ES2821753T3 - Procedimientos de producción de Fab y de anticuerpos biespecíficos - Google Patents
Procedimientos de producción de Fab y de anticuerpos biespecíficos Download PDFInfo
- Publication number
- ES2821753T3 ES2821753T3 ES14719931T ES14719931T ES2821753T3 ES 2821753 T3 ES2821753 T3 ES 2821753T3 ES 14719931 T ES14719931 T ES 14719931T ES 14719931 T ES14719931 T ES 14719931T ES 2821753 T3 ES2821753 T3 ES 2821753T3
- Authority
- ES
- Spain
- Prior art keywords
- residue
- light chain
- heavy chain
- domain
- igg
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/46—Hybrid immunoglobulins
- C07K16/468—Immunoglobulins having two or more different antigen binding sites, e.g. multifunctional antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2863—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against receptors for growth factors, growth regulators
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/32—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against translation products of oncogenes
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/31—Immunoglobulins specific features characterized by aspects of specificity or valency multispecific
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/40—Immunoglobulins specific features characterized by post-translational modification
- C07K2317/41—Glycosylation, sialylation, or fucosylation
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/515—Complete light chain, i.e. VL + CL
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/52—Constant or Fc region; Isotype
- C07K2317/522—CH1 domain
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/52—Constant or Fc region; Isotype
- C07K2317/524—CH2 domain
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/52—Constant or Fc region; Isotype
- C07K2317/526—CH3 domain
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/55—Fab or Fab'
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/567—Framework region [FR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
- C07K2317/64—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments comprising a combination of variable region and constant region components
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/94—Stability, e.g. half-life, pH, temperature or enzyme-resistance
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Organic Chemistry (AREA)
- Immunology (AREA)
- Medicinal Chemistry (AREA)
- Biophysics (AREA)
- General Health & Medical Sciences (AREA)
- Genetics & Genomics (AREA)
- Biochemistry (AREA)
- Molecular Biology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Life Sciences & Earth Sciences (AREA)
- Oncology (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Peptides Or Proteins (AREA)
Abstract
Un procedimiento para la producción de un primer y un segundo fragmento, de unión a antígeno (Fab), que comprende: (1) la coexpresión de un primer ácido nucleico, un segundo ácido nucleico, un tercer ácido nucleico y un cuarto ácido nucleico en una célula hospedadora, en los que: (a) el primer ácido nucleico codifica tanto un dominio variable de la primera cadena pesada como un dominio constante CH1 de la primera cadena pesada de IgG, en el que dicho dominio variable de la primera cadena pesada comprende una lisina en el resto 39 y un ácido glutámico en el resto que está cuatro aminoácidos corriente arriba del primer resto del HFR3 de acuerdo con Kabat, y dicho dominio constante CH1 de la primera cadena pesada de IgG comprende una alanina o una arginina en el resto 172 y una glicina en el resto 174; (b) el segundo ácido nucleico codifica tanto un dominio variable de la primera cadena ligera como un dominio constante de la primera cadena ligera, en el que dicho dominio variable de la primera cadena ligera es un isotipo kappa y comprende una arginina en el resto 1 y un ácido aspártico en el resto 38, y dicho dominio constante de la primera cadena ligera comprende una tirosina en el resto 135 y un triptófano en el resto 176; (c) el tercer ácido nucleico codifica tanto un dominio variable de la segunda cadena pesada como un dominio constante CH1 de la segunda cadena pesada de IgG, en el que dicho dominio variable de la segunda cadena pesada comprende una tirosina en el resto 39 y dicho dominio constante CH1 de la segunda cadena pesada de IgG comprende una secuencia de WT, y el cuarto ácido nucleico codifica tanto un dominio variable de la segunda cadena ligera como un dominio constante de la segunda cadena ligera, en el que dicho dominio variable de la segunda cadena ligera comprende una arginina en el resto 38 y dicho dominio constante de la segunda cadena ligera comprende una secuencia de WT; o (d) el tercer ácido nucleico codifica tanto un dominio variable de la segunda cadena pesada como un dominio constante CH1 de la segunda cadena pesada de IgG, en el que dicho dominio variable de la segunda cadena pesada comprende una tirosina en el resto 39 y dicho dominio constante CH1 de la segunda cadena pesada de IgG comprende un ácido aspártico en el resto 228, y el cuarto ácido nucleico codifica tanto un dominio variable de la segunda cadena ligera como un dominio constante de la segunda cadena ligera, en el que dicho dominio variable de la segunda cadena ligera comprende una arginina en el resto 38 y dicho dominio constante de la segunda cadena ligera comprende una lisina en el resto 122 en el que cada uno de dichos dominios variables de las primeras cadena pesada y cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que dirigen la unión a un primer antígeno y además en el que cada uno de dichos dominios variables de las segundas cadena pesada y cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que dirigen la unión a un segundo antígeno que difiere de dicho primer antígeno; en el que dichos dominios constantes de las primera y segunda cadena pesada de IgG son el isotipo IgG1 o IgG4 humano; (2) el cultivo de dicha célula hospedadora en condiciones tales que se produzcan dichos dominios variable y constante CH1 de IgG de las primera y segunda cadena pesada y dichos dominios variable y constante de la primera y segunda cadena ligera; y (3) la recuperación a partir de dicha célula hospedadora de un primer y segundo Fab, en el que dicho primer Fab comprende dichos dominios variable y constante de la primera cadena pesada y dichos dominios variable y constante de la primera cadena ligera, y dicho segundo Fab comprende dichos dominios variable y constante de la segunda cadena pesada y dichos dominios variable y constante de la segunda cadena ligera.
Description
DESCRIPCIÓN
Procedimientos de producción de Fab y de anticuerpos biespecíficos
Las terapias con anticuerpos representan un segmento cada vez mayor del mercado farmacéutico mundial. Los productos basados en anticuerpos aprobados incluyen tratamientos para el cáncer, la artritis reumatoide, enfermedades infecciosas, enfermedades cardiovasculares y trastornos autoinmunitarios. Sin embargo, para mejorar los resultados de los pacientes, a menudo se desea la coadministración de dos o más agentes que alteran distintas dianas terapéuticas o rutas bioquímicas. En este contexto, la terapia con anticuerpos tiene limitaciones.
La coadministración de dos o más terapias con anticuerpos precisa múltiples inyecciones o, alternativamente, una única inyección de una coformulación de dos composiciones de anticuerpos distintas. Si bien las inyecciones múltiples permiten flexibilidad en la dosis y el momento de la administración, las molestias e incomodidad asociadas con las inyecciones múltiples pueden reducir el cumplimiento terapéutico del paciente. Por otra parte, mientras que una coformulación de múltiples agentes de anticuerpo permitiría menos inyecciones, la dificultad y/o el gasto asociados al diseño de una formulación farmacéutica adecuada que proporcione la estabilidad y biodisponibilidad necesarias para cada ingrediente de anticuerpo pueden ser prohibitivos. Adicionalmente, cualquier régimen de tratamiento que implique la administración de agentes de anticuerpo separados incurrirá en los costos de fabricación y administrativos adicionales asociados al desarrollo de cada agente individual.
El anticuerpo arquetípico está compuesto por dos fragmentos de unión a antígeno idénticos (los Fab) que no solo dirigen la unión a un determinante antigénico particular, sino que también proporcionan la interfaz para el ensamblaje entre las parejas de cadena pesada (HC, forma siglada de heavy chain)-cadena ligera (LC, forma siglada de light chain). Los anticuerpos biespecíficos - agentes singulares capaces de unirse a dos antígenos distintos - se han propuesto como un medio para abordar las limitaciones asociadas con la coadministración o la coformulación de agentes de anticuerpo separados. Los anticuerpos biespecíficos pueden integrar la actividad de unión de dos Mab (forma siglada de monoclonal antibody, anticuerpo monoclonal) terapéuticos distintos, proporcionando un beneficio de costo y conveniencia al paciente. En determinadas circunstancias, los anticuerpos biespecíficos pueden suscitar actividades sinérgicas o nuevas más allá de lo que puede lograr una combinación de anticuerpos. Un ejemplo de actividad nueva proporcionada por anticuerpos biespecíficos sería la conexión de dos tipos de celulares diferentes a través de la unión de receptores de superficie celular distintos. Como alternativa, los anticuerpos biespecíficos podrían entrecruzar dos receptores en la superficie de la misma célula conduciendo a nuevos mecanismos agonistas/antagonistas.
La capacidad de generar anticuerpos biespecíficos con una arquitectura completamente de IgG ha sido un desafío que existe desde hace tiempo en la ingeniería de anticuerpos. Una propuesta para la generación de anticuerpos biespecíficos completamente IgG implica la coexpresión de ácidos nucleicos que codifiquen dos parejas HC-LC distintas que, cuando se expresan, se ensamblen para formar un único anticuerpo que comprendan dos Fab distintos. Sin embargo, sigue habiendo desafíos con este enfoque. Específicamente, los polipéptidos expresados de cada Fab deseado deben ensamblarse con buena especificidad para reducir la generación de subproductos mal emparejados, y el heterotetrámero resultante debe ensamblarse con buena estabilidad. Se han desvelado en la técnica procedimientos para dirigir el ensamblaje de parejas HC-HC particulares mediante la introducción de modificaciones en regiones de la interfaz HC-HC. (Véanse Klein y col., mAbs; 4(6); 1-11 (2012); Cater y col., J. Immunol. Methods; 248; 7-15 (2001); Gunasekaran, y col., J. Biol. Chem.; 285; 19637-19646 (2010); Zhu y col., Protein Sci.; 6: 781-788 (1997); e Igawa y col., Protein Eng. Des. Sel.; 23; 667-677 (2010)).
Jordan, JL, y col. (Proteins, Vol. 77, páginas 832-41,2009) desvelan la producción de los Fab de un anticuerpo (BHA10), en la que se utiliza amplificación mediante PCR de regiones variable pesada y variable ligera mutantes a partir de fragmentos variables monocatenarios (los scFv) para construir una secuencia de cadena ligera y cadena pesada de anticuerpo de longitud completa, seguido de la transformación de las secuencias genéticas en células hospedadoras CHO, la expresión y purificación del anticuerpo de longitud completa y la digestión del anticuerpo de longitud completa para formar fragmentos Fab.
Schaefer W y col. (Proceedings of the National Academy of Sciences, Vol. 108, N.° 27, páginas 11187-11192, 2011) desvelan un procedimiento de producción de anticuerpos biespecíficos que implica el intercambio de dominios Fab de parejas de HC/LC completos. Para uno de los "brazos" del anticuerpo biespecífico, los dominios variable y constante de LC se recombinan con el dominio CH2 y CH3 de HC, de manera que la cadena expresada sea quimérica. Los dominios variable y constante (CHI) de HC se expresan por separado (como una LC nativa), lo que da como resultado un dominio Fab con las mismas secuencias nativas pero con la posición de las parejas de HC y LC invertida.
El documento WO 2007/109254 A2 desvela una población de moléculas de scFv estabilizadas, en las que las moléculas de scFv estabilizadas comprenden (i) un engarce de scFv interpuesto entre un dominio VH y un dominio VL, en las que los dominios VH y VL están unidos mediante un enlace disulfuro entre un aminoácido en el dominio VH y un aminoácido en el dominio VL, y en los que los dominios VH y VL de las moléculas de scFv tienen valores de Tm superiores a 55 °C, o (ii) un engarce de scFv interpuesto entre un dominio VH y un dominio VL, en las que los dominios VH y VL están unidos mediante un enlace disulfuro entre un aminoácido en el VH y un aminoácido en el
dominio VL, y en las que las moléculas de scFv tienen un Tso superior a 49 °C.
Spasevska I (BioSciences Master Reviews, enero de 2013) proporciona una revisión de anticuerpos biespecíficos y resume los diversos procedimientos utilizados para generar anticuerpos biespecíficos, incluido la estrategia de cuadroma o hibridoma híbrido, la estrategia de botones en ojales y la estrategia CrossMab.
Rudikoff y col. (PNAS, Vol. 79, páginas 1979-1983, 1982) describen el aislamiento y caracterización de propiedades estructurales y funcionales de una variante de una proteína de unión parental S107. La variante contenía una sustitución de un único aminoácido, de un ácido glutámico a alanina en el resto 35 de HCDR1 (numerado de acuerdo con Kabat). La variante no se une a la fosfocolina unida al transportador o como hapteno libre en solución, pero conserva los determinantes antigénicos (idiotipos) del parental. En términos del modelo tridimensional del sitio de unión a fosfocolina, el ácido glutámico 35 proporciona un enlace de hidrógeno con la tirosina 94 de la cadena ligera que parece ser fundamental para la estabilidad de esta porción del sitio de unión. Por lo tanto, la eliminación de este enlace y la presencia de la cadena lateral de alanina más pequeña es concordante con la pérdida de actividad de unión. Estos resultados sugieren que un pequeño número de sustituciones en anticuerpos, tales como las que presumiblemente se introducen por mutación somática, en algunas situaciones puede ser eficaz para modificar la especificidad de unión al antígeno.
Salfeld J G (Nature Biotechnology, Vol. 25, N.° 12, páginas 1369-72, 2007) proporciona una revisión de las propiedades de diversos isotipos de anticuerpo que deben tenerse en cuenta al desarrollar anticuerpos terapéuticos. Sin embargo, sigue existiendo la necesidad de procedimientos alternativos.
En conformidad con la presente invención, se han identificado procedimientos para lograr el ensamblaje de Fab particulares mediante la coexpresión de ácidos nucleicos que codifican parejas HC-LC particulares que contienen restos diseñados en la interfaz de los dominios variables de la cadena pesada-cadena ligera (Vh/Vl) y de los dominios constantes de la cadena pesada-cadena ligera (Chi/Cl). Más particularmente, los procedimientos de la presente invención logran una especificidad y, o estabilidad mejoradas en el ensamblaje de Fab particulares. Aún más particularmente, los procedimientos de la presente invención permiten combinar las especificidades de unión y las actividades de unión de las regiones variables de dos anticuerpos terapéuticos distintos en un único compuesto de anticuerpo biespecífico.
Por lo tanto, la presente invención proporciona un procedimiento para la producción de un primer y un segundo fragmento, de unión a antígeno (Fab), que comprende: (1) la coexpresión de un primer ácido nucleico, un segundo ácido nucleico, un tercer ácido nucleico y un cuarto ácido nucleico en una célula hospedadora, en los que: (a) el primer ácido nucleico codifica tanto un dominio variable de la primera cadena pesada como un dominio constante CH1 de la primera cadena pesada de IgG, en el que dicho dominio variable de la primera cadena pesada comprende una lisina en el resto 39 (39K) y un ácido glutámico en el resto que está cuatro aminoácidos corriente arriba del primer resto del HFR3 de acuerdo con Kabat, y dicho dominio constante CH1 de la primera cadena pesada de IgG comprende una alanina o una arginina en el resto 172 (172A) y una glicina en el resto 174 (174G); (b) el segundo ácido nucleico codifica tanto un dominio variable de la primera cadena ligera como un dominio constante de la primera cadena ligera, en el que dicho dominio variable de la primera cadena ligera es un isotipo kappa y comprende una arginina en el resto 1(lR) y un ácido aspártico en el resto 38 (38D), y dicho dominio constante de la primera cadena ligera comprende una tirosina en el resto 135 (135Y) y un triptófano en el resto 176 (176W); (c) el tercer ácido nucleico codifica tanto un dominio variable de la segunda cadena pesada como un dominio constante CH1 de la segunda cadena pesada de IgG, en el que dicho dominio variable de la segunda cadena pesada comprende una tirosina en el resto 39 (39Y) y dicho dominio constante CH1 de la segunda cadena pesada de IgG comprende una secuencia de WT (forma siglada de wild type: tipo silvestre) y el cuarto ácido nucleico codifica tanto un dominio variable de la segunda cadena ligera como un dominio constante de la segunda cadena ligera, en el que dicho dominio variable de la segunda cadena ligera comprende una arginina en el resto 38 (38R) y dicho dominio constante de la segunda cadena ligera comprende una secuencia de WT; o (d) el tercer ácido nucleico codifica tanto un dominio variable de la segunda cadena pesada como un dominio constante CH1 de la segunda cadena pesada de IgG, en el que dicho dominio variable de la segunda cadena pesada comprende una tirosina en el resto 39 y dicho dominio constante CH1 de la segunda cadena pesada de IgG comprende un ácido aspártico en el resto 228, y el cuarto ácido nucleico codifica tanto un dominio variable de la segunda cadena ligera como un dominio constante de la segunda cadena ligera, en el que dicho dominio variable de la segunda cadena ligera comprende una arginina en el resto 38 y dicho dominio constante de la segunda cadena ligera comprende una lisina en el resto 122, en el que cada uno de dichos dominios variables de las primeras cadena pesada y cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que dirigen la unión a un primer antígeno y además en el que cada uno de dichos dominios variables de las segundas cadena pesada y cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que dirigen la unión a un segundo antígeno que difiere de dicho primer antígeno; en el que dichos dominios constantes de las primera y segunda cadena pesada de IgG son el isotipo IgG1 o IgG4 humano; (2) el cultivo de dicha célula hospedadora en condiciones tales que se produzcan dichos dominios variable y constante CH1 de IgG de las primera y segunda cadena pesada y dichos dominios variable y constante de la primera y segunda cadena ligera; y (3) la recuperación a partir de dicha célula hospedadora de un primer y segundo Fab, en el que dicho primer Fab comprende dichos dominios variable y constante de la primera cadena pesada y dichos dominios constante y variable de la primera cadena ligera, y dicho
segundo Fab comprende dichos dominios variable y constante de la segunda cadena pesada y dichos dominios variable y constante de la segunda cadena ligera. Más en particular para esta realización, la presente invención proporciona un procedimiento que comprende uno o más de lo siguiente: dicho primer ácido nucleico codifica un dominio constante CH1 de cadena pesada que comprende además una metionina o una isoleucina en el resto 190 (190M o 190I); dicho segundo ácido nucleico codifica un dominio constante de la cadena ligera que comprende además una leucina en el resto 133 (133L); dicho segundo ácido nucleico codifica un dominio constante de la cadena ligera que comprende además una glutamina o un ácido aspártico en el resto 174 (174Q o 174D), y dicho tercer ácido nucleico codifica un dominio variable de la cadena pesada que además comprende una arginina en el resto 105 (105R), con dicho cuarto ácido nucleico que codifica un dominio variable de la cadena ligera comprendiendo además un ácido aspártico en el resto 42 (42D).
La presente invención también proporciona un procedimiento de producción de un anticuerpo biespecífico que comprende: (1) la coexpresión de un primer ácido nucleico, un segundo ácido nucleico, un tercer ácido nucleico y un cuarto ácido nucleico en una célula hospedadora: (a) el primer ácido nucleico codifica una primera cadena pesada de IgG, en la que dicha primera cadena pesada comprende un dominio variable que comprende una lisina en el resto 39 (39K) y un ácido glutámico en el resto que está cuatro aminoácidos corriente arriba del primer resto del HFR3 de acuerdo con Kabat, y un dominio constante CH1 que comprende una alanina o una arginina en el resto 172 (172A) y una glicina en el resto 174 (174G); (b) el segundo ácido nucleico codifica una primera cadena ligera, en la que dicha primera cadena ligera comprende un dominio variable kappa que comprende una arginina en el resto 1(1R) y un ácido aspártico en el resto 38 (38D), y un dominio constante que comprende una tirosina en el resto 135 (135Y) y un triptófano en el resto 176 (176W); (c) el tercer ácido nucleico codifica una segunda cadena pesada de IgG, en la que dicha segunda cadena pesada comprende un dominio variable que comprende una tirosina en el resto 39 (39Y) y un dominio constante CH1 que comprende una secuencia de WT; y el cuarto ácido nucleico codifica una segunda cadena ligera, en la que dicha segunda cadena ligera comprende un dominio variable que comprende una arginina en el resto 38 (38R) y un dominio constante que comprende una secuencia de WT; o (d) el tercer ácido nucleico codifica una segunda cadena pesada de IgG, en la que dicha segunda cadena pesada comprende un dominio variable que comprende una tirosina en el resto 39, y un dominio constante CH1 que comprende un ácido aspártico en el resto 228 y el cuarto ácido nucleico codifica una segunda cadena ligera, en la que dicha segunda cadena ligera comprende un dominio variable que comprende una arginina en el resto 38 y un dominio constante que comprende una lisina en el resto 122, en el que cada uno de dichos dominios variables de las primeras cadena pesada y cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que dirigen la unión a un primer antígeno y además en el que cada uno de dichos dominios variables de las segundas cadena pesada y cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que dirigen la unión a un segundo antígeno que difiere de dicho primer antígeno; y en el que dichos dominios constantes de las primera y segunda cadena pesada de IgG son un isotipo IgG1 o IgG4 humano; (2) el cultivo de dicha célula hospedadora en condiciones tales que se produzcan dichas primera y segunda cadenas pesadas de IgG y dichas primera y segunda cadenas ligeras; y (3) la recuperación a partir de dicha célula hospedadora de un anticuerpo biespecífico que comprende un primer y un segundo fragmento, de unión a antígeno (Fab), en el que dicho primer Fab comprende dicha primera cadena pesada de IgG y dicha primera cadena ligera y dicho segundo Fab comprende dicha segunda cadena pesada de IgG y dicha segunda cadena ligera. Más en particular para esta realización, la presente invención proporciona un procedimiento que comprende uno o más de lo siguiente: dicho primer ácido nucleico codifica un dominio constante CH1 de cadena pesada que comprende además una metionina o una isoleucina en el resto 190 (190M o 190I); dicho segundo ácido nucleico codifica un dominio constante de la cadena ligera que comprende además una leucina en el resto 133 (133L); dicho segundo ácido nucleico codifica un dominio constante de la cadena ligera que comprende además una glutamina o un ácido aspártico en el resto 174 (174Q o 174D), y dicho tercer ácido nucleico codifica un dominio variable de la cadena pesada que además comprende una arginina en el resto 105 (105R), con dicho cuarto ácido nucleico que codifica un dominio variable de la cadena ligera comprendiendo además un ácido aspártico en el resto 42 (42D).
En el presente documento se desvela un procedimiento para la producción de un fragmento, de unión a antígeno (Fab), que comprende: (1) la coexpresión en una célula hospedadora de: (a) un primer ácido nucleico que codifica tanto un dominio variable de la cadena pesada como un dominio constante CH1 de cadena pesada de IgG, en el que dicho dominio variable de la cadena pesada comprende una lisina en el resto 39 (39K) y un ácido glutámico en el resto que está cuatro aminoácidos corriente arriba del primer resto del HFR3 de acuerdo con Kabat, y dicho dominio CH1 de cadena pesada comprende una alanina en el resto 172 (172A) y una glicina en el resto 174 (174G); y (b) un segundo ácido nucleico que codifica tanto un dominio variable de la cadena ligera como un dominio constante de la cadena ligera, en el que dicho dominio variable de la cadena ligera es un isotipo kappa y comprende una arginina en el resto 1 (1R) y un ácido aspártico en el resto 38 (38D), y dicho dominio constante de la cadena ligera comprende una tirosina en el resto 135 (135Y) y un triptófano en el resto 176 (176W), en los que cada uno de dichos dominios variables de la cadena pesada y la cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que se unen directamente a el mismo antígeno; (2) el cultivo de dicha célula hospedadora en condiciones tales que se produzcan dichos dominios variable y constante de la cadena pesada y dichos dominios variable y constante de la cadena ligera; y (3) la recuperación de dicha célula hospedadora de un Fab que comprende dichos dominios variable y constante de la cadena pesada y dichos dominios variable y constante de la cadena ligera. Más en particular para la presente divulgación, en el presente documento se desvela un procedimiento que comprende uno o más de los siguientes: dicho primer ácido nucleico codifica un dominio constante CH1 de cadena pesada que
comprende además una metionina o una isoleucina en el resto 190 (190M o 190I); dicho segundo ácido nucleico codifica un dominio constante de la cadena ligera que comprende además una leucina en el resto 133 (133L); y dicho segundo ácido nucleico codifica un dominio constante de la cadena ligera que comprende además una glutamina o un ácido aspártico en el resto 174 (174Q o 174D).
En el presente documento se desvela además un procedimiento para la producción de un fragmento, de unión a antígeno (Fab), que comprende: (1) la coexpresión en una célula hospedadora de: (a) un primer ácido nucleico que codifica tanto un dominio variable de la cadena pesada como un dominio constante CH1 de cadena pesada de IgG, en el que dicho dominio variable de la cadena pesada comprende una lisina en el resto 39 (39k ) y un ácido glutámico en el resto que está cuatro aminoácidos corriente arriba del primer resto de1HFR3 de acuerdo con Kabat, y dicho dominio CH1 de cadena pesada comprende una arginina en el resto 172 (172R) y una glicina en el resto 174 (174G); y (b) un segundo ácido nucleico que codifica tanto un dominio variable de la cadena ligera como un dominio constante de la cadena ligera, en el que dicho dominio variable de la cadena ligera es un isotipo kappa y comprende una arginina en el resto 1 (1R) y un ácido aspártico en el resto 38 (38D), y dicho dominio constante de la cadena ligera comprende una tirosina en el resto 135 (135Y) y un triptófano en el resto 176 (176W), en los que cada uno de dichos dominios variables de la cadena pesada y la cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que se unen directamente a el mismo antígeno; (2) el cultivo de dicha célula hospedadora en condiciones tales que se produzcan dichos dominios variable y constante de la cadena pesada y dichos dominios variable y constante de la cadena ligera; y (3) la recuperación de dicha célula hospedadora de un Fab que comprende dichos dominios variable y constante de la cadena pesada y dichos dominios variable y constante de la cadena ligera. Más en particular para la presente divulgación, en el presente documento se desvela un procedimiento que comprende uno o más de los siguientes: dicho primer ácido nucleico codifica un dominio constante CH1 de cadena pesada que comprende además una metionina o una isoleucina en el resto 190 (190M o 190I); dicho segundo ácido nucleico codifica un dominio constante de la cadena ligera que comprende además una leucina en el resto 133 (133L); y dicho segundo ácido nucleico codifica un dominio constante de la cadena ligera que comprende además una glutamina o un ácido aspártico en el resto 174 (174Q o 174D).
Aún más, en el presente documento se desvela un procedimiento para la producción de un fragmento, de unión a antígeno (Fab), que comprende: (1) la coexpresión en una célula hospedadora de: (a) un primer ácido nucleico que codifica tanto un dominio variable de la cadena pesada como un dominio constante CH1 de cadena pesada de IgG, en el que dicho dominio variable de la cadena pesada comprende una lisina en el resto 39 (39K) y un ácido glutámico en el resto que está cuatro aminoácidos corriente arriba del primer resto de1HFR3 de acuerdo con Kabat, y dicho dominio CH1 de cadena pesada comprende una alanina en el resto 172 (172A) y una glicina en el resto 174 (174G); y (b) un segundo ácido nucleico que codifica tanto un dominio variable de la cadena ligera como un dominio constante de la cadena ligera, en el que dicho dominio variable de la cadena ligera es un isotipo kappa y comprende una arginina en el resto 1 (1R) y un ácido aspártico en el resto 38 (38D), y dicho dominio constante de la cadena ligera comprende una fenilalanina en el resto 135 (135F) y un triptófano en el resto 176 (176W), en los que cada uno de dichos dominios variables de la cadena pesada y la cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que se unen directamente a el mismo antígeno; (2) el cultivo de dicha célula hospedadora en condiciones tales que se produzcan dichos dominios variable y constante de la cadena pesada y dichos dominios variable y constante de la cadena ligera; y (3) la recuperación de dicha célula hospedadora de un Fab que comprende dichos dominios variable y constante de la cadena pesada y dichos dominios variable y constante de la cadena ligera.
Aún más, en el presente documento se desvela un procedimiento para la producción de un fragmento, de unión a antígeno (Fab), que comprende: (1) la coexpresión en una célula hospedadora de: (a) un primer ácido nucleico que codifica tanto un dominio variable de la cadena pesada como un dominio constante CH1 de cadena pesada de IgG, en el que dicho dominio variable de cadena pesada comprende una tirosina en el resto 39 (39Y) y dicho dominio CH1 de cadena pesada comprende una secuencia de WT; y (b) un segundo ácido nucleico que codifica tanto un dominio variable de la cadena ligera como un dominio constante de la cadena ligera, en el que dicho dominio variable de la cadena ligera comprende una arginina en el resto 38 (38R) y dicho dominio constante de la cadena ligera comprende una secuencia de WT, en los que cada uno de dichos dominios variables de la cadena pesada y la cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que se unen directamente a el mismo antígeno; (2) el cultivo de dicha célula hospedadora en condiciones tales que se produzcan dichos dominios variable y constante de la cadena pesada y dichos dominios variable y constante de la cadena ligera; y (3) la recuperación de dicha célula hospedadora de un Fab que comprende dichos dominios variable y constante de la cadena pesada y dichos dominios variable y constante de la cadena ligera. Más en particular para la presente divulgación, en el presente documento se desvela un procedimiento que comprende lo siguiente: dicho primer ácido nucleico codifica un dominio variable de la cadena pesada que además comprende una arginina en el resto 105 (105R) y dicho segundo ácido nucleico codifica un dominio variable de la cadena ligera que comprende además un ácido aspártico en el resto 42 (42D).
Aún más, en el presente documento se desvela un procedimiento para la producción de un fragmento, de unión a antígeno (Fab), que comprende: (1) la coexpresión en una célula hospedadora de: (a) un primer ácido nucleico que codifica tanto un dominio variable de la cadena pesada como un dominio constante CH1 de cadena pesada de IgG, en el que dicho dominio variable de la cadena pesada comprende una tirosina en el resto 39 (39Y) y dicho dominio CH1 de la cadena pesada comprende un ácido aspártico en el resto 228 (228D); y (b) un segundo ácido nucleico
que codifica tanto un dominio variable de la cadena ligera como un dominio constante de la cadena ligera, en el que dicho dominio variable de la cadena ligera comprende una arginina en el resto 38 (38R) y dicho dominio constante de la cadena ligera comprende una lisina en el resto 122 (122K), en los que cada uno de dichos dominios variables de la cadena pesada y la cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que se unen directamente a el mismo antígeno; (2) el cultivo de dicha célula hospedadora en condiciones tales que se produzcan dichos dominios variable y constante de la cadena pesada y dichos dominios variable y constante de la cadena ligera; y (3) la recuperación de dicha célula hospedadora de un Fab que comprende dichos dominios variable y constante de la cadena pesada y dichos dominios variable y constante de la cadena ligera. Más en particular para la presente divulgación, en el presente documento se desvela un procedimiento que comprende lo siguiente: dicho primer ácido nucleico codifica un dominio variable de la cadena pesada que además comprende una arginina en el resto 105 (105R) y dicho segundo ácido nucleico codifica un dominio variable de la cadena ligera que comprende además un ácido aspártico en el resto 42 (42D).
Aún más, en el presente documento se desvela un procedimiento para la producción de un fragmento, de unión a antígeno (Fab), que comprende: (1) la coexpresión en una célula hospedadora de: (a) un primer ácido nucleico que codifica tanto un dominio variable de la cadena pesada como un dominio constante CH1 de cadena pesada de IgG, en el que dicho dominio variable de la cadena pesada comprende una lisina en el resto 39 (39k ) y un ácido glutámico en el resto que está cuatro aminoácidos corriente arriba del primer resto de1HFR3 de acuerdo con Kabat, y dicho dominio CH1 de la cadena pesada comprende una secuencia de WT; y (b) un segundo ácido nucleico que codifica tanto un dominio variable de la cadena ligera como un dominio constante de la cadena ligera, en el que dicho dominio variable de la cadena ligera es un isotipo kappa y comprende una arginina en el resto 1 (1R) y un ácido aspártico en el resto 38 (38D), y dicho dominio constante de la cadena ligera comprende una secuencia de WT, en los que cada uno de dichos dominios variables de la cadena pesada y la cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que se unen directamente a el mismo antígeno; (2) el cultivo de dicha célula hospedadora en condiciones tales que se produzcan dichos dominios variable y constante de la cadena pesada y dichos dominios variable y constante de la cadena ligera; y (3) la recuperación de dicha célula hospedadora de un Fab que comprende dichos dominios variable y constante de la cadena pesada y dichos dominios variable y constante de la cadena ligera.
Más particularmente, en el presente documento se desvela un procedimiento para la producción de un fragmento, de unión a antígeno (Fab), que comprende: (1) la coexpresión en una célula hospedadora de: (a) un primer ácido nucleico que codifica tanto un dominio variable de la cadena pesada como un dominio constante CH1 de cadena pesada de IgG, en el que dicho dominio variable de la cadena pesada comprende una lisina en el resto 39 (39K) y un ácido glutámico en el resto que está cuatro aminoácidos corriente arriba del primer resto de1HFR3 de acuerdo con Kabat, y dicho dominio constante CH1 de cadena pesada de IgG comprende un ácido aspártico en el resto 228 (228D); y (b) un segundo ácido nucleico que codifica tanto un dominio variable de la cadena ligera como un dominio constante de la cadena ligera, en el que dicho dominio variable de la cadena ligera es un isotipo kappa y comprende una arginina en el resto 1 (1R) y un ácido aspártico en el resto 38 (38D), y dicho dominio constante de la cadena ligera comprende una lisina en el resto 122 (122K), en los que cada uno de dichos dominios variables de la cadena pesada y la cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que se unen directamente a el mismo antígeno; (2) el cultivo de dicha célula hospedadora en condiciones tales que se produzcan dichos dominios variable y constante de la cadena pesada y dichos dominios variable y constante de la cadena ligera; y (3) la recuperación de dicha célula hospedadora de un Fab que comprende dichos dominios variable y constante de la cadena pesada y dichos dominios variable y constante de la cadena ligera.
Aún más, en el presente documento se desvela un procedimiento para la producción de un fragmento, de unión a antígeno (Fab), que comprende: (1) la coexpresión en una célula hospedadora de: (a) un primer ácido nucleico que codifica tanto un dominio variable de la cadena pesada como un dominio constante CH1 de cadena pesada de IgG, en el que dicho dominio variable de la cadena pesada comprende una tirosina en el resto 39 (39Y) y dicho dominio CH1 de la cadena pesada comprende una alanina en el resto 172 (172A) y una glicina en el resto 174 (174G); y (b) un segundo ácido nucleico que codifica tanto un dominio variable de la cadena ligera como un dominio constante de la cadena ligera, en el que dicho dominio variable de la cadena ligera comprende una arginina en el resto 38 (38R) y dicho dominio constante de la cadena ligera comprende una tirosina en el resto 135 (135Y) y un triptófano en el resto 176 (176W), en los que cada uno de dichos dominios variables de la cadena pesada y la cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que se unen directamente a el mismo antígeno; (2) el cultivo de dicha célula hospedadora en condiciones tales que se produzcan dichos dominios variable y constante de la cadena pesada y dichos dominios variable y constante de la cadena ligera; y (3) la recuperación de dicha célula hospedadora de un Fab que comprende dichos dominios variable y constante de la cadena pesada y dichos dominios variable y constante de la cadena ligera. Más en particular para la presente divulgación, en el presente documento se desvela un procedimiento que comprende lo siguiente: dicho primer ácido nucleico codifica un dominio variable de la cadena pesada que además comprende una arginina en el resto 105 (105R) y dicho segundo ácido nucleico codifica un dominio variable de la cadena ligera que comprende además un ácido aspártico en el resto 42 (42D).
Aún más, en el presente documento se desvela un procedimiento para la producción de un primer y un segundo fragmento, de unión a antígeno (Fab), que comprende: (1) la coexpresión en una célula hospedadora de: (a) un primer ácido nucleico que codifica tanto un dominio variable de la primera cadena pesada como un dominio
constante CH1 de la primera cadena pesada de IgG, en el que dicho dominio variable de la primera cadena pesada comprende una lisina en el resto 39 (39K) y un ácido glutámico en el resto que está cuatro aminoácidos corriente arriba del primer resto del HFR3 de acuerdo con Kabat, y dicho dominio constante CH1 de la primera cadena pesada de IgG comprende una arginina en el resto 172 (172R) y una glicina en el resto 174 (174G); (b) un segundo ácido nucleico que codifica tanto un dominio variable de la primera cadena ligera como un dominio constante de la primera cadena ligera, en el que dicho dominio variable de la primera cadena ligera es un isotipo kappa y comprende una arginina en el resto 1 (1R) y un ácido aspártico en el resto 38 (38D), y dicho dominio constante de la primera cadena ligera comprende una tirosina en el resto 135 (135Y) y un triptófano en el resto 176 (176W); (c) un tercer ácido nucleico que codifica tanto un dominio variable de la segunda cadena pesada como un dominio constante CH1 de la segunda cadena pesada de IgG, en el que dicho dominio variable de la segunda cadena pesada comprende una tirosina en el resto 39 (39Y) y dicho dominio constante CH1 de la segunda cadena pesada de IgG comprende una secuencia de WT; y (d) un cuarto ácido nucleico que codifica tanto un dominio variable de la segunda cadena ligera como un dominio constante de la segunda cadena ligera, en el que dicho dominio variable de la segunda cadena ligera comprende una arginina en el resto 38 (38R) y dicho dominio constante de la segunda cadena ligera comprende una secuencia de WT, en el que cada uno de dichos dominios variables de las primeras cadena pesada y cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que dirigen la unión a un primer antígeno y además en el que cada uno de dichos dominios variables de las segundas cadena pesada y cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que dirigen la unión a un segundo antígeno que difiere de dicho primer antígeno; (2) el cultivo de dicha célula hospedadora en condiciones tales que se produzcan dichos dominios variable y constante CH1 de IgG de las primera y segunda cadena pesada y dichos dominios variable y constante de la primera y segunda cadena ligera; y (3) la recuperación a partir de dicha célula hospedadora de un primer y segundo Fab, en el que dicho primer Fab comprende dichos dominios variable y constante de la primera cadena pesada y dichos dominios constante y variable de la primera cadena ligera, y dicho segundo Fab comprende dichos dominios variable y constante de la segunda cadena pesada y dichos dominios variable y constante de la segunda cadena ligera. Más en particular para la presente divulgación, en el presente documento se desvela un procedimiento que comprende uno o más de los siguientes: dicho primer ácido nucleico codifica un dominio constante CH1 de cadena pesada que comprende además una metionina o una isoleucina en el resto 190 (190M o 190I); dicho segundo ácido nucleico codifica un dominio constante de la cadena ligera que comprende además una leucina en el resto 133 (133L); dicho segundo ácido nucleico codifica un dominio constante de la cadena ligera que comprende además una glutamina o un ácido aspártico en el resto 174 (174Q o 174D), y dicho tercer ácido nucleico codifica un dominio variable de la cadena pesada que además comprende una arginina en el resto 105 (105R), con dicho cuarto ácido nucleico que codifica un dominio variable de la cadena ligera comprendiendo además un ácido aspártico en el resto 42 (42D).
Aún más, en el presente documento se desvela un procedimiento para la producción de un primer y un segundo fragmento, de unión a antígeno (Fab), que comprende: (1) la coexpresión en una célula hospedadora de: (a) un primer ácido nucleico que codifica tanto un dominio variable de la primera cadena pesada como un dominio constante CH1 de la primera cadena pesada de IgG, en el que dicho dominio variable de la primera cadena pesada comprende una lisina en el resto 39 (39K) y un ácido glutámico en el resto que está cuatro aminoácidos corriente arriba del primer resto del HFR3 de acuerdo con Kabat, y dicho dominio constante CH1 de la primera cadena pesada de IgG comprende una alanina en el resto 172 (172A) y una glicina en el resto 174 (174G); (b) un segundo ácido nucleico que codifica tanto un dominio variable de la primera cadena ligera como un dominio constante de la primera cadena ligera, en el que dicho dominio variable de la primera cadena ligera es un isotipo kappa y comprende una arginina en el resto 1 (1R) y un ácido aspártico en el resto 38 (38D), y dicho dominio constante de la primera cadena ligera comprende una tirosina en el resto 135 (135Y) y un triptófano en el resto 176 (176W); (c) un tercer ácido nucleico que codifica tanto un dominio variable de la segunda cadena pesada como un dominio constante CH1 de la segunda cadena pesada de IgG, en el que dicho dominio variable de la segunda cadena pesada comprende una tirosina en el resto 39 (39Y) y dicho dominio constante CH1 de la segunda cadena pesada de IgG comprende un ácido aspártico en el resto 228 (228D); y (d) un cuarto ácido nucleico que codifica tanto un dominio variable de la segunda cadena ligera como un dominio constante de la segunda cadena ligera, en el que dicho dominio variable de la segunda cadena ligera comprende una arginina en el resto 38 (38R) y dicho dominio constante de la segunda cadena ligera comprende una lisina en el resto 122 (122K), en el que cada uno de dichos dominios variables de las primeras cadena pesada y cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que dirigen la unión a un primer antígeno y además en el que cada uno de dichos dominios variables de las segundas cadena pesada y cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que dirigen la unión a un segundo antígeno que difiere de dicho primer antígeno; (2) el cultivo de dicha célula hospedadora en condiciones tales que se produzcan dichos dominios variable y constante CH1 de IgG de las primera y segunda cadena pesada y dichos dominios variable y constante de la primera y segunda cadena ligera; y (3) la recuperación a partir de dicha célula hospedadora de un primer y segundo Fab, en el que dicho primer Fab comprende dichos dominios variable y constante de la primera cadena pesada y dichos dominios constante y variable de la primera cadena ligera, y dicho segundo Fab comprende dichos dominios variable y constante de la segunda cadena pesada y dichos dominios variable y constante de la segunda cadena ligera. Más en particular para la presente divulgación, en el presente documento se desvela un procedimiento que comprende uno o más de los siguientes: dicho primer ácido nucleico codifica un dominio constante CH1 de cadena pesada que comprende además una metionina o una isoleucina en el resto 190 (190M o 190I); dicho segundo ácido nucleico codifica un dominio constante de la cadena ligera que comprende además una leucina en el resto 133 (133L); dicho segundo
ácido nucleico codifica un dominio constante de la cadena ligera que comprende además una glutamina o un ácido aspártico en el resto 174 (174Q o 174D), y dicho tercer ácido nucleico codifica un dominio variable de la cadena pesada que además comprende una arginina en el resto 105 (105R), con dicho cuarto ácido nucleico codificando un dominio variable de la cadena ligera que comprende además un ácido aspártico en el resto 42 (42D).
Aún más, en el presente documento se desvela un procedimiento para la producción de un primer y un segundo fragmento, de unión a antígeno (Fab), que comprende: (1) la coexpresión en una célula hospedadora de: (a) un primer ácido nucleico que codifica tanto un dominio variable de la primera cadena pesada como un dominio constante CH1 de la primera cadena pesada de IgG, en el que dicho dominio variable de la primera cadena pesada comprende una lisina en el resto 39 (39K) y un ácido glutámico en el resto que está cuatro aminoácidos corriente arriba del primer resto del HFR3 de acuerdo con Kabat, y dicho dominio constante CH1 de la primera cadena pesada de IgG comprende una arginina en el resto 172 (172R) y una glicina en el resto 174 (174G); (b) un segundo ácido nucleico que codifica tanto un dominio variable de la primera cadena ligera como un dominio constante de la primera cadena ligera, en el que dicho dominio variable de la primera cadena ligera es un isotipo kappa y comprende una arginina en el resto 1 (1R) y un ácido aspártico en el resto 38 (38D), y dicho dominio constante de la primera cadena ligera comprende una tirosina en el resto 135 (135Y) y un triptófano en el resto 176 (176W); (c) un tercer ácido nucleico que codifica tanto un dominio variable de la segunda cadena pesada como un dominio constante CH1 de la segunda cadena pesada de IgG, en el que dicho dominio variable de la segunda cadena pesada comprende una tirosina en el resto 39 (39Y) y dicho dominio constante CH1 de la segunda cadena pesada de IgG comprende un ácido aspártico en el resto 228 (228D); y (d) un cuarto ácido nucleico que codifica tanto un dominio variable de la segunda cadena ligera como un dominio constante de la segunda cadena ligera, en el que dicho dominio variable de la segunda cadena ligera comprende una arginina en el resto 38 (38R) y dicho dominio constante de la segunda cadena ligera comprende una lisina en el resto 122 (122K), en el que cada uno de dichos dominios variables de las primeras cadena pesada y cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que dirigen la unión a un primer antígeno y además en el que cada uno de dichos dominios variables de las segundas cadena pesada y cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que dirigen la unión a un segundo antígeno que difiere de dicho primer antígeno; (2) el cultivo de dicha célula hospedadora en condiciones tales que se produzcan dichos dominios variable y constante CH1 de IgG de las primera y segunda cadena pesada y dichos dominios variable y constante de la primera y segunda cadena ligera; y (3) la recuperación a partir de dicha célula hospedadora de un primer y segundo Fab, en el que dicho primer Fab comprende dichos dominios variable y constante de la primera cadena pesada y dichos dominios constante y variable de la primera cadena ligera, y dicho segundo Fab comprende dichos dominios variable y constante de la segunda cadena pesada y dichos dominios variable y constante de la segunda cadena ligera. Más en particular para la presente divulgación, en el presente documento se desvela un procedimiento que comprende uno o más de los siguientes: dicho primer ácido nucleico codifica un dominio constante CH1 de cadena pesada que comprende además una metionina o una isoleucina en el resto 190 (190M o 190I); dicho segundo ácido nucleico codifica un dominio constante de la cadena ligera que comprende además una leucina en el resto 133 (133L); dicho segundo ácido nucleico codifica un dominio constante de la cadena ligera que comprende además una glutamina o un ácido aspártico en el resto 174 (174Q o 174D), y dicho tercer ácido nucleico codifica un dominio variable de la cadena pesada que además comprende una arginina en el resto 105 (105R), con dicho cuarto ácido nucleico codificando un dominio variable de la cadena ligera que comprende además un ácido aspártico en el resto 42 (42D).
Aún más, en el presente documento se desvela un procedimiento para la producción de un primer y un segundo fragmento, de unión a antígeno (Fab), que comprende: (1) la coexpresión en una célula hospedadora de: (a) un primer ácido nucleico que codifica tanto un dominio variable de la primera cadena pesada como un dominio constante CH1 de la primera cadena pesada de IgG, en el que dicho dominio variable de la primera cadena pesada comprende una lisina en el resto 39 (39K) y un ácido glutámico en el resto que está cuatro aminoácidos corriente arriba del primer resto del HFR3 de acuerdo con Kabat, y dicho dominio constante CH1 de la cadena pesada de IgG comprende una alanina en el resto 172 (172A) y una glicina en el resto 174 (174G); (b) un segundo ácido nucleico que codifica tanto un dominio variable de la primera cadena ligera como un dominio constante de la primera cadena ligera, en el que dicho dominio variable de la primera cadena ligera es un isotipo kappa y comprende una arginina en el resto 1 (1R) y un ácido aspártico en el resto 38 (38D), y dicho dominio constante de la primera cadena ligera comprende una fenilalanina en el resto 135 (135F) y un triptófano en el resto 176 (176W); (c) un tercer ácido nucleico que codifica tanto un dominio variable de la segunda cadena pesada como un dominio constante CH1 de la segunda cadena pesada de IgG, en el que dicho dominio variable de la segunda cadena pesada comprende una tirosina en el resto 39 (39Y) y dicho dominio constante CH1 de la segunda cadena pesada de IgG comprende una secuencia de WT; y (d) un cuarto ácido nucleico que codifica tanto un dominio variable de la segunda cadena ligera como un dominio constante de la segunda cadena ligera, en el que dicho dominio variable de la segunda cadena ligera comprende una arginina en el resto 38 (38R) y dicho dominio constante de la segunda cadena ligera comprende una secuencia de WT, en el que cada uno de dichos dominios variables de las primeras cadena pesada y cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que dirigen la unión a un primer antígeno y además en el que cada uno de dichos dominios variables de las segundas cadena pesada y cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que dirigen la unión a un segundo antígeno que difiere de dicho primer antígeno; (2) el cultivo de dicha célula hospedadora en condiciones tales que se produzcan dichos dominios variable y constante CH1 de IgG de las primera y segunda cadena pesada y dichos dominios variable y constante de la primera y segunda cadena ligera; y (3) la recuperación a partir de dicha
célula hospedadora de un primer y segundo Fab, en el que dicho primer Fab comprende dichos dominios variable y constante de la primera cadena pesada y dichos dominios constante y variable de la primera cadena ligera, y dicho segundo Fab comprende dichos dominios variable y constante de la segunda cadena pesada y dichos dominios variable y constante de la segunda cadena ligera.
Aún más, en el presente documento se desvela un procedimiento para la producción de un primer y un segundo fragmento, de unión a antígeno (Fab), que comprende: (1) la coexpresión en una célula hospedadora de: (a) un primer ácido nucleico que codifica tanto un dominio variable de la primera cadena pesada como un dominio constante CH1 de la primera cadena pesada de IgG, en el que dicho dominio variable de la primera cadena pesada comprende una tirosina en el resto 39 (39Y) y dicho dominio constante CH1 de la primera cadena pesada de IgG comprende una alanina en el resto 172 (172A) y una glicina en el resto 174 (174G); (b) un segundo ácido nucleico que codifica tanto un dominio variable de la primera cadena ligera como un dominio constante de la primera cadena ligera, en el que dicho dominio variable de la primera cadena ligera comprende una arginina en el resto 38 (38R), y dicho dominio constante de la primera cadena ligera comprende una tirosina en el resto 135 (135Y) y un triptófano en el resto 176 (176W); (c) un tercer ácido nucleico que codifica tanto un dominio variable de la segunda cadena pesada como un dominio constante CH1 de la segunda cadena pesada de IgG, en el que dicho dominio variable de la segunda cadena pesada comprende una lisina en el resto 39 (39K) y un ácido glutámico en el resto que está cuatro aminoácidos corriente arriba del primer resto del HFR3 de acuerdo con Kabat, y dicho dominio constante CH1 de la segunda cadena pesada de IgG comprende una secuencias de WT; y (d) un cuarto ácido nucleico que codifica tanto un dominio variable de la segunda cadena ligera como un dominio constante de la segunda cadena ligera, en el que dicho dominio variable de la cadena ligera es un isotipo kappa y comprende una arginina en el resto 1 (1R) y un ácido aspártico en el resto 38 (38D), y dicho dominio constante de la segunda cadena ligera comprende una secuencia de WT, en el que cada uno de dichos dominios variables de las primeras cadena pesada y cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que dirigen la unión a un primer antígeno y además en el que cada uno de dichos dominios variables de las segundas cadena pesada y cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que dirigen la unión a un segundo antígeno que difiere de dicho primer antígeno; (2) el cultivo de dicha célula hospedadora en condiciones tales que se produzcan dichos dominios variable y constante CH1 de IgG de las primera y segunda cadena pesada y dichos dominios variable y constante de la primera y segunda cadena ligera; y (3) la recuperación a partir de dicha célula hospedadora de un primer y segundo Fab, en el que dicho primer Fab comprende dichos dominios variable y constante de la primera cadena pesada y dichos dominios constante y variable de la primera cadena ligera, y dicho segundo Fab comprende dichos dominios variable y constante de la segunda cadena pesada y dichos dominios variable y constante de la segunda cadena ligera. Más en particular para la presente divulgación, en el presente documento se desvela un procedimiento que comprende lo siguiente: dicho primer ácido nucleico codifica un dominio variable de la cadena pesada que además comprende una arginina en el resto 105 (105R) y dicho segundo ácido nucleico codifica un dominio variable de la cadena ligera que comprende además un ácido aspártico en el resto 42 (42D).
Aún más, en el presente documento se desvela un procedimiento para la producción de un primer y un segundo fragmento, de unión a antígeno (Fab), que comprende: (1) la coexpresión en una célula hospedadora de: (a) un primer ácido nucleico que codifica tanto un dominio variable de la primera cadena pesada como un dominio constante CH1 de la primera cadena pesada de IgG, en el que dicho dominio variable de la primera cadena pesada comprende una tirosina en el resto 39 (39Y) y dicho dominio constante CH1 de la primera cadena pesada de IgG comprende una alanina en el resto 172 (172A) y una glicina en el resto 174 (174G); (b) un segundo ácido nucleico que codifica tanto un dominio variable de la primera cadena ligera como un dominio constante de la primera cadena ligera, en el que dicho dominio variable de la primera cadena ligera comprende una arginina en el resto 38 (38R), y dicho dominio constante de la primera cadena ligera comprende una tirosina en el resto 135 (135Y) y un triptófano en el resto 176 (176W); (c) un tercer ácido nucleico que codifica tanto un dominio variable de la segunda cadena pesada como un dominio constante CH1 de la segunda cadena pesada de IgG, en el que dicho dominio variable de la segunda cadena pesada comprende una lisina en el resto 39 (39K) y un ácido glutámico en el resto que está cuatro aminoácidos corriente arriba del primer resto del HFR3 de acuerdo con Kabat, y dicho dominio constante CH1 de la segunda cadena pesada de IgG comprende un ácido aspártico en el resto 228 (228D); y (d) un cuarto ácido nucleico que codifica tanto un dominio variable de la segunda cadena ligera como un dominio constante de la segunda cadena ligera, en el que dicho dominio variable de la cadena ligera es un isotipo kappa y comprende una arginina en el resto 1 (1R) y un ácido aspártico en el resto 38 (38D), y dicho dominio constante de la segunda cadena ligera comprende una lisina en el resto 122 (122K), en el que cada uno de dichos dominios variables de las primeras cadena pesada y cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que dirigen la unión a un primer antígeno y además en el que cada uno de dichos dominios variables de las segundas cadena pesada y cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que dirigen la unión a un segundo antígeno que difiere de dicho primer antígeno; (2) el cultivo de dicha célula hospedadora en condiciones tales que se produzcan dichos dominios variable y constante CH1 de IgG de las primera y segunda cadena pesada y dichos dominios variable y constante de la primera y segunda cadena ligera; y (3) la recuperación a partir de dicha célula hospedadora de un primer y segundo Fab, en el que dicho primer Fab comprende dichos dominios variable y constante de la primera cadena pesada y dichos dominios constante y variable de la primera cadena ligera, y dicho segundo Fab comprende dichos dominios variable y constante de la segunda cadena pesada y dichos dominios variable y constante de la segunda cadena ligera. Más en particular para
la presente divulgación, en el presente documento se desvela un procedimiento que comprende lo siguiente: dicho primer ácido nucleico codifica un dominio variable de la cadena pesada que además comprende una arginina en el resto 105 (105R) y dicho segundo ácido nucleico codifica un dominio variable de la cadena ligera que comprende además un ácido aspártico en el resto 42 (42D).
Aún más, en el presente documento se desvela un procedimiento para la producción de un anticuerpo biespecífico que comprende: (1) la coexpresión en una célula hospedadora de: (a) un primer ácido nucleico que codifica una primera cadena pesada de IgG, en la que dicha primera cadena pesada comprende un dominio variable que comprende una lisina en el resto 39 (39K) y un ácido glutámico en el resto que está 4 aminoácidos corriente arriba del primer resto del HFR3 de acuerdo con Kabat, y un dominio constante CH1 que comprende una arginina en el resto 172 (172R) y una glicina en el resto 174 (174G); (b) un segundo ácido nucleico que codifica una primera cadena ligera, en la que dicha primera cadena ligera comprende un dominio variable kappa que comprende una arginina en el resto 1 (1R) y un ácido aspártico en el resto 38 (38D), y un dominio constante que comprende una tirosina en el resto 135 (135Y) y un triptófano en el resto 176 (176W); (c) un tercer ácido nucleico que codifica una segunda cadena pesada de IgG, en la que dicha segunda cadena pesada comprende un dominio variable que comprende una tirosina en el resto 39 (39Y) y un dominio constante CH1 que comprende una secuencia de WT; y (d) un cuarto ácido nucleico que codifica una segunda cadena ligera, en la que dicha segunda cadena ligera comprende un dominio variable que comprende una arginina en el resto 38 (38R) y un dominio constante que comprende una secuencia de WT, en el que cada uno de dichos dominios variables de las primeras cadena pesada y cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que dirigen la unión a un primer antígeno y además en el que cada uno de dichos dominios variables de las segundas cadena pesada y cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que dirigen la unión a un segundo antígeno que difiere de dicho primer antígeno; (2) el cultivo de dicha célula hospedadora en condiciones tales que se produzcan dichas primera y segunda cadenas pesadas de IgG y dichas primera y segunda cadenas ligeras; y (3) la recuperación a partir de dicha célula hospedadora de un anticuerpo biespecífico que comprende un primer y un segundo fragmento, de unión a antígeno (Fab), en el que dicho primer Fab comprende dicha primera cadena pesada de IgG y dicha primera cadena ligera y dicho segundo Fab comprende dicha segunda cadena pesada de IgG y dicha segunda cadena ligera. Más en particular para la presente divulgación, en el presente documento se desvela un procedimiento que comprende uno o más de los siguientes: dicho primer ácido nucleico codifica un dominio constante CH1 de cadena pesada que comprende además una metionina o una isoleucina en el resto 190 (190M o 190I); dicho segundo ácido nucleico codifica un dominio constante de la cadena ligera que comprende además una leucina en el resto 133 (133L); dicho segundo ácido nucleico codifica un dominio constante de la cadena ligera que comprende además una glutamina o un ácido aspártico en el resto 174 (174Q o 174D), y dicho tercer ácido nucleico codifica un dominio variable de la cadena pesada que además comprende una arginina en el resto 105 (105R), con dicho cuarto ácido nucleico codificando un dominio variable de la cadena ligera que comprende además un ácido aspártico en el resto 42 (42D).
Aún más, en el presente documento se desvela un procedimiento para la producción de un anticuerpo biespecífico que comprende: (1) la coexpresión en una célula hospedadora de: (a) un primer ácido nucleico que codifica una primera cadena pesada de IgG, en la que dicha primera cadena pesada comprende un dominio variable que comprende una lisina en el resto 39 (39K) y un ácido glutámico en el resto que está cuatro aminoácidos corriente arriba del primer resto del HFR3 de acuerdo con Kabat, y un dominio constante CH1 que comprende una alanina en el resto 172 (172A) y una glicina en el resto 174 (174G); (b) un segundo ácido nucleico que codifica una primera cadena ligera, en la que dicha primera cadena ligera comprende un dominio variable kappa que comprende una arginina en el resto 1 (1R) y un ácido aspártico en el resto 38 (38D), y un dominio constante que comprende una tirosina en el resto 135 (135Y) y un triptófano en el resto 176 (176W); (c) un tercer ácido nucleico que codifica una segunda cadena pesada de IgG, en la que dicha segunda cadena pesada comprende un dominio variable que comprende una tirosina en el resto 39 (39Y) y un dominio constante CH1 que comprende un ácido aspártico en el resto 228 (228D); y (d) un cuarto ácido nucleico que codifica una segunda cadena ligera, en la que dicha segunda cadena ligera comprende un dominio variable que comprende una arginina en el resto 38 (38R) y un dominio constante que comprende una lisina en el resto 122 (122K), en el que cada uno de dichos dominios variables de las primeras cadena pesada y cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que dirigen la unión a un primer antígeno y además en el que cada uno de dichos dominios variables de las segundas cadena pesada y cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que dirigen la unión a un segundo antígeno que difiere de dicho primer antígeno; (2) el cultivo de dicha célula hospedadora en condiciones tales que se produzcan dichas primera y segunda cadenas pesadas de IgG y dichas primera y segunda cadenas ligeras; y (3) la recuperación a partir de dicha célula hospedadora de un anticuerpo biespecífico que comprende un primer y un segundo fragmento, de unión a antígeno (Fab), en el que dicho primer Fab comprende dicha primera cadena pesada de IgG y dicha primera cadena ligera y dicho segundo Fab comprende dicha segunda cadena pesada de IgG y dicha segunda cadena ligera. Más en particular para la presente divulgación, en el presente documento se desvela un procedimiento que comprende uno o más de los siguientes: dicho primer ácido nucleico codifica un dominio constante CH1 de cadena pesada que comprende además una metionina o una isoleucina en el resto 190 (190M o 190I); dicho segundo ácido nucleico codifica un dominio constante de la cadena ligera que comprende además una leucina en el resto 133 (133L); dicho segundo ácido nucleico codifica un dominio constante de la cadena ligera que comprende además una glutamina o un ácido aspártico en el resto 174 (174Q o 174D), y dicho tercer ácido nucleico codifica un dominio variable de la cadena
pesada que además comprende una arginina en el resto 105 (105R), con dicho cuarto ácido nucleico codificando un dominio variable de la cadena ligera que comprende además un ácido aspártico en el resto 42 (42D).
Aún más, en el presente documento se desvela un procedimiento para la producción de un anticuerpo biespecífico que comprende: (1) la coexpresión en una célula hospedadora de: (a) un primer ácido nucleico que codifica una primera cadena pesada de IgG, en la que dicha primera cadena pesada comprende un dominio variable que comprende una lisina en el resto 39 (39K) y un ácido glutámico en el resto que está cuatro aminoácidos corriente arriba del primer resto del HFR3 de acuerdo con Kabat, y un dominio constante CH1 que comprende una arginina en el resto 172 (172R) y una glicina en el resto 174 (174G); (b) un segundo ácido nucleico que codifica una primera cadena ligera, en la que dicha primera cadena ligera comprende un dominio variable kappa que comprende una arginina en el resto 1 (1R) y un ácido aspártico en el resto 38 (38D), y un dominio constante que comprende una tirosina en el resto 135 (135Y) y un triptófano en el resto 176 (176W); (c) un tercer ácido nucleico que codifica una segunda cadena pesada de IgG, en la que dicha segunda cadena pesada comprende un dominio variable que comprende una tirosina en el resto 39 (39Y) y un dominio constante CH1 que comprende un ácido aspártico en el resto 228 (228D); y (d) un cuarto ácido nucleico que codifica una segunda cadena ligera, en la que dicha segunda cadena ligera comprende un dominio variable que comprende una arginina en el resto 38 (38R) y un dominio constante que comprende una lisina en el resto 122 (122K), en el que cada uno de dichos dominios variables de las primeras cadena pesada y cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que dirigen la unión a un primer antígeno y además en el que cada uno de dichos dominios variables de las segundas cadena pesada y cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que dirigen la unión a un segundo antígeno que difiere de dicho primer antígeno; (2) el cultivo de dicha célula hospedadora en condiciones tales que se produzcan dichas primera y segunda cadenas pesadas de IgG y dichas primera y segunda cadenas ligeras; y (3) la recuperación a partir de dicha célula hospedadora de un anticuerpo biespecífico que comprende un primer y un segundo fragmento, de unión a antígeno (Fab), en el que dicho primer Fab comprende dicha primera cadena pesada de IgG y dicha primera cadena ligera y dicho segundo Fab comprende dicha segunda cadena pesada de IgG y dicha segunda cadena ligera. Más en particular para la presente divulgación, en el presente documento se desvela un procedimiento que comprende uno o más de los siguientes: dicho primer ácido nucleico codifica un dominio constante CH1 de cadena pesada que comprende además una metionina o una isoleucina en el resto 190 (190M o 190I); dicho segundo ácido nucleico codifica un dominio constante de la cadena ligera que comprende además una leucina en el resto 133 (133L); dicho segundo ácido nucleico codifica un dominio constante de la cadena ligera que comprende además una glutamina o un ácido aspártico en el resto 174 (174Q o 174D), y dicho tercer ácido nucleico codifica un dominio variable de la cadena pesada que además comprende una arginina en el resto 105 (105R), con dicho cuarto ácido nucleico codificando un dominio variable de la cadena ligera que comprende además un ácido aspártico en el resto 42 (42D).
Aún más, en el presente documento se desvela un procedimiento para la producción de un anticuerpo biespecífico que comprende: (1) la coexpresión en una célula hospedadora de: (a) un primer ácido nucleico que codifica una primera cadena pesada de IgG, en la que dicha primera cadena pesada comprende un dominio variable que comprende una tirosina en el resto 39 (39Y), y un dominio constante CH1 que comprende una alanina en el resto 172 (172A) y una glicina en el resto 174 (174G); (b) un segundo ácido nucleico que codifica una primera cadena ligera, en la que dicha primera cadena ligera comprende un dominio variable que comprende una arginina en el resto 38 (38R) y un dominio constante que comprende una tirosina en el resto 135 (135Y) y un triptófano en el resto 176 (176W); (c) un tercer ácido nucleico que codifica una segunda cadena pesada de IgG, en la que dicha cadena pesada comprende un dominio variable que comprende una lisina en el resto 39 (39K) y un ácido glutámico en el resto que está cuatro aminoácidos corriente arriba del primer resto del HFR3 de acuerdo con Kabat y un dominio constante que comprende una secuencia de WT; y (d) un cuarto ácido nucleico que codifica la segunda cadena ligera, en la que dicha segunda cadena ligera comprende un dominio variable kappa que comprende una arginina en el resto 1 (1R) y un ácido aspártico en el resto 38 (38D), y un dominio constante que comprende una secuencia de WT, en el que cada uno de dichos dominios variables de las primeras cadena pesada y cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que dirigen la unión a un primer antígeno y además en el que cada uno de dichos dominios variables de las segundas cadena pesada y cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que dirigen la unión a un segundo antígeno que difiere de dicho primer antígeno; (2) el cultivo de dicha célula hospedadora en condiciones tales que se produzcan dichas primera y segunda cadenas pesadas de IgG y dichas primera y segunda cadenas ligeras; y (3) la recuperación a partir de dicha célula hospedadora de un anticuerpo biespecífico que comprende un primer y un segundo fragmento, de unión a antígeno (Fab), en el que dicho primer Fab comprende dicha primera cadena pesada de IgG y dicha primera cadena ligera y dicho segundo Fab comprende dicha segunda cadena pesada de IgG y dicha segunda cadena ligera. Más en particular para la presente divulgación, en el presente documento se desvela un procedimiento que comprende lo siguiente: dicho primer ácido nucleico codifica un dominio variable de la cadena pesada que además comprende una arginina en el resto 105 (105R) y dicho segundo ácido nucleico codifica un dominio variable de la cadena ligera que comprende además un ácido aspártico en el resto 42 (42D).
Aún más, en el presente documento se desvela un procedimiento para la producción de un anticuerpo biespecífico que comprende: (1) la coexpresión en una célula hospedadora de: (a) un primer ácido nucleico que codifica una primera cadena pesada de IgG, en la que dicha primera cadena pesada comprende un dominio variable que comprende una tirosina en el resto 39 (39Y), y un dominio constante CH1 que comprende una alanina en el resto
172 (172A) y una glicina en el resto 174 (174G); (b) un segundo ácido nucleico que codifica una primera cadena ligera, en la que dicha primera cadena ligera comprende un dominio variable que comprende una arginina en el resto 38 (38R) y un dominio constante que comprende una tirosina en el resto 135 (135Y) y un triptófano en el resto 176 (176W); (c) un tercer ácido nucleico que codifica una segunda cadena pesada de IgG, en la que dicha cadena pesada comprende un dominio variable que comprende una lisina en el resto 39 (39K) y un ácido glutámico en el resto que está cuatro aminoácidos corriente arriba del primer resto del HFR3 de acuerdo con Kabat y un dominio constante que comprende un ácido aspártico en el resto 228 (228D); y (d) un cuarto ácido nucleico que codifica la segunda cadena ligera, en la que dicha segunda cadena ligera comprende un dominio variable kappa que comprende una arginina en el resto 1 (1R) y un ácido aspártico en el resto 38 (38D), y un dominio constante que comprende una lisina en el resto 122 (122K), en el que cada uno de dichos dominios variables de las primeras cadena pesada y cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que dirigen la unión a un primer antígeno y además en el que cada uno de dichos dominios variables de las segundas cadena pesada y cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que dirigen la unión a un segundo antígeno que difiere de dicho primer antígeno; (2) el cultivo de dicha célula hospedadora en condiciones tales que se produzcan dichas primera y segunda cadenas pesadas de IgG y dichas primera y segunda cadenas ligeras; y (3) la recuperación a partir de dicha célula hospedadora de un anticuerpo biespecífico que comprende un primer y un segundo fragmento, de unión a antígeno (Fab), en el que dicho primer Fab comprende dicha primera cadena pesada de IgG y dicha primera cadena ligera y dicho segundo Fab comprende dicha segunda cadena pesada de IgG y dicha segunda cadena ligera. Más en particular para la presente divulgación, en el presente documento se desvela un procedimiento que comprende lo siguiente: dicho primer ácido nucleico codifica un dominio variable de la cadena pesada que además comprende una arginina en el resto 105 (105R) y dicho segundo ácido nucleico codifica un dominio variable de la cadena ligera que comprende además un ácido aspártico en el resto 42 (42D).
Como una realización particular adicional de los procedimientos para la producción de un anticuerpo biespecífico, como se proporciona en el presente documento, la presente invención proporciona un procedimiento en el que una de dichas primera y segunda cadenas pesadas de IgG comprende además un dominio constante CH3 que comprende una lisina en el resto 356 y una lisina en el resto 399, y la otra de dichas primera y segunda cadenas pesadas de IgG comprende además un dominio constante CH3 que comprende un ácido aspártico en el resto 392 y un ácido aspártico en el resto 409.
Aún más particularmente, en el presente documento se desvela un procedimiento para la producción de un anticuerpo biespecífico que comprende: (1) la coexpresión en una célula hospedadora de: (a) un primer ácido nucleico que codifica una primera cadena pesada de IgG, en la que dicha primera cadena pesada comprende un dominio variable que comprende una lisina en el resto 39 (39K) y un ácido glutámico en el resto que está cuatro aminoácidos corriente arriba del primer resto del HFR3 de acuerdo con Kabat, un dominio constante CH1 que comprende una alanina en el resto 172 (172A) y una glicina en el resto 174 (174G), y un dominio constante CH3 que comprende una lisina en el resto 356 (356K) y una lisina en el resto 399 (399K); (b) un segundo ácido nucleico que codifica una primera cadena ligera, en la que dicha primera cadena ligera comprende un dominio variable kappa que comprende una arginina en el resto 1 (1R) y un ácido aspártico en el resto 38 (38D), y un dominio constante que comprende una tirosina en el resto 135 (135y ) y un triptófano en el resto 176 (176W); (c) un tercer ácido nucleico que codifica una segunda cadena pesada de IgG, en la que dicha segunda cadena pesada comprende un dominio variable que comprende una tirosina en el resto 39 (39Y), un dominio constante CH1 que comprende una secuencia de WT y un dominio constante CH3 que comprende un ácido aspártico en el resto 392 (392D) y un ácido aspártico en el resto 409 ( 409D); y (d) un cuarto ácido nucleico que codifica una segunda cadena ligera, en la que dicha segunda cadena ligera comprende un dominio variable que comprende una arginina en el resto 38 (38R) y un dominio constante que comprende una secuencia de WT, en el que cada uno de dichos dominios variables de las primeras cadena pesada y cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que dirigen la unión a un primer antígeno y además en el que cada uno de dichos dominios variables de las segundas cadena pesada y cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que dirigen la unión a un segundo antígeno que difiere de dicho primer antígeno; (2) el cultivo de dicha célula hospedadora en condiciones tales que se produzcan dichas primera y segunda cadenas pesadas de IgG y dichas primera y segunda cadenas ligeras; y (3) la recuperación a partir de dicha célula hospedadora de un anticuerpo biespecífico que comprende un primer y un segundo fragmento, de unión a antígeno (Fab), en el que dicho primer Fab comprende dicha primera cadena pesada de IgG y dicha primera cadena ligera y dicho segundo Fab comprende dicha segunda cadena pesada de IgG y dicha segunda cadena ligera.
En otras realizaciones particulares, la célula hospedadora para su uso en los procedimientos de la presente invención es una célula de mamífero, más particularmente una célula HEK293 o CHO, y el dominio constante de la cadena pesada de IgG producido mediante los procedimientos de la presente invención es el isotipo IgG1 o IgG4, y más particularmente el IgG1.
La presente invención proporciona Fab y anticuerpos biespecíficos, cada uno producido de acuerdo con los procedimientos de la presente invención. En el presente documento se desvelan células hospedadoras que comprenden ácidos nucleicos que los codifican. En particular, la presente invención proporciona cualquiera de los Fab y anticuerpos biespecíficos como se ejemplifica en cualquiera de los Ejemplos en el presente documento.
En otra divulgación particular, en el presente documento se desvela un anticuerpo biespecífico que comprende una primera cadena pesada de IgG, en la que dicha primera cadena pesada comprende un dominio variable que comprende una lisina en el resto 39 (39K) y un ácido glutámico en el resto que está cuatro aminoácidos corriente arriba del primer resto del HFR3 de acuerdo con Kabat, un dominio constante CH1 que comprende una alanina en el resto 172 (172A) y una glicina en el resto 174 (174G), y un dominio constante CH3 que comprende una lisina en el resto 356 (356K) y una lisina en el resto 399 (399K); (b) una primera cadena ligera, en la que dicha primera cadena ligera comprende un dominio variable kappa que comprende una arginina en el resto 1 (1R) y un ácido aspártico en el resto 38 (38D), y un dominio constante que comprende una tirosina en el resto 135 (135Y) y un triptófano en el resto 176 (176W); (c) una segunda cadena pesada de IgG, en la que dicha segunda cadena pesada comprende un dominio variable que comprende una tirosina en el resto 39 (39Y), un dominio constante CH1 que comprende una secuencia de WT y un dominio constante CH3 que comprende un ácido aspártico en el resto 392 (392D) y un ácido aspártico en el resto 409 ( 409D); y (d) una segunda cadena ligera, en la que dicha segunda cadena ligera comprende un dominio variable que comprende una arginina en el resto 38 (38R) y un dominio constante que comprende una secuencia de WT, en el que cada uno de dichos primeros dominios variables de cadena pesada y cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que dirigen la unión a un primer antígeno y además en el que cada uno de dichos segundos dominios variables de cadena pesada y cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que dirigen la unión a un segundo antígeno que difiere de dicho primer antígeno.
Breve descripción de figuras
Figura 1: Diagramas esquemáticos de los formatos de diseño de IgG (A) , Fab-Fab (B) e IgG-Fab (C) . El "*" en el diagrama de BsAb (forma siglada de bi-specific antibody , anticuerpo biespecífico) de IgG indica un dominio CH3 de anticuerpo heterodimerizado. El formato Fab-Fab (B) podría prepararse expresando un engarce polipeptídico entre el extremo C de la HC de Fab 1 y el extremo N de la HC o la LC de Fab 2. Como alternativa, un polipéptido podría conectar el extremo C de la LC de Fab 1 y el extremo N de la LC o la HC de Fab 2. De forma similar, el Fab adicional en el IgG-Fab (C) podría estar unido al extremo N de la HC o de la LC o al extremo C de la LC.
Figuras 2 y 3: Trazados de resonancia de plasmón superficial (Biacore) que demuestran el comportamiento de unión doble de los BsAb de IgG anti-HER-2/anti-EGFR (Fig. 2) y anti-cMET/anti-Axl (Fig. 3). La unión biespecífica de los BsAb con Fab rediseñado (Diseños HE (Fig. 2) y Diseños MA (Fig. 3)) es evidente por los aumentos en la señal durante ambos ciclos de inyección (300-540 s y 940-1180 s). Los MAb monoespecíficos IgG1 pertuzumab (pG1) e IgG1 matuzumab (mG1) (Fig. 2), e IgG1 METMAb (METG1) e IgG1 Anti-Axl (Ax1G1) (Fig. 3) no demuestran esta actividad. Las moléculas de control sin los rediseños de Fab (es decir, Control de HE y Control de MA), pero que portan mutaciones de heterodimerización de Ch3, también demuestran actividad de unión biespecífica.
La estructura general de un "anticuerpo" es muy conocida. Para un anticuerpo de longitud completa del tipo IgG, hay cuatro cadenas de aminoácidos (dos cadenas "pesadas" y dos cadenas "ligeras") que están entrecruzadas a través de enlaces disulfuro intra- e intercatenarios. Cuando se expresan en determinados sistemas biológicos, por ejemplo, líneas celulares de mamífero, los anticuerpos que tienen secuencias no modificadas de Fc humano se glucosilan en la región Fc. Los anticuerpos también se pueden estar glucosilados en otras posiciones. Las estructuras de las subunidades y las configuraciones tridimensionales de los anticuerpos son bien conocidas. Cada cadena pesada está compuesta por una región variable de la cadena pesada N-terminal ("Vh") y una región constante de la cadena pesada (" Ch"). La región constante de la cadena pesada está compuesta por tres dominios (Ch1, Ch2 y Ch3) para IgG, así como una región de bisagra ("bisagra") entre los dominios Ch1 y Ch2. Cada cadena ligera está compuesta por una región variable de la cadena ligera ("Vl") y una región constante de la cadena ligera (" Ch"). Las regiones Cl y Vl pueden ser de los isotipos kappa ("k") o lambda ("A"). Los anticuerpos IgG se pueden dividir adicionalmente en subclases, por ejemplo, IgG1, IgG2, IgG3, IgG4, como lo aprecia un experto en la técnica
Las regiones variables de cada pareja de cadena pesada - cadena ligera se asocian para formar sitios de unión. La región variable de la cadena pesada (Vh) y la región variable de la cadena ligera (Vl) se puede subdividir en regiones de hipervariabilidad, denominadas regiones determinantes de complementariedad (las "CDR"), intercaladas con regiones más conservadas, denominadas regiones marco conservadas ("FR"). Cada Vh y Vl se compone de tres CDR y cuatro FR, ordenados desde el extremo amino al extremo carboxilo en el siguiente orden: FR1, CDR1, FR2, CDR2, FR3, CDR3, FR4. Las CDR de la cadena pesada pueden denominarse "CDRH1, CDRH2 y CDRH3 "y las 3 CDR de la cadena ligera pueden denominarse" CDRL1, CDRL2 y CDRL3". Las FR de la cadena pesada pueden denominarse HFR1, HFR2, HFR3 y HFR4, mientras que las FR de la cadena ligera pueden denominarse LFR1, LFR2, LFR3 y LFR4. Las CDR contienen la mayoría de los restos que forman interacciones específicas con el antígeno
Un anticuerpo IgG de tipo silvestre contiene dos fragmentos idénticos denominados "fragmento, de unión de antígeno "(o Fab), cada uno de los cuales se compone de los dominios Vh y Ch1 de una cadena pesada y los dominios Vl y Cl de una cadena ligera. Cada Fab dirige la unión del anticuerpo al mismo antígeno. Como se usa en el presente documento, la expresión "anticuerpo biespecífico" o "BsAb de IgG" se refiere a un anticuerpo IgG que comprende dos Fab distintos, cada uno de los cuales se une directamente a un antígeno distinto, y está compuesto por dos cadenas pesadas distintas y dos cadenas ligeras distintas. Los dominios Vh y Ch1 de una cadena pesada se
asocian con los dominios Vl y Cl de una cadena ligera para formar un "primer" Fab, mientras que los dominios Vh y Ch1 de la otra cadena pesada se asocian con los dominios Vl y Cl de la otra cadena ligera para formar un "segundo" Fab. Más particularmente, la expresión "anticuerpo biespecífico", como se usa en el presente documento, se refiere a una clase IgG1, IgG2 o IgG4 de anticuerpo biespecífico. Aún más particularmente, la expresión "anticuerpo biespecífico" se refiere a una clase IgG1 o IgG4 de anticuerpo biespecífico, y más particularmente a una clase IgG1.
Los procedimientos ejemplificados en el presente documento se pueden utilizar para coexpresar dos fracciones de Fab distintas, por ejemplo, Fab con distintas regiones Fv, con una falta de coincidencia reducida de las respectivas parejas HC/LC. Además de los anticuerpos biespecíficos y de los Fab individuales, los procedimientos de la presente invención pueden emplearse en la preparación de otros compuestos biespecíficos de unión a antígeno. Como se usa en el presente documento, la expresión "compuesto biespecífico de unión a antígeno" se refiere a moléculas Fab-Fab e IgG-Fab. La Figura 1, incluida en el presente documento, proporciona un diagrama esquemático de la estructura de anticuerpos biespecíficos (BsAb de IgG) así como los formatos de Fab-Fab e IgG-Fab contemplados por los procedimientos y compuestos de la presente invención.
Los procedimientos y compuestos de la presente invención comprenden modificaciones de aminoácidos diseñadas en restos particulares dentro de los dominios variables y constantes de polipéptidos de cadena pesada y la cadena ligera. Como apreciará un experto en la materia, pueden emplearse diversas convenciones de numeración para designar restos de aminoácidos particulares dentro de las secuencias de las regiones variables de IgG. Las convenciones de numeración comúnmente utilizadas incluyen la numeración de Kabat y el índice EU (véase, Kabat y col., Sequences of Proteins of Immunological Interest, 5a Ed, Public Health Service, National Institutes of Health, Bethesda, MD (1991)). Otras convenciones que incluyen correcciones o sistemas de numeración alternativos para dominios variables incluyen a Chothia (Chothia C, Lesk AM (1987), JMol Biol 196: 901-917; Chothia, y col. (1989), Nature 342: 877-883), iMg T (Lefranc, y col. (2003), Dev Comp Immunol 27: 55-77) y AHo (Honegger A, Pluckthun A (2001) J Mol Biol 309: 657-670). Estas referencias proporcionan esquemas de numeración de secuencias de aminoácidos para regiones variables de inmunoglobulinas que definen la ubicación de restos de aminoácidos de las regiones variables de secuencias de anticuerpos. A menos que se indique expresamente otra cosa en el presente documento, todas las referencias a restos de aminoácidos (es decir, los números) de la región variable de la cadena pesada de inmunoglobulina (es decir, VH) que aparecen en los ejemplos y reivindicaciones se basan en el sistema de numeración de Kabat, al igual que todas las referencias a restos de VL y CL. Todas las referencias a la región constante CH1 de la cadena pesada de inmunoglobulina y la bisagra que aparecen en los ejemplos y reivindicaciones también se basan en el sistema Kabat, mientras que todas las referencias a las regiones constantes Ch2 y Ch3 de la cadena pesada de inmunoglobulina se basan en el sistema de numeración del Índice EU. Con conocimiento del número de resto de acuerdo con la numeración Kabat o del índice EU, un experto en la materia puede aplicar las enseñanzas de la técnica para identificar modificaciones de la secuencia de aminoácidos dentro de la presente invención, de acuerdo con cualquier convención de numeración comúnmente utilizada. Téngase en cuenta que, mientras que los ejemplos y reivindicaciones de la presente invención emplean a Kabat o el índice EU para identificar restos de aminoácidos particulares, se entiende que las SEQ ID que aparecen en el Listado de Secuencias que acompaña a la presente solicitud, según lo generado por Patent In Version 3.5, proporcionan la numeración secuencial de aminoácidos dentro de un polipéptido dado y, por lo tanto, no se ajustan a los números de aminoácidos correspondientes proporcionados por Kabat o el índice EU.
Sin embargo, como también apreciará un experto en la materia, la longitud de la secuencia de las CDR puede variar entre moléculas de IgG individuales y, adicionalmente, la numeración de restos individuales dentro de una CDR puede variar dependiendo de la convención de numeración aplicada. Por lo tanto, para reducir la ambigüedad en la designación de restos de aminoácidos dentro de las CDR, la divulgación de la presente invención emplea en primer lugar a Kabat para identificar el (primer) aminoácido N-terminal del HFR3. El resto de aminoácido que se va a modificar se designa entonces como estando cuatro (4) restos de aminoácido corriente arriba (es decir, en la dirección N-terminal) a partir del primer aminoácido en el HFR3 de referencia. Por ejemplo, el Diseño A de la presente invención comprende la sustitución de un aminoácido de WT en HCDR2 por un ácido glutámico (E). Este reemplazo se realiza en el resto ubicado cuatro aminoácidos corriente arriba del primer aminoácido de HFR3, de acuerdo con Kabat. En el sistema de numeración de Kabat, el resto de aminoácido X66 es el resto de aminoácido más N-terminal (el primero) la región marco conservada de cadena pesada de la región variable tres (HFR3). Un experto en la materia puede emplear tal estrategia para identificar el primer resto de aminoácido (el más N-terminal) de la región marco conservada de cadena pesada tres (HFR3) de cualquier región variable de IgG1 o IgG4 humanas. Una vez que se determina este punto de referencia, a continuación se puede localizar el resto de aminoácido cuatro corriente arriba (N-terminal) de esta ubicación y reemplazar ese resto de aminoácido (utilizando procedimientos convencionales de inserción/deleción) por un ácido glutámico (E) para lograr la modificación del "Diseño A" de la invención. Dada cualquier secuencia problema de aminoácidos variable de la cadena pesada de inmunoglobulina IgG1 o IgG4 de interés para su uso en los procedimientos de la invención, un experto en la técnica de ingeniería de anticuerpos sería capaz de localizar el resto de HFR3 N-terminal en dicha secuencia problema y después contar cuatro restos de aminoácidos corriente arriba de la misma para llegar a la ubicación en HCDR2 que debería modificarse a ácido glutámico (E).
Como se usa en el presente documento, la frase "un/una [nombre del aminoácido] sustituido en el resto...", en referencia a un polipéptido de cadena pesada o de cadena ligera, se refiere a la sustitución del aminoácido parental por el aminoácido indicado. Por ejemplo, una cadena pesada que comprende "una lisina sustituida en el resto 39" se
refiere a una cadena pesada en la que la secuencia de aminoácidos parental se ha mutado para contener una lisina en el resto número 39 en lugar del aminoácido parental. Dichas mutaciones también pueden representarse indicando un número de resto de aminoácido particular, precedido por el aminoácido parental y seguido por el aminoácido de sustitución. Por ejemplo, "Q39K" se refiere a un reemplazo de una glutamina en el resto 39 por una lisina. De forma similar, "39K" se refiere a un reemplazo de un aminoácido parental por una lisina.
Un anticuerpo o Fab de la presente invención puede obtenerse a partir de una única copia o clon (por ejemplo, un anticuerpo monoclonal (mAb, forma siglada de monoclonal antibody)), incluyendo cualquier clon eucariotico, procariótico o de fago. Preferentemente, un compuesto de la presente invención existe en una población homogénea o sustancialmente homogénea. En una realización, el anticuerpo, Fab u otro compuesto de unión a antígeno, o un ácido nucleico que codifique al mismo, se proporciona en forma "aislada". Como se usa en el presente documento, el término "aislado" se refiere a una proteína, péptido o ácido nucleico que está exento o sustancialmente exento de otras especies macromoleculares que se encuentran en un entorno celular.
Un compuesto como se desvela en el presente documento se puede producir utilizando técnicas bien conocidas en la técnica, por ejemplo, tecnologías recombinantes, tecnologías de presentación en fagos, tecnologías sintéticas o combinaciones de tales tecnologías, u otras tecnologías fácilmente conocidas en la técnica. En particular, los procedimientos y procedimientos de los Ejemplos en el presente documento pueden emplearse fácilmente. Un anticuerpo o Fab de la presente invención puede diseñarse técnicamente adicionalmente para que comprenda regiones marco conservadas obtenidas de regiones marco conservadas completamente humanas. Para llevar a cabo realizaciones de la presente invención puede utilizarse una diversidad de distintas secuencias de armazón humanas. Preferentemente, las regiones marco conservadas de un compuesto de la presente invención son de origen humano o son sustancialmente humanas (al menos el 95 %, 97 % o 99 % de origen humano). Las secuencias de las regiones marco conservadas de origen humano pueden obtenerse de The Immunoglobulin Factsbook, por Marie-Paule Lefranc, Gerard Lefranc, Academic Press 2001, ISBN 012441351.
Los vectores de expresión capaces de dirigir la expresión de los genes a los que están unidos operativamente son bien conocidos en la técnica. Los vectores de expresión pueden codificar un péptido señal que facilita la secreción del producto (o productos) polipeptídico deseado a partir de una célula hospedadora. El péptido señal puede ser un péptido señal de inmunoglobulina o un péptido señal heterólogo. Los polipéptidos deseados, por ejemplo, los componentes de los anticuerpos biespecíficos o Fab preparados de acuerdo con los procedimientos de la presente invención, pueden expresarse de forma independiente utilizando distintos promotores a los que están unidos operativamente en un único vector o, alternativamente, los productos deseados pueden expresarse de forma independiente utilizando distintos promotores a los que están unidos operativamente en vectores separados. Como se usa en el presente documento, una "célula hospedadora" se refiere a una célula que se transfecta, transforma, transduce o infecta de manera estable o transitoria con secuencias nucleotídicas que codifican un producto o productos polipeptídicos deseados. La creación y aislamiento de líneas de células hospedadoras que producen un anticuerpo biespecífico, Fab u otro compuesto de unión a antígeno de la presente invención se puede lograr utilizando técnicas convencionales conocidas en la técnica.
Las células de mamífero son células hospedadoras preferentes para la expresión de los Fab o anticuerpos biespecíficos de acuerdo con la presente invención. Las células de mamíferos particulares son las células HEK 293, NS0, DG-44 y CHO. Preferentemente, los polipéptidos expresados se secretan en el medio en el que se cultivan las células hospedadoras, del cual se pueden recuperar los polipéptidos aislados. El medio, en el que se ha secretado un polipéptido expresado puede purificarse mediante técnicas convencionales. Por ejemplo, el medio se puede aplicar y eluir de una columna de Proteína A o G utilizando procedimientos convencionales. Los agregados solubles y los multímeros pueden eliminarse de forma eficaz mediante técnicas comunes, entre ellas la exclusión por tamaño, la interacción hidrófoba, el intercambio iónico o la cromatografía de hidroxiapatita. Los productos recuperados pueden congelarse inmediatamente, por ejemplo a -70 °C, o puede liofilizarse.
Los siguientes Ejemplos ilustran adicionalmente la invención y proporcionan procedimientos típicos para llevar a cabo diversas realizaciones. Sin embargo, se entiende que los Ejemplos se establecen a modo de ilustración y no de limitación, y que un experto en la técnica puede realizar diversas modificaciones. Además, Lewis y col., Nature Biotech., 32(2); febrero de 2014, proporcionan una ilustración adicional de realizaciones de la presente invención.
Ejemplo 1. Diseño asistido por ordenador para identificar modificaciones de restos de la interfaz Ch1/Cl que discriminan entre interfaces de Ch1/Cl de inmunoglobulina diseñadas y nativas.
Los restos por la modificación inicial en la interfaz Ch1/Cl se seleccionan utilizando una combinación de estrategias de diseño asistidas por ordenador y racionales. Utilizando una estructura cristalina de un Fab IgG1/A (ID de PDB 3TV3 (véase, Lewis, S.M. y Kuhlman, B.A. (2011), PLoS ONE 6(6): e20872)), recortado a restos 112-228 de la cadena pesada y los restos 106A-211 de la cadena ligera, se emplean el paquete de programas informáticos Rosetta y las aplicaciones de modelado relacionadas para desarrollar secuencias potenciales para su modificación de acuerdo con una función de aptitud deseada (ver, Kaufmann y col. (2010), Biochemistry 49; 2987-2998; Leaver-Fay y col. (2011), Methods Enzymol. 487; 545-574; Kuhlman y col. (2003), Science 302(5649); 1364-1368; y Leaver-Fay y col. (2011), PLos ONE 6(7): e20937). En resumen, Rosetta calcula una puntuación de aptitud y la energía de unión basándose en una suma ponderada de potenciales energéticos que tratan fenómenos tales como las fuerzas
de van der Waals y las fuerzas de enlaces de hidrógeno. En general, las sumas de estos distintos parámetros se miden en unidades conocidas como Unidad de Energía de Rosetta (UER). Estos valores se interpretan como energías libres, pero no se pueden traducir directamente en unidades típicas de energía.
Utilizando una función de aptitud que favorece la unión y la estabilidad de los complejos de Ch1 diseñado/CL diseñado y no favorece la afinidad de unión de complejos de Ch1 diseñado/CL de WT y de Ch1 de tipo silvestre/CL diseñado no deseados, se identifican modificaciones de la secuencia inicial que dan como resultado la ortogonalidad de unión para las parejas de Ch1/Cl diseñados.
Las mutaciones identificadas se someten a un reacoplamiento asistido por ordenador del complejo de Ch1/Cl utilizando RosettaDock a través de RosettaScripts (véase, Chaudhury y col. (2011), PLoS On E 6(8): e2247 y Fleishman y col. (2011), PLoS ONE 6(6): e20161). Esto permite la determinación de las posiciones de unión óptimas para los complejos diseñados y permite la comparación con las energías de unión de los complejos de WT acoplados de manera similar y los complejos de Ch1 diseñado/CL de WT y de Ch1 de WT/Cl diseñado no deseados. Un déficit en la puntuación total por ordenador y las energías de unión para estos complejos no deseados predice que se unirán débilmente entre sí en comparación con los complejos Ch1 de WT/Cl de WT y de Ch1 diseñado/CL diseñado. Las energías totales se calculan utilizando una función de puntuación convencional de Rosetta, "Score 12 prime". (véase Leaver-Fay y col. (2013), Methods Enzymol. 523; 109-143). Las energías de enlace se calculan como el cambio en la puntuación separada de energía libre (AG) según lo informado por la herramienta InterfaceAnalyzer de Rosetta (véase, Lewis, S.M. y Kuhlman, B.A. (2011), PLoS One 6(6): e20872). Las construcciones de diseño representativas y su puntuación total y energías de enlace correspondientes se proporcionan en la Tabla 1.
Tabla 1. Resultados del diseño multiestado asistido por ordenador por Rosetta.

Se identificaron más de cuarenta diseños discretos iniciales, que entran en aproximadamente veinte paradigmas de diseño diferentes (es decir, mutaciones con distintas combinaciones de sustituciones de aminoácidos y distintas posiciones de restos), después de filtrar muchas más secuencias generadas de manera asistida por ordenador. Se sintetizaron los paradigmas de diseño seleccionados y se interrogaron adicionalmente de forma experimental en una construcción de IgG1/A de longitud completa o una construcción de IgG1/A que carece de dominios variables, cada una como se describe a continuación (véanse las Tablas 2 y 3). Basándose en los experimentos, tres diseños, El Diseño 1.0, Diseño 2.1, y Diseño 5.0 y Diseño 1.0+5.0 demostraron buenas propiedades biofísicas y discriminación termodinámica para la asociación Ch1 diseñado/CL diseñado sobre la asociación Ch1 diseñado/CL de WT o Ch1 de WT/Cl diseñado, como se demuestra en los ensayos de exposición térmica (descritos a continuación).
Síntesis de artículos de prueba.
Para probar los diseños, se crea una IgG1 pertuzumab humana (véase, Nahta y col. (2004), Cancer Res. 64; 2343 2346) con una Vl kappa humana quimérica y una Cl lambda (Ca). En resumen, el inserto de dominio Vh de pertuzumab se genera utilizando un procedimiento de síntesis de oligonucleótidos solapantes basado en PCR (Casimiro y col. (1997), Structure 5; 1407-1412), utilizando la secuencia de la estructura cristalina publicada (Franklin y col. (2004), Cancer Cell 5; 317-328). El inserto contiene sitios de restricción Agel y Nhel apropiados que permiten que se ligue directamente en un vector pE (Lonza) linealizado del laboratorio que contiene una secuencia de un dominio constante de IgG1. El gen de Vl de pertuzumab también se genera utilizando síntesis de oligonucleótidos solapantes. Se construye una secuencia de ADN que codifica el dominio Vl fusionado con Ca utilizando PCR y un molde plasmídico del laboratorio que contiene la secuencia de Ca. Se diseñan oligonucleótidos flanqueantes en 5' y
3', y dos cebadores internos, para aparear el extremo C del dominio Vl de pertuzumab con el extremo N de Ca. El inserto de cadena ligera está diseñado con sitios de restricción HindlII y EcoRI para el ligamiento directo en un vector pE (Lonza) linealizado del laboratorio con un sistema marcador de GS seleccionable. Cada vector de expresión de mamífero pE está diseñado técnicamente para contener una secuencia señal de cadena ligera de anticuerpo de ratón común que se traduce en fase como parte de la proteína expresada y se escinde antes de la secreción. Todas las construcciones de ligamiento se transforman en células competentes de la cepa TOP 10 de E. coli (Life Technologies). Se seleccionan colonias bacterianas transformadas, se cultivan y se preparan los plásmidos. Las secuencias correctas se confirman mediante secuenciación de ADN. Las secuencias codificadas de las proteínas maduras de la cadena pesada y la cadena ligera se proporcionan respectivamente mediante las SEQ ID NO: 1 y la SEQ ID NO: 2.
Para investigar aún más la capacidad de los diseños de Ch1/Cl para proporcionar una interfaz nueva y específica que se distinga de interfaces Ch1/Cl de WT, es útil eliminar los dominios variables, los que, si están presentes, añaden complejidad a la interpretación de los datos. Por lo tanto, se construyen construcciones de IgG1 humana y lambda humana que carecen de genes variables (Vh y Vl). Para eliminar los genes variables se utiliza una estrategia de subclonación basada en recombinasa. En resumen, para el plásmido de la cadena pesada, se sintetizan químicamente dos oligonucleótidos bicatenarios que abarcan 15 pares de bases 5' de un sitio Xhol, a través de la secuencia señal de la cadena ligera del anticuerpo común de ratón seguido inmediatamente por un sitio Nhel y 15 pares de bases flanqueantes (que codifican el extremo N del dominio Ch1 de IgG1 para una recombinación eficaz). Esta pareja de oligonucleótidos bicatenarios tiene el dominio Vh delecionado. Para el plásmido de la cadena ligera, se sintetizan químicamente dos oligonucleótidos bicatenarios que abarcan 15 pares de bases 5' de un sitio BamHI, a través de la secuencia señal de la cadena ligera del anticuerpo común de ratón seguido inmediatamente por un Xmal y 15 pares de bases flanqueantes (que codifican el extremo N del dominio Cl lambda para una recombinación eficaz). Esta pareja de oligonucleótidos bicatenarios tiene el dominio Vl delecionado. Los genes variables se digieren de los plásmidos de la cadena pesada y de la cadena ligera de pertuzumab parentales utilizando respectivamente las enzimas Xhol/Nhel y BamHI/Xmal. Las parejas de oligonucleótidos correspondientes se insertan en los plásmidos linealizados utilizando el kit n-Fusion HD Cloning kit (Clontech) basado en recombinasa de acuerdo con el protocolo del fabricante. Las secuencias de las construcciones de IgG1/A de cadena pesada y cadena ligera que carecen de dominios variables se proporcionan respectivamente mediante la SEQ ID NO: 3 y la SEQ ID NO: 4. Para generar series pequeñas de mutaciones, puede utilizarse el kit QuikChange II Site Directed Mutagenesis Kit (Agilent) siguiendo las instrucciones proporcionadas por el fabricante. Para generar series grandes de mutaciones (normalmente >3 mutaciones por cadena), se puede emplear una estrategia de síntesis de genes (bloques G, IDT). Los genes sintetizados se diseñan para ser compatibles con la construcción de cadena pesada y cadena ligera que carecen de dominios variables (descrito anteriormente). Sin embargo, dentro de la construcción de la cadena pesada, se deleciona un sitio Xho I corriente arriba de la secuencia señal de la cadena ligera de ratón común utilizando mutagénesis dirigida y se genera un nuevo sitio Xho I en el extremo C (extremo 3') de la región codificante del dominio Ch1. Los genes sintetizados se ligan al plásmido de la cadena pesada utilizando los sitios de restricción NheI y XhoI nuevos. Los genes sintetizados se añaden al plásmido de la cadena ligera utilizando los sitios de restricción BamHI y EcoRI.
Expresión y caracterización de proteínas.
Cada plásmido se amplía mediante transformación en E. coli TOP10, se mezcla con 100 ml de caldo de luria en un matraz con deflectores de 250 ml y se agitado durante una noche a 220 rpm. Las purificaciones de plásmidos a gran escala se realizan utilizando BenchPro 2100 (Life Technologies) de acuerdo con las instrucciones del fabricante. Para la producción de proteínas, los plásmidos que portan las secuencias de ADN de la cadena pesada y la cadena ligera se transfectan (proporción de plásmidos de 1:2 para los plásmidos de la cadena pesada y la cadena ligera, respectivamente) en células HEK293F, utilizando reactivos de transfección Freestyle y los protocolos proporcionados por el fabricante (Life Technologies). Las células transfectadas se cultivan a 37 °C en una incubadora de CO2 al 5 % mientras se agita a 125 rpm durante 5 días. La proteína secretada se recoge mediante centrifugación a 10Krpm durante 5 min. Los sobrenadantes se pasan a través de filtros de 2 pm (tanto a gran escala como a pequeña escala) para su purificación. Se realizan purificaciones a pequeña escala (1 ml) incubando directamente 1 ml de sobrenadante transfectado con perlas magnéticas de Proteína G (Millipore) lavadas en solución salina tamponada con fosfato (PBS) resuspendidas en 100 pl. Las perlas se lavan 2 veces con PBS y 1 vez con PBS diluido 10 veces. La proteína se eluye de las perlas añadiendo 130 pl de acetato 0,01 M, pH 3,0. Después de la recolección, los eluyentes se neutralizan inmediatamente añadiendo 20 pl de Tris 0,1 M, pH 9,0. La concentración de las proteínas purificadas se determina midiendo la absorbancia de las soluciones a 280 nm utilizando un espectrofotómetro NanoDrop UV-Vis de Thermo Scientific (Grimsley, G.R. y Pace, C.N.(2004), Curr. Protoc. Protein Sci., Ch. 3 (3.1)). Las identidades de los plásmidos transfectados representativos y de las secuencias que generan se proporcionan en la Tabla 2. Los procedimientos de caracterización y los datos resultantes para cada uno de estos diseños de cadena pesada/cadena ligera se describen a continuación.
Ta bla 2. Composición de la secuencia de los diseños de especificidad de la interfaz de Ch1/Cl basados en
Rosetta.
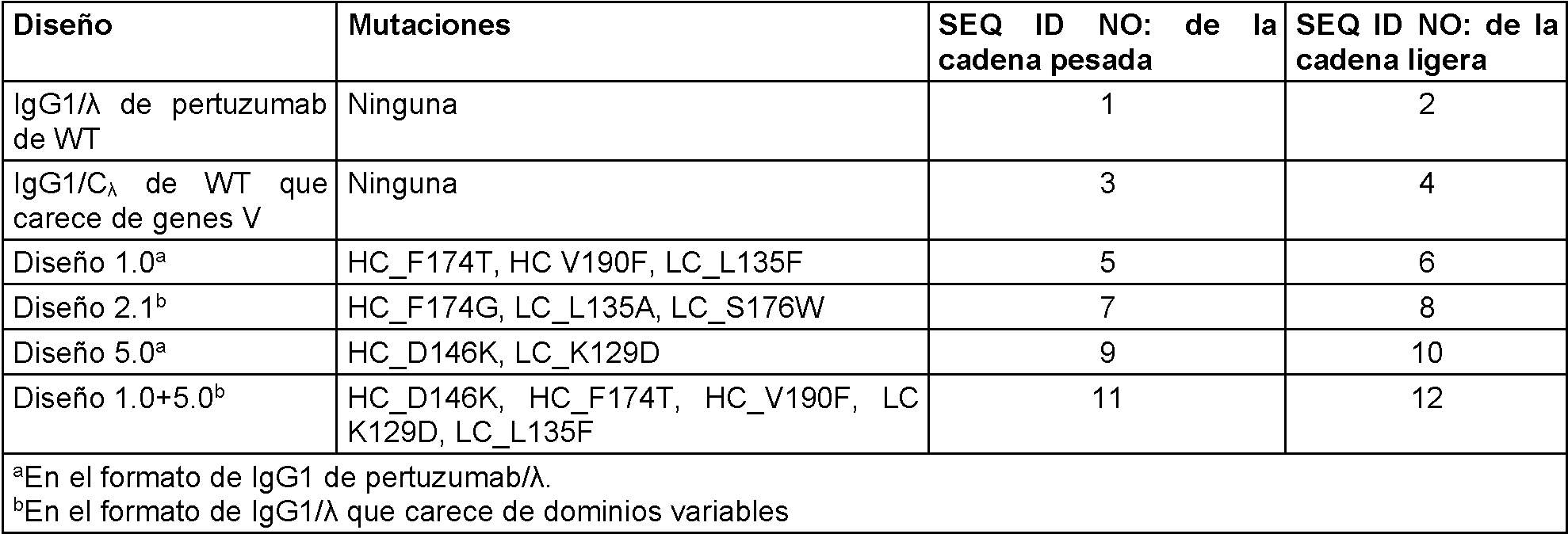
Las proteínas se pueden caracterizar utilizando múltiples procedimientos, como se describe en el presente documento. Por ejemplo, para evaluar la expresión y el ensamblaje de los componentes de la HC y la LC se utilizan análisis por electroforesis en gel de poliacrilamida con dodecilsulfato de sodio (SDS-PAGE). La SDS-PAGE se puede realizar utilizando geles BisTris NuPAGE® Novex al 4-12 % de acuerdo con los protocolos del fabricante (Life Technologies). En cada pocillo se cargan aproximadamente 15 pl de material purificado de las purificaciones con perlas magnéticas (véase más arriba). Para muestras reducidas, se añade DTT 0,5 M al 10 % en H2O. Las bandas de proteína en los geles se detectan utilizando SimplyBlue™ Safe Stain (Life Technologies).
Además, se pueden realizar ensayos inmunoabsorbentes ligados a enzima (los ELISA) para la detección de muestras de proteínas expuestas térmicamente para comparar la estabilidad de las muestras de los diseños frente a las proteínas de control de tipo silvestre y los diseños con falta de coincidencia. Pueden determinarse para cada muestra los valores de T50, definida como la temperatura a la que permanece el 50 % de la señal ELISA que detecta la actividad proteica, después de calentar a temperatura elevada durante un período de tiempo específico, para comparar la estabilidad de las construcciones de Hc /LC diseñadas con respecto a la estabilidad de los controles de tipo silvestre y las parejas con falta de coincidencia. Para las proteínas de IgGIde pertuzumab/A, se recubren placas de 96 pocillos de alta unión de proteínas con fondo en U de 96 pocillos (Greiner bio-one, n.° de cat. 650061) durante una noche a 4 °C con 100 pl/pocillo de un anticuerpo policlonal anti-CA humano (Southern Biotech, n.° de cat. 2070 01), a 2 ug/ml en un tampón de NaHCO30,05 M, pH 8,3. A continuación, las placas se lavan cuatro veces con PBS con Tween80 al 0,02 % (PBST) y se bloquean durante 1 hora con caseína (Thermo, n.° de cat. 37528) a 37 °C. Las placas se lavan de nuevo, seguido de la adición de sobrenadantes de cultivo HEK293F aislados que contienen los diseños de proteína IgG1 de pertuzumab/A (100 pl/pocillo). Se preexponen alícuotas de cada sobrenadante a diversas temperaturas durante 1 hora, utilizando un instrumento de PCR con una ventana de gradiente térmico de 25 °C. Las proteínas de IgG1 de pertuzumab/A expuestas térmicamente (con o sin mutaciones en los dominios Ch1/Cl) se incuban en la placa durante 1 hora a 37 °C. A continuación, se lavan las placas y se añade Fc de HER-2 humano (R&D systems, n.° de cat. 1129-ER-020) biotinilado en el laboratorio 200 ng/ml a 100 pl/pocillo (diluido en caseína) durante 1 hora a 37 °C. Las placas se lavan de nuevo seguido de la adición de estreptavidina-HRP (Jackson Immunoresearch, n.° de cat. 016-030-084) diluida 1:2000 en caseína. A continuación, se lavan las placas y se añade el sustrato de 1 componente SureBlue Reserve TMB (KPL, n.° de cat. 53-00-01) a 100 pl/pocillo. Se deja que la reacción proceda durante 5-15 minutos y a continuación se interrumpe mediante la adición de H3PO4 al 1 %. Se lee la absorbancia a 450 nm utilizando un lector de placas SpectraMax 190 UV (Molecular Devices). Se sigue un procedimiento similar para la detección de las proteínas de IgG1/A menos genes variables expuestas térmicamente, utilizando un anticuerpo policlonal anti-CH1 humano (2 pg/ml en caseína; Meridian Life Sciences, n.° de cat. W90075C) para capturar proteínas de los sobrenadantes y un anticuerpo policlonal anti-CA humano marcado con HRP (dilución 1:2000 en caseína; Southern Biotech, n.° de cat. 2070-05) para la detección (que sustituye al Fc de HER-2-biotina y la estreptavidina-HRP).
Los resultados de la caracterización para cada uno de los diseños representados en la Tabla 2 se proporcionan a continuación en la Tabla 3. Se descubrió que tres diseños, el Diseño 2.1, el Diseño 5.0 y el Diseño 1.0+5.0, en que la estabilidad térmica de la proteína IgG que contenía Ch1/Cl de HC diseñada/LC diseñada fue superior tanto desde el punto de vista asistido por ordenador como experimental con respecto a al menos una de las parejas HC diseñada/LC de WT o HC de WT/LC diseñada con falta de coincidencia (Tabla 3). En algunos casos (incluidos los diseños 2.1 y 1.0+5.0), los diseños se analizaron en IgG1/CA, proteína que carece de dominios variables. Tanto para el Diseño 1.0+50 como para el Diseño 2.1, se pudo observar una clara preferencia por la pareja de HC diseñada/LC diseñada mediante análisis por SDS-PAGE, como es evidente por una banda fuerte a ~100 kDa que se parece a la de las parejas de HC/LC de tipo silvestre. Las parejas con falta de coincidencia de Diseño 1.0+5.0 (es decir, HC Diseñada/LC de WT y HC de WT/LC Diseñada) se expresaron demasiado mal para ser vistas en un gel de SDS-PAGE. Las parejas con falta de coincidencia de Diseño 2.1 demostraron bandas adicionales por debajo de la banda principal, lo que es indicativo de una proteína no ensamblada.
Tabla 3: Caracterización de proteínas de anticuerpo con Ch1/Cl diseñados.

Los resultados de la caracterización demuestran que el Diseño 1.0+5.0 mantiene una alta afinidad y una interfaz de Ch1/Cl estable, con baja capacidad para reconocer los dominios Ch1/Cl de la inmunoglobulina nativa. Adicionalmente, el diseño 2.1 demuestra una alta estabilidad y especificidad por sí mismo, al tiempo que discrimina frente a la unión a los dominios Ch1/Cl de la inmunoglobulina nativa (wt).
La cromatografía analítica de exclusión por tamaño con dispersión de luz estática en línea (SEC/LS, forma siglada de size exclusión chromatography with in-line light static scattering) es otra herramienta de caracterización utilizada para confirmar que los complejos de anticuerpos de HC/LC heterotetraméricos se asocian correctamente y continúan demostrando un comportamiento biofísico monodisperso. Se puede realizar SEC/LS para cada muestra, utilizando 30-80 |jl de eluyente purificado de la purificación a pequeña escala descrita anteriormente (concentraciones ~0,1-0,4 mg/ml). Para la SEC/LS, las proteínas se inyectan en una columna de HPLC analítica Sepax Zenix SEC 200 (7,8x300 mm) equilibrada en fosfato 10 mM, NaCl 150 mM, NaN3 al 0,02 %, pH 6,8, utilizando un sistema de HPLC Agilent 1100. Los datos de dispersión de luz estática para el material eluido de la columna de SEC se recogen utilizando un detector de dispersión de luz estática miniDAWN TREOS acoplado a un medidor de índice de refracción en línea Optilab T-rEX (Wyatt Technologies). Los datos de UV se analizan utilizando HPCHEM (Agilent). Los pesos moleculares de las proteínas se determinan por sus perfiles de dispersión de luz estática utilizando ASTRa V (Wyatt Technologies). El análisis por SEC/LS indica que todas las proteínas descritas en la Tabla 3 demostraron ser altamente monodispersas con agregados solubles <5 % e indistinguibles de las construcciones de IgG de tipo silvestre y de IgG menos dominio variable.
Ejemplo 2. Optimización del Diseño 2.1.
El Diseño 2.1, como se describe en el Ejemplo 1, se optimiza adicionalmente para mejorar la especificidad del ensamblaje de la interfaz de Ch1/Cl diseñados frente a una interfaz de Ch1/Cl de WT. Para ayudar en el procedimiento de diseño, en primer lugar se resuelven las estructuras cristalinas del laboratorio del Diseño 1.0+5.0 y el Diseño 2.1.
Para generar proteína para cristalografía, se producen proteínas Ch1/Ca aisladas (unidas por disulfuro) en E. coli. Las proteínas Ch1/Ca aisladas (sin genes variables o Fc de IgG) se subclonan en el plásmido pET-DUET de Novagen. El inserto de Ch1 (con una secuencia señal de pelB para la secreción en el entorno periplásmico oxidativo) se sintetiza (con una etiqueta C-terminal de hexahistidina) utilizando PCR solapante y se subclona en el casete 1 del plásmido utilizando los sitios Nhel y BamHI. El inserto de Ca se sintetiza e inserta de manera similar entre los sitios Ndel y Xhol (sin etiqueta his). Los Diseños 1.0 5.0 y el Diseño 2.1 se generan a partir del plásmido de WT
utilizando mutagénesis por QuikChange II (Agilent). Cada plásmido se transforma para la expresión en células químicamente competentes CodonPlus BL21 (DE3) (Agilent). Para cada preparación de proteínas, se utilizan células transformadas y precultivadas para inocular 2X1,4 l de caldo luria complementado con carbenicilina 100 ug/ml y cloranfenicol 35 ug/ml. Se deja agitar los cultivos a 220 rpm a 37 °C hasta que la DO600 alcanza 1-1,5. En esta fase, la temperatura de cultivo se reduce a 30 °C y se añade isopropiM-tio-6-D-galactopiranósido 1 mM. Los cultivos se dejan crecer durante 3-4 horas y se recogen mediante centrifugación durante 20 min a 4000 g. Las proteínas se resuspenden en 50 ml de un tampón de extracción periplásmica (sacarosa 500 mM, Tris 100 mM, pH 8, EDTA 1 mM y lisozima de clara de huevo de gallina 100 ug/ml). Las proteínas extraídas se diluyen 10 veces en tampón citrato 10 mM, NaCI 10 mM, pH 5,5, y se pasan por una columna de intercambio catiónico SP Sepharose FF HiTrap de 5 ml (GE Healthcare) a 5 ml/min, utilizando un AKTA Explorer (GE Healthecare). Las proteínas se eluyen de la columna utilizando un gradiente de NaCl de hasta 0,7 M. Las proteínas se dializan en PBS y se capturan en una columna de afinidad Ni-Sepharose HiTRAP. A continuación, las proteínas se eluyen utilizando un gradiente de imidazol de hasta 0,3 M. A continuación, las proteínas se concentran a ~ 3-10 mg/ml utilizando dispositivos centrífugos VivaSpin6, se dializan en Tris 10 mM, NaCl 100 mM, pH 8,0 y se filtran.
Para cristalografía, las proteínas purificadas se criban utilizando el procedimiento de cristalización por difusión de vapor, mediante el cual la proteína se mezcla primero con una solución de pocillo y se deposita en una cámara pequeña con una solución de pocillo, se sella y se deja equilibrar con solución de pocillo, concentrando tanto la proteína como los reactivos precipitantes en la gota de proteína. Dichos cribados se realizan en un formato de 96 pocillos (Intelli-plate, Art Robins Instrument) utilizando los aditivos (screens) disponibles en el mercado: las series PEGs, PEGs Ii, ComPAS, Classics II (Qiagen). La configuración inicial utiliza un robot Phoenix (Art Robins Instrument), que deposita 0,3 pl de proteína en 0,3 pl de solución de pocillo.
Para la proteína Ch1/Ca de WT proteína, el cribado inicial se realiza a 6 mg/ml de proteína. Los cristales de proteína crecieron después de 2 días en las siguientes condiciones: Etanol al 15 %/MPD al 50 %/Acetato de sodio 10 mM. Estas condiciones iniciales de cristalización se optimizan en un conjunto de experimentos de difusión por vapor en que se varía la concentración de dos componentes, mientras que el tercero se mantiene constante. Los experimentos de optimización se realizan en Intelli-plates con formato de 48 pocillos (Art Robins Instrument). Los experimentos de optimización dan como resultado cristales finos en forma de aguja que difractan por debajo de 3 A de resolución.
A continuación, la proteína se vuelve a cribar a una concentración más alta de 9,2 mg/ml. Al día siguiente se realiza una siembra en estriado utilizando los cristales en forma de aguja de la etapa anterior. La siembra en estriado es un procedimiento que promueve la nucleación de cristales al proporcionar un núcleo ya preparado (cristales semilla) para ayudar a la nucleación y facilitar el crecimiento de cristales ordenados. Esta técnica da como resultado una nueva condición de cristalización: PEG4K al 30 %. La optimización de esta condición se realiza a 21 °C variando la concentración de PEG4K, el tamaño de la gota que contiene la mezcla de proteína y solución de depósito, y la relación del contenido de proteína y depósito en la gota. Se siembran gotas de cristalización y aparecen cristales al día siguiente, que crecen hasta el tamaño final en 3 días. Los cristales se transfieren a una solución de crioprotección de solución de depósito con un aumento de un 10 % de PEG4K y complementada con PEG400 al 20 %, y se congelan instantáneamente por inmersión en nitrógeno líquido antes de enviarlos a Advanced Photon Source para la obtención de datos.
El diseño 1.0+5.0 se criba y se siembra en estriado de manera similar, utilizando semillas de cristal de WT. Los cristales intercrecidos en forma de aguja aparecen después de 3 días en dos condiciones: isopropanol al 20 %/PEG4K al 20 %/citrato de trisodio 100 mM y PEG6K al 33 %/citrato de trisodio 10 mM. Ambas condiciones se optimizan, utilizando la técnica descrita anteriormente, dando como resultado monocristales individuales para la optimización de la 2a condición. Los cristales individuales finales del Diseño 1.0+5.0 se hacen crecer a 21 °C mezclando 1,2 pl de proteína 3,9 mg/ml y 1,2 pl de solución de depósito, que contiene PEG6K al 40 % y citrato de trisodio deshidratado 10 mM. Los cristales se crioprotegen utilizando una solución de depósito con un aumento de un 10 % del contenido de PEG6K y se complementa con etilenglicol al 20 %.
El Diseño 2.1 cristaliza directamente en las condiciones desarrolladas para el Diseño 1.0+5.0. Los cristales individuales se hacen crecer a 21 °C mezclando 1,5 pl de proteína 5,1 mg/ml con 1,5 pl de depósito, que contiene PEG6K al 39% y citrato de trisodio 10 mM. Los cristales se crioprotegen utilizando la misma técnica que para el Diseño 1.0+5.0.
Las conformaciones de los restos diseñados observados en la estructura del modelo asistido por ordenador y la estructura cristalina experimental del Diseño 1.0+5.0 fueron muy similares (es decir, los restos diseñados adoptaron las mismas conformaciones en el modelo y en el cristal del laboratorio experimental del Diseño 1.0+5.0). Sin embargo, los restos diseñados del Diseño 2.1 mostraron una orientación sustancialmente distinta en el modelo asistido por ordenador que en una estructura cristalina del laboratorio. Específicamente, el resto diseñado de la cadena ligera 176W y el resto nativo de la cadena pesada H172 de la estructura cristalina del laboratorio no adoptaron las conformaciones del modelo asistido por ordenador de Rosetta. El cristal también reveló una isomerización trans-cis entre los restos de la cadena pesada G174 (mutado a partir de F) y P175. Este reordenamiento estructural no fue anticipado por el modelo, pero tampoco estaba dentro de los grados de libertad del modelado. Se generaron modificaciones adicionales para el Diseño 2.1 siguiendo procedimientos de diseño
asistido por ordenador, esencialmente como se describe en el Ejemplo 1, pero utilizando la estructura de cristal del Diseño 2.1 del laboratorio como punto de partida en lugar del modelo original de estructura cristalina 3TV3
Siguiendo los procedimientos de biología molecular esencialmente como se describe en el Ejemplo 1, se construyen modificaciones del Diseño 2.1 en la construcción IgG/CA que carece de dominios variables. La Tabla 4 proporciona las identidades y las mutaciones correspondientes de los diseños optimizados adicionalmente representativos del Diseño 2.1.
Tabla 4: Optimización del Diseño 2.1.

Las proteínas del Diseño 2.1 optimizado se expresan utilizando el sistema de HEK293F transitorio como se describe en el Ejemplo 1. Cada uno de los diseños se prueba en cuanto a la estabilidad térmica mediante exposición térmica a temperaturas que varían de 70-95 °C utilizando la metodología descrita en el Ejemplo 1. La presencia sostenida de cada proteína de diseño después del calentamiento se determina utilizando el ELISA de IgG1/A menos gen variable, también como se describe en el Ejemplo 1. Los resultados de la prueba de estabilidad a la exposición térmica para los diseños optimizados representativos del Diseño 2.1, así como de IgG1/ Ca de WT. (sin Vh/Vl), y del Diseño 2.1, se proporcionan a continuación en la Tabla 5.
Tabla 5: Optimización del Diseño 2.1

Los datos del desafío térmico de la Tabla 5 indican que el Diseño 2.1.3.2, el Diseño 2.1.3.3 y el Diseño 2.1.3.3a fueron las construcciones más estables.
Para evaluar adicionalmente la especificidad de los diseños optimizados del Diseño 2.1, se realiza un procedimiento de espectrometría de masas (EM) para medir directamente la especificidad frente a los dominios Ch1/Cl de WT. En resumen, en la escala de transfección de 2 ml, se cotransfecta un dominio Cl diseñado con un dominio Cl de WT y una cadena pesada diseñada o una cadena pesada de WT. De esta manera, las proteínas de Cl diseñado o de WT compiten directamente entre sí durante la expresión de las proteínas, para unirse a la proteína de la cadena pesada y la secreción en el medio celular. Las proteínas ensambladas de IgG/CL menos los genes variables se purifican automáticamente mediante un HPLC Agilent series 1100 con automuestreador y colector de muestras. Las proteínas se capturan en una columna de HPLC de PG (proteína G) (Applied Biosystems, n.° de cat. 2-1002-00) a 2 ml/min, se lavan con solución salina tamponada con fosfato (PBS) y se eluyen con H2O desionizada destilada, ácido fórmico al 0,2 %. Los eluyentes proteicos se concentran/secan en un Labconco CentriVap Speedvac durante 3 horas a 40 °C en vacío. Las proteínas se resuspenden en 100 pl de agua desionizada destilada y se neutralizan con 20 ml de Tris 0,1 M, pH 8,0 (MediaTech, Inc., n.° de cat. 46-031-CM). Los disulfuros intermoleculares (HC/LC y HC/HC) se reducen mediante la adición de 10 pl de ditiotreitol 1 M recién solubilizado (DTT, Sigma, n.° de cat. 43815-1G). Las muestras se recolectan secuencialmente utilizando un HPLC Agilent serie 1100 con un automuestreador y se capturan en una columna analítica de fase inversa C4 para desalar utilizando agua, fase móvil de ácido fórmico al 0,2 %. Después de la separación de la proteína de sus componentes de tampón, las proteínas se extraen de la columna c4 utilizando un pulso de agua/acetonitrilo al 10 %/90 % (ambos con ácido fórmico al 0,2 %) y se inyectan en un analizador de peso molecular con sistema de cromatografía líquida/espectrometría de masas por tiempo de vuelo Agilent 6210. Los pesos moleculares teóricos promediados en masa de los componentes de cadena ligera y cadena pesada se determinan utilizando el programa GPMaw (v. 8.20). Las dos cadenas ligeras separadas del experimento de competición se pueden discriminar fácilmente entre sí basándose en sus distintos pesos moleculares. Los recuentos relativos de las cadenas ligeras ionizadas que golpean el detector se utilizan para cuantificar la relación de proteína con Cl diseñado y Cl de WT que está unida al componente de cadena pesada, y estos datos se muestran en la Tabla 6.
Tabla 6. Resultados del ensayo de competición de CL/EM de especificidad de LC.

Los resultados de los experimentos de competición de CL/EM indican que utilizando los Diseños 2.1.3.2 y 2.1.3.3a se obtiene una especificidad significativa frente a las secuencias de WT. Las proteínas de Diseño 2.1.3.2Ca y Diseño 2.1.3.3aCA superaron significativamente al Ca de WT (y al Ck de WT) en la unión a su contraparte de la proteína de cadena pesada que contienen las mutaciones de la cadena pesada 2.1.3.2 o 2.1.3.3a. Por el contrario, las proteínas de Ca con Diseño 2.1.3.2 y Diseño 2.1.3.3a no compitieron bien con el CA de WT (y el Ck de WT) en la unión a la proteína de HC de WT. En el experimento, el Ca de Diseño 2.1.3.3a proporcionó una especificidad ligeramente mejor que el Ca de diseño 2.1.3.2.
Ejemplo 3. Diseños para generar dominios Vh y Vl diseñados que se unen entre sí de forma más fuerte de lo que se unen respectivamente a los dominios Vl o Vh de WT.
Para optimizar adicionalmente el ensamblaje específico cadena pesada-cadena ligera al coexpresar dos Fab, se diseñan modificaciones de cadena pesada variable/cadena ligera variable (VhNl). En primer lugar se identifica la posición 1 de la Vl y la posición 62 de la Vh para su modificación. La posición 1 de la Vl se modifica al resto con carga positiva arginina (R) y la posición 62 de la Vh se modifica al resto con carga negativa ácido glutámico (E). Esta combinación de modificaciones de carga se denomina Diseño A. Un segundo diseño modifica la posición 38 de la Vl y la posición 39 de la Vh para generar una pareja de cargas (Q38D en Vl y Q39K en Vh) en el sitio de la anterior interacción por enlace de hidrógeno. Esta introducción de una pareja de cargas se denomina Diseño B.
El Diseño A, Diseño B y una combinación de Diseño A y B, denominado Diseño AB, se introducen en los plásmidos para los plásmidos de la cadena ligera y la cadena pesada de pertuzumab para expresión en mamíferos. Además, se construyen plásmidos que contienen modificaciones del Diseño 1.0+5.0 (con Vh y Vl de WT de pertuzumab) para generar cadenas pesadas y cadenas ligeras para mejorar potencialmente la especificidad de los diseños de dominio variable con respecto al emparejamiento con cadenas pesadas y ligeras totalmente de tipo silvestre. Las mutaciones se introducen utilizando el kit de mutagénesis QuikChange II (Agilent) de acuerdo con las construcciones de los protocolos del fabricante. Los procedimientos seguidos para la producción y purificación de plásmidos son esencialmente como se describe en el Ejemplo 1. Las identidades y las secuencias correspondientes del Diseño A, el diseño B y el diseño AB se proporcionan en la Tabla 7.
Tabla 7. SEQ ID NO de los diseños de dominio variable y dominio constante en las HC y LC de pertuzumab.

Cada uno de los plásmidos de la cadena pesada y de la cadena ligera diseñados se coexpresan transitoriamente en HEK293F esencialmente como se describe en el Ejemplo 1. Para explorar la especificidad, las cadenas pesadas y cadenas ligeras diseñadas también se expresan con una cadena ligera o una cadena pesada con falta de coincidencia como control para explorar la especificidad. La cadena pesada y la cadena ligera con falta de coincidencia contienen dominios Vh y Vl de WT y el Diseño 1.0+5.0 en los dominios constantes, para añadir especificidad adicional (indicado a continuación en la Tabla 8 como HC(WT15) y LC(WT15), respectivamente). Los sobrenadantes de expresión se someten a una exposición térmica mediante incubación durante 1 hora a temperaturas que varían de 45-75 °C y se analizan en cuanto a la unión al Fc de hHER-2 utilizando un ELISA (procedimientos descritos en el Ejemplo 1). Este formato de ELISA es sensible a la estabilidad de los dominios variables. Adicionalmente, todas las proteínas se purifican de sus sobrenadantes utilizando el protocolo de perlas magnéticas con proteína G, esencialmente como se describe en el Ejemplo 1, y se forman moléculas de IgG completamente ensambladas. En cada uno de los casos (Diseño A y Diseño B), la estabilidad térmica aparente de las parejas de cadena pesada y cadena ligera coincidentes es significativamente mayor que las parejas con falta de coincidencia. El resultado indica que las parejas diseñadas coincidentes están favorecidas termodinámicamente con respecto a las parejas con falta de coincidencia, y proporciona una base termodinámica para la asociación específica de la cadena pesada y la cadena ligera del Diseño A consigo mismas y la cadena pesada y la cadena ligera del Diseño B consigo mismas, con respecto a la asociación con la cadena pesada y las cadenas ligeras que contienen dominios variables de WT. Combinando los diseños en una sola construcción, el Diseño AB, se mejoró adicionalmente la especificidad termodinámica y dio como resultado una expresión reducida de las parejas con falta de coincidencia. Los resultados del análisis de exposición térmica se proporcionan en la Tabla 8.
Tabla 8. Sumario de los datos de la exposición térmica con el Diseño A, el Diseño B y el Diseño AB.

Los resultados de la Tabla 8 indican que la realización de cualquiera de las tres modificaciones de pareja de cargas compensatorias descritas anteriormente mantiene la termoestabilidad del ensamblaje cadena pesada/cadena ligera dentro de las construcciones de diseño al tiempo que se reduce la termoestabilidad de los diseños con falta de coincidencia. Estos diseños del dominio variable se pueden añadir a los diseños del dominio constante descritos anteriormente en los Ejemplos 1 y 2, para ayudar a mejorar el ensamblaje específico cadena pesada/cadena ligera. Ejemplo 4. Diseños multiestado asistidos por ordenador para crear modificaciones adicionales en la interfaz de Vh/Vl que se distingan de la interfaz de Vh/Vl de la inmunoglobulina nativa.
Utilizando el ID de PDB 3TCL (véase, McLellan y col. (2011), Nature 480(7377); 336-343) y un protocolo de diseño de multiestado esencialmente como se describe en el Ejemplo 1, se diseñan mutaciones compensatorias adicionales de la interfaz de Vh/ Vl que dirigen la unión de los dominios Vh y Vl diseñados a los dominios Vh y Vl de WT. Los diseños discretos se construyen físicamente dentro de la región Fv de la IgG pertuzumab, con distintos paradigmas de diseño (es decir, mutaciones con combinaciones de aminoácidos y posiciones de restos muy distintas). Las construcciones de diseño se mutan, se expresan en células HEK293F, y se analizan en cuanto al nivel de expresión y la estabilidad térmica utilizando protocolos similares a los descritos anteriormente en los Ejemplos 1 3. Tres diseños discretos que se muestran en la Tabla 9 (indicados como H.4, H.5 y H.6) demuestran expresarse bien y son tan estables como pertuzumab de WT.
Tabla 9. Datos de números de ID de secuencia y de exposición térmica para los diseños H.4, H.5 y H.6.

Ejemplo 5. La combinación de los diseños de la interfaz de Ch1/Cl y Vh/Vl dan como resultado un emparejamiento HC/LC altamente específico.
En este ejemplo, los Diseños de dominio variable H.4, H.6 y AB se examinan junto con los Diseños de dominio constante 2.1.3.2 y 2.1.3.3a. La especificidad que ofrecen los diseños de Vh/Vl y Ch1/Cl aislados y en combinación entre sí se mide utilizando un experimento de competición de CL/EM similar al descrito en el Ejemplo 3 (careciendo las proteínas de IgG/CL de dominios variables), pero en este caso se utilizan cadenas pesadas y cadenas ligeras de inmunoglobulina de longitud completa. En el experimento, dos cadenas ligeras de longitud completa (con Vl y Cl) se coexpresan y se fuerzan a competir por unirse a una única cadena pesada antes de la secreción. Las identidades de los diseños y los correspondientes números de SEQ ID para las construcciones utilizadas en los experimentos de especificidad se proporcionan en la Tabla 10. De nuevo, las secuencias de Vh y Vl de pertuzumab se utilizaron en cada construcción como vector para los diseños.
Tabla 10. Identidad e identificación de secuencia para las construcciones utilizadas en el Ejemplo 5.

Los datos de especificidad por CL/EM para las combinaciones analizadas se proporcionan en la Tabla 11.
Tabla 11. Análisis por CL/EM de los diseños de la interfaz de Vh/Vl y Ch1/Cl de forma aislada y en combinación.

continuación

Los datos de la Tabla 11 indican que la generación de especificidad en la interfaz de Vh/Vl mediante la combinación del Diseño AB en un Fab y el Diseño H.4 en el otro Fab dio como resultado una especificidad significativa (especificidad del ~ 70-80 %) sin ningún diseño de dominio constante. El emparejamiento de los diseños de dominios Vh/Vl más selectivamente específicos (AB en un Fab y H.4 en el otro) con los diseños de dominio constante más selectivos (2.1.3.2 o 2.1.3.3a) dieron como resultado una especificidad mejorada en general, lo que indica que, si bien los dominios variables pueden dominar, los dominios constantes contribuyen a la especificidad (Tabla 11). La mejor combinación utilizó una combinación de Diseño AB (en Vh/Vl) y 2.1.3.3a (en Ch1/Cl) en el Fab n.° 1 y de Diseño H.4 (en Vh/Vl) con un Ch1/Cl de WT en el Fab n.° 2. Esta combinación generó repetidamente un conjunto altamente específico de interacciones HC/LC con aproximadamente el 90% de especificidad en ambas
direcciones (Tabla 11).
Ejemplo 6. Logro de un ensamblaje específico de HC/LC de Fab mejorado dentro de los anticuerpos biespecíficos de IgG (los BsAb).
Se construyen dos conjuntos de anticuerpos biespecíficos de IgG (los BsAb) para probar cómo la combinación de los diseños AB2133a y H.4WT puede permitir el ensamblaje específico cadena pesada/cadena ligera de Fab específicos. Todos los protocolos de subclonación y mutagénesis seguidos son esencialmente como se describe en los Ejemplos anteriores. El primer BsAb consiste en una combinación de pertuzumab (anti-HER-2) y matuzumab (anti-EGFR) (véase, Bier y col. (1998), Cancer Immunol. Immunother. 46; 167-173) y el segundo consiste en una combinación de MetMAb (anti-cMET) (véase, Jin y col. (2008), Cancer Res. 68; 4360-4368) y un anticuerpo anti-Axl YW327.6S2 (véanse el documento WO2011/014457 y Ye y col. (2010), Oncogene 29; 5254-5264). Todas las secuencias de los anticuerpos nativos están disponibles públicamente. Para simplificar la capacidad de los inventores de observar ensamblajes específicos utilizando CL/EM, todos las HC se desglucosilan mutando la asparagina 297 (el sitio de glucosilación unida en N en el dominio Ch2 del anticuerpo) a glutamina. Para promover la heterodimerización en Fc de IgG, el ácido aspártico 399 y el ácido glutámico 356 se mutan ambos a lisina en una de las cadenas pesadas de la pareja anti-HER-2/anti-EGFR y una de las cadenas pesadas de la pareja anti-MET/anti-AxI. La cadena pesada restante en cada pareja tenía la lisina 409 y la lisina 392 mutadas a ácido aspártico. (véase, Gunasekaran y col. (2010), JBC 285; 19637-19646). Cabe señalar que pueden sustituirse otros diseños para promover la heterodimerización de la cadena pesada, para lograr el mismo efecto global. Los números de ID de secuencia de las cadenas de inmunoglobulina utilizadas para generar los BsAb de IgG se proporcionan en la Tabla 12.
Tabla 12. Números de ID de secuencia de los HC y LC construidos para demostrar el ensamblaje específico de los BsAb de IgG utilizando las interfaces de diseño de Vh/Vl y Ch1/Cl de Fab.

continuación

Para determinar si las interfaces Vh/ Vl (AB y H.4) y Ch1/Cl (lamda o kappa 2.1.3.3a y de WT) diseñadas permitirían el ensamblaje específico de un BsAb de IgG con respecto a lo que ocurre de forma natural sin diseños de interfaz del FAb en su lugar, se realizan transfecciones transitorias de construcciones de Fab diseñadas particulares, seguido de análisis CL/EM. Para cada BsAb de IgG, se transfectan simultáneamente dos cadenas pesadas y dos cadenas ligeras, utilizando plásmidos distintos, en células HEK293F de mamífero utilizando protocolos de transfección esencialmente como se describe en los Ejemplos anteriores. Los BsAb de IgG diseñados incluyen la mutación de desglucosilación y las mutaciones de heterodimerización del Fc como se describe anteriormente. Adicionalmente, mediante la transfección de las cadenas pesadas y las cadenas ligeras apropiadas, también se crea un conjunto de control de los BsAb de IgG con las mutaciones de desglucosilación y de heterodimerización del Fc, y cadenas ligeras con los dominios Ck o Ca, pero sin las modificaciones de los Vh/Vl y Ch1/Cl diseñados. En cada pareja BsAb de IgG diseñado, una cadena pesada y una cadena ligera (que se muestran viables tanto en el isotipo Ca como en el Ck) contenían el Diseño H.4, mientras que las otras cadena pesada y cadena ligera (que se muestran viables tanto en el isotipo Ca como en el Ck) contenían el Diseño 2.1.3.3a. La composición exacta de la cadena pesada y la cadena ligera de cada BsAb de IgG sintetizado se proporciona en la Tabla 13.
Tabla 13. Los elementos HC y LC de cada BsAb de IgG y el porcentaje resultante de ensamblajes correctos e incorrectos de un BsAb de IgG, basado en las intensidades de CL/EM de las especies completamente heterotetraméricas.

continuación

Los datos de la Tabla 13 demuestran que la incorporación de los diseños de Vh/Vl y Ch1/Cl en los BsAb de IgG mejoraron significativamente el ensamblaje correcto de las especies heterotetraméricas deseadas (es decir, HC1/LC1+HC2/LC2). Sin los diseños de Fab, el ensamblaje correcto promedio fue aproximadamente del 70 % y del 65 % respectivamente para los BsAb de IgG anti-HER-2/anti-EGFR y anti-cMET/anti-Axl. Con los diseños de Fab incorporados, el ensamblaje correcto promedio fue de aproximadamente del 87 % y del 96 % respectivamente para los BsAb de IgG anti-HER-2/anti-EGFR y anti-cMET/anti-Axl, respectivamente.
A continuación, los BsAb de IgG pueden analizarse en cuanto a su naturaleza oligomérica utilizando cromatografía de exclusión por tamaño (SEC) analítica. En primer lugar, las BsAb de IgG se purifican a escala de 1 ml a partir de sobrenadantes de HEK293F utilizando el procedimiento de perlas magnéticas con proteína G, esencialmente como se describe en el Ejemplo 1. Para el análisis por SEC, se aplicaron entre 10-50 |jg de cada proteína a una columna de SEC analítica Yarra G3000 (7,8x300 mm) (Phenomenex) con todos los demás parámetros de ensayo similares al protocolo descrito en el Ejemplo 1. La SEC de las IgG de control pertuzumab (anti-HER-2) y matuzumab (anti-EGFR) demostró tiempos de retención de SEC ligeramente distintos para las dos proteínas, debido a diferencias en sus dominios variables. Adicionalmente, los BsAb de IgG anti-HER-2/anti-EGFR analizados demuestran un comportamiento principalmente monomérico, con tiempos de retención de SEC entre lo observado para los controles de pertuzumab y matuzumab no biespecíficos, lo que podría esperarse si las proteínas contuvieran un de pertuzumab y un Fab matuzumab. De forma similar pertuzumab y matuzumab, las IgG de control METMAb y anti-Axl demuestran por SEC tiempos de retención ligeramente distintos. Los BsAb de IgG anti-cMet/anti-Axl también demuestran un comportamiento principalmente monomérico, con tiempos de retención que se aproximan al promedio de los anticuerpos de control, anticuerpos no biespecíficos. Además, los dos IgG de control, los BsAb anticMet/anti-Axl que no tenían los diseños de especificidad de Fab incorporados, y que demostraron poblaciones significativas de emparejamientos de cadenas ligeras no coincidentes, también mostraron por SEC múltiples especies monoméricas. Los cuatro BsAb anti-cMet/anti-Axl que contienen los diseños de especificidad de Fab no demostraron este comportamiento.
Ejemplo 7 Actividad funcional de los BSAb de IgG diseñados
El comportamiento de unión doble de los BsAb sintetizados puede evaluarse utilizando ensayos de ELISA tipo sándwich y de resonancia de plasmón superficial, como sigue.
Se desarrollan dos ELISA de tipo sándwich, uno para la detección de la actividad del BsAb anti-HER-2/anti-EGFR y otro para la detección de la actividad del BsAb anti-cMET/anti-AxI. Para ambos ELISA, se recubren placas de microtitulación Immulon transparentes de 96 pocillos de fondo redondo de alta unión (Greiner bio-one, n.° de cat.
650061) durante una noche a 2-8 °C con 50 jl/pocillo de Fc de hHER-2 1 jg/ml o Fc de hHGFR(cMet) 1 jg/ml (ambos de R&D systems), en un tampón de Na2CO3 50 mM a pH 8. Las placas se lavan 4 veces con PBST y se bloquean con 100 jl/pocillo de tampón de caseína (Pierce) durante 1 hora a 37 °C. A continuación, las placas se lavan 4 veces con PBST y se añaden los controles de IgG parental o los artículos de prueba de BsAb de IgG a 50 jl/pocillo y 5 jg/ml, y se diluyen en serie 1:3 en la placa. Los artículos de prueba se incuban en la placa durante 1 hora a 37 °C. A continuación, las placas se lavan 4 veces con PBST y se añaden 50 jl/pocillo de Fc de hEGFR-biotina o Fc de hAxl-biotina 0,2 jg/ml (ambos de R&D systems) durante 1 hora a 37 °C. A continuación, las placas se lavan 4 veces con PBST seguido de la adición de 50 jl/pocillo de estreptavidina-HRP (Jackson Labs) diluida
1:2000 en PBST. La estreptavidina-HRP se incuba en cada pocilio durante 1 hora a 37 °C. A continuación, las placas se lavan 4 veces con PBST y se añaden 100 pl/pocillo de sustrato TMB de 1 componente (laboratorios KPL). Después de aproximadamente 10 minutos, se añaden a cada placa 100 ml/pocillo H3P04 (en H2O) al 1 % para interrumpir la reacción. Se lee la absorbancia (450 nm) de cada pocillo de las placas utilizando un lector de placas UV SpectraMax (Molecular Devices). El marcaje con biotina de las proteínas Fc de hEGFR y Fc de hAxl se realiza utilizando EZ-Link Sulfo-NHS-LC-Biotina (Thermo Scientific), de acuerdo con el protocolo del fabricante.
Ambos ELISA de tipo sándwich fueron capaces de demostrar el comportamiento de unión doble de los BsAb. Para ambos BsAb de IgG anti-HER-2/anti-EGFR como para el anti-cMet/anti-Axl, los controles de IgG monoclonales (pG1, mG1, METG1 o AxlG1) no demostraron capacidad para generar señales en los ELISA de tipo sándwich. Los BsAb de IgG de control sin rediseños de Fab (Control de HE AA, Control de HE Ak, Control de mA AA, Control de MA Ak) generaron en el ensayo curvas de unión sigmoideas. Todos los BsAb de IgG con los rediseños de Fab también demostraron curvas de unión sigmoideas. Los valores de CE50 promedio para los BsAb de IgG de control y diseñados fueron los siguientes: CE50 del Control de HE = 470 ±90 ng/ml; CE50 del Diseño de HE = 280 ±20 ng/ml; CE50 del Control de MA = 260 ±80; y CE50 del Diseño de MA = 220 ±20.
Además, se pueden realizar experimentos de resonancia de plasmón superficial para evaluar el comportamiento de unión doble de los BsAb utilizando, por ejemplo, un Biacore3000 utilizando HBS-Ep como tampón de ejecución (GE Healthcare). En resumen, se inmovilizan Fc de hHER-2-biotina y Fc de hAxl-biotina (ambos a 20 pg/ml) sobre las superficies de chip sensor EA mediante inyección de 20 pl durante 2 minutos a 10pl/min. A continuación, se inyectan 20 pl de cada IgG de control, el BsAb de IgG de control o el BsAb de IgG diseñado, diluidos a 30 nM en tampón HBS-EP, sobre estas superficies del chip sensor a 5 pl/min, seguido de una inyección secundaria de 20 pl de Fc de hEGFR 20 nM o de Fc de hHGFR(cMet). Las superficies del chip sensor de Fc de hHER-2 y Fc de hAxl se regeneran elevando el caudal a 50 pl/min e inyectando dos inyecciones de 5 pl de una solución de glicina 0,1 M respectivamente a pH 2,5 y pH 2,0.
Ninguna de las IgG monoclonales (pG1, mG1, METG1 o AxlG1) demostraron actividad de unión doble en el ensayo (Figuras 2 y 3). Tanto los BsAb de IgG de control como los BsAb que contenían diseños de Fab demostraron en el ensayo una fuerte actividad de unión doble.
Ejemplo 8 - Optimización del diseño de dominio constante 2133a utilizando CHI/Ckappa
En determinados contextos, se determinó que el diseño de dominio constante (Ch1/Cl) indicado como 2133a proporciona una especificidad de emparejamiento de HC/LC menos correcta cuando se utiliza en Ch1/Ck, en comparación con su uso en Ch1/Ca (Véase, por ejemplo, el ensamblaje de los anticuerpos biespecíficos EGFRxHER2 de la Tabla 13). Además, se descubrió que el diseño de dominio constante 2133a se desestabilizó cuando se utilizó en Ch1/Ck, en comparación con Ch1/Ck de WT (véase a continuación la Tabla 15).
Para evaluar la estabilidad del diseño 2133a, se generan proteínas IgG1/CK que carecen de dominios variables [WT = SEQ ID NO: 3 (HC) y 63 (LC); Diseño 2133a = SEQ ID NO: 18 (HC) y 64 (LC)], utilizando procedimientos de biología molecular, de expresión y de purificación, como se describe en general en los ejemplos anteriores. La estabilidad de las dos proteínas purificadas (las IgG de WT y con 2133a que carecen de dominios variables o Fv) se caracteriza utilizando calorimetría de barrido diferencial (CBD) como sigue. Los puntos medios de las transiciones de desplegamiento térmico (indicadas como 'Tm') de los dominios Ch1/Ck proporcionan una medida de su estabilidad relativa. La Tm del dominio Ch1/Ck que contiene 2133a fue de 67,7 °C, mientras que la de Ch1/Ck de WT era 70,8 °C. La CBD se realiza utilizando una c Bd capilar automatizada (capDSC, GE Healthcare). Las soluciones de proteínas y las soluciones de referencia (tampón) se muestrean automáticamente de una placa de 96 pocillos utilizando el accesorio robótico. Antes de cada exploración de proteínas, se realiza al menos una exploración de tampón/tampón para definir los valores de iniciales para la resta. Todas las placas de 96 pocillos que contienen proteína se almacenan dentro del instrumento a 6_°C. Las muestras se procesan a una concentración de proteína de 1,0 mg/ml en PBS. Las exploraciones se realizan a de 10 a 95_°C, a 90_°C/h utilizando el modo de retroalimentación baja. Las exploraciones se analizan utilizando el programa informático Origin suministrado por el fabricante. Tras la resta de las exploraciones para los valores iniciales de referencia, los valores iniciales de exploración de proteínas distintos de cero se corrigen utilizando un polinomio de tercer grado. Basándose en los análisis, la proteína IgG1/CK portando el diseño 2133a era menos estable que la proteína de WT (véase a continuación la Tabla 15).
Utilizando una estructura cristalina del laboratorio de Ch1/Ca con el diseño 2133a, los inventores identificaron a Ch1_A172 (el diseño 2133a ya contiene una sustitución H172A) y Ch1_V190 como posiciones de restos para aleatorizar. Las construcciones IgG1 con 2133a / Ck que carecen de dominios variables (SEQ ID NO: 18 y 64) se utilizan para crear las bibliotecas para cribado y análisis. Las bibliotecas se generan utilizando el kit de mutagénesis dirigida QuikChange II (Agilent), utilizando protocolos proporcionados por el fabricante. Las construcciones se expresan mediante transfección transitoria en células HEK293F como se describe en general en el Ejemplo 1. Los títulos de las proteínas se evalúan utilizando el procedimiento de recolección y cuantificación de proteína G por HPLC como se describe en general en el Ejemplo 2. Las proteínas se evalúan en cuanto a sus propiedades de estabilidad utilizando un ensayo de exposición térmica similar al descrito en el Ejemplo 1. De forma singular para este ensayo, las placas se recubren con un anticuerpo policlonal de oveja anti-Fd humano (CHI) (Meridian Life Sciences, n.° de cat. W90075C) a 1 pg/ml y 100 pl/pocillo en un tampón de NaHCO30,05 M, pH 8,3 durante 1 hora a
37 °C o durante una noche a 4 °C. La proteína IgG1/ Ck térmicamente resistente se detecta añadiendo un anticuerpo de detección (anti-kappa humana de cabra marcado con HRP, Southern Biotechnology, n.° de cat. 2060-5) a una dilución de 1:10.000 en PBS-T a cada pocilio, a 100 pl/pocillo, e incubando durante 1 hora a 37 °C. Otros parámetros de ensayo se describen en general anteriormente.
A partir de la biblioteca, se identificaron en el ensayo de exposición térmica tres mutantes de HC, A172R, V190M y V190I, que estabilizaron los dominios Ch1/Ck que contienen 2133a. Además, se generaron combinaciones que comprenden Ch1_A172R_V190M o Ch1_A172R_V190I. La Tabla 14 proporciona un listado de números de ID de secuencia para estas proteínas mutantes de Ch1 con 2133a.
Se generan en células HEK293F transfecciones a mayor escala (>100 ml) de las modificaciones de mutantes simples y dobles de las construcciones de Ch1/Ck con diseño 2133a. Las células transfectadas se cultivan como se describe en general en el Ejemplo 1 para cultivos a pequeña escala. Los sobrenadantes con proteína se clarifican utilizando filtros de 0,2 pm. Las proteínas Ch1/Ck (-Fv) se purifican utilizando procedimientos convencionales de cromatografía de afinidad con proteína A. A las proteínas se les intercambia el tampón a PBS y se analizan mediante CBD como se describe anteriormente para las proteínas Ch1/Ck (-Fv) de WT y con 2133a. Los resultados de los análisis de CBD mostraron que las combinaciones de mutantes simples y dobles se estabilizaban para los dominios Ch1/Ck con 2133a (Tabla 15).
Tabla 14. Números de ID de secuencia de los diseños de HC y LC que mejoran la estabilidad o la especificidad del diseño 2133a en CH1/Ck.

Tabla 15. Resultados de la expresión y de la calorimetría de barrido diferencial (CBD) para mutantes de la proteína IgG1/CK que contiene 2133a que carecen de dominios variables.

Utilizando el ensayo de competición de LC como se describe en general en el Ejemplo 2, se evalúa la especificidad proporcionada por las mutaciones del diseño 2133a en Ch1/Ck en lugar de en Ch1/Ca. Como se muestra a continuación en la Tabla 16, la proteína Ck de WT (SEQ ID 63) muestra poca tendencia a asociarse con la proteína HC con 2133a (SEQ ID 18) con o sin las mutaciones estabilizantes representadas en la Tabla 15. Sin embargo, se observó que el dominio CK que contiene 2133a (SEQ ID 64) podría asociarse con un HC de WT (SEQ ID 3) de forma más fuerte que un dominio CK de WT (SEQ ID 63, véase a continuación la Tabla 16).
Utilizando estructuras cristalinas del laboratorio de Ch1/Ca con 2133a/2133a y WT/WT, se identificaron las posiciones de restos de CK con 2133a V133 y S174 como posiciones en que podrían generarse posibles nuevas interacciones con dominios de Ch1 que contiene 2133a, que podrían ser incompatible con Ch1 de Wt . En el cribado de mutaciones de CK con 2133a que mantuvieron la unión a la HC con diseño 2133a, al tiempo que disminuye la unión con HC de WT, se descubrió que tres mutaciones (Ck_V133L, Ck_S174Q y Ck_S174D) proporcionan una especificidad beneficiosa en el ensayo de competición de CK de LC (Tabla 16) (Los números de ID de secuencia de estas construcciones se proporcionan a continuación en la Tabla 14). Cada una de estas mutaciones mantuvo el dominio del CK con diseño 2133a en la unión a Ch1 con 2133a, con respecto a VK de WT, al tiempo que disminuye la proporción de la unión del CK con el diseño 2133a a Ch1 de WT, en comparación con CK de WT. Adicionalmente, la mutación V133L podría combinarse con S174Q o S174D, para proporcionar mejoras adicionales en la especificidad (Tabla 16).
Tabla 16. Competición de las proteínas Ckappa en la unión a una única HC de IgG1 (sin dominios variables) con variantes del diseño 2.1.3.3a

A continuación, se añadieron los mutantes de Ck y Ch1 con 2133a a dos HC y LC de longitud completa distintas
(incluidos los dominios variables), para evaluar su capacidad para afectar el ensamblaje específico de anticuerpos biespecíficos. Los mutantes de Ch1 con 2133a A172R y V190M (indicados como 'MR'), y A172R y V190I (indicados como 'IR') se combinaron cada uno para el análisis, al igual que los mutantes de Ck con diseño 2133a compatible V133L y S174D (indicados como 'LD'), y V133L y S174Q (indicados como 'LQ'). Los mutantes se añadieron a una pareja de HC/LC de IgG1/kappa de Pertuzumab (anti-HER2) y de MetMAb (anti-cMet) que contenía los diseños 2133a. Para promover la heterodimerización de cadenas pesadas, las HC de Pertuzumab y MetMAb contenían las mutaciones K409D y K392D, indicado como '(-)', al tiempo que las HC de Pertuzumab y Trastuzumab complementarias contenían las mutaciones D399K y E356K, indicado como '(+)' (véase, Gunasekaran y col., (2010), JBC 285; 19637-19646). Los HC que contienen tanto (+) como (-) también tienen la mutación N297Q para eliminar la glucosilación unida en N. Las parejas de HC/LC de Pertuzumab se coexpresaron con una pareja de HC/LC de IgG1 Matuzumab que contenía H4WT /kappa para formar un anticuerpo biespecífico de IgG HER2xEGFR. Las parejas de HC/LC de MetMAb se coexpresaron con una pareja de HC/LC IgG1 Trastuzumab que contenía 4WT/kappa para formar un anticuerpo biespecífico de IgG cMetxHER2. Los números de ID de secuencia para todas las secuencias utilizadas en el estudio se proporcionan anteriormente en la Tabla 14. Todas las lC de este estudio fueron completamente kappa (es decir, VKCK).
La capacidad para coexpresar cada una de las parejas de anticuerpos que consisten en 2 HC y 2 LC (cuatro cadenas en total) y hacer que se ensamblen en los BsAb de IgG correctamente formados se determinó mediante EM, como se describe en general en el anterior Ejemplo 6. Los resultados de los estudios de coexpresión se proporcionan a continuación en la Tabla 17. Todos los puntos de datos son el promedio de entre 3 y 9 mediciones individuales y el error representa la desviación típica. Se analizaron las diferencias entre el ensamblaje correcto en ausencia y presencia de los diseños 'MR', 'IR', 'LD' y/o 'LQ' en cuanto a su significación utilizando una prueba de la t convencional o para datos emparejados.
Tabla 17. Ensamblaje específico de los BsAb de IgG utilizando diseños 2133a de CHI/Ckappa variantes.

continuación

Tanto las mutaciones emparejadas 'LD' como las 'LQ' proporcionaron mejoras significativas en el emparejamiento correcto de la LC dentro de los anticuerpos biespecíficos de IgG con respecto la utilización de las LC kappa con AB2133a sin modificar. La adición de combinaciones de mutantes 'LD' y 'LQ' al Ck con AB2133a proporcionó respectivamente un beneficio promedio del 13% y el 12% en el ensamblaje correcto de la LC con respecto a lo obtenido en su ausencia. Mientras que las mutaciones de la HC 'MR' e 'IR' son estabilizantes para la interacción de Ch1/Ck con 2133a, su impacto sobre la especificidad fue menos claro. La adición de las mutaciones de la HC 'MR' e 'IR' de forma aislada disminuyó el ensamblaje correcto del anticuerpo biespecífico de IgG en todos los casos. En la mayoría de los casos, la adición de los mutantes de HC 'MR' o '|R' a las mutaciones LC 'LQ' o 'LD' condujo a un aumento o una disminución del ensamblaje correcto; sin embargo, la adición de 'IR' a 'LQ' dentro del anticuerpo biespecífico de IgG Anti-HER2xAnti-EGFR condujo a un aumento de aproximadamente el 10% en el ensamblaje correcto con respecto a lo observado con 'LQ' solo. Por lo tanto, mientras que las mutaciones 'MR' e 'IR' mejoran la estabilidad de los anticuerpos biespecíficos que contienen Ch1/Ck con el diseño 2133a, parece ser un caso específico si las mutaciones 'MR' e 'IR' mejoran la especificidad.
Ejemplo 9 - Diseños adicionales para la especificidad, para mejorar la especificidad de la LC al expresar anticuerpos biespecíficos de IgG
Para mejorar adicionalmente la especificidad del ensamblaje de los anticuerpos biespecíficos de IgG, se buscaron diseños adicionales dentro de los dominios variables, que impulsen una especificidad mejorada del emparejamiento HC/LC. Se identificó para la manipulación una pareja de aminoácidos de carga/polar en HC_Q105/LC_K42. LC_K42 se mutó a D y HC_Q105 se mutó a R dentro del diseño IgG1 pertuzumab/kappa H4WT. Después de analizar la expresión y los datos de competencia de LC (como se describe en general en los ejemplos anteriores), LC_K42D y hC_Q105R, cuando se añaden a los diseños de dominio variable con H4, proporcionan una ligera mejora en el emparejamiento de LC de pertuzumab con H4 (+ K42D) con su diseño afín de HC H4 (+Q105R), cuando se coexpresan con una LC de pertuzumab con AB2133a (mejora de ~ 20 %). La coexpresión de la LC de pertuzumab con H4 (+K42D) con la LC de pertuzumab con el diseño AB2133a y HC tampoco disminuyó notablemente el nivel de ensamblaje observado de la pareja LC y HC de pertuzumab con el diseño AB2133a. Esta mutación de diseño adicional (HC_Q105R/LC_K42D) se indica como 'd R' en las siguiente Tablas 18 y 19.
La inspección de una estructura cristalina de Fab (id de pdb: 3HC4) revela una lisina en el resto 228 de la HC y un ácido aspártico en el resto 122 de la LC, cerca del extremo distal del anticuerpo Fab, ubicado cerca del enlace disulfuro HC/LC. Para proporcionar una dirección basada en la carga que pueda favorecer el emparejamiento HC/LC adecuado, estos restos cargados se modificaron (HC_K228D/LC_D122K) en IgG1 Pertuzumab H4WT/kappa. (Para garantizar que el enlace disulfuro HC/LC no se alterara por el cambio de carga, el resto de HC 230 se mutó a glicina y el resto de HC 127 se mutó a cisteína). Este cambio de carga y la modificación de la cisteína se denomina 'CS'.
Para determinar si los diseños 'CS' y 'DR' podrían mejorar el ensamblaje correcto de HC/LC al expresar anticuerpos biespecíficos de IgG, estos diseños se analizaron de forma aislada y en combinación en anticuerpos que contenían el diseño IgG1 con H4WT/kappa. Las moléculas de IgG1 pertuzumab/kappa conteniendo diseños AB2133a se emparejaron con otros anticuerpos IgG1/kappa que contenían diseños H4Wt (con y sin las mutaciones 'DR' y/o 'CS'), incluyendo BHA10 (Jordan, JL, y col. (2009) Proteins 77:832-41), Matuzumab y Trastuzumab (es decir, Herceptin). Adicionalmente, Pertuzumab con IgG1con H4WT/kappa (con y sin las mutaciones 'DR' y/o 'CS') se analizaron en cuanto al ensamblaje de IgG biespecíficas con Trastuzumab que contenía diseños AB2133a en IgG1/kappa. Las HC de pertuzumab y trastuzumab que contenían los diseños de Fab con AB2133a contenían las mutaciones K409D y K392D, indicado como '(-)', mientras que los diseños complementarios H4WT (con y sin las mutaciones 'DR' y/o 'CS') contenían las mutaciones D399K y E356K, indicado como '(+)' (véase, Gunasekaran y col., (2010), JBC 285; 19637-19646). Los HC que contienen tanto (+) como (-) también tenían la mutación N297Q para eliminar la glucosilación unida en N. Para generar anticuerpos biespecíficos de IgG, la HC y la LC de Pertuzumab se cotransfectan con la HC y la LC de un segundo anticuerpo en 2 ml de células HEK293F. El material resultante se secreta a partir de las células, se purificado como se describe en el Ejemplo 2 y caracteriza mediante EM. Los números de ID de secuencia de todas las HC y LC utilizadas en el experimento se proporcionan en la Tabla 18.
Tabla 18. Números de ID de secuencia de los diseños de HC y LC que mejoran la especificidad del ensamblaje HC/LC.

Los resultados de las mediciones por EM del porcentaje de parejas HC/LC formadas correctamente se proporcionan en la Tabla 19. Todos los puntos de datos son el promedio de entre 3-5 mediciones individuales y el error representa la desviación típica. Se analizaron las diferencias entre el ensamblaje correcto en ausencia y presencia de los diseños 'DR', 'CS' o 'CS DR' en cuanto a su significación utilizando una prueba de la t para datos emparejados.
Tabla 19. Ensamblaje específico de anticuerpos biespecíficos IgG que utilizan las LC completamente kappa (es decir, VkCk) con y sin VH_Q105R/VL_K42D (DR), ii) CH1_S127C_K228D_C230G/ CL_D122K (CS), o la combinación de (i) y (ii).

continuación

Al igual que con los datos del Ejemplo 8, estaba claro a partir de los datos de la Tabla 19 que los diseños AB2133a no proporcionaron el mismo grado de especificidad cuando se utilizaron LC completamente kappa (VkCk).
Los datos de la Tabla 19 demuestran tendencias que muestran que los diseños 'DR' y 'CS', cuando se añaden al Fab que contiene H4WT, generalmente mejoran la especificidad del apareamiento HC/LC correcto dentro de los anticuerpos biespecíficos de IgG expresados en una única célula. En algunos casos, se descubrió que 'CS' o 'DR' individual mejoraba significativamente (es decir, P<0,05) el ensamblaje correcto. Sin embargo, cuando se combinaron los dos diseños ('CS DR'), las mejoras en la especificidad del emparejamiento HC/LC correcto fueron estadísticamente significativas para todos los grupos. Se observaron mejoras en la especificidad cuando los diseños
se colocaron en el lado H4WT del BsAb de IgG.
En general, los diseños descritos en el Ejemplo 8 y el Ejemplo 9 se puede utilizar para mejorar la estabilidad y la especificidad del emparejamiento HC/LC dentro de los anticuerpos biespecíficos de IgG. Esto fue particularmente evidente cuando ambas Lc del anticuerpo biespecífico de IgG eran completamente kappa; un escenario en que los diseños AB2133a proporcionan menos especificidad que cuando los diseños AB2133a se utilizan dentro de una LC de VkCA.
Secuencias: (mutaciones indicadas mediante subrayado, negrita)
SEQ ID NO: 1: HC DE PERTUZUMAB (pG1)
E V QL VE S GGGL Y QPGGSLRLS C AAS GFTFTD YTMD WVRQ APGKGLE WV
AD YNPNSGGSIYNQRFKGRFTLS VDRSKNTL YLQMNSLRAEDT AVYY C A
RNLGPSFYFDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCL
VKD YFPEP VT V S WNS G ALTS G VHTFP A VLQ S S GL Y SL S S Y VT VP S S SLGT Q
TYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKP
KDTLMISRTPEVTCVVYDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQY
NSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREP
QVYTLPPSRDELTKNQYSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPP
VLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP
G
SEQ ID NO: 2: LC de PERTUZUMAB (pA, Vl KAPPA/Cl LAMBDA)
DIQMTQSPSSLSASVGDRVTITCKASQDVSIGVAWYQQKPGKAPKLLIYSA
SYRYTGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQYYIYPYTFGQGT
KVEIKGQPKAAPSVTLFPPSSEELQANKATLVCLISDFYPGAVTVAWKAD
SSPVKAGVETTTPSKQSNNKYAASSYLSLTPEQWKSHRSYSCQVTHEGST
VEKTVAPTEC
SEQ ID NO: 3: CONSTRUCCIÓN DE TIPO SILVESTRE DE HC HUMANA (MENOS DOMINIOS VARIABLES)
ASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGV
HTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPK
SCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHE
DPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGK
EYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCL
VKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQ
QGNVFSCSVMHEALHNHYTQKSLSLSPG
SEQ ID NO: 4: DOMINIO Cl LAMBDA
GQPKAAPSVTLFPPSSEELQANKATLVCLISDFYPGAVTVAWKADSSPVK
AGVETTTPSKQSNNKYAASSYFSFTPEQWKSHRSYSCQVTHEGSTVEKTV
APTEC
SEQ ID NO: 5: DISENO de HC 1.0
E V QL VE S GGGL V QPGGSLRLS C AAS GFTFTD YTMD WVRQ APGKGLE WV
ADVNPNSGGSIYNQRFKGRFTLS VDRSKNTL YLQMNSLRAEDT AVYY C A
RNLGPSFYFDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCL
VKD YFPEP VT Y S WNS G ALT S G VHTTP AVLQ S S GL Y SLS SF VT VP S S SL GT Q
TYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKP
KDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGYEVHNAKTKPREEQY
NST YRV V S VLT VLHQD WLN GKE YKCKV SNKALP APIEKTIS KAKGQPREP
QV YTLPP SRDELTKN Q V SLT CL VKGF YP S DI AVE WESN GQPENN YKTTPP
VLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP
G
SEQ ID NO: 6: DISEÑO de LA CADENA LC 1.0
DIQMTQSPSSLSASVGDRVTITCKASQDVSIGVAWYQQKPGKAPKLLIYSA
SYRYTGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQYYIYPYTFGQGT
KVEIKGQPKAAPSVTLFPPSSEELQANKATLVCFISDFYPGAVTVAWKAD
SSPVKAGVETTTPSKQSNNKYAASSYLSLTPEQWKSHRSYSCQVTHEGST
VEKTVAPTEC
SEQ ID NO: 7: DISEÑO de HC menos Vh 2.1, 2.1.2.1, 2.1.2.2
ASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGV
HT GP AVLQ SSGL Y SLS S VVTVPS S SLGT QTYICNVNHKPSNTKVDKKVEP
KS CDKTHT CPPCP APELLGGPS VFLFPPKPKDTLMISRTPEVT C VVVD V SH
EDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNG
KEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTC
LVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRW
QQGNVFSCSVMHEALHNHYTQKSLSLSPG
SEQ ID NO: 8: DISEÑO de Cl 2.1, 2.1.1.1 Y 2.1.1.2
GQPKAAP S VTLFPP S SEELQ ANKATL V CAI SDF YPG A VT V A WKAD S SP VK
AGVETTTPSKQSNNKYAAWSYLSLTPEQWKSHRSYSCQVTHEGSTVEKT
VAPTEC
SEQ ID NO: 9: DISEÑO de HC 5.0
E V QL VE S GGGL V QPGGSLRLS C AAS GFTFTD YTMD WVRQ APGKGLE WV
AD VNPNSGGSI YNQRFKGRFTLS VDRSKNTL YLQMNSLRAEDT AVYY C A
RNLGPSFYFDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCL
VKKYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQ
TYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKP
KDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQY
NSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREP
QV YTLPP SRDELTKN Q V SLT CL VKGF YP SDI AVE WESN GQPENN YKTTPP
VLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP
G
SEQ ID NO: 10: DISEÑO de LC 5.0
DIQMTQSPSSLSASVGDRVTITCKASQDVSIGVAWYQQKPGKAPKLLIYSA
SYRYTGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQYYIYPYTFGQGT
KVEIKGQPKAAPSVTLFPPSSEELQANDATLVCLISDFYPGAVTVAWKAD
SSPVKAGVETTTPSKQSNNKYAASSYLSLTPEQWKSHRSYSCQVTHEGST
YEKTVAPTEC
SEQ ID NO: 11: DISEÑO de HC menos Vh 1.0+5.0
ASTKGPSVFPLAPSSKSTSGGTAALGCLVKKYFPEPVTYSWNSGALTSGV
HTTPAVLQSSGLYSLSSFVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPK
S CDKTHTCPPCP APELL GGP S VFLFPPKPKDTLMISRTPE VT C V V VD V SHE
DPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGK
EYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCL
VKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQ
QGNVFSCSVMHEALHNHYTQKSLSLSPG
SEQ ID NO: 12: DISEÑO de Cl 1.0+5.0
GQPKAAPSVTLFPPSSEELQANDATLVCFISDFYPGAVTVAWKADSSPVK
AGVETTTPSKQSNNKYAASSYLSLTPEQWKSHRSYSCQVTHEGSTVEKTV
APTEC
SEQ ID NO: 13: AB2133a(-)pG1 (Diseño AB2.1.3.3a en (-)pG1 HC)
E V QL VE S GGGL VQPGG SLRL SC AAS GFTFTD YTMD WVRK APGKGLE WV
AD VNPNSGGSIYNQEFKGRFTLS VDRSKNTL YLQMNSLRAEDT AVYY C A
RNLGPSFYFDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCL
VKD YFPEP VT V S WNS G ALT S G V AT GP AVLQ S S GL Y SL S S V VT VP S S SLGT
QTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPK
PKDTLMISRTPEVT C VVVD V SHEDPE VKFNWYVDGVEVHNAKTKPREEQ
YQSTYRVV S VLTVLHQD WLNGKEYKCKV SNKALPAPIEKTISKAKGQPR
EPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYDTT
PPVLDSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLS
PG
SEQ ID NO: 14: H.4WTAxlK (LC anti-AxI con Vl con H.4 y Ck de tipo silvestre)
DIQMTQSPSSLSASVGDRVTITCRASQDVSTAVAWYQRKPGKAPKLLIYS
ASFLYSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQSYTTPPTFGQGT
KVEIKRT V AAP S VFIFPP SDEQLKS GT AS V VCLLNNF YPRE AKV Q WKVDN
ALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLS
SPVTKSFNRGEC
SEQ ID NO: 15: DISEÑO de Cl 2.1.3.2
GQPKAAPSVTLFPPSSEELQANKATLVCFISDFYPGAVTVAWKADSSPVK
AGVETTTPSKQSNNKYAAWSYLSLTPEQWKSHRSYSCQVTHEGSTVEKT
VAPTEC
SEQ ID NO: 16: H.4WTAxIA (LC anti-AxI con Vl con H.4 y CA de tipo silvestre)
DIQMTQSPSSLSASVGDRVTITCRASQDVSTAVAWYQRKPGKAPKLLIYS
ASFLYSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQSYTTPPTFGQGT
KVEIKGQPKAAPSVTLFPPSSEELQANKATLVCLISDFYPGAVTVAWKAD
SSPVKAGVETTTPSKQSNNKYAASSYLSLTPEQWKSHRSYSCQVTHEGST
VEKTVAPTEC
SEQ ID NO: 17: H.4WT(+)AxlG1 (Diseño H.4 en (+)AxlG1 HC)
EVQLVESGGGLVQPGGSLRLSCAASGFSLSGSW1HWVRYAPGKGLEWVG
WINPYRGYAYYADSVKGRFTISADTSKNTAYLQMNSLRAEDTAVYYCAR
E Y SG W GGS S V G Y AMD Y W GQ GTL VT V S S ASTKGP S VFPL AP S SKST S GGT
AALGCLVKDYFPEPVTYSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTYP
SSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSV
FLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKT
KPREEQYQSTYRVV S VLTVLHQDWLNGKEYKCKV SNKALPAPIEKTISKA
KGQPREPQ V YTLPP SRKELTKN Q V SLT CL VKGF YP SDI AVE WE SN GQPEN
NYKTTPPVLKSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQ
KSLSLSPG
SEQ ID NO: 18: DISENO de HC menos Vh 2.1.3.2 Y 2.1.3.3A
ASTKGP S VFPL AP S SKST S GGT AALGCL VKD YFPEP VT V S WNS G ALT S G V
AT GP AVLQ SSGL Y SLS S VVTVPS S SLGT QTYICNVNHKPSNTKVDKKVEP
KSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSH
EDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNG
KEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTC
LVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRW
QQGNVFSCSVMHEALHNHYTQKSLSLSPG
SEQ ID NO: 19: DISEÑO de HC menos Vh 2.1.3.3
ASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVS
T GP AVLQ S S GL Y SLS S V VT VP S S SLGTQT YICN VNHKP SNTKVDKKVEPKS
CDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHED
PEVKFNWYVDGVE VHNAKTKPREEQ YNSTYRVV S VLT VLHQD WLN GKE
YKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLV
KGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQ
GNVFSCSVMHEALHNHYTQKSLSLSPG
SEQ ID NO: 20: DISEÑO de CI 2.1.3.3 Y 2.1.3.3A
GQPKAAPSVTLFPPSSEELQANKATLVCYISDFYPGAVTVAWKADSSPVK
AGVETTTPSKQSNNKYAAWSYLSLTPEQWKSHRSYSCQVTHEGSTVEKT
VAPTEC
SEQ ID NO: 21: DISEÑO de HC A
E V QL VE S GGGL V QPGGSLRLS C AAS GFTFTD YTMD WVRQ APGKGLE WV
ADVNPNSGGSIYNQEFKGRFTLS VDRSKNTL YLQMNSLRAEDT AVYY C A
RNLGPSFYFDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCL
VKD YFPEP VT Y S WNS G ALTS G YHTFP A VLQ S S GL Y SL S S V VT VP S S SLGT Q
TYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKP
KDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQY
NSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREP
QVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPP
VLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP
G
SEQ ID NO: 22: DISEÑO de LC A
RIQMTQSPSSLSASVGDRVTITCKASQDVSIGVAWYQQKPGKAPKLLIYSA
SYRYTGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQYYIYPYTFGQGT
KVEIKGQPKAAPSVTLFPPSSEELQANKATLVCLISDFYPGAVTVAWKAD
SSPVKAGVETTTPSKQSNNKYAASSYLSLTPEQWKSHRSYSCQVTHEGST
VEKTVAPTEC
SEQ ID NO: 23: DISEÑO de HC B
EVQLVESGGGLVQPGGSLRLSCAASGFTFTDYTMDWVRKAPGKGLEWV
AD VNPNSGGSI YNQRFKGRFTLS VDRSKNTL YLQMNSLRAEDT AVYY C A
RNLGP SF YFD Y W GQGTL VT V S S ASTKGP S VFPL AP S SKST S GGT A ALGC L
VKD YFPEP VTV S WNS G ALT S G VHTFP AVLQ S S GL Y SL S S V VT VP S S SLGT Q
TYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKP
KDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQY
NSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREP
QVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPP
VLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP
G
SEQ ID NO: 24: DISEÑO de LC B
DIQMTQSPS SLS AS V GDRVTITCKASQD V SIGVA WY QDKPGKAPKLLIY S A
SYRYTGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQYYIYPYTFGQGT
KVEIKGQPKAAPSVTLFPPSSEELQANKATLVCLISDFYPGAVTVAWKAD
SSPVKAGVETTTPSKQSNNKYAASSYLSLTPEQWKSHRSYSCQVTHEGST
VEKTVAPTEC
SEQ ID NO: 25: DISEÑO de HC AB
EVQLVESGGGLVQPGGSLRLSCAASGFTFTDYTMDWVRKAPGKGLEWV
ADVNPN S GGSIYNQEFKGRFTLS VDRSKNTL YLQMN SLRAEDT AVYY C A
RNLGPSFYFDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCL
YKD YFPEP YT Y S WNS G AFTS G YHTFP A YFQ S S GE Y SE S S Y VT VP S S S FGTQ
TYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKP
KDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQY
NSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREP
QV YTLPP SRDELTKN Q V SLT CL VKGF YP SDI AVE WESN GQPENN YKTTPP
VLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP
G
SEQ ID NO: 26: DISEÑO de LC AB
RIQMTQSPSSLSASVGDRVTITCKASQDVSIGVAWYQDKPGKAPKLLIYSA
SYRYTGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQYYIYPYTFGQGT
KVEIKGQPKAAPSVTLFPPSSEELQANKATLVCLISDFYPGAVTVAWKAD
SSPVKAGVETTTPSKQSNNKYAASSYLSLTPEQWKSHRSYSCQVTHEGST
VEKTVAPTEC
SEQ ID NO: 27: DISEÑO de HC 1.0+5.0
E V QL VE S GGGL V QPGGSLRL S C AAS GFTFTD YTMD WVRQ APGKGLE WV
ADVNPNSGGSIYNQRFKGRFTLSVDRSKNTLYLQMNSLRAEDTAVYYCA
RNLGPSFYFDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCL
VKKYFPEPVTVSWNSGALTSGVHTTPAVLQSSGLYSLSSFVTVPSSSLGTQ
TYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKP
KDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQY
NSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREP
QV YTLPP SRDELTKN Q V SLT CL VKGF YP S DI AVE WESN GQPENN YKTTPP
VLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP
G
SEQ ID NO: 28: DISEÑO de LC 1.0+5.0
DIQMTQSPSSLSASVGDRVTITCKASQDVSIGVAWYQQKPGKAPKLLIYSA
SYRYTGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQYYIYPYTFGQGT
KVEIKGQPKAAPSVTLFPPSSEELQANDATLVCFISDFYPGAVTVAWKAD
SSPVKAGVETTTPSKQSNNKYAASSYLSLTPEQWKSHRSYSCQVTHEGST
VEKTVAPTEC
SEQ ID NO: 29: DISEÑO de HC H.4
E V QL VE S GGGL VQPGG SLRL SC AAS GFTFTD YTMD WVRY APGKGLE WV
ADVNPNSGGSIYNQRFKGRFTLS VDRSKNTL YLQMNSLRAEDT AVYY C A
RNLGPSFYFDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCL
VKD YFPEP VT Y S WNS G ALTS G YHTFP A VLQ S S GL Y SL S S V VT VP S S SLGT Q
TYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKP
KDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQY
NSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREP
QVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPP
VLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP
G
SEQ ID NO: 30: DISEÑO de LC H.4, H.5, H.6 LAMBDA
DIQMTQSPS SLS AS V GDRVTITCKASQD V SIGVA WY QRKPGKAPKLLIY S A
SYRYTGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQYYIYPYTFGQGT
KVEIKGQPKAAPSVTLFPPSSEELQANKATLVCLISDFYPGAVTVAWKAD
SSPVKAGVETTTPSKQSNNKYAASSYLSLTPEQWKSHRSYSCQVTHEGST
VEKTVAPTEC
SEQ ID NO: 31: DISEÑO de HC H.5
E V QL VE S GGGL VQPGG SLRL SC AAS GFTFTD YTMD WVRF APGKGLE WV
ADVNPNSGGSIYNQRFKGRFTLSVDRSKNTLYLQMNSLRAEDTAVYYCA
RNLGPSFYFDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCL
VKD YFPEP VTV S WNS G ALTS G VHTFP A VLQ S S GL Y SLS S V VT VP S S SLGT Q
TYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKP
KDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQY
NSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREP
QVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPP
VLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP
G
SEQ ID NO: 32: DISEÑO de HC H.6
E V QL VE S GGGL VQPGG SLRL SC AAS GFTFTD YTMD WVRW APGKGLE WV
AD VNPNSGGSI YNQRFKGRFTLS VDRSKNTL YLQMNSLRAEDT AVYY C A
RNLGPSFYFDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCL
VKD YFPEP VTV S WNS G ALTS G VHTFP A VLQ S S GL Y SLS S V VT VP S S SLGT Q
TYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKP
KDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQY
NSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREP
QVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPP
VLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP
G
S E Q ID NO : 33: LC de P E R T U Z U M A B K A P P A (pA, V l K A P P A /C l K A P P A )
DIQMTQSPSSLSASVGDRVTITCKASQDVSIGVAWYQQKPGKAPKLLIYSA
SYRYTGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQYYIYPYTFGQGT
KVEIKRT V AAP S VFIFPP SDEQLKS GT AS V VCLLNNF YPRE AKV Q WKVDN
ALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKYYACEVTHQGLS
SPVTKSFNRGEC
SEQ ID NO: 34: DISEÑO de LC AB KAPPA
RIQMTQSPSSLSASVGDRVTITCKASQDVSIGVAWYQDKPGKAPKLLIYSA
SYRYTGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQYYIYPYTFGQGT
KVEIKRT V AAP S VFIFPP SDEQLKS GT AS V VCLLNNF YPRE AKV Q WKVDN
ALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLS
SPVTKSFNRGEC
SEQ ID NO: 35: DISEÑO de HC 2.1.3.3a
E V QL VE S GGGL V QPGGSLRLS C AAS GFTFTD YTMD WVRQ APGKGLE WV
AD VNPNSGGSIYNQRFKGRFTLS VDRSKNTL YLQMNSLRAEDT AVYY C A
RNLGPSFYFDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCL
VKD YFPEP VT V S WNS G ALT S G V AT GP AVLQ S S GL Y SL S S V VT VP S S SLGT
QTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPK
PKDTLMISRTPEVT C VVVD V SHEDPE VKFNWYVDGVEVHNAKTKPREEQ
YNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPRE
PQ V YTLPP SRDELTKN Q V SLT CL VKGF YP SDI AVE WESN GQPENN YKTTP
PVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP
G
SEQ ID NO: 36: DISEÑO de LC 2.1.3.3a
DIQMTQSPSSLSASVGDRVTITCKASQDVSIGVAWYQQKPGKAPKLLIYSA
SYRYTGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQYYIYPYTFGQGT
KVEIKGQPKAAPSVTLFPPSSEELQANKATLVCYISDFYPGAVTVAWKAD
SSPVKAGVETTTPSKQSNNKYAAWSYLSLTPEQWKSHRSYSCQVTHEGS
TVEKTVAPTEC
SEQ ID NO: 37: DISEÑOS DE HC AB2.1.3.3a y AB2.1.3.2
E V QL VE S GGGL VQPGG SLRL SC AAS GFTFTD YTMD WVRK APGKGLE WV
AD VNPNSGGSI YNQEFKGRFTLS VDRSKNTL YLQMNSLRAEDT AVYY C A
RNLGPSFYFDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCL
VKD YFPEP VTV S WNS G ALT S G V AT GP AVLQ S S GL Y SL S S V VT VP S S SLGT
QTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPK
PKDTLMISRTPEVT C VVVD V SHEDPE VKFNWYVDGVEVHNAKTKPREEQ
YNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPRE
PQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTP
PVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP
G
S E Q ID NO : 38: D IS E Ñ O de LC A B 2.1.3.3 a (A B 2133apA )
RIQMTQSPSSLSASVGDRVTITCKASQDVSIGVAWYQDKPGKAPKLLIYSA
SYRYTGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQYYIYPYTFGQGT
KVEIKGQPKAAPSVTLFPPSSEELQANKATLVCYISDFYPGAVTVAWKAD
SSPVKAGVETTTPSKQSNNKYAAWSYLSLTPEQWKSHRSYSCQVTHEGS
TYEKTYAPTEC
SEQ ID NO: 39: DISEÑO de HC H.42.1.3.3a
EVQLVESGGGLVQPGGSLRLSCAASGFTFTDYTMDWVRYAPGKGLEWV
AD VNPNSGGSIYN QRFKGRFTLS VDRSKNTL YLQMNSLRAEDT AVYY C A
RNLGPSFYFDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCL
VKD YFPEP VT V S WNS G ALT S G V AT GP AVLQ S S GL Y SL S S V VT VP S S SL GT
QTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPK
PKDTLMISRTPEVT C VVVD V SHEDPE VKFNWYVDGVEVHNAKTKPREEQ
YNST YRV V S VLT VLHQD WLN GKE YKCKV SNKALP APIEKTISKAKGQPRE
PQ V YTLPP SRDELTKN Q V SLTCL VKGF YP SDI AVE WE SN GQPENN YKTTP
PVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP
G
SEQ ID NO: 40: DISEÑO de LC H.42.1.3.3a
DIQMTQSPSSLSASVGDRVTITCKASQDVSIGVAWYQRKPGKAPKLLIYSA
SYRYTGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQYYIYPYTFGQGT
KVEIKGQPKAAPSVTLFPPSSEELQANKATLVCYISDFYPGAVTVAWKAD
SSPVKAGVETTTPSKQSNNKYAAWSYLSLTPEQWKSHRSYSCQVTHEGS
TYEKTYAPTEC
SEQ ID NO: 41: DISEÑO de HC H.4 KAPPA
DIQMTQSPSSLSASVGDRVTITCKASQDVSIGVAWYQRKPGKAPKLLIYSA
SYRYTGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQYYIYPYTFGQGT
KVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDN
ALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLS
SPVTKSFNRGEC
SEQ ID NO: 42: DISEÑO de LC AB2.1.3.2
RIQMTQSPSSLSASVGDRVTITCKASQDVSIGVAWYQDKPGKAPKLLIYSA
SYRYTGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQYYIYPYTFGQGT
KVEIKGQPKAAPSVTLFPPSSEELQANKATLVCFISDFYPGAVTVAWKAD
SSPVKAGVETTTPSKQSNNKYAAWSYLSLTPEQWKSHRSYSCQVTHEGS
TYEKTYAPTEC
SEQ ID NO: 43: HC de Matuzumab (mG1)
QVQLVQSGAEVKKPGASVKVSCKASGYTFTSHWMHWVRQAPGQGLEWI
GEFNP SN GRTN YNEKFKSKATMT VDT STNT AYMEL S SLRSEDT AV Y Y C A
SRDYDYDGRYFDYWGQGTLVTYSSASTKGPSVFPLAPSSKSTSGGTAALG
CLVKDYFPEPVTVSWNSGALTSGVHTFPAYLQSSGLYSLSSVVTVPSSSLG
TQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPP
KPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREE
QYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQP
REPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKT
TPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLS
LSPG
SEQ ID NO: 44: LC de Matuzumab (mA, Vl y Cl lambda [Ca])
DIQMTQSPS SLS AS V GDRVTITCS AS S S VT YM YWY QQKPGKAPKLLIYDT S
NLASGVPSRFSGSGSGTDYTFTISSLQPEDIATYYCQQWSSHIFTFGQGTKV
EIKGQPKAAPSVTLFPPSSEELQANKATLVCLISDFYPGAVTVAWKADSSP
VKAGVETTTPSKQSNNKYAASSYLSLTPEQWKSHRSYSCQVTHEGSTVEK
TVAPTEC
SEQ ID NO: 45: LC de Matuzumab (mA, Vl y Cl kappa [Ck])
DIQMTQSPS SLS AS V GDRVTITCS AS S S VT YM YWY QQKPGKAPKLLI YDT S
NLASGVPSRFSGSGSGTDYTFTISSLQPEDIATYYCQQWSSHIFTFGQGTKV
EIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNAL
QSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSP
VTKSFNRGEC
SEQ ID NO: 46: HC de METMAb (METG1)
EVQLVESGGGLVQPGGSLRLSCAASGYTFTSYWLHWVRKAPGKGLEWV
GMIDPSNSDTRFNPNFKDRFTISADTSKNTAYLQMNSLRAEDTAVYYCAT
YRS Y VTPLD Y W GQ GTL VT V S S ASTKGP S VFPL AP S SKST S GGT AALGCL V
KD YFPEP VT V S WNS G ALTS G VHTFP AVLQ S S GL Y SLS S V VT VP S S SLGT QT
YICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPK
DTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYN
STYRVV S VLTVLHQDWLNGKEYKCKV SNKALPAPIEKTISKAKGQPREPQ
V YTLPP SRDELTKN Q V SLT CL VKGF YP SDIA VE WE SN GQPENN YKTTPP V
LDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG
SEQ ID NO: 47: LC de METMAb (META, Vl kappa y Cl lambda [Ca])
DIQMTQSPSSLSASVGDRVTITCKSSQSLLYTSSQKNYLAWYQQKPGKAP
KLLIYWASTRESGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQYYAYP
WTFGQGTKVEIKGQPKAAPSVTLFPPSSEELQANKATLVCLISDFYPGAVT
VAWKADSSPVKAGVETTTPSKQSNNKYAASSYLSLTPEQWKSHRSYSCQ
VTHEGSTVEKTVAPTEC
S E Q ID NO : 48: LC de M E T M A b (M E T k , V l ka p p a y C l kap pa [C k])
DIQMTQSPSSLSASVGDRVTITCKSSQSLLYTSSQKNYLAWYQQKPGKAP
KLLIYWASTRESGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQYYAYP
WTFGQGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKV
QWKYDNALQSGNSQESYTEQDSKDSTYSLSSTLTLSKADYEKHKYYACE
VTHQGLSSPVTKSFNRGEC
SEQ ID NO: 49: HC de anti-AxI (AxlG1)
EVQLVESGGGLVQPGGSLRLSCAASGFSLSGSW1HWVRQAPGKGLEWVG
WINPYRGYAYYADSVKGRFTISADTSKNTAYLQMNSLRAEDTAVYYCAR
E Y SG W GGS S V G Y AMD Y W GQ GTL VT V S S ASTKGP S VFPL AP S SKST S GGT
AALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVP
SSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSV
FLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKT
KPREEQYN STYRVV S VLTVLHQDWLNGKEYKCKV SNKALPAPIEKTISKA
KGQPREPQ V YTLPP SRDELTKN Q V SLT CL VKGF YP SDI AVE WE SN GQPEN
NYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQ
KSLSLSPG
SEQ ID NO: 50: LC de anti-AxI (AxIA, Vl kappa y Cl lambda [Ca])
DIQMTQSPS SLS AS V GDRVTITCRASQD V STAVAWY QQKPGKAPKLLIY S
ASFLYSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQSYTTPPTFGQGT
KVEIKGQPKAAPSVTLFPPSSEELQANKATLVCLISDFYPGAVTVAWKAD
SSPVKAGVETTTPSKQSNNKYAASSYLSLTPEQWKSHRSYSCQVTHEGST
VEKTVAPTEC
SEQ ID NO: 51: LC de anti-AxI (AxIk, Vl kappa y Cl kappa [Ck])
DIQMTQSPS SLS AS VGDRVTITCRASQDV STAVAWY QQKPGKAPKLLIY S
ASFLYSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQSYTTPPTFGQGT
KVEIKRT V AAP S VFIFPP SDEQLKS GT AS V VCLLNNF YPRE AKV Q WKVDN
ALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLS
SPVTKSFNRGEC
SEQ ID NO: 52: (-)pG1 (HA de IgG1 Pertuzumab con CH3_K409D,K392D)
E V QL VE S GGGL V QPGGSLRLS C AAS GFTFTD YTMD WVRQ APGKGLE WV
AD VNPNSGGSIYNQRFKGRFTLS VDRSKNTL YLQMNSLRAEDT AVYY C A
RNLGPSFYFDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCL
VKD YFPEP VT V S WNS G ALTS G VHTFP A VLQ S S GL Y SLS S V VT VP S S SLGT Q
TYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKP
KDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQY
QSTYRVV S VLTVLHQDWLNGKEYKCKV SNKALPAPIEKTISKAKGQPREP
QVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYDTTPP
VLDSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP
G
S E Q ID NO : 53: (+ )m G 1 (H C de IgG1 M a tu z u m a b con C h3 _ D 399 K ,E 356 K )
Q Y QL VQ S G AE VKKPG AS VKV S CKAS G YTFTSH WMH WVRQ APGQGLE WI
GEFNP SN GRTN YNEKFKSKATMT VDT STNT AYMEL S SLRSEDT AV Y Y C A
SRDYDYDGRYFDYWGQGTLVTYSSASTKGPSVFPLAPSSKSTSGGTAALG
CLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLG
TQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPP
KPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREE
QYQSTYRVV S VLTVLHQDWLNGKEYKCKV SNKALPAPIEKTISKAKGQP
REPQVYTLPPSRKELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKT
TPPVLKSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLS
LSPG
SEQ ID NO: 54: (-)METG1 (HC de IgG1 METMAb con CH3_K409D,K392D)
EVQLVESGGGLVQPGGSLRLSCAASGYTFTSYWLHWVRQAPGKGLEWV
GMIDPSNSDTRFNPNFKDRFTISADTSKNTAYFQMNSFRAEDTAVYYCAT
YRSYVTPFDYWGQGTFVTVSSASTKGPSVFPFAPSSKSTSGGTAAFGCFV
KD YFPEP VT V S WNS G AFTS G VHTFP AVFQ S S GE Y SE S S V VT VP S S SFGT QT
YICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPK
DTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQ
STYRVV S VLTVLHQDWLNGKEYKCKV SNKALPAPIEKTISKAKGQPREPQ
V YTLPP SRDELTKN Q V SLT CL VKGF YP SDI AVE WE SN GQPENN YDTTPP V
LDSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG
SEQ ID NO: 55: (+)AxlG1 (HC de IgG1 anti-AxI con Ch3_D399K,E356K)
EVQLVESGGGLVQPGGSLRLSCAASGFSLSGSW1HWVRQAPGKGLEWVG
WINPYRGYAYYADSVKGRFTISADTSKNTAYLQMNSLRAEDTAVYYCAR
E Y S G W GGS S V G Y AMD Y W GQGTL VT V S S ASTKGP S VFPL AP S S KST S GGT
AALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVP
SSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSV
FLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKT
KPREEQYQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKA
KGQPREPQVYTLPPSRKELTKNQVSLTCLVKGFYPSDIAVEWESNGQPEN
NYKTTPPVLKSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQ
KSLSLSPG
SEQ ID NO: 56: AB2133apK (LC de Pertuzumab con AB en Vl y 2.1.3.3a en Ck)
RIQMTQSPSSLSASVGDRVTITCKASQDVSIGVAWYQDKPGKAPKLLIYSA
SYRYTGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQYYIYPYTFGQGT
KVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCYLNNFYPREAKVQWKVDN
ALQSGNSQESVTEQDSKDSTYSLWSTLTLSKADYEKHKVYACEVTHQGL
SSPVTKSFNRGEC
S E Q ID NO : 57: H .4W T (+)m G 1 (D ise ñ o H .4 en (+ )m G 1 H C )
QVQLVQSGAEVKKPGASVKVSCKASGYTFTSHWMHWVRYAPGQGLEWI
GEFNP SN GRTN YNEKFKSKATMT YDT STNT AYMEL S SLRSEDT AV Y Y C A
SRDYDYDGRYFDYWGQGTLVTYSSASTKGPSVFPLAPSSKSTSGGTAALG
CLYKDYFPEPVTYSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLG
T QTYICNVNHKPSNTKVDKKVEPKS CDKTHT CPPCP APELLGGPS VFLFPP
KPKDTLMISRTPEVT C VV VD V SHEDPE VKFNWYVDGVE VHNAKTKPREE
Q YQSTYRVV S VLT VLHQD WLN GKEYKCKV SNKALP APIEKTISKAKGQP
REPQVYTLPPSRKELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKT
TPPVLKSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLS
LSPG
SEQ ID NO: 58: H.4WTmA (LC de Matuzumab con Vl con H.4 y Ca de tipo silvestre)
DIQMT QSPSSLSASV GDRVTIT C S AS S S VT YM Y WY QRKPGKAPKLLI YDT S
NLASGVPSRFSGSGSGTDYTFTISSLQPEDIATYYCQQWSSHIFTFGQGTKV
EIKGQPKAAPSVTLFPPSSEELQANKATLVCLISDFYPGAVTVAWKADSSP
VKAGVETTTPSKQSNNKYAASSYLSLTPEQWKSHRSYSCQVTHEGSTVEK
TVAPTEC
SEQ ID NO: 59: H.4WTim (LC de Matuzumab con Vl con H.4 y Ck de tipo silvestre)
DIQMTQSP S SLS AS V GDRVTITCS AS S S VTYM YWY QRKPGKAPKLLI YDTS
NLASGVPSRFSGSGSGTDYTFTISSLQPEDIATYYCQQWSSHIFTFGQGTKV
EIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNAL
QSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSP
VTKSFNRGEC
SEQ ID NO: 60: AB2133a(-)METG1 (Diseño AB2.1.3.3a en (-)METG1 HC)
E V QL VE S GGGL V QPGGSLRLS C AAS G YTFT S Y WLH W VRK APGKGLE WV
GMIDP SN SDTRFNPEFKDRFTIS ADTSKNT AYLQMN SLRAEDT AV Y Y C AT
YRS Y VTPLD Y W GQ GTL VT V S S ASTKGP S VFPL AP S SKS T S GGT AALGCL V
KDYFPEPVTVSWNSGALTSGVATGPAVLQSSGLYSLSSVVTVPSSSLGTQ
TYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKP
KDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQY
QSTYRVV S VLTVLHQD WLNGKEYKCKV SNKALP APIEKTISKAKGQPREP
QVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYDTTPP
VLDSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP
G
SEQ ID NO: 61: AB2133aMETA (LC de METMAB con AB en Vl y CA con 2.1.3.3a)
RIQMTQSPS SLS AS V GDRVTITCKS SQ SLLYTS SQKNYL AWY QDKPGKAP
KLLIYWASTRESGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQYYAYP
WTFGQGTKVEIKGQPKAAPSVTLFPPSSEELQANKATLVCYISDFYPGAVT
VAWKADSSPVKAGVETTTPSKQSNNKYAAWSYLSLTPEQWKSHRSYSC
QVTHEGSTVEKTVAPTEC
S E Q ID NO: 62: A B 2133 a M E T K (LC de M E T M A B con A B en V l y C k con 2.1.3.3 a )
RIQMTQSPS SLS AS V GDRVTITCKS SQ SLLYTS SQKNYL AWY QDKPGKAP
KLLIYWASTRESGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQYYAYP
WTFGQGTKVEIKRT VAAPS VFIFPPSDEQLKSGT AS VV C YLNNF YPRE AK
VQWKVDNALQSGNSQESVTEQDSKDSTYSLWSTLTLSKADYEKHKVYA
CEVTHQGLSSPVTKSFNRGEC
SEQ ID NO: 63: Ck de tipo silvestre
RT V AAP S VFIFPP SDEQLKS GT AS V VCLLNNF YPRE AKV Q WKVDN ALQ S G
NSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTK
SFNRGEC
SEQ ID NO: 64 Ck con 2133a
RTVAAPSVFIFPPSDEQLKSGTASVVCYLNNFYPREAKVQWKVDNALQSG
NSQESYTEQDSKDSTYSLWSTLTLSKADYEKHKVYACEVTHQGLSSPVTK SFNRGEC
SEQ ID NO: 65: DISEÑO de HC menos Vh 2133a A172R
ASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGV
RT GP AVLQ SSGL Y SLS S VVTVPS S SLGT QTYICNVNHKPSNTKVDKKVEP
KSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSH
EDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNG
KEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTC
LVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRW
QQGNVFSCSVMHEALHNHYTQKSLSLSPG
SEQ ID NO: 66: DISEÑO de HC menos Vh 2133a V190M
ASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGV
AT GP AVLQS SGLY SLS SMVTVPS S SLGT QTYICNVNHKPSNTKVDKKVEP
KSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSH
EDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNG
KEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTC
LVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRW
QQGNVFSCSVMHEALHNHYTQKSLSLSPG
SEQ ID NO: 67: DISEÑO de HC menos Vh 2133a V190I
ASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGV
ATGPAVLQSSGLYSLSSIVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPK
SCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHE
DPE VKFN W Y VDG VE VHN AKTKPREEQ YN ST YRV V S VLT VLHQD WLN GK
EYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCL
VKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQ
QGNVFSCSVMHEALHNHYTQKSLSLSPG
S E Q ID NO: 68: D IS E Ñ O D E H C m en os V h 2133 a A 172 R V 190M
ASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGV
RT GP AVLQS SGLY SLS SM VT VPS S SLGT QTYICN VNHKPSNTKVDKKVEP
KSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSH
EDPEYKFNWYYDGYEYHNAKTKPREEQYNSTYRYYSVLTYLHQDWLNG
KEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTC
LVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRW
QQGNVFSCSVMHEALHNHYTQKSLSLSPG
SEQ ID NO: 69: DISEÑO DE HC menos Vh 2133a A172R V190I
ASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGV
RTGPAVLQSSGLYSLSSIVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPK
S CDKTHTCPPCP APELL GGP S VFLFPPKPKDTLMISRTPE VT C V V VD V SHE
DPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGK
EYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCL
VKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQ
QGNVFSCSVMHEALHNHYTQKSLSLSPG
SEQ ID NO: 70: Ck 2133a_V133L
RT V AAP S VFIFPP SDEQLKS GT AS VLC YLNNF YPRE AKV Q WKVDN ALQ S G
NSQESVTEQDSKDSTYSLWSTLTLSKADYEKHKVYACEVTHQGLSSPVTK SFNRGEC
SEQ ID NO: 71: CK_2133a_S174Q
RTVAAPSVFIFPPSDEQLKSGTASVVCYLNNFYPREAKVQWKVDNALQSG
NSQESVTEQDSKDSTYQLWSTLTLSKADYEKHKVYACEVTHQGLSSPVT
KSFNRGEC
SEQ ID NO: 72: CK_2133a_S174D
RTVAAPSVFIFPPSDEQLKSGTASVVCYLNNFYPREAKVQWKVDNALQSG
NSQESVTEQDSKDSTYDLWSTLTLSKADYEKHKVYACEVTHQGLSSPVT
KSFNRGEC
SEQ ID NO: 73: CK_2133a_V133L_S174Q
RT V AAP S VFIFPP SDEQLKS GT AS VLC YLNNF YPRE AKV Q WKVDN ALQ S G
NSQESVTEQDSKDSTYQLWSTLTLSKADYEKHKVYACEVTHQGLSSPVT
KSFNRGEC
SEQ ID NO: 74: CK_2133a_V133L_S174D
RT V AAP S VFIFPP SDEQLKS GT AS VLC YLNNF YPRE AKV Q WKVDN ALQ S G
NSQESVTEQDSKDSTYDLWSTLTLSKADYEKHKVYACEVTHQGLSSPVT
KSFNRGEC
S E Q ID NO : 75: (-)P G 1 _ A B 2133 a _ M R (P e rtu zu m a b )
EVQLVESGGGLVQPGGSLRLSCAASGFTFTDYTMDWVRKAPGKGLEWV
ADVNPNSGGSIYNQEFKGRFTLS VDRSKNTL YLQMNSLRAEDT AVYY C A
RNLGPSFYFDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCL
VKDYFPEPVTVSWNSGALTSGVRTGPAVLQSSGLYSLSSMVTVPSSSLGT
QTYICNVNHKPSNTKYDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPK
PKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQ
YQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPR
EPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYDTT
PPVLDSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLS
PG
SEQ ID NO: 76: (-)PG1_AB2133a_IR (Pertuzumab)
E V QL VE S GGGL VQPGG SLRL SC AAS GFTFTDYTMD WVRK APGKGLE WV
AD VNPNSGGSI YNQEFKGRFTLS VDRSKNTL YLQMNSLRAEDT AVYY C A
RNLGPSFYFDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCL
VKD YFPEP VT V S WNS G ALT S G VRT GPAVLQ S S GL Y SLS SI VT VP S S SLGT Q
TYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKP
KDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQY
QSTYRVV S VLTVLHQDWLNGKEYKCKV SNKALPAPIEKTISKAKGQPREP
Q V YTLPP SRDELTKN Q V SLT CL VKGF YP SDI AVE WESN GQPENN YDTTPP
VLDSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP
G
SEQ ID NO: 77: (-)MetG1_AB2133a_MR (MetMAb)
E V QL VE S GGGL V QPGGSLRLS C AAS G YTFT S Y WLH WVRK APGKGLE WV
GMIDP SN SDTRFNPEFKDRFTIS ADTSKNT AYLQMN SLRAEDT AVYY C AT
YRS Y VTPLD Y W GQ GTL VT V S S ASTKGP S VFPL AP S SKST S GGT AALGCL V
KD YFPEP VTV S WNS G ALT S G VRT GP AVLQ S S GL Y SLS SM VT VP S S SLGT Q
TYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKP
KDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQY
QSTYRVV S VLTVLHQDWLNGKEYKCKV SNKALPAPIEKTISKAKGQPREP
QV YTLPP SRDELTKN Q V SLT CL VKGF YP SDI AVE WESN GQPENN YDTTPP
VLDSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP
G
SEQ ID NO: 78: (-)MetG1_AB2133a_IR (MetMAb)
E V QL VE S GGGL V QPGGSLRLS C AAS G YTFT S Y WLH WVRK APGKGLE WV
GMIDP SN SDTRFNPEFKDRFTI S ADT SKNT AYLQMNSLRAEDT AVYY C AT
YRS Y VTPLD Y W GQ GTL VTV S S ASTKGP S VFPL AP S SKST S GGT AALGCL V
KDYFPEPVTVSWNSGALTSGVRTGPAVLQSSGLYSLSSIVTVPSSSLGTQT
YICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPK
DTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQ
STYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQ
V YTLPP SRDELTKN Q V SLT CL VKGF YP SDI AVE WE SN GQPENN YDTTPP V
LDSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG
S E Q ID NO : 79: P K _ A B 2133 a_ LD (P e rtu zu m a b )
RIQMTQSPS SLS AS VGDRVTITCKASQD V SIGV AWY QDKPGKAPKLLI Y S A
SYRYTGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQYYIYPYTFGQGT
KYEIKRT V AAP S VFIFPP SDEQLKS GT AS VLC YLNNF YPRE AKV Q WKVDN
ALQSGNSQESVTEQDSKDSTYDLWSTLTLSKADYEKHKVYACEVTHQGL
SSPYTKSFNRGEC
SEQ ID NO: 80: PK_AB2133a_LQ (Pertuzumab)
RIQMTQSPS SLS AS VGDRVTITCKASQD V SIGV AWY QDKPGKAPKLLI Y S A
SYRYTGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQYYIYPYTFGQGT
KYEIKRT V AAP S VFIFPP SDEQLKS GT AS VLC YLNNF YPRE AKV Q WKVDN
ALQSGNSQESVTEQDSKDSTYQLWSTLTLSKADYEKHKVYACEVTHQGL
SSPYTKSFNRGEC
SEQ ID NO: 81: MetK_AB2133a_LD (MetMAb)
RIQMTQSPS SLS AS V GDRVTITCKS SQ SLLYTS SQKNYL AWY QDKPGKAP
KLLIYWASTRESGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQYYAYP
WTFGQGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVLCYLNNFYPREAKV
QWKVDNALQSGNSQESVTEQDSKDSTYDLWSTLTLSKADYEKHKVYAC
EVTHQGLSSPVTKSFNRGEC
SEQ ID NO: 82: MetK_AB2133a_LQ (MetMAb)
RIQMTQSPS SLS AS V GDRVTITCKS SQ SLLYTS SQKNYL AWY QDKPGKAP
KLLIYWASTRESGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQYYAYP
WTFGQGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVLCYLNNFYPREAKV
QWKVDNALQSGNSQESVTEQDSKDSTYQLWSTLTLSKADYEKHKVYAC
EVTHQGLSSPVTKSFNRGEC
SEQ ID NO 83: (+)TG1_H4 (Trastuzumab)
EVQLVESGGGLVQPGGSLRLSCAASGFNIKDTY1HWVRYAPGKGLEWVA
RIYPTN G YTRY AD S VKGRFTIS ADT SKNT AYLQMNSLRAEDT AV Y Y C S R
WGGDGFYAMDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGC
L VKD YFPEP VT V S WN S G ALT S G VHTFP AVLQ S SGL Y SLS S V VT VP S S SL GT
QTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPK
PKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQ
YQSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPR
EPQ V YTLPP SRKELTKN Q V SLT CL VKGF YP SDI AVE WE SN GQPENN YKTT
PPVLKSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSL
SPG
SEQ ID NO 84: (+)TG1_H4 (Trastuzumab) CS
EVQLVESGGGLVQPGGSLRLSCAASGFNIKDTY1HWVRYAPGKGLEWVA
RIYPTN G YTRY AD S VKGRFTIS ADT SKNT AYLQMNSLRAEDT AY Y Y C SR
WGGDGFYAMDYWGQGTLVTVSSASTKGPSVFPLAPCSKSTSGGTAALGC
LVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGT
QTYICNVNHKPSNTKVDKKVEPDSGDKTHTCPPCPAPELLGGPSVFLFPPK
PKDTLMISRTPEVT C VVVD V SHEDPE VKFNWYYDGVEVHNAKTKPREEQ
YQSTYRVV S VLTVLHQD WLNGKEYKCKV SNKALPAPIEKTISKAKGQPR
EPQ V YTLPP SRKELTKN Q Y SLT CL YKGF YP SDI AVE WE SN GQPENN YKTT
PPVLKSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSL
SPG
SEQ ID NO 85: (+)TG1_H4 (Trastuzumab) DR
EVQLVESGGGLVQPGGSLRLSCAASGFNIKDTY1HWVRYAPGKGLEWVA
RI YPTN G YTRY AD S VKGRFTI S ADT SKNT AYLQMNSLRAEDT AY Y Y C SR
W GGDGF Y AMD Y W GRGTL VT V S S ASTKGP S VFPL AP S SKST S GGT AALGC
LVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGT
QTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPK
PKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQ
YQSTYRVV S VLTVLHQD WLNGKEYKCKV SNKALPAPIEKTISKAKGQPR
EPQ V YTLPP SRKELTKN Q V SLT CL VKGF YP SDI AVE WE SN GQPENN YKTT
PPVLKSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSL
SPG
SEQ ID NO 86: (+)TG1_H4 (Trastuzumab) CS+DR
EVQLVESGGGLVQPGGSLRLSCAASGFNIKDTY1HWVRYAPGKGLEWVA
RI YPTN G YTRY AD S VKGRFTI S ADT SKNT AYLQMNSLRAEDT AV Y Y C SR
WGGDGFYAMD YWGRGTLVTVSSASTKGPSVFPLAPCSKSTSGGTAALGC
LVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGT
QTYICNVNHKPSNTKVDKKVEPDSGDKTHTCPPCPAPELLGGPSVFLFPPK
PKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQ
YQSTYRVV S VLTVLHQD WLNGKEYKCKV SNKALPAPIEKTISKAKGQPR
EPQ V YTLPP SRKELTKN Q V SLT CL VKGF YP SDI AVE WE SN GQPENN YKTT
PPVLKSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSL
SPG
SEQ ID NO 87: Tk_H4 (Trastuzumab)
DIQMTQSPSSLSASVGDRVTITCRASQDVNTAVAWYQRKPGKAPKLLIYS
ASFLYSGVPSRFSGSRSGTDFTLTISSLQPEDFATYYCQQHYTTPPTFGQGT
KVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDN
ALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLS
SPVTKSFNRGEC
S E Q ID N O 88: T k_ H 4 (T ra s tu z u m a b ) C S
DIQMTQSPSSLSASVGDRVTITCRASQDVNTAVAWYQRKPGKAPKLLIYS
ASFLYSGVPSRFSGSRSGTDFTLTISSLQPEDFATYYCQQHYTTPPTFGQGT
KVEIKRTVAAPSVFIFPPSKEQLKSGTASVVCLLNNFYPREAKVQWKVDN
ALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLS
SPVTKSFNRGEC
SEQ ID NO 89: Tk_H4 (Trastuzumab) DR
DIQMTQSPSSLSASVGDRVTITCRASQDVNTAVAWYQRKPGDAPKLLIYS
ASFLYSGVPSRFSGSRSGTDFTLTISSLQPEDFATYYCQQHYTTPPTFGQGT
KVEIKRT V AAP S VFIFPP SDEQFKS GT AS V VCLLNNF YPRE AKV Q WKVDN
AFQSGNSQESVTEQDSKDSTYSFSSTFTFSKADYEKHKVYACEVTHQGFS
SPVTKSFNRGEC
SEQ ID NO 90: Tk_H4 (Trastuzumab) CS+DR
DIQMTQSPSSFSASVGDRVTITCRASQDVNTAVAWYQRKPGDAPKFFIYS
ASFFYSGVPSRFSGSRSGTDFTFTISSFQPEDFATYYCQQHYTTPPTFGQGT
KVEIKRTVAAPSVFIFPPSKEQLKSGTASVVCLLNNFYPREAKVQWKVDN
AFQSGNSQESVTEQDSKDSTYSFSSTFTFSKADYEKHKVYACEVTHQGFS
SPVTKSFNRGEC
SEQ ID NO 91: (+)PG1 H4WT (Pertuzumab)
EVQFVESGGGFVQPGGSFRFSCAASGFTFTDYTMDWVRYAPGKGFEWV
AD VNPNSGGSIYNQRFKGRFTFS VDRSKNTF YFQMNSFRAEDT AVYY C A
RNFGPSFYFDYWGQGTFVTVSSASTKGPSVFPFAPSSKSTSGGTAAFGCF
VKD YFPEP VT V S WNS G AFTS G VHTFP A VFQ S S GE Y SE S S V VT VP S S SFGT Q
TYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKP
KDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQY
QSTYRVV S VLTVLHQD WLNGKEYKCKV SNKALPAPIEKTISKAKGQPREP
QV YTLPP SRKELTKN Q V SLTCL VKGF YP SDI AVE WE SN GQPENN YKTTPP
VLKSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP
G
SEQ ID NO 92: (+)PG1 H4WT CS (Pertuzumab)
EVQLVESGGGLVQPGGSLRLSCAASGFTFTDYTMDWVRYAPGKGLEWV
AD VNPNSGGSI YNQRFKGRFTLSVDRSKNTLYLQMNSLRAEDT AVYY C A
RNLGPSFYFDYWGQGTLVTVSSASTKGPSVFPLAPCSKSTSGGTAALGCL
VKD YFPEP VTV S WNS G ALTS G VHTFP A VLQ S S GL Y SL S S V VT VP S S SLGT Q
TYICNVNHKPSNTKVDKKVEPDSGDKTHTCPPCPAPELLGGPSVFLFPPKP
KDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQY
QSTYRVV S VLTVLHQD WLNGKEYKCKV SNKALPAPIEKTISKAKGQPREP
QV YTLPP SRKELTKN Q V SLTCL VKGF YP SDI AVE WE SN GQPENN YKTTPP
VLKSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP
G
S E Q ID N O 93: (+ )P G 1 H 4 W T DR (P e rtu z u m a b )
EVQLVESGGGLVQPGGSLRLSCAASGFTFTDYTMDWVRYAPGKGLEWV
ADVNPNSGGSIYNQRFKGRFTLS VDRSKNTL YLQMNSLRAEDT AVYY C A
RNLGPSFYFDYWGRGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCL
YKD YFPEP YT Y S WNS G ALTS G YHTFP A YLQ S S GL Y SL S S Y YT YP S S SLGTQ
TYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKP
KDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQY
QSTYRVV S VLTVLHQD WLNGKEYKCKV SNKALPAPIEKTISKAKGQPREP
QV YTLPP SRKELTKN Q V SLTCL VKGF YP SDI AVE WE SN GQPENN YKTTPP
VLKSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP
G
SEQ ID NO 94: (+)PG1 H4WT CS DR (Pertuzumab)
EVQLVESGGGLVQPGGSLRLSCAASGFTFTDYTMDWVRYAPGKGLEWV
AD VNPNSGGSI YNQRFKGRFTLS VDRSKNTL YLQMNSLRAEDT AVYY C A
RNLGPSFYFDYWGRGTLVTVSSASTKGPSVFPLAPCSKSTSGGTAALGCL
VKD YFPEP VTV S WNS G ALTS G VHTFP A VLQ S S GL Y SL S S V VT VP S S SLGT Q
TYICNVNHKPSNTKVDKKVEPDSGDKTHTCPPCPAPELLGGPSVFLFPPKP
KDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQY
QSTYRVV S VLTVLHQD WLNGKEYKCKV SNKALPAPIEKTISKAKGQPREP
QV YTLPP SRKELTKN Q V SLTCL VKGF YP SDI AVE WE SN GQPENN YKTTPP
VLKSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSP
G
SEQ ID NO: 95: Pk H4WT CS (Pertuzumab)
DIQMTQSPSSLSASVGDRVTITCKASQDVSIGVAWYQRKPGKAPKLLIYSA
SYRYTGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQYYIYPYTFGQGT
KVEIKRTVAAPSVFIFPPSKEQLKSGTASVVCLLNNFYPREAKVQWKVDN
ALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLS
SPVTKSFNRGEC
SEQ ID NO: 96: Pk H4WT DR (Pertuzumab)
DIQMTQSPS SLS AS V GDRVTITCKASQD V SIGVA WY QRKPGD APKLLI Y S A
SYRYTGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQYYIYPYTFGQGT
KVEIKRT V AAP S VFIFPP SDEQLKS GT AS V VCLLNNF YPRE AKV Q WKVDN
ALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLS
SPVTKSFNRGEC
SEQ ID NO: 97: Pk H4WT CS DR (Pertuzumab)
DIQMTQSPS SLS AS V GDRVTIT CKASQD V SIGVAWY QRKPGD APKLLI Y S A
SYRYTGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQYYIYPYTFGQGT
KVEIKRTVAAPSVFIFPPSKEQLKSGTASVVCLLNNFYPREAKVQWKVDN
ALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLS
SPVTKSFNRGEC
S E Q ID NO: 98: (+ )M G 1 H 4 W T CS
QVQLVQSGAEVKKPGASVKVSCKASGYTFTSHWMHWVRYAPGQGLEWI
GEFNP SN GRTN YNEKFKSKATMT VDT STNT AYMEL S SLRSEDT AV Y Y C A
SRDYDYDGRYFDYWGQGTLVTVSSASTKGPSVFPLAPCSKSTSGGTAAL
GCL VKD YFPEP VT V S WNS G ALT S G VHTFP A VLQ S S GL Y SL S S V VT VP S S SL
GTQTYICNVNHKPSNTKVDKKVEPDSGDKTHTCPPCPAPELLGGPSVFLFP
PKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPRE
e q y q s t y r v v s v l t v l h q d w l n g k e y k c k v s n k a l p a p ie k t is k a k g q
PREPQ V YTLPP SRKELTKN Q V SLT CL VKGF YP SDIA VE WE SN GQPENN YK
TTPPVLKSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSL
SLSPG
SEQ ID NO: 99: (+)MG1 H4WT DR
QVQLVQSGAEVKKPGASVKVSCKASGYTFTSHWMHWVRYAPGQGLEWI
GEFNPSNGRTNYNEKFKSKATMTVDTSTNTAYMELSSLRSEDTAVYYCA
SRDYDYDGRYFDYWGRGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALG
CLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLG
TQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPP
KPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREE
QYQSTYRVV S VLTVLHQDWLNGKEYKCKV SNKALPAPIEKTISKAKGQP
REPQVYTLPPSRKELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKT
TPPVLKSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLS
LSPG
SEQ ID NO: 100: (+)MG1 H4WT CS+DR
QVQLVQSGAEVKKPGASVKVSCKASGYTFTSHWMHWVRYAPGQGLEWI
GEFNPSNGRTNYNEKFKSKATMTVDTSTNTAYMELSSLRSEDTAVYYCA
SRDYDYDGRYFDYWGRGTLVTVSSASTKGPSVFPLAPCSKSTSGGTAAL
GCL VKD YFPEP VTV S WNS G ALT S G VHTFP A VLQ S S GL Y SL S S V VT VP S S SL
GTQTYICNVNHKPSNTKVDKKVEPDSGDKTHTCPPCPAPELLGGPSVFLFP
PKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPRE
EQYQSTYRVV S VLTVLHQDWLNGKEYKCKV SNKALPAPIEKTISKAKGQ
PREPQ V YTLPP SRKELTKN Q V SLT CL VKGF YP SDI AVE WE SN GQPENN YK
TTPPVLKSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSL
SLSPG
SEQ ID NO: 101: Mk H4WT CS
DIQMTQSPSSLSASVGDRVTITCSASSSVTYMYWYQRKPGKAPKLLIYDTS
NLASGVPSRFSGSGSGTDYTFTISSLQPEDIATYYCQQWSSHIFTFGQGTKV
EIKRTVAAPSVFIFPPSKEQLKSGTASVVCLLNNFYPREAKVQWKVDNAL
QSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSP
VTKSFNRGEC
S E Q ID NO : 102: M k H 4 W T DR
DIQMTQSPS SLS AS V GDRVTITCS AS S S VTYM YWY QRKPGD APKLLI YDTS
NLASGVPSRFSGSGSGTDYTFTISSLQPEDIATYYCQQWSSHIFTFGQGTKV
EIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNAL
QSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSP
VTKSFNRGEC
SEQ ID NO: 103: Mk H4WT CS+DR
DIQMTQSPS SLS AS V GDRVTITCS AS S S VTYM YWY QRKPGD APKLLI YDTS
NLASGVPSRFSGSGSGTDYTFTISSLQPEDIATYYCQQWSSHIFTFGQGTKV
EIKRT V AAP S VFIFPP SKEQLKS GT AS V V CLLNNF YPRE AKV Q WKVDN AL
QSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSP
VTKSFNRGEC
SEQ ID NO: 104: (+)BHA10G1 H4WT
QVQLVQSGAEVKKPGSSVKVSCKASGYTFTTYYLHWVRYAPGQGLEWM
G WIYPGN VH AQ YNEKFKGRVTIT ADKST ST AYMEL S SLRSEDT AV Y Y C A
RSWEGFPYWGQGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKD
YFPEP VT V S WNS G ALT S G VHTFP AVLQ S S GL Y SLS S V VT VP S S SLGT QT YI
CNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKD
TLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQS
TYRVV S VLTVLHQDWLNGKEYKCKV SNKALPAPIEKTISKAKGQPREPQV
YTLPP SRKELTKN Q V SLT CL VKGF YP SDI AVE WESN GQPENN YKTTPP VL
KSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG
SEQ ID NO: 105: (+)BHA10G1 H4WT CS
QVQLVQSGAEVKKPGSSVKVSCKASGYTFTTYYLHWVRYAPGQGLEWM
GWI YPGN VHAQ YNEKFKGRVTIT ADKST ST AYMEL S SLRSEDT AV Y Y C A
RSWEGFPYWGQGTTVTVSSASTKGPSVFPLAPCSKSTSGGTAALGCLVKD
YFPEP VTV S WNSG ALTSG VHTFP AVLQS SGL Y SLS S VVT VPS S SLGT QTYI
CNVNHKPSNTKVDKKVEPDSGDKTHTCPPCPAPELLGGPSVFLFPPKPKD
TLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQS
TYRVV S VLTVLHQDWLNGKEYKCKV SNKALPAPIEKTISKAKGQPREPQV
YTLPP S RKELTKN Q V SLT CL VKGF YP SDI AVE WESN GQPENN YKTTPP VL
KSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG
SEQ ID NO: 106: (+)BHA10G1 H4WT DR
QVQLVQSGAEVKKPGSSVKVSCKASGYTFTTYYLHWVRYAPGQGLEWM
G WIYPGN VH AQ YNEKFKGRVTIT ADKST ST AYMEL S SLRSEDT AV Y Y C A
RSWEGFPYWGRGTTVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKD
YFPEP YT V S WNS G ALT S G VHTFP AVLQ S S GL Y SL S S V VT VP S S SLGT QT YI
CNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKD
TLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQS
TYRVV S VLTVLHQDWLNGKEYKCKV SNKALPAPIEKTISKAKGQPREPQV
YTLPP S RKELTKN Q V SLT CL VKGF YP SDI AVE WESN GQPENN YKTTPP VL
KSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG
SEQ ID NO: 107: (+)BHA10G1 H4WT CS+DR
QVQLVQSGAEVKKPGSSVKVSCKASGYTFTTYYLHWVRYAPGQGLEWM
GWI YPGN VHAQ YNEKFKGRVTIT ADKST ST AYMEL S SLRSEDT AV Y Y C A
RSWEGFPYWGRGTTVTVSSASTKGPSVFPLAPCSKSTSGGTAALGCLVKD
YFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYI
CNVNHKPSNTKVDKKVEPDSGDKTHTCPPCPAPELLGGPSVFLFPPKPKD
TLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYQS
TYRVV S VLTVLHQDWLNGKEYKCKV SNKALPAPIEKTISKAKGQPREPQV
YTLPP S RKELTKN Q V SLT CL VKGF YP SDI AVE WESN GQPENN YKTTPP VL
KSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG
SEQ ID NO: 108: (-)TG1 AB2133a (Trastuzumab)
EVQLVESGGGLVQPGGSLRLSCAASGFNIKDTY1HWVRKAPGKGLEWVA
RIYPTNGYTRYADEVKGRFTISADTSKNTAYLQMNSLRAEDTAVYYCSR
WGGDGFYAMDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGC
LVKDYFPEPVTVSWNSGALTSGVATGPAVLQSSGLYSLSSVVTVPSSSLG
TQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPP
KPKDTLMISRTPEVT C VV VD V SHEDPE VKFNWYVDGVE VHNAKTKPREE
QYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQP
REPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYDT
TPPVLDSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLS
LSPG
SEQ ID NO: 109: BHA10k H4WT
DIQMTQSPSSLSASVGDRVTITCKASQNVGINVAWYQRKPGKAPKSLISSA
SYRYSGVPSRFSGSGSGTDFTLTISSLQPEDFATYFCQQYDTYPFTFGQGTK
VEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNA
LQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSS
PVTKSFNRGEC
S E Q ID NO : 110: B H A 10 k H 4 W T CS
DIQMTQSPSSLSASVGDRVTITCKASQNVGINVAWYQRKPGKAPKSLISSA
SYRYSGVPSRFSGSGSGTDFTLTISSLQPEDFATYFCQQYDTYPFTFGQGTK
VEIKRTVAAPS VFIFPP SKEQLKSGT AS VV CLLNNF YPRE AKV Q WKVDNA
LQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSS
PYTKSFNRGEC
SEQ ID NO: 111: BHA10k H4WT DR
DIQMTQSPS SLS AS V GDRVTITCKASQNV GINV AWY QRKPGD APKSLIS S A
SYRYSGVPSRFSGSGSGTDFTLTISSLQPEDFATYFCQQYDTYPFTFGQGTK
VEIKRTVAAPS VFIFPP SDEQFKS GT AS VV CLLNNF YPRE AKVQ WKVDNA
FQSGNSQESVTEQDSKDSTYSFSSTFTFSKADYEKHKVYACEVTHQGFSS
PVTKSFNRGEC
SEQ ID NO: 112: BHA10k H4WT CS+DR
DIQMTQSPS SLS AS V GDRVTITCKASQNV GINV AWY QRKPGD APKSLIS S A
SYRYSGVPSRFSGSGSGTDFTLTISSLQPEDFATYFCQQYDTYPFTFGQGTK
VEIKRTVAAPS VFIFPP SKEQLKSGT AS VV CLLNNF YPRE AKV Q WKVDNA
LQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSS
PVTKSFNRGEC
SEQ ID NO: 113: Tk AB2133a (Trastuzumab)
RIQMTQSPSSLSASVGDRVTITCRASQDVNTAVAWYQDKPGKAPKLLIYS
ASFLYSGVPSRFSGSRSGTDFTLTISSLQPEDFATYYCQQHYTTPPTFGQGT
KVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCYLNNFYPREAKVQWKVDN
ALQSGNSQESVTEQDSKDSTYSLWSTLTLSKADYEKHKVYACEVTHQGL
S SP VTKSFNRGEC
Claims (17)
1. Un procedimiento para la producción de un primer y un segundo fragmento, de unión a antígeno (Fab), que comprende:
(1) la coexpresión de un primer ácido nucleico, un segundo ácido nucleico, un tercer ácido nucleico y un cuarto ácido nucleico en una célula hospedadora, en los que:
(a) el primer ácido nucleico codifica tanto un dominio variable de la primera cadena pesada como un dominio constante CH1 de la primera cadena pesada de IgG, en el que dicho dominio variable de la primera cadena pesada comprende una lisina en el resto 39 y un ácido glutámico en el resto que está cuatro aminoácidos corriente arriba del primer resto del HFR3 de acuerdo con Kabat, y dicho dominio constante CH1 de la primera cadena pesada de IgG comprende una alanina o una arginina en el resto 172 y una glicina en el resto 174;
(b) el segundo ácido nucleico codifica tanto un dominio variable de la primera cadena ligera como un dominio constante de la primera cadena ligera, en el que dicho dominio variable de la primera cadena ligera es un isotipo kappa y comprende una arginina en el resto 1 y un ácido aspártico en el resto 38, y dicho dominio constante de la primera cadena ligera comprende una tirosina en el resto 135 y un triptófano en el resto 176; (c) el tercer ácido nucleico codifica tanto un dominio variable de la segunda cadena pesada como un dominio constante CH1 de la segunda cadena pesada de IgG, en el que dicho dominio variable de la segunda cadena pesada comprende una tirosina en el resto 39 y dicho dominio constante CH1 de la segunda cadena pesada de IgG comprende una secuencia de WT, y el cuarto ácido nucleico codifica tanto un dominio variable de la segunda cadena ligera como un dominio constante de la segunda cadena ligera, en el que dicho dominio variable de la segunda cadena ligera comprende una arginina en el resto 38 y dicho dominio constante de la segunda cadena ligera comprende una secuencia de WT; o
(d) el tercer ácido nucleico codifica tanto un dominio variable de la segunda cadena pesada como un dominio constante CH1 de la segunda cadena pesada de IgG, en el que dicho dominio variable de la segunda cadena pesada comprende una tirosina en el resto 39 y dicho dominio constante CH1 de la segunda cadena pesada de IgG comprende un ácido aspártico en el resto 228, y el cuarto ácido nucleico codifica tanto un dominio variable de la segunda cadena ligera como un dominio constante de la segunda cadena ligera, en el que dicho dominio variable de la segunda cadena ligera comprende una arginina en el resto 38 y dicho dominio constante de la segunda cadena ligera comprende una lisina en el resto 122
en el que cada uno de dichos dominios variables de las primeras cadena pesada y cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que dirigen la unión a un primer antígeno y además en el que cada uno de dichos dominios variables de las segundas cadena pesada y cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que dirigen la unión a un segundo antígeno que difiere de dicho primer antígeno;
en el que dichos dominios constantes de las primera y segunda cadena pesada de IgG son el isotipo IgG1 o IgG4 humano;
(2) el cultivo de dicha célula hospedadora en condiciones tales que se produzcan dichos dominios variable y constante CH1 de IgG de las primera y segunda cadena pesada y dichos dominios variable y constante de la primera y segunda cadena ligera; y
(3) la recuperación a partir de dicha célula hospedadora de un primer y segundo Fab, en el que dicho primer Fab comprende dichos dominios variable y constante de la primera cadena pesada y dichos dominios variable y constante de la primera cadena ligera, y dicho segundo Fab comprende dichos dominios variable y constante de la segunda cadena pesada y dichos dominios variable y constante de la segunda cadena ligera.
2. Un procedimiento de acuerdo con la reivindicación 1, en el que dicho dominio constante CH1 de la primera cadena pesada de IgG comprende además una metionina o una isoleucina sustituida en el resto 190.
3. Un procedimiento de acuerdo con la reivindicación 1 o la reivindicación 2, en el que dicho dominio constante de la primera cadena ligera es un isotipo kappa y comprende además una leucina sustituida en el resto 133.
4. Un procedimiento de acuerdo con una cualquiera de las reivindicaciones 2-3, en el que dicho dominio constante de la primera cadena ligera es un isotipo kappa y comprende además una glutamina o un ácido aspártico sustituido en el resto 174.
5. Un procedimiento de acuerdo con una cualquiera de las reivindicaciones 1-4, en el que dicho dominio variable de la segunda cadena pesada comprende además una arginina sustituida en el resto 105 y dicho dominio variable de la segunda cadena ligera comprende además un ácido aspártico sustituido en el resto 42.
6. Un procedimiento de acuerdo con una cualquiera de las reivindicaciones 1-6, en el que dicha célula hospedadora es una célula de mamífero.
7. Un procedimiento de acuerdo con una cualquiera de las reivindicaciones 1-7, en el que dichos dominios constantes de la primera y segunda cadena ligera son un isotipo kappa.
8. Un procedimiento para la producción de un anticuerpo biespecífico que comprende:
(1) la coexpresión de un primer ácido nucleico, un segundo ácido nucleico, un tercer ácido nucleico y un cuarto ácido nucleico en una célula hospedadora, en los que:
(a) el primer ácido nucleico codifica una primera cadena pesada de IgG, en la que dicha primera cadena pesada comprende un dominio variable que comprende una lisina sustituida en el resto 39 y un ácido glutámico en el resto que está cuatro aminoácidos corriente arriba del primer resto de1HFR3 de acuerdo con Kabat, y un dominio constante CH1 que comprende una alanina o una arginina en el resto 172 y una glicina en el resto 174;
(b) el segundo ácido nucleico codifica una primera cadena ligera, en la que dicha primera cadena ligera comprende un dominio variable kappa que comprende una arginina en el resto 1 y un ácido aspártico en el resto 38, y un dominio constante que comprende una tirosina en el resto 135 y un triptófano en el resto 176; (c) el tercer ácido nucleico codifica una segunda cadena pesada de IgG, en la que dicha segunda cadena pesada comprende un dominio variable que comprende una tirosina en el resto 39 y un dominio constante CH1 que comprende una secuencia de WT, y el cuarto ácido nucleico codifica una segunda cadena ligera, en la que dicha segunda cadena ligera comprende un dominio variable que comprende una arginina en el resto 38 y un dominio constante que comprende una secuencia de WT; o
(d) el tercer ácido nucleico codifica una segunda cadena pesada de IgG, en la que dicha segunda cadena pesada comprende un dominio variable que comprende una tirosina en el resto 39 y un dominio constante CH1 que comprende un ácido aspártico en el resto 228, y el cuarto ácido nucleico codifica una segunda cadena ligera, en la que dicha segunda cadena ligera comprende un dominio variable que comprende una arginina en el resto 38 y un dominio constante que comprende una lisina en el resto 122,
en el que cada uno de dichos dominios variables de las primeras cadena pesada y cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que dirigen la unión a un primer antígeno y además en el que cada uno de dichos dominios variables de las segundas cadena pesada y cadena ligera comprende tres regiones determinantes de complementariedad (las CDR) que dirigen la unión a un segundo antígeno que difiere de dicho primer antígeno; y
en el que dichos dominios constantes de las primera y segunda cadena pesada de IgG son el isotipo IgG1 o IgG4 humano;
(2) el cultivo de dicha célula hospedadora en condiciones tales que se produzcan dichas primera y segunda cadenas pesadas de IgG y dichas primera y segunda cadenas ligeras; y
(3) la recuperación a partir de dicha célula hospedadora de un anticuerpo biespecífico que comprende un primer y un segundo fragmento, de unión a antígeno (Fab), en el que dicho primer Fab comprende dicha primera cadena pesada de IgG y dicha primera cadena ligera y dicho segundo Fab comprende dicha segunda cadena pesada de IgG y dicha segunda cadena ligera.
9. Un procedimiento de acuerdo con la reivindicación 8, en el que dicho dominio constante CH1 de la primera cadena pesada de IgG comprende además una metionina o una isoleucina en el resto 190.
10. Un procedimiento de acuerdo con la reivindicación 8 o la reivindicación 9, en el que dicho dominio constante de la primera cadena ligera es un isotipo kappa y comprende además una leucina en el resto 133.
11. Un procedimiento de acuerdo con una cualquiera de las reivindicaciones 8-10, en el que dicho dominio constante de la primera cadena ligera es un isotipo kappa y comprende además una glutamina o un ácido aspártico en el resto 174.
12. Un procedimiento de acuerdo con una cualquiera de las reivindicaciones 8-11, en el que dicho dominio variable de la segunda cadena pesada comprende además una arginina en el resto 105 y dicho dominio variable de la segunda cadena ligera comprende además un ácido aspártico en el resto 42.
13. Un procedimiento de acuerdo con una cualquiera de las reivindicaciones 8 a 12, en el que una de dichas primera y segunda cadenas pesadas de IgG comprende además un dominio constante CH3 que comprende una lisina en el resto 356 y una lisina en el resto 399, y la otra de dichas primera y segunda cadenas pesadas de IgG comprende además un dominio constante CH3 que comprende un ácido aspártico en el resto 392 y un ácido aspártico en el resto 409.
14. Un procedimiento de acuerdo con una cualquiera de las reivindicaciones 8-13, en el que dicha célula hospedadora es una célula de mamífero.
15. Un procedimiento de acuerdo con una cualquiera de las reivindicaciones 8-14, en el que dichos dominios constantes de la primera y segunda cadena ligera son un isotipo kappa.
16. Un fragmento, de unión a antígeno (Fab), producido de acuerdo con una cualquiera de las reivindicaciones 1-7.
17. Un anticuerpo biespecífico producido de acuerdo con una cualquiera de las reivindicaciones 8-15.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201361791598P | 2013-03-15 | 2013-03-15 | |
| PCT/US2014/024688 WO2014150973A1 (en) | 2013-03-15 | 2014-03-12 | Methods for producing fabs and bi-specific antibodies |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| ES2821753T3 true ES2821753T3 (es) | 2021-04-27 |
Family
ID=50588838
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| ES14719931T Active ES2821753T3 (es) | 2013-03-15 | 2014-03-12 | Procedimientos de producción de Fab y de anticuerpos biespecíficos |
Country Status (4)
| Country | Link |
|---|---|
| US (3) | US10047167B2 (es) |
| EP (1) | EP2970435B1 (es) |
| ES (1) | ES2821753T3 (es) |
| WO (1) | WO2014150973A1 (es) |
Families Citing this family (77)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9771573B2 (en) | 2012-10-03 | 2017-09-26 | Zymeworks Inc. | Methods of quantitating heavy and light chain polypeptide pairs |
| US9914785B2 (en) | 2012-11-28 | 2018-03-13 | Zymeworks Inc. | Engineered immunoglobulin heavy chain-light chain pairs and uses thereof |
| BR112015012385A2 (pt) | 2012-11-28 | 2019-08-27 | Zymeworks Inc | constructo de polipeptídeo de ligação de antígeno isolado, polinucleotídeo isolado ou conjunto de polinucleotídeos isolados, vetor ou conjunto de vetores, célula isolada, composição farmacêutica, uso do constructo, método para tratar um sujeito tendo uma doença ou distúrbio ou câncer ou doença vascular, método para inibir, reduzir ou bloquear um sinal dentro de uma célula, método para obter o constructo, método para preparar o constructo, meio de armazenamento legível por computador, método implementado por computador e método para produzir um constructo de polipeptídeo de ligação de antígeno bi-específico |
| ES2821753T3 (es) * | 2013-03-15 | 2021-04-27 | Lilly Co Eli | Procedimientos de producción de Fab y de anticuerpos biespecíficos |
| ES2936810T3 (es) | 2014-05-16 | 2023-03-22 | Pfizer | Anticuerpos biespecíficos con interfaces CH1-CL de ingeniería |
| DK3107938T3 (da) | 2014-05-28 | 2022-07-11 | Zymeworks Inc | Modificerede, antigenbindende polypeptidkonstrukter og anvendelser heraf |
| MA41375A (fr) | 2015-01-22 | 2017-11-28 | Lilly Co Eli | Anticorps igg bispécifiques et leurs procédés de préparation |
| CN107787332B (zh) | 2015-04-24 | 2022-09-09 | 豪夫迈·罗氏有限公司 | 多特异性抗原结合蛋白 |
| JP7525980B2 (ja) * | 2015-08-28 | 2024-07-31 | アレクトル エルエルシー | 抗Siglec-7抗体及びその使用方法 |
| MX2018004285A (es) * | 2015-10-08 | 2018-11-09 | Zymeworks Inc | Construcciones polipeptidicas de union al antigeno que comprenden cadenas ligeras kappa y lambda y usos de estas. |
| CA3003759A1 (en) * | 2015-11-03 | 2017-05-11 | Merck Patent Gmbh | Bi-specific antibodies for enhanced tumor selectivity and inhibition and uses thereof |
| AU2017238172B2 (en) | 2016-03-21 | 2024-06-27 | Marengo Therapeutics, Inc. | Multispecific and multifunctional molecules and uses thereof |
| JP7301540B2 (ja) | 2016-05-26 | 2023-07-03 | チールー ピュージェット サウンド バイオセラピューティクス コーポレイション | 抗体の混合物 |
| DK3478830T3 (da) | 2016-07-01 | 2024-05-21 | Resolve Therapeutics Llc | Optimerede binucleasefusioner og metoder |
| MX2019001651A (es) | 2016-08-10 | 2019-09-04 | Univ Ajou Ind Academic Coop Found | Citocina fusionada a fc heterodimerico, y composicion farmaceutica que comprende la misma. |
| US11820828B2 (en) | 2016-12-22 | 2023-11-21 | Eli Lilly And Company | Methods for producing fabs and IgG bispecific antibodies |
| JP7123063B2 (ja) * | 2017-02-02 | 2022-08-22 | メルク パテント ゲゼルシャフト ミット ベシュレンクテル ハフツング | 抗体ドメインの好ましい対形成 |
| WO2018151820A1 (en) | 2017-02-16 | 2018-08-23 | Elstar Therapeutics, Inc. | Multifunctional molecules comprising a trimeric ligand and uses thereof |
| JP7116736B2 (ja) | 2017-03-02 | 2022-08-10 | ノバルティス アーゲー | 操作されたヘテロ二量体タンパク質 |
| WO2018222901A1 (en) | 2017-05-31 | 2018-12-06 | Elstar Therapeutics, Inc. | Multispecific molecules that bind to myeloproliferative leukemia (mpl) protein and uses thereof |
| MX2019015293A (es) | 2017-06-30 | 2020-02-17 | Zymeworks Inc | Fab quimericos estabilizados. |
| CA3073537A1 (en) | 2017-08-22 | 2019-02-28 | Sanabio, Llc | Soluble interferon receptors and uses thereof |
| CN109957026A (zh) * | 2017-12-22 | 2019-07-02 | 成都恩沐生物科技有限公司 | 共价多特异性抗体 |
| SG11202005009RA (en) * | 2018-01-15 | 2020-06-29 | I Mab Biopharma Us Ltd | MODIFIED Cκ AND CH1 DOMAINS |
| WO2019148410A1 (en) | 2018-02-01 | 2019-08-08 | Merck Sharp & Dohme Corp. | Anti-pd-1 antibodies |
| WO2019148412A1 (en) | 2018-02-01 | 2019-08-08 | Merck Sharp & Dohme Corp. | Anti-pd-1/lag3 bispecific antibodies |
| SG11202007482WA (en) | 2018-02-08 | 2020-09-29 | Dragonfly Therapeutics Inc | Antibody variable domains targeting the nkg2d receptor |
| WO2019178364A2 (en) | 2018-03-14 | 2019-09-19 | Elstar Therapeutics, Inc. | Multifunctional molecules and uses thereof |
| WO2019178362A1 (en) | 2018-03-14 | 2019-09-19 | Elstar Therapeutics, Inc. | Multifunctional molecules that bind to calreticulin and uses thereof |
| WO2019199916A1 (en) | 2018-04-13 | 2019-10-17 | Eli Lilly And Company | Fab-based trispecific antibodies |
| EP3802611A2 (en) | 2018-06-01 | 2021-04-14 | Novartis AG | Binding molecules against bcma and uses thereof |
| WO2019236417A1 (en) * | 2018-06-04 | 2019-12-12 | Biogen Ma Inc. | Anti-vla-4 antibodies having reduced effector function |
| WO2020010250A2 (en) | 2018-07-03 | 2020-01-09 | Elstar Therapeutics, Inc. | Anti-tcr antibody molecules and uses thereof |
| BR112021007175A2 (pt) | 2018-10-23 | 2021-08-10 | Dragonfly Therapeutics, Inc. | proteínas fundidas a fc heterodimérico |
| EP3927745A1 (en) | 2019-02-21 | 2021-12-29 | Marengo Therapeutics, Inc. | Multifunctional molecules that bind to t cells and uses thereof to treat autoimmune disorders |
| EP3927746A1 (en) | 2019-02-21 | 2021-12-29 | Marengo Therapeutics, Inc. | Multifunctional molecules that bind to calreticulin and uses thereof |
| SG11202109061YA (en) | 2019-02-21 | 2021-09-29 | Marengo Therapeutics Inc | Multifunctional molecules that bind to t cell related cancer cells and uses thereof |
| AU2020226904A1 (en) | 2019-02-21 | 2021-09-16 | Marengo Therapeutics, Inc. | Anti-TCR antibody molecules and uses thereof |
| EP3927747A1 (en) | 2019-02-21 | 2021-12-29 | Marengo Therapeutics, Inc. | Antibody molecules that bind to nkp30 and uses thereof |
| CA3134016A1 (en) | 2019-05-09 | 2020-11-12 | Genentech, Inc. | Methods of making antibodies |
| AU2020279224A1 (en) | 2019-05-21 | 2021-12-16 | Novartis Ag | Trispecific binding molecules against BCMA and uses thereof |
| US12037378B2 (en) | 2019-05-21 | 2024-07-16 | Novartis Ag | Variant CD58 domains and uses thereof |
| EP3972998A1 (en) | 2019-05-21 | 2022-03-30 | Novartis AG | Cd19 binding molecules and uses thereof |
| MX2022001682A (es) | 2019-08-08 | 2022-05-13 | Regeneron Pharma | Nuevos formatos de moleculas de union a antigenos. |
| US20210130477A1 (en) | 2019-11-05 | 2021-05-06 | Regeneron Pharmaceuticals, Inc. | N-TERMINAL scFv MULTISPECIFIC BINDING MOLECULES |
| EP4077397A2 (en) | 2019-12-20 | 2022-10-26 | Regeneron Pharmaceuticals, Inc. | Novel il2 agonists and methods of use thereof |
| WO2021138407A2 (en) | 2020-01-03 | 2021-07-08 | Marengo Therapeutics, Inc. | Multifunctional molecules that bind to cd33 and uses thereof |
| US20230137966A1 (en) * | 2020-02-12 | 2023-05-04 | Eli Lilly And Company | Crystallization of Antibodies or Antigen-Binding Fragments |
| IL296428A (en) | 2020-03-25 | 2022-11-01 | Lilly Co Eli | Multispecific binding proteins and methods for their development |
| US20230128499A1 (en) | 2020-03-27 | 2023-04-27 | Novartis Ag | Bispecific combination therapy for treating proliferative diseases and autoimmune diseases |
| CN115843312A (zh) | 2020-04-24 | 2023-03-24 | 马伦戈治疗公司 | 结合至t细胞相关癌细胞的多功能性分子及其用途 |
| EP4149963A1 (en) | 2020-05-12 | 2023-03-22 | Regeneron Pharmaceuticals, Inc. | Novel il10 agonists and methods of use thereof |
| CN116917316A (zh) | 2020-08-26 | 2023-10-20 | 马伦戈治疗公司 | 与NKp30结合的抗体分子及其用途 |
| GB2616354A (en) | 2020-08-26 | 2023-09-06 | Marengo Therapeutics Inc | Methods of detecting TRBC1 or TRBC2 |
| EP4204450A4 (en) | 2020-08-26 | 2024-11-13 | Marengo Therapeutics Inc | MULTIFUNCTIONAL MOLECULES BINDING TO CALRETICULIN AND USES THEREOF |
| WO2022081516A1 (en) | 2020-10-13 | 2022-04-21 | Janssen Biotech, Inc. | Bioengineered t cell mediated immunity, materials and other methods for modulating cluster of differentiation iv &/or viii |
| CA3199095A1 (en) | 2020-11-06 | 2022-05-12 | Novartis Ag | Cd19 binding molecules and uses thereof |
| KR20230104222A (ko) | 2020-11-06 | 2023-07-07 | 노파르티스 아게 | B 세포 악성종양 치료를 위한 항-cd19 작용제 및 b 세포 표적화제 병용 요법 |
| WO2022104186A1 (en) * | 2020-11-16 | 2022-05-19 | Tavotek Biotherapeutics (Hong Kong) Limited | A shielded and homing bispecific antibody that simultaneously inhibits angiogenic pathway targets and her2 family proteins and uses thereof |
| JP2024515591A (ja) | 2021-04-08 | 2024-04-10 | マレンゴ・セラピューティクス,インコーポレーテッド | Tcrに結合する多機能性分子およびその使用 |
| CN117597365A (zh) | 2021-05-04 | 2024-02-23 | 再生元制药公司 | 多特异性fgf21受体激动剂及其应用 |
| EP4334353A1 (en) | 2021-05-04 | 2024-03-13 | Regeneron Pharmaceuticals, Inc. | Multispecific fgf21 receptor agonists and their uses |
| EP4373851A2 (en) | 2021-07-19 | 2024-05-29 | Regeneron Pharmaceuticals, Inc. | Il12 receptor agonists and methods of use thereof |
| WO2023022965A2 (en) | 2021-08-16 | 2023-02-23 | Regeneron Pharmaceuticals, Inc. | Novel il27 receptor agonists and methods of use thereof |
| KR20240099460A (ko) | 2021-11-11 | 2024-06-28 | 리제너론 파아마슈티컬스, 인크. | Cd20-pd1 결합 분자 및 이의 사용 방법 |
| CN114106192B (zh) * | 2021-12-20 | 2024-06-14 | 广州爱思迈生物医药科技有限公司 | 双特异性抗体及其应用 |
| WO2023220647A1 (en) | 2022-05-11 | 2023-11-16 | Regeneron Pharmaceuticals, Inc. | Multispecific binding molecule proproteins and uses thereof |
| US20230382969A1 (en) | 2022-05-27 | 2023-11-30 | Regeneron Pharmaceuticals, Inc. | Interleukin-2 proproteins and uses thereof |
| WO2023235848A1 (en) | 2022-06-04 | 2023-12-07 | Regeneron Pharmaceuticals, Inc. | Interleukin-2 proproteins and uses thereof |
| US20240067691A1 (en) | 2022-08-18 | 2024-02-29 | Regeneron Pharmaceuticals, Inc. | Interferon receptor agonists and uses thereof |
| WO2024040247A1 (en) | 2022-08-18 | 2024-02-22 | Regeneron Pharmaceuticals, Inc. | Interferon proproteins and uses thereof |
| WO2024130175A2 (en) | 2022-12-16 | 2024-06-20 | Regeneron Pharmaceuticals, Inc. | Antigen-binding molecules that bind to aav particles and uses |
| WO2024151978A1 (en) | 2023-01-13 | 2024-07-18 | Regeneron Pharmaceuticals, Inc. | Il12 receptor agonists and methods of use thereof |
| US20240247069A1 (en) | 2023-01-13 | 2024-07-25 | Regeneron Pharmaceuticals, Inc. | Fgfr3 binding molecules and methods of use thereof |
| WO2024182540A2 (en) | 2023-02-28 | 2024-09-06 | Regeneron Pharmaceuticals, Inc. | T cell activators and methods of use thereof |
| WO2024182451A2 (en) | 2023-02-28 | 2024-09-06 | Regeneron Pharmaceuticals, Inc. | Multivalent anti-spike protein binding molecules and uses thereof |
| WO2024182455A2 (en) | 2023-02-28 | 2024-09-06 | Regeneron Pharmaceuticals, Inc. | Multivalent anti-spike protein binding molecules and uses thereof |
Family Cites Families (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CA2603408C (en) | 2005-03-31 | 2018-08-21 | Chugai Seiyaku Kabushiki Kaisha | Methods for producing polypeptides by regulating polypeptide association |
| AU2007227292B2 (en) | 2006-03-17 | 2012-04-12 | Biogen Ma Inc. | Stabilized polypeptide compositions |
| US20090182127A1 (en) | 2006-06-22 | 2009-07-16 | Novo Nordisk A/S | Production of Bispecific Antibodies |
| WO2011014457A1 (en) | 2009-07-27 | 2011-02-03 | Genentech, Inc. | Combination treatments |
| UY35148A (es) | 2012-11-21 | 2014-05-30 | Amgen Inc | Immunoglobulinas heterodiméricas |
| US9914785B2 (en) | 2012-11-28 | 2018-03-13 | Zymeworks Inc. | Engineered immunoglobulin heavy chain-light chain pairs and uses thereof |
| ES2821753T3 (es) * | 2013-03-15 | 2021-04-27 | Lilly Co Eli | Procedimientos de producción de Fab y de anticuerpos biespecíficos |
| MA41375A (fr) * | 2015-01-22 | 2017-11-28 | Lilly Co Eli | Anticorps igg bispécifiques et leurs procédés de préparation |
-
2014
- 2014-03-12 ES ES14719931T patent/ES2821753T3/es active Active
- 2014-03-12 WO PCT/US2014/024688 patent/WO2014150973A1/en active Application Filing
- 2014-03-12 US US14/773,418 patent/US10047167B2/en active Active
- 2014-03-12 EP EP14719931.9A patent/EP2970435B1/en active Active
-
2018
- 2018-07-06 US US16/029,196 patent/US10294307B2/en active Active
-
2019
- 2019-03-11 US US16/298,113 patent/US10562982B2/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| US20160039947A1 (en) | 2016-02-11 |
| US10294307B2 (en) | 2019-05-21 |
| EP2970435A1 (en) | 2016-01-20 |
| US10562982B2 (en) | 2020-02-18 |
| WO2014150973A1 (en) | 2014-09-25 |
| US10047167B2 (en) | 2018-08-14 |
| US20180305466A1 (en) | 2018-10-25 |
| EP2970435B1 (en) | 2020-08-12 |
| US20190211115A1 (en) | 2019-07-11 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| ES2821753T3 (es) | Procedimientos de producción de Fab y de anticuerpos biespecíficos | |
| US11976136B2 (en) | IgG bispecific antibodies and processes for preparation | |
| ES2935274T3 (es) | Anticuerpo con intercambio de dominios | |
| CN104955953B (zh) | 高效诱导抗体重链恒定区的异源二聚体形成的ch3域变体对,其制备方法及用途 | |
| ES2751386T3 (es) | Polipéptidos Fc variantes con unión potenciada al receptor de Fc neonatal | |
| BR112020023508A2 (pt) | Anticorpos anti-cd3 e usos dos mesmos | |
| CN112424223A (zh) | 抗序列相似家族19成员a5的抗体在治疗神经性疼痛中的用途 | |
| JP6215056B2 (ja) | 拮抗性dr3リガンド | |
| CN108948196A (zh) | Cd40l-特异性tn3-衍生的支架及其使用方法 | |
| JP7099709B2 (ja) | ヒト化抗ベイシジン抗体およびその使用 | |
| US20240043552A1 (en) | Methods for Producing Fabs and IgG Bispecific Antibodies | |
| CN107428838A (zh) | 结合tfpi的新型抗体以及包含所述抗体的组合物 | |
| JP2023509212A (ja) | 新型ポリペプチド複合物 | |
| AU2019274652A1 (en) | Monospecific and multispecific anti-TMEFF2 antibodies and there uses | |
| JP2021500873A (ja) | システイン操作された抗原結合分子 | |
| CA3210307A1 (en) | Bispecific antibody | |
| IL256263A (en) | Cys80-linked immunoglobulins | |
| JP7483865B2 (ja) | T細胞受容体の定常ドメインを含むタンパク質 | |
| JP7123063B2 (ja) | 抗体ドメインの好ましい対形成 | |
| CN118843796A (zh) | 稳定的单一免疫球蛋白可变结构域 |