EP3518657B1 - Plant promoter for transgene expression - Google Patents
Plant promoter for transgene expression Download PDFInfo
- Publication number
- EP3518657B1 EP3518657B1 EP17858870.3A EP17858870A EP3518657B1 EP 3518657 B1 EP3518657 B1 EP 3518657B1 EP 17858870 A EP17858870 A EP 17858870A EP 3518657 B1 EP3518657 B1 EP 3518657B1
- Authority
- EP
- European Patent Office
- Prior art keywords
- sequence
- plant
- gene
- pavir
- seq
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 230000014509 gene expression Effects 0.000 title claims description 151
- 108700019146 Transgenes Proteins 0.000 title description 231
- 210000004027 cell Anatomy 0.000 claims description 448
- 241000196324 Embryophyta Species 0.000 claims description 416
- 108090000623 proteins and genes Proteins 0.000 claims description 362
- 241001520808 Panicum virgatum Species 0.000 claims description 251
- 150000007523 nucleic acids Chemical class 0.000 claims description 138
- 102000040430 polynucleotide Human genes 0.000 claims description 138
- 108091033319 polynucleotide Proteins 0.000 claims description 138
- 239000002157 polynucleotide Substances 0.000 claims description 136
- 102000039446 nucleic acids Human genes 0.000 claims description 100
- 108020004707 nucleic acids Proteins 0.000 claims description 100
- 230000009261 transgenic effect Effects 0.000 claims description 76
- 239000013598 vector Substances 0.000 claims description 68
- 102000004169 proteins and genes Human genes 0.000 claims description 57
- 108091026890 Coding region Proteins 0.000 claims description 46
- 239000004009 herbicide Substances 0.000 claims description 43
- 240000008042 Zea mays Species 0.000 claims description 38
- 108091032955 Bacterial small RNA Proteins 0.000 claims description 37
- 239000003550 marker Substances 0.000 claims description 36
- 230000002363 herbicidal effect Effects 0.000 claims description 33
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 claims description 26
- 235000007244 Zea mays Nutrition 0.000 claims description 22
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 claims description 19
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 claims description 16
- 102000052510 DNA-Binding Proteins Human genes 0.000 claims description 15
- 240000007594 Oryza sativa Species 0.000 claims description 14
- 235000016709 nutrition Nutrition 0.000 claims description 14
- 244000068988 Glycine max Species 0.000 claims description 13
- 229910052757 nitrogen Inorganic materials 0.000 claims description 13
- 101710163270 Nuclease Proteins 0.000 claims description 12
- 230000000749 insecticidal effect Effects 0.000 claims description 12
- 101710096438 DNA-binding protein Proteins 0.000 claims description 10
- 235000010469 Glycine max Nutrition 0.000 claims description 10
- 241000219146 Gossypium Species 0.000 claims description 10
- 235000007164 Oryza sativa Nutrition 0.000 claims description 10
- 235000007238 Secale cereale Nutrition 0.000 claims description 10
- 235000021307 Triticum Nutrition 0.000 claims description 10
- 229920000742 Cotton Polymers 0.000 claims description 9
- 244000020551 Helianthus annuus Species 0.000 claims description 9
- 235000003222 Helianthus annuus Nutrition 0.000 claims description 9
- 235000011684 Sorghum saccharatum Nutrition 0.000 claims description 9
- 210000002308 embryonic cell Anatomy 0.000 claims description 9
- 235000009566 rice Nutrition 0.000 claims description 9
- 235000014698 Brassica juncea var multisecta Nutrition 0.000 claims description 8
- 235000004977 Brassica sinapistrum Nutrition 0.000 claims description 8
- 235000002637 Nicotiana tabacum Nutrition 0.000 claims description 8
- 244000075850 Avena orientalis Species 0.000 claims description 7
- 235000007319 Avena orientalis Nutrition 0.000 claims description 7
- 235000006008 Brassica napus var napus Nutrition 0.000 claims description 7
- 235000006618 Brassica rapa subsp oleifera Nutrition 0.000 claims description 7
- 241000219194 Arabidopsis Species 0.000 claims description 6
- 244000061176 Nicotiana tabacum Species 0.000 claims description 6
- 240000000111 Saccharum officinarum Species 0.000 claims description 6
- 235000007201 Saccharum officinarum Nutrition 0.000 claims description 6
- 235000021015 bananas Nutrition 0.000 claims description 5
- 102000042567 non-coding RNA Human genes 0.000 claims description 5
- 108091027963 non-coding RNA Proteins 0.000 claims description 3
- 241000209056 Secale Species 0.000 claims description 2
- 240000000385 Brassica napus var. napus Species 0.000 claims 1
- 240000008790 Musa x paradisiaca Species 0.000 claims 1
- 240000006394 Sorghum bicolor Species 0.000 claims 1
- 244000098338 Triticum aestivum Species 0.000 claims 1
- 210000001519 tissue Anatomy 0.000 description 105
- 108020004414 DNA Proteins 0.000 description 92
- 238000000034 method Methods 0.000 description 88
- 108020005345 3' Untranslated Regions Proteins 0.000 description 82
- 108020003589 5' Untranslated Regions Proteins 0.000 description 74
- 150000001413 amino acids Chemical class 0.000 description 55
- 235000018102 proteins Nutrition 0.000 description 51
- 230000001105 regulatory effect Effects 0.000 description 51
- 108091028043 Nucleic acid sequence Proteins 0.000 description 48
- 125000003729 nucleotide group Chemical group 0.000 description 46
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 45
- 239000002773 nucleotide Substances 0.000 description 45
- 239000000523 sample Substances 0.000 description 40
- 230000009466 transformation Effects 0.000 description 39
- 239000013615 primer Substances 0.000 description 33
- 241000589158 Agrobacterium Species 0.000 description 28
- 238000009396 hybridization Methods 0.000 description 25
- 230000002194 synthesizing effect Effects 0.000 description 23
- 230000004568 DNA-binding Effects 0.000 description 22
- 108020004999 messenger RNA Proteins 0.000 description 22
- 108091034117 Oligonucleotide Proteins 0.000 description 21
- 238000004519 manufacturing process Methods 0.000 description 21
- 238000003752 polymerase chain reaction Methods 0.000 description 21
- 238000013518 transcription Methods 0.000 description 21
- 230000035897 transcription Effects 0.000 description 21
- 238000003556 assay Methods 0.000 description 20
- 238000004458 analytical method Methods 0.000 description 18
- 150000001875 compounds Chemical class 0.000 description 18
- 239000013612 plasmid Substances 0.000 description 18
- 102000004190 Enzymes Human genes 0.000 description 17
- 108090000790 Enzymes Proteins 0.000 description 17
- 230000027455 binding Effects 0.000 description 17
- 230000015572 biosynthetic process Effects 0.000 description 17
- 238000006243 chemical reaction Methods 0.000 description 17
- 229940088598 enzyme Drugs 0.000 description 17
- 108090000765 processed proteins & peptides Proteins 0.000 description 17
- 238000005516 engineering process Methods 0.000 description 16
- 230000001404 mediated effect Effects 0.000 description 16
- 239000000203 mixture Substances 0.000 description 16
- 102000004196 processed proteins & peptides Human genes 0.000 description 16
- 108091005957 yellow fluorescent proteins Proteins 0.000 description 16
- 210000002257 embryonic structure Anatomy 0.000 description 15
- 238000011426 transformation method Methods 0.000 description 15
- 238000001514 detection method Methods 0.000 description 14
- 239000007850 fluorescent dye Substances 0.000 description 14
- 229920001184 polypeptide Polymers 0.000 description 14
- 241000209140 Triticum Species 0.000 description 13
- 230000009418 agronomic effect Effects 0.000 description 13
- 238000012163 sequencing technique Methods 0.000 description 13
- 230000014616 translation Effects 0.000 description 13
- 230000015556 catabolic process Effects 0.000 description 12
- 230000030279 gene silencing Effects 0.000 description 12
- -1 rRNA Proteins 0.000 description 12
- 241000238631 Hexapoda Species 0.000 description 11
- 235000002017 Zea mays subsp mays Nutrition 0.000 description 11
- 238000012258 culturing Methods 0.000 description 11
- 238000006731 degradation reaction Methods 0.000 description 11
- XDDAORKBJWWYJS-UHFFFAOYSA-N glyphosate Chemical compound OC(=O)CNCP(O)(O)=O XDDAORKBJWWYJS-UHFFFAOYSA-N 0.000 description 11
- 230000002441 reversible effect Effects 0.000 description 11
- 238000003786 synthesis reaction Methods 0.000 description 11
- 238000013519 translation Methods 0.000 description 11
- 108010020183 3-phosphoshikimate 1-carboxyvinyltransferase Proteins 0.000 description 10
- 108010000700 Acetolactate synthase Proteins 0.000 description 10
- 108091079001 CRISPR RNA Proteins 0.000 description 10
- 239000005562 Glyphosate Substances 0.000 description 10
- 230000003321 amplification Effects 0.000 description 10
- 239000003795 chemical substances by application Substances 0.000 description 10
- 229940097068 glyphosate Drugs 0.000 description 10
- 230000007062 hydrolysis Effects 0.000 description 10
- 238000006460 hydrolysis reaction Methods 0.000 description 10
- 238000007481 next generation sequencing Methods 0.000 description 10
- 238000003199 nucleic acid amplification method Methods 0.000 description 10
- 108700008625 Reporter Genes Proteins 0.000 description 9
- 244000082988 Secale cereale Species 0.000 description 9
- 108020004459 Small interfering RNA Proteins 0.000 description 9
- JFDZBHWFFUWGJE-UHFFFAOYSA-N benzonitrile Chemical compound N#CC1=CC=CC=C1 JFDZBHWFFUWGJE-UHFFFAOYSA-N 0.000 description 9
- 244000275904 brauner Senf Species 0.000 description 9
- 238000013461 design Methods 0.000 description 9
- 239000012634 fragment Substances 0.000 description 9
- 239000004055 small Interfering RNA Substances 0.000 description 9
- 108020001991 Protoporphyrinogen Oxidase Proteins 0.000 description 8
- 235000016383 Zea mays subsp huehuetenangensis Nutrition 0.000 description 8
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 8
- 229940024606 amino acid Drugs 0.000 description 8
- 235000001014 amino acid Nutrition 0.000 description 8
- 230000000692 anti-sense effect Effects 0.000 description 8
- 238000004422 calculation algorithm Methods 0.000 description 8
- 238000002866 fluorescence resonance energy transfer Methods 0.000 description 8
- 230000006870 function Effects 0.000 description 8
- 230000001965 increasing effect Effects 0.000 description 8
- 238000003780 insertion Methods 0.000 description 8
- 230000037431 insertion Effects 0.000 description 8
- 235000009973 maize Nutrition 0.000 description 8
- 230000008488 polyadenylation Effects 0.000 description 8
- 238000011160 research Methods 0.000 description 8
- 230000001131 transforming effect Effects 0.000 description 8
- 238000011144 upstream manufacturing Methods 0.000 description 8
- 108010073062 Transcription Activator-Like Effectors Proteins 0.000 description 7
- 230000003111 delayed effect Effects 0.000 description 7
- 230000004345 fruit ripening Effects 0.000 description 7
- 239000003112 inhibitor Substances 0.000 description 7
- 230000000670 limiting effect Effects 0.000 description 7
- 239000000463 material Substances 0.000 description 7
- 239000002245 particle Substances 0.000 description 7
- 230000032361 posttranscriptional gene silencing Effects 0.000 description 7
- 230000008569 process Effects 0.000 description 7
- 210000001938 protoplast Anatomy 0.000 description 7
- 238000012033 transcriptional gene silencing Methods 0.000 description 7
- 238000012546 transfer Methods 0.000 description 7
- 102000040650 (ribonucleotides)n+m Human genes 0.000 description 6
- TWQHGBJNKVFWIU-UHFFFAOYSA-N 8-[4-(4-quinolin-2-ylpiperazin-1-yl)butyl]-8-azaspiro[4.5]decane-7,9-dione Chemical compound C1C(=O)N(CCCCN2CCN(CC2)C=2N=C3C=CC=CC3=CC=2)C(=O)CC21CCCC2 TWQHGBJNKVFWIU-UHFFFAOYSA-N 0.000 description 6
- 108091033409 CRISPR Proteins 0.000 description 6
- 101100442689 Caenorhabditis elegans hdl-1 gene Proteins 0.000 description 6
- 108010035563 Chloramphenicol O-acetyltransferase Proteins 0.000 description 6
- 108091092195 Intron Proteins 0.000 description 6
- 108010025815 Kanamycin Kinase Proteins 0.000 description 6
- 108091027974 Mature messenger RNA Proteins 0.000 description 6
- 240000003829 Sorghum propinquum Species 0.000 description 6
- 108091023040 Transcription factor Proteins 0.000 description 6
- 102000040945 Transcription factor Human genes 0.000 description 6
- 241000700605 Viruses Species 0.000 description 6
- 239000002253 acid Substances 0.000 description 6
- 230000001580 bacterial effect Effects 0.000 description 6
- 238000003776 cleavage reaction Methods 0.000 description 6
- 238000010367 cloning Methods 0.000 description 6
- 230000000295 complement effect Effects 0.000 description 6
- 238000011161 development Methods 0.000 description 6
- 230000018109 developmental process Effects 0.000 description 6
- 235000013399 edible fruits Nutrition 0.000 description 6
- 229910052739 hydrogen Inorganic materials 0.000 description 6
- 238000002887 multiple sequence alignment Methods 0.000 description 6
- 210000000056 organ Anatomy 0.000 description 6
- 108091008146 restriction endonucleases Proteins 0.000 description 6
- 230000007017 scission Effects 0.000 description 6
- HULCBRRKIWCSOF-UHNVWZDZSA-N (2r)-2-[[(1s)-3-amino-1-carboxy-3-oxopropyl]amino]pentanedioic acid Chemical compound NC(=O)C[C@@H](C(O)=O)N[C@@H](C(O)=O)CCC(O)=O HULCBRRKIWCSOF-UHNVWZDZSA-N 0.000 description 5
- IAJOBQBIJHVGMQ-UHFFFAOYSA-N 2-amino-4-[hydroxy(methyl)phosphoryl]butanoic acid Chemical compound CP(O)(=O)CCC(N)C(O)=O IAJOBQBIJHVGMQ-UHFFFAOYSA-N 0.000 description 5
- 102000000452 Acetyl-CoA carboxylase Human genes 0.000 description 5
- 108010016219 Acetyl-CoA carboxylase Proteins 0.000 description 5
- LMKYZBGVKHTLTN-NKWVEPMBSA-N D-nopaline Chemical compound NC(=N)NCCC[C@@H](C(O)=O)N[C@@H](C(O)=O)CCC(O)=O LMKYZBGVKHTLTN-NKWVEPMBSA-N 0.000 description 5
- 102000053602 DNA Human genes 0.000 description 5
- 108700020911 DNA-Binding Proteins Proteins 0.000 description 5
- 108010060309 Glucuronidase Proteins 0.000 description 5
- 102000053187 Glucuronidase Human genes 0.000 description 5
- 108010043121 Green Fluorescent Proteins Proteins 0.000 description 5
- HULCBRRKIWCSOF-UHFFFAOYSA-N L,L-succinamopine Natural products NC(=O)CC(C(O)=O)NC(C(O)=O)CCC(O)=O HULCBRRKIWCSOF-UHFFFAOYSA-N 0.000 description 5
- VPRLICVDSGMIKO-UHFFFAOYSA-N Mannopine Natural products NC(=O)CCC(C(O)=O)NCC(O)C(O)C(O)C(O)CO VPRLICVDSGMIKO-UHFFFAOYSA-N 0.000 description 5
- 102100029028 Protoporphyrinogen oxidase Human genes 0.000 description 5
- 108091036066 Three prime untranslated region Proteins 0.000 description 5
- 241000589634 Xanthomonas Species 0.000 description 5
- HCHKCACWOHOZIP-UHFFFAOYSA-N Zinc Chemical compound [Zn] HCHKCACWOHOZIP-UHFFFAOYSA-N 0.000 description 5
- 230000004913 activation Effects 0.000 description 5
- 210000004436 artificial bacterial chromosome Anatomy 0.000 description 5
- 239000002299 complementary DNA Substances 0.000 description 5
- 210000005069 ears Anatomy 0.000 description 5
- 230000000694 effects Effects 0.000 description 5
- 238000012226 gene silencing method Methods 0.000 description 5
- 230000012010 growth Effects 0.000 description 5
- 239000001257 hydrogen Substances 0.000 description 5
- VPRLICVDSGMIKO-SZWOQXJISA-N mannopine Chemical compound NC(=O)CC[C@@H](C(O)=O)NC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CO VPRLICVDSGMIKO-SZWOQXJISA-N 0.000 description 5
- 230000011987 methylation Effects 0.000 description 5
- 238000007069 methylation reaction Methods 0.000 description 5
- 238000012545 processing Methods 0.000 description 5
- 230000008929 regeneration Effects 0.000 description 5
- 238000011069 regeneration method Methods 0.000 description 5
- 239000000126 substance Substances 0.000 description 5
- 230000002103 transcriptional effect Effects 0.000 description 5
- 229910052725 zinc Inorganic materials 0.000 description 5
- 239000011701 zinc Substances 0.000 description 5
- JYEUMXHLPRZUAT-UHFFFAOYSA-N 1,2,3-triazine Chemical compound C1=CN=NN=C1 JYEUMXHLPRZUAT-UHFFFAOYSA-N 0.000 description 4
- 239000005631 2,4-Dichlorophenoxyacetic acid Substances 0.000 description 4
- KDCGOANMDULRCW-UHFFFAOYSA-N 7H-purine Chemical compound N1=CNC2=NC=NC2=C1 KDCGOANMDULRCW-UHFFFAOYSA-N 0.000 description 4
- 241000219195 Arabidopsis thaliana Species 0.000 description 4
- 108090000994 Catalytic RNA Proteins 0.000 description 4
- 102000053642 Catalytic RNA Human genes 0.000 description 4
- 108020004705 Codon Proteins 0.000 description 4
- 108700020475 Cullin Proteins 0.000 description 4
- 102000052581 Cullin Human genes 0.000 description 4
- 108010042407 Endonucleases Proteins 0.000 description 4
- VGGSQFUCUMXWEO-UHFFFAOYSA-N Ethene Chemical compound C=C VGGSQFUCUMXWEO-UHFFFAOYSA-N 0.000 description 4
- 239000005977 Ethylene Substances 0.000 description 4
- 102000004144 Green Fluorescent Proteins Human genes 0.000 description 4
- 241000209219 Hordeum Species 0.000 description 4
- 206010020649 Hyperkeratosis Diseases 0.000 description 4
- 108060001084 Luciferase Proteins 0.000 description 4
- 239000005089 Luciferase Substances 0.000 description 4
- 240000005561 Musa balbisiana Species 0.000 description 4
- 238000000636 Northern blotting Methods 0.000 description 4
- 238000002944 PCR assay Methods 0.000 description 4
- 206010034133 Pathogen resistance Diseases 0.000 description 4
- 238000012228 RNA interference-mediated gene silencing Methods 0.000 description 4
- MEFKEPWMEQBLKI-AIRLBKTGSA-N S-adenosyl-L-methioninate Chemical compound O[C@@H]1[C@H](O)[C@@H](C[S+](CC[C@H](N)C([O-])=O)C)O[C@H]1N1C2=NC=NC(N)=C2N=C1 MEFKEPWMEQBLKI-AIRLBKTGSA-N 0.000 description 4
- 108020003224 Small Nucleolar RNA Proteins 0.000 description 4
- 102000042773 Small Nucleolar RNA Human genes 0.000 description 4
- 108091027967 Small hairpin RNA Proteins 0.000 description 4
- 229940100389 Sulfonylurea Drugs 0.000 description 4
- 108091028113 Trans-activating crRNA Proteins 0.000 description 4
- ISAKRJDGNUQOIC-UHFFFAOYSA-N Uracil Chemical compound O=C1C=CNC(=O)N1 ISAKRJDGNUQOIC-UHFFFAOYSA-N 0.000 description 4
- 241000607479 Yersinia pestis Species 0.000 description 4
- 101710185494 Zinc finger protein Proteins 0.000 description 4
- 102100023597 Zinc finger protein 816 Human genes 0.000 description 4
- 150000007513 acids Chemical class 0.000 description 4
- 238000013459 approach Methods 0.000 description 4
- 230000003115 biocidal effect Effects 0.000 description 4
- 230000002759 chromosomal effect Effects 0.000 description 4
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical compound NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 description 4
- USIUVYZYUHIAEV-UHFFFAOYSA-N diphenyl ether Chemical compound C=1C=CC=CC=1OC1=CC=CC=C1 USIUVYZYUHIAEV-UHFFFAOYSA-N 0.000 description 4
- 230000009368 gene silencing by RNA Effects 0.000 description 4
- 239000005090 green fluorescent protein Substances 0.000 description 4
- 230000002779 inactivation Effects 0.000 description 4
- 230000000977 initiatory effect Effects 0.000 description 4
- 239000002243 precursor Substances 0.000 description 4
- 230000001172 regenerating effect Effects 0.000 description 4
- 108091092562 ribozyme Proteins 0.000 description 4
- 241000894007 species Species 0.000 description 4
- 229960000268 spectinomycin Drugs 0.000 description 4
- UNFWWIHTNXNPBV-WXKVUWSESA-N spectinomycin Chemical compound O([C@@H]1[C@@H](NC)[C@@H](O)[C@H]([C@@H]([C@H]1O1)O)NC)[C@]2(O)[C@H]1O[C@H](C)CC2=O UNFWWIHTNXNPBV-WXKVUWSESA-N 0.000 description 4
- 238000006467 substitution reaction Methods 0.000 description 4
- 238000012176 true single molecule sequencing Methods 0.000 description 4
- 241001515965 unidentified phage Species 0.000 description 4
- UPMXNNIRAGDFEH-UHFFFAOYSA-N 3,5-dibromo-4-hydroxybenzonitrile Chemical compound OC1=C(Br)C=C(C#N)C=C1Br UPMXNNIRAGDFEH-UHFFFAOYSA-N 0.000 description 3
- CAAMSDWKXXPUJR-UHFFFAOYSA-N 3,5-dihydro-4H-imidazol-4-one Chemical class O=C1CNC=N1 CAAMSDWKXXPUJR-UHFFFAOYSA-N 0.000 description 3
- 108091000044 4-hydroxy-tetrahydrodipicolinate synthase Proteins 0.000 description 3
- 241000589155 Agrobacterium tumefaciens Species 0.000 description 3
- 240000007087 Apium graveolens Species 0.000 description 3
- 244000105624 Arachis hypogaea Species 0.000 description 3
- 235000010777 Arachis hypogaea Nutrition 0.000 description 3
- 241000219310 Beta vulgaris subsp. vulgaris Species 0.000 description 3
- 239000005489 Bromoxynil Substances 0.000 description 3
- IMXSCCDUAFEIOE-UHFFFAOYSA-N D-Octopin Natural products OC(=O)C(C)NC(C(O)=O)CCCN=C(N)N IMXSCCDUAFEIOE-UHFFFAOYSA-N 0.000 description 3
- IMXSCCDUAFEIOE-RITPCOANSA-N D-octopine Chemical compound [O-]C(=O)[C@@H](C)[NH2+][C@H](C([O-])=O)CCCNC(N)=[NH2+] IMXSCCDUAFEIOE-RITPCOANSA-N 0.000 description 3
- 208000005156 Dehydration Diseases 0.000 description 3
- 101100491986 Emericella nidulans (strain FGSC A4 / ATCC 38163 / CBS 112.46 / NRRL 194 / M139) aromA gene Proteins 0.000 description 3
- 102100031780 Endonuclease Human genes 0.000 description 3
- 102000004533 Endonucleases Human genes 0.000 description 3
- YQYJSBFKSSDGFO-UHFFFAOYSA-N Epihygromycin Natural products OC1C(O)C(C(=O)C)OC1OC(C(=C1)O)=CC=C1C=C(C)C(=O)NC1C(O)C(O)C2OCOC2C1O YQYJSBFKSSDGFO-UHFFFAOYSA-N 0.000 description 3
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 3
- 108700039691 Genetic Promoter Regions Proteins 0.000 description 3
- 235000004341 Gossypium herbaceum Nutrition 0.000 description 3
- 240000002024 Gossypium herbaceum Species 0.000 description 3
- 235000007340 Hordeum vulgare Nutrition 0.000 description 3
- 240000008415 Lactuca sativa Species 0.000 description 3
- 235000003228 Lactuca sativa Nutrition 0.000 description 3
- 108091026898 Leader sequence (mRNA) Proteins 0.000 description 3
- 235000007688 Lycopersicon esculentum Nutrition 0.000 description 3
- 244000070406 Malus silvestris Species 0.000 description 3
- 240000004658 Medicago sativa Species 0.000 description 3
- 108700011259 MicroRNAs Proteins 0.000 description 3
- 241000208125 Nicotiana Species 0.000 description 3
- 108010033272 Nitrilase Proteins 0.000 description 3
- 108700026244 Open Reading Frames Proteins 0.000 description 3
- 240000003768 Solanum lycopersicum Species 0.000 description 3
- 235000002597 Solanum melongena Nutrition 0.000 description 3
- 244000061458 Solanum melongena Species 0.000 description 3
- 235000002595 Solanum tuberosum Nutrition 0.000 description 3
- 244000061456 Solanum tuberosum Species 0.000 description 3
- 229920002472 Starch Polymers 0.000 description 3
- 108020004566 Transfer RNA Proteins 0.000 description 3
- 235000005824 Zea mays ssp. parviglumis Nutrition 0.000 description 3
- 230000009471 action Effects 0.000 description 3
- 229960001570 ademetionine Drugs 0.000 description 3
- 239000000427 antigen Substances 0.000 description 3
- 108091007433 antigens Proteins 0.000 description 3
- 102000036639 antigens Human genes 0.000 description 3
- 101150037081 aroA gene Proteins 0.000 description 3
- 108010005774 beta-Galactosidase Proteins 0.000 description 3
- 102000005936 beta-Galactosidase Human genes 0.000 description 3
- 238000004364 calculation method Methods 0.000 description 3
- 238000010276 construction Methods 0.000 description 3
- 235000005822 corn Nutrition 0.000 description 3
- 238000012217 deletion Methods 0.000 description 3
- 230000037430 deletion Effects 0.000 description 3
- 239000003623 enhancer Substances 0.000 description 3
- 230000002068 genetic effect Effects 0.000 description 3
- 239000010903 husk Substances 0.000 description 3
- 108010002685 hygromycin-B kinase Proteins 0.000 description 3
- 238000010191 image analysis Methods 0.000 description 3
- 238000012405 in silico analysis Methods 0.000 description 3
- 238000000338 in vitro Methods 0.000 description 3
- 238000001727 in vivo Methods 0.000 description 3
- 208000015181 infectious disease Diseases 0.000 description 3
- 238000002865 local sequence alignment Methods 0.000 description 3
- 210000001161 mammalian embryo Anatomy 0.000 description 3
- 229910052751 metal Inorganic materials 0.000 description 3
- 239000002184 metal Substances 0.000 description 3
- 239000002679 microRNA Substances 0.000 description 3
- 230000004048 modification Effects 0.000 description 3
- 238000012986 modification Methods 0.000 description 3
- 238000005457 optimization Methods 0.000 description 3
- 230000037361 pathway Effects 0.000 description 3
- 230000029553 photosynthesis Effects 0.000 description 3
- 238000010672 photosynthesis Methods 0.000 description 3
- 101150075980 psbA gene Proteins 0.000 description 3
- 238000010791 quenching Methods 0.000 description 3
- 230000000171 quenching effect Effects 0.000 description 3
- 230000002829 reductive effect Effects 0.000 description 3
- 230000008439 repair process Effects 0.000 description 3
- 230000010076 replication Effects 0.000 description 3
- 230000004044 response Effects 0.000 description 3
- 238000012216 screening Methods 0.000 description 3
- 230000001568 sexual effect Effects 0.000 description 3
- HBMJWWWQQXIZIP-UHFFFAOYSA-N silicon carbide Chemical compound [Si+]#[C-] HBMJWWWQQXIZIP-UHFFFAOYSA-N 0.000 description 3
- 229910010271 silicon carbide Inorganic materials 0.000 description 3
- 125000006850 spacer group Chemical group 0.000 description 3
- 235000019698 starch Nutrition 0.000 description 3
- 239000008107 starch Substances 0.000 description 3
- 239000000758 substrate Substances 0.000 description 3
- 238000001262 western blot Methods 0.000 description 3
- GOCUAJYOYBLQRH-UHFFFAOYSA-N 2-(4-{[3-chloro-5-(trifluoromethyl)pyridin-2-yl]oxy}phenoxy)propanoic acid Chemical compound C1=CC(OC(C)C(O)=O)=CC=C1OC1=NC=C(C(F)(F)F)C=C1Cl GOCUAJYOYBLQRH-UHFFFAOYSA-N 0.000 description 2
- YUVKUEAFAVKILW-UHFFFAOYSA-N 2-(4-{[5-(trifluoromethyl)pyridin-2-yl]oxy}phenoxy)propanoic acid Chemical compound C1=CC(OC(C)C(O)=O)=CC=C1OC1=CC=C(C(F)(F)F)C=N1 YUVKUEAFAVKILW-UHFFFAOYSA-N 0.000 description 2
- OOLBCHYXZDXLDS-UHFFFAOYSA-N 2-[4-(2,4-dichlorophenoxy)phenoxy]propanoic acid Chemical compound C1=CC(OC(C)C(O)=O)=CC=C1OC1=CC=C(Cl)C=C1Cl OOLBCHYXZDXLDS-UHFFFAOYSA-N 0.000 description 2
- ABOOPXYCKNFDNJ-UHFFFAOYSA-N 2-{4-[(6-chloroquinoxalin-2-yl)oxy]phenoxy}propanoic acid Chemical compound C1=CC(OC(C)C(O)=O)=CC=C1OC1=CN=C(C=C(Cl)C=C2)C2=N1 ABOOPXYCKNFDNJ-UHFFFAOYSA-N 0.000 description 2
- PRZRAMLXTKZUHF-UHFFFAOYSA-N 5-oxo-n-sulfonyl-4h-triazole-1-carboxamide Chemical class O=S(=O)=NC(=O)N1N=NCC1=O PRZRAMLXTKZUHF-UHFFFAOYSA-N 0.000 description 2
- 241000208140 Acer Species 0.000 description 2
- 102000002260 Alkaline Phosphatase Human genes 0.000 description 2
- 108020004774 Alkaline Phosphatase Proteins 0.000 description 2
- 235000003840 Amygdalus nana Nutrition 0.000 description 2
- 244000296825 Amygdalus nana Species 0.000 description 2
- 108020005544 Antisense RNA Proteins 0.000 description 2
- 235000015849 Apium graveolens Dulce Group Nutrition 0.000 description 2
- 235000010591 Appio Nutrition 0.000 description 2
- 101100332650 Arabidopsis thaliana EC1.2 gene Proteins 0.000 description 2
- 235000017060 Arachis glabrata Nutrition 0.000 description 2
- 235000018262 Arachis monticola Nutrition 0.000 description 2
- 102000003823 Aromatic-L-amino-acid decarboxylases Human genes 0.000 description 2
- 108090000121 Aromatic-L-amino-acid decarboxylases Proteins 0.000 description 2
- 108010055400 Aspartate kinase Proteins 0.000 description 2
- 235000014469 Bacillus subtilis Nutrition 0.000 description 2
- 241000894006 Bacteria Species 0.000 description 2
- 241000218993 Begonia Species 0.000 description 2
- 241000219198 Brassica Species 0.000 description 2
- 240000007124 Brassica oleracea Species 0.000 description 2
- 235000003899 Brassica oleracea var acephala Nutrition 0.000 description 2
- 235000011299 Brassica oleracea var botrytis Nutrition 0.000 description 2
- 235000011301 Brassica oleracea var capitata Nutrition 0.000 description 2
- 235000001169 Brassica oleracea var oleracea Nutrition 0.000 description 2
- 240000003259 Brassica oleracea var. botrytis Species 0.000 description 2
- 238000010354 CRISPR gene editing Methods 0.000 description 2
- 235000002566 Capsicum Nutrition 0.000 description 2
- 102000014914 Carrier Proteins Human genes 0.000 description 2
- 241000723418 Carya Species 0.000 description 2
- 208000034656 Contusions Diseases 0.000 description 2
- 241000219112 Cucumis Species 0.000 description 2
- 240000008067 Cucumis sativus Species 0.000 description 2
- 235000010799 Cucumis sativus var sativus Nutrition 0.000 description 2
- 235000009854 Cucurbita moschata Nutrition 0.000 description 2
- 229920001651 Cyanoacrylate Polymers 0.000 description 2
- 239000003155 DNA primer Substances 0.000 description 2
- 102000016928 DNA-directed DNA polymerase Human genes 0.000 description 2
- 108010014303 DNA-directed DNA polymerase Proteins 0.000 description 2
- 244000000626 Daucus carota Species 0.000 description 2
- 235000002767 Daucus carota Nutrition 0.000 description 2
- 241000489947 Diabrotica virgifera virgifera Species 0.000 description 2
- 239000005506 Diclofop Substances 0.000 description 2
- 108700007698 Genetic Terminator Regions Proteins 0.000 description 2
- 229930182566 Gentamicin Natural products 0.000 description 2
- CEAZRRDELHUEMR-URQXQFDESA-N Gentamicin Chemical compound O1[C@H](C(C)NC)CC[C@@H](N)[C@H]1O[C@H]1[C@H](O)[C@@H](O[C@@H]2[C@@H]([C@@H](NC)[C@@](C)(O)CO2)O)[C@H](N)C[C@@H]1N CEAZRRDELHUEMR-URQXQFDESA-N 0.000 description 2
- 108020005004 Guide RNA Proteins 0.000 description 2
- 101000687346 Homo sapiens PR domain zinc finger protein 2 Proteins 0.000 description 2
- 101000848922 Homo sapiens Protein FAM72A Proteins 0.000 description 2
- 244000017020 Ipomoea batatas Species 0.000 description 2
- 235000002678 Ipomoea batatas Nutrition 0.000 description 2
- 239000005571 Isoxaflutole Substances 0.000 description 2
- 108091022912 Mannose-6-Phosphate Isomerase Proteins 0.000 description 2
- 102000048193 Mannose-6-phosphate isomerases Human genes 0.000 description 2
- 235000017587 Medicago sativa ssp. sativa Nutrition 0.000 description 2
- 206010027146 Melanoderma Diseases 0.000 description 2
- 241001465754 Metazoa Species 0.000 description 2
- MWCLLHOVUTZFKS-UHFFFAOYSA-N Methyl cyanoacrylate Chemical compound COC(=O)C(=C)C#N MWCLLHOVUTZFKS-UHFFFAOYSA-N 0.000 description 2
- 229930193140 Neomycin Natural products 0.000 description 2
- 108091005461 Nucleic proteins Proteins 0.000 description 2
- 108020005187 Oligonucleotide Probes Proteins 0.000 description 2
- 239000005590 Oxyfluorfen Substances 0.000 description 2
- OQMBBFQZGJFLBU-UHFFFAOYSA-N Oxyfluorfen Chemical compound C1=C([N+]([O-])=O)C(OCC)=CC(OC=2C(=CC(=CC=2)C(F)(F)F)Cl)=C1 OQMBBFQZGJFLBU-UHFFFAOYSA-N 0.000 description 2
- 238000012408 PCR amplification Methods 0.000 description 2
- 102100024885 PR domain zinc finger protein 2 Human genes 0.000 description 2
- 239000002033 PVDF binder Substances 0.000 description 2
- UOZODPSAJZTQNH-UHFFFAOYSA-N Paromomycin II Natural products NC1C(O)C(O)C(CN)OC1OC1C(O)C(OC2C(C(N)CC(N)C2O)OC2C(C(O)C(O)C(CO)O2)N)OC1CO UOZODPSAJZTQNH-UHFFFAOYSA-N 0.000 description 2
- 240000007377 Petunia x hybrida Species 0.000 description 2
- 235000010627 Phaseolus vulgaris Nutrition 0.000 description 2
- 244000046052 Phaseolus vulgaris Species 0.000 description 2
- 241000219843 Pisum Species 0.000 description 2
- 235000010582 Pisum sativum Nutrition 0.000 description 2
- 241000219000 Populus Species 0.000 description 2
- 101710096655 Probable acetoacetate decarboxylase 1 Proteins 0.000 description 2
- 102100034514 Protein FAM72A Human genes 0.000 description 2
- 108010076504 Protein Sorting Signals Proteins 0.000 description 2
- 102000005135 Protoporphyrinogen oxidase Human genes 0.000 description 2
- 235000011432 Prunus Nutrition 0.000 description 2
- CZPWVGJYEJSRLH-UHFFFAOYSA-N Pyrimidine Chemical compound C1=CN=CN=C1 CZPWVGJYEJSRLH-UHFFFAOYSA-N 0.000 description 2
- 241000220324 Pyrus Species 0.000 description 2
- 241000219492 Quercus Species 0.000 description 2
- 108010092799 RNA-directed DNA polymerase Proteins 0.000 description 2
- 241000589771 Ralstonia solanacearum Species 0.000 description 2
- 101100087805 Ralstonia solanacearum rip19 gene Proteins 0.000 description 2
- 241000208422 Rhododendron Species 0.000 description 2
- 241000209072 Sorghum Species 0.000 description 2
- 238000002105 Southern blotting Methods 0.000 description 2
- 241000187747 Streptomyces Species 0.000 description 2
- 235000021536 Sugar beet Nutrition 0.000 description 2
- 235000012308 Tagetes Nutrition 0.000 description 2
- 241000736851 Tagetes Species 0.000 description 2
- 108010022394 Threonine synthase Proteins 0.000 description 2
- 241000219793 Trifolium Species 0.000 description 2
- 241000219873 Vicia Species 0.000 description 2
- 241000209149 Zea Species 0.000 description 2
- 108020002494 acetyltransferase Proteins 0.000 description 2
- 239000000980 acid dye Substances 0.000 description 2
- NUFNQYOELLVIPL-UHFFFAOYSA-N acifluorfen Chemical compound C1=C([N+]([O-])=O)C(C(=O)O)=CC(OC=2C(=CC(=CC=2)C(F)(F)F)Cl)=C1 NUFNQYOELLVIPL-UHFFFAOYSA-N 0.000 description 2
- DZBUGLKDJFMEHC-UHFFFAOYSA-N acridine Chemical compound C1=CC=CC2=CC3=CC=CC=C3N=C21 DZBUGLKDJFMEHC-UHFFFAOYSA-N 0.000 description 2
- 239000003242 anti bacterial agent Substances 0.000 description 2
- 229940088710 antibiotic agent Drugs 0.000 description 2
- 108010051210 beta-Fructofuranosidase Proteins 0.000 description 2
- 229960003237 betaine Drugs 0.000 description 2
- 108091008324 binding proteins Proteins 0.000 description 2
- 238000005422 blasting Methods 0.000 description 2
- 238000009395 breeding Methods 0.000 description 2
- 230000001488 breeding effect Effects 0.000 description 2
- 208000034526 bruise Diseases 0.000 description 2
- 235000014633 carbohydrates Nutrition 0.000 description 2
- 150000001720 carbohydrates Chemical class 0.000 description 2
- 230000032823 cell division Effects 0.000 description 2
- 230000003915 cell function Effects 0.000 description 2
- 210000002421 cell wall Anatomy 0.000 description 2
- 230000001413 cellular effect Effects 0.000 description 2
- 230000008859 change Effects 0.000 description 2
- 239000002738 chelating agent Substances 0.000 description 2
- 230000019113 chromatin silencing Effects 0.000 description 2
- 210000000349 chromosome Anatomy 0.000 description 2
- AGOYDEPGAOXOCK-KCBOHYOISA-N clarithromycin Chemical compound O([C@@H]1[C@@H](C)C(=O)O[C@@H]([C@@]([C@H](O)[C@@H](C)C(=O)[C@H](C)C[C@](C)([C@H](O[C@H]2[C@@H]([C@H](C[C@@H](C)O2)N(C)C)O)[C@H]1C)OC)(C)O)CC)[C@H]1C[C@@](C)(OC)[C@@H](O)[C@H](C)O1 AGOYDEPGAOXOCK-KCBOHYOISA-N 0.000 description 2
- 239000003184 complementary RNA Substances 0.000 description 2
- 238000012790 confirmation Methods 0.000 description 2
- 239000000356 contaminant Substances 0.000 description 2
- 244000038559 crop plants Species 0.000 description 2
- 101150065438 cry1Ab gene Proteins 0.000 description 2
- 238000005520 cutting process Methods 0.000 description 2
- OILAIQUEIWYQPH-UHFFFAOYSA-N cyclohexane-1,2-dione Chemical class O=C1CCCCC1=O OILAIQUEIWYQPH-UHFFFAOYSA-N 0.000 description 2
- 229940104302 cytosine Drugs 0.000 description 2
- 230000007423 decrease Effects 0.000 description 2
- 239000005547 deoxyribonucleotide Substances 0.000 description 2
- 102000004419 dihydrofolate reductase Human genes 0.000 description 2
- 201000010099 disease Diseases 0.000 description 2
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 2
- 239000000975 dye Substances 0.000 description 2
- 239000012636 effector Substances 0.000 description 2
- 238000004520 electroporation Methods 0.000 description 2
- 238000000295 emission spectrum Methods 0.000 description 2
- 239000000839 emulsion Substances 0.000 description 2
- 238000001976 enzyme digestion Methods 0.000 description 2
- 230000001747 exhibiting effect Effects 0.000 description 2
- 239000000835 fiber Substances 0.000 description 2
- MHMNJMPURVTYEJ-UHFFFAOYSA-N fluorescein-5-isothiocyanate Chemical compound O1C(=O)C2=CC(N=C=S)=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 MHMNJMPURVTYEJ-UHFFFAOYSA-N 0.000 description 2
- 239000000499 gel Substances 0.000 description 2
- 238000010353 genetic engineering Methods 0.000 description 2
- 229960002518 gentamicin Drugs 0.000 description 2
- 239000011521 glass Substances 0.000 description 2
- 238000002873 global sequence alignment Methods 0.000 description 2
- 239000003292 glue Substances 0.000 description 2
- IAJOBQBIJHVGMQ-BYPYZUCNSA-N glufosinate-P Chemical compound CP(O)(=O)CC[C@H](N)C(O)=O IAJOBQBIJHVGMQ-BYPYZUCNSA-N 0.000 description 2
- KWIUHFFTVRNATP-UHFFFAOYSA-N glycine betaine Chemical compound C[N+](C)(C)CC([O-])=O KWIUHFFTVRNATP-UHFFFAOYSA-N 0.000 description 2
- PCHJSUWPFVWCPO-UHFFFAOYSA-N gold Chemical compound [Au] PCHJSUWPFVWCPO-UHFFFAOYSA-N 0.000 description 2
- 239000010931 gold Substances 0.000 description 2
- 229910052737 gold Inorganic materials 0.000 description 2
- 239000003630 growth substance Substances 0.000 description 2
- UYTPUPDQBNUYGX-UHFFFAOYSA-N guanine Chemical compound O=C1NC(N)=NC2=C1N=CN2 UYTPUPDQBNUYGX-UHFFFAOYSA-N 0.000 description 2
- 238000002744 homologous recombination Methods 0.000 description 2
- 230000006801 homologous recombination Effects 0.000 description 2
- 238000011065 in-situ storage Methods 0.000 description 2
- 230000002401 inhibitory effect Effects 0.000 description 2
- 230000005764 inhibitory process Effects 0.000 description 2
- 238000002955 isolation Methods 0.000 description 2
- OYIKARCXOQLFHF-UHFFFAOYSA-N isoxaflutole Chemical compound CS(=O)(=O)C1=CC(C(F)(F)F)=CC=C1C(=O)C1=C(C2CC2)ON=C1 OYIKARCXOQLFHF-UHFFFAOYSA-N 0.000 description 2
- 229940088649 isoxaflutole Drugs 0.000 description 2
- 229960000318 kanamycin Drugs 0.000 description 2
- 229930027917 kanamycin Natural products 0.000 description 2
- SBUJHOSQTJFQJX-NOAMYHISSA-N kanamycin Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CN)O[C@@H]1O[C@H]1[C@H](O)[C@@H](O[C@@H]2[C@@H]([C@@H](N)[C@H](O)[C@@H](CO)O2)O)[C@H](N)C[C@@H]1N SBUJHOSQTJFQJX-NOAMYHISSA-N 0.000 description 2
- 229930182823 kanamycin A Natural products 0.000 description 2
- 229920005610 lignin Polymers 0.000 description 2
- 239000002502 liposome Substances 0.000 description 2
- 239000012528 membrane Substances 0.000 description 2
- 108091070501 miRNA Proteins 0.000 description 2
- 238000001823 molecular biology technique Methods 0.000 description 2
- 238000010369 molecular cloning Methods 0.000 description 2
- 238000002703 mutagenesis Methods 0.000 description 2
- 231100000350 mutagenesis Toxicity 0.000 description 2
- 229960004927 neomycin Drugs 0.000 description 2
- QJGQUHMNIGDVPM-UHFFFAOYSA-N nitrogen group Chemical group [N] QJGQUHMNIGDVPM-UHFFFAOYSA-N 0.000 description 2
- 239000002751 oligonucleotide probe Substances 0.000 description 2
- 230000002018 overexpression Effects 0.000 description 2
- 238000002888 pairwise sequence alignment Methods 0.000 description 2
- 229960001914 paromomycin Drugs 0.000 description 2
- UOZODPSAJZTQNH-LSWIJEOBSA-N paromomycin Chemical compound N[C@@H]1[C@@H](O)[C@H](O)[C@H](CN)O[C@@H]1O[C@H]1[C@@H](O)[C@H](O[C@H]2[C@@H]([C@@H](N)C[C@@H](N)[C@@H]2O)O[C@@H]2[C@@H]([C@@H](O)[C@H](O)[C@@H](CO)O2)N)O[C@@H]1CO UOZODPSAJZTQNH-LSWIJEOBSA-N 0.000 description 2
- 235000020232 peanut Nutrition 0.000 description 2
- 239000012071 phase Substances 0.000 description 2
- 125000000951 phenoxy group Chemical group [H]C1=C([H])C([H])=C(O*)C([H])=C1[H] 0.000 description 2
- 150000008300 phosphoramidites Chemical class 0.000 description 2
- 229920000642 polymer Polymers 0.000 description 2
- 229920002981 polyvinylidene fluoride Polymers 0.000 description 2
- 230000029279 positive regulation of transcription, DNA-dependent Effects 0.000 description 2
- 230000004952 protein activity Effects 0.000 description 2
- 102000021127 protein binding proteins Human genes 0.000 description 2
- 108091011138 protein binding proteins Proteins 0.000 description 2
- 238000001243 protein synthesis Methods 0.000 description 2
- 235000014774 prunus Nutrition 0.000 description 2
- ZCCUUQDIBDJBTK-UHFFFAOYSA-N psoralen Chemical compound C1=C2OC(=O)C=CC2=CC2=C1OC=C2 ZCCUUQDIBDJBTK-UHFFFAOYSA-N 0.000 description 2
- 238000003753 real-time PCR Methods 0.000 description 2
- 230000008707 rearrangement Effects 0.000 description 2
- 230000014493 regulation of gene expression Effects 0.000 description 2
- 230000003252 repetitive effect Effects 0.000 description 2
- 238000003757 reverse transcription PCR Methods 0.000 description 2
- 230000005070 ripening Effects 0.000 description 2
- 238000000926 separation method Methods 0.000 description 2
- 238000002864 sequence alignment Methods 0.000 description 2
- 244000000034 soilborne pathogen Species 0.000 description 2
- 239000007790 solid phase Substances 0.000 description 2
- 230000009870 specific binding Effects 0.000 description 2
- ATHGHQPFGPMSJY-UHFFFAOYSA-N spermidine Chemical compound NCCCCNCCCN ATHGHQPFGPMSJY-UHFFFAOYSA-N 0.000 description 2
- 230000010473 stable expression Effects 0.000 description 2
- 235000000346 sugar Nutrition 0.000 description 2
- 150000008163 sugars Chemical class 0.000 description 2
- RWQNBRDOKXIBIV-UHFFFAOYSA-N thymine Chemical compound CC1=CNC(=O)NC1=O RWQNBRDOKXIBIV-UHFFFAOYSA-N 0.000 description 2
- 230000001052 transient effect Effects 0.000 description 2
- 230000014621 translational initiation Effects 0.000 description 2
- 230000032258 transport Effects 0.000 description 2
- 239000001226 triphosphate Substances 0.000 description 2
- 229940035893 uracil Drugs 0.000 description 2
- 239000013603 viral vector Substances 0.000 description 2
- 230000000007 visual effect Effects 0.000 description 2
- VIXCLRUCUMWJFF-KGLIPLIRSA-N (1R,5S)-benzobicyclon Chemical compound CS(=O)(=O)c1ccc(C(=O)C2=C(Sc3ccccc3)[C@H]3CC[C@H](C3)C2=O)c(Cl)c1 VIXCLRUCUMWJFF-KGLIPLIRSA-N 0.000 description 1
- PXFBZOLANLWPMH-UHFFFAOYSA-N 16-Epiaffinine Natural products C1C(C2=CC=CC=C2N2)=C2C(=O)CC2C(=CC)CN(C)C1C2CO PXFBZOLANLWPMH-UHFFFAOYSA-N 0.000 description 1
- NDUPDOJHUQKPAG-UHFFFAOYSA-M 2,2-Dichloropropanoate Chemical compound CC(Cl)(Cl)C([O-])=O NDUPDOJHUQKPAG-UHFFFAOYSA-M 0.000 description 1
- OVSKIKFHRZPJSS-UHFFFAOYSA-N 2,4-D Chemical compound OC(=O)COC1=CC=C(Cl)C=C1Cl OVSKIKFHRZPJSS-UHFFFAOYSA-N 0.000 description 1
- 229940087195 2,4-dichlorophenoxyacetate Drugs 0.000 description 1
- GQQIAHNFBAFBCS-UHFFFAOYSA-N 2-[2-chloro-5-(1,3-dioxo-4,5,6,7-tetrahydroisoindol-2-yl)-4-fluorophenoxy]acetic acid Chemical compound C1=C(Cl)C(OCC(=O)O)=CC(N2C(C3=C(CCCC3)C2=O)=O)=C1F GQQIAHNFBAFBCS-UHFFFAOYSA-N 0.000 description 1
- YHKBGVDUSSWOAB-UHFFFAOYSA-N 2-chloro-3-{2-chloro-5-[4-(difluoromethyl)-3-methyl-5-oxo-4,5-dihydro-1H-1,2,4-triazol-1-yl]-4-fluorophenyl}propanoic acid Chemical compound O=C1N(C(F)F)C(C)=NN1C1=CC(CC(Cl)C(O)=O)=C(Cl)C=C1F YHKBGVDUSSWOAB-UHFFFAOYSA-N 0.000 description 1
- CDUVSERIDNVFDD-UHFFFAOYSA-N 2-pyrimidin-2-ylbenzenecarbothioic s-acid Chemical class OC(=S)C1=CC=CC=C1C1=NC=CC=N1 CDUVSERIDNVFDD-UHFFFAOYSA-N 0.000 description 1
- VXGRJERITKFWPL-UHFFFAOYSA-N 4',5'-Dihydropsoralen Natural products C1=C2OC(=O)C=CC2=CC2=C1OCC2 VXGRJERITKFWPL-UHFFFAOYSA-N 0.000 description 1
- BZTDTCNHAFUJOG-UHFFFAOYSA-N 6-carboxyfluorescein Chemical compound C12=CC=C(O)C=C2OC2=CC(O)=CC=C2C11OC(=O)C2=CC=C(C(=O)O)C=C21 BZTDTCNHAFUJOG-UHFFFAOYSA-N 0.000 description 1
- OGHAROSJZRTIOK-KQYNXXCUSA-O 7-methylguanosine Chemical compound C1=2N=C(N)NC(=O)C=2[N+](C)=CN1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O OGHAROSJZRTIOK-KQYNXXCUSA-O 0.000 description 1
- 101150014984 ACO gene Proteins 0.000 description 1
- 230000005730 ADP ribosylation Effects 0.000 description 1
- 240000002460 Abroma augustum Species 0.000 description 1
- 239000002890 Aclonifen Substances 0.000 description 1
- 101710159080 Aconitate hydratase A Proteins 0.000 description 1
- 101710159078 Aconitate hydratase B Proteins 0.000 description 1
- HRPVXLWXLXDGHG-UHFFFAOYSA-N Acrylamide Chemical compound NC(=O)C=C HRPVXLWXLXDGHG-UHFFFAOYSA-N 0.000 description 1
- 101710197633 Actin-1 Proteins 0.000 description 1
- 229930024421 Adenine Natural products 0.000 description 1
- GFFGJBXGBJISGV-UHFFFAOYSA-N Adenine Chemical compound NC1=NC=NC2=C1N=CN2 GFFGJBXGBJISGV-UHFFFAOYSA-N 0.000 description 1
- 241000743339 Agrostis Species 0.000 description 1
- 241001504639 Alcedo atthis Species 0.000 description 1
- 108700028369 Alleles Proteins 0.000 description 1
- 241000219496 Alnus Species 0.000 description 1
- 108091093088 Amplicon Proteins 0.000 description 1
- 244000144730 Amygdalus persica Species 0.000 description 1
- 239000004382 Amylase Substances 0.000 description 1
- 108010065511 Amylases Proteins 0.000 description 1
- 102000013142 Amylases Human genes 0.000 description 1
- 235000002764 Apium graveolens Nutrition 0.000 description 1
- 108091023037 Aptamer Proteins 0.000 description 1
- 241000203069 Archaea Species 0.000 description 1
- 235000006549 Arenga pinnata Nutrition 0.000 description 1
- 244000208946 Arenga pinnata Species 0.000 description 1
- 241001167018 Aroa Species 0.000 description 1
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 1
- 229930192334 Auxin Natural products 0.000 description 1
- 241000932522 Avena hispanica Species 0.000 description 1
- 235000002988 Avena strigosa Nutrition 0.000 description 1
- 238000012935 Averaging Methods 0.000 description 1
- 235000000832 Ayote Nutrition 0.000 description 1
- 244000063299 Bacillus subtilis Species 0.000 description 1
- 101100497219 Bacillus thuringiensis subsp. kurstaki cry1Ac gene Proteins 0.000 description 1
- 108700003860 Bacterial Genes Proteins 0.000 description 1
- 235000021537 Beetroot Nutrition 0.000 description 1
- JDWQITFHZOBBFE-UHFFFAOYSA-N Benzofenap Chemical compound C=1C=C(Cl)C(C)=C(Cl)C=1C(=O)C=1C(C)=NN(C)C=1OCC(=O)C1=CC=C(C)C=C1 JDWQITFHZOBBFE-UHFFFAOYSA-N 0.000 description 1
- 235000003932 Betula Nutrition 0.000 description 1
- 241000219429 Betula Species 0.000 description 1
- 235000018185 Betula X alpestris Nutrition 0.000 description 1
- 235000018212 Betula X uliginosa Nutrition 0.000 description 1
- 241000219495 Betulaceae Species 0.000 description 1
- 239000005484 Bifenox Substances 0.000 description 1
- 241000606545 Biplex Species 0.000 description 1
- 241000339490 Brachyachne Species 0.000 description 1
- 235000011331 Brassica Nutrition 0.000 description 1
- 235000005156 Brassica carinata Nutrition 0.000 description 1
- 244000257790 Brassica carinata Species 0.000 description 1
- 244000178993 Brassica juncea Species 0.000 description 1
- 240000002791 Brassica napus Species 0.000 description 1
- 235000017647 Brassica oleracea var italica Nutrition 0.000 description 1
- 101150060228 CCOMT gene Proteins 0.000 description 1
- 102100025238 CD302 antigen Human genes 0.000 description 1
- QCMYYKRYFNMIEC-UHFFFAOYSA-N COP(O)=O Chemical class COP(O)=O QCMYYKRYFNMIEC-UHFFFAOYSA-N 0.000 description 1
- 238000010453 CRISPR/Cas method Methods 0.000 description 1
- 235000002567 Capsicum annuum Nutrition 0.000 description 1
- 240000004160 Capsicum annuum Species 0.000 description 1
- 235000018306 Capsicum chinense Nutrition 0.000 description 1
- 244000185501 Capsicum chinense Species 0.000 description 1
- 240000008574 Capsicum frutescens Species 0.000 description 1
- 235000002568 Capsicum frutescens Nutrition 0.000 description 1
- 241001515826 Cassava vein mosaic virus Species 0.000 description 1
- 241000701489 Cauliflower mosaic virus Species 0.000 description 1
- 244000241235 Citrullus lanatus Species 0.000 description 1
- 235000012828 Citrullus lanatus var citroides Nutrition 0.000 description 1
- 108020004635 Complementary DNA Proteins 0.000 description 1
- 241000218631 Coniferophyta Species 0.000 description 1
- 241000195493 Cryptophyta Species 0.000 description 1
- 235000015510 Cucumis melo subsp melo Nutrition 0.000 description 1
- 235000010071 Cucumis prophetarum Nutrition 0.000 description 1
- 241000219122 Cucurbita Species 0.000 description 1
- 240000004244 Cucurbita moschata Species 0.000 description 1
- 240000001980 Cucurbita pepo Species 0.000 description 1
- 235000009852 Cucurbita pepo Nutrition 0.000 description 1
- 235000009804 Cucurbita pepo subsp pepo Nutrition 0.000 description 1
- 108030005585 Cyanamide hydratases Proteins 0.000 description 1
- 244000193629 Cyphomandra crassifolia Species 0.000 description 1
- 235000000298 Cyphomandra crassifolia Nutrition 0.000 description 1
- 230000004543 DNA replication Effects 0.000 description 1
- 238000001712 DNA sequencing Methods 0.000 description 1
- 102000004163 DNA-directed RNA polymerases Human genes 0.000 description 1
- 108090000626 DNA-directed RNA polymerases Proteins 0.000 description 1
- 239000005504 Dicamba Substances 0.000 description 1
- 244000182625 Dictamnus albus Species 0.000 description 1
- 235000014866 Dictamnus albus Nutrition 0.000 description 1
- 108700016256 Dihydropteroate synthases Proteins 0.000 description 1
- 208000035240 Disease Resistance Diseases 0.000 description 1
- 102100032049 E3 ubiquitin-protein ligase LRSAM1 Human genes 0.000 description 1
- 238000012286 ELISA Assay Methods 0.000 description 1
- 101000889905 Enterobacteria phage RB3 Intron-associated endonuclease 3 Proteins 0.000 description 1
- 101000889904 Enterobacteria phage T4 Defective intron-associated endonuclease 3 Proteins 0.000 description 1
- 101000889900 Enterobacteria phage T4 Intron-associated endonuclease 1 Proteins 0.000 description 1
- 101000889899 Enterobacteria phage T4 Intron-associated endonuclease 2 Proteins 0.000 description 1
- 101100169274 Escherichia coli (strain K12) cydC gene Proteins 0.000 description 1
- 244000166124 Eucalyptus globulus Species 0.000 description 1
- 244000004281 Eucalyptus maculata Species 0.000 description 1
- 241000208367 Euonymus Species 0.000 description 1
- 108091029865 Exogenous DNA Proteins 0.000 description 1
- 108700024394 Exon Proteins 0.000 description 1
- 241001070947 Fagus Species 0.000 description 1
- 240000000731 Fagus sylvatica Species 0.000 description 1
- 235000010099 Fagus sylvatica Nutrition 0.000 description 1
- DHAHEVIQIYRFRG-UHFFFAOYSA-N Fluoroglycofen Chemical compound C1=C([N+]([O-])=O)C(C(=O)OCC(=O)O)=CC(OC=2C(=CC(=CC=2)C(F)(F)F)Cl)=C1 DHAHEVIQIYRFRG-UHFFFAOYSA-N 0.000 description 1
- 241001536358 Fraxinus Species 0.000 description 1
- 241000233866 Fungi Species 0.000 description 1
- 108010008945 General Transcription Factors Proteins 0.000 description 1
- 102000006580 General Transcription Factors Human genes 0.000 description 1
- 101100420606 Geobacillus stearothermophilus sacB gene Proteins 0.000 description 1
- 239000005561 Glufosinate Substances 0.000 description 1
- 235000009438 Gossypium Nutrition 0.000 description 1
- 102100033636 Histone H3.2 Human genes 0.000 description 1
- 108010033040 Histones Proteins 0.000 description 1
- 101100273718 Homo sapiens CD302 gene Proteins 0.000 description 1
- 108010001336 Horseradish Peroxidase Proteins 0.000 description 1
- 108020004684 Internal Ribosome Entry Sites Proteins 0.000 description 1
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 1
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 1
- FBOZXECLQNJBKD-ZDUSSCGKSA-N L-methotrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FBOZXECLQNJBKD-ZDUSSCGKSA-N 0.000 description 1
- 235000007661 Lactuca perennis Nutrition 0.000 description 1
- 240000004628 Lactuca perennis Species 0.000 description 1
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 1
- 241000209510 Liliopsida Species 0.000 description 1
- 101710084376 Lipase 3 Proteins 0.000 description 1
- 241000209082 Lolium Species 0.000 description 1
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 1
- 239000004472 Lysine Substances 0.000 description 1
- SUSRORUBZHMPCO-UHFFFAOYSA-N MC-4379 Chemical compound C1=C([N+]([O-])=O)C(C(=O)OC)=CC(OC=2C(=CC(Cl)=CC=2)Cl)=C1 SUSRORUBZHMPCO-UHFFFAOYSA-N 0.000 description 1
- 241000218922 Magnoliophyta Species 0.000 description 1
- 241000220225 Malus Species 0.000 description 1
- 235000005087 Malus prunifolia Nutrition 0.000 description 1
- 235000010624 Medicago sativa Nutrition 0.000 description 1
- 241000589195 Mesorhizobium loti Species 0.000 description 1
- 239000005578 Mesotrione Substances 0.000 description 1
- 239000004368 Modified starch Substances 0.000 description 1
- 229920000881 Modified starch Polymers 0.000 description 1
- 101100496109 Mus musculus Clec2i gene Proteins 0.000 description 1
- 239000000020 Nitrocellulose Substances 0.000 description 1
- 239000004677 Nylon Substances 0.000 description 1
- 108700020796 Oncogene Proteins 0.000 description 1
- 102000043276 Oncogene Human genes 0.000 description 1
- 241000209094 Oryza Species 0.000 description 1
- 108090000854 Oxidoreductases Proteins 0.000 description 1
- 229910019142 PO4 Inorganic materials 0.000 description 1
- 239000006002 Pepper Substances 0.000 description 1
- 241000219833 Phaseolus Species 0.000 description 1
- 108010060806 Photosystem II Protein Complex Proteins 0.000 description 1
- 240000009134 Physalis philadelphica Species 0.000 description 1
- 235000002489 Physalis philadelphica Nutrition 0.000 description 1
- 208000012641 Pigmentation disease Diseases 0.000 description 1
- 235000008331 Pinus X rigitaeda Nutrition 0.000 description 1
- 235000011613 Pinus brutia Nutrition 0.000 description 1
- 241000018646 Pinus brutia Species 0.000 description 1
- 235000016761 Piper aduncum Nutrition 0.000 description 1
- 240000003889 Piper guineense Species 0.000 description 1
- 235000017804 Piper guineense Nutrition 0.000 description 1
- 235000008184 Piper nigrum Nutrition 0.000 description 1
- 241000758706 Piperaceae Species 0.000 description 1
- 240000004713 Pisum sativum Species 0.000 description 1
- 241000209048 Poa Species 0.000 description 1
- 101710124239 Poly(A) polymerase Proteins 0.000 description 1
- 108091036407 Polyadenylation Proteins 0.000 description 1
- 108010059820 Polygalacturonase Proteins 0.000 description 1
- 241000985694 Polypodiopsida Species 0.000 description 1
- 241000183024 Populus tremula Species 0.000 description 1
- 241000709992 Potato virus X Species 0.000 description 1
- 241000677647 Proba Species 0.000 description 1
- 229940124158 Protease/peptidase inhibitor Drugs 0.000 description 1
- 101710142009 Protein insensitive Proteins 0.000 description 1
- 241001290151 Prunus avium subsp. avium Species 0.000 description 1
- 235000006040 Prunus persica var persica Nutrition 0.000 description 1
- 235000014443 Pyrus communis Nutrition 0.000 description 1
- 108091034057 RNA (poly(A)) Proteins 0.000 description 1
- 102000009572 RNA Polymerase II Human genes 0.000 description 1
- 108010009460 RNA Polymerase II Proteins 0.000 description 1
- 102000044126 RNA-Binding Proteins Human genes 0.000 description 1
- 230000004570 RNA-binding Effects 0.000 description 1
- 101710105008 RNA-binding protein Proteins 0.000 description 1
- 238000011529 RT qPCR Methods 0.000 description 1
- 101100272715 Ralstonia solanacearum (strain GMI1000) brg11 gene Proteins 0.000 description 1
- 244000088415 Raphanus sativus Species 0.000 description 1
- 235000006140 Raphanus sativus var sativus Nutrition 0.000 description 1
- 108091081062 Repeated sequence (DNA) Proteins 0.000 description 1
- 108091027981 Response element Proteins 0.000 description 1
- 241000589187 Rhizobium sp. Species 0.000 description 1
- 108091028664 Ribonucleotide Proteins 0.000 description 1
- 235000011449 Rosa Nutrition 0.000 description 1
- 241000220317 Rosa Species 0.000 description 1
- CGNLCCVKSWNSDG-UHFFFAOYSA-N SYBR Green I Chemical compound CN(C)CCCN(CCC)C1=CC(C=C2N(C3=CC=CC=C3S2)C)=C2C=CC=CC2=[N+]1C1=CC=CC=C1 CGNLCCVKSWNSDG-UHFFFAOYSA-N 0.000 description 1
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 1
- 238000012300 Sequence Analysis Methods 0.000 description 1
- 235000000208 Solanum incanum Nutrition 0.000 description 1
- 244000302301 Solanum incanum Species 0.000 description 1
- 235000010797 Solanum verrucosum Nutrition 0.000 description 1
- 240000008287 Solanum verrucosum Species 0.000 description 1
- 235000009337 Spinacia oleracea Nutrition 0.000 description 1
- 244000300264 Spinacia oleracea Species 0.000 description 1
- 101000951943 Stenotrophomonas maltophilia Dicamba O-demethylase, oxygenase component Proteins 0.000 description 1
- 241000187391 Streptomyces hygroscopicus Species 0.000 description 1
- 239000005618 Sulcotrione Substances 0.000 description 1
- 238000010459 TALEN Methods 0.000 description 1
- 108700026226 TATA Box Proteins 0.000 description 1
- 239000005620 Tembotrione Substances 0.000 description 1
- 241000492514 Tetragonolobus Species 0.000 description 1
- RYYWUUFWQRZTIU-UHFFFAOYSA-N Thiophosphoric acid Chemical class OP(O)(S)=O RYYWUUFWQRZTIU-UHFFFAOYSA-N 0.000 description 1
- MZZINWWGSYUHGU-UHFFFAOYSA-J ToTo-1 Chemical compound [I-].[I-].[I-].[I-].C12=CC=CC=C2C(C=C2N(C3=CC=CC=C3S2)C)=CC=[N+]1CCC[N+](C)(C)CCC[N+](C)(C)CCC[N+](C1=CC=CC=C11)=CC=C1C=C1N(C)C2=CC=CC=C2S1 MZZINWWGSYUHGU-UHFFFAOYSA-J 0.000 description 1
- 241000723873 Tobacco mosaic virus Species 0.000 description 1
- 108010043645 Transcription Activator-Like Effector Nucleases Proteins 0.000 description 1
- 102000006289 Transcription Factor TFIIA Human genes 0.000 description 1
- 108010083262 Transcription Factor TFIIA Proteins 0.000 description 1
- 108700009124 Transcription Initiation Site Proteins 0.000 description 1
- 108090000941 Transcription factor TFIIB Proteins 0.000 description 1
- 102000004408 Transcription factor TFIIB Human genes 0.000 description 1
- 108091032917 Transfer-messenger RNA Proteins 0.000 description 1
- 241000219977 Vigna Species 0.000 description 1
- ULHRKLSNHXXJLO-UHFFFAOYSA-L Yo-Pro-1 Chemical compound [I-].[I-].C1=CC=C2C(C=C3N(C4=CC=CC=C4O3)C)=CC=[N+](CCC[N+](C)(C)C)C2=C1 ULHRKLSNHXXJLO-UHFFFAOYSA-L 0.000 description 1
- GRRMZXFOOGQMFA-UHFFFAOYSA-J YoYo-1 Chemical compound [I-].[I-].[I-].[I-].C12=CC=CC=C2C(C=C2N(C3=CC=CC=C3O2)C)=CC=[N+]1CCC[N+](C)(C)CCC[N+](C)(C)CCC[N+](C1=CC=CC=C11)=CC=C1C=C1N(C)C2=CC=CC=C2O1 GRRMZXFOOGQMFA-UHFFFAOYSA-J 0.000 description 1
- PTFCDOFLOPIGGS-UHFFFAOYSA-N Zinc dication Chemical compound [Zn+2] PTFCDOFLOPIGGS-UHFFFAOYSA-N 0.000 description 1
- 241000746966 Zizania Species 0.000 description 1
- FJJCIZWZNKZHII-UHFFFAOYSA-N [4,6-bis(cyanoamino)-1,3,5-triazin-2-yl]cyanamide Chemical compound N#CNC1=NC(NC#N)=NC(NC#N)=N1 FJJCIZWZNKZHII-UHFFFAOYSA-N 0.000 description 1
- 230000021736 acetylation Effects 0.000 description 1
- 238000006640 acetylation reaction Methods 0.000 description 1
- 102000005421 acetyltransferase Human genes 0.000 description 1
- 230000002378 acidificating effect Effects 0.000 description 1
- DDBMQDADIHOWIC-UHFFFAOYSA-N aclonifen Chemical compound C1=C([N+]([O-])=O)C(N)=C(Cl)C(OC=2C=CC=CC=2)=C1 DDBMQDADIHOWIC-UHFFFAOYSA-N 0.000 description 1
- 230000033289 adaptive immune response Effects 0.000 description 1
- 229960000643 adenine Drugs 0.000 description 1
- 238000013019 agitation Methods 0.000 description 1
- 239000002168 alkylating agent Substances 0.000 description 1
- 108090000637 alpha-Amylases Proteins 0.000 description 1
- 102000004139 alpha-Amylases Human genes 0.000 description 1
- 235000019418 amylase Nutrition 0.000 description 1
- 229940051880 analgesics and antipyretics pyrazolones Drugs 0.000 description 1
- 238000004873 anchoring Methods 0.000 description 1
- 238000000137 annealing Methods 0.000 description 1
- 239000001387 apium graveolens Substances 0.000 description 1
- 235000021016 apples Nutrition 0.000 description 1
- 229960001230 asparagine Drugs 0.000 description 1
- 235000009582 asparagine Nutrition 0.000 description 1
- 239000002363 auxin Substances 0.000 description 1
- XOEMATDHVZOBSG-UHFFFAOYSA-N azafenidin Chemical compound C1=C(OCC#C)C(Cl)=CC(Cl)=C1N1C(=O)N2CCCCC2=N1 XOEMATDHVZOBSG-UHFFFAOYSA-N 0.000 description 1
- 244000000005 bacterial plant pathogen Species 0.000 description 1
- 101150103518 bar gene Proteins 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- GINJFDRNADDBIN-FXQIFTODSA-N bilanafos Chemical class OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCP(C)(O)=O GINJFDRNADDBIN-FXQIFTODSA-N 0.000 description 1
- 238000003766 bioinformatics method Methods 0.000 description 1
- 239000012472 biological sample Substances 0.000 description 1
- 125000004057 biotinyl group Chemical group [H]N1C(=O)N([H])[C@]2([H])[C@@]([H])(SC([H])([H])[C@]12[H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C(*)=O 0.000 description 1
- 150000005693 branched-chain amino acids Chemical class 0.000 description 1
- JEDYYFXHPAIBGR-UHFFFAOYSA-N butafenacil Chemical compound O=C1N(C)C(C(F)(F)F)=CC(=O)N1C1=CC=C(Cl)C(C(=O)OC(C)(C)C(=O)OCC=C)=C1 JEDYYFXHPAIBGR-UHFFFAOYSA-N 0.000 description 1
- 101150081794 bxn gene Proteins 0.000 description 1
- 238000010805 cDNA synthesis kit Methods 0.000 description 1
- 108010035812 caffeoyl-CoA O-methyltransferase Proteins 0.000 description 1
- 239000001511 capsicum annuum Substances 0.000 description 1
- 150000004657 carbamic acid derivatives Chemical class 0.000 description 1
- 238000004113 cell culture Methods 0.000 description 1
- 108091092356 cellular DNA Proteins 0.000 description 1
- 108091092328 cellular RNA Proteins 0.000 description 1
- 235000013339 cereals Nutrition 0.000 description 1
- 235000019693 cherries Nutrition 0.000 description 1
- 229960005091 chloramphenicol Drugs 0.000 description 1
- WIIZWVCIJKGZOK-RKDXNWHRSA-N chloramphenicol Chemical compound ClC(Cl)C(=O)N[C@H](CO)[C@H](O)C1=CC=C([N+]([O-])=O)C=C1 WIIZWVCIJKGZOK-RKDXNWHRSA-N 0.000 description 1
- 108010031100 chloroplast transit peptides Proteins 0.000 description 1
- 239000013599 cloning vector Substances 0.000 description 1
- 238000004590 computer program Methods 0.000 description 1
- 235000008504 concentrate Nutrition 0.000 description 1
- 239000012141 concentrate Substances 0.000 description 1
- 239000000470 constituent Substances 0.000 description 1
- 238000011109 contamination Methods 0.000 description 1
- 101150102059 cry3Aa gene Proteins 0.000 description 1
- 101150049887 cspB gene Proteins 0.000 description 1
- 101150041068 cspJ gene Proteins 0.000 description 1
- 101150010904 cspLB gene Proteins 0.000 description 1
- 210000004748 cultured cell Anatomy 0.000 description 1
- 210000000805 cytoplasm Anatomy 0.000 description 1
- 101150012655 dcl1 gene Proteins 0.000 description 1
- 230000000593 degrading effect Effects 0.000 description 1
- 230000001934 delay Effects 0.000 description 1
- 125000002637 deoxyribonucleotide group Chemical group 0.000 description 1
- IWEDIXLBFLAXBO-UHFFFAOYSA-N dicamba Chemical compound COC1=C(Cl)C=CC(Cl)=C1C(O)=O IWEDIXLBFLAXBO-UHFFFAOYSA-N 0.000 description 1
- XPPKVPWEQAFLFU-UHFFFAOYSA-J diphosphate(4-) Chemical compound [O-]P([O-])(=O)OP([O-])([O-])=O XPPKVPWEQAFLFU-UHFFFAOYSA-J 0.000 description 1
- 235000011180 diphosphates Nutrition 0.000 description 1
- NAGJZTKCGNOGPW-UHFFFAOYSA-N dithiophosphoric acid Chemical class OP(O)(S)=S NAGJZTKCGNOGPW-UHFFFAOYSA-N 0.000 description 1
- 230000008641 drought stress Effects 0.000 description 1
- 239000003814 drug Substances 0.000 description 1
- 238000001962 electrophoresis Methods 0.000 description 1
- 230000008030 elimination Effects 0.000 description 1
- 238000003379 elimination reaction Methods 0.000 description 1
- 108010050663 endodeoxyribonuclease CreI Proteins 0.000 description 1
- 230000007613 environmental effect Effects 0.000 description 1
- 230000002255 enzymatic effect Effects 0.000 description 1
- 230000007247 enzymatic mechanism Effects 0.000 description 1
- 108010065744 ethylene forming enzyme Proteins 0.000 description 1
- 241001233957 eudicotyledons Species 0.000 description 1
- 230000005284 excitation Effects 0.000 description 1
- 238000000695 excitation spectrum Methods 0.000 description 1
- 238000002474 experimental method Methods 0.000 description 1
- 239000013604 expression vector Substances 0.000 description 1
- 235000013312 flour Nutrition 0.000 description 1
- 238000000684 flow cytometry Methods 0.000 description 1
- FOUWCSDKDDHKQP-UHFFFAOYSA-N flumioxazin Chemical compound FC1=CC=2OCC(=O)N(CC#C)C=2C=C1N(C1=O)C(=O)C2=C1CCCC2 FOUWCSDKDDHKQP-UHFFFAOYSA-N 0.000 description 1
- 108010021843 fluorescent protein 583 Proteins 0.000 description 1
- 230000004907 flux Effects 0.000 description 1
- BGZZWXTVIYUUEY-UHFFFAOYSA-N fomesafen Chemical compound C1=C([N+]([O-])=O)C(C(=O)NS(=O)(=O)C)=CC(OC=2C(=CC(=CC=2)C(F)(F)F)Cl)=C1 BGZZWXTVIYUUEY-UHFFFAOYSA-N 0.000 description 1
- 238000009472 formulation Methods 0.000 description 1
- 230000004927 fusion Effects 0.000 description 1
- 108020001507 fusion proteins Proteins 0.000 description 1
- 102000037865 fusion proteins Human genes 0.000 description 1
- 238000010363 gene targeting Methods 0.000 description 1
- 238000001415 gene therapy Methods 0.000 description 1
- 230000004034 genetic regulation Effects 0.000 description 1
- BRZYSWJRSDMWLG-CAXSIQPQSA-N geneticin Natural products O1C[C@@](O)(C)[C@H](NC)[C@@H](O)[C@H]1O[C@@H]1[C@@H](O)[C@H](O[C@@H]2[C@@H]([C@@H](O)[C@H](O)[C@@H](C(C)O)O2)N)[C@@H](N)C[C@H]1N BRZYSWJRSDMWLG-CAXSIQPQSA-N 0.000 description 1
- 238000010362 genome editing Methods 0.000 description 1
- 230000035784 germination Effects 0.000 description 1
- 230000013595 glycosylation Effects 0.000 description 1
- 238000006206 glycosylation reaction Methods 0.000 description 1
- 238000003065 hierarchial clustering Methods 0.000 description 1
- 239000005556 hormone Substances 0.000 description 1
- 229940088597 hormone Drugs 0.000 description 1
- 230000001900 immune effect Effects 0.000 description 1
- 238000003018 immunoassay Methods 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 238000005462 in vivo assay Methods 0.000 description 1
- 238000011534 incubation Methods 0.000 description 1
- 230000001939 inductive effect Effects 0.000 description 1
- 108091006086 inhibitor proteins Proteins 0.000 description 1
- 239000003999 initiator Substances 0.000 description 1
- 239000012212 insulator Substances 0.000 description 1
- 230000010354 integration Effects 0.000 description 1
- 230000002452 interceptive effect Effects 0.000 description 1
- 230000003834 intracellular effect Effects 0.000 description 1
- 239000001573 invertase Substances 0.000 description 1
- 235000011073 invertase Nutrition 0.000 description 1
- 238000005304 joining Methods 0.000 description 1
- 238000011005 laboratory method Methods 0.000 description 1
- CONWAEURSVPLRM-UHFFFAOYSA-N lactofen Chemical compound C1=C([N+]([O-])=O)C(C(=O)OC(C)C(=O)OCC)=CC(OC=2C(=CC(=CC=2)C(F)(F)F)Cl)=C1 CONWAEURSVPLRM-UHFFFAOYSA-N 0.000 description 1
- 229910052747 lanthanoid Inorganic materials 0.000 description 1
- 150000002602 lanthanoids Chemical class 0.000 description 1
- 150000002632 lipids Chemical class 0.000 description 1
- 238000001638 lipofection Methods 0.000 description 1
- 239000007788 liquid Substances 0.000 description 1
- 239000006249 magnetic particle Substances 0.000 description 1
- 230000014759 maintenance of location Effects 0.000 description 1
- 239000011159 matrix material Substances 0.000 description 1
- 235000012054 meals Nutrition 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 239000002609 medium Substances 0.000 description 1
- 230000000442 meristematic effect Effects 0.000 description 1
- KPUREKXXPHOJQT-UHFFFAOYSA-N mesotrione Chemical compound [O-][N+](=O)C1=CC(S(=O)(=O)C)=CC=C1C(=O)C1C(=O)CCCC1=O KPUREKXXPHOJQT-UHFFFAOYSA-N 0.000 description 1
- 238000012269 metabolic engineering Methods 0.000 description 1
- 229960000485 methotrexate Drugs 0.000 description 1
- 238000000520 microinjection Methods 0.000 description 1
- 238000007431 microscopic evaluation Methods 0.000 description 1
- 230000003278 mimic effect Effects 0.000 description 1
- 235000019426 modified starch Nutrition 0.000 description 1
- 230000004879 molecular function Effects 0.000 description 1
- 230000000877 morphologic effect Effects 0.000 description 1
- 210000003205 muscle Anatomy 0.000 description 1
- 230000035772 mutation Effects 0.000 description 1
- 239000002105 nanoparticle Substances 0.000 description 1
- 239000013642 negative control Substances 0.000 description 1
- 229920001220 nitrocellulos Polymers 0.000 description 1
- 230000009871 nonspecific binding Effects 0.000 description 1
- 210000004940 nucleus Anatomy 0.000 description 1
- 230000030648 nucleus localization Effects 0.000 description 1
- 229920001778 nylon Polymers 0.000 description 1
- 239000003921 oil Substances 0.000 description 1
- 235000019198 oils Nutrition 0.000 description 1
- 229940124276 oligodeoxyribonucleotide Drugs 0.000 description 1
- 239000011022 opal Substances 0.000 description 1
- 210000003463 organelle Anatomy 0.000 description 1
- 230000008520 organization Effects 0.000 description 1
- 210000004681 ovum Anatomy 0.000 description 1
- 230000036961 partial effect Effects 0.000 description 1
- 230000007918 pathogenicity Effects 0.000 description 1
- 235000010987 pectin Nutrition 0.000 description 1
- 239000001814 pectin Substances 0.000 description 1
- 229920001277 pectin Polymers 0.000 description 1
- JZPKLLLUDLHCEL-UHFFFAOYSA-N pentoxazone Chemical compound O=C1C(=C(C)C)OC(=O)N1C1=CC(OC2CCCC2)=C(Cl)C=C1F JZPKLLLUDLHCEL-UHFFFAOYSA-N 0.000 description 1
- 239000000137 peptide hydrolase inhibitor Substances 0.000 description 1
- 239000010452 phosphate Substances 0.000 description 1
- 108010082527 phosphinothricin N-acetyltransferase Proteins 0.000 description 1
- 125000001476 phosphono group Chemical group [H]OP(*)(=O)O[H] 0.000 description 1
- 230000026731 phosphorylation Effects 0.000 description 1
- 238000006366 phosphorylation reaction Methods 0.000 description 1
- 230000004962 physiological condition Effects 0.000 description 1
- 230000035790 physiological processes and functions Effects 0.000 description 1
- 230000003032 phytopathogenic effect Effects 0.000 description 1
- 230000019612 pigmentation Effects 0.000 description 1
- 239000001739 pinus spp. Substances 0.000 description 1
- 230000008121 plant development Effects 0.000 description 1
- 230000037039 plant physiology Effects 0.000 description 1
- 238000004161 plant tissue culture Methods 0.000 description 1
- 239000013600 plasmid vector Substances 0.000 description 1
- 230000010152 pollination Effects 0.000 description 1
- 229920002401 polyacrylamide Polymers 0.000 description 1
- 230000003234 polygenic effect Effects 0.000 description 1
- 238000006116 polymerization reaction Methods 0.000 description 1
- 230000000379 polymerizing effect Effects 0.000 description 1
- 239000013641 positive control Substances 0.000 description 1
- 101150054546 ppo gene Proteins 0.000 description 1
- 238000011533 pre-incubation Methods 0.000 description 1
- 238000001556 precipitation Methods 0.000 description 1
- 238000002360 preparation method Methods 0.000 description 1
- 239000002987 primer (paints) Substances 0.000 description 1
- FKLQIONHGSFYJY-UHFFFAOYSA-N propan-2-yl 5-[4-bromo-1-methyl-5-(trifluoromethyl)pyrazol-3-yl]-2-chloro-4-fluorobenzoate Chemical compound C1=C(Cl)C(C(=O)OC(C)C)=CC(C=2C(=C(N(C)N=2)C(F)(F)F)Br)=C1F FKLQIONHGSFYJY-UHFFFAOYSA-N 0.000 description 1
- 230000004853 protein function Effects 0.000 description 1
- 235000015136 pumpkin Nutrition 0.000 description 1
- 150000003212 purines Chemical class 0.000 description 1
- YXIIPOGUBVYZIW-UHFFFAOYSA-N pyraflufen Chemical compound ClC1=C(OC(F)F)N(C)N=C1C1=CC(OCC(O)=O)=C(Cl)C=C1F YXIIPOGUBVYZIW-UHFFFAOYSA-N 0.000 description 1
- JEXVQSWXXUJEMA-UHFFFAOYSA-N pyrazol-3-one Chemical class O=C1C=CN=N1 JEXVQSWXXUJEMA-UHFFFAOYSA-N 0.000 description 1
- FKERUJTUOYLBKB-UHFFFAOYSA-N pyrazoxyfen Chemical compound C=1C=C(Cl)C=C(Cl)C=1C(=O)C=1C(C)=NN(C)C=1OCC(=O)C1=CC=CC=C1 FKERUJTUOYLBKB-UHFFFAOYSA-N 0.000 description 1
- 150000003230 pyrimidines Chemical class 0.000 description 1
- 125000000714 pyrimidinyl group Chemical group 0.000 description 1
- 238000012175 pyrosequencing Methods 0.000 description 1
- 238000011002 quantification Methods 0.000 description 1
- 238000003259 recombinant expression Methods 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 230000007115 recruitment Effects 0.000 description 1
- 230000000306 recurrent effect Effects 0.000 description 1
- 108010054624 red fluorescent protein Proteins 0.000 description 1
- 230000022532 regulation of transcription, DNA-dependent Effects 0.000 description 1
- 238000012552 review Methods 0.000 description 1
- PYWVYCXTNDRMGF-UHFFFAOYSA-N rhodamine B Chemical compound [Cl-].C=12C=CC(=[N+](CC)CC)C=C2OC2=CC(N(CC)CC)=CC=C2C=1C1=CC=CC=C1C(O)=O PYWVYCXTNDRMGF-UHFFFAOYSA-N 0.000 description 1
- 239000002336 ribonucleotide Substances 0.000 description 1
- 125000002652 ribonucleotide group Chemical group 0.000 description 1
- 229920002477 rna polymer Polymers 0.000 description 1
- 238000007480 sanger sequencing Methods 0.000 description 1
- 238000007423 screening assay Methods 0.000 description 1
- 230000028327 secretion Effects 0.000 description 1
- 230000005562 seed maturation Effects 0.000 description 1
- 230000035945 sensitivity Effects 0.000 description 1
- 238000007841 sequencing by ligation Methods 0.000 description 1
- 238000002741 site-directed mutagenesis Methods 0.000 description 1
- 239000002689 soil Substances 0.000 description 1
- 238000010532 solid phase synthesis reaction Methods 0.000 description 1
- 238000011895 specific detection Methods 0.000 description 1
- 229940063673 spermidine Drugs 0.000 description 1
- 230000007480 spreading Effects 0.000 description 1
- 238000003892 spreading Methods 0.000 description 1
- 235000020354 squash Nutrition 0.000 description 1
- 238000010186 staining Methods 0.000 description 1
- 230000035882 stress Effects 0.000 description 1
- PQTBTIFWAXVEPB-UHFFFAOYSA-N sulcotrione Chemical compound ClC1=CC(S(=O)(=O)C)=CC=C1C(=O)C1C(=O)CCCC1=O PQTBTIFWAXVEPB-UHFFFAOYSA-N 0.000 description 1
- OORLZFUTLGXMEF-UHFFFAOYSA-N sulfentrazone Chemical compound O=C1N(C(F)F)C(C)=NN1C1=CC(NS(C)(=O)=O)=C(Cl)C=C1Cl OORLZFUTLGXMEF-UHFFFAOYSA-N 0.000 description 1
- YROXIXLRRCOBKF-UHFFFAOYSA-N sulfonylurea Chemical class OC(=N)N=S(=O)=O YROXIXLRRCOBKF-UHFFFAOYSA-N 0.000 description 1
- 230000001629 suppression Effects 0.000 description 1
- IUQAXCIUEPFPSF-UHFFFAOYSA-N tembotrione Chemical compound ClC1=C(COCC(F)(F)F)C(S(=O)(=O)C)=CC=C1C(=O)C1C(=O)CCCC1=O IUQAXCIUEPFPSF-UHFFFAOYSA-N 0.000 description 1
- 230000002123 temporal effect Effects 0.000 description 1
- 238000012360 testing method Methods 0.000 description 1
- MPLHNVLQVRSVEE-UHFFFAOYSA-N texas red Chemical compound [O-]S(=O)(=O)C1=CC(S(Cl)(=O)=O)=CC=C1C(C1=CC=2CCCN3CCCC(C=23)=C1O1)=C2C1=C(CCC1)C3=[N+]1CCCC3=C2 MPLHNVLQVRSVEE-UHFFFAOYSA-N 0.000 description 1
- 229940113082 thymine Drugs 0.000 description 1
- 239000003104 tissue culture media Substances 0.000 description 1
- IYMLUHWAJFXAQP-UHFFFAOYSA-N topramezone Chemical compound CC1=C(C(=O)C2=C(N(C)N=C2)O)C=CC(S(C)(=O)=O)=C1C1=NOCC1 IYMLUHWAJFXAQP-UHFFFAOYSA-N 0.000 description 1
- 230000005026 transcription initiation Effects 0.000 description 1
- 230000005030 transcription termination Effects 0.000 description 1
- 108091006106 transcriptional activators Proteins 0.000 description 1
- 238000001890 transfection Methods 0.000 description 1
- 235000011178 triphosphate Nutrition 0.000 description 1
- 230000034512 ubiquitination Effects 0.000 description 1
- 238000010798 ubiquitination Methods 0.000 description 1
- 241001430294 unidentified retrovirus Species 0.000 description 1
- 230000017260 vegetative to reproductive phase transition of meristem Effects 0.000 description 1
- 239000003981 vehicle Substances 0.000 description 1
- 230000003612 virological effect Effects 0.000 description 1
Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/82—Vectors or expression systems specially adapted for eukaryotic hosts for plant cells, e.g. plant artificial chromosomes (PACs)
- C12N15/8216—Methods for controlling, regulating or enhancing expression of transgenes in plant cells
- C12N15/8222—Developmentally regulated expression systems, tissue, organ specific, temporal or spatial regulation
- C12N15/823—Reproductive tissue-specific promoters
- C12N15/8234—Seed-specific, e.g. embryo, endosperm
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/82—Vectors or expression systems specially adapted for eukaryotic hosts for plant cells, e.g. plant artificial chromosomes (PACs)
- C12N15/8216—Methods for controlling, regulating or enhancing expression of transgenes in plant cells
- C12N15/8222—Developmentally regulated expression systems, tissue, organ specific, temporal or spatial regulation
- C12N15/823—Reproductive tissue-specific promoters
- C12N15/8233—Female-specific, e.g. pistil, ovule
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/82—Vectors or expression systems specially adapted for eukaryotic hosts for plant cells, e.g. plant artificial chromosomes (PACs)
- C12N15/8216—Methods for controlling, regulating or enhancing expression of transgenes in plant cells
- C12N15/8222—Developmentally regulated expression systems, tissue, organ specific, temporal or spatial regulation
- C12N15/823—Reproductive tissue-specific promoters
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02A—TECHNOLOGIES FOR ADAPTATION TO CLIMATE CHANGE
- Y02A40/00—Adaptation technologies in agriculture, forestry, livestock or agroalimentary production
- Y02A40/10—Adaptation technologies in agriculture, forestry, livestock or agroalimentary production in agriculture
- Y02A40/146—Genetically Modified [GMO] plants, e.g. transgenic plants
Definitions
- the present invention refers to a nucleic acid vector construct including a promoter with ambryonic cell preferred expression suitable for preparing transgenic plants, as well to transgenic plants comprising said promoter operably linked to a heterologous coding sequence.
- desirable traits include, for example, improving nutritional value quality, increasing yield, conferring pest or disease resistance, increasing drought and stress tolerance, improving horticultural qualities (e.g., pigmentation and growth), imparting herbicide tolerance, enabling the production of industrially useful compounds and/or materials from the plant, and/or enabling the production of pharmaceuticals.
- Transgenic plant species comprising multiple transgenes stacked at a single genomic locus are produced via plant transformation technologies.
- Plant transformation technologies result in the introduction of a transgene into a plant cell, recovery of a fertile transgenic plant that contains the stably integrated copy of the transgene in the plant genome, and subsequent transgene expression via transcription and translation results in transgenic plants that possess desirable traits and phenotypes.
- novel gene regulatory elements that allow the production of transgenic plant species to highly express multiple transgenes engineered as a trait stack are desirable.
- novel gene regulatory elements that allow the expression of a transgene within particular tissues or organs of a plant are desirable. For example, increased resistance of a plant to infection by soil-borne pathogens might be accomplished by transforming the plant genome with a pathogen-resistance gene such that pathogen-resistance protein is robustly expressed within the roots of the plant.
- the disclosure relates to a nucleic acid vector comprising a promoter operably linked to: a) a polylinker sequence; b) a non-Panicum virgatum (Pavir.J00490) egg cell heterologous gene; or c) a combination of a) and b), wherein said promoter comprises a polynucleotide sequence that has at least 98% sequence identity with SEQ ID NO:1, further the nucleic acid vector comprises a 3' untranslated polynucleic acid sequence and said promoter has embryonic cell preferred expression.
- the promoter is 1,290 bp in length.
- the promoter consists of a polynucleotide sequence that has at least 98% sequence identity with SEQ ID NO:1.
- the promoter comprises a sequence encoding a selectable maker.
- the promoter is operably linked to a transgene (heterologous coding sequence).
- the transgene encodes a selectable marker or a gene product conferring insecticidal resistance, herbicide tolerance, nitrogen use efficiency, water use efficiency, expression of an RNAi, or nutritional quality.
- the nucleic acid vector comprises a 5' untranslated polynucleotide sequence.
- the nucleic acid vector comprises an intron sequence.
- the subject disclosure relates to a transgenic plant comprising the nucleic acid vector.
- the plant is selected from the group consisting of Zea mays, wheat, rice, sorghum, oats, rye, bananas, sugar cane, soybean, cotton, Arabidopsis, tobacco, sunflower, and canola.
- the transgene is inserted into the genome of said plant.
- the transgenic plant includes a promoter that comprises a polynucleotide sequence having at least 98% sequence identity with SEQ ID NO:1 and said promoter is operably linked to a transgene.
- the transgenic plant comprises a 3' untranslated sequence.
- the transgenic promoter drives embryonic cell tissue specific expression of a transgene in the transgenic plant.
- the transgenic plant comprises a promoter that is 1,290 bp in length.
- the disclosure relates to a method for producing a transgenic plant cell, the method comprising the steps of: a) transforming a plant cell with a gene expression cassette comprising a Panicum virgatum (Pavir.J00490) egg cell promoter operably linked to at least one polynucleotide sequence of interest; b) isolating the transformed plant cell comprising the gene expression cassette; and, c) producing a transgenic plant cell comprising the Panicum virgatum (Pavir.J00490) egg cell promoter operably linked to at least one polynucleotide sequence of interest.
- the transforming of a plant cell is performed with a plant transformation method.
- These transformation methods can include a plant transformation method is selected from the group consisting of an Agrobacterium-mediated transformation method, a biolistics transformation method, a silicon carbide transformation method, a protoplast transformation method, and a liposome transformation method.
- the polynucleotide sequence of interest is expressed in a plant cell.
- the polynucleotide sequence of interest is stably integrated into the genome of the transgenic plant cell.
- the method further comprising the steps of: d) regenerating the transgenic plant cell into a transgenic plant; and, e) obtaining the transgenic plant, wherein the transgenic plant comprises the gene expression cassette comprising the Panicum virgatum (Pavir.J00490) egg cell promoter of claim 1 operably linked to at least one polynucleotide sequence of interest.
- the transgenic plant cell is a monocotyledonous transgenic plant cell or a dicotyledonous transgenic plant cell. Accordingly, the dicotyledonous transgenic plant cell may include Arabidopsis plant cell, a tobacco plant cell, a soybean plant cell, a canola plant cell, and a cotton plant cell.
- the monocotyledonous transgenic plant cell can include a Zea mays plant cell, a rice plant cell, and a wheat plant cell.
- the Panicum virgatum (Pavir.J00490) egg cell promoter comprises the polynucleotide of SEQ ID NO:1.
- the method comprises introducing into the plant cell a polynucleotide sequence of interest operably linked to a Panicum virgatum (Pavir.J00490) egg cell promoter.
- the polynucleotide sequence of interest operably linked to the Panicum virgatum (Pavir.J00490) egg cell promoter is introduced into the plant cell by a plant transformation method.
- a plant transformation method include Agrobacterium-mediated transformation method, a biolistics transformation method, a silicon carbide transformation method, a protoplast transformation method, and a liposome transformation method.
- the polynucleotide sequence of interest is expressed in embryonic cell tissue.
- the polynucleotide sequence of interest is stably integrated into the genome of the plant cell.
- the transgenic plant cell is a monocotyledonous plant cell or a dicotyledonous plant cell.
- Exemplary dicotyledonous plant cells include an Arabidopsis plant cell, a tobacco plant cell, a soybean plant cell, a canola plant cell, and a cotton plant cell.
- exemplary monocotyledonous plant cells include a Zea mays plant cell, a rice plant cell, and a wheat plant cell.
- the disclosure relates to a transgenic plant cell comprising a Panicum virgatum (Pavir.J00490) egg cell promoter.
- the transgenic plant cell comprises a transgenic event.
- the transgenic event comprises an agronomic trait.
- agronomic traits can include an insecticidal resistance trait, herbicide tolerance trait, nitrogen use efficiency trait, water use efficiency trait, nutritional quality trait, DNA binding trait, selectable marker trait, small RNA trait, or any combination thereof.
- an herbicide tolerant trait may comprise the aad -1 coding sequence.
- the transgenic plant cell produces a commodity product.
- Such commodity products can include protein concentrate, protein isolate, grain, meal, flour, oil, or fiber.
- the transgenic plant cell is selected from the group consisting of a dicotyledonous plant cell or a monocotyledonous plant cell.
- Exemplary dicotyledonous plant cells include an Arabidopsis plant cell, a tobacco plant cell, a soybean plant cell, a canola plant cell, and a cotton plant cell.
- exemplary monocotyledonous plant cells include a Zea mays plant cell, a rice plant cell, and a wheat plant cell.
- the Panicum virgatum (Pavir.J00490) egg cell promoter comprises a polynucleotide with at least 98% sequence identity to the polynucleotide of SEQ ID NO:1.
- the Panicum virgatum (Pavir.J00490) egg cell promoter is 1,290 bp in length.
- the Panicum virgatum (Pavir.J00490) egg cell promoter consists of SEQ ID NO:1.
- the first polynucleotide sequence of interest is operably linked to the 3' end of SEQ ID NO: 1.
- the agronomic trait is expressed in embryonic cell tissue.
- the disclosure relates to an isolated polynucleotide comprising a nucleic acid sequence with at least 98% sequence identity to the polynucleotide of SEQ ID NO:1.
- the isolated polynucleotide is specifically expressed in embryonic cell tissue.
- the isolated polynucleotide is expressed within a plant cell.
- the isolated polynucleotide comprises an open-reading frame polynucleotide coding for a polypeptide and a termination sequence.
- the polynucleotide of SEQ ID NO: 1 is 1,290 bp in length.
- the disclosure relates to a gene expression cassette comprising a promoter operably linked to a heterologous coding sequence, wherein the promoter comprises a polynucleotide comprising a sequence identity of at least 98% to SEQ ID NO:1.
- the polynucleotide has at least 98% sequence identity to SEQ ID NO:1.
- the gene expression cassette comprises an intron.
- the gene expression cassette comprises a 5' UTR.
- the promoter has tissue preferred expression.
- the promoter is operably linked to a heterologous coding sequence that encodes a polypeptide or a small RNA gene.
- Examples of the encoded polypeptide or small RNA gene include a heterologous coding sequence conferring insecticidal resistance, herbicide tolerance, a nucleic acid conferring nitrogen use efficiency, a nucleic acid conferring water use efficiency, a nucleic acid conferring nutritional quality, a nucleic acid encoding a DNA binding protein, and a nucleic acid encoding a selectable marker.
- the gene expression cassette comprises a 3' untranslated region. In additional embodiments, the gene expression cassette comprises a 5' untranslated region.
- the gene expression cassette comprises a terminator region
- the subject disclosure relates to a recombinant vector comprising the gene expression cassette, wherein the vector is selected from the group consisting of a plasmid, a cosmid, a bacterial artificial chromosome, a virus, and a bacteriophage.
- the subject disclosure relates to a transgenic cell comprising the gene expression cassette.
- the transgenic cell is a transgenic plant cell.
- the transgenic plant comprises the transgenic plant cell.
- the transgenic plant is a monocotyledonous plant or dicotyledonous plant.
- Examples of a monocotyledonous plant is include a maize plant, a rice plant, and a wheat plant.
- the transgenic plant produces a seed comprising the gene expression cassette.
- the promoter is a tissue preferred promoter.
- the tissue preferred promoter is an embryonic cell preferred promoter.
- transgenic plant products are becoming increasingly complex.
- Commercially viable transgenic plants now require the stacking of multiple transgenes into a single locus.
- Plant promoters and 3' UTRs used for basic research or biotechnological applications are generally unidirectional, directing only one gene that has been fused at its 3' end (downstream) for the promoter, or at its 5' end (upstream) for the 3' UTR.
- each transgene/heterologous coding sequence usually requires a promoter and 3' UTR for expression, wherein multiple regulatory elements are required to express multiple transgenes/heterologous coding sequences within one gene stack.
- the same promoter and/or 3' UTR is routinely used to obtain optimal levels of expression patterns of different transgenes/heterologous coding sequences. Obtaining optimal levels of transgene expression is necessary for the production of a single polygenic trait.
- multi-gene constructs driven by the same promoter and/or 3' UTR are known to cause gene silencing resulting in less efficacious transgenic products in the field.
- the repeated promoter and/or 3' UTR elements may lead to homology-based gene silencing.
- transgenes within a transgene may lead to gene intra locus homologous recombination resulting in polynucleotide rearrangements.
- the silencing and rearrangement of transgenes will likely have an undesirable affect on the performance of a transgenic plant produced to express transgenes.
- excess of transcription factor (TF)-binding sites due to promoter repetition can cause depletion of endogenous TFs leading to transcriptional inactivation.
- TF transcription factor
- tissue-specific promoters related to specific cell types, developmental stages and/or functions in the plant that are not expressed in other plant tissues.
- Tissue specific (i.e., tissue preferred) or organ specific promoters drive gene expression in a certain tissue such as in the kernel, root, leaf, or tapetum of the plant.
- Tissue and developmental stage specific promoters and/or 3' UTRs can be initially identified from observing the expression of genes/heterologous coding sequences, which are expressed in particular tissues or at particular time periods during plant development.
- tissue specific/preferred promoters and/or 3' UTRs are required for certain applications in the transgenic plant industry and are desirable as they permit specific expression of heterologous genes in a tissue and/or developmental stage selective manner, indicating expression of the heterologous gene differentially at various organs, tissues and/or times, but not in other undesirable tissues.
- increased resistance of a plant to infection by soil-borne pathogens might be accomplished by transforming the plant genome with a pathogen-resistance gene such that pathogen-resistance protein is robustly expressed within the roots of the plant.
- tissue specific/preferred promoters and/or 3' UTRs to confine the expression of the transgenes/heterologous coding sequences encoding an agronomic trait in specific tissues types like developing parenchyma cells.
- a particular problem in the identification of promoters and/or 3' UTRs is how to identify the promoters, and to relate the identified promoter to developmental properties of the cell for specific/preferred tissue expression.
- Another problem regarding the identification of a promoter is the requirement to clone all relevant cis-acting and trans-activating transcriptional control elements so that the cloned DNA fragment drives transcription in the wanted specific expression pattern.
- control elements are located distally from the translation initiation or start site, the size of the polynucleotide that is selected to comprise the promoter is of importance for providing the level of expression and the expression patterns of the promoter polynucleotide sequence.
- promoter lengths include functional information, and different genes have been shown to have promoters longer or shorter than promoters of the other genes in the genome. Elucidating the transcription start site of a promoter and predicting the functional gene elements in the promoter region is challenging.
- promoter regulatory elements requires that an appropriate sequence of a specific size containing the necessary cis- and trans-regulatory elements is obtained that will result in driving expression of an operably linked transgene/heterologous coding sequence in a desirable manner.
- Panicum virgatum Panicum virgatum (Pavir.J00490) egg cell gene regulatory elements to express transgenes/heterologous coding sequences in planta.
- intron refers to any nucleic acid sequence comprised in a gene (or expressed polynucleotide sequence of interest) that is transcribed but not translated. Introns include untranslated nucleic acid sequence within an expressed sequence of DNA, as well as the corresponding sequence in RNA molecules transcribed therefrom. A construct described herein can also contain sequences that enhance translation and/or mRNA stability such as introns. An example of one such intron is the first intron of gene II of the histone H3 variant of Arabidopsis thaliana or any other commonly known intron sequence. Introns can be used in combination with a promoter sequence to enhance translation and/or mRNA stability.
- isolated means having been removed from its natural environment, or removed from other compounds present when the compound is first formed.
- isolated embraces materials isolated from natural sources as well as materials (e.g., nucleic acids and proteins) recovered after preparation by recombinant expression in a host cell, or chemically-synthesized compounds such as nucleic acid molecules, proteins, and peptides.
- purified relates to the isolation of a molecule or compound in a form that is substantially free of contaminants normally associated with the molecule or compound in a native or natural environment, or substantially enriched in concentration relative to other compounds present when the compound is first formed, and means having been increased in purity as a result of being separated from other components of the original composition.
- purified nucleic acid is used herein to describe a nucleic acid sequence which has been separated, produced apart from, or purified away from other biological compounds including, but not limited to polypeptides, lipids and carbohydrates, while effecting a chemical or functional change in the component (e.g., a nucleic acid may be purified from a chromosome by removing protein contaminants and breaking chemical bonds connecting the nucleic acid to the remaining DNA in the chromosome).
- synthetic refers to a polynucleotide (i.e., a DNA or RNA) molecule that was created via chemical synthesis as an in vitro process.
- a synthetic DNA may be created during a reaction within an Eppendorf TM tube, such that the synthetic DNA is enzymatically produced from a native strand of DNA or RNA.
- Other laboratory methods may be utilized to synthesize a polynucleotide sequence.
- Oligonucleotides may be chemically synthesized on an oligo synthesizer via solid-phase synthesis using phosphoramidites.
- the synthesized oligonucleotides may be annealed to one another as a complex, thereby producing a "synthetic" polynucleotide.
- Other methods for chemically synthesizing a polynucleotide are known in the art, and can be readily implemented for use in the present disclosure.
- a “gene” includes a DNA region encoding a gene product (see infra), as well as all DNA regions which regulate the production of the gene product, whether or not such regulatory sequences are adjacent to coding and/or transcribed sequences. Accordingly, a gene includes, but is not necessarily limited to, promoter sequences, terminators, translational regulatory sequences such as ribosome binding sites and internal ribosome entry sites, enhancers, silencers, insulators, boundary elements, replication origins, matrix attachment sites, introns and locus control regions.
- nucleic acid sequence is a DNA sequence present in nature that was produced by natural means or traditional breeding techniques but not generated by genetic engineering (e.g., using molecular biology/transformation techniques).
- transgene or “heterologous coding sequence” is defined to be a nucleic acid sequence that encodes a gene product, including for example, but not limited to, an mRNA.
- the transgene/heterologous coding sequence is an exogenous nucleic acid, where the transgene/heterologous coding sequence has been introduced into a host cell by genetic engineering (or the progeny thereof) where the transgene/heterologous coding sequence is not normally found.
- a transgene encodes an industrially or pharmaceutically useful compound, or a gene encoding a desirable agricultural trait (e.g., an herbicide-resistance gene).
- a transgene/heterologous coding sequence is an antisense nucleic acid sequence, wherein expression of the antisense nucleic acid sequence inhibits expression of a target nucleic acid sequence.
- the transgene/heterologous coding sequence is an endogenous nucleic acid, wherein additional genomic copies of the endogenous nucleic acid are desired, or a nucleic acid that is in the antisense orientation with respect to the sequence of a target nucleic acid in a host organism.
- heterologous coding sequence means any coding sequence other than the one that naturally encodes the Zea mays egg cell gene, or any homolog of the expressed Zea mays egg cell protein.
- the term "heterologous" is used in the context of this invention for any combination of nucleic acid sequences that is not normally found intimately associated in nature.
- non-Panicum virgatum (Pavir.J00490) egg cell transgene or "non-Panicum virgatum (Pavir.J00490) egg cell gene” is any transgene that has less than 80% sequence identity with the Panicum virgatum (Pavir.J00490) egg cell gene coding sequence (SEQ ID NO:6 with the Phytozome Locus Name of Pavir.J00490 and Transcript Name of Pavir.J00490.1 (primary) that is located at contig00432:15569..16493 reverse.
- a "gene product” as defined herein is any product produced by the gene.
- the gene product can be the direct transcriptional product of a gene (e.g., mRNA, tRNA, rRNA, antisense RNA, interfering RNA, ribozyme, structural RNA or any other type of RNA) or a protein produced by translation of a mRNA.
- Gene products also include RNAs which are modified, by processes such as capping, polyadenylation, methylation, and editing, and proteins modified by, for example, methylation, acetylation, phosphorylation, ubiquitination, ADP-ribosylation, myristilation, and glycosylation.
- Gene expression can be influenced by external signals, for example, exposure of a cell, tissue, or organism to an agent that increases or decreases gene expression. Expression of a gene can also be regulated anywhere in the pathway from DNA to RNA to protein. Regulation of gene expression occurs, for example, through controls acting on transcription, translation, RNA transport and processing, degradation of intermediary molecules such as mRNA, or through activation, inactivation, compartmentalization, or degradation of specific protein molecules after they have been made, or by combinations thereof. Gene expression can be measured at the RNA level or the protein level by any method known in the art, including, without limitation, Northern blot, RT-PCR, Western blot, or in vitro, in situ, or in vivo protein activity assay(s).
- gene expression relates to the process by which the coded information of a nucleic acid transcriptional unit (including, e.g., genomic DNA) is converted into an operational, non-operational, or structural part of a cell, often including the synthesis of a protein.
- Gene expression can be influenced by external signals; for example, exposure of a cell, tissue, or organism to an agent that increases or decreases gene expression. Expression of a gene can also be regulated anywhere in the pathway from DNA to RNA to protein.
- Gene expression occurs, for example, through controls acting on transcription, translation, RNA transport and processing, degradation of intermediary molecules such as mRNA, or through activation, inactivation, compartmentalization, or degradation of specific protein molecules after they have been made, or by combinations thereof.
- Gene expression can be measured at the RNA level or the protein level by any method known in the art, including, without limitation, Northern blot, RT-PCR, Western blot, or in vitro, in situ, or in vivo protein activity assay(s).
- HBGS homology-based gene silencing
- TGS transcriptional gene silencing
- PTGS post-transcriptional gene silencing
- dsRNA double-stranded RNA
- TGS and PTGS have been difficult to achieve because it generally relies on the analysis of distinct silencing loci.
- a single transgene locus can triggers both TGS and PTGS, owing to the production of dsRNA corresponding to promoter and transcribed sequences of different target genes. Mourrain et al. (2007) Planta 225:365-79 . It is likely that siRNAs are the actual molecules that trigger TGS and PTGS on homologous sequences: the siRNAs would in this model trigger silencing and methylation of homologous sequences in cis and in trans through the spreading of methylation of transgene sequences into the endogenous promoter.
- nucleic acid molecule may refer to a polymeric form of nucleotides, which may include both sense and anti-sense strands of RNA, cDNA, genomic DNA, and synthetic forms and mixed polymers of the above.
- a nucleotide may refer to a ribonucleotide, deoxyribonucleotide, or a modified form of either type of nucleotide.
- a “nucleic acid molecule” as used herein is synonymous with “nucleic acid” and “polynucleotide”.
- a nucleic acid molecule is usually at least 10 bases in length, unless otherwise specified.
- the term may refer to a molecule of RNA or DNA of indeterminate length.
- the term includes single- and double-stranded forms of DNA.
- a nucleic acid molecule may include either or both naturally-occurring and modified nucleotides linked together by naturally occurring and/or non-naturally occurring nucleotide linkages.
- Nucleic acid molecules may be modified chemically or biochemically, or may contain non-natural or derivatized nucleotide bases, as will be readily appreciated by those of skill in the art. Such modifications include, for example, labels, methylation, substitution of one or more of the naturally occurring nucleotides with an analog, internucleotide modifications (e.g., uncharged linkages: for example, methyl phosphonates, phosphotriesters, phosphoramidites, carbamates, etc.; charged linkages: for example, phosphorothioates, phosphorodithioates, etc.; pendent moieties: for example, peptides; intercalators: for example, acridine, psoralen, etc.; chelators; alkylators; and modified linkages: for example, alpha anomeric nucleic acids, etc.).
- the term "nucleic acid molecule” also includes any topological conformation, including single-stranded, double-stranded, partially du
- RNA is made by the sequential addition of ribonucleotide-5'-triphosphates to the 3' terminus of the growing chain (with a requisite elimination of the pyrophosphate).
- discrete elements e.g., particular nucleotide sequences
- discrete elements may be "downstream” or "3"' relative to a further element if they are or would be bonded to the same nucleic acid in the 3' direction from that element.
- a base "position”, as used herein, refers to the location of a given base or nucleotide residue within a designated nucleic acid.
- the designated nucleic acid may be defined by alignment (see below) with a reference nucleic acid.
- Hybridization relates to the binding of two polynucleotide strands via Hydrogen bonds. Oligonucleotides and their analogs hybridize by hydrogen bonding, which includes Watson-Crick, Hoogsteen or reversed Hoogsteen hydrogen bonding, between complementary bases.
- nucleic acid molecules consist of nitrogenous bases that are either pyrimidines (cytosine (C), uracil (U), and thymine (T)) or purines (adenine (A) and guanine (G)).
- base pairing This nitrogenous bases form hydrogen bonds between a pyrimidine and a purine, and the bonding of the pyrimidine to the purine is referred to as "base pairing." More specifically, A will hydrogen bond to T or U, and G will bond to C. “Complementary” refers to the base pairing that occurs between two distinct nucleic acid sequences or two distinct regions of the same nucleic acid sequence.
- oligonucleotide and “specifically complementary” are terms that indicate a sufficient degree of complementarity such that stable and specific binding occurs between the oligonucleotide and the DNA or RNA target.
- the oligonucleotide need not be 100% complementary to its target sequence to be specifically hybridizable.
- An oligonucleotide is specifically hybridizable when binding of the oligonucleotide to the target DNA or RNA molecule interferes with the normal function of the target DNA or RNA, and there is sufficient degree of complementarity to avoid nonspecific binding of the oligonucleotide to non-target sequences under conditions where specific binding is desired, for example under physiological conditions in the case of in vivo assays or systems. Such binding is referred to as specific hybridization.
- Hybridization conditions resulting in particular degrees of stringency will vary depending upon the nature of the chosen hybridization method and the composition and length of the hybridizing nucleic acid sequences. Generally, the temperature of hybridization and the ionic strength (especially the Na+ and/or Mg2+ concentration) of the hybridization buffer will contribute to the stringency of hybridization, though wash times also influence stringency. Calculations regarding hybridization conditions required for attaining particular degrees of stringency are discussed in Sambrook et al. (ed.), Molecular Cloning: A Laboratory Manual, 2nd ed., vol. 1-3, Cold Spring Harbor Laboratory Press, Cold Spring Harbor, New York, 1989, chs. 9 and 11 .
- stringent conditions encompass conditions under which hybridization will only occur if there is less than 50% mismatch between the hybridization molecule and the DNA target.
- Stringent conditions include further particular levels of stringency.
- “moderate stringency” conditions are those under which molecules with more than 50% sequence mismatch will not hybridize; conditions of “high stringency” are those under which sequences with more than 20% mismatch will not hybridize; and conditions of “very high stringency” are those under which sequences with more than 10% mismatch will not hybridize.
- stringent conditions can include hybridization at 65°C, followed by washes at 65°C with 0.1x SSC/0.1% SDS for 40 minutes.
- specifically hybridizable nucleic acid molecules can remain bound under very high stringency hybridization conditions. In these and further embodiments, specifically hybridizable nucleic acid molecules can remain bound under high stringency hybridization conditions. In these and further embodiments, specifically hybridizable nucleic acid molecules can remain bound under moderate stringency hybridization conditions.
- Oligonucleotide An oligonucleotide is a short nucleic acid polymer. Oligonucleotides may be formed by cleavage of longer nucleic acid segments, or by polymerizing individual nucleotide precursors. Automated synthesizers allow the synthesis of oligonucleotides up to several hundred base pairs in length. Because oligonucleotides may bind to a complementary nucleotide sequence, they may be used as probes for detecting DNA or RNA. Oligonucleotides composed of DNA (oligodeoxyribonucleotides) may be used in PCR, a technique for the amplification of small DNA sequences. In PCR, the oligonucleotide is typically referred to as a "primer", which allows a DNA polymerase to extend the oligonucleotide and replicate the complementary strand.
- percent sequence identity or “percent identity” or “identity” are used interchangeably to refer to a sequence comparison based on identical matches between correspondingly identical positions in the sequences being compared between two or more amino acid or nucleotide sequences.
- the percent identity refers to the extent to which two optimally aligned polynucleotide or peptide sequences are invariant throughout a window of alignment of components, e.g., nucleotides or amino acids.
- Hybridization experiments and mathematical algorithms known in the art may be used to determine percent identity.
- Many mathematical algorithms exist as sequence alignment computer programs known in the art that calculate percent identity. These programs may be categorized as either global sequence alignment programs or local sequence alignment programs.
- Global sequence alignment programs calculate the percent identity of two sequences by comparing alignments end-to-end in order to find exact matches, dividing the number of exact matches by the length of the shorter sequences, and then multiplying by 100. Basically, the percentage of identical nucleotides in a linear polynucleotide sequence of a reference (“query) polynucleotide molecule as compared to a test ("subject") polynucleotide molecule when the two sequences are optimally aligned (with appropriate nucleotide insertions, deletions, or gaps).
- Local sequence alignment programs are similar in their calculation, but only compare aligned fragments of the sequences rather than utilizing an end-to-end analysis.
- Local sequence alignment programs such as BLAST can be used to compare specific regions of two sequences.
- a BLAST comparison of two sequences results in an E-value, or expectation value, that represents the number of different alignments with scores equivalent to or better than the raw alignment score, S, that are expected to occur in a database search by chance. The lower the E value, the more significant the match.
- database size is an element in E-value calculations, E-values obtained by BLASTing against public databases, such as GENBANK, have generally increased over time for any given query/entry match.
- a "high" BLAST match is considered herein as having an E-value for the top BLAST hit of less than 1E-30; a medium BLASTX E-value is 1E-30 to 1E-8; and a low BLASTX E-value is greater than 1E-8.
- the protein function assignment in the present invention is determined using combinations of E-values, percent identity, query coverage and hit coverage.
- Query coverage refers to the percent of the query sequence that is represented in the BLAST alignment.
- Hit coverage refers to the percent of the database entry that is represented in the BLAST alignment.
- function of a query polypeptide is inferred from function of a protein homolog where either (1) hit_p ⁇ 1e-30 or % identity >35% AND query_coverage >50% AND hit_coverage >50%, or (2) hit_p ⁇ le-8 AND query_coverage >70% AND hit_coverage >70%.
- the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using an AlignX alignment program of the Vector NTI suite (Invitrogen, Carlsbad, CA).
- the AlignX alignment program is a global sequence alignment program for polynucleotides or proteins.
- the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the MegAlign program of the LASERGENE bioinformatics computing suite (MegAlign TM ( ⁇ 1993-2016). DNASTAR. Madison, WI).
- the MegAlign program is global sequence alignment program for polynucleotides or proteins.
- the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the Clustal suite of alignment programs, including, but not limited to, ClustalW and ClustalV ( Higgins and Sharp (1988) Gene. Dec. 15;73(1):237-44 ; Higgins and Sharp (1989) CABIOS 5:151-3 ; Higgins et al. (1992) Comput. Appl. Biosci. 8:189-91 ).
- the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the GCG suite of programs (Wisconsin Package Version 9.0, Genetics Computer Group (GCG), Madison, WI). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the BLAST suite of alignment programs, for example, but not limited to, BLASTP, BLASTN, BLASTX, etc. ( Altschul et al. (1990) J. Mol. Biol. 215:403-10 ).
- the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the FASTA suite of alignment programs, including, but not limited to, FASTA, TFASTX, TFASTY, SSEARCH, LALIGN etc. ( Pearson (1994) Comput. Methods Genome Res. [Proc. Int. Symp.], Meeting Date 1992 (Suhai and Sandor, Eds.), Plenum: New York, NY, pp. 111-20 ).
- the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the T-Coffee alignment program ( Notredame, et. al. (2000) J. Mol. Biol. 302, 205-17 ).
- the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the DIALIGN suite of alignment programs, including, but not limited to DIALIGN, CHAOS, DIALIGN-TX, DIALIGN-T etc. ( Al Ait, et. al. (2013) DIALIGN at GOBICS Nuc. Acids Research 41, W3-W7 ). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the MUSCLE suite of alignment programs ( Edgar (2004) Nucleic Acids Res. 32(5): 1792-1797 ).
- the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the MAFFT alignment program ( Katoh, et. al. (2002) Nucleic Acids Research 30(14): 3059-3066 ). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the Genoogle program ( Albrecht, Felipe. arXiv150702987v1 [cs.DC] 10 Jul. 2015 ). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the HMMER suite of programs ( Eddy. (1998) Bioinformatics, 14:755-63 ).
- the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the PLAST suite of alignment programs, including, but not limited to, TPLASTN, PLASTP, KLAST, and PLASTX ( Nguyen & Lavenier. (2009) BMC Bioinformatics, 10:329 ).
- the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the USEARCH alignment program ( Edgar (2010) Bioinformatics 26(19), 2460-61 ).
- the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the SAM suite of alignment programs ( Hughey & Krogh (Jan.
- the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the IDF Searcher ( O'Kane, K.C., The Effect of Inverse Document Frequency Weights on Indexed Sequence Retrieval, Online Journal of Bioinformatics, Volume 6 (2) 162-173, 2005 ). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the Parasail alignment program. ( Daily, Jeff. Parasail: SIMD C library for global, semi-global, and local pairwise sequence alignments. BMC Bioinformatics. 17:18. February 10, 2016 ).
- the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the ScalaBLAST alignment program ( Oehmen C, Nieplocha J. "ScalaBLAST: A scalable implementation of BLAST for high-performance data-intensive bioinformatics analysis.” IEEE Transactions on Parallel & Distributed Systems 17 (8): 740-749 AUG 2006 ).
- the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the SWIPE alignment program ( Rognes, T. Faster Smilth-Waterman database searches with inter-sequence SIMD parallelization. BMC Bioiinformatics. 12, 221 (2011 )).
- the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the ACANA alignment program ( Weichun Huang, David M. Umbach, and Leping Li, Accurate anchoring alignment of divergent sequences. Bioinformatics 22:29-34, Jan 1 2006 ). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the DOTLET alignment program ( Junier, T. & Pagni, M. DOTLET: diagonal plots in a web browser. Bioinformatics 16(2): 178-9 Feb. 2000 ).
- the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the G-PAS alignment program (Frohmberg, W., et al.
- operably linked relates to a first nucleic acid sequence is operably linked with a second nucleic acid sequence when the first nucleic acid sequence is in a functional relationship with the second nucleic acid sequence.
- a promoter is operably linked with a coding sequence when the promoter affects the transcription or expression of the coding sequence.
- operably linked nucleic acid sequences are generally contiguous and, where necessary to join two protein-coding regions, in the same reading frame.
- G-PAS 2.0 an improved version of protein alignment tool with an efficient backtracking routine on multiple GPUs. Bulletin of the Polish Academy of Sciences Technical Sciences, Vol. 60, 491 Nov. 2012 ).
- the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the GapMis alignment program ( Flouri, T. et. al., Gap Mis: A tool for pairwise sequence alignment with a single gap. Recent Pat DNA Gene Seq. 7(2): 84-95 Aug. 2013 ).
- the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the EMBOSS suite of alignment programs, including, but not limited to: Matcher, Needle, Stretcher, Water, Wordmatch, etc. ( Rice, P., Longden, I. & Bleasby, A. EMBOSS: The European Molecular Biology Open Software Suite. Trends in Genetics 16(6) 276-77 (2000 )).
- the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the Ngila alignment program ( Cartwright, R. Ngila: global pairwise alignments with logarithmic and affine gap costs. Bioinformatics. 23(11): 1427-28.
- the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the probA, also known as propA, alignment program ( Mückstein, U., Hofacker, IL, & Stadler, PF. Stochastic pairwise alignments. Bioinformatics 18 Suppl. 2:S153-60. 2002 ). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the SEQALN suite of alignment programs ( Hardy, P. & Waterman, M. The Sequence Alignment Software Library at USC. 1997 ).
- the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the SIM suite of alignment programs, including, but not limited to, GAP, NAP, LAP, etc. ( Huang, X & Miller, W. A Time-Efficient, Linear-Space Local Similarity Algorithm. Advances in Applied Mathematics, vol. 12 (1991) 337-57 ).
- the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the UGENE alignment program ( Okonechnikov, K., Golosova, O. & Fursov, M. Unipro UGENE: a unified bioinformatics toolkit. Bioinformatics.
- the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the BAli-Phy alignment program ( Suchard, MA & Redelings, BD. BAli-Phy: simultaneous Bayesian inference of alignment and phylogeny. Bioinformatics. 22:2047-48. 2006 ). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the Base-By-Base alignment program ( Brodie, R., et. al. Base-By-Base: Single nucleotide-level analysis of whole viral genome alignments, BMC Bioinformatics, 5, 96, 2004 ).
- the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the DECIPHER alignment program ( ES Wright (2015) "DECIPHER: harnessing local sequence context to improve protein multiple sequence alignment.” BMC Bioinformatics, doi:10.1186/s12859-015-0749-z .). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the FSA alignment program ( Bradley, RK, et. al. (2009) Fast Statistical Alignment. PLoS Computational Biology. 5:e1000392 ).
- the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the Geneious alignment program ( Kearse, M., et. al. (2012). Geneious Basic: an integrated and extendable desktop software platform for the organization and analysis of sequence data. Bioinformatics, 28(12), 1647-49 ). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the Kalign alignment program ( Lassmann, T. & Sonnhammer, E. Kalign - an accurate and fast multiple sequence alignment algorithm. BMC Bioinformatics 2005 6:298 ).
- the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the MAVID alignment program ( Bray, N. & Pachter, L. MAVID: Constrained Ancestral Alignment of Multiple Sequences. Genome Res. 2004 Apr; 14(4): 693-99 ). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the MSA alignment program ( Lipman, DJ, et.al. A tool for multiple sequence alignment. Proc. Nat'l Acad. Sci. USA. 1989; 86:4412-15 ).
- the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the MultAlin alignment program ( Corpet, F., Multiple sequence alignment with hierarchial clustering. Nucl. Acids Res., 1988, 16(22), 10881-90 ). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the LAGAN or MLAGAN alignment programs ( Brudno, et. al. LAGAN and Multi-LAGAN: efficient tools for large-scale multiple alignment of genomic DNA. Genome Research 2003 Apr; 13(4): 721-31 ).
- the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the Opal alignment program ( Wheeler, T.J., & Kececiouglu, J.D. Multiple alignment by aligning alignments. Proceedings of the 15th ISCB conference on Intelligent Systems for Molecular Biology. Bioinformatics. 23, i559-68, 2007 ).
- the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the PicXAA suite of programs, including, but not limited to, PicXAA, PicXAA-R, PicXAA-Web, etc. ( Mohammad, S., Sahraeian, E. & Yoon, B.
- the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the PSAlign alignment program ( SZE, S.-H., Lu, Y., & Yang, Q. (2006) A polynomial time solvable formulation of multiple sequence alignment Journal of Computational Biology, 13, 309-19 ). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the StatAlign alignment program ( Novak, ⁇ ., et.al.
- the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the Gap alignment program of Needleman and Wunsch ( Needleman and Wunsch, Journal of Molecular Biology 48:443-453, 1970 ). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the BestFit alignment program of Smith and Waterman ( Smith and Waterman, Advances in Applied Mathematics, 2:482-489, 1981 , Smith et al., Nucleic Acids Research 11:2205-2220, 1983 ). These programs produces biologically meaningful multiple sequence alignments of divergent sequences. The calculated best match alignments for the selected sequences are lined up so that identities, similarities, and differences can be seen.
- similarity refers to a comparison between amino acid sequences, and takes into account not only identical amino acids in corresponding positions, but also functionally similar amino acids in corresponding positions. Thus similarity between polypeptide sequences indicates functional similarity, in addition to sequence similarity.
- homology is sometimes used to refer to the level of similarity between two or more nucleic acid or amino acid sequences in terms of percent of positional identity (i.e., sequence similarity or identity). Homology also refers to the concept of evolutionary relatedness, often evidenced by similar functional properties among different nucleic acids or proteins that share similar sequences.
- variants means substantially similar sequences.
- naturally occurring variants can be identified with the use of well- known molecular biology techniques, such as, for example, with polymerase chain reaction (PCR) and hybridization techniques as outlined herein.
- PCR polymerase chain reaction
- a variant comprises a deletion and/or addition of one or more nucleotides at one or more internal sites within the native polynucleotide and/or a substitution of one or more nucleotides at one or more sites in the native polynucleotide.
- a "native" nucleotide sequence comprises a naturally occurring nucleotide sequence.
- naturally occurring variants can be identified with the use of well-known molecular biology techniques, as, for example, with polymerase chain reaction (PCR) and hybridization techniques as outlined below.
- Variant nucleotide sequences also include synthetically derived nucleotide sequences, such as those generated, for example, by using site-directed mutagenesis.
- variants of a particular nucleotide sequence of the invention will have at least about 40%, 45%, 50%>, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%o, 99% or more sequence identity to that particular nucleotide sequence as determined by sequence alignment programs and parameters described elsewhere herein.
- a biologically active variant of a nucleotide sequence of the invention may differ from that sequence by as few as 1-15 nucleic acid residues, as few as 1-10, such as 6-10, as few as 5, as few as 4, 3, 2, or even 1 nucleic acid residue.
- operably linked relates to a first nucleic acid sequence is operably linked with a second nucleic acid sequence when the first nucleic acid sequence is in a functional relationship with the second nucleic acid sequence.
- a promoter is operably linked with a coding sequence when the promoter affects the transcription or expression of the coding sequence.
- operably linked nucleic acid sequences are generally contiguous and, where necessary to join two protein-coding regions, in the same reading frame. However, elements need not be contiguous to be operably linked.
- promoter refers to a region of DNA that generally is located upstream (towards the 5' region of a gene) of a gene and is needed to initiate and drive transcription of the gene.
- a promoter may permit proper activation or repression of a gene that it controls.
- a promoter may contain specific sequences that are recognized by transcription factors. These factors may bind to a promoter DNA sequence, which results in the recruitment of RNA polymerase, an enzyme that synthesizes RNA from the coding region of the gene.
- the promoter generally refers to all gene regulatory elements located upstream of the gene, including, upstream promoters, 5' UTR, introns, and leader sequences.
- upstream-promoter refers to a contiguous polynucleotide sequence that is sufficient to direct initiation of transcription.
- an upstream-promoter encompasses the site of initiation of transcription with several sequence motifs, which include TATA Box, initiator sequence, TFIIB recognition elements and other promoter motifs ( Jennifer, E.F. et al., (2002) Genes & Dev., 16: 2583-2592 ).
- the upstream promoter provides the site of action to RNA polymerase II which is a multi-subunit enzyme with the basal or general transcription factors like, TFIIA, B, D, E, F and H. These factors assemble into a transcription pre initiation complex that catalyzes the synthesis of RNA from DNA template.
- the activation of the upstream-promoter is done by the additional sequence of regulatory DNA sequence elements to which various proteins bind and subsequently interact with the transcription initiation complex to activate gene expression.
- These gene regulatory elements sequences interact with specific DNA-binding factors. These sequence motifs may sometimes be referred to as cis -elements.
- Such cis -elements to which tissue-specific or development-specific transcription factors bind, individually or in combination, may determine the spatiotemporal expression pattern of a promoter at the transcriptional level.
- These cis -elements vary widely in the type of control they exert on operably linked genes. Some elements act to increase the transcription of operably-linked genes in response to environmental responses (e.g., temperature, moisture, and wounding).
- cis -elements may respond to developmental cues (e.g., germination, seed maturation, and flowering) or to spatial information (e.g., tissue specificity). See, for example, Langridge et al., (1989) Proc. Natl. Acad. Sci. USA 86:3219-23 . These cis- elements are located at a varying distance from transcription start point, some cis- elements (called proximal elements) are adjacent to a minimal core promoter region while other elements can be positioned several kilobases upstream or downstream of the promoter (enhancers).
- proximal elements are adjacent to a minimal core promoter region while other elements can be positioned several kilobases upstream or downstream of the promoter (enhancers).
- 5' untranslated region or "5' UTR” is defined as the untranslated segment in the 5' terminus of pre-mRNAs or mature mRNAs.
- a 5' UTR typically harbors on its 5' end a 7-methylguanosine cap and is involved in many processes such as splicing, polyadenylation, mRNA export towards the cytoplasm, identification of the 5' end of the mRNA by the translational machinery, and protection of the mRNAs against degradation.
- transcription terminator is defined as the transcribed segment in the 3' terminus of pre-mRNAs or mature mRNAs. For example, longer stretches of DNA beyond "polyadenylation signal" site is transcribed as a pre-mRNA. This DNA sequence usually contains transcription termination signal for the proper processing of the pre-mRNA into mature mRNA.
- 3' untranslated region or "3' UTR” is defined as the untranslated segment in a 3' terminus of the pre-mRNAs or mature mRNAs. For example, on mature mRNAs this region harbors the poly-(A) tail and is known to have many roles in mRNA stability, translation initiation, and mRNA export.
- the 3' UTR is considered to include the polyadenylation signal and transcription terminator.
- polyadenylation signal designates a nucleic acid sequence present in mRNA transcripts that allows for transcripts, when in the presence of a poly-(A) polymerase, to be polyadenylated on the polyadenylation site, for example, located 10 to 30 bases downstream of the poly-(A) signal.
- Many polyadenylation signals are known in the art and are useful for the present invention.
- An exemplary sequence includes AAUAAA and variants thereof, as described in Loke J., et al., (2005) Plant Physiology 138(3); 1457-1468 .
- a "DNA binding transgene” is a polynucleotide coding sequence that encodes a DNA binding protein.
- the DNA binding protein is subsequently able to bind to another molecule.
- a binding protein can bind to, for example, a DNA molecule (a DNA-binding protein), a RNA molecule (an RNA-binding protein), and/or a protein molecule (a protein-binding protein).
- a DNA-binding protein binds to itself (to form homodimers, homotrimers, etc.) and/or it can bind to one or more molecules of a different protein or proteins.
- a binding protein can have more than one type of binding activity. For example, zinc finger proteins have DNA-binding, RNA-binding, and protein-binding activity.
- DNA binding proteins include; meganucleases, zinc fingers, CRISPRs, and TALEN binding domains that can be "engineered” to bind to a predetermined nucleotide sequence.
- the engineered DNA binding proteins e.g., zinc fingers, CRISPRs, or TALENs
- Non-limiting examples of methods for engineering DNA-binding proteins are design and selection.
- a designed DNA binding protein is a protein not occurring in nature whose design/composition results principally from rational criteria. Rational criteria for design include application of substitution rules and computerized algorithms for processing information in a database storing information of existing ZFP, CRISPR, and/or TALEN designs and binding data. See, for example, U.S.
- Patents 6,140,081 ; 6,453,242 ; and 6,534,261 see also WO 98/53058 ; WO 98/53059 ; WO 98/53060 ; WO 02/016536 and WO 03/016496 and U.S. Publication Nos. 20110301073 , 20110239315 and 20119145940 .
- a “zinc finger DNA binding protein” (or binding domain) is a protein, or a domain within a larger protein, that binds DNA in a sequence-specific manner through one or more zinc fingers, which are regions of amino acid sequence within the binding domain whose structure is stabilized through coordination of a zinc ion.
- the term zinc finger DNA binding protein is often abbreviated as zinc finger protein or ZFP.
- Zinc finger binding domains can be "engineered” to bind to a predetermined nucleotide sequence.
- Non-limiting examples of methods for engineering zinc finger proteins are design and selection.
- a designed zinc finger protein is a protein not occurring in nature whose design/composition results principally from rational criteria.
- Rational criteria for design include application of substitution rules and computerized algorithms for processing information in a database storing information of existing ZFP designs and binding data. See, for example, U.S. Pat. Nos. 6,140,081 ; 6,453,242 ; 6,534,261 and 6,794,136 ; see also WO 98/53058 ; WO 98/53059 ; WO 98/53060 ; WO 02/016536 and WO 03/016496 .
- the DNA-binding domain of one or more of the nucleases comprises a naturally occurring or engineered (non-naturally occurring) TAL effector DNA binding domain.
- TAL effector DNA binding domain e.g., U.S. Patent Publication No. 20110301073 .
- the plant pathogenic bacteria of the genus Xanthomonas are known to cause many diseases in important crop plants. Pathogenicity of Xanthomonas depends on a conserved type III secretion (T3S) system which injects more than different effector proteins into the plant cell. Among these injected proteins are transcription activator-like (TALEN) effectors which mimic plant transcriptional activators and manipulate the plant transcriptome (see Kay et al., (2007) Science 318:648-651 ).
- T3S conserved type III secretion
- TAL-effectors contain a DNA binding domain and a transcriptional activation domain.
- AvrBs3 from Xanthomonas campestgris pv. Vesicatoria (see Bonas et al., (1989) Mol Gen Genet 218: 127-136 and WO2010079430 ).
- TAL-effectors contain a centralized domain of tandem repeats, each repeat containing approximately 34 amino acids, which are key to the DNA binding specificity of these proteins. In addition, they contain a nuclear localization sequence and an acidic transcriptional activation domain (for a review see Schornack S, et al., (2006) J Plant Physiol 163(3): 256-272 ).
- Ralstonia solanacearum two genes, designated brg11 and hpx17 have been found that are homologous to the AvrBs3 family of Xanthomonas in the R. solanacearum biovar strain GMI1000 and in the biovar 4 strain RS1000 (See Heuer et al., (2007) Appl and Enviro Micro 73(13): 4379-4384 ).
- These genes are 98.9% identical in nucleotide sequence to each other but differ by a deletion of 1,575 bp in the repeat domain of hpx17.
- both gene products have less than 40% sequence identity with AvrBs3 family proteins of Xanthomonas. See, e.g., U.S. Patent Publication No. 20110301073 .
- TAL effectors depends on the sequences found in the tandem repeats.
- the repeated sequence comprises approximately 102 bp and the repeats are typically 91-100% homologous with each other (Bonas et al., ibid).
- Polymorphism of the repeats is usually located at positions 12 and 13 and there appears to be a one-to-one correspondence between the identity of the hypervariable diresidues at positions 12 and 13 with the identity of the contiguous nucleotides in the TAL-effector's target sequence (see Moscou and Bogdanove, (2009) Science 326:1501 and Boch et al., (2009) Science 326:1509-1512 ).
- the natural code for DNA recognition of these TAL-effectors has been determined such that an HD sequence at positions 12 and 13 leads to a binding to cytosine (C), NG binds to T, NI to A, C, G or T, NN binds to A or G, and ING binds to T.
- C cytosine
- NG binds to T
- NI to A
- NN binds to A or G
- ING binds to T.
- These DNA binding repeats have been assembled into proteins with new combinations and numbers of repeats, to make artificial transcription factors that are able to interact with new sequences and activate the expression of a non-endogenous reporter gene in plant cells (Boch et al., ibid).
- Engineered TAL proteins have been linked to a Fok I cleavage half domain to yield a TAL effector domain nuclease fusion (TALEN) exhibiting activity in a yeast reporter assay (plasmid based target).
- the CRISPR (Clustered Regularly Interspaced Short Palindromic Repeats)/Cas (CRISPR Associated) nuclease system is a recently engineered nuclease system based on a bacterial system that can be used for genome engineering. It is based on part of the adaptive immune response of many bacteria and Archaea. When a virus or plasmid invades a bacterium, segments of the invader's DNA are converted into CRISPR RNAs (crRNA) by the 'immune' response.
- crRNA CRISPR RNAs
- This crRNA then associates, through a region of partial complementarity, with another type of RNA called tracrRNA to guide the Cas9 nuclease to a region homologous to the crRNA in the target DNA called a "protospacer.”
- Cas9 cleaves the DNA to generate blunt ends at the double-stranded break (DSB) at sites specified by a 20-nucleotide guide sequence contained within the crRNA transcript.
- Cas9 requires both the crRNA and the tracrRNA for site specific DNA recognition and cleavage.
- This system has now been engineered such that the crRNA and tracrRNA can be combined into one molecule (the "single guide RNA"), and the crRNA equivalent portion of the single guide RNA can be engineered to guide the Cas9 nuclease to target any desired sequence (see Jinek et al., (2012) Science 337, pp. 816-821 , Jinek et al., (2013), eLife 2:e00471 , and David Segal, (2013) eLife 2:e00563 ).
- the crRNA associates with the tracrRNA to guide the Cpf1 nuclease to a region homologous to the crRNA to cleave DNA with staggered ends (see Zetsche, Bernd, et al. Cell 163.3 (2015): 759-771 .).
- the CRISPR/Cas system can be engineered to create a DSB at a desired target in a genome, and repair of the DSB can be influenced by the use of repair inhibitors to cause an increase in error prone repair.
- the DNA binding transgene is a site specific nuclease that comprises an engineered (non-naturally occurring) Meganuclease (also described as a homing endonuclease).
- the recognition sequences of homing endonucleases or meganucleases such as I -Sce I , I -Ceu I, PI -Psp I, PI -Sce, I -Sce IV , I -Csm I, I -Pan I, I-Sc e II, I -Ppo I, I- S ceIII, I-CreI, I-TevI, I- Tev II and I- Tev III are known. See also U.S.
- Patent No. 5,420,032 U.S. Patent No. 6,833,252 ; Belfort et al., (1997) Nucleic Acids Res. 25:3379-30 3388 ; Dujon et al., (1989) Gene 82:115-118 ; Perler et al., (1994) Nucleic Acids Res. 22, 11127 ; Jasin (1996) Trends Genet. 12:224-228 ; Gimble et al., (1996) J. Mol. Biol. 263:163-180 ; Argast et al., (1998) J. Mol. Biol. 280:345-353 and the New England Biolabs catalogue.
- DNA-binding specificity of homing endonucleases and meganucleases can be engineered to bind non-natural target sites. See, for example, Chevalier et al., (2002)Molec. Cell 10:895-905 ; Epinat et al., (2003) Nucleic Acids Res. 5 31:2952-2962 ; Ashworth et al., (2006) Nature 441:656-659 ; Paques et al., (2007) Current Gene Therapy 7:49-66 ; U.S. Patent Publication No. 20070117128 .
- DNA-binding domains of the homing endonucleases and meganucleases may be altered in the context of the nuclease as a whole (i.e., such that the nuclease includes the cognate cleavage domain) or may be fused to a heterologous cleavage domain.
- transformation encompasses all techniques that a nucleic acid molecule can be introduced into such a cell. Examples include, but are not limited to: transfection with viral vectors; transformation with plasmid vectors; electroporation; lipofection; microinjection ( Mueller et al., (1978) Cell 15:579-85 ); Agrobacterium -mediated transfer; direct DNA uptake; WHISKERS TM -mediated transformation; and microprojectile bombardment. These techniques may be used for both stable transformation and transient transformation of a plant cell. "Stable transformation” refers to the introduction of a nucleic acid fragment into a genome of a host organism resulting in genetically stable inheritance.
- transgenic organisms refer to the introduction of a nucleic acid fragment into the nucleus, or DNA-containing organelle, of a host organism resulting in gene expression without genetically stable inheritance.
- a transgene is a gene sequence (e.g., an herbicide-resistance gene), a gene encoding an industrially or pharmaceutically useful compound, or a gene encoding a desirable agricultural trait.
- the transgene is an antisense nucleic acid sequence, wherein expression of the antisense nucleic acid sequence inhibits expression of a target nucleic acid sequence.
- a transgene may contain regulatory sequences operably linked to the transgene (e.g., a promoter).
- a polynucleotide sequence of interest is a transgene.
- a polynucleotide sequence of interest is an endogenous nucleic acid sequence, wherein additional genomic copies of the endogenous nucleic acid sequence are desired, or a nucleic acid sequence that is in the antisense orientation with respect to the sequence of a target nucleic acid molecule in the host organism.
- a transgenic "event” is produced by transformation of plant cells with heterologous DNA, i.e., a nucleic acid construct that includes a transgene of interest, regeneration of a population of plants resulting from the insertion of the transgene into the genome of the plant, and selection of a particular plant characterized by insertion into a particular genome location.
- the term “event” refers to the original transformant and progeny of the transformant that include the heterologous DNA.
- the term “event” also refers to progeny produced by a sexual outcross between the transformant and another variety that includes the genomic/transgene DNA.
- the inserted transgene DNA and flanking genomic DNA (genomic/transgene DNA) from the transformed parent is present in the progeny of the cross at the same chromosomal location.
- the term "event” also refers to DNA from the original transformant and progeny thereof comprising the inserted DNA and flanking genomic sequence immediately adjacent to the inserted DNA that would be expected to be transferred to a progeny that receives inserted DNA including the transgene of interest as the result of a sexual cross of one parental line that includes the inserted DNA (e.g., the original transformant and progeny resulting from selfing) and a parental line that does not contain the inserted DNA.
- PCR Polymerase Chain Reaction
- sequence information from the ends of the region of interest or beyond needs to be available, such that oligonucleotide primers can be designed; these primers will be identical or similar in sequence to opposite strands of the template to be amplified.
- the 5' terminal nucleotides of the two primers may coincide with the ends of the amplified material.
- PCR can be used to amplify specific RNA sequences, specific DNA sequences from total genomic DNA, and cDNA transcribed from total cellular RNA, bacteriophage or plasmid sequences, etc. See generally Mullis et al., Cold Spring Harbor Symp. Quant. Biol., 51:263 (1987 ); Erlich, ed., PCR Technology, (Stockton Press, NY, 1989 ).
- primer refers to an oligonucleotide capable of acting as a point of initiation of synthesis along a complementary strand when conditions are suitable for synthesis of a primer extension product.
- the synthesizing conditions include the presence of four different deoxyribonucleotide triphosphates and at least one polymerization-inducing agent such as reverse transcriptase or DNA polymerase. These are present in a suitable buffer, which may include constituents which are co-factors or which affect conditions such as pH and the like at various suitable temperatures.
- a primer is preferably a single strand sequence, such that amplification efficiency is optimized, but double stranded sequences can be utilized.
- the term "probe” refers to an oligonucleotide that hybridizes to a target sequence.
- the probe hybridizes to a portion of the target situated between the annealing site of the two primers.
- a probe includes about eight nucleotides, about ten nucleotides, about fifteen nucleotides, about twenty nucleotides, about thirty nucleotides, about forty nucleotides, or about fifty nucleotides. In some embodiments, a probe includes from about eight nucleotides to about fifteen nucleotides.
- a probe can further include a detectable label, e.g., a fluorophore (Texas-Red ® , Fluorescein isothiocyanate, etc.,).
- the detectable label can be covalently attached directly to the probe oligonucleotide, e.g., located at the probe's 5' end or at the probe's 3' end.
- a probe including a fluorophore may also further include a quencher, e.g., Black Hole Quencher TM , Iowa Black TM , etc.
- restriction endonucleases and “restriction enzymes” refer to bacterial enzymes, each of which cut double-stranded DNA at or near a specific nucleotide sequence.
- Type -2 restriction enzymes recognize and cleave DNA at the same site, and include but are not limited to XbaI, BamHI, HindIII, EcoRI, XhoI, SalI, KpnI, AvaI, PstI and SmaI.
- vector is used interchangeably with the terms “construct”, “cloning vector” and “expression vector” and means the vehicle by which a DNA or RNA sequence (e.g. a foreign gene) can be introduced into a host cell, so as to transform the host and promote expression (e.g. transcription and translation) of the introduced sequence.
- a "non-viral vector” is intended to mean any vector that does not comprise a virus or retrovirus.
- a “vector” is a sequence of DNA comprising at least one origin of DNA replication and at least one selectable marker gene.
- a vector can also include one or more genes, antisense molecules, and/or selectable marker genes and other genetic elements known in the art.
- a vector may transduce, transform, or infect a cell, thereby causing the cell to express the nucleic acid molecules and/or proteins encoded by the vector.
- plasmid defines a circular strand of nucleic acid capable of autosomal replication in either a prokaryotic or a eukaryotic host cell.
- the term includes nucleic acid which may be either DNA or RNA and may be single- or double-stranded.
- the plasmid of the definition may also include the sequences which correspond to a bacterial origin of replication.
- selectable marker gene defines a gene or other expression cassette which encodes a protein which facilitates identification of cells into which the selectable marker gene is inserted.
- a “selectable marker gene” encompasses reporter genes as well as genes used in plant transformation to, for example, protect plant cells from a selective agent or provide resistance/tolerance to a selective agent. In one embodiment only those cells or plants that receive a functional selectable marker are capable of dividing or growing under conditions having a selective agent.
- selective agents can include, for example, antibiotics, including spectinomycin, neomycin, kanamycin, paromomycin, gentamicin, and hygromycin.
- selectable markers include neomycin phosphotransferase (npt II), which expresses an enzyme conferring resistance to the antibiotic kanamycin, and genes for the related antibiotics neomycin, paromomycin, gentamicin, and G418, or the gene for hygromycin phosphotransferase (hpt), which expresses an enzyme conferring resistance to hygromycin.
- npt II neomycin phosphotransferase
- hpt hygromycin phosphotransferase
- selectable marker genes can include genes encoding herbicide resistance including bar or pat (resistance against glufosinate ammonium or phosphinothricin), acetolactate synthase (ALS, resistance against inhibitors such as sulfonylureas (SUs), imidazolinones (IMIs), triazolopyrimidines (TPs), pyrimidinyl oxybenzoates (POBs), and sulfonylamino carbonyl triazolinones that prevent the first step in the synthesis of the branched-chain amino acids), glyphosate, 2,4-D, and metal resistance or sensitivity.
- bar or pat resistance against glufosinate ammonium or phosphinothricin
- ALS acetolactate synthase
- inhibitors such as sulfonylureas (SUs), imidazolinones (IMIs), triazolopyrimidines (TPs), pyrimidin
- reporter genes that can be used as a selectable marker gene include the visual observation of expressed reporter gene proteins such as proteins encoding ⁇ -glucuronidase (GUS), luciferase, green fluorescent protein (GFP), yellow fluorescent protein (YFP), DsRed, ⁇ -galactosidase, chloramphenicol acetyltransferase (CAT), alkaline phosphatase, and the like.
- GUS ⁇ -glucuronidase
- GFP green fluorescent protein
- YFP yellow fluorescent protein
- DsRed ⁇ -galactosidase
- CAT chloramphenicol acetyltransferase
- alkaline phosphatase and the like.
- reporter gene proteins such as proteins encoding ⁇ -glucuronidase (GUS), luciferase, green fluorescent protein (GFP), yellow fluorescent protein (YFP), DsRed, ⁇ -galactosidase, chloramphenicol acetyl
- detectable marker refers to a label capable of detection, such as, for example, a radioisotope, fluorescent compound, bioluminescent compound, a chemiluminescent compound, metal chelator, or enzyme.
- detectable markers include, but are not limited to, the following: fluorescent labels (e.g., FITC, rhodamine, lanthanide phosphors), enzymatic labels (e.g., horseradish peroxidase, ⁇ -galactosidase, luciferase, alkaline phosphatase), chemiluminescent, biotinyl groups, predetermined polypeptide epitopes recognized by a secondary reporter (e.g., leucine zipper pair sequences, binding sites for secondary antibodies, metal binding domains, epitope tags).
- a detectable marker can be attached by spacer arms of various lengths to reduce potential steric hindrance.
- an expression cassette refers to a segment of DNA that can be inserted into a nucleic acid or polynucleotide at specific restriction sites or by homologous recombination.
- the segment of DNA comprises a polynucleotide that encodes a polypeptide of interest, and the cassette and restriction sites are designed to ensure insertion of the cassette in the proper reading frame for transcription and translation.
- an expression cassette can include a polynucleotide that encodes a polypeptide of interest and having elements in addition to the polynucleotide that facilitate transformation of a particular host cell.
- a gene expression cassette may also include elements that allow for enhanced expression of a polynucleotide encoding a polypeptide of interest in a host cell. These elements may include, but are not limited to: a promoter, a minimal promoter, an enhancer, a response element, a terminator sequence, a polyadenylation sequence, and the like.
- linker or “spacer” is a bond, molecule or group of molecules that binds two separate entities to one another. Linkers and spacers may provide for optimal spacing of the two entities or may further supply a labile linkage that allows the two entities to be separated from each other. Labile linkages include photocleavable groups, acid-labile moieties, base-labile moieties and enzyme-cleavable groups.
- polylinker or “multiple cloning site” as used herein defines a cluster of three or more Type -2 restriction enzyme sites located within 10 nucleotides of one another on a nucleic acid sequence.
- polylinker refers to a stretch of nucleotides that are targeted for joining two sequences via any known seamless cloning method (i.e., Gibson Assembly ® , NEBuilder HiFiDNA Assembly ® , Golden Gate Assembly, BioBrick ® Assembly, etc.). Constructs comprising a polylinker are utilized for the insertion and/or excision of nucleic acid sequences such as the coding region of a gene.
- control refers to a sample used in an analytical procedure for comparison purposes.
- a control can be "positive” or “negative”.
- a positive control such as a sample from a known plant exhibiting the desired expression
- a negative control such as a sample from a known plant lacking the desired expression.
- plant includes a whole plant and any descendant, cell, tissue, or part of a plant.
- a class of plant that can be used in the present invention is generally as broad as the class of higher and lower plants amenable to mutagenesis including angiosperms (monocotyledonous and dicotyledonous plants), gymnosperms, ferns and multicellular algae.
- plant includes dicot and monocot plants.
- plant parts include any part(s) of a plant, including, for example and without limitation: seed (including mature seed and immature seed); a plant cutting; a plant cell; a plant cell culture; a plant organ (e.g., pollen, embryos, flowers, fruits, shoots, leaves, roots, stems, and explants).
- a plant tissue or plant organ may be a seed, protoplast, callus, or any other group of plant cells that is organized into a structural or functional unit.
- a plant cell or tissue culture may be capable of regenerating a plant having the physiological and morphological characteristics of the plant from which the cell or tissue was obtained, and of regenerating a plant having substantially the same genotype as the plant.
- Regenerable cells in a plant cell or tissue culture may be embryos, protoplasts, meristematic cells, callus, pollen, leaves, anthers, roots, root tips, silk, flowers, kernels, ears, cobs, husks, or stalks.
- Plant parts include harvestable parts and parts useful for propagation of progeny plants.
- Plant parts useful for propagation include, for example and without limitation: seed; fruit; a cutting; a seedling; a tuber; and a rootstock.
- a harvestable part of a plant may be any useful part of a plant, including, for example and without limitation: flower; pollen; seedling; tuber; leaf; stem; fruit; seed; and root.
- a plant cell is the structural and physiological unit of the plant, comprising a protoplast and a cell wall.
- a plant cell may be in the form of an isolated single cell, or an aggregate of cells (e.g., a friable callus and a cultured cell), and may be part of a higher organized unit (e.g., a plant tissue, plant organ, and plant).
- a plant cell may be a protoplast, a gamete producing cell, or a cell or collection of cells that can regenerate into a whole plant.
- a seed which comprises multiple plant cells and is capable of regenerating into a whole plant, is considered a "plant cell" in embodiments herein.
- small RNA refers to several classes of non-coding ribonucleic acid (ncRNA).
- ncRNA non-coding ribonucleic acid
- the term small RNA describes the short chains of ncRNA produced in bacterial cells, animals, plants, and fungi. These short chains of ncRNA may be produced naturally within the cell or may be produced by the introduction of an exogenous sequence that expresses the short chain or ncRNA.
- the small RNA sequences do not directly code for a protein, and differ in function from other RNA in that small RNA sequences are only transcribed and not translated.
- the small RNA sequences are involved in other cellular functions, including gene expression and modification. Small RNA molecules are usually made up of about 20 to 30 nucleotides.
- the small RNA sequences may be derived from longer precursors. The precursors form structures that fold back on each other in self-complementary regions; they are then processed by the nuclease Dicer in animals or DCL1 in plants.
- RNAs include microRNAs (miRNAs), short interfering RNAs (siRNAs), antisense RNA, short hairpin RNA (shRNA), and small nucleolar RNAs (snoRNAs).
- miRNAs microRNAs
- siRNAs short interfering RNAs
- antisense RNA short hairpin RNA
- shRNA short hairpin RNA
- sinoRNAs small nucleolar RNAs
- Certain types of small RNA such as microRNA and siRNA, are important in gene silencing and RNA interference (RNAi).
- RNAi RNA interference
- Gene silencing is a process of genetic regulation in which a gene that would normally be expressed is "turned off by an intracellular element, in this case, the small RNA.
- the protein that would normally be formed by this genetic information is not formed due to interference, and the information coded in the gene is blocked from expression.
- small RNA encompasses RNA molecules described in the literature as "tiny RNA” ( Storz, (2002) Science 296:1260-3 ; Illangasekare et al., (1999) RNA 5:1482-1489 ); prokaryotic "small RNA” (sRNA) ( Wassarman et al., (1999) Trends Microbiol.
- RNA eukaryotic "noncoding RNA (ncRNA)”; “micro-RNA (miRNA)”; “small non-mRNA (snmRNA)”; “functional RNA (fRNA)”; “transfer RNA (tRNA)”; “catalytic RNA” [e.g., ribozymes, including self-acylating ribozymes ( Illangaskare et al., (1999) RNA 5:1482-1489 ); "small nucleolar RNAs (snoRNAs),” “tmRNA” (a.k.a. "10S RNA,” Muto et al., (1998) Trends Biochem Sci.
- ncRNA noncoding RNA
- miRNA micro-RNA
- snmRNA small non-mRNA
- fRNA functional RNA
- tRNA transfer RNA
- catalytic RNA e.g., ribozymes, including self-acylating ribozymes ( Illangaskare e
- RNAi molecules including without limitation "small interfering RNA (siRNA),” “endoribonuclease-prepared siRNA (e-siRNA),” “short hairpin RNA (shRNA),” and “small temporally regulated RNA (stRNA),” “diced siRNA (d-siRNA),” and aptamers, oligonucleotides and other synthetic nucleic acids that comprise at least one uracil base.
- siRNA small interfering RNA
- e-siRNA endoribonuclease-prepared siRNA
- shRNA short hairpin RNA
- stRNA small temporally regulated RNA
- d-siRNA small temporally regulated RNA
- aptamers oligonucleotides and other synthetic nucleic acids that comprise at least one uracil base.
- Panicum virgatum (Pavir.J00490) egg cell Gene Regulatory Elements and Nucleic Acids Comprising the Same
- a promoter from a Zea egg cell gene to express non-Panicum virgatum (Pavir.J00490) egg cell transgenes in plant.
- a promoter can be the Panicum virgatum (Pavir.J00490) egg cell gene promoter of SEQ ID NO:1.
- a nucleic acid vector comprising a promoter, wherein the promoter comprises a polynucleic acid sequence that is at least 98%, 99%, 99.5%, 99.8%, or 100% identical to SEQ ID NO:1.
- a promoter is a Panicum virgatum (Pavir.J00490) egg cell gene promoter comprising a polynucleotide of at least 98%, 99%, 99.5%, 99.8%, or 100% identity to the polynucleotide of SEQ ID NO:1.
- a polynucleotide comprising a Panicum virgatum (Pavir.J00490) egg cell gene promoter that is operably linked to a polylinker.
- a gene expression cassette is disclosed comprising a Panicum virgatum (Pavir.J00490) egg cell gene promoter that is operably linked to a non-Panicum virgatum (Pavir.J00490) egg cell transgene.
- a nucleic acid vector is provided comprising a Panicum virgatum (Pavir.J00490) egg cell gene promoter that is operably linked to a non-Panicum virgatum (Pavir.J00490) egg cell transgene.
- a nucleic acid vector comprises a Panicum virgatum (Pavir.J00490) egg cell gene promoter that is operably linked to a transgene, wherein the transgene can be an insecticidal resistance transgene, an herbicide tolerance transgene, a nitrogen use efficiency transgene, a water use efficiency transgene, a nutritional quality transgene, a DNA binding transgene, a small RNA transgene, selectable marker transgene, or combinations thereof.
- the transgene can be an insecticidal resistance transgene, an herbicide tolerance transgene, a nitrogen use efficiency transgene, a water use efficiency transgene, a nutritional quality transgene, a DNA binding transgene, a small RNA transgene, selectable marker transgene, or combinations thereof.
- a nucleic acid vector comprises a gene expression cassette as disclosed herein.
- a vector can be a plasmid, a cosmid, a bacterial artificial chromosome (BAC), a bacteriophage, a virus, or an excised polynucleotide fragment for use in direct transformation or gene targeting such as a donor DNA.
- BAC bacterial artificial chromosome
- Transgene expression may also be regulated by a 5' UTR region located downstream of the promoter sequence. Both a promoter and a 5' UTR can regulate transgene expression. While a promoter is necessary to drive transcription, the presence of a 5' UTR can increase expression levels resulting in mRNA transcript for translation and protein synthesis. A 5' UTR gene region aids stable expression of a transgene.
- an 5' UTR is operably linked to a Panicum virgatum (Pavir.J00490) egg cell gene promoter.
- a 5' UTR can be the Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR of SEQ ID NO:7.
- a polynucleotide comprising a 5' UTR, wherein the 5' UTR is at least 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, 99.5%, 99.8%, or 100% identical to SEQ ID NO:7.
- a 5' UTR is a Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR comprising a polynucleotide of at least 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, 99.5%, 99.8%, or 100% identity to the polynucleotide of SEQ ID NO:7.
- an isolated polynucleotide comprising at least 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, 99.5%, 99.8%, or 100% identity to the polynucleotide of SEQ ID NO:7.
- a nucleic acid vector is provided comprising a Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR of SEQ ID NO:7.
- a polynucleotide is provided comprising a Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR that is operably linked to a polylinker.
- a gene expression cassette comprising a Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR that is operably linked to a non-Panicum virgatum (Pavir.J00490) egg cell transgene.
- a nucleic acid vector is provided comprising a Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR that is operably linked to a non-Panicum virgatum (Pavir.J00490) egg cell transgene.
- the 5' UTR consists of SEQ ID NO: 7.
- a nucleic acid vector comprises a Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR that is operably linked to a transgene, wherein the transgene can be an insecticidal resistance transgene, an herbicide tolerance transgene, a nitrogen use efficiency transgene, a water use efficiency transgene, a nutritional quality transgene, a DNA binding transgene, a small RNA transgene, selectable marker transgene, or combinations thereof.
- the transgene can be an insecticidal resistance transgene, an herbicide tolerance transgene, a nitrogen use efficiency transgene, a water use efficiency transgene, a nutritional quality transgene, a DNA binding transgene, a small RNA transgene, selectable marker transgene, or combinations thereof.
- Transgene expression may also be regulated by an intron region located downstream of the promoter sequence. Both a promoter and an intron can regulate transgene expression. While a promoter is necessary to drive transcription, the presence of an intron can increase expression levels resulting in mRNA transcript for translation and protein synthesis. An intron gene region aids stable expression of a transgene. In a further embodiment an intron is operably linked to a Panicum virgatum (Pavir.J00490) egg cell gene promoter.
- a nucleic acid vector comprising a recombinant gene expression cassette wherein the recombinant gene expression cassette comprises a Panicum virgatum (Pavir.J00490) egg cell gene promoter operably linked to a polylinker sequence, a non-Panicum virgatum (Pavir.J00490) egg cell gene or Panicum virgatum (Pavir.J00490) egg cell transgene or combination thereof.
- a Panicum virgatum Panicum virgatum
- the recombinant gene expression cassette comprises a Panicum virgatum (Pavir.J00490) egg cell gene promoter operably linked to a polylinker sequence, a non-Panicum virgatum (Pavir.J00490) egg cell gene or Panicum virgatum (Pavir.J00490) egg cell transgene or combination thereof.
- the recombinant gene cassette comprises a Panicum virgatum (Pavir.J00490) egg cell gene promoter operably linked to a non-Panicum virgatum (Pavir.J00490) egg cell gene or transgene.
- the recombinant gene cassette comprises a Panicum virgatum (Pavir.J00490) egg cell gene promoter as disclosed herein is operably linked to a polylinker sequence.
- the polylinker is operably linked to the Panicum virgatum (Pavir.J00490) egg cell gene promoter in a manner such that insertion of a coding sequence into one of the restriction sites of the polylinker will operably link the coding sequence allowing for expression of the coding sequence when the vector is transformed or transfected into a host cell.
- a nucleic acid vector comprising a gene cassette that consists of a Panicum virgatum (Pavir.J00490) egg cell gene promoter and a non- Panicum virgatum (Pavir.J00490) egg cell gene and a 3' untranslated polynucleotide sequence.
- the Panicum virgatum (Pavir.J00490) egg cell gene promoter of SEQ ID NO: 1 is operably linked to the 5' end of the non-Panicum virgatum (Pavir.J00490) egg cell gene or transgene.
- the Panicum virgatum (Pavir.J00490) egg cell gene promoter sequence comprises SEQ ID NO: 1 or a sequence that has 98, 99 or 100% sequence identity with SEQ ID NO: 1.
- a nucleic acid vector comprising a gene cassette that consists of a Panicum virgatum (Pavir.J00490) egg cell gene promoter, a non-Panicum virgatum (Pavir.J00490) egg cell gene and a 3' untranslated polynucleotide sequence, wherein the Panicum virgatum (Pavir.J00490) egg cell gene promoter is operably linked to the 5' end of the non- Panicum virgatum (Pavir.J00490) egg cell gene, and the Panicum virgatum (Pavir.J00490) egg cell gene promoter sequence comprises SEQ ID NO:1 or a sequence that has 98, 99 or 100% sequence identity with SEQ ID NO: 1.
- Panicum virgatum (Pavir.J00490) egg cell gene promoter sequence consists of SEQ ID NO: 1,or a 1,290 bp sequence that has 98, or 99% sequence identity with SEQ ID NO: 1.
- a nucleic acid vector comprising a recombinant gene expression cassette wherein the recombinant gene expression cassette comprises a Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR operably linked to a polylinker sequence, a non-Panicum virgatum (Pavir.J00490) egg cell gene or Panicum virgatum (Pavir.J00490) egg cell transgene or combination thereof.
- the recombinant gene expression cassette comprises a Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR operably linked to a polylinker sequence, a non-Panicum virgatum (Pavir.J00490) egg cell gene or Panicum virgatum (Pavir.J00490) egg cell transgene or combination thereof.
- the recombinant gene cassette comprises a Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR operably linked to a non-Panicum virgatum (Pavir.J00490) egg cell gene or transgene.
- the recombinant gene cassette comprises a Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR as disclosed herein is operably linked to a polylinker sequence.
- the polylinker is operably linked to the Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR in a manner such that insertion of a coding sequence into one of the restriction sites of the polylinker will operably link the coding sequence allowing for expression of the coding sequence when the vector is transformed or transfected into a host cell.
- a nucleic acid vector can comprise a gene cassette that consists of a Panicum virgatum
- Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR and a non-Panicum virgatum (Pavir.J00490) egg cell gene are operably linked to the 5' end of the non-Panicum virgatum (Pavir.J00490) egg cell gene or transgene.
- the Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR sequence can comprise SEQ ID NO:7 or a sequence that has 80, 85, 90, 95, 99 or 100% sequence identity with SEQ ID NO:7.
- a nucleic acid vector comprising a gene cassette that consists of a Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR, a non-Panicum virgatum (Pavir.J00490) egg cell gene, wherein the Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR is operably linked to the 5' end of the non-Panicum virgatum (Pavir.J00490) egg cell gene, and the Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR sequence comprises SEQ ID NO:7 or a sequence that has 80, 85, 90, 95, 99 or 100% sequence identity with SEQ ID NO:7.
- Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR sequence consists of SEQ ID NO:7, or a 67 bp sequence that has 80, 85, 90, 95, or 99% sequence identity with SEQ ID NO:7.
- a Panicum virgatum (Pavir.J00490) egg cell gene promoter may also comprise one or more additional sequence elements.
- a Panicum virgatum (Pavir.J00490) egg cell gene promoter may comprise an exon (e.g., a leader or signal peptide such as a chloroplast transit peptide or ER retention signal).
- a Panicum virgatum (Pavir.J00490) egg cell gene promoter may encode an exon incorporated into the Panicum virgatum (Pavir.J00490) egg cell gene promoter as a further embodiment.
- a 3' UTR terminator can be the Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR of SEQ ID NO:2.
- a polynucleotide comprising a 3' UTR, wherein the 3' UTR is at least 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, 99.5%, 99.8%, or 100% identical to SEQ ID NO:2.
- a 3' UTR is a Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR comprising a polynucleotide of at least 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, 99.5%, 99.8%, or 100% identity to the polynucleotide of SEQ ID NO:2.
- an isolated polynucleotide comprising at least 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, 99.5%, 99.8%, or 100% identity to the polynucleotide of SEQ ID NO:2.
- a nucleic acid vector is provided comprising a Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR of SEQ ID NO:2.
- a polynucleotide is provided comprising a Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR that is operably linked to a polylinker.
- a gene expression cassette comprising a Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR that is operably linked to a non-Panicum virgatum (Pavir.J00490) egg cell transgene.
- a nucleic acid vector is provided comprising a Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR that is operably linked to a non-Panicum virgatum (Pavir.J00490) egg cell transgene.
- the 3' UTR consists of SEQ ID NO: 2.
- a nucleic acid vector comprises a Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR that is operably linked to a transgene, wherein the transgene can be an insecticidal resistance transgene, an herbicide tolerance transgene, a nitrogen use efficiency transgene, a water use efficiency transgene, a nutritional quality transgene, a DNA binding transgene, a small RNA transgene, selectable marker transgene, or combinations thereof.
- the transgene can be an insecticidal resistance transgene, an herbicide tolerance transgene, a nitrogen use efficiency transgene, a water use efficiency transgene, a nutritional quality transgene, a DNA binding transgene, a small RNA transgene, selectable marker transgene, or combinations thereof.
- a nucleic acid vector comprising a recombinant gene expression cassette wherein the recombinant gene expression cassette comprises a Panicum virgatum (Pavir.J00490) egg cell gene 3'UTR operably linked to a polylinker sequence, a non-Panicum virgatum (Pavir.J00490) egg cell gene or Panicum virgatum (Pavir.J00490) egg cell transgene or combination thereof.
- the recombinant gene expression cassette comprises a Panicum virgatum (Pavir.J00490) egg cell gene 3'UTR operably linked to a polylinker sequence, a non-Panicum virgatum (Pavir.J00490) egg cell gene or Panicum virgatum (Pavir.J00490) egg cell transgene or combination thereof.
- the recombinant gene cassette comprises a Panicum virgatum (Pavir.J00490) egg cell gene 3'UTR operably linked to a non-Panicum virgatum (Pavir.J00490) egg cell gene or transgene.
- the recombinant gene cassette comprises a Panicum virgatum (Pavir.J00490) egg cell gene 3'UTR as disclosed herein is operably linked to a polylinker sequence.
- the polylinker is operably linked to the Panicum virgatum (Pavir.J00490) egg cell gene 3'UTR in a manner such that insertion of a coding sequence into one of the restriction sites of the polylinker will operably link the coding sequence allowing for expression of the coding sequence when the vector is transformed or transfected into a host cell.
- a nucleic acid vector comprising a gene cassette that consists of a Panicum virgatum (Pavir.J00490) egg cell gene 3'UTR and a non- Panicum virgatum (Pavir.J00490) egg cell gene.
- the Panicum virgatum (Pavir.J00490) egg cell gene 3'UTR of SEQ ID NO: 2 is operably linked to the 3' end of the non- Panicum virgatum (Pavir.J00490) egg cell gene or transgene.
- Panicum virgatum (Pavir.J00490) egg cell gene 3'UTR sequence comprises SEQ ID NO: 2 or a sequence that has 80, 85, 90, 95, 99 or 100% sequence identity with SEQ ID NO: 2.
- a nucleic acid vector comprising a gene cassette that consists of a Panicum virgatum (Pavir.J00490) egg cell gene 3'UTR, a non-Panicum virgatum (Pavir.J00490) egg cell gene, wherein the Panicum virgatum (Pavir.J00490) egg cell gene 3'UTR is operably linked to the 3' end of the non-Panicum virgatum (Pavir.J00490) egg cell gene, and the Panicum virgatum (Pavir.J00490) egg cell gene 3'UTR sequence comprises SEQ ID NO:2 or a sequence that has 80, 85, 90, 95, 99 or 100% sequence identity with SEQ ID NO: 2.
- Panicum virgatum (Pavir.J00490) egg cell gene 3'UTR sequence consists of SEQ ID NO:2, or a 942 bp sequence that has 80, 85, 90, 95, or 99% sequence identity with SEQ ID NO: 2.
- a nucleic acid construct comprising a Panicum virgatum (Pavir.J00490) egg cell gene promoter and a non-Panicum virgatum (Pavir.J00490) egg cell gene and a 3' untranslated region, and optionally one or more of the following elements:
- the nucleic acid vector further comprises a sequence encoding a selectable maker.
- the recombinant gene cassette is operably linked to an Agrobacterium T-DNA border.
- the recombinant gene cassette further comprises a first and second T-DNA border, wherein the first T-DNA border is operably linked to one end of a gene construct, and the second T-DNA border is operably linked to the other end of a gene construct.
- the first and second Agrobacterium T-DNA borders can be independently selected from T-DNA border sequences originating from bacterial strains selected from the group consisting of a nopaline synthesizing Agrobacterium T-DNA border, an ocotopine synthesizing Agrobacterium T-DNA border, a mannopine synthesizing Agrobacterium T-DNA border, a succinamopine synthesizing Agrobacterium T-DNA border, or any combination thereof.
- an Agrobacterium strain selected from the group consisting of a nopaline synthesizing strain, a mannopine synthesizing strain, a succinamopine synthesizing strain, or an octopine synthesizing strain is provided, wherein said strain comprises a plasmid wherein the plasmid comprises a transgene operably linked to a sequence selected from SEQ ID NO:1 or a sequence having 98 or 99% sequence identity with SEQ ID NO:1.
- the first and second Agrobacterium T-DNA borders can be independently selected from T-DNA border sequences originating from bacterial strains selected from the group consisting of a nopaline synthesizing Agrobacterium T-DNA border, an ocotopine synthesizing Agrobacterium T-DNA border, a mannopine synthesizing Agrobacterium T-DNA border, a succinamopine synthesizing Agrobacterium T-DNA border, or any combination thereof.
- an Agrobacterium strain selected from the group consisting of a nopaline synthesizing strain, a mannopine synthesizing strain, a succinamopine synthesizing strain, or an octopine synthesizing strain is provided, wherein said strain comprises a plasmid wherein the plasmid comprises a transgene operably linked to a sequence selected from SEQ ID NO:7 or a sequence having 80, 85, 90, 95, or 99% sequence identity with SEQ ID NO:7.
- an Agrobacterium strain selected from the group consisting of a nopaline synthesizing strain, a mannopine synthesizing strain, a succinamopine synthesizing strain, or an octopine synthesizing strain is provided, wherein said strain comprises a plasmid wherein the plasmid comprises a transgene operably linked to a sequence selected from SEQ ID NO:2 or a sequence having 80, 85, 90, 95, or 99% sequence identity with SEQ ID NO:2.
- Transgenes of interest that are suitable for use in the present disclosed constructs include, but are not limited to, coding sequences that confer (1) resistance to pests or disease, (2) tolerance to herbicides, (3) value added agronomic traits, such as; yield improvement, nitrogen use efficiency, water use efficiency, and nutritional quality, (4) binding of a protein to DNA in a site specific manner, (5) expression of small RNA, and (6) selectable markers.
- the transgene encodes a selectable marker or a gene product conferring insecticidal resistance, herbicide tolerance, small RNA expression, nitrogen use efficiency, water use efficiency, or nutritional quality.
- Various insect resistance genes can be operably linked to the Panicum virgatum (Pavir.J00490) egg cell gene promoter comprising SEQ ID NO: 1, or a sequence that has 98 or 99% sequence identity with SEQ ID NO: 1.
- the insect resistance genes can be operably linked to the Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR comprising SEQ ID NO:7, or a sequence that has 80, 85, 90, 95 or 99% sequence identity with SEQ ID NO:7.
- the insect resistance genes can be operably linked to the Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR comprising SEQ ID NO: 2, or a sequence that has 80, 85, 90, 95 or 99% sequence identity with SEQ ID NO: 2.
- the operably linked sequences can then be incorporated into a chosen vector to allow for identification and selection of transformed plants ("transformants").
- Exemplary insect resistance coding sequences are known in the art.
- insect resistance coding sequences that can be operably linked to the regulatory elements of the subject disclosure the following traits are provided.
- Coding sequences that provide exemplary Lepidopteran insect resistance include: cry1A ; cry1A.105 ; cry1Ab ; cry1Ab (truncated); cry1Ab-Ac (fusion protein); cry1Ac (marketed as Widestrike ® ); cry1C ; cry1F (marketed as Widestrike ® ); cry1Fa2 ; cry2Ab2 ; cry2Ae ; cry9C ; mocrylF ; pinII (protease inhibitor protein); vip3A(a) ; and vip3Aa20.
- Coding sequences that provide exemplary Coleopteran insect resistance include: cry34Ab1 (marketed as Herculex ® ); cry35Ab1 (marketed as Herculex ® ); cry3A; cry3Bb1 ; dvsnf7 ; and mcry3A. Coding sequences that provide exemplary multi-insect resistance include ecry31.Ab.
- cry34Ab1 marketed as Herculex ®
- cry35Ab1 marketed as Herculex ®
- herbicide tolerance genes can be operably linked to the Panicum virgatum (Pavir.J00490) egg cell gene promoter comprising SEQ ID NO: 1, or a sequence that has 98 or 99% sequence identity with SEQ ID NO: 1.
- the herbicide tolerance genes can be operably linked to the Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR comprising SEQ ID NO:7, or a sequence that has 80, 85, 90, 95 or 99% sequence identity with SEQ ID NO:7.
- the herbicide tolerance genes can be operably linked to the Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR comprising SEQ ID NO: 2, or a sequence that has 80, 85, 90, 95 or 99% sequence identity with SEQ ID NO: 2.
- the operably linked sequences can then be incorporated into a chosen vector to allow for identification and selection of transformed plants ("transformants").
- Exemplary herbicide tolerance coding sequences are known in the art.
- the following traits are provided.
- the glyphosate herbicide contains a mode of action by inhibiting the EPSPS enzyme (5-enolpyruvylshikimate-3-phosphate synthase).
- EPSPS enzyme 5-enolpyruvylshikimate-3-phosphate synthase
- This enzyme is involved in the biosynthesis of aromatic amino acids that are essential for growth and development of plants.
- Various enzymatic mechanisms are known in the art that can be utilized to inhibit this enzyme.
- the genes that encode such enzymes can be operably linked to the gene regulatory elements of the subject disclosure.
- selectable marker genes include, but are not limited to genes encoding glyphosate resistance genes include: mutant EPSPS genes such as 2mEPSPS genes, cp4 EPSPS genes, mEPSPS genes, dgt-28 genes; aroA genes; and glyphosate degradation genes such as glyphosate acetyl transferase genes ( gat ) and glyphosate oxidase genes ( gox ). These traits are currently marketed as Gly-Tol TM , Optimum ® GAT ® , Agrisure ® GT and Roundup Ready ® . Resistance genes for glufosinate and/or bialaphos compounds include dsm-2, bar and pat genes.
- the bar and pat traits are currently marketed as LibertyLink ® . Also included are tolerance genes that provide resistance to 2,4-D such as aad-1 genes (it should be noted that aad-1 genes have further activity on arloxyphenoxypropionate herbicides) and aad-12 genes (it should be noted that aad-12 genes have further activity on pyidyloxyacetate synthetic auxins). These traits are marketed as Enlist ® crop protection technology. Resistance genes for ALS inhibitors (sulfonylureas, imidazolinones, triazolopyrimidines, pyrimidinylthiobenzoates, and sulfonylamino-carbonyl-triazolinones) are known in the art.
- ALS inhibitor resistance genes include hra genes, the csr1-2 genes, Sr-HrA genes, and surB genes. Some of the traits are marketed under the tradename Clearfield ® .
- Herbicides that inhibit HPPD include the pyrazolones such as pyrazoxyfen, benzofenap, and topramezone; triketones such as mesotrione, sulcotrione, tembotrione, benzobicyclon; and diketonitriles such as isoxaflutole. These exemplary HPPD herbicides can be tolerated by known traits.
- HPPD inhibitors examples include hppdPF_W336 genes (for resistance to isoxaflutole) and avhppd-03 genes (for resistance to meostrione).
- An example of oxynil herbicide tolerant traits include the bxn gene, which has been showed to impart resistance to the herbicide/antibiotic bromoxynil.
- Resistance genes for dicamba include the dicamba monooxygenase gene ( dmo ) as disclosed in International PCT Publication No. WO 2008/105890 .
- PPO or PROTOX inhibitor type herbicides e.g., acifluorfen, butafenacil, flupropazil, pentoxazone, carfentrazone, fluazolate, pyraflufen, aclonifen, azafenidin, flumioxazin, flumiclorac, bifenox, oxyfluorfen, lactofen, fomesafen, fluoroglycofen, and sulfentrazone
- PPO or PROTOX inhibitor type herbicides e.g., acifluorfen, butafenacil, flupropazil, pentoxazone, carfentrazone, fluazolate, pyraflufen, aclonifen, azafenidin, flumioxazin, flumiclorac, bifenox, oxyfluorfen, lactofen, fomesafen, fluoroglycofen, and sulfentrazone
- Exemplary genes conferring resistance to PPO include over expression of a wild-type Arabidopsis thaliana PPO enzyme ( Lermontova I and Grimm B, (2000) Overexpression of plastidic protoporphyrinogen IX oxidase leads to resistance to the diphenyl-ether herbicide acifluorfen. Plant Physiol 122:75-83 .), the B. subtilis PPO gene ( Li, X. and Nicholl D. 2005. Development of PPO inhibitor-resistant cultures and crops. Pest Manag. Sci.
- Resistance genes for pyridinoxy or phenoxy proprionic acids and cyclohexones include the ACCase inhibitor-encoding genes (e.g., Acc1-S1, Acc1-S2 and Acc1-S3).
- Exemplary genes conferring resistance to cyclohexanediones and/or aryloxyphenoxypropanoic acid include haloxyfop, diclofop, fenoxyprop, fluazifop, and quizalofop.
- herbicides can inhibit photosynthesis, including triazine or benzonitrile are provided tolerance by psbA genes (tolerance to triazine), 1s + genes (tolerance to triazine), and nitrilase genes (tolerance to benzonitrile).
- psbA genes tolerance to triazine
- 1s + genes tolerance to triazine
- nitrilase genes tolerance to benzonitrile
- agronomic trait genes can be operably linked to the Panicum virgatum (Pavir.J00490) egg cell gene promoter comprising SEQ ID NO: 1, or a sequence that has 98 or 99% sequence identity with SEQ ID NO: 1.
- the agronomic trait genes can be operably linked to the Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR comprising SEQ ID NO:7, or a sequence that has 80, 85, 90, 95 or 99% sequence identity with SEQ ID NO:7.
- the agronomic trait genes can be operably linked to the Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR comprising SEQ ID NO: 2, or a sequence that has 80, 85, 90, 95 or 99% sequence identity with SEQ ID NO: 2.
- the operably linked sequences can then be incorporated into a chosen vector to allow for identification and selection of transformed plants ("transformants").
- Exemplary agronomic trait coding sequences are known in the art.
- agronomic trait coding sequences that can be operably linked to the regulatory elements of the subject disclosure, the following traits are provided.
- Delayed fruit softening as provided by the pg genes inhibit the production of polygalacturonase enzyme responsible for the breakdown of pectin molecules in the cell wall, and thus causes delayed softening of the fruit. Further, delayed fruit ripening/senescence of acc genes act to suppress the normal expression of the native acc synthase gene, resulting in reduced ethylene production and delayed fruit ripening. Whereas, the accd genes metabolize the precursor of the fruit ripening hormone ethylene, resulting in delayed fruit ripening. Alternatively, the sam-k genes cause delayed ripening by reducing S-adenosylmethionine (SAM), a substrate for ethylene production.
- SAM S-adenosylmethionine
- Drought stress tolerance phenotypes as provided by cspB genes maintain normal cellular functions under water stress conditions by preserving RNA stability and translation.
- Another example includes the EcBetA genes that catalyze the production of the osmoprotectant compound glycine betaine conferring tolerance to water stress.
- the RmBetA genes catalyze the production of the osmoprotectant compound glycine betaine conferring tolerance to water stress.
- Photosynthesis and yield enhancement is provided with the bbx32 gene that expresses a protein that interacts with one or more endogenous transcription factors to regulate the plant's day/night physiological processes.
- Ethanol production can be increase by expression of the amy797E genes that encode a thermostable alpha-amylase enzyme that enhances bioethanol production by increasing the thermostability of amylase used in degrading starch.
- modified amino acid compositions can result by the expression of the cordapA genes that encode a dihydrodipicolinate synthase enzyme that increases the production of amino acid lysine.
- DNA binding transgene genes can be operably linked to the Panicum virgatum (Pavir.J00490) egg cell gene promoter comprising SEQ ID NO: 1, or a sequence that has 98 or 99% sequence identity with SEQ ID NO: 1.
- the DNA binding transgene genes can be operably linked to the Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR comprising SEQ ID NO:7, or a sequence that has 80, 85, 90, 95 or 99% sequence identity with SEQ ID NO:7.
- the DNA binding transgene genes can be operably linked to the Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR comprising SEQ ID NO: 2, or a sequence that has 80, 85, 90, 95 or 99% sequence identity with SEQ ID NO: 2.
- the operably linked sequences can then be incorporated into a chosen vector to allow for identification and selectable of transformed plants ("transformants").
- Exemplary DNA binding protein coding sequences are known in the art.
- the following types of DNA binding proteins can include; Zinc Fingers, TALENS, CRISPRS, and meganucleases. The above list of DNA binding protein coding sequences is not meant to be limiting. Any DNA binding protein coding sequences is encompassed by the present disclosure.
- RNA sequences can be operably linked to the Panicum virgatum (Pavir.J00490) egg cell gene promoter comprising SEQ ID NO: 1, or a sequence that has 98 or 99% sequence identity with SEQ ID NO: 1.
- the small RNA sequences can be operably linked to the Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR comprising SEQ ID NO: 2, or a sequence that has 80, 85, 90, 95 or 99% sequence identity with SEQ ID NO: 2.
- the operably linked sequences can then be incorporated into a chosen vector to allow for identification and selection of transformed plants ("transformants").
- Exemplary small RNA traits are known in the art.
- delayed fruit ripening/senescence of the anti-efe small RNA delays ripening by suppressing the production of ethylene via silencing of the ACO gene that encodes an ethylene-forming enzyme.
- the altered lignin production of ccomt small RNA reduces content of guanacyl (G) lignin by inhibition of the endogenous S-adenosyl-L-methionine: trans-caffeoyl CoA 3-O-methyltransferase (CCOMT gene).
- the Black Spot Bruise Tolerance in Solanum verrucosum can be reduced by the Ppo5 small RNA which triggers the degradation of Ppo5 transcripts to block black spot bruise development.
- the dvsnf7 small RNA that inhibits Western Corn Rootworm with dsRNA containing a 240 bp fragment of the Western Corn Rootworm Snf7 gene.
- Modified starch/carbohydrates can result from small RNA such as the pPhL small RNA (degrades PhL transcripts to limit the formation of reducing sugars through starch degradation) and pR1 small RNA (degrades R1 transcripts to limit the formation of reducing sugars through starch degradation).
- selectable markers also described as reporter genes can be operably linked to the Panicum virgatum (Pavir.J00490) egg cell gene promoter comprising SEQ ID NO: 1, or a sequence that has 98 or 99% sequence identity with SEQ ID NO: 1.
- the selectable markers also described as reporter genes can be operably linked to the Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR comprising SEQ ID NO:7, or a sequence that has 80, 85, 90, 95 or 99% sequence identity with SEQ ID NO:7.
- the selectable markers also described as reporter genes can be operably linked to the Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR comprising SEQ ID NO: 2, or a sequence that has 80, 85, 90, 95 or 99% sequence identity with SEQ ID NO: 2.
- the operably linked sequences can then be incorporated into a chosen vector to allow for identification and selectable of transformed plants ("transformants").
- transformationants Many methods are available to confirm expression of selectable markers in transformed plants, including for example DNA sequencing and PCR (polymerase chain reaction), Southern blotting, RNA blotting, immunological methods for detection of a protein expressed from the vector. But, usually the reporter genes are observed through visual observation of proteins that when expressed produce a colored product.
- reporter genes are known in the art and encode ⁇ -glucuronidase (GUS), luciferase , green fluorescent protein (GFP), yellow fluorescent protein (YFP, Phi-YFP), red fluorescent protein (DsRFP, RFP, etc), ⁇ -galactosidase , and the like (See Sambrook, et al., Molecular Cloning: A Laboratory Manual, Third Edition, Cold Spring Harbor Press, N.Y., 2001 , the content of which is incorporated herein by reference in its entirety).
- GUS ⁇ -glucuronidase
- GFP green fluorescent protein
- YFP yellow fluorescent protein
- DsRFP red fluorescent protein
- RFP red fluorescent protein
- Selectable marker genes are utilized for selection of transformed cells or tissues.
- Selectable marker genes include genes encoding antibiotic resistance, such as those encoding neomycin phosphotransferase II (NEO), spectinomycin/streptinomycin resistance (AAD), and hygromycin phosphotransferase (HPT or HGR) as well as genes conferring resistance to herbicidal compounds.
- Herbicide resistance genes generally code for a modified target protein insensitive to the herbicide or for an enzyme that degrades or detoxifies the herbicide in the plant before it can act. For example, resistance to glyphosate has been obtained by using genes coding for mutant target enzymes, 5-enolpyruvylshikimate-3-phosphate synthase (EPSPS).
- EPSPS 5-enolpyruvylshikimate-3-phosphate synthase
- EPSPS Genes and mutants for EPSPS are well known, and further described below. Resistance to glufosinate ammonium, bromoxynil, and 2,4-dichlorophenoxyacetate (2,4-D) have been obtained by using bacterial genes encoding PAT or DSM-2, a nitrilase, an AAD-1, or an AAD-12, each of which are examples of proteins that detoxify their respective herbicides.
- herbicides can inhibit the growing point or meristem, including imidazolinone or sulfonylurea, and genes for resistance/tolerance of acetohydroxyacid synthase (AHAS) and acetolactate synthase (ALS) for these herbicides are well known.
- Glyphosate resistance genes include mutant 5-enolpyruvylshikimate-3-phosphate synthase (EPSPs) and dgt-28 genes (via the introduction of recombinant nucleic acids and/or various forms of in vivo mutagenesis of native EPSPs genes), aroA genes and glyphosate acetyl transferase (GAT) genes, respectively).
- Resistance genes for other phosphono compounds include bar and pat genes from Streptomyces species, including Streptomyces hygroscopicus and Streptomyces viridichromogenes, and pyridinoxy or phenoxy proprionic acids and cyclohexones (ACCase inhibitor-encoding genes).
- Exemplary genes conferring resistance to cyclohexanediones and/or aryloxyphenoxypropanoic acid include genes of acetyl coenzyme A carboxylase (ACCase); Acc1-S1, Acc1-S2 and Acc1-S3.
- herbicides can inhibit photosynthesis, including triazine (psbA and 1s+ genes) or benzonitrile (nitrilase gene).
- selectable markers can include positive selection markers such as phosphomannose isomerase (PMI) enzyme.
- selectable marker genes include, but are not limited to genes encoding: 2,4-D; neomycin phosphotransferase II; cyanamide hydratase; aspartate kinase; dihydrodipicolinate synthase; tryptophan decarboxylase; dihydrodipicolinate synthase and desensitized aspartate kinase; bar gene; tryptophan decarboxylase; neomycin phosphotransferase (NEO); hygromycin phosphotransferase (HPT or HYG); dihydrofolate reductase (DHFR); phosphinothricin acetyltransferase; 2,2-dichloropropionic acid dehalogenase; acetohydroxyacid synthase; 5-enolpyruvyl-shikimate-phosphate synthase (aroA); haloarylnitrilase; acetyl
- An embodiment also includes selectable marker genes encoding resistance to: chloramphenicol; methotrexate; hygromycin; spectinomycin; bromoxynil; glyphosate; and phosphinothricin.
- selectable marker genes encoding resistance to: chloramphenicol; methotrexate; hygromycin; spectinomycin; bromoxynil; glyphosate; and phosphinothricin.
- selectable marker genes encoding resistance to: chloramphenicol; methotrexate; hygromycin; spectinomycin; bromoxynil; glyphosate; and phosphinothricin.
- the coding sequences are synthesized for optimal expression in a plant.
- a coding sequence of a gene has been modified by codon optimization to enhance expression in plants.
- An insecticidal resistance transgene, an herbicide tolerance transgene, a nitrogen use efficiency transgene, a water use efficiency transgene, a nutritional quality transgene, a DNA binding transgene, or a selectable marker transgene can be optimized for expression in a particular plant species or alternatively can be modified for optimal expression in dicotyledonous or monocotyledonous plants.
- Plant preferred codons may be determined from the codons of highest frequency in the proteins expressed in the largest amount in the particular plant species of interest.
- a coding sequence, gene, or transgene is designed to be expressed in plants at a higher level resulting in higher transformation efficiency.
- Methods for plant optimization of genes are well known. Guidance regarding the optimization and production of synthetic DNA sequences can be found in, for example, WO2013016546 , WO2011146524 , WO1997013402 , US Patent No. 6166302 , and US Patent No. 5380831 .
- Suitable methods for transformation of plants include any method by which DNA can be introduced into a cell, for example and without limitation: electroporation (see, e.g., U.S. Patent 5,384,253 ); micro-projectile bombardment (see, e.g., U.S. Patents 5,015,580 , 5,550,318 , 5,538,880 , 6,160,208 , 6,399,861 , and 6,403,865 ); Agrobacterium-mediated transformation (see, e.g., U.S. Patents 5,635,055 , 5,824,877 , 5,591,616 ; 5,981,840 , and 6,384,301 ); and protoplast transformation (see, e.g., U.S. Patent 5,508,184 ).
- a DNA construct may be introduced directly into the genomic DNA of the plant cell using techniques such as agitation with silicon carbide fibers (see, e.g., U.S. Patents 5,302,523 and 5,464,765 ), or the DNA constructs can be introduced directly to plant tissue using biolistic methods, such as DNA particle bombardment (see, e.g., Klein et al. (1987) Nature 327:70-73 ). Alternatively, the DNA construct can be introduced into the plant cell via nanoparticle transformation (see, e.g., US Patent Publication No. 20090104700 ).
- gene transfer may be achieved using non- Agrobacterium bacteria or viruses such as Rhizobium sp. NGR234, Sinorhizoboium meliloti , Mesorhizobium loti , potato virus X, cauliflower mosaic virus and cassava vein mosaic virus and/or tobacco mosaic virus, See, e.g., Chung et al. (2006) Trends Plant Sci. 11(1): 1-4 .
- non- Agrobacterium bacteria or viruses such as Rhizobium sp. NGR234, Sinorhizoboium meliloti , Mesorhizobium loti , potato virus X, cauliflower mosaic virus and cassava vein mosaic virus and/or tobacco mosaic virus, See, e.g., Chung et al. (2006) Trends Plant Sci. 11(1): 1-4 .
- a transformed cell After effecting delivery of an exogenous nucleic acid to a recipient cell, a transformed cell is generally identified for further culturing and plant regeneration. In order to improve the ability to identify transformants, one may desire to employ a selectable marker gene with the transformation vector used to generate the transformant. In an illustrative embodiment, a transformed cell population can be assayed by exposing the cells to a selective agent or agents, or the cells can be screened for the desired marker gene trait.
- Cells that survive exposure to a selective agent, or cells that have been scored positive in a screening assay may be cultured in media that supports regeneration of plants.
- any suitable plant tissue culture media may be modified by including further substances, such as growth regulators.
- Tissue may be maintained on a basic media with growth regulators until sufficient tissue is available to begin plant regeneration efforts, or following repeated rounds of manual selection, until the morphology of the tissue is suitable for regeneration (e.g., at least 2 weeks), then transferred to media conducive to shoot formation. Cultures are transferred periodically until sufficient shoot formation has occurred. Once shoots are formed, they are transferred to media conducive to root formation. Once sufficient roots are formed, plants can be transferred to soil for further growth and maturity.
- a transformed plant cell, callus, tissue or plant may be identified and isolated by selecting or screening the engineered plant material for traits encoded by the marker genes present on the transforming DNA. For instance, selection can be performed by growing the engineered plant material on media containing an inhibitory amount of the antibiotic or herbicide to which the transforming gene construct confers resistance. Further, transformed plants and plant cells can also be identified by screening for the activities of any visible marker genes (e.g ., the ⁇ -glucuronidase, luciferase, or green fluorescent protein genes) that may be present on the recombinant nucleic acid constructs. Such selection and screening methodologies are well known to those skilled in the art. Molecular confirmation methods that can be used to identify transgenic plants are known to those with skill in the art. Several exemplary methods are further described below.
- any visible marker genes e.g ., the ⁇ -glucuronidase, luciferase, or green fluorescent protein genes
- Molecular Beacons have been described for use in sequence detection. Briefly, a FRET oligonucleotide probe is designed that overlaps the flanking genomic and insert DNA junction. The unique structure of the FRET probe results in it containing a secondary structure that keeps the fluorescent and quenching moieties in close proximity.
- the FRET probe and PCR primers are cycled in the presence of a thermostable polymerase and dNTPs. Following successful PCR amplification, hybridization of the FRET probe(s) to the target sequence results in the removal of the probe secondary structure and spatial separation of the fluorescent and quenching moieties.
- a fluorescent signal indicates the presence of the flanking genomic/transgene insert sequence due to successful amplification and hybridization.
- Such a molecular beacon assay for detection of as an amplification reaction is an embodiment of the subject disclosure.
- Hydrolysis probe assay otherwise known as TAQMAN ® (Life Technologies, Foster City, Calif.), is a method of detecting and quantifying the presence of a DNA sequence.
- a FRET oligonucleotide probe is designed with one oligo within the transgene and one in the flanking genomic sequence for event-specific detection.
- the FRET probe and PCR primers are cycled in the presence of a thermostable polymerase and dNTPs.
- Hybridization of the FRET probe results in cleavage and release of the fluorescent moiety away from the quenching moiety on the FRET probe.
- a fluorescent signal indicates the presence of the flanking/transgene insert sequence due to successful amplification and hybridization.
- Such a hydrolysis probe assay for detection of as an amplification reaction is an embodiment of the subject disclosure.
- KASPar ® assays are a method of detecting and quantifying the presence of a DNA sequence. Briefly, the genomic DNA sample comprising the integrated gene expression cassette polynucleotide is screened using a polymerase chain reaction (PCR) based assay known as a KASPar ® assay system.
- PCR polymerase chain reaction
- the KASPar ® assay used in the practice of the subject disclosure can utilize a KASPar ® PCR assay mixture which contains multiple primers.
- the primers used in the PCR assay mixture can comprise at least one forward primers and at least one reverse primer.
- the forward primer contains a sequence corresponding to a specific region of the DNA polynucleotide
- the reverse primer contains a sequence corresponding to a specific region of the genomic sequence.
- the primers used in the PCR assay mixture can comprise at least one forward primers and at least one reverse primer.
- the KASPar ® PCR assay mixture can use two forward primers corresponding to two different alleles and one reverse primer.
- One of the forward primers contains a sequence corresponding to specific region of the endogenous genomic sequence.
- the second forward primer contains a sequence corresponding to a specific region of the DNA polynucleotide.
- the reverse primer contains a sequence corresponding to a specific region of the genomic sequence.
- the fluorescent signal or fluorescent dye is selected from the group consisting of a HEX fluorescent dye, a FAM fluorescent dye, a JOE fluorescent dye, a TET fluorescent dye, a Cy 3 fluorescent dye, a Cy 3.5 fluorescent dye, a Cy 5 fluorescent dye, a Cy 5.5 fluorescent dye, a Cy 7 fluorescent dye, and a ROX fluorescent dye.
- the amplification reaction is run using suitable second fluorescent DNA dyes that are capable of staining cellular DNA at a concentration range detectable by flow cytometry, and have a fluorescent emission spectrum which is detectable by a real time thermocycler.
- suitable nucleic acid dyes are known and are continually being identified. Any suitable nucleic acid dye with appropriate excitation and emission spectra can be employed, such as YO-PRO-1 ® , SYTOX Green ® , SYBR Green I ® , SYTO11 ® , SYTO12 ® , SYTO13 ® , BOBO ® , YOYO ® , and TOTO ® .
- a second fluorescent DNA dye is SYTO13 ® used at less than 10 ⁇ M, less than 4 ⁇ M, or less than 2.7 ⁇ M.
- NGS Next Generation Sequencing
- DNA sequence analysis can be used to determine the nucleotide sequence of the isolated and amplified fragment.
- the amplified fragments can be isolated and sub-cloned into a vector and sequenced using chain-terminator method (also referred to as Sanger sequencing) or Dye-terminator sequencing.
- the amplicon can be sequenced with Next Generation Sequencing.
- NGS technologies do not require the sub-cloning step, and multiple sequencing reads can be completed in a single reaction.
- the Genome Sequencher FLX TM which is marketed by 454 Life Sciences/Roche is a long read NGS, which uses emulsion PCR and pyrosequencing to generate sequencing reads. DNA fragments of 300 - 800 bp or libraries containing fragments of 3 - 20 kb can be used. The reactions can produce over a million reads of about 250 to 400 bases per run for a total yield of 250 to 400 megabases. This technology produces the longest reads but the total sequence output per run is low compared to other NGS technologies.
- the Illumina Genome Analyser TM which is marketed by Solexa TM is a short read NGS which uses sequencing by synthesis approach with fluorescent dye-labeled reversible terminator nucleotides and is based on solid-phase bridge PCR. Construction of paired end sequencing libraries containing DNA fragments of up to 10 kb can be used. The reactions produce over 100 million short reads that are 35 - 76 bases in length. This data can produce from 3-6 gigabases per run.
- the Sequencing by Oligo Ligation and Detection (SOLiD) system marketed by Applied Biosystems TM is a short read technology.
- This NGS technology uses fragmented double stranded DNA that are up to 10 kb in length.
- the system uses sequencing by ligation of dye-labelled oligonucleotide primers and emulsion PCR to generate one billion short reads that result in a total sequence output of up to 30 gigabases per run.
- tSMS of Helicos Bioscience TM and SMRT of Pacific Biosciences TM apply a different approach which uses single DNA molecules for the sequence reactions.
- the tSMS Helicos TM system produces up to 800 million short reads that result in 21 gigabases per run. These reactions are completed using fluorescent dye-labelled virtual terminator nucleotides that is described as a 'sequencing by synthesis' approach.
- the SMRT Next Generation Sequencing system marketed by Pacific Biosciences TM uses a real time sequencing by synthesis. This technology can produce reads of up to 1,000 bp in length as a result of not being limited by reversible terminators. Raw read throughput that is equivalent to one-fold coverage of a diploid human genome can be produced per day using this technology.
- the detection can be completed using blotting assays, including Western blots, Northern blots, and Southern blots.
- blotting assays are commonly used techniques in biological research for the identification and quantification of biological samples. These assays include first separating the sample components in gels by electrophoresis, followed by transfer of the electrophoretically separated components from the gels to transfer membranes that are made of materials such as nitrocellulose, polyvinylidene fluoride (PVDF), or Nylon. Analytes can also be directly spotted on these supports or directed to specific regions on the supports by applying vacuum, capillary action, or pressure, without prior separation. The transfer membranes are then commonly subj ected to a post-transfer treatment to enhance the ability of the analytes to be distinguished from each other and detected, either visually or by automated readers.
- PVDF polyvinylidene fluoride
- the detection can be completed using an ELISA assay, which uses a solid-phase enzyme immunoassay to detect the presence of a substance, usually an antigen, in a liquid sample or wet sample.
- a substance usually an antigen
- Antigens from the sample are attached to a surface of a plate.
- a further specific antibody is applied over the surface so it can bind to the antigen.
- This antibody is linked to an enzyme, and, in the final step, a substance containing the enzyme's substrate is added. The subsequent reaction produces a detectable signal, most commonly a color change in the substrate.
- a plant, plant tissue, or plant cell comprises a Panicum virgatum (Pavir.J00490) egg cell gene promoter.
- a plant, plant tissue, or plant cell comprises the Panicum virgatum (Pavir.J00490) egg cell gene promoter of a sequence selected from SEQ ID NO: 1 or a sequence that has 98% or 99.5% sequence identity with a sequence selected from SEQ ID NO: 1.
- a plant, plant tissue, or plant cell comprises a gene expression cassette comprising a sequence selected from SEQ ID NO: 1, or a sequence that has 98% or 99.5% sequence identity with a sequence selected from SEQ ID NO: 1 that is operably linked to a non- Panicum virgatum (Pavir.J00490) egg cell gene.
- a plant, plant tissue, or plant cell comprises a gene expression cassette comprising a Panicum virgatum (Pavir.J00490) egg cell gene promoter that is operably linked to a transgene, wherein the transgene can be an insecticidal resistance transgene, an herbicide tolerance transgene, a nitrogen use efficiency transgene, a water use efficiency transgene, a nutritional quality transgene, a DNA binding transgene, a selectable marker transgene, or combinations thereof.
- a transgene can be an insecticidal resistance transgene, an herbicide tolerance transgene, a nitrogen use efficiency transgene, a water use efficiency transgene, a nutritional quality transgene, a DNA binding transgene, a selectable marker transgene, or combinations thereof.
- a plant, plant tissue, or plant cell comprising a Panicum virgatum (Pavir.J00490) egg cell gene promoter derived sequence operably linked to a transgene, wherein the Panicum virgatum (Pavir.J00490) egg cell gene promoter derived sequence comprises a sequence SEQ ID NO: 1 or a sequence having 98% or 99.5% sequence identity with SEQ ID NO:1.
- a plant, plant tissue, or plant cell wherein the plant, plant tissue, or plant cell comprises SEQ ID NO: 1, or a sequence that has 98% or 99.5% sequence identity with SEQ ID NO: 1 operably linked to a non- Panicum virgatum (Pavir.J00490) egg cell gene.
- the plant, plant tissue, or plant cell is a dicotyledonous or monocotyledonous plant or a cell or tissue derived from a dicotyledonous or monocotyledonous plant.
- the plant is selected from the group consisting of Zea mays, wheat, rice, sorghum, oats, rye, bananas, sugar cane, soybean, cotton, sunflower, and canola.
- the plant is Zea mays.
- the plant, plant tissue, or plant cell comprises SEQ ID NO: 1 or a sequence having 98% or 99.5% sequence identity with SEQ ID NO:1 operably linked to a non- Panicum virgatum (Pavir.J00490) egg cell gene.
- the plant, plant tissue, or plant cell comprises a promoter operably linked to a transgene wherein the promoter consists of SEQ ID NO: 1or a sequence having 98% or 99.5% sequence identity with SEQ ID NO: 1.
- the gene construct comprising Panicum virgatum (Pavir.J00490) egg cell gene promoter sequence operably linked to a transgene is incorporated into the genome of the plant, plant tissue, or plant cell.
- a plant, plant tissue, or plant cell comprises a Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR.
- a plant, plant tissue, or plant cell comprises the Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR of a sequence selected from SEQ ID NO:7 or a sequence that has 80%, 85%, 90%, 95% or 99.5% sequence identity with a sequence selected from SEQ ID NO:7.
- a plant, plant tissue, or plant cell comprises a gene expression cassette comprising a sequence selected from SEQ ID NO:7, or a sequence that has 80%, 85%, 90%, 95% or 99.5% sequence identity with a sequence selected from SEQ ID NO:7 that is operably linked to a non- Panicum virgatum (Pavir.J00490) egg cell gene.
- a plant, plant tissue, or plant cell comprises a gene expression cassette comprising a Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR that is operably linked to a transgene, wherein the transgene can be an insecticidal resistance transgene, an herbicide tolerance transgene, a nitrogen use efficiency transgene, a water use efficiency transgene, a nutritional quality transgene, a DNA binding transgene, a selectable marker transgene, or combinations thereof.
- a transgene can be an insecticidal resistance transgene, an herbicide tolerance transgene, a nitrogen use efficiency transgene, a water use efficiency transgene, a nutritional quality transgene, a DNA binding transgene, a selectable marker transgene, or combinations thereof.
- a plant, plant tissue, or plant cell comprising a Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR derived sequence operably linked to a transgene, wherein the Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR derived sequence comprises a sequence SEQ ID NO:7 or a sequence having 80%, 85%, 90%, 95% or 99.5% sequence identity with SEQ ID NO:7.
- a plant, plant tissue, or plant cell wherein the plant, plant tissue, or plant cell comprises SEQ ID NO:7, or a sequence that has 80%, 85%, 90%, 95% or 99.5% sequence identity with SEQ ID NO:7 operably linked to a non- Panicum virgatum (Pavir.J00490) egg cell gene.
- the plant, plant tissue, or plant cell is a dicotyledonous or monocotyledonous plant or a cell or tissue derived from a dicotyledonous or monocotyledonous plant.
- the plant is selected from the group consisting of Zea mays, wheat, rice, sorghum, oats, rye, bananas, sugar cane, soybean, cotton, sunflower, and canola.
- the plant is Zea mays.
- the plant, plant tissue, or plant cell comprises SEQ ID NO:7 or a sequence having 80%, 85%, 90%, 95% or 99.5% sequence identity with SEQ ID NO:7 operably linked to a non- Panicum virgatum (Pavir.J00490) egg cell gene.
- the plant, plant tissue, or plant cell comprises a 5' UTR operably linked to a transgene wherein the 5' UTR consists of SEQ ID NO:7 or a sequence having 80%, 85%, 90%, 95% or 99.5% sequence identity with SEQ ID NO:7.
- the gene construct comprising Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR sequence operably linked to a transgene is incorporated into the genome of the plant, plant tissue, or plant cell.
- a plant, plant tissue, or plant cell comprises a Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR.
- a plant, plant tissue, or plant cell comprises the Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR of a sequence selected from SEQ ID NO:2 or a sequence that has 80%, 85%, 90%, 95% or 99.5% sequence identity with a sequence selected from SEQ ID NO:2.
- a plant, plant tissue, or plant cell comprises a gene expression cassette comprising a sequence selected from SEQ ID NO:2, or a sequence that has 80%, 85%, 90%, 95% or 99.5% sequence identity with a sequence selected from SEQ ID NO:2 that is operably linked to a non- Panicum virgatum (Pavir.J00490) egg cell gene.
- a plant, plant tissue, or plant cell comprises a gene expression cassette comprising a Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR that is operably linked to a transgene, wherein the transgene can be an insecticidal resistance transgene, an herbicide tolerance transgene, a nitrogen use efficiency transgene, a water use efficiency transgene, a nutritional quality transgene, a DNA binding transgene, a selectable marker transgene, or combinations thereof.
- the transgene can be an insecticidal resistance transgene, an herbicide tolerance transgene, a nitrogen use efficiency transgene, a water use efficiency transgene, a nutritional quality transgene, a DNA binding transgene, a selectable marker transgene, or combinations thereof.
- a plant, plant tissue, or plant cell comprising a Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR derived sequence operably linked to a transgene, wherein the Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR derived sequence comprises a sequence SEQ ID NO:2 or a sequence having 80%, 85%, 90%, 95% or 99.5% sequence identity with SEQ ID NO:2.
- a plant, plant tissue, or plant cell wherein the plant, plant tissue, or plant cell comprises SEQ ID NO:2, or a sequence that has 80%, 85%, 90%, 95% or 99.5% sequence identity with SEQ ID NO:2 operably linked to a non- Panicum virgatum (Pavir.J00490) egg cell gene.
- the plant, plant tissue, or plant cell is a dicotyledonous or monocotyledonous plant or a cell or tissue derived from a dicotyledonous or monocotyledonous plant.
- the plant is selected from the group consisting of Zea mays, wheat, rice, sorghum, oats, rye, bananas, sugar cane, soybean, cotton, sunflower, and canola.
- the plant is Zea mays.
- the plant, plant tissue, or plant cell comprises SEQ ID NO:2 or a sequence having 80%, 85%, 90%, 95% or 99.5% sequence identity with SEQ ID NO:2 operably linked to a non- Panicum virgatum (Pavir.J00490) egg cell gene.
- the plant, plant tissue, or plant cell comprises a 3' UTR operably linked to a transgene wherein the 3' UTR consists of SEQ ID NO:2 or a sequence having 80%, 85%, 90%, 95% or 99.5% sequence identity with SEQ ID NO:2.
- the gene construct comprising Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR sequence operably linked to a transgene is incorporated into the genome of the plant, plant tissue, or plant cell.
- a plant, plant tissue, or plant cell according to the methods disclosed herein can be a dicotyledonous plant.
- the dicotyledonous plant, plant tissue, or plant cell can be, but not limited to alfalfa, rapeseed, canola, Indian mustard, Ethiopian mustard, soybean, sunflower, cotton, beans, broccoli, cabbage, cauliflower, celery, cucumber, eggplant, lettuce; melon, pea, pepper, peanut, potato, pumpkin, radish, spinach, sugarbeet, sunflower, tobacco, tomato, and watermelon.
- the present disclosure also encompasses seeds of the transgenic plants described above, wherein the seed has the transgene or gene construct containing the gene regulatory elements of the subject disclosure.
- the present disclosure further encompasses the progeny, clones, cell lines or cells of the transgenic plants described above wherein said progeny, clone, cell line or cell has the transgene or gene construct containing the gene regulatory elements of the subject disclosure.
- the present disclosure also encompasses the cultivation of transgenic plants described above, wherein the transgenic plant has the transgene or gene construct containing the gene regulatory elements of the subject disclosure. Accordingly, such transgenic plants may be engineered to, inter alia , have one or more desired traits or transgenic events containing the gene regulatory elements of the subject disclosure, by being transformed with nucleic acid molecules according to the invention, and may be cropped or cultivated by any method known to those of skill in the art.
- a method of expressing at least one transgene in a plant comprises growing a plant comprising a Panicum virgatum (Pavir.J00490) egg cell gene promoter operably linked to at least one transgene or a polylinker sequence.
- a Panicum virgatum (Pavir.J00490) egg cell gene promoter consists of a sequence selected from SEQ ID NO: 1 or a sequence that has 98% or 99.5% sequence identity with a sequence selected from SEQ ID NO:1.
- a method of expressing at least one transgene in a plant comprising growing a plant comprising a Panicum virgatum (Pavir.J00490) egg cell gene gene promoter operably linked to at least one transgene.
- a method of expressing at least one transgene in a plant tissue or plant cell comprising culturing a plant tissue or plant cell comprising a Panicum virgatum (Pavir.J00490) egg cell gene promoter operably linked to at least one transgene.
- a method of expressing at least one transgene in a plant comprises growing a plant comprising a gene expression cassette comprising a Panicum virgatum (Pavir.J00490) egg cell gene promoter operably linked to at least one transgene.
- the Panicum virgatum (Pavir.J00490) egg cell gene promoter consists of a sequence selected from SEQ ID NO: 1 or a sequence that has 98% or 99.5% sequence identity with a sequence selected from SEQ ID NO: 1.
- a method of expressing at least one transgene in a plant comprises growing a plant comprising a gene expression cassette comprising a Panicum virgatum (Pavir.J00490) egg cell gene promoter operably linked to at least one transgene.
- a method of expressing at least one transgene in a plant comprises growing a plant comprising a gene expression cassette comprising a Panicum virgatum (Pavir.J00490) egg cell gene promoter operably linked to at least one transgene.
- a method of expressing at least one transgene in a plant tissue or plant cell comprises culturing a plant tissue or plant cell comprising a gene expression cassette containing a Panicum virgatum (Pavir.J00490) egg cell gene promoter operably linked to at least one transgene.
- a method of expressing at least one transgene in a plant tissue or plant cell comprises culturing a plant tissue or plant cell comprising a gene expression cassette, a Panicum virgatum (Pavir.J00490) egg cell gene promoter operably linked to at least one transgene.
- a method of expressing at least one transgene in a plant comprises growing a plant comprising a Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR operably linked to at least one transgene or a polylinker sequence.
- the Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR consists of a sequence selected from SEQ ID NO:7 or a sequence that has 80%, 85%, 90%, 95% or 99.5% sequence identity with a sequence selected from SEQ ID NO:7.
- a method of expressing at least one transgene in a plant comprising growing a plant comprising a Panicum virgatum (Pavir.J00490) egg cell gene gene 5' UTR operably linked to at least one transgene.
- a method of expressing at least one transgene in a plant tissue or plant cell comprising culturing a plant tissue or plant cell comprising a Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR operably linked to at least one transgene.
- a method of expressing at least one transgene in a plant comprises growing a plant comprising a gene expression cassette comprising a Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR operably linked to at least one transgene.
- the Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR consists of a sequence selected from SEQ ID NO:7 or a sequence that has 80%, 85%, 90%, 95% or 99.5% sequence identity with a sequence selected from SEQ ID NO:7.
- a method of expressing at least one transgene in a plant comprises growing a plant comprising a gene expression cassette comprising a Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR operably linked to at least one transgene.
- a method of expressing at least one transgene in a plant comprises growing a plant comprising a gene expression cassette comprising a Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR operably linked to at least one transgene.
- a method of expressing at least one transgene in a plant tissue or plant cell comprises culturing a plant tissue or plant cell comprising a gene expression cassette containing a Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR operably linked to at least one transgene.
- a method of expressing at least one transgene in a plant tissue or plant cell comprises culturing a plant tissue or plant cell comprising a gene expression cassette, a Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR operably linked to at least one transgene.
- a method of expressing at least one transgene in a plant comprises growing a plant comprising a Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR operably linked to at least one transgene or a polylinker sequence.
- the Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR consists of a sequence selected from SEQ ID NO:2 or a sequence that has 80%, 85%, 90%, 95% or 99.5% sequence identity with a sequence selected from SEQ ID NO:2.
- a method of expressing at least one transgene in a plant comprising growing a plant comprising a Panicum virgatum (Pavir.J00490) egg cell gene gene 3' UTR operably linked to at least one transgene.
- a method of expressing at least one transgene in a plant tissue or plant cell comprising culturing a plant tissue or plant cell comprising a Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR operably linked to at least one transgene.
- a method of expressing at least one transgene in a plant comprises growing a plant comprising a gene expression cassette comprising a Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR operably linked to at least one transgene.
- the Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR consists of a sequence selected from SEQ ID NO:2 or a sequence that has 80%, 85%, 90%, 95% or 99.5% sequence identity with a sequence selected from SEQ ID NO:2.
- a method of expressing at least one transgene in a plant comprises growing a plant comprising a gene expression cassette comprising a Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR operably linked to at least one transgene.
- a method of expressing at least one transgene in a plant comprises growing a plant comprising a gene expression cassette comprising a Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR operably linked to at least one transgene.
- a method of expressing at least one transgene in a plant tissue or plant cell comprises culturing a plant tissue or plant cell comprising a gene expression cassette containing a Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR operably linked to at least one transgene.
- a method of expressing at least one transgene in a plant tissue or plant cell comprises culturing a plant tissue or plant cell comprising a gene expression cassette, a Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR operably linked to at least one transgene.
- Example 1 Novel Design of a Combination of Optimized Regulatory Elements from Panicum virgatum (Pavir.J00490) egg cell Gene
- the promoter from a Panicum virgatum (Pavir.J00490) egg cell gene (SEQ ID NO:1) and a 3' UTR from a Panicum virgatum (Pavir.J00490) egg cell gene (SEQ ID NO:2) was identified from the Panicum virgatum genomic DNA (gDNA) sequence.
- These regulatory element sequences were identified by BLASTing the Phytozome database ( Goodstein DM, Shu S, Howson R, Neupane R, Hayes RD, Fazo J, Mitros T, Dirks W, Hellsten U, Putnam N, Rokhsar DS (2012) Nucleic Acids Res.
- the in silico analyses included the identification of polynucleotide sequences from any other surrounding genes as needed, checking for the presence of repetitive sequences that could result in silencing of gene expression, or the presence of 5' UTRs that may contain noncoding exons and introns. Based on these analyses, the Panicum virgatum (Pavir.J00490) egg cell promoter sequences were synthesized and moved forward for additional usage to drive expression of a transgene. From the assessment of the contiguous chromosomal sequence that spanned millions of base pairs, a 1,290 bp polynucleotide sequence (SEQ ID NO:1) was identified and isolated for use in expression of heterologous coding sequences.
- SEQ ID NO:1 1,290 bp polynucleotide sequence
- This novel polynucleotide sequence was analyzed for use as a regulatory sequence to drive expression of a gene and is provided in the base pairs 1-1,290 of SEQ ID NO:3. Likewise, from the assessment of the contiguous chromosomal sequence that spanned millions of base pairs, a 67 bp polynucleotide sequence (SEQ ID NO:7) was identified and isolated for use in terminating of heterologous coding sequences. This novel polynucleotide sequence was analyzed for use as a regulatory sequence as a 5' UTR to drive expression of a gene and is provided in the base pairs 1,291-1,357 of SEQ ID NO:3.
- SEQ ID NO:2 a 942 bp polynucleotide sequence (SEQ ID NO:2) was identified and isolated for use in terminating of heterologous coding sequences.
- This novel polynucleotide sequence was analyzed for use as a regulatory sequence to terminate expression of a gene and is provided in the base pairs 1,941-2,882 of SEQ ID NO:3.
- the pDAB 129556 vector was built to incorporate the novel combination of regulatory polynucleotide sequences flanking a transgene.
- the vector construct pDAB 129556 contained a gene expression cassette, in which the PhiYFP transgene was driven by the Panicum virgatum (Pavir.J00490) egg cell promoter of SEQ ID NO: 1 and containing the Panicum virgatum (Pavir.J00490) egg cell 5' UTR of SEQ ID NO:7 was flanked by Panicum virgatum (Pavir.J00490) egg cell 3' UTR of SEQ ID NO:2.
- a sequence listing of this gene expression cassette is provided as SEQ ID NO:4.
- the vector also contained a selectable marker gene expression cassette that contained the aad-1 transgene ( U.S. Patent No. 7,838,733 ) driven by the Oryza sativa Actin1 promoter ( U.S. Patent No. 5,641,876 ) and was terminated by the Zea mays Lipase 3' UTR ( U.S. Patent No. 7,179,902 ).
- a sequence listing of this gene expression cassette is provided as SEQ ID NO:5.
- This construct was built by synthesizing the newly designed promoter and 3' UTR from a Panicum virgatum (Pavir.J00490) egg cell gene and cloning the promoter into a GeneArt Seamless Cloning TM (Life Technologies) entry vector using a third party provider.
- the resulting entry vector was labeled as pDAB 129546 contained the Panicum virgatum (Pavir.J00490) egg cell gene promoter driving the PhiYFP transgene which was used for particle bombardment of Zea mays tissues.
- Clones of the entry vector, pDAB 129546, were obtained and plasmid DNA was isolated and confirmed via restriction enzyme digestions and sequencing.
- the pDAB 129546 entry vector was integrated into a destination vector using the Gateway TM cloning system (Life Technologies). Clones of the resulting binary plasmid, pDAB 129556, were obtained and plasmid DNA was isolated and confirmed via restriction enzyme digestions and sequencing. The resulting constructs contained a combination of regulatory elements that drive expression of a transgene and terminate expression of a transgene.
- the experimental pDAB 129546 construct was transformed into Zea mays c.v. B104 via particle bombardment transformation of isolated immature embryos.
- Zea mays c.v. B104 immature embryos were randomly isolated from eight ears with embryo size averaging from 1.8-2.4 mm.
- the immature embryos were collected in infection media and placed on osmolysis media for incubation under bright lights with a photon flux of 50uM and a temperature at 27°C overnight.
- the day after isolation 36 immature embryos per plate were arranged inside a target circle and were used for particle bombardment (PB).
- PB particle bombardment
- Gold particles were coated with 5 ⁇ l of DNA (of a 1.0 ⁇ g/ ⁇ l stock) using a CaC12 /spermidine precipitation.
- the parameters used for bombardment were: 1.0 micron gold particles, 1100 psi rupture discs, 27 inches Hg vacuum, and 6 cm bombardment distance.
- novel Panicum virgatum (Pavir.J00490) egg cell gene regulatory elements (the Panicum virgatum (Pavir.J00490) egg cell promoter of SEQ ID NO: 1, the Panicum virgatum (Pavir.J00490) egg cell 5' UTR of SEQ ID NO:7 and the Panicum virgatum (Pavir.J00490) egg cell 3' UTR of SEQ ID NO:2) were identified and characterized.
- novel promoter regulatory elements for use in gene expression constructs.
- FAM 6-Carboxy Fluorescein Amidite
- the level of fluorescence generated for each reaction was analyzed using the Roche LightCycler ® 480 Real-Time PCR system according to the manufacturer's recommendations. Transgene copy number was determined by comparison of LightCycler ® 480 outputs of Target/Reference gene values for unknown samples to Target/Reference gene values of known copy number standards (1-Copy representing hemizygous plants, 2-Copy representing homozygous plants).
- Cp scores i.e., the point at which the florescence signal crosses the background threshold using the fit points algorithm (LightCycler ® software release 1.5), and the Relative Quant module (based on the ⁇ Ct method), were used to perform the analysis of real time PCR data.
- Table 1 List of forward and reverse nucleotide primer and fluorescent probes (synthesized by Applied Biosystems) used for gene of interest copy number and relative expression detection.
- AAD1_F SEQ ID NO:8 TGTTCGGTTCCCTCTACCAA
- AAD1_P AAD1_R SEQ ID NO:10 CAACATCCATCACCTTGACTGA
- phiYFP_F SEQ ID NO:11 CGTGTTGGGAAAGAACTTGGA
- phiYFP_P phiYFPR
- SEQ ID NO:13 CCGTGGTTGGCTTGGTCT
- Invertase_F SEQ ID NO:14 TGGCGGACGACGACTTGT
- Maize Reference Invertase Invertase_P Invertase_R SEQ ID NO:16 AAAGTTTGGAGGCTGCCGT
- Cullin_F SEQ ID NO:17 CTGCAACATCAATGCTAAGTTTGA
- Maize Reference cullin Cullin_P Cullin _R SEQ ID NO:19 AGCCTTTCGGATCCATTGAA
- Table 2 PCR mixture for DNA copy number analysis.
- Hydrolysis probe PCR is used for detecting the relative level of phiyfp transcript. Immature ear tissue samples containing unfertilized egg cell were collected. RNA is extracted with the KingFisher total RNA Kit (Thermo Scientific, Cat# 97020196). cDNA is made from ⁇ 500 ng of RNA with high capacity cDNA synthesis kit (Invitrogen, Carlsbad, CA, CAT#: 4368814) using random primer (TVN oligo-SEQ ID NO:20 : TTTTTTTTTTTTTTTTVN) in a 20 ⁇ L reaction containing 2.5 units/ ⁇ l of MultiScribe reverse transcriptase, 200 nM of TVN oligo and 4 mM of dNTP. The reaction is started with 10 minutes at 25°C for pre-incubation, then 120 minutes for synthesis at 37°C and 5 minutes at 85 °C for inactivation.
- the newly synthesized cDNA is then used for amplification.
- qPCR set up, running conditions and signal capture are the same as for DNA copy number analysis except Cullin is used as the reference gene for corn.
- GOI expression data is calculated using 2 - ⁇ Ct relative to the level of Cullin.
- Example 7 Microscopic analysis of egg cell-specific promoter expression patterns in unfertilized maize ovules
- T0 maize transgenic plants containing egg cell-specific promoter construct pDAB129557 were grown in greenhouse. Wild type plants were grown in the same greenhouse. The plants were detasseled and immature ear were harvested during different development stages from silk emergence to the stage when silk length was 7cm. The surrounding husk leaves were removed from the ears, and cut into sections of 6-8 kernels. These sections were attached kernel-side up to a sample stage with cyanoacrylate glue and sectioned at 250 microns thick on a Leica VT1200 vibratome. These sections were mounted on glass slides in a drop of water and examined on a Leica DM5000 upright compound microscope and images were captured with a Leica DFC T7000 digital camera using a YFP filter set.
- Kernel sections from transgenic line pDAB129559 showed YFP-expressing cells/tissue in the embryo sac. No YFP fluorescence was observed from the embryo sac of the kernels obtained from non-transgenic control plant.
- novel Panicum virgatum (Pavir.J00490) egg cell gene regulatory elements (the Panicum virgatum (Pavir.J00490) egg cell promoter of SEQ ID NO: 1, the Panicum virgatum (Pavir.J00490) egg cell 5' UTR of SEQ ID NO:7 and the Panicum virgatum (Pavir.J00490) egg cell 3' UTR of SEQ ID NO:2) were identified and characterized.
- novel promoter regulatory elements for use in gene expression constructs.
- Example 8 Microscopic and transcript abundance analysis of egg cell-specific promoter expression patterns in fertilized maize ovules
- T0 maize transgenic plants containing egg cell-specific promoter construct pDAB129556 were grown in greenhouse. Wild type plants were grown in the same greenhouse. The plants were detasseled and ear were cross pollinated using pollen from non-transgenic maize plants. The fertilized ears were harvested 4 days after pollination. The surrounding husk leaves were removed from the ears, and cut into sections of 6-8 kernels. These sections were attached kernel-side up to a sample stage with cyanoacrylate glue and sectioned at 250 microns thick on a Leica VT1200 vibratome. These sections were mounted on glass slides in a drop of water and examined on a Leica DM5000 upright compound microscope and images were captured with a Leica DFC T7000 digital camera using a YFP filter set.
- novel Panicum virgatum (Pavir.J00490) egg cell gene regulatory elements (the Panicum virgatum (Pavir.J00490) egg cell promoter of SEQ ID NO: 1, the Panicum virgatum (Pavir.J00490) egg cell 5' UTR of SEQ ID NO:7 and the Panicum virgatum (Pavir.J00490) egg cell 3' UTR of SEQ ID NO:2) were identified and characterized.
- novel promoter regulatory elements for use in gene expression constructs.
- Example 9 Agrobacterium-mediated Transformation of Genes Operably Linked to the Panicum virgatum (Pavir.J00490) egg cell Promoter, the Panicum virgatum (Pavir.J00490) egg cell 5' UTR and/or Panicum virgatum (Pavir.J00490) egg cell 3' UTR
- Soybean may be transformed with genes operably linked to the Panicum virgatum (Pavir.J00490) egg cell promoter, the Panicum virgatum (Pavir.J00490) egg cell 5' UTR and/or Panicum virgatum (Pavir.J00490) egg cell 3' UTR by utilizing the same techniques previously described in Example #11 or Example #13 of patent application WO 2007/053482 .
- Cotton may be transformed with genes operably linked to the Panicum virgatum (Pavir.J00490) egg cell promoter, the Panicum virgatum (Pavir.J00490) egg cell 5' UTR and/or Panicum virgatum (Pavir.J00490) egg cell 3' UTR by utilizing the same techniques previously described in Examples #14 of U.S. Patent No. 7,838,733 or Example #12 of patent application WO 2007/053482 (Wright et al. ) .
- Canola may be transformed with genes operably linked to the Panicum virgatum (Pavir.J00490) egg cell promoter, the Panicum virgatum (Pavir.J00490) egg cell 5' UTR and/or Panicum virgatum (Pavir.J00490) egg cell 3' UTR by utilizing the same techniques previously described in Example #26 of U.S. Patent No. 7,838,733 or Example #22 of patent application WO 2007/053482 (Wright et al. ).
- Wheat may be transformed with genes operably linked to the Panicum virgatum (Pavir.J00490) egg cell promoter, the Panicum virgatum (Pavir.J00490) egg cell 5' UTR and/or Panicum virgatum (Pavir.J00490) egg cell 3' UTR by utilizing the same techniques previously described in Example #23 of patent application WO 2013/116700A1 (Lira et al. ).
- Rice may be transformed with genes operably linked to the Panicum virgatum (Pavir.J00490) egg cell promoter, the Panicum virgatum (Pavir.J00490) egg cell 5' UTR and/or Panicum virgatum (Pavir.J00490) egg cell 3' UTR by utilizing the same techniques previously described in Example #19 of patent application WO 2013/116700A1 (Lira et al. ).
- Example 10 Agrobacterium-mediated Transformation of Genes Operably Linked to the Panicum virgatum (Pavir.J00490) egg cell Regulatory Elements
- additional crops can be transformed according to embodiments of the subject disclosure using techniques that are known in the art.
- Agrobacterium-mediated transformation of rye see, e.g., Popelka JC, Xu J, Altpeter F., "Generation of rye with low transgene copy number after biolistic gene transfer and production of (Secale cereale L.) plants instantly marker-free transgenic rye," Transgenic Res. 2003 Oct;12(5):587-96 .).
- Agrobacterium-mediated transformation of sorghum see, e.g., Zhao et al., "Agrobacterium-mediated sorghum transformation," Plant Mol Biol. 2000 Dec;44(6):789-98 .
- Agrobacterium-mediated transformation of barley see, e.g., Tingay et al., "Agrobacterium tumefaciens-mediated barley transformation," The Plant Journal, (1997) 11: 1369-1376 .
- Agrobacterium-mediated transformation of wheat see, e.g., Cheng et al., “Genetic Transformation of Wheat Mediated by Agrobacterium tumefaciens," Plant Physiol. 1997 Nov;115(3):971-980 .
- Agrobacterium- mediated transformation of rice see, e.g., Hiei et al., "Transformation of rice mediated by Agrobacterium tumefaciens," Plant Mol. Biol. 1997 Sep;35(1-2):205-18 .
- Oats Avena sativa and strigosa ) , Peas ( Pisum , Vigna , and Tetragonolobus spp.), Sunflower ( Helianthus annuus ), Squash ( Cucurbita spp.), Cucumber ( Cucumis sativa ), Tobacco ( Nicotiana spp.), Arabidopsis ( Arabidopsis thaliana ), Turfgrass (Lolium, Agrostis, Poa, Cynodon, and other genera), Clover ( Trifolium ), Vetch ( Vicia ). Transformation of such plants, with genes operably linked to the 3' UTR of Panicum virgatum (Pavir.J00490) egg cell gene, for example, is contemplated in embodiments of the subject disclosure.
- Panicum virgatum (Pavir.J00490) egg cell promoter Use of the Panicum virgatum (Pavir.J00490) egg cell promoter, the Panicum virgatum (Pavir.J00490) egg cell 5' UTR and/or Panicum virgatum (Pavir.J00490) egg cell 3' UTR to drive operably linked genes can be deployed in many deciduous and evergreen timber species. Such applications are also within the scope of embodiments of this disclosure.
- alder Alnus spp.
- ash Fraxinus spp.
- aspen and poplar species Populus spp.
- beech Fagus spp.
- birch Betula spp.
- cherry Prunus spp.
- eucalyptus Eucalyptus spp.
- hickory Carya spp.
- maple Acer spp.
- oak Quercus spp.
- pine Pinus spp.
- Panicum virgatum (Pavir.J00490) egg cell promoter Use of Panicum virgatum (Pavir.J00490) egg cell promoter, the Panicum virgatum (Pavir.J00490) egg cell 5' UTR and/or Panicum virgatum (Pavir.J00490) egg cell 3' UTR to drive operably linked genes can be deployed in ornamental and fruit-bearing species. Such applications are also within the scope of embodiments of this disclosure.
- Examples include, but are not limited to; rose ( Rosa spp.), burning bush ( Euonymus spp.), petunia ( Petunia spp.), begonia ( Begonia spp.), rhododendron ( Rhododendron spp.), crabapple or apple ( Malus spp.), pear ( Pyrus spp.), peach ( Prunus spp.), and marigolds ( Tagetes spp.).
Landscapes
- Health & Medical Sciences (AREA)
- Genetics & Genomics (AREA)
- Engineering & Computer Science (AREA)
- Life Sciences & Earth Sciences (AREA)
- Biomedical Technology (AREA)
- Biotechnology (AREA)
- Organic Chemistry (AREA)
- Chemical & Material Sciences (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Engineering & Computer Science (AREA)
- Molecular Biology (AREA)
- Biochemistry (AREA)
- Plant Pathology (AREA)
- Microbiology (AREA)
- Physics & Mathematics (AREA)
- Cell Biology (AREA)
- General Health & Medical Sciences (AREA)
- Biophysics (AREA)
- Reproductive Health (AREA)
- Pregnancy & Childbirth (AREA)
- Developmental Biology & Embryology (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Breeding Of Plants And Reproduction By Means Of Culturing (AREA)
- Insects & Arthropods (AREA)
- Pest Control & Pesticides (AREA)
Description
- The present invention refers to a nucleic acid vector construct including a promoter with ambryonic cell preferred expression suitable for preparing transgenic plants, as well to transgenic plants comprising said promoter operably linked to a heterologous coding sequence.
- Many plant species are capable of being transformed with transgenes to introduce agronomically desirable traits or characteristics. The resulting plant species are developed and/or modified to have particular desirable traits. Generally, desirable traits include, for example, improving nutritional value quality, increasing yield, conferring pest or disease resistance, increasing drought and stress tolerance, improving horticultural qualities (e.g., pigmentation and growth), imparting herbicide tolerance, enabling the production of industrially useful compounds and/or materials from the plant, and/or enabling the production of pharmaceuticals.
- Transgenic plant species comprising multiple transgenes stacked at a single genomic locus are produced via plant transformation technologies. Plant transformation technologies result in the introduction of a transgene into a plant cell, recovery of a fertile transgenic plant that contains the stably integrated copy of the transgene in the plant genome, and subsequent transgene expression via transcription and translation results in transgenic plants that possess desirable traits and phenotypes. However, novel gene regulatory elements that allow the production of transgenic plant species to highly express multiple transgenes engineered as a trait stack are desirable.
- Likewise, novel gene regulatory elements that allow the expression of a transgene within particular tissues or organs of a plant are desirable. For example, increased resistance of a plant to infection by soil-borne pathogens might be accomplished by transforming the plant genome with a pathogen-resistance gene such that pathogen-resistance protein is robustly expressed within the roots of the plant. Alternatively, it may be desirable to express a transgene in plant tissues that are in a particular growth or developmental phase such as, for example, cell division or elongation. Furthermore, it may be desirable to express a transgene in leaf and stem tissues of a plant to provide tolerance against herbicides, or resistance against above ground insects and pests.
- Therefore, a need exists for new gene regulatory elements that can drive the desired levels of expression of transgenes in specific plant tissues.
- The invention refers to the subject matter as defined in the claims. In embodiments of the subject disclosure, the disclosure relates to a nucleic acid vector comprising a promoter operably linked to: a) a polylinker sequence; b) a non-Panicum virgatum (Pavir.J00490) egg cell heterologous gene; or c) a combination of a) and b), wherein said promoter comprises a polynucleotide sequence that has at least 98% sequence identity with SEQ ID NO:1, further the nucleic acid vector comprises a 3' untranslated polynucleic acid sequence and said promoter has embryonic cell preferred expression. In an aspect of this embodiment, the promoter is 1,290 bp in length. In further aspects, the promoter consists of a polynucleotide sequence that has at least 98% sequence identity with SEQ ID NO:1. In another aspect, the promoter comprises a sequence encoding a selectable maker. In yet another aspect, the promoter is operably linked to a transgene (heterologous coding sequence). In some instances the transgene encodes a selectable marker or a gene product conferring insecticidal resistance, herbicide tolerance, nitrogen use efficiency, water use efficiency, expression of an RNAi, or nutritional quality. In an additional aspect, the nucleic acid vector comprises a 5' untranslated polynucleotide sequence. In an additional aspect, the nucleic acid vector comprises an intron sequence. In additional aspects, a polynucleotide sequence that has at least 98% sequence identity with SEQ ID NO: 1 operably linked to a transgene.
- In yet another embodiment, the subject disclosure relates to a transgenic plant comprising the nucleic acid vector. In an aspect, the plant is selected from the group consisting of Zea mays, wheat, rice, sorghum, oats, rye, bananas, sugar cane, soybean, cotton, Arabidopsis, tobacco, sunflower, and canola. In further aspects, the transgene is inserted into the genome of said plant. In another aspect, the transgenic plant includes a promoter that comprises a polynucleotide sequence having at least 98% sequence identity with SEQ ID NO:1 and said promoter is operably linked to a transgene. In further aspects, the transgenic plant comprises a 3' untranslated sequence. In other aspects, the transgenic promoter drives embryonic cell tissue specific expression of a transgene in the transgenic plant. In yet another aspect, the transgenic plant comprises a promoter that is 1,290 bp in length.
- In the subject disclosure a method for producing a transgenic plant is described. The disclosure relates to a method for producing a transgenic plant cell, the method comprising the steps of: a) transforming a plant cell with a gene expression cassette comprising a Panicum virgatum (Pavir.J00490) egg cell promoter operably linked to at least one polynucleotide sequence of interest; b) isolating the transformed plant cell comprising the gene expression cassette; and, c) producing a transgenic plant cell comprising the Panicum virgatum (Pavir.J00490) egg cell promoter operably linked to at least one polynucleotide sequence of interest. In an aspect, the transforming of a plant cell is performed with a plant transformation method. These transformation methods can include a plant transformation method is selected from the group consisting of an Agrobacterium-mediated transformation method, a biolistics transformation method, a silicon carbide transformation method, a protoplast transformation method, and a liposome transformation method. In further aspects, the polynucleotide sequence of interest is expressed in a plant cell. In other aspects, the polynucleotide sequence of interest is stably integrated into the genome of the transgenic plant cell. In additional aspects, the method further comprising the steps of: d) regenerating the transgenic plant cell into a transgenic plant; and, e) obtaining the transgenic plant, wherein the transgenic plant comprises the gene expression cassette comprising the Panicum virgatum (Pavir.J00490) egg cell promoter of claim 1 operably linked to at least one polynucleotide sequence of interest. In a further aspect, the transgenic plant cell is a monocotyledonous transgenic plant cell or a dicotyledonous transgenic plant cell. Accordingly, the dicotyledonous transgenic plant cell may include Arabidopsis plant cell, a tobacco plant cell, a soybean plant cell, a canola plant cell, and a cotton plant cell. Likewise, the monocotyledonous transgenic plant cell can include a Zea mays plant cell, a rice plant cell, and a wheat plant cell. In another aspect, the Panicum virgatum (Pavir.J00490) egg cell promoter comprises the polynucleotide of SEQ ID NO:1. In subsequent aspects, first polynucleotide sequence of interest operably linked to the 3' end of SEQ ID NO: 1. In additional aspects, the method comprises introducing into the plant cell a polynucleotide sequence of interest operably linked to a Panicum virgatum (Pavir.J00490) egg cell promoter. In further aspects, the polynucleotide sequence of interest operably linked to the Panicum virgatum (Pavir.J00490) egg cell promoter is introduced into the plant cell by a plant transformation method. Examples of such a plant transformation method include Agrobacterium-mediated transformation method, a biolistics transformation method, a silicon carbide transformation method, a protoplast transformation method, and a liposome transformation method. In further aspects, the polynucleotide sequence of interest is expressed in embryonic cell tissue. In additional aspects, the polynucleotide sequence of interest is stably integrated into the genome of the plant cell. In yet another aspect, the transgenic plant cell is a monocotyledonous plant cell or a dicotyledonous plant cell. Exemplary dicotyledonous plant cells include an Arabidopsis plant cell, a tobacco plant cell, a soybean plant cell, a canola plant cell, and a cotton plant cell. Likewise, exemplary monocotyledonous plant cells include a Zea mays plant cell, a rice plant cell, and a wheat plant cell.
- In embodiments of the subject disclosure, the disclosure relates to a transgenic plant cell comprising a Panicum virgatum (Pavir.J00490) egg cell promoter. In an aspect, the transgenic plant cell comprises a transgenic event. In further aspects, the transgenic event comprises an agronomic trait. Such agronomic traits can include an insecticidal resistance trait, herbicide tolerance trait, nitrogen use efficiency trait, water use efficiency trait, nutritional quality trait, DNA binding trait, selectable marker trait, small RNA trait, or any combination thereof. For example, an herbicide tolerant trait may comprise the aad-1 coding sequence. In a subsequent aspect, the transgenic plant cell produces a commodity product. Such commodity products can include protein concentrate, protein isolate, grain, meal, flour, oil, or fiber. In other aspects, the transgenic plant cell is selected from the group consisting of a dicotyledonous plant cell or a monocotyledonous plant cell. Exemplary dicotyledonous plant cells include an Arabidopsis plant cell, a tobacco plant cell, a soybean plant cell, a canola plant cell, and a cotton plant cell. Likewise, exemplary monocotyledonous plant cells include a Zea mays plant cell, a rice plant cell, and a wheat plant cell. In an aspect the Panicum virgatum (Pavir.J00490) egg cell promoter comprises a polynucleotide with at least 98% sequence identity to the polynucleotide of SEQ ID NO:1. In subsequent aspects, the Panicum virgatum (Pavir.J00490) egg cell promoter is 1,290 bp in length. In further aspects, the Panicum virgatum (Pavir.J00490) egg cell promoter consists of SEQ ID NO:1. In yet another aspect, the first polynucleotide sequence of interest is operably linked to the 3' end of SEQ ID NO: 1. In subsequent aspects, the agronomic trait is expressed in embryonic cell tissue.
- The disclosure relates to an isolated polynucleotide comprising a nucleic acid sequence with at least 98% sequence identity to the polynucleotide of SEQ ID NO:1. In an aspect, the isolated polynucleotide is specifically expressed in embryonic cell tissue. In another aspect, the isolated polynucleotide is expressed within a plant cell. In other aspects, the isolated polynucleotide comprises an open-reading frame polynucleotide coding for a polypeptide and a termination sequence. In an aspect the polynucleotide of SEQ ID NO: 1 is 1,290 bp in length.
- The disclosure relates to a gene expression cassette comprising a promoter operably linked to a heterologous coding sequence, wherein the promoter comprises a polynucleotide comprising a sequence identity of at least 98% to SEQ ID NO:1. In some embodiments, the polynucleotide has at least 98% sequence identity to SEQ ID NO:1. In additional embodiments, the gene expression cassette comprises an intron. In further embodiments, the gene expression cassette comprises a 5' UTR. In subsequent embodiments, the promoter has tissue preferred expression. In other embodiments, the promoter is operably linked to a heterologous coding sequence that encodes a polypeptide or a small RNA gene. Examples of the encoded polypeptide or small RNA gene include a heterologous coding sequence conferring insecticidal resistance, herbicide tolerance, a nucleic acid conferring nitrogen use efficiency, a nucleic acid conferring water use efficiency, a nucleic acid conferring nutritional quality, a nucleic acid encoding a DNA binding protein, and a nucleic acid encoding a selectable marker. In additional embodiments, the gene expression cassette comprises a 3' untranslated region. In additional embodiments, the gene expression cassette comprises a 5' untranslated region. In additional embodiments, the gene expression cassette comprises a terminator region In other embodiments the subject disclosure relates to a recombinant vector comprising the gene expression cassette, wherein the vector is selected from the group consisting of a plasmid, a cosmid, a bacterial artificial chromosome, a virus, and a bacteriophage. In other embodiments the subject disclosure relates to a transgenic cell comprising the gene expression cassette. In an aspect of this embodiment, the transgenic cell is a transgenic plant cell. In other aspects of this embodiment the transgenic plant comprises the transgenic plant cell. In further aspects the transgenic plant is a monocotyledonous plant or dicotyledonous plant. Examples of a monocotyledonous plant is include a maize plant, a rice plant, and a wheat plant. In further aspects of the embodiment, the transgenic plant produces a seed comprising the gene expression cassette. In other embodiments, the promoter is a tissue preferred promoter. In some embodiments, the tissue preferred promoter is an embryonic cell preferred promoter.
- The foregoing and other features will become more apparent from the following detailed description of several embodiments. The scope of the invention is only defined by the appending claims.
- Development of transgenic plant products is becoming increasingly complex. Commercially viable transgenic plants now require the stacking of multiple transgenes into a single locus. Plant promoters and 3' UTRs used for basic research or biotechnological applications are generally unidirectional, directing only one gene that has been fused at its 3' end (downstream) for the promoter, or at its 5' end (upstream) for the 3' UTR. Accordingly, each transgene/heterologous coding sequence usually requires a promoter and 3' UTR for expression, wherein multiple regulatory elements are required to express multiple transgenes/heterologous coding sequences within one gene stack. With an increasing number of transgenes/heterologous coding sequences in gene stacks, the same promoter and/or 3' UTR is routinely used to obtain optimal levels of expression patterns of different transgenes/heterologous coding sequences. Obtaining optimal levels of transgene expression is necessary for the production of a single polygenic trait. Unfortunately, multi-gene constructs driven by the same promoter and/or 3' UTR are known to cause gene silencing resulting in less efficacious transgenic products in the field. The repeated promoter and/or 3' UTR elements may lead to homology-based gene silencing. In addition, repetitive sequences within a transgene may lead to gene intra locus homologous recombination resulting in polynucleotide rearrangements. The silencing and rearrangement of transgenes will likely have an undesirable affect on the performance of a transgenic plant produced to express transgenes. Further, excess of transcription factor (TF)-binding sites due to promoter repetition can cause depletion of endogenous TFs leading to transcriptional inactivation. Given the need to introduce multiple genes into plants for metabolic engineering and trait stacking, a variety of promoters and/or 3' UTRs are required to develop transgenic crops that drive the expression of multiple genes/heterologous coding sequences.
- A particular problem in promoter and/or 3' UTR identification is the need to identify tissue-specific promoters, related to specific cell types, developmental stages and/or functions in the plant that are not expressed in other plant tissues. Tissue specific (i.e., tissue preferred) or organ specific promoters drive gene expression in a certain tissue such as in the kernel, root, leaf, or tapetum of the plant. Tissue and developmental stage specific promoters and/or 3' UTRs can be initially identified from observing the expression of genes/heterologous coding sequences, which are expressed in particular tissues or at particular time periods during plant development. These tissue specific/preferred promoters and/or 3' UTRs are required for certain applications in the transgenic plant industry and are desirable as they permit specific expression of heterologous genes in a tissue and/or developmental stage selective manner, indicating expression of the heterologous gene differentially at various organs, tissues and/or times, but not in other undesirable tissues. For example, increased resistance of a plant to infection by soil-borne pathogens might be accomplished by transforming the plant genome with a pathogen-resistance gene such that pathogen-resistance protein is robustly expressed within the roots of the plant. Alternatively, it may be desirable to express a transgene/heterologous coding sequence in plant tissues that are in a particular growth or developmental phase such as, for example, cell division or elongation. Another application is the desirability of using tissue specific/preferred promoters and/or 3' UTRs to confine the expression of the transgenes/heterologous coding sequences encoding an agronomic trait in specific tissues types like developing parenchyma cells. As such, a particular problem in the identification of promoters and/or 3' UTRs is how to identify the promoters, and to relate the identified promoter to developmental properties of the cell for specific/preferred tissue expression.
- Another problem regarding the identification of a promoter is the requirement to clone all relevant cis-acting and trans-activating transcriptional control elements so that the cloned DNA fragment drives transcription in the wanted specific expression pattern. Given that such control elements are located distally from the translation initiation or start site, the size of the polynucleotide that is selected to comprise the promoter is of importance for providing the level of expression and the expression patterns of the promoter polynucleotide sequence. It is known that promoter lengths include functional information, and different genes have been shown to have promoters longer or shorter than promoters of the other genes in the genome. Elucidating the transcription start site of a promoter and predicting the functional gene elements in the promoter region is challenging. Further adding to the challenge are the complexity, diversity and inherent degenerate nature of regulatory motifs and cis- and trans-regulatory elements (Blanchette, Mathieu, et al. "Genome-wide computational prediction of transcriptional regulatory modules reveals new insights into human gene expression." Genome research 16.5 (2006): 656-668). The cis- and trans-regulatory elements are located in the distal parts of the promoter which regulate the spatial and temporal expression of a gene/heterologous coding sequence to occur only at required sites and at specific times (Porto, Milena Silva, et al. "Plant promoters: an approach of structure and function." Molecular biotechnology 56.1 (2014): 38-49). Accordingly, the identification of promoter regulatory elements requires that an appropriate sequence of a specific size containing the necessary cis- and trans-regulatory elements is obtained that will result in driving expression of an operably linked transgene/heterologous coding sequence in a desirable manner.
- Provided are methods and compositions for overcoming such problems through the use of Panicum virgatum (Pavir.J00490) egg cell gene regulatory elements to express transgenes/heterologous coding sequences in planta.
- Throughout the application, a number of terms are used. In order to provide a clear and consistent understanding of the specification and claims, including the scope to be given such terms, the following definitions are provided.
- As used herein, the term "intron" refers to any nucleic acid sequence comprised in a gene (or expressed polynucleotide sequence of interest) that is transcribed but not translated. Introns include untranslated nucleic acid sequence within an expressed sequence of DNA, as well as the corresponding sequence in RNA molecules transcribed therefrom. A construct described herein can also contain sequences that enhance translation and/or mRNA stability such as introns. An example of one such intron is the first intron of gene II of the histone H3 variant of Arabidopsis thaliana or any other commonly known intron sequence. Introns can be used in combination with a promoter sequence to enhance translation and/or mRNA stability.
- The term "isolated", as used herein means having been removed from its natural environment, or removed from other compounds present when the compound is first formed. The term "isolated" embraces materials isolated from natural sources as well as materials (e.g., nucleic acids and proteins) recovered after preparation by recombinant expression in a host cell, or chemically-synthesized compounds such as nucleic acid molecules, proteins, and peptides.
- The term "purified", as used herein relates to the isolation of a molecule or compound in a form that is substantially free of contaminants normally associated with the molecule or compound in a native or natural environment, or substantially enriched in concentration relative to other compounds present when the compound is first formed, and means having been increased in purity as a result of being separated from other components of the original composition. The term "purified nucleic acid" is used herein to describe a nucleic acid sequence which has been separated, produced apart from, or purified away from other biological compounds including, but not limited to polypeptides, lipids and carbohydrates, while effecting a chemical or functional change in the component (e.g., a nucleic acid may be purified from a chromosome by removing protein contaminants and breaking chemical bonds connecting the nucleic acid to the remaining DNA in the chromosome).
- The term "synthetic", as used herein refers to a polynucleotide (i.e., a DNA or RNA) molecule that was created via chemical synthesis as an in vitro process. For example, a synthetic DNA may be created during a reaction within an Eppendorf™ tube, such that the synthetic DNA is enzymatically produced from a native strand of DNA or RNA. Other laboratory methods may be utilized to synthesize a polynucleotide sequence. Oligonucleotides may be chemically synthesized on an oligo synthesizer via solid-phase synthesis using phosphoramidites. The synthesized oligonucleotides may be annealed to one another as a complex, thereby producing a "synthetic" polynucleotide. Other methods for chemically synthesizing a polynucleotide are known in the art, and can be readily implemented for use in the present disclosure.
- The term "about" as used herein means greater or lesser than the value or range of values stated by 10 percent, but is not intended to designate any value or range of values to only this broader definition. Each value or range of values preceded by the term "about" is also intended to encompass the embodiment of the stated absolute value or range of values.
- For the purposes of the present disclosure, a "gene," includes a DNA region encoding a gene product (see infra), as well as all DNA regions which regulate the production of the gene product, whether or not such regulatory sequences are adjacent to coding and/or transcribed sequences. Accordingly, a gene includes, but is not necessarily limited to, promoter sequences, terminators, translational regulatory sequences such as ribosome binding sites and internal ribosome entry sites, enhancers, silencers, insulators, boundary elements, replication origins, matrix attachment sites, introns and locus control regions.
- As used herein the terms "native" or "natural" define a condition found in nature. A "native DNA sequence" is a DNA sequence present in nature that was produced by natural means or traditional breeding techniques but not generated by genetic engineering (e.g., using molecular biology/transformation techniques).
- As used herein a "transgene" or "heterologous coding sequence" is defined to be a nucleic acid sequence that encodes a gene product, including for example, but not limited to, an mRNA. In one embodiment the transgene/heterologous coding sequence is an exogenous nucleic acid, where the transgene/heterologous coding sequence has been introduced into a host cell by genetic engineering (or the progeny thereof) where the transgene/heterologous coding sequence is not normally found. In one example, a transgene encodes an industrially or pharmaceutically useful compound, or a gene encoding a desirable agricultural trait (e.g., an herbicide-resistance gene). In yet another example, a transgene/heterologous coding sequence is an antisense nucleic acid sequence, wherein expression of the antisense nucleic acid sequence inhibits expression of a target nucleic acid sequence. In one embodiment the transgene/heterologous coding sequence is an endogenous nucleic acid, wherein additional genomic copies of the endogenous nucleic acid are desired, or a nucleic acid that is in the antisense orientation with respect to the sequence of a target nucleic acid in a host organism. As used herein, "heterologous coding sequence" means any coding sequence other than the one that naturally encodes the Zea mays egg cell gene, or any homolog of the expressed Zea mays egg cell protein. The term "heterologous" is used in the context of this invention for any combination of nucleic acid sequences that is not normally found intimately associated in nature.
- As used herein the term "non-Panicum virgatum (Pavir.J00490) egg cell transgene" or "non-Panicum virgatum (Pavir.J00490) egg cell gene" is any transgene that has less than 80% sequence identity with the Panicum virgatum (Pavir.J00490) egg cell gene coding sequence (SEQ ID NO:6 with the Phytozome Locus Name of Pavir.J00490 and Transcript Name of Pavir.J00490.1 (primary) that is located at contig00432:15569..16493 reverse.
- A "gene product" as defined herein is any product produced by the gene. For example the gene product can be the direct transcriptional product of a gene (e.g., mRNA, tRNA, rRNA, antisense RNA, interfering RNA, ribozyme, structural RNA or any other type of RNA) or a protein produced by translation of a mRNA. Gene products also include RNAs which are modified, by processes such as capping, polyadenylation, methylation, and editing, and proteins modified by, for example, methylation, acetylation, phosphorylation, ubiquitination, ADP-ribosylation, myristilation, and glycosylation. Gene expression can be influenced by external signals, for example, exposure of a cell, tissue, or organism to an agent that increases or decreases gene expression. Expression of a gene can also be regulated anywhere in the pathway from DNA to RNA to protein. Regulation of gene expression occurs, for example, through controls acting on transcription, translation, RNA transport and processing, degradation of intermediary molecules such as mRNA, or through activation, inactivation, compartmentalization, or degradation of specific protein molecules after they have been made, or by combinations thereof. Gene expression can be measured at the RNA level or the protein level by any method known in the art, including, without limitation, Northern blot, RT-PCR, Western blot, or in vitro, in situ, or in vivo protein activity assay(s).
- As used herein the term "gene expression" relates to the process by which the coded information of a nucleic acid transcriptional unit (including, e.g., genomic DNA) is converted into an operational, non-operational, or structural part of a cell, often including the synthesis of a protein. Gene expression can be influenced by external signals; for example, exposure of a cell, tissue, or organism to an agent that increases or decreases gene expression. Expression of a gene can also be regulated anywhere in the pathway from DNA to RNA to protein. Regulation of gene expression occurs, for example, through controls acting on transcription, translation, RNA transport and processing, degradation of intermediary molecules such as mRNA, or through activation, inactivation, compartmentalization, or degradation of specific protein molecules after they have been made, or by combinations thereof. Gene expression can be measured at the RNA level or the protein level by any method known in the art, including, without limitation, Northern blot, RT-PCR, Western blot, or in vitro, in situ, or in vivo protein activity assay(s).
- As used herein, "homology-based gene silencing" (HBGS) is a generic term that includes both transcriptional gene silencing and post-transcriptional gene silencing. Silencing of a target locus by an unlinked silencing locus can result from transcription inhibition (transcriptional gene silencing; TGS) or mRNA degradation (post-transcriptional gene silencing; PTGS), owing to the production of double-stranded RNA (dsRNA) corresponding to promoter or transcribed sequences, respectively. The involvement of distinct cellular components in each process suggests that dsRNA-induced TGS and PTGS likely result from the diversification of an ancient common mechanism. However, a strict comparison of TGS and PTGS has been difficult to achieve because it generally relies on the analysis of distinct silencing loci. In some instances, a single transgene locus can triggers both TGS and PTGS, owing to the production of dsRNA corresponding to promoter and transcribed sequences of different target genes. Mourrain et al. (2007) Planta 225:365-79. It is likely that siRNAs are the actual molecules that trigger TGS and PTGS on homologous sequences: the siRNAs would in this model trigger silencing and methylation of homologous sequences in cis and in trans through the spreading of methylation of transgene sequences into the endogenous promoter.
- As used herein, the term "nucleic acid molecule" (or "nucleic acid" or "polynucleotide") may refer to a polymeric form of nucleotides, which may include both sense and anti-sense strands of RNA, cDNA, genomic DNA, and synthetic forms and mixed polymers of the above. A nucleotide may refer to a ribonucleotide, deoxyribonucleotide, or a modified form of either type of nucleotide. A "nucleic acid molecule" as used herein is synonymous with "nucleic acid" and "polynucleotide". A nucleic acid molecule is usually at least 10 bases in length, unless otherwise specified. The term may refer to a molecule of RNA or DNA of indeterminate length. The term includes single- and double-stranded forms of DNA. A nucleic acid molecule may include either or both naturally-occurring and modified nucleotides linked together by naturally occurring and/or non-naturally occurring nucleotide linkages.
- Nucleic acid molecules may be modified chemically or biochemically, or may contain non-natural or derivatized nucleotide bases, as will be readily appreciated by those of skill in the art. Such modifications include, for example, labels, methylation, substitution of one or more of the naturally occurring nucleotides with an analog, internucleotide modifications (e.g., uncharged linkages: for example, methyl phosphonates, phosphotriesters, phosphoramidites, carbamates, etc.; charged linkages: for example, phosphorothioates, phosphorodithioates, etc.; pendent moieties: for example, peptides; intercalators: for example, acridine, psoralen, etc.; chelators; alkylators; and modified linkages: for example, alpha anomeric nucleic acids, etc.). The term "nucleic acid molecule" also includes any topological conformation, including single-stranded, double-stranded, partially duplexed, triplexed, hairpinned, circular, and padlocked conformations.
- Transcription proceeds in a 5' to 3' manner along a DNA strand. This means that RNA is made by the sequential addition of ribonucleotide-5'-triphosphates to the 3' terminus of the growing chain (with a requisite elimination of the pyrophosphate). In either a linear or circular nucleic acid molecule, discrete elements (e.g., particular nucleotide sequences) may be referred to as being "upstream" or "5' " relative to a further element if they are bonded or would be bonded to the same nucleic acid in the 5' direction from that element. Similarly, discrete elements may be "downstream" or "3"' relative to a further element if they are or would be bonded to the same nucleic acid in the 3' direction from that element.
- A base "position", as used herein, refers to the location of a given base or nucleotide residue within a designated nucleic acid. The designated nucleic acid may be defined by alignment (see below) with a reference nucleic acid.
- Hybridization relates to the binding of two polynucleotide strands via Hydrogen bonds. Oligonucleotides and their analogs hybridize by hydrogen bonding, which includes Watson-Crick, Hoogsteen or reversed Hoogsteen hydrogen bonding, between complementary bases. Generally, nucleic acid molecules consist of nitrogenous bases that are either pyrimidines (cytosine (C), uracil (U), and thymine (T)) or purines (adenine (A) and guanine (G)). These nitrogenous bases form hydrogen bonds between a pyrimidine and a purine, and the bonding of the pyrimidine to the purine is referred to as "base pairing." More specifically, A will hydrogen bond to T or U, and G will bond to C. "Complementary" refers to the base pairing that occurs between two distinct nucleic acid sequences or two distinct regions of the same nucleic acid sequence.
- "Specifically hybridizable" and "specifically complementary" are terms that indicate a sufficient degree of complementarity such that stable and specific binding occurs between the oligonucleotide and the DNA or RNA target. The oligonucleotide need not be 100% complementary to its target sequence to be specifically hybridizable. An oligonucleotide is specifically hybridizable when binding of the oligonucleotide to the target DNA or RNA molecule interferes with the normal function of the target DNA or RNA, and there is sufficient degree of complementarity to avoid nonspecific binding of the oligonucleotide to non-target sequences under conditions where specific binding is desired, for example under physiological conditions in the case of in vivo assays or systems. Such binding is referred to as specific hybridization.
- Hybridization conditions resulting in particular degrees of stringency will vary depending upon the nature of the chosen hybridization method and the composition and length of the hybridizing nucleic acid sequences. Generally, the temperature of hybridization and the ionic strength (especially the Na+ and/or Mg2+ concentration) of the hybridization buffer will contribute to the stringency of hybridization, though wash times also influence stringency. Calculations regarding hybridization conditions required for attaining particular degrees of stringency are discussed in Sambrook et al. (ed.), Molecular Cloning: A Laboratory Manual, 2nd ed., vol. 1-3, Cold Spring Harbor Laboratory Press, Cold Spring Harbor, New York, 1989, chs. 9 and 11.
- As used herein, "stringent conditions" encompass conditions under which hybridization will only occur if there is less than 50% mismatch between the hybridization molecule and the DNA target. "Stringent conditions" include further particular levels of stringency. Thus, as used herein, "moderate stringency" conditions are those under which molecules with more than 50% sequence mismatch will not hybridize; conditions of "high stringency" are those under which sequences with more than 20% mismatch will not hybridize; and conditions of "very high stringency" are those under which sequences with more than 10% mismatch will not hybridize.
- In particular embodiments, stringent conditions can include hybridization at 65°C, followed by washes at 65°C with 0.1x SSC/0.1% SDS for 40 minutes.
- The following are representative, non-limiting hybridization conditions:
- Very High Stringency: Hybridization in 5x SSC buffer at 65°C for 16 hours; wash twice in 2x SSC buffer at room temperature for 15 minutes each; and wash twice in 0.5x SSC buffer at 65°C for 20 minutes each.
- High Stringency: Hybridization in 5x-6x SSC buffer at 65-70°C for 16-20 hours; wash twice in 2x SSC buffer at room temperature for 5-20 minutes each; and wash twice in 1x SSC buffer at 55-70°C for 30 minutes each.
- Moderate Stringency: Hybridization in 6x SSC buffer at room temperature to 55°C for 16-20 hours; wash at least twice in 2x-3x SSC buffer at room temperature to 55°C for 20-30 minutes each.
- In particular embodiments, specifically hybridizable nucleic acid molecules can remain bound under very high stringency hybridization conditions. In these and further embodiments, specifically hybridizable nucleic acid molecules can remain bound under high stringency hybridization conditions. In these and further embodiments, specifically hybridizable nucleic acid molecules can remain bound under moderate stringency hybridization conditions.
- Oligonucleotide: An oligonucleotide is a short nucleic acid polymer. Oligonucleotides may be formed by cleavage of longer nucleic acid segments, or by polymerizing individual nucleotide precursors. Automated synthesizers allow the synthesis of oligonucleotides up to several hundred base pairs in length. Because oligonucleotides may bind to a complementary nucleotide sequence, they may be used as probes for detecting DNA or RNA. Oligonucleotides composed of DNA (oligodeoxyribonucleotides) may be used in PCR, a technique for the amplification of small DNA sequences. In PCR, the oligonucleotide is typically referred to as a "primer", which allows a DNA polymerase to extend the oligonucleotide and replicate the complementary strand.
- The terms "percent sequence identity" or "percent identity" or "identity" are used interchangeably to refer to a sequence comparison based on identical matches between correspondingly identical positions in the sequences being compared between two or more amino acid or nucleotide sequences. The percent identity refers to the extent to which two optimally aligned polynucleotide or peptide sequences are invariant throughout a window of alignment of components, e.g., nucleotides or amino acids. Hybridization experiments and mathematical algorithms known in the art may be used to determine percent identity. Many mathematical algorithms exist as sequence alignment computer programs known in the art that calculate percent identity. These programs may be categorized as either global sequence alignment programs or local sequence alignment programs.
- Global sequence alignment programs calculate the percent identity of two sequences by comparing alignments end-to-end in order to find exact matches, dividing the number of exact matches by the length of the shorter sequences, and then multiplying by 100. Basically, the percentage of identical nucleotides in a linear polynucleotide sequence of a reference ("query) polynucleotide molecule as compared to a test ("subject") polynucleotide molecule when the two sequences are optimally aligned (with appropriate nucleotide insertions, deletions, or gaps).
- Local sequence alignment programs are similar in their calculation, but only compare aligned fragments of the sequences rather than utilizing an end-to-end analysis. Local sequence alignment programs such as BLAST can be used to compare specific regions of two sequences. A BLAST comparison of two sequences results in an E-value, or expectation value, that represents the number of different alignments with scores equivalent to or better than the raw alignment score, S, that are expected to occur in a database search by chance. The lower the E value, the more significant the match. Because database size is an element in E-value calculations, E-values obtained by BLASTing against public databases, such as GENBANK, have generally increased over time for any given query/entry match. In setting criteria for confidence of polypeptide function prediction, a "high" BLAST match is considered herein as having an E-value for the top BLAST hit of less than 1E-30; a medium BLASTX E-value is 1E-30 to 1E-8; and a low BLASTX E-value is greater than 1E-8. The protein function assignment in the present invention is determined using combinations of E-values, percent identity, query coverage and hit coverage. Query coverage refers to the percent of the query sequence that is represented in the BLAST alignment. Hit coverage refers to the percent of the database entry that is represented in the BLAST alignment. In one embodiment of the invention, function of a query polypeptide is inferred from function of a protein homolog where either (1) hit_p<1e-30 or % identity >35% AND query_coverage >50% AND hit_coverage >50%, or (2) hit_p<le-8 AND query_coverage >70% AND hit_coverage >70%. The following abbreviations are produced during a BLAST analysis of a sequence.
- SEQ NUM -
- provides the SEQ ID NO for the listed recombinant polynucleotide sequences.
- CONTIG ID -
- provides an arbitrary sequence name taken from the name of the clone from which the cDNA sequence was obtained.
- PROTEIN NUM -
- provides the SEQ ID NO for the recombinant polypeptide sequence
- NCBI GI
- provides the GenBank ID number for the top BLAST hit for the sequence. The top BLAST hit is indicated by the National Center for Biotechnology Information GenBank Identifier number.
- NCBI GI DESCRIPTION
- refers to the description of the GenBank top BLAST hit for sequence.
- E_VALUE
- provides the expectation value for the top BLAST match.
- MATCH LENGTH -
- provides the length of the sequence which is aligned in the top BLAST match
- TOP
- refers to the percentage of identically matched nucleotides
- HIT PCT IDENT - - -
- (or residues) that exist along the length of that portion of the sequences which is aligned in the top BLAST match.
- CAT TYPE
- indicates the classification scheme used to classify the sequence. GO BP = Gene Ontology Consortium -biological process; GO CC = Gene Ontology Consortium - cellular component; GO MF = Gene Ontology Consortium - molecular function; KEGG = KEGG functional hierarchy (KEGG = Kyoto Encyclopedia of Genes and Genomes); EC = Enzyme Classification from ENZYME data bank release 25.0; POI = Pathways of Interest.
- CAT DESC
- provides the classification scheme subcategory to which the query sequence was assigned.
- PRODUCT CAT DESC
- provides the FunCAT annotation category to which the query sequence was assigned.
- PRODUCT_HIT_DESC
- provides the description of the BLAST hit which resulted in assignment of the sequence to the function category provided in the cat_desc column.
- HIT E
- provides the E value for the BLAST hit in the hit desc column.
- PCT IDENT -
- refers to the percentage of identically matched nucleotides (or residues) that exist along the length of that portion of the sequences which is aligned in the BLAST match provided in hit desc.
- QRY_RANGE
- lists the range of the query sequence aligned with the hit.
- HIT_RANGE
- lists the range of the hit sequence aligned with the query.
- QRY CVRG
- provides the percent of query sequence length that matches to the hit (NCBI) sequence in the BLAST match (% qry cvrg = (match length/query total length) × 100).
- HIT CVRG
- provides the percent of hit sequence length that matches to the query sequence in the match generated using BLAST (% hit cvrg = (match length/hit total length) × 100).
- Methods for aligning sequences for comparison are well-known in the art. Various programs and alignment algorithms are described. In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using an AlignX alignment program of the Vector NTI suite (Invitrogen, Carlsbad, CA). The AlignX alignment program is a global sequence alignment program for polynucleotides or proteins. In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the MegAlign program of the LASERGENE bioinformatics computing suite (MegAlign™ (©1993-2016). DNASTAR. Madison, WI). The MegAlign program is global sequence alignment program for polynucleotides or proteins. In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the Clustal suite of alignment programs, including, but not limited to, ClustalW and ClustalV (Higgins and Sharp (1988) Gene. Dec. 15;73(1):237-44; Higgins and Sharp (1989) CABIOS 5:151-3; Higgins et al. (1992) Comput. Appl. Biosci. 8:189-91). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the GCG suite of programs (Wisconsin Package Version 9.0, Genetics Computer Group (GCG), Madison, WI). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the BLAST suite of alignment programs, for example, but not limited to, BLASTP, BLASTN, BLASTX, etc. (Altschul et al. (1990) J. Mol. Biol. 215:403-10). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the FASTA suite of alignment programs, including, but not limited to, FASTA, TFASTX, TFASTY, SSEARCH, LALIGN etc. (Pearson (1994) Comput. Methods Genome Res. [Proc. Int. Symp.], Meeting Date 1992 (Suhai and Sandor, Eds.), Plenum: New York, NY, pp. 111-20). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the T-Coffee alignment program (Notredame, et. al. (2000) J. Mol. Biol. 302, 205-17). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the DIALIGN suite of alignment programs, including, but not limited to DIALIGN, CHAOS, DIALIGN-TX, DIALIGN-T etc. (Al Ait, et. al. (2013) DIALIGN at GOBICS Nuc. Acids Research 41, W3-W7). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the MUSCLE suite of alignment programs (Edgar (2004) Nucleic Acids Res. 32(5): 1792-1797). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the MAFFT alignment program (Katoh, et. al. (2002) Nucleic Acids Research 30(14): 3059-3066). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the Genoogle program (Albrecht, Felipe. arXiv150702987v1 [cs.DC] 10 Jul. 2015). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the HMMER suite of programs (Eddy. (1998) Bioinformatics, 14:755-63). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the PLAST suite of alignment programs, including, but not limited to, TPLASTN, PLASTP, KLAST, and PLASTX (Nguyen & Lavenier. (2009) BMC Bioinformatics, 10:329). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the USEARCH alignment program (Edgar (2010) Bioinformatics 26(19), 2460-61). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the SAM suite of alignment programs (Hughey & Krogh (Jan. 1995) Technical Report UCSCOCRL-95-7, University of California, Santa Cruz). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the IDF Searcher (O'Kane, K.C., The Effect of Inverse Document Frequency Weights on Indexed Sequence Retrieval, Online Journal of Bioinformatics, Volume 6 (2) 162-173, 2005). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the Parasail alignment program. (Daily, Jeff. Parasail: SIMD C library for global, semi-global, and local pairwise sequence alignments. BMC Bioinformatics. 17:18. February 10, 2016). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the ScalaBLAST alignment program (Oehmen C, Nieplocha J. "ScalaBLAST: A scalable implementation of BLAST for high-performance data-intensive bioinformatics analysis." IEEE Transactions on Parallel & Distributed Systems 17 (8): 740-749 AUG 2006). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the SWIPE alignment program (Rognes, T. Faster Smilth-Waterman database searches with inter-sequence SIMD parallelization. BMC Bioiinformatics. 12, 221 (2011)). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the ACANA alignment program (Weichun Huang, David M. Umbach, and Leping Li, Accurate anchoring alignment of divergent sequences. Bioinformatics 22:29-34, Jan 1 2006). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the DOTLET alignment program (Junier, T. & Pagni, M. DOTLET: diagonal plots in a web browser. Bioinformatics 16(2): 178-9 Feb. 2000). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the G-PAS alignment program (Frohmberg, W., et al. As used herein the term "operably linked" relates to a first nucleic acid sequence is operably linked with a second nucleic acid sequence when the first nucleic acid sequence is in a functional relationship with the second nucleic acid sequence. For instance, a promoter is operably linked with a coding sequence when the promoter affects the transcription or expression of the coding sequence. When recombinantly produced, operably linked nucleic acid sequences are generally contiguous and, where necessary to join two protein-coding regions, in the same reading frame. However, elements need not be contiguous to be operably linked. G-PAS 2.0 - an improved version of protein alignment tool with an efficient backtracking routine on multiple GPUs. Bulletin of the Polish Academy of Sciences Technical Sciences, Vol. 60, 491 Nov. 2012). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the GapMis alignment program (Flouri, T. et. al., Gap Mis: A tool for pairwise sequence alignment with a single gap. Recent Pat DNA Gene Seq. 7(2): 84-95 Aug. 2013). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the EMBOSS suite of alignment programs, including, but not limited to: Matcher, Needle, Stretcher, Water, Wordmatch, etc. (Rice, P., Longden, I. & Bleasby, A. EMBOSS: The European Molecular Biology Open Software Suite. Trends in Genetics 16(6) 276-77 (2000)). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the Ngila alignment program (Cartwright, R. Ngila: global pairwise alignments with logarithmic and affine gap costs. Bioinformatics. 23(11): 1427-28. June 1, 2007). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the probA, also known as propA, alignment program (Mückstein, U., Hofacker, IL, & Stadler, PF. Stochastic pairwise alignments. Bioinformatics 18 Suppl. 2:S153-60. 2002). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the SEQALN suite of alignment programs (Hardy, P. & Waterman, M. The Sequence Alignment Software Library at USC. 1997). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the SIM suite of alignment programs, including, but not limited to, GAP, NAP, LAP, etc. (Huang, X & Miller, W. A Time-Efficient, Linear-Space Local Similarity Algorithm. Advances in Applied Mathematics, vol. 12 (1991) 337-57). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the UGENE alignment program (Okonechnikov, K., Golosova, O. & Fursov, M. Unipro UGENE: a unified bioinformatics toolkit. Bioinformatics. 2012 28:1166-67). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the BAli-Phy alignment program (Suchard, MA & Redelings, BD. BAli-Phy: simultaneous Bayesian inference of alignment and phylogeny. Bioinformatics. 22:2047-48. 2006). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the Base-By-Base alignment program (Brodie, R., et. al. Base-By-Base: Single nucleotide-level analysis of whole viral genome alignments, BMC Bioinformatics, 5, 96, 2004). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the DECIPHER alignment program (ES Wright (2015) "DECIPHER: harnessing local sequence context to improve protein multiple sequence alignment." BMC Bioinformatics, doi:10.1186/s12859-015-0749-z.). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the FSA alignment program (Bradley, RK, et. al. (2009) Fast Statistical Alignment. PLoS Computational Biology. 5:e1000392). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the Geneious alignment program (Kearse, M., et. al. (2012). Geneious Basic: an integrated and extendable desktop software platform for the organization and analysis of sequence data. Bioinformatics, 28(12), 1647-49). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the Kalign alignment program (Lassmann, T. & Sonnhammer, E. Kalign - an accurate and fast multiple sequence alignment algorithm. BMC Bioinformatics 2005 6:298). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the MAVID alignment program (Bray, N. & Pachter, L. MAVID: Constrained Ancestral Alignment of Multiple Sequences. Genome Res. 2004 Apr; 14(4): 693-99). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the MSA alignment program (Lipman, DJ, et.al. A tool for multiple sequence alignment. Proc. Nat'l Acad. Sci. USA. 1989; 86:4412-15). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the MultAlin alignment program (Corpet, F., Multiple sequence alignment with hierarchial clustering. Nucl. Acids Res., 1988, 16(22), 10881-90). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the LAGAN or MLAGAN alignment programs (Brudno, et. al. LAGAN and Multi-LAGAN: efficient tools for large-scale multiple alignment of genomic DNA. Genome Research 2003 Apr; 13(4): 721-31). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the Opal alignment program (Wheeler, T.J., & Kececiouglu, J.D. Multiple alignment by aligning alignments. Proceedings of the 15th ISCB conference on Intelligent Systems for Molecular Biology. Bioinformatics. 23, i559-68, 2007). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the PicXAA suite of programs, including, but not limited to, PicXAA, PicXAA-R, PicXAA-Web, etc. (Mohammad, S., Sahraeian, E. & Yoon, B. PicXAA: greedy probabilistic construction of maximum expected accuracy alignment of multiple sequences. Nucleic Acids Research. 38(15):4917-28. 2010). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the PSAlign alignment program (SZE, S.-H., Lu, Y., & Yang, Q. (2006) A polynomial time solvable formulation of multiple sequence alignment Journal of Computational Biology, 13, 309-19). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the StatAlign alignment program (Novak, Á., et.al. (2008) StatAlign: an extendable software package for joint Bayesian estimation of alignments and evolutionary trees. Bioinformatics, 24(20):2403-04). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the Gap alignment program of Needleman and Wunsch (Needleman and Wunsch, Journal of Molecular Biology 48:443-453, 1970). In an embodiment, the subject disclosure relates to calculating percent identity between two polynucleotides or amino acid sequences using the BestFit alignment program of Smith and Waterman (Smith and Waterman, Advances in Applied Mathematics, 2:482-489, 1981, Smith et al., Nucleic Acids Research 11:2205-2220, 1983). These programs produces biologically meaningful multiple sequence alignments of divergent sequences. The calculated best match alignments for the selected sequences are lined up so that identities, similarities, and differences can be seen.
- The term "similarity" refers to a comparison between amino acid sequences, and takes into account not only identical amino acids in corresponding positions, but also functionally similar amino acids in corresponding positions. Thus similarity between polypeptide sequences indicates functional similarity, in addition to sequence similarity.
- The term "homology" is sometimes used to refer to the level of similarity between two or more nucleic acid or amino acid sequences in terms of percent of positional identity (i.e., sequence similarity or identity). Homology also refers to the concept of evolutionary relatedness, often evidenced by similar functional properties among different nucleic acids or proteins that share similar sequences.
- As used herein, the term "variants" means substantially similar sequences. For nucleotide sequences, naturally occurring variants can be identified with the use of well- known molecular biology techniques, such as, for example, with polymerase chain reaction (PCR) and hybridization techniques as outlined herein.
- For nucleotide sequences, a variant comprises a deletion and/or addition of one or more nucleotides at one or more internal sites within the native polynucleotide and/or a substitution of one or more nucleotides at one or more sites in the native polynucleotide. As used herein, a "native" nucleotide sequence comprises a naturally occurring nucleotide sequence. For nucleotide sequences, naturally occurring variants can be identified with the use of well-known molecular biology techniques, as, for example, with polymerase chain reaction (PCR) and hybridization techniques as outlined below. Variant nucleotide sequences also include synthetically derived nucleotide sequences, such as those generated, for example, by using site-directed mutagenesis. Generally, variants of a particular nucleotide sequence of the invention will have at least about 40%, 45%, 50%>, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%o, 99% or more sequence identity to that particular nucleotide sequence as determined by sequence alignment programs and parameters described elsewhere herein. A biologically active variant of a nucleotide sequence of the invention may differ from that sequence by as few as 1-15 nucleic acid residues, as few as 1-10, such as 6-10, as few as 5, as few as 4, 3, 2, or even 1 nucleic acid residue.
- As used herein the term "operably linked" relates to a first nucleic acid sequence is operably linked with a second nucleic acid sequence when the first nucleic acid sequence is in a functional relationship with the second nucleic acid sequence. For instance, a promoter is operably linked with a coding sequence when the promoter affects the transcription or expression of the coding sequence. When recombinantly produced, operably linked nucleic acid sequences are generally contiguous and, where necessary to join two protein-coding regions, in the same reading frame. However, elements need not be contiguous to be operably linked.
- As used herein, the term "promoter" refers to a region of DNA that generally is located upstream (towards the 5' region of a gene) of a gene and is needed to initiate and drive transcription of the gene. A promoter may permit proper activation or repression of a gene that it controls. A promoter may contain specific sequences that are recognized by transcription factors. These factors may bind to a promoter DNA sequence, which results in the recruitment of RNA polymerase, an enzyme that synthesizes RNA from the coding region of the gene. The promoter generally refers to all gene regulatory elements located upstream of the gene, including, upstream promoters, 5' UTR, introns, and leader sequences.
- As used herein, the term "upstream-promoter" refers to a contiguous polynucleotide sequence that is sufficient to direct initiation of transcription. As used herein, an upstream-promoter encompasses the site of initiation of transcription with several sequence motifs, which include TATA Box, initiator sequence, TFIIB recognition elements and other promoter motifs (Jennifer, E.F. et al., (2002) Genes & Dev., 16: 2583-2592). The upstream promoter provides the site of action to RNA polymerase II which is a multi-subunit enzyme with the basal or general transcription factors like, TFIIA, B, D, E, F and H. These factors assemble into a transcription pre initiation complex that catalyzes the synthesis of RNA from DNA template.
- The activation of the upstream-promoter is done by the additional sequence of regulatory DNA sequence elements to which various proteins bind and subsequently interact with the transcription initiation complex to activate gene expression. These gene regulatory elements sequences interact with specific DNA-binding factors. These sequence motifs may sometimes be referred to as cis-elements. Such cis-elements, to which tissue-specific or development-specific transcription factors bind, individually or in combination, may determine the spatiotemporal expression pattern of a promoter at the transcriptional level. These cis-elements vary widely in the type of control they exert on operably linked genes. Some elements act to increase the transcription of operably-linked genes in response to environmental responses (e.g., temperature, moisture, and wounding). Other cis-elements may respond to developmental cues (e.g., germination, seed maturation, and flowering) or to spatial information (e.g., tissue specificity). See, for example, Langridge et al., (1989) Proc. Natl. Acad. Sci. USA 86:3219-23. These cis- elements are located at a varying distance from transcription start point, some cis- elements (called proximal elements) are adjacent to a minimal core promoter region while other elements can be positioned several kilobases upstream or downstream of the promoter (enhancers).
- As used herein, the terms "5' untranslated region" or "5' UTR" is defined as the untranslated segment in the 5' terminus of pre-mRNAs or mature mRNAs. For example, on mature mRNAs, a 5' UTR typically harbors on its 5' end a 7-methylguanosine cap and is involved in many processes such as splicing, polyadenylation, mRNA export towards the cytoplasm, identification of the 5' end of the mRNA by the translational machinery, and protection of the mRNAs against degradation.
- As used herein, the terms "transcription terminator" is defined as the transcribed segment in the 3' terminus of pre-mRNAs or mature mRNAs. For example, longer stretches of DNA beyond "polyadenylation signal" site is transcribed as a pre-mRNA. This DNA sequence usually contains transcription termination signal for the proper processing of the pre-mRNA into mature mRNA.
- As used herein, the term "3' untranslated region" or "3' UTR" is defined as the untranslated segment in a 3' terminus of the pre-mRNAs or mature mRNAs. For example, on mature mRNAs this region harbors the poly-(A) tail and is known to have many roles in mRNA stability, translation initiation, and mRNA export. In addition, the 3' UTR is considered to include the polyadenylation signal and transcription terminator.
- As used herein, the term "polyadenylation signal" designates a nucleic acid sequence present in mRNA transcripts that allows for transcripts, when in the presence of a poly-(A) polymerase, to be polyadenylated on the polyadenylation site, for example, located 10 to 30 bases downstream of the poly-(A) signal. Many polyadenylation signals are known in the art and are useful for the present invention. An exemplary sequence includes AAUAAA and variants thereof, as described in Loke J., et al., (2005) Plant Physiology 138(3); 1457-1468.
- A "DNA binding transgene" is a polynucleotide coding sequence that encodes a DNA binding protein. The DNA binding protein is subsequently able to bind to another molecule. A binding protein can bind to, for example, a DNA molecule (a DNA-binding protein), a RNA molecule (an RNA-binding protein), and/or a protein molecule (a protein-binding protein). In the case of a protein-binding protein, it can bind to itself (to form homodimers, homotrimers, etc.) and/or it can bind to one or more molecules of a different protein or proteins. A binding protein can have more than one type of binding activity. For example, zinc finger proteins have DNA-binding, RNA-binding, and protein-binding activity.
- Examples of DNA binding proteins include; meganucleases, zinc fingers, CRISPRs, and TALEN binding domains that can be "engineered" to bind to a predetermined nucleotide sequence. Typically, the engineered DNA binding proteins (e.g., zinc fingers, CRISPRs, or TALENs) are proteins that are non-naturally occurring. Non-limiting examples of methods for engineering DNA-binding proteins are design and selection. A designed DNA binding protein is a protein not occurring in nature whose design/composition results principally from rational criteria. Rational criteria for design include application of substitution rules and computerized algorithms for processing information in a database storing information of existing ZFP, CRISPR, and/or TALEN designs and binding data. See, for example,
U.S. Patents 6,140,081 ;6,453,242 ; and6,534,261 ; see alsoWO 98/53058 WO 98/53059 WO 98/53060 WO 02/016536 WO 03/016496 U.S. Publication Nos. 20110301073 ,20110239315 and20119145940 . - A "zinc finger DNA binding protein" (or binding domain) is a protein, or a domain within a larger protein, that binds DNA in a sequence-specific manner through one or more zinc fingers, which are regions of amino acid sequence within the binding domain whose structure is stabilized through coordination of a zinc ion. The term zinc finger DNA binding protein is often abbreviated as zinc finger protein or ZFP. Zinc finger binding domains can be "engineered" to bind to a predetermined nucleotide sequence. Non-limiting examples of methods for engineering zinc finger proteins are design and selection. A designed zinc finger protein is a protein not occurring in nature whose design/composition results principally from rational criteria. Rational criteria for design include application of substitution rules and computerized algorithms for processing information in a database storing information of existing ZFP designs and binding data. See, for example,
U.S. Pat. Nos. 6,140,081 ;6,453,242 ;6,534,261 and6,794,136 ; see alsoWO 98/53058 WO 98/53059 WO 98/53060 WO 02/016536 WO 03/016496 - In other examples, the DNA-binding domain of one or more of the nucleases comprises a naturally occurring or engineered (non-naturally occurring) TAL effector DNA binding domain. See, e.g.,
U.S. Patent Publication No. 20110301073 . The plant pathogenic bacteria of the genus Xanthomonas are known to cause many diseases in important crop plants. Pathogenicity of Xanthomonas depends on a conserved type III secretion (T3S) system which injects more than different effector proteins into the plant cell. Among these injected proteins are transcription activator-like (TALEN) effectors which mimic plant transcriptional activators and manipulate the plant transcriptome (see Kay et al., (2007) Science 318:648-651). These proteins contain a DNA binding domain and a transcriptional activation domain. One of the most well characterized TAL-effectors is AvrBs3 from Xanthomonas campestgris pv. Vesicatoria (see Bonas et al., (1989) Mol Gen Genet 218: 127-136 andWO2010079430 ). TAL-effectors contain a centralized domain of tandem repeats, each repeat containing approximately 34 amino acids, which are key to the DNA binding specificity of these proteins. In addition, they contain a nuclear localization sequence and an acidic transcriptional activation domain (for a review see Schornack S, et al., (2006) J Plant Physiol 163(3): 256-272). In addition, in the phytopathogenic bacteria Ralstonia solanacearum two genes, designated brg11 and hpx17 have been found that are homologous to the AvrBs3 family of Xanthomonas in the R. solanacearum biovar strain GMI1000 and in the biovar 4 strain RS1000 (See Heuer et al., (2007) Appl and Enviro Micro 73(13): 4379-4384). These genes are 98.9% identical in nucleotide sequence to each other but differ by a deletion of 1,575 bp in the repeat domain of hpx17. However, both gene products have less than 40% sequence identity with AvrBs3 family proteins of Xanthomonas. See, e.g.,U.S. Patent Publication No. 20110301073 . - Specificity of these TAL effectors depends on the sequences found in the tandem repeats. The repeated sequence comprises approximately 102 bp and the repeats are typically 91-100% homologous with each other (Bonas et al., ibid). Polymorphism of the repeats is usually located at positions 12 and 13 and there appears to be a one-to-one correspondence between the identity of the hypervariable diresidues at positions 12 and 13 with the identity of the contiguous nucleotides in the TAL-effector's target sequence (see Moscou and Bogdanove, (2009) Science 326:1501 and Boch et al., (2009) Science 326:1509-1512). Experimentally, the natural code for DNA recognition of these TAL-effectors has been determined such that an HD sequence at positions 12 and 13 leads to a binding to cytosine (C), NG binds to T, NI to A, C, G or T, NN binds to A or G, and ING binds to T. These DNA binding repeats have been assembled into proteins with new combinations and numbers of repeats, to make artificial transcription factors that are able to interact with new sequences and activate the expression of a non-endogenous reporter gene in plant cells (Boch et al., ibid). Engineered TAL proteins have been linked to a FokI cleavage half domain to yield a TAL effector domain nuclease fusion (TALEN) exhibiting activity in a yeast reporter assay (plasmid based target).
- The CRISPR (Clustered Regularly Interspaced Short Palindromic Repeats)/Cas (CRISPR Associated) nuclease system is a recently engineered nuclease system based on a bacterial system that can be used for genome engineering. It is based on part of the adaptive immune response of many bacteria and Archaea. When a virus or plasmid invades a bacterium, segments of the invader's DNA are converted into CRISPR RNAs (crRNA) by the 'immune' response. This crRNA then associates, through a region of partial complementarity, with another type of RNA called tracrRNA to guide the Cas9 nuclease to a region homologous to the crRNA in the target DNA called a "protospacer." Cas9 cleaves the DNA to generate blunt ends at the double-stranded break (DSB) at sites specified by a 20-nucleotide guide sequence contained within the crRNA transcript. Cas9 requires both the crRNA and the tracrRNA for site specific DNA recognition and cleavage. This system has now been engineered such that the crRNA and tracrRNA can be combined into one molecule (the "single guide RNA"), and the crRNA equivalent portion of the single guide RNA can be engineered to guide the Cas9 nuclease to target any desired sequence (see Jinek et al., (2012) Science 337, pp. 816-821, Jinek et al., (2013), eLife 2:e00471, and David Segal, (2013) eLife 2:e00563). In other examples, the crRNA associates with the tracrRNA to guide the Cpf1 nuclease to a region homologous to the crRNA to cleave DNA with staggered ends (see Zetsche, Bernd, et al. Cell 163.3 (2015): 759-771.). Thus, the CRISPR/Cas system can be engineered to create a DSB at a desired target in a genome, and repair of the DSB can be influenced by the use of repair inhibitors to cause an increase in error prone repair.
- In other examples, the DNA binding transgene is a site specific nuclease that comprises an engineered (non-naturally occurring) Meganuclease (also described as a homing endonuclease). The recognition sequences of homing endonucleases or meganucleases such as I-SceI, I-CeuI, PI-PspI, PI-Sce, I-SceIV, I-CsmI, I-PanI, I-SceII, I-PpoI, I-SceIII, I-CreI, I-TevI, I-TevII and I-TevIII are known. See also
U.S. Patent No. 5,420,032 ;U.S. Patent No. 6,833,252 ; Belfort et al., (1997) Nucleic Acids Res. 25:3379-30 3388; Dujon et al., (1989) Gene 82:115-118; Perler et al., (1994) Nucleic Acids Res. 22, 11127; Jasin (1996) Trends Genet. 12:224-228; Gimble et al., (1996) J. Mol. Biol. 263:163-180; Argast et al., (1998) J. Mol. Biol. 280:345-353 and the New England Biolabs catalogue. In addition, the DNA-binding specificity of homing endonucleases and meganucleases can be engineered to bind non-natural target sites. See, for example, Chevalier et al., (2002)Molec. Cell 10:895-905; Epinat et al., (2003) Nucleic Acids Res. 5 31:2952-2962; Ashworth et al., (2006) Nature 441:656-659; Paques et al., (2007) Current Gene Therapy 7:49-66;U.S. Patent Publication No. 20070117128 . The DNA-binding domains of the homing endonucleases and meganucleases may be altered in the context of the nuclease as a whole (i.e., such that the nuclease includes the cognate cleavage domain) or may be fused to a heterologous cleavage domain. - As used herein, the term "transformation" encompasses all techniques that a nucleic acid molecule can be introduced into such a cell. Examples include, but are not limited to: transfection with viral vectors; transformation with plasmid vectors; electroporation; lipofection; microinjection (Mueller et al., (1978) Cell 15:579-85); Agrobacterium-mediated transfer; direct DNA uptake; WHISKERS™-mediated transformation; and microprojectile bombardment. These techniques may be used for both stable transformation and transient transformation of a plant cell. "Stable transformation" refers to the introduction of a nucleic acid fragment into a genome of a host organism resulting in genetically stable inheritance. Once stably transformed, the nucleic acid fragment is stably integrated in the genome of the host organism and any subsequent generation. Host organisms containing the transformed nucleic acid fragments are referred to as "transgenic" organisms. "Transient transformation" refers to the introduction of a nucleic acid fragment into the nucleus, or DNA-containing organelle, of a host organism resulting in gene expression without genetically stable inheritance.
- An exogenous nucleic acid sequence. In one example, a transgene is a gene sequence (e.g., an herbicide-resistance gene), a gene encoding an industrially or pharmaceutically useful compound, or a gene encoding a desirable agricultural trait. In yet another example, the transgene is an antisense nucleic acid sequence, wherein expression of the antisense nucleic acid sequence inhibits expression of a target nucleic acid sequence. A transgene may contain regulatory sequences operably linked to the transgene (e.g., a promoter). In some embodiments, a polynucleotide sequence of interest is a transgene. However, in other embodiments, a polynucleotide sequence of interest is an endogenous nucleic acid sequence, wherein additional genomic copies of the endogenous nucleic acid sequence are desired, or a nucleic acid sequence that is in the antisense orientation with respect to the sequence of a target nucleic acid molecule in the host organism.
- As used herein, the term a transgenic "event" is produced by transformation of plant cells with heterologous DNA, i.e., a nucleic acid construct that includes a transgene of interest, regeneration of a population of plants resulting from the insertion of the transgene into the genome of the plant, and selection of a particular plant characterized by insertion into a particular genome location. The term "event" refers to the original transformant and progeny of the transformant that include the heterologous DNA. The term "event" also refers to progeny produced by a sexual outcross between the transformant and another variety that includes the genomic/transgene DNA. Even after repeated back-crossing to a recurrent parent, the inserted transgene DNA and flanking genomic DNA (genomic/transgene DNA) from the transformed parent is present in the progeny of the cross at the same chromosomal location. The term "event" also refers to DNA from the original transformant and progeny thereof comprising the inserted DNA and flanking genomic sequence immediately adjacent to the inserted DNA that would be expected to be transferred to a progeny that receives inserted DNA including the transgene of interest as the result of a sexual cross of one parental line that includes the inserted DNA (e.g., the original transformant and progeny resulting from selfing) and a parental line that does not contain the inserted DNA.
- As used herein, the terms "Polymerase Chain Reaction" or "PCR" define a procedure or technique in which minute amounts of nucleic acid, RNA and/or DNA, are amplified as described in
U.S. Pat. No. 4,683,195 issued July 28, 1987 . Generally, sequence information from the ends of the region of interest or beyond needs to be available, such that oligonucleotide primers can be designed; these primers will be identical or similar in sequence to opposite strands of the template to be amplified. The 5' terminal nucleotides of the two primers may coincide with the ends of the amplified material. PCR can be used to amplify specific RNA sequences, specific DNA sequences from total genomic DNA, and cDNA transcribed from total cellular RNA, bacteriophage or plasmid sequences, etc. See generally Mullis et al., Cold Spring Harbor Symp. Quant. Biol., 51:263 (1987); Erlich, ed., PCR Technology, (Stockton Press, NY, 1989). - As used herein, the term "primer" refers to an oligonucleotide capable of acting as a point of initiation of synthesis along a complementary strand when conditions are suitable for synthesis of a primer extension product. The synthesizing conditions include the presence of four different deoxyribonucleotide triphosphates and at least one polymerization-inducing agent such as reverse transcriptase or DNA polymerase. These are present in a suitable buffer, which may include constituents which are co-factors or which affect conditions such as pH and the like at various suitable temperatures. A primer is preferably a single strand sequence, such that amplification efficiency is optimized, but double stranded sequences can be utilized.
- As used herein, the term "probe" refers to an oligonucleotide that hybridizes to a target sequence. In the TaqMan® or TaqMan®-style assay procedure, the probe hybridizes to a portion of the target situated between the annealing site of the two primers. A probe includes about eight nucleotides, about ten nucleotides, about fifteen nucleotides, about twenty nucleotides, about thirty nucleotides, about forty nucleotides, or about fifty nucleotides. In some embodiments, a probe includes from about eight nucleotides to about fifteen nucleotides. A probe can further include a detectable label, e.g., a fluorophore (Texas-Red®, Fluorescein isothiocyanate, etc.,). The detectable label can be covalently attached directly to the probe oligonucleotide, e.g., located at the probe's 5' end or at the probe's 3' end. A probe including a fluorophore may also further include a quencher, e.g., Black Hole Quencher™, Iowa Black™, etc.
- As used herein, the terms "restriction endonucleases" and "restriction enzymes" refer to bacterial enzymes, each of which cut double-stranded DNA at or near a specific nucleotide sequence. Type -2 restriction enzymes recognize and cleave DNA at the same site, and include but are not limited to XbaI, BamHI, HindIII, EcoRI, XhoI, SalI, KpnI, AvaI, PstI and SmaI.
- As used herein, the term "vector" is used interchangeably with the terms "construct", "cloning vector" and "expression vector" and means the vehicle by which a DNA or RNA sequence (e.g. a foreign gene) can be introduced into a host cell, so as to transform the host and promote expression (e.g. transcription and translation) of the introduced sequence. A "non-viral vector" is intended to mean any vector that does not comprise a virus or retrovirus. In some embodiments a "vector " is a sequence of DNA comprising at least one origin of DNA replication and at least one selectable marker gene. Examples include, but are not limited to, a plasmid, cosmid, bacteriophage, bacterial artificial chromosome (BAC), or virus that carries exogenous DNA into a cell. A vector can also include one or more genes, antisense molecules, and/or selectable marker genes and other genetic elements known in the art. A vector may transduce, transform, or infect a cell, thereby causing the cell to express the nucleic acid molecules and/or proteins encoded by the vector. The term "plasmid" defines a circular strand of nucleic acid capable of autosomal replication in either a prokaryotic or a eukaryotic host cell. The term includes nucleic acid which may be either DNA or RNA and may be single- or double-stranded. The plasmid of the definition may also include the sequences which correspond to a bacterial origin of replication.
- As used herein, the term "selectable marker gene" as used herein defines a gene or other expression cassette which encodes a protein which facilitates identification of cells into which the selectable marker gene is inserted. For example a "selectable marker gene" encompasses reporter genes as well as genes used in plant transformation to, for example, protect plant cells from a selective agent or provide resistance/tolerance to a selective agent. In one embodiment only those cells or plants that receive a functional selectable marker are capable of dividing or growing under conditions having a selective agent. Examples of selective agents can include, for example, antibiotics, including spectinomycin, neomycin, kanamycin, paromomycin, gentamicin, and hygromycin. These selectable markers include neomycin phosphotransferase (npt II), which expresses an enzyme conferring resistance to the antibiotic kanamycin, and genes for the related antibiotics neomycin, paromomycin, gentamicin, and G418, or the gene for hygromycin phosphotransferase (hpt), which expresses an enzyme conferring resistance to hygromycin. Other selectable marker genes can include genes encoding herbicide resistance including bar or pat (resistance against glufosinate ammonium or phosphinothricin), acetolactate synthase (ALS, resistance against inhibitors such as sulfonylureas (SUs), imidazolinones (IMIs), triazolopyrimidines (TPs), pyrimidinyl oxybenzoates (POBs), and sulfonylamino carbonyl triazolinones that prevent the first step in the synthesis of the branched-chain amino acids), glyphosate, 2,4-D, and metal resistance or sensitivity. Examples of "reporter genes" that can be used as a selectable marker gene include the visual observation of expressed reporter gene proteins such as proteins encoding β-glucuronidase (GUS), luciferase, green fluorescent protein (GFP), yellow fluorescent protein (YFP), DsRed, β-galactosidase, chloramphenicol acetyltransferase (CAT), alkaline phosphatase, and the like. The phrase "marker-positive" refers to plants that have been transformed to include a selectable marker gene.
- As used herein, the term "detectable marker" refers to a label capable of detection, such as, for example, a radioisotope, fluorescent compound, bioluminescent compound, a chemiluminescent compound, metal chelator, or enzyme. Examples of detectable markers include, but are not limited to, the following: fluorescent labels (e.g., FITC, rhodamine, lanthanide phosphors), enzymatic labels (e.g., horseradish peroxidase, β-galactosidase, luciferase, alkaline phosphatase), chemiluminescent, biotinyl groups, predetermined polypeptide epitopes recognized by a secondary reporter (e.g., leucine zipper pair sequences, binding sites for secondary antibodies, metal binding domains, epitope tags). In an embodiment, a detectable marker can be attached by spacer arms of various lengths to reduce potential steric hindrance.
- As used herein, the terms "cassette", "expression cassette" and "gene expression cassette" refer to a segment of DNA that can be inserted into a nucleic acid or polynucleotide at specific restriction sites or by homologous recombination. As used herein the segment of DNA comprises a polynucleotide that encodes a polypeptide of interest, and the cassette and restriction sites are designed to ensure insertion of the cassette in the proper reading frame for transcription and translation. In an embodiment, an expression cassette can include a polynucleotide that encodes a polypeptide of interest and having elements in addition to the polynucleotide that facilitate transformation of a particular host cell. In an embodiment, a gene expression cassette may also include elements that allow for enhanced expression of a polynucleotide encoding a polypeptide of interest in a host cell. These elements may include, but are not limited to: a promoter, a minimal promoter, an enhancer, a response element, a terminator sequence, a polyadenylation sequence, and the like.
- As used herein a "linker" or "spacer" is a bond, molecule or group of molecules that binds two separate entities to one another. Linkers and spacers may provide for optimal spacing of the two entities or may further supply a labile linkage that allows the two entities to be separated from each other. Labile linkages include photocleavable groups, acid-labile moieties, base-labile moieties and enzyme-cleavable groups. The terms "polylinker" or "multiple cloning site" as used herein defines a cluster of three or more Type -2 restriction enzyme sites located within 10 nucleotides of one another on a nucleic acid sequence. In other instances the term "polylinker" as used herein refers to a stretch of nucleotides that are targeted for joining two sequences via any known seamless cloning method (i.e., Gibson Assembly®, NEBuilder HiFiDNA Assembly®, Golden Gate Assembly, BioBrick® Assembly, etc.). Constructs comprising a polylinker are utilized for the insertion and/or excision of nucleic acid sequences such as the coding region of a gene.
- As used herein, the term "control" refers to a sample used in an analytical procedure for comparison purposes. A control can be "positive" or "negative". For example, where the purpose of an analytical procedure is to detect a differentially expressed transcript or polypeptide in cells or tissue, it is generally preferable to include a positive control, such as a sample from a known plant exhibiting the desired expression, and a negative control, such as a sample from a known plant lacking the desired expression.
- As used herein, the term "plant" includes a whole plant and any descendant, cell, tissue, or part of a plant. A class of plant that can be used in the present invention is generally as broad as the class of higher and lower plants amenable to mutagenesis including angiosperms (monocotyledonous and dicotyledonous plants), gymnosperms, ferns and multicellular algae. Thus, "plant" includes dicot and monocot plants. The term "plant parts" include any part(s) of a plant, including, for example and without limitation: seed (including mature seed and immature seed); a plant cutting; a plant cell; a plant cell culture; a plant organ (e.g., pollen, embryos, flowers, fruits, shoots, leaves, roots, stems, and explants). A plant tissue or plant organ may be a seed, protoplast, callus, or any other group of plant cells that is organized into a structural or functional unit. A plant cell or tissue culture may be capable of regenerating a plant having the physiological and morphological characteristics of the plant from which the cell or tissue was obtained, and of regenerating a plant having substantially the same genotype as the plant. In contrast, some plant cells are not capable of being regenerated to produce plants. Regenerable cells in a plant cell or tissue culture may be embryos, protoplasts, meristematic cells, callus, pollen, leaves, anthers, roots, root tips, silk, flowers, kernels, ears, cobs, husks, or stalks.
- Plant parts include harvestable parts and parts useful for propagation of progeny plants. Plant parts useful for propagation include, for example and without limitation: seed; fruit; a cutting; a seedling; a tuber; and a rootstock. A harvestable part of a plant may be any useful part of a plant, including, for example and without limitation: flower; pollen; seedling; tuber; leaf; stem; fruit; seed; and root.
- A plant cell is the structural and physiological unit of the plant, comprising a protoplast and a cell wall. A plant cell may be in the form of an isolated single cell, or an aggregate of cells (e.g., a friable callus and a cultured cell), and may be part of a higher organized unit (e.g., a plant tissue, plant organ, and plant). Thus, a plant cell may be a protoplast, a gamete producing cell, or a cell or collection of cells that can regenerate into a whole plant. As such, a seed, which comprises multiple plant cells and is capable of regenerating into a whole plant, is considered a "plant cell" in embodiments herein.
- As used herein, the term "small RNA" refers to several classes of non-coding ribonucleic acid (ncRNA). The term small RNA describes the short chains of ncRNA produced in bacterial cells, animals, plants, and fungi. These short chains of ncRNA may be produced naturally within the cell or may be produced by the introduction of an exogenous sequence that expresses the short chain or ncRNA. The small RNA sequences do not directly code for a protein, and differ in function from other RNA in that small RNA sequences are only transcribed and not translated. The small RNA sequences are involved in other cellular functions, including gene expression and modification. Small RNA molecules are usually made up of about 20 to 30 nucleotides. The small RNA sequences may be derived from longer precursors. The precursors form structures that fold back on each other in self-complementary regions; they are then processed by the nuclease Dicer in animals or DCL1 in plants.
- Many types of small RNA exist either naturally or produced artificially, including microRNAs (miRNAs), short interfering RNAs (siRNAs), antisense RNA, short hairpin RNA (shRNA), and small nucleolar RNAs (snoRNAs). Certain types of small RNA, such as microRNA and siRNA, are important in gene silencing and RNA interference (RNAi). Gene silencing is a process of genetic regulation in which a gene that would normally be expressed is "turned off by an intracellular element, in this case, the small RNA. The protein that would normally be formed by this genetic information is not formed due to interference, and the information coded in the gene is blocked from expression.
- As used herein, the term "small RNA" encompasses RNA molecules described in the literature as "tiny RNA" (Storz, (2002) Science 296:1260-3; Illangasekare et al., (1999) RNA 5:1482-1489); prokaryotic "small RNA" (sRNA) (Wassarman et al., (1999) Trends Microbiol. 7:37-45); eukaryotic "noncoding RNA (ncRNA)"; "micro-RNA (miRNA)"; "small non-mRNA (snmRNA)"; "functional RNA (fRNA)"; "transfer RNA (tRNA)"; "catalytic RNA" [e.g., ribozymes, including self-acylating ribozymes (Illangaskare et al., (1999) RNA 5:1482-1489); "small nucleolar RNAs (snoRNAs)," "tmRNA" (a.k.a. "10S RNA," Muto et al., (1998) Trends Biochem Sci. 23:25-29; and Gillet et al., (2001) Mol Microbiol. 42:879-885); RNAi molecules including without limitation "small interfering RNA (siRNA)," "endoribonuclease-prepared siRNA (e-siRNA)," "short hairpin RNA (shRNA)," and "small temporally regulated RNA (stRNA)," "diced siRNA (d-siRNA)," and aptamers, oligonucleotides and other synthetic nucleic acids that comprise at least one uracil base.
- Unless otherwise specifically explained, all technical and scientific terms used herein have the same meaning as commonly understood by those of ordinary skill in the art to which this disclosure belongs. Definitions of common terms in molecular biology can be found in, for example: Lewin, Genes V, Oxford University Press, 1994 (ISBN 0-19-854287-9); Kendrew et al. (eds.), The Encyclopedia of Molecular Biology, Blackwell Science Ltd., 1994 (ISBN 0-632-02182-9); and Meyers (ed.), Molecular Biology and Biotechnology: A Comprehensive Desk Reference, VCH Publishers, Inc., 1995 (ISBN 1-56081-569-8).
- As used herein, the articles, "a," "an," and "the" include plural references unless the context clearly and unambiguously dictates otherwise.
- Provided are methods and compositions for using a promoter from a Zea egg cell gene to express non-Panicum virgatum (Pavir.J00490) egg cell transgenes in plant. In an embodiment, a promoter can be the Panicum virgatum (Pavir.J00490) egg cell gene promoter of SEQ ID NO:1.
- According to the invention, a nucleic acid vector is provided comprising a promoter, wherein the promoter comprises a polynucleic acid sequence that is at least 98%, 99%, 99.5%, 99.8%, or 100% identical to SEQ ID NO:1. In an embodiment, a promoter is a Panicum virgatum (Pavir.J00490) egg cell gene promoter comprising a polynucleotide of at least 98%, 99%, 99.5%, 99.8%, or 100% identity to the polynucleotide of SEQ ID NO:1. Further, a polynucleotide is disclosed comprising a Panicum virgatum (Pavir.J00490) egg cell gene promoter that is operably linked to a polylinker. Also a gene expression cassette is disclosed comprising a Panicum virgatum (Pavir.J00490) egg cell gene promoter that is operably linked to a non-Panicum virgatum (Pavir.J00490) egg cell transgene. Herein, a nucleic acid vector is provided comprising a Panicum virgatum (Pavir.J00490) egg cell gene promoter that is operably linked to a non-Panicum virgatum (Pavir.J00490) egg cell transgene. In one embodiment, the promoter consists of SEQ ID NO: 1. In an illustrative embodiment, a nucleic acid vector comprises a Panicum virgatum (Pavir.J00490) egg cell gene promoter that is operably linked to a transgene, wherein the transgene can be an insecticidal resistance transgene, an herbicide tolerance transgene, a nitrogen use efficiency transgene, a water use efficiency transgene, a nutritional quality transgene, a DNA binding transgene, a small RNA transgene, selectable marker transgene, or combinations thereof.
- In an embodiment, a nucleic acid vector comprises a gene expression cassette as disclosed herein. In an embodiment, a vector can be a plasmid, a cosmid, a bacterial artificial chromosome (BAC), a bacteriophage, a virus, or an excised polynucleotide fragment for use in direct transformation or gene targeting such as a donor DNA.
- Transgene expression may also be regulated by a 5' UTR region located downstream of the promoter sequence. Both a promoter and a 5' UTR can regulate transgene expression. While a promoter is necessary to drive transcription, the presence of a 5' UTR can increase expression levels resulting in mRNA transcript for translation and protein synthesis. A 5' UTR gene region aids stable expression of a transgene. In a further embodiment an 5' UTR is operably linked to a Panicum virgatum (Pavir.J00490) egg cell gene promoter. In an embodiment, a 5' UTR can be the Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR of SEQ ID NO:7.
- In an embodiment, a polynucleotide is provided comprising a 5' UTR, wherein the 5' UTR is at least 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, 99.5%, 99.8%, or 100% identical to SEQ ID NO:7. In an embodiment, a 5' UTR is a Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR comprising a polynucleotide of at least 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, 99.5%, 99.8%, or 100% identity to the polynucleotide of SEQ ID NO:7. In an embodiment, an isolated polynucleotide is provided comprising at least 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, 99.5%, 99.8%, or 100% identity to the polynucleotide of SEQ ID NO:7. In an embodiment, a nucleic acid vector is provided comprising a Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR of SEQ ID NO:7. In an embodiment, a polynucleotide is provided comprising a Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR that is operably linked to a polylinker. In an embodiment, a gene expression cassette is provided comprising a Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR that is operably linked to a non-Panicum virgatum (Pavir.J00490) egg cell transgene. In an embodiment, a nucleic acid vector is provided comprising a Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR that is operably linked to a non-Panicum virgatum (Pavir.J00490) egg cell transgene. In one embodiment, the 5' UTR consists of SEQ ID NO: 7. In an illustrative embodiment, a nucleic acid vector comprises a Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR that is operably linked to a transgene, wherein the transgene can be an insecticidal resistance transgene, an herbicide tolerance transgene, a nitrogen use efficiency transgene, a water use efficiency transgene, a nutritional quality transgene, a DNA binding transgene, a small RNA transgene, selectable marker transgene, or combinations thereof.
- Transgene expression may also be regulated by an intron region located downstream of the promoter sequence. Both a promoter and an intron can regulate transgene expression. While a promoter is necessary to drive transcription, the presence of an intron can increase expression levels resulting in mRNA transcript for translation and protein synthesis. An intron gene region aids stable expression of a transgene. In a further embodiment an intron is operably linked to a Panicum virgatum (Pavir.J00490) egg cell gene promoter.
- In accordance with one embodiment a nucleic acid vector is provided comprising a recombinant gene expression cassette wherein the recombinant gene expression cassette comprises a Panicum virgatum (Pavir.J00490) egg cell gene promoter operably linked to a polylinker sequence, a non-Panicum virgatum (Pavir.J00490) egg cell gene or Panicum virgatum (Pavir.J00490) egg cell transgene or combination thereof. In one embodiment the recombinant gene cassette comprises a Panicum virgatum (Pavir.J00490) egg cell gene promoter operably linked to a non-Panicum virgatum (Pavir.J00490) egg cell gene or transgene. In one embodiment the recombinant gene cassette comprises a Panicum virgatum (Pavir.J00490) egg cell gene promoter as disclosed herein is operably linked to a polylinker sequence. The polylinker is operably linked to the Panicum virgatum (Pavir.J00490) egg cell gene promoter in a manner such that insertion of a coding sequence into one of the restriction sites of the polylinker will operably link the coding sequence allowing for expression of the coding sequence when the vector is transformed or transfected into a host cell.
- In accordance with one embodiment a nucleic acid vector is provided comprising a gene cassette that consists of a Panicum virgatum (Pavir.J00490) egg cell gene promoter and a non-Panicum virgatum (Pavir.J00490) egg cell gene and a 3' untranslated polynucleotide sequence. In an embodiment, the Panicum virgatum (Pavir.J00490) egg cell gene promoter of SEQ ID NO: 1 is operably linked to the 5' end of the non-Panicum virgatum (Pavir.J00490) egg cell gene or transgene. In a further embodiment the Panicum virgatum (Pavir.J00490) egg cell gene promoter sequence comprises SEQ ID NO: 1 or a sequence that has 98, 99 or 100% sequence identity with SEQ ID NO: 1. In accordance with one embodiment a nucleic acid vector is provided comprising a gene cassette that consists of a Panicum virgatum (Pavir.J00490) egg cell gene promoter, a non-Panicum virgatum (Pavir.J00490) egg cell gene and a 3' untranslated polynucleotide sequence, wherein the Panicum virgatum (Pavir.J00490) egg cell gene promoter is operably linked to the 5' end of the non- Panicum virgatum (Pavir.J00490) egg cell gene, and the Panicum virgatum (Pavir.J00490) egg cell gene promoter sequence comprises SEQ ID NO:1 or a sequence that has 98, 99 or 100% sequence identity with SEQ ID NO: 1. In a further embodiment the Panicum virgatum (Pavir.J00490) egg cell gene promoter sequence consists of SEQ ID NO: 1,or a 1,290 bp sequence that has 98, or 99% sequence identity with SEQ ID NO: 1.
- In accordance with one embodiment a nucleic acid vector is provided comprising a recombinant gene expression cassette wherein the recombinant gene expression cassette comprises a Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR operably linked to a polylinker sequence, a non-Panicum virgatum (Pavir.J00490) egg cell gene or Panicum virgatum (Pavir.J00490) egg cell transgene or combination thereof. In one embodiment the recombinant gene cassette comprises a Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR operably linked to a non-Panicum virgatum (Pavir.J00490) egg cell gene or transgene. In one embodiment the recombinant gene cassette comprises a Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR as disclosed herein is operably linked to a polylinker sequence. The polylinker is operably linked to the Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR in a manner such that insertion of a coding sequence into one of the restriction sites of the polylinker will operably link the coding sequence allowing for expression of the coding sequence when the vector is transformed or transfected into a host cell.
- A nucleic acid vector can comprise a gene cassette that consists of a Panicum virgatum
- (Pavir.J00490) egg cell gene 5' UTR and a non-Panicum virgatum (Pavir.J00490) egg cell gene. For example, the Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR of SEQ ID NO:7 is operably linked to the 5' end of the non-Panicum virgatum (Pavir.J00490) egg cell gene or transgene. The Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR sequence can comprise SEQ ID NO:7 or a sequence that has 80, 85, 90, 95, 99 or 100% sequence identity with SEQ ID NO:7. As an example a nucleic acid vector is described comprising a gene cassette that consists of a Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR, a non-Panicum virgatum (Pavir.J00490) egg cell gene, wherein the Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR is operably linked to the 5' end of the non-Panicum virgatum (Pavir.J00490) egg cell gene, and the Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR sequence comprises SEQ ID NO:7 or a sequence that has 80, 85, 90, 95, 99 or 100% sequence identity with SEQ ID NO:7. In a further embodiment the Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR sequence consists of SEQ ID NO:7, or a 67 bp sequence that has 80, 85, 90, 95, or 99% sequence identity with SEQ ID NO:7.
- A Panicum virgatum (Pavir.J00490) egg cell gene promoter may also comprise one or more additional sequence elements. In some embodiments, a Panicum virgatum (Pavir.J00490) egg cell gene promoter may comprise an exon (e.g., a leader or signal peptide such as a chloroplast transit peptide or ER retention signal). For example and without limitation, a Panicum virgatum (Pavir.J00490) egg cell gene promoter may encode an exon incorporated into the Panicum virgatum (Pavir.J00490) egg cell gene promoter as a further embodiment.
- Further provided are methods and compositions for using a 3' UTR from a Zea egg cell gene to terminate non-Panicum virgatum (Pavir.J00490) egg cell transgenes in plant. In an embodiment, a 3' UTR terminator can be the Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR of SEQ ID NO:2.
- In an embodiment, a polynucleotide is provided comprising a 3' UTR, wherein the 3' UTR is at least 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, 99.5%, 99.8%, or 100% identical to SEQ ID NO:2. In an embodiment, a 3' UTR is a Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR comprising a polynucleotide of at least 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, 99.5%, 99.8%, or 100% identity to the polynucleotide of SEQ ID NO:2. In an embodiment, an isolated polynucleotide is provided comprising at least 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, 99.5%, 99.8%, or 100% identity to the polynucleotide of SEQ ID NO:2. In an embodiment, a nucleic acid vector is provided comprising a Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR of SEQ ID NO:2. In an embodiment, a polynucleotide is provided comprising a Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR that is operably linked to a polylinker. In an embodiment, a gene expression cassette is provided comprising a Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR that is operably linked to a non-Panicum virgatum (Pavir.J00490) egg cell transgene. In an embodiment, a nucleic acid vector is provided comprising a Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR that is operably linked to a non-Panicum virgatum (Pavir.J00490) egg cell transgene. In one embodiment, the 3' UTR consists of SEQ ID NO: 2. In an illustrative embodiment, a nucleic acid vector comprises a Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR that is operably linked to a transgene, wherein the transgene can be an insecticidal resistance transgene, an herbicide tolerance transgene, a nitrogen use efficiency transgene, a water use efficiency transgene, a nutritional quality transgene, a DNA binding transgene, a small RNA transgene, selectable marker transgene, or combinations thereof.
- In accordance with one embodiment a nucleic acid vector is provided comprising a recombinant gene expression cassette wherein the recombinant gene expression cassette comprises a Panicum virgatum (Pavir.J00490) egg cell gene 3'UTR operably linked to a polylinker sequence, a non-Panicum virgatum (Pavir.J00490) egg cell gene or Panicum virgatum (Pavir.J00490) egg cell transgene or combination thereof. In one embodiment the recombinant gene cassette comprises a Panicum virgatum (Pavir.J00490) egg cell gene 3'UTR operably linked to a non-Panicum virgatum (Pavir.J00490) egg cell gene or transgene. In one embodiment the recombinant gene cassette comprises a Panicum virgatum (Pavir.J00490) egg cell gene 3'UTR as disclosed herein is operably linked to a polylinker sequence. The polylinker is operably linked to the Panicum virgatum (Pavir.J00490) egg cell gene 3'UTR in a manner such that insertion of a coding sequence into one of the restriction sites of the polylinker will operably link the coding sequence allowing for expression of the coding sequence when the vector is transformed or transfected into a host cell.
- In accordance with one embodiment a nucleic acid vector is provided comprising a gene cassette that consists of a Panicum virgatum (Pavir.J00490) egg cell gene 3'UTR and a non-Panicum virgatum (Pavir.J00490) egg cell gene. In an embodiment, the Panicum virgatum (Pavir.J00490) egg cell gene 3'UTR of SEQ ID NO: 2 is operably linked to the 3' end of the non-Panicum virgatum (Pavir.J00490) egg cell gene or transgene. In a further embodiment the Panicum virgatum (Pavir.J00490) egg cell gene 3'UTR sequence comprises SEQ ID NO: 2 or a sequence that has 80, 85, 90, 95, 99 or 100% sequence identity with SEQ ID NO: 2. In accordance with one embodiment a nucleic acid vector is provided comprising a gene cassette that consists of a Panicum virgatum (Pavir.J00490) egg cell gene 3'UTR, a non-Panicum virgatum (Pavir.J00490) egg cell gene, wherein the Panicum virgatum (Pavir.J00490) egg cell gene 3'UTR is operably linked to the 3' end of the non-Panicum virgatum (Pavir.J00490) egg cell gene, and the Panicum virgatum (Pavir.J00490) egg cell gene 3'UTR sequence comprises SEQ ID NO:2 or a sequence that has 80, 85, 90, 95, 99 or 100% sequence identity with SEQ ID NO: 2. In a further embodiment the Panicum virgatum (Pavir.J00490) egg cell gene 3'UTR sequence consists of SEQ ID NO:2, or a 942 bp sequence that has 80, 85, 90, 95, or 99% sequence identity with SEQ ID NO: 2.
- In one embodiment a nucleic acid construct is provided comprising a Panicum virgatum (Pavir.J00490) egg cell gene promoter and a non-Panicum virgatum (Pavir.J00490) egg cell gene and a 3' untranslated region, and optionally one or more of the following elements:
- a) a 5' untranslated region;
- b) an intron; and
- the Panicum virgatum (Pavir.J00490) egg cell gene promoter consists of SEQ ID NO:1 or a sequence having 98% sequence identity with SEQ ID NO:1;
- the Panicum virgatum (Pavir.J00490) egg cell gene 5'UTR consists of SEQ ID NO:7 or a sequence having 95% sequence identity with SEQ ID NO:7; and
- the 3' untranslated region consists of a known 3' untranslated region, SEQ ID NO:2 or a sequence having 95% sequence identity with SEQ ID NO:2; further wherein said Panicum virgatum (Pavir.J00490) egg cell gene promoter is operably linked to said transgene and each optional element, when present, is also operably linked to both the promoter and the transgene. In a further embodiment a transgenic cell is provided comprising the nucleic acid construct disclosed immediately above. In one embodiment the transgenic cell is a plant cell, and in a further embodiment a plant is provided wherein the plant comprises said transgenic cells.
- In accordance with one embodiment the nucleic acid vector further comprises a sequence encoding a selectable maker. In accordance with one embodiment the recombinant gene cassette is operably linked to an Agrobacterium T-DNA border. In accordance with one embodiment the recombinant gene cassette further comprises a first and second T-DNA border, wherein the first T-DNA border is operably linked to one end of a gene construct, and the second T-DNA border is operably linked to the other end of a gene construct. The first and second Agrobacterium T-DNA borders can be independently selected from T-DNA border sequences originating from bacterial strains selected from the group consisting of a nopaline synthesizing Agrobacterium T-DNA border, an ocotopine synthesizing Agrobacterium T-DNA border, a mannopine synthesizing Agrobacterium T-DNA border, a succinamopine synthesizing Agrobacterium T-DNA border, or any combination thereof. In one embodiment an Agrobacterium strain selected from the group consisting of a nopaline synthesizing strain, a mannopine synthesizing strain, a succinamopine synthesizing strain, or an octopine synthesizing strain is provided, wherein said strain comprises a plasmid wherein the plasmid comprises a transgene operably linked to a sequence selected from SEQ ID NO:1 or a sequence having 98 or 99% sequence identity with SEQ ID NO:1. In another embodiment, the first and second Agrobacterium T-DNA borders can be independently selected from T-DNA border sequences originating from bacterial strains selected from the group consisting of a nopaline synthesizing Agrobacterium T-DNA border, an ocotopine synthesizing Agrobacterium T-DNA border, a mannopine synthesizing Agrobacterium T-DNA border, a succinamopine synthesizing Agrobacterium T-DNA border, or any combination thereof. In an embodiment an Agrobacterium strain selected from the group consisting of a nopaline synthesizing strain, a mannopine synthesizing strain, a succinamopine synthesizing strain, or an octopine synthesizing strain is provided, wherein said strain comprises a plasmid wherein the plasmid comprises a transgene operably linked to a sequence selected from SEQ ID NO:7 or a sequence having 80, 85, 90, 95, or 99% sequence identity with SEQ ID NO:7. In one embodiment an Agrobacterium strain selected from the group consisting of a nopaline synthesizing strain, a mannopine synthesizing strain, a succinamopine synthesizing strain, or an octopine synthesizing strain is provided, wherein said strain comprises a plasmid wherein the plasmid comprises a transgene operably linked to a sequence selected from SEQ ID NO:2 or a sequence having 80, 85, 90, 95, or 99% sequence identity with SEQ ID NO:2.
- Transgenes of interest that are suitable for use in the present disclosed constructs include, but are not limited to, coding sequences that confer (1) resistance to pests or disease, (2) tolerance to herbicides, (3) value added agronomic traits, such as; yield improvement, nitrogen use efficiency, water use efficiency, and nutritional quality, (4) binding of a protein to DNA in a site specific manner, (5) expression of small RNA, and (6) selectable markers. In accordance with one embodiment, the transgene encodes a selectable marker or a gene product conferring insecticidal resistance, herbicide tolerance, small RNA expression, nitrogen use efficiency, water use efficiency, or nutritional quality.
- Various insect resistance genes can be operably linked to the Panicum virgatum (Pavir.J00490) egg cell gene promoter comprising SEQ ID NO: 1, or a sequence that has 98 or 99% sequence identity with SEQ ID NO: 1. In addition, the insect resistance genes can be operably linked to the Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR comprising SEQ ID NO:7, or a sequence that has 80, 85, 90, 95 or 99% sequence identity with SEQ ID NO:7. Likewise, the insect resistance genes can be operably linked to the Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR comprising SEQ ID NO: 2, or a sequence that has 80, 85, 90, 95 or 99% sequence identity with SEQ ID NO: 2. The operably linked sequences can then be incorporated into a chosen vector to allow for identification and selection of transformed plants ("transformants"). Exemplary insect resistance coding sequences are known in the art. As embodiments of insect resistance coding sequences that can be operably linked to the regulatory elements of the subject disclosure, the following traits are provided. Coding sequences that provide exemplary Lepidopteran insect resistance include: cry1A; cry1A.105; cry1Ab; cry1Ab(truncated); cry1Ab-Ac (fusion protein); cry1Ac (marketed as Widestrike®); cry1C; cry1F (marketed as Widestrike®); cry1Fa2; cry2Ab2; cry2Ae; cry9C; mocrylF; pinII(protease inhibitor protein); vip3A(a); and vip3Aa20. Coding sequences that provide exemplary Coleopteran insect resistance include: cry34Ab1 (marketed as Herculex®); cry35Ab1 (marketed as Herculex®); cry3A; cry3Bb1; dvsnf7; and mcry3A. Coding sequences that provide exemplary multi-insect resistance include ecry31.Ab. The above list of insect resistance genes is not meant to be limiting. Any insect resistance genes are encompassed by the present disclosure.
- Various herbicide tolerance genes can be operably linked to the Panicum virgatum (Pavir.J00490) egg cell gene promoter comprising SEQ ID NO: 1, or a sequence that has 98 or 99% sequence identity with SEQ ID NO: 1. Likewise, the herbicide tolerance genes can be operably linked to the Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR comprising SEQ ID NO:7, or a sequence that has 80, 85, 90, 95 or 99% sequence identity with SEQ ID NO:7. Likewise, the herbicide tolerance genes can be operably linked to the Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR comprising SEQ ID NO: 2, or a sequence that has 80, 85, 90, 95 or 99% sequence identity with SEQ ID NO: 2. The operably linked sequences can then be incorporated into a chosen vector to allow for identification and selection of transformed plants ("transformants"). Exemplary herbicide tolerance coding sequences are known in the art. As embodiments of herbicide tolerance coding sequences that can be operably linked to the regulatory elements of the subject disclosure, the following traits are provided. The glyphosate herbicide contains a mode of action by inhibiting the EPSPS enzyme (5-enolpyruvylshikimate-3-phosphate synthase). This enzyme is involved in the biosynthesis of aromatic amino acids that are essential for growth and development of plants. Various enzymatic mechanisms are known in the art that can be utilized to inhibit this enzyme. The genes that encode such enzymes can be operably linked to the gene regulatory elements of the subject disclosure. In an embodiment, selectable marker genes include, but are not limited to genes encoding glyphosate resistance genes include: mutant EPSPS genes such as 2mEPSPS genes, cp4 EPSPS genes, mEPSPS genes, dgt-28 genes; aroA genes; and glyphosate degradation genes such as glyphosate acetyl transferase genes (gat) and glyphosate oxidase genes (gox). These traits are currently marketed as Gly-Tol™, Optimum® GAT®, Agrisure® GT and Roundup Ready®. Resistance genes for glufosinate and/or bialaphos compounds include dsm-2, bar and pat genes. The bar and pat traits are currently marketed as LibertyLink®. Also included are tolerance genes that provide resistance to 2,4-D such as aad-1 genes (it should be noted that aad-1 genes have further activity on arloxyphenoxypropionate herbicides) and aad-12 genes (it should be noted that aad-12 genes have further activity on pyidyloxyacetate synthetic auxins). These traits are marketed as Enlist® crop protection technology. Resistance genes for ALS inhibitors (sulfonylureas, imidazolinones, triazolopyrimidines, pyrimidinylthiobenzoates, and sulfonylamino-carbonyl-triazolinones) are known in the art. These resistance genes most commonly result from point mutations to the ALS encoding gene sequence. Other ALS inhibitor resistance genes include hra genes, the csr1-2 genes, Sr-HrA genes, and surB genes. Some of the traits are marketed under the tradename Clearfield®. Herbicides that inhibit HPPD include the pyrazolones such as pyrazoxyfen, benzofenap, and topramezone; triketones such as mesotrione, sulcotrione, tembotrione, benzobicyclon; and diketonitriles such as isoxaflutole. These exemplary HPPD herbicides can be tolerated by known traits. Examples of HPPD inhibitors include hppdPF_W336 genes (for resistance to isoxaflutole) and avhppd-03 genes (for resistance to meostrione). An example of oxynil herbicide tolerant traits include the bxn gene, which has been showed to impart resistance to the herbicide/antibiotic bromoxynil. Resistance genes for dicamba include the dicamba monooxygenase gene (dmo) as disclosed in International
PCT Publication No. WO 2008/105890 . Resistance genes for PPO or PROTOX inhibitor type herbicides (e.g., acifluorfen, butafenacil, flupropazil, pentoxazone, carfentrazone, fluazolate, pyraflufen, aclonifen, azafenidin, flumioxazin, flumiclorac, bifenox, oxyfluorfen, lactofen, fomesafen, fluoroglycofen, and sulfentrazone) are known in the art. Exemplary genes conferring resistance to PPO include over expression of a wild-type Arabidopsis thaliana PPO enzyme (Lermontova I and Grimm B, (2000) Overexpression of plastidic protoporphyrinogen IX oxidase leads to resistance to the diphenyl-ether herbicide acifluorfen. Plant Physiol 122:75-83.), the B. subtilis PPO gene (Li, X. and Nicholl D. 2005. Development of PPO inhibitor-resistant cultures and crops. Pest Manag. Sci. 61:277-285 and Choi KW, Han O, Lee HJ, Yun YC, Moon YH, Kim MK, Kuk YI, Han SU and Guh JO, (1998) Generation of resistance to the diphenyl ether herbicide, oxyfluorfen, via expression of the Bacillus subtilis protoporphyrinogen oxidase gene in transgenic tobacco plants. Biosci Biotechnol Biochem 62:558-560.) Resistance genes for pyridinoxy or phenoxy proprionic acids and cyclohexones include the ACCase inhibitor-encoding genes (e.g., Acc1-S1, Acc1-S2 and Acc1-S3). Exemplary genes conferring resistance to cyclohexanediones and/or aryloxyphenoxypropanoic acid include haloxyfop, diclofop, fenoxyprop, fluazifop, and quizalofop. Finally, herbicides can inhibit photosynthesis, including triazine or benzonitrile are provided tolerance by psbA genes (tolerance to triazine), 1s+ genes (tolerance to triazine), and nitrilase genes (tolerance to benzonitrile). The above list of herbicide tolerance genes is not meant to be limiting. Any herbicide tolerance genes are encompassed by the present disclosure. - Various agronomic trait genes can be operably linked to the Panicum virgatum (Pavir.J00490) egg cell gene promoter comprising SEQ ID NO: 1, or a sequence that has 98 or 99% sequence identity with SEQ ID NO: 1. In addition, the agronomic trait genes can be operably linked to the Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR comprising SEQ ID NO:7, or a sequence that has 80, 85, 90, 95 or 99% sequence identity with SEQ ID NO:7. Likewise, the agronomic trait genes can be operably linked to the Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR comprising SEQ ID NO: 2, or a sequence that has 80, 85, 90, 95 or 99% sequence identity with SEQ ID NO: 2. The operably linked sequences can then be incorporated into a chosen vector to allow for identification and selection of transformed plants ("transformants"). Exemplary agronomic trait coding sequences are known in the art. As embodiments of agronomic trait coding sequences that can be operably linked to the regulatory elements of the subject disclosure, the following traits are provided. Delayed fruit softening as provided by the pg genes inhibit the production of polygalacturonase enzyme responsible for the breakdown of pectin molecules in the cell wall, and thus causes delayed softening of the fruit. Further, delayed fruit ripening/senescence of acc genes act to suppress the normal expression of the native acc synthase gene, resulting in reduced ethylene production and delayed fruit ripening. Whereas, the accd genes metabolize the precursor of the fruit ripening hormone ethylene, resulting in delayed fruit ripening. Alternatively, the sam-k genes cause delayed ripening by reducing S-adenosylmethionine (SAM), a substrate for ethylene production. Drought stress tolerance phenotypes as provided by cspB genes maintain normal cellular functions under water stress conditions by preserving RNA stability and translation. Another example includes the EcBetA genes that catalyze the production of the osmoprotectant compound glycine betaine conferring tolerance to water stress. In addition, the RmBetA genes catalyze the production of the osmoprotectant compound glycine betaine conferring tolerance to water stress. Photosynthesis and yield enhancement is provided with the bbx32 gene that expresses a protein that interacts with one or more endogenous transcription factors to regulate the plant's day/night physiological processes. Ethanol production can be increase by expression of the amy797E genes that encode a thermostable alpha-amylase enzyme that enhances bioethanol production by increasing the thermostability of amylase used in degrading starch. Finally, modified amino acid compositions can result by the expression of the cordapA genes that encode a dihydrodipicolinate synthase enzyme that increases the production of amino acid lysine. The above list of agronomic trait coding sequences is not meant to be limiting. Any agronomic trait coding sequence is encompassed by the present disclosure.
- Various DNA binding transgene genes can be operably linked to the Panicum virgatum (Pavir.J00490) egg cell gene promoter comprising SEQ ID NO: 1, or a sequence that has 98 or 99% sequence identity with SEQ ID NO: 1. In addition, the DNA binding transgene genes can be operably linked to the Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR comprising SEQ ID NO:7, or a sequence that has 80, 85, 90, 95 or 99% sequence identity with SEQ ID NO:7. Likewise, the DNA binding transgene genes can be operably linked to the Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR comprising SEQ ID NO: 2, or a sequence that has 80, 85, 90, 95 or 99% sequence identity with SEQ ID NO: 2. The operably linked sequences can then be incorporated into a chosen vector to allow for identification and selectable of transformed plants ("transformants"). Exemplary DNA binding protein coding sequences are known in the art. As embodiments of DNA binding protein coding sequences that can be operably linked to the regulatory elements of the subject disclosure, the following types of DNA binding proteins can include; Zinc Fingers, TALENS, CRISPRS, and meganucleases. The above list of DNA binding protein coding sequences is not meant to be limiting. Any DNA binding protein coding sequences is encompassed by the present disclosure.
- Various small RNA sequences can be operably linked to the Panicum virgatum (Pavir.J00490) egg cell gene promoter comprising SEQ ID NO: 1, or a sequence that has 98 or 99% sequence identity with SEQ ID NO: 1. Likewise, the small RNA sequences can be operably linked to the Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR comprising SEQ ID NO: 2, or a sequence that has 80, 85, 90, 95 or 99% sequence identity with SEQ ID NO: 2. The operably linked sequences can then be incorporated into a chosen vector to allow for identification and selection of transformed plants ("transformants"). Exemplary small RNA traits are known in the art. As embodiments of small RNA coding sequences that can be operably linked to the regulatory elements of the subject disclosure, the following traits are provided. For example, delayed fruit ripening/senescence of the anti-efe small RNA delays ripening by suppressing the production of ethylene via silencing of the ACO gene that encodes an ethylene-forming enzyme. The altered lignin production of ccomt small RNA reduces content of guanacyl (G) lignin by inhibition of the endogenous S-adenosyl-L-methionine: trans-caffeoyl CoA 3-O-methyltransferase (CCOMT gene). Further, the Black Spot Bruise Tolerance in Solanum verrucosum can be reduced by the Ppo5 small RNA which triggers the degradation of Ppo5 transcripts to block black spot bruise development. Also included is the dvsnf7 small RNA that inhibits Western Corn Rootworm with dsRNA containing a 240 bp fragment of the Western Corn Rootworm Snf7 gene. Modified starch/carbohydrates can result from small RNA such as the pPhL small RNA (degrades PhL transcripts to limit the formation of reducing sugars through starch degradation) and pR1 small RNA (degrades R1 transcripts to limit the formation of reducing sugars through starch degradation). Additional, benefits such as reduced acrylamide resulting from the asn1 small RNA that triggers degradation of Asn1 to impair asparagine formation and reduce polyacrylamide. Finally, the non-browning phenotype of pgas ppo suppression small RNA results in suppressing PPO to produce apples with a non-browning phenotype. The above list of small RNAs is not meant to be limiting. Any small RNA encoding sequences are encompassed by the present disclosure.
- Various selectable markers also described as reporter genes can be operably linked to the Panicum virgatum (Pavir.J00490) egg cell gene promoter comprising SEQ ID NO: 1, or a sequence that has 98 or 99% sequence identity with SEQ ID NO: 1. In addition, the selectable markers also described as reporter genes can be operably linked to the Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR comprising SEQ ID NO:7, or a sequence that has 80, 85, 90, 95 or 99% sequence identity with SEQ ID NO:7. Likewise, the selectable markers also described as reporter genes can be operably linked to the Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR comprising SEQ ID NO: 2, or a sequence that has 80, 85, 90, 95 or 99% sequence identity with SEQ ID NO: 2. The operably linked sequences can then be incorporated into a chosen vector to allow for identification and selectable of transformed plants ("transformants"). Many methods are available to confirm expression of selectable markers in transformed plants, including for example DNA sequencing and PCR (polymerase chain reaction), Southern blotting, RNA blotting, immunological methods for detection of a protein expressed from the vector. But, usually the reporter genes are observed through visual observation of proteins that when expressed produce a colored product. Exemplary reporter genes are known in the art and encode β-glucuronidase (GUS), luciferase, green fluorescent protein (GFP), yellow fluorescent protein (YFP, Phi-YFP), red fluorescent protein (DsRFP, RFP, etc), β-galactosidase, and the like (See Sambrook, et al., Molecular Cloning: A Laboratory Manual, Third Edition, Cold Spring Harbor Press, N.Y., 2001, the content of which is incorporated herein by reference in its entirety).
- Selectable marker genes are utilized for selection of transformed cells or tissues. Selectable marker genes include genes encoding antibiotic resistance, such as those encoding neomycin phosphotransferase II (NEO), spectinomycin/streptinomycin resistance (AAD), and hygromycin phosphotransferase (HPT or HGR) as well as genes conferring resistance to herbicidal compounds. Herbicide resistance genes generally code for a modified target protein insensitive to the herbicide or for an enzyme that degrades or detoxifies the herbicide in the plant before it can act. For example, resistance to glyphosate has been obtained by using genes coding for mutant target enzymes, 5-enolpyruvylshikimate-3-phosphate synthase (EPSPS). Genes and mutants for EPSPS are well known, and further described below. Resistance to glufosinate ammonium, bromoxynil, and 2,4-dichlorophenoxyacetate (2,4-D) have been obtained by using bacterial genes encoding PAT or DSM-2, a nitrilase, an AAD-1, or an AAD-12, each of which are examples of proteins that detoxify their respective herbicides.
- In an embodiment, herbicides can inhibit the growing point or meristem, including imidazolinone or sulfonylurea, and genes for resistance/tolerance of acetohydroxyacid synthase (AHAS) and acetolactate synthase (ALS) for these herbicides are well known. Glyphosate resistance genes include mutant 5-enolpyruvylshikimate-3-phosphate synthase (EPSPs) and dgt-28 genes (via the introduction of recombinant nucleic acids and/or various forms of in vivo mutagenesis of native EPSPs genes), aroA genes and glyphosate acetyl transferase (GAT) genes, respectively). Resistance genes for other phosphono compounds include bar and pat genes from Streptomyces species, including Streptomyces hygroscopicus and Streptomyces viridichromogenes, and pyridinoxy or phenoxy proprionic acids and cyclohexones (ACCase inhibitor-encoding genes). Exemplary genes conferring resistance to cyclohexanediones and/or aryloxyphenoxypropanoic acid (including haloxyfop, diclofop, fenoxyprop, fluazifop, quizalofop) include genes of acetyl coenzyme A carboxylase (ACCase); Acc1-S1, Acc1-S2 and Acc1-S3. In an embodiment, herbicides can inhibit photosynthesis, including triazine (psbA and 1s+ genes) or benzonitrile (nitrilase gene). Futhermore, such selectable markers can include positive selection markers such as phosphomannose isomerase (PMI) enzyme.
- In an embodiment, selectable marker genes include, but are not limited to genes encoding: 2,4-D; neomycin phosphotransferase II; cyanamide hydratase; aspartate kinase; dihydrodipicolinate synthase; tryptophan decarboxylase; dihydrodipicolinate synthase and desensitized aspartate kinase; bar gene; tryptophan decarboxylase; neomycin phosphotransferase (NEO); hygromycin phosphotransferase (HPT or HYG); dihydrofolate reductase (DHFR); phosphinothricin acetyltransferase; 2,2-dichloropropionic acid dehalogenase; acetohydroxyacid synthase; 5-enolpyruvyl-shikimate-phosphate synthase (aroA); haloarylnitrilase; acetyl-coenzyme A carboxylase; dihydropteroate synthase (sul I); and 32 kD photosystem II polypeptide (psbA). An embodiment also includes selectable marker genes encoding resistance to: chloramphenicol; methotrexate; hygromycin; spectinomycin; bromoxynil; glyphosate; and phosphinothricin. The above list of selectable marker genes is not meant to be limiting. Any reporter or selectable marker gene are encompassed by the present disclosure.
- In some embodiments the coding sequences are synthesized for optimal expression in a plant. For example, in an embodiment, a coding sequence of a gene has been modified by codon optimization to enhance expression in plants. An insecticidal resistance transgene, an herbicide tolerance transgene, a nitrogen use efficiency transgene, a water use efficiency transgene, a nutritional quality transgene, a DNA binding transgene, or a selectable marker transgene can be optimized for expression in a particular plant species or alternatively can be modified for optimal expression in dicotyledonous or monocotyledonous plants. Plant preferred codons may be determined from the codons of highest frequency in the proteins expressed in the largest amount in the particular plant species of interest. In an embodiment, a coding sequence, gene, or transgene is designed to be expressed in plants at a higher level resulting in higher transformation efficiency. Methods for plant optimization of genes are well known. Guidance regarding the optimization and production of synthetic DNA sequences can be found in, for example,
WO2013016546 ,WO2011146524 ,WO1997013402 ,US Patent No. 6166302 , andUS Patent No. 5380831 . - Suitable methods for transformation of plants include any method by which DNA can be introduced into a cell, for example and without limitation: electroporation (see, e.g.,
U.S. Patent 5,384,253 ); micro-projectile bombardment (see, e.g.,U.S. Patents 5,015,580 ,5,550,318 ,5,538,880 ,6,160,208 ,6,399,861 , and6,403,865 ); Agrobacterium-mediated transformation (see, e.g.,U.S. Patents 5,635,055 ,5,824,877 ,5,591,616 ;5,981,840 , and6,384,301 ); and protoplast transformation (see, e.g.,U.S. Patent 5,508,184 ). - A DNA construct may be introduced directly into the genomic DNA of the plant cell using techniques such as agitation with silicon carbide fibers (see, e.g.,
U.S. Patents 5,302,523 and5,464,765 ), or the DNA constructs can be introduced directly to plant tissue using biolistic methods, such as DNA particle bombardment (see, e.g., Klein et al. (1987) Nature 327:70-73). Alternatively, the DNA construct can be introduced into the plant cell via nanoparticle transformation (see, e.g.,US Patent Publication No. 20090104700 ). - In addition, gene transfer may be achieved using non-Agrobacterium bacteria or viruses such as Rhizobium sp. NGR234, Sinorhizoboium meliloti, Mesorhizobium loti, potato virus X, cauliflower mosaic virus and cassava vein mosaic virus and/or tobacco mosaic virus, See, e.g., Chung et al. (2006) Trends Plant Sci. 11(1): 1-4.
- Through the application of transformation techniques, cells of virtually any plant species may be stably transformed, and these cells may be developed into transgenic plants by well-known techniques. For example, techniques that may be particularly useful in the context of cotton transformation are described in
U.S. Patent Nos 5,846,797 ,5,159,135 ,5,004,863 , and6,624,344 ; techniques for transforming Brassica plants in particular are described, for example, inU.S. Patent 5,750,871 ; techniques for transforming soy bean are described, for example, inU.S. Patent 6,384,301 ; and techniques for transforming Zea mays are described, for example, inU.S. Patents 7,060,876 and5,591,616 , and InternationalPCT Publication WO 95/06722 - After effecting delivery of an exogenous nucleic acid to a recipient cell, a transformed cell is generally identified for further culturing and plant regeneration. In order to improve the ability to identify transformants, one may desire to employ a selectable marker gene with the transformation vector used to generate the transformant. In an illustrative embodiment, a transformed cell population can be assayed by exposing the cells to a selective agent or agents, or the cells can be screened for the desired marker gene trait.
- Cells that survive exposure to a selective agent, or cells that have been scored positive in a screening assay, may be cultured in media that supports regeneration of plants. In an embodiment, any suitable plant tissue culture media may be modified by including further substances, such as growth regulators. Tissue may be maintained on a basic media with growth regulators until sufficient tissue is available to begin plant regeneration efforts, or following repeated rounds of manual selection, until the morphology of the tissue is suitable for regeneration (e.g., at least 2 weeks), then transferred to media conducive to shoot formation. Cultures are transferred periodically until sufficient shoot formation has occurred. Once shoots are formed, they are transferred to media conducive to root formation. Once sufficient roots are formed, plants can be transferred to soil for further growth and maturity.
- A transformed plant cell, callus, tissue or plant may be identified and isolated by selecting or screening the engineered plant material for traits encoded by the marker genes present on the transforming DNA. For instance, selection can be performed by growing the engineered plant material on media containing an inhibitory amount of the antibiotic or herbicide to which the transforming gene construct confers resistance. Further, transformed plants and plant cells can also be identified by screening for the activities of any visible marker genes (e.g., the β-glucuronidase, luciferase, or green fluorescent protein genes) that may be present on the recombinant nucleic acid constructs. Such selection and screening methodologies are well known to those skilled in the art. Molecular confirmation methods that can be used to identify transgenic plants are known to those with skill in the art. Several exemplary methods are further described below.
- Molecular Beacons have been described for use in sequence detection. Briefly, a FRET oligonucleotide probe is designed that overlaps the flanking genomic and insert DNA junction. The unique structure of the FRET probe results in it containing a secondary structure that keeps the fluorescent and quenching moieties in close proximity. The FRET probe and PCR primers (one primer in the insert DNA sequence and one in the flanking genomic sequence) are cycled in the presence of a thermostable polymerase and dNTPs. Following successful PCR amplification, hybridization of the FRET probe(s) to the target sequence results in the removal of the probe secondary structure and spatial separation of the fluorescent and quenching moieties. A fluorescent signal indicates the presence of the flanking genomic/transgene insert sequence due to successful amplification and hybridization. Such a molecular beacon assay for detection of as an amplification reaction is an embodiment of the subject disclosure.
- Hydrolysis probe assay, otherwise known as TAQMAN® (Life Technologies, Foster City, Calif.), is a method of detecting and quantifying the presence of a DNA sequence. Briefly, a FRET oligonucleotide probe is designed with one oligo within the transgene and one in the flanking genomic sequence for event-specific detection. The FRET probe and PCR primers (one primer in the insert DNA sequence and one in the flanking genomic sequence) are cycled in the presence of a thermostable polymerase and dNTPs. Hybridization of the FRET probe results in cleavage and release of the fluorescent moiety away from the quenching moiety on the FRET probe. A fluorescent signal indicates the presence of the flanking/transgene insert sequence due to successful amplification and hybridization. Such a hydrolysis probe assay for detection of as an amplification reaction is an embodiment of the subject disclosure.
- KASPar® assays are a method of detecting and quantifying the presence of a DNA sequence. Briefly, the genomic DNA sample comprising the integrated gene expression cassette polynucleotide is screened using a polymerase chain reaction (PCR) based assay known as a KASPar® assay system. The KASPar® assay used in the practice of the subject disclosure can utilize a KASPar® PCR assay mixture which contains multiple primers. The primers used in the PCR assay mixture can comprise at least one forward primers and at least one reverse primer. The forward primer contains a sequence corresponding to a specific region of the DNA polynucleotide, and the reverse primer contains a sequence corresponding to a specific region of the genomic sequence. In addition, the primers used in the PCR assay mixture can comprise at least one forward primers and at least one reverse primer. For example, the KASPar® PCR assay mixture can use two forward primers corresponding to two different alleles and one reverse primer. One of the forward primers contains a sequence corresponding to specific region of the endogenous genomic sequence. The second forward primer contains a sequence corresponding to a specific region of the DNA polynucleotide. The reverse primer contains a sequence corresponding to a specific region of the genomic sequence. Such a KASPar® assay for detection of an amplification reaction is an embodiment of the subject disclosure.
- In some embodiments the fluorescent signal or fluorescent dye is selected from the group consisting of a HEX fluorescent dye, a FAM fluorescent dye, a JOE fluorescent dye, a TET fluorescent dye, a Cy 3 fluorescent dye, a Cy 3.5 fluorescent dye, a Cy 5 fluorescent dye, a Cy 5.5 fluorescent dye, a Cy 7 fluorescent dye, and a ROX fluorescent dye.
- In other embodiments the amplification reaction is run using suitable second fluorescent DNA dyes that are capable of staining cellular DNA at a concentration range detectable by flow cytometry, and have a fluorescent emission spectrum which is detectable by a real time thermocycler. It should be appreciated by those of ordinary skill in the art that other nucleic acid dyes are known and are continually being identified. Any suitable nucleic acid dye with appropriate excitation and emission spectra can be employed, such as YO-PRO-1®, SYTOX Green®, SYBR Green I®, SYTO11®, SYTO12®, SYTO13®, BOBO®, YOYO®, and TOTO®. In one embodiment, a second fluorescent DNA dye is SYTO13® used at less than 10 µM, less than 4 µM, or less than 2.7 µM.
- In further embodiments, Next Generation Sequencing (NGS) can be used for detection. As described by Brautigma et al., 2010, DNA sequence analysis can be used to determine the nucleotide sequence of the isolated and amplified fragment. The amplified fragments can be isolated and sub-cloned into a vector and sequenced using chain-terminator method (also referred to as Sanger sequencing) or Dye-terminator sequencing. In addition, the amplicon can be sequenced with Next Generation Sequencing. NGS technologies do not require the sub-cloning step, and multiple sequencing reads can be completed in a single reaction. Three NGS platforms are commercially available, the Genome Sequencer FLX™ from 454 Life Sciences / Roche, the Illumina Genome Analyser™ from Solexa and Applied Biosystems' SOLiD™ (acronym for: 'Sequencing by Oligo Ligation and Detection'). In addition, there are two single molecule sequencing methods that are currently being developed. These include the true Single Molecule Sequencing (tSMS) from Helicos Bioscience™ and the Single Molecule Real Time™ sequencing (SMRT) from Pacific Biosciences.
- The Genome Sequencher FLX™ which is marketed by 454 Life Sciences/Roche is a long read NGS, which uses emulsion PCR and pyrosequencing to generate sequencing reads. DNA fragments of 300 - 800 bp or libraries containing fragments of 3 - 20 kb can be used. The reactions can produce over a million reads of about 250 to 400 bases per run for a total yield of 250 to 400 megabases. This technology produces the longest reads but the total sequence output per run is low compared to other NGS technologies.
- The Illumina Genome Analyser™ which is marketed by Solexa™ is a short read NGS which uses sequencing by synthesis approach with fluorescent dye-labeled reversible terminator nucleotides and is based on solid-phase bridge PCR. Construction of paired end sequencing libraries containing DNA fragments of up to 10 kb can be used. The reactions produce over 100 million short reads that are 35 - 76 bases in length. This data can produce from 3-6 gigabases per run.
- The Sequencing by Oligo Ligation and Detection (SOLiD) system marketed by Applied Biosystems™ is a short read technology. This NGS technology uses fragmented double stranded DNA that are up to 10 kb in length. The system uses sequencing by ligation of dye-labelled oligonucleotide primers and emulsion PCR to generate one billion short reads that result in a total sequence output of up to 30 gigabases per run.
- tSMS of Helicos Bioscience™ and SMRT of Pacific Biosciences™ apply a different approach which uses single DNA molecules for the sequence reactions. The tSMS Helicos™ system produces up to 800 million short reads that result in 21 gigabases per run. These reactions are completed using fluorescent dye-labelled virtual terminator nucleotides that is described as a 'sequencing by synthesis' approach.
- The SMRT Next Generation Sequencing system marketed by Pacific Biosciences™ uses a real time sequencing by synthesis. This technology can produce reads of up to 1,000 bp in length as a result of not being limited by reversible terminators. Raw read throughput that is equivalent to one-fold coverage of a diploid human genome can be produced per day using this technology.
- In another embodiment, the detection can be completed using blotting assays, including Western blots, Northern blots, and Southern blots. Such blotting assays are commonly used techniques in biological research for the identification and quantification of biological samples. These assays include first separating the sample components in gels by electrophoresis, followed by transfer of the electrophoretically separated components from the gels to transfer membranes that are made of materials such as nitrocellulose, polyvinylidene fluoride (PVDF), or Nylon. Analytes can also be directly spotted on these supports or directed to specific regions on the supports by applying vacuum, capillary action, or pressure, without prior separation. The transfer membranes are then commonly subj ected to a post-transfer treatment to enhance the ability of the analytes to be distinguished from each other and detected, either visually or by automated readers.
- In a further embodiment the detection can be completed using an ELISA assay, which uses a solid-phase enzyme immunoassay to detect the presence of a substance, usually an antigen, in a liquid sample or wet sample. Antigens from the sample are attached to a surface of a plate. Then, a further specific antibody is applied over the surface so it can bind to the antigen. This antibody is linked to an enzyme, and, in the final step, a substance containing the enzyme's substrate is added. The subsequent reaction produces a detectable signal, most commonly a color change in the substrate.
- In an embodiment, a plant, plant tissue, or plant cell comprises a Panicum virgatum (Pavir.J00490) egg cell gene promoter. In one embodiment a plant, plant tissue, or plant cell comprises the Panicum virgatum (Pavir.J00490) egg cell gene promoter of a sequence selected from SEQ ID NO: 1 or a sequence that has 98% or 99.5% sequence identity with a sequence selected from SEQ ID NO: 1. In an embodiment, a plant, plant tissue, or plant cell comprises a gene expression cassette comprising a sequence selected from SEQ ID NO: 1, or a sequence that has 98% or 99.5% sequence identity with a sequence selected from SEQ ID NO: 1 that is operably linked to a non-Panicum virgatum (Pavir.J00490) egg cell gene. In an illustrative embodiment, a plant, plant tissue, or plant cell comprises a gene expression cassette comprising a Panicum virgatum (Pavir.J00490) egg cell gene promoter that is operably linked to a transgene, wherein the transgene can be an insecticidal resistance transgene, an herbicide tolerance transgene, a nitrogen use efficiency transgene, a water use efficiency transgene, a nutritional quality transgene, a DNA binding transgene, a selectable marker transgene, or combinations thereof.
- In accordance with one embodiment a plant, plant tissue, or plant cell is provided wherein the plant, plant tissue, or plant cell comprises a Panicum virgatum (Pavir.J00490) egg cell gene promoter derived sequence operably linked to a transgene, wherein the Panicum virgatum (Pavir.J00490) egg cell gene promoter derived sequence comprises a sequence SEQ ID NO: 1 or a sequence having 98% or 99.5% sequence identity with SEQ ID NO:1. In one embodiment a plant, plant tissue, or plant cell is provided wherein the plant, plant tissue, or plant cell comprises SEQ ID NO: 1, or a sequence that has 98% or 99.5% sequence identity with SEQ ID NO: 1 operably linked to a non- Panicum virgatum (Pavir.J00490) egg cell gene. In one embodiment the plant, plant tissue, or plant cell is a dicotyledonous or monocotyledonous plant or a cell or tissue derived from a dicotyledonous or monocotyledonous plant. In one embodiment the plant is selected from the group consisting of Zea mays, wheat, rice, sorghum, oats, rye, bananas, sugar cane, soybean, cotton, sunflower, and canola. In one embodiment the plant is Zea mays. In accordance with one embodiment the plant, plant tissue, or plant cell comprises SEQ ID NO: 1 or a sequence having 98% or 99.5% sequence identity with SEQ ID NO:1 operably linked to a non-Panicum virgatum (Pavir.J00490) egg cell gene. In one embodiment the plant, plant tissue, or plant cell comprises a promoter operably linked to a transgene wherein the promoter consists of SEQ ID NO: 1or a sequence having 98% or 99.5% sequence identity with SEQ ID NO: 1. In accordance with one embodiment the gene construct comprising Panicum virgatum (Pavir.J00490) egg cell gene promoter sequence operably linked to a transgene is incorporated into the genome of the plant, plant tissue, or plant cell.
- In an embodiment, a plant, plant tissue, or plant cell comprises a Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR. In one embodiment a plant, plant tissue, or plant cell comprises the Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR of a sequence selected from SEQ ID NO:7 or a sequence that has 80%, 85%, 90%, 95% or 99.5% sequence identity with a sequence selected from SEQ ID NO:7. In an embodiment, a plant, plant tissue, or plant cell comprises a gene expression cassette comprising a sequence selected from SEQ ID NO:7, or a sequence that has 80%, 85%, 90%, 95% or 99.5% sequence identity with a sequence selected from SEQ ID NO:7 that is operably linked to a non-Panicum virgatum (Pavir.J00490) egg cell gene. In an illustrative embodiment, a plant, plant tissue, or plant cell comprises a gene expression cassette comprising a Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR that is operably linked to a transgene, wherein the transgene can be an insecticidal resistance transgene, an herbicide tolerance transgene, a nitrogen use efficiency transgene, a water use efficiency transgene, a nutritional quality transgene, a DNA binding transgene, a selectable marker transgene, or combinations thereof.
- In accordance with one embodiment a plant, plant tissue, or plant cell is provided wherein the plant, plant tissue, or plant cell comprises a Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR derived sequence operably linked to a transgene, wherein the Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR derived sequence comprises a sequence SEQ ID NO:7 or a sequence having 80%, 85%, 90%, 95% or 99.5% sequence identity with SEQ ID NO:7. In one embodiment a plant, plant tissue, or plant cell is provided wherein the plant, plant tissue, or plant cell comprises SEQ ID NO:7, or a sequence that has 80%, 85%, 90%, 95% or 99.5% sequence identity with SEQ ID NO:7 operably linked to a non- Panicum virgatum (Pavir.J00490) egg cell gene. In one embodiment the plant, plant tissue, or plant cell is a dicotyledonous or monocotyledonous plant or a cell or tissue derived from a dicotyledonous or monocotyledonous plant. In one embodiment the plant is selected from the group consisting of Zea mays, wheat, rice, sorghum, oats, rye, bananas, sugar cane, soybean, cotton, sunflower, and canola. In one embodiment the plant is Zea mays. In accordance with one embodiment the plant, plant tissue, or plant cell comprises SEQ ID NO:7 or a sequence having 80%, 85%, 90%, 95% or 99.5% sequence identity with SEQ ID NO:7 operably linked to a non- Panicum virgatum (Pavir.J00490) egg cell gene. In one embodiment the plant, plant tissue, or plant cell comprises a 5' UTR operably linked to a transgene wherein the 5' UTR consists of SEQ ID NO:7 or a sequence having 80%, 85%, 90%, 95% or 99.5% sequence identity with SEQ ID NO:7. In accordance with one embodiment the gene construct comprising Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR sequence operably linked to a transgene is incorporated into the genome of the plant, plant tissue, or plant cell.
- In an embodiment, a plant, plant tissue, or plant cell comprises a Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR. In one embodiment a plant, plant tissue, or plant cell comprises the Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR of a sequence selected from SEQ ID NO:2 or a sequence that has 80%, 85%, 90%, 95% or 99.5% sequence identity with a sequence selected from SEQ ID NO:2. In an embodiment, a plant, plant tissue, or plant cell comprises a gene expression cassette comprising a sequence selected from SEQ ID NO:2, or a sequence that has 80%, 85%, 90%, 95% or 99.5% sequence identity with a sequence selected from SEQ ID NO:2 that is operably linked to a non-Panicum virgatum (Pavir.J00490) egg cell gene. In an illustrative embodiment, a plant, plant tissue, or plant cell comprises a gene expression cassette comprising a Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR that is operably linked to a transgene, wherein the transgene can be an insecticidal resistance transgene, an herbicide tolerance transgene, a nitrogen use efficiency transgene, a water use efficiency transgene, a nutritional quality transgene, a DNA binding transgene, a selectable marker transgene, or combinations thereof.
- In accordance with one embodiment a plant, plant tissue, or plant cell is provided wherein the plant, plant tissue, or plant cell comprises a Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR derived sequence operably linked to a transgene, wherein the Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR derived sequence comprises a sequence SEQ ID NO:2 or a sequence having 80%, 85%, 90%, 95% or 99.5% sequence identity with SEQ ID NO:2. In one embodiment a plant, plant tissue, or plant cell is provided wherein the plant, plant tissue, or plant cell comprises SEQ ID NO:2, or a sequence that has 80%, 85%, 90%, 95% or 99.5% sequence identity with SEQ ID NO:2 operably linked to a non- Panicum virgatum (Pavir.J00490) egg cell gene. In one embodiment the plant, plant tissue, or plant cell is a dicotyledonous or monocotyledonous plant or a cell or tissue derived from a dicotyledonous or monocotyledonous plant. In one embodiment the plant is selected from the group consisting of Zea mays, wheat, rice, sorghum, oats, rye, bananas, sugar cane, soybean, cotton, sunflower, and canola. In one embodiment the plant is Zea mays. In accordance with one embodiment the plant, plant tissue, or plant cell comprises SEQ ID NO:2 or a sequence having 80%, 85%, 90%, 95% or 99.5% sequence identity with SEQ ID NO:2 operably linked to a non- Panicum virgatum (Pavir.J00490) egg cell gene. In one embodiment the plant, plant tissue, or plant cell comprises a 3' UTR operably linked to a transgene wherein the 3' UTR consists of SEQ ID NO:2 or a sequence having 80%, 85%, 90%, 95% or 99.5% sequence identity with SEQ ID NO:2. In accordance with one embodiment the gene construct comprising Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR sequence operably linked to a transgene is incorporated into the genome of the plant, plant tissue, or plant cell.
- In an embodiment, a plant, plant tissue, or plant cell according to the methods disclosed herein can be a dicotyledonous plant. The dicotyledonous plant, plant tissue, or plant cell can be, but not limited to alfalfa, rapeseed, canola, Indian mustard, Ethiopian mustard, soybean, sunflower, cotton, beans, broccoli, cabbage, cauliflower, celery, cucumber, eggplant, lettuce; melon, pea, pepper, peanut, potato, pumpkin, radish, spinach, sugarbeet, sunflower, tobacco, tomato, and watermelon.
- One of skill in the art will recognize that after the exogenous sequence is stably incorporated in transgenic plants and confirmed to be operable, it can be introduced into other plants by sexual crossing. Any of a number of standard breeding techniques can be used, depending upon the species to be crossed.
- The present disclosure also encompasses seeds of the transgenic plants described above, wherein the seed has the transgene or gene construct containing the gene regulatory elements of the subject disclosure. The present disclosure further encompasses the progeny, clones, cell lines or cells of the transgenic plants described above wherein said progeny, clone, cell line or cell has the transgene or gene construct containing the gene regulatory elements of the subject disclosure.
- The present disclosure also encompasses the cultivation of transgenic plants described above, wherein the transgenic plant has the transgene or gene construct containing the gene regulatory elements of the subject disclosure. Accordingly, such transgenic plants may be engineered to, inter alia, have one or more desired traits or transgenic events containing the gene regulatory elements of the subject disclosure, by being transformed with nucleic acid molecules according to the invention, and may be cropped or cultivated by any method known to those of skill in the art.
- In an embodiment, a method of expressing at least one transgene in a plant comprises growing a plant comprising a Panicum virgatum (Pavir.J00490) egg cell gene promoter operably linked to at least one transgene or a polylinker sequence. In an embodiment the Panicum virgatum (Pavir.J00490) egg cell gene promoter consists of a sequence selected from SEQ ID NO: 1 or a sequence that has 98% or 99.5% sequence identity with a sequence selected from SEQ ID NO:1. In an embodiment, a method of expressing at least one transgene in a plant comprising growing a plant comprising a Panicum virgatum (Pavir.J00490) egg cell gene gene promoter operably linked to at least one transgene. In an embodiment, a method of expressing at least one transgene in a plant tissue or plant cell comprising culturing a plant tissue or plant cell comprising a Panicum virgatum (Pavir.J00490) egg cell gene promoter operably linked to at least one transgene.
- In an embodiment, a method of expressing at least one transgene in a plant comprises growing a plant comprising a gene expression cassette comprising a Panicum virgatum (Pavir.J00490) egg cell gene promoter operably linked to at least one transgene. In one embodiment the Panicum virgatum (Pavir.J00490) egg cell gene promoter consists of a sequence selected from SEQ ID NO: 1 or a sequence that has 98% or 99.5% sequence identity with a sequence selected from SEQ ID NO: 1. In an embodiment, a method of expressing at least one transgene in a plant comprises growing a plant comprising a gene expression cassette comprising a Panicum virgatum (Pavir.J00490) egg cell gene promoter operably linked to at least one transgene. In an embodiment, a method of expressing at least one transgene in a plant comprises growing a plant comprising a gene expression cassette comprising a Panicum virgatum (Pavir.J00490) egg cell gene promoter operably linked to at least one transgene. In an embodiment, a method of expressing at least one transgene in a plant tissue or plant cell comprises culturing a plant tissue or plant cell comprising a gene expression cassette containing a Panicum virgatum (Pavir.J00490) egg cell gene promoter operably linked to at least one transgene. In an embodiment, a method of expressing at least one transgene in a plant tissue or plant cell comprises culturing a plant tissue or plant cell comprising a gene expression cassette, a Panicum virgatum (Pavir.J00490) egg cell gene promoter operably linked to at least one transgene.
- In an embodiment, a method of expressing at least one transgene in a plant comprises growing a plant comprising a Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR operably linked to at least one transgene or a polylinker sequence. In an embodiment the Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR consists of a sequence selected from SEQ ID NO:7 or a sequence that has 80%, 85%, 90%, 95% or 99.5% sequence identity with a sequence selected from SEQ ID NO:7. In an embodiment, a method of expressing at least one transgene in a plant comprising growing a plant comprising a Panicum virgatum (Pavir.J00490) egg cell gene gene 5' UTR operably linked to at least one transgene. In an embodiment, a method of expressing at least one transgene in a plant tissue or plant cell comprising culturing a plant tissue or plant cell comprising a Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR operably linked to at least one transgene.
- In an embodiment, a method of expressing at least one transgene in a plant comprises growing a plant comprising a gene expression cassette comprising a Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR operably linked to at least one transgene. In one embodiment the Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR consists of a sequence selected from SEQ ID NO:7 or a sequence that has 80%, 85%, 90%, 95% or 99.5% sequence identity with a sequence selected from SEQ ID NO:7. In an embodiment, a method of expressing at least one transgene in a plant comprises growing a plant comprising a gene expression cassette comprising a Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR operably linked to at least one transgene. In an embodiment, a method of expressing at least one transgene in a plant comprises growing a plant comprising a gene expression cassette comprising a Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR operably linked to at least one transgene. In an embodiment, a method of expressing at least one transgene in a plant tissue or plant cell comprises culturing a plant tissue or plant cell comprising a gene expression cassette containing a Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR operably linked to at least one transgene. In an embodiment, a method of expressing at least one transgene in a plant tissue or plant cell comprises culturing a plant tissue or plant cell comprising a gene expression cassette, a Panicum virgatum (Pavir.J00490) egg cell gene 5' UTR operably linked to at least one transgene.
- In an embodiment, a method of expressing at least one transgene in a plant comprises growing a plant comprising a Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR operably linked to at least one transgene or a polylinker sequence. In an embodiment the Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR consists of a sequence selected from SEQ ID NO:2 or a sequence that has 80%, 85%, 90%, 95% or 99.5% sequence identity with a sequence selected from SEQ ID NO:2. In an embodiment, a method of expressing at least one transgene in a plant comprising growing a plant comprising a Panicum virgatum (Pavir.J00490) egg cell gene gene 3' UTR operably linked to at least one transgene. In an embodiment, a method of expressing at least one transgene in a plant tissue or plant cell comprising culturing a plant tissue or plant cell comprising a Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR operably linked to at least one transgene.
- In an embodiment, a method of expressing at least one transgene in a plant comprises growing a plant comprising a gene expression cassette comprising a Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR operably linked to at least one transgene. In one embodiment the Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR consists of a sequence selected from SEQ ID NO:2 or a sequence that has 80%, 85%, 90%, 95% or 99.5% sequence identity with a sequence selected from SEQ ID NO:2. In an embodiment, a method of expressing at least one transgene in a plant comprises growing a plant comprising a gene expression cassette comprising a Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR operably linked to at least one transgene. In an embodiment, a method of expressing at least one transgene in a plant comprises growing a plant comprising a gene expression cassette comprising a Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR operably linked to at least one transgene. In an embodiment, a method of expressing at least one transgene in a plant tissue or plant cell comprises culturing a plant tissue or plant cell comprising a gene expression cassette containing a Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR operably linked to at least one transgene. In an embodiment, a method of expressing at least one transgene in a plant tissue or plant cell comprises culturing a plant tissue or plant cell comprising a gene expression cassette, a Panicum virgatum (Pavir.J00490) egg cell gene 3' UTR operably linked to at least one transgene.
- The following examples are provided to illustrate certain particular features and/or embodiments. The examples should not be construed to limit the disclosure to the particular features or embodiments exemplified.
- The promoter from a Panicum virgatum (Pavir.J00490) egg cell gene (SEQ ID NO:1) and a 3' UTR from a Panicum virgatum (Pavir.J00490) egg cell gene (SEQ ID NO:2) was identified from the Panicum virgatum genomic DNA (gDNA) sequence. These regulatory element sequences were identified by BLASTing the Phytozome database (Goodstein DM, Shu S, Howson R, Neupane R, Hayes RD, Fazo J, Mitros T, Dirks W, Hellsten U, Putnam N, Rokhsar DS (2012) Nucleic Acids Res. 40: D1178-1186) with an Arabidopsis thaliana egg cell gene DD45/EC1.2 (Genbank Acc. No. At2g21740). The resulting hits were analyzed and a single coding sequence was selected for further analysis. For the identification of a novel promoter region, 1 to 3 kb of nucleotides were retrieved upstream of the translational start site (ATG codon) and additional in silico analyses was performed. For the identification of a novel 3' UTR region, .5 to 2 kb of nucleotides were retrieved downstream of the stop site and additional in silico analyses was perforemed. The in silico analyses included the identification of polynucleotide sequences from any other surrounding genes as needed, checking for the presence of repetitive sequences that could result in silencing of gene expression, or the presence of 5' UTRs that may contain noncoding exons and introns. Based on these analyses, the Panicum virgatum (Pavir.J00490) egg cell promoter sequences were synthesized and moved forward for additional usage to drive expression of a transgene. From the assessment of the contiguous chromosomal sequence that spanned millions of base pairs, a 1,290 bp polynucleotide sequence (SEQ ID NO:1) was identified and isolated for use in expression of heterologous coding sequences. This novel polynucleotide sequence was analyzed for use as a regulatory sequence to drive expression of a gene and is provided in the base pairs 1-1,290 of SEQ ID NO:3. Likewise, from the assessment of the contiguous chromosomal sequence that spanned millions of base pairs, a 67 bp polynucleotide sequence (SEQ ID NO:7) was identified and isolated for use in terminating of heterologous coding sequences. This novel polynucleotide sequence was analyzed for use as a regulatory sequence as a 5' UTR to drive expression of a gene and is provided in the base pairs 1,291-1,357 of SEQ ID NO:3. Finally, from the assessment of the contiguous chromosomal sequence that spanned millions of base pairs, a 942 bp polynucleotide sequence (SEQ ID NO:2) was identified and isolated for use in terminating of heterologous coding sequences. This novel polynucleotide sequence was analyzed for use as a regulatory sequence to terminate expression of a gene and is provided in the base pairs 1,941-2,882 of SEQ ID NO:3.
- The pDAB 129556 vector was built to incorporate the novel combination of regulatory polynucleotide sequences flanking a transgene. The vector construct pDAB 129556 contained a gene expression cassette, in which the PhiYFP transgene was driven by the Panicum virgatum (Pavir.J00490) egg cell promoter of SEQ ID NO: 1 and containing the Panicum virgatum (Pavir.J00490) egg cell 5' UTR of SEQ ID NO:7 was flanked by Panicum virgatum (Pavir.J00490) egg cell 3' UTR of SEQ ID NO:2. A sequence listing of this gene expression cassette is provided as SEQ ID NO:4. The vector also contained a selectable marker gene expression cassette that contained the aad-1 transgene (
U.S. Patent No. 7,838,733 ) driven by the Oryza sativa Actin1 promoter (U.S. Patent No. 5,641,876 ) and was terminated by the Zea mays Lipase 3' UTR (U.S. Patent No. 7,179,902 ). A sequence listing of this gene expression cassette is provided as SEQ ID NO:5. This construct was built by synthesizing the newly designed promoter and 3' UTR from a Panicum virgatum (Pavir.J00490) egg cell gene and cloning the promoter into a GeneArt Seamless Cloning™ (Life Technologies) entry vector using a third party provider. The resulting entry vector was labeled as pDAB 129546 contained the Panicum virgatum (Pavir.J00490) egg cell gene promoter driving the PhiYFP transgene which was used for particle bombardment of Zea mays tissues. Clones of the entry vector, pDAB 129546, were obtained and plasmid DNA was isolated and confirmed via restriction enzyme digestions and sequencing. In addition, the pDAB 129546 entry vector was integrated into a destination vector using the Gateway™ cloning system (Life Technologies). Clones of the resulting binary plasmid, pDAB 129556, were obtained and plasmid DNA was isolated and confirmed via restriction enzyme digestions and sequencing. The resulting constructs contained a combination of regulatory elements that drive expression of a transgene and terminate expression of a transgene. - The experimental pDAB 129546 construct was transformed into Zea mays c.v. B104 via particle bombardment transformation of isolated immature embryos. For example, Zea mays c.v. B104 immature embryos were randomly isolated from eight ears with embryo size averaging from 1.8-2.4 mm. The immature embryos were collected in infection media and placed on osmolysis media for incubation under bright lights with a photon flux of 50uM and a temperature at 27°C overnight. The day after isolation 36 immature embryos per plate were arranged inside a target circle and were used for particle bombardment (PB). Three plates per constructs were used of which one had immature embryos sized between 2.2-2.4 and two had immature embryos sized between 1.8-2.2 mm. Gold particles were coated with 5 µl of DNA (of a 1.0 µg/µl stock) using a CaC12 /spermidine precipitation. The parameters used for bombardment were: 1.0 micron gold particles, 1100 psi rupture discs, 27 inches Hg vacuum, and 6 cm bombardment distance.
- Once bombardments were completed, the plates were placed into a clear box and returned to the same culturing conditions as indicated above. Immature embryos were harvested after 72 hours for microscopic image analysis of the expressing YFP protein. The image analysis was done using a Leica M165 FC fluorescent stereo microscope equipped Leica Planapo 2.0x objective, and Leica DFC310 FX 1.4-megapixel camera.
- The image analysis of YFP expression in bombarded immature embryos indicate that the novel Panicum virgatum (Pavir.J00490) egg cell gene promoter and the Panicum virgatum (Pavir.J00490) egg cell gene 3'UTR successfully drove the YFP expression in corn as compared to untransformed immature embryos that did not result in expression of the YFP protein in corn.
- The Panicum virgatum (Pavir.J00490) egg cell promoter regulatory element of SEQ ID NO: 1 containing the Panicum virgatum (Pavir.J00490) egg cell 5' UTR of SEQ ID NO:7 and the Panicum virgatum (Pavir.J00490) egg cell 3' UTR regulatory element of SEQ ID NO:2, as provided in pDAB129546, resulted in expression of the YFP transgene in Zea mays immature embryos. As such, novel Panicum virgatum (Pavir.J00490) egg cell gene regulatory elements (the Panicum virgatum (Pavir.J00490) egg cell promoter of SEQ ID NO: 1, the Panicum virgatum (Pavir.J00490) egg cell 5' UTR of SEQ ID NO:7 and the Panicum virgatum (Pavir.J00490) egg cell 3' UTR of SEQ ID NO:2) were identified and characterized. Disclosed for the first time are novel promoter regulatory elements for use in gene expression constructs.
- Various types of molecular analyses were employed to screen for low copy, simple events. DNA was extracted with a QIAGEN MagAttract™ kit using THERMO FISHER KingFisher™ magnetic particle processors and the supplier's recommended protocols. Integrated transgene copy number analysis was performed using specific Hydrolysis Probe assays for the phiyfp, and aad1 genes. In addition, contamination by inadvertent integration of the binary vector plasmid backbone was detected by a Hydrolysis Probe assay specific for the Spectinomycin (Spec) resistance gene borne on the binary vector backbone. Hydrolysis Probe assays for endogenous maize genes Invertase (GenBank™ Accession No. U16123) and Cullin (GenBank™ Accession No. XM_008664750) were developed as internal reference standards. Table 1 lists the oligonucleotide sequences of the Hydrolysis Probe assay components (primers and BHQ probes were synthesized by INTEGRATED DNA TECHNOLOGIES, Coralville, IA, MGB probes were synthesized by APPLIED BIOSYSTEMS, Grand Island, NY). Biplex Hydrolysis Probe PCR reactions were set up according to Table 2 with about 10 ng of DNA, and assay conditions are presented in Table 3.
- For amplification, Fast Advanced™ Master mix (Life Technologies, Carlsbad, CA) was prepared at 1X final concentration in a 10 µL volume multiplex reaction containing 0.1% of PVP, 0.4 µM of each primer, and 0.2 µM of each probe. The FAM (6-Carboxy Fluorescein Amidite) fluorescent moiety was excited at 465 nm and fluorescence was measured at 510 nm; the corresponding values for the HEX (hexachlorofluorescein) fluorescent moiety were 533 nm and 580 nm, and for VIC® the values were 538 nm and 554 nm. The level of fluorescence generated for each reaction was analyzed using the Roche LightCycler®480 Real-Time PCR system according to the manufacturer's recommendations. Transgene copy number was determined by comparison of LightCycler®480 outputs of Target/Reference gene values for unknown samples to Target/Reference gene values of known copy number standards (1-Copy representing hemizygous plants, 2-Copy representing homozygous plants).
- Cp scores, i.e., the point at which the florescence signal crosses the background threshold using the fit points algorithm (LightCycler® software release 1.5), and the Relative Quant module (based on the ΔΔCt method), were used to perform the analysis of real time PCR data.
Table 1: List of forward and reverse nucleotide primer and fluorescent probes (synthesized by Applied Biosystems) used for gene of interest copy number and relative expression detection. Name Oligo Sequence Notes AAD1_F SEQ ID NO:8 TGTTCGGTTCCCTCTACCAA For aad1 detection AAD1_P 
AAD1_R SEQ ID NO:10 CAACATCCATCACCTTGACTGA phiYFP_F SEQ ID NO:11 CGTGTTGGGAAAGAACTTGGA For phiyfp detection phiYFP_P 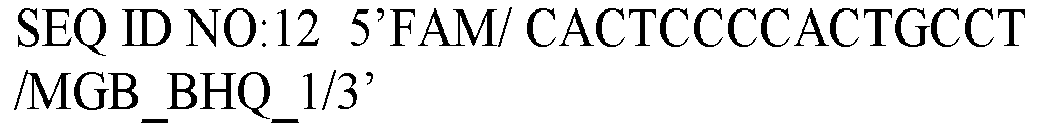
phiYFPR SEQ ID NO:13 CCGTGGTTGGCTTGGTCT Invertase_F SEQ ID NO:14 TGGCGGACGACGACTTGT Maize Reference Invertase Invertase_P 
Invertase_R SEQ ID NO:16 AAAGTTTGGAGGCTGCCGT Cullin_F SEQ ID NO:17 CTGCAACATCAATGCTAAGTTTGA Maize Reference cullin Cullin_P 
Cullin _R SEQ ID NO:19 AGCCTTTCGGATCCATTGAA Table 2: PCR mixture for DNA copy number analysis. Number of Reactions µl each Final Concentration H2O 0.5 µL PVP (10%) 0.1 µL 0.1% ROCHE 2X Master Mix 5 µL 1X GOI Forward Primer (10 µM) 0.4 µL 0.4 µM GOI Reverse Primer (10 µM) 0.4 µL 0.4 µM GOI Probe (5 µM) 0.4 µL 0.2 µM Reference Forward Primer (10 µM) 0.4 µL 0.4 µM Reference Reverse Primer (10 µM) 0.4 µL 0.4 µM Reference Probe (5µM) 0.4 µL 0.2 µM Table 3: Thermocycler conditions for hydrolysis probe PCR amplification. PCR Steps Temp (°C) Time No. of cycles Denature/Activation 95 10 min 1 Denature 95 10 sec 40 Anneal/Extend 58 35 sec Acquire 72 1 sec Cool 40 10 sec 1 - Hydrolysis probe PCR is used for detecting the relative level of phiyfp transcript. Immature ear tissue samples containing unfertilized egg cell were collected. RNA is extracted with the KingFisher total RNA Kit (Thermo Scientific, Cat# 97020196). cDNA is made from ~500 ng of RNA with high capacity cDNA synthesis kit (Invitrogen, Carlsbad, CA, CAT#: 4368814) using random primer (TVN oligo-SEQ ID NO:20 : TTTTTTTTTTTTTTTTTTTTVN) in a 20 µL reaction containing 2.5 units/µl of MultiScribe reverse transcriptase, 200 nM of TVN oligo and 4 mM of dNTP. The reaction is started with 10 minutes at 25°C for pre-incubation, then 120 minutes for synthesis at 37°C and 5 minutes at 85 °C for inactivation.
- The newly synthesized cDNA is then used for amplification. qPCR set up, running conditions and signal capture are the same as for DNA copy number analysis except Cullin is used as the reference gene for corn. GOI expression data is calculated using 2-ΔΔCt relative to the level of Cullin.
- T0 maize transgenic plants containing egg cell-specific promoter construct pDAB129557 were grown in greenhouse. Wild type plants were grown in the same greenhouse. The plants were detasseled and immature ear were harvested during different development stages from silk emergence to the stage when silk length was 7cm. The surrounding husk leaves were removed from the ears, and cut into sections of 6-8 kernels. These sections were attached kernel-side up to a sample stage with cyanoacrylate glue and sectioned at 250 microns thick on a Leica VT1200 vibratome. These sections were mounted on glass slides in a drop of water and examined on a Leica DM5000 upright compound microscope and images were captured with a Leica DFC T7000 digital camera using a YFP filter set.
- Kernel sections from transgenic line pDAB129559 showed YFP-expressing cells/tissue in the embryo sac. No YFP fluorescence was observed from the embryo sac of the kernels obtained from non-transgenic control plant.
- The Panicum virgatum (Pavir.J00490) egg cell promoter regulatory element of SEQ ID NO: 1 containing the Panicum virgatum (Pavir.J00490) egg cell 5' UTR of SEQ ID NO:7 and the Panicum virgatum (Pavir.J00490) egg cell 3' UTR regulatory element of SEQ ID NO:2, as provided in pDAB129557, resulted in expression of the YFP transgene in Zea mays immature embryos. As such, novel Panicum virgatum (Pavir.J00490) egg cell gene regulatory elements (the Panicum virgatum (Pavir.J00490) egg cell promoter of SEQ ID NO: 1, the Panicum virgatum (Pavir.J00490) egg cell 5' UTR of SEQ ID NO:7 and the Panicum virgatum (Pavir.J00490) egg cell 3' UTR of SEQ ID NO:2) were identified and characterized. Disclosed for the first time are novel promoter regulatory elements for use in gene expression constructs.
- T0 maize transgenic plants containing egg cell-specific promoter construct pDAB129556 were grown in greenhouse. Wild type plants were grown in the same greenhouse. The plants were detasseled and ear were cross pollinated using pollen from non-transgenic maize plants. The fertilized ears were harvested 4 days after pollination. The surrounding husk leaves were removed from the ears, and cut into sections of 6-8 kernels. These sections were attached kernel-side up to a sample stage with cyanoacrylate glue and sectioned at 250 microns thick on a Leica VT1200 vibratome. These sections were mounted on glass slides in a drop of water and examined on a Leica DM5000 upright compound microscope and images were captured with a Leica DFC T7000 digital camera using a YFP filter set.
- Transcript analysis of the kernels containing unfertilized embryos obtained from pDAB129556 transgenic plants showed YFP transcript while no transcript was detected from the non-transgenic control plants.
- The Panicum virgatum (Pavir.J00490) egg cell promoter regulatory element of SEQ ID NO: 1 containing the Panicum virgatum (Pavir.J00490) egg cell 5' UTR of SEQ ID NO:7 and the Panicum virgatum (Pavir.J00490) egg cell 3' UTR regulatory element of SEQ ID NO:2, as provided in pDAB129556, resulted in expression of the YFP transgene in Zea mays immature embryos. As such, novel Panicum virgatum (Pavir.J00490) egg cell gene regulatory elements (the Panicum virgatum (Pavir.J00490) egg cell promoter of SEQ ID NO: 1, the Panicum virgatum (Pavir.J00490) egg cell 5' UTR of SEQ ID NO:7 and the Panicum virgatum (Pavir.J00490) egg cell 3' UTR of SEQ ID NO:2) were identified and characterized. Disclosed for the first time are novel promoter regulatory elements for use in gene expression constructs.
- Soybean may be transformed with genes operably linked to the Panicum virgatum (Pavir.J00490) egg cell promoter, the Panicum virgatum (Pavir.J00490) egg cell 5' UTR and/or Panicum virgatum (Pavir.J00490) egg cell 3' UTR by utilizing the same techniques previously described in Example #11 or Example #13 of patent application
WO 2007/053482 . - Cotton may be transformed with genes operably linked to the Panicum virgatum (Pavir.J00490) egg cell promoter, the Panicum virgatum (Pavir.J00490) egg cell 5' UTR and/or Panicum virgatum (Pavir.J00490) egg cell 3' UTR by utilizing the same techniques previously described in Examples #14 of
U.S. Patent No. 7,838,733 or Example #12 of patent applicationWO 2007/053482 (Wright et al. ). - Canola may be transformed with genes operably linked to the Panicum virgatum (Pavir.J00490) egg cell promoter, the Panicum virgatum (Pavir.J00490) egg cell 5' UTR and/or Panicum virgatum (Pavir.J00490) egg cell 3' UTR by utilizing the same techniques previously described in Example #26 of
U.S. Patent No. 7,838,733 or Example #22 of patent applicationWO 2007/053482 (Wright et al. ). - Wheat may be transformed with genes operably linked to the Panicum virgatum (Pavir.J00490) egg cell promoter, the Panicum virgatum (Pavir.J00490) egg cell 5' UTR and/or Panicum virgatum (Pavir.J00490) egg cell 3' UTR by utilizing the same techniques previously described in Example #23 of patent application
WO 2013/116700A1 (Lira et al. ). - Rice may be transformed with genes operably linked to the Panicum virgatum (Pavir.J00490) egg cell promoter, the Panicum virgatum (Pavir.J00490) egg cell 5' UTR and/or Panicum virgatum (Pavir.J00490) egg cell 3' UTR by utilizing the same techniques previously described in Example #19 of patent application
WO 2013/116700A1 (Lira et al. ). - In light of the subject disclosure, additional crops can be transformed according to embodiments of the subject disclosure using techniques that are known in the art. For Agrobacterium-mediated transformation of rye, see, e.g., Popelka JC, Xu J, Altpeter F., "Generation of rye with low transgene copy number after biolistic gene transfer and production of (Secale cereale L.) plants instantly marker-free transgenic rye," Transgenic Res. 2003 Oct;12(5):587-96.). For Agrobacterium-mediated transformation of sorghum, see, e.g., Zhao et al., "Agrobacterium-mediated sorghum transformation," Plant Mol Biol. 2000 Dec;44(6):789-98. For Agrobacterium-mediated transformation of barley, see, e.g., Tingay et al., "Agrobacterium tumefaciens-mediated barley transformation," The Plant Journal, (1997) 11: 1369-1376. For Agrobacterium-mediated transformation of wheat, see, e.g., Cheng et al., "Genetic Transformation of Wheat Mediated by Agrobacterium tumefaciens," Plant Physiol. 1997 Nov;115(3):971-980. For Agrobacterium-mediated transformation of rice, see, e.g., Hiei et al., "Transformation of rice mediated by Agrobacterium tumefaciens," Plant Mol. Biol. 1997 Sep;35(1-2):205-18.
- The Latin names for these and other plants are given below. It should be clear that other (non-Agrobacterium) transformation techniques can be used to transform genes operably linked to the Panicum virgatum (Pavir.J00490) egg cell promoter or the Panicum virgatum (Pavir.J00490) egg cell 5' UTR, for example, into these and other plants. Examples include, but are not limited to; Maize (Zea mays), Wheat (Triticum spp.), Rice (Oryza spp. and Zizania spp.), Barley (Hordeum spp.), Cotton (Abroma augusta and Gossypium spp.), Soybean (Glycine max), Sugar and table beets (Beta spp.), Sugar cane (Arenga pinnata), Tomato (Lycopersicon esculentum and other spp., Physalis ixocarpa, Solanum incanum and other spp., and Cyphomandra betacea), Potato (Solanum tuberosum), Sweet potato (Ipomoea batatas), Rye (Secale spp.), Peppers (Capsicum annuum, chinense, and frutescens), Lettuce (Lactuca sativa, perennis, and pulchella), Cabbage (Brassica spp.), Celery (Apium graveolens), Eggplant (Solanum melongena), Peanut (Arachis hypogea), Sorghum (Sorghum spp.), Alfalfa (Medicago sativa), Carrot (Daucus carota), Beans (Phaseolus spp. and other genera), Oats (Avena sativa and strigosa), Peas (Pisum, Vigna, and Tetragonolobus spp.), Sunflower (Helianthus annuus), Squash (Cucurbita spp.), Cucumber (Cucumis sativa), Tobacco (Nicotiana spp.), Arabidopsis (Arabidopsis thaliana), Turfgrass (Lolium, Agrostis, Poa, Cynodon, and other genera), Clover (Trifolium), Vetch (Vicia). Transformation of such plants, with genes operably linked to the 3' UTR of Panicum virgatum (Pavir.J00490) egg cell gene, for example, is contemplated in embodiments of the subject disclosure.
- Use of the Panicum virgatum (Pavir.J00490) egg cell promoter, the Panicum virgatum (Pavir.J00490) egg cell 5' UTR and/or Panicum virgatum (Pavir.J00490) egg cell 3' UTR to drive operably linked genes can be deployed in many deciduous and evergreen timber species. Such applications are also within the scope of embodiments of this disclosure. These species include, but are not limited to; alder (Alnus spp.), ash (Fraxinus spp.), aspen and poplar species (Populus spp.), beech (Fagus spp.), birch (Betula spp.), cherry (Prunus spp.), eucalyptus (Eucalyptus spp.), hickory (Carya spp.), maple (Acer spp.), oak (Quercus spp.), and pine (Pinus spp.).
- Use of Panicum virgatum (Pavir.J00490) egg cell promoter, the Panicum virgatum (Pavir.J00490) egg cell 5' UTR and/or Panicum virgatum (Pavir.J00490) egg cell 3' UTR to drive operably linked genes can be deployed in ornamental and fruit-bearing species. Such applications are also within the scope of embodiments of this disclosure. Examples include, but are not limited to; rose (Rosa spp.), burning bush (Euonymus spp.), petunia (Petunia spp.), begonia (Begonia spp.), rhododendron (Rhododendron spp.), crabapple or apple (Malus spp.), pear (Pyrus spp.), peach (Prunus spp.), and marigolds (Tagetes spp.).
-
- <110> Dow AgroSciences LLC Kumar, Sandeep Barone, Pierluigi Hemingway, Daren Etchison, Emily Asberry, Andrew Pence, Heather Bowling, Andrew
- <120> PLANT PROMOTER FOR TRANSGENE EXPRESSION
- <130> 79403-US-PSP
- <160> 7
- <170> PatentIn version 3.5
- <210> 1
<211> 1289
<212> DNA
<213> Panicum virgatum - <400> 1


- <210> 2
<211> 942
<212> DNA
<213> Panicum virgatum - <400> 2

- <210> 3
<211> 2882
<212> DNA
<213> Panicum virgatum - <400> 3



- <210> 4
<211> 3231
<212> DNA
<213> Artificial Sequence - <220>
<223> PhiYFP Gene Expression Cassette from pDAB129557 - <400> 4



- <210> 5
<211> 3307
<212> DNA
<213> artificial sequence - <220>
<223> AAD-1 Gene Expression Cassette from pDAB129557 - <400> 5



- <210> 6
<211> 583
<212> DNA
<213> Panicum virgatum - <400> 6

- <210> 7
<211> 67
<212> DNA
<213> Panicum virgatum - <400> 7

Claims (13)
- A nucleic acid vector comprising a promoter operably linked to:a) a polylinker sequence;b) a non-Panicum virgatum (Pavir.J00490) egg cell heterologous coding sequence; orc) a combination of a) and b);wherein said promoter comprises a polynucleotide sequence that has at least 98% sequence identity with SEQ ID NO: 1,
further comprising a 3' untranslated polynucleotide sequence, wherein said promoter has embryonic cell preferred expression. - The nucleic acid vector of claim 1, wherein said promoter is 1,290 bp in length.
- The nucleic acid vector of claim 1, wherein said promoter consists of a polynucleotide sequence that has at least 98% sequence identity with SEQ ID NO:1.
- The nucleic acid vector of claim 1, further comprising a sequence encoding a selectable maker.
- The nucleic acid vector of claim 1, wherein said promoter is operably linked to a heterologous coding sequence, wherein preferably the heterologous coding sequence encodes a selectable marker, an insecticidal resistance protein, a small RNA molecule, a site specific nuclease protein, a herbicide tolerance protein, a nitrogen use efficiency protein, a water use efficiency protein, a nutritional quality protein or a DNA binding protein.
- The nucleic acid vector of claim 1, wherein the 3' untranslated polynucleotide sequence is at least 80% identical to SEQ ID NO: 2.
- The nucleic acid vector of claim 1, further comprising a 5' untranslated polynucleotide sequence.
- The nucleic acid vector of claim 7, wherein the 5' untranslated polynucleotide sequence is at least 80% identical to SEQ ID NO:7.
- The nucleic acid vector of claim 1, further comprising an intron sequence.
- A transgenic plant comprising a polynucleotide sequence that has at least 98% sequence identity with SEQ ID NO:1 operably linked to a heterologous coding sequence, wherein the promoter has embryonic cell preferred expression.
- The transgenic plant of claim 10, wherein said plant is selected from the group consisting of Zea mays, wheat, rice, sorghum, oats, rye, bananas, sugar cane, soybean, cotton, Arabidopsis, tobacco, sunflower, and canola, wherein preferably said plant is Zea mays.
- The transgenic plant of claim 10, wherein the heterologous coding sequence is inserted into the genome of said plant.
- The transgenic plant of claim 10, wherein a promoter comprises a polynucleotide sequence having at least 98% sequence identity with SEQ ID NO:1 and said promoter is operably linked to a heterologous coding sequence, wherein the transgenic plant preferably fulfills one of the following:i) the transgenic plant further comprising a 3' untranslated sequence,ii) said heterologous coding sequence having embryonic cell tissue preferred expression,iii) said promoter is 1,290 bp in length.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201662403250P | 2016-10-03 | 2016-10-03 | |
| PCT/US2017/050585 WO2018067265A1 (en) | 2016-10-03 | 2017-09-08 | Plant promoter for transgene expression |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| EP3518657A1 EP3518657A1 (en) | 2019-08-07 |
| EP3518657A4 EP3518657A4 (en) | 2020-03-18 |
| EP3518657B1 true EP3518657B1 (en) | 2022-07-13 |
Family
ID=61757809
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| EP17858870.3A Active EP3518657B1 (en) | 2016-10-03 | 2017-09-08 | Plant promoter for transgene expression |
Country Status (9)
| Country | Link |
|---|---|
| US (1) | US10519459B2 (en) |
| EP (1) | EP3518657B1 (en) |
| CN (1) | CN109996436B (en) |
| AR (1) | AR109792A1 (en) |
| BR (1) | BR112019005687A2 (en) |
| CA (1) | CA3038520A1 (en) |
| TW (1) | TW201814047A (en) |
| WO (1) | WO2018067265A1 (en) |
| ZA (1) | ZA201901754B (en) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108753813B (en) * | 2018-06-08 | 2021-08-24 | 中国水稻研究所 | Method for obtaining marker-free transgenic plants |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2016048909A1 (en) * | 2014-09-22 | 2016-03-31 | Pioneer Hi-Bred International, Inc. | Methods for reproducing plants asexually and compositions thereof |
Family Cites Families (52)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5380831A (en) | 1986-04-04 | 1995-01-10 | Mycogen Plant Science, Inc. | Synthetic insecticidal crystal protein gene |
| US4683195A (en) | 1986-01-30 | 1987-07-28 | Cetus Corporation | Process for amplifying, detecting, and/or-cloning nucleic acid sequences |
| US5750871A (en) | 1986-05-29 | 1998-05-12 | Calgene, Inc. | Transformation and foreign gene expression in Brassica species |
| US5004863B2 (en) | 1986-12-03 | 2000-10-17 | Agracetus | Genetic engineering of cotton plants and lines |
| ES2039474T3 (en) | 1986-12-05 | 1993-10-01 | Ciba-Geigy Ag | IMPROVED PROCEDURE FOR THE TRANSFORMATION OF PLANT PROTOPLASTS. |
| US5015580A (en) | 1987-07-29 | 1991-05-14 | Agracetus | Particle-mediated transformation of soybean plants and lines |
| US5244802A (en) | 1987-11-18 | 1993-09-14 | Phytogen | Regeneration of cotton |
| US5416011A (en) | 1988-07-22 | 1995-05-16 | Monsanto Company | Method for soybean transformation and regeneration |
| US5302523A (en) | 1989-06-21 | 1994-04-12 | Zeneca Limited | Transformation of plant cells |
| US7705215B1 (en) | 1990-04-17 | 2010-04-27 | Dekalb Genetics Corporation | Methods and compositions for the production of stably transformed, fertile monocot plants and cells thereof |
| US5550318A (en) | 1990-04-17 | 1996-08-27 | Dekalb Genetics Corporation | Methods and compositions for the production of stably transformed, fertile monocot plants and cells thereof |
| US5641876A (en) | 1990-01-05 | 1997-06-24 | Cornell Research Foundation, Inc. | Rice actin gene and promoter |
| JP3209744B2 (en) | 1990-01-22 | 2001-09-17 | デカルブ・ジェネティクス・コーポレーション | Transgenic corn with fruiting ability |
| US5484956A (en) | 1990-01-22 | 1996-01-16 | Dekalb Genetics Corporation | Fertile transgenic Zea mays plant comprising heterologous DNA encoding Bacillus thuringiensis endotoxin |
| US6403865B1 (en) | 1990-08-24 | 2002-06-11 | Syngenta Investment Corp. | Method of producing transgenic maize using direct transformation of commercially important genotypes |
| US5384253A (en) | 1990-12-28 | 1995-01-24 | Dekalb Genetics Corporation | Genetic transformation of maize cells by electroporation of cells pretreated with pectin degrading enzymes |
| US5420032A (en) | 1991-12-23 | 1995-05-30 | Universitge Laval | Homing endonuclease which originates from chlamydomonas eugametos and recognizes and cleaves a 15, 17 or 19 degenerate double stranded nucleotide sequence |
| US5792632A (en) | 1992-05-05 | 1998-08-11 | Institut Pasteur | Nucleotide sequence encoding the enzyme I-SceI and the uses thereof |
| US7060876B2 (en) | 1992-07-07 | 2006-06-13 | Japan Tobacco Inc. | Method for transforming monocotyledons |
| EP1983056A1 (en) | 1992-07-07 | 2008-10-22 | Japan Tobacco Inc. | Method for transforming monocotyledons |
| WO1995006722A1 (en) | 1993-09-03 | 1995-03-09 | Japan Tobacco Inc. | Method of transforming monocotyledon by using scutellum of immature embryo |
| US5635055A (en) | 1994-07-19 | 1997-06-03 | Exxon Research & Engineering Company | Membrane process for increasing conversion of catalytic cracking or thermal cracking units (law011) |
| US5846797A (en) | 1995-10-04 | 1998-12-08 | Calgene, Inc. | Cotton transformation |
| DE69638032D1 (en) | 1995-10-13 | 2009-11-05 | Dow Agrosciences Llc | MODIFIED BACILLUS THURINGIENSIS GENE FOR THE CONTROL OF LEPIDOPTERA IN PLANTS |
| US5981840A (en) | 1997-01-24 | 1999-11-09 | Pioneer Hi-Bred International, Inc. | Methods for agrobacterium-mediated transformation |
| GB9710807D0 (en) | 1997-05-23 | 1997-07-23 | Medical Res Council | Nucleic acid binding proteins |
| GB9710809D0 (en) | 1997-05-23 | 1997-07-23 | Medical Res Council | Nucleic acid binding proteins |
| US6140081A (en) | 1998-10-16 | 2000-10-31 | The Scripps Research Institute | Zinc finger binding domains for GNN |
| US6453242B1 (en) | 1999-01-12 | 2002-09-17 | Sangamo Biosciences, Inc. | Selection of sites for targeting by zinc finger proteins and methods of designing zinc finger proteins to bind to preselected sites |
| US6534261B1 (en) | 1999-01-12 | 2003-03-18 | Sangamo Biosciences, Inc. | Regulation of endogenous gene expression in cells using zinc finger proteins |
| WO2000042207A2 (en) | 1999-01-14 | 2000-07-20 | Monsanto Technology Llc | Soybean transformation method |
| US6794136B1 (en) | 2000-11-20 | 2004-09-21 | Sangamo Biosciences, Inc. | Iterative optimization in the design of binding proteins |
| US9029523B2 (en) | 2000-04-26 | 2015-05-12 | Ceres, Inc. | Promoter, promoter control elements, and combinations, and uses thereof |
| JP2002060786A (en) | 2000-08-23 | 2002-02-26 | Kao Corp | Germicidal stainproofing agent for hard surface |
| JP2005500061A (en) | 2001-08-20 | 2005-01-06 | ザ スクリップス リサーチ インスティテュート | Zinc finger binding domain for CNN |
| US7179902B2 (en) | 2002-06-27 | 2007-02-20 | Dow Agrosciences Llc | Use of regulatory sequences in transgenic plants |
| US7078234B2 (en) * | 2002-12-18 | 2006-07-18 | Monsanto Technology Llc | Maize embryo-specific promoter compositions and methods for use thereof |
| PL2319932T5 (en) | 2004-04-30 | 2017-09-29 | Dow Agrosciences Llc | Novel herbicide resistance gene |
| EP2650365B1 (en) | 2005-10-18 | 2016-09-14 | Precision Biosciences | Rationally designed meganucleases with altered sequence specificity and DNA-binding affinity |
| CA2628263C (en) | 2005-10-28 | 2016-12-13 | Dow Agrosciences Llc | Aryloxyalkanoate auxin herbicide resistance genes and uses thereof |
| US7838729B2 (en) | 2007-02-26 | 2010-11-23 | Monsanto Technology Llc | Chloroplast transit peptides for efficient targeting of DMO and uses thereof |
| WO2009046384A1 (en) | 2007-10-05 | 2009-04-09 | Dow Agrosciences Llc | Methods for transferring molecular substances into plant cells |
| EP2206723A1 (en) | 2009-01-12 | 2010-07-14 | Bonas, Ulla | Modular DNA-binding domains |
| US20110239315A1 (en) | 2009-01-12 | 2011-09-29 | Ulla Bonas | Modular dna-binding domains and methods of use |
| TW201144442A (en) | 2010-05-17 | 2011-12-16 | Dow Agrosciences Llc | Production of DHA and other LC-PUFAs in plants |
| EP2571512B1 (en) | 2010-05-17 | 2017-08-23 | Sangamo BioSciences, Inc. | Novel dna-binding proteins and uses thereof |
| TW201307553A (en) | 2011-07-26 | 2013-02-16 | Dow Agrosciences Llc | Production of DHA and other LC-PUFAs in plants |
| WO2013103367A1 (en) | 2012-01-06 | 2013-07-11 | Pioneer Hi-Bred International, Inc. | Somatic ovule specific promoter and methods of use |
| RU2626535C2 (en) | 2012-02-01 | 2017-07-28 | ДАУ АГРОСАЙЕНСИЗ ЭлЭлСи | Synthetic transit chloroplast peptides derived from brassica |
| US9816097B2 (en) * | 2012-05-29 | 2017-11-14 | Agrivida, Inc. | Strong constitutive promoters for heterologous expression of proteins in plants |
| BR102014021330A2 (en) * | 2013-08-30 | 2015-09-22 | Dow Agrosciences Llc | constructs for transgene expression using panicum ubiquitin gene regulatory elements |
| US10648951B2 (en) | 2017-11-14 | 2020-05-12 | Ge Sensing & Inspection Technologies Gmbh | Classification of ultrasonic indications using pattern recognition |
-
2017
- 2017-09-08 US US15/698,714 patent/US10519459B2/en active Active
- 2017-09-08 CA CA3038520A patent/CA3038520A1/en active Pending
- 2017-09-08 CN CN201780073339.6A patent/CN109996436B/en active Active
- 2017-09-08 WO PCT/US2017/050585 patent/WO2018067265A1/en unknown
- 2017-09-08 EP EP17858870.3A patent/EP3518657B1/en active Active
- 2017-09-08 BR BR112019005687A patent/BR112019005687A2/en active Search and Examination
- 2017-09-15 TW TW106131749A patent/TW201814047A/en unknown
- 2017-10-03 AR ARP170102756A patent/AR109792A1/en unknown
-
2019
- 2019-03-20 ZA ZA2019/01754A patent/ZA201901754B/en unknown
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2016048909A1 (en) * | 2014-09-22 | 2016-03-31 | Pioneer Hi-Bred International, Inc. | Methods for reproducing plants asexually and compositions thereof |
Non-Patent Citations (1)
| Title |
|---|
| YUKINOSUKE OHNISHI ET AL: "Dynamics of Male and Female Chromatin during Karyogamy in Rice Zygotes", PLANT PHYSIOLOGY, vol. 165, no. 4, 19 June 2014 (2014-06-19), Rockville, Md, USA, pages 1533 - 1543, XP055745570, ISSN: 0032-0889, DOI: 10.1104/pp.114.236059 * |
Also Published As
| Publication number | Publication date |
|---|---|
| EP3518657A4 (en) | 2020-03-18 |
| BR112019005687A2 (en) | 2019-07-02 |
| US10519459B2 (en) | 2019-12-31 |
| AR109792A1 (en) | 2019-01-23 |
| WO2018067265A1 (en) | 2018-04-12 |
| ZA201901754B (en) | 2020-10-28 |
| US20180094271A1 (en) | 2018-04-05 |
| CN109996436A (en) | 2019-07-09 |
| EP3518657A1 (en) | 2019-08-07 |
| TW201814047A (en) | 2018-04-16 |
| CN109996436B (en) | 2023-09-29 |
| CA3038520A1 (en) | 2018-04-12 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20170081676A1 (en) | Plant promoter and 3' utr for transgene expression | |
| US11814633B2 (en) | Plant terminator for transgene expression | |
| US10443065B2 (en) | Plant promotor and 3′ UTR for transgene expression | |
| EP3519574B1 (en) | Plant promoter for transgene expression | |
| US10294485B2 (en) | Plant promoter and 3′ UTR for transgene expression | |
| US10457955B2 (en) | Plant promoter for transgene expression | |
| EP3518657B1 (en) | Plant promoter for transgene expression | |
| US20220098606A1 (en) | Plant promoter for transgene expression | |
| US10731171B2 (en) | Plant promoter for transgene expression | |
| US20200277621A1 (en) | Use of a maize untranslated region for transgene expression in plants | |
| US20200299708A1 (en) | Plant pathogenesis-related protein promoter for transgene expression | |
| US20170121726A1 (en) | Plant promoter for transgene expression |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: THE INTERNATIONAL PUBLICATION HAS BEEN MADE |
|
| PUAI | Public reference made under article 153(3) epc to a published international application that has entered the european phase |
Free format text: ORIGINAL CODE: 0009012 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: REQUEST FOR EXAMINATION WAS MADE |
|
| 17P | Request for examination filed |
Effective date: 20190418 |
|
| AK | Designated contracting states |
Kind code of ref document: A1 Designated state(s): AL AT BE BG CH CY CZ DE DK EE ES FI FR GB GR HR HU IE IS IT LI LT LU LV MC MK MT NL NO PL PT RO RS SE SI SK SM TR |
|
| AX | Request for extension of the european patent |
Extension state: BA ME |
|
| DAV | Request for validation of the european patent (deleted) | ||
| DAX | Request for extension of the european patent (deleted) | ||
| A4 | Supplementary search report drawn up and despatched |
Effective date: 20200218 |
|
| RIC1 | Information provided on ipc code assigned before grant |
Ipc: A01H 1/00 20060101AFI20200212BHEP Ipc: C07K 14/15 20060101ALI20200212BHEP Ipc: A01H 5/00 20180101ALI20200212BHEP Ipc: A01H 5/10 20180101ALI20200212BHEP |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: EXAMINATION IS IN PROGRESS |
|
| 17Q | First examination report despatched |
Effective date: 20201105 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: EXAMINATION IS IN PROGRESS |
|
| RAP3 | Party data changed (applicant data changed or rights of an application transferred) |
Owner name: CORTEVA AGRISCIENCE LLC |
|
| GRAP | Despatch of communication of intention to grant a patent |
Free format text: ORIGINAL CODE: EPIDOSNIGR1 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: GRANT OF PATENT IS INTENDED |
|
| INTG | Intention to grant announced |
Effective date: 20220225 |
|
| GRAS | Grant fee paid |
Free format text: ORIGINAL CODE: EPIDOSNIGR3 |
|
| GRAA | (expected) grant |
Free format text: ORIGINAL CODE: 0009210 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: THE PATENT HAS BEEN GRANTED |
|
| AK | Designated contracting states |
Kind code of ref document: B1 Designated state(s): AL AT BE BG CH CY CZ DE DK EE ES FI FR GB GR HR HU IE IS IT LI LT LU LV MC MK MT NL NO PL PT RO RS SE SI SK SM TR |
|
| REG | Reference to a national code |
Ref country code: CH Ref legal event code: EP |
|
| REG | Reference to a national code |
Ref country code: DE Ref legal event code: R096 Ref document number: 602017059521 Country of ref document: DE |
|
| REG | Reference to a national code |
Ref country code: AT Ref legal event code: REF Ref document number: 1503820 Country of ref document: AT Kind code of ref document: T Effective date: 20220815 |
|
| REG | Reference to a national code |
Ref country code: IE Ref legal event code: FG4D |
|
| REG | Reference to a national code |
Ref country code: LT Ref legal event code: MG9D |
|
| REG | Reference to a national code |
Ref country code: NL Ref legal event code: MP Effective date: 20220713 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: SE Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20220713 Ref country code: RS Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20220713 Ref country code: PT Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20221114 Ref country code: NO Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20221013 Ref country code: NL Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20220713 Ref country code: LV Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20220713 Ref country code: LT Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20220713 Ref country code: FI Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20220713 Ref country code: ES Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20220713 |
|
| REG | Reference to a national code |
Ref country code: AT Ref legal event code: MK05 Ref document number: 1503820 Country of ref document: AT Kind code of ref document: T Effective date: 20220713 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: PL Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20220713 Ref country code: IS Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20221113 Ref country code: HR Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20220713 Ref country code: GR Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20221014 |
|
| REG | Reference to a national code |
Ref country code: DE Ref legal event code: R097 Ref document number: 602017059521 Country of ref document: DE |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: SM Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20220713 Ref country code: RO Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20220713 Ref country code: MC Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20220713 Ref country code: DK Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20220713 Ref country code: CZ Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20220713 Ref country code: AT Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20220713 |
|
| REG | Reference to a national code |
Ref country code: CH Ref legal event code: PL |
|
| PLBE | No opposition filed within time limit |
Free format text: ORIGINAL CODE: 0009261 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: NO OPPOSITION FILED WITHIN TIME LIMIT |
|
| REG | Reference to a national code |
Ref country code: BE Ref legal event code: MM Effective date: 20220930 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: SK Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20220713 Ref country code: EE Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20220713 |
|
| 26N | No opposition filed |
Effective date: 20230414 |
|
| P01 | Opt-out of the competence of the unified patent court (upc) registered |
Effective date: 20230517 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: LU Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20220908 Ref country code: AL Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20220713 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: LI Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20220930 Ref country code: IE Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20220908 Ref country code: CH Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20220930 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: SI Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20220713 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: BE Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20220930 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: IT Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20220713 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: HU Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT; INVALID AB INITIO Effective date: 20170908 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: CY Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20220713 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: MK Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20220713 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: TR Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20220713 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: BG Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20220713 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: MT Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20220713 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: DE Payment date: 20240827 Year of fee payment: 8 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: GB Payment date: 20240814 Year of fee payment: 8 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: FR Payment date: 20240828 Year of fee payment: 8 |