleic acid Nutrition 0.000 description 1
- 210000000056 organ Anatomy 0.000 description 1
- XNOPRXBHLZRZKH-DSZYJQQASA-N oxytocin Chemical compound C([C@H]1C(=O)N[C@H](C(N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CSSC[C@H](N)C(=O)N1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC(C)C)C(=O)NCC(N)=O)=O)[C@@H](C)CC)C1=CC=C(O)C=C1 XNOPRXBHLZRZKH-DSZYJQQASA-N 0.000 description 1
- 229960001723 oxytocin Drugs 0.000 description 1
- 229940098695 palmitic acid Drugs 0.000 description 1
- 239000002245 particle Substances 0.000 description 1
- 239000006072 paste Substances 0.000 description 1
- 230000037361 pathway Effects 0.000 description 1
- 239000008188 pellet Substances 0.000 description 1
- 239000000546 pharmaceutical excipient Substances 0.000 description 1
- RLZZZVKAURTHCP-UHFFFAOYSA-N phenanthrene-3,4-diol Chemical compound C1=CC=C2C3=C(O)C(O)=CC=C3C=CC2=C1 RLZZZVKAURTHCP-UHFFFAOYSA-N 0.000 description 1
- PTMHPRAIXMAOOB-UHFFFAOYSA-L phosphoramidate Chemical compound NP([O-])([O-])=O PTMHPRAIXMAOOB-UHFFFAOYSA-L 0.000 description 1
- 239000002504 physiological saline solution Substances 0.000 description 1
- 239000006187 pill Substances 0.000 description 1
- 229920001308 poly(aminoacid) Polymers 0.000 description 1
- 229920001282 polysaccharide Polymers 0.000 description 1
- 239000005017 polysaccharide Substances 0.000 description 1
- 239000013641 positive control Substances 0.000 description 1
- 239000011591 potassium Substances 0.000 description 1
- 229910052700 potassium Inorganic materials 0.000 description 1
- 244000144977 poultry Species 0.000 description 1
- 239000000843 powder Substances 0.000 description 1
- 239000002243 precursor Substances 0.000 description 1
- 239000003755 preservative agent Substances 0.000 description 1
- 230000002265 prevention Effects 0.000 description 1
- 230000002250 progressing effect Effects 0.000 description 1
- CPNGPNLZQNNVQM-UHFFFAOYSA-N pteridine Chemical compound N1=CN=CC2=NC=CN=C21 CPNGPNLZQNNVQM-UHFFFAOYSA-N 0.000 description 1
- 150000003195 pteridines Chemical class 0.000 description 1
- 150000003212 purines Chemical class 0.000 description 1
- 150000003230 pyrimidines Chemical class 0.000 description 1
- 229920005604 random copolymer Polymers 0.000 description 1
- 238000003753 real-time PCR Methods 0.000 description 1
- 230000001105 regulatory effect Effects 0.000 description 1
- BOLDJAUMGUJJKM-LSDHHAIUSA-N renifolin D Natural products CC(=C)[C@@H]1Cc2c(O)c(O)ccc2[C@H]1CC(=O)c3ccc(O)cc3O BOLDJAUMGUJJKM-LSDHHAIUSA-N 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 108091008146 restriction endonucleases Proteins 0.000 description 1
- 239000000523 sample Substances 0.000 description 1
- 229920006395 saturated elastomer Polymers 0.000 description 1
- 235000003441 saturated fatty acids Nutrition 0.000 description 1
- 150000004671 saturated fatty acids Chemical class 0.000 description 1
- HFHDHCJBZVLPGP-UHFFFAOYSA-N schardinger α-dextrin Chemical compound O1C(C(C2O)O)C(CO)OC2OC(C(C2O)O)C(CO)OC2OC(C(C2O)O)C(CO)OC2OC(C(O)C2O)C(CO)OC2OC(C(C2O)O)C(CO)OC2OC2C(O)C(O)C1OC2CO HFHDHCJBZVLPGP-UHFFFAOYSA-N 0.000 description 1
- 230000007017 scission Effects 0.000 description 1
- 238000010187 selection method Methods 0.000 description 1
- 230000008313 sensitization Effects 0.000 description 1
- 238000002864 sequence alignment Methods 0.000 description 1
- 210000002966 serum Anatomy 0.000 description 1
- SQVRNKJHWKZAKO-OQPLDHBCSA-N sialic acid Chemical compound CC(=O)N[C@@H]1[C@@H](O)C[C@@](O)(C(O)=O)OC1[C@H](O)[C@H](O)CO SQVRNKJHWKZAKO-OQPLDHBCSA-N 0.000 description 1
- 125000003808 silyl group Chemical group [H][Si]([H])([H])[*] 0.000 description 1
- JUJBNYBVVQSIOU-UHFFFAOYSA-M sodium;4-[2-(4-iodophenyl)-3-(4-nitrophenyl)tetrazol-2-ium-5-yl]benzene-1,3-disulfonate Chemical compound [Na+].C1=CC([N+](=O)[O-])=CC=C1N1[N+](C=2C=CC(I)=CC=2)=NC(C=2C(=CC(=CC=2)S([O-])(=O)=O)S([O-])(=O)=O)=N1 JUJBNYBVVQSIOU-UHFFFAOYSA-M 0.000 description 1
- 206010041823 squamous cell carcinoma Diseases 0.000 description 1
- 239000003381 stabilizer Substances 0.000 description 1
- 239000007858 starting material Substances 0.000 description 1
- 229960004274 stearic acid Drugs 0.000 description 1
- 239000008223 sterile water Substances 0.000 description 1
- 238000007920 subcutaneous administration Methods 0.000 description 1
- 125000001424 substituent group Chemical group 0.000 description 1
- 238000006467 substitution reaction Methods 0.000 description 1
- 239000001384 succinic acid Substances 0.000 description 1
- 150000003900 succinic acid esters Chemical class 0.000 description 1
- 125000000472 sulfonyl group Chemical group *S(*)(=O)=O 0.000 description 1
- 239000000375 suspending agent Substances 0.000 description 1
- 239000000725 suspension Substances 0.000 description 1
- 239000003765 sweetening agent Substances 0.000 description 1
- 208000024891 symptom Diseases 0.000 description 1
- 239000006188 syrup Substances 0.000 description 1
- 235000020357 syrup Nutrition 0.000 description 1
- 239000003826 tablet Substances 0.000 description 1
- 201000003120 testicular cancer Diseases 0.000 description 1
- 239000002562 thickening agent Substances 0.000 description 1
- 150000003573 thiols Chemical class 0.000 description 1
- 229940113082 thymine Drugs 0.000 description 1
- COKMIXFXJJXBQG-NRFANRHFSA-N tirofiban Chemical compound C1=CC(C[C@H](NS(=O)(=O)CCCC)C(O)=O)=CC=C1OCCCCC1CCNCC1 COKMIXFXJJXBQG-NRFANRHFSA-N 0.000 description 1
- 229960003425 tirofiban Drugs 0.000 description 1
- 229960000984 tocofersolan Drugs 0.000 description 1
- 235000019149 tocopherols Nutrition 0.000 description 1
- 229930003802 tocotrienol Natural products 0.000 description 1
- 239000011731 tocotrienol Substances 0.000 description 1
- 235000019148 tocotrienols Nutrition 0.000 description 1
- 229940068778 tocotrienols Drugs 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
- 208000022810 undifferentiated (embryonal) sarcoma Diseases 0.000 description 1
- 235000021122 unsaturated fatty acids Nutrition 0.000 description 1
- 150000004670 unsaturated fatty acids Chemical class 0.000 description 1
- 201000005112 urinary bladder cancer Diseases 0.000 description 1
- 229960003726 vasopressin Drugs 0.000 description 1
- 235000015112 vegetable and seed oil Nutrition 0.000 description 1
- 239000008158 vegetable oil Substances 0.000 description 1
- 239000003981 vehicle Substances 0.000 description 1
- 108700026220 vif Genes Proteins 0.000 description 1
- 230000004580 weight loss Effects 0.000 description 1
- 238000001262 western blot Methods 0.000 description 1
- RZFHLOLGZPDCHJ-XZXLULOTSA-N α-Tocotrienol Chemical compound OC1=C(C)C(C)=C2O[C@@](CC/C=C(C)/CC/C=C(C)/CCC=C(C)C)(C)CCC2=C1C RZFHLOLGZPDCHJ-XZXLULOTSA-N 0.000 description 1
- 235000004835 α-tocopherol Nutrition 0.000 description 1
- 239000002076 α-tocopherol Substances 0.000 description 1
- 235000019145 α-tocotrienol Nutrition 0.000 description 1
- 239000011730 α-tocotrienol Substances 0.000 description 1
- 235000007680 β-tocopherol Nutrition 0.000 description 1
- 239000011590 β-tocopherol Substances 0.000 description 1
- 235000019151 β-tocotrienol Nutrition 0.000 description 1
- 239000011723 β-tocotrienol Substances 0.000 description 1
- FGYKUFVNYVMTAM-WAZJVIJMSA-N β-tocotrienol Chemical compound OC1=CC(C)=C2O[C@@](CC/C=C(C)/CC/C=C(C)/CCC=C(C)C)(C)CCC2=C1C FGYKUFVNYVMTAM-WAZJVIJMSA-N 0.000 description 1
- 239000002478 γ-tocopherol Substances 0.000 description 1
- QUEDXNHFTDJVIY-DQCZWYHMSA-N γ-tocopherol Chemical compound OC1=C(C)C(C)=C2O[C@@](CCC[C@H](C)CCC[C@H](C)CCCC(C)C)(C)CCC2=C1 QUEDXNHFTDJVIY-DQCZWYHMSA-N 0.000 description 1
- QUEDXNHFTDJVIY-UHFFFAOYSA-N γ-tocopherol Chemical class OC1=C(C)C(C)=C2OC(CCCC(C)CCCC(C)CCCC(C)C)(C)CCC2=C1 QUEDXNHFTDJVIY-UHFFFAOYSA-N 0.000 description 1
- 235000019150 γ-tocotrienol Nutrition 0.000 description 1
- 239000011722 γ-tocotrienol Substances 0.000 description 1
- OTXNTMVVOOBZCV-WAZJVIJMSA-N γ-tocotrienol Chemical compound OC1=C(C)C(C)=C2O[C@@](CC/C=C(C)/CC/C=C(C)/CCC=C(C)C)(C)CCC2=C1 OTXNTMVVOOBZCV-WAZJVIJMSA-N 0.000 description 1
- 239000002446 δ-tocopherol Substances 0.000 description 1
- 235000019144 δ-tocotrienol Nutrition 0.000 description 1
- 239000011729 δ-tocotrienol Substances 0.000 description 1
- ODADKLYLWWCHNB-LDYBVBFYSA-N δ-tocotrienol Chemical compound OC1=CC(C)=C2O[C@@](CC/C=C(C)/CC/C=C(C)/CCC=C(C)C)(C)CCC2=C1 ODADKLYLWWCHNB-LDYBVBFYSA-N 0.000 description 1
Images










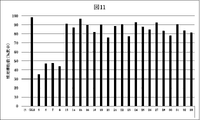























Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/113—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K31/00—Medicinal preparations containing organic active ingredients
- A61K31/70—Carbohydrates; Sugars; Derivatives thereof
- A61K31/7088—Compounds having three or more nucleosides or nucleotides
- A61K31/7125—Nucleic acids or oligonucleotides having modified internucleoside linkage, i.e. other than 3'-5' phosphodiesters
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K48/00—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Engineering & Computer Science (AREA)
- Genetics & Genomics (AREA)
- Molecular Biology (AREA)
- General Health & Medical Sciences (AREA)
- Biotechnology (AREA)
- Biomedical Technology (AREA)
- Public Health (AREA)
- General Engineering & Computer Science (AREA)
- Epidemiology (AREA)
- Pharmacology & Pharmacy (AREA)
- Veterinary Medicine (AREA)
- Biochemistry (AREA)
- Medicinal Chemistry (AREA)
- Organic Chemistry (AREA)
- Zoology (AREA)
- Animal Behavior & Ethology (AREA)
- Wood Science & Technology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Microbiology (AREA)
- Plant Pathology (AREA)
- Biophysics (AREA)
- Physics & Mathematics (AREA)
- Pharmaceuticals Containing Other Organic And Inorganic Compounds (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
Description
本発明は、アンチセンス効果によって標的遺伝子の発現を阻害又は制御する活性を有するアンチセンス核酸の副作用を減じる構造に関し、より詳しくは、核酸間のホスホロチオエート結合を至適に用いることで、アンチセンス効果の維持と副作用低減の両立を可能としたアンチセンス核酸に関する。 The present invention relates to structures that reduce the side effects of antisense nucleic acids that have the activity of inhibiting or regulating the expression of target genes through antisense effects. It relates to an antisense nucleic acid capable of maintaining both the maintenance of and the reduction of side effects.
近年、オリゴヌクレオチドは、核酸医薬と称される医薬品としての開発が進められており、特に標的遺伝子の選択性の高さの観点から、アンチセンス法を利用した核酸医薬の開発が精力的に進められている。アンチセンス法は、標的遺伝子のmRNA(センス鎖)の部分配列に相補的なオリゴヌクレオチド(アンチセンス核酸(ASO))を細胞内に導入することにより、標的遺伝子がコードするタンパク質の発現を選択的に阻害又は制御する方法である。 In recent years, oligonucleotides have been developed as medicines called nucleic acid medicines, and especially from the viewpoint of high selectivity of target genes, the development of nucleic acid medicines using the antisense method is vigorously progressing. It is The antisense method selectively inhibits the expression of a protein encoded by a target gene by introducing into cells an oligonucleotide (antisense nucleic acid (ASO)) complementary to a partial sequence of the mRNA (sense strand) of the target gene. is a method of inhibiting or controlling
ASOとして臨床試験が実施されているパイプラインの大半を占めているのが、PS型ASOである。PS型ASOは、天然の核酸間結合であるホスホジエステル結合(図1.A)のリン酸基の酸素原子の一つを硫黄原子に置換しホスホロチオエート化(PS化)したものである(図1.B)。PS化は、ヌクレアーゼ耐性(非特許文献1)、細胞内への取り込み(非特許文献2)等の点で向上が見られるが、肝毒性等の様々な副作用の原因となっていることが知られている(非特許文献3)。 PS-type ASOs account for the majority of ASOs in clinical trials in the pipeline. PS-type ASO is obtained by substituting one of the oxygen atoms of the phosphate group of the phosphodiester bond (Fig. 1.A), which is a natural internucleic acid bond, with a sulfur atom and phosphorothioate (PS) (Fig. 1 .B). PS conversion is seen to improve nuclease resistance (Non-Patent Document 1), uptake into cells (Non-Patent Document 2), etc., but it is known to cause various side effects such as hepatotoxicity. (Non-Patent Document 3).
PS型ASOの代表例の一つとして、第二世代の核酸構造と呼ばれるGapmer構造を持つ抗コレステロール血症治療薬としてIonis Pharmaceuticals社により開発されたmipomersenが挙げられる。2013年に世界初の全身投与型核酸医薬品としてホモ接合性家族性高コレステロール血症を対象に米国において承認されたが、PS型ASOの持つ肝毒性等の様々な副作用が認められた(非特許文献4)。また、欧州においては副作用を理由に承認に至っていない(非特許文献5)。 One representative example of PS-type ASO is mipomersen, which was developed by Ionis Pharmaceuticals as an anticholesterolemia drug having a gapmer structure called a second-generation nucleic acid structure. In 2013, it was approved in the United States as the world's first systemically administered nucleic acid drug for homozygous familial hypercholesterolemia, but various side effects such as hepatotoxicity of PS type ASO were observed (non-patent Reference 4). In addition, it has not been approved in Europe due to side effects (Non-Patent Document 5).
本発明の目的は、副作用を減じたアンチセンス核酸(ASO)を提供することである。 It is an object of the present invention to provide antisense nucleic acids (ASO) with reduced side effects.
本発明のさらなる目的は、ASOの副作用の原因とされるPS化修飾を至適に用いることで、ASOのアンチセンス効果を維持したまま副作用を低減したASOを提供することである。 A further object of the present invention is to provide ASO with reduced side effects while maintaining the antisense effect of ASO by optimally using the PS modification that is considered to be the cause of the side effects of ASO.
本発明のさらに別の目的は、上記ASOと、それに対して少なくとも一部が相補的なポリヌクレオチドとを含む二本鎖核酸複合体を提供することである。 Yet another object of the present invention is to provide a double-stranded nucleic acid complex comprising the ASO and a polynucleotide at least partially complementary thereto.
本発明の他の目的は、以下の記載から明らかとなろう。 Other objects of the present invention will become clear from the description below.
本発明者等は、ASOにおいて、天然の核酸間結合であるホスホジエステル結合と、リン酸基の酸素原子の一つを硫黄原子に置換したホスホロチオエート化(PS化)結合を交互に持つ構造(図1.C)をアンチセンス活性部位に用いることにより、アンチセンス効果を維持したまま副作用を低減する効果を見出した。 The present inventors have found that ASO has a structure (Fig. 1.C) was found to have the effect of reducing side effects while maintaining the antisense effect by using it in the antisense active site.
また、本発明者等は、上記構造を有するASOとそれに対して少なくとも一部が相補的なポリヌクレオチドとを含む二本鎖核酸も同様に、上記ASOに基づくアンチセンス効果を維持する一方で、その副作用は低減されることを見出した。 The present inventors also found that a double-stranded nucleic acid comprising an ASO having the above structure and a polynucleotide at least partially complementary thereto similarly maintains the antisense effect based on the above ASO, It has been found that its side effects are reduced.
従って、本発明は以下に関する:
1.以下の式(XX)で表されるPSPOユニットを含む、アンチセンス核酸Accordingly, the present invention relates to:
1. An antisense nucleic acid comprising a PSPO unit represented by the following formula (XX)

[式中、
Aは、独立に、化学修飾されていてもよいヌクレオシドから選択され、
nは、2以上の整数を表す]。
2.以下の式(XX’)で表される構造を有する、上記1に記載のアンチセンス核酸[In the formula,
A is independently selected from optionally chemically modified nucleosides,
n represents an integer of 2 or more].
2. 1. The antisense nucleic acid according to 1 above, which has a structure represented by the following formula (XX'):

[式中、
Aは、独立に、化学修飾されていてもよいヌクレオシドから選択され、
nは、2以上の整数を表し、
Yは、上記PSPOユニットの5’側に位置し、かつアンチセンス核酸の5’末端に位置する構成単位を含む、1つまたは複数の化学修飾ヌクレオチドを含む5’ウィング領域;式(XX’-a)もしくは式(XX’-b)[In the formula,
A is independently selected from optionally chemically modified nucleosides,
n represents an integer of 2 or more,
Y is a 5′ wing region containing one or more chemically modified nucleotides, comprising a building block located 5′ to the PSPO unit and located at the 5′ end of the antisense nucleic acid; formula (XX′- a) or formula (XX'-b)

で表される部分;またはY-PSPOユニット-NL-(ここで、NLはヌクレオチドリンカーを表す)であり、そして、
Zは、上記PSPOユニットの3’側に位置し、かつアンチセンス核酸の3’末端に位置する構成単位を含む、1つまたは複数の化学修飾ヌクレオチドを含む3’ウィング領域;化学修飾されていてもよいヌクレオシド;式(XX’-c)もしくは式(XX’-d)or Y-PSPO unit -NL- (where NL represents a nucleotide linker), and
Z is a 3' wing region containing one or more chemically modified nucleotides, comprising a building block located 3' to the PSPO unit and located at the 3' end of the antisense nucleic acid; good nucleoside; formula (XX'-c) or formula (XX'-d)

で表される部分;または-NL-PSPOユニット-Z(ここで、NLはヌクレオチドリンカーを表す)である]。
3.少なくとも4つの連続した化学修飾されていてもよいヌクレオチドを構成単位として含み、核酸間結合としてホスホジエステル結合とホスホロチオエート化結合を交互に有する1つまたは複数のモチーフを含むアンチセンス核酸であって、
上記モチーフが以下の式(I)または(II)で表される、上記1に記載のアンチセンス核酸。or -NL-PSPO unit-Z, where NL represents a nucleotide linker].
3. An antisense nucleic acid comprising at least four consecutive nucleotides that may be chemically modified as constituent units and comprising one or more motifs having alternating phosphodiester bonds and phosphorothioate bonds as internucleic acid bonds,
2. The antisense nucleic acid according to 1 above, wherein the motif is represented by the following formula (I) or (II).

[式中、
A1~Aiは、それぞれ互いに独立に、化学修飾されていてもよいヌクレオシドから選択され、
Rは、独立に、式(I)が核酸間結合としてホスホジエステル結合とホスホロチオエート化結合を交互に有するように、S-またはO-から選択され、
ここで、部分構造(I-a)[In the formula,
A 1 to A i are each independently selected from optionally chemically modified nucleosides,
R is independently selected from S - or O - such that formula (I) has alternating phosphodiester and phosphorothioated linkages as internucleic acid linkages;
Here, partial structure (Ia)

は、存在していても、存在していなくてもよく、
当該部分構造(I-a)が存在する場合には、i=6~100の整数であり、そして
当該部分構造(I-a)が存在しない場合には、i=5である]、
または、may or may not exist,
i = an integer of 6 to 100 when the partial structure (Ia) is present, and i = 5 when the partial structure (Ia) is not present],
or,

[式中、
A1~AiおよびRは、式(I)に関して定義されるとおりであり、
ここで、部分構造(II-a)[In the formula,
A 1 -A i and R are as defined with respect to Formula (I);
Here, partial structure (II-a)

は、存在していても、存在していなくてもよく、
当該部分構造(II-a)が存在する場合には、i=6~100の整数であり、そして 当該部分構造(II-a)が存在しない場合には、i=5である]。
4.A1~Aiのうちの連続した少なくとも4つが、化学修飾されていてもよいデオキシリボヌクレオシドである、上記3に記載のアンチセンス核酸。
5.(a)上記モチーフの5’側に位置し、かつアンチセンス核酸の5’末端に位置する構成単位を含む、1つまたは複数の化学修飾ヌクレオチドを含む5’ウィング領域、および/または、
(b)上記モチーフの3’側に位置し、かつアンチセンス核酸の3’末端に位置する構成単位を含む、1つまたは複数の化学修飾ヌクレオチドを含む3’ウィング領域、
および任意選択的に、
(c)上記5’ウィング領域と上記モチーフの間、上記モチーフと上記3’ウィング領域の間および/または上記モチーフ間に介在し、1~20塩基の長さを有する少なくとも1つのヌクレオチドリンカー、
をさらに含み、
上記5’ウィング領域および3’ウィング領域は、それぞれ互いに独立に、1~10塩基の長さを有する、
上記4に記載のアンチセンス核酸。
6.上記デオキシリボヌクレオシドが化学修飾されていない、上記4または5のいずれか1つに記載のアンチセンス核酸。
7.上記5’ウィング領域および上記3’ウィング領域を含み、
上記5’ウィング領域が、式(III)may or may not exist,
i=an integer of 6 to 100 when the partial structure (II-a) is present, and i=5 when the partial structure (II-a) is not present].
4. 3. The antisense nucleic acid according to 3 above, wherein at least 4 consecutive ones of A 1 to A i are optionally chemically modified deoxyribonucleosides.
5. (a) a 5' wing region comprising one or more chemically modified nucleotides located 5' to the motif and comprising building blocks located at the 5' end of the antisense nucleic acid, and/or
(b) a 3' wing region comprising one or more chemically modified nucleotides located 3' to the motif and comprising building blocks located at the 3' end of the antisense nucleic acid;
and optionally,
(c) at least one nucleotide linker interposed between said 5' wing region and said motif, between said motif and said 3' wing region and/or between said motif and having a length of 1-20 bases;
further comprising
the 5′ wing region and the 3′ wing region each independently have a length of 1 to 10 bases;
4. The antisense nucleic acid according to 4 above.
6. 6. The antisense nucleic acid of any one of 4 or 5 above, wherein said deoxyribonucleoside is not chemically modified.
7. comprising said 5′ wing region and said 3′ wing region;
The 5′ wing region is represented by formula (III)

[式中、
Xは、独立して化学修飾ヌクレオシドであり、
cは、1~9の整数を表す]
で表され、
上記3’ウィング領域が、式(IV)[In the formula,
X is independently a chemically modified nucleoside;
c represents an integer of 1 to 9]
is represented by
The 3′ wing region is represented by formula (IV)

[式中、
Xは、独立して化学修飾ヌクレオシドであり、
dは、1~9の整数を表す]
で表されるか;
あるいは、
上記5’ウィング領域が、式(III’)または式(III’’):[In the formula,
X is independently a chemically modified nucleoside;
d represents an integer of 1 to 9]
is represented by;
or,
The 5′ wing region is represented by formula (III′) or formula (III″):

[式中、
Xは、独立して化学修飾ヌクレオシドであり、
c’は、0~4の整数を表す]、
または[In the formula,
X is independently a chemically modified nucleoside;
c' represents an integer of 0 to 4],
or

[式中、
Xは、独立して化学修飾ヌクレオシドであり、
c’は、0~4の整数を表す]
で表され、
上記3’ウィング領域が、式(IV’)または式(IV’’):[In the formula,
X is independently a chemically modified nucleoside;
c' represents an integer of 0 to 4]
is represented by
wherein the 3' wing region has formula (IV') or formula (IV''):

[式中、
Xは、独立して化学修飾ヌクレオシドであり、
d’は、0~4の整数を表す]
または[In the formula,
X is independently a chemically modified nucleoside;
d' represents an integer of 0 to 4]
or

[式中、
Xは、独立して化学修飾ヌクレオシドであり、
d’は、0~4の整数を表す]
で表される、
上記5または6に記載のアンチセンス核酸。
8.Xが独立して、核酸類似体である、上記7に記載のアンチセンス核酸。
9.核酸類似体が、架橋化核酸である、上記8に記載のアンチセンス核酸。
10.架橋化核酸が、LNA、cEt-BNA、アミドBNA及びcMOE-BNAからなる群から選択される、上記9に記載のアンチセンス核酸。
11.長さが8~100塩基である、上記1~10のいずれか1つに記載のアンチセンス核酸。
12.式(V)[In the formula,
X is independently a chemically modified nucleoside;
d' represents an integer of 0 to 4]
represented by
The antisense nucleic acid according to 5 or 6 above.
8. 8. The antisense nucleic acid of 7 above, wherein X is independently a nucleic acid analogue.
9. 9. The antisense nucleic acid of 8 above, wherein the nucleic acid analogue is a crosslinked nucleic acid.
10. 10. The antisense nucleic acid of 9 above, wherein the cross-linked nucleic acid is selected from the group consisting of LNA, cEt-BNA, amide BNA and cMOE-BNA.
11. 11. The antisense nucleic acid of any one of 1 to 10 above, which is 8 to 100 bases in length.
12. Formula (V)

[式中、
A1~Aiは、独立して、化学修飾されていないデオキシリボヌクレオシドであり、
Rは、独立に、式(V)のA1からAiまでの間の領域が、核酸間結合としてホスホジエステル結合とホスホロチオエート化結合を交互に有するように、S-またはO-から選択され、
Xは、独立して化学修飾ヌクレオシドであり、
eは1~9の整数、gは1~9の整数を表し、
ここで、部分構造(V-a)[In the formula,
A 1 to A i are independently chemically unmodified deoxyribonucleosides;
R is independently selected from S - or O - such that the region between A 1 and A i of formula (V) has alternating phosphodiester and phosphorothioated bonds as internucleic acid linkages;
X is independently a chemically modified nucleoside;
e is an integer of 1 to 9, g is an integer of 1 to 9,
Here, the partial structure (Va)

は、存在していても、存在していなくてもよく、
当該部分構造(V-a)が存在する場合には、i=6~96の整数であり、そして
当該部分構造(V-a)が存在しない場合には、i=5である]
で表される構造、または、
式(VI)may or may not exist,
i = an integer of 6 to 96 when the partial structure (Va) exists, and i = 5 when the partial structure (Va) does not exist]
or a structure represented by
Formula (VI)

[式中、
A1~Aiは、独立して、化学修飾されていないデオキシリボヌクレオシドであり、
Rは、独立に、式(VI)のA1からAiまでの間の領域が、核酸間結合としてホスホジエステル結合とホスホロチオエート化結合を交互に有するように、S-またはO-から選択され、
Xは、独立して化学修飾ヌクレオシドであり、
eは1~9の整数、gは1~9の整数を表し、
ここで、部分構造(VI-a)[In the formula,
A 1 to A i are independently chemically unmodified deoxyribonucleosides;
R is independently selected from S - or O - such that the region between A 1 and A i of formula (VI) has alternating phosphodiester and phosphorothioated bonds as internucleic acid linkages;
X is independently a chemically modified nucleoside;
e is an integer of 1 to 9, g is an integer of 1 to 9,
Here, partial structure (VI-a)

は、存在していても、存在していなくてもよく、
当該部分構造(VI-a)が存在する場合には、i=6~96の整数であり、そして
当該部分構造(VI-a)が存在しない場合には、i=5である]
で表される構造、または、
式(V’)may or may not exist,
i = an integer of 6 to 96 when the partial structure (VI-a) exists, and i = 5 when the partial structure (VI-a) does not exist]
or a structure represented by
Formula (V')

[式中、
A1~Aiは、独立して、化学修飾されていないデオキシリボヌクレオシドであり、
Rは、独立に、式(V’)のA1からAiまでの間の領域が、核酸間結合としてホスホジエステル結合とホスホロチオエート化結合を交互に有するように、S-またはO-から選択され、
Xは、独立して化学修飾ヌクレオシドであり、
e’は0~4の整数を示し、そしてg’は0~4の整数を表し、
ここで、部分構造(V’-a)[In the formula,
A 1 to A i are independently chemically unmodified deoxyribonucleosides;
R is independently selected from S — or O — such that the region between A 1 and A i of formula (V′) has alternating phosphodiester and phosphorothioated bonds as internucleic acid linkages. ,
X is independently a chemically modified nucleoside;
e' represents an integer from 0 to 4 and g' represents an integer from 0 to 4,
Here, the partial structure (V'-a)

は常に存在し、そして
i=6~96の整数である]
で表される構造、または、
式(VI’)is always present, and i = an integer from 6 to 96]
or a structure represented by
Formula (VI')

[式中、
A1~Aiは、独立して、化学修飾されていないデオキシリボヌクレオシドであり、
Rは、独立に、式(VI’)のA1からAiまでの間の領域が、核酸間結合としてホスホジエステル結合とホスホロチオエート化結合を交互に有するように、S-またはO-から選択され、
Xは、独立して化学修飾ヌクレオシドであり、
e’は0~4の整数を示し、そしてg’は0~4の整数を表し、
ここで、部分構造(VI’-a)[In the formula,
A 1 to A i are independently chemically unmodified deoxyribonucleosides;
R is independently selected from S — or O — such that the region between A 1 and A i of formula (VI′) has alternating phosphodiester and phosphorothioated bonds as internucleic acid linkages. ,
X is independently a chemically modified nucleoside;
e' represents an integer from 0 to 4 and g' represents an integer from 0 to 4,
Here, the partial structure (VI'-a)

は常に存在し、そして
i=6~96の整数である]
で表される構造を有する、上記3~11のいずれか1つに記載のアンチセンス核酸。
13.上記モチーフが、式(VII)is always present, and i = an integer from 6 to 96]
12. The antisense nucleic acid according to any one of 3 to 11 above, which has a structure represented by
13. The motif is represented by formula (VII)

[式中、Xは、独立して化学修飾ヌクレオシドであり、
Qは、S-またはO-であり、そして
fは、1~10の整数である]
で表される1つまたは複数の構造により、1か所または複数か所で中断されている、上記3~12のいずれか1つに記載のアンチセンス核酸。
14.A1~Aiが、それぞれ互いに独立に、化学修飾ヌクレオシドから選択される、上記3に記載のアンチセンス核酸。
15.上記化学修飾ヌクレオシドが核酸類似体である、上記14に記載のアンチセンス核酸。
16.式(VIII)[wherein X is independently a chemically modified nucleoside;
Q is S - or O - , and f is an integer from 1 to 10]
13. The antisense nucleic acid according to any one of 3 to 12 above, which is interrupted at one or more positions by one or more structures represented by:
14. 4. The antisense nucleic acid of 3 above, wherein A 1 to A i are each independently selected from chemically modified nucleosides.
15. 15. The antisense nucleic acid of 14 above, wherein said chemically modified nucleoside is a nucleic acid analogue.
16. Formula (VIII)

[式中、
XおよびX1~Xiは、独立して核酸類似体であり、
Rは、独立に、式(VIII)のX1からXiまでの間の領域が、核酸間結合としてホスホジエステル結合とホスホロチオエート化結合を交互に有するように、S-またはO-から選択され、
eは1~9の整数、gは1~9の整数を表し、
ここで、部分構造(VIII-a)[In the formula,
X and X 1 -X i are independently nucleic acid analogues;
R is independently selected from S - or O - such that the region between X 1 and X i of formula (VIII) has alternating phosphodiester and phosphorothioated bonds as internucleic acid linkages;
e is an integer of 1 to 9, g is an integer of 1 to 9,
Here, partial structure (VIII-a)

は、存在していても、存在していなくてもよく、
当該部分構造(VIII-a)が存在する場合には、i=6~96の整数であり、そして
当該部分構造(VIII-a)が存在しない場合には、i=5である]
で表される構造、または、
式(IX)may or may not exist,
i = an integer of 6 to 96 when the partial structure (VIII-a) is present, and i = 5 when the partial structure (VIII-a) is not present]
or a structure represented by
Formula (IX)

[式中、
XおよびX1~Xiは、独立して核酸類似体であり、
Rは、独立に、式(IX)のX1からXiまでの間の領域が、核酸間結合としてホスホジエステル結合とホスホロチオエート化結合を交互に有するように、S-またはO-から選択され、
eは1~9の整数、gは1~9の整数を表し、
ここで、部分構造(IX-a)[In the formula,
X and X 1 -X i are independently nucleic acid analogues;
R is independently selected from S - or O - such that the region between X 1 and X i of formula (IX) has alternating phosphodiester and phosphorothioated bonds as internucleic acid linkages;
e is an integer of 1 to 9, g is an integer of 1 to 9,
Here, partial structure (IX-a)

は、存在していても、存在していなくてもよく、
当該部分構造(IX-a)が存在する場合には、i=6~96の整数であり、そして
当該部分構造(IX-a)が存在しない場合には、i=5である]
で表される構造、または、
式(VIII’)may or may not exist,
i = an integer of 6 to 96 when the partial structure (IX-a) exists, and i = 5 when the partial structure (IX-a) does not exist]
or a structure represented by
Formula (VIII')

[式中、
XおよびX1~Xiは、独立して核酸類似体であり、
Rは、独立に、式(VIII’)のX1からXiまでの間の領域が、核酸間結合としてホスホジエステル結合とホスホロチオエート化結合を交互に有するように、S-またはO-から選択され、
e’は0~4の整数を示し、そしてg’は0~4の整数を表し、
ここで、部分構造(VIII’-a)[In the formula,
X and X 1 -X i are independently nucleic acid analogues;
R is independently selected from S — or O — such that the region between X 1 and X i of formula (VIII′) has alternating phosphodiester and phosphorothioated bonds as internucleic acid linkages. ,
e' represents an integer from 0 to 4 and g' represents an integer from 0 to 4,
Here, the partial structure (VIII'-a)

は常に存在し、そして
i=6~96の整数である]
で表される構造、または、
式(IX’)is always present, and i = an integer from 6 to 96]
or a structure represented by
Formula (IX')

[式中、
XおよびX1~Xiは、独立して核酸類似体であり、
Rは、独立に、式(IX’)のX1からXiまでの間の領域が、核酸間結合としてホスホジエステル結合とホスホロチオエート化結合を交互に有するように、S-またはO-から選択され、
e’は0~4の整数を示し、そしてg’は0~4の整数を表し、
ここで、部分構造(IX’-a)[In the formula,
X and X 1 -X i are independently nucleic acid analogues;
R is independently selected from S — or O — such that the region between X 1 and X i of formula (IX′) has alternating phosphodiester and phosphorothioated bonds as internucleic acid linkages. ,
e' represents an integer from 0 to 4 and g' represents an integer from 0 to 4,
Here, partial structure (IX'-a)

は常に存在し、そして
i=6~96の整数である]
で表される構造を有する、上記3、14および15のいずれか1つに記載のアンチセンス核酸。
17.(i)上記1~16のいずれか1つに記載のアンチセンス核酸、および
(ii)化学修飾されていてもよいヌクレオチドを構成単位として少なくとも含むポリヌクレオチドであって、少なくとも一部が上記(i)アンチセンス核酸に対して相補的なポリヌクレオチドを含む相補鎖、
を含む二本鎖核酸複合体。
18.(ii)相補鎖におけるポリヌクレオチドが、化学修飾されていてもよいデオキシリボヌクレオチドおよび/または化学修飾されていてもよいリボヌクレオチドを構成単位として少なくとも含む、上記17に記載の二本鎖核酸複合体。
19.(ii)相補鎖におけるポリヌクレオチドが、化学修飾されていてもよいデオキシリボヌクレオチドのみを構成単位として含む、上記18に記載の二本鎖核酸複合体。
20.(ii)相補鎖におけるポリヌクレオチドが、化学修飾されていないデオキシリボヌクレオチドのみを構成単位として含む、上記19に記載の二本鎖核酸複合体。
21.(ii)相補鎖におけるポリヌクレオチドが、化学修飾されていないリボヌクレオチドのみを構成単位として含む、上記18に記載の二本鎖核酸複合体。
22.(ii)相補鎖におけるポリヌクレオチドが、化学修飾されていてもよいデオキシリボヌクレオチドおよび化学修飾されていてもよいリボヌクレオチドのみを構成単位として含む、上記18に記載の二本鎖核酸複合体。
23.上記ポリヌクレオチドが、上記デオキシリボヌクレオチドとリボヌクレオチドを交互に含む、上記22に記載の二本鎖核酸複合体。
24.上記デオキシリボヌクレオチドおよびリボヌクレオチドが化学修飾されていない、上記22または23に記載の二本鎖核酸複合体。
25.(ii)相補鎖におけるポリヌクレオチドが少なくとも1つのバルジを含む、上記17~24のいずれか1つに記載の二本鎖核酸複合体。
26.(ii)相補鎖におけるポリヌクレオチドが、上記(i)アンチセンス核酸に対して少なくとも1つのミスマッチを含む、上記17~25のいずれか1つに記載の二本鎖核酸複合体。
27.上記(ii)相補鎖におけるポリヌクレオチドの長さが、8~100塩基である、上記17~26のいずれか1つに記載の二本鎖核酸複合体。
28.上記(i)アンチセンス核酸が、上記(ii)相補鎖におけるポリヌクレオチドと同じ長さを有する、上記17~27のいずれか1つに記載の二本鎖核酸複合体。
29.上記(i)アンチセンス核酸の長さが、上記(ii)相補鎖におけるポリヌクレオチドの長さと異なる、上記17~27のいずれか1つに記載の二本鎖核酸複合体。
30.少なくとも1つのリガンドを含む、上記17~29のいずれか1つに記載の二本鎖核酸複合体。
31.少なくとも1つのリガンドが、上記(ii)相補鎖のポリヌクレオチドの1つまたは複数の構成単位に結合している、上記30に記載の二本鎖核酸複合体。
32.上記少なくとも1つのリガンドが、タンパク質リガンド、ペプチドリガンド、アプタマーリガンド、糖鎖リガンド、脂質リガンド、低分子リガンドおよび生体分子/生体活性分子リガンドからなる群から選択される、上記30または31に記載の二本鎖核酸複合体。
33.上記少なくとも1つのリガンドが、環状アルギニン-グリシン-アスパラギン酸(RGD)配列含有ペプチド、N-アセチルガラクトサミン、コレステロール、ビタミンE(トコフェロール)、ステアリン酸、ドコサン酸、アニスアミド、葉酸、アナンダミドまたはスペルミンである、上記32に記載の二本鎖核酸複合体。
34.哺乳動物において標的遺伝子の発現を減少させるための、上記1~16のいずれか1つに記載のアンチセンス核酸。
35.標的遺伝子mRNAのいずれかの領域に相補的なアンチセンス鎖である、上記34に記載のアンチセンス核酸。
36.哺乳動物において、標的遺伝子の発現が亢進している細胞の増殖を抑制するための、上記1~16のいずれか1つに記載のアンチセンス核酸。
37.上記標的遺伝子ががん遺伝子であり、上記細胞が癌細胞である、上記36に記載のアンチセンス核酸。
38.哺乳動物において標的遺伝子の発現を減少させるための、上記17~33のいずれか1つに記載の二本鎖核酸複合体。
39.上記(i)アンチセンス核酸が、標的遺伝子mRNAのいずれかの領域に相補的なアンチセンス鎖である、上記38に記載の二本鎖核酸複合体。
40.哺乳動物において、標的遺伝子の発現が亢進している細胞の増殖を抑制するための、上記17~33のいずれか1つに記載の二本鎖核酸複合体。
41.上記標的遺伝子ががん遺伝子であり、上記細胞が癌細胞である、上記40に記載の二本鎖核酸複合体。
42.上記1~16のいずれか1つに記載のアンチセンス核酸または上記17~33のいずれか1つに記載の二本鎖核酸複合体と、任意に薬理学的に許容可能な担体とを含む、医薬組成物。
43.癌を治療および/または予防するための、上記42に記載の医薬組成物。
44.上記1~16のいずれか1つに記載のアンチセンス核酸または上記17~33のいずれか1つに記載の二本鎖核酸複合体を細胞と接触させる工程を含む、細胞内の転写産物レベルを低減する方法であって、
アンチセンス核酸が該転写産物のいずれかの領域に相補的なアンチセンス鎖である、方法。
45.上記転写産物が、タンパク質をコードするmRNA転写産物である、上記44に記載の方法。
46.上記転写産物が、タンパク質をコードしない転写産物である、上記44に記載の方法。
47.哺乳動物において標的遺伝子の発現を低減させるための、上記1~16のいずれか1つに記載のアンチセンス核酸または上記17~33のいずれか1つに記載の二本鎖核酸複合体の使用。
48.哺乳動物において標的遺伝子の発現を低減させるための薬剤を製造するための、上記1~16のいずれか1つに記載のアンチセンス核酸または上記17~33のいずれか1つに記載の二本鎖核酸複合体の使用。
49.上記1~16のいずれか1つに記載のアンチセンス核酸または上記17~33のいずれか1つに記載の二本鎖核酸複合体を哺乳動物に投与する工程を含む、哺乳動物において標的遺伝子の発現レベルを低減する方法であって、
アンチセンス核酸が、標的遺伝子mRNAのいずれかの領域に相補的なアンチセンス鎖である、方法。
50.上記投与が経腸管的投与である、上記49に記載の方法。
51.上記投与が非経腸管的投与である、上記49に記載の方法。
52.上記核酸複合体の投与量が、0.001mg/kg/日~50mg/kg/日である、上記49~51のいずれか1つに記載の方法。
53.上記哺乳動物がヒトある、上記49~52のいずれか1つに記載の方法。
54.上記少なくとも1つのリガンドが、環状ペプチド、N-アセチルガラクトサミン、コレステロール、ビタミンE(トコフェロール)もしくはその類縁体、ステアリン酸、ドコサン酸、アニスアミド、葉酸もしくはその類縁体、アナンダミドまたはスペルミンである、上記32に記載の二本鎖核酸複合体。
is always present, and i = an integer from 6 to 96]
16. The antisense nucleic acid according to any one of 3, 14 and 15 above, which has a structure represented by
17. (i) the antisense nucleic acid according to any one of 1 to 16 above; ) a complementary strand comprising a polynucleotide complementary to the antisense nucleic acid;
A double-stranded nucleic acid complex comprising
18. (ii) The double-stranded nucleic acid complex according to 17 above, wherein the polynucleotide in the complementary strand comprises at least optionally chemically modified deoxyribonucleotides and/or optionally chemically modified ribonucleotides as structural units.
19. (ii) The double-stranded nucleic acid complex according to 18 above, wherein the polynucleotide in the complementary strand contains only optionally chemically modified deoxyribonucleotides as constituent units.
20. (ii) The double-stranded nucleic acid complex according to 19 above, wherein the polynucleotide in the complementary strand contains only chemically unmodified deoxyribonucleotides as constituent units.
21. (ii) The double-stranded nucleic acid complex according to 18 above, wherein the polynucleotide in the complementary strand contains only chemically unmodified ribonucleotides as constituent units.
22. (ii) The double-stranded nucleic acid complex according to 18 above, wherein the polynucleotide in the complementary strand comprises only optionally chemically modified deoxyribonucleotides and optionally chemically modified ribonucleotides as constituent units.
23. 23. The double-stranded nucleic acid complex according to 22 above, wherein the polynucleotide comprises alternating deoxyribonucleotides and ribonucleotides.
24. 24. The double-stranded nucleic acid complex according to 22 or 23 above, wherein the deoxyribonucleotides and ribonucleotides are not chemically modified.
25. (ii) The double-stranded nucleic acid complex according to any one of 17 to 24 above, wherein the polynucleotide in the complementary strand comprises at least one bulge.
26. (ii) The double-stranded nucleic acid complex according to any one of 17 to 25 above, wherein the polynucleotide in the complementary strand contains at least one mismatch to the (i) antisense nucleic acid.
27. 27. The double-stranded nucleic acid complex according to any one of 17 to 26 above, wherein the length of the polynucleotide in the (ii) complementary strand is 8 to 100 bases.
28. 28. The double-stranded nucleic acid complex according to any one of 17 to 27 above, wherein the (i) antisense nucleic acid has the same length as the polynucleotide in the (ii) complementary strand.
29. 28. The double-stranded nucleic acid complex according to any one of 17 to 27 above, wherein the length of the (i) antisense nucleic acid is different from the length of the polynucleotide in the (ii) complementary strand.
30. 30. The double-stranded nucleic acid complex according to any one of 17-29 above, comprising at least one ligand.
31. 31. The double-stranded nucleic acid complex according to 30 above, wherein at least one ligand is bound to one or more constituent units of the polynucleotide of the (ii) complementary strand.
32. 32. The two of 30 or 31 above, wherein said at least one ligand is selected from the group consisting of protein ligands, peptide ligands, aptamer ligands, carbohydrate ligands, lipid ligands, small molecule ligands and biomolecule/bioactive molecule ligands. Stranded nucleic acid complex.
33. the at least one ligand is a cyclic arginine-glycine-aspartic acid (RGD) sequence-containing peptide, N-acetylgalactosamine, cholesterol, vitamin E (tocopherol), stearic acid, docosanoic acid, anisamide, folic acid, anandamide or spermine; 32. The double-stranded nucleic acid complex according to 32 above.
34. 17. The antisense nucleic acid of any one of 1-16 above, for decreasing expression of a target gene in a mammal.
35. 35. The antisense nucleic acid of 34 above, which is an antisense strand complementary to any region of the target gene mRNA.
36. 17. The antisense nucleic acid according to any one of 1 to 16 above, for suppressing proliferation of cells in mammals in which target gene expression is enhanced.
37. 37. The antisense nucleic acid of 36 above, wherein the target gene is an oncogene and the cell is a cancer cell.
38. 34. The double-stranded nucleic acid complex according to any one of 17-33 above, for decreasing the expression of a target gene in a mammal.
39. 39. The double-stranded nucleic acid complex according to 38 above, wherein the (i) antisense nucleic acid is an antisense strand complementary to any region of the target gene mRNA.
40. 34. The double-stranded nucleic acid complex according to any one of 17 to 33 above, which is for suppressing proliferation of cells in which target gene expression is enhanced in mammals.
41. 41. The double-stranded nucleic acid complex according to 40 above, wherein the target gene is an oncogene and the cell is a cancer cell.
42. comprising the antisense nucleic acid of any one of 1 to 16 above or the double-stranded nucleic acid complex of any one of 17 to 33 above, and optionally a pharmacologically acceptable carrier, pharmaceutical composition.
43. 43. The pharmaceutical composition according to 42 above, for treating and/or preventing cancer.
44. A step of contacting a cell with the antisense nucleic acid according to any one of 1 to 16 above or the double-stranded nucleic acid complex according to any one of 17 to 33 above, and measuring the intracellular transcript level A method of reducing
A method wherein the antisense nucleic acid is an antisense strand complementary to any region of said transcript.
45. 45. The method of 44 above, wherein said transcript is an mRNA transcript encoding a protein.
46. 45. The method of 44 above, wherein said transcript is a non-protein-encoding transcript.
47. Use of the antisense nucleic acid according to any one of 1 to 16 above or the double-stranded nucleic acid complex according to any one of 17 to 33 above for reducing the expression of a target gene in a mammal.
48. The antisense nucleic acid according to any one of 1 to 16 above or the double strand according to any one of 17 to 33 for producing a drug for reducing the expression of a target gene in a mammal Use of Nucleic Acid Complexes.
49. of a target gene in a mammal, comprising administering to the mammal the antisense nucleic acid of any one of 1 to 16 or the double-stranded nucleic acid complex of any one of 17 to 33. A method of reducing expression levels comprising:
A method wherein the antisense nucleic acid is an antisense strand complementary to any region of the target gene mRNA.
50. 50. The method of 49 above, wherein said administration is enteral administration.
51. 50. The method of 49 above, wherein said administration is parenteral administration.
52. 52. The method according to any one of 49 to 51 above, wherein the dose of said nucleic acid complex is 0.001 mg/kg/day to 50 mg/kg/day.
53. 53. The method of any one of 49-52, wherein said mammal is a human.
54. 33. 33 above, wherein said at least one ligand is a cyclic peptide, N-acetylgalactosamine, cholesterol, vitamin E (tocopherol) or analogues thereof, stearic acid, docosanoic acid, anisamide, folic acid or analogues thereof, anandamide or spermine. A double-stranded nucleic acid complex as described.
ASOにおいて、天然の核酸間結合であるホスホジエステル結合と、リン酸基の酸素原子の一つを硫黄原子に置換したホスホロチオエート化(PS化)結合を交互に持つ構造(図1.C)をアンチセンス活性部位に用いることにより、アンチセンス効果を維持したまま副作用を低減する効果を得ることが可能である。 In ASO, a structure with alternating phosphodiester bonds, which are natural internucleic acid bonds, and phosphorothioate (PS) bonds, in which one of the oxygen atoms of the phosphate group is substituted with a sulfur atom (Fig. 1.C), is called an anti- By using it in the sense active site, it is possible to obtain the effect of reducing side effects while maintaining the antisense effect.
また、上記ASOを用いることにより、副作用の低減と、標的細胞、好ましくは標的癌細胞の増殖の特異的かつ効率的な抑制を両立することが可能である。 Moreover, by using the ASO, it is possible to achieve both reduction of side effects and specific and efficient suppression of proliferation of target cells, preferably target cancer cells.
さらに、上記ASOとそれに対して少なくとも一部が相補的なポリヌクレオチドとを含む二本鎖核酸を用いることにより、上記ASOに基づくアンチセンス効果を維持したまま副作用を低減する効果を得ることが可能である。 Furthermore, by using a double-stranded nucleic acid containing the ASO and a polynucleotide at least partially complementary thereto, it is possible to obtain the effect of reducing side effects while maintaining the antisense effect based on the ASO. is.
上述のように、本発明のアンチセンス核酸は、それを構成するポリヌクレオチドのバックボーンの少なくとも一部に、天然の核酸間結合であるホスホジエステル結合(PO型結合)と、リン酸基の酸素原子の一つを硫黄原子に置換したホスホロチオエート化(PS化)結合(PS型結合)を交互に持つ構造(PS-PO構造)を用いた核酸である。このような構造を採用することにより、本発明のアンチセンス核酸は、アンチセンス効果を維持したまま副作用を低減することができる。このPS-PO構造によって、全PS型構造に比べて、アンチセンス活性部位の核酸分子、例えばDNA分子のS原子置換による脂質性が半減し、加えてPS型とPO型の結合が交互に規則的に連続する配列効果により、天然に近似したバックボーン構造効果が増大する効果を狙ったものである。このようにASOの骨格を大きく変動することによって天然の核酸と同程度の安全性(副作用の低減)を確保することができた。 As described above, the antisense nucleic acid of the present invention has a phosphodiester bond (PO-type bond), which is a natural internucleic acid bond, and an oxygen atom of a phosphate group, in at least a part of the backbone of the polynucleotide that constitutes it. It is a nucleic acid using a structure (PS-PO structure) having alternating phosphorothioated (PS) bonds (PS-type bonds) in which one of is substituted with a sulfur atom. By adopting such a structure, the antisense nucleic acid of the present invention can reduce side effects while maintaining its antisense effect. This PS-PO structure halves the lipidity due to substitution of S atoms in nucleic acid molecules, for example DNA molecules, in the antisense active site compared to the full PS-type structure, and additionally, PS-type and PO-type bonds are alternately ordered. This is intended to increase the effect of a backbone structure similar to that of nature due to the effect of a continuously continuous sequence. By greatly varying the skeleton of ASO in this way, it was possible to ensure the same degree of safety (reduction of side effects) as that of natural nucleic acids.
このPS-PO構造は、RNAバックボーンの例としては、Nucleic Acids Research, 2015, Vol.43(9), 4569-4578、 Cell, 2012, Vol.150, 883-894、 PCT/US2012/052874などに記載のものが知られているが、これらの文献における核酸の作用メカニズムはRNA干渉によるものであり、本発明のようなアンチセンス効果に基づくアンチセンス核酸ではない。また、DNAのバックボーンにPS-PO構造を持ち、その副作用を減じる効果を報告された例は無い。 This PS-PO structure is described in Nucleic Acids Research, 2015, Vol. 43(9), 4569-4578, Cell, 2012, Vol. 150, 883-894, PCT/US2012/052874, etc., the mechanism of action of nucleic acids in these documents is due to RNA interference, and antisense effects based on the antisense effect of the present invention are known. Not a sense nucleic acid. In addition, there is no reported example of the effect of having a PS-PO structure in the backbone of DNA and reducing its side effects.
ここで、「アンチセンス核酸」(本明細書では、「ASO」とも呼ぶ)とは、ポリヌクレオチドから構成される核酸であって、アンチセンス効果を有するものをいう。アンチセンス核酸は、典型的には、一本鎖構造を有する。 Here, "antisense nucleic acid" (herein also referred to as "ASO") refers to a nucleic acid composed of a polynucleotide and having an antisense effect. Antisense nucleic acids typically have a single-stranded structure.
本明細書において、「アンチセンス効果」とは、標的転写産物(RNAセンス鎖)と、例えば、その部分配列に相補的なDNA鎖、又は通常アンチセンス効果が生じるように設計された鎖等とがハイブリダイズすることによって生じる、標的遺伝子の発現又は標的転写産物レベルの抑制を意味する。ある場合においては、ハイブリダイゼーション産物により前記転写産物を被覆することによって生じ得る翻訳の阻害又はエクソンスキッピング等のスプライシング機能変換効果、及び/又は、ハイブリダイズした部分が認識されることにより生じ得る前記転写産物の分解によって生じる、前記抑制も包含し得る。 As used herein, the term "antisense effect" refers to a target transcript (RNA sense strand) and, for example, a DNA strand complementary to a partial sequence thereof, or a strand designed to normally produce an antisense effect. hybridizing to target gene expression or target transcript levels. In some cases, inhibition of translation or splicing function conversion effects such as exon skipping, which may result from covering the transcript with a hybridization product, and/or the transcription, which may result from recognition of the hybridized portion. Said inhibition caused by product degradation may also be included.
上記のように、本発明のアンチセンス核酸はポリヌクレオチドを含む。本発明の1つの実施態様において、上記アンチセンス核酸はポリヌクレオチドであり、すなわち、ポリヌクレオチドのみからなる。 As noted above, antisense nucleic acids of the invention include polynucleotides. In one embodiment of the invention, the antisense nucleic acid is a polynucleotide, ie consists exclusively of polynucleotides.
本発明の1つの実施態様において、本発明は、アンチセンス核酸であって、それを構成するポリヌクレオチドのバックボーンの少なくとも一部にPS-PO構造を持つアンチセンス核酸に関する。上記アンチセンス核酸は一本鎖であることができる。 In one embodiment of the present invention, the present invention relates to an antisense nucleic acid having a PS-PO structure in at least part of the backbone of the polynucleotide that constitutes it. The antisense nucleic acid can be single stranded.
本発明の1つの実施態様において、本発明は、以下の式(XX)で表されるPSPOユニットを含む、アンチセンス核酸に関する In one embodiment of the present invention, the present invention relates to an antisense nucleic acid comprising a PSPO unit represented by formula (XX) below

[式中、
Aは、独立に、化学修飾されていてもよいヌクレオシドから選択され、
nは、2以上の整数、好ましくは2~50、例えば5~20の整数を表す]。[In the formula,
A is independently selected from optionally chemically modified nucleosides,
n represents an integer of 2 or more, preferably an integer of 2 to 50, for example 5 to 20].
また、本発明のさらなる実施態様において、本発明は、以下の式(XX’)で表される構造を有する、アンチセンス核酸に関する In a further embodiment of the present invention, the present invention also relates to an antisense nucleic acid having a structure represented by the following formula (XX')

[式中、
Aは、独立に、化学修飾されていてもよいヌクレオシドから選択され、
nは、2以上の整数、好ましくは2~50、例えば5~20の整数を表し、
Yは、上記PSPOユニットの5’側に位置し、かつアンチセンス核酸の5’末端に位置する構成単位を含む、1つまたは複数の化学修飾ヌクレオチドを含む5’ウィング領域;式(XX’-a)もしくは式(XX’-b)[In the formula,
A is independently selected from optionally chemically modified nucleosides,
n is an integer of 2 or more, preferably an integer of 2 to 50, for example 5 to 20;
Y is a 5′ wing region containing one or more chemically modified nucleotides, comprising a building block located 5′ to the PSPO unit and located at the 5′ end of the antisense nucleic acid; formula (XX′- a) or formula (XX'-b)

で表される部分;またはY-PSPOユニット-NL-(ここで、NLはヌクレオチドリンカーを表す)であり、そして、
Zは、上記PSPOユニットの3’側に位置し、かつアンチセンス核酸の3’末端に位置する構成単位を含む、1つまたは複数の化学修飾ヌクレオチドを含む3’ウィング領域;化学修飾されていてもよいヌクレオシド;式(XX’-c)もしくは式(XX’-d)or Y-PSPO unit -NL- (where NL represents a nucleotide linker), and
Z is a 3' wing region containing one or more chemically modified nucleotides, comprising a building block located 3' to the PSPO unit and located at the 3' end of the antisense nucleic acid; good nucleoside; formula (XX'-c) or formula (XX'-d)

で表される部分;または-NL-PSPOユニット-Z(ここで、NLはヌクレオチドリンカーを表す)である]。 or -NL-PSPO unit-Z, where NL represents a nucleotide linker].
本発明の1つの実施態様において、本発明は、核酸間結合としてホスホジエステル結合とホスホロチオエート化結合を交互に有する1つまたは複数のモチーフを含む、アンチセンス核酸に関する。当該モチーフは、少なくとも4つの連続した化学修飾されていてもよいヌクレオチドを構成単位として含むことができる。 In one embodiment of the invention, the invention relates to antisense nucleic acids comprising one or more motifs having alternating phosphodiester and phosphorothioated bonds as internucleic acid linkages. The motif can include at least four consecutive nucleotides that may be chemically modified as constituent units.
上記モチーフは、以下の式(I)または(II)で表される: The above motifs are represented by formula (I) or (II) below:

[式中、
A1~Aiは、それぞれ互いに独立に、化学修飾されていてもよいヌクレオシドから選択され、
Rは、独立に、式(I)が核酸間結合としてホスホジエステル結合とホスホロチオエート化結合を交互に有するように、S-またはO-から選択され、
ここで、部分構造(I-a)[In the formula,
A 1 to A i are each independently selected from optionally chemically modified nucleosides,
R is independently selected from S - or O - such that formula (I) has alternating phosphodiester and phosphorothioated linkages as internucleic acid linkages;
Here, partial structure (Ia)

は、存在していても、存在していなくてもよく、
当該部分構造(I-a)が存在する場合には、i=6~100の整数であり、そして
当該部分構造(I-a)が存在しない場合には、i=5である]、
または、may or may not exist,
i = an integer of 6 to 100 when the partial structure (Ia) is present, and i = 5 when the partial structure (Ia) is not present],
or,

[式中、
A1~AiおよびRは、式(I)に関して定義されるとおりであり、
ここで、部分構造(II-a)[In the formula,
A 1 -A i and R are as defined with respect to Formula (I);
Here, partial structure (II-a)

は、存在していても、存在していなくてもよく、
当該部分構造(II-a)が存在する場合には、i=6~100の整数であり、そして 当該部分構造(II-a)が存在しない場合には、i=5である]。may or may not exist,
i=an integer of 6 to 100 when the partial structure (II-a) is present, and i=5 when the partial structure (II-a) is not present].
式(I)または(II)に示されるように、上記モチーフは、交互にホスホジエステル結合(以下、「PO結合」ともいう)とホスホロチオエート化結合(以下、「PS結合」ともいう)を介して結合された化学修飾されていてもよいヌクレオシドから構成される。 As shown in formula (I) or (II), the motif is alternately linked via a phosphodiester bond (hereinafter also referred to as "PO bond") and a phosphorothioate bond (hereinafter also referred to as "PS bond"). It is composed of linked nucleosides, which may be chemically modified.
上記モチーフは、PS結合とPO結合の繰り返しを少なくとも2つ有する。下記のように、部分構造(I-a)が存在せず、i=5の場合の式(I)(あるいは、部分構造(II-a)が存在せず、i=5の場合の式(II))が、上記繰り返しが2つの場合に相当する: The above motif has at least two repeats of PS and PO bonds. As shown below, the formula (I) when the partial structure (Ia) does not exist and i = 5 (or the formula when the partial structure (II-a) does not exist and i = 5 ( II)) corresponds to the two iterations above:
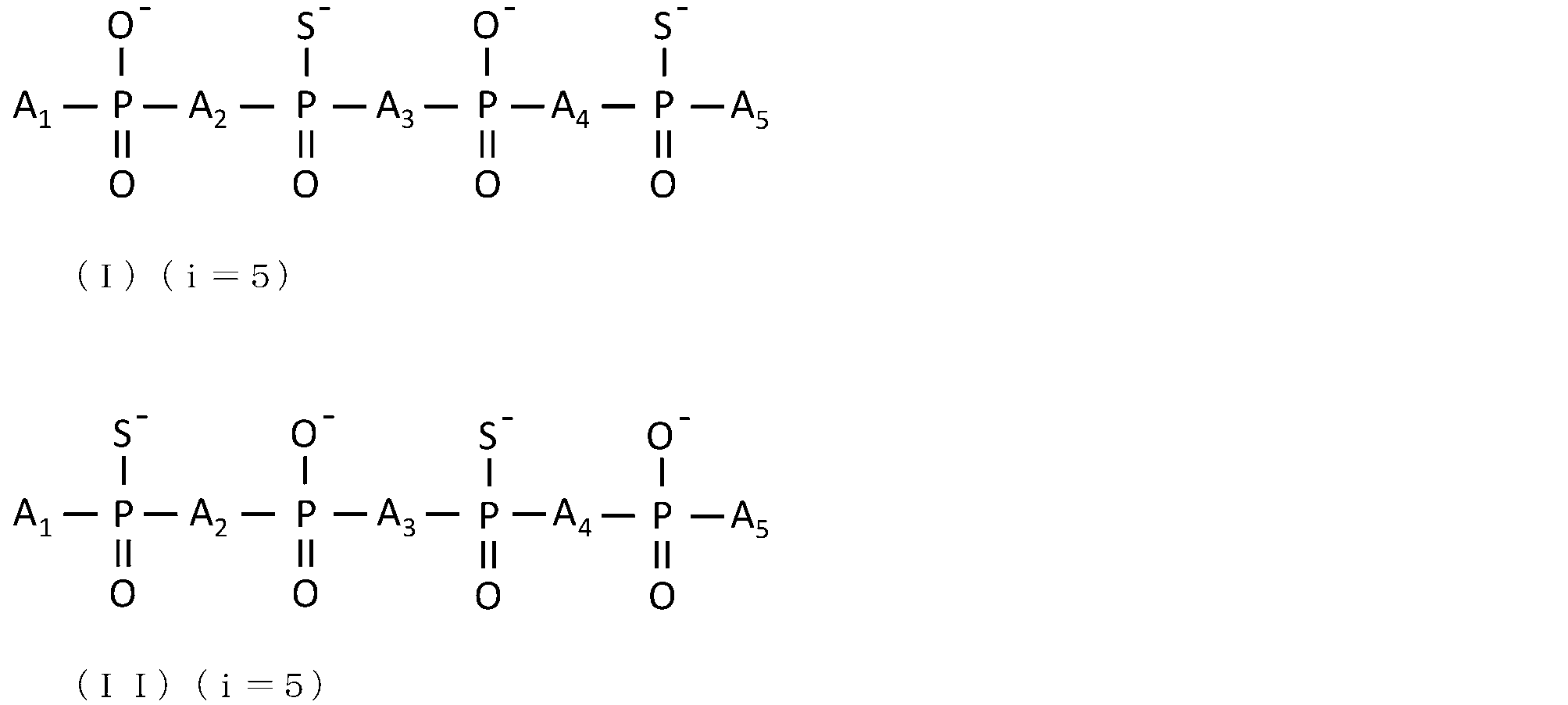
また、上記モチーフは、iの数に応じて種々の数のPS結合とPO結合の繰り返しを有する構造を取り得る。 In addition, the above motif can have a structure having various numbers of repeats of PS bonds and PO bonds depending on the number of i.
例えば、i=7の場合には、上記モチーフは下記の式(I)または(II)で表される。 For example, when i=7, the above motif is represented by formula (I) or (II) below.

i=7の場合の上記モチーフは、PS結合とPO結合の繰り返しを3つ有する。そして、それぞれ、以下の部分: The above motif when i=7 has three repeats of PS and PO bonds. and, respectively, the following parts:

が、部分構造 but the substructure

に相当する。 corresponds to
なお、上記2つの式からも明らかなように、上記モチーフにおいて、最初の結合(A1とA2との間の結合)はPS結合であっても、またはPO結合であってもよい。As is clear from the above two formulas, in the above motif, the first bond (bond between A1 and A2 ) may be a PS bond or a PO bond.
また、例えば、i=8の場合には、上記モチーフは下記の式(I)または(II)で表される: Further, for example, when i=8, the above motif is represented by the following formula (I) or (II):

この場合、上記モチーフはPS結合とPO結合の繰り返しを3つ有するが、それに加えてさらにもう1つのPO結合(式(I))またはPS結合(式(II))を有する。このように、上記モチーフは、必ずしも最初の結合としてPO結合から始まってPS結合で終わるか、あるいはPS結合で始まってPO結合で終わる必要はない。すなわち、上記モチーフは、PS結合とPO結合が交互に繰り返される構造であれば、上記のような、PS結合で始まってPS結合で終わる(またはPO結合で始まってPO結合で終わる)構造であることもできる。 In this case, the motif has three repeats of PS and PO bonds, and additionally has one more PO bond (Formula (I)) or PS bond (Formula (II)). Thus, the motif does not necessarily have to start with a PO bond and end with a PS bond as the first bond, or start with a PS bond and end with a PO bond. That is, if the motif has a structure in which PS bonds and PO bonds are alternately repeated, it has a structure starting with a PS bond and ending with a PS bond (or starting with a PO bond and ending with a PO bond) as described above. can also
上記式(I)または(II)において、Rは、iの数に応じて、上記のようにPS結合とPO結合が交互に存在するように、S-またはO-から独立に選択される。In formula (I) or (II) above, R is independently selected from
本発明の1つの好ましい実施態様において、上記式(I)または(II)におけるiは、5~50、より好ましくは8~30、さらに好ましくは10~25の整数、例えば、11、12、13、14、15、16、17、18、19、20、21、22、23、24または25である。 In one preferred embodiment of the present invention, i in formula (I) or (II) above is an integer from 5 to 50, more preferably from 8 to 30, even more preferably from 10 to 25, such as 11, 12, 13 , 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24 or 25.
本発明のアンチセンス核酸は、1つまたは複数の上記のモチーフを含む。本発明の1つの実施態様において、本発明のアンチセンス核酸は、上記モチーフを1~10個、好ましくは1、2、3、4または5個含む。本発明の1つの好ましい実施態様において、本発明のアンチセンス核酸は、上記モチーフを1個含む。 Antisense nucleic acids of the invention contain one or more of the above motifs. In one embodiment of the invention, the antisense nucleic acid of the invention comprises 1-10, preferably 1, 2, 3, 4 or 5 of the above motifs. In one preferred embodiment of the invention, the antisense nucleic acid of the invention contains one of the above motifs.
また、本発明の他の実施態様において、本発明のアンチセンス核酸は、上記モチーフのみからなる。 Also, in another embodiment of the present invention, the antisense nucleic acid of the present invention consists only of the above motif.
上記のように、上記モチーフは、少なくとも4つの連続した化学修飾されていてもよいヌクレオチドを構成単位として含むことができる。 As described above, the motif can comprise at least 4 contiguous, optionally chemically modified, nucleotides as constituent units.
また、本発明の1つの実施態様において、アンチセンス核酸は、リボヌクレオチドを含まないか、あるいは、リボヌクレオチドも化学修飾されたリボヌクレオチドも含まない。 Also, in one embodiment of the invention, the antisense nucleic acid does not contain ribonucleotides, or does not contain ribonucleotides or chemically modified ribonucleotides.
本発明の1つの実施態様において、上記の少なくとも4つの連続した化学修飾されていてもよいヌクレオチドには、リボヌクレオチドが含まれない。
本発明の1つの好ましい実施態様において、上記の少なくとも4つの連続した化学修飾されていてもよいヌクレオチドは、デオキシリボヌクレオチドである。In one embodiment of the present invention, the at least four consecutive optionally chemically modified nucleotides do not include ribonucleotides.
In one preferred embodiment of the present invention, the at least four consecutive optionally chemically modified nucleotides are deoxyribonucleotides.
「少なくとも4つの連続した化学修飾されていてもよいデオキシリボヌクレオチド」は、少なくとも4つ、5つ、6つ、7つ、8つ、9つまたは10個の連続した化学修飾されていてもよいデオキシリボヌクレオチド、例えば、4~20塩基の連続したデオキシリボヌクレオチド(化学修飾されていてもよい)を含む領域であることができ、好ましくは5~16塩基の連続したデオキシリボヌクレオチド(化学修飾されていてもよい)を含む領域であり、より好ましくは6~14塩基、例えば7~13塩基の連続したデオキシリボヌクレオチド(化学修飾されていてもよい)を含む領域である。この領域には、RNA鎖にハイブリダイズした際に、RNA鎖を切断するRNaseHによって認識されるヌクレオチド、例えば天然型デオキシリボヌクレオチドや核酸間結合のみが化学修飾されたデオキシリボヌクレオチドを用いることもでき、そのような場合に当該領域は、RNaseHの基質となる。このような領域は、「ギャップ領域」とも呼ばれる。 "At least 4 consecutive optionally chemically modified deoxyribonucleotides" means at least 4, 5, 6, 7, 8, 9 or 10 consecutive optionally chemically modified deoxyribonucleotides It can be a region containing nucleotides, for example, 4 to 20 consecutive deoxyribonucleotides (which may be chemically modified), preferably 5 to 16 consecutive deoxyribonucleotides (which may be chemically modified). ), more preferably 6 to 14 bases, for example, a region containing 7 to 13 consecutive deoxyribonucleotides (which may be chemically modified). In this region, nucleotides recognized by RNase H that cleaves RNA strands when hybridized to RNA strands, such as natural deoxyribonucleotides and deoxyribonucleotides in which only the internucleic acid bond is chemically modified, can be used. In such cases, the region becomes a substrate for RNaseH. Such regions are also called "gap regions".
本発明の1つの実施態様において、上記デオキシリボヌクレオチドは化学修飾されておらず、好ましくは、核酸間結合以外の部分は化学修飾されていない。さらに、本発明の1つの実施態様において、本発明のアンチセンス核酸は、RNaseHの基質となる領域を含み、従って、アンチセンス核酸全体としてもRNaseHの基質となることができる。この場合、上記アンチセンス核酸は、RNaseH依存的にアンチセンス効果を奏する。 In one embodiment of the present invention, the deoxyribonucleotides are not chemically modified, and preferably portions other than the internucleic acid linkages are not chemically modified. Furthermore, in one embodiment of the present invention, the antisense nucleic acid of the present invention contains a region that serves as a substrate for RNaseH, and therefore the antisense nucleic acid as a whole can also serve as a substrate for RNaseH. In this case, the antisense nucleic acid exerts an antisense effect in an RNaseH-dependent manner.
また、本発明の他の実施態様において、上記デオキシリボヌクレオチドにおいて、各ヌクレオチドは互いに独立に化学修飾されている。デオキシリボヌクレオチドに関して利用可能な修飾はこの分野において知られている。 In another embodiment of the present invention, each nucleotide in the above deoxyribonucleotide is independently chemically modified. Modifications available for deoxyribonucleotides are known in the art.
本発明の1つの実施態様において、本発明のアンチセンス核酸では、上記モチーフにおいて、A1~Aiのうちの連続した少なくとも4つが、化学修飾されていてもよいデオキシリボヌクレオシドである。この態様において、A1~Aiのうちの連続した少なくとも4つ、例えば少なくとも5つ、6つ、7つ、8つ、9つまたは10個が化学修飾されていてもよいデオキシリボヌクレオシドであることができ、例えば、A1~Aiのうちの連続した4~20個、好ましくは5~16個、より好ましくは6~14個、例えば7~13個が、化学修飾されていてもよいデオキシリボヌクレオシドであることができる。本発明のさらなる1つの実施態様において、上記モチーフでは、A1~Aiの全てが化学修飾されていてもよいデオキシリボヌクレオシドである。これらの態様において、好ましくは、上記デオキシリボヌクレオシドは化学修飾されていない。In one embodiment of the present invention, in the antisense nucleic acid of the present invention, at least four consecutive A 1 to A i in the above motif are optionally chemically modified deoxyribonucleosides. In this embodiment, at least 4, for example, at least 5, 6, 7, 8, 9 or 10 consecutive ones of A 1 to A i are optionally chemically modified deoxyribonucleosides. For example, 4 to 20, preferably 5 to 16, more preferably 6 to 14, for example 7 to 13 consecutive deoxyribonucleotides among A 1 to A i may be chemically modified. can be a nucleoside. In a further embodiment of the present invention, in the above motif, all of A 1 to A i are optionally chemically modified deoxyribonucleosides. In these embodiments, preferably the deoxyribonucleosides are not chemically modified.
本発明の1つの実施態様において、核酸間結合を介して結合されたA1~Aiのうちの連続した少なくとも4つがRNaseHの基質となる。この場合、アンチセンス核酸全体としてもRNaseHの基質となることができる。In one embodiment of the present invention, at least four contiguous A 1 to A i bound via internucleic acid bonds are substrates for RNaseH. In this case, the entire antisense nucleic acid can also serve as a substrate for RNaseH.
本明細書において、「核酸」とは、天然型核酸、非天然型核酸及び/又は核酸類似体をいうが、「核酸」はモノマーヌクレオチドを意味する場合もあり、複数のモノマーから構成されるオリゴヌクレオチドやポリヌクレオチドを意味する場合もある。「核酸鎖」という文言は、ここではオリゴヌクレオチドやポリヌクレオチドを称するためにも用いられる。核酸鎖は、その全部又は一部を、自動合成機の使用といった化学合成法によって調製してもよく、ポリメラーゼ、ライゲース又は制限酵素反応に限定されるわけではないが、酵素処理により調製してもよい。本発明の1つの実施態様において、本発明のアンチセンス核酸におけるポリヌクレオチド(および相補鎖におけるポリヌクレオチド)は、化学合成または酵素的反応によって人工的に調製されたものである。 As used herein, the term "nucleic acid" refers to natural nucleic acids, non-natural nucleic acids and/or nucleic acid analogues. It may also refer to nucleotides or polynucleotides. The term "nucleic acid strand" is also used herein to refer to oligonucleotides and polynucleotides. The nucleic acid strand may be prepared in whole or in part by chemical synthesis methods such as the use of an automatic synthesizer, and may be prepared by enzymatic treatment, although not limited to polymerase, ligase or restriction enzyme reactions. good. In one embodiment of the invention, the polynucleotides in the antisense nucleic acids of the invention (and the polynucleotides in the complementary strand) are artificially prepared by chemical synthesis or enzymatic reactions.
本明細書において、「天然型核酸」とは、ヌクレオチドを基本単位とし、リン酸が各ヌクレオチド間で糖の3’と5’位炭素の間にジエステル結合の橋をつくって結ばれ重合した自然界に存在するポリヌクレオチドをいう。通常は、アデニン、グアニン、シトシン及びウラシルのいずれかの塩基を有するリボヌクレオチドが連結したRNA及び/又はアデニン、グアニン、シトシン及びチミンのいずれかの塩基を有するデオキシリボヌクレオチドが連結したDNAが該当する。なお、本明細書では、上記の各ヌクレオチド間の結合を「核酸間結合」ともいう。 As used herein, the term "native nucleic acid" refers to a naturally occurring nucleic acid in which nucleotides are the basic unit and phosphoric acid is linked between nucleotides by forming a diester bond bridge between the 3' and 5' carbons of the sugar and polymerized. A polynucleotide present in a Generally, this includes RNA linked with ribonucleotides having any of adenine, guanine, cytosine and uracil bases and/or DNA linked with deoxyribonucleotides with any of adenine, guanine, cytosine and thymine bases. In the present specification, the binding between each nucleotide is also referred to as "nucleic acid binding".
本明細書において、「非天然型核酸」とは、非天然型ヌクレオチドを含む又はそれからなる核酸をいう。ここで「非天然型ヌクレオチド」とは、人工的に構築された又は人工的に化学修飾された自然界に存在しないヌクレオチドであって、前記天然に存在するヌクレオチドに類似の性質及び/又は構造を有するヌクレオチド、又は天然に存在するヌクレオシド若しくは塩基に類似の性質及び/又は構造を有するヌクレオシド若しくは塩基を含むヌクレオチドをいう。例えば、脱塩基ヌクレオシド、アラビノヌクレオシド、2’-デオキシウリジン、α-デオキシリボヌクレオシド、β-L-デオキシリボヌクレオシド、その他の糖修飾を有するヌクレオチドが挙げられる。さらに、置換五単糖(2’-O-メチルリボース、2’-デオキシ-2’-フルオロリボース、3’-O-メチルリボース、1’,2’-デオキシリボース)、アラビノース、置換アラビノース糖;置換六単糖及びアルファ-アノマーの糖修飾を有するヌクレオチドが含まれる。また、非天然型ヌクレオチドは、人工的に構築された塩基類似体又は人工的に化学修飾された塩基(修飾塩基)を包含するヌクレオチドも含む。「塩基類似体」には、例えば、2-オキソ(1H)-ピリジン-3-イル基、5位置換-2-オキソ(1H)-ピリジン-3-イル基、2-アミノ-6-(2-チアゾリル)プリン-9-イル基、2-アミノ-6-(2-チアゾリル)プリン-9-イル基、2-アミノ-6-(2-オキサゾリル)プリン-9-イル基等が挙げられる。「修飾塩基」には、例えば、修飾化ピリミジン(例えば、5-ヒドロキシシトシン、5-フルオロウラシル、4-チオウラシル)、修飾化プリン(例えば、6-メチルアデニン、6-チオグアノシン)及び他の複素環塩基等が挙げられる。また、メチルホスホネート型DNA/RNA、ホスホロチオエート型DNA/RNA(すなわち、チオリン酸結合を有するDNA/RNA)、ホスホルアミデート型DNA/RNA、2’-O-メチル型DNA/RNA等の化学修飾核酸や核酸類似体も含むこともできる。本明細書では、これらをまとめて「化学修飾ヌクレオチド」とも呼ぶ。 As used herein, the term "non-natural nucleic acid" refers to a nucleic acid containing or consisting of non-natural nucleotides. Here, "non-natural nucleotide" is an artificially constructed or artificially chemically modified nucleotide that does not exist in nature, and has similar properties and / or structures to the naturally occurring nucleotide A nucleotide or a nucleotide containing nucleosides or bases that have similar properties and/or structures to naturally occurring nucleosides or bases. Examples include abasic nucleosides, arabinonucleosides, 2'-deoxyuridine, α-deoxyribonucleosides, β-L-deoxyribonucleosides, and nucleotides with other sugar modifications. Furthermore, substituted pentasaccharides (2′-O-methylribose, 2′-deoxy-2′-fluororibose, 3′-O-methylribose, 1′,2′-deoxyribose), arabinose, substituted arabinose sugars; Nucleotides with substituted hexoses and alpha-anomeric sugar modifications are included. Non-natural nucleotides also include nucleotides containing artificially constructed base analogues or artificially chemically modified bases (modified bases). "Base analogs" include, for example, 2-oxo(1H)-pyridin-3-yl group, 5-substituted-2-oxo(1H)-pyridin-3-yl group, 2-amino-6-(2 -thiazolyl)purin-9-yl group, 2-amino-6-(2-thiazolyl)purin-9-yl group, 2-amino-6-(2-oxazolyl)purin-9-yl group and the like. "Modified bases" include, for example, modified pyrimidines (eg 5-hydroxycytosine, 5-fluorouracil, 4-thiouracil), modified purines (eg 6-methyladenine, 6-thioguanosine) and other heterocyclic A base etc. are mentioned. In addition, chemical modifications such as methylphosphonate-type DNA/RNA, phosphorothioate-type DNA/RNA (that is, DNA/RNA having a thiophosphate bond), phosphoramidate-type DNA/RNA, 2′-O-methyl-type DNA/RNA, etc. Nucleic acids and nucleic acid analogues can also be included. These are also collectively referred to herein as "chemically modified nucleotides".
本明細書において「核酸類似体」とは、天然型核酸に類似の構造及び/又は性質を有する人工的に構築された化合物をいう。例えば、ペプチド核酸(PNA:Peptide Nucleic Acid)、ホスフェート基を有するペプチド核酸(PHONA)、架橋化核酸(BNA/LNA:Bridged Nucleic Acid/Locked Nucleic Acid)、モルフォリノ核酸、塩基性ポリアミノ酸(Poly L-Lys、Poly L-Arg)等が挙げられる。なお、これらの核酸類似体は、上記のような化学修飾をさらに受けていてもよい。 As used herein, the term "nucleic acid analogue" refers to an artificially constructed compound having a structure and/or properties similar to those of naturally occurring nucleic acids. For example, peptide nucleic acid (PNA: Peptide Nucleic Acid), peptide nucleic acid having a phosphate group (PHONA), crosslinked nucleic acid (BNA/LNA: Bridged Nucleic Acid/Locked Nucleic Acid), morpholino nucleic acid, basic polyamino acid (Poly L- Lys, Poly L-Arg) and the like. These nucleic acid analogues may be further chemically modified as described above.
本発明の1つの実施態様において、本発明のアンチセンス核酸または二本鎖核酸複合体は、上記のような各種核酸を適宜組み合わせて含むかまたは組み合わせてなる核酸(ポリヌクレオチド)を、アンチセンス核酸および/または相補的な核酸鎖に有することができる。 In one embodiment of the present invention, the antisense nucleic acid or the double-stranded nucleic acid complex of the present invention comprises a nucleic acid (polynucleotide) containing a suitable combination of various nucleic acids as described above, or a combination of such nucleic acids (polynucleotide) as an antisense nucleic acid. and/or on complementary nucleic acid strands.
本明細書において、「ヌクレオチド」とはヌクレオシドの糖部分がリン酸とエステルをつくっている化合物を意味し、ここで「ヌクレオシド」とは、プリン塩基またはピリミジン塩基のような窒素を含む有機塩基と糖の還元基とがグリコシド結合によって結合した配糖体化合物を意味する。 As used herein, "nucleotide" means a compound in which the sugar moiety of a nucleoside forms an ester with a phosphoric acid, where "nucleoside" refers to nitrogen-containing organic bases such as purine bases or pyrimidine bases. It means a glycoside compound in which a reducing group of sugar is linked via a glycosidic bond.
また、「デオキシリボヌクレオチド」は、糖部分がD-2-デオキシリボースからなるヌクレオチドであり、「リボヌクレオチド」は、糖部分がD-リボースからなるヌクレオチドである。そして「デオキシリボヌクレオシド」は、糖部分がD-2-デオキシリボースからなるヌクレオシドであり、「リボヌクレオシド」は、糖部分がD-リボースからなるヌクレオシドである。 A "deoxyribonucleotide" is a nucleotide whose sugar moiety is D-2-deoxyribose, and a "ribonucleotide" is a nucleotide whose sugar moiety is D-ribose. A "deoxyribonucleoside" is a nucleoside whose sugar moiety is D-2-deoxyribose, and a "ribonucleoside" is a nucleoside whose sugar moiety is D-ribose.
「ポリヌクレオチド」とは、ヌクレオチドを基本単位とし、リン酸が各ヌクレオチド間で糖の3’と5’位炭素の間にジエステル結合の橋をつくって結ばれた、複数のヌクレオチドが重合した鎖状の物質を意味する。これは、いわゆるオリゴヌクレオチドも包含する。なお、本明細書では、このようなポリヌクレオチドにその構成単位として含まれるヌクレオチド(重合した状態にある)についても同様に「ヌクレオチド」と呼ぶことがある。 A “polynucleotide” is a polymerized chain of multiple nucleotides in which nucleotides are the basic unit and phosphoric acid is linked between each nucleotide by forming a diester bond bridge between the 3′ and 5′ carbons of the sugar. means a substance in the form of This also includes so-called oligonucleotides. In the present specification, nucleotides (in a polymerized state) contained as constituent units in such polynucleotides are also sometimes referred to as "nucleotides".
ここで、上記「デオキシリボヌクレオチド」は、天然に存在するデオキシリボヌクレオチドを意味する。当該デオキシリボヌクレオチドは、その塩基、糖若しくはリン酸塩結合が化学修飾されていてもよい。同様に、「リボヌクレオチド」は、天然に存在するリボヌクレオチドを意味する。当該リボヌクレオチドは、その塩基、糖若しくはリン酸塩結合が化学修飾されていてもよい。化学修飾としては例えば上述したようなものが考えられる。 Here, the above "deoxyribonucleotide" means a naturally occurring deoxyribonucleotide. The deoxyribonucleotides may be chemically modified at their base, sugar or phosphate linkages. Similarly, "ribonucleotide" means a naturally occurring ribonucleotide. The ribonucleotide may be chemically modified at its base, sugar or phosphate linkage. Examples of chemical modification include those described above.
本発明の1つの実施態様において、化学修飾ヌクレオチドは、塩基部位が修飾されていてもよい。塩基部位の修飾としては、例えば、シトシンの5-メチル化、5-フルオロ化、5-ブロモ化、5-ヨード化、N4-メチル化、チミジンの5-デメチル化、5-フルオロ化、5-ブロモ化、5-ヨード化、アデニンのN6-メチル化、8-ブロモ化、グアニンのN2-メチル化、8-ブロモ化が挙げられる。さらにまた、ある実施態様における化学修飾ヌクレオチドにおいては、リン酸ジエステル結合部位が修飾されていてもよい。リン酸ジエステル結合部位の修飾としては、例えば、ホスホロチオエート化、メチルホスホネート化、メチルチオホスホネート化、キラル-メチルホスホネート化、ホスホロジチオエート化、ホスホロアミデート化が挙げられるが、体内動態に優れているという観点から、ホスホロチオエート化(チオリン酸結合)が好ましい。また、このような塩基部位の化学修飾やリン酸ジエステル結合部位の化学修飾は同一のヌクレオチドに対して、複数種組み合わせて施されていてもよい。 In one embodiment of the present invention, chemically modified nucleotides may have modified base sites. Examples of base site modifications include cytosine 5-methylation, 5-fluorination, 5-bromination, 5-iodination, N4-methylation, thymidine 5-demethylation, 5-fluorination, 5- Bromination, 5-iodination, N6-methylation of adenine, 8-bromination, N2-methylation of guanine, 8-bromination can be mentioned. Furthermore, in chemically modified nucleotides in certain embodiments, the phosphodiester binding site may be modified. Modifications of the phosphodiester binding site include, for example, phosphorothioate, methylphosphonate, methylthiophosphonate, chiral-methylphosphonate, phosphorodithioate, and phosphoramidate, which are excellent in pharmacokinetics. phosphorothioate (thiophosphoric acid linkage) is preferred from the viewpoint of In addition, a plurality of types of such chemical modification of the base site and chemical modification of the phosphodiester binding site may be combined for the same nucleotide.
当業者であれば、ヌクレオチドの種類(例えば、デオキシリボヌクレオチド、リボヌクレオチド)に応じて、適宜、それぞれにおいて可能な化学修飾を選択して施すことが可能である。 A person skilled in the art can appropriately select and apply possible chemical modifications to each type of nucleotide (eg, deoxyribonucleotide, ribonucleotide).
上記のような化学修飾は同一のヌクレオチドに対して、複数種組み合わせて施されていてもよい。 A plurality of chemical modifications as described above may be combined for the same nucleotide.
本発明の1つの実施態様において、化学修飾ヌクレオチドは糖部位が修飾されていてもよく、例えば上記化学修飾は、2’-O-メチル化、2’-O-メトキシエチル(MOE)化、2’-O-アミノプロピル(AP)化、2’-フルオロ化からなる群から選択される。 In one embodiment of the present invention, the chemically modified nucleotide may be modified at the sugar moiety, for example, the chemical modification is 2'-O-methylation, 2'-O-methoxyethyl (MOE), 2 selected from the group consisting of '-O-aminopropyl (AP), 2'-fluorination;
また、本発明においては、ヌクレオシドも同様に化学修飾を受けていてもよい。具体的には、各ヌクレオシドは、その塩基または糖部分が、上述のような化学修飾を施されていてもよく、化学修飾は、同一のヌクレオシドに対して複数種組み合わせて施されていてもよい。上記のような「核酸類似体」も、化学修飾ヌクレオシドの一例である。核酸類似体は、上記のような化学修飾をさらに受けていてもよい。なお、本明細書では、ポリヌクレオチドにその構造単位として組み込まれたヌクレオシドも、ポリヌクレオチドの末端を構成するヌクレオシド(5’末端に-OH基を有するヌクレオシドまたは3’末端に-OH基を有するヌクレオシド)も、同様に「ヌクレオシド」と呼ぶことがある。 In addition, in the present invention, nucleosides may be similarly chemically modified. Specifically, each nucleoside may be chemically modified at its base or sugar moiety as described above, and the same nucleoside may be subjected to a combination of multiple chemical modifications. . "Nucleic acid analogues" as described above are also examples of chemically modified nucleosides. Nucleic acid analogues may be further chemically modified as described above. In the present specification, a nucleoside incorporated into a polynucleotide as its structural unit also refers to a nucleoside that constitutes the end of a polynucleotide (a nucleoside having an —OH group at the 5′ end or a nucleoside having an —OH group at the 3′ end). ) are also sometimes referred to as "nucleosides".
通常、上記のような化学修飾は、塩基対形成には影響を及ぼさず、従って、ヌクレオチド間の相補性やポリヌクレオチド間の相補性には影響を及ぼさないと考えられる。すなわち、通常、相補的な2つのヌクレオチドは、化学修飾された後も塩基対を形成する能力を維持することができ、従って依然として相補的であることができる。 Generally, chemical modifications such as those described above do not affect base pairing, and therefore are not expected to affect complementarity between nucleotides or complementarity between polynucleotides. That is, two normally complementary nucleotides can maintain the ability to form base pairs after being chemically modified, and thus can still be complementary.
しかしながら、ある場合において、化学修飾の数や位置によっては、ここで開示するアンチセンス核酸や二本鎖核酸が奏するアンチセンス効果等に影響を与えることになるかもしれない。これらの態様は、標的遺伝子の配列等によっても異なるため、一概には言えないが、当業者であれば、アンチセンス法に関する文献の記載等を参酌しながら、決定することができる。また、化学修飾後のアンチセンス核酸が有するアンチセンス効果を測定し、得られた測定値が、化学修飾前のアンチセンス核酸のそれよりも有意に低下していなければ(例えば、化学修飾後のアンチセンス核酸の測定値が化学修飾前のアンチセンス核酸の測定値の30%以上であれば)、当該化学修飾は評価することができる。アンチセンス効果の測定は、例えば、細胞等に被検核酸化合物を導入し、該被検核酸化合物が奏するアンチセンス効果によって抑制された該細胞等における標的遺伝子の発現量(mRNA量、cDNA量、タンパク質量等)を、ノザンブロッティング、定量的PCR、ウェスタンブロッティング等の公知の手法を適宜利用することによって行うことができる。あるいは、例えば、細胞に被検核酸化合物を導入し、該被検核酸化合物が奏する標的遺伝子発現抑制に起因する細胞増殖抑制を、WST(または類似の色素MTT、XTT、MTS等)をホルマザン色素へ還元する酵素活性を測定する比色定量法、BrdU取込量の測定、フローサイトメトリー等の公知の手法を用いて測定することにより行うことができる。 However, in some cases, depending on the number and position of chemical modifications, the antisense effects and the like exhibited by the antisense nucleic acids and double-stranded nucleic acids disclosed herein may be affected. Since these aspects differ depending on the sequence of the target gene, etc., they cannot be generalized, but a person skilled in the art can determine them by referring to the descriptions in the literature on the antisense method. In addition, if the antisense effect of the antisense nucleic acid after chemical modification is measured and the obtained measured value is not significantly lower than that of the antisense nucleic acid before chemical modification (for example, If the measured value of the antisense nucleic acid is 30% or more of the measured value of the antisense nucleic acid before chemical modification), the chemical modification can be evaluated. The antisense effect can be measured, for example, by introducing a test nucleic acid compound into a cell or the like, and measuring the expression level of a target gene (mRNA amount, cDNA amount, protein amount, etc.) can be carried out by appropriately using known techniques such as Northern blotting, quantitative PCR, and Western blotting. Alternatively, for example, a nucleic acid compound to be tested is introduced into a cell, and cell growth suppression caused by suppression of target gene expression performed by the nucleic acid compound to be tested is treated by adding WST (or similar dyes MTT, XTT, MTS, etc.) to a formazan dye. It can be measured using a known method such as a colorimetric method for measuring reducing enzyme activity, measurement of the amount of BrdU incorporated, flow cytometry, or the like.
上述のように、本発明のアンチセンス核酸のポリヌクレオチドは、任意選択で核酸類似体を含むことができる。本発明において使用される核酸類似体の例としては、例えばRNA誘導体が挙げられる。RNA誘導体の例としては、架橋型核酸塩基(「架橋化核酸」とも呼ぶ)、糖部化学修飾体等を挙げることができ、例えばBNA/LNA、ヘキシトール核酸(HNA)、シクロヘキセン核酸(CeNA)、グリコール核酸(GNA)、トレオース核酸(TNA)、トリシクロ-DNA(tcDNA)、2’-OMe、2’-F、2’-O-MOE、4’-O-アミノアルキル等が挙げられる。 As noted above, the polynucleotides of the antisense nucleic acids of the invention can optionally include nucleic acid analogs. Examples of nucleic acid analogues for use in the present invention include, for example, RNA derivatives. Examples of RNA derivatives include crosslinked nucleobases (also referred to as “crosslinked nucleic acids”), chemically modified sugar moieties, and the like, such as BNA/LNA, hexitol nucleic acid (HNA), cyclohexene nucleic acid (CeNA), Glycol nucleic acid (GNA), threose nucleic acid (TNA), tricyclo-DNA (tcDNA), 2'-OMe, 2'-F, 2'-O-MOE, 4'-O-aminoalkyl and the like.
本発明の1つの実施態様において、上記核酸類似体は、BNA/LNA、好ましくは下記の式(1)で表されるBNAである。 In one embodiment of the invention, the nucleic acid analogue is BNA/LNA, preferably BNA represented by formula (1) below.

[式(1)中、Baseは、置換基を有していてもよい芳香族複素環基若しくは芳香族炭化水素環基、例えば、天然型ヌクレオシドの塩基部位(プリン塩基、ピリミジン塩基)又は非天然型(化学修飾)ヌクレオシドの塩基部位を示す。なお、塩基部位の化学修飾の例は、前述の通りである。R1、R2は、同一又は異なっていてもよく、水素原子、核酸合成の水酸基の保護基、アルキル基、アルケニル基、シクロアルキル基、アリール基、アラルキル基、アシル基、スルホニル基、シリル基、リン酸基、核酸合成の保護基で保護されたリン酸基、又は、-P(R3)R4(ここで、R3及びR4は、同一又は異なっていてもよく、水酸基、核酸合成の保護基で保護された水酸基、メルカプト基、核酸合成の保護基で保護されたメルカプト基、アミノ基、炭素数1~5のアルコキシ基、炭素数1~5のアルキルチオ基、炭素数1~6のシアノアルコキシ基又は炭素数1~5のアルキル基で置換されたアミノ基を示す)を示す]。[In the formula (1), Base is an optionally substituted aromatic heterocyclic group or aromatic hydrocarbon ring group, for example, a base portion of a natural nucleoside (purine base, pyrimidine base) or a non-natural Type (chemically modified) nucleoside base sites are indicated. Examples of chemical modification of base sites are as described above. R 1 and R 2 may be the same or different and may be a hydrogen atom, a hydroxyl-protecting group for nucleic acid synthesis, an alkyl group, an alkenyl group, a cycloalkyl group, an aryl group, an aralkyl group, an acyl group, a sulfonyl group, or a silyl group. , a phosphate group, a phosphate group protected by a protecting group for nucleic acid synthesis, or —P(R 3 )R 4 (wherein R 3 and R 4 may be the same or different, hydroxyl group, nucleic acid A hydroxyl group protected with a protective group for synthesis, a mercapto group, a mercapto group protected with a protective group for nucleic acid synthesis, an amino group, an alkoxy group having 1 to 5 carbon atoms, an alkylthio group having 1 to 5 carbon atoms, and 1 to 1 carbon atoms. 6 cyanoalkoxy group or an amino group substituted with an alkyl group having 1 to 5 carbon atoms)].
なお、前記化学式において示されている化合物はヌクレオシドであるが、本明細書において、「LNA」や「BNA」には、当該ヌクレオシドにリン酸基が結合した形態(ヌクレオチド)も含まれる。すなわち、本明細書において「LNA」や「BNA」という語句を用いた場合には、ポリヌクレオチド中に、ヌクレオチドとして組み込まれているLNA/BNAも意味する。またこれは、「核酸類似体」という語句を使用する場合にもあてはまる。 The compounds shown in the above chemical formulas are nucleosides, but in the present specification, "LNA" and "BNA" also include forms (nucleotides) in which a phosphate group is bound to the nucleoside. That is, when the terms "LNA" and "BNA" are used in this specification, they also mean LNA/BNA incorporated as nucleotides into a polynucleotide. This is also the case when using the phrase "nucleic acid analogue".
また、BNAとしては、例えば、LNA(ロックド核酸(Locked Nucleic Acid(登録商標)、2’,4’-BNA)とも称される、α-L-メチレンオキシ(4’-CH2-O-2’)BNA)の他に、β-D-メチレンオキシ(4’-CH2-O-2’)BNA、ENAとも称されるエチレンオキシ(4’-(CH2)2-O-2’)BNA)、β-D-チオ(4’-CH2-S-2’)BNA、アミノオキシ(4’-CH2-O-N(R3)-2’)BNA、2’,4’-BNANCとも称されるオキシアミノ(4’-CH2-N(R3)-O-2’)BNA、2’,4’-BNACOC、3’アミノ-2’,4’-BNA、5’-メチルBNA、cEt-BNAとも称される(4’-CH(CH3)-O-2’)BNA、cMOE-BNAとも称される(4’-CH(CH2OCH3)-O-2’)BNA、AmNAとも称されるアミドBNA(4’-C(O)-N(R)-2’)BNA(R=H、Me)、当業者に知られた他のBNAが挙げられる。BNAs include, for example, α-L-methyleneoxy (4'-CH 2 -O-2 ') BNA), β-D-methyleneoxy (4'-CH 2 -O-2') BNA, ethyleneoxy (4'-(CH 2 ) 2 -O-2') also called ENA BNA), β-D-thio(4′-CH 2 -S-2′)BNA, aminooxy(4′-CH 2 -ON(R 3 )-2′)BNA, 2′,4′- Oxyamino(4′-CH 2 —N(R 3 )-O-2′)BNA, also called BNANC, 2′,4′-BNACOC, 3′amino-2′,4′-BNA, 5′- (4′-CH(CH 3 )-O-2′)BNA, also called methyl BNA, cEt-BNA, (4′-CH(CH 2 OCH 3 )-O-2′, also called cMOE-BNA ) BNA, amide BNA (4′-C(O)—N(R)-2′) BNA (R═H, Me), also called AmNA, and other BNAs known to those skilled in the art.
本発明の1つの実施態様では、核酸類似体(例えばLNA/BNA)はさらに、上述の化学修飾(または化学修飾の組み合わせ)を受けていてもよい。本発明の1つの実施態様では、核酸類似体(例えばLNA/BNA)は、ホスホロチオエート化が施されたヌクレオチドとして、上記ポリヌクレオチドに組み込まれている。 In one embodiment of the invention, the nucleic acid analogues (eg LNA/BNA) may further undergo chemical modifications (or combinations of chemical modifications) as described above. In one embodiment of the invention, the nucleic acid analogues (eg LNA/BNA) are incorporated into the polynucleotide as phosphorothioated nucleotides.
当業者であれば、ヌクレオチドの種類(例えば、デオキシリボヌクレオチド、リボヌクレオチド)や核酸類似体の種類に応じて、適宜、それぞれにおいて可能な化学修飾を選択して施すことが可能である。 Those skilled in the art can appropriately select possible chemical modifications according to the types of nucleotides (eg, deoxyribonucleotides, ribonucleotides) and nucleic acid analogs.
本発明の1つの実施態様において、本発明のアンチセンス核酸は、1つまたは複数の化学修飾ヌクレオチドを含むウィング領域を含むことができる。ウィング領域は、主に、アンチセンス核酸のヌクレアーゼ耐性と、標的となるmRNAに対する当該核酸の親和性とを高めるために、化学修飾ヌクレオチドを配置した領域である。「1つまたは複数の化学修飾ヌクレオチドを含むウィング領域」は、上記PSPOユニットの、または上記モチーフの、好ましくは前記少なくとも4つの連続した化学修飾されていてもよいデオキシリボヌクレオチドを含む領域(以下「DNAギャップ領域」とも称する)の、5’末側及び/又は3’末側に配置されるものであり、好ましくはアンチセンス核酸の5’末端および/または3’末端に配置されるものである。従って、本発明の1つの好ましい実施態様において、上記ウィング領域は、アンチセンス核酸の5’末端に位置する構成単位および/またはアンチセンス核酸の3’末端に位置する構成単位を含む。 In one embodiment of the invention, an antisense nucleic acid of the invention can comprise wing regions comprising one or more chemically modified nucleotides. The wing region is a region in which chemically modified nucleotides are arranged mainly to increase the nuclease resistance of the antisense nucleic acid and the affinity of the nucleic acid for target mRNA. A "wing region containing one or more chemically modified nucleotides" is a region of the PSPO unit or of the motif, preferably containing the at least four contiguous deoxyribonucleotides that may be chemically modified (hereinafter "DNA (also referred to as "gap region"), preferably at the 5' and/or 3' end of the antisense nucleic acid. Thus, in one preferred embodiment of the invention, the wing region comprises a building block located at the 5' end of the antisense nucleic acid and/or a building block located at the 3' end of the antisense nucleic acid.
本発明の1つの実施態様において、上記PSPOユニットの、または上記モチーフの、例えば該DNAギャップ領域の5’末端に配置された化学修飾ヌクレオチド、例えば核酸類似体を含む領域(以下「5’ウィング領域」とも称する)、ならびに、上記PSPOユニットの、または上記モチーフの、例えば該DNAギャップ領域の3’末端に配置された化学修飾ヌクレオチド、例えば核酸類似体を含む領域(以下「3’ウィング領域」とも称する)は、それぞれ独立したものであり、化学修飾ヌクレオチドを少なくとも1種含んでいればよく、さらに、かかる化学修飾ヌクレオチド以外に天然型のヌクレオチド(デオキシリボヌクレオチド又はリボヌクレオチド)も含まれていてもよい。また、5’ウィング領域及び3’ウィング領域の鎖長は独立的に、通常1~10塩基であることができ、好ましくは1~7塩基、又は2~5塩基、例えば2~4塩基である。 In one embodiment of the present invention, a region comprising a chemically modified nucleotide, such as a nucleic acid analogue, placed at the 5' end of said PSPO unit or of said motif, for example of said DNA gap region (hereinafter "5' wing region ), and a region containing chemically modified nucleotides, such as nucleic acid analogues, placed at the 3′ end of the PSPO unit or of the motif, such as the DNA gap region (hereinafter also referred to as the “3′ wing region”). ) are each independent and may contain at least one chemically modified nucleotide, and may also contain natural nucleotides (deoxyribonucleotides or ribonucleotides) in addition to such chemically modified nucleotides. . In addition, the chain length of the 5' wing region and the 3' wing region can be independently usually 1 to 10 bases, preferably 1 to 7 bases, or 2 to 5 bases, for example 2 to 4 bases. .
さらに、5’ウィング領域及び3’ウィング領域における化学修飾ヌクレオチド及び天然型のヌクレオチドの種類や数や位置については、ある実施形態におけるアンチセンス核酸が奏するアンチセンス効果等に影響を与える場合もあるため、好ましい態様は、配列等によっても変わり得る。一概には言えないが、当業者であれば、例えば、Tachasらの米国特許第8299039号明細書の記載のようなアンチセンス法に関する文献の記載を参酌しながら、好ましい態様を決定することができる。また、前記「少なくとも4つ以上の連続した化学修飾されていてもよいデオキシリボヌクレオチド」を含む領域同様に、化学修飾後、例えば核酸類似体導入後の核酸(または当該核酸を含む二本鎖核酸)が有するアンチセンス効果を測定し、得られた測定値が、これらの前の核酸(または当該核酸を含む二本鎖核酸)のそれよりも有意に低下していなければ、当該化学修飾、例えば核酸類似体は好ましい態様であると評価することができる。 Furthermore, the type, number, and position of chemically modified nucleotides and natural nucleotides in the 5' wing region and 3' wing region may affect the antisense effect of the antisense nucleic acid in certain embodiments. , preferred aspects may vary depending on the sequence and the like. Although it cannot be said unconditionally, a person skilled in the art can determine a preferred embodiment while taking into consideration the description of the antisense method literature such as the description of Tachas et al., US Pat. No. 8,299,039. . In addition, similarly to the region containing "at least four or more contiguous deoxyribonucleotides that may be chemically modified", a nucleic acid (or a double-stranded nucleic acid containing the nucleic acid) after chemical modification, for example, after introduction of a nucleic acid analogue The chemical modification, e.g., nucleic acid Analogs can be evaluated as a preferred embodiment.
なお、PS-PO構造は、従来技術のPS型アンチセンス鎖構造に比べて酵素耐性が弱くなる傾向がある。従って、PS-PO構造を有するアンチセンス核酸には、至適な酵素耐性を持たせる必要がある。本発明では、本発明において用いられるようなPS-PO構造を有するアンチセンス核酸において、中央に少なくとも4塩基以上の鎖長のDNA(好ましくは化学修飾されていないDNA)が配置され、さらにRNA(すなわち、標的転写産物)と強い結合能力を持つ修飾ヌクレオチド、好ましくは核酸類似体、例えばLNA(又は他のBNA)が両端に配置されることによって、当該アンチセンス鎖が、至適な酵素耐性を有し、その結果、PS型構造を有するアンチセンス核酸と同等の標的転写産物の発現抑制効果、標的細胞増殖の抑制効果を有することが見出された。 Note that the PS-PO structure tends to have weaker enzyme resistance than the conventional PS-type antisense strand structure. Therefore, an antisense nucleic acid having a PS-PO structure must be endowed with optimal enzyme resistance. In the present invention, in the antisense nucleic acid having a PS-PO structure as used in the present invention, DNA having a chain length of at least 4 bases (preferably chemically unmodified DNA) is arranged in the center, and RNA ( That is, the antisense strand is endowed with optimal enzyme resistance by flanking modified nucleotides, preferably nucleic acid analogues, such as LNA (or other BNA), which have strong binding capacity to target transcripts). As a result, it was found to have an effect of suppressing the expression of target transcripts and an effect of suppressing target cell growth equivalent to antisense nucleic acids having a PS structure.
よって、本発明の1つの実施態様において、本発明のアンチセンス核酸は、上記5’ウィング領域および3’ウィング領域を含む。そして、上記5’ウィング領域および3’ウィング領域はそれぞれ独立に、核酸類似体を含んでいることが望ましい。本発明の1つの実施態様において、上記5’ウィング領域および3’ウィング領域はそれぞれ、核酸類似体からなる。この場合、核酸類似体はさらに化学修飾されていてもよく、さらに化学修飾されていなくてもよい。上記5’ウィング領域および3’ウィング領域はそれぞれ、BNA/LNAを含んでいてもよく、この場合、LNA/BNAはさらに化学修飾されていてもよい。本発明の1つの実施態様において、LNA/BNAはホスホロチオエート化されている。 Thus, in one embodiment of the invention, an antisense nucleic acid of the invention comprises the 5' wing region and the 3' wing region described above. The 5' wing region and 3' wing region preferably each independently contain a nucleic acid analogue. In one embodiment of the invention, the 5' and 3' wing regions each consist of nucleic acid analogues. In this case, the nucleic acid analog may or may not be chemically modified. The 5' and 3' wing regions may each contain BNA/LNA, in which case the LNA/BNA may be further chemically modified. In one embodiment of the invention the LNA/BNA is phosphorothioated.
また、本発明の1つの実施態様において、アンチセンス核酸は、リボヌクレオチドを含まないか、あるいは、リボヌクレオチドも化学修飾されたリボヌクレオチドも含まない。 Also, in one embodiment of the invention, the antisense nucleic acid does not contain ribonucleotides, or does not contain ribonucleotides or chemically modified ribonucleotides.
本発明の1つの実施態様において、上記ウィング領域における核酸間結合は、PS型構造(すなわちPS結合が連続した構造)を有してもよく、PO型構造(すなわちPO結合が連続した構造)を有していてもよく、またはPS-PO構造を有していてもよい。上記ウィング領域の長さが短い場合、例えば4塩基以下の場合には、好ましくは、上記ウィング領域における核酸間結合は、PS型構造を有していてもよい。 In one embodiment of the present invention, the nucleic acid bond in the wing region may have a PS-type structure (that is, a structure in which PS bonds are continuous), or a PO-type structure (that is, a structure in which PO bonds are continuous). or may have a PS-PO structure. When the length of the wing region is short, for example, 4 bases or less, the internucleic acid bond in the wing region may preferably have a PS-type structure.
また、本発明の1つの実施態様において、上記5’ウィング領域は、式(III) Also, in one embodiment of the present invention, the 5' wing region has formula (III)

[式中、
Xは、独立して化学修飾ヌクレオシドであり、
cは、1~9の整数を表す]
で表される。[In the formula,
X is independently a chemically modified nucleoside;
c represents an integer of 1 to 9]
is represented by
また、本発明の1つの態様において、上記3’ウィング領域は、式(IV) Also, in one aspect of the present invention, the 3' wing region has formula (IV)

[式中、
Xは、独立して化学修飾ヌクレオシドであり、
dは、1~9の整数を表す]
で表される。[In the formula,
X is independently a chemically modified nucleoside;
d represents an integer of 1 to 9]
is represented by
ここで、式(III)または(IV)において、好ましくは、Xは核酸類似体であり、より好ましくは架橋化核酸である。本発明の1つの好ましい実施態様において、上記架橋化核酸は、LNA、cEt-BNA、アミドBNA及びcMOE-BNAからなる群から選択される。好ましくは、XはLNAである。また、cおよびdは、好ましくは、それぞれ互いに独立に、1~6の整数、すなわち、1、2、3、4、5または6を示し、最も好ましくは、cおよびdはいずれも1である。 Here, in formula (III) or (IV), preferably X is a nucleic acid analogue, more preferably a cross-linked nucleic acid. In one preferred embodiment of the invention, said cross-linking nucleic acid is selected from the group consisting of LNA, cEt-BNA, amide BNA and cMOE-BNA. Preferably X is an LNA. Also, c and d preferably each independently represent an integer from 1 to 6, i.e. 1, 2, 3, 4, 5 or 6, most preferably both c and d are 1 .
さらに、本発明の1つの実施態様において、上記5’ウィング領域は、式(III’)または式(III’’)で表される: Further, in one embodiment of the present invention, the 5' wing region is represented by Formula (III') or Formula (III''):

[式中、
Xは、独立して化学修飾ヌクレオシドであり、
c’は、0~4の整数を表す]、
または[In the formula,
X is independently a chemically modified nucleoside;
c' represents an integer of 0 to 4],
or

[式中、
Xは、独立して化学修飾ヌクレオシドであり、
c’は、0~4の整数を表す]。[In the formula,
X is independently a chemically modified nucleoside;
c′ represents an integer from 0 to 4].
また、本発明の1つの態様において、上記3’ウィング領域は、式(IV’)または式(IV’’)で表される: Also, in one embodiment of the present invention, the 3' wing region is represented by formula (IV') or formula (IV''):

[式中、
Xは、独立して化学修飾ヌクレオシドであり、
d’は、0~4の整数を表す]、
または[In the formula,
X is independently a chemically modified nucleoside;
d' represents an integer of 0 to 4],
or

[式中、
Xは、独立して化学修飾ヌクレオシドであり、
d’は、0~4の整数を表す]。[In the formula,
X is independently a chemically modified nucleoside;
d' represents an integer of 0 to 4].
ここで、式(III’)、(III’’)、(IV’)または(IV’’)において、好ましくは、Xは核酸類似体であり、より好ましくは架橋化核酸である。本発明の1つの好ましい実施態様において、上記架橋化核酸は、LNA、cEt-BNA、アミドBNA及びcMOE-BNAからなる群から選択される。好ましくは、XはLNAである。また、c’およびd’は、好ましくは、それぞれ互いに独立に、0~3の整数、すなわち、0、1、2または3を示し、最も好ましくは、c’およびd’はいずれも0である。 wherein in formula (III'), (III''), (IV') or (IV''), preferably X is a nucleic acid analogue, more preferably a cross-linked nucleic acid. In one preferred embodiment of the invention, said cross-linking nucleic acid is selected from the group consisting of LNA, cEt-BNA, amide BNA and cMOE-BNA. Preferably X is an LNA. Also, c' and d' preferably each independently represent an integer of 0 to 3, i.e., 0, 1, 2 or 3, most preferably both c' and d' are 0 .
本発明の1つの実施態様において、本発明のアンチセンス核酸は、上記5’ウィング領域と上記モチーフの間、上記モチーフと上記3’ウィング領域の間および/または上記モチーフ間に介在するヌクレオチドリンカーを含むことができる。 In one embodiment of the present invention, the antisense nucleic acid of the present invention comprises a nucleotide linker intervening between said 5′ wing region and said motif, between said motif and said 3′ wing region and/or between said motifs. can contain.
ここで、「ヌクレオチドリンカー」とは、上記5’ウィング領域と上記モチーフの間、上記モチーフと上記3’ウィング領域の間または上記モチーフ間(上記モチーフを複数有する場合)をつなぐリンカーであり、ヌクレオチド(または化学修飾ヌクレオチド)から構成される。また、「ヌクレオチドリンカー」は、上記5’ウィング領域と上記PSPOユニットの間、上記PSPOユニットと上記3’ウィング領域の間、または複数の上記PSPOユニットの間をつなぐリンカーであることもできる。上記ヌクレオチドリンカーは、好ましくは、1~20、より好ましくは1~10、さらに好ましくは1~5、特に1~3塩基の長さを有する。 Here, the "nucleotide linker" is a linker that connects between the 5' wing region and the motif, between the motif and the 3' wing region, or between the motifs (when there are multiple motifs), (or chemically modified nucleotides). A "nucleotide linker" can also be a linker that connects between the 5' wing region and the PSPO unit, between the PSPO unit and the 3' wing region, or between a plurality of the PSPO units. The nucleotide linker preferably has a length of 1-20, more preferably 1-10, more preferably 1-5, especially 1-3 bases.
本発明の1つの実施態様において、上記ヌクレオチドリンカーは、以下の式(X)または式(XI)で表される構造を有するか、式(X)または式(XI)の単位からなるホモポリマーであるか、式(X)および式(XI)の単位からなるランダム、交互、ブロックもしくはグラジエントコポリマーであるか、またはそれらの組み合わせである: In one embodiment of the present invention, the nucleotide linker has a structure represented by formula (X) or formula (XI) below, or is a homopolymer consisting of units of formula (X) or formula (XI) is a random, alternating, block or gradient copolymer consisting of units of formula (X) and formula (XI), or a combination thereof:

[式中、Aは、独立して、化学修飾されていてもよいヌクレオシド、例えば化学修飾されていないデオキシリボヌクレオシドもしくはリボヌクレオシドから選択される]。この態様において、上記ホモポリマー、コポリマーまたはそれらの組み合わせは、1~20個、好ましくは1~10個、より好ましくは1~5個、例えば1、2、3、4または5個の上記単位から構成されることができる。 [wherein A is independently selected from optionally chemically modified nucleosides, such as chemically unmodified deoxyribonucleosides or ribonucleosides]. In this embodiment, said homopolymer, copolymer or combination thereof comprises from 1 to 20, preferably from 1 to 10, more preferably from 1 to 5, such as 1, 2, 3, 4 or 5 of said units. can be configured.
また、本発明のさらなる実施態様において、上記ヌクレオチドリンカーは、以下の式(XII)で表される: In yet a further embodiment of the invention, said nucleotide linker is represented by formula (XII) below:

[式中、
Aは、独立して、化学修飾されていてもよいヌクレオシド、例えば化学修飾されていないデオキシリボヌクレオシドもしくはリボヌクレオシドから選択され、
aおよびbは互いに独立して、0~20の整数、好ましくは1~10、より好ましくは1~5、特に1~3の整数であり、
ただし、a=0の場合には、bは1~20の整数、好ましくは1~10、例えば1~5または1~3の整数であり、b=0の場合には、aは1~20の整数、好ましくは1~10、例えば1~5または1~3の整数であり、
aおよびbの両方が1以上である場合、-AP(=O)O--単位および-AP(=O)S--単位の配置は、ランダム、交互、ブロック、グラジエントまたはこれらの組み合わせである]。[In the formula,
A is independently selected from optionally chemically modified nucleosides, such as chemically unmodified deoxyribonucleosides or ribonucleosides;
a and b are independently of each other integers from 0 to 20, preferably from 1 to 10, more preferably from 1 to 5, especially from 1 to 3;
However, when a = 0, b is an integer of 1 to 20, preferably 1 to 10, such as 1 to 5 or 1 to 3, and when b = 0, a is 1 to 20 is an integer of preferably 1 to 10, such as 1 to 5 or 1 to 3,
When both a and b are 1 or greater, the arrangement of -AP(=O)O-- units and -AP (=O)S-- units is random, alternating, block, gradient or combinations thereof ].
例えば、上記ヌクレオチドリンカーは、PS型結合および/またはPO型結合に関して、以下のような配置を有することができる(式(X)で表される単位をpo、式(XI)で表される単位をpsで示す): For example, the nucleotide linker can have the following arrangement with respect to PS-type linkage and/or PO-type linkage (po for unit represented by formula (X), unit represented by formula (XI) in ps):

本発明の1つの実施態様において、上記ヌクレオチドリンカーは、PS-PO構造を2回繰り返した構造(-ps-po-ps-po-または-po-ps-po-ps-)からなる構造ではなく、好ましくは当該構造を含まない。 In one embodiment of the present invention, the nucleotide linker is not a structure consisting of a PS-PO structure repeated twice (-ps-po-ps-po- or -po-ps-po-ps-) , preferably free of such structures.
本発明の1つの実施態様において、本発明のアンチセンス核酸は、上記のヌクレオチドリンカーを含まない。 In one embodiment of the invention, the antisense nucleic acids of the invention do not contain a nucleotide linker as described above.
本発明のアンチセンス核酸は、上記のモチーフ(M)、5’ウィング領域(5W)、3’ウィング領域(3W)およびヌクレオチドリンカー(NL)から選択される1つまたは複数を任意の組み合わせで有することができる(ただし、少なくとも1つのモチーフを含む)。本発明のアンチセンス核酸は、例えば以下のような構成を取ることができる: The antisense nucleic acid of the present invention has one or more selected from the above motif (M), 5' wing region (5W), 3' wing region (3W) and nucleotide linker (NL) in any combination. (provided that it contains at least one motif). Antisense nucleic acids of the present invention can have, for example, the following configurations:

本発明のさらなる1つの実施態様において、本発明のアンチセンス核酸は、上記モチーフ、上記5’ウィング領域および3’ウィング領域からなる。 In a further embodiment of the invention, the antisense nucleic acid of the invention consists of said motif, said 5' wing region and 3' wing region.
本発明の1つの好ましい実施態様において、本発明のアンチセンス核酸は、以下の式(V)または(VI)で表される:
式(V)In one preferred embodiment of the invention, the antisense nucleic acids of the invention are represented by formula (V) or (VI) below:
Formula (V)

[式中、
A1~Aiは、独立して、化学修飾されていないデオキシリボヌクレオシドであり、
Rは、独立に、式(V)のA1からAiまでの間の領域が、核酸間結合としてホスホジエステル結合とホスホロチオエート化結合を交互に有するように、S-またはO-から選択され、
Xは、独立して化学修飾ヌクレオシドであり、
eは1~9の整数、好ましくは1~6の整数、例えば、1、2、3、4、5または6を示し、そしてgは1~9の整数、好ましくは1~6の整数、例えば、1、2、3、4、5または6を表し、
ここで、部分構造(V-a)[In the formula,
A 1 to A i are independently chemically unmodified deoxyribonucleosides;
R is independently selected from S - or O - such that the region between A 1 and A i of formula (V) has alternating phosphodiester and phosphorothioated bonds as internucleic acid linkages;
X is independently a chemically modified nucleoside;
e represents an integer from 1 to 9, preferably an integer from 1 to 6, such as 1, 2, 3, 4, 5 or 6, and g represents an integer from 1 to 9, preferably an integer from 1 to 6, such as , 1, 2, 3, 4, 5 or 6;
Here, the partial structure (Va)

は、存在していても、存在していなくてもよく、
当該部分構造(V-a)が存在する場合には、i=6~96の整数、好ましくは8~30、より好ましくは9~25、さらに好ましくは10~20の整数、例えば、11、12、13、14、15、16、17、18、19であり、そして
当該部分構造(V-a)が存在しない場合には、i=5である]、
または、
式(VI)may or may not exist,
When the partial structure (Va) is present, i = an integer of 6 to 96, preferably 8 to 30, more preferably 9 to 25, still more preferably an integer of 10 to 20, such as 11, 12 , 13, 14, 15, 16, 17, 18, 19, and i=5 if the substructure (Va) is absent],
or,
Formula (VI)

[式中、
A1~Aiは、独立して、化学修飾されていないデオキシリボヌクレオシドであり、
Rは、独立に、式(VI)のA1からAiまでの間の領域が、核酸間結合としてホスホジエステル結合とホスホロチオエート化結合を交互に有するように、S-またはO-から選択され、
Xは、独立して化学修飾ヌクレオシドであり、
eは1~9の整数、好ましくは1~6の整数、例えば、1、2、3、4、5または6を示し、そしてgは1~9の整数、好ましくは1~6の整数、例えば、1、2、3、4、5または6を表し、
ここで、部分構造(VI-a)[In the formula,
A 1 to A i are independently chemically unmodified deoxyribonucleosides;
R is independently selected from S - or O - such that the region between A 1 and A i of formula (VI) has alternating phosphodiester and phosphorothioated bonds as internucleic acid linkages;
X is independently a chemically modified nucleoside;
e represents an integer from 1 to 9, preferably an integer from 1 to 6, such as 1, 2, 3, 4, 5 or 6, and g represents an integer from 1 to 9, preferably an integer from 1 to 6, such as , 1, 2, 3, 4, 5 or 6;
Here, partial structure (VI-a)

は、存在していても、存在していなくてもよく、
当該部分構造(VI-a)が存在する場合には、i=6~96、好ましくは8~30、より好ましくは9~25、さらに好ましくは10~20の整数、例えば、11、12、13、14、15、16、17、18、19の整数であり、そして
当該部分構造(VI-a)が存在しない場合には、i=5である]。may or may not exist,
When the partial structure (VI-a) is present, i = an integer of 6 to 96, preferably 8 to 30, more preferably 9 to 25, still more preferably 10 to 20, such as 11, 12, 13 , 14, 15, 16, 17, 18, 19, and i=5 if the substructure (VI-a) is not present].
ここで、式(V)または(VI)において、好ましくは、Xは核酸類似体であり、より好ましくは架橋化核酸であり、さらに好ましくは、LNA、cEt-BNA、アミドBNA及びcMOE-BNAからなる群から選択される。好ましくは、XはLNAである。また、eおよびgは、好ましくは、それぞれ互いに独立に、1~6の整数、すなわち、1、2、3、4、5または6を示し、最も好ましくは、eおよびgはいずれも1である。 wherein in formula (V) or (VI) preferably X is a nucleic acid analogue, more preferably a crosslinked nucleic acid, more preferably from LNA, cEt-BNA, amide BNA and cMOE-BNA selected from the group consisting of Preferably X is an LNA. Also, e and g preferably each independently represent an integer from 1 to 6, i.e. 1, 2, 3, 4, 5 or 6, most preferably both e and g are 1 .
本発明の別の好ましい実施態様において、本発明のアンチセンス核酸は、以下の式(V’)または(VI’)で表される:
式(V’)In another preferred embodiment of the invention, the antisense nucleic acid of the invention is represented by formula (V') or (VI') below:
Formula (V')

[式中、
A1~Aiは、独立して、化学修飾されていないデオキシリボヌクレオシドであり、
Rは、独立に、式(V’)のA1からAiまでの間の領域が、核酸間結合としてホスホジエステル結合とホスホロチオエート化結合を交互に有するように、S-またはO-から選択され、
Xは、独立して化学修飾ヌクレオシドであり、
e’は0~4の整数、好ましくは0~3の整数、すなわち、0、1、2または3を示し、そしてg’は0~4の整数、好ましくは0~3の整数、すなわち、0、1、2または3を表し、
ここで、部分構造(V’-a)[In the formula,
A 1 to A i are independently chemically unmodified deoxyribonucleosides;
R is independently selected from S — or O — such that the region between A 1 and A i of formula (V′) has alternating phosphodiester and phosphorothioated bonds as internucleic acid linkages. ,
X is independently a chemically modified nucleoside;
e′ represents an integer from 0 to 4, preferably an integer from 0 to 3,
Here, the partial structure (V'-a)

は常に存在し、そして
i=6~96の整数、好ましくは6~96の範囲内の偶数であり、より好ましくは8~30の範囲内の偶数、さらに好ましくは8~26の範囲内の偶数、より一層好ましくは10~20の範囲内の偶数、例えば、10、12、14、16、18または20である]、または、
式(VI’)is always present, and i = an integer from 6 to 96, preferably an even number in the range from 6 to 96, more preferably an even number in the range from 8 to 30, more preferably an even number in the range from 8 to 26 , even more preferably an even number in the
Formula (VI')

[式中、
A1~Aiは、独立して、化学修飾されていないデオキシリボヌクレオシドであり、
Rは、独立に、式(VI’)のA1からAiまでの間の領域が、核酸間結合としてホスホジエステル結合とホスホロチオエート化結合を交互に有するように、S-またはO-から選択され、
Xは、独立して化学修飾ヌクレオシドであり、
e’は0~4の整数、好ましくは0~3の整数、すなわち、0、1、2または3を示し、そしてg’は0~4の整数、好ましくは0~3の整数、すなわち、0、1、2または3を表し、
ここで、部分構造(VI’-a)[In the formula,
A 1 to A i are independently chemically unmodified deoxyribonucleosides;
R is independently selected from S — or O — such that the region between A 1 and A i of formula (VI′) has alternating phosphodiester and phosphorothioated bonds as internucleic acid linkages. ,
X is independently a chemically modified nucleoside;
e′ represents an integer from 0 to 4, preferably an integer from 0 to 3,
Here, the partial structure (VI'-a)

は常に存在し、そして
i=6~96の整数、好ましくは6~96の範囲内の偶数であり、より好ましくは8~30の範囲内の偶数、さらに好ましくは8~26の範囲内の偶数、より一層好ましくは10~20の範囲内の偶数、例えば、10、12、14、16、18または20である]。is always present, and i = an integer from 6 to 96, preferably an even number in the range from 6 to 96, more preferably an even number in the range from 8 to 30, more preferably an even number in the range from 8 to 26 , more preferably an even number in the
ここで、式(V’)または(VI’)において、好ましくは、Xは核酸類似体であり、より好ましくは架橋化核酸であり、さらに好ましくは、LNA、cEt-BNA、アミドBNA及びcMOE-BNAからなる群から選択される。好ましくは、XはLNAである。また、e’およびg’は、好ましくは、それぞれ互いに独立に、0、1、2または3を示し、最も好ましくは、eおよびgはいずれも0である。 Here, in formula (V′) or (VI′), preferably X is a nucleic acid analogue, more preferably a crosslinked nucleic acid, more preferably LNA, cEt-BNA, amide BNA and cMOE- selected from the group consisting of BNA; Preferably X is an LNA. Also, e' and g' preferably each independently represent 0, 1, 2 or 3, and most preferably both e and g are 0.
本発明の別の実施態様において、本発明のアンチセンス核酸では、上記モチーフが、式(VII) In another embodiment of the invention, in the antisense nucleic acid of the invention, said motif is represented by formula (VII)

[式中、Xは、独立して化学修飾ヌクレオシドであり、
Qは、S-またはO-であり、そして
fは、1~10の整数である]
で表される1つまたは複数の構造により、1か所または複数か所で中断されている。例えば、上記式(VII)で中断されたモチーフは以下のような構造を有する:[wherein X is independently a chemically modified nucleoside;
Q is S - or O - , and f is an integer from 1 to 10]
is interrupted at one or more places by one or more structures represented by For example, the interrupted motif in formula (VII) above has the structure:

[式中、A1~Ai、X、Qおよびfは、上記で定義されたとおりであり、好ましくは、A1~Aiは、化学修飾されていないデオキシリボヌクレオチドである]。[wherein A 1 -A i , X, Q and f are as defined above, preferably A 1 -A i are chemically unmodified deoxyribonucleotides].
このように、上記モチーフは、適切な核酸間結合を有するポリヌクレオチド鎖が形成される様式で、上記式(VII)により中断されていてもよい。 Thus, the motif may be interrupted by formula (VII) above in such a way that a polynucleotide chain with appropriate internucleic acid linkages is formed.
従って、本発明の1つの態様において、本発明は、核酸間結合としてホスホジエステル結合とホスホロチオエート化結合を交互に有する1つまたは複数のモチーフを含むアンチセンス核酸であって、当該モチーフが上記の式(I)または(II)で表され、かつ、上記モチーフが、上記式(VII)で表される1つまたは複数の構造により、1か所または複数か所で中断されているアンチセンス核酸に関する。この態様は、図2の5で示される態様に相当する。 Accordingly, in one aspect of the invention, the invention provides an antisense nucleic acid comprising one or more motifs having alternating phosphodiester and phosphorothioated bonds as internucleic acid linkages, wherein the motifs have the formula Antisense nucleic acids represented by (I) or (II) and wherein the motif is interrupted at one or more locations by one or more structures represented by formula (VII) . This aspect corresponds to the aspect indicated by 5 in FIG.
ここで、上記式(VII)において、Xは好ましくは、独立して核酸類似体であり、より好ましくは架橋化核酸であり、さらに好ましくは、LNA、cEt-BNA、アミドBNA及びcMOE-BNAからなる群から選択される。最も好ましくは、XはLNAである。また、fは、好ましくは、それぞれ互いに独立に、1~6の整数、例えば、1、2、3、4、5または6を示し、最も好ましくは、fは1である。 Here, in formula (VII) above, X is preferably independently a nucleic acid analogue, more preferably a crosslinked nucleic acid, more preferably from LNA, cEt-BNA, amide BNA and cMOE-BNA. selected from the group consisting of Most preferably X is an LNA. Also, f preferably each independently represents an integer from 1 to 6, eg 1, 2, 3, 4, 5 or 6, most preferably f is 1.
上記式(VII)は、式(III)または(IV)の一部と類似する構造(または当該一部と同一の構造)であって、化学修飾ヌクレオシド、好ましくは核酸類似体と核酸間結合からなる。上記モチーフが、上記式(VII)で表される1つまたは複数の構造により、1か所または複数か所で中断されると、例えば、中断構造が大きい場合および/または中断構造の数が多い場合、上記アンチセンス核酸に、少なくとも4つの連続した化学修飾されていてもよいヌクレオチド、特にRNaseHに認識されるような少なくとも4つの連続したデオキシリボヌクレオチド(核酸間結合のみが化学修飾されていてもよい)を含むギャップ領域が存在しなくなる場合が生じる(図2の5参照)。このような場合、上記アンチセンス核酸は、RNaseHの基質を含まず、従って、RNaseH非依存的にアンチセンス効果を奏する(例えばハイブリダイゼーション産物により標的転写産物を被覆することによって生じ得る翻訳の阻害又はエクソンスキッピング等のスプライシング機能変換効果による)。 Formula (VII) above is a structure similar to (or the same structure as) a portion of formula (III) or (IV), comprising a chemically modified nucleoside, preferably a nucleic acid analog, and an internucleic acid bond Become. When the motif is interrupted at one or more locations by one or more structures represented by formula (VII) above, for example, the number of interrupted structures is large and/or the number of interrupted structures is large. In this case, the antisense nucleic acid contains at least 4 consecutive nucleotides that may be chemically modified, particularly at least 4 consecutive deoxyribonucleotides that are recognized by RNaseH (only the internucleic acid bond may be chemically modified ) does not exist (see 5 in FIG. 2). In such cases, the antisense nucleic acid does not contain a substrate for RNaseH, and thus exerts an antisense effect in an RNaseH-independent manner (e.g., inhibition of translation or inhibition of translation, which may occur by covering the target transcript with a hybridization product). due to splicing function conversion effects such as exon skipping).
従って、本発明の本発明の1つの実施態様において、本発明のアンチセンス核酸は、RNaseHの基質となる領域を含まず、従って、アンチセンス核酸全体としてもRNaseHの基質とならない。 Therefore, in one embodiment of the present invention, the antisense nucleic acid of the present invention does not contain a region that serves as a substrate for RNaseH, and therefore the antisense nucleic acid as a whole does not serve as a substrate for RNaseH.
本発明のさらなる実施態様において、本発明のアンチセンス核酸では、上記モチーフにおいて、A1~Aiが、それぞれ互いに独立に、化学修飾ヌクレオシドから選択される。本発明の1つの実施態様において、上記化学修飾ヌクレオシドは核酸類似体であり、より好ましくは架橋化核酸である。上記架橋化核酸は、好ましくは、LNA、cEt-BNA、アミドBNA及びcMOE-BNAからなる群から選択される。In a further embodiment of the invention, in the antisense nucleic acid of the invention, in said motif, A 1 -A i are each independently selected from chemically modified nucleosides. In one embodiment of the invention, the chemically modified nucleosides are nucleic acid analogues, more preferably crosslinked nucleic acids. The cross-linking nucleic acids are preferably selected from the group consisting of LNA, cEt-BNA, amide BNA and cMOE-BNA.
本発明の1つの実施態様において、本発明のアンチセンス核酸は、以下の式(VIII)または(IX)で表される: In one embodiment of the invention, the antisense nucleic acid of the invention is represented by formula (VIII) or (IX) below:

[式中、
XおよびX1~Xiは、独立して核酸類似体であり、
Rは、独立に、式(VIII)のX1からXiまでの間の領域が、核酸間結合としてホスホジエステル結合とホスホロチオエート化結合を交互に有するように、S-またはO-から選択され、
eは1~9の整数、好ましくは1~6の整数、例えば、1、2、3、4、5または6を示し、そしてgは1~9、好ましくは1~6の整数、例えば、1、2、3、4、5または6の整数を表し、
ここで、部分構造(VIII-a)[In the formula,
X and X 1 -X i are independently nucleic acid analogues;
R is independently selected from S - or O - such that the region between X 1 and X i of formula (VIII) has alternating phosphodiester and phosphorothioated bonds as internucleic acid linkages;
e represents an integer from 1 to 9, preferably from 1 to 6, such as 1, 2, 3, 4, 5 or 6, and g represents an integer from 1 to 9, preferably from 1 to 6, such as 1 , represents an integer of 2, 3, 4, 5 or 6,
Here, partial structure (VIII-a)

は、存在していても、存在していなくてもよく、
当該部分構造(VIII-a)が存在する場合には、i=6~96の整数、好ましくは8~30、より好ましくは9~25、さらに好ましくは10~20の整数、例えば、11、12、13、14、15、16、17、18、19であり、そして
当該部分構造(VIII-a)が存在しない場合には、i=5である]、
または、
式(IX)may or may not exist,
When the partial structure (VIII-a) is present, i = an integer of 6 to 96, preferably 8 to 30, more preferably 9 to 25, still more preferably an integer of 10 to 20, such as 11, 12 , 13, 14, 15, 16, 17, 18, 19, and i=5 if the substructure (VIII-a) is absent],
or,
Formula (IX)

[式中、
XおよびX1~Xiは、独立して核酸類似体であり、
Rは、独立に、式(IX)のX1からXiまでの間の領域が、核酸間結合としてホスホジエステル結合とホスホロチオエート化結合を交互に有するように、S-またはO-から選択され、
eは1~9の整数、好ましくは1~6の整数、例えば、1、2、3、4、5または6を示し、そしてgは1~9の整数、好ましくは1~6の整数、例えば、1、2、3、4、5または6を表し、
ここで、部分構造(IX-a)[In the formula,
X and X 1 -X i are independently nucleic acid analogues;
R is independently selected from S - or O - such that the region between X 1 and X i of formula (IX) has alternating phosphodiester and phosphorothioated bonds as internucleic acid linkages;
e represents an integer from 1 to 9, preferably an integer from 1 to 6, such as 1, 2, 3, 4, 5 or 6, and g represents an integer from 1 to 9, preferably an integer from 1 to 6, such as , 1, 2, 3, 4, 5 or 6;
Here, partial structure (IX-a)

は、存在していても、存在していなくてもよく、
当該部分構造(IX-a)が存在する場合には、i=6~96の整数、好ましくは8~30、より好ましくは9~25、さらに好ましくは10~20の整数、例えば、11、12、13、14、15、16、17、18、19であり、そして
当該部分構造(IX-a)が存在しない場合には、i=5である]。may or may not exist,
When the partial structure (IX-a) is present, i = an integer of 6 to 96, preferably 8 to 30, more preferably 9 to 25, still more preferably an integer of 10 to 20, such as 11, 12 , 13, 14, 15, 16, 17, 18, 19, and i=5 if the substructure (IX-a) is not present].
本発明の1つの好ましい実施態様において、上記式(VIII)または(IX)において、XおよびX1~Xiは、独立して、架橋化核酸であり、好ましくはLNA、cEt-BNA、アミドBNA及びcMOE-BNAからなる群から選択される架橋化核酸である。In one preferred embodiment of the present invention, in formula (VIII) or (IX) above, X and X 1 -X i are independently a cross-linking nucleic acid, preferably LNA, cEt-BNA, amide BNA and cMOE-BNA.
本発明の別の実施態様において、本発明のアンチセンス核酸は、以下の式(VIII’)または(IX’)で表される:
(VIII’)In another embodiment of the invention, the antisense nucleic acid of the invention is represented by Formula (VIII') or (IX') below:
(VIII')

[式中、
XおよびX1~Xiは、独立して核酸類似体であり、
Rは、独立に、式(VIII’)のX1からXiまでの間の領域が、核酸間結合としてホスホジエステル結合とホスホロチオエート化結合を交互に有するように、S-またはO-から選択され、
e’は0~4の整数、好ましくは0~3の整数、すなわち、0、1、2または3を示し、そしてg’は0~4の整数、好ましくは0~3の整数、すなわち、0、1、2または3を表し、
ここで、部分構造(VIII’-a)[In the formula,
X and X 1 -X i are independently nucleic acid analogues;
R is independently selected from S — or O — such that the region between X 1 and X i of formula (VIII′) has alternating phosphodiester and phosphorothioated bonds as internucleic acid linkages. ,
e′ represents an integer from 0 to 4, preferably an integer from 0 to 3,
Here, the partial structure (VIII'-a)

は常に存在し、そして
i=6~96の整数、好ましくは6~96の範囲内の偶数であり、より好ましくは8~30の範囲内の偶数、さらに好ましくは8~26の範囲内の偶数、より一層好ましくは10~20の範囲内の偶数、例えば、10、12、14、16、18または20である]、 または、
式(IX’)is always present, and i = an integer from 6 to 96, preferably an even number in the range from 6 to 96, more preferably an even number in the range from 8 to 30, more preferably an even number in the range from 8 to 26 , even more preferably an even number in the
Formula (IX')
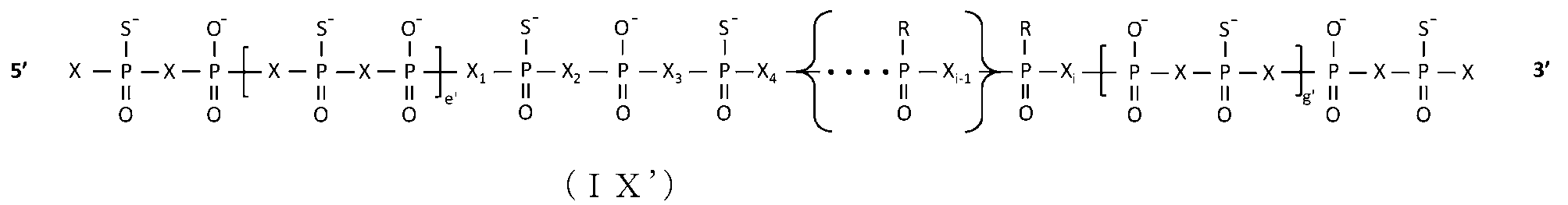
[式中、
XおよびX1~Xiは、独立して核酸類似体であり、
Rは、独立に、式(IX’)のX1からXiまでの間の領域が、核酸間結合としてホスホジエステル結合とホスホロチオエート化結合を交互に有するように、S-またはO-から選択され、
e’は0~4の整数、好ましくは0~3の整数、すなわち、0、1、2または3を示し、そしてg’は0~4の整数、好ましくは0~3の整数、すなわち、0、1、2または3を表し、
ここで、部分構造(IX’-a)[In the formula,
X and X 1 -X i are independently nucleic acid analogues;
R is independently selected from S — or O — such that the region between X 1 and X i of formula (IX′) has alternating phosphodiester and phosphorothioated bonds as internucleic acid linkages. ,
e′ represents an integer from 0 to 4, preferably an integer from 0 to 3,
Here, partial structure (IX'-a)

は常に存在し、そして
i=6~96の整数、好ましくは6~96の範囲内の偶数であり、より好ましくは8~30の範囲内の偶数、さらに好ましくは8~26の範囲内の偶数、より一層好ましくは10~20の範囲内の偶数、例えば、10、12、14、16、18または20である]。is always present, and i = an integer from 6 to 96, preferably an even number in the range from 6 to 96, more preferably an even number in the range from 8 to 30, more preferably an even number in the range from 8 to 26 , more preferably an even number in the
本発明の1つの好ましい実施態様において、上記式(VIII’)または(IX’)において、XおよびX1~Xiは、独立して、架橋化核酸であり、好ましくはLNA、cEt-BNA、アミドBNA及びcMOE-BNAからなる群から選択される架橋化核酸である。In one preferred embodiment of the present invention, in formula (VIII') or (IX') above, X and X 1 -X i are independently cross-linked nucleic acids, preferably LNA, cEt-BNA, A cross-linked nucleic acid selected from the group consisting of amide-BNA and cMOE-BNA.
上記アンチセンス核酸におけるポリヌクレオチドの長さは特に制限はないが、好ましくは少なくとも8塩基であり、少なくとも10塩基であり、少なくとも12塩基であり、少なくとも13塩基であり、少なくとも14塩基であり、又は少なくとも15塩基である。前記長さは、好ましくは100塩基以下、35塩基以下、25塩基以下、20塩基以下、19塩基以下、18塩基以下または17塩基以下であることができる。前記長さの範囲は、好ましくは10~35塩基であり、より好ましくは12~25塩基であり、さらに好ましくは13~20塩基である。通常、前記標的に対する核酸鎖によるアンチセンス効果の強さや、費用、合成収率等の他の要素に応じて、前記長さは選択される。なお、本発明におけるポリヌクレオチド(アンチセンス核酸、相補鎖)は、脱塩基ヌクレオシド等を含み得るが、そのような場合であっても、本明細書では、1ヌクレオチドに相当する長さを1塩基の長さとして表す。 The length of the polynucleotide in the antisense nucleic acid is not particularly limited, but is preferably at least 8 bases, at least 10 bases, at least 12 bases, at least 13 bases, at least 14 bases, or At least 15 bases. Said length may preferably be 100 bases or less, 35 bases or less, 25 bases or less, 20 bases or less, 19 bases or less, 18 bases or less or 17 bases or less. The length range is preferably 10 to 35 bases, more preferably 12 to 25 bases, even more preferably 13 to 20 bases. The length is generally selected according to the strength of the antisense effect of the nucleic acid strand on the target and other factors such as cost and synthesis yield. The polynucleotide (antisense nucleic acid, complementary strand) in the present invention may contain an abasic nucleoside or the like. Expressed as the length of
また、本発明の1つの実施態様において、上記アンチセンス核酸は、合成、精製および/または単離されたアンチセンス核酸である。当該アンチセンス核酸は、標的遺伝子の発現や転写産物(タンパク質をコードするmRNA転写産物またはタンパク質をコードしない転写産物)のレベルをアンチセンス効果によって抑制する活性を有する。 Also, in one embodiment of the invention, the antisense nucleic acid is a synthetic, purified and/or isolated antisense nucleic acid. The antisense nucleic acid has the activity of suppressing the expression of a target gene and the level of transcription products (mRNA transcripts encoding proteins or transcripts that do not encode proteins) by antisense effects.
本発明のアンチセンス核酸は、標的転写産物(典型的には遺伝子の転写産物)の選択に応じて、標的細胞、好ましくは標的癌細胞の増殖を抑制することができる。典型的には、標的遺伝子の発現亢進を伴う細胞を標的細胞とし、本発明のアンチセンス核酸により、その増殖を抑制することができる。例えば、本発明のアンチセンス核酸により、標的癌細胞においてがん遺伝子(例えば、アポトーシス抑制機能を有するBCL2遺伝子、またはBCR-ABL遺伝子もしくはSTAT3遺伝子)を標的遺伝子としてその発現を抑制することにより、当該癌細胞の増殖を抑制することができる。 The antisense nucleic acids of the present invention can inhibit the proliferation of target cells, preferably target cancer cells, depending on the selection of target transcripts (typically gene transcripts). Typically, target cells are cells with increased expression of the target gene, and the antisense nucleic acid of the present invention can suppress their proliferation. For example, by using the antisense nucleic acid of the present invention to suppress the expression of an oncogene (e.g., BCL2 gene having an apoptosis-suppressing function, BCR-ABL gene or STAT3 gene) in target cancer cells as a target gene, It can suppress the growth of cancer cells.
アンチセンス効果によって発現が抑制される「標的遺伝子」又は「標的転写産物」としては、特に制限はなく、例えば、各種疾患において発現が亢進している遺伝子が挙げられる。本発明の1つの実施態様において、上記標的遺伝子は、がん遺伝子である。また「標的遺伝子の転写産物」とは、標的遺伝子をコードするゲノムDNAから転写されたmRNAのことであり、塩基の修飾を受けていないmRNAや、スプライシングを受けていないmRNA前駆体等も含まれる。通常、「転写産物」は、DNA依存性RNAポリメラーゼによって合成される、いかなるRNAでもよい。 The "target gene" or "target transcript" whose expression is suppressed by the antisense effect is not particularly limited, and examples thereof include genes whose expression is enhanced in various diseases. In one embodiment of the invention, the target gene is an oncogene. The term "transcription product of a target gene" refers to mRNA transcribed from genomic DNA encoding the target gene, and includes unmodified mRNA and unspliced mRNA precursors. . Generally, a "transcript" is any RNA synthesized by a DNA-dependent RNA polymerase.
「合成、精製および/または単離されたアンチセンス核酸」という文言は、ここではポリヌクレオチド鎖を含むアンチセンス核酸であって、ポリヌクレオチドの各構成単位はそれぞれ天然に生じる物質であっても、天然には生じない物質でもあってもよいが、ポリヌクレオチド自体(すなわちポリヌクレオチド全体)としては、天然では生じないものおよび/または天然では実質的に生じないもの(典型的には人工的に構築されたもの)を意味する。 The phrase "synthetic, purified and/or isolated antisense nucleic acid" as used herein refers to an antisense nucleic acid comprising a polynucleotide chain, even if each constituent unit of the polynucleotide is a naturally occurring substance, It may be a non-naturally occurring substance, but the polynucleotide itself (i.e., the entire polynucleotide) is non-naturally occurring and/or substantially non-naturally occurring (typically artificially constructed). means that the
「相補的」という文言は、ヌクレオチドの塩基が他のヌクレオチドの塩基と、水素結合を介して、いわゆるワトソン-クリック型塩基対(天然型塩基対)や非ワトソン-クリック型塩基対(フーグスティーン型塩基対等)を形成できる関係のことを意味する。例えば、DNAにおいては、アデニン(A)がチミジン(T)に対して相補的であり、RNAにおいては、アデニン(A)はウラシル(U)に対して相補的である。 The term "complementary" refers to the so-called Watson-Crick base pairing (natural base pairing) or non-Watson-Crick base pairing (Hoogsteen type base pairs, etc.). For example, in DNA adenine (A) is complementary to thymidine (T) and in RNA adenine (A) is complementary to uracil (U).
例えば、アンチセンス核酸のポリヌクレオチドのある位置のヌクレオチドが、標的遺伝子の転写産物のある位置のヌクレオチドと水素結合を介して塩基対を形成できる場合、上記ポリヌクレオチドと上記転写産物は、当該水素結合の位置において相補的であると考えられる。 For example, when a nucleotide at a certain position in a polynucleotide of an antisense nucleic acid can form a base pair with a nucleotide at a certain position in a transcription product of a target gene through hydrogen bonding, the polynucleotide and the transcription product form the hydrogen bond. are considered to be complementary at the positions of
あるポリヌクレオチドが他のポリヌクレオチドとハイブリダイズもしくはアニーリング(本明細書では、これらの語を互換的に使用する)するためには、両ポリヌクレオチドは、塩基配列の全ての位置において相補的である必要はない。そして、本発明に関しても、アンチセンス核酸が機能を発揮するためには、塩基配列の全ての位置において相補的である必要はなく、一部の位置におけるミスマッチが許容される。 In order for one polynucleotide to hybridize or anneal (the terms are used interchangeably herein) with another polynucleotide, the two polynucleotides are complementary at all positions in their base sequences. No need. Also in the present invention, in order for the antisense nucleic acid to exert its function, it is not necessary to be complementary at all positions of the base sequence, and mismatches at some positions are allowed.
例えば、標的転写産物の塩基配列と、アンチセンス核酸におけるポリヌクレオチドの塩基配列とは、完全に相補的である必要はなく、すなわち、両者は全ての位置で相補的である必要はない。 For example, the base sequence of the target transcript and the base sequence of the polynucleotide in the antisense nucleic acid need not be completely complementary, ie, the two need not be complementary at all positions.
本発明では、アンチセンス核酸におけるポリヌクレオチドは、その少なくとも一部が、標的転写産物に対して相補的である。本発明の1つの実施態様において、標的転写産物の塩基配列とアンチセンス核酸におけるポリヌクレオチドの塩基配列は、その少なくとも70%以上、好ましくは80%以上、さらに好ましくは90%以上(例えば、95%、96%、97%、98%、99%以上、または100%)が相補的であればよい。例えば、70%のヌクレオチドが相補的な場合、両者は70%の「相補性」を有する。本発明の好ましい1つの実施態様において、両者は完全に相補的であり、すなわち、100%の相補性を有する。 In the present invention, the polynucleotide in the antisense nucleic acid is at least partially complementary to the target transcript. In one embodiment of the present invention, the base sequence of the target transcript and the base sequence of the polynucleotide in the antisense nucleic acid are at least 70% or more, preferably 80% or more, more preferably 90% or more (e.g., 95% , 96%, 97%, 98%, 99% or more, or 100%) are complementary. For example, if 70% of the nucleotides are complementary, the two have 70% "complementarity." In one preferred embodiment of the invention, both are fully complementary, ie have 100% complementarity.
なお、2つのポリヌクレオチドの相補性(例えば、標的転写産物とアンチセンス核酸のポリヌクレオチドとの相補性)は、両者が異なる長さを有する場合には、二本鎖形成領域(ミスマッチを含む場合にはそれらを含めた二本鎖形成領域全体)における相補性として算出することができる。 In addition, the complementarity of two polynucleotides (for example, the complementarity between the target transcript and the polynucleotide of the antisense nucleic acid), when both have different lengths, is can be calculated as complementarity in the entire double-strand forming region including them).
配列の相補性は、BLASTプログラム等を利用することにより決定することができる。そして、当業者であれば、例えば、標的遺伝子の塩基配列の情報に基づいて、標的転写産物に相補的なアンチセンス核酸を容易に設計することができる。 Sequence complementarity can be determined by using the BLAST program or the like. A person skilled in the art can easily design an antisense nucleic acid complementary to the target transcript, for example, based on information about the base sequence of the target gene.
本発明の別の態様において、本発明は、
(i)上記アンチセンス核酸、および
(ii)化学修飾されていてもよいヌクレオチドを構成単位として少なくとも含むポリヌクレオチドであって、少なくとも一部が上記(i)アンチセンス核酸に対して相補的なポリヌクレオチドを含む相補鎖、
を含む二本鎖核酸複合体、
に関する。In another aspect of the invention, the invention comprises:
(i) the antisense nucleic acid; and (ii) a polynucleotide comprising at least nucleotides that may be chemically modified as structural units, at least a portion of which is complementary to the (i) antisense nucleic acid. a complementary strand comprising nucleotides,
a double-stranded nucleic acid complex comprising
Regarding.
本発明の1つの実施態様において、相補鎖におけるポリヌクレオチドは、構成単位としての、化学修飾されていてもよいヌクレオチドからなる。また、本発明のさらなる実施態様において、上記相補鎖は、上記ポリヌクレオチドからなる。 In one embodiment of the invention, the polynucleotide in the complementary strand consists of nucleotides, optionally chemically modified, as building blocks. In yet a further embodiment of the invention said complementary strand consists of said polynucleotide.
上記のように、PS-PO構造は従来技術のPS型アンチセンス鎖構造に比べて酵素耐性が弱くなる傾向があるため、PS-PO構造を有するアンチセンス核酸には、至適な酵素耐性を持たせる必要がある。本発明では、本発明において用いられるようなPS-PO構造を有するアンチセンス核酸を、それに相補的な鎖との二本鎖核酸構造とすることにより、当該二本鎖核酸が、至適な酵素耐性を有し、その結果、PS型構造を有するアンチセンス核酸と同等またはそれ以上の標的転写産物の発現抑制効果、標的細胞増殖の抑制効果を有することも見出された。 As described above, the PS-PO structure tends to have weaker enzyme resistance than the PS-type antisense strand structure of the prior art. need to have. In the present invention, the antisense nucleic acid having a PS-PO structure as used in the present invention is made into a double-stranded nucleic acid structure with a strand complementary thereto, so that the double-stranded nucleic acid can be used as an optimal enzyme. It was also found that it has resistance, and as a result, it has an effect of suppressing the expression of target transcripts and the proliferation of target cells equal to or greater than that of an antisense nucleic acid having a PS-type structure.
上記相補鎖は、上記のようにアンチセンス核酸に対して少なくとも一部が相補的である核酸である。上記の相補的な核酸は、合成、精製および/または単離された核酸である。ここで、「合成、精製および/または単離された核酸」という文言は、ポリヌクレオチド鎖を含み、上記アンチセンス核酸に対して少なくとも一部が相補的な核酸であって、ポリヌクレオチドの各構成単位はそれぞれ天然に生じる物質であっても、天然には生じない物質でもあってもよいが、ポリヌクレオチド自体(すなわちポリヌクレオチド全体)としては、天然では生じないものおよび/または天然では実質的に生じないもの(典型的には人工的に構築されたもの)を意味する。 The complementary strand is a nucleic acid that is at least partially complementary to the antisense nucleic acid as described above. The above complementary nucleic acids are synthetic, purified and/or isolated nucleic acids. Here, the phrase "synthetic, purified and/or isolated nucleic acid" includes a polynucleotide chain and is a nucleic acid that is at least partially complementary to the antisense nucleic acid, wherein each constituent of the polynucleotide Each unit may be a naturally occurring substance or a non-naturally occurring substance, but the polynucleotide itself (i.e., the entire polynucleotide) is non-naturally occurring and/or substantially means something that does not occur (typically constructed artificially).
上記相補鎖におけるポリヌクレオチドは、「化学修飾されていてもよいヌクレオチド」を構成単位として少なくとも含む。この文言は、上記ポリヌクレオチドが、化学修飾されているかもしくはされていないヌクレオチドを有することを意味する。ここで、必須の構成単位である上記ヌクレオチドは、デオキシリボヌクレオチドであっても、リボヌクレオチドであっても、これらの組み合わせであってもよい。また、当該ヌクレオチドはそれぞれ独立に、化学修飾されていても、化学修飾されていなくてもよい。化学修飾としては、アンチセンス核酸に関して述べたような化学修飾を使用することができる。化学修飾されているヌクレオチドは、例えば、核酸間結合を介して結合された核酸類似体(本明細書では、簡便のために、このようなヌクレオチドの形態にある核酸類似体も、ヌクレオシドの形態にある核酸類似体も、同様に「核酸類似体」と呼ぶことがある)であってもよく、当該核酸類似体はさらに別の上記のような化学修飾をされていてもよい。このように、アンチセンス核酸に対して親和性を持つものであれば、ヌクレオチド以外にも、ペプチド鎖をもつPNAやモルフォリノ核酸、あるいは塩基性ポリアミノ酸(Poly L-Lys、Poly L-Arg)等の核酸類似体を相補鎖の構成単位に使用することができる。なお、本明細書では、このような核酸類似体を構成単位として含む構造も、ポリヌクレオチド(または核酸もしくは核酸鎖)と呼ぶ。 The polynucleotide in the complementary strand includes at least "nucleotides that may be chemically modified" as structural units. This term means that the polynucleotide has nucleotides that are chemically modified or not. Here, the above nucleotides, which are essential structural units, may be deoxyribonucleotides, ribonucleotides, or combinations thereof. In addition, each of the nucleotides may or may not be chemically modified independently. As chemical modifications, chemical modifications such as those described for antisense nucleic acids can be used. Nucleotides that have been chemically modified are, for example, nucleic acid analogs linked via internucleic acid linkages (herein, for convenience, nucleic acid analogs in the form of such nucleotides are also referred to in the form of nucleosides). A given nucleic acid analogue may also be referred to as a “nucleic acid analogue”), and the nucleic acid analogue may be chemically modified as described above. Thus, other than nucleotides, PNAs having peptide chains, morpholino nucleic acids, basic polyamino acids (Poly L-Lys, Poly L-Arg), etc., can be used as long as they have affinity for antisense nucleic acids. can be used as building blocks of complementary strands. In the present specification, structures containing such nucleic acid analogues as structural units are also referred to as polynucleotides (or nucleic acids or nucleic acid chains).
ここで、上記相補鎖を構成するポリヌクレオチドは、核酸間結合として、連続したPS型構造を有してもよく、連続したPO型構造を有していてもよく、またはPS-PO構造を有していてもよく、あるいはこれらの組み合わせを有していてもよい。 Here, the polynucleotide constituting the complementary strand may have a continuous PS-type structure, a continuous PO-type structure, or a PS-PO structure as an internucleic acid bond. or a combination thereof.
本発明の1つの実施態様において、相補鎖におけるポリヌクレオチドは、化学修飾されていてもよいデオキシリボヌクレオチドおよび/または化学修飾されていてもよいリボヌクレオチドを構成単位として少なくとも含む。 In one embodiment of the present invention, the polynucleotide in the complementary strand contains at least optionally chemically modified deoxyribonucleotides and/or optionally chemically modified ribonucleotides as constituent units.
本発明のさらなる1つの実施態様において、相補鎖におけるポリヌクレオチドは、化学修飾されていてもよいデオキシリボヌクレオチドのみを構成単位として含む。本発明の別の実施態様において、相補鎖におけるポリヌクレオチドは、化学修飾されていないデオキシリボヌクレオチドのみを構成単位として含む。 In a further embodiment of the present invention, the polynucleotide in the complementary strand contains only optionally chemically modified deoxyribonucleotides as constituent units. In another embodiment of the present invention, the polynucleotide in the complementary strand contains only chemically unmodified deoxyribonucleotides as building blocks.
本発明の別の実施態様において、相補鎖におけるポリヌクレオチドは、化学修飾されていてもよいリボヌクレオチドのみを構成単位として含む。本発明の1つの実施態様において、相補鎖におけるポリヌクレオチドは、化学修飾されていないリボヌクレオチドのみを構成単位として含む
本発明のさらなる1つの実施態様において、相補鎖におけるポリヌクレオチドは、化学修飾されていてもよいデオキシリボヌクレオチドおよび化学修飾されていてもよいリボヌクレオチドのみを構成単位として含む。好ましくは、上記デオキシリボヌクレオチドおよびリボヌクレオチドは化学修飾されていない。In another embodiment of the present invention, the polynucleotide in the complementary strand contains only ribonucleotides, which may be chemically modified, as constituent units. In one embodiment of the present invention, the polynucleotide in the complementary strand contains only chemically unmodified ribonucleotides as constituent units. In a further embodiment of the present invention, the polynucleotide in the complementary strand is chemically modified. It contains only deoxyribonucleotides which may be optionally chemically modified and ribonucleotides which may be chemically modified as constituent units. Preferably, said deoxyribonucleotides and ribonucleotides are not chemically modified.
この態様において、上記ポリヌクレオチドにおける、デオキシリボヌクレオチドの数とリボヌクレオチドの数の比は特に限定はされない。本発明の1つの実施態様において、当該ポリヌクレオチドは、その総ヌクレオチド数に対して、1~90%、好ましくは5~70%、より好ましくは10~50%、例えば30~50%の数のリボヌクレオチドを含むことができる。例えば、上記ポリヌクレオチドは、当該ポリヌクレオチドの総ヌクレオチド数に対して、例えば10、20、30、40、50、60、70、80または90%の数のリボヌクレオチドを含むことができる。これらの場合、残りの部分が、デオキシリボヌクレオチドである。また、本発明のさらなる実施態様では、相補鎖におけるポリヌクレオチドは、1~12個のリボヌクレオチド、例えば、2~10個、3~9個または5~8個のリボヌクレオチドを含むことができる。本発明のさらなる1つの実施態様において、相補鎖におけるポリヌクレオチドは、1、2、3、4、5、6、7、8、9、10、11、12、13、14または15個のリボヌクレオチドを含む。これらは、デオキシリボヌクレオチドにも当てはまる。相補鎖のポリヌクレオチドにおけるリボヌクレオチドの位置およびデオキシリボヌクレオチドの位置は、特に制限はされない。 In this aspect, the ratio of the number of deoxyribonucleotides to the number of ribonucleotides in the polynucleotide is not particularly limited. In one embodiment of the present invention, the polynucleotide is 1-90%, preferably 5-70%, more preferably 10-50%, for example 30-50% of the total number of nucleotides. It can contain ribonucleotides. For example, the polynucleotide can comprise, for example, 10, 20, 30, 40, 50, 60, 70, 80 or 90% of the total number of nucleotides in the polynucleotide. In these cases the remainder are deoxyribonucleotides. In yet further embodiments of the invention, the polynucleotides in the complementary strand can comprise 1-12 ribonucleotides, such as 2-10, 3-9 or 5-8 ribonucleotides. In a further embodiment of the invention the polynucleotide in the complementary strand is 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14 or 15 ribonucleotides including. These also apply to deoxyribonucleotides. The position of the ribonucleotide and the position of the deoxyribonucleotide in the polynucleotide of the complementary strand are not particularly limited.
相補鎖のポリヌクレオチドが、化学修飾されていてもよいデオキシリボヌクレオチドおよび化学修飾されていてもよいリボヌクレオチドのみを構成単位として含み、かつ上記ポリヌクレオチドがリボヌクレオチドを複数個含む場合には、各リボヌクレオチドは互いに離れて存在していてもよく、または連続して存在していても、両者が組み合わされて存在していてもよい。これらは、デオキシリボヌクレオチドにも当てはまる。 When the polynucleotide of the complementary strand contains only deoxyribonucleotides that may be chemically modified and ribonucleotides that may be chemically modified as constituent units, and the polynucleotide contains a plurality of ribonucleotides, each ribonucleotide Nucleotides may be present separately from each other, or may be present consecutively, or both may be present in combination. These also apply to deoxyribonucleotides.
本発明の1つの態様において、相補鎖のポリヌクレオチドは、化学修飾されていてもよいリボヌクレオチドと化学修飾されていてもよいデオキシリボヌクレオチドとを複数個ずつ含み、リボヌクレオチドとデオキシリボヌクレオチドは交互にまたはほぼ交互に存在する。この場合に、リボヌクレオチドとデオキシリボヌクレオチドは、1個ずつ、2個ずつ、3個ずつ、4個ずつ、5個ずつまたは6個ずつ、交互に(またはほぼ交互に)存在していてもよい。好ましくは、上記デオキシリボヌクレオチドおよびリボヌクレオチドは化学修飾されていない。 In one aspect of the present invention, the polynucleotide of the complementary strand comprises a plurality of each of optionally chemically modified ribonucleotides and optionally chemically modified deoxyribonucleotides, and the ribonucleotides and deoxyribonucleotides are alternately or exist almost alternately. In this case, ribonucleotides and deoxyribonucleotides may be alternately (or nearly alternately) present one at a time, two at a time, three at a time, four at a time, five at a time, or six at a time. Preferably, said deoxyribonucleotides and ribonucleotides are not chemically modified.
本発明のさらなる実施態様において、相補鎖のポリヌクレオチドは、当該ポリヌクレオチドの5’末端領域および/または3’末端領域における全ての構成単位が化学修飾されていてもよいデオキシリボヌクレオチドであり、それら以外の領域における全ての構成単位が化学修飾されていてもよいリボヌクレオチドである。好ましくは、上記デオキシリボヌクレオチドおよびリボヌクレオチドは化学修飾されていない。ここで、「5’末端領域」は、上記ポリヌクレオチドの5’末端に位置する構成単位(5’末端から数えて1番目の構成単位)と5’末端から数えて2~n番目の構成単位とを含む領域である。ここでnは、3~20の整数であることができ、好ましくは3~10の整数、例えば4、5、6、7、8または9であることができる。「3’末端領域」は、上記ポリヌクレオチドの3’末端に位置する構成単位(3’末端から数えて1番目の構成単位)と3’末端から数えて2~m番目の構成単位とを含む領域である。ここでmは、3~20の整数であることができ、好ましくは3~10の整数、例えば4、5、6、7、8または9であることができる。
In a further embodiment of the present invention, the polynucleotide of the complementary strand is a deoxyribonucleotide in which all structural units in the 5'-terminal region and/or 3'-terminal region of the polynucleotide may be chemically modified, and other is a ribonucleotide in which all structural units in the region may be chemically modified. Preferably, said deoxyribonucleotides and ribonucleotides are not chemically modified. Here, the "5' end region" refers to the structural unit located at the 5' end of the polynucleotide (the first structural unit counting from the 5' end) and the 2nd to nth structural units counting from the 5' end is a region containing Here n can be an integer from 3 to 20, preferably an integer from 3 to 10,
本発明の1つの好ましい実施態様において、相補鎖のポリヌクレオチドは、当該ポリヌクレオチドの5’末端領域および3’末端領域における全ての構成単位がデオキシリボヌクレオチドであり、そして、5’末端および3’末端領域以外の領域における全ての構成単位がリボヌクレオチドであり、ここで、上記5’末端領域は、5’末端に位置する構成単位と5’末端から数えて2~n番目(n=3~6)の構成単位からなる領域であり、上記3’末端領域は、3’末端に位置する構成単位と3’末端から数えて2~m番目(m=3~6)の構成単位とからなる領域である。例えば、実施例1に記載の配列番号12で表される相補鎖が、この態様に該当するものであり、5’末端に位置する構成単位と5’末端から数えて2~5番目の構成単位とからなる領域における全ての構成単位、ならびに3’末端に位置する構成単位と3’末端から数えて2~5番目の構成単位とからなる領域における全ての構成単位がデオキシリボヌクレオチドであり、それ以外の領域(5’末端から数えて6~11番目の構成単位からなる領域)における全ての構成単位がリボヌクレオチドである。好ましくは、上記デオキシリボヌクレオチドおよびリボヌクレオチドは化学修飾されていない。 In one preferred embodiment of the present invention, the polynucleotide of the complementary strand has deoxyribonucleotides as all structural units in the 5'-terminal region and the 3'-terminal region of the polynucleotide, and the 5'-terminal and 3'-terminal All structural units in the region other than the region are ribonucleotides, wherein the 5' end region is the 2nd to nth (n = 3 to 6 ), and the 3′-terminal region is a region consisting of the structural unit located at the 3′-end and the 2nd to m-th (m=3-6) structural units counted from the 3′-end. is. For example, the complementary strand represented by SEQ ID NO: 12 described in Example 1 corresponds to this embodiment, and the structural unit located at the 5' end and the 2nd to 5th structural units counted from the 5' end All structural units in the region consisting of and all structural units in the region consisting of the structural unit located at the 3' end and the 2nd to 5th structural units counting from the 3' end are deoxyribonucleotides, and other (the region consisting of the 6th to 11th structural units counted from the 5' end) are all ribonucleotides. Preferably, said deoxyribonucleotides and ribonucleotides are not chemically modified.
本発明の他の実施態様において、相補鎖のポリヌクレオチドは、化学修飾されていないデオキシリボヌクレオチドと、糖が化学修飾されたヌクレオチドのみからなるか、あるいは、相補鎖のポリヌクレオチドは、化学修飾されていないリボヌクレオチドと、糖が化学修飾されたヌクレオチドのみからなる。好ましくは、上記化学修飾は、2’-O-メチル化、2’-O-メトキシエチル(MOE)化、2’-O-アミノプロピル(AP)化、2’-フルオロ化からなる群から選択される。 In another embodiment of the present invention, the complementary strand of polynucleotide consists only of chemically unmodified deoxyribonucleotides and chemically modified sugar nucleotides, or the complementary strand of polynucleotide is chemically modified. It consists only of ribonucleotides without sugars and nucleotides with chemically modified sugars. Preferably, the chemical modification is selected from the group consisting of 2'-O-methylation, 2'-O-methoxyethyl (MOE), 2'-O-aminopropyl (AP), and 2'-fluorination. be done.
本発明のさらなる実施態様において、相補鎖のポリヌクレオチドは、当該ポリヌクレオチドの5’末端領域および/または3’末端領域における全ての構成単位が化学修飾クレオチド、好ましくは糖が化学修飾されたヌクレオチド(化学修飾は、例えば、2’-O-メチル化、2’-O-メトキシエチル(MOE)化、2’-O-アミノプロピル(AP)化、2’-フルオロ化からなる群から選択される)、より好ましくは2’-O-メチル型デオキシリボヌクレオチド/リボヌクレオチドであり、そして、5’末端および3’末端領域以外の領域における全ての構成単位が化学修飾されていないデオキシリボヌクレオチドもしくはリボヌクレオチドである。ここで、5’末端領域および/または3’末端領域は上記の意味を有する。本発明の1つの好ましい実施態様において、相補鎖のポリヌクレオチドは、当該ポリヌクレオチドの5’末端領域および3’末端領域における全ての構成単位が糖が化学修飾されたヌクレオチド(化学修飾は、例えば、2’-O-メチル化、2’-O-メトキシエチル(MOE)化、2’-O-アミノプロピル(AP)化、2’-フルオロ化からなる群から選択される)、より好ましくは2’-O-メチル型デオキシリボヌクレオチド/リボヌクレオチドであり、そして、5’末端および3’末端領域以外の領域における全ての構成単位がデオキシリボヌクレオチドもしくはリボヌクレオチドであり、ここで、5’末端領域は、5’末端に位置する構成単位と5’末端から数えて2~n番目(n=3~6)の構成単位とからなる領域であり、3’末端領域は、3’末端に位置する構成単位と3’末端から数えて2~m番目(m=3~6)の構成単位とからなる領域である。例えば、実施例1に記載の配列番号7で表される相補鎖が、この態様に該当するものであり、5’末端に位置する構成単位と5’末端から数えて2および3番目の構成単位とからなる領域における全ての構成単位、ならびに3’末端に位置する構成単位と3’末端から数えて2および3番目の構成単位とからなる領域における全ての構成単位が2’-O-メチル型デオキシリボヌクレオチド/リボヌクレオチドであり、それ以外の領域(5’末端から数えて4~13番目の構成単位からなる領域)における全ての構成単位が化学修飾されていないリボヌクレオチドである。なお、化学修飾ヌクレオチドで構成される5’末端領域および/または3’末端領域は、核酸間結合として、連続したPS型構造を有してもよく、連続したPO型構造を有していてもよく、またはPS-PO構造を有していてもよい。例えば、5’末端領域は核酸間結合として連続したPS型構造を有し、3’末端領域は核酸間結合として連続したPO型構造を有することもできる(例えば、配列番号7)。
In a further embodiment of the present invention, the polynucleotide of the complementary strand is a nucleotide in which all constituent units in the 5′-terminal region and/or the 3′-terminal region of the polynucleotide are chemically modified nucleotides, preferably sugars are chemically modified ( Chemical modification is selected from the group consisting of, for example, 2'-O-methylation, 2'-O-methoxyethyl (MOE), 2'-O-aminopropyl (AP), and 2'-fluorination ), more preferably 2′-O-methyl deoxyribonucleotides/ribonucleotides, and all structural units in regions other than the 5′-terminal and 3′-terminal regions are chemically unmodified deoxyribonucleotides or ribonucleotides be. Here, the 5'-terminal region and/or the 3'-terminal region have the meanings given above. In one preferred embodiment of the present invention, the complementary strand of the polynucleotide is a nucleotide in which all structural units in the 5′-terminal region and 3′-terminal region of the polynucleotide are chemically modified sugars (chemical modification is, for example, 2′-O-methylation, 2′-O-methoxyethyl (MOE), 2′-O-aminopropyl (AP), 2′-fluorination), more preferably 2 '-O-methyl type deoxyribonucleotides/ribonucleotides, and all constituent units in the region other than the 5'-terminal and 3'-terminal regions are deoxyribonucleotides or ribonucleotides, wherein the 5'-terminal region is A region consisting of structural units located at the 5' end and
本発明のさらなる実施態様において、相補鎖におけるポリヌクレオチドは、少なくとも4つの連続した化学修飾されていてもよいデオキシリボヌクレオチドとその5’側に位置する5’ウィング領域および3’側に位置する3’ウィング領域とからなる。この態様において、上記デオキシリボヌクレオチドはその一部または全部が化学修飾されていてもよく、好ましくは、上記デオキシリボヌクレオチドはその一部または全部が、より好ましくは全部が、核酸間結合としてホスホロチオエート化結合を有する。好ましくは、上記デオキシリボヌクレオチドは、核酸間結合以外は化学修飾されていない。好ましくは、上記5’ウィング領域および3’ウィング領域は、核酸間結合としてホスホロチオエート化結合を有するLNA/BNAからなる。 In a further embodiment of the present invention, the polynucleotide in the complementary strand comprises at least four consecutive deoxyribonucleotides, which may be chemically modified, and a 5' wing region located on the 5' side thereof and a 3' located on the 3' side thereof. wing area; In this embodiment, part or all of the deoxyribonucleotides may be chemically modified, preferably part or all, more preferably all of the deoxyribonucleotides are phosphorothioated bonds as internucleic acid bonds. have. Preferably, the deoxyribonucleotides are not chemically modified except for internucleic acid linkages. Preferably, the 5' and 3' wing regions consist of LNA/BNA with phosphorothioated bonds as internucleic acid linkages.
上述のように、相補鎖におけるポリヌクレオチドは、上記アンチセンス核酸と少なくとも一部が相補的なポリヌクレオチドである。相補鎖におけるポリヌクレオチドの塩基配列と上記アンチセンス核酸におけるポリヌクレオチドの塩基配列とは、両者が少なくとも部分的に二本鎖を形成することが可能であれば、完全に相補的である必要はなく、例えば、少なくとも70%以上、好ましくは80%以上、さらに好ましくは90%以上(例えば、95%、96%、97%、98%、99%以上)の相補性を有していればよい。 As noted above, the polynucleotide in the complementary strand is a polynucleotide that is at least partially complementary to the antisense nucleic acid. The base sequence of the polynucleotide in the complementary strand and the base sequence of the polynucleotide in the antisense nucleic acid do not need to be completely complementary as long as they can at least partially form a double strand. , for example, at least 70% or more, preferably 80% or more, more preferably 90% or more (eg, 95%, 96%, 97%, 98%, 99% or more) of complementarity.
本発明の1つの好ましい実施態様において、両ポリヌクレオチドは100%の相補性を有する。ここで、相補性は上記のように二本鎖形成領域(二本鎖形成領域全体)における相補性として算出する。この態様では、例えば、相補鎖のポリヌクレオチドの長さが、アンチセンス核酸のポリヌクレオチドの長さより長い場合には、アンチセンス核酸のポリヌクレオチド全体が相補鎖のポリヌクレオチドの一部分と完全に相補的であり、その完全に相補的な部分が二本鎖形成領域となる。また、相補鎖のポリヌクレオチドの長さが、アンチセンス核酸のポリヌクレオチドより短い場合には、相補鎖のポリヌクレオチド全体がアンチセンス核酸のポリヌクレオチドの一部分と完全に相補的であり、その完全に相補的な部分が二本鎖形成領域となる。そして、アンチセンス核酸のポリヌクレオチドと相補鎖のポリヌクレオチドが同じ長さを有する場合には、両ポリヌクレオチドは全体にわたって完全に相補的である。 In one preferred embodiment of the invention, both polynucleotides have 100% complementarity. Here, complementarity is calculated as complementarity in the double-strand forming region (entire double-strand forming region) as described above. In this aspect, for example, when the length of the polynucleotide of the complementary strand is longer than the length of the polynucleotide of the antisense nucleic acid, the entire polynucleotide of the antisense nucleic acid is completely complementary to a portion of the polynucleotide of the complementary strand. and its completely complementary portion becomes the double-strand forming region. In addition, when the length of the complementary strand polynucleotide is shorter than that of the antisense nucleic acid polynucleotide, the entire complementary strand polynucleotide is completely complementary to a portion of the antisense nucleic acid polynucleotide, and the complete The complementary portion becomes the double-strand forming region. When the polynucleotide of the antisense nucleic acid and the polynucleotide of the complementary strand have the same length, both polynucleotides are completely complementary throughout.
本発明では、アンチセンス核酸におけるポリヌクレオチドと相補鎖におけるポリヌクレオチドが、上述の相補性に基づいて「アニーリング」し、二本鎖を形成することができる。当業者であれば、2本の核酸鎖がアニーリングできる条件(温度、塩濃度等)を容易に決定することができる。 In the present invention, the polynucleotides in the antisense nucleic acid and the polynucleotides in the complementary strand can "anneal" to form a double strand based on the complementarity described above. A person skilled in the art can easily determine the conditions (temperature, salt concentration, etc.) under which two nucleic acid strands can be annealed.
相補鎖におけるポリヌクレオチドは、上述のように、化学修飾されていてもよいヌクレオチドを含む。RNA分解酵素等の核酸分解酵素に対する耐性が高いという観点から、相補鎖におけるポリヌクレオチドにおいて、ヌクレオチド(例えばデオキシリボヌクレオチドおよび/またはリボヌクレオチド)は、アンチセンス核酸に関して述べたような化学修飾を受けていてもよい。例えば、相補鎖のポリヌクレオチドが特定の細胞の核内に送達されるまで、RNaseA等のRNA分解酵素による分解を抑制しつつも、特定の細胞内においてはRNaseHにより該ポリヌクレオチドが分解されることにより、アンチセンス効果を発揮し易いという観点から、相補鎖におけるポリヌクレオチドは、核酸類似体を含んでいてもよい。 The polynucleotides in the complementary strand contain nucleotides that may be chemically modified, as described above. From the viewpoint of high resistance to nucleases such as RNases, in the polynucleotide in the complementary strand, nucleotides (e.g., deoxyribonucleotides and/or ribonucleotides) are chemically modified as described for antisense nucleic acids. good too. For example, until the polynucleotide of the complementary strand is delivered to the nucleus of a specific cell, the polynucleotide is degraded by RNaseH in a specific cell while suppressing the degradation by an RNA degrading enzyme such as RNaseA. The polynucleotide in the complementary strand may contain a nucleic acid analogue, from the viewpoint that antisense effects are likely to be exerted.
化学修飾、例えば核酸類似体の数や位置は、ある実施形態における核酸複合体が奏するアンチセンス効果等に影響を与える場合もあるため、相補鎖のポリヌクレオチドにおける核酸類似体の数及び化学修飾の位置には好ましい態様が存在する。この好ましい態様は、化学修飾対象となる核酸の種類、配列等によっても異なるため、一概には言えないが、前述のアンチセンス核酸におけるポリヌクレオチド同様に、化学修飾後、例えば核酸類似体導入後の核酸複合体が有するアンチセンス効果を測定することにより特定することができる。 Chemical modifications, such as the number and positions of nucleic acid analogues, may affect the antisense effect of a nucleic acid complex in certain embodiments. There are preferred aspects of the position. Since this preferred embodiment differs depending on the type, sequence, etc. of the nucleic acid to be chemically modified, it cannot be generalized. It can be identified by measuring the antisense effect of the nucleic acid complex.
本発明の1つの実施態様において、相補鎖におけるポリヌクレオチドは、アンチセンス核酸の5’ウィング領域及び/又は3’ウィング領域に対して相補的な領域に、化学修飾ヌクレオチド、例えば核酸類似体を有する。 In one embodiment of the invention, the polynucleotide in the complementary strand has chemically modified nucleotides, such as nucleic acid analogues, in the region complementary to the 5' wing region and/or 3' wing region of the antisense nucleic acid. .
相補鎖におけるポリヌクレオチドの長さは特に制限されないが、少なくとも8塩基であり、少なくとも10塩基であり、少なくとも12塩基であり、少なくとも13塩基であり、少なくとも14塩基であり、少なくとも15塩基、または少なくとも16塩基である。前記長さは、好ましくは100塩基以下、35塩基以下、25塩基以下、20塩基以下、19塩基以下、18塩基以下または17塩基以下であることができる。前記長さの範囲は、好ましくは10~35塩基であり、より好ましくは12~25塩基であり、さらに好ましくは13~20塩基である。通常、酵素耐性に関する効果や、費用、合成収率等の他の要素に応じて、長さは選択される。 The length of the polynucleotide in the complementary strand is not particularly limited, but is at least 8 bases, at least 10 bases, at least 12 bases, at least 13 bases, at least 14 bases, at least 15 bases, or at least 16 bases. Said length may preferably be 100 bases or less, 35 bases or less, 25 bases or less, 20 bases or less, 19 bases or less, 18 bases or less or 17 bases or less. The length range is preferably 10 to 35 bases, more preferably 12 to 25 bases, even more preferably 13 to 20 bases. The length is usually selected according to its effect on enzyme resistance and other factors such as cost and synthetic yield.
本発明の1つの実施形態において、アンチセンス核酸におけるポリヌクレオチドの長さと相補鎖におけるポリヌクレオチドの長さは同一であってもよく、異なっていてもよい。 In one embodiment of the present invention, the length of the polynucleotide in the antisense nucleic acid and the length of the polynucleotide in the complementary strand may be the same or different.
本発明の1つの実施形態において、アンチセンス核酸におけるポリヌクレオチドの長さは、相補鎖におけるポリヌクレオチドの長さよりも大きい。 In one embodiment of the invention, the length of the polynucleotide in the antisense nucleic acid is greater than the length of the polynucleotide in the complementary strand.
本発明の他の実施形態において、アンチセンス核酸におけるポリヌクレオチドの長さは、相補鎖におけるポリヌクレオチドの長さよりも小さい。 In other embodiments of the invention, the length of the polynucleotide in the antisense nucleic acid is less than the length of the polynucleotide in the complementary strand.
さらに、本発明の1つの実施態様において、相補鎖におけるポリヌクレオチドは、アンチセンス核酸におけるポリヌクレオチドに対して少なくとも1つのミスマッチを含む。 Furthermore, in one embodiment of the invention, the polynucleotide in the complementary strand contains at least one mismatch to the polynucleotide in the antisense nucleic acid.
「ミスマッチ」とは、アンチセンス核酸におけるポリヌクレオチドと相補鎖におけるポリヌクレオチドとの間のアニーリングによって形成された二本鎖形成領域(以下、単に「二本鎖形成領域」とも呼ぶ)内のある位置において、両ポリヌクレオチド鎖のヌクレオチド間でワトソン-クリック型塩基対が形成されないことをいう。 A "mismatch" is a position within a double-strand forming region formed by annealing between a polynucleotide in an antisense nucleic acid and a polynucleotide in a complementary strand (hereinafter also simply referred to as a "double-strand forming region"). In the above, it means that Watson-Crick base pairs are not formed between the nucleotides of both polynucleotide chains.
ただし、ここでいうミスマッチは、アンチセンス核酸のポリヌクレオチドと相補鎖のポリヌクレオチドが二本鎖形成領域内で同一の数のヌクレオチドおよび/または核酸類似体(以下、まとめて「ヌクレオチド等」とも呼ぶ)を有し、上記位置を除く全ての位置において塩基対を形成しているにもかかわらずに、当該位置でのみ塩基対が形成されないことを意味する。従って、これは、オーバーハングや、二本鎖形成領域内の両ポリヌクレオチドの長さの相違に起因して生じるバルジのような構造は含まない。なおこれは、ミスマッチとオーバーハングやバルジとを区別することを意図するものであり、本発明の核酸複合体において、ミスマッチとバルジ(および/またはオーバーハング)が同時に存在することを妨げるものではない。 However, the mismatch here means that the polynucleotide of the antisense nucleic acid and the polynucleotide of the complementary strand have the same number of nucleotides and / or nucleic acid analogues (hereinafter collectively referred to as "nucleotides etc." ), and although base pairs are formed at all positions other than the above position, base pairs are not formed only at the position. Therefore, it does not include overhangs or bulge-like structures caused by differences in length of both polynucleotides within the duplex forming region. This is intended to distinguish between mismatches and overhangs or bulges, and does not prevent the simultaneous presence of mismatches and bulges (and/or overhangs) in the nucleic acid complex of the present invention. .
従って、「相補鎖におけるポリヌクレオチドは、アンチセンス核酸におけるポリヌクレオチドに対して少なくとも1つのミスマッチを含む」とは、アンチセンス核酸のポリヌクレオチドと相補鎖のポリヌクレオチドが二本鎖形成領域内において同一の長さを有し、かつ、後者が、両ポリヌクレオチド間でワトソン-クリック型塩基対を形成しないようなヌクレオチド等を当該二本鎖形成領域内において少なくとも1つ含むことを意味する。ミスマッチの例としては、A対G、C対A、U対C、A対A、G対G、C対C等や、リボヌクレオチドを用いたU対G、U対C、U対T等が挙げられるが、同様に、例えば、非塩基残基対ヌクレオチド等、非環状残基対ヌクレオチド等も含まれる。広い意味において、ここで用いられるミスマッチには、特定の位置における二本鎖の熱力学的安定性がその位置におけるワトソン-クリック型塩基対の熱力学的安定性よりも低くなるように、その位置またはその近傍での熱力学的安定性を減少させる、その位置での任意の変換も含まれる。 Therefore, "the polynucleotide in the complementary strand contains at least one mismatch with respect to the polynucleotide in the antisense nucleic acid" means that the polynucleotide of the antisense nucleic acid and the polynucleotide of the complementary strand are identical in the double-strand forming region. and the latter contains at least one such nucleotide in the double-strand forming region that does not form a Watson-Crick base pair between both polynucleotides. Examples of mismatches include A vs. G, C vs. A, U vs. C, A vs. A, G vs. G, C vs. C, etc., and U vs. G, U vs. C, U vs. T, etc. using ribonucleotides. but also includes, for example, non-basic residues to nucleotides, etc., acyclic residues to nucleotides, etc. In a broad sense, a mismatch as used herein includes a mismatch at a particular position such that the thermodynamic stability of the duplex at that position is lower than the thermodynamic stability of the Watson-Crick base pair at that position. Also included is any transformation at that position that reduces the thermodynamic stability at or near it.
本発明の1つの実施態様において、上記核酸複合体は、相補鎖におけるポリヌクレオチドが、アンチセンス核酸におけるポリヌクレオチドに対して少なくとも1つのミスマッチを含む。ミスマッチの数は、二本鎖核酸の形成が妨げられない範囲内であれば特に制限はされず、ミスマッチを複数個含む場合には、各ミスマッチは互いに離れて存在していてもよく、または連続して存在していても、両者が組み合わされて存在していてもよい。本発明の1つの実施態様では、相補鎖におけるポリヌクレオチドは、アンチセンス核酸におけるポリヌクレオチドに対して1つのミスマッチを含む。 In one embodiment of the invention, the nucleic acid complex contains at least one mismatch in the polynucleotide in the complementary strand to the polynucleotide in the antisense nucleic acid. The number of mismatches is not particularly limited as long as it does not interfere with the formation of a double-stranded nucleic acid. It may exist as a combination of both. In one embodiment of the invention, the polynucleotide in the complementary strand contains one mismatch to the polynucleotide in the antisense nucleic acid.
ミスマッチの位置は、ミスマッチ構造を形成できる位置であれば特に制限はされない。 The position of the mismatch is not particularly limited as long as it can form a mismatch structure.
例えば、アンチセンス核酸のポリヌクレオチドおよび相補鎖のポリヌクレオチドがそれぞれ10~35塩基の長さを有する場合には、例えば、二本鎖形成領域の5’末端(アンチセンス核酸のポリヌクレオチドの上記領域内の5’末端)から数えて、2~15番目の位置に、例えば6~11番目(例えば6、7、8、9、10または11番目)の位置にミスマッチを導入することができる。
For example, when the polynucleotide of the antisense nucleic acid and the polynucleotide of the complementary strand each have a length of 10 to 35 bases, for example, the 5′ end of the double strand forming region (the above region of the polynucleotide of the antisense nucleic acid Mismatches can be introduced at
本発明の核酸複合体が少なくとも1つのミスマッチを有する場合、ミスマッチの部分、すなわち、二本鎖が形成されていない部分において、DNaseまたはRNaseの攻撃を適度に受けるため、細胞内または生体内において、標的mRNAに送達される頃までの間に、当該相補鎖のみが適度に切断されて(相補鎖のポリヌクレオチドがデオキシリボヌクレオチド、リボヌクレオチドまたはこれらの組み合わせのいずれの場合であっても)、アンチセンス核酸のポリヌクレオチドのみとなり、当該アンチセンス核酸のポリヌクレオチドが標的mRNAと良好に二本鎖を形成するのを促進することも考えられる。 When the nucleic acid complex of the present invention has at least one mismatch, the portion of the mismatch, that is, the portion where the double strand is not formed, is moderately attacked by DNase or RNase. By the time it is delivered to the target mRNA, only the complementary strand is moderately cleaved (whether the polynucleotide of the complementary strand is deoxyribonucleotides, ribonucleotides, or a combination thereof) to form an antisense It is also conceivable that the polynucleotide of the antisense nucleic acid is only a polynucleotide of the nucleic acid, and that the polynucleotide of the antisense nucleic acid promotes good double-strand formation with the target mRNA.
上記のようなミスマッチを有する場合、アンチセンス核酸におけるポリヌクレオチドと相補鎖におけるポリヌクレオチドは完全に相補的ではなくなるが、上記のように、本発明ではこのように両者が完全に相補的でなくてもよい。本発明の1つの好ましい態様では、相補鎖のポリヌクレオチドがミスマッチを含む場合、両ポリヌクレオチドは、ミスマッチ部分を除く二本鎖形成領域において、100%の相補性を有する。 When there is a mismatch as described above, the polynucleotide in the antisense nucleic acid and the polynucleotide in the complementary strand are not completely complementary. good too. In one preferred embodiment of the present invention, when complementary polynucleotides contain mismatches, both polynucleotides have 100% complementarity in the double-strand forming region excluding the mismatched portion.
本発明の別の実施態様において、相補鎖におけるポリヌクレオチドは、ミスマッチを含まない。 In another embodiment of the invention, the polynucleotides in the complementary strand do not contain mismatches.
また、例えば相補鎖におけるポリヌクレオチドを適度に切断するという観点から、上記のようなミスマッチを形成させる代わりに、または、ミスマッチ形成に加えて、相補鎖におけるポリヌクレオチドに上述のように、少なくとも1つのリボヌクレオチドを含ませることも可能である。リボヌクレオチドは概して、デオキシリボヌクレオチドや化学修飾ヌクレオチド(例えば核酸類似体)よりも核酸分解酵素に対する耐性が弱いため、相補鎖においてリボヌクレオチド導入部位を起点としたポリヌクレオチドの切断が適度に促進され得ると考えられる。 Also, for example, from the viewpoint of moderately cleaving the polynucleotide in the complementary strand, instead of forming mismatches as described above, or in addition to mismatch formation, the polynucleotide in the complementary strand may be added with at least one It is also possible to include ribonucleotides. Since ribonucleotides generally have weaker resistance to nucleolytic enzymes than deoxyribonucleotides and chemically modified nucleotides (for example, nucleic acid analogues), cleavage of polynucleotides starting from the ribonucleotide introduction site in the complementary strand can be moderately promoted. Conceivable.
従って、本発明の1つの実施態様において、相補鎖におけるポリヌクレオチドは、構成単位として1つまたは複数のリボヌクレオチドを含む。本発明のさらなる実施態様において、相補鎖におけるポリヌクレオチドは、アンチセンス核酸におけるポリヌクレオチドに対して少なくとも1つのミスマッチを含み、かつ、構成単位としてリボヌクレオチドを含む。本発明のさらに1つの実施態様において、相補鎖におけるポリヌクレオチドは、アンチセンス核酸におけるポリヌクレオチドに対して少なくとも1つのミスマッチを含み、かつ、リボヌクレオチドを構成単位として含み、かつ、当該リボヌクレオチドの少なくとも1つが当該ミスマッチを形成する。例えば、相補鎖におけるポリヌクレオチドは、アンチセンス核酸におけるポリヌクレオチドに対して、G対Uのミスマッチ(アンチセンス核酸がGで、相補鎖がU)を1つ含むことができる。 Thus, in one embodiment of the invention, the polynucleotides in the complementary strand comprise one or more ribonucleotides as building blocks. In a further embodiment of the invention, the polynucleotide in the complementary strand contains at least one mismatch to the polynucleotide in the antisense nucleic acid and contains ribonucleotides as building blocks. In a further embodiment of the present invention, the polynucleotide in the complementary strand contains at least one mismatch to the polynucleotide in the antisense nucleic acid, and contains ribonucleotides as constituent units, and at least One forms the mismatch. For example, the polynucleotide in the complementary strand can contain one G to U mismatch (G in the antisense nucleic acid and U in the complementary strand) to the polynucleotide in the antisense nucleic acid.
相補鎖がリボヌクレオチドを含む場合、当該リボヌクレオチドの位置は、特に制限はされない。上記ポリヌクレオチドが10~35塩基の長さを有する場合には、5’末端から数えて、1~35番目、例えば2~30番目、3~25番目、4~20番目、5~15番目、6~11番目(例えば、6、7、8、9、10または11番目)の位置にリボヌクレオチドを含むことができる。 When the complementary strand contains ribonucleotides, the positions of the ribonucleotides are not particularly limited. When the polynucleotide has a length of 10 to 35 bases, counting from the 5' end, 1st to 35th, for example, 2nd to 30th, 3rd to 25th, 4th to 20th, 5th to 15th, Ribonucleotides at positions 6-11 (eg, 6, 7, 8, 9, 10 or 11) can be included.
また、本発明の1つの実施態様において、相補鎖におけるポリヌクレオチドは少なくとも1つのバルジを含む。 Also, in one embodiment of the invention, the polynucleotide in the complementary strand comprises at least one bulge.
ここで、「バルジ」とは、アンチセンス核酸のポリヌクレオチドと相補鎖のポリヌクレオチドとの間のアニーリングによって形成された二本鎖領域(以下、単に「二本鎖領域」とも呼ぶ)内で、後者に対応する1個の塩基または連続する2個以上の塩基が前者に不足していることにより生じる、塩基対を形成せずに二本鎖核酸から外部に飛び出した後者ポリヌクレオチド内のヌクレオチド(および/または化学修飾ヌクレオチド)から形成されるふくらみ構造を意味する。 Here, the "bulge" is a double-stranded region formed by annealing between the polynucleotide of the antisense nucleic acid and the polynucleotide of the complementary strand (hereinafter also simply referred to as "double-stranded region"). Nucleotides in the latter polynucleotide ( and/or chemically modified nucleotides).
バルジの数は、二本鎖の形成が可能な範囲内であれば特に制限はされない。本発明の1つの実施態様では、相補鎖におけるポリヌクレオチドは1~4つのバルジ、例えば、1~3つのバルジを含むことができる。本発明のさらなる1つの実施態様において、相補鎖におけるポリヌクレオチドは、1つのバルジを含む。 The number of bulges is not particularly limited as long as it allows the formation of double strands. In one embodiment of the invention, the polynucleotide in the complementary strand can contain 1-4 bulges, eg, 1-3 bulges. In a further embodiment of the invention the polynucleotide in the complementary strand comprises one bulge.
バルジの位置は、バルジ構造を形成できる位置であれば特に制限はされない。例えば、アンチセンス核酸のポリヌクレオチドおよび相補鎖のポリヌクレオチドがそれぞれ10~35塩基の長さを有する場合には、例えば、二本鎖形成領域の5’末端(アンチセンス核酸のポリヌクレオチドの上記領域の5’末端)から数えて、2~15番目の位置に、例えば6~12番目(例えば6、7、8、9、10、11または12番目)の位置になるように、相補鎖のポリヌクレオチドの対応の位置にバルジを導入することができる。
The position of the bulge is not particularly limited as long as the bulge structure can be formed. For example, when the polynucleotide of the antisense nucleic acid and the polynucleotide of the complementary strand each have a length of 10 to 35 bases, for example, the 5′ end of the double strand forming region (the above region of the polynucleotide of the antisense
バルジを構成するヌクレオチド等の数(アンチセンス核酸のポリヌクレオチドと塩基対を形成していないヌクレオチドの数)は、バルジ構造を形成できる数であれば特に制限はされない。本発明の1つの実施態様において、上記バルジは、1つのバルジあたり1~7つ、例えば、1~5つまたは2~4つのヌクレオチド等で構成されることができる。 The number of nucleotides constituting the bulge (the number of nucleotides not forming base pairs with the polynucleotide of the antisense nucleic acid) is not particularly limited as long as it can form a bulge structure. In one embodiment of the invention, the bulge can consist of 1-7, such as 1-5 or 2-4 nucleotides per bulge.
複数のバルジを有する場合、各バルジは、同一の数のヌクレオチド等で構成されていても、あるいは、各バルジはそれぞれ独立に異なる数のヌクレオチド等で構成されていてもよい。 When a plurality of bulges are provided, each bulge may be composed of the same number of nucleotides or the like, or each bulge may be composed of independently different numbers of nucleotides or the like.
本発明の1つの実施態様において、上記バルジは、ヌクレオチドおよび/または修飾ヌクレオチドから構成される。 In one embodiment of the invention, the bulge is composed of nucleotides and/or modified nucleotides.
本発明のさらなる1つの実施態様において、上記バルジを構成するヌクレオチドとしては、デオキシリボヌクレオチドおよび/またはリボヌクレオチド(いずれも修飾されていても、修飾されていなくてもよい)が使用される。好ましくは、上記デオキシリボヌクレオチドおよびリボヌクレオチドは化学修飾されていない。 In a further embodiment of the present invention, deoxyribonucleotides and/or ribonucleotides (both of which may or may not be modified) are used as the nucleotides constituting the bulge. Preferably, said deoxyribonucleotides and ribonucleotides are not chemically modified.
当業者であれば、アンチセンス核酸におけるポリヌクレオチドの種類や塩基配列に応じて、バルジが形成されるように、相補鎖におけるポリヌクレオチドの構成単位を適宜選択することが可能である。 A person skilled in the art can appropriately select the constituent unit of the polynucleotide in the complementary strand so as to form a bulge according to the type and base sequence of the polynucleotide in the antisense nucleic acid.
本発明の1つの好ましい実施態様において、上記バルジを構成するヌクレオチドは、その一部または全部がリボヌクレオチド、好ましくはウラシル(U)である。より好ましくは、上記バルジを構成するヌクレオチドは、その一部または全部が、化学修飾されていないリボヌクレオチド、好ましくは化学修飾されていないウラシル(U)である。 In one preferred embodiment of the present invention, part or all of the nucleotides constituting the bulge are ribonucleotides, preferably uracil (U). More preferably, part or all of the nucleotides constituting the bulge are chemically unmodified ribonucleotides, preferably chemically unmodified uracil (U).
相補鎖におけるポリヌクレオチドがバルジを含む本発明の核酸複合体は、バルジ構造の部分(すなわち、二本鎖が形成されていない部分)において、DNaseまたはRNaseの攻撃を適度に受けるため、細胞内または生体内において、標的mRNAに送達される頃までの間に、当該相補鎖のみが適度に切断されて(相補鎖のポリヌクレオチドがデオキシリボヌクレオチド、リボヌクレオチドまたはこれらの組み合わせのいずれの場合であっても)、アンチセンス核酸のポリヌクレオチドのみとなり、当該アンチセンス核酸のポリヌクレオチドが標的mRNAと良好に二本鎖を形成するのを促進すると考えられる。 The nucleic acid complex of the present invention, in which the polynucleotide in the complementary strand contains a bulge, is moderately attacked by DNase or RNase in the portion of the bulge structure (that is, the portion where the double strand is not formed). In vivo, only the complementary strand is moderately cleaved by the time it is delivered to the target mRNA (regardless of whether the polynucleotide of the complementary strand is deoxyribonucleotide, ribonucleotide, or a combination thereof) ), resulting in only the polynucleotide of the antisense nucleic acid, which is thought to promote good double-stranded formation of the polynucleotide of the antisense nucleic acid with the target mRNA.
なお、相補鎖におけるポリヌクレオチドは少なくとも1つのバルジを含む場合、上記の相補性は、バルジ構造部分を二本鎖形成領域から除いた後に算出する。すなわち、上記相補性の算出の際、バルジ構造部分は二本鎖形成領域に含めない。また、上記のように、アンチセンス核酸と相補鎖は、本発明の1つの好ましい実施態様において、両ポリヌクレオチドは100%の相補性を有する。この態様では、例えば、相補鎖のポリヌクレオチド(バルジ形成部分を除く)の長さが、アンチセンス核酸のポリヌクレオチドの長さより長い場合には、アンチセンス核酸のポリヌクレオチド全体が相補鎖のポリヌクレオチドの一部分と完全に相補的であり(バルジ形成部分を除く)、その完全に相補的な部分が二本鎖形成領域となる。また、相補鎖のポリヌクレオチド(バルジ形成部分を除く)の長さが、アンチセンス核酸のポリヌクレオチドより短い場合には、相補鎖のポリヌクレオチド全体(バルジ形成部分を除く)がアンチセンス核酸のポリヌクレオチドの一部分と完全に相補的であり、その完全に相補的な部分が二本鎖形成領域となる。そして、アンチセンス核酸のポリヌクレオチドと相補鎖のポリヌクレオチド(バルジ形成部分を除く)が同じ長さを有する場合には、バルジ構造部分を除いて両ポリヌクレオチドは全体にわたって完全に相補的である。 When the polynucleotide in the complementary strand contains at least one bulge, the above complementarity is calculated after excluding the bulge structure portion from the double-strand forming region. That is, the bulge structure portion is not included in the double-strand forming region when calculating the above complementarity. Also, as noted above, the antisense nucleic acid and the complementary strand have 100% complementarity in one preferred embodiment of the present invention. In this aspect, for example, when the length of the complementary polynucleotide (excluding the bulge-forming portion) is longer than the length of the polynucleotide of the antisense nucleic acid, the entire polynucleotide of the antisense nucleic acid is the complementary polynucleotide (excluding the bulge-forming portion), and the fully complementary portion becomes the double-strand forming region. In addition, when the length of the complementary strand polynucleotide (excluding the bulge-forming portion) is shorter than that of the antisense nucleic acid, the entire complementary strand polynucleotide (excluding the bulge-forming portion) is the antisense nucleic acid polynucleotide. It is completely complementary to a part of the nucleotide, and the completely complementary part becomes the double-strand forming region. When the polynucleotide of the antisense nucleic acid and the polynucleotide of the complementary strand (excluding the bulge-forming portion) have the same length, both polynucleotides are completely complementary except for the bulge-structure portion.
以上のように、上記アンチセンス核酸とその相補鎖を含む二本鎖核酸を用いた場合、当該二本鎖核酸が、至適な酵素耐性を有し、その結果、PS型構造を有するアンチセンス核酸と同等またはそれ以上の標的転写産物の発現抑制効果、標的細胞増殖の抑制効果を有することが見出された。そして、上記二本鎖核酸複合体では、種々のポリヌクレオチドを相補鎖として使用することができる。 As described above, when a double-stranded nucleic acid containing the antisense nucleic acid and its complementary strand is used, the double-stranded nucleic acid has optimal enzyme resistance, and as a result, antisense having a PS structure. It was found to have an effect of suppressing the expression of target transcripts and an effect of suppressing target cell growth equal to or greater than those of nucleic acids. Various polynucleotides can be used as complementary strands in the double-stranded nucleic acid complex.
さらに、本発明では、ある特定のポリヌクレオチドを相補鎖として用いた場合、例えば、相補鎖のポリヌクレオチドがアンチセンス核酸に対して少なくとも1つのミスマッチを含む場合、および相補鎖のポリヌクレオチドがデオキシリボヌクレオチドとリボヌクレオチドを交互に含む場合に、他のポリヌクレオチドを相補鎖として使用した場合に比べて、当該核酸複合体の副作用がさらに低減すること、具体的には肝毒性(特にAST値)がさらに低減することも見出された。 Furthermore, in the present invention, when a specific polynucleotide is used as the complementary strand, for example, when the complementary strand contains at least one mismatch to the antisense nucleic acid, and when the complementary strand contains deoxyribonucleotides and ribonucleotides alternately, side effects of the nucleic acid complex are further reduced compared to the case where other polynucleotides are used as complementary strands, specifically hepatotoxicity (especially AST value) is further reduced It was also found to reduce
また、本発明の1つの実施態様において、上記核酸複合体はオーバーハングを有することができる。 Moreover, in one embodiment of the present invention, the nucleic acid complex can have overhangs.
ここで、「オーバーハング」とは、一方の鎖が二本鎖を形成する相補性の他鎖の末端を超えて伸びる1本鎖領域から生じる、末端塩基対非形成型ヌクレオチド(または化学修飾ヌクレオチド)のことをいう。各オーバーハングは、少なくとも1つのヌクレオチド(または化学修飾ヌクレオチド)を含む。好ましくは、各オーバーハングは、2ヌクレオチドオーバーハングである。オーバーハングを構成するヌクレオチドは任意に選択することができる。オーバーハングのヌクレオチドは、標的転写産物と塩基対を形成してもしなくてもよい。上記2ヌクレオチドオーバーハングの例としては、UU、TT、AA、GG、CC、AC、CA、AG、GA、GCおよびCGが挙げられるが、これらに限定はされない。 Here, an "overhang" is a terminal base-paired non-forming nucleotide (or chemically modified nucleotide ). Each overhang contains at least one nucleotide (or chemically modified nucleotide). Preferably each overhang is a two nucleotide overhang. The nucleotides that make up the overhang can be chosen arbitrarily. The overhanging nucleotides may or may not base pair with the target transcript. Examples of such two nucleotide overhangs include, but are not limited to, UU, TT, AA, GG, CC, AC, CA, AG, GA, GC and CG.
オーバーハングの位置としては、アンチセンス核酸におけるポリヌクレオチドの5’末端、アンチセンス核酸におけるポリヌクレオチドの3’末端、アンチセンス核酸におけるポリヌクレオチドの5’末端および3’末端、相補鎖におけるポリヌクレオチドの5’末端、相補鎖におけるポリヌクレオチドの3’末端、相補鎖におけるポリヌクレオチドの5’末端および3’末端、アンチセンス核酸のポリヌクレオチドの5’末端および相補鎖のポリヌクレオチドの5’末端、またはアンチセンス核酸のポリヌクレオチドの3’末端および相補鎖のポリヌクレオチドの3’末端が可能である。 The position of the overhang includes the 5' end of the polynucleotide in the antisense nucleic acid, the 3' end of the polynucleotide in the antisense nucleic acid, the 5' and 3' ends of the polynucleotide in the antisense nucleic acid, and the polynucleotide in the complementary strand. the 5' end of the polynucleotide on the complementary strand, the 3' end of the polynucleotide on the complementary strand, the 5' and 3' ends of the polynucleotide on the complementary strand, the 5' end of the polynucleotide on the antisense nucleic acid and the 5' end of the polynucleotide on the complementary strand, or The 3' end of the polynucleotide of the antisense nucleic acid and the 3' end of the polynucleotide of the complementary strand are possible.
本発明の他の実施態様において、上記核酸複合体はオーバーハングを含まない。 In another embodiment of the invention, the nucleic acid complex does not contain overhangs.
また、本発明の1つの実施態様において、相補鎖におけるポリヌクレオチドは、デオキシリボヌクレオチドと任意に核酸類似体とを構成単位として少なくとも含む。上記デオキシリボヌクレオチドは化学修飾されていても、化学修飾されていなくてもよい。本発明の1つの実施態様において、相補鎖におけるポリヌクレオチドは、化学修飾されていてもよいデオキシリボヌクレオチドと任意に核酸類似体のみを構成単位として含む。本発明の別の実施態様において、相補鎖におけるポリヌクレオチドは、化学修飾されたデオキシリボヌクレオチドと任意に核酸類似体のみを構成単位として含む。 Also, in one embodiment of the present invention, the polynucleotide in the complementary strand comprises at least deoxyribonucleotides and optionally nucleic acid analogues as constituent units. The above deoxyribonucleotides may or may not be chemically modified. In one embodiment of the present invention, the polynucleotide in the complementary strand comprises deoxyribonucleotides, which may be chemically modified, and optionally nucleic acid analogues only as building blocks. In another embodiment of the invention, the polynucleotides in the complementary strand comprise only chemically modified deoxyribonucleotides and optionally nucleic acid analogues as building blocks.
さらに、本発明の1つの実施態様において、相補的な核酸鎖におけるポリヌクレオチドは、核酸類似体を含む。本発明の他の実施態様において、相補的な核酸鎖におけるポリヌクレオチドは、核酸類似体を含まない。また、本発明の別の実施態様において、相補的な核酸鎖におけるポリヌクレオチドは、リボヌクレオチドを含まない。本発明のさらに別の実施態様において、相補的な核酸鎖におけるポリヌクレオチドは、デオキシリボヌクレオチドを含まない。 Furthermore, in one embodiment of the invention, the polynucleotides in the complementary nucleic acid strands comprise nucleic acid analogues. In other embodiments of the invention, the polynucleotides in the complementary nucleic acid strand do not contain nucleic acid analogues. Also, in another embodiment of the invention, the polynucleotides in the complementary nucleic acid strand do not contain ribonucleotides. In yet another embodiment of the invention, the polynucleotides in the complementary nucleic acid strand do not contain deoxyribonucleotides.
なお、上述のように、本発明の1つの実施態様において、相補鎖は、デオキシリボヌクレオチドのみからなる。この態様でも、上記二本鎖核酸複合体は標的転写産物のレベルを良好に抑制できるが、これは以下の機構によるものと考えられる:アンチセンス核酸におけるポリヌクレオチドと相補的な核酸鎖におけるポリヌクレオチドにより形成されたDNA-DNA二本鎖が標的転写産物に送達されるまでの間にDNaseに認識され、当該DNaseによって相補的な核酸鎖におけるポリヌクレオチドが分解される。その後、残ったアンチセンス活性部分におけるポリヌクレオチドが標的転写産物とDNA-RNA二本鎖を形成し、RNaseHによってこの部分が認識され、分解される。 In addition, as described above, in one embodiment of the present invention, the complementary strand consists only of deoxyribonucleotides. In this embodiment, the double-stranded nucleic acid complex can also successfully suppress target transcript levels, which is believed to be due to the following mechanism: a polynucleotide in the antisense nucleic acid and a polynucleotide in the complementary nucleic acid strand. The DNA-DNA duplex formed by is recognized by DNase before it is delivered to the target transcript, and the DNase degrades the polynucleotide in the complementary nucleic acid strand. Polynucleotides in the remaining antisense-active portion then form DNA-RNA duplexes with target transcripts, which are then recognized and degraded by RNaseH.
本発明の1つの実施態様において、上記アンチセンス核酸または上記二本鎖核酸複合体は、細胞または哺乳動物において標的遺伝子の発現を減少させるためのアンチセンス核酸または核酸複合体である。また、本発明のさらなる実施態様において、上記アンチセンス核酸または核酸複合体は、標的細胞(好ましくは癌細胞)内の標的遺伝子(好ましくはがん遺伝子)の発現を抑制することにより、当該標的細胞の増殖を抑制するためのアンチセンス核酸または核酸複合体である。典型的には、上記標的遺伝子の発現亢進を伴う細胞を標的細胞とすることができる。また、本発明のさらなる実施態様において、上記アンチセンス核酸または核酸複合体は、標的組織および/または標的部位において、標的遺伝子の発現を抑制するためのアンチセンス核酸または核酸複合体である。 In one embodiment of the invention, said antisense nucleic acid or said double-stranded nucleic acid complex is an antisense nucleic acid or nucleic acid complex for reducing expression of a target gene in a cell or mammal. In a further embodiment of the present invention, the antisense nucleic acid or nucleic acid complex suppresses the expression of target genes (preferably oncogenes) in target cells (preferably cancer cells), antisense nucleic acid or nucleic acid complex for inhibiting the proliferation of Typically, the target cell can be a cell with increased expression of the target gene. In a further embodiment of the present invention, the antisense nucleic acid or nucleic acid complex is an antisense nucleic acid or nucleic acid complex for suppressing target gene expression in a target tissue and/or target site.
本発明のさらなる1つの実施態様において、アンチセンス核酸におけるポリヌクレオチドは、標的遺伝子mRNAのいずれかの領域に相補的なアンチセンス鎖である。本発明の1つの実施態様において、上記標的遺伝子はヒトbcl-2、ヒトBCR-ABLまたはヒトSTAT3である。 In a further embodiment of the invention, the polynucleotide in the antisense nucleic acid is the antisense strand complementary to any region of the target gene mRNA. In one embodiment of the invention, the target gene is human bcl-2, human BCR-ABL or human STAT3.
本発明の1つの実施態様において、上記アンチセンス核酸におけるポリヌクレオチドは、以下の(a)~(d)から選択されるポリヌクレオチドである:
(a)配列番号2、17、19または22で示される塩基配列を有するポリヌクレオチド、
(b)上記(a)のポリヌクレオチドと70%以上の配列同一性を有するポリヌクレオチド、
(c)上記(a)のポリヌクレオチドのうちの少数のヌクレオチドが置換し、欠失し、付加し及び/又は挿入されたポリヌクレオチド、
(d)上記(a)~(c)のいずれかのポリヌクレオチドを部分配列として含むポリヌクレオチド。In one embodiment of the present invention, the polynucleotide in the antisense nucleic acid is a polynucleotide selected from (a) to (d) below:
(a) a polynucleotide having a nucleotide sequence represented by SEQ ID NO: 2, 17, 19 or 22;
(b) a polynucleotide having 70% or more sequence identity with the polynucleotide of (a) above;
(c) a polynucleotide in which a small number of nucleotides of the polynucleotide of (a) have been substituted, deleted, added and/or inserted;
(d) A polynucleotide comprising any of the polynucleotides (a) to (c) above as a partial sequence.
上記(b)のポリヌクレオチドは、上記(a)のポリヌクレオチドの塩基配列と70%以上、好ましくは80%以上、より好ましくは85%以上、さらに好ましくは90%以上、特に好ましくは95%以上、例えば96%以上、97%以上、98%以上、99%以上又は99.5%以上の配列同一性を有する。好ましくは、上記(b)のポリヌクレオチドは、標的転写産物の発現抑制活性を有し、および/または副作用が低減されている。 The polynucleotide (b) is 70% or more, preferably 80% or more, more preferably 85% or more, still more preferably 90% or more, particularly preferably 95% or more of the base sequence of the polynucleotide (a) , eg, 96% or greater, 97% or greater, 98% or greater, 99% or greater, or 99.5% or greater, sequence identity. Preferably, the polynucleotide of (b) above has the activity of suppressing the expression of the target transcript and/or has reduced side effects.
上記(c)のポリヌクレオチドは、上記(a)のポリヌクレオチドのうちの少数の、好ましくは、1個~数個、例えば1、2、3、4、5、6、7、8、9または10個のヌクレオチドが置換し、欠失し、付加し及び/又は挿入されたポリヌクレオチドであることができる。好ましくは、上記(c)のポリヌクレオチドは、標的転写産物の発現抑制活性を有し、および/または副作用が低減されている。 The polynucleotide of (c) is a small number of the polynucleotides of (a), preferably one to several, such as 1, 2, 3, 4, 5, 6, 7, 8, 9 or It can be a polynucleotide in which 10 nucleotides have been replaced, deleted, added and/or inserted. Preferably, the polynucleotide of (c) above has the activity of suppressing the expression of the target transcript and/or has reduced side effects.
上記(d)のポリヌクレオチドは、上記(a)~(c)のいずれかのポリヌクレオチドを部分配列として含むポリヌクレオチドであり、好ましくは標的転写産物の発現抑制活性を有し、および/または副作用が低減されている。本発明の1つの実施態様において、上記(d)のポリヌクレオチドの長さは8~100塩基である。好ましくは、前記長さは、少なくとも10塩基であり、少なくとも12塩基であり、又は少なくとも13塩基である。前記長さは、好ましくは100塩基以下、35塩基以下、25塩基以下または20塩基以下であることができる。 The polynucleotide (d) above is a polynucleotide comprising any of the polynucleotides (a) to (c) above as a partial sequence, preferably has an activity to suppress the expression of a target transcript and/or has side effects is reduced. In one embodiment of the present invention, the length of the polynucleotide of (d) above is 8-100 bases. Preferably, said length is at least 10 bases, at least 12 bases, or at least 13 bases. Said length may preferably be 100 bases or less, 35 bases or less, 25 bases or less or 20 bases or less.
本明細書において、塩基配列に関する「配列同一性」とは、比較すべき2つ塩基配列の塩基ができるだけ多く一致するように両塩基配列を整列させ、一致した塩基数を全塩基数で除したものを百分率(%)で表したものである。上記整列の際には、必要に応じ、比較する2つの配列の一方又は双方に適宜ギャップを挿入する。このような配列の整列化は、例えばBLAST、FASTA、CLUSTAL W等の周知のプログラムを用いて行なうことができる(Karlin及びAltschul, Proc. Natl. Acad. Sci. U.S.A.,87:2264-2268, 1993; Altschulら, Nucleic Acids Res.,25:3389-3402, 1997)。ギャップが挿入される場合、上記全塩基数は、1つのギャップを1つの塩基として数えた塩基数となる。このようにして数えた全塩基数が、比較する2つの配列間で異なる場合には、同一性(%)は、長い方の配列の全塩基数で、一致した塩基数を除して算出される。 As used herein, the term "sequence identity" with respect to base sequences means that two base sequences to be compared are aligned so that as many bases as possible match each other, and the number of matched bases is divided by the total number of bases. is expressed as a percentage (%). In the above alignment, gaps are appropriately inserted in one or both of the two sequences to be compared, if necessary. Such sequence alignments can be performed using well-known programs such as BLAST, FASTA, CLUSTAL W (Karlin and Altschul, Proc. Natl. Acad. Sci. USA, 87: 2264-2268, 1993; Altschul et al., Nucleic Acids Res., 25:3389-3402, 1997). When a gap is inserted, the above total number of bases is the number of bases with one gap being counted as one base. If the total number of bases counted in this way differs between the two sequences being compared, the percent identity is calculated by dividing the number of matched bases by the total number of bases in the longer sequence. be.
通常、上述の化学修飾(例えば核酸類似体)の存在は、上記の配列同一性に影響を及ぼさない。 Generally, the presence of such chemical modifications (eg, nucleic acid analogs) does not affect the sequence identity.
本発明の1つの実施態様において、上記(ii)相補鎖におけるポリヌクレオチドは、以下の(a’)~(d’)から選択されるポリヌクレオチドである:
(a’)配列番号7~16、18、20、21および23のいずれか1つで示される塩基配列を有するポリヌクレオチド、
(b’)上記(a’)のポリヌクレオチドと70%以上の配列同一性を有するポリヌクレオチド、
(c’)上記(a’)のポリヌクレオチドのうちの少数のヌクレオチドが置換し、欠失し、付加し及び/又は挿入されたポリヌクレオチド、
(d’)上記(a’)~(c’)のいずれか1つのポリヌクレオチドを部分配列として含むポリヌクレオチド。In one embodiment of the present invention, the polynucleotide in (ii) the complementary strand is a polynucleotide selected from (a′) to (d′) below:
(a') a polynucleotide having a nucleotide sequence represented by any one of SEQ ID NOS: 7-16, 18, 20, 21 and 23;
(b') a polynucleotide having 70% or more sequence identity with the polynucleotide of (a') above;
(c') a polynucleotide in which a small number of nucleotides of the polynucleotide of (a') are substituted, deleted, added and/or inserted;
(d') A polynucleotide comprising any one of the polynucleotides (a') to (c') above as a partial sequence.
上記(b’)のポリヌクレオチドは、上記(a’)のポリヌクレオチドの塩基配列と70%以上、好ましくは80%以上、より好ましくは85%以上、さらに好ましくは90%以上、特に好ましくは95%以上、例えば96%以上、97%以上、98%以上、99%以上又は99.5%以上の配列同一性を有する。好ましくは、上記(b’)のポリヌクレオチドは、アンチセンス核酸と少なくとも一部が相補的であり、より好ましくはアンチセンス核酸と100%の相補性を有する。 The polynucleotide (b') is 70% or more, preferably 80% or more, more preferably 85% or more, still more preferably 90% or more, particularly preferably 95% or more of the base sequence of the polynucleotide (a'). % or greater, such as 96% or greater, 97% or greater, 98% or greater, 99% or greater or 99.5% or greater, sequence identity. Preferably, the polynucleotide of (b') above is at least partially complementary to the antisense nucleic acid, more preferably 100% complementary to the antisense nucleic acid.
上記(c’)のポリヌクレオチドは、上記(a’)のポリヌクレオチドのうちの少数の、好ましくは、1個~数個、例えば1、2、3、4、5、6、7、8、9または10個のヌクレオチドが置換し、欠失し、付加し及び/又は挿入されたポリヌクレオチドであることができる。好ましくは、上記(c’)のポリヌクレオチドは、アンチセンス核酸と少なくとも一部が相補的であり、より好ましくはアンチセンス核酸と100%の相補性を有する。 The polynucleotide of (c′) is a small number of the polynucleotides of (a′), preferably one to several, for example 1, 2, 3, 4, 5, 6, 7, 8, It can be a polynucleotide in which 9 or 10 nucleotides have been replaced, deleted, added and/or inserted. Preferably, the polynucleotide of (c') above is at least partially complementary to the antisense nucleic acid, more preferably 100% complementary to the antisense nucleic acid.
上記(d’)のポリヌクレオチドは、上記(a’)~(c’)のいずれかのポリヌクレオチドを部分配列として含むポリヌクレオチドであり、好ましくはアンチセンス核酸と少なくとも一部が相補的であり、より好ましくはアンチセンス核酸と100%の相補性を有する。本発明の1つの実施態様において、上記(d’)のポリヌクレオチドの長さは8~100塩基である。好ましくは、前記長さは、少なくとも10塩基であり、少なくとも12塩基であり、少なくとも13塩基であり、少なくとも14塩基であり、少なくとも15塩基、または少なくとも16塩基である。前記長さは、好ましくは100塩基以下、45塩基以下、35塩基以下、30塩基以下、25塩基以下、24塩基以下、23塩基以下、22塩基以下、21塩基以下または20塩基以下であることができる。 The polynucleotide (d') above is a polynucleotide comprising any of the polynucleotides (a') to (c') above as a partial sequence, and is preferably at least partially complementary to the antisense nucleic acid. , more preferably 100% complementary to the antisense nucleic acid. In one embodiment of the present invention, the length of the polynucleotide of (d') is 8-100 bases. Preferably, said length is at least 10 bases, at least 12 bases, at least 13 bases, at least 14 bases, at least 15 bases, or at least 16 bases. The length is preferably 100 bases or less, 45 bases or less, 35 bases or less, 30 bases or less, 25 bases or less, 24 bases or less, 23 bases or less, 22 bases or less, 21 bases or less, or 20 bases or less. can.
本発明の1つの実施態様において、上記アンチセンス核酸または二本鎖核酸複合体は、標的部位への送達を目的としたリガンドを、例えば1~10個、好ましくは1~6個、例えば1、2、3、4または5個含むことができる。上記アンチセンス核酸または二本鎖核酸複合体が複数のリガンドを含む場合、それらのリガンドは同じであってもよく、あるいは各々互いに異なっていてもよい。 In one embodiment of the present invention, the antisense nucleic acid or double-stranded nucleic acid complex comprises, for example, 1 to 10, preferably 1 to 6, such as 1, 2, 3, 4 or 5 may be included. When the antisense nucleic acid or double-stranded nucleic acid complex contains multiple ligands, the ligands may be the same or different from each other.
上記二本鎖核酸複合体がリガンドを有する場合、例えば、上記相補鎖にリガンド分子が結合していても良い。 When the double-stranded nucleic acid complex has a ligand, for example, a ligand molecule may be bound to the complementary strand.
本発明において、「リガンド」とは、レセプターと結合する能力を有する物質を意味しており、典型的にはレセプターに特異的に結合可能な物質を利用することができる。レセプターはリガンドを結合可能な物質であれば特に限定されないが、例えば、細胞膜上に存在する種々のレセプターが挙げられる。すなわち、ここで用いる場合、「リガンド」と「レセプター」の用語は、互いに結合可能な相手、好ましくは互いに特異的に結合可能な相手の意味で用いており、それらの結合により何らかの生体反応が惹起されるものに限定されない。例えば、標的細胞の細胞膜表面に存在するレセプターに特異的に結合可能な物質をリガンドとして使用することができる。 In the present invention, the term "ligand" means a substance capable of binding to a receptor, and typically substances capable of specifically binding to a receptor can be used. The receptor is not particularly limited as long as it is a substance capable of binding a ligand, and examples thereof include various receptors present on cell membranes. That is, as used herein, the terms "ligand" and "receptor" are used to mean a partner capable of binding to each other, preferably a partner capable of specifically binding to each other, and their binding elicits some biological reaction. is not limited to For example, a substance that can specifically bind to a receptor present on the cell membrane surface of target cells can be used as a ligand.
上記リガンドは、例えば、タンパク質、ペプチド、アプタマー、糖鎖、脂質、低分子、生体分子/生体活性分子であることができるが、これらに限定はされない。 The ligands can be, for example but not limited to, proteins, peptides, aptamers, carbohydrates, lipids, small molecules, biomolecules/bioactive molecules.
「タンパク質」は、α-L-アミノ酸(グリシンを含む)がペプチド結合により直鎖状に連結したものを意味する。本明細書においては、タンパク質は、アミノ酸のみからなる単純タンパク質も、アミノ酸以外の構成成分を含む複合タンパク質も含む概念であり、100残基以上のアミノ酸から構成されるものを指す。リガンドとして使用されるタンパク質(以下、「タンパク質リガンド」とも呼ぶ)の例としては、脂肪酸結合タンパク質FABP1~12(fatty acid binding protein 1-12)、外膜特異的リポタンパク質分子シャペロンLolA、外膜特異的リポタンパク質受容体LolB、リポキシゲナーゼおよびシクロオキゲナーゼが挙げられる。 "Protein" means a linear chain of α-L-amino acids (including glycine) linked by peptide bonds. As used herein, protein is a concept that includes both simple proteins consisting of only amino acids and complex proteins containing components other than amino acids, and refers to those consisting of 100 or more amino acid residues. Examples of proteins used as ligands (hereinafter also referred to as "protein ligands") include fatty acid binding proteins FABP1-12 (fatty acid binding protein 1-12), outer membrane-specific lipoprotein molecular chaperone LolA, outer membrane-specific lipoprotein receptor LolB, lipoxygenase and cyclooxygenase.
またリガンドとして使用できるタンパク質としては、抗体も挙げることができる(以下、「抗体リガンド」とも呼ぶ)。例えば、適切なレセプターを選択し、それを抗原として認識する抗体をリガンドとして使用することにより、本発明のアンチセンス核酸を、当該レセプターが存在する標的細胞や標的組織(典型的には、当該レセプターが表面に存在する標的細胞や標的組織)に特異的に送達することができる。 Proteins that can be used as ligands also include antibodies (hereinafter also referred to as "antibody ligands"). For example, by selecting an appropriate receptor and using an antibody that recognizes it as an antigen as a ligand, the antisense nucleic acid of the present invention can be used as a target cell or tissue in which the receptor exists (typically, the receptor can be specifically delivered to target cells or target tissues on which the drug is present.
また、リガンドとしてはペプチドを使用することもできる。「ペプチド」とは、2分子以上のアミノ酸がペプチド結合で連結した物質であり、本明細書においては、100残基未満のアミノ酸が連結した物質を指す。本発明においては、好ましくは、60残基以下のアミノ酸、例えば50残基以下、40残基以下、30残基以下、20残基以下、または10残基以下のアミノ酸、例えば9残基以下、8残基以下、7残基以下、6残基以下、5残基以下のアミノ酸が連結したペプチドがリガンドとして使用される。リガンドとして使用されるペプチド(以下、「ペプチドリガンド」とも呼ぶ)は、特に限定されないが、その例としては、環状RGD配列含有ペプチドのような環状ペプチド、インスリン、グルカゴン様ペプチド-1、バソプレシン、オキシトシンが挙げられる。 Peptides can also be used as ligands. A "peptide" is a substance in which two or more amino acid molecules are linked by peptide bonds, and in this specification, refers to a substance in which less than 100 amino acid residues are linked. In the present invention, preferably 60 amino acids or less, such as 50 residues or less, 40 residues or less, 30 residues or less, 20 residues or less, or 10 residues or less, such as 9 residues or less, A peptide in which 8 residues or less, 7 residues or less, 6 residues or less, or 5 residues or less are linked is used as a ligand. Peptides used as ligands (hereinafter also referred to as "peptide ligands") are not particularly limited, but examples thereof include cyclic peptides such as cyclic RGD sequence-containing peptides, insulin, glucagon-like peptide-1, vasopressin, and oxytocin. is mentioned.
ここで、「環状RGD配列含有ペプチド」(以後、「cRGD」、「cRGDペプチド」とも呼ぶ)は、少なくとも1つのアルギニン-グリシン-アスパラギン酸(RGD)配列を有し、環状構造を形成するペプチドである。上記の「環状ペプチド」は、好ましくは、環状RGD配列含有ペプチドと同一のまたは類似のリガンド特性、特に標的特異性を有するペプチドである。なお、環状ペプチドの配列長は特に制限されないが、環構造を形成する観点から、アミノ酸数が通常3以上、例えば、4~15または5~10であることが好ましい。 Here, the "cyclic RGD sequence-containing peptide" (hereinafter also referred to as "cRGD" or "cRGD peptide") is a peptide having at least one arginine-glycine-aspartic acid (RGD) sequence and forming a cyclic structure. be. The above "cyclic peptides" are preferably peptides with identical or similar ligand properties, particularly target specificities, to the cyclic RGD sequence-containing peptides. Although the sequence length of the cyclic peptide is not particularly limited, it is preferable that the number of amino acids is usually 3 or more, for example, 4-15 or 5-10, from the viewpoint of forming a ring structure.
RGD配列は、細胞表面上の細胞接着分子であるインテグリン分子(特にαVβ3やαVβ5等)に結合してこれを活性化することや、細胞側のエンドサイトーシスを誘導することが知られており、RGDぺプチドの腫瘍標的リガンドとしての使用も知られている。The RGD sequence binds to and activates integrin molecules ( particularly αVβ3 and αVβ5 ) , which are cell adhesion molecules on the cell surface, and induces cell-side endocytosis. is known, and the use of RGD peptides as tumor-targeting ligands is also known.
本発明では、斯かるRGD配列を有し、環状構造を形成するペプチドであれば、任意のcRGDペプチドを使用することが可能である。 In the present invention, any cRGD peptide can be used as long as it has such an RGD sequence and forms a cyclic structure.
cRGDペプチドの配列長は特に制限されないが、環構造を形成する観点から、アミノ酸数が通常3以上、例えば、4~15または5~10であることが好ましい。 The sequence length of the cRGD peptide is not particularly limited, but from the viewpoint of forming a ring structure, it preferably has 3 or more amino acids, for example, 4-15 or 5-10 amino acids.
また、RGD配列以外の部分を構成するアミノ酸の種類およびこれらの配列は任意である。従って、cRGDペプチドは、生体を構成する20種類のアミノ酸の他に、その他の種類の天然アミノ酸や合成アミノ酸を含んでいてもよい。ただし、本発明のアンチセンス核酸の投与対象に望ましくない影響を及ぼさず、当該複合体の活性を実質的に損なわず、さらにRGD配列の機能を妨げないアミノ酸およびそれらの配列が好ましい。 In addition, the types of amino acids that constitute portions other than the RGD sequence and their sequences are arbitrary. Therefore, the cRGD peptide may contain other types of natural amino acids and synthetic amino acids in addition to the 20 types of amino acids that constitute the body. However, amino acids and sequences thereof that do not exert undesired effects on subjects to which the antisense nucleic acid of the present invention is administered, do not substantially impair the activity of the complex, and do not interfere with the function of the RGD sequence are preferred.
上述のように、cRGDペプチドは、少なくとも1つのRGD配列を有する。本発明の1つの実施態様において、上記cRGDペプチドは、1つのRGD配列を有する。 As noted above, cRGD peptides have at least one RGD sequence. In one embodiment of the invention, the cRGD peptide has one RGD sequence.
cRGDペプチドの具体例としては、以下のアミノ酸配列を有するペプチドが挙げられるがこれに限定はされない:
cRGDfK(Arg-Gly-Asp-D-Phe-Lys)(配列番号24)。Specific examples of cRGD peptides include, but are not limited to, peptides having the following amino acid sequences:
cRGDfK (Arg-Gly-Asp-D-Phe-Lys) (SEQ ID NO:24).
上記cRGDペプチドは、周知の自動合成装置によって合成することが可能であり、または市販されているもの(例えば、Selleck社製「Cyclo(-RGDfK)」)を使用することも可能である。 The cRGD peptide can be synthesized by a well-known automatic synthesizer, or a commercially available product (eg, “Cyclo(-RGDfK)” manufactured by Selleck) can be used.
さらに、リガンドとしてはアプタマーを使用することもできる(以下、「アプタマーリガンド」とも呼ぶ)。アプタマーとは、特定の分子と、典型的にはハイブリダイズ以外の手段で、特異的に結合する核酸分子であり、通常、核酸の配列をランダムに変化させて、標的の分子と特異的に結合するものを当業者に公知の方法(例えばSELEX法や一段階セレクション法)を用いて選択することによって得ることができる。従って、標的分子に特異的に結合するアプタマーをリガンドとして使用することにより、本発明のアンチセンス核酸を、当該標的分子が存在する標的細胞や標的組織(典型的には、当該標的分子が表面に存在する標的細胞や標的組織)に特異的に送達することができる。 Furthermore, aptamers can also be used as ligands (hereinafter also referred to as "aptamer ligands"). Aptamers are nucleic acid molecules that specifically bind to a specific molecule, typically by means other than hybridizing, usually by randomly altering the sequence of the nucleic acid to specifically bind to the target molecule. can be obtained by selecting those that do using methods known to those skilled in the art (for example, the SELEX method and the one-step selection method). Therefore, by using an aptamer that specifically binds to a target molecule as a ligand, the antisense nucleic acid of the present invention can be used as a target cell or tissue in which the target molecule is present (typically, the target molecule is present on the surface thereof). specific delivery to existing target cells or target tissues).
リガンドとしては糖鎖を使用することもできる。ここで「糖鎖」とは、グルコース、ガラクトース、マンノース、フコース、キシロース、N-アセチルグルコサミン、N-アセチルガラクトサミン、シアル酸などの単糖およびこれらの誘導体がグリコシド結合によって鎖状に結合した分子を指す。リガンドとして使用される糖鎖(以下、「糖鎖リガンド」とも呼ぶ)は、特に限定されないが、その例としては、N-アセチルガラクトサミン、ヒアルロン酸、デキストリンおよびセルロースが挙げられる。 Sugar chains can also be used as ligands. Here, the term "sugar chain" refers to a molecule in which monosaccharides such as glucose, galactose, mannose, fucose, xylose, N-acetylglucosamine, N-acetylgalactosamine, sialic acid, and derivatives thereof are bound in a chain by glycosidic bonds. Point. Sugar chains used as ligands (hereinafter also referred to as "sugar chain ligands") are not particularly limited, but examples thereof include N-acetylgalactosamine, hyaluronic acid, dextrin and cellulose.
リガンドとしては脂質を使用することもできる。本明細書で使用する場合に、「脂質」には、単純脂質、複合脂質および誘導脂質が含まれる。リガンドとして使用される脂質(以下、「脂質リガンド」とも呼ぶ)は、特に限定されないが、例えば、複合脂質であるリン脂質や糖脂質、誘導脂質である脂肪酸やステロイドが挙げられる。リン脂質の例としてはスフィンゴリン脂質、糖脂質の例としてはスフィンゴ糖脂質、脂肪酸の例としては、直鎖状または分岐状のC4~C30飽和または不飽和脂肪酸、例えば、ラウリン酸、ミリスチン酸、パルミチン酸、ステアリン酸、オレイン酸、リノレン酸、ドコサン酸が挙げられ、ステロイドの例としてはコレステロールが挙げられる。また、脂溶性ビタミンであるビタミンE(トコフェロール)もリガンドとして使用できる脂質の一例として挙げることができる。トコフェロールは、例えば、α-トコフェロール、β-トコフェロール、γ-トコフェロールおよびδ-トコフェロールからなる群から選択される。また、本発明では、トコフェロールの類縁体を使用することもできる。Lipids can also be used as ligands. As used herein, "lipid" includes simple lipids, complex lipids and derived lipids. Lipids used as ligands (hereinafter also referred to as “lipid ligands”) are not particularly limited, but examples thereof include phospholipids and glycolipids that are complex lipids, and fatty acids and steroids that are derivative lipids. Examples of phospholipids are sphingophospholipids, examples of glycolipids are glycosphingolipids, examples of fatty acids are linear or branched C4 - C30 saturated or unsaturated fatty acids such as lauric acid, myristic Acids, palmitic acid, stearic acid, oleic acid, linolenic acid, docosanoic acid and examples of steroids include cholesterol. Vitamin E (tocopherol), which is a fat-soluble vitamin, is also an example of a lipid that can be used as a ligand. Tocopherols are for example selected from the group consisting of α-tocopherol, β-tocopherol, γ-tocopherol and δ-tocopherol. Analogues of tocopherol can also be used in the present invention.
ここで、「類縁体(analog)」とは、ある化合物と同一または類似の基本骨格を有し、類似した構造および性質を有する化合物、特に同一または類似のリガンド特性を有する化合物を指す。類縁体には、例えば、生合成中間体、代謝産物、置換基を有する化合物などが含まれる。ある化合物が別の化合物の類縁体であるかどうかは、当業者であれば判定することが可能である。
本明細書において、「トコフェロール類縁体」には、トコフェロールの不飽和アナログ(例えば、α-トコトリエノール、β-トコトリエノール、γ-トコトリエノール、δ-トコトリエノール等のトコトリエノール)、トコフェロールもしくは上記不飽和アナログの薬学的に許容可能なエステル(例えば、酢酸エステル、コハク酸エステル、プロピオン酸エステル)、およびそれらの薬学的に許容可能な塩(例えば、ナトリウム塩、カリウム塩、カルシウム塩、マグネシウム塩)が含まれる。上記の塩は、特に、コハク酸のような二カルボン酸とのエステルの場合に形成させることが可能である。上記のトコフェロール類縁体は、トコフェロールと同一のまたは類似のリガンド特性、特に標的特異性を有することができる。As used herein, the term "analog" refers to a compound having the same or similar basic skeleton and similar structures and properties as a given compound, especially compounds having the same or similar ligand properties. Analogs include, for example, biosynthetic intermediates, metabolites, compounds with substituents, and the like. One skilled in the art can determine whether a compound is an analog of another compound.
As used herein, "tocopherol analogs" include unsaturated analogs of tocopherol (e.g., tocotrienols such as α-tocotrienol, β-tocotrienol, γ-tocotrienol, δ-tocotrienol), pharmaceutical compounds of tocopherol or the unsaturated analogs described above. acceptable esters (eg, acetates, succinates, propionates), and pharmaceutically acceptable salts thereof (eg, sodium, potassium, calcium, magnesium salts). The above salts can be formed especially in the case of esters with dicarboxylic acids such as succinic acid. The tocopherol analogues described above may have the same or similar ligand properties, particularly target specificities, as tocopherol.
リガンドとしては低分子・低分子化合物を使用することもできる。リガンドとして使用され得る低分子・低分子化合物(以下、「低分子リガンド」とも呼ぶ)は、特に限定されないが、その例としては、アニスアミド、チロフィバン、および2-ピロリジン-1-イル-N-[4-[4-(2-ピロリジン-1-イル-アセチルアミノ)-ベンジル]-フェニル]-アセトアミドが挙げられる。 A low-molecular-weight compound can also be used as a ligand. Low-molecular-weight compounds that can be used as ligands (hereinafter also referred to as "low-molecular-weight ligands") are not particularly limited, but examples thereof include anisamide, tirofiban, and 2-pyrrolidin-1-yl-N-[ 4-[4-(2-pyrrolidin-1-yl-acetylamino)-benzyl]-phenyl]-acetamide.
リガンドとしては生体分子/生体活性分子を使用することもできる。リガンドとして使用され得る生体分子/生体活性分子(以下、「生体分子/生体活性分子リガンド」とも呼ぶ)は、生体に関連する分子、または生体に影響を与え得る活性を有する分子であれば特に限定されないが、その例としては、葉酸、アナンダミド、スペルミンが挙げられる。 Biomolecules/bioactive molecules can also be used as ligands. Biomolecules/bioactive molecules that can be used as ligands (hereinafter also referred to as “biomolecule/bioactive molecule ligands”) are particularly limited as long as they are molecules that are relevant to living organisms or molecules that have activity that can affect living organisms. Examples include, but are not limited to, folic acid, anandamide, and spermine.
例えば、「葉酸」は、すべての細胞がDNA合成に必要とするビタミンである。多くの癌細胞において葉酸受容体が過剰発現していることが報告されており、従って、葉酸は癌標的リガンドとして広く使用されている。また、葉酸と葉酸受容体の複合体がエンドサイトーシスによって細胞内に取り込まれることや、多くの癌細胞において、葉酸の取り込みが多いことも報告されている。 For example, "folic acid" is a vitamin that all cells require for DNA synthesis. Folate receptors have been reported to be overexpressed in many cancer cells, and folate is therefore widely used as a cancer targeting ligand. It has also been reported that complexes of folic acid and folate receptors are taken up into cells by endocytosis, and that many cancer cells take up a lot of folic acid.
本発明では、このような葉酸も上記リガンドとして使用することができ、葉酸は例えば、市販のもの(例えば、Sigma-Aldrich社製「葉酸」)を容易に入手することが可能である。また、本発明では、葉酸の類縁体を使用することもできる。 In the present invention, such folic acid can also be used as the ligand, and folic acid can be easily obtained commercially (for example, "Folic acid" manufactured by Sigma-Aldrich). Analogues of folic acid can also be used in the present invention.
ここで、本明細書において、「葉酸類縁体」は、ベンゾイル部分を介してアミノ酸部分(好ましくはグルタミン酸部分)と結合した縮合ピリミジン複素環を有する化合物、すなわち、アミノ酸部分、ベンゾイル部分および縮合ピリミジン複素環をベースとした化合物を指す(葉酸自体は除く)。上記「縮合ピリミジン複素環」としては、例えば、プテリジン又は二環式ピロロピリミジンなど5若しくは6員環の複素環をさらに融合させたピリミジンを挙げることができる。葉酸またはその類縁体の例としては、葉酸(プテロイル-グルタミン酸)骨格をベースとし、任意選択的に置換された葉酸、ホリニン酸、プテロポリグルタミン酸、ならびに葉酸レセプター結合プテリジン、例えば、テトラヒドロプテリン、ジヒドロ葉酸、テトラヒドロ葉酸、デアザおよびジデアザアナログが挙げられる。上記の葉酸類縁体は、葉酸と同一のまたは類似のリガンド特性、特に標的特異性を有することができる。 Here, as used herein, a "folic acid analogue" is a compound having a fused pyrimidine heterocycle attached to an amino acid moiety (preferably a glutamic acid moiety) via a benzoyl moiety, namely an amino acid moiety, a benzoyl moiety and a fused pyrimidine heterocycle. Refers to ring-based compounds (excluding folic acid itself). Examples of the above-mentioned "fused pyrimidine heterocycle" include pyrimidine further fused with a 5- or 6-membered heterocyclic ring such as pteridine or bicyclic pyrrolopyrimidine. Examples of folic acid or analogs thereof include optionally substituted folic acid, folinic acid, pteropolyglutamic acid based on the folic acid (pteroyl-glutamic acid) backbone, and folate receptor-binding pteridines such as tetrahydropterin, dihydrofolic acid. , tetrahydrofolic acid, deaza and dideaza analogues. The folic acid analogues described above may have the same or similar ligand properties, particularly target specificities, as folic acid.
また、当業者は、他の生体分子/生体活性分子リガンドについても、それぞれのレセプターの情報、例えば、各種組織や細胞における発現レベルや発現特異性等を考慮に入れながら、本発明のアンチセンス核酸の所望の標的に応じて、適切な生体分子/生体活性分子リガンドを適宜選択することが可能である。 In addition, those skilled in the art will also consider other biomolecules/bioactive molecule ligands, antisense nucleic acids of the present invention, while taking into consideration the information of each receptor, for example, the expression level and expression specificity in various tissues and cells. Appropriate biomolecules/bioactive molecule ligands can be selected as appropriate, depending on the desired target of .
本発明の1つの好ましい態様において、上記リガンドは、タンパク質リガンド、ペプチドリガンド、アプタマーリガンド、糖鎖リガンド、脂質リガンド、低分子リガンドおよび生体分子/生体活性分子リガンドからなる群から選択され、より好ましくはペプチドリガンド、糖鎖リガンド、脂質リガンド、低分子リガンドおよび生体分子/生体活性分子リガンドからなる群から選択される。 In one preferred embodiment of the present invention, the ligand is selected from the group consisting of protein ligands, peptide ligands, aptamer ligands, carbohydrate ligands, lipid ligands, small molecule ligands and biomolecule/bioactive molecule ligands, more preferably selected from the group consisting of peptide ligands, carbohydrate ligands, lipid ligands, small molecule ligands and biomolecule/bioactive molecule ligands.
本発明のさらなる好ましい態様において、上記リガンドは、環状ペプチド、例えば環状アルギニン-グリシン-アスパラギン酸(RGD)配列含有ペプチド、葉酸もしくはその類縁体、ビタミンE(トコフェロール)もしくはその類縁体、ステアリン酸、ドコサン酸、アナンダミド、スペルミン、コレステロール、アニスアミドまたはN-アセチルガラクトサミンから選択される。 In a further preferred embodiment of the invention, the ligand is a cyclic peptide such as a cyclic arginine-glycine-aspartic acid (RGD) sequence-containing peptide, folic acid or analogues thereof, vitamin E (tocopherol) or analogues thereof, stearic acid, docosane selected from acids, anandamide, spermine, cholesterol, anisamide or N-acetylgalactosamine.
本発明の別の実施態様において、上記リガンドは、ペプチドリガンド、生体分子/生体活性分子リガンドまたは脂質リガンドから選択され、例えば、環状RGD配列含有ペプチド、葉酸またはビタミンE(トコフェロール)から選択される。 In another embodiment of the invention, the ligand is selected from peptide ligands, biomolecule/bioactive molecule ligands or lipid ligands, eg selected from cyclic RGD sequence-containing peptides, folic acid or vitamin E (tocopherol).
好ましくは、上記のようなリガンドを有する本発明のアンチセンス核酸または二本鎖核酸複合体は、上記リガンドが特異的に結合可能なレセプターを有する細胞や組織(例えばそれらの表面に有する)を標的細胞または標的組織とすることができる。標的細胞や標的組織の種類は特に限定されず、目的などに応じて適宜の細胞や組織を標的とすることができる。例えば、標的細胞は組織や臓器を形成する細胞であってもよい。あるいは、標的細胞は、白血病細胞のように単独で存在する細胞であってもよく、固形がん細胞のように組織に腫瘍を形成している細胞やリンパ組織や他の組織に浸潤している細胞などであってもよい(以下、これらの細胞をまとめて単に「癌細胞」とも呼ぶ)。 Preferably, the antisense nucleic acid or double-stranded nucleic acid complex of the present invention with a ligand as described above targets a cell or tissue having a receptor (e.g., on their surface) to which the ligand can specifically bind. It can be a cell or a target tissue. The types of target cells and target tissues are not particularly limited, and appropriate cells or tissues can be targeted depending on the purpose. For example, target cells may be cells that form a tissue or organ. Alternatively, the target cell may be a solitary cell, such as a leukemic cell, which is a tumor-forming cell in a tissue, such as a solid cancer cell, or invades a lymphoid tissue or other tissue. It may be a cell or the like (hereinbelow, these cells are also collectively referred to simply as "cancer cells").
本発明の1つの実施態様において、上記リガンドは、直接結合していても、リンカーを介して間接的に結合していてもよい。例えば、上記リガンドは、上記ポリヌクレオチドの5’末端または3’末端に、および/またはそれ以外の部位、例えばポリヌクレオチド全体の個数に対してm%の個数を有する、下記に定義する中央領域内における1つまたは複数の構成単位に、直接またはリンカーを介して結合させることができる(ここで、mは、1~70の整数、例えば2~60の整数、5~50の整数、10~40の整数であり、例えば、1、2、3、4、5、6、7、8、9、10、15、20、25、30、35、40、45、50、55、60または65であることができる)。ここで、「中央領域」とは、上記ポリヌクレオチドが奇数個の構成単位からなる場合には、上記ポリヌクレオチドの中央に位置する1個の構成単位と、当該中央構成単位から5’方向および3’方向にそれぞれ同じ数の構成単位とを含む領域であって、上記ポリヌクレオチドの中央と当該領域の中央とが同一である領域を意味し、上記ポリヌクレオチドが偶数個の構成単位からなる場合には、上記ポリヌクレオチドの中央に位置する2個の構成単位と、当該中央構成単位から5’方向および3’方向にそれぞれ同じ数の構成単位とを含む領域であって、上記ポリヌクレオチドの中央と当該領域の中央とが同一である領域を意味する。 In one embodiment of the invention, the ligand may be directly bound or indirectly bound via a linker. For example, the ligand may be at the 5′ or 3′ end of the polynucleotide and/or at other sites, such as within the central region defined below, having a number of m % relative to the total number of polynucleotides. (where m is an integer from 1 to 70, such as an integer from 2 to 60, an integer from 5 to 50, an integer from 10 to 40 is an integer of, for example, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60 or 65 be able to). Here, when the polynucleotide consists of an odd number of structural units, the “central region” refers to one structural unit located in the center of the polynucleotide, and 5′ and 3 A region containing the same number of structural units in the ' direction, wherein the center of the polynucleotide is the same as the center of the region, and the polynucleotide consists of an even number of structural units. is a region containing two structural units located in the center of the polynucleotide and the same number of structural units in the 5′ direction and the 3′ direction from the central structural unit, and It means a region that is the same as the center of the region.
本発明の1つの実施態様において、上記リガンドは、上記ポリヌクレオチドの5’末端に結合している。本発明の他の実施態様において、上記ポリヌクレオチドが10~35塩基の長さを有する場合には、上記リガンドは、上記ポリヌクレオチドの5’末端から数えて、1~35番目、例えば2~30番目、3~25番目、4~20番目、5~15番目、6~11番目(例えば、6、7、8、9、10または11番目)の構成単位に、例えばその2’位または4’位を介して結合している。 In one embodiment of the invention, the ligand is attached to the 5' end of the polynucleotide. In another embodiment of the present invention, when the polynucleotide has a length of 10-35 bases, the ligand is 1-35, such as 2-30, counted from the 5' end of the polynucleotide. th, 3rd to 25th, 4th to 20th, 5th to 15th, 6th to 11th (eg, 6th, 7th, 8th, 9th, 10th or 11th) structural unit, such as its 2′ or 4′ It is connected through the position.
上記のようなリガンドを、任意選択的にリンカーを介して、ポリヌクレオチドに結合させる方法は当業者によく知られている。当業者は、使用するリガンドやリンカーの種類に応じて適宜適切な公知の方法を選択することにより、上記結合を達成することが可能であるが、例えば、リガンドとしてcRGDfK、リンカーとしてAzido-PEG4-NHS esterを使用して、リガンドをヌクレオチドの2’位から懸垂させる場合の方法を以下に簡単に説明する:Methods for attaching such ligands, optionally via linkers, to polynucleotides are well known to those skilled in the art. A person skilled in the art can achieve the above binding by appropriately selecting an appropriate known method depending on the type of ligand and linker to be used. - A brief description of the method when the NHS ester is used to suspend the ligand from the 2' position of the nucleotide:
(a)リガンドとリンカーとの結合
cRGDfKとAzido-PEG4-NHS esterを、NHSエステルとcRGDfKのリジンのアミノ基との縮合反応により結合させて、cRGDfKにアミド結合によりアジド-PEG4が連結しているアジド化cRGDfKを作成する。(a) Coupling of Ligand and Linker cRGDfK and Azido-PEG 4 -NHS ester were coupled by a condensation reaction between the NHS ester and the amino group of the lysine of cRGDfK, and azido-PEG 4 was linked to cRGDfK via an amide bond. to generate azide cRGDfK.
(b)アルキン修飾ヌクレオチドを含むポリヌクレオチドの調製
(リンカーを介して)リガンドを結合させたい位置の構成単位をアルキン修飾ヌクレオチドとしたポリヌクレオチドを調製する。このようなポリヌクレオチドの調製方法は、当業者には公知であり、例えば、標準的なオリゴ合成においてアルキンホスホロアミダイトを用いることにより合成することができる。アルキン修飾ヌクレオチドの調製のためには、例えば、2’-O-プロパルギルアデノシン、2’-O-プロパルギルシチジン、2’-O-プロパルギルグアノシン、2’-O-プロパルギルウリジンまたは2’-O-プロパルギル脱塩基リボースを使用することができる。(b) Preparation of Polynucleotide Containing Alkyne-Modified Nucleotide A polynucleotide having alkyne-modified nucleotide as a structural unit at a position to which a ligand is to be bound (via a linker) is prepared. Methods for preparing such polynucleotides are known to those skilled in the art, and can be synthesized, for example, by using alkyne phosphoramidites in standard oligosynthesis. For the preparation of alkyne modified nucleotides, for example 2'-O-propargyladenosine, 2'-O-propargylcytidine, 2'-O-propargylguanosine, 2'-O-propargyluridine or 2'-O-propargyl Abasic ribose can be used.
(c)クリック反応
アジドとアルキンによる付加感化反応(クリック反応)を用いて、アジド化cRGDfKとアルキン修飾ヌクレオチドとを結合させる。(c) Click Reaction Azide-modified cRGDfK and alkyne-modified nucleotide are combined using an addition sensitization reaction (click reaction) with azide and alkyne.
これにより、所望の位置のヌクレオチド(または化学修飾ヌクレオチドまたは核酸類似体)の2’の部位に、トリアゾールを介してPEG4が結合し、そこにアミド結合によって結合したcRGDfKを有するポリヌクレオチド、すなわち、リガンドがリンカーを介してヌクレオチドの2’位から懸垂しているポリヌクレオチドが得られる。そのようなポリヌクレオチドの例を図34に示す。As a result, PEG 4 is attached via a triazole to the 2′ site of the nucleotide (or chemically modified nucleotide or nucleic acid analogue) at the desired position, and a polynucleotide having cRGDfK attached thereto by an amide bond, i.e., A polynucleotide is obtained in which the ligand is suspended from the 2' position of the nucleotide via the linker. Examples of such polynucleotides are shown in FIG.
上記のように、リンカーを介してリガンドが相補鎖のポリヌクレオチドに結合している場合、当該ポリヌクレオチドにおける結合を担う構成単位は、リンカーとの結合のために化学修飾されていてもよい。例えば、上記構成単位(デオシキリボヌクレオチド、リボヌクレオチドまたは核酸類似体)のリンカー結合部位をアミノ化、チオール化、アルキン化またはジベンゾシクロオクチン化することにより、それぞれ、リンカーにおけるアミン反応性基、チオール反応性基、アルキン反応性基またはジベンゾシクロオクチン反応性基との反応を介して、上記構成単位とリンカーとの間に共有結合を形成させることができる。このような化学修飾がなされたヌクレオチドを、ここでは「リンカーとの結合のために化学修飾されたヌクレオチド」とも呼び、このような修飾は、上で説明した化学修飾の一態様を構成するものである。なお、「リンカーとの結合のために化学修飾されたヌクレオチド」は、上記で例示したような反応の結果としてリンカーの一端と共有結合を形成するため、反応前と反応後では異なる構造を取り得るが、リンカーと共有結合を形成している形態のヌクレオチドも、ここでは「リンカーとの結合のために化学修飾されたヌクレオチド」として呼ぶことができる。同様に、上記リガンドをポリヌクレオチドに直接結合させる場合にも、例えば、リンカーを介したリガンドの結合に関して上述したような化学修飾や反応性基を適宜、リガンドを結合させるポリヌクレオチドの構成単位(ヌクレオチドまたは核酸類似体)および/またはリガンドに導入し、公知の反応、例えば上述したような反応を使用することにより、当該構成単位とリガンドとの間で共有結合を形成させることが可能である。この場合、上記のような化学修飾がされたヌクレオチド(デオキシリボヌクレオチドもしくはリボヌクレオチド)を「リガンドとの結合のために化学修飾されたヌクレオチド」とも呼ぶ。 As described above, when a ligand is bound to a complementary polynucleotide via a linker, the constituent unit responsible for binding in the polynucleotide may be chemically modified for binding to the linker. For example, by aminating, thiolating, alkylating or dibenzocyclooctylating the linker binding site of the above building blocks (deoxyribonucleotides, ribonucleotides or nucleic acid analogues), amine-reactive groups in the linker, thiol Covalent bonds can be formed between the building blocks and linkers through reaction with reactive groups, alkyne-reactive groups or dibenzocyclooctyne-reactive groups. Such chemically modified nucleotides are also referred to herein as "chemically modified nucleotides for binding to a linker", and such modifications constitute one aspect of the chemical modification described above. be. In addition, since the "nucleotide chemically modified for binding to the linker" forms a covalent bond with one end of the linker as a result of the reaction as exemplified above, it can have a different structure before and after the reaction. However, a nucleotide in a form that forms a covalent bond with a linker can also be referred to herein as a "nucleotide chemically modified for attachment to a linker." Similarly, in the case of directly binding the ligand to a polynucleotide, for example, chemical modifications and reactive groups as described above with respect to binding of the ligand via a linker are appropriately added to the polynucleotide constituting unit (nucleotide) to which the ligand is bound. or nucleic acid analogues) and/or ligands to form covalent bonds between the building blocks and the ligands using known reactions, such as those described above. In this case, the chemically modified nucleotides (deoxyribonucleotides or ribonucleotides) as described above are also referred to as "nucleotides chemically modified for binding to ligands."
本発明の1つの実施態様において、上記相補鎖におけるポリヌクレオチドは、リンカーを介してリガンドが結合している構成単位として、リンカーとの結合のために化学修飾されたヌクレオチド(デオキシリボヌクレオチドもしくはリボヌクレオチド)、好ましくはリンカーとの結合のために化学修飾されたリボヌクレオチドを少なくとも1つ含む。このリンカーとの結合のために化学修飾されたリボヌクレオチドに、リガンドを結合させることができる。 In one embodiment of the present invention, the polynucleotide in the complementary strand is a nucleotide (deoxyribonucleotide or ribonucleotide) chemically modified for binding to the linker as a constituent unit to which a ligand is bound via a linker. , preferably at least one ribonucleotide chemically modified for attachment to a linker. A ligand can be attached to a ribonucleotide that has been chemically modified for attachment to this linker.
本発明の他の実施態様において、上記相補鎖におけるポリヌクレオチドは、化学修飾されていないデオキシリボヌクレオチドおよびリンカーとの結合のために化学修飾されたリボヌクレオチドのみを構成単位として含む。本発明のさらなる実施態様において、上記相補鎖におけるポリヌクレオチドは、化学修飾されていないデオキシリボヌクレオチド、化学修飾されていないリボヌクレオチドおよびリンカーとの結合のために化学修飾されたリボヌクレオチドのみを構成単位として含む。これらの実施態様では、このリンカーとの結合のために化学修飾されたリボヌクレオチドに、リガンドを結合させることができる。 In another embodiment of the present invention, the polynucleotide in the complementary strand comprises as building blocks only chemically unmodified deoxyribonucleotides and chemically modified ribonucleotides for attachment to a linker. In a further embodiment of the present invention, the polynucleotide in the complementary strand consists only of deoxyribonucleotides that are not chemically modified, ribonucleotides that are not chemically modified, and ribonucleotides that are chemically modified for binding to a linker as constituent units. include. In these embodiments, ligands can be attached to ribonucleotides that have been chemically modified for attachment to this linker.
本発明の1つの実施態様において、相補鎖におけるポリヌクレオチドは、アンチセンス核酸におけるポリヌクレオチドに対して少なくとも1つのミスマッチを含み、かつ、構成単位としてリンカーとの結合のために化学修飾されたヌクレオチド(好ましくはリボヌクレオチド)を含む。本発明のさらに1つの実施態様において、相補鎖におけるポリヌクレオチドは、アンチセンス核酸におけるポリヌクレオチドに対して少なくとも1つのミスマッチを含み、かつ、リンカーとの結合のために化学修飾されたヌクレオチド(好ましくはリボヌクレオチド)を構成単位として含み、かつ、当該ヌクレオチドの少なくとも1つが当該ミスマッチを形成し、すなわち、この実施態様では、リガンドが結合している構成単位が上記ミスマッチを形成する。例えば、上記ミスマッチは、G対Uのミスマッチ(アンチセンス核酸がGで、相補鎖がU)であることができる。 In one embodiment of the present invention, the polynucleotide in the complementary strand contains at least one mismatch to the polynucleotide in the antisense nucleic acid and is a nucleotide chemically modified for attachment to a linker as a building block ( preferably ribonucleotides). In a further embodiment of the invention, the polynucleotide in the complementary strand contains at least one mismatch to the polynucleotide in the antisense nucleic acid and is chemically modified for attachment to the linker (preferably ribonucleotides) as constituent units, and at least one of the nucleotides forms the mismatch, ie, in this embodiment, the constituent unit to which the ligand is bound forms the mismatch. For example, the mismatch can be a G to U mismatch (G for the antisense nucleic acid and U for the complementary strand).
また、上記相補鎖が複数のリガンドを含む場合、これらのリガンドは同一の構成単位に結合していてもよく(例えば、同一の構成単位の同一の位置(例えば2’位)に結合していてもよい)、または互いに異なる構成単位に結合していてもよい。前者の場合、例えば、適当な分岐リンカーを用いることにより、複数のリガンドを多量体(例えば2~10量体、好ましくは2~6量体、例えば2、3、4、5または6量体)として同一の構成単位に結合させてもよい。本願では、本発明の核酸複合体において、複数のリガンドを多量体として同一の構成単位に結合させた場合でも、良好な活性が達成されることも見出された。 In addition, when the complementary strand contains a plurality of ligands, these ligands may be bound to the same structural unit (for example, they are bound to the same position (eg, 2' position) of the same structural unit). may be used), or they may be bound to structural units different from each other. In the former case, multiple ligands are multimerized (eg 2-10-mers, preferably 2-6-mers, eg 2-, 3-, 4-, 5- or 6-mers) by using suitable branched linkers, for example. may be bound to the same structural unit as In the present application, it was also found that in the nucleic acid complex of the present invention, good activity is achieved even when multiple ligands are bound to the same structural unit as multimers.
分岐リンカーとしては種々のものが公知であり、当業者であれば使用するリガンドに応じて適宜適切な分岐リンカーを選択することが可能である。 Various branched linkers are known, and a person skilled in the art can appropriately select an appropriate branched linker according to the ligand to be used.
本発明においては、例えば、分岐リンカーとして、ポリヌクレオチドと2つのcRGDfKとを以下に示すように連結するリンカーを使用することができる。この場合、2つのcRGDfKを2量体の形態で、同一の構成単位ヌクレオチドに結合させることができる。 In the present invention, for example, a linker that connects a polynucleotide and two cRGDfKs as shown below can be used as a branched linker. In this case, two cRGDfKs can be bound to the same building block nucleotide in the form of a dimer.


1つの実施態様において、上記アンチセンス核酸は、ポリヌクレオチドのみからなる。本発明の別の実施態様において、上記アンチセンス核酸は、ポリヌクレオチドおよびリガンドのみからなる。本発明のさらなる実施態様において、上記アンチセンス核酸は、ポリヌクレオチド、リガンドおよびリンカーのみからなる。
本発明の他の実施態様において、上記二本鎖核酸複合体は、上記アンチセンス核酸および上記相補鎖のみからなる。本発明のさらなる実施態様において、上記二本鎖核酸複合体は、アンチセンス核酸、相補鎖およびリガンドのみからなる。本発明のさらに他の実施態様において、上記二本鎖核酸複合体は、アンチセンス核酸、相補鎖、リガンドおよびリンカーのみからなる。In one embodiment, the antisense nucleic acid consists solely of polynucleotides. In another embodiment of the invention, the antisense nucleic acid consists only of a polynucleotide and a ligand. In a further embodiment of the invention said antisense nucleic acid consists only of a polynucleotide, a ligand and a linker.
In another embodiment of the invention, the double-stranded nucleic acid complex consists only of the antisense nucleic acid and the complementary strand. In a further embodiment of the invention the double-stranded nucleic acid complex consists only of the antisense nucleic acid, the complementary strand and the ligand. In yet another embodiment of the invention, the double-stranded nucleic acid complex consists only of the antisense nucleic acid, complementary strand, ligand and linker.
以上、いくつかの実施態様において、アンチセンス核酸または二本鎖核酸複合体の好適な典型例について説明したが、いくつかの実施態様におけるアンチセンス核酸または二本鎖核酸複合体は上記典型例に限定されるものではない。また、いくつかの実施形態において、アンチセンス核酸のポリヌクレオチドおよび/または相補的な核酸鎖のポリヌクレオチドは、当業者であれば公知の方法を適宜選択することにより調製することができる。例えば、標的転写産物の塩基配列(典型的には標的遺伝子の塩基配列)の情報に基づいて、核酸の塩基配列を設計し、市販の核酸自動合成機(アプライドバイオシステムズ社製、べックマン社製等)を用いて合成し、次いで、得られるポリヌクレオチドを逆相カラム等を用いて精製することにより、核酸を調製することができる。そして、このようにして調製した核酸を適当な緩衝液中にて混合し、約90~98℃にて数分間(例えば、5分間)かけて変性させた後、必要に応じて約30~70℃にて約1~8時間かけてアニーリングさせることにより、いくつかの実施形態におけるアンチセンス核酸または二本鎖核酸複合体を調製することができる。なお、二本鎖核酸複合体において、上記相補鎖のポリヌクレオチドにリガンドが結合している場合には、当該二本鎖核酸複合体は、例えば、予めリガンドを結合させたポリヌクレオチドを用いて、前記の通りアンチセンス核酸のポリヌクレオチドとアニーリングすることにより、調製することができる。 Preferred typical examples of antisense nucleic acids or double-stranded nucleic acid complexes have been described above in some embodiments, and antisense nucleic acids or double-stranded nucleic acid complexes in some embodiments are It is not limited. In some embodiments, the polynucleotide of the antisense nucleic acid and/or the polynucleotide of the complementary nucleic acid strand can be prepared by appropriately selecting methods known to those skilled in the art. For example, based on the information of the nucleotide sequence of the target transcript (typically the nucleotide sequence of the target gene), the nucleotide sequence of the nucleic acid is designed, and a commercially available automatic nucleic acid synthesizer (Applied Biosystems, Beckman) etc.), and then purifying the resulting polynucleotide using a reversed-phase column or the like, a nucleic acid can be prepared. Then, the nucleic acid thus prepared is mixed in a suitable buffer solution and denatured at about 90-98° C. for several minutes (eg, 5 minutes). The antisense nucleic acid or double-stranded nucleic acid complexes in some embodiments can be prepared by annealing for about 1-8 hours at 0°C. In the double-stranded nucleic acid complex, when a ligand is bound to the polynucleotide of the complementary strand, the double-stranded nucleic acid complex is prepared, for example, by using a polynucleotide bound with a ligand in advance, It can be prepared by annealing an antisense nucleic acid to a polynucleotide as described above.
上述のように、アンチセンス核酸(ASO)としてDNAからなるオリゴヌクレオチドを細胞に導入した場合、標的遺伝子の転写産物(mRNA)と当該ASOとが結合して、部分的に二本鎖が形成され、この二本鎖が蓋の役割をして、リボソームによる翻訳を生じさせず、標的遺伝子がコードするタンパク質の発現が阻害されることが知られている。 As described above, when an oligonucleotide composed of DNA is introduced into a cell as an antisense nucleic acid (ASO), the transcription product (mRNA) of the target gene binds to the ASO to partially form a double strand. , this double strand is known to act as a lid to prevent translation by the ribosome and inhibit the expression of the protein encoded by the target gene.
また、ASOとしてDNAからなるオリゴヌクレオチドを細胞に導入した場合、部分的にDNA-RNAのヘテロオリゴヌクレオチドが形成され、RNaseHによってこの部分が認識され、標的遺伝子のmRNAが分解されるため、標的遺伝子がコードするタンパク質の発現が阻害されることも知られている。ASOが蓋の役割をする場合に比べ、このRNaseH依存的経路の場合の方が、多くの場合において遺伝子発現の抑制効果が高いことも明らかになっている。 In addition, when an oligonucleotide composed of DNA is introduced into cells as an ASO, a DNA-RNA heterooligonucleotide is partially formed, this portion is recognized by RNaseH, and the mRNA of the target gene is degraded. is also known to inhibit the expression of proteins encoded by It has also been clarified that, in many cases, this RNaseH-dependent pathway is more effective in suppressing gene expression than when ASO acts as a lid.
ASOとしてDNAを用いた場合のアンチセンス効果に関連して、特表2015-502134号公報では、LNA/DNAギャップマーとそれに対するRNAからなる相補鎖とをアニーリングさせた二本鎖アンチセンス核酸が開示されている。ここでは、当該二本鎖核酸のアンチセンス効果について記載されている。当該文献におけるような二本鎖核酸は、HDO(heteroduplex oligonucleotide)と呼ばれるものである。 In relation to the antisense effect when DNA is used as an ASO, Japanese Patent Application Publication No. 2015-502134 discloses a double-stranded antisense nucleic acid obtained by annealing an LNA/DNA gapmer and a complementary strand consisting of an RNA to the LNA/DNA gapmer. disclosed. Here, the antisense effect of the double-stranded nucleic acid is described. A double-stranded nucleic acid as in the literature is called an HDO (heteroduplex oligonucleotide).
ASOとしてmRNA前駆体の特定領域に相補的でかつRNaseHの基質とならない修飾DNAからなるオリゴヌクレオチドを細胞に導入すると、部分的にDNA-RNAのヘテロオリゴヌクレオチドが形成され標的遺伝子のエクソンを読み飛ばすこと(エクソンスキッピング法)が知られている。 When an oligonucleotide consisting of modified DNA that is complementary to a specific region of the pre-mRNA and is not a substrate for RNase H is introduced into cells as an ASO, a DNA-RNA heterooligonucleotide is partially formed, skipping exons of the target gene. (exon skipping method) is known.
<標的遺伝子の発現又は標的転写産物を抑制するための組成物>
本発明のアンチセンス核酸または二本鎖核酸複合体は、特異性高く効率良く標的細胞内に取り込まれて、当該細胞内の標的遺伝子の発現又は標的転写産物レベルを抑制し、当該細胞の増殖を極めて効果的に抑制することができる。従って、上記アンチセンス核酸または二本鎖核酸複合体を有効成分として含有する、例えば、標的遺伝子の発現および/または標的細胞(例えば癌細胞)の増殖をアンチセンス効果によって抑制するための組成物を、本発明は提供することができる。本発明のアンチセンス核酸または二本鎖核酸複合体は、優れた特異性と効率で標的組織や標的部位に送達することができ、高い特異性および効率で標的細胞の増殖を抑制できるため、低濃度の投与により高い薬効を得ることができる。そして、発明のアンチセンス核酸または二本鎖核酸複合体は特に、副作用が少ないという利点も有する。従って、代謝性疾患、腫瘍、感染症といった標的遺伝子の発現亢進に伴う疾患を治療、予防するための医薬組成物も提供することができる。<Composition for Suppressing Target Gene Expression or Target Transcript>
The antisense nucleic acid or double-stranded nucleic acid complex of the present invention is efficiently incorporated into target cells with high specificity, suppresses the expression of target genes or the level of target transcripts in the cells, and inhibits the proliferation of the cells. It can be suppressed very effectively. Therefore, a composition containing the antisense nucleic acid or double-stranded nucleic acid complex as an active ingredient, for example, for suppressing the expression of a target gene and/or the proliferation of target cells (eg, cancer cells) by the antisense effect , the present invention can provide. The antisense nucleic acid or double-stranded nucleic acid complex of the present invention can be delivered to a target tissue or target site with excellent specificity and efficiency, and can suppress the proliferation of target cells with high specificity and efficiency. High drug efficacy can be obtained by administration of a high concentration. In addition, the antisense nucleic acid or double-stranded nucleic acid complex of the invention particularly has the advantage of less side effects. Therefore, it is possible to provide pharmaceutical compositions for treating and preventing diseases associated with increased expression of target genes, such as metabolic diseases, tumors, and infectious diseases.
従って、本発明の1つの実施態様において、本発明は、哺乳動物において、好ましくは標的組織・標的部位における、標的遺伝子の発現を減少させるための、上記アンチセンス核酸または二本鎖核酸複合体に関する。 Therefore, in one embodiment of the present invention, the present invention relates to the above antisense nucleic acid or double-stranded nucleic acid complex for reducing the expression of a target gene in a mammal, preferably in a target tissue/target site. .
また、本発明のさらなる実施態様において、本発明は、哺乳動物において、好ましくは標的組織・標的部位における、標的遺伝子の発現が亢進している細胞の増殖を抑制するための、上記アンチセンス核酸または二本鎖核酸複合体に関する。上記アンチセンス核酸または二本鎖核酸複合体は、癌細胞の増殖を抑制するためのアンチセンス核酸または二本鎖核酸複合体であることができ、または、癌治療用および/または予防用アンチセンス核酸または二本鎖核酸複合体であることができる。 In a further embodiment of the present invention, the present invention provides the antisense nucleic acid or It relates to a double-stranded nucleic acid complex. The antisense nucleic acid or double-stranded nucleic acid complex can be an antisense nucleic acid or double-stranded nucleic acid complex for inhibiting cancer cell growth, or an antisense nucleic acid for cancer treatment and/or prevention. It can be a nucleic acid or a double-stranded nucleic acid complex.
さらに、本発明の1つの実施態様において、本発明は、上記アンチセンス核酸または二本鎖核酸複合体と、任意に薬理学的に許容可能な担体とを含む、医薬組成物に関する。 Furthermore, in one embodiment of the present invention, the present invention relates to a pharmaceutical composition comprising the above antisense nucleic acid or double-stranded nucleic acid complex and optionally a pharmacologically acceptable carrier.
また、本発明の別の実施態様において、本発明は、上記医薬組成物を製造するための、上記アンチセンス核酸または二本鎖核酸複合体の使用に関する。 Moreover, in another embodiment of the present invention, the present invention relates to the use of the above antisense nucleic acid or double-stranded nucleic acid complex for producing the above pharmaceutical composition.
本発明の1つの実施態様において、本発明は、上記アンチセンス核酸または二本鎖核酸複合体を哺乳動物に投与する工程を含む、遺伝子の発現亢進を伴う疾患を治療または予防する方法に関する。
さらに別の実施態様において、本発明は、上記アンチセンス核酸または二本鎖核酸複合体を哺乳動物に投与する工程を含む、哺乳動物において癌を治療する方法に関する。In one embodiment of the present invention, the present invention relates to a method for treating or preventing a disease associated with increased gene expression, comprising the step of administering the above antisense nucleic acid or double-stranded nucleic acid complex to a mammal.
In yet another embodiment, the present invention relates to a method of treating cancer in a mammal, comprising administering the antisense nucleic acid or double-stranded nucleic acid complex described above to the mammal.
上記医薬組成物は、癌細胞の増殖を抑制するための医薬組成物であることができ、または、上記医薬組成物は、癌治療用および/または予防用医薬組成物であることができる。 The pharmaceutical composition can be a pharmaceutical composition for suppressing the growth of cancer cells, or the pharmaceutical composition can be a pharmaceutical composition for treating and/or preventing cancer.
上記癌細胞の癌および上記癌は、例えば、脳腫瘍;頭、首、肺、子宮又は食道の扁平上皮癌;メラノーマ;肺又は子宮の腺癌;腎癌;悪性混合腫瘍;肝細胞癌;基底細胞癌;勅細胞腫様歯肉腫;口腔内腫瘤;肛門周囲腺癌;肛門嚢腫瘤;肛門嚢アポクリン腺癌;セルトリ細胞腫;膣前庭癌;皮脂腺癌;皮脂腺上皮腫;脂腺腺腫;汗腺癌;鼻腔内腺癌;鼻腺癌;甲状腺癌;大腸癌;気管支腺癌;腺癌;腺管癌;乳腺癌;複合型乳腺癌;乳腺悪性混合腫瘍;乳管内乳頭状腺癌;線維肉腫;血管周皮腫;肉腫;骨肉腫;軟骨肉腫;軟部組織肉腫;組織球肉腫;粘液肉腫;未分化肉腫;肺癌;肥満細胞腫;皮膚平滑筋腫;腹腔内平滑筋腫;平滑筋腫;慢性型リンパ球性白血病;リンパ腫;消化管型リンパ腫;消化器型リンパ腫;小~中細胞型リンパ腫;副腎髄質腫瘍;顆粒膜細胞腫;褐色細胞腫;頭頸部癌;乳癌;肺癌;結腸癌;卵巣癌;前立腺癌;神経膠腫;神経膠芽腫;星状細胞腫;多形神経膠芽腫;炎症性乳癌;ウィルムス腫瘍;ユーイング肉腫;横紋筋肉腫;上衣腫;髄芽腫;腎癌;肝癌;黒色腫;膵臓癌;骨巨細胞腫;甲状腺癌;リンパ芽球性T細胞白血病;慢性骨髄性白血病;慢性リンパ球性白血病;ヘアリー細胞白血病;急性リンパ芽球性白血病;急性骨髄性白血病;AML;慢性好中球性白血病;急性リンパ芽球性T細胞白血病;形質細胞腫;免疫芽球性大細胞型白血病;マントル細胞白血病;多発性骨髄腫;巨核芽球性白血病;急性巨核球性白血病;前骨髄球性白血病;赤白血病;ホジキンリンパ腫;非ホジキンリンパ腫;リンパ芽球性T細胞リンパ腫;バーキットリンパ腫;濾胞性リンパ腫;神経芽細胞腫;膀胱癌;尿路上皮癌;外陰癌;子宮頸癌;子宮内膜癌;中皮腫;食道癌;唾液腺癌;肝細胞癌;胃癌;上咽頭癌;頬癌;口腔癌GIST(消化管間葉性腫瘍);上皮様細胞癌;肺胞基底上皮腺癌および精巣癌からなる群から選択される。 Cancers of said cancer cells and said cancers are, for example, brain tumors; squamous cell carcinoma of the head, neck, lung, uterus or esophagus; melanoma; adenocarcinoma of the lung or uterus; renal cancer; carcinoma; gingival sarcoma; intraoral mass; perianal adenocarcinoma; anal cyst mass; anal sac apocrine adenocarcinoma; thyroid cancer; colorectal cancer; bronchial adenocarcinoma; adenocarcinoma; ductal carcinoma; breast adenocarcinoma; chondrosarcoma; soft tissue sarcoma; histiocytic sarcoma; myxosarcoma; undifferentiated sarcoma; lung cancer; Leukemia; lymphoma; gastrointestinal lymphoma; gastrointestinal lymphoma; small-to-medium cell lymphoma; adrenal medullary tumor; glioma; glioblastoma; astrocytoma; glioblastoma multiforme; inflammatory breast cancer; Wilms tumor; cancer; giant cell tumor of bone; thyroid cancer; lymphoblastic T-cell leukemia; chronic myeloid leukemia; chronic lymphocytic leukemia; chronic neutrophilic leukemia; acute lymphoblastic T-cell leukemia; plasmacytoma; immunoblastic large cell leukemia; mantle cell leukemia; multiple myeloma; Hodgkin's Lymphoma; Non-Hodgkin's Lymphoma; Lymphoblastic T-cell Lymphoma; Burkitt's Lymphoma; Follicular Lymphoma; Cancer; Endometrial cancer; Mesothelioma; Esophageal cancer; Salivary gland cancer; Hepatocellular carcinoma; It is selected from the group consisting of epithelial adenocarcinoma and testicular cancer.
本発明のさらなる実施態様において、本発明は、上記アンチセンス核酸または二本鎖核酸複合体を細胞と接触させる工程を含む、細胞内の転写産物レベルを低減する方法に関する。 In a further embodiment of the invention, the invention relates to a method of reducing transcript levels in a cell comprising contacting said antisense nucleic acid or double-stranded nucleic acid complex with said cell.
本発明の別の実施態様において、本発明は、上記アンチセンス核酸または二本鎖核酸複合体を細胞、好ましくは癌細胞と接触させる工程を含む、当該細胞の増殖を抑制する方法に関する。 In another embodiment of the present invention, the present invention relates to a method for suppressing proliferation of cells, preferably cancer cells, comprising the step of contacting the above antisense nucleic acid or double-stranded nucleic acid complex with said cells.
本発明の別の実施態様において、本発明は、哺乳動物において、好ましくは標的組織・標的部位における、標的遺伝子の発現を低減させるための、上記アンチセンス核酸または二本鎖核酸複合体の使用に関する。 In another embodiment of the present invention, the present invention relates to the use of the above antisense nucleic acid or double-stranded nucleic acid complex for reducing expression of a target gene in a mammal, preferably in a target tissue/target site. .
本発明の別の実施態様において、本発明は、哺乳動物において、好ましくは標的組織・標的部位における、標的細胞、好ましくは癌細胞の増殖を抑制するための、上記アンチセンス核酸または二本鎖核酸複合体の使用に関する。 In another embodiment of the present invention, the present invention provides the above antisense nucleic acid or double-stranded nucleic acid for suppressing proliferation of target cells, preferably cancer cells, preferably in target tissues/target sites in mammals. Concerning the use of complexes.
本発明はさらに、哺乳動物において、好ましくは標的組織・標的部位における、標的遺伝子の発現を低減させるための薬剤を製造するための、上記アンチセンス核酸または二本鎖核酸複合体の使用に関する。本発明はまた、哺乳動物において、好ましくは標的組織・標的部位における、標的細胞、好ましくは癌細胞の増殖を抑制するための薬剤を製造するための、上記アンチセンス核酸または二本鎖核酸複合体の使用に関する。 The present invention further relates to the use of the above antisense nucleic acid or double-stranded nucleic acid complex for manufacturing a drug for reducing target gene expression in a mammal, preferably in a target tissue/target site. The present invention also provides the above antisense nucleic acid or double-stranded nucleic acid complex for producing a drug for suppressing the growth of target cells, preferably cancer cells, preferably in target tissues/target sites in mammals. regarding the use of
さらなる実施態様において、本発明は、上記アンチセンス核酸または二本鎖核酸複合体を哺乳動物に投与する工程を含む、哺乳動物において、好ましくは標的組織・標的部位における、標的遺伝子の発現レベルを低減する方法に関する。本発明の別の実施態様において、本発明は、上記アンチセンス核酸または二本鎖核酸複合体を哺乳動物に投与する工程を含む、哺乳動物において、好ましくは標的組織・標的部位における、標的細胞、好ましくは癌細胞の増殖を抑制する方法に関する。 In a further embodiment, the present invention reduces the expression level of a target gene in a mammal, preferably in a target tissue/target site, comprising the step of administering the antisense nucleic acid or double-stranded nucleic acid complex to the mammal. on how to. In another embodiment of the present invention, the present invention provides a target cell, preferably in a target tissue/target site, in a mammal, comprising the step of administering the antisense nucleic acid or double-stranded nucleic acid complex to the mammal. Preferably, it relates to a method for suppressing proliferation of cancer cells.
これらの態様では、好ましくは、アンチセンス核酸のポリヌクレオチドは、上記転写産物のいずれかの領域に相補的なアンチセンス鎖である。 In these aspects, preferably the polynucleotide of the antisense nucleic acid is the antisense strand complementary to the region of any of the above transcripts.
別の実施態様において、本発明は、アンチセンス核酸のデリバリー手段として様々なドラッグデリバリーシステム(DDS)を用いて利用することができる。DDS複合体としては、界面活性剤ペプチド(Med. Mol. Morphol., 46, pp.86, 2013)、多糖シゾフィラン(J. Control. Release, 151, pp.155, 2011)、シクロデキストリン(Mol. Pharm., 12, pp.3129, 2015)、カチオニックリポソーム(J. Control. Release., 100, pp.165, 2004)、核酸ミセル粒子(Mol. Pharm., 11, pp.904, 2014)、アテロコラーゲン(Proc. Natl. Acad. Sci. USA, 102, pp.12179, 2005)などが挙げられる。 In another embodiment, the present invention can be utilized using various drug delivery systems (DDS) as a means of delivering antisense nucleic acids. DDS complexes include surfactant peptide (Med. Mol. Morphol., 46, pp.86, 2013), polysaccharide schizophyllan (J. Control. Release, 151, pp.155, 2011), cyclodextrin (Mol. Pharm., 12, pp.3129, 2015), cationic liposomes (J. Control. Release., 100, pp.165, 2004), nucleic acid micelle particles (Mol. Pharm., 11, pp.904, 2014), Atelocollagen (Proc. Natl. Acad. Sci. USA, 102, pp. 12179, 2005) and the like.
1つの実施態様において、上記転写産物は、タンパク質をコードするmRNA転写産物である。好ましくは、上記タンパク質はヒトBCL2、ヒトBCR-ABLまたはヒトSTAT3である。他の実施態様において、上記転写産物は、タンパク質をコードしない転写産物である。 In one embodiment, the transcript is a protein-encoding mRNA transcript. Preferably, said protein is human BCL2, human BCR-ABL or human STAT3. In other embodiments, the transcript is a non-protein-encoding transcript.
また、本発明の1つの実施態様において、上記標的遺伝子は、ヒトbcl-2、ヒトBCR-ABLまたはヒトSTAT3である。 Also, in one embodiment of the invention, the target gene is human bcl-2, human BCR-ABL or human STAT3.
1つの好ましい実施態様において、上記哺乳動物はヒトである。 In one preferred embodiment, the mammal is human.
アンチセンス核酸または二本鎖核酸複合体を含む上記組成物や薬剤は、公知の製剤学的方法により所望の投与形態や剤形に製剤化することができる。例えば、カプセル剤、錠剤、丸剤、液剤、散剤、顆粒剤、細粒剤、フィルムコーティング剤、ペレット剤、トローチ剤、舌下剤、咀嚼剤、バッカル剤、ペースト剤、シロップ剤、懸濁剤、エリキシル剤、乳剤、塗布剤、軟膏剤、硬膏剤、パップ剤、経皮吸収型製剤、ローション剤、吸引剤、エアゾール剤、注射剤、坐剤等として、経腸管的(経口的等)又は非経腸管的に使用することができる。 The above compositions and drugs containing antisense nucleic acids or double-stranded nucleic acid complexes can be formulated into desired administration forms and dosage forms by known pharmaceutical methods. For example, capsules, tablets, pills, liquids, powders, granules, fine granules, film coating agents, pellets, lozenges, sublingual agents, chewing agents, buccal agents, pastes, syrups, suspensions, Enteral (oral, etc.) or It can be used enterally.
これら製剤化においては、薬理学上もしくは飲食品として許容可能な担体、具体的には、滅菌水や生理食塩水、植物油、溶剤、基剤、乳化剤、懸濁剤、界面活性剤、pH調節剤、安定剤、香味剤、芳香剤、賦形剤、ベヒクル、防腐剤、結合剤、希釈剤、等張化剤、無痛化剤、増量剤、崩壊剤、緩衝剤、コーティング剤、滑沢剤、着色剤、甘味剤、粘稠剤、矯味矯臭剤、溶解補助剤あるいはその他の添加剤等と適宜組み合わせることができる。 In these formulations, pharmacologically acceptable carriers or foods and beverages, specifically sterile water, physiological saline, vegetable oils, solvents, bases, emulsifiers, suspending agents, surfactants, pH adjusters , stabilizers, flavoring agents, fragrances, excipients, vehicles, preservatives, binders, diluents, tonicity agents, soothing agents, bulking agents, disintegrants, buffers, coating agents, lubricants, Coloring agents, sweetening agents, thickening agents, flavoring agents, solubilizing agents, other additives, and the like can be appropriately combined.
上記アンチセンス核酸または二本鎖核酸複合体、または組成物または薬剤の好ましい投与形態としては特に制限はなく、経腸管的(経口的等)又は非経腸管的、より具体的には、静脈内投与、動脈内投与、腹腔内投与、皮下投与、皮内投与、気道内投与、直腸投与及び筋肉内投与、輸液による投与が挙げられる。 Preferred administration forms of the antisense nucleic acid or double-stranded nucleic acid complex, composition, or drug are not particularly limited, and can be enteral (oral, etc.) or parenteral, more specifically, intravenous administration, intraarterial administration, intraperitoneal administration, subcutaneous administration, intradermal administration, intratracheal administration, rectal administration and intramuscular administration, and administration by infusion.
各実施形態においてアンチセンス核酸または二本鎖核酸複合体や組成物は、ヒトを含む動物を対象として使用することができ、すなわち、ヒトおよび/またはヒト以外の動物を対象とすることができる。ヒト以外の動物としては特に制限はなく、種々の家畜、家禽、ペット、実験用動物等を対象とすることができる。 In each embodiment, the antisense nucleic acid or double-stranded nucleic acid complex or composition can be used for animals including humans, that is, for humans and/or non-human animals. Animals other than humans are not particularly limited, and various livestock, poultry, pets, experimental animals, and the like can be used.
いくつかの実施形態におけるアンチセンス核酸(または二本鎖核酸複合体)または組成物を投与又は摂取する場合、その投与量又は摂取量は、対象の年齢、体重、症状、健康状態、組成物の種類(医薬品、飲食品など)等に応じて、適宜選択されるが、ある実施形態にかかるアンチセンス核酸または組成物の有効摂取量は、ヌクレオチド換算で0.001mg/kg/日~50mg/kg/日であることが好ましい。 When administering or ingesting an antisense nucleic acid (or double-stranded nucleic acid complex) or composition in some embodiments, the dosage or ingestion is determined according to the subject's age, weight, symptoms, health condition, composition Depending on the type (medicine, food and drink, etc.), etc., the effective intake of the antisense nucleic acid or composition according to an embodiment is 0.001 mg/kg/day to 50 mg/kg in terms of nucleotides. / day.
後述の実施例で示されるように、がん遺伝子であるbcl-2(あるいはBCR-ABLまたはSTAT3)を標的とする本発明の二本鎖核酸複合体は、非常に高い効率で標的細胞の増殖を抑制することができる。また、本発明の二本鎖アンチセンス核酸は、優れた特異性と効率で、標的組織や標的部位に送達することが可能である。さらに、本発明の二本鎖核酸複合体は、その副作用が極めて少ない。従って、本発明は、対象に対して、本発明のアンチセンス核酸または二本鎖核酸複合体を添加または投与し、標的遺伝子の発現又は標的転写産物をアンチセンス効果によって抑制する方法を提供することができる。また、本発明は、本発明のアンチセンス核酸または二本鎖核酸複合体を対象に投与することによって、必要に応じて組織・部位特異的に、標的遺伝子の発現亢進等を伴う細胞の増殖を抑制し、それによってこのような発現亢進等を伴う各種疾患を治療、予防するための方法をも提供することができる。 As shown in Examples below, the double-stranded nucleic acid complex of the present invention, which targets the oncogene bcl-2 (or BCR-ABL or STAT3), can proliferate target cells with very high efficiency. can be suppressed. In addition, the double-stranded antisense nucleic acid of the present invention can be delivered to target tissues and target sites with excellent specificity and efficiency. Furthermore, the double-stranded nucleic acid complex of the present invention has extremely few side effects. Accordingly, the present invention provides a method of adding or administering the antisense nucleic acid or double-stranded nucleic acid complex of the present invention to a subject to suppress the expression of a target gene or target transcript by the antisense effect. can be done. In addition, the present invention provides that administration of the antisense nucleic acid or double-stranded nucleic acid complex of the present invention to a subject results in tissue- or site-specific cell proliferation accompanied by, for example, target gene expression enhancement. It is also possible to provide a method for suppressing and thereby treating and preventing various diseases associated with such increased expression.
以下、例に基づいて本発明をより具体的に説明するが、実施形態は以下の例に限定されるものではない。 Hereinafter, the present invention will be described more specifically based on examples, but the embodiments are not limited to the following examples.
例1
[2本鎖核酸の合成]
ヒトBCL2遺伝子の配列に基づいて、該遺伝子を標的とするPS-PO型アンチセンス核酸を基本骨格とする2本鎖核酸を設計した。BCL2遺伝子に対する2本鎖核酸の具体例としては、アンチセンス鎖ヌクレオチドの配列(16mer)を配列番号1~6に、相補鎖ヌクレオチド配列を配列番号7~16に示す(表1)。各々の遺伝子配列においてアンチセンス鎖とそれぞれの相補鎖をアニーリングさせることで2本鎖核酸を形成する。配列番号1~6と7~12で各々形成される2本鎖核酸をBNSP-1~36とする(表2参照)。また、配列番号1と14から形成される2本鎖核酸をBNSP-37、配列番号2と13から形成される2本鎖核酸をBNSP-38、配列番号2と14から形成される2本鎖核酸をBNSP-39、配列番号2と15から形成される2本鎖核酸をBNSP-40、配列番号2と16から形成される2本鎖核酸をBNSP-41、配列番号17と10から形成される2本鎖核酸をBNSP-42とする。尚、配列番号13~16の5’末端には、Example 1
[Synthesis of double-stranded nucleic acid]
Based on the sequence of the human BCL2 gene, a double-stranded nucleic acid having a PS-PO type antisense nucleic acid targeting the gene as a basic skeleton was designed. Specific examples of double-stranded nucleic acids for the BCL2 gene are shown in SEQ ID NOS: 1-6 for antisense strand nucleotide sequences (16mer) and SEQ ID NOS: 7-16 for complementary strand nucleotide sequences (Table 1). A double-stranded nucleic acid is formed by annealing the antisense strand and each complementary strand in each gene sequence. The double-stranded nucleic acids formed by SEQ ID NOs: 1-6 and 7-12, respectively, are designated as BNSP-1-36 (see Table 2). Further, the double-stranded nucleic acid formed from SEQ ID NOS: 1 and 14 is BNSP-37, the double-stranded nucleic acid formed from SEQ ID NOS: 2 and 13 is BNSP-38, and the double-stranded nucleic acid formed from SEQ ID NOS: 2 and 14 BNSP-39 for the nucleic acid, BNSP-40 for the double-stranded nucleic acid formed from SEQ ID NOS:2 and 15, BNSP-41 for the double-stranded nucleic acid formed from SEQ ID NOS:2 and 16, and BNSP-41 for the double-stranded nucleic acid formed from SEQ ID NOS:17 and 10 This double-stranded nucleic acid is referred to as BNSP-42. In addition, at the 5′ ends of SEQ ID NOs: 13 to 16,
![]()
![]()
で表示している5’-Octyl-tochopherol(Link Technology社製)を結合させた。これらの2本鎖核酸のうち、配列番号17については日本テクノサービス株式会社製の核酸合成機(型番:M-8-MX_A8S)を用いて合成し、それ以外は株式会社ジーンデザイン社に合成を委託し合成した。配列表記として下線で示すヌクレオチドはRNA、 5'-Octyl-tochopherol (manufactured by Link Technology) indicated by is bound. Among these double-stranded nucleic acids, SEQ ID NO: 17 was synthesized using a nucleic acid synthesizer (model number: M-8-MX_A8S) manufactured by Nippon Techno Service Co., Ltd., and others were synthesized by Gene Design Co., Ltd. Commissioned and synthesized. Nucleotides underlined as sequence notation are RNA;
![]()
![]()
はLNA、それ以外はDNAを表す。また、ヌクレオチドの結合様式としてpsはチオリン酸結合、poはホスホジエステル結合を示し、N(m)は2’-OMe修飾ヌクレオチドを表す。represents LNA, otherwise represents DNA. In addition, ps indicates a thiophosphate bond, po indicates a phosphodiester bond, and N (m) indicates a 2′-OMe modified nucleotide as the binding mode of nucleotides.


例2
[細胞培養]
後述の実験に用いるヒト癌由来細胞株は、以下の方法で維持した細胞株を用いた。Example 2
[Cell culture]
Human cancer-derived cell lines used in the experiments described later were cell lines maintained by the following method.
ヒト上皮様細胞癌由来細胞株(A431細胞株:JCRB細胞バンクより購入、細胞番号:JCRB0004)、ヒト肝癌由来細胞株(HepG2細胞株:理研セルバンクより購入、細胞番号:RBRC-RCB1886)及びヒト膵臓癌由来細胞株(HPAC細胞株:ATCC細胞バンクより購入、細胞番号:CRL-2119)は、10質量%のウシ胎児血清、100ユニット/mlのペニシリン及び100μgのストレプトマイシンを添加した成長培地(DMEM:GIBCO社製)を用い、ヒト膵臓癌由来細胞株(AsPC-1細胞株:ATCC細胞バンクより購入、細胞番号:CRL-1682)、ヒト胃癌由来細胞株(MKN45細胞株:JCRB細胞バンクより購入、細胞番号:JCRB0254)、ヒト膵臓癌由来細胞株(PANC-1細胞株:理研セルバンクより購入、細胞番号:RBRC-RCB2095)、ヒト前立腺癌由来細胞株(DU145細胞株:理研セルバンクより購入、細胞番号:RBRC-RCB2143)、ヒト前立腺癌由来細胞株(PC-3細胞株:理研セルバンクより購入、細胞番号:RBRC-RCB2145)、及びヒト卵巣癌由来細胞株(OVCAR-3細胞株:理研セルバンクより購入、細胞番号:RBRC-RCB2135)は、10質量%のウシ胎児血清、100ユニット/mlのペニシリン及び100μgのストレプトマイシンを添加した成長培地(RPMI1640:GIBCO社製)を用い、ヒト肺胞基底上皮腺癌由来細胞株(A549細胞株:JCRB細胞バンクより購入、細胞番号:JCRB0076)、ヒト腎癌由来細胞株(Caki-1細胞株:JCRB細胞バンクより購入、細胞番号:JCRB0801)、ヒト胃癌由来細胞株(HGC-27細胞株:理研セルバンクより購入、細胞番号:RBRC-RCB0500)、及びヒト膀胱癌由来細胞株(T24細胞株:理研セルバンクより購入、細胞番号:RBRC-RCB2536)は、10質量%のウシ胎児血清、MEM用非必須アミノ酸(NEAA)、100ユニット/mlのペニシリン及び100μgのストレプトマイシンを添加した成長培地(MEM:GIBCO社)を用い、ヒト卵巣癌由来細胞株(MCAS細胞株:JCRB細胞バンクより購入、細胞番号:JCRB0240)は、20質量%のウシ胎児血清、100ユニット/mlのペニシリン及び100μgのストレプトマイシンを添加した成長培地(MEM:GIBCO社)を用い、ヒト乳腺癌由来細胞株(MCF-7細胞株:JCRB細胞バンクより購入、細胞番号:JCRB0134)は、10質量%のウシ胎児血清、1mM ピルビン酸ナトリウム、10μg/ml インスリン、MEM用非必須アミノ酸(NEAA)、100ユニット/mlのペニシリン及び100μgのストレプトマイシンを添加した成長培地(MEM:GIBCO社)を用い、ヒト大腸癌由来細胞株(HCT116細胞株:ATCC細胞バンクより購入、細胞番号:CCL-247)は、10質量%のウシ胎児血清、100ユニット/mlのペニシリン及び100μgのストレプトマイシンを添加した成長培地(McCoy’s 5a:GIBCO社)を用い、37℃、5質量%CO2条件下にて維持した。Human epithelial-like cell carcinoma-derived cell line (A431 cell line: purchased from JCRB Cell Bank, cell number: JCRB0004), human liver cancer-derived cell line (HepG2 cell line: purchased from Riken Cell Bank, cell number: RBRC-RCB1886) and human pancreas Cancer-derived cell line (HPAC cell line: purchased from ATCC cell bank, cell number: CRL-2119) was grown in growth medium (DMEM: GIBCO), human pancreatic cancer-derived cell line (AsPC-1 cell line: purchased from ATCC cell bank, cell number: CRL-1682), human gastric cancer-derived cell line (MKN45 cell line: purchased from JCRB cell bank, Cell number: JCRB0254), human pancreatic cancer-derived cell line (PANC-1 cell line: purchased from Riken Cell Bank, cell number: RBRC-RCB2095), human prostate cancer-derived cell line (DU145 cell line: purchased from Riken Cell Bank, cell number : RBRC-RCB2143), human prostate cancer-derived cell line (PC-3 cell line: purchased from Riken Cell Bank, cell number: RBRC-RCB2145), and human ovarian cancer-derived cell line (OVCAR-3 cell line: purchased from Riken Cell Bank , cell number: RBRC-RCB2135) is human alveolar basal epithelial adenocarcinoma using a growth medium (RPMI1640: manufactured by GIBCO) supplemented with 10 mass% fetal bovine serum, 100 units/ml penicillin and 100 μg streptomycin. Derived cell line (A549 cell line: purchased from JCRB cell bank, cell number: JCRB0076), human kidney cancer-derived cell line (Caki-1 cell line: purchased from JCRB cell bank, cell number: JCRB0801), human gastric cancer-derived cell line (HGC-27 cell line: purchased from Riken Cell Bank, cell number: RBRC-RCB0500) and human bladder cancer-derived cell line (T24 cell line: purchased from Riken Cell Bank, cell number: RBRC-RCB2536) Fetal bovine serum, non-essential amino acids for MEM (NEAA), 100 units / ml of penicillin and 100 μg of streptomycin using a growth medium (MEM: GIBCO), human ovarian cancer-derived cell line (MCAS cell line: JCRB cell Purchased from Bank, cell number: JCRB0240) contains 20% by mass fetal bovine serum, 100 units/ml penicillin and 100 μg streptomycin. Human mammary adenocarcinoma-derived cell line (MCF-7 cell line: purchased from JCRB cell bank, cell number: JCRB0134) was added with growth medium (MEM: GIBCO), 10 mass% fetal bovine serum, 1 mM pyruvate Using a growth medium (MEM: GIBCO) supplemented with sodium, 10 μg/ml insulin, non-essential amino acids for MEM (NEAA), 100 units/ml penicillin and 100 μg streptomycin, human colon cancer-derived cell line (HCT116 cell line : purchased from ATCC cell bank, cell number: CCL-247), using a growth medium (McCoy's 5a: GIBCO) supplemented with 10 mass% fetal bovine serum, 100 units/ml penicillin and 100 μg streptomycin , 37° C., 5 wt % CO 2 conditions.
例3
[細胞増殖アッセイ]
後述の実験で行った細胞増殖アッセイは、特に断りのない限り、以下の方法で行った。Example 3
[Cell Proliferation Assay]
Unless otherwise specified, the cell proliferation assays performed in the experiments described later were performed by the following method.
96穴マイクロプレートを用い、加湿条件下(37℃、5% CO2)、100μl/ウェルの培地で細胞を培養した。細胞増殖アッセイには細胞増殖試薬 WST-1(ロッシュ社製)を1ウェルに対し10μl添加し、マイクロプレートリーダー(Bio Rad社製)を用いて吸光度を測定した。Cells were cultured in 100 μl/well medium under humidified conditions (37° C., 5% CO 2 ) using 96-well microplates. In the cell proliferation assay, 10 μl of cell proliferation reagent WST-1 (manufactured by Roche) was added per well, and absorbance was measured using a microplate reader (manufactured by Bio Rad).
例4
[定量RT-PCR]
後述の実験で行った定量RT-PCRは、特に断りのない限り、以下の方法で行った。Rneasy Mini Kit(QIAGEN社)を用いて、培養細胞からトータルRNAを抽出した。上記トータルRNAを用いた定量RT-PCRはQuant-Fast Probe RT-PCR Kit(QIAGEN社製)を使用し、推奨される条件で行った。プライマーはApplied Biosystem社製 TaqMan Gene Expression Assays Probeを使用した。内因性コントロールプライマーには同社製β-Actinを用いた。上記定量RT-PCRの増幅は、ROTOR-Gene Q (QIAGEN社製)を用いて行った。mRNA発現量はDelta Delta CT法により算出した。Example 4
[Quantitative RT-PCR]
Quantitative RT-PCR performed in the experiments described later was performed by the following method unless otherwise specified. Total RNA was extracted from cultured cells using Rneasy Mini Kit (QIAGEN). Quantitative RT-PCR using the above total RNA was performed using Quant-Fast Probe RT-PCR Kit (manufactured by QIAGEN) under recommended conditions. TaqMan Gene Expression Assays Probes manufactured by Applied Biosystems were used as primers. β-Actin manufactured by the same company was used as an endogenous control primer. Amplification of the quantitative RT-PCR was performed using ROTOR-Gene Q (manufactured by QIAGEN). The mRNA expression level was calculated by the Delta Delta CT method.
例5
[ヒトBCL2遺伝子遺伝子を標的とする2本鎖核酸の細胞増殖抑制活性試験]
上記のヒトBCL2遺伝子を標的とする2本鎖核酸のインビトロにおける細胞増殖抑制活性を調べるために、以下の実験を行った。まず、表2に示した2本鎖核酸BNPS-1~36(計36本)を用意した。次いで、リポフェクトアミン2000(インビトロジェン社)を用いて、上述の実施例2に示した計16細胞株に3nMの2本鎖核酸をトランスフェクトした。トランスフェクトした細胞株を、トランスフェクトから72時間培養し、上述の実施例3に記載の細胞増殖アッセイ法により2本鎖核酸の細胞増殖抑制活性を測定した。example 5
[Test of cell growth inhibitory activity of double-stranded nucleic acid targeting human BCL2 gene]
In order to examine the in vitro cell growth inhibitory activity of the double-stranded nucleic acid targeting the human BCL2 gene, the following experiment was performed. First, double-stranded nucleic acids BNPS-1 to 36 (36 in total) shown in Table 2 were prepared. A total of 16 cell lines shown in Example 2 above were then transfected with 3 nM of double-stranded nucleic acid using Lipofectamine 2000 (Invitrogen). The transfected cell lines were cultured for 72 hours after transfection and the cytostatic activity of the double-stranded nucleic acid was measured by the cell proliferation assay described in Example 3 above.
また、上記の2本鎖核酸に代えて、非標的遺伝子に対する2本鎖核酸を用いて、同様の細胞増殖アッセイを行った。 Also, a similar cell proliferation assay was performed using a double-stranded nucleic acid against a non-target gene instead of the above double-stranded nucleic acid.
その結果をA549細胞株は図4、A431細胞株は図5、AsPC-1細胞株は図6、HPAC細胞株は図7、HepG2細胞株は図8、MCF-7細胞株は図9、OVCAR-3細胞株は図10、MCAS細胞株は図11、Caki-1細胞株は図12、DU145細胞株は図13、PC-3細胞株は図14、T24細胞株は図15、HCT116細胞株は図16、HGC-27細胞株は図17、MKN45細胞株は図18、PANC-1細胞株は図19に示す。図4~18から分かるように、PS結合を6個減らしたアンチセンス鎖に様々な構造の相補鎖をアニーリングしたBNSP-7~12の2本鎖核酸は、アンチセンス鎖が全てPS結合を基本骨格とするBNSP-1~6とヒトBCL2遺伝子を標的とすることで各種癌細胞株に対して同等の増殖抑制活性を示した。また、図19から分かるように、PS結合とPO結合が完全に交互である構造を持つアンチセンス鎖が、全てPS結合を基本骨格とするBNSP-1、4と、ヒトBCL2遺伝子を標的とすることでPANC-1細胞株に対して同等の増殖抑制活性を示した。
The results are shown in Figure 4 for A549 cell line, Figure 5 for A431 cell line, Figure 6 for AsPC-1 cell line, Figure 7 for HPAC cell line, Figure 8 for HepG2 cell line, Figure 9 for MCF-7 cell line, and Figure 9 for OVCAR. -3 cell line in Figure 10, MCAS cell line in Figure 11, Caki-1 cell line in Figure 12, DU145 cell line in Figure 13, PC-3 cell line in Figure 14, T24 cell line in Figure 15,
例6
[ヒトBCL2遺伝子を標的とする2本鎖核酸のmRNA発現抑制活性試験]
上記のヒトBCL2遺伝子を標的とする2本鎖核酸のインビトロにおけるmRNA発現抑制活性を調べるために、以下の実験を行った。アンチセンス配列番号1~6と相補鎖配列番号10をアニーリングさせた2本鎖核酸BNSP-4、BNSP-10、BNSP-16、BNSP-22、BNSP-28、BNSP-34を用意した。次いで、リポフェクトアミン2000(インビトロジェン社)を用いて、OVCAR-3細胞株及びA431細胞株に10nMの上記2本鎖核酸をトランスフェクトした。トランスフェクトした細胞株を、トランスフェクトから24時間培養し、上述の実施例4に記載の定量RT-PCR法により2本鎖核酸のmRNA発現抑制活性を定量した。Example 6
[Test of mRNA expression suppression activity of double-stranded nucleic acid targeting human BCL2 gene]
In order to examine the in vitro mRNA expression-suppressing activity of the double-stranded nucleic acid targeting the human BCL2 gene, the following experiment was performed. Double-stranded nucleic acids BNSP-4, BNSP-10, BNSP-16, BNSP-22, BNSP-28 and BNSP-34 were prepared by annealing the
また、上記の2本鎖核酸に代えて、非標的遺伝子に対する2本鎖核酸を用いて、同様のmRNA発現抑制活性を定量した。 In addition, instead of the double-stranded nucleic acid described above, a double-stranded nucleic acid against a non-target gene was used to quantify similar mRNA expression-suppressing activity.
その結果をOVCAR-3細胞株は図20、A431細胞株は図21に示す。図20より分かる通り、BNSP-10はヒトBCL2遺伝子を標的とすることで各種癌細胞株に対してアンチセンス鎖が全てPS結合を基本骨格とするBNSP-4と同等のmRNA発現抑制活性を示した。また、図20、21よりわかる通り、その他のBNSP-16、BNSP-22、BNSP-28、BNSP-34よりもBNSP-10は強いmRNA発現抑制活性を示した。 The results are shown in FIG. 20 for the OVCAR-3 cell line and in FIG. 21 for the A431 cell line. As can be seen from FIG. 20, by targeting the human BCL2 gene, BNSP-10 exhibits an mRNA expression-suppressing activity equivalent to that of BNSP-4, in which all antisense strands have a PS bond as a basic skeleton, against various cancer cell lines. rice field. Moreover, as can be seen from FIGS. 20 and 21, BNSP-10 exhibited stronger mRNA expression suppression activity than other BNSP-16, BNSP-22, BNSP-28 and BNSP-34.
例7
[PS-PO型2本鎖核酸の膵癌同所移植マウスモデルにおける肝毒性発現検証及び薬効評価]
上記のPS-PO型2本鎖核酸とアンチセンス鎖が全てPS結合を基本骨格とする2本鎖核酸を比較して後述する2項目において差が出るかどうか評価するため、以下の実験を行った。
1.肝毒性の発現検証
2.膵癌部位の増殖抑制効果Example 7
[Verification of expression of hepatotoxicity and efficacy evaluation in pancreatic cancer orthotopic transplantation mouse model of PS-PO type double-stranded nucleic acid]
The following experiment was performed in order to compare the PS-PO type double-stranded nucleic acid and the double-stranded nucleic acid in which all the antisense strands have a PS bond as a basic skeleton and evaluate whether there is a difference in the two items described later. rice field.
1. Verification of expression of
飼育環境下で数日間馴化したBALB/cA Jcl-nu/nuマウス(6週令:雄、日本クレア株式会社より購入)に三種混合麻酔薬(ドミトール0.3mg/kg+ドルミカム4mg/kg+ベトルファール5mg/kg)をマウス体重10gあたり80μl、腹腔内投与して全身麻酔を施した後、1匹あたり1×106個のヒト癌細胞株を膵臓に注入し、膵臓同所移植モデルマウスを作製した(ShamとしてPBSを注入するマウスも作製)。尚、移植翌日から毎日(午後)体重を測定し、人道的エンドポイントから急激な体重減少(数日間で20%以上)、自力歩行不能かつ摂食・摂水不能な重篤状態に陥ったマウスには安楽死処置を施すこととした。癌細胞移植4日後(day4)、体重を指標に群分けを行い(6群×6匹)、Saline及びBNSP-37~41を3mg/kgの用量で尾静脈より投与した。また、Sham群にはSalineを投与した。投与期間及び回数は1日1回(day4,6,8,12,15,18,20,22,25)の合計9回実施した。体重測定等で経過を観察し、癌細胞移植から26日後、麻酔状態下にて腹部静脈より静脈血を採取した後、肝臓及び膵臓を摘出した。肝毒性の血液生化学的検査は株式会社LSIメディエンスに委託し、アスパラギン酸アミノトランスフェラーゼ(AST)、アラニンアミノトランスフェラーゼ(ALT)の定量を行った。また、肝肥大を評価するため、摘出した肝臓重量を測定し、マウス体重で補正することで肝重量比を算出した。その結果をAST値は図22、ALT値は図23、肝重量比は図24に示す。さらに、膵臓重量比を比較することでBNSP-37~41の抗腫瘍効果を評価した。その結果を図25に示す。図22~24から分かる通り、アンチセンス鎖が全てPS結合を基本骨格とする2本鎖核酸(BNSP-37)では、AST、ALT、肝重量比全てにおいてSaline投与群より明らかな肝毒性の発現が見られたが、アンチセンス鎖のPS結合を6個減らしたBNSP-38~41はSaline投与群と同程度であり、BNSP-37と比較して統計学的有意に肝毒性マーカー及び肝肥大を抑制していることが明らかとなった。さらに、図25から分かる通り、抗腫瘍効果ではBNSP-39がBNSP-37と同程度の統計学的に有意な癌増殖抑制作用を示し、薬効を維持したまま肝毒性を著しく減じることが可能になる構造が見出された。BALB/cA Jcl-nu/nu mice (6-week-old: male, purchased from Clea Japan, Inc.) acclimated for several days in a breeding environment were treated with a triple anesthetic (0.3 mg/kg of domitol + 4 mg/kg of dormicum + 5 mg/kg of betorfal). kg) was administered intraperitoneally at a dose of 80 μl per 10 g of mouse body weight to give general anesthesia, and then 1×10 6 human cancer cell lines per animal were injected into the pancreas to prepare pancreatic orthotopic transplantation model mice ( A mouse injected with PBS was also prepared as a sham). In addition, the body weight was measured every day (afternoon) from the day after the transplantation, and from the humane endpoint, the mouse fell into a serious state of rapid weight loss (more than 20% in several days), inability to walk on its own, and inability to eat or drink water. was to be euthanized. Four days after cancer cell transplantation (day 4), the animals were divided into groups (6 groups x 6 animals) using body weight as an index, and 3 mg/kg of Saline and BNSP-37 to 41 were administered through the tail vein. In addition, Saline was administered to the Sham group. The administration period and frequency were once a day (
例8
[2本鎖核酸の合成]
ヒトBCL2、BCR-ABL及びSTAT3遺伝子の配列に基づいて、該遺伝子を標的とするDNA-DNAを基本骨格とし、糖部位にリガンド結合部位を有する塩基を含む2本鎖核酸を設計した。各標的遺伝子に対する2本鎖核酸の具体例としては、BCL2遺伝子に対する相補鎖ヌクレオチド配列(16mer)を配列番号18に示す。また、BCR-ABL遺伝子に対するアンチセンス鎖ヌクレオチドの配列(20mer)を配列番号19に、相補鎖ヌクレオチド配列を配列番号20及び21に示す。さらに、STAT3遺伝子に対するアンチセンス鎖ヌクレオチドの配列(20mer)を配列番号22に、相補鎖ヌクレオチド配列を配列番号23に示す。各々の遺伝子配列においてアンチセンス鎖とそれぞれの相補鎖をアニーリングさせることで2本鎖核酸を形成する。ヒトBCL2遺伝子を標的とした配列番号2と18から形成される2本鎖核酸をBNSP-43、ヒトBCR-ABL遺伝子を標的とした配列番号19と20から形成される2本鎖核酸をBNSP-44、配列番号19と21から形成される2本鎖核酸をBNSP-45、ヒトSTAT3遺伝子を標的とした配列番号22と23から形成される2本鎖核酸をBNSP-46とする。核酸は社内でDNA/RNA自動合成機(NTSH-8:日本テクノサービス株式会社製)を用い、常法に従い合成した。また、アンチセンス鎖とそれぞれの相補鎖のアニーリングによる2本鎖核酸の形成も社内で行った。
配列表記として下線で示すヌクレオチドはRNA、Example 8
[Synthesis of double-stranded nucleic acid]
Based on the sequences of the human BCL2, BCR-ABL and STAT3 genes, a double-stranded nucleic acid was designed having a DNA-DNA skeleton targeting the genes and containing a base having a ligand-binding site in the sugar moiety. As a specific example of the double-stranded nucleic acid for each target gene, SEQ ID NO: 18 shows the complementary strand nucleotide sequence (16mer) for the BCL2 gene. Also, the antisense strand nucleotide sequence (20mer) for the BCR-ABL gene is shown in SEQ ID NO: 19, and the complementary strand nucleotide sequences are shown in SEQ ID NOS: 20 and 21. Furthermore, the antisense strand nucleotide sequence (20mer) for the STAT3 gene is shown in SEQ ID NO:22, and the complementary strand nucleotide sequence is shown in SEQ ID NO:23. A double-stranded nucleic acid is formed by annealing the antisense strand and each complementary strand in each gene sequence. The double-stranded nucleic acid formed from SEQ ID NOS: 2 and 18 targeting the human BCL2 gene is BNSP-43, and the double-stranded nucleic acid formed from SEQ ID NOS: 19 and 20 targeting the human BCR-ABL gene is BNSP- 44, the double-stranded nucleic acid formed from SEQ ID NOs: 19 and 21 is called BNSP-45, and the double-stranded nucleic acid formed from SEQ ID NOs: 22 and 23 targeting the human STAT3 gene is called BNSP-46. Nucleic acids were synthesized in-house using an automatic DNA/RNA synthesizer (NTSH-8: manufactured by Nippon Techno Service Co., Ltd.) according to a conventional method. The formation of double-stranded nucleic acids by annealing the antisense strand and their respective complementary strands was also performed in-house.
Nucleotides underlined as sequence notation are RNA;
![]()
![]()
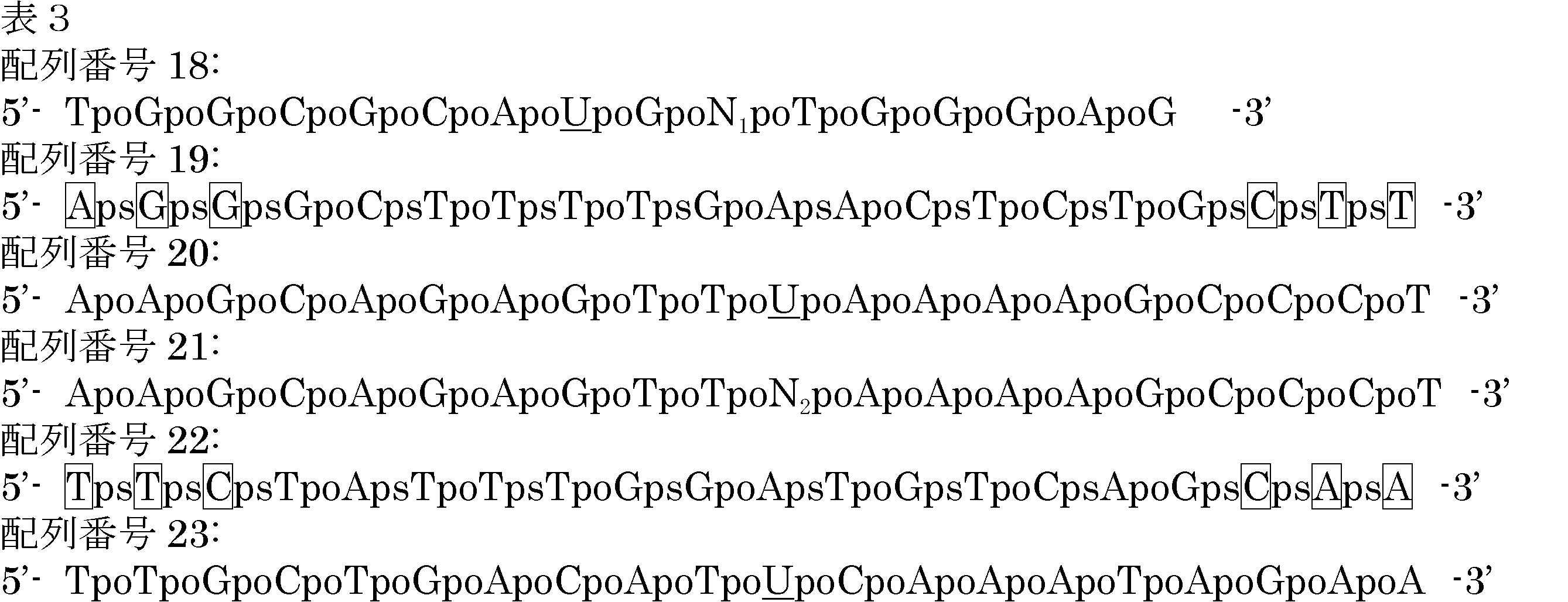
例9
[糖部2’部位へのRGD付加]
上記相補鎖のうち、Propargyl基を有するBNSP-43相補鎖(配列番号18)へのcRGD付加は以下の通り行った。
(1)cRGDfK (Monomeric RGD:Cyclo(-RGDfK) Selleck社製S7834)のペプチドのN末端に縮合反応によりAzido-PEG4-NHS esterを結合させアジド化ペプチドを作製した。
(2)30%DMSO溶液中、BNSP-43相補鎖(配列番号18)とアジド化ペプチドを原料として、Cu(II)錯体の存在下、クリック反応を行った。30%DMSO溶液中、peptide-N3 5等量、CuSO4・5H2O 5等量を加え40℃で16時間反応させた。
(3)クリック反応による過剰なCuはオリゴDNAのリン酸ジエステル、塩基部あるいはトリアゾールに付着している可能性があり、陽イオン交換樹脂(Ag(登録商標)MP-50(バイオラッド社製)によりNa+に置換した。。
(4)アンチセンス鎖(配列番号2)とcRGDの付加したBNSP-43相補鎖(配列番号18)をアニーリングさせた2本鎖核酸をBNSP-43-cRGDとする。
(5)さらに、多量体のcRGDを付加した2本鎖核酸の場合には、2本鎖核酸名に「DicRGD」(二量体)や「TEcRGD」(四量体)を付して呼ぶ(例えば、「BNSP-43-DEcRGD」、「BNSP-43-TEcRGD」)。Example 9
[Addition of RGD to
Of the above complementary strands, addition of cRGD to the BNSP-43 complementary strand (SEQ ID NO: 18) having a Propargyl group was carried out as follows.
(1) Azido-PEG4-NHS ester was bound to the N-terminus of a peptide of cRGDfK (Monomeric RGD: Cyclo(-RGDfK) Selleck S7834) by a condensation reaction to prepare an azide peptide.
(2) Using the BNSP-43 complementary strand (SEQ ID NO: 18) and the azide peptide as starting materials, a click reaction was performed in the presence of a Cu(II) complex in a 30% DMSO solution. In a 30% DMSO solution, 5 equivalents of peptide-N3 and 5 equivalents of CuSO4.5H2O were added and reacted at 40°C for 16 hours.
(3) Excess Cu due to the click reaction may be attached to the phosphodiester, base portion, or triazole of the oligo-DNA, and the cation exchange resin (Ag (registered trademark) MP-50 (manufactured by Bio-Rad) was substituted for Na+ by.
(4) BNSP-43-cRGD is a double-stranded nucleic acid obtained by annealing the antisense strand (SEQ ID NO: 2) and the cRGD-added BNSP-43 complementary strand (SEQ ID NO: 18).
(5) Furthermore, in the case of a double-stranded nucleic acid to which a multimeric cRGD is added, it is called by adding "DicRGD" (dimer) or "TEcRGD" (tetramer) to the name of the double-stranded nucleic acid ( For example, "BNSP-43-DEcRGD", "BNSP-43-TEcRGD").
例10
[葉酸の付加]
葉酸は、PEG3-Folate(base click社製:BCFA-111-1)をクリック反応によりPropargyl基を有するBNSP-45相補鎖(配列番号21)に付加した。アンチセンス鎖(配列番号19)とPEG3-Folateを付加したBNSP-45相補鎖(配列番号21)をアニーリングさせた2本鎖核酸をBNSP-45-PEG-3-Folateとする。さらに、アンチセンス鎖(配列番号19)と社内で合成したPEG11-Folate及びPEG23-Folateを付加したBNSP-45相補鎖(配列番号21)をアニーリングさせた2本鎖核酸をBNSP-45-PEG-11-Folate及びBNSP-45-PEG-23-Folateとする。example 10
[Addition of folic acid]
Folic acid was added to the BNSP-45 complementary strand (SEQ ID NO: 21) having a Propargyl group by click reaction with PEG3-Folate (manufactured by base click: BCFA-111-1). A double-stranded nucleic acid obtained by annealing the antisense strand (SEQ ID NO: 19) and the BNSP-45 complementary strand (SEQ ID NO: 21) added with PEG3-Folate is designated as BNSP-45-PEG-3-Folate. Furthermore, a double-stranded nucleic acid obtained by annealing the antisense strand (SEQ ID NO: 19) and the in-house synthesized PEG11-Folate and PEG23-Folate-added BNSP-45 complementary strand (SEQ ID NO: 21) to BNSP-45-PEG- 11-Folate and BNSP-45-PEG-23-Folate.
例11
[細胞培養]
後述の実験に用いるヒト癌由来細胞株は、以下の方法で維持した細胞株を用いた。
ヒト肺胞基底上皮腺癌由来細胞株(A549細胞株:JCRB細胞バンクより購入、細胞番号:JCRB0076)は、10質量%のウシ胎児血清、MEM用非必須アミノ酸(NEAA)、100ユニット/mlのペニシリン及び100μgのストレプトマイシンを添加した成長培地(MEM:GIBCO社)、ヒト膵臓癌由来細胞株(PANC-1細胞株:理研セルバンクより購入、細胞番号:RBRC-RCB2095)、ヒト慢性骨髄性白血病細胞株(K562細胞株:JCRB細胞バンクより購入、細胞番号:JCRB0019)、ヒト膵臓癌由来細胞株(AsPC-1細胞株:ATCC細胞バンクより購入、細胞番号:CRL-1682)は、10質量%のウシ胎児血清、100ユニット/mlのペニシリン及び100μgのストレプトマイシンを添加した成長培地(RPMI1640:GIBCO社製)を用い、ヒト末梢血単核細胞(PBMC:クラボウ社より購入、製品番号:HC-0001)は、5質量%のウシ胎児血清、10μg/mLのDNaseIを添加した成長培地(LGM-3 lymphocyte:ロンザ社製)を用いた。Example 11
[Cell culture]
Human cancer-derived cell lines used in the experiments described later were cell lines maintained by the following method.
Human alveolar basal epithelial adenocarcinoma-derived cell line (A549 cell line: purchased from JCRB cell bank, cell number: JCRB0076) was prepared with 10 mass% fetal bovine serum, non-essential amino acids for MEM (NEAA), 100 units/ml Growth medium supplemented with penicillin and 100 μg of streptomycin (MEM: GIBCO), human pancreatic cancer-derived cell line (PANC-1 cell line: purchased from Riken Cell Bank, cell number: RBRC-RCB2095), human chronic myelogenous leukemia cell line (K562 cell line: purchased from JCRB cell bank, cell number: JCRB0019), human pancreatic cancer-derived cell line (AsPC-1 cell line: purchased from ATCC cell bank, cell number: CRL-1682) is 10% by mass of bovine Using a growth medium supplemented with fetal serum, 100 units/ml penicillin and 100 μg streptomycin (RPMI1640: manufactured by GIBCO), human peripheral blood mononuclear cells (PBMC: purchased from Kurabo Industries, product number: HC-0001) were , 5% by mass of fetal bovine serum and 10 μg/mL of DNase I (LGM-3 lymphocyte: manufactured by Lonza) was used.
例12
[ヒトBCL2遺伝子を標的とする2本鎖核酸のmRNA発現抑制活性試験]
上記のヒトBCL2遺伝子を標的とする2本鎖核酸のインビトロにおけるmRNA発現抑制活性を調べるために、以下の実験を行った。2本鎖核酸BNSP-1、BNSP-4、BNSP-7、BNSP-10及びPS結合とPO結合が完全に交互である構造を持つアンチセンス鎖(配列番号17)と相補鎖(配列番号10)をアニーリングさせたBNSP-42を用意した。次いで、リポフェクトアミン2000(インビトロジェン社)を用いて、PANC-1細胞株、AsPC-1細胞株及びA549細胞株に10nMとなるよう上記2本鎖核酸をトランスフェクトした。トランスフェクトした細胞株を、トランスフェクトから24時間培養し、上述の実施例4に記載の定量RT-PCR法により2本鎖核酸のmRNA発現抑制活性を定量した。Example 12
[Test of mRNA expression suppression activity of double-stranded nucleic acid targeting human BCL2 gene]
In order to examine the in vitro mRNA expression-suppressing activity of the double-stranded nucleic acid targeting the human BCL2 gene, the following experiment was conducted. Double-stranded nucleic acids BNSP-1, BNSP-4, BNSP-7, BNSP-10 and antisense strand (SEQ ID NO: 17) and complementary strand (SEQ ID NO: 10) having a structure in which PS and PO bonds are completely alternated was prepared by annealing BNSP-42. Then, using Lipofectamine 2000 (Invitrogen), PANC-1 cell line, AsPC-1 cell line and A549 cell line were transfected with the double-stranded nucleic acid at 10 nM. The transfected cell line was cultured for 24 hours after transfection, and the mRNA expression-suppressing activity of the double-stranded nucleic acid was quantified by the quantitative RT-PCR method described in Example 4 above.
また、上記の2本鎖核酸に代えて、非標的遺伝子に対する2本鎖核酸を用いて、同様のmRNA発現抑制活性を定量した。 In addition, instead of the double-stranded nucleic acid described above, a double-stranded nucleic acid against a non-target gene was used to quantify similar mRNA expression-suppressing activity.
その結果をPANC-1細胞株は図26、ASPC-1細胞株は図27、A549細胞株は図28に示す。図26から分かる通り、PS結合とPO結合が完全に交互である構造を持つアンチセンス鎖が、全てPS結合を基本骨格とするBNSP-1、4とヒトBCL2遺伝子を標的とすることでPANC-1細胞株に対して同等のmRNA発現抑制活性を示した。図27、28より分かる通り、BNSP-7及びBNSP-10はヒトBCL2遺伝子を標的とすることでmRNA発現抑制活性を示した。 The results are shown in FIG. 26 for the PANC-1 cell line, FIG. 27 for the ASPC-1 cell line, and FIG. 28 for the A549 cell line. As can be seen from FIG. 26, antisense strands with a structure in which PS bonds and PO bonds are completely alternated target BNSP-1, 4 and human BCL2 genes, all of which have PS bonds as a backbone, resulting in PANC- Equivalent mRNA expression-suppressing activity was shown for 1 cell line. As can be seen from Figures 27 and 28, BNSP-7 and BNSP-10 showed mRNA expression-suppressing activity by targeting the human BCL2 gene.
例13
[cRGDを相補鎖中央部に結合させたヒトBCL2遺伝子を標的とする2本鎖核酸のmRNA発現抑制活性試験]
上記のヒトBCL2遺伝子を標的とするcRGDを結合させた2本鎖核酸のインビトロにおけるmRNA発現抑制活性を調べるために、以下の実験を行った。相補鎖中央部に1量体、2量体、4量体のcRGDを結合させた2本鎖核酸BNSP-43-cRGD、BNSP-43-DicRGD、BNSP-43-TEcRGD、並びにBNSP-10を用意し、PANC-1細胞株には3μM、K562細胞株には300nMとなるよう添加した。2本鎖核酸添加後、24時間培養し、上述の実施例4に記載の定量RT-PCR法により2本鎖核酸のmRNA発現抑制活性を定量した。Example 13
[Test of mRNA expression-suppressing activity of double-stranded nucleic acid targeting human BCL2 gene with cRGD bound to the center of complementary strand]
In order to examine the in vitro mRNA expression-suppressing activity of the above-described cRGD-bound double-stranded nucleic acid targeting the human BCL2 gene, the following experiment was performed. Prepare double-stranded nucleic acids BNSP-43-cRGD, BNSP-43-DicRGD, BNSP-43-TEcRGD, and BNSP-10 in which monomer, dimer, and tetramer cRGD are bound to the center of the
また、上記の2本鎖核酸に代えて、非標的遺伝子に対する2本鎖核酸を用いて、同様のmRNA発現抑制活性を定量した。 In addition, instead of the double-stranded nucleic acid described above, a double-stranded nucleic acid against a non-target gene was used to quantify similar mRNA expression-suppressing activity.
その結果をPANC-1細胞株は図29、K562細胞株は図30に示す。図29から分かる通り、ヒトBCL2遺伝子を標的とする2本鎖核酸に1量体のcRGDを結合させることでリガンドの結合していないBNSP-10よりもPANC-1細胞株に対してmRNA発現抑制活性が増強していることが明らかとなった。また、図30より分かる通り、ヒトBCL2遺伝子を標的とする2本鎖核酸に結合させたcRGDの数依存的にK562細胞株に対してmRNA発現抑制活性が増強していることが明らかとなった。 The results are shown in FIG. 29 for the PANC-1 cell line and in FIG. 30 for the K562 cell line. As can be seen from FIG. 29, by binding a monomeric cRGD to a double-stranded nucleic acid targeting the human BCL2 gene, mRNA expression was suppressed more in the PANC-1 cell line than in the unliganded BNSP-10. It was found that the activity was enhanced. In addition, as can be seen from FIG. 30, it was revealed that the mRNA expression-suppressing activity against the K562 cell line was enhanced depending on the number of cRGDs bound to the double-stranded nucleic acid targeting the human BCL2 gene. .
例14
[葉酸を相補鎖中央部に結合させたヒトBCR-ABL遺伝子を標的とする2本鎖核酸のmRNA発現抑制活性試験]
上記のヒトBCR-ABL遺伝子を標的とする葉酸を結合させた2本鎖核酸のインビトロにおけるmRNA発現抑制活性を調べるために、以下の実験を行った。相補鎖中央部に異なる長さのPEGを介して葉酸を結合させた2本鎖核酸BNSP-45-PEG3-Folate、BNSP-45-PEG11-Folate、BNSP-45-PEG23-Folate、並びに及びBNSP-44を用意し、K562細胞株に300nMとなるよう添加した。2本鎖核酸添加後、24時間培養し、上述の実施例4に記載の定量RT-PCR法により2本鎖核酸のmRNA発現抑制活性を定量した。Example 14
[Test of mRNA expression suppression activity of double-stranded nucleic acid targeting human BCR-ABL gene with folic acid bound to the center of complementary strand]
In order to examine the in vitro mRNA expression-suppressing activity of the double-stranded nucleic acid bound with folic acid targeting the human BCR-ABL gene, the following experiment was conducted. Double-stranded nucleic acids BNSP-45-PEG3-Folate, BNSP-45-PEG11-Folate, BNSP-45-PEG23-Folate, and BNSP- 44 was prepared and added to the K562 cell line at 300 nM. After addition of the double-stranded nucleic acid, the cells were cultured for 24 hours, and the mRNA expression-suppressing activity of the double-stranded nucleic acid was quantified by the quantitative RT-PCR method described in Example 4 above.
また、上記の2本鎖核酸に代えて、非標的遺伝子に対する2本鎖核酸を用いて、同様のmRNA発現抑制活性を定量した。
その結果を図31に示す。図31から分かる通り、ヒトBCR-ABL遺伝子を標的とする2本鎖核酸に葉酸を結合させることでリガンドの結合していないBNSP-44よりもK562細胞株に対してmRNA発現抑制活性が増強していることが明らかとなった。また、PEG3、PEG11、PEG23の比較では、PEGの長さは短い方がmRNA発現抑制活性が増強することが明らかとなった。In addition, instead of the double-stranded nucleic acid described above, a double-stranded nucleic acid against a non-target gene was used to quantify similar mRNA expression-suppressing activity.
The results are shown in FIG. As can be seen from FIG. 31, by binding folic acid to the double-stranded nucleic acid targeting the human BCR-ABL gene, the mRNA expression-suppressing activity against the K562 cell line was enhanced more than that of BNSP-44 to which no ligand was bound. It became clear that Moreover, a comparison of PEG3, PEG11, and PEG23 revealed that the shorter the PEG, the higher the mRNA expression-suppressing activity.
このように本願では、ポリヌクレオチドとリガンドとの結合に、ポリアルキレングリコール(例えばPEG)をベースとするリンカー、すなわちポリアルキレングリコールリンカー(例えばPEGリンカー)を使用することができる。当該リンカーのポリアルキレングリコール(例えばPEG)の長さは、1~100の整数、例えば1~50の整数、2~30の整数または1~12の整数、例えば1、2、3、4、5、6、7または8であることができるが、上記の比較では、ポリアルキレングリコール(例えばPEG)の長さは短い方が有利あることが見出された。よって、本発明の1つの実施態様において、上記長さは、好ましくは1~30、より好ましくは1~20、特に好ましくは2~15である。 Thus, in the present application, polyalkylene glycol (eg, PEG)-based linkers, ie, polyalkylene glycol linkers (eg, PEG linkers), can be used to attach the polynucleotide to the ligand. The length of the polyalkylene glycol (eg, PEG) of the linker is an integer of 1-100, such as an integer of 1-50, an integer of 2-30 or an integer of 1-12, such as 1, 2, 3, 4, 5. , 6, 7 or 8, but in the above comparison it was found that shorter polyalkylene glycol (eg PEG) lengths are advantageous. Thus, in one embodiment of the invention, the length is preferably 1-30, more preferably 1-20, particularly preferably 2-15.
例15
[ヒトSTAT3遺伝子を標的とする2本鎖核酸のmRNA発現抑制活性試験]
上記のヒトSTAT3遺伝子を標的とする2本鎖核酸のインビトロにおけるmRNA発現抑制活性を調べるために、以下の実験を行った。2本鎖核酸BNSP-46を用意し、リポフェクトアミン2000(インビトロジェン社)を用いて、AsPC-1細胞株に0.3、1、3nMとなるようトランスフェクトした。トランスフェクトした細胞株を、トランスフェクトから24時間培養し、上述の実施例4に記載の定量RT-PCR法により2本鎖核酸のmRNA発現抑制活性を定量した。example 15
[Test of mRNA expression suppression activity of double-stranded nucleic acid targeting human STAT3 gene]
In order to examine the in vitro mRNA expression-suppressing activity of the double-stranded nucleic acid targeting the human STAT3 gene, the following experiment was performed. A double-stranded nucleic acid BNSP-46 was prepared and transfected into AsPC-1 cell line at 0.3, 1 and 3 nM using Lipofectamine 2000 (Invitrogen). The transfected cell line was cultured for 24 hours after transfection, and the mRNA expression-suppressing activity of the double-stranded nucleic acid was quantified by the quantitative RT-PCR method described in Example 4 above.
また、上記の2本鎖核酸に代えて、非標的遺伝子に対する2本鎖核酸を用いて、同様のmRNA発現抑制活性を定量した。
その結果を図32に示す。図32から分かる通り、ヒトSTAT3遺伝子を標的とすることでAsPC-1細胞株に対して用量依存的なmRNA発現抑制活性を示した。In addition, instead of the double-stranded nucleic acid described above, a double-stranded nucleic acid against a non-target gene was used to quantify similar mRNA expression-suppressing activity.
The results are shown in FIG. As can be seen from FIG. 32, targeting the human STAT3 gene showed dose-dependent mRNA expression-suppressing activity against the AsPC-1 cell line.
例16
[PS-PO型2本鎖核酸のPBMC(ヒト末梢血単核細胞)におけるインターフェロン-α(IFN-α)発現誘導作用の検証]
上記のPS-PO型2本鎖核酸と、アンチセンス鎖が全てPS結合を基本骨格とする1本鎖核酸及びアンチセンス鎖が全てPS結合を基本骨格とする2本鎖核酸を比較してIFN-α発現誘導作用において差が出るかどうか評価するため、以下の実験を行った。Example 16
[Verification of interferon-α (IFN-α) expression-inducing action in PBMC (human peripheral blood mononuclear cells) of PS-PO type double-stranded nucleic acid]
The above PS-PO type double-stranded nucleic acid, a single-stranded nucleic acid in which all antisense strands have PS bonds as a basic skeleton, and a double-stranded nucleic acid in which all antisense strands have PS bonds as a basic skeleton are compared, and IFN In order to evaluate whether there is a difference in the effect of inducing -α expression, the following experiment was performed.
1本鎖核酸(配列番号1)、2本鎖核酸BNSP-1、BNSP-4、BNSP-7、BNSP-10を用意した。次いで、リポフェクトアミン2000(インビトロジェン社)を用いて、PBMC細胞に30、100、300nMとなるよう上記2本鎖核酸をトランスフェクトした。トランスフェクトした細胞株を、トランスフェクトから24時間培養し、常法によりIFN-αの発現量をELISA法により定量した。 A single-stranded nucleic acid (SEQ ID NO: 1), double-stranded nucleic acids BNSP-1, BNSP-4, BNSP-7 and BNSP-10 were prepared. Then, using Lipofectamine 2000 (Invitrogen), PBMC cells were transfected with the above double-stranded nucleic acid at concentrations of 30, 100 and 300 nM. The transfected cell line was cultured for 24 hours after transfection, and the expression level of IFN-α was quantified by ELISA in a conventional manner.
また、上記の2本鎖核酸に代えて、IFN-α発現ポジティブコントロールとしてCpGPo(インビトロジェン社:ODN2216)を用いて、同様のIFN-α発現量を定量した。 In addition, CpGPo (Invitrogen: ODN2216) was used as an IFN-α expression positive control in place of the double-stranded nucleic acid, and the IFN-α expression level was similarly quantified.
その結果を図33に示す。図33から分かる通り、1本鎖核酸と比較して、2本鎖核酸にすることでIFN-α誘導能は約2分の1に低下し、さらにアンチセンス鎖をPS-PO型にした2本鎖核酸ではIFN-αが全く誘導されないことが明らかとなった。このような結果も、本願の二本鎖核酸複合体が副作用の低減効果を有することを支持するものである。 The results are shown in FIG. As can be seen from FIG. 33, compared to the single-stranded nucleic acid, the double-stranded nucleic acid reduces the IFN-α inducing ability to about half, and the antisense strand is PS-PO type. It was found that IFN-α was not induced at all with the main strand nucleic acid. Such results also support that the double-stranded nucleic acid complex of the present application has the effect of reducing side effects.
Claims (30)
(i)式(V)

A1~Aiは、独立して、化学修飾されていないデオキシリボヌクレオシドであり、
Rは、独立に、式(V)のA1からAiまでの間の領域が、核酸間結合としてホスホジエステル結合とホスホロチオエート化結合を交互に有するように、S-またはO-から選択され、
Xは、独立して化学修飾ヌクレオシドであり、
eは1~9の整数、gは1~9の整数を表し、
ここで、部分構造(V-a)

当該部分構造(V-a)が存在する場合には、i=6~96の整数であり、そして
当該部分構造(V-a)が存在しない場合には、i=5である]
で表される構造、または、
式(VI)

A1~Aiは、独立して、化学修飾されていないデオキシリボヌクレオシドであり、
Rは、独立に、式(VI)のA1からAiまでの間の領域が、核酸間結合としてホスホジエステル結合とホスホロチオエート化結合を交互に有するように、S-またはO-から選択され、
Xは、独立して化学修飾ヌクレオシドであり、
eは1~9の整数、gは1~9の整数を表し、
ここで、部分構造(VI-a)

当該部分構造(VI-a)が存在する場合には、i=6~96の整数であり、そして
当該部分構造(VI-a)が存在しない場合には、i=5である]
で表される構造、または、
式(V’)

A1~Aiは、独立して、化学修飾されていないデオキシリボヌクレオシドであり、
Rは、独立に、式(V’)のA1からAiまでの間の領域が、核酸間結合としてホスホジエステル結合とホスホロチオエート化結合を交互に有するように、S-またはO-から選択され、
Xは、独立して化学修飾ヌクレオシドであり、
e’は0~4の整数を示し、そしてg’は0~4の整数を表し、
ここで、部分構造(V’-a)

i=6~96の整数である]
で表される構造、または、
式(VI’)

A1~Aiは、独立して、化学修飾されていないデオキシリボヌクレオシドであり、
Rは、独立に、式(VI’)のA1からAiまでの間の領域が、核酸間結合としてホスホジエステル結合とホスホロチオエート化結合を交互に有するように、S-またはO-から選択され、
Xは、独立して化学修飾ヌクレオシドであり、
e’は0~4の整数を示し、そしてg’は0~4の整数を表し、
ここで、部分構造(VI’-a)

i=6~96の整数である]
で表される構造を有するアンチセンス核酸、および
(ii)化学修飾されていてもよいヌクレオチドを構成単位として少なくとも含むポリヌクレオチドであって、少なくとも一部が上記(i)アンチセンス核酸に対して相補的なポリヌクレオチドを含む相補鎖、
を含む二本鎖核酸複合体と、任意に薬理学的に許容可能な担体とを含む、医薬組成物であって、
上記(ii)相補鎖におけるポリヌクレオチドが、
- 核酸間結合として、連続したホスホジエステル結合型構造を有し、
- 当該ポリヌクレオチドの5’末端領域および/または3’末端領域における全ての構成単位が化学修飾ヌクレオチドであり、そして、当該化学修飾ヌクレオチドを構成単位とする領域以外の領域における全ての構成単位が化学修飾されていないデオキシリボヌクレオチドもしくはリボヌクレオチドであり、
- ここで、上記5’末端領域は、5’末端に位置する構成単位と5’末端から数えて2~n番目(n=3~6)の構成単位とからなる領域であり、上記3’末端領域は、3’末端に位置する構成単位と3’末端から数えて2~m番目(m=3~6)の構成単位とからなる領域であり、
- ただし、上記化学修飾ヌクレオチドを構成単位とする領域は、核酸間結合として、連続したホスホロチオエート化結合型構造または連続したホスホジエステル結合型構造を有する、
上記医薬組成物。 (i) and (ii) below :
(i) Formula (V)
A 1 to A i are independently chemically unmodified deoxyribonucleosides;
R is independently selected from S - or O - such that the region between A 1 and A i of formula (V) has alternating phosphodiester and phosphorothioated bonds as internucleic acid linkages;
X is independently a chemically modified nucleoside;
e is an integer of 1 to 9, g is an integer of 1 to 9,
Here, the partial structure (Va)
i = an integer of 6 to 96 when the partial structure (Va) exists, and i = 5 when the partial structure (Va) does not exist]
or a structure represented by
Formula (VI)
A 1 to A i are independently chemically unmodified deoxyribonucleosides;
R is independently selected from S - or O - such that the region between A 1 and A i of formula (VI) has alternating phosphodiester and phosphorothioated bonds as internucleic acid linkages;
X is independently a chemically modified nucleoside;
e is an integer of 1 to 9, g is an integer of 1 to 9,
Here, partial structure (VI-a)
i = an integer of 6 to 96 when the partial structure (VI-a) exists, and i = 5 when the partial structure (VI-a) does not exist]
or a structure represented by
Formula (V')
A 1 to A i are independently chemically unmodified deoxyribonucleosides;
R is independently selected from S — or O — such that the region between A 1 and A i of formula (V′) has alternating phosphodiester and phosphorothioated bonds as internucleic acid linkages. ,
X is independently a chemically modified nucleoside;
e' represents an integer from 0 to 4 and g' represents an integer from 0 to 4,
Here, the partial structure (V'-a)
or a structure represented by
Formula (VI')
A 1 to A i are independently chemically unmodified deoxyribonucleosides;
R is independently selected from S — or O — such that the region between A 1 and A i of formula (VI′) has alternating phosphodiester and phosphorothioated bonds as internucleic acid linkages. ,
X is independently a chemically modified nucleoside;
e' represents an integer from 0 to 4 and g' represents an integer from 0 to 4,
Here, the partial structure (VI'-a)
and (ii) a polynucleotide comprising at least a nucleotide that may be chemically modified as a constituent unit, at least a portion of which is complementary to the (i) antisense nucleic acid a complementary strand comprising a specific polynucleotide ,
A pharmaceutical composition comprising a double-stranded nucleic acid complex comprising
The polynucleotide in the above (ii) complementary strand is
- having a continuous phosphodiester bond type structure as an internucleic acid bond,
- All structural units in the 5' terminal region and / or 3' terminal region of the polynucleotide are chemically modified nucleotides, and all structural units in regions other than the region having the chemically modified nucleotide as a structural unit are chemical an unmodified deoxyribonucleotide or ribonucleotide,
- Here, the 5' end region is a region consisting of a structural unit located at the 5' end and the 2nd to n-th (n = 3 to 6) structural units counted from the 5' end, and the 3' The terminal region is a region consisting of a structural unit located at the 3' end and the 2nd to m-th (m = 3 to 6) structural units counted from the 3' end,
- However, the region having the chemically modified nucleotide as a constituent unit has a continuous phosphorothioate bond type structure or a continuous phosphodiester bond type structure as an internucleic acid bond,
A pharmaceutical composition as described above.
(i)式(V)(i) Formula (V)

AA. 11 ~A~A ii は、独立して、化学修飾されていないデオキシリボヌクレオシドであり、is independently a chemically unmodified deoxyribonucleoside,
Rは、独立に、式(V)のAR is independently A of formula (V) 11 からAfrom A ii までの間の領域が、核酸間結合としてホスホジエステル結合とホスホロチオエート化結合を交互に有するように、Sso that the region between S -- またはOor O -- から選択され、is selected from
Xは、独立して化学修飾ヌクレオシドであり、X is independently a chemically modified nucleoside;
eは1~9の整数、gは1~9の整数を表し、e is an integer of 1 to 9, g is an integer of 1 to 9,
ここで、部分構造(V-a)Here, the partial structure (Va)

当該部分構造(V-a)が存在する場合には、i=6~96の整数であり、そしてwhen the partial structure (Va) is present, i = an integer of 6 to 96, and
当該部分構造(V-a)が存在しない場合には、i=5である]i=5 when the partial structure (Va) does not exist]
で表される構造、または、or a structure represented by
式(VI)Formula (VI)

AA. 11 ~A~A ii は、独立して、化学修飾されていないデオキシリボヌクレオシドであり、is independently a chemically unmodified deoxyribonucleoside,
Rは、独立に、式(VI)のAR is independently A of formula (VI) 11 からAfrom A ii までの間の領域が、核酸間結合としてホスホジエステル結合とホスホロチオエート化結合を交互に有するように、Sso that the region between S -- またはOor O -- から選択され、is selected from
Xは、独立して化学修飾ヌクレオシドであり、X is independently a chemically modified nucleoside;
eは1~9の整数、gは1~9の整数を表し、e is an integer of 1 to 9, g is an integer of 1 to 9,
ここで、部分構造(VI-a)Here, partial structure (VI-a)

当該部分構造(VI-a)が存在する場合には、i=6~96の整数であり、そしてwhen the partial structure (VI-a) is present, i = an integer from 6 to 96, and
当該部分構造(VI-a)が存在しない場合には、i=5である]i=5 when the partial structure (VI-a) does not exist]
で表される構造、または、or a structure represented by
式(V’)Formula (V')

AA. 11 ~A~A ii は、独立して、化学修飾されていないデオキシリボヌクレオシドであり、is independently a chemically unmodified deoxyribonucleoside,
Rは、独立に、式(V’)のAR is independently A of formula (V') 11 からAfrom A ii までの間の領域が、核酸間結合としてホスホジエステル結合とホスホロチオエート化結合を交互に有するように、Sso that the region between S -- またはOor O -- から選択され、is selected from
Xは、独立して化学修飾ヌクレオシドであり、X is independently a chemically modified nucleoside;
e’は0~4の整数を示し、そしてg’は0~4の整数を表し、e' represents an integer from 0 to 4, and g' represents an integer from 0 to 4,
ここで、部分構造(V’-a)Here, the partial structure (V'-a)

i=6~96の整数である]i = an integer from 6 to 96]
で表される構造、または、or a structure represented by
式(VI’)Formula (VI')

AA. 11 ~A~A ii は、独立して、化学修飾されていないデオキシリボヌクレオシドであり、is independently a chemically unmodified deoxyribonucleoside,
Rは、独立に、式(VI’)のAR is independently A of formula (VI') 11 からAfrom A ii までの間の領域が、核酸間結合としてホスホジエステル結合とホスホロチオエート化結合を交互に有するように、Sso that the region between S -- またはOor O -- から選択され、is selected from
Xは、独立して化学修飾ヌクレオシドであり、X is independently a chemically modified nucleoside;
e’は0~4の整数を示し、そしてg’は0~4の整数を表し、e' represents an integer from 0 to 4, and g' represents an integer from 0 to 4,
ここで、部分構造(VI’-a)Here, the partial structure (VI'-a)

i=6~96の整数である]i = an integer from 6 to 96]
で表される構造を有するアンチセンス核酸、およびAn antisense nucleic acid having a structure represented by, and
(ii)化学修飾されていてもよいヌクレオチドを構成単位として少なくとも含むポリヌクレオチドであって、少なくとも一部が上記(i)アンチセンス核酸に対して相補的なポリヌクレオチドを含む相補鎖、(ii) a complementary strand comprising a polynucleotide comprising at least a nucleotide that may be chemically modified as a constituent unit, at least a portion of which is complementary to the above (i) antisense nucleic acid;
を含む二本鎖核酸複合体と、任意に薬理学的に許容可能な担体とを含む、医薬組成物であって、A pharmaceutical composition comprising a double-stranded nucleic acid complex comprising
上記(ii)相補鎖におけるポリヌクレオチドが、The polynucleotide in the above (ii) complementary strand is
- 化学修飾されていてもよいデオキシリボヌクレオチドおよび化学修飾されていてもよいリボヌクレオチドのみを構成単位として含み、- Contains only deoxyribonucleotides that may be chemically modified and ribonucleotides that may be chemically modified as structural units,
- 核酸間結合として、連続したホスホジエステル結合型構造を有し、- having a continuous phosphodiester bond type structure as an internucleic acid bond,
- 上記(i)アンチセンス核酸に対して少なくとも1つのミスマッチを含み、- contains at least one mismatch to the (i) antisense nucleic acid;
- 上記の化学修飾されていてもよいリボヌクレオチドが上記ミスマッチを構成するヌクレオチドとして使用される、- the optionally chemically modified ribonucleotide is used as the nucleotide constituting the mismatch,
上記医薬組成物。A pharmaceutical composition as described above.
(i)式(V)(i) Formula (V)

AA. 11 ~A~A ii は、独立して、化学修飾されていないデオキシリボヌクレオシドであり、is independently a chemically unmodified deoxyribonucleoside,
Rは、独立に、式(V)のAR is independently A of formula (V) 11 からAfrom A ii までの間の領域が、核酸間結合としてホスホジエステル結合とホスホロチオエート化結合を交互に有するように、Sso that the region between S -- またはOor O -- から選択され、is selected from
Xは、独立して化学修飾ヌクレオシドであり、X is independently a chemically modified nucleoside;
eは1~9の整数、gは1~9の整数を表し、e is an integer of 1 to 9, g is an integer of 1 to 9,
ここで、部分構造(V-a)Here, the partial structure (Va)

当該部分構造(V-a)が存在する場合には、i=6~96の整数であり、そしてwhen the partial structure (Va) is present, i = an integer of 6 to 96, and
当該部分構造(V-a)が存在しない場合には、i=5である]i=5 when the partial structure (Va) does not exist]
で表される構造、または、or a structure represented by
式(VI)Formula (VI)

AA. 11 ~A~A ii は、独立して、化学修飾されていないデオキシリボヌクレオシドであり、is independently a chemically unmodified deoxyribonucleoside,
Rは、独立に、式(VI)のAR is independently A of formula (VI) 11 からAfrom A ii までの間の領域が、核酸間結合としてホスホジエステル結合とホスホロチオエート化結合を交互に有するように、Sso that the region between S -- またはOor O -- から選択され、is selected from
Xは、独立して化学修飾ヌクレオシドであり、X is independently a chemically modified nucleoside;
eは1~9の整数、gは1~9の整数を表し、e is an integer of 1 to 9, g is an integer of 1 to 9,
ここで、部分構造(VI-a)Here, partial structure (VI-a)

当該部分構造(VI-a)が存在する場合には、i=6~96の整数であり、そしてwhen the partial structure (VI-a) is present, i = an integer from 6 to 96, and
当該部分構造(VI-a)が存在しない場合には、i=5である]i=5 when the partial structure (VI-a) does not exist]
で表される構造、または、or a structure represented by
式(V’)Formula (V')

AA. 11 ~A~A ii は、独立して、化学修飾されていないデオキシリボヌクレオシドであり、is independently a chemically unmodified deoxyribonucleoside,
Rは、独立に、式(V’)のAR is independently A of formula (V') 11 からAfrom A ii までの間の領域が、核酸間結合としてホスホジエステル結合とホスホロチオエート化結合を交互に有するように、Sso that the region between S -- またはOor O -- から選択され、is selected from
Xは、独立して化学修飾ヌクレオシドであり、X is independently a chemically modified nucleoside;
e’は0~4の整数を示し、そしてg’は0~4の整数を表し、e' represents an integer from 0 to 4, and g' represents an integer from 0 to 4,
ここで、部分構造(V’-a)Here, the partial structure (V'-a)

i=6~96の整数である]i = an integer from 6 to 96]
で表される構造、または、or a structure represented by
式(VI’)Formula (VI')

AA. 11 ~A~A ii は、独立して、化学修飾されていないデオキシリボヌクレオシドであり、is independently a chemically unmodified deoxyribonucleoside,
Rは、独立に、式(VI’)のAR is independently A of formula (VI') 11 からAfrom A ii までの間の領域が、核酸間結合としてホスホジエステル結合とホスホロチオエート化結合を交互に有するように、Sso that the region between S -- またはOor O -- から選択され、is selected from
Xは、独立して化学修飾ヌクレオシドであり、X is independently a chemically modified nucleoside;
e’は0~4の整数を示し、そしてg’は0~4の整数を表し、e' represents an integer from 0 to 4, and g' represents an integer from 0 to 4,
ここで、部分構造(VI’-a)Here, the partial structure (VI'-a)

i=6~96の整数である]i = an integer from 6 to 96]
で表される構造を有するアンチセンス核酸、およびAn antisense nucleic acid having a structure represented by, and
(ii)化学修飾されていてもよいヌクレオチドを構成単位として少なくとも含むポリヌクレオチドであって、少なくとも一部が上記(i)アンチセンス核酸に対して相補的なポリヌクレオチドを含む相補鎖、(ii) a complementary strand comprising a polynucleotide comprising at least a nucleotide that may be chemically modified as a constituent unit, at least a portion of which is complementary to the above (i) antisense nucleic acid;
を含む二本鎖核酸複合体と、任意に薬理学的に許容可能な担体とを含む、医薬組成物であって、A pharmaceutical composition comprising a double-stranded nucleic acid complex comprising
上記(ii)相補鎖におけるポリヌクレオチドが、The polynucleotide in the above (ii) complementary strand is
- 化学修飾されていてもよいデオキシリボヌクレオチドおよび化学修飾されていてもよいリボヌクレオチドのみを構成単位として含み、- Contains only deoxyribonucleotides that may be chemically modified and ribonucleotides that may be chemically modified as structural units,
- 核酸間結合として、連続したホスホジエステル結合型構造を有し、- having a continuous phosphodiester bond type structure as an internucleic acid bond,
- 少なくとも1つのバルジを含み、- includes at least one bulge;
- 上記バルジを構成するヌクレオチドの全部が、化学修飾されていてもよいリボヌクレオチドである、- All of the nucleotides that make up the bulge are ribonucleotides that may be chemically modified,
上記医薬組成物。A pharmaceutical composition as described above.
(i)式(V)(i) Formula (V)

AA. 11 ~A~A ii は、独立して、化学修飾されていないデオキシリボヌクレオシドであり、is independently a chemically unmodified deoxyribonucleoside,
Rは、独立に、式(V)のAR is independently A of formula (V) 11 からAfrom A ii までの間の領域が、核酸間結合としてホスホジエステル結合とホスホロチオエート化結合を交互に有するように、Sso that the region between S -- またはOor O -- から選択され、is selected from
Xは、独立して化学修飾ヌクレオシドであり、X is independently a chemically modified nucleoside;
eは1~9の整数、gは1~9の整数を表し、e is an integer of 1 to 9, g is an integer of 1 to 9,
ここで、部分構造(V-a)Here, the partial structure (Va)

当該部分構造(V-a)が存在する場合には、i=6~96の整数であり、そしてwhen the partial structure (Va) is present, i = an integer of 6 to 96, and
当該部分構造(V-a)が存在しない場合には、i=5である]i=5 when the partial structure (Va) does not exist]
で表される構造、または、or a structure represented by
式(VI)Formula (VI)

AA. 11 ~A~A ii は、独立して、化学修飾されていないデオキシリボヌクレオシドであり、is independently a chemically unmodified deoxyribonucleoside,
Rは、独立に、式(VI)のAR is independently A of formula (VI) 11 からAfrom A ii までの間の領域が、核酸間結合としてホスホジエステル結合とホスホロチオエート化結合を交互に有するように、Sso that the region between S -- またはOor O -- から選択され、is selected from
Xは、独立して化学修飾ヌクレオシドであり、X is independently a chemically modified nucleoside;
eは1~9の整数、gは1~9の整数を表し、e is an integer of 1 to 9, g is an integer of 1 to 9,
ここで、部分構造(VI-a)Here, partial structure (VI-a)

当該部分構造(VI-a)が存在する場合には、i=6~96の整数であり、そしてwhen the partial structure (VI-a) is present, i = an integer from 6 to 96, and
当該部分構造(VI-a)が存在しない場合には、i=5である]i=5 when the partial structure (VI-a) does not exist]
で表される構造、または、or a structure represented by
式(V’)Formula (V')

AA. 11 ~A~A ii は、独立して、化学修飾されていないデオキシリボヌクレオシドであり、is independently a chemically unmodified deoxyribonucleoside,
Rは、独立に、式(V’)のAR is independently A of formula (V') 11 からAfrom A ii までの間の領域が、核酸間結合としてホスホジエステル結合とホスホロチオエート化結合を交互に有するように、Sso that the region between S -- またはOor O -- から選択され、is selected from
Xは、独立して化学修飾ヌクレオシドであり、X is independently a chemically modified nucleoside;
e’は0~4の整数を示し、そしてg’は0~4の整数を表し、e' represents an integer from 0 to 4, and g' represents an integer from 0 to 4,
ここで、部分構造(V’-a)Here, the partial structure (V'-a)

i=6~96の整数である]i = an integer from 6 to 96]
で表される構造、または、or a structure represented by
式(VI’)Formula (VI')

AA. 11 ~A~A ii は、独立して、化学修飾されていないデオキシリボヌクレオシドであり、is independently a chemically unmodified deoxyribonucleoside,
Rは、独立に、式(VI’)のAR is independently A of formula (VI') 11 からAfrom A ii までの間の領域が、核酸間結合としてホスホジエステル結合とホスホロチオエート化結合を交互に有するように、Sso that the region between S -- またはOor O -- から選択され、is selected from
Xは、独立して化学修飾ヌクレオシドであり、X is independently a chemically modified nucleoside;
e’は0~4の整数を示し、そしてg’は0~4の整数を表し、e' represents an integer from 0 to 4, and g' represents an integer from 0 to 4,
ここで、部分構造(VI’-a)Here, the partial structure (VI'-a)

i=6~96の整数である]i = an integer from 6 to 96]
で表される構造を有するアンチセンス核酸、およびAn antisense nucleic acid having a structure represented by, and
(ii)化学修飾されていてもよいヌクレオチドを構成単位として少なくとも含むポリヌクレオチドであって、少なくとも一部が上記(i)アンチセンス核酸に対して相補的なポリヌクレオチドを含む相補鎖、(ii) a complementary strand comprising a polynucleotide comprising at least a nucleotide that may be chemically modified as a constituent unit, at least a portion of which is complementary to the above (i) antisense nucleic acid;
を含む二本鎖核酸複合体と、任意に薬理学的に許容可能な担体とを含む、医薬組成物であって、A pharmaceutical composition comprising a double-stranded nucleic acid complex comprising
上記(ii)相補鎖におけるポリヌクレオチドが、The polynucleotide in the above (ii) complementary strand is
- 化学修飾されていてもよいデオキシリボヌクレオチドおよび化学修飾されていてもよいリボヌクレオチドのみを構成単位として含み、- Contains only deoxyribonucleotides that may be chemically modified and ribonucleotides that may be chemically modified as structural units,
- 核酸間結合として、連続したホスホジエステル結合型構造を有し、- having a continuous phosphodiester bond type structure as an internucleic acid bond,
- 上記デオキシリボヌクレオチドとリボヌクレオチドを交互に含む、- comprising alternating deoxyribonucleotides and ribonucleotides as described above,
上記医薬組成物。A pharmaceutical composition as described above.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2016179153 | 2016-09-14 | ||
| JP2016179153 | 2016-09-14 | ||
| PCT/JP2017/030447 WO2018051762A1 (en) | 2016-09-14 | 2017-08-25 | Antisense oligonucleotide with reduced side effects |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JPWO2018051762A1 JPWO2018051762A1 (en) | 2019-06-24 |
| JP7128517B2 true JP7128517B2 (en) | 2022-08-31 |
Family
ID=61619936
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2018539601A Active JP7128517B2 (en) | 2016-09-14 | 2017-08-25 | Antisense nucleic acid with reduced side effects |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JP7128517B2 (en) |
| WO (1) | WO2018051762A1 (en) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20220135972A1 (en) * | 2019-02-22 | 2022-05-05 | National University Corporation Tokyo Medical And Dental University | Optimal ps modification pattern for heteronucleic acids |
| WO2023080159A1 (en) * | 2021-11-02 | 2023-05-11 | レナセラピューティクス株式会社 | Ligand-bound nucleic acid complex |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2000003720A1 (en) | 1998-07-14 | 2000-01-27 | Isis Pharmaceuticals, Inc. | Carbohydrate or 2'-modified oligonucleotides having alternating internucleoside linkages |
| US20090203896A1 (en) | 2003-06-03 | 2009-08-13 | Balkrishen Bhat | Modulation of survivin expression |
| WO2015017675A2 (en) | 2013-07-31 | 2015-02-05 | Isis Pharmaceuticals, Inc. | Methods and compounds useful in conditions related to repeat expansion |
| JP2016509837A (en) | 2013-03-01 | 2016-04-04 | 国立大学法人 東京医科歯科大学 | Chimeric single-stranded antisense polynucleotide and double-stranded antisense agent |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR960705589A (en) * | 1993-11-16 | 1996-11-08 | 라이오넬 엔, 사이몬 | Chimeric oligonucleoside compounds (Chimeric Oligonucleoside Compounds) |
| AU3465599A (en) * | 1998-04-01 | 1999-10-18 | Hybridon, Inc. | Mixed-backbone oligonucleotides containing pops blocks to obtain reduced phosphorothioate content |
-
2017
- 2017-08-25 WO PCT/JP2017/030447 patent/WO2018051762A1/en active Application Filing
- 2017-08-25 JP JP2018539601A patent/JP7128517B2/en active Active
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2000003720A1 (en) | 1998-07-14 | 2000-01-27 | Isis Pharmaceuticals, Inc. | Carbohydrate or 2'-modified oligonucleotides having alternating internucleoside linkages |
| US20090203896A1 (en) | 2003-06-03 | 2009-08-13 | Balkrishen Bhat | Modulation of survivin expression |
| JP2016509837A (en) | 2013-03-01 | 2016-04-04 | 国立大学法人 東京医科歯科大学 | Chimeric single-stranded antisense polynucleotide and double-stranded antisense agent |
| WO2015017675A2 (en) | 2013-07-31 | 2015-02-05 | Isis Pharmaceuticals, Inc. | Methods and compounds useful in conditions related to repeat expansion |
Non-Patent Citations (6)
| Title |
|---|
| JEONG J.H. et al,J. Biomater. Sci. Polymer Edn,2005年,Vol.16 No.11,pp.1409-1419 |
| KURRECK J. et al.,Nucleic Acids Research,2002年,Vol.30 No.9,p.1911-1918 |
| LI Song et al,Pharmaceutical Research,1998年,Vol.15 No.10,p.1540-1545 |
| PATIL S.V. et al,Bioorganic & Medicinal Chemistry Letters,1994年,Vol.4, No.22,pp.2663-2666 |
| SCHMAJUK G. et al,J. Biol. Chem.,1999年,Vol.274, No.31,pp.21783-21789 |
| ZHOU W. et al,Bioorganic & Medicinal Chemistry Letters,1998年,8,p.3269-3274 |
Also Published As
| Publication number | Publication date |
|---|---|
| WO2018051762A1 (en) | 2018-03-22 |
| JPWO2018051762A1 (en) | 2019-06-24 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6960123B2 (en) | Chimeric double-stranded nucleic acid | |
| JP6877414B2 (en) | KRAS expression modulator | |
| WO2020196662A1 (en) | Double-stranded nucleic acid complex and use thereof | |
| JP6472087B2 (en) | Double-stranded agent for delivering therapeutic oligonucleotides | |
| JP5816556B2 (en) | UNA oligomer structure for therapeutic agents | |
| WO2018003739A1 (en) | Nucleic acid composite including functional ligand | |
| JP2021502120A (en) | Nucleic acid for suppressing LPA expression in cells | |
| WO2017068790A1 (en) | Nucleic acid complex | |
| EP4206213A1 (en) | Compounds and methods for modulation of smn2 | |
| EP2101789B1 (en) | Combined telomerase inhibitor and gemcitabine for the treatment of cancer | |
| US20240043837A1 (en) | Modulation of signal transducer and activator of transcription 3 (stat3) expression | |
| WO2017068791A1 (en) | Nucleic acid complex having at least one bulge structure | |
| KR20220069103A (en) | Chemical modification of small interfering RNAs with minimal fluorine content | |
| JPWO2019022196A1 (en) | Single-stranded oligonucleotide | |
| TWI840345B (en) | Modulators of irf4 expression | |
| JP7128517B2 (en) | Antisense nucleic acid with reduced side effects | |
| WO2020171149A1 (en) | Optimal ps modification pattern for heteronucleic acids | |
| JP7306653B2 (en) | Novel cancer therapy using structurally enhanced S-TuD | |
| JP6826984B2 (en) | Acyl-amino-LNA oligonucleotides and / or hydrocarbyl-amino-LNA oligonucleotides | |
| CN116096420A (en) | Prevention or treatment of aneurysms using miR-33b inhibitors | |
| JPWO2019044974A1 (en) | Small Guide Antisense Nucleic Acids and Their Use | |
| RU2822093C1 (en) | Nucleic acids for inhibiting expression of lpa in cell | |
| JP2024089860A (en) | Nucleic acid complex for modulating zic5 expression | |
| CN117625610A (en) | saRNA, conjugates and pharmaceutical compositions for enhancing STING expression |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20200824 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20210922 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20211022 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20220323 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20220413 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20220803 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20220812 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7128517 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |