JP4829477B2 - Voice quality conversion device, voice quality conversion method, and voice quality conversion program - Google Patents
Voice quality conversion device, voice quality conversion method, and voice quality conversion program Download PDFInfo
- Publication number
- JP4829477B2 JP4829477B2 JP2004079079A JP2004079079A JP4829477B2 JP 4829477 B2 JP4829477 B2 JP 4829477B2 JP 2004079079 A JP2004079079 A JP 2004079079A JP 2004079079 A JP2004079079 A JP 2004079079A JP 4829477 B2 JP4829477 B2 JP 4829477B2
- Authority
- JP
- Japan
- Prior art keywords
- voice
- target speaker
- speech
- synthesized sound
- unit
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images






































Abstract
Description
本発明は、声質変換装置および声質変換方法ならびに声質変換プログラムに関する。 The present invention relates to a voice quality conversion device, a voice quality conversion method, and a voice quality conversion program.
従来から、ある話者が発声した音声を、別の話者の声質を持つ音声へと変換する、声質変換技術についての研究がなされてきた。例えば、特許文献1において、話者Aの声質を話者Bの声質へと変換する技術が開示されている。特許文献1における声質変換法を図38に示す。この声質変換法では、話者Aの音声をLPC分析101によって分析し、話者Aのコードブック103を用い、ベクトル量子化105によって量子化する。また、話者Bの音声をLPC分析102によって分析し、話者Bのコードブック104を用い、ベクトル量子化106によって量子化する。それぞれ量子化されたデータは、時間軸の整合をDPマッチングによる対応付け107によって対応付け(写像)がなされ、写像を元に、ヒストグラムを用いた変換コードブック作成108によってスペクトル変換コードブック109を作成する。話者Aの声質がスペクトル変換コードブック109を用いて声質変換される。
Conventionally, research has been conducted on a voice quality conversion technique for converting a voice uttered by a speaker into a voice having a voice quality of another speaker. For example,
さらに近年では、一人ないし複数の話者の音声データから生成ならびに蓄積された音声合成用データベースを用いて、入力されたテキストの内容を音声として出力する音声合成装置において、所望の声質を持つ音声を合成するための声質変換技術も研究されている。この方法の利点は、ある声質を持つ合成音を生成する際に、その声質を持つ話者の音声データをその都度録音してデータベースを生成ならびに蓄積する必要がなく、1人ないし複数の標準話者データベースを予め蓄積しておけば、そのデータベースを目的の声質を持つように声質変換することで、所望の声質を持つ合成音が生成できるという点にある。 Furthermore, in recent years, in a speech synthesizer that outputs the contents of input text as speech using a speech synthesis database generated and accumulated from speech data of one or more speakers, speech having a desired voice quality can be obtained. Voice quality conversion technology for synthesis is also being studied. The advantage of this method is that when a synthesized sound having a certain voice quality is generated, it is not necessary to create and store a database by recording voice data of a speaker having that voice quality each time, and one or a plurality of standard stories. If a user database is stored in advance, a synthesized sound having a desired voice quality can be generated by converting the voice quality of the database so as to have a desired voice quality.
例えば、特許文献2において、予め記憶してある音声データベースと目標話者の音声との間の写像コードブックを作成し、これを変換関数として変換された音声データベースをテキスト音声合成用データベースとして用いる技術が開示されている。特許文献2における声質変換法を図39に示す。複数の登録話者の音響特徴パラメータを含む音声データベースを予め記憶する。この声質変換装置は、複数の登録話者の音響特徴パラメータを含む音声データベース203とそのコードブック204を予め記憶しておく。入力された目標話者の少なくとも1単語の音声信号に基づいて、声質変換をすべき目標話者に最も近い話者を、複数の登録話者の中から選択する選択手段201と、選択手段201によって選択された話者の音響空間と目標話者の音響空間との間の差分を計算することにより、選択された話者から目標話者への写像コードブック205を計算する生成手段202と、入力された音声合成すべき文字列に基づいて、音声データベース203に記憶された選択された話者の音声の音響特徴パラメータを上記選択された話者のコードブックを用いて量子化し、選択された話者のコードブックと写像コードブックの対応関係に基づいて文字列に対応する目標話者の音声信号の音響特徴パラメータを生成する写像処理手段206と、写像処理手段206によって生成された目標話者の音声信号の音響特徴パラメータに基づいて、文字列に対応する目標話者の音声信号を発生して出力する音声合成手段207とを備えている。また、生成手段202は、移動ベクトル場平滑化法を用いて、選択された話者から目標話者への写像コードブックを計算するようにしている。 For example, in Patent Document 2, a mapping code book between a speech database stored in advance and a target speaker's speech is created, and a speech database converted as a conversion function is used as a text speech synthesis database. Is disclosed. The voice quality conversion method in Patent Document 2 is shown in FIG. A speech database including acoustic feature parameters of a plurality of registered speakers is stored in advance. This voice quality conversion device stores a speech database 203 including acoustic feature parameters of a plurality of registered speakers and its code book 204 in advance. Based on the input speech signal of at least one word of the target speaker, a selection unit 201 that selects a speaker closest to the target speaker to be subjected to voice quality conversion from a plurality of registered speakers, and a selection unit 201 Generating means 202 for calculating a mapping codebook 205 from the selected speaker to the target speaker by calculating a difference between the acoustic space of the speaker selected by and the acoustic space of the target speaker; Based on the input character string to be synthesized, the acoustic feature parameters of the selected speaker's speech stored in the speech database 203 are quantized using the selected speaker's codebook and selected. Mapping processing means 206 for generating an acoustic feature parameter of the target speaker's speech signal corresponding to the character string based on the correspondence between the speaker codebook and the mapping codebook, and mapping processing means 206 Therefore, based on the acoustic feature parameters of the generated target speaker's voice signal, and a voice synthesis section 207 which generates a sound signal of a target speaker corresponding to the character string output. The generation unit 202 calculates a mapping code book from the selected speaker to the target speaker by using the moving vector field smoothing method.
なお、音声信号処理、音声認識の一般的な技術については、非特許文献1、非特許文献2において解説されている。
Note that non-patent
特許文献1に開示されている声質変換方法では、変換元話者Aから変換目標話者Bへと声質変換する場合に、AとBが全く同一内容の発声をしている原音の音声データ(あるいは特徴量データ)を用いて変換関数を作成する必要があった。このため、この方法で声質変換を実施するためには、話者Aと話者Bの全く同一内容の音声データがその都度必要となってしまい、自由な声質変換ができなかった。
In the voice quality conversion method disclosed in
また、特許文献2に開示されている声質変換および音声合成方法では、目標話者の音声の音響空間と音声データベースの音響空間との間の差分を取って移動ベクトル場平滑化法を用いて写像コードブックを求めるため、データベースの情報量が目標話者の情報量に比べ圧倒的に多い場合、非常に疎な対応付けを平滑化して全体の対応付けとする必要があった。このため、対応付けの精度が低く、変換後の音声の音質が劣化する、あるいは目標音声の声質との類似度が低いという問題点が生じた。 Further, in the voice quality conversion and speech synthesis method disclosed in Patent Document 2, the difference between the acoustic space of the target speaker's speech and the acoustic space of the speech database is taken and mapped using the moving vector field smoothing method. In order to obtain a code book, when the amount of information in the database is overwhelmingly larger than the amount of information of the target speaker, it is necessary to smooth the very sparse association to make the entire association. For this reason, there is a problem that the accuracy of association is low, the sound quality of the converted speech is deteriorated, or the similarity with the voice quality of the target speech is low.
したがって、本発明の主たる目的は、変換目標話者の発声内容に依存しない自由な声質変換を実現する装置および方法ならびにプログラムを提供することにある。 Therefore, a main object of the present invention is to provide an apparatus, a method, and a program for realizing free voice quality conversion that does not depend on the utterance content of the conversion target speaker.
本発明の他の目的は、所望の声質へ高精度に変換できる変換関数の同定を可能とする装置および方法ならびにプログラムを提供することにある。 Another object of the present invention is to provide an apparatus, a method, and a program that enable identification of a conversion function that can be converted into a desired voice quality with high accuracy.
本発明のさらに他の目的は、変換目標話者音声と同一あるいは類似の発声内容を持つ合成音の自動生成を可能とする装置および方法ならびにプログラムを提供することにある。 Still another object of the present invention is to provide an apparatus, a method, and a program capable of automatically generating a synthesized sound having the same or similar utterance content as the conversion target speaker voice.
前記目的を達成するために、本発明に係る声質変換装置は、第1のアスペクトによれば、変換目標となる話者の音声(「目標話者音声」という)を入力する目標話者音声入力部と、音声合成用のデータを記憶する音声合成用データ記憶部と、入力された目標話者音声と同一又は類似の発声内容を記述する発音記号列を入力する発音記号入力部と、を備える。また、入力された発音記号列にしたがって、音声合成用データ記憶部に記憶されている音声合成用のデータに基づき、音声を合成して出力する音声合成部と、音声合成部から出力される音声信号(「合成音」という)の特徴パラメータを抽出する合成音特徴パラメータ抽出部と、目標話者音声の特徴パラメータを抽出する目標話者音声特徴パラメータ抽出部と、を備える。さらに、合成音特徴パラメータ抽出部からの合成音の特徴パラメータと、目標話者音声特徴パラメータ抽出部からの目標話者音声の特徴パラメータとを入力し、特徴パラメータを表す空間において、合成音の第1の部分と、目標話者音声の第2の部分との時間軸上の対応関係を求め、合成音の第1の部分におけるスペクトル形状を、目標話者音声の第2の部分におけるスペクトル形状に変換する変換関数の同定を行う変換関数生成部と、を備える構成とされる。 In order to achieve the above object, according to the first aspect, a voice quality conversion apparatus according to the present invention is a target speaker voice input for inputting a voice of a speaker as a conversion target (referred to as “target speaker voice”). A speech synthesis data storage unit that stores data for speech synthesis, and a phonetic symbol input unit that inputs a phonetic symbol string describing the utterance content that is the same as or similar to the input target speaker voice. . In addition, a speech synthesis unit that synthesizes and outputs speech based on speech synthesis data stored in the speech synthesis data storage unit according to the input phonetic symbol string, and a speech output from the speech synthesis unit A synthesized sound feature parameter extracting unit that extracts a feature parameter of a signal (referred to as “synthesized sound”), and a target speaker voice feature parameter extracting unit that extracts a feature parameter of the target speaker voice. Further, the synthesized speech feature parameter from the synthesized speech feature parameter extraction unit and the target speaker speech feature parameter from the target speaker speech feature parameter extraction unit are input, and in the space representing the feature parameter, 1 to obtain a correspondence relationship on the time axis between the first portion and the second portion of the target speaker voice, and change the spectrum shape in the first portion of the synthesized speech to the spectrum shape in the second portion of the target speaker voice. A conversion function generation unit that identifies a conversion function to be converted.
また、本発明に係る声質変換方法は、第2のアスペクトによれば、声質変換装置により声質を変換する方法である。声質変換方法は、声質の変換目標となる話者の音声(「目標話者音声」という)を入力するステップと、目標話者音声の発声内容を記述する発音記号列を入力し、記憶部に予め記憶されている音声合成用のデータを用いて、発音記号列から、合成音を作成するステップと、を含む。また、合成音と目標話者音声とを分析し、それぞれの特徴パラメータを抽出するステップと、目標話者音声の特徴パラメータと合成音の特徴パラメータとの時間軸上の対応付けを行うステップと、対応付けがなされた目標話者音声及び合成音の特徴パラメータに基づき、合成音のスペクトル形状を、目標話者音声のスペクトル形状に、変換するための変換関数を生成するステップと、を含む。 According to the second aspect, the voice quality conversion method according to the present invention is a method for converting voice quality by a voice quality conversion device. The voice quality conversion method includes a step of inputting a voice of a speaker as a voice quality conversion target (referred to as “target speaker voice”), a phonetic symbol string describing the utterance content of the target speaker voice, Creating synthesized speech from a phonetic symbol string using speech synthesis data stored in advance. A step of analyzing the synthesized sound and the target speaker voice and extracting each feature parameter; and a step of correlating the feature parameter of the target speaker voice and the feature parameter of the synthesized sound on the time axis; Generating a conversion function for converting the spectrum shape of the synthesized speech into the spectrum shape of the target speaker speech based on the feature parameters of the target speaker speech and the synthesized speech associated with each other.
さらに、本発明に係る声質変換方法は、第3のアスペクトによれば、声質変換装置により声質を変換する方法である。声質変換方法は、声質の変換目標となる話者の音声(「目標話者音声」という)を入力するステップと、入力される目標話者音声を音声認識するステップと、音声認識の結果から目標話者音声の発声内容を記述する発音記号列を生成するステップと、を含む。さらに、(a)記憶部に予め記憶されている音声合成用のデータを用いて、発音記号列から、合成音を作成するステップと、(b)合成音と目標話者音声とを分析し、それぞれの特徴パラメータを抽出するステップと、(c)目標話者音声の特徴パラメータと合成音の特徴パラメータとの時間軸上の対応付けを行うステップと、(d)対応付けされた2つの特徴パラメータに基づいて、合成音のスペクトル形状を目標話者音声のスペクトル形状に変換する変換関数を生成するステップと、(e)生成された変換関数を用いて変換対象となる音声の声質を変換するステップと、(f)声質の変換結果を、音声合成用のデータとして記憶部に格納するステップと、を収束条件に至るまで繰り返す。 Further, according to the third aspect, the voice quality conversion method according to the present invention is a method for converting voice quality by a voice quality conversion device. The voice quality conversion method includes a step of inputting a voice of a speaker as a voice quality conversion target (referred to as “target speaker voice”), a step of recognizing the input target speaker voice, and a target from the result of the voice recognition. Generating a phonetic symbol string describing the utterance content of the speaker voice. Furthermore, (a) a step of creating a synthesized sound from a phonetic symbol string using speech synthesis data stored in advance in the storage unit; (b) analyzing the synthesized sound and the target speaker voice; A step of extracting each feature parameter, (c) a step of associating the feature parameter of the target speaker speech with the feature parameter of the synthesized sound on the time axis, and (d) two feature parameters associated with each other And a step of generating a conversion function for converting the spectrum shape of the synthesized sound into the spectrum shape of the target speaker speech, and (e) converting the voice quality of the speech to be converted using the generated conversion function And (f) the step of storing the voice quality conversion result in the storage unit as data for speech synthesis is repeated until the convergence condition is reached.
また、本発明に係る声質変換プログラムは、第4のアスペクトによれば、声質変換装置を構成するコンピュータに実行させるプログラムである。このプログラムは、声質の変換目標となる話者の音声(「目標話者音声」という)を入力する処理と、目標話者音声の発声内容を記述する発音記号列を入力し、記憶部に予め記憶されている音声合成用のデータを用いて、発音記号列から、合成音を作成する処理と、を実行させる。また、合成音と目標話者音声とを分析し、それぞれの特徴パラメータを抽出する処理と、目標話者音声の特徴パラメータと合成音の特徴パラメータとの時間軸上の対応付けを行う処理と、対応付けがなされた目標話者音声及び合成音の特徴パラメータに基づき、合成音のスペクトル形状を、目標話者音声のスペクトル形状に、変換するための変換関数を生成する処理と、を実行させる。 According to the fourth aspect, a voice quality conversion program according to the present invention is a program that is executed by a computer constituting the voice quality conversion device. This program inputs a voice of a speaker as a voice quality conversion target (referred to as “target speaker voice”) and a phonetic symbol string describing the utterance content of the target speaker voice, and stores them in advance in the storage unit. Using the stored speech synthesis data, a process of creating a synthesized sound from a phonetic symbol string is executed. A process of analyzing the synthesized sound and the target speaker voice and extracting each feature parameter; a process of associating the feature parameter of the target speaker voice and the feature parameter of the synthesized sound on the time axis; A process of generating a conversion function for converting the spectrum shape of the synthesized speech into the spectrum shape of the target speaker speech is executed based on the characteristic parameters of the target speaker speech and the synthesized speech associated with each other.
さらに、本発明に係る声質変換プログラムは、第5のアスペクトによれば、声質変換装置を構成するコンピュータに実行させるプログラムである。このプログラムは、声質の変換目標となる話者の音声(「目標話者音声」という)を入力する処理と、入力される目標話者音声を音声認識する処理と、音声認識の結果から目標話者音声の発声内容を記述する発音記号列を生成する処理と、を実行させる。さらに、(a)記憶部に予め記憶されている音声合成用のデータを用いて、発音記号列から合成音を作成する処理と、(b)合成音と目標話者音声とを分析し、それぞれの特徴パラメータを抽出する処理と、(c)目標話者音声の特徴パラメータと合成音の特徴パラメータとの時間軸上の対応付けを行う処理と、(d)対応付けされた2つの特徴パラメータに基づいて、合成音のスペクトル形状を目標話者音声のスペクトル形状に変換する変換関数を生成する処理と、(e)生成された変換関数を用いて変換対象となる音声の声質を変換する処理と、(f)声質の変換結果を、音声合成用のデータとして記憶部に格納する処理と、を収束条件に至るまで繰り返す処理を実行させる。 Furthermore, according to the fifth aspect, the voice quality conversion program according to the present invention is a program that is executed by a computer constituting the voice quality conversion device. This program inputs the voice of the speaker that is the voice quality conversion target (referred to as “target speaker voice”), the process of recognizing the input target speaker voice, and the result of the speech recognition. Generating a phonetic symbol string describing the utterance content of the person's voice. Furthermore, (a) a process of creating a synthesized sound from a phonetic symbol string using speech synthesis data stored in advance in the storage unit, and (b) analyzing the synthesized sound and the target speaker voice, (C) processing for extracting feature parameters of the target speaker voice, and processing for associating the feature parameters of the target speaker speech with the feature parameters of the synthesized speech on the time axis, and (d) two feature parameters associated with each other And a process for generating a conversion function for converting the spectrum shape of the synthesized sound into the spectrum shape of the target speaker voice, and (e) a process for converting the voice quality of the voice to be converted using the generated conversion function; (F) A process of storing the voice quality conversion result in the storage unit as data for voice synthesis and a process of repeating until the convergence condition is reached.
本発明によれば、目標話者音声と同一あるいは類似の発声内容を持つ変換元音声を予め用意することなく、目標話者音声の声質への変換を行うことができる。したがって、使用者の負担が軽減する。この理由は、目標話者音声と同一あるいは類似の発声内容を表す発音記号列を入力することで、目標話者音声と同一あるいは類似の発声内容を持つ合成音を生成することができるためである。 According to the present invention, conversion to target voice quality can be performed without preparing a conversion source voice having the same or similar utterance content as the target speaker voice in advance. Therefore, the burden on the user is reduced. This is because a synthesized sound having the same or similar utterance content as the target speaker voice can be generated by inputting a phonetic symbol string representing the same or similar utterance content as the target speaker voice. .
また、学習用音声の対応付けおよび声質変換を行うための変換関数の同定が高精度にできる。したがって、従来に比べて所望の声質に近い声質を持つ高音質な音声が得られる。この理由の1つは、合成音作成に使用されるデータを目標話者音声の情報から推定することによって、目標話者音声への変換関数を同定しやすいように合成音を作成することができるためである。もう1つの理由は、合成音作成時に使用されたデータを記憶しておくことによって、このデータを音声から抽出する特徴パラメータに加えて変換関数生成に用いることができるためである。 In addition, it is possible to identify a conversion function for performing learning speech association and voice quality conversion with high accuracy. Accordingly, it is possible to obtain a high-quality sound having a voice quality close to a desired voice quality as compared with the prior art. One reason for this is that by estimating the data used to create the synthesized speech from the information of the target speaker speech, the synthesized speech can be created so that the conversion function to the target speaker speech can be easily identified. Because. Another reason is that by storing the data used when creating the synthesized sound, this data can be used for generating a conversion function in addition to the feature parameter extracted from the speech.
さらに、目標話者音声と同一あるいは類似の発声内容を表す発音記号列を予め用意することなく、目標話者音声と同一あるいは類似の発声内容の合成音が作成できる。したがって、処理が自動化し、処理速度が向上する。この理由は、目標話者音声を音声認識することによって、目標話者音声と同一あるいは類似の発声内容を表す発音記号列を自動的に生成することができるためである。 Furthermore, a synthesized sound having the same or similar utterance content as that of the target speaker voice can be created without preparing a phonetic symbol string representing the same or similar utterance content as that of the target speaker voice. Therefore, the processing is automated and the processing speed is improved. This is because a phonetic symbol string representing the utterance content identical or similar to the target speaker voice can be automatically generated by recognizing the target speaker voice.
[第1の実施形態]
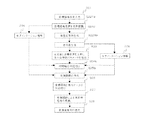
図1に、本発明の第1の実施形態に係る声質変換装置のブロック図を示す。声質変換装置は、目標話者音声入力部11と、発音記号列入力部12と、音声合成用データ記憶部13と、音声合成部14と、目標話者音声特徴パラメータ抽出部15と、合成音特徴パラメータ抽出部16と、変換関数生成部17と、声質変換部18とを備えている。
[First Embodiment]
FIG. 1 shows a block diagram of a voice quality conversion apparatus according to the first embodiment of the present invention. The voice quality conversion apparatus includes a target speaker
目標話者音声入力部11は、目標とする声質を持つ音声データを入力する。発音記号列入力部12は、作成したい音声の発声内容が記述されている発音記号列を入力する。この時、入力される発音記号列は、目標話者音声入力部11から入力される目標話者音声と同一あるいは類似の発声内容の音声を合成するように記述してあるものとする。音声合成用データ記憶部13は、音声合成部14で用いる、音声や音節等の単位、時間長情報等のデータを記憶している。音声合成部14は、発音記号列に対応するデータにしたがって、音声合成用データ記憶部13に蓄えられたデータから合成用のデータを算出し、これを用いて音声を合成して出力する。
The target speaker
また、目標話者音声特徴パラメータ抽出部15は、目標話者音声入力部11から入力された音声データに対しスペクトル分析を施して、特徴パラメータを抽出する。合成音特徴パラメータ抽出部16は、音声合成部14から入力された音声データに対しスペクトル分析を施して、特徴パラメータを抽出する。ここで、目標話者音声および合成音から抽出する特徴パラメータとしては、例えば非特許文献1に記載してあるようなLPC(linear predictive Coding)係数、フォルマント周波数ならびにバンド帯域幅、韻律データ等の内、少なくとも1つを含む。変換関数生成部17は、目標話者音声から抽出された特徴パラメータおよび合成音から抽出された特徴パラメータによって、合成音の声質から目標話者音声の声質へと変換する関数を同定する。声質変換部18は、同定された変換関数を用いて、変換対象である被変換入力信号を変換して変換後出力信号を出力する。
Further, the target speaker voice feature parameter extraction unit 15 performs spectrum analysis on the voice data input from the target speaker
次に、本発明の第1の実施形態に係る声質変換装置の動作を図1および図13を参照して説明する。図13は、本発明の第1の実施形態に係る声質変換装置の動作を示すフローチャートである。まず、ユーザが望む声質を持つ話者の音声データを目標音声として用意し、目標話者音声入力部11に入力する(ステップS11)。次に、目標話者音声入力部11に入力した目標話者音声と同一あるいは類似の発声内容を持つように発音記号列を作成し、発音記号列入力部12に入力する。入力された発音記号列に対応するデータにしたがって音声合成用データ記憶部13から合成用のデータを算出し、音声合成部14において合成音を生成する。この時、目標話者音声と合成音の発声の時間長は、ずれていても構わない。音声合成用データと発音記号との対応付けの規則は、発音記号が指定されると音声合成用データ記憶部13に記憶されている音声素片データや時間長情報等の音声合成用データから当該発音記号に対応した音声合成用データを算出するように予め作成されている(ステップS12)。
Next, the operation of the voice quality conversion apparatus according to the first embodiment of the present invention will be described with reference to FIG. 1 and FIG. FIG. 13 is a flowchart showing the operation of the voice quality conversion apparatus according to the first embodiment of the present invention. First, voice data of a speaker having a voice quality desired by the user is prepared as a target voice and input to the target speaker voice input unit 11 (step S11). Next, a phonetic symbol string is created so as to have the same or similar utterance content as the target speaker voice input to the target speaker
また、目標話者音声特徴パラメータ抽出部15において、目標話者音声に対し分析を行い、目標話者音声の特徴パラメータを抽出する。また、合成音特徴パラメータ抽出部16において、合成音に対し分析を行い、合成音の特徴パラメータを抽出する(ステップS13)。合成音と目標音声の時間軸のずれを修正するために、目標話者音声から抽出したパラメータと合成音から抽出した特徴パラメータを用いて、合成音と目標音声の間で時間軸の対応付けを行う。対応付けの方法としては、DPマッチングによる時間軸伸縮等が考えられる(ステップS14)。全学習データ(目標話者音声と合成音の組)の時間軸の対応付けが行われた後、この時間軸対応付け済みの特徴パラメータを用いて、変換関数生成部17で合成音の声質から目標話者音声の声質へと変換する関数を作成する(ステップS15)。
Further, the target speaker voice feature parameter extraction unit 15 analyzes the target speaker voice and extracts feature parameters of the target speaker voice. In addition, the synthesized sound feature parameter extraction unit 16 analyzes the synthesized sound and extracts a feature parameter of the synthesized sound (step S13). In order to correct the time lag between the synthesized speech and the target speech, the time axis is correlated between the synthesized speech and the target speech using the parameters extracted from the target speaker speech and the feature parameters extracted from the synthesized speech. Do. As a method of association, time axis expansion and contraction by DP matching can be considered (step S14). After all learning data (a set of the target speaker voice and synthesized sound) is associated with the time axis, the conversion
さらに、被変換入力信号のどの部分にどのような変換関数が適用されるかを決定するために、被変換入力信号(素片データ)と作成された変換関数との対応付けを行う(ステップS16)。被変換入力信号に対応付けられた変換関数を用いて、被変換入力信号を変換する(ステップS17)。変換されたデータを変換後出力信号として出力する(ステップS18)。 Further, in order to determine which conversion function is applied to which part of the converted input signal, the converted input signal (element data) is associated with the created conversion function (step S16). ). The converted input signal is converted using the conversion function associated with the converted input signal (step S17). The converted data is output as a post-conversion output signal (step S18).
本発明の第1の実施形態によれば、目標話者音声と同一あるいは類似の発声内容の合成音を音声合成で生成してから分析するため、目標話者音声の発声内容にかかわらず、高精度の対応付けを行ったうえで変換関数を生成することが可能となる。このため、変換目標話者の発声内容に依存しない自由な声質変換を実現することができる。したがって、目標話者音声の発声内容に合わせて、その都度変換元音声を入力する必要がなくなるので、使用者の負担を軽減し、処理を迅速化することができる。 According to the first embodiment of the present invention, since the synthesized sound having the same or similar utterance content as that of the target speaker voice is generated by the voice synthesis, the analysis is performed. Therefore, regardless of the utterance content of the target speaker voice, It is possible to generate a conversion function after associating accuracy. For this reason, free voice quality conversion independent of the utterance content of the conversion target speaker can be realized. Therefore, it is not necessary to input the conversion source voice each time according to the utterance content of the target speaker voice, so that the burden on the user can be reduced and the processing can be speeded up.
[第2の実施形態]
図2に、本発明の第2の実施形態に係る声質変換装置のブロック図を示す。図2において、図1と同一の符号は、同一部あるいは相当部を示し、その説明を省略する。第2の実施形態に係る声質変換装置は、第1の実施形態に係る声質変換装置に、さらに音声認識部19を備えている。音声認識部19は、目標話者音声入力部11aで入力された目標話者音声を音声認識し、目標話者音声の発声内容を発音記号とともに発声記号列入力部12aへ出力する。
[Second Embodiment]
FIG. 2 shows a block diagram of a voice quality conversion apparatus according to the second embodiment of the present invention. 2, the same reference numerals as those in FIG. 1 denote the same or corresponding parts, and the description thereof is omitted. The voice quality conversion device according to the second embodiment further includes a voice recognition unit 19 in addition to the voice quality conversion device according to the first embodiment. The voice recognition unit 19 recognizes the target speaker voice input by the target speaker voice input unit 11a, and outputs the utterance content of the target speaker voice to the utterance symbol string input unit 12a together with the phonetic symbols.
次に、本発明の第2の実施形態に係る声質変換装置の動作を図2および図14を参照して説明する。ただし、図14において、ステップS21およびS23〜S28は、それぞれ図13のS11およびS13〜S18と同様の動作をするため、新たに追加したステップの動作のみを説明する。ステップS21で目標話者音声入力部11aから入力された目標話者音声を音声認識部19で音声認識して(ステップS221)発音記号列を生成し(ステップS222)、生成された発音記号列を用いて合成音を作成する(ステップS223)。 Next, the operation of the voice quality conversion apparatus according to the second embodiment of the present invention will be described with reference to FIG. 2 and FIG. However, since steps S21 and S23 to S28 in FIG. 14 perform the same operations as S11 and S13 to S18 in FIG. 13, respectively, only the operations of the newly added steps will be described. The target speaker voice input from the target speaker voice input unit 11a in step S21 is voice-recognized by the voice recognition unit 19 (step S221) to generate a phonetic symbol string (step S222). A synthesized sound is created by using it (step S223).
本発明の第2の実施形態によれば、目標話者音声の音声認識結果を合成音生成のための発音記号列として入力するため、ユーザがテキスト等で発音記号列を入力する必要が無く、処理の自動化を図ることが可能となる。本発明は、目標話者音声として多くの文を用いて対応付けの高精度化を図る際に有効である。 According to the second embodiment of the present invention, since the speech recognition result of the target speaker voice is input as a phonetic symbol string for generating a synthesized sound, there is no need for the user to input a phonetic symbol string as text, Processing can be automated. The present invention is effective in increasing the accuracy of association using many sentences as target speaker voices.
[第3の実施形態]
本発明の第3の実施形態に係る声質変換装置は、第1の実施形態に係る声質変換装置の構成に加え、音声合成部で使用したセグメンテーション情報を記憶し、変換関数生成部に出力するセグメンテーション情報記憶部により構成される。このような構成を採用し、変換関数生成部でセグメンテーション情報を用いることにより、所望の声質へ高精度に変換できる変換関数の同定が可能である。なお、以下の説明において、セグメンテーション情報とは、時刻情報に対応づいた音素(音素ラベル)を主とし、ピッチパターンあるいはパワー等の韻律情報を付加したものでもよい。
[Third Embodiment]
The voice quality conversion apparatus according to the third embodiment of the present invention stores the segmentation information used in the speech synthesis unit in addition to the configuration of the voice quality conversion apparatus according to the first embodiment, and outputs the segmentation information to the conversion function generation unit An information storage unit is used. By adopting such a configuration and using segmentation information in the conversion function generation unit, it is possible to identify a conversion function that can be converted to a desired voice quality with high accuracy. In the following description, the segmentation information may mainly be phonemes (phoneme labels) corresponding to time information, and may be added with prosodic information such as a pitch pattern or power.
図3に、本発明の第3の実施形態に係る声質変換装置のブロック図を示す。図3において、目標話者音声入力部11と、発音記号列入力部12と、音声合成用データ記憶部13と、目標話者音声特徴パラメータ抽出部15と、合成音特徴パラメータ抽出部16と、声質変換部18は、図1と同等であり、その説明を省略する。本発明の第3の実施形態に係る声質変換装置は、さらに合成音セグメンテーション情報記憶部20を備えている。合成音セグメンテーション情報記憶部20は、音声合成部14aで発音記号列に従って音声を合成する際に用いられるセグメンテーション情報を記憶して、変換関数生成部17aへと出力する。
FIG. 3 is a block diagram of a voice quality conversion apparatus according to the third embodiment of the present invention. In FIG. 3, a target speaker
次に、本発明の第3の実施形態に係る声質変換装置の動作を図3および図15を参照して説明する。ただし、図15において、図13の同一の符号は、同一あるいは同等の処理を行い、その説明を省略し、新たに追加したステップの動作のみを説明する。ステップS12aでは、音声合成部14で音声を合成する際に用いられたセグメンテーション情報23aを合成音セグメンテーション情報記憶部20に記憶し、変換関数生成部17aへ出力する。変換関数生成部17aに入力されたセグメンテーション情報23aは、時間軸の対応付け(ステップS14a)、および変換関数の作成(ステップS15a)で用いられる。
Next, the operation of the voice quality conversion apparatus according to the third embodiment of the present invention will be described with reference to FIG. 3 and FIG. However, in FIG. 15, the same reference numerals in FIG. 13 perform the same or equivalent processing, the description thereof is omitted, and only the operation of the newly added step will be described. In step S12a, the segmentation information 23a used when the
本発明の第3の実施形態によれば、合成音を生成する際に利用するセグメンテーション情報を変換関数生成時に活用するため、合成音特徴パラメータと目標話者音声特徴パラメータとを対応付ける際の処理の簡素化、高精度化を図ることが可能となる。 According to the third embodiment of the present invention, since the segmentation information used when generating the synthesized sound is used when generating the conversion function, the process of associating the synthesized sound feature parameter with the target speaker voice feature parameter is performed. Simplification and high accuracy can be achieved.
[第4の実施形態]
図4に、本発明の第4の実施形態に係る声質変換装置のブロック図を示す。図4において、図2と同一の符号は、同一部あるいは相当部を示し、その説明を省略する。本発明の第4の実施形態に係る声質変換装置は、図2に対し、さらに合成音セグメンテーション情報記憶部20を備えている。なお、合成音セグメンテーション情報記憶部20は、図3で説明したものと同様である。
[Fourth Embodiment]
FIG. 4 shows a block diagram of a voice quality conversion apparatus according to the fourth embodiment of the present invention. 4, the same reference numerals as those in FIG. 2 denote the same or corresponding parts, and the description thereof is omitted. The voice quality conversion apparatus according to the fourth embodiment of the present invention further includes a synthesized sound segmentation
次に、本発明の第4の実施形態に係る声質変換装置の動作を図4および図16を参照して説明する。ただし、図16において、図13の同一の符号は、同一あるいは同等の処理を行い、その説明を省略し、新たに追加したステップの動作のみを説明する。ステップS223aでは、音声合成部14aで音声を合成する際に用いられたセグメンテーション情報23bを出力し、変換関数生成部17aへ入力する。入力されたセグメンテーション情報23bは、時間軸の対応付け(ステップS24a)、および変換関数の作成(ステップS25b)で用いられる。 Next, the operation of the voice quality conversion apparatus according to the fourth embodiment of the present invention will be described with reference to FIG. 4 and FIG. However, in FIG. 16, the same reference numerals in FIG. 13 perform the same or equivalent processing, the description thereof is omitted, and only the operation of the newly added step will be described. In step S223a, the segmentation information 23b used when the speech synthesizer 14a synthesizes speech is output and input to the conversion function generator 17a. The input segmentation information 23b is used in time axis association (step S24a) and creation of a conversion function (step S25b).
本発明の第4の実施形態によれば、目標話者音声を音声合成して発音記号列を自動生成し、これを用いて合成音を生成する際に利用するセグメンテーション情報を変換関数生成時に活用するため、処理の自動化を図りつつ、合成音特徴パラメータと目標話者音声特徴パラメータとを対応付ける際の処理の簡素化、高精度化を図ることが可能となる。 According to the fourth embodiment of the present invention, the target speaker's speech is synthesized with speech to automatically generate a phonetic symbol string, and the segmentation information used when generating the synthesized speech using this is used when generating the conversion function. Therefore, it is possible to simplify the processing and increase the accuracy when associating the synthesized speech feature parameter with the target speaker speech feature parameter while automating the processing.
[第5の実施形態]
図5に、本発明の第5の実施形態に係る声質変換装置のブロック図を示す。図5において、図1と同一の符号は、同一部あるいは相当部を示し、その説明を省略する。本発明の第5の実施形態に係る声質変換装置は、さらにセグメンテーション情報入力部22を備えている。セグメンテーション情報入力部22は、目標話者音声入力部11で入力された目標話者音声を不図示の手段で分析してセグメンテーション情報23cを抽出し、音声合成部14bに出力する。
[Fifth Embodiment]
FIG. 5 shows a block diagram of a voice quality conversion apparatus according to the fifth embodiment of the present invention. 5, the same reference numerals as those in FIG. 1 denote the same or corresponding parts, and the description thereof is omitted. The voice quality conversion device according to the fifth embodiment of the present invention further includes a segmentation information input unit 22. The segmentation information input unit 22 analyzes the target speaker voice input by the target speaker
次に、本発明の第5の実施形態に係る声質変換装置の動作を図5および図17を参照して説明する。ただし、図17において、図13の同一の符号は、同一あるいは同等の処理を行い、その説明を省略し、新たに追加したステップの動作のみを説明する。ステップS12bでは、目標話者音声入力部11で入力された目標話者音声に基づいたセグメンテーション情報23cを入力する。入力されたセグメンテーション情報23cは、音声合成部14bに出力され、発音記号列入力部12で入力された発音記号列の発声内容を持ち、発声の時間長が目標話者音声と同一である音声が音声合成部14bにおいて合成される。
Next, the operation of the voice quality conversion apparatus according to the fifth embodiment of the present invention will be described with reference to FIGS. However, in FIG. 17, the same reference numerals in FIG. 13 perform the same or equivalent processing, the description thereof is omitted, and only the operation of the newly added step will be described. In step S12b, segmentation information 23c based on the target speaker voice input by the target speaker
本発明の第5の実施形態によれば、目標話者音声に基づいたセグメンテーション情報を入力して合成音を生成するため、生成された合成音の時間長情報は当該目標話者音声の時間長情報と等しくなり、変換関数生成部での時間軸の対応付け処理を不必要とする、あるいは簡素化することが可能となる。 According to the fifth embodiment of the present invention, since the segmented information based on the target speaker voice is input to generate the synthesized sound, the time length information of the generated synthesized sound is the time length of the target speaker voice. It becomes equal to information, and it becomes unnecessary or can simplify the time axis association processing in the conversion function generation unit.
[第6の実施形態]
図6に、本発明の第6の実施形態に係る声質変換装置のブロック図を示す。図6において、図2と同一の符号は、同一部あるいは相当部を示し、その説明を省略する。本発明の第6の実施形態に係る声質変換装置は、さらにセグメンテーション情報入力部22を備えている。セグメンテーション情報入力部22は、目標話者音声入力部11aで入力された目標話者音声を不図示の手段で分析してセグメンテーション情報23cを抽出し、音声合成部14bに出力する。
[Sixth Embodiment]
FIG. 6 shows a block diagram of a voice quality conversion apparatus according to the sixth embodiment of the present invention. 6, the same reference numerals as those in FIG. 2 denote the same or corresponding parts, and the description thereof is omitted. The voice quality conversion device according to the sixth embodiment of the present invention further includes a segmentation information input unit 22. The segmentation information input unit 22 analyzes the target speaker voice input by the target speaker voice input unit 11a by means (not shown), extracts the segmentation information 23c, and outputs it to the voice synthesis unit 14b.
次に、本発明の第6の実施形態に係る声質変換装置の動作を図6および図18を参照して説明する。ただし、図18において、図13の同一の符号は、同一あるいは同等の処理を行い、その説明を省略し、新たに追加したステップの動作のみを説明する。ステップS222aでは、目標話者音声入力部11aで入力された目標話者音声に基づいたセグメンテーション情報23cを入力する。入力されたセグメンテーション情報23cは音声合成部14bに出力され、発音記号列入力部12aで入力された発音記号列の発声内容を持ち、発声の時間長が目標話者音声と同一である音声が合成される。 Next, the operation of the voice quality conversion apparatus according to the sixth embodiment of the present invention will be described with reference to FIG. 6 and FIG. However, in FIG. 18, the same reference numerals in FIG. 13 perform the same or equivalent processing, the description thereof is omitted, and only the operation of the newly added step will be described. In step S222a, segmentation information 23c based on the target speaker voice input by the target speaker voice input unit 11a is input. The input segmentation information 23c is output to the speech synthesizer 14b, and the speech having the utterance content of the phonetic symbol string input by the phonetic symbol string input unit 12a and having the same utterance time length as the target speaker voice is synthesized. Is done.
本発明の第6の実施形態によれば、目標話者音声に基づいたセグメンテーション情報を入力して合成音を生成するため、生成された合成音の時間長情報は当該目標話者音声の時間長情報と等しくなり、変換関数生成部での時間軸の対応付け処理を不必要とする、あるいは簡素化することが可能となる。さらに、本発明では、音声認識によって目標話者音声から発音記号列を生成しているため、処理の自動化を図りつつ、発音記号列と目標話者音声から抽出される時間長情報との整合性が取りやすくすることが可能となる。 According to the sixth embodiment of the present invention, since the segmentation information based on the target speaker voice is input to generate the synthesized sound, the time length information of the generated synthesized sound is the time length of the target speaker voice. It becomes equal to information, and it becomes unnecessary or can simplify the time axis association processing in the conversion function generation unit. Further, in the present invention, since the phonetic symbol string is generated from the target speaker voice by voice recognition, the consistency between the phonetic symbol string and the time length information extracted from the target speaker voice is achieved while automating the process. Can be easily removed.
[第7の実施形態]
図7に、本発明の第7の実施形態に係る声質変換装置のブロック図を示す。図7において、図2と同一の符号は、同一部あるいは相当部を示し、その説明を省略する。本発明の第7の実施形態に係る声質変換装置は、さらに目標話者音声セグメンテーション情報記憶部21を備えている。目標話者音声セグメンテーション情報記憶部21は、目標話者音声入力部11aで入力された目標話者音声のセグメンテーション情報を記憶して、変換関数生成部17bに出力する。
[Seventh Embodiment]
FIG. 7 shows a block diagram of a voice quality conversion apparatus according to the seventh embodiment of the present invention. 7, the same reference numerals as those in FIG. 2 denote the same or corresponding parts, and the description thereof is omitted. The voice quality conversion device according to the seventh embodiment of the present invention further includes a target speaker voice segmentation
次に、本発明の第7の実施形態に係る声質変換装置の動作を図7および図19を参照して説明する。ただし、図19において、図14の同一の符号は、同一あるいは同等の処理を行い、その説明を省略し、新たに追加したステップの動作のみを説明する。ステップS221aでは、目標話者音声信号を音声認識部19で音声認識した結果、抽出されるセグメンテーション情報23dを出力する。セグメンテーション情報23dは、変換関数生成部17bへ出力され、時間軸の対応付け(ステップS24a)、および変換関数の作成(ステップS25a)で用いられる。 Next, the operation of the voice quality conversion apparatus according to the seventh embodiment of the present invention will be described with reference to FIGS. However, in FIG. 19, the same reference numerals in FIG. 14 perform the same or equivalent processing, the description thereof is omitted, and only the operation of the newly added step will be described. In step S221a, segmentation information 23d extracted as a result of speech recognition of the target speaker speech signal by the speech recognition unit 19 is output. The segmentation information 23d is output to the conversion function generation unit 17b, and is used for time axis association (step S24a) and creation of the conversion function (step S25a).
本発明の第7の実施形態によれば、目標話者音声を音声認識する際に同時に目標話者音声のセグメンテーション情報を抽出して変換関数生成部に入力するため、目標話者音声の特徴パラメータに加えてセグメンテーション情報を変換関数生成に用いることができ、合成音特徴パラメータと目標話者音声特徴パラメータとを対応付ける際の処理の簡素化、高精度化を図ることが可能となる。 According to the seventh embodiment of the present invention, when the target speaker voice is recognized, the segmentation information of the target speaker voice is simultaneously extracted and input to the conversion function generation unit. In addition to this, segmentation information can be used for generating a conversion function, and it is possible to simplify and increase the accuracy of the process when associating the synthesized speech feature parameters with the target speaker speech feature parameters.
[第8の実施形態]
図8に、本発明の第8の実施形態に係る声質変換装置のブロック図を示す。図8において、図2と同一の符号は、同一部あるいは相当部を示し、その説明を省略する。本発明の第8の実施形態に係る声質変換装置は、さらに目標話者音声セグメンテーション情報記憶部21aを備えている。目標話者音声セグメンテーション情報記憶部21aは、目標話者音声入力部11aで入力された目標話者音声のセグメンテーション情報を記憶して、音声合成部14bに出力する。
[Eighth Embodiment]
FIG. 8 shows a block diagram of a voice quality conversion apparatus according to the eighth embodiment of the present invention. 8, the same reference numerals as those in FIG. 2 denote the same or corresponding parts, and the description thereof is omitted. The voice quality conversion device according to the eighth embodiment of the present invention further includes a target speaker voice segmentation information storage unit 21a. The target speaker voice segmentation information storage unit 21a stores the segmentation information of the target speaker voice input by the target speaker voice input unit 11a and outputs it to the voice synthesis unit 14b.
次に、本発明の第8の実施形態に係る声質変換装置の動作を図8および図20を参照して説明する。ただし、図20において、図14の同一の符号は、同一あるいは同等の処理を行い、その説明を省略し、新たに追加したステップの動作のみを説明する。ステップS221aでは、目標話者を音声認識部19で音声認識した結果抽出されるセグメンテーション情報23eを出力する。ステップS223bにおいて、音声合成部14bは、セグメンテーション情報23eを入力し、発音記号列入力部12aで入力された発音記号列の発声内容を持ち、目標話者音声のセグメンテーション情報23eに基づいた音声を合成する。 Next, the operation of the voice quality conversion apparatus according to the eighth embodiment of the present invention will be described with reference to FIGS. However, in FIG. 20, the same reference numerals in FIG. 14 perform the same or equivalent processing, the description thereof is omitted, and only the operation of the newly added step will be described. In step S221a, segmentation information 23e extracted as a result of speech recognition of the target speaker by the speech recognition unit 19 is output. In step S223b, the speech synthesizer 14b inputs the segmentation information 23e, synthesizes speech based on the segmentation information 23e of the target speaker speech having the utterance content of the phonetic symbol string input by the phonetic symbol string input unit 12a. To do.
本発明の第8の実施形態によれば、目標話者音声を音声認識する際に同時に同音声のセグメンテーション情報を抽出して音声合成部に入力するため、目標話者音声に基づいたセグメンテーション情報を用いて合成音を生成することができ、合成音特徴パラメータと目標話者音声特徴パラメータとを対応付ける際の処理の簡素化、高精度化を図ることが可能となる。 According to the eighth embodiment of the present invention, when the target speaker voice is recognized, the segmentation information of the same voice is simultaneously extracted and input to the voice synthesizer. Thus, a synthesized sound can be generated, and it is possible to simplify and increase the accuracy of the process when associating the synthesized sound feature parameter with the target speaker voice feature parameter.
[第9の実施形態]
図9に、本発明の第9の実施形態に係る声質変換装置のブロック図を示す。図9において、図2と同一の符号は、同一部あるいは相当部を示し、その説明を省略する。本発明の第9の実施形態に係る声質変換装置は、さらに目標話者音声セグメンテーション情報記憶部21bを備えている。目標話者音声セグメンテーション情報記憶部21bは、目標話者音声入力部11aで入力された目標話者音声のセグメンテーション情報を記憶して、音声合成部14bおよび変換関数生成部17bに出力する。
[Ninth Embodiment]
FIG. 9 shows a block diagram of a voice quality conversion apparatus according to the ninth embodiment of the present invention. 9, the same reference numerals as those in FIG. 2 denote the same or corresponding parts, and the description thereof is omitted. The voice quality conversion device according to the ninth embodiment of the present invention further includes a target speaker voice segmentation information storage unit 21b. The target speaker voice segmentation information storage unit 21b stores the segmentation information of the target speaker voice input by the target speaker voice input unit 11a and outputs the segmentation information to the voice synthesis unit 14b and the conversion function generation unit 17b.
次に、本発明の第9の実施形態に係る声質変換装置の動作を図9および図21を参照して説明する。ただし、図21において、図14の同一の符号は、同一あるいは同等の処理を行い、その説明を省略し、新たに追加したステップの動作のみを説明する。ステップS221aでは、目標話者を音声認識部19で音声認識した結果抽出されるセグメンテーション情報23fを出力する。セグメンテーション情報23fは、音声合成部14bへ出力され、発音記号列入力部12aで入力された発音記号列の発声内容を持ち、目標話者音声のセグメンテーション情報23fに基づいた音声を合成する。さらに、セグメンテーション情報23fは、変換関数生成部17bにも出力され、時間軸の対応付け(ステップS24a)、および変換関数の作成(ステップS25a)で用いられる。 Next, the operation of the voice quality conversion apparatus according to the ninth embodiment of the present invention will be described with reference to FIG. 9 and FIG. However, in FIG. 21, the same reference numerals in FIG. 14 perform the same or equivalent processing, the description thereof is omitted, and only the operation of the newly added step will be described. In step S221a, segmentation information 23f extracted as a result of speech recognition of the target speaker by the speech recognition unit 19 is output. The segmentation information 23f is output to the speech synthesizer 14b, has the utterance contents of the phonetic symbol string input by the phonetic symbol string input unit 12a, and synthesizes speech based on the segmentation information 23f of the target speaker speech. Further, the segmentation information 23f is also output to the conversion function generation unit 17b, and is used for time axis association (step S24a) and generation of the conversion function (step S25a).
本発明の第9の実施形態によれば、目標話者音声を音声認識する際に同時に同音声のセグメンテーション情報を抽出して音声合成部および変換関数生成部に入力するため、目標話者音声に基づいたセグメンテーション情報を用いて合成音を生成することができ、かつ、目標話者音声の特徴パラメータに加えてセグメンテーション情報を変換関数生成に用いることができる。したがって、合成音特徴パラメータと目標話者音声特徴パラメータとを対応付ける際の処理の簡素化、高精度化を図ることが可能となる。 According to the ninth embodiment of the present invention, when the target speaker speech is recognized, the segmentation information of the same speech is simultaneously extracted and input to the speech synthesizer and the conversion function generator. The synthesized speech can be generated using the segmentation information based on the segmentation information, and the segmentation information can be used for generating the conversion function in addition to the feature parameter of the target speaker voice. Therefore, it is possible to simplify and increase the accuracy of the process when associating the synthesized speech feature parameter with the target speaker speech feature parameter.
[第10の実施形態]
図10に、本発明の第10の実施形態に係る声質変換装置のブロック図を示す。図10において、図2と同一の符号は、同一部あるいは相当部を示し、その説明を省略する。本発明の第10の実施形態に係る声質変換装置は、さらに合成音セグメンテーション情報記憶部20と目標話者音声セグメンテーション情報記憶部21を備えている。合成音セグメンテーション情報記憶部20は、図3で説明した合成音セグメンテーション情報記憶部20と同じである。また目標話者音声セグメンテーション情報記憶部21は、図7で説明した目標話者音声セグメンテーション情報記憶部21と同様のものである。
[Tenth embodiment]
FIG. 10 shows a block diagram of a voice quality conversion apparatus according to the tenth embodiment of the present invention. 10, the same reference numerals as those in FIG. 2 denote the same or corresponding parts, and the description thereof is omitted. The voice quality conversion device according to the tenth embodiment of the present invention further includes a synthesized speech segmentation
次に、本発明の第10の実施形態に係る声質変換装置の動作を図10および図22を参照して説明する。ただし、図22において、図13の同一の符号は、同一あるいは同等の処理を行い、その説明を省略し、新たに追加したステップの動作のみを説明する。ステップS221aでは、目標話者を音声認識部19で音声認識した結果抽出されるセグメンテーション情報23dを出力する。セグメンテーション情報23dは、変換関数生成部17cに出力される。また、ステップS223aでは、音声合成部14aで音声を合成する際に用いられたセグメンテーション情報23gを記憶し、変換関数生成部17cへ出力される。変換関数生成部17cに入力されたセグメンテーション情報23fおよび23gは時間軸の対応付け(ステップS24b)、および変換関数の作成(ステップS25b)で用いられる。 Next, the operation of the voice quality conversion apparatus according to the tenth embodiment of the present invention will be described with reference to FIG. 10 and FIG. However, in FIG. 22, the same reference numerals in FIG. 13 perform the same or equivalent processing, the description thereof is omitted, and only the operation of the newly added step will be described. In step S221a, segmentation information 23d extracted as a result of speech recognition of the target speaker by the speech recognition unit 19 is output. The segmentation information 23d is output to the conversion function generation unit 17c. In step S223a, segmentation information 23g used when the speech synthesizer 14a synthesizes speech is stored and output to the conversion function generator 17c. The segmentation information 23f and 23g input to the conversion function generation unit 17c is used for time axis association (step S24b) and generation of a conversion function (step S25b).
本発明の第10の実施形態によれば、変換関数生成部において合成音と目標話者音声両方のセグメンテーション情報を利用できるため、合成音および目標話者音声の特徴パラメータに加えてセグメンテーション情報を変換関数生成に用いることができ、合成音特徴パラメータと目標話者音声特徴パラメータとを対応付ける際の処理の簡素化、高精度化を図ることが可能となる。 According to the tenth embodiment of the present invention, since the segmentation information of both the synthesized sound and the target speaker voice can be used in the conversion function generation unit, the segmentation information is converted in addition to the characteristic parameters of the synthesized sound and the target speaker voice. It can be used for function generation, and it is possible to simplify and increase the accuracy of the process when associating the synthesized speech feature parameters with the target speaker speech feature parameters.
[第11の実施形態]
図11に、本発明の第11の実施形態に係る声質変換装置のブロック図を示す。図11において、図2と同一の符号は、同一部あるいは相当部を示し、その説明を省略する。本発明の第11の実施形態に係る声質変換装置は、さらに合成音セグメンテーション情報記憶部20と目標話者音声セグメンテーション情報記憶部21aを備えている。合成音セグメンテーション情報記憶部20および目標話者音声セグメンテーション情報記憶部21aは、図3の合成音セグメンテーション情報記憶部20および図8の目標話者音声セグメンテーション情報記憶部21aと同様のものである。
[Eleventh embodiment]
FIG. 11 shows a block diagram of a voice quality conversion apparatus according to the eleventh embodiment of the present invention. 11, the same reference numerals as those in FIG. 2 denote the same or corresponding parts, and the description thereof is omitted. The voice quality conversion device according to the eleventh embodiment of the present invention further includes a synthesized speech segmentation
次に、本発明の第11の実施形態に係る声質変換装置の動作を図11および図23を参照して説明する。ただし、図23において、図20の同一の符号は、同一あるいは同等の処理を行い、その説明を省略し、新たに追加したステップの動作のみを説明する。ステップS223cでは、音声合成部14cで音声を合成する際に用いられたセグメンテーション情報23gを記憶し、変換関数生成部17aへ入力する。入力されたセグメンテーション情報23gは時間軸の対応付け(ステップS24a)、および変換関数の作成(ステップS25a)で用いられる。 Next, the operation of the voice quality conversion apparatus according to the eleventh embodiment of the present invention will be described with reference to FIG. 11 and FIG. However, in FIG. 23, the same reference numerals in FIG. 20 perform the same or equivalent processing, and the description thereof will be omitted, and only the operation of the newly added step will be described. In step S223c, segmentation information 23g used when the speech synthesizer 14c synthesizes speech is stored and input to the conversion function generator 17a. The input segmentation information 23g is used for time axis association (step S24a) and creation of a conversion function (step S25a).
本発明の第11の実施形態によれば、目標話者音声を音声認識する際に同時に同音声のセグメンテーション情報を抽出して音声合成部に入力するため、目標話者音声に基づいたセグメンテーション情報を用いて合成音を生成することができる。また、合成音を生成する際に利用するセグメンテーション情報を変換関数生成時に活用するため、合成音の特徴パラメータに加えてセグメンテーション情報を変換関数生成に用いることができる。したがって、合成音特徴パラメータと目標話者音声特徴パラメータとを対応付ける際の処理の簡素化、高精度化を図ることが可能となる。 According to the eleventh embodiment of the present invention, when the target speaker voice is recognized, the segmentation information of the same voice is simultaneously extracted and input to the voice synthesizer. Can be used to generate synthesized sounds. Further, since the segmentation information used when generating the synthesized sound is used when generating the conversion function, the segmentation information can be used for generating the conversion function in addition to the characteristic parameter of the synthesized sound. Therefore, it is possible to simplify and increase the accuracy of the process when associating the synthesized speech feature parameter with the target speaker speech feature parameter.
[第12の実施形態]
図12に、本発明の第12の実施形態に係る声質変換装置のブロック図を示す。図12において、図2と同一の符号は、同一部あるいは相当部を示し、その説明を省略する。本発明の第12の実施形態に係る声質変換装置は、さらに合成音セグメンテーション情報記憶部20と目標話者音声セグメンテーション情報記憶部21bを備えている。合成音セグメンテーション情報記憶部20および目標話者音声セグメンテーション情報記憶部21bは、それぞれ図3の合成音セグメンテーション情報記憶部20および図9の目標話者音声セグメンテーション情報記憶部21bと同様のものである。
[Twelfth embodiment]
FIG. 12 shows a block diagram of a voice quality conversion apparatus according to the twelfth embodiment of the present invention. 12, the same reference numerals as those in FIG. 2 denote the same or corresponding parts, and the description thereof is omitted. The voice quality conversion device according to the twelfth embodiment of the present invention further includes a synthesized speech segmentation
次に、本発明の第12の実施形態に係る声質変換装置の動作を図12および図24を参照して説明する。ただし、図24において、図21の同一の符号は、同一あるいは同等の処理を行い、その説明を省略し、新たに追加したステップの動作のみを説明する。ステップS223cでは、音声合成部14cで音声を合成する際に用いられたセグメンテーション情報23gを記憶し、変換関数生成部17cへ入力する。入力されたセグメンテーション情報23gは時間軸の対応付け(ステップS24b)、および変換関数の作成(ステップS25b)で用いられる。 Next, the operation of the voice quality conversion device according to the twelfth embodiment of the present invention will be described with reference to FIGS. However, in FIG. 24, the same reference numerals in FIG. 21 perform the same or equivalent processing, and the description thereof is omitted, and only the operation of the newly added step will be described. In step S223c, segmentation information 23g used when the speech synthesizer 14c synthesizes speech is stored and input to the conversion function generator 17c. The input segmentation information 23g is used for time axis association (step S24b) and creation of a conversion function (step S25b).
本発明の第12の実施形態によれば、目標話者音声を音声認識する際に同時に同音声のセグメンテーション情報を抽出して音声合成部および変換関数生成部に入力するため、目標話者音声に基づいたセグメンテーション情報を用いて合成音を生成することができる。また、目標話者音声の特徴パラメータに加えてセグメンテーション情報を変換関数生成に用いることができる。また、変換関数生成部において合成音と目標話者音声両方のセグメンテーション情報を利用できるため、合成音および目標話者音声の特徴パラメータに加えてセグメンテーション情報を変換関数生成に用いることができる。したがって、合成音特徴パラメータと目標話者音声特徴パラメータとを対応付ける際の処理の簡素化、高精度化を図ることが可能となる。 According to the twelfth embodiment of the present invention, when the target speaker speech is recognized, the segmentation information of the same speech is simultaneously extracted and input to the speech synthesizer and the conversion function generator. A synthesized sound can be generated using the segmentation information based thereon. In addition to the feature parameters of the target speaker's voice, segmentation information can be used for generating a conversion function. Further, since the segmentation information of both the synthesized sound and the target speaker voice can be used in the conversion function generation unit, the segmentation information can be used for generating the conversion function in addition to the characteristic parameters of the synthesized sound and the target speaker voice. Therefore, it is possible to simplify and increase the accuracy of the process when associating the synthesized speech feature parameter with the target speaker speech feature parameter.
図25は、本発明の第1の実施例に係る声質変換装置のブロック図である。声質変換装置は、目標話者音声入力部11、発音記号列入力部12、音声合成用データ記憶部13、音声合成部14、LPC分析部25、26、30、DPマッチング部27、スペクトル形状変換部28、変換関数導出部29、対応フレーム探索部31、スペクトル変換部32を備える。なお、図25において、図1と同一の符号は、同一物あるいは相当物を示し、特に記載無き場合、その説明を省略する。
FIG. 25 is a block diagram of the voice quality conversion apparatus according to the first embodiment of the present invention. The voice quality conversion device includes a target speaker
本実施例では、あらかじめ少なくとも1人以上の話者から音声合成用のデータベースが作成されており、音声合成用データ記憶部13に保存されているものとする。データベースは、音声素片、継続時間長、ピッチパターン等のデータを含んでいる。ただし、必ずしもこれらの全てのデータをデータベース内に記憶しておく必要はなく、これらのうち1つないし2つのデータだけでもよい。 In the present embodiment, it is assumed that a database for speech synthesis is created in advance from at least one speaker and is stored in the speech synthesis data storage unit 13. The database includes data such as speech segments, durations, and pitch patterns. However, it is not always necessary to store all these data in the database, and only one or two of them may be stored.
今、目標話者音声の発声内容Cが明らかになっており、予めこの発声内容と同一あるいは類似の発声内容を持つ合成音を生成できるような発音記号列が発音記号列入力部12から入力され用意されているとする。この発音記号列に従って、音声合成部14は、音声合成用データ内の素片の声質を持った発声の合成音Bを合成する。目標話者音声入力部11から入力される目標話者音声としては、操作開始時点で録音装置に発声する場合、予め保存してあった音声データを用いる場合等が考えられる。また、目標話者音声が複数あっても構わない。
Now, the utterance content C of the target speaker voice has been clarified, and a phonetic symbol string that can generate a synthesized sound having the same or similar utterance content as the utterance content is input from the phonetic symbol string input unit 12 in advance. Suppose that it is prepared. In accordance with this phonetic symbol string, the
次に、LPC分析部25は、目標話者音声入力部11から入力された、話者Aの発声内容Cの音声(以降では、目標Aとする)を例えば20msecといった長さの分析フレームごとにLPC分析し、目標AのLPC係数35aを抽出する。また、LPC分析部26は、音声合成部14で作成した合成音Bの発声内容Cの音声(以降では、合成音Bとする)を同様にLPC分析し、合成音BのLPC係数35bを抽出する。本実施例では分析方法(特徴パラメータ抽出)として、LPC分析を説明するが、他に、LSP(line spectrum pair)分析、PARCOR(partial auto-correlation)分析等のスペクトル分析や零交叉計数法、自己相関法等のピッチ抽出法、およびこれら複数の組み合わせによる分析等が考えられる。また、抽出する特徴パラメータとしてLPC係数のほかに、自己相関係数、ケプストラム係数等や、ピッチ周波数等の韻律パラメータを用いることもできる。
Next, the LPC analysis unit 25 inputs the voice of the utterance content C of the speaker A (hereinafter referred to as target A) input from the target speaker
次に、声質変換の主要部となる、DPマッチング部27、スペクトル形状変換部28、変換関数導出部29、対応フレーム探索部31、スペクトル変換部32における処理の流れを説明する。図26は、声質変換の主要部における音声データの処理の流れを説明する図である。LPC分析された目標話者音声(目標A)と合成音Bとは、DPマッチング部27によってDPマッチングが行われて対応関係が求められる。求められた対応関係を用いて、合成音Bから目標Aへの変換関数が、スペクトル形状変換部28、および変換関数導出部29により生成される。
Next, the flow of processing in the DP matching unit 27, the spectrum shape conversion unit 28, the conversion function derivation unit 29, the corresponding
変換対象となる音声素片は、対応フレーム探索部31によって合成音素片との対応付けがなされる。この場合、対応付けは、例えば変換対象となる音声素片と合成音素片とのそれぞれのLPC係数での特徴空間で距離が小さくなるものを選択することでなされる。変換対象となる音声素片は、対応付けがされた合成音素片に対応する先に求めた変換関数によってスペクトル変換がなされ、目標の声質を持つ音声素片が生成されることとなる。以下に、各部についてより詳しく説明する。
The speech unit to be converted is associated with the synthesized speech unit by the corresponding
DP(dynamic programming)マッチング部27は、目標AのLPC係数35aと合成音BのLPC係数35bとを用いて、目標Aと合成音Bの時間軸を合わせるために、DP(dynamic programming)マッチングによる時間軸伸縮を行う。これにより、目標Aと合成音Bとの分析フレームごとの対応が作成される。この時、DPマッチングで用いる特徴量空間内距離を表す尺度としては、差分ベクトルの二乗和、WLR(weighted likelihood ratio)尺度、最尤スペクトル距離、LPCケプストラム距離等を用いることができる。 The DP (dynamic programming) matching unit 27 uses DP (dynamic programming) matching to match the time axes of the target A and the synthesized sound B using the LPC coefficient 35a of the target A and the LPC coefficient 35b of the synthesized sound B. Perform time axis expansion and contraction. Thereby, the correspondence for each analysis frame between the target A and the synthesized sound B is created. At this time, as a scale representing the distance in the feature amount space used in DP matching, a sum of squares of a difference vector, a weighted likelihood ratio (WLR) scale, a maximum likelihood spectral distance, an LPC cepstrum distance, and the like can be used.
図27は、分析フレームごとのDPマッチングを模式的に表した図である。目標話者音声(目標A)のフレームをA1、A2、A3、A4、A5、・・Am、・・とし、合成音BのフレームをB1、B2、B3、B4、B5、・・Bn、・・とする。目標話者音声(目標A)と合成音Bとをフレーム毎にLPC分析し、その上で、例えば、フレームA1とフレームB1との特徴量空間内距離、フレームA1とフレームB2との特徴量空間内距離、フレームA2とフレームB1との特徴量空間内距離、の中で最も距離の短い対応関係を選択する。ここでは、フレームA2とフレームB1との特徴量空間内距離が選択されたとすると、次には、例えば、フレームA3とフレームB1との特徴量空間内距離、フレームA2とフレームB2との特徴量空間内距離、フレームA3とフレームB2との特徴量空間内距離、の中で最も距離の短い対応を選択する。このようにして、特徴量空間内距離の最小の距離の対応を順次求めていき、目標話者音声(目標A)と合成音BとのDPマッチングが行われる。 FIG. 27 is a diagram schematically illustrating DP matching for each analysis frame. Frames of the target speaker voice (target A) are A1, A2, A3, A4, A5,... Am, .., and a frame of the synthesized sound B is B1, B2, B3, B4, B5,.・ Let's say. The target speaker voice (target A) and the synthesized sound B are subjected to LPC analysis for each frame, and then, for example, the distance in the feature amount space between the frames A1 and B1, and the feature amount space between the frames A1 and B2. A correspondence relationship having the shortest distance among the internal distances and the distances within the feature amount space between the frames A2 and B1 is selected. Here, assuming that the distance in the feature amount space between the frame A2 and the frame B1 is selected, then, for example, the distance in the feature amount space between the frame A3 and the frame B1, and the feature amount space between the frame A2 and the frame B2. The correspondence with the shortest distance is selected from the internal distance and the distance in the feature amount space between the frame A3 and the frame B2. In this way, correspondence of the minimum distance of the feature amount space distance is sequentially obtained, and DP matching between the target speaker voice (target A) and the synthesized sound B is performed.
次に、スペクトル形状変換部28は、分析フレームごとに対応付けられた目標AのLPC係数35aと合成音BのLPC係数35bとを用いて、合成音Bの声質が目標Aの声質へと変換されるような変換関数を同定する。合成音Bから目標Aへと声質変換されるような変換を実現するには、合成音Bの分析フレームごとの周波数特性が目標Aの周波数特性とできるだけ等しくなるように、合成音Bの周波数領域のデータを変換関数で変換すればよい。これを分析フレームごとに考えると、合成音Bの1つの分析フレームBn(n番目の分析フレームBnとする)の周波数特性が、この分析フレームに時間軸上で対応付けられた目標Aの分析フレームAm(m番目の分析フレームAmとする)の周波数特性に変換されるような変換関数を同定すればよいということになる。そこで、分析フレームをフーリエ変換して波形の周波数領域の形状(スペクトル包絡)を求め、周波数軸上でDPマッチング等による伸縮を行い、合成音Bから目標Aへの変換関数を求める。すなわち、合成音Bの分析フレームBnのスペクトル形状を、目標Aの分析フレームAmのスペクトル形状に合致させるような変換を行う。 Next, the spectrum shape conversion unit 28 converts the voice quality of the synthesized sound B into the voice quality of the target A using the LPC coefficient 35a of the target A and the LPC coefficient 35b of the synthesized sound B that are associated with each analysis frame. Identify the transformation function as In order to realize a conversion in which the voice quality is converted from the synthesized sound B to the target A, the frequency region of the synthesized sound B is set so that the frequency characteristics of each analysis frame of the synthesized sound B are as equal as possible to the frequency characteristics of the target A. Can be converted with a conversion function. When this is considered for each analysis frame, the frequency characteristic of one analysis frame Bn (referred to as the nth analysis frame Bn) of the synthesized sound B is the analysis frame of the target A associated with this analysis frame on the time axis. This means that it is only necessary to identify a conversion function that is converted into the frequency characteristic of Am (m-th analysis frame Am). Therefore, the analysis frame is subjected to Fourier transform to obtain the shape (spectrum envelope) of the frequency domain of the waveform, and expansion / contraction by DP matching or the like on the frequency axis is performed to obtain a conversion function from the synthesized sound B to the target A. That is, conversion is performed so that the spectrum shape of the analysis frame Bn of the synthesized sound B matches the spectrum shape of the analysis frame Am of the target A.
さらに、スペクトル形状変換について説明する。図28は、周波数軸上でのDPマッチングを模式的に表した図である。目標話者音声(目標A)と合成音Bのスペクトル包絡をそれぞれSA、SBとする。周波数軸上でスペクトル包絡SAとスペクトル包絡SBとの対応関係をDPマッチングによって求める。対応関係を表すパスP0、・・Pi、・・Pnが変換関数に相当し、合成音BのスペクトルをパスP0、・・Pi、・・Pnによって非線型に写像することで目標話者音声(目標A)のスペクトルが得られることとなる。なお、予めスペクトル包絡SA、SBに対し、高域強調あるいは低域強調等の前処理を行い、前処理がなされたスペクトル包絡に対してDPマッチングを行うようにしてもよい。 Further, spectral shape conversion will be described. FIG. 28 is a diagram schematically illustrating DP matching on the frequency axis. The spectral envelopes of the target speaker voice (target A) and synthesized sound B are SA and SB, respectively. A correspondence relationship between the spectrum envelope SA and the spectrum envelope SB is obtained on the frequency axis by DP matching. The paths P0,..., Pi,... Pn representing the correspondence relationship correspond to transformation functions, and the target speaker's voice ((Pi,... Pn) is non-linearly mapped by the paths P0,. A spectrum of target A) will be obtained. Note that pre-processing such as high-frequency emphasis or low-frequency emphasis may be performed on the spectrum envelopes SA and SB in advance, and DP matching may be performed on the pre-processed spectrum envelope.
以上で説明したように、変換関数同定においては、LPC分析部26で合成音Bのn番目の分析フレームBnをLPC分析した結果から、スペクトル包絡SBnを導出する。同様に、Bnに時間軸上で対応付けられた目標Aの分析フレームAmのスペクトル包絡SAmを同定する。その上で、SBnがSAmに変換されるような変換関数を作成する。このようにして、合成音Bのn番目の分析フレームBnから、時間軸上で対応付けられた目標Aの分析フレームAmへの変換関数が求まるので、これを当該フレーム全てに適用し、合成音A全体に対する変換関数を求めることができる。 As described above, in the conversion function identification, the spectrum envelope SBn is derived from the result of LPC analysis of the nth analysis frame Bn of the synthesized sound B by the LPC analysis unit 26. Similarly, the spectrum envelope SAm of the analysis frame Am of the target A associated with Bn on the time axis is identified. Then, a conversion function is created so that SBn is converted to SAm. In this way, since the conversion function from the nth analysis frame Bn of the synthesized sound B to the analysis frame Am of the target A associated on the time axis is obtained, this is applied to all the frames and the synthesized sound is applied. A conversion function for the entire A can be obtained.
なお、以上の説明では、目標Aと合成音Bといった1文だけを学習データとして用いて変換関数をフレームごとに求める例を示したが、学習データをさらに増やした場合、目標Aと合成音BのLPC係数を特徴量空間内で、例えば音素ごとにクラスタリングし、クラスタの代表点ごとに変換関数を同定することも可能である。また、GMM(Guassian Mixture model)等の確率密度分布で特徴量空間を表現して、密度分布状態で対応付ける方法も考えられる。 In the above description, the conversion function is obtained for each frame using only one sentence such as the target A and the synthesized sound B as learning data. However, when the learning data is further increased, the target A and the synthesized sound B are obtained. It is also possible to cluster the LPC coefficients in the feature amount space, for example, for each phoneme, and identify a conversion function for each representative point of the cluster. Also, a method of expressing the feature amount space with a probability density distribution such as GMM (Guassian Mixture model) and associating it with the density distribution state is conceivable.
図29は、特徴量空間内でクラスタリングされた音素間の変換関数を模式的に示す図である。合成音Bの特徴パラメータ空間内と目標Aの特徴パラメータ空間内とにおいて、例えば音素(a、i、u、e、o、s)がそれぞれクラスタに分類され、合成音Bの特徴量空間内のクラスタ中の代表点が変換関数によって目標Aの特徴量空間内のクラスタ中の代表点に変換される。 FIG. 29 is a diagram schematically showing a conversion function between phonemes clustered in the feature amount space. In the feature parameter space of the synthesized sound B and the feature parameter space of the target A, for example, phonemes (a, i, u, e, o, s) are classified into clusters, respectively. The representative points in the cluster are converted into the representative points in the cluster in the feature amount space of the target A by the conversion function.
次に、変換対象である音声合成用素片データと変換関数との対応付けを行う。そのために、LPC分析部30は、あらかじめ音声合成用の素片信号をLPC分析して、素片データの分析フレームごとのLPC係数を求めておく。 Next, the speech synthesis segment data to be converted is associated with the conversion function. For this purpose, the LPC analysis unit 30 performs an LPC analysis on a speech synthesis unit signal in advance to obtain an LPC coefficient for each analysis frame of the unit data.
対応フレーム探索部31は、LPC分析部30が出力する素片データの分析フレーム毎のLPC係数に対して合成音Bのフレーム毎のLPC係数35b中の特徴量空間内距離が最も近いものを対応フレームとして求める。
The corresponding
変換関数導出部29は、スペクトル形状変換部28によって求めた合成音Bのフレームごとの変換関数を素片データの変換関数とする。この時、学習データを増やした場合は、図29で説明した変換関数の同定時と同様に、フレームごとではなくクラスタごとに変換関数を設定するといったことも可能である。 The conversion function deriving unit 29 sets the conversion function for each frame of the synthesized sound B obtained by the spectrum shape conversion unit 28 as the conversion function of the segment data. At this time, when the learning data is increased, the conversion function can be set not for each frame but for each cluster, as in the case of identification of the conversion function described with reference to FIG.
スペクトル変換部32は、変換関数導出部29において求めた素片に対する変換関数の中から、先の対応フレームに対する変換関数を選択し、選択された変換関数を用いて素片信号(素片データ)のスペクトルを変換する。これにより、目標Aの声質を持つ変換後素片信号(合成音を作成できる素片データ)を得ることができる。 The spectrum conversion unit 32 selects a conversion function for the previous corresponding frame from the conversion functions for the segment obtained by the conversion function deriving unit 29, and uses the selected conversion function to generate a segment signal (segment data). Convert the spectrum of. Thereby, the post-conversion segment signal (the segment data which can produce a synthetic sound) with the voice quality of the target A can be obtained.
さらに、この素片データを、音声合成用データ記憶部13に保存されている変換前の音声合成用データベース内の素片データと差し替えることで、任意のテキストに対して目標Aの声質を持つ合成音を作成できるデータベースが完成する。 Further, by replacing this segment data with the segment data in the speech synthesis database before conversion stored in the speech synthesis data storage unit 13, synthesis having the voice quality of the target A for any text A database that can create sounds is completed.
なお、第1の実施例では、合成音を作成するための発音記号列が予め分かっているものとしたが、目標話者音声の発声内容を漢字かな混じり文等のテキストデータで表して形態素解析等を用いて分析し、その結果によって発音記号列を生成することも可能である。 In the first embodiment, it is assumed that the phonetic symbol string for generating the synthesized sound is known in advance. However, the utterance content of the target speaker voice is expressed as text data such as kanji-kana mixed sentences, and morphological analysis is performed. Etc., and a phonetic symbol string can be generated based on the result.
また、被変換対象である入力信号は、上記の素片データ以外にも、上記以外の素片データを使うこともできる。例えば、音声合成用データ記憶部13に保存されている素片データが旅行用の会話のデータであり、入力信号となる素片データが一般の会話用のデータである場合などがある。 In addition to the above-described unit data, other input unit data can be used as the input signal to be converted. For example, there is a case where the segment data stored in the voice synthesis data storage unit 13 is travel conversation data, and the segment data serving as an input signal is general conversation data.
さらに、上記の素片データで作成された合成音、上記以外の素片データで作成された合成音、ユーザの発声による音声等を被変換対象である入力信号とすることもできる。 Furthermore, a synthesized sound created with the above-mentioned segment data, a synthesized sound created with other segment data, a voice uttered by the user, or the like can be used as an input signal to be converted.
さらに、第1の実施例の変形として、変換関数生成部内の合成音と目標話者音声の時間軸対応付け処理を行わないで変換関数の同定を行うという方法も考えられる。この方法を実現できる理由を以下に示す。本発明では、合成音と目標話者音声の発声内容を同一あるいは類似のものにして処理を行っているため、合成音および目標話者音声の音素情報は同一の部分が多く、特徴量空間内の特徴パラメータの分布が互いに類似している。このため、例えば、音素ごとにクラスタリングして変換関数を求める場合、合成音と目標話者音声の時間軸対応を取らなくても、変換関数を生成することができる。この方法を用いれば、時間軸対応付け処理を行わないので、処理速度の大幅な向上を図ることが可能である。 Furthermore, as a modification of the first embodiment, a method of identifying the conversion function without performing the time axis association processing of the synthesized sound and the target speaker voice in the conversion function generation unit is also conceivable. The reason why this method can be realized will be described below. In the present invention, processing is performed with the utterance contents of the synthesized sound and the target speaker voice being the same or similar, so that the phoneme information of the synthesized sound and the target speaker voice has many identical parts, The distributions of the feature parameters are similar to each other. Therefore, for example, when a conversion function is obtained by clustering for each phoneme, the conversion function can be generated without taking the time axis correspondence between the synthesized sound and the target speaker voice. If this method is used, the time-axis association process is not performed, so that the processing speed can be greatly improved.
図30は、本発明の第2の実施例に係る声質変換装置のブロック図である。声質変換装置は、目標話者音声入力部11、発音記号列入力部12、音声合成用データ記憶部13、音声合成部14a、音声認識部19、合成音セグメンテーション情報記憶部20、目標話者音声セグメンテーション情報記憶部21、LPC分析部25、26、30、DPマッチング部27a、スペクトル形状変換部28、変換関数導出部29、対応フレーム探索部31、スペクトル変換部32を備える。なお、図30において、図25と同一の符号は、同一物あるいは相当物を示し、特に記載無き場合、その説明を省略する。
FIG. 30 is a block diagram of a voice quality conversion apparatus according to the second embodiment of the present invention. The voice quality conversion apparatus includes a target speaker
音声認識部19は、入力された目標話者音声信号に対し音声認識を行うことによって、目標話者音声信号と同一あるいは類似の発声内容を持つ合成音を生成するための発音記号列を生成し、発音記号列入力部12に出力する。今、発声内容Cを持つ音声が目標話者音声であるとすると、これを音声認識することによって、発声内容Cを持つ発音記号列を自動的に生成することができる。このため、発音記号列が予め明らかでない場合でも、目標話者音声と同一あるいは類似の発生内容を持つ合成音を生成することができ、目標話者音声のみを入力してしまえば、第1の実施例と同様の処理を自動的に行うことができる。この時の音声認識の方法としては、例えば非特許文献2にあるようなHMM(hidden Markov model)による音声認識法等がある。 The voice recognition unit 19 generates a phonetic symbol string for generating a synthesized sound having the same or similar utterance content as the target speaker voice signal by performing voice recognition on the input target speaker voice signal. To the phonetic symbol string input unit 12. Assuming that the speech having the utterance content C is the target speaker speech, the phonetic symbol string having the utterance content C can be automatically generated by recognizing the speech. For this reason, even if the phonetic symbol string is not clear in advance, it is possible to generate a synthesized sound having the same or similar content as the target speaker voice, and if only the target speaker voice is input, the first Processing similar to that in the embodiment can be automatically performed. As a speech recognition method at this time, for example, there is a speech recognition method by HMM (hidden Markov model) as described in Non-Patent Document 2.
合成音セグメンテーション情報記憶部20は、音声合成部14aにおいて音声を合成する際に音声合成用データ内から算出されて用いられるセグメンテーション情報を、変換関数の生成時に活用するためにDPマッチング部27aに出力する。今、発声内容Cを持つ音声が目標話者音声であるとすると、これを音声認識部19において音声認識することによって、発声内容Cを持つ発音記号列を自動的に生成し発音記号列入力部12に出力される。発音記号列が音声合成部14aに入力されたとすると、音声合成部14aは、この発音記号列にしたがって音声合成用データ記憶部13から発声内容Cに対応したセグメンテーション情報を算出する。合成音セグメンテーション情報記憶部20は、このセグメンテーション情報を記憶しておき、セグメンテーション情報23iとしてDPマッチング部27aに出力し、変換関数生成の際に利用する。例えば、目標話者音声を分析して抽出された特徴パラメータの時間変化に対して、セグメンテーション情報と合成音を分析して抽出された特徴パラメータの時間変化を対応付けることで、目標話者音声と合成音の時間軸対応付けを簡素化、高精度化することができる。セグメンテーション情報としては、図31に示すような、フレーム番号と音素が対応付けられた表(例えば、フレーム番号1、2、・・10、11、・・、50、51、・・に対しそれぞれ音素「i」、「i」、・・「i」、「e」、・・「u」、「s」、・・が対応している)を用いる。その他の利用法としては、目標話者音声と合成音の組が複数文であった場合、音素セグメンテーション情報を用いてクラスタリングするといった方法も考えられる。
The synthesized speech segmentation
目標話者音声セグメンテーション情報記憶部21は、音声認識部19が目標話者音声信号を音声認識する際に、出力される目標話者音声のセグメンテーション情報を入力する。今、発声内容Cを持つ目標話者音声を目標話者音声入力部11に入力したとする。音声認識部19は、この目標話者音声を音声認識して、発声内容Cを記述する発音記号列を生成して発音記号列入力部12に出力する一方で、音声認識の結果であるセグメンテーション情報を目標話者音声セグメンテーション情報記憶部21に出力し、目標話者音声セグメンテーション情報記憶部21は、セグメンテーション情報を記憶しておく。このセグメンテーション情報23hを、DPマッチング部27aに出力して合成音と目標話者音声との対応付け処理に利用する。利用法としては、合成音を分析して抽出された特徴パラメータの時間変化に対して、セグメンテーション情報と目標話者音声を分析して抽出された特徴パラメータの時間変化を対応付けることで、目標話者音声と合成音の時間軸対応付けを簡素化、高精度化することができる。なお、セグメンテーション情報としては、図31で示した表と同様のものを用いる。
The target speaker voice segmentation
DPマッチング部27aは、実施例1で説明したDPマッチング部27と同様に、目標AのLPC係数35aと合成音BのLPC係数35bとを用いて、目標Aと合成音Bの時間軸を合わせるために、DPマッチングによる時間軸伸縮を行う。さらに、DPマッチング部27aは、合成音セグメンテーション情報記憶部20が出力するセグメンテーション情報23hと、目標話者音声セグメンテーション情報記憶部21が出力するセグメンテーション情報23iとを用いてDPマッチングによる時間軸対応付けの簡素化、高精度化を図っている。
Similarly to the DP matching unit 27 described in the first embodiment, the DP matching unit 27a uses the LPC coefficient 35a of the target A and the LPC coefficient 35b of the synthesized sound B to match the time axes of the target A and the synthesized sound B. Therefore, time axis expansion / contraction by DP matching is performed. Further, the DP matching unit 27a uses the segmentation information 23h output from the synthesized speech segmentation
次にセグメンテーション情報を用いたDPマッチングによる時間軸対応付けの一例について説明する。図32は、セグメンテーション情報を用いたDPマッチングによる時間軸対応付けの第1の例を示す図である。縦軸方向に分析された目標A(音素「a」「s」「u」)、横軸方向に分析された合成音B(音素「a」「s」「u」)が配置されている。セグメンテーション情報23hとして、目標Aの音素「a」と「s」の間に音素境界P1が、目標Aの音素「s」と「u」の間に音素境界Q1が音声合成部14aにおいて設定されている。また、セグメンテーション情報23iとして、合成音Bの音素「a」と「s」の間に音素境界P2が、目標Aの音素「s」と「u」の間に音素境界Q2が音声認識部19において設定されている。この時、音素境界P1と音素境界P2との交点を拘束点Pとし、音素境界Q1と音素境界Q2との交点を拘束点Qとする。DPマッチングを音素「a」、「s」、「u」に対して順次行い、DPパスを求めていく。この時、DPパスが拘束点P、拘束点Qを通るように制約を課してDPパスを求めるようにする。すなわち、拘束点を通るようにDPパスを決定することにより、制約条件付のDPマッチングを行い、音素境界同士が対応付けられるようにする。なお、拘束点は、必ずしも通らなくてもよく、拘束点の近傍を通るような緩やかな制約を課してもよい。 Next, an example of time axis association by DP matching using segmentation information will be described. FIG. 32 is a diagram illustrating a first example of time axis association by DP matching using segmentation information. A target A (phoneme “a” “s” “u”) analyzed in the vertical axis direction and a synthesized sound B (phoneme “a” “s” “u”) analyzed in the horizontal axis direction are arranged. As the segmentation information 23h, a phoneme boundary P1 is set between the phonemes “a” and “s” of the target A, and a phoneme boundary Q1 is set between the phonemes “s” and “u” of the target A. Yes. Further, as segmentation information 23i, the phoneme boundary P2 between the phonemes “a” and “s” of the synthesized sound B and the phoneme boundary Q2 between the phonemes “s” and “u” of the target A are Is set. At this time, the intersection between the phoneme boundary P1 and the phoneme boundary P2 is defined as a constraint point P, and the intersection between the phoneme boundary Q1 and the phoneme boundary Q2 is defined as a constraint point Q. DP matching is sequentially performed on the phonemes “a”, “s”, and “u” to obtain a DP path. At this time, a restriction is imposed so that the DP path passes through the restriction point P and the restriction point Q, and the DP path is obtained. That is, by determining the DP path so as to pass through the constraint point, DP matching with a constraint condition is performed so that phoneme boundaries are associated with each other. Note that the constraint point does not necessarily pass, and a gentle constraint that passes in the vicinity of the constraint point may be imposed.
セグメンテーション情報は、ある発声内容に対して、各音素の開始時刻と終了時刻、および音素のラベル等が記述された情報である。セグメンテーション情報によって、音素のラベルとその音素の開始時刻、終了時刻が示されるために、目標Aあるいは合成音Bにおける音素の境界が明確に示されることとなる。したがって、目標Aと合成音Bとの各フレーム間の時間軸上の対応付け(DPパス)を求める際に、セグメンテーション情報を用いて制約を付けることで、DPマッチングによる対応付けが音素境界付近であいまいになった場合であっても、精度の高い対応付けを実現することができることとなる。 The segmentation information is information in which the start time and end time of each phoneme, the phoneme label, and the like are described for a certain utterance content. Since the segmentation information indicates the phoneme label and the start time and end time of the phoneme, the phoneme boundary in the target A or the synthesized sound B is clearly shown. Therefore, when obtaining the correspondence (DP path) between each frame of the target A and the synthesized sound B on the time axis, by using the segmentation information, the association by DP matching is performed near the phoneme boundary. Even if it is ambiguous, it is possible to realize highly accurate association.
次にセグメンテーション情報を用いたDPマッチングによる時間軸対応付けの他の例について説明する。図33は、セグメンテーション情報を用いたDPマッチングによる時間軸対応付けの第2の例を示す図である。目標Aと合成音Bは、図32で説明したと同様に配置されている。ただし、図33において、図32と異なる点は、セグメンテーション情報23hが入力されていない。すなわち、目標話者音声セグメンテーション情報記憶部21が存在せず、目標Aに音素境界がないことである。この場合、通常のDPマッチングによってDPパスを求めた上で、DPパスが合成音Bの音素境界P1を通る点に対応する目標Aの推定音素境界P3を求める。また、DPパスが合成音Bの音素境界Q1を通る点に対応する目標Aの推定音素境界Q3を求める。すなわち、制約条件なしでDPマッチングを行った後に、セグメンテーション情報がある音声の音素境界と対応付いた箇所を、セグメンテーション情報がない音声の音素境界として推定することができる。通常、DPマッチングを行っただけでは、音素境界を判定することができないため、音素境界が推定できるこの方法は、変換関数を選択する際などにより有効な手段となる。
Next, another example of time axis association by DP matching using segmentation information will be described. FIG. 33 is a diagram illustrating a second example of time axis association by DP matching using segmentation information. The target A and the synthesized sound B are arranged in the same manner as described with reference to FIG. However, in FIG. 33, the difference from FIG. 32 is that segmentation information 23h is not input. That is, the target speaker voice segmentation
以上の説明では、セグメンテーション情報をDPマッチングに適用する例について説明したが、他にセグメンテーション情報を、スペクトル変換部32において被変換入力信号(素片信号)を変換する際に適用することも可能である。すなわち、被変換入力信号の各フレームがどの変換関数で変換されるかを判定する際に、そのフレームのセグメンテーション情報に付するラベル情報を用いれば、どの集合(例えば、音素毎のクラスタ等)に属するかを容易に判別することができる。この様子を図34に示す。図34において、ラベル情報(「i」「i」「e」「u」)は、特徴パラメータ空間中の各クラスタに対応付けがなされ、ラベル情報から直接的に特徴量空間内のクラスタ中の代表点に変換することができる。 In the above description, an example in which segmentation information is applied to DP matching has been described. However, it is also possible to apply segmentation information when the converted input signal (element signal) is converted in the spectrum conversion unit 32. is there. That is, when determining which conversion function is used to convert each frame of the input signal to be converted, to which set (for example, a cluster for each phoneme), the label information attached to the segmentation information of the frame is used. It can be easily determined whether it belongs. This is shown in FIG. In FIG. 34, label information (“i”, “i”, “e”, “u”) is associated with each cluster in the feature parameter space, and the representative in the cluster in the feature amount space directly from the label information. Can be converted to a point.
次に声質変換方法を繰り返し行い精度を高めて行く例について説明する。図35は、本発明の第3の実施例に係る声質変換方法を表すフローチャート図である。図35において、ステップS31〜S39は、それぞれ図14のステップS21、S221、S222、S223、S23、S24、S25、S26、S27と同等の処理を行うステップであり、その説明を省略する。ステップS40において、変換後の信号を音声合成用のデータとして音声合成用データ記憶部13に登録する。 Next, an example in which the voice quality conversion method is repeated to increase the accuracy will be described. FIG. 35 is a flowchart showing a voice quality conversion method according to the third embodiment of the present invention. 35, steps S31 to S39 are steps for performing processing equivalent to steps S21, S221, S222, S223, S23, S24, S25, S26, and S27 of FIG. 14, respectively, and description thereof is omitted. In step S40, the converted signal is registered in the voice synthesis data storage unit 13 as voice synthesis data.
ステップS40において、繰り返しが所定の収束条件に達したか否かを判定する。達していなければ、ステップS34に戻り、変換後の音声合成用データを用いて合成音を生成する。達していればステップS42で一連の処理が終了する。収束条件としては、例えば、目標話者音声と合成音とのLPC係数空間内距離が一定値以下になった場合、もしくはこの一定値以下の状態が一定回数継続した場合がある。また、スペクトルやパワー等の前回との差分値の合計値が一定値以下になった場合、もしくはこの一定値以下の状態が一定回数継続した場合を収束条件としてもよい。さらに繰り返し回数が一定回数繰り返した場合等を収束条件としてもよい。 In step S40, it is determined whether or not the repetition has reached a predetermined convergence condition. If not, the process returns to step S34 to generate a synthesized sound using the converted voice synthesis data. If it has reached, a series of processing ends in step S42. As the convergence condition, for example, there is a case where the distance in the LPC coefficient space between the target speaker voice and the synthesized sound becomes a certain value or less, or a state where this certain value or less continues for a certain number of times. Further, the convergence condition may be a case where the total value of the difference values from the previous time such as spectrum and power becomes equal to or less than a certain value, or a case where the condition below this certain value continues for a certain number of times. Furthermore, the convergence condition may be a case where the number of repetitions is a fixed number of times.
第3の実施例では、第1の実施例のように、素片を被変換入力信号として音声合成用データの声質を変換する場合には、変換後の音声合成用データを用いて再度目標話者音声と同一あるいは類似の発声内容の合成音を生成し、実施例1と同様の方法で変換関数の生成を行い、素片を変換するという処理を複数回繰り返す。さらに、第2の実施例を組み合わせて用いることで、最初に目標話者音声を入力してしまえば、繰り返しの処理も全て自動で行うことができ、変換精度(声質の類似度)を高めていくことが可能となる。なお、図35では、セグメンテーション情報を用いない例を示したが、勿論セグメンテーション情報を用いてもよい。 In the third embodiment, as in the first embodiment, when converting the voice quality of speech synthesis data using a segment as a converted input signal, the target speech is again generated using the speech synthesis data after conversion. A synthesized sound having the same or similar utterance content as the person's voice is generated, a conversion function is generated in the same manner as in the first embodiment, and the process of converting the segment is repeated a plurality of times. Furthermore, by using the second embodiment in combination, if the target speaker voice is first input, all of the repeated processing can be performed automatically, improving the conversion accuracy (similarity of voice quality). It is possible to go. In addition, although the example which does not use segmentation information was shown in FIG. 35, of course, you may use segmentation information.
なお、以上説明した実施例1〜3において、音声合成用データ記憶部13に複数人数分の音声データからなる音声合成用データを記憶しておき、入力された目標話者の声質によって使用する音声合成用データを選択することができるようにすることも可能である。例えば、目標話者音声が男声であった場合は男声の素片データを用い、女声であった場合は女声の素片データを用いるといった方法が考えられる。この方法を用いれば、極端な変換を避けて変換処理による音質の劣化を少なくすることが可能となる。 In the first to third embodiments described above, speech synthesis data consisting of speech data for a plurality of people is stored in the speech synthesis data storage unit 13 and used for the voice quality of the input target speaker. It is also possible to select the data for synthesis. For example, when the target speaker voice is a male voice, a male voice segment data is used, and when the target speaker voice is a female voice, a female voice segment data is used. If this method is used, it is possible to avoid extreme conversion and reduce deterioration in sound quality due to the conversion process.
次に、本発明の声質変換装置、声質変換方法あるいは声質変換プログラムによって生成された合成音データを用いて合成音を生成する装置について説明する。図36は、本発明の第4の実施例に係る合成音生成装置を表すブロック図である。図36において、記号列入力部41、音声合成出力部42、データ記憶部43は、それぞれ図1の発音記号列入力部12、音声合成部14、音声合成用データ記憶部13と同等の機能を有するものである。ただし、音声合成出力部42は、生成された合成音を出力する機能を持つ。また、データ記憶部43は、先に説明した声質変換装置、声質変換方法あるいは声質変換プログラムによって生成される変換後出力信号を合成音データとして蓄えるものである。音声合成出力部42は、記号列入力部41に入力される記号列に基づいてデータ記憶部43から読み出した合成音データを用いて合成音を生成して出力する。出力される合成音は、変換後出力信号、すなわち目標話者の声質に変換されたデータに基づいて生成されるので、目標話者の声質を備えた合成音となる。
Next, the voice quality conversion apparatus, voice quality conversion method or apparatus for generating synthesized sound using the synthesized voice data generated by the voice quality conversion program will be described. FIG. 36 is a block diagram showing a synthesized sound generating apparatus according to the fourth embodiment of the present invention. 36, a symbol
次に、本発明の声質変換装置、声質変換方法あるいは声質変換プログラムによって生成された合成音データを用いて合成音を生成する他の装置について説明する。図37は、本発明の第5の実施例に係る合成音生成装置を表すブロック図である。図37において、音声入力部51は、ユーザの発する音声信号を入力する。変換データ記憶部53は、先に説明した声質変換装置、声質変換方法あるいは声質変換プログラムによって生成される、分析フレーム毎のLPC係数と対応する変換関数とを記憶している。音声変換出力部52は、音声入力部51から出力される音声信号をフレーム毎に、例えばLPC分析し、分析されたフレームにパラメータ空間距離の最も近いフレームを変換データ記憶部53内において探索して対応する変換関数を読出し、この変換関数によって音声信号のスペクトルを変換して出力する。出力される合成音は、目標話者の声質に変換されたデータに基づいて生成されるので、目標話者の声質を備えた合成音となる。 Next, another apparatus for generating a synthesized sound using the synthesized sound data generated by the voice quality conversion apparatus, voice quality conversion method or voice quality conversion program of the present invention will be described. FIG. 37 is a block diagram showing a synthesized sound generating apparatus according to the fifth embodiment of the present invention. In FIG. 37, the voice input unit 51 inputs a voice signal emitted by the user. The conversion data storage unit 53 stores an LPC coefficient for each analysis frame and a corresponding conversion function generated by the voice quality conversion device, voice quality conversion method, or voice quality conversion program described above. The voice conversion output unit 52 performs, for example, LPC analysis on the voice signal output from the voice input unit 51 for each frame, and searches the converted data storage unit 53 for a frame having a parameter space distance closest to the analyzed frame. The corresponding conversion function is read out, and the spectrum of the audio signal is converted and output by this conversion function. Since the output synthesized sound is generated based on the data converted into the voice quality of the target speaker, it becomes a synthesized sound having the voice quality of the target speaker.
本発明によれば、電話機やトランシーバー等の通信機器で、自由に声質を変えるといった用途に適用できる。また、パーソナルコンピュータや携帯電話等で、電子メールやチャットのテキストを読み上げる際の合成音の声質をユーザの望む声質にするといった用途にも適用できる。さらに、アニメーションの音声の録音や外国映画の吹き替え等をテキスト音声合成で行う場合に、登場人物に合ったキャラクタ音声の声質を生成するといった用途にも適用できる。 INDUSTRIAL APPLICABILITY According to the present invention, it can be applied to uses such as changing the voice quality freely in communication equipment such as a telephone and a transceiver. In addition, the present invention can also be applied to a case where the voice quality of the synthesized sound when reading a text of an e-mail or chat on a personal computer or a mobile phone is set to a voice quality desired by the user. Furthermore, when voice recording of animation, dubbing of a foreign movie, or the like is performed by text voice synthesis, the present invention can be applied to the use of generating voice quality of character voice that matches a character.
11、11a 目標話者音声入力部
12、12a 発音記号列入力部
13 音声合成用データ記憶部
14、14a、14b、14c 音声合成部
15 目標話者音声特徴パラメータ抽出部
16 合成音特徴パラメータ抽出部
17、17a、17b、17c 変換関数生成部
18 声質変換部
19 音声認識部
20 合成音セグメンテーション情報記憶部
21、21a、21b 目標話者音声セグメンテーション情報記憶部
22 セグメンテーション情報入力部
23a、23b、23c、23d、23e、23f、23g、23h、23i セグメンテーション情報
25、26、30 LPC分析部
27、27a DPマッチング部
28 スペクトル形状変換部
29 変換関数導出部
31 対応フレーム探索部
32 スペクトル変換部
35a、35b LPC係数
41 記号列入力部
42 音声合成出力部
43 データ記憶部
51 音声入力部
52 音声変換出力部
53 変換データ記憶部
11, 11a Target speaker voice input unit 12, 12a Phonetic symbol string input unit 13 Speech synthesis
Claims (27)
音声合成用のデータを記憶する音声合成用データ記憶部と、
前記入力された目標話者音声と同一又は類似の発声内容を記述する発音記号列を入力する発音記号入力部と、
前記入力された発音記号列にしたがって、前記音声合成用データ記憶部に記憶されている音声合成用のデータに基づき、音声を合成して出力する音声合成部と、
前記音声合成部から出力される音声信号(「合成音」という)の特徴パラメータを抽出する合成音特徴パラメータ抽出部と、
前記目標話者音声の特徴パラメータを抽出する目標話者音声特徴パラメータ抽出部と、
前記合成音特徴パラメータ抽出部からの前記合成音の特徴パラメータと、目標話者音声特徴パラメータ抽出部からの前記目標話者音声の特徴パラメータとを入力し、特徴パラメータを表す空間において、前記合成音の第1の部分と、前記目標話者音声の第2の部分との時間軸上の対応関係を求め、前記合成音の前記第1の部分におけるスペクトル形状を、前記目標話者音声の前記第2の部分におけるスペクトル形状に変換する変換関数の同定を行う変換関数生成部と、
を備えている、ことを特徴とする声質変換装置。 A target speaker voice input unit for inputting a voice of a speaker to be converted (referred to as “target speaker voice”);
A voice synthesis data storage unit for storing voice synthesis data;
A phonetic symbol input unit for inputting a phonetic symbol string describing the same or similar utterance content as the input target speaker voice;
A speech synthesis unit that synthesizes and outputs speech based on speech synthesis data stored in the speech synthesis data storage unit according to the input phonetic symbol string;
A synthesized sound feature parameter extracting unit that extracts feature parameters of a speech signal (referred to as “synthesized sound”) output from the speech synthesizer;
A target speaker voice feature parameter extraction unit for extracting feature parameters of the target speaker voice;
The synthesized sound feature parameter extraction unit from the synthesized sound feature parameter extraction unit and the target speaker voice feature parameter extraction unit from the target speaker voice feature parameter extraction unit are input, and the synthesized sound is expressed in a space representing the feature parameter. Corresponding to the second part of the target speaker voice on the time axis, and the spectrum shape of the first part of the synthesized sound is determined as the first part of the target speaker voice. A conversion function generation unit for identifying a conversion function to be converted into a spectral shape in the part 2;
A voice quality conversion device characterized by comprising:
発声内容を記述する記号列を入力する記号列入力部と、
前記入力された記号列にしたがって前記音声合成用データ記憶部内の音声合成用データから音声を合成して出力する音声合成出力部と、
を備えている、ことを特徴とする合成音生成装置。 A data storage unit that stores a converted signal output from the voice quality conversion unit of the voice quality conversion device according to claim 2 as voice synthesis data;
A symbol string input unit for inputting a symbol string describing the utterance content;
A speech synthesis output unit that synthesizes and outputs speech from speech synthesis data in the speech synthesis data storage unit according to the input symbol string;
A synthesized sound generating device comprising:
被変換音声信号を入力する音声入力部と、
前記入力された被変換音声信号の特徴パラメータを求め、求めた特徴パラメータに対応する前記変換データ記憶部内の前記合成音の特徴パラメータを探索し、前記合成音の特徴パラメータに対応する前記変換関数を読み出し、前記変換関数によって前記被変換音声信号を変換して出力する音声変換出力部と、
を備えている、ことを特徴とする合成音生成装置。
A conversion data storage unit that stores in association with claim 1 conversion function identified to correspond to the characteristic parameters and the characteristic parameters of the synthesized speech in voice quality conversion device according,
An audio input unit for inputting the converted audio signal;
The feature parameter of the input converted speech signal is obtained, the feature parameter of the synthesized sound in the converted data storage unit corresponding to the obtained feature parameter is searched, and the conversion function corresponding to the feature parameter of the synthesized sound is obtained. A voice conversion output unit for reading and converting the converted voice signal by the conversion function;
A synthesized sound generating device comprising:
声質の変換目標となる話者の音声(「目標話者音声」という)を入力するステップと、
前記目標話者音声の発声内容を記述する発音記号列を入力し、記憶部に予め記憶されている音声合成用のデータを用いて、前記発音記号列から、合成音を作成するステップと、
前記合成音を分析し、前記合成音の特徴パラメータを抽出するステップと、
前記目標話者音声を分析し、前記目標話者音声の特徴パラメータを抽出するステップと、
前記目標話者音声の特徴パラメータと前記合成音の特徴パラメータとの時間軸上の対応付けを行うステップと、
対応付けがなされた前記目標話者音声及び前記合成音の特徴パラメータに基づき、前記合成音のスペクトル形状を、前記目標話者音声のスペクトル形状に、変換するための変換関数を生成するステップと、
を含む、ことを特徴とする声質変換方法。 A method for converting voice quality by a voice quality conversion device,
Inputting the voice of the speaker that is the voice quality conversion target (referred to as "target speaker voice");
Inputting a phonetic symbol string describing the utterance content of the target speaker voice, and creating synthesized speech from the phonetic symbol string using data for speech synthesis stored in advance in a storage unit;
Analyzing the synthesized sound and extracting characteristic parameters of the synthesized sound;
Analyzing the target speaker voice and extracting feature parameters of the target speaker voice;
Correlating the feature parameter of the target speaker voice and the feature parameter of the synthesized sound on the time axis;
Generating a conversion function for converting the spectrum shape of the synthesized speech into the spectrum shape of the target speaker speech based on the target speaker speech and the synthesized speech feature parameters that are associated with each other; and
A voice quality conversion method comprising:
前記音声認識の結果から前記発音記号列を生成する、ことを特徴とする請求項10記載の声質変換方法。 Recognizing the input target speaker voice,
The voice quality conversion method according to claim 10, wherein the phonetic symbol string is generated from a result of the voice recognition.
声質の変換目標となる話者の音声(「目標話者音声」という)を入力するステップと、
入力される前記目標話者音声を音声認識するステップと、
前記音声認識の結果から前記目標話者音声の発声内容を記述する発音記号列を生成するステップと、
を含み、さらに、
(a)記憶部に予め記憶されている音声合成用のデータを用いて、前記発音記号列から、合成音を作成するステップと、
(b)前記合成音と前記目標話者音声とを分析し、それぞれの特徴パラメータを抽出するステップと、
(c)前記目標話者音声の特徴パラメータと前記合成音の特徴パラメータとの時間軸上の対応付けを行うステップと、
(d)対応付けされた2つの前記特徴パラメータに基づいて、前記合成音のスペクトル形状を前記目標話者音声のスペクトル形状に変換する変換関数を生成するステップと、
(e)前記生成された変換関数を用いて変換対象となる音声の声質を変換するステップと、
(f)前記声質の変換結果を、前記音声合成用のデータとして前記記憶部に格納するステップと、
を所定の収束条件に至るまで繰り返すことを特徴とする声質変換方法。 A method for converting voice quality by a voice quality conversion device,
Inputting the voice of the speaker that is the voice quality conversion target (referred to as "target speaker voice");
Recognizing the input target speaker voice;
Generating a phonetic symbol string describing the utterance content of the target speaker voice from the result of the voice recognition;
Including,
(A) creating synthesized speech from the phonetic symbol string using speech synthesis data stored in advance in the storage unit;
(B) analyzing the synthesized sound and the target speaker voice and extracting respective characteristic parameters;
(C) associating the feature parameter of the target speaker voice with the feature parameter of the synthesized sound on the time axis;
(D) generating a conversion function for converting the spectrum shape of the synthesized sound into the spectrum shape of the target speaker voice based on the two corresponding feature parameters;
(E) converting the voice quality of the voice to be converted using the generated conversion function;
(F) storing the conversion result of the voice quality in the storage unit as the data for voice synthesis;
Is repeated until a predetermined convergence condition is reached.
声質の変換目標となる話者の音声(「目標話者音声」という)を入力する処理と、
前記目標話者音声の発声内容を記述する発音記号列を入力し、記憶部に予め記憶されている音声合成用のデータを用いて、前記発音記号列から、合成音を作成する処理と、
前記合成音と前記目標話者音声とを分析し、それぞれの特徴パラメータを抽出する処理と、
前記目標話者音声の特徴パラメータと前記合成音の特徴パラメータとの時間軸上の対応付けを行う処理と、
対応付けがなされた前記目標話者音声及び前記合成音の特徴パラメータに基づき、前記合成音のスペクトル形状を、前記目標話者音声のスペクトル形状に、変換するための変換関数を生成する処理と、
を実行させるプログラム。 In the computer that composes the voice quality conversion device,
Input the voice of the speaker that is the voice quality conversion target (referred to as "target speaker voice"),
A process of inputting a phonetic symbol string describing the utterance content of the target speaker voice and creating a synthesized sound from the phonetic symbol string using data for speech synthesis stored in a storage unit in advance,
A process of analyzing the synthesized sound and the target speaker voice and extracting respective characteristic parameters;
A process for associating the feature parameter of the target speaker voice and the feature parameter of the synthesized sound on the time axis;
A process for generating a conversion function for converting a spectrum shape of the synthesized sound into a spectrum shape of the target speaker sound based on the target speaker voice and the characteristic parameter of the synthesized sound that are associated with each other;
A program that executes
前記変換関数を用いて、変換対象となる音声信号を前記目標話者音声の声質を持つ音声信号に変換する処理を、さらに前記コンピュータに実行させるプログラム。 The program according to claim 19, wherein
A program for causing the computer to further execute a process of converting an audio signal to be converted into an audio signal having a voice quality of the target speaker voice using the conversion function.
入力される前記目標話者音声を音声認識する処理と、
前記音声認識の結果から前記発音記号列を生成する処理とを、前記コンピュータに実行させるプログラム。 The program according to claim 19, wherein
Processing for recognizing the input target speaker voice;
A program for causing the computer to execute processing for generating the phonetic symbol string from the result of the speech recognition.
前記合成音の少なくとも時刻情報に対応づいた音素列を含むセグメンテーション情報を入力して、前記セグメンテーション情報に基づき前記合成音を生成する処理を、前記コンピュータに実行させるプログラム。 In the program according to any one of claims 19 to 21,
A program for causing the computer to execute a process of inputting segmentation information including a phoneme string corresponding to at least time information of the synthesized sound and generating the synthesized sound based on the segmentation information.
前記合成音の生成時に用いられる、少なくとも時刻情報に対応づいた音素列を含む第1のセグメンテーション情報によって、前記時間軸上の対応付けを行う処理を、前記コンピュータに実行させるプログラム。 In the program according to any one of claims 19 to 21,
A program for causing the computer to execute a process of performing association on the time axis by using first segmentation information including at least a phoneme string corresponding to time information, which is used when generating the synthesized sound.
前記音声認識された目標話者音声の、少なくとも時刻情報に対応づいた音素列を含む第2のセグメンテーション情報によって、前記時間軸上の対応付けを行う処理を、前記コンピュータに実行させるプログラム。 The program according to any one of claims 19 to 21 and 23,
A program for causing the computer to execute a process of performing association on the time axis by using second segmentation information including at least a phoneme string corresponding to time information of the target speaker voice recognized by the voice.
前記音声認識された目標話者音声の、少なくとも時刻情報に対応づいた音素列を含む第2のセグメンテーション情報に基づき、前記合成音を生成する処理を、前記コンピュータに実行させるプログラム。 The program according to any one of claims 19 to 21 and 23,
A program for causing the computer to execute a process of generating the synthesized sound based on second segmentation information including at least a phoneme string corresponding to time information of the target speaker voice recognized by the voice.
前記音声認識された目標話者音声の、少なくとも時刻情報に対応づいた音素列を含む第2のセグメンテーション情報によって、前記時間軸上の対応付けを行い、前記第2のセグメンテーション情報に基づき前記合成音を生成する処理を、前記コンピュータに実行させるプログラム。 The program according to any one of claims 19 to 21 and 23,
Corresponding on the time axis is performed by second segmentation information including at least a phoneme sequence corresponding to time information of the target speaker speech recognized by the speech, and the synthesized sound is based on the second segmentation information. The program which makes the said computer perform the process which produces | generates.
声質の変換目標となる話者の音声(「目標話者音声」という)を入力する処理と、
入力される前記目標話者音声を音声認識する処理と、
前記音声認識の結果から前記目標話者音声の発声内容を記述する発音記号列を生成する処理と、を実行させ、さらに、
(a)記憶部に予め記憶されている音声合成用のデータを用いて、前記発音記号列から合成音を作成する処理と、
(b)前記合成音と前記目標話者音声とを分析し、それぞれの特徴パラメータを抽出する処理と、
(c)前記目標話者音声の特徴パラメータと前記合成音の特徴パラメータとの時間軸上の対応付けを行う処理と、
(d)対応付けされた2つの前記特徴パラメータに基づいて、前記合成音のスペクトル形状を前記目標話者音声のスペクトル形状に変換する変換関数を生成する処理と、
(e)前記生成された変換関数を用いて変換対象となる音声の声質を変換する処理と、
(f)前記声質の変換結果を、前記音声合成用のデータとして前記記憶部に格納する処理と、
を所定の収束条件に至るまで繰り返す、
処理を実行させるプログラム。
In the computer that composes the voice quality conversion device,
Input the voice of the speaker that is the voice quality conversion target (referred to as "target speaker voice"),
Processing for recognizing the input target speaker voice;
Generating a phonetic symbol string describing the utterance content of the target speaker voice from the result of the voice recognition, and
(A) a process of creating a synthesized sound from the phonetic symbol string using speech synthesis data stored in advance in the storage unit;
(B) a process of analyzing the synthesized sound and the target speaker voice and extracting respective characteristic parameters;
(C) a process of associating the feature parameter of the target speaker voice and the feature parameter of the synthesized sound on the time axis;
(D) generating a conversion function for converting the spectrum shape of the synthesized sound into the spectrum shape of the target speaker voice based on the two associated feature parameters;
(E) a process of converting the voice quality of the voice to be converted using the generated conversion function;
(F) a process of storing the conversion result of the voice quality in the storage unit as the data for voice synthesis;
Is repeated until a predetermined convergence condition is reached,
A program that executes processing.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2004079079A JP4829477B2 (en) | 2004-03-18 | 2004-03-18 | Voice quality conversion device, voice quality conversion method, and voice quality conversion program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2004079079A JP4829477B2 (en) | 2004-03-18 | 2004-03-18 | Voice quality conversion device, voice quality conversion method, and voice quality conversion program |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2005266349A JP2005266349A (en) | 2005-09-29 |
| JP4829477B2 true JP4829477B2 (en) | 2011-12-07 |
Family
ID=35090955
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2004079079A Expired - Fee Related JP4829477B2 (en) | 2004-03-18 | 2004-03-18 | Voice quality conversion device, voice quality conversion method, and voice quality conversion program |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP4829477B2 (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111179905A (en) * | 2020-01-10 | 2020-05-19 | 北京中科深智科技有限公司 | Rapid dubbing generation method and device |
Families Citing this family (20)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101351841B (en) * | 2005-12-02 | 2011-11-16 | 旭化成株式会社 | Voice quality conversion system |
| JP4769086B2 (en) * | 2006-01-17 | 2011-09-07 | 旭化成株式会社 | Voice quality conversion dubbing system and program |
| JP4241736B2 (en) | 2006-01-19 | 2009-03-18 | 株式会社東芝 | Speech processing apparatus and method |
| JP2007193151A (en) * | 2006-01-20 | 2007-08-02 | Casio Comput Co Ltd | Musical sound control device and program of musical sound control processing |
| JP4355772B2 (en) | 2007-02-19 | 2009-11-04 | パナソニック株式会社 | Force conversion device, speech conversion device, speech synthesis device, speech conversion method, speech synthesis method, and program |
| CN101578659B (en) | 2007-05-14 | 2012-01-18 | 松下电器产业株式会社 | Voice tone converting device and voice tone converting method |
| CN101359473A (en) * | 2007-07-30 | 2009-02-04 | 国际商业机器公司 | Auto speech conversion method and apparatus |
| JP5226867B2 (en) * | 2009-05-28 | 2013-07-03 | インターナショナル・ビジネス・マシーンズ・コーポレーション | Basic frequency moving amount learning device, fundamental frequency generating device, moving amount learning method, basic frequency generating method, and moving amount learning program for speaker adaptation |
| WO2011151956A1 (en) * | 2010-06-04 | 2011-12-08 | パナソニック株式会社 | Voice quality conversion device, method therefor, vowel information generating device, and voice quality conversion system |
| JP5961950B2 (en) * | 2010-09-15 | 2016-08-03 | ヤマハ株式会社 | Audio processing device |
| JP2013003470A (en) * | 2011-06-20 | 2013-01-07 | Toshiba Corp | Voice processing device, voice processing method, and filter produced by voice processing method |
| JP5665780B2 (en) * | 2012-02-21 | 2015-02-04 | 株式会社東芝 | Speech synthesis apparatus, method and program |
| RU2510954C2 (en) * | 2012-05-18 | 2014-04-10 | Александр Юрьевич Бредихин | Method of re-sounding audio materials and apparatus for realising said method |
| FR2991805B1 (en) * | 2012-06-11 | 2016-12-09 | Airbus | DEVICE FOR AIDING COMMUNICATION IN THE AERONAUTICAL FIELD. |
| JP2015212845A (en) * | 2015-08-24 | 2015-11-26 | 株式会社東芝 | Voice processing device, voice processing method, and filter produced by voice processing method |
| TW202009924A (en) * | 2018-08-16 | 2020-03-01 | 國立臺灣科技大學 | Timbre-selectable human voice playback system, playback method thereof and computer-readable recording medium |
| KR20210114518A (en) | 2019-02-21 | 2021-09-23 | 구글 엘엘씨 | End-to-end voice conversion |
| CN111564158A (en) * | 2020-04-29 | 2020-08-21 | 上海紫荆桃李科技有限公司 | Configurable sound changing device |
| CN112652318B (en) * | 2020-12-21 | 2024-03-29 | 北京捷通华声科技股份有限公司 | Tone color conversion method and device and electronic equipment |
| CN112820268A (en) * | 2020-12-29 | 2021-05-18 | 深圳市优必选科技股份有限公司 | Personalized voice conversion training method and device, computer equipment and storage medium |
-
2004
- 2004-03-18 JP JP2004079079A patent/JP4829477B2/en not_active Expired - Fee Related
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111179905A (en) * | 2020-01-10 | 2020-05-19 | 北京中科深智科技有限公司 | Rapid dubbing generation method and device |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2005266349A (en) | 2005-09-29 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20230043916A1 (en) | Text-to-speech processing using input voice characteristic data | |
| US11735162B2 (en) | Text-to-speech (TTS) processing | |
| US11062694B2 (en) | Text-to-speech processing with emphasized output audio | |
| JP4829477B2 (en) | Voice quality conversion device, voice quality conversion method, and voice quality conversion program | |
| JP5665780B2 (en) | Speech synthesis apparatus, method and program | |
| US11410684B1 (en) | Text-to-speech (TTS) processing with transfer of vocal characteristics | |
| US10692484B1 (en) | Text-to-speech (TTS) processing | |
| TWI721268B (en) | System and method for speech synthesis | |
| US11763797B2 (en) | Text-to-speech (TTS) processing | |
| US20160379638A1 (en) | Input speech quality matching | |
| US20070213987A1 (en) | Codebook-less speech conversion method and system | |
| US10699695B1 (en) | Text-to-speech (TTS) processing | |
| US11282495B2 (en) | Speech processing using embedding data | |
| JP2014062970A (en) | Voice synthesis, device, and program | |
| JP5574344B2 (en) | Speech synthesis apparatus, speech synthesis method and speech synthesis program based on one model speech recognition synthesis | |
| WO2012032748A1 (en) | Audio synthesizer device, audio synthesizer method, and audio synthesizer program | |
| Gibson | Two-pass decision tree construction for unsupervised adaptation of HMM-based synthesis models | |
| Wen et al. | Prosody Conversion for Emotional Mandarin Speech Synthesis Using the Tone Nucleus Model. | |
| Huang et al. | Hierarchical prosodic pattern selection based on Fujisaki model for natural mandarin speech synthesis | |
| Wu et al. | Synthesis of spontaneous speech with syllable contraction using state-based context-dependent voice transformation | |
| Hirose | Modeling of fundamental frequency contours for HMM-based speech synthesis: Representation of fundamental frequency contours for statistical speech synthesis | |
| EP1589524A1 (en) | Method and device for speech synthesis | |
| CN115798452A (en) | End-to-end voice splicing synthesis method | |
| Pobar et al. | Development of Croatian unit selection and statistical parametric speech synthesis | |
| SARANYA | DEVELOPMENT OF BILINGUAL TTS USING FESTVOX FRAMEWORK |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20070115 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20090909 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20090915 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20091116 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20100112 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20110916 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20140922 Year of fee payment: 3 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 4829477 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| LAPS | Cancellation because of no payment of annual fees |